
Abstract
In recent years, the popularity of procedures for collecting intensive longitudinal data, such as the experience-sampling method, has increased greatly. The data collected using such designs allow researchers to study the dynamics of psychological functioning and how these dynamics differ across individuals. To this end, the data are often modeled with multilevel regression models. An important question that arises when researchers design intensive longitudinal studies is how to determine the number of participants needed to test specific hypotheses regarding the parameters of these models with sufficient power. Power calculations for intensive longitudinal studies are challenging because of the hierarchical data structure in which repeated observations are nested within the individuals and because of the serial dependence that is typically present in these data. We therefore present a user-friendly application and step-by-step tutorial for performing simulation-based power analyses for a set of models that are popular in intensive longitudinal research. Because many studies use the same sampling protocol (i.e., a fixed number of at least approximately equidistant observations) within individuals, we assume that this protocol is fixed and focus on the number of participants. All included models explicitly account for the temporal dependencies in the data by assuming serially correlated errors or including autoregressive effects.
Keywords
Over recent years, psychological research has increasingly focused on investigating how complex psychological processes evolve dynamically across time within single individuals. To this end, researchers use intensive longitudinal (IL) designs and data-collection methods, such as the experience-sampling method (ESM; Myin-Germeys et al., 2009, 2018), in which individuals are repeatedly measured. The repeated measurements allow researchers to study dynamic aspects of psychological functioning within individuals and individual differences in these dynamics. Examples of such dynamics are emotional variability and stability and emotional inertia (Kuppens & Verduyn, 2015). Individual differences in these dynamics have been consistently linked to individual differences in well-being and health (e.g., Brose et al., 2015; Dejonckheere et al., 2018; Kuppens et al., 2010).
Given the increased focus on dynamic psychological processes within individuals, it is no surprise that the recent debate on the reproducibility and transparency of psychological research (Munafò et al., 2017) has led to the development of guidelines for conducting IL research (Trull & Ebner-Priemer, 2020) and the promotion of open-science practices in IL research (Kirtley et al., in press). Here, we aim to continue along this path and focus on sample-size planning for IL designs. A fixed sampling schedule within individuals is common practice in IL studies not only for the reasons outlined in the previous paragraph, but also because of its feasibility and because it reduces the participants’ burden. Therefore, we focus on assessing the number of participants needed while assuming a fixed number of (at least approximately) equidistant observations within individuals. Adequate sample-size planning allows control of the accuracy and power of statistical testing and modeling and is therefore of crucial importance for the replicability of empirical findings (see Ioannidis, 2005; Szucs & Ioannidis, 2017).
Although power analyses are often used to inform sample-size planning in general (Cohen, 1988), they are not yet well established in IL research. One reason for this is that performing power calculations to select the number of participants in the context of IL studies is challenging because of the intricacies of the data (Bolger, 2011; De Jong et al., 2010). First, IL data have a multilevel structure, in that repeated observations are nested within individuals. Second, observations are closer in time in comparison with traditional longitudinal designs. This likely leads to considerable temporal dependencies between data measured at adjacent observations. As we noted earlier, it is often the very purpose of an IL study to capture such temporal dependencies, as they reflect psychological dynamics that are often of inherent interest.
But not only the data structure is complicated; the applied statistical models are as well, as they should capture such dynamics and individual differences therein. First, the models have to distinguish interindividual differences from intra-individual changes (e.g., Hamaker et al., 2015; Molenaar, 2004). Multilevel regression approaches offer an established way of doing this. Second, models should also take temporal dependencies into account, either to control for them or to quantify and model them. This requires that one includes either serially correlated errors or the lagged outcome variable as a predictor in the multilevel models. Although there are several resources available to help researchers perform power analyses for multilevel models (e.g., Arend & Schäfer, 2019; Browne et al., 2009; Cools et al., 2008; Green & MacLeod, 2016; Hedeker et al., 1999; Landau & Stahl, 2013; Lane & Hennes, 2018; Mathieu et al., 2012; Raudenbush, 1997; Raudenbush & Liu, 2001; Snijders & Bosker, 1993; Zhang, 2014; Zhang & Wang, 2009), these do not account for the temporal dependencies that characterize IL data.
We therefore present a user-friendly application for performing simulation-based power analyses for IL studies. The obtained power results can inform sample-size planning by shedding light on the number of participants needed to obtain accurate and significant parameter estimates. The application was developed in R (R Core Team, 2020) using the shiny package (Chang et al., 2019). It covers a set of models that are widely used to study individual differences in IL studies and properly account for the temporal dependency.
In this article, we first briefly review existing approaches to computing power in multilevel models and then discuss the multilevel models that are covered by our application. Next, we introduce the Shiny app and discuss how it can be used for sample-size planning. Using an already published data set, we illustrate how to perform sample-size planning with the app. We conclude the article with a general discussion of additional considerations and possible extensions.
Disclosures
The R code for the Shiny application is available via a Git repository hosted on GitHub at https://github.com/ginettelafit/PowerAnalysisIL and via OSF at https://osf.io/vguey/. The OSF project also includes the R Markdown document used in the illustrations.
