
Abstract
Measurement quality has recently been highlighted as an important concern for advancing a cumulative psychological science. An implication is that researchers should move beyond mechanistically reporting coefficient alpha toward more carefully assessing the internal structure and reliability of multi-item scales. Yet a researcher may be discouraged upon discovering that a prominent alternative to alpha, namely, coefficient omega, can be calculated in a variety of ways. In this Tutorial, I alleviate this potential confusion by describing alternative forms of omega and providing guidelines for choosing an appropriate omega estimate pertaining to the measurement of a target construct represented with a confirmatory factor analysis model. Several applied examples demonstrate how to compute different forms of omega in R.
Keywords
Measurement is an important aspect of the replication crisis facing psychology and related fields (Fried & Flake, 2018; Loken & Gelman, 2017), and it is well known that measurement error produces biased estimates of the associations among constructs that observed variables represent (e.g., Cole & Preacher, 2014). Yet researchers often present very little reliability and validity evidence for their variables, frequently reporting only coefficient alpha to convey the psychometric quality of tests (Flake, Pek, & Hehman, 2017). Furthermore, psychometricians have established that alpha is based on a highly restricted (and thus unrealistic) psychometric model and consequently can provide misleading reliability estimates (e.g., Sijtsma, 2009). The persistent popularity of alpha suggests that applied researchers are not aware of its limitations or alternative reliability estimates.
Although many reliability estimates have been presented in the literature, distinguishing among them and their software implementations can be confusing. In this Tutorial, I describe the calculation of different forms of coefficient omega (McDonald, 1999), which are reliability estimates calculated from parameter estimates of factor-analytic models specified to represent associations between a test’s items and the test’s target construct. Thus, being informed of a test’s internal factor structure is inherent in choosing an appropriate omega estimate. The main purposes of this Tutorial are to clarify distinctions among different omega estimates and to demonstrate how they can be calculated using routines readily available in R (R Core Team, 2018). Throughout, I use example data to illustrate these reliability estimates.
Disclosures
The complete R code and output (as a single .rmd file and resulting .pdf file) for the examples presented, data files, and a supplementary document describing additional analyses are available on OSF, at https://osf.io/m94rp/.
What Is Reliability?
Observed scores on any given psychological test or scale are determined by a combination of systematic (signal) and random (noise) influences. Reliability is defined as a population-based quantification of measurement precision (e.g., Mellenbergh, 1996) as a function of the signal-to-noise ratio. Measurement error, or unreliability, produces biased estimates of effects meant to represent true associations among constructs (Bollen, 1989; Cole & Preacher, 2014), and measurement error is a culprit in the replication crisis (Loken & Gelman, 2017). Thus, using tests with maximally reliable scores and using statistical methods to account for measurement error (e.g., Savalei, 2019) can help psychology progress as a replicable science; calculating and reporting accurate reliability estimates is integral to this goal.
Although the reliability concept pertains to any empirical measurement, this Tutorial focuses on composite reliability, that is, the reliability of observed scores calculated as composites (i.e., the sum or mean) of individual test components. These individual components are most commonly items within a test or scale. A formal definition of composite reliability based on classical test theory (CTT; e.g., Lord & Novick, 1968) first posits that an observed score x for individual test taker i on item j equals the individual’s true score t for that item plus an error score e:
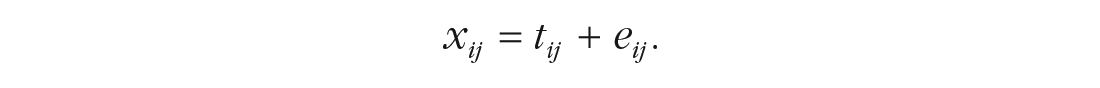
Next, if Xi denotes an individual’s observed total score, calculated by summing
1
the observed item scores (i.e., Xi =
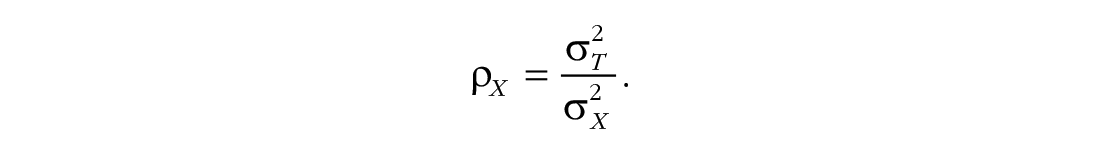
Because true scores are unobserved, reliability cannot be calculated directly from this formula, which has led to the development of various approaches to estimating reliability, most prominently coefficient alpha (Cronbach, 1951). (See Revelle & Condon, 2019, for a review relating composite reliability, test-retest reliability, and interrater reliability to this formal variance-ratio definition of reliability.)
It is important to recognize that the CTT true score does not necessarily equate to a construct score (Borsboom, 2005). Thus, a true score may be determined by a construct that a test is designed to measure (the target construct) as well as by other systematic influences. Most often, researchers want to know how reliably a test measures the target construct itself, and for this reason it is important to establish the dimensionality, or internal structure, of a test before estimating reliability (Savalei & Reise, 2019). Factor analysis is commonly used to investigate and confirm the internal structure of a multi-item test, and as shown throughout this Tutorial, parameter estimates of factor-analytic models lead to reliability estimates representing how precisely test scores measure target constructs represented by the models’ factors. In this framework, a one-factor model is adequate to explain the item-response data of a unidimensional test measuring a single target construct; conversely, poor fit of a one-factor model is evidence of multidimensionality. The formal definition of reliability from CTT can be adapted to this context so that reliability is the proportion of a scale score’s variance explained by a target construct (Savalei & Reise, 2019). Therefore, it is crucial to determine how a test represents that construct with respect to its internal factor structure. If reliability is estimated using the parameters of an incorrect (i.e., misspecified) factor model, then the reliability estimate is likely to be biased with respect to the measurement of the target construct. The key idea to this Tutorial is that a reliability coefficient should estimate how well an observed test score measures a target construct, which does not necessarily correspond to how well the score captures replicable variation because some replicable variation may be irrelevant to the target construct; thus, it is critical for the target construct to be accurately represented in a factor model for the test.
