
Abstract
Critical-effect-size values represent the smallest detectable effect that can reach statistical significance given a specific sample size, alpha level, and test statistic. It can be useful to calculate the critical effect size when designing a study and evaluate whether such effects are plausible. Reporting critical-effect-size values may be useful when the sample size has not been planned a priori, there is uncertainty about the expected sample size that can be collected, or researchers plan to analyze the data with a statistical hypothesis test. To assist researchers in calculating critical-effect-size values, we developed an R package that allows researchers to report critical-effect-size values for group comparisons, correlations, linear regressions, and meta-analyses. Reflecting on critical-effect-size values could benefit researchers during the planning phase of the study by helping them to understand the limitations of their research design. Critical-effect-size values are also useful when evaluating studies performed by other researchers when a priori power analyses were not performed, especially when nonsignificant results are observed.
Keywords
The “critical effect size” refers to the smallest effect size that can be statistically significant given the test performed, the sample size, and the alpha level (Lakens, 2022). Consider a study that tests a bivariate correlation with
Null hypothesis significance testing (NHST) remains the most prominent approach for statistical inference in science even though there are widespread concerns about the misuse of hypothesis tests (Chow, 1988; Cohen, 1994; Cortina & Dunlap, 1997; Gigerenzer et al., 2004; Hagen, 1997; Haig, 2017; Krueger, 2001; Lakens, 2021; Miller, 2017; Nickerson, 2000). Over the past decades, numerous proposals have emerged to improve the use of hypothesis testing. These include complementing hypothesis tests with effect sizes and their confidence intervals, preregistering hypotheses before the data are collected, and conducting power analyses to determine the sample size a priori based on a smallest effect size of interest (American Psychological Association [APA], 2020; Cumming et al., 2012). Researchers often publish studies with low power for medium to small effect sizes (Szucs & Ioannidis, 2017) and use resource limitations as the main justification for the sample size (Lakens, 2022). However, low power makes it challenging to distinguish signal from noise, and this combined with the selective reporting of statistically significant results in the published literature lead to an overestimation of effect sizes (Altoè et al., 2020). Certain types of research questions can be studied by relying on online data collection, which has made it cheaper and more feasible to collect very large samples. Studies with very large samples are well powered to detect even small effect sizes, but they also require researchers to carefully consider the possibility that an effect might be statistically significant but practically insignificant (Anvari et al., 2023; Kirk, 1996). The risk is that researchers will heuristically or opportunistically accept all effects as potentially important. For this reason, “researchers need to explicitly state the mechanisms that can amplify the importance of an observed effect size and the mechanisms that counteract it” (Anvari et al., 2023, p. 504).
We believe there are two clear benefits to reporting critical-effect-size values for a corresponding test. In the following sections, we illustrate examples of common scenarios and go through the main problems of certain research scenarios and possible solutions, highlighting the utility of critical-effect-size values in such contexts.
Small Sample Sizes and Uncertain Sample-Size Determination
First, when sample sizes are small, the critical-effect-size values inform readers about whether the effect sizes that could lead to rejecting the null hypothesis are in line with realistic expectations. If the sample size is small and only very large effects would yield a statistically significant result and the underlying mechanism that is examined is unlikely to lead to such large effect sizes, researchers will realize they are not able to collect sufficient data to perform an informative hypothesis test. An a priori power analysis would typically lead to a similar conclusion, but reporting critical-effect-size values will focus the attention more strongly on which effect sizes are reasonable to expect. In case of already conducted studies with small sample sizes, it could be argued that it would be more informative to use retrospective design analysis (Altoè et al., 2020), but this would require both knowledge of the plausible effect size and/or the smallest effect size of interest, which is the minimum effect that could be considered meaningful based on practical relevance, theoretical importance, and/or specific research interests (Mesquida & Lakens, 2024; Riesthuis, 2024), which are not always easy to determine. The use of critical-effect-size values can be used in a simple and efficient way to evaluate which findings could have not been found significant because of sample-size limitations and based on the complexity of the test. Power analysis provides information about how likely it is to detect a specific effect size if it truly exists in the population. However, it does not indicate the minimum effect size required to reach statistical significance, which could provide additional insights into the strengths and limitations of a study design.