Power Analyses in Intensive Longitudinal Studies
We use statistical power as the criterion for estimating the number of participants needed in an IL study. High power is desirable because it improves the reproducibility of research findings and prevents the overestimation of effect sizes (see Ioannidis, 2005; Szucs & Ioannidis, 2017). Formally, power is defined as the probability of correctly rejecting the null hypothesis when the alternative hypothesis is true in the population under study (Cohen, 1988). The power to detect an effect is therefore determined by the size of the effect in the population, the predetermined Type I error rate (i.e., the significance level), and the standard error of the test statistic used. Power is higher if the population effect is larger, the Type I error rate is higher, and the standard error of the test statistic is smaller. The standard error, in turn, is related to sample size, in that larger sample sizes lead to smaller standard errors. The latter point explains why power analysis can inform sample-size planning.
In general, two approaches can be used for performing power analysis: the analytic approach and the simulation-based approach. In the analytic approach, power is determined by using formulas for the standard errors of the estimated effects, expressing them as a function of the parameters of the multilevel model under study and the sample size. Using these formulas, it is possible to estimate the sample size that allows reaching a predetermined value of power (see, e.g., Cohen, 1988; Hedeker et al., 1999; Moerbeek & Maas, 2005; Moerbeek et al., 2000, 2001; Raudenbush, 1997; Raudenbush & Liu, 2001; Snijders & Bosker, 1993; C. Wang et al., 2015). However, as is true for many other complex models, so far no analytic formulas have been derived for multilevel models that include temporal dependencies (see Arend & Schäfer, 2019). Also, the analytic approach usually relies on asymptotic estimation theory and might, therefore, be inaccurate in practice when dealing with small numbers of participants and measurements per participant. For example, Snijders and Bosker (1993) determined the optimal sample sizes for two-level linear models by using normal approximations for the distribution of the estimated coefficients. However, in small samples, the distribution of the estimator can be nonnormal and is potentially heavy-tailed, which results in unreliable standard error estimates.
The simulation-based approach uses the hypothesized population model and concrete specifications of the associated parameters to generate a large number of data sets. Each of these data sets is then analyzed with the model under study and the parameters of interest are tested for significance. Because the data have been randomly generated, the parameter estimates and the test results will vary across the data sets. Hence, one can compute the power as the proportion of simulated data sets for which the null hypothesis about the parameters of interest has been rejected (see, e.g., Arend & Schäfer, 2019; Astivia et al., 2019; Bolger, 2011; Browne et al., 2009; Cools et al., 2008; Green & MacLeod, 2016; Landau & Stahl, 2013; Lane & Hennes, 2018; Maas & Hox, 2005; Mathieu et al., 2012; Zhang, 2014; Zhang & Wang, 2009). Performing these calculations while varying the number of participants allows one to determine the number of participants necessary to reach a predetermined level of power (e.g., 80%). The simulation-based approach is a good alternative when analytic formulations are not available or too difficult to derive. Therefore, we adopt this approach in this article, given the complexity of IL data and associated modeling questions.
Population Models of Interest
We focus on a set of research questions regarding IL data that can be addressed using specific multilevel regression models (Raudenbush & Bryk, 2002). Figure 1 provides a graphical representation of the different models. These models correspond to a hypothetical data set that we use for illustration purposes and are covered by the application we introduce in the next main section. Table 1 shows a few rows of this data set involving individuals diagnosed with major depressive disorder (MDD) and healthy control individuals. The participants responded to momentary questionnaires at six equidistant time points. The first column contains the participants’ identification numbers, and the second column the observation numbers. The third and fourth columns contain the data for the Level 1, or time-varying, variables: affect (for negative affect) and anhedonia, which were measured at every observation. The final two columns contain the data for two Level 2, or time-invariant, variables. The depression variable refers to the sum score on a continuous self-report instrument assessing the experience of depressive symptoms at baseline. Finally, diagnosis is a binary variable that equals 1 for participants diagnosed with MDD and 0 otherwise. Formulas for the models in Figure 1 are given in Table 2, and Table 3 provides an overview of the effects of interest.

Graphical representation of the population models of interest.
Example Rows of the Hypothetical Data Set

Note: Affect (negative affect) and anhedonia are the Level 1 variables, and depression and diagnosis are the Level 2 variables. PID = participant identification number.
Formulas for the Models in Figure 1 and Available in the PowerAnalysisIL Application

Overview of the Effects of Interest for the Models in Figure 1 and Available in the PowerAnalysisIL Application

Group differences in mean level
Model 1 in Figure 1 estimates differences between the two groups of individuals in the mean of the outcome variable affect (e.g., Heininga et al., 2019; Myin-Germeys et al., 2001, 2003). This model includes the affect
it
value as the outcome variable for the ith individual at the tth observation and a Level 2 dummy variable that indicates the diagnosis group (i.e., diagnosis
i
). For participants in the reference group (healthy control participants), the mean level of affect equals β00; for individuals diagnosed with MDD, the mean level of affect is given by β00 + β01. Within both diagnosis groups, interindividual differences in affect are modeled by the random intercept γ0i. The random intercept expresses the deviation of each participant’s affect level from the group-specific mean level. It is normally distributed, and the standard deviation is denoted by
Effect of a Level 2 continuous predictor on the mean level
Model 2 in Figure 1 focuses on the effect of a continuous Level 2 predictor on the outcome of interest.