Because the reliability estimates presented herein are calculated from factor-analytic models, familiarity with factor analysis, especially confirmatory factor analysis (CFA; a type of structural equation modeling, or SEM), is beneficial. I emphasize the use of CFA over exploratory factor analysis (EFA) for reliability assessment because using CFA implies having strong, a priori hypotheses about the underlying causal associations between one or more target constructs (represented by the model’s factors) and observed item scores. In the preliminary stages of scale development, EFA is valuable for uncovering systematic influences on item responses that might map onto hypothesized constructs, whereas specification of a CFA model implies that the item-construct relations underpinning certain reliability estimates have been more well established (Flora & Flake, 2017; Zinbarg, Yovel, Revelle, & McDonald, 2006). Establishing these item-construct associations is critical for reliability to be meaningfully estimated because choice of an appropriate reliability estimate depends on the interpretation of the final measurement model chosen for a test (Savalei & Reise, 2019). For readers unfamiliar with CFA, I present basic principles that should enable use of the procedures presented here, but I strongly encourage such readers to acquire further background knowledge (e.g., see Brown, 2015).
This Tutorial focuses on forms of coefficient omega that estimate how reliably a total score for a test measures a single construct that is common to all items in the test, even if the test is multidimensional (e.g., a test designed to produce a total score as well as subscale scores). First, I demonstrate reliability estimation for unidimensional tests represented by one-factor models. Often, a test is designed to measure a single construct, but a one-factor model does not adequately represent the test’s internal structure. In this situation, reliability estimates based on a one-factor model are likely to be inaccurate, and instead reliability estimates should be based on a multidimensional (i.e., multifactor) model. In other situations, a test may be explicitly designed to measure multiple constructs (i.e., a test with subscales), but a meaningful total score is still of interest. Thus, after addressing the unidimensional case, I present omega estimates of total-score reliability for multidimensional tests; the online supplement addresses reliability assessment for subscale scores.
Reliability of Unidimensional Tests: Omega to Alpha
Figure 1 shows a path diagram of a one-factor model for a hypothetical 10-item test. Path diagrams represent latent variables, or factors, with ovals and represent observed variables (i.e., item-response variables in the present context) with rectangles. Linear associations are represented by straight, unidirectional arrows. For example, because the factor f and an error term e1 are the two entities with arrows pointing at item x1 in Figure 1, f and e1 are the two linear influences on x1. The arrow from f to x1 is labeled as λ1, which is a factor-loading parameter giving the strength of the association between f and x1. The effects implied by these two arrows in the path diagram combine to form the linear regression equation
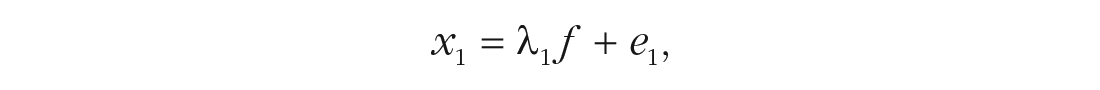
which indicates that item x1 is a dependent variable regressed on the factor f as a single independent variable with slope coefficient λ1 and error e1. This one-factor model consists of an analogous equation for each observed item such that
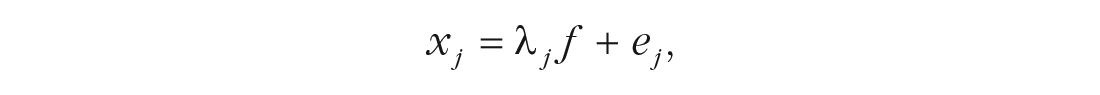
where xj is the jth item regressed on factor f with factor loading λ j (the intercept term is omitted from this and other equations without loss of generality). This equation in which item scores are influenced by a single factor, but to varying degrees (i.e., λ j varies across items), is known as the congeneric model in the psychometric literature. As shown later, when a model consists of more than one factor, this equation expands to a multiple regression equation with each xj simultaneously regressed on multiple factors.
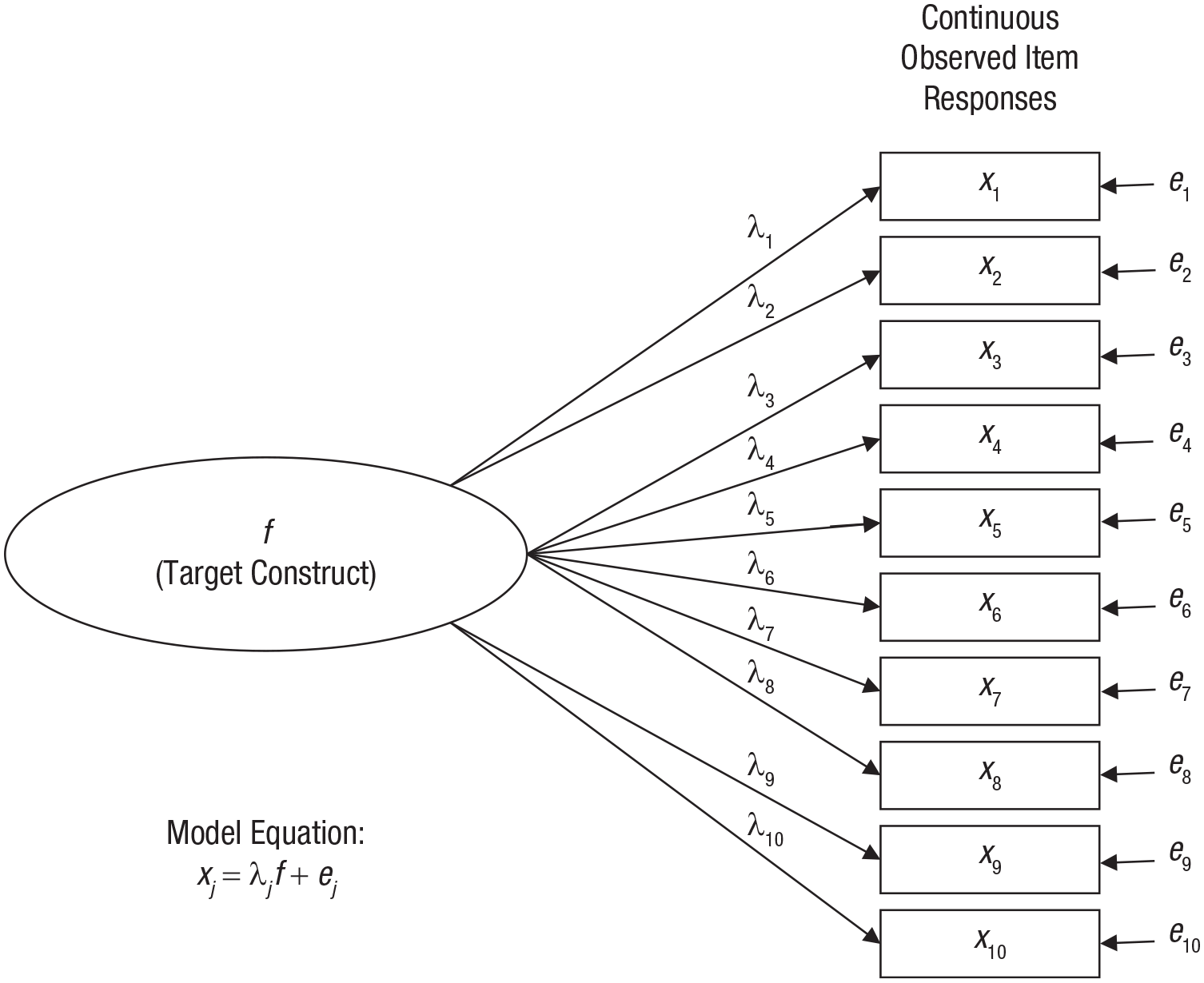
One-factor model for a unidimensional test consisting of 10 continuously scored items. See the text for further explanation.