Consider the following two scenarios as examples. First, imagine researchers who conduct a study involving a between-groups comparison. Because of severe resource constraints, they are able to collect only a limited sample size of
To provide a more tangible illustration of the practical applications of the critical effect sizes, we examine a real-world instance drawn from published research. The study of interest was conducted on musicians and nonmusicians to detect differences in working memory; a modest sample size of 57 participants (42 musicians and 15 control subjects) was collected (Weiss et al., 2014). The two groups were compared on a variety of tasks related to verbal working memory and auditory skills. Regarding the verbal working memory, the syllable-span task was administered, and scores were computed for the maximal span and the total number of sequences they correctly repeated. A two-tailed
Beyond critical-effect-size values, researchers should reason before conducting a study what conclusions can realistically be drawn from their experimental design. For example, because interaction effects are examined in addition to main effects, power may decrease because interactions are generally associated with smaller effect sizes, may require corrections for multiple tests, and interaction coefficients present larger standard errors than main-effects coefficients. Such a reduction in statistical power may require a larger sample size to detect the effects of interest reliably. If this is not feasible and sample-size constraints make it impossible to detect significance for a plausible effect because it is smaller than the critical-effect-size value, alternative data-collection strategies, such as multisite studies, should be explored (Byers-Heinlein et al., 2020; Jarke et al., 2022; Moshontz et al., 2018; Sirois et al., 2023). Finally, if participating in or leading a multisite study is not an option, researchers should evaluate whether collecting the sample for exploratory analysis without making inferences might still be valuable. Such data could later be included in a meta-analysis.
Large Sample Sizes and Meta-Analysis
When sample sizes are very large, the critical-effect-size values will make it clear that trivially small effect sizes will be statistically significant. Reporting critical-effect-size values will focus the attention of researchers on the difference between statistical significance and practical significance and raises awareness of the importance of interpreting the size of the effect. This is especially important in correlational studies with large sample sizes in psychology, in which systematic but uncontrolled sources of variability may lead to significant but very small and not meaningfully interpretable nonzero effects, a phenomenon referred to as the “crud factor” (Orben & Lakens, 2020).
Imagine researchers who gain access to a very large archival data set (
Consider now another real-world instance involving the study by Kramer et al. (2014), which explored the impact of emotional content on Facebook users’ experiences. With a notably large sample size of
A similar scenario may arise in a meta-analysis. Despite potential loss of precision because of substantial heterogeneity across effect sizes in different studies, meta-analyses typically synthesize a large amount of evidence, and as a consequence, even very small average effect sizes can reach statistical significance. Although the focus of meta-analysis is generally on estimating effect sizes with uncertainty, statistical significance is routinely reported and interpreted. Signaling the critical-effect-size values beforehand can serve as a clear warning that statistically significant results should not automatically be interpreted as practically significant, thus urging caution when interpreting the results (Anvari et al., 2023). For this reason, the ongoing call to specify which effects constitute an “important difference” (Boring, 1919; Hodges & Lehmann, 1954; Kirk, 1996) has become especially urgent.
Finally, routinely reasoning about critical effect sizes alongside the use of commonly known practices to enhance the quality of research (i.e., power analysis, design analysis, data simulation) will bring benefits to researchers by making it clear that significance is strictly related to the sample size, the alpha level, and the statistic test used to analyze the data. Nevertheless, in educational settings, critical-effect-size values will help students to better grasp such concepts and therefore give a more critical approach to published research and for their future studies.
How to Compute Critical-Effect-Size Values
In this section, we provide guidance and formulas for computing standardized critical effect sizes with examples for frequently encountered effect sizes, including standardized mean differences (Cohen’s
Summary of the Critical-Effect-Size Equations