2
For the hypothetical data set, we investigate whether the individual-specific depression level, depression
i
, predicts individual differences in the mean level of affect
it
as captured by the random intercept γ0i. These random intercepts are assumed to be normally distributed with mean β00 + β01depression
i
and standard deviation
Effect of a Level 1 continuous predictor
Next, we focus on the effect of a continuous Level 1 predictor on the outcome, through Models 3 and 4 in Figure 1. For example, we might be interested in the extent to which anhedonia
it
predicts affect
it
in individuals diagnosed with MDD. Model 3 specifies a corresponding multilevel model with AR(1) Level 1 errors. The mean slope of anhedonia
it
is denoted by β10, which is the parameter of interest. This model captures interindividual differences by including a random intercept γ0i and a random slope γ1i. These random effects are bivariate normally distributed. β00 then indicates the mean of the random intercepts, and β10 the mean of the random slopes. Their standard deviations are denoted by
Group differences in the effect of a Level 1 continuous predictor
Models structured like Models 5 and 6 in Figure 1 correspond to a class of multilevel models that are used to investigate differences between two groups of participants with respect to the association between a Level 1 predictor and the outcome of interest (while assuming AR(1) errors). In our illustration, these models thus include the outcome affect it , the Level 1 predictor anhedonia it , the Level 2 variable diagnosis i , and a cross-level interaction (Raudenbush & Bryk, 2002) between the Level 1 and Level 2 predictors. β00 and β00 + β01 represent the mean intercept of all individuals in the reference (healthy) and MDD groups, respectively. The mean slope for the reference group is indicated by β10, and the mean slope for the MDD group amounts to β10 + β11. Therefore, the effect of interest is the difference between the two groups in the mean slope, β11. Model 5 includes random intercepts γ0i as well as random slopes γ1i. Model 6 is more restrictive and does not include random slopes.
Cross-level interaction between two continuous predictors
Models 7 and 8 in Figure 1 focus on a cross-level interaction between the continuous Level 2 predictor depression i and the continuous Level 1 predictor anhedonia it (e.g., Arend & Schäfer, 2019), to investigate whether the level of depression (as measured at baseline) moderates the effect of anhedonia on affect. Therefore, the effect of interest is again β11. As was the case for Models 5 and 6, Model 7 includes both random intercepts and random slopes, whereas Model 8 assumes that the slope does not vary across participants.
Multilevel autoregressive models
Models 9 to 11 (see Fig. 1) are multilevel AR(1) autoregressive models (Hamaker & Grasman, 2015) that explicitly focus on the amount of temporal dependence in the outcome. In such models, the lagged outcome variable (i.e., the observed outcome at the previous measurement occasion) is included as the predictor of interest. Such autoregressive effects have been extensively studied, for example, in affective research (Kuppens et al., 2010). Model 9 allows us to study the mean autoregressive effect across individuals as well as individual differences therein, through β10 and γ1i, respectively. To satisfy the stationarity assumption of the model, both effects have to range between −1 and 1. Given that temporal dependence is now captured through the autoregressive effect, the residuals ε it are assumed to be independent and normally distributed with mean 0 and standard deviation σε. Some researchers person-mean-center the lagged outcome variable, although Hamaker and Grasman (2015) showed in an extensive simulation study that this results in an underestimation of β10. The resulting bias will have an impact on power.
Model 10 extends Model 9 in that it allows us to estimate the difference in the mean autoregressive effect between two groups of individuals (L. P. Wang et al., 2012). The mean autoregressive effect is β10 for the reference group (healthy control individuals) and β10 + β11 for the MDD group. Therefore, the effect of interest is β11.
Finally, models structured like Model 11 are used to estimate a cross-level interaction effect between a continuous Level 2 predictor and the lagged outcome, to study if the Level 2 predictor moderates the autoregressive effect (e.g., Brose et al., 2015; Koval et al., 2013). Consequently, β11 is the effect of interest. In this case, Hamaker and Grasman (2015) clearly recommended person-mean centering the lagged predictor.
A Shiny App to Perform Power Analysis
In this section, we present the Shiny app, PowerAnalysisIL, that we developed to compute power as a function of the number of participants for the models described in the previous section. Figure 2 shows a screenshot of the opening page of the app, where users select the population model of interest, set the parameter values, and run their power analysis. The app was implemented using the R package shiny. It is available via a Git repository hosted on GitHub at https://github.com/ginettelafit/PowerAnalysisIL. Users can download the app and run it locally on their computer in R or RStudio (RStudio Team, 2015). In what follows, we describe how the app works.

Screenshot of the opening page of PowerAnalysisIL, a Shiny app to perform power analysis to select the number of participants in intensive longitudinal studies.
App input
First, the user indicates which multilevel model (i.e., Model 1–Model 11) will be used to estimate the effect of interest and specifies plausible values for all model parameters. For instance, if one wants to focus on differences in mean affect between individuals diagnosed with MDD and healthy control individuals, one selects Model 1. Next, the sample sizes that should be considered in the power computations have to be provided. In the case of Model 1, one has to set a range of values for the number of participants in the reference (healthy) group and the number of participants diagnosed with MDD. Using this information, the software will create a Level 2 dummy predictor indicating group membership for each group size. For instance, possible sample sizes for the healthy control and MDD groups could amount to 20, 30, 40, and 80 and 15, 20, 25, and 30, respectively. Then, one sets the expected number of completed equidistant observations per individual (e.g., 60). If the selected model includes continuous Level 1 or Level 2 predictors, their mean and standard deviation have to be provided, assuming that they are normally distributed. For Level 1 continuous predictors, one indicates whether they should be grand-mean or person-mean centered. Finally, one sets the estimation method (i.e., maximum likelihood [ML] or restricted maximum likelihood [REML] estimation 3 ), the desired significance level (α), and the number of Monte Carlo replicates in the power simulations (e.g., 1,000). For Models 1 through 8, the app also allows estimating multilevel models with independent errors (i.e., assuming ρε = 0). Comparing the power of models with and without AR(1) errors makes it possible to assess the impact of temporal dependence.