Because scores on the factor f are unobserved, the λ j factor-loading parameters cannot be estimated with the usual ordinary least squares method for linear regression. Instead, the factor loadings (and other model parameters) are estimated as a function of a covariance (or correlation) matrix among the observed item scores, typically using a maximum likelihood (ML) function. In addition to factor loadings, other model parameters include the factor variance and the variances of the individual error terms. Because the factor is unobserved, its scale is arbitrary, and the model cannot be estimated (i.e., the model is not identified) unless a parameter is constrained to define the factor’s scale. In all the examples in this Tutorial, I have set the scale of each factor by constraining its variance to be equal to 1 (which also serves to simplify equations for omega reliability estimates). 2 A variety of statistics is available to evaluate how well a CFA model fits the item-level data (and thereby evaluate the tenability of unidimensionality). In the examples presented, I report the root mean square error of approximation (RMSEA), comparative-fit index (CFI), and Tucker-Lewis index (TLI); smaller values (e.g., .08 or lower) of RMSEA are indicative of better model fit, whereas larger values (e.g., .90 or greater) of CFI and TLI indicate better model fit.
Coefficient omega
Numerous authors have shown that if the equation for the CTT true score is reexpressed as the one-factor model such that an individual’s true score tij for item j is presumed to equal the product of the item’s factor loading λ
j
and the individual’s factor score fi (i.e., tij = λjfi ) and the factor variance is fixed to 1, then reliability is a function of the factor-loading parameters (e.g., Jöreskog, 1971; McDonald, 1999). Conceptually, because the factor loading quantifies the strength of the association between an item and a factor, the extent to which a set of items (as represented by their total score) reliably measures the factor is a function of the items’ factor loadings. Therefore, the reliability of the total score on a unidimensional test can be estimated from parameter estimates of a one-factor model fitted to the item scores. I refer to this reliability estimate as ω
u
, and its formula is presented in Table 1: The numerator of ω
u
represents the amount of total-score variance explained by the common factor f as a function of the estimated factor loadings (i.e., the numerator estimates the
Formulas for Coefficient Omega Estimates for Three Underlying Factor Models

Note: For the one-factor model, λ
j
is the factor loading for generic item xj, f is an unobserved factor (or latent variable), and ej is the error term for item j. For categorical items, τ
jc
refers to a threshold parameter used to link continuous latent-response variable
The
After the one-factor model is estimated, one can obtain a residual covariance (or correlation) matrix to diagnose the presence of large error covariance between any pair of items; a residual covariance between two items is the difference between their observed covariance and the corresponding model-implied covariance. Green and Yang (2009a) described scenarios in which a unidimensional test might produce correlated errors, although large residual correlations may also be evidence of multidimensionality. Large residual correlations diminish the fit of the one-factor model to data, which can prompt researchers to modify their hypothesized CFA model to explicitly specify free error-covariance parameters. 5
Coefficient alpha
If the population factor loadings are equal across all items, then the j subscript can be dropped from λ in the equation for the one-factor model, which leads to what is known as the essential tau-equivalence model. If this model is correct, it can be shown that ω u is equivalent to alpha as long as the errors ej remain uncorrelated (see McDonald, 1999, or Green & Yang, 2009a, for details). Taken together, alpha is an estimate of total-score reliability for the measurement of a single construct common to all items in a test under the conditions that (a) a one-factor model is correct (i.e., the test is unidimensional), (b) the factor loadings are equal across all items (i.e., essential tau equivalence), and (c) the errors ej are independent across items. Because it is unlikely for all of these conditions to hold in any real situation, some researchers have called for abandoning alpha in favor of alternative reliability estimates (e.g., McNeish, 2018). However, Savalei and Reise (2019) contended that only severe violations of essential tau equivalence cause alpha to produce a notably biased reliability estimate, whereas multidimensionality and error correlation are more likely to be problematic for the interpretation of alpha as a reliability estimate for the measurement of a single target construct (Green & Yang, 2009a; Zinbarg et al., 2006), largely because alpha does not disentangle replicable variation due to a target construct from other sources of replicable variation.