Note: See text for details When possible, we also included the equation to calculate the critical effect size without computing the standard error. For the paired t test, this is feasible when using the standard deviation of differences. For the two-sample t test, it is possible only under the assumption of homogeneity of variances.
The t test
For the

where
Equation 2 describes a general formulation of a standardized effect-size measure, where

The critical
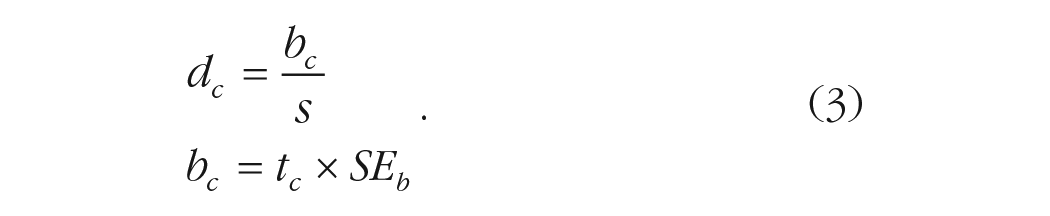
Another way of conceptualizing the critical effect size is by removing the sample size from the
One-sample t test
For the one-sample
Two-sample t test
We can apply the one-sample approach to the two-sample case. When assuming homogeneity of the variances between the two groups, we have
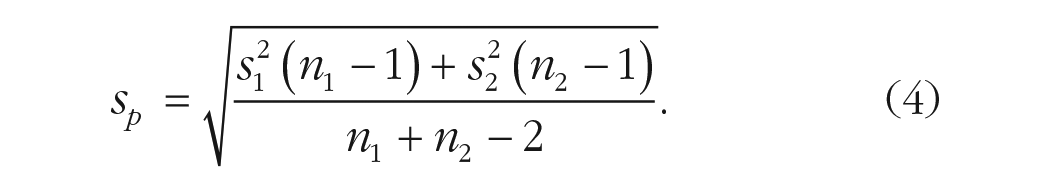
When relaxing the assumption of equal variances (i.e., using the Welch’s
Paired-sample t test
For the paired-sample case, the situation is less straightforward. The reason is that the

Even if the hypothesis testing is computed using
Hedges’s correction
The effect size calculated as in the previous step is known to be inflated, especially for small samples. For this reason, there is a corrected version of the effect size, called “Hedges’s
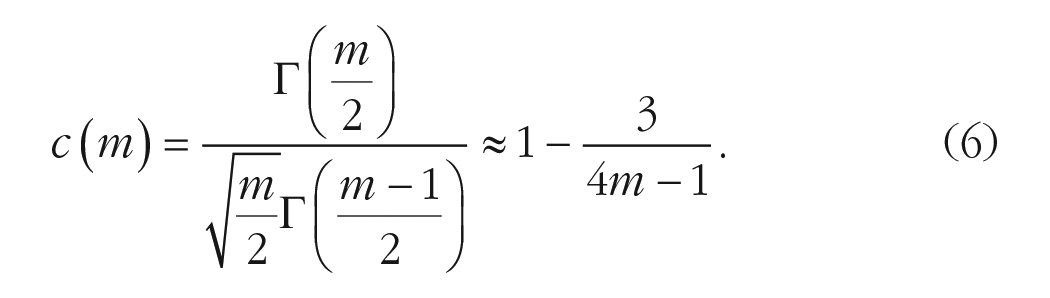
The correction is applied as
Correlation test
Hypothesis testing for the Pearson’s correlation coefficient is usually done using the t statistics or a z statistic. The general approach presented for the
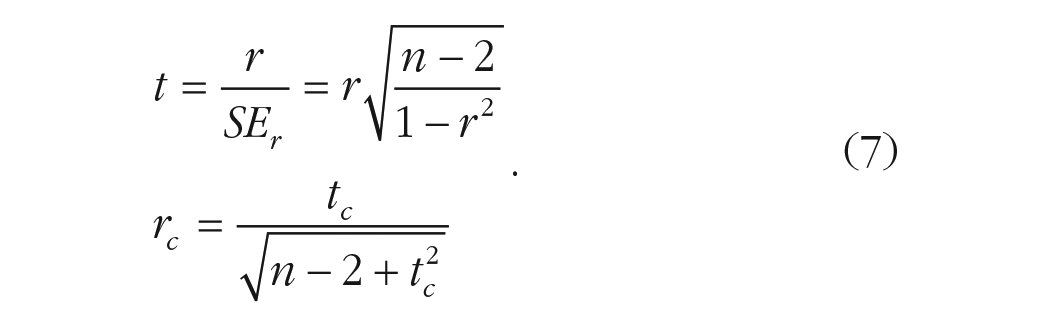
Another approach for hypothesis testing of the Pearson’s correlation coefficient is using the Fisher’s