Simulation
On the basis of this input, the app repeatedly simulates the data for each indicated sample size. For the multilevel AR models (i.e., Models 9–11), simply sampling the random effects from a normal distribution might yield data that are not stationary (i.e., the normal distribution does not restrict the random autoregressive effects to belong to the interval [−1,1]). To guarantee stationarity, without changing the specified mean and standard deviation of the random slopes, we draw the random slopes from a beta distribution and linearly transform them so that they fall into the interval (−1,1). 4 For each simulated data set, the multilevel model is fitted by means of the lme function from the nlme package (Pinheiro et al., 2019), and the effect of interest is tested (i.e., two-sided Wald test). In case of convergence problems, the app shows a warning message signaling the total number of replicates that failed to converge. Convergence issues in multilevel models arise when the estimated covariance matrix of the random effects is singular (see Bates et al., 2015) and might be caused by not having enough observations within participants, by having a small number of participants, or by scaling issues (see, e.g., Clark, 2020). If this happens, we recommend evaluating the following alternatives: increasing the number of participants, increasing the number of repeated measurements per person, centering predictors, or checking the specified values of the model parameters. Finally, we note that the simulation-based approach is computationally intensive and therefore may demand a lot of computational time. Depending on the number of participants, the number of observations per participant, the number of Monte Carlo replicates, the population model of interest, and the operating system, the simulation can run for multiple hours. Therefore, while performing the power analysis, the app displays a message indicating the number of participants for which power is currently being computed. Moreover, users can estimate the expected number of hours necessary to perform the simulation analysis by using the “Estimate Computational Time” option. 5
App output
For the effect of interest as well as all other fixed effects included in the model, the app provides a power curve, which shows how the estimated power varies as a function of sample size (i.e., the number of participants). The estimated power is computed as the proportion of Monte Carlo replicates in which the effect was significant (at the specified α level). Furthermore, the app presents a summary of the results for each sample size. This summary includes power and measures to evaluate the estimation performance (see Morris et al., 2019): the average of the estimates of each fixed effect; the bias (i.e., the difference between the average of the estimates and the true value); the standard error; and the (1 − α)% coverage proportion, computed as the proportion of Monte Carlo replicates for which the (1 − α)% confidence interval includes the true value. Moreover, summary statistics are provided for the variance components of the within-individual errors (i.e., ρε in the AR(1) error in Models 1–8 and σε in Models 1–11) and for the random effects (i.e., standard deviations
Illustrations
In this section, we illustrate how the app can be used to perform a power analysis to decide on the number of participants needed to test three different research hypotheses. For all models, the values of a large number of model parameters have to be specified. We recommend choosing these values on the basis of data from a pilot study or existing IL studies with similar measures and designs (see, e.g., Lane & Hennes, 2018). To this end, we use information from a clinical data set reported on by Heininga et al. (2019).
Data set
The data set includes 38 individuals who have been diagnosed with MDD (score of 1 on the diagnosis variable) and 40 control participants (score of 0). They all participated in a 7-day ESM study, in which they were asked to repeatedly fill in a questionnaire containing 27 items measuring various constructs, including negative affect (i.e., affect; five items; responses were averaged) and anhedonia (one item). Participants answered these items on a sliding scale ranging from not at all on the left (0) to very much on the right (100). The questions were semirandomly presented 10 times a day between 9:30 a.m. and 9:30 p.m. within intervals of 66 min. Therefore, the design included 70 measurement occasions per participant. Depressive symptoms (depression) were measured before the ESM testing period using the sum score on the Quick Inventory of Depressive Symptomatology (Rush et al., 2003).
Illustration 1: power to estimate the effect of a Level 2 predictor
Suppose we are planning a study to test the hypothesis that depression is positively related to negative affect and thus want to run Model 2 (see Fig. 1). The data will be collected using an IL design, including 70 measurement occasions per individual. How many participants do we need to involve?
To perform the simulation-based power analysis, we need to specify the parameter values of the model of interest. Pilot data or the results from previous studies examining the same hypothesis can be used to obtain appropriate values. Here, we use the clinical data set and apply Model 2 to get estimates of these parameters. The continuous Level 2 predictor, depression, is centered using the grand mean. Table 4 shows the estimated parameter values. Note that estimation of this model is not part of the app (i.e., this step has to be conducted separately). In our OSF project page (https://osf.io/vguey/), we show how to obtain the parameter values of Model 2 using the clinical data set.