Overall, estimates of ω u are unbiased with varying factor loadings (i.e., violation of tau equivalence), when alpha underestimates population reliability (e.g., Zinbarg, Revelle, Yovel, & Li, 2005). Furthermore, Yang and Green (2010) showed that ω u estimates are largely robust when the estimated model contains more factors than the true model, even with samples as small as 50. Trizano-Hermosilla and Alvarado (2016) found that increasing levels of skewness in the univariate item distributions produced increasingly negatively biased ω u estimates, especially for short tests (i.e., six items in their study), but that item skewness caused greater bias for alpha than for ω u .
Example calculation of ω u in R
To demonstrate calculation of ω u using R, I use data for five items measuring the personality trait openness as completed by 2,800 participants in the Synthetic Aperture Personality Assessment project (Revelle, Wilt, & Rosenthal, 2010). These data are available on this Tutorial’s OSF site as well as in the psych package for R (Revelle, 2020). These items have a 6-point, ordered categorical Likert-type response scale and thus are treated as continuous variables for CFA and reliability estimation; as I describe later, when items have fewer than five response categories, it is important to explicitly account for their categorical nature. With these data, alpha equals .60 for the five-item openness test, but one should not justify using alpha by merely assuming that the test is unidimensional and that its scores conform to the essential tau-equivalence model; rather, the test’s factor structure should be tested to determine an appropriate reliability estimate. Furthermore, it is important to note that I reverse-scored two negatively worded items (Items O2 and O5) before fitting one-factor CFA models to the data because not doing so would produce a mix of positive and negative factor loadings. Such a mix will reduce the numerator of ω u and lead to a misleadingly low reliability estimate; the absolute strength of the factor loadings is what should matter in representing how well the items measure the factor.
For all examples in this Tutorial, I used the R package lavaan (Version 0.6-5; Rosseel, 2012) to estimate CFA models. Once a CFA model was estimated, functions from the semTools package (Version 0.5-3; Jorgensen, Pornprasertmanit, Schoemann, & Rosseel, 2020) were used to obtain reliability estimates based on the CFA model object created by lavaan. I have assumed that readers have some elementary familiarity with R, including how to install packages and manage data sets (files on the OSF site provide complete code corresponding to all examples in this Tutorial). The lavaan package is loaded as follows:
In this example, I fitted the one-factor model depicted in Figure 1 to the data for the five openness items using direct ML estimation to incorporate cases with incomplete data (see Brown, 2015). The one-factor model (here named
This string indicates that a factor named
The
The results can be viewed using the summary function:
The
The factor-loading estimates of the
These estimates of
This call to
The results listed in the
As is any statistic calculated with sample data, ω
u
is a point estimate of a population parameter and is subject to sampling error; thus, its precision can be conveyed with a confidence interval (CI). Kelley and Pornprasertmanit (2016) reviewed different approaches to constructing CIs around omega estimates, ultimately recommending bootstrapping. The
The output gives
Although the factor-loading estimates varied across items, the difference between ω
u
and alpha (.61 vs. .60) is quite small. But, as mentioned earlier, when a one-factor model includes error correlations among items, the difference between ω
u
and alpha can be substantial. In this case, the
The second line uses the
Factor Analysis of Ordered, Categorical Items
Most often, item responses are scored with an ordered, categorical scale (e.g., Likert-type items scored with discrete integers) or a binary response scale (e.g., 1 = yes, 0 = no). These scales produce categorical data for which the traditional, linear factor-analytic model is technically incorrect; thus, fitting CFA models to the observed Pearson product-moment covariance (or correlation) matrix among item scores can produce inaccurate results (see Flora, LaBrish, & Chalmers, 2012). Just as binary or ordinal logistic regression is recommended over linear multiple regression for a categorical outcome, a categorical-variable method is recommended for factor analysis of categorical item scores: One can fit a CFA model to polychoric correlations, rather than product-moment covariance or correlations, to account for items’ categorical nature (see Finney & DiStefano, 2013). A polychoric correlation measures the bivariate association between two binary or ordinally scaled variables, explicitly accounting for its nonlinear nature, and is thus appropriate for representing the associations among items eliciting ordered, categorical responses. As the number of item-response categories increases (e.g., to five or more response options), the item scores may behave more like continuous variables, and so CFA estimates obtained with product-moment covariances become closer to results obtained with polychoric correlations (Rhemtulla et al., 2012).