One can still use Equation 1, substituting

Linear regression
Hypothesis testing on regression coefficients (e.g., using the
Meta-analysis
Meta-analysis allows one to pool information from multiple studies related to a specific research question. The main advantage of meta-analysis is pooling multiple studies to obtain a more precise and powerful estimation of the effect. From a statistical point of view, a meta-analysis can be considered as a weighted linear regression with heterogeneous variances. Similar to standard linear regression, hypothesis testing is performed using Wald
Other models
Despite the fact that we discussed only linear models, the same approach could be applied to other types of models, such as generalized linear models. In fact, one simply needs to multiply the critical value of the chosen distribution (e.g.,
Examples in R
In this section, we introduce the aforementioned user-friendly implementation of the mathematical computations as functions of the package
First, the package should be downloaded and opened with the library function:

For our examples on real data, we used from the package

We want to know the critical value for a

The output gives a wide range of values: the Cohen’s
In the next example, we show the use of the package’s function

The direction of the hypothesis and the test to apply, either the
Discussion
With the present article, we propose that researchers compute and report the critical-effect-size value(s) in their empirical articles. This is not intended to replace other strategies aimed at enhancing the NHST approach to inference. Such strategies, such as the emphasis on estimating effect sizes with confidence intervals (APA, 2020) or the a priori planning for statistical power, are valuable in their own right. Instead, our proposal serves as a complementary tool, especially beneficial for facilitating the interpretation of results when statistical power deviates from an optimal level (typically falling below but occasionally exceeding it). Critical-effect-size values can be retrospectively applied even to already published studies. This possible application facilitates potential reframing of the original interpretations. Serving as a tool for retrospective analysis, critical-effect-size values may enable a reconsideration of the relevance of previously reported findings.
An advantage of reporting critical-effect-size values is that they can be precisely computed in any scenario without requiring assumptions about the expected effect size, as is the case with power calculations. The critical-effect-size value represents a directly interpretable benchmark that is especially useful in situations in which statistical power is below the desired level and researchers are left otherwise uncertain about how to proceed with the interpretation of a study’s findings. For example, say that one reads a published article reporting some effects as statistically significant and others as not: The reader suspects that the study may be underpowered but is widely uncertain about the magnitude of possible true effects. To what extent can the reported results be interpreted, precisely? Knowing the critical-effect-size value provides a clear benchmark. Conversely, say that an effect achieves significance in a very large sample: Researchers tend to draw substantive conclusions based on this. But is it of real theoretical relevance? If in comparing two groups, such as controls versus treatment, any Cohen’s
Reporting the critical-effect-size value(s) can also be an efficient way to allow researchers to evaluate which findings are statistically significant. For example, in a correlation table, researchers customarily add an asterisk to all statistically significant correlations. But as long as all correlations are based on the same sample size, researchers can simply remark “the critical effect size is
Beyond enhancing study design and statistical inferences based on hypothesis tests, reporting critical-effect-size values can also serve an educational purpose. It underscores how the distinction between a significant and nonsignificant result is not determined solely by the presence or absence of a true effect but also by the sample size and the complexity of the analysis. By highlighting a critical-effect-size value, researchers can become more aware of the possibility of Type 2 errors when results are nonsignificant. Conversely, in studies with exceedingly large samples and in many meta-analyses, the critical-effect-size value(s) may serve as a reminder that any observed effect larger than a trivially small value will likely achieve significance. This emphasizes that the mere attainment of statistical significance in a test is not particularly surprising, especially in nonexperimental studies.
Real-case scenarios may not always be that simple. Hence, we chose to expand the application of computing critical-effect-size values beyond Cohen’s
We suggest that reporting critical-effect-size values is particularly valuable when sample-size planning was not feasible or did not occur a priori. In cases in which optimal power can be attained with a sufficiently large sample size for an effect of a specific magnitude of interest and this is truly determined a priori, the interpretation of both significance and nonsignificance becomes straightforward. However, when power analysis did not inform the sample size or when power is likely but indeterminably low, reporting critical-effect-size values for the obtained sample can help provide context for interpretation. Critical-effect-size values can be computed and interpreted even retrospectively or for studies that have already been published.
In conclusion, reporting critical-effect-size values in empirical articles serves as a valuable addition to researchers’ tool kit, aimed at augmenting transparency and facilitating the interpretability of their findings. Although not designed to supplant existing practices, it provides a useful aid in interpreting newly presented and previously published results, thus advancing the understanding of research outcomes.
Footnotes
Transparency
Action Editor: Pamela Davis-Kean
Editor: David A. Sbarra
Author Contributions