Illustration 1: Estimated Parameters Using the Clinical Data Set to Estimate the Effect of Depressive Symptoms on Negative Affect in Individuals With Major Depressive Disorder

Step 1: app input
We select Model 2 and fill in the values of the model parameters (see Figs. 3a and 3b). We indicate that we want to consider the following values for the number of participants: 15, 30, 45, 60, 80, and 100. We set the number of measurements within each participant to 70. We specify the fixed effects: The fixed intercept β00 is set to 43.01, and the effect of the Level 2 continuous variable β01 is set to 1.50. Next, we set the standard deviation, σε, and autocorrelation, ρε, of the within-individual errors as 12.62 and .46, respectively. The standard deviation of the random intercept,

Illustration 1: the effect of depression on negative affect in individuals with major depressive disorder. These screenshots of the PowerAnalysisIL app show (a) the window in which Model 2 has been selected and the sample size has been set, (b) the values to which the parameters of the model have been set, and (c) the power curve for estimating the effect of interest.
Step 2: app output
The app provides power curves showing power as a function of the indicated sample sizes. Figure 3c shows the estimated power curve for Illustration 1. We observe that when the number of participants is 15, the power for the effect of interest (i.e., β01 = 1.50) is 53.8%. This result implies that in only 538 out of the 1,000 simulated data sets, the null hypothesis that depression does not have a significant effect on negative affect was rejected. We observe that when the number of participants increases, the power increases as well. Specifically, power greater than 80% is achieved when the number of participants is greater than 30.
The app also provides information about the distribution of the estimates of the fixed and random effects across the Monte Carlo replicates. Table 5 shows the summary statistics for the fixed effects. For instance, the coverage rate for β01 is close to 95%, which indicates a satisfactory estimation of the 95% confidence interval. The app also calculates the power for the fixed intercept, although this is of little interest here.
Illustration 1: Summary of Fixed Effects in the Model of the Effect of Depression on Negative Affect in Individuals With Major Depressive Disorder

Note: This table summarizes results across 1,000 Monte Carlo replicates.
Illustration 2: power to detect the effect of a Level 1 predictor
Now we turn to the effect of a Level 1 predictor, anhedonia, on negative affect for individuals diagnosed with MDD, and thus to Model 3. To set the values of the model parameters, we again analyzed the clinical data set, and we obtained the results shown in Table 6.
Illustration 2: Estimated Parameters Using the Clinical Data Set to Estimate the Effect of Anhedonia on Negative Affect in Individuals With Major Depressive Disorder

Step 1: app input
We select Model 3 and set the sample size to the following numbers of participants: 15, 20, 30, 40, 60, and 100, restricting the number of measurements within participants to 70 (see Fig. 4a). Subsequently, we specify the associated parameter values (see Fig. 4b). The fixed intercept β00 is 42.90, and the fixed slope β10 is 0.13. The standard deviation of the Level 1 errors is 12.00, and the autocorrelation is .43. The standard deviations of the random intercept and random slope are 15.00 and 0.12, respectively. The correlation between the random effects is .003. The mean and standard deviation of the Level 1 variable are 51.70 and 23.70, respectively. To guarantee that the fixed slope reflects the (average) within-person association between anhedonia and negative affect, we select the option to person-mean-center the Level 1 variable. Finally, to account for temporal dependencies, we choose the option to estimate the AR(1) correlated errors.

Illustration 2: the effect of anhedonia on negative affect in individuals with major depressive disorder. These screenshots of the PowerAnalysisIL app show (a) the window in which Model 3 has been selected and the sample size has been set, (b) the values to which the parameters of the model have been set, and (c) the power curve for estimating the effect of interest.
Step 2: app output
From the power curve in Figure 4c, we conclude that power is greater than 99% when there are more than 15 participants. Summary statistics of the fixed effects can be found in Table 7. Table 8 shows the summary statistics of the estimated standard deviation and autocorrelation of the Level 1 errors, the standard deviations of the random effects, and the correlation between the random effects. We observe that when the number of participants increases, the bias of the estimates of
Illustration 2: Summary of Fixed Effects in the Model of the Effect of Anhedonia on Negative Affect in Individuals With Major Depressive Disorder

Note: This table summarizes results across 1,000 Monte Carlo replicates.
Illustration 2: Summary of the Variance Components in the Model of the Effect of Anhedonia on Negative Affect in Individuals With Major Depressive Disorder

Note: This table summarizes results across 1,000 Monte Carlo replicates.

Illustration 2: the effect of anhedonia on negative affect in individuals with major depressive disorder. This PowerAnalysisIL screenshot shows the distributions of the estimated parameters across 1,000 Monte Carlo replicates when the number of participants is 100. For each model parameter, a kernel density plot (upper plot) and a boxplot (lower plot) are presented. In the boxplots, the box extends from the 25th percentile to the 75th percentile, the solid vertical line represents the median, and the two lines outside the box extend to the minimum and maximum. The dashed vertical lines indicate the true model parameters.