CFA models can be readily fitted to polychoric correlations with most SEM software, including the lavaan package in R. Doing so subtly revises the one-factor model given earlier to
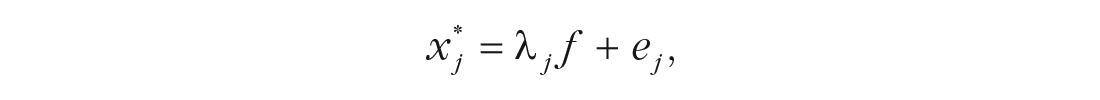
such that now the factor loading λ
j
represents the strength of the linear association between the factor f and a latent-response variable
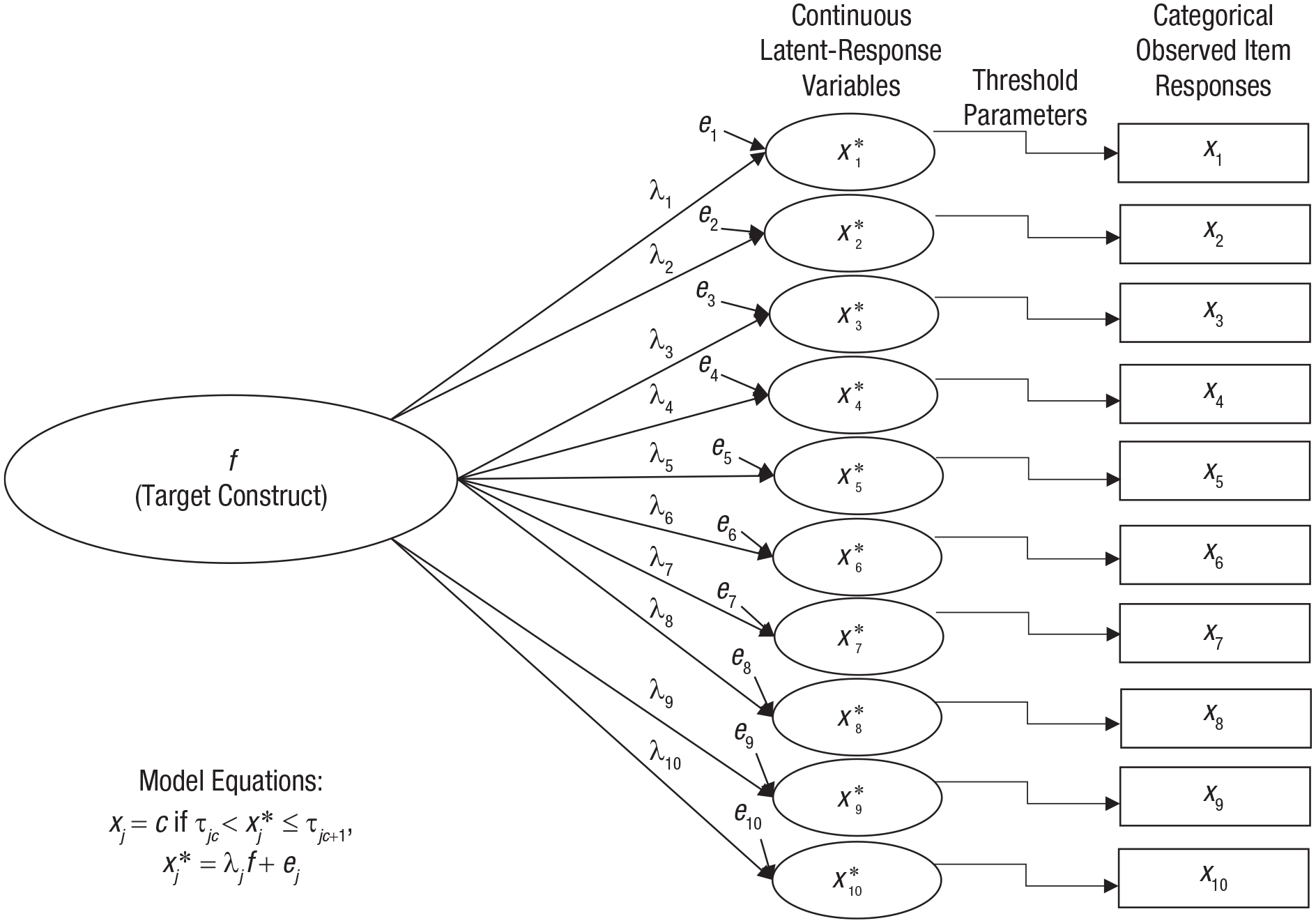
One-factor model for a unidimensional test consisting of 10 ordinally scaled items. See the text for further explanation.
Categorical omega
Because the factor loadings estimated from polychoric correlations represent the associations between the factor and latent-response variables rather than the observed item responses themselves, applying the ω
u
formula presented earlier in this context would give the proportion of variance explained by the factor relative to the variance of the sum of the latent-response variables (i.e.,
Yang and Green (2015) asserted that applied researchers should be more interested in the reliability of an observed total score X than in the reliability of a latent total score X* because observed scores, rather than latent scores, are most frequently used to differentiate among individuals in research and practice. Yang and Green established that, compared with ω u , ω u-cat produces more accurate reliability estimates for total score X with ordinal item-level data, especially when the univariate item-response distributions differ across items.
Example calculation of ω u-cat in R
To demonstrate estimation of ω u-cat in R, I use data from a subsample of 500 participants who completed the four-item psychoticism scale by Jonason and Webster (2010) online via an open-access personality-testing website (https://openpsychometrics.org/about). With these data, alpha for the psychoticism scale was .77, but it should not be assumed that the scale is unidimensional and conforms to the essential tau-equivalence model; instead, its factor structure should be tested to determine an appropriate reliability estimate. Because the psychoticism items have a 4-point response scale, I fitted the one-factor model to the interitem polychoric correlations using WLSMV, a robust weighted least squares estimator that is recommended over the ML estimator for CFA with polychoric correlations (Finney & DiStefano, 2013).
Specifically, the one-factor model is specified in the same way as in the previous example with items treated as continuous variables:
This code indicates that the factor
But now, the
Again, the results can be viewed using the
This call to
Results listed in the
These results also give an estimate of alpha (.80) that differs from the estimate reported earlier for the psychoticism scale (i.e., .77); this alpha is an example of ordinal alpha (Zumbo, Gadermann, & Zeisser, 2007) because it is based on the model estimated using polychoric correlations, whereas the first alpha estimate used the traditional calculation from interitem product-moment covariances. Note that ordinal alpha is a reliability estimate for the sum of the continuous, latent-response variables (i.e., x* variables described earlier) rather than for X, the sum of the observed, categorical item-response variables (Yang & Green, 2015). Additionally, ordinal alpha still carries the assumption of equal factor loadings (i.e., tau equivalence). For these reasons, I advocate ignoring the
As with ω
u
, the
includes the option
In sum, because the psychoticism items have only four response categories, any reliability estimate based on a factor-analytic model should account for the items’ categorical nature. Because the one-factor model adequately explains the polychoric correlations among the items, it is reasonable to consider the psychoticism scale a unidimensional test. Therefore, ω u-cat = .79 (95% CI = [.75, .83]) is an appropriate estimate of the proportion of the psychoticism scale’s total-score variance that is due to a single psychoticism factor.