Illustration 3: power to detect the differences in the autoregressive effects between two groups
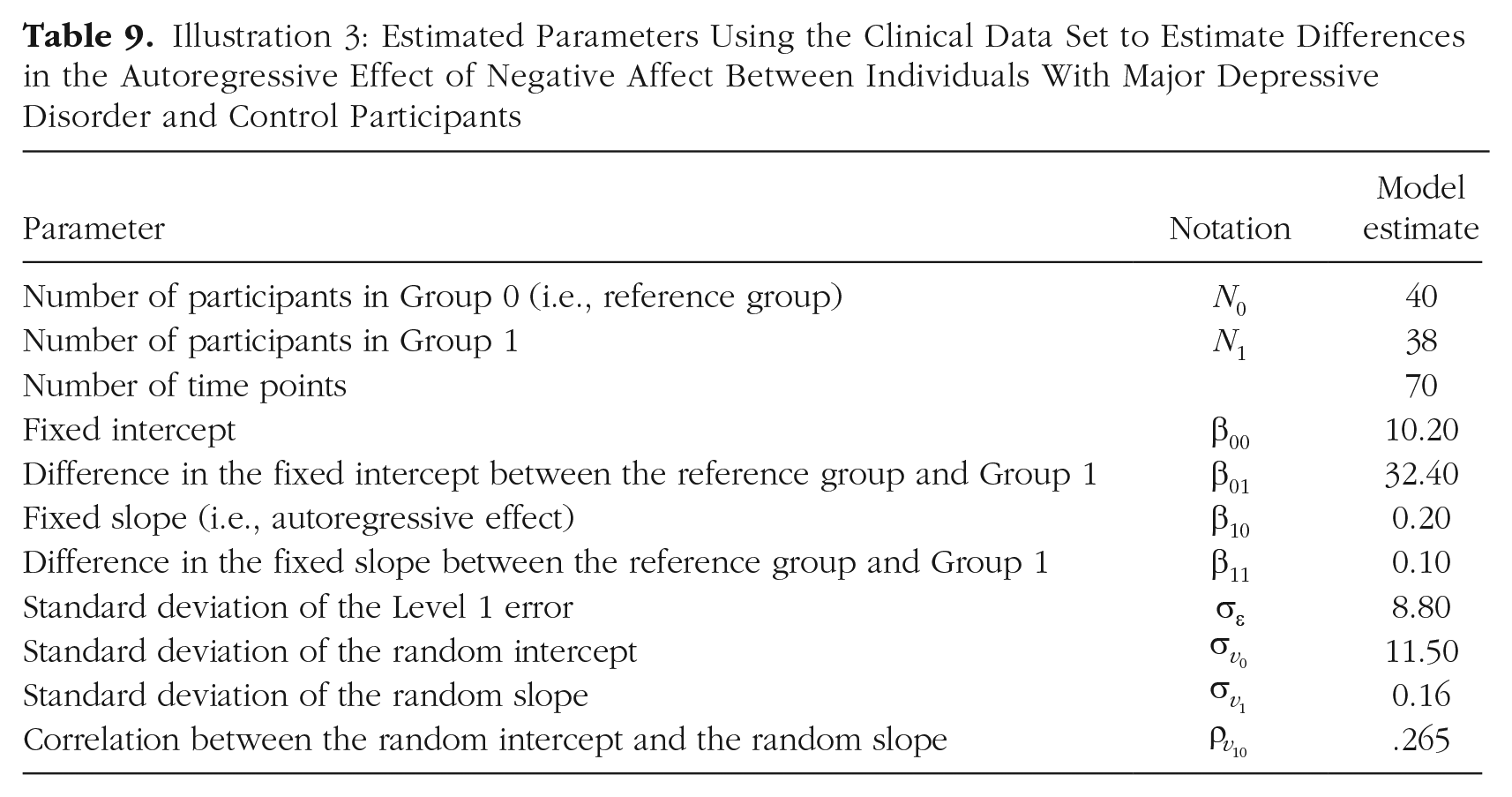
Finally, we focus on whether the autoregressive effect of negative affect differs between individuals diagnosed with MDD and control participants, and thus on Model 10. As in the previous examples, we use the clinical data set to obtain estimates of the parameter values, shown in Table 9.
Illustration 3: Estimated Parameters Using the Clinical Data Set to Estimate Differences in the Autoregressive Effect of Negative Affect Between Individuals With Major Depressive Disorder and Control Participants
Step 1: app input
We select “Model 10: Multilevel AR(1) model - Group differences in the autoregressive effects.” The number of participants in the reference group (i.e., healthy control group) and the number of participants in Group 1 (i.e., MDD group) are both set to 20, 40, 60, 80, 100, 200, and 250, and the number of measurements within participants is set to 70 (see Fig. 6a). We specify the parameter values as follows (see Fig. 6b): The fixed intercept (β00) is 10.20, and the difference in the fixed intercept between the two groups (β01) is 32.40. The autoregressive effect (β10) is 0.20. The difference in the autoregressive effect between the two groups (β11) is 0.10. The standard deviation of the Level 1 errors is 8.80. The standard deviations of the random intercept and random slope are 11.50 and 0.16, respectively. The correlation between the random effects is .265. We person-mean-center the lagged outcome variable.