Reliability Estimates for Multidimensional Scales
Often, tests are designed to measure a single construct but end up having a multidimensional structure, especially as the content of the test broadens. Occasionally, multidimensionality is intentional, as when a test is designed to produce subscale scores in addition to a total score. In other situations, the breadth of the construct’s definition or the format of items produces unintended multidimensionality, even if a general target construct that influences all items is still present. In either case, the one-factor model presented earlier is incorrect, and thus it is generally inappropriate to use alpha or ω u to represent the reliability of a total score from a multidimensional test. Instead, reliability estimates for observed scores derived from multidimensional tests should be interpretable with respect to the target constructs.
For example, Flake, Barron, Hulleman, McCoach, and Welsh (2015) developed a 19-item test to measure a broad construct, termed psychological cost, from Eccles’s (2005) expectancy-value theory of motivation. Although this psychological-cost scale (PCS) was designed to produce a meaningful total score representing a general cost construct, the item content was derived from several more specific content domains (termed task-effort cost, outside-effort cost, loss of valued alternatives, and emotional cost). Consequently, although a general cost factor is expected to influence responses to all 19 items, it may be best to consider the PCS multidimensional because of excess covariance among items from the same content domain beyond the covariance explained by a general construct.
Bifactor models
One way to represent such a multidimensional structure is with a bifactor model, in which a general factor influences all items and specific factors (also known as group factors) capture covariation among subsets of items that remains over and above the covariance due to the general factor. Specific factors do not represent subscales per se but instead represent the shared aspects of a subset of items that are independent from the general factor (in fact, in some situations, specific factors may be used to capture method artifacts, such as item-wording effects). A bifactor model for the PCS includes a general cost factor influencing all items along with four specific factors capturing excess covariance among items from the same content domain. A path diagram of this model is in Figure 3, which shows that each item has a nonzero general-factor loading (i.e., the general factor, g, influences all items) along with a nonzero loading on a specific factor pertaining to the item’s content domain (i.e., each specific factor, sk, influences only a subset of items). Because each item is directly influenced by two factors, the equation for this model is a multiple regression equation with each item simultaneously regressed on the general factor and one of the specific factors. The general factor must be uncorrelated with the specific factors to guarantee model identification (Yung, Thissen, & McLeod, 1999), whereas in other CFA models, all factors freely correlate with each other (allowing the general factor in a bifactor model to correlate with one of the specific factors causes errors such as nonconvergence or improper solutions).
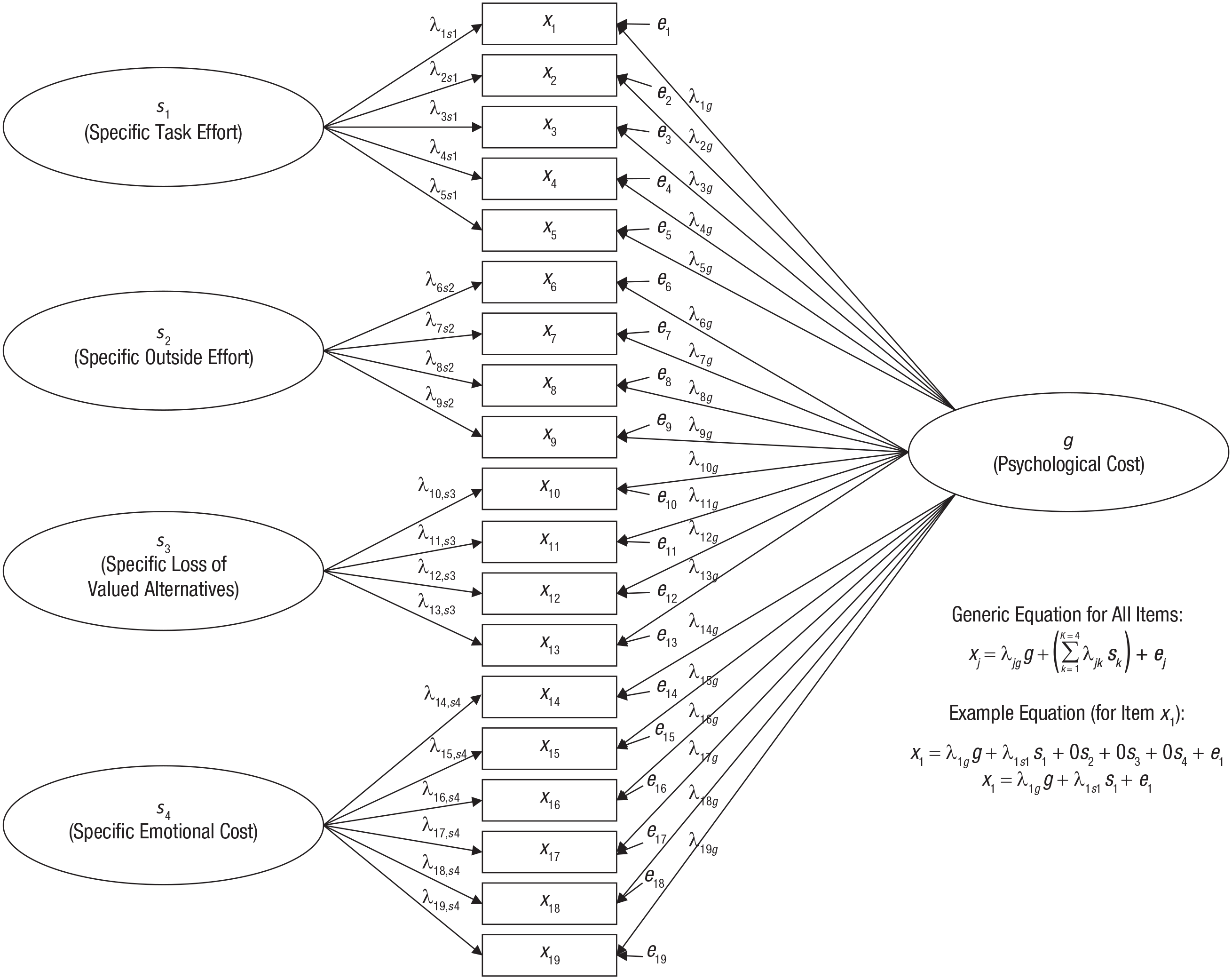
Bifactor model for the psychological-cost scale. See the text for further explanation.
Omega-hierarchical
When item-response data are well represented by a bifactor model, a reliability measure known as omega-hierarchical (or ω h ) represents the proportion of total-score variance due to a single, general construct that influences all items, despite the multidimensional nature of the item set (Rodriguez, Reise, & Haviland, 2016; Zinbarg et al., 2005). Just as the parameter estimates from a one-factor model are used to estimate reliability with ω u , parameter estimates from a bifactor model are used to calculate ω h , the formula of which is in Table 1. This formula for ω h is like that for ω u , except that the numerator is a function of the general-factor loadings only; the denominator again represents the estimated variance of the total score X. Therefore, ω h represents the extent to which the total score provides a reliable measure of a construct represented by a general factor that influences all items in a multidimensional scale over and above extraneous influences captured by the specific factors.
Although several prominent resources have presented ω h and discussed its conceptual advantages for estimating reliability of total scores from multidimensional tests (e.g., McDonald, 1999; Revelle & Zinbarg, 2009; Rodriguez et al., 2016; Zinbarg et al., 2005), little research has studied the finite-sample properties of ω h estimates. Notably, Zinbarg et al. (2006) showed that ω h estimates calculated using the CFA method described here are largely unbiased and are more accurate reliability estimates than alpha, showing trivial effects of design factors including the magnitude and heterogeneity of factor loadings, variation in sample size ranging from 50 to 200, the number of items, the number of specific factors, and the presence of cross-loadings. Yet no research to date has directly addressed whether ω h estimates are robust to model misspecification (e.g., incorrectly using a bifactor model for a test with a different multidimensional structure).
As with ω u , when the bifactor model is fitted to polychoric correlations among ordered, categorical items, applying the formula for ω h leads to a reliability estimate in the x* latent-response-variable metric rather than the metric of the observed total score X. Instead, the approach of Green and Yang (2009b) can be applied to produce a version of ω h that gives a reliability estimate of the proportion of total observed score variance due to the general factor; this estimate is referred to as ω h-cat . Although ω h-cat is not presented in Table 1, its equation is simply an adaptation of the equation for ω u-cat in which the loadings from the one-factor model are replaced with general-factor loadings from a bifactor model.
Example calculation of ω h in R
To demonstrate the estimation of ω h using R, I use data my colleagues and I collected administering the PCS to 154 students in an introductory statistics course (Flake, Ferland, & Flora, 2017). With these data, alpha for the PCS total score is .96, but this may be a misleading reliability estimate because of multidimensionality; that is, alpha is a function of total variance due to all systematic influences on the items (i.e., both general and specific factors) rather than a measure of how reliably the total score measures a single target construct represented by a general factor. I fitted the bifactor model depicted in Figure 3 to the item-response data, treating the item responses as continuous variables because they were given on a 6-point scale.
The syntax to specify the bifactor model for lavaan is
where
where the
The results from the
produces the following output:
Estimates listed under the
Higher-order models
In this bifactor-model example, I considered multidimensionality among the PCS items a nuisance for the measurement of a broad, general psychological-cost target construct. In other situations, researchers may hypothesize an alternative multidimensional structure such that there is a broad, overarching construct indirectly influencing all items in a test through more conceptually narrow constructs that directly influence different subsets of items. Such hypotheses imply that the item-level data arise from a higher-order model, in which a higher-order factor (also known as a second-order factor) causes individual differences in several more conceptually narrow lower-order factors (or first-order factors), which in turn directly influence the observed item responses. In this context, researchers may evaluate the extent to which the test produces reliable total scores (as measures of the construct represented by the higher-order factor) as well as subscale scores (as measures of the constructs represented by the lower-order factors).
When item scores arise from a higher-order model, a reliability measure termed omega-higher-order, or ω
ho
, represents the proportion of total-score variance that is due to the higher-order factor; parameter estimates from a higher-order model are used to calculate ω
ho
. As does ω
h
, ω
ho
represents the reliability of a total score for measuring a single construct that influences all items, despite the multidimensional nature of the test. Thus, the conceptual distinction between ω
h
and ω
ho
owes to the subtle difference between the interpretation of the general factor in the bifactor model and the higher-order factor in the higher-order model: In short, whereas the bifactor model’s general factor influences all items directly (while the specific factors are held constant), a higher-order factor influences all items indirectly via the lower-order factors (see Yung et al., 1999, for further detail). The online supplement to this article presents a formula for ω
ho
and demonstrates the estimation of a higher-order model for the PCS and subsequent calculation of ω
ho
as a function of the model’s parameter estimates. When the
Exploratory Omega Estimates
The examples presented thus far used
Conclusion
Researchers should not mechanistically report alpha and instead should investigate the internal dimensional structure of a test to choose an appropriate reliability estimate for the measurement of a construct of interest, that is, an appropriate form of coefficient omega. This Tutorial has described alternative forms of omega that depend on a test’s underlying factor structure. Examples have been presented to demonstrate how to compute different omega estimates in R, mainly using
The flowchart in Figure 4 summarizes recommendations for choosing an appropriate omega estimate; this chart applies to a situation in which a test is intended to measure a construct that is common to all items. The dimensional structure of the test determines the appropriate form of omega: ω u (or ω u-cat if the item responses are categorical) is appropriate for a unidimensional test (i.e., the item-response data conform to a one-factor model), and ω h or ω ho (or the categorical-variable analogue) is appropriate for the reliability of a total score calculated from a multidimensional item set conforming to a bifactor or higher-order model, respectively. If the test is multidimensional but a suitable CFA model cannot be hypothesized or does not adequately fit the data, then an EFA approach can be used both to discover potential reasons for multidimensionality and to obtain a preliminary, exploratory omega estimate.