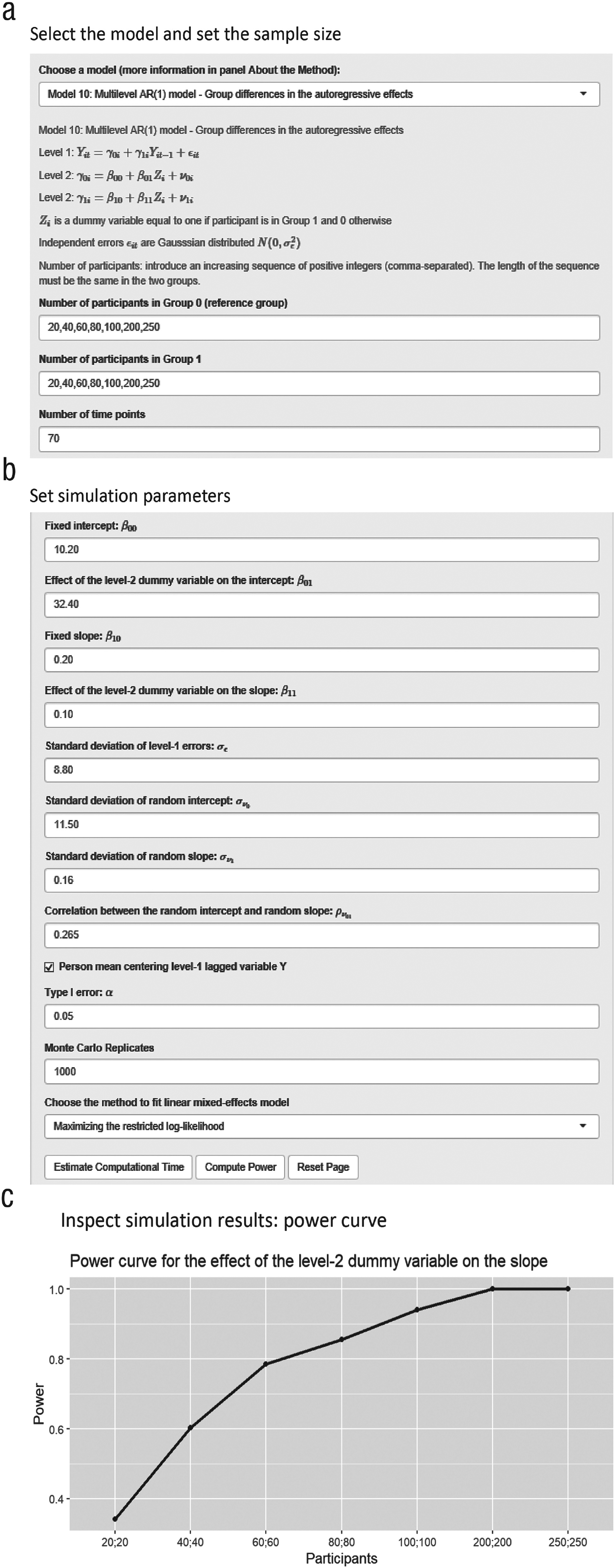
Illustration 3: differences between groups in the autoregressive effect of negative affect. These screenshots of the PowerAnalysisIL app show (a) the window in which Model 10 has been selected and the sample size has been set, (b) the values to which the parameters of the model have been set, and (c) the power curve for estimating the effect of interest.
Step 2: app output
Figure 6c shows the estimated power curve. The power to test the difference in the autoregressive effect (β11) between the two groups is larger than 80% when there are 80 participants diagnosed with MDD and 80 healthy control participants. As shown in Table 10, there is a downward bias in the estimated value of the fixed slope in the reference group (β10). Furthermore, when the number of participants increases, the 95% coverage proportion of the fixed slope diminishes. This is related to the bias in the estimate of the fixed slope and the narrowing of confidence intervals (i.e., smaller standard errors) when the sample size increases. This result is in line with Hamaker and Grasman’s (2015) simulations for this model, which showed that the estimated fixed slope is negatively biased when the lagged dependent variable is person-mean centered.
Illustration 3: Summary of Fixed Effects in the Model of Differences Between Groups in the Autoregressive Effect of Negative Affect

Note: This table summarizes results across 1,000 Monte Carlo replicates.
Discussion
IL designs allow studying within-person psychological dynamics. When multiple participants are included in an IL study, multilevel models are a powerful approach to capture these within-person processes as well as interindividual differences therein. When planning IL studies, it is obviously essential to collect a sufficient amount of data to ensure reliable estimates and sufficient power. In this article, we have focused on the number of participants who are needed to obtain sufficient statistical power for testing hypotheses about specific parameters of the multilevel models that are popular in IL studies. These power questions cannot be addressed by existing software for standard multilevel models, as standard models do not account for temporal dependencies in the outcome variable. Therefore, we have presented a Shiny app developed in R that uses simulation to compute power for models with an AR(1) error structure or with the lagged outcome variable as a predictor. The app yields power curves that show how estimated power varies as a function of the number of participants. In the following, we discuss limitations of the current version of the Shiny app as well as potential extensions.
Accommodating uncertainty about the hypothesized model parameters
Using simulation-based power analysis for multilevel models is challenging, in that users have to specify all the parameter values of the population model of interest. Following Lane and Hennes (2018) and Maxwell et al. (2008), we recommend basing these values on a literature review, on data from a pilot study (as we did by means of the clinical data set), or on previously conducted studies with similar measures and designs. Having said that, we acknowledge that the second and third approaches may imply that data are used from a small or unrepresentative sample, which may produce biased estimates as input for the power analysis (e.g., Albers & Lakens, 2018). Therefore, a more robust power-calculation approach would account for uncertainty regarding the hypothesized model parameters. This can be achieved by performing a sensitivity analysis in which the values of the model parameters are varied to some extent (e.g., Lane & Hennes, 2018; Y. A. Wang & Rhemtulla, 2021). This way, one can assess whether and to what extent using different possible parameter values influences the obtained power results. We note, however, that the current version of the app cannot display power curves as a function of sets of different plausible parameter values. Therefore, users have to perform a sensitivity analysis by conducting a separate power analysis for each set of parameter values.
Selecting the numbers of measurement occasions and persons
When multilevel modeling is applied to IL data, the obtained power is a function of both the number of measurement occasions and the number of participants. In this article, we have targeted the number of participants and kept the number and spacing of the measurement occasions fixed. Although this worked well for the research questions that we considered (i.e., we considered a relatively large number of measurement occasions), it is important to note that other research questions might call for increasing the number of measurement occasions. It makes sense, for instance, that when interindividual differences in within-person effects are of interest, the number of measurement occasions should be large as well. Indeed, earlier work of de Haan-Rietdijk et al. (2017), Krone et al. (2016), Liu (2017), Schultzberg and Muthén (2018), and Timmons and Preacher (2015) has demonstrated the effect that the number and spacing of the measurement occasions can have on estimation accuracy of multilevel approaches for IL data. Thus, how to best plan for adequate power depends on where power vulnerabilities are (see, e.g., Lane & Hennes, 2018).
What do users have to do when they are interested in studying not only how the number of participants affects power, but also how the number of measurement occasions affects power? Although one cannot get power curves for that from our app, a relatively simple solution consists of conducting repeated simulations with different numbers of measurement occasions while keeping the vector of sample sizes fixed. However, adding more participants or more measurements per participant may come with additional costs for researchers and may also increase participants’ burden. Therefore, researchers designing IL studies might be interested in balancing the two sample-size components to optimize power and minimize costs and participants’ burden. One way to achieve this is to obtain a set of combinations (i.e., of the number of participants and the number of measurement occasions per participant) that yield equal power and to select the combination that optimizes budgetary feasibility or other concerns. We note, however, that the current version of the app does not allow users to obtain such a set of combinations that produce equivalent power. We therefore recommend Brandmaier et al. (2015), Moerbeek (2011), and von Oertzen (2010) for a broader discussion on this topic.
Other remarks and future extensions
In the current Tutorial, we have illustrated how to use the PowerAnalysisIL app to estimate the number of participants needed for sufficient power to answer three specific research questions. For each research question, we focused on computing power for a single (fixed) effect. Yet the app also providespower curves for all other fixed effects included in a model. Therefore, in studies that involve testing multiple fixed effects, the number of participants should be large enough to detect all these effects with high power.
Even though the app is already quite extensive and includes no fewer than 11 models, many additional models could be included. For instance, in many applications, the objective is to assess the significance of the random effects. This is not possible in the current version of the app. Also, we have focused on two-levels models in which repeated measurements are nested within individuals. In the future, the proposed approach could be extended to three-level models (i.e., occasions nested within days, which in turn are nested within individuals). Three-level models are especially relevant if the dynamics under study differ systematically across days. Ignoring these differences could affect the reliability of the estimated results (de Haan-Rietdijk et al., 2016) and consequently the power.
The app simulates and analyzes data under the assumption that the measurement occasions are equally spaced and contain no missing data. In IL research, participants might not respond at some measurement occasions or during night breaks (e.g., Fuller-Tyszkiewicz et al., 2013; Santangelo et al., 2014; Stone et al., 2003). Whereas missingness might sometimes occur completely at random, in other cases it might be systematic (e.g., associated with certain affective states or certain times or contexts), which can lead to unreliable estimates (Courvoisier et al., 2012). To account for this, it would be useful to extend the simulation approach to study the effect of different types of missing data and attrition on power. For instance, when data can be assumed to be missing completely at random, users could simply specify the expected number of completed measurement occasions. Studying the effects of other mechanisms of missingness is more involved, however, because the mechanism has to be fully specified in order to simulate data.
Finally, we would like to highlight that power is not the only criterion to base sample-size selection on. Aside from maximizing the likelihood that a hypothesized effect in a population is detected, researchers might, for instance, be interested in increasing the precision of an estimate by controlling the width of the confidence interval of interest (e.g., Maxwell et al., 2008). Given that sample-size planning is important for the two related objectives of power and precision, our simulation-based approach could be extended in this direction, allowing users to additionally select the sample size that yields a targeted confidence-interval width.
Conclusion
This Tutorial has introduced a Shiny app for selecting the number of participants in IL designs. The application performs simulation-based power analysis for effects in multilevel models. We hope that the application contributes to good research practices by allowing rigorous sample-size planning for IL studies, which is of crucial importance to increase the reliability and replicability of psychological research.
Footnotes
Acknowledgements
We would like to thank our colleagues within the Research Group of Quantitative Psychology and Individual Differences and the Center for Contextual Psychiatry, particularly Leonie Cloos, for testing the app and providing useful feedback.
Transparency
Action Editor: Mijke Rhemtulla
Editor: Daniel J. Simons
Author Contributions
G. Lafit, J. K. Adolf, W. Viechtbauer, and E. Ceulemans conceptualized the application. G. Lafit, J. K. Adolf, and E. Ceulemans conceptualized the Tutorial. G. Lafit developed the Shiny app. G. Lafit and E. Dejonckheere analyzed and interpreted the clinical data set. G. Lafit, J. K. Adolf, and E. Ceulemans wrote the manuscript. E. Dejonckheere, I. Myin-Germeys, and W. Viechtbauer provided critical revisions of the manuscript and Shiny app.