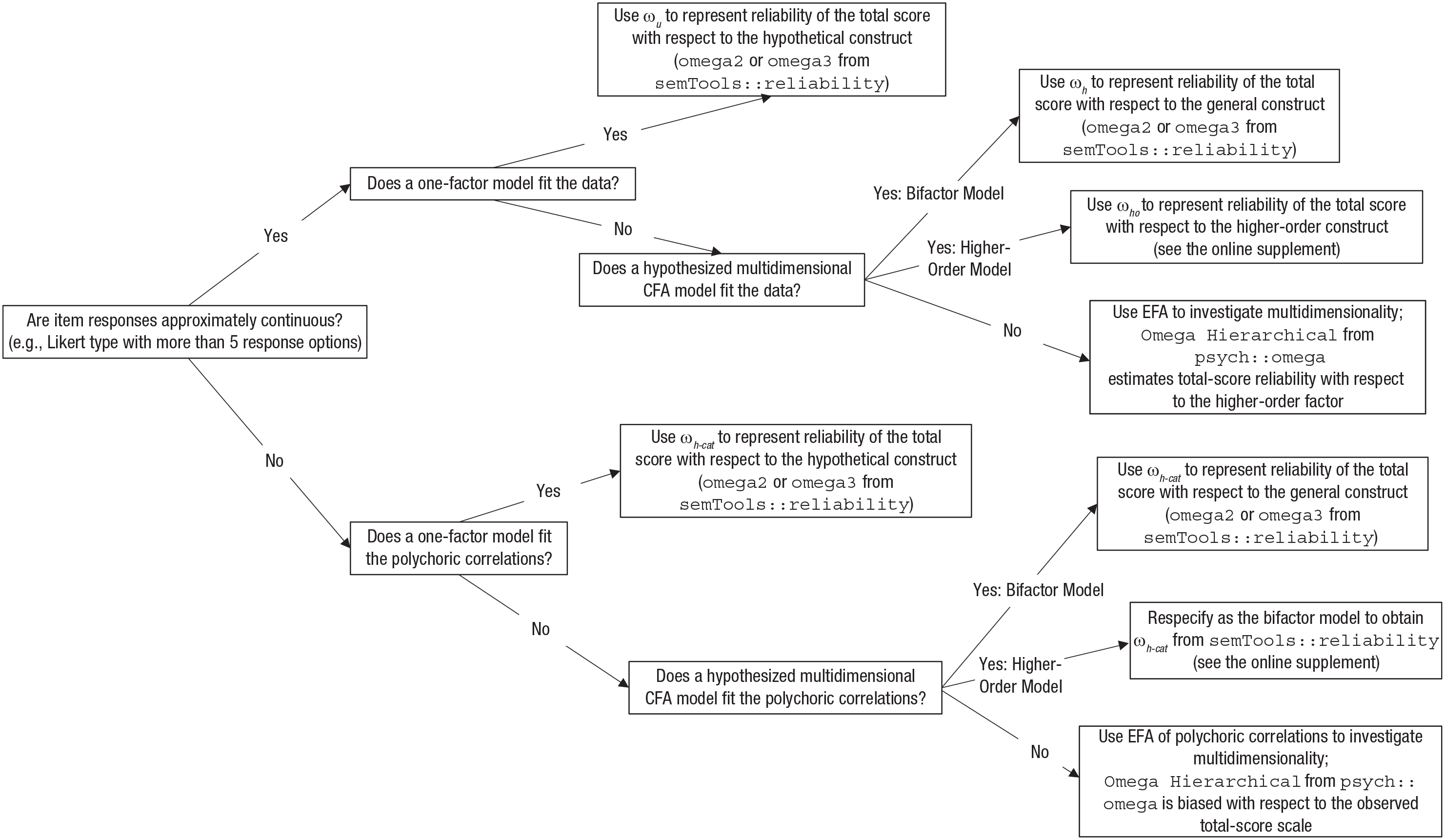
Flowchart for determining the appropriate omega estimate for measurement of a hypothetical construct influencing all items in a scale. CFA = confirmatory factor analysis; EFA = exploratory factor analysis.
An important issue often overlooked is that item responses typically have a categorical scale; therefore, deciding whether to treat the data as categorical (i.e., by fitting the factor model to polychoric correlations) affects both model-fit statistics and parameter estimates used to calculate omega estimates. Furthermore, Green and Yang (2009b) showed that when the measurement model is fitted to polychoric correlations, it is necessary to rescale the model’s parameter estimates to obtain reliability estimates in the metric of the observed total-score scale instead of a latent-response scale; ω u-cat is an appropriate substitute for ω u in this situation.
Although the essential tau-equivalence model underlying alpha is unlikely to be correct for a given test, it is also important for an omega estimate to be based on a properly specified measurement model, which highlights the importance of model comparisons and replication for evaluating a test’s internal structure (using factor analysis) and ultimately estimating the reliability of its scores. Further research is needed to examine the finite-sample properties of different omega estimates under correct model specification as well as their robustness to model misspecification, especially for multidimensional cases. Nevertheless, the extant studies clearly support a general preference for omega estimates over alpha (e.g., Trizano-Hermosilla & Alvarado, 2016; Yang & Green, 2010; Zinbarg et al., 2006). Yet, just as researchers should not blindly report alpha for the reliability of a test, they should not thoughtlessly report an omega coefficient without first investigating the test’s internal structure. The main conceptual benefit of using an omega coefficient to estimate reliability is realized when omega is based on a thoughtful modeling process that focuses on how well a test measures a target construct. Moving beyond mindless reliance on coefficient alpha and giving more careful attention to measurement quality is an important aspect of overcoming the replication crisis.
Supplemental Material
Flora_AMPPSOpenPracticesDisclosure – Supplemental material for Your Coefficient Alpha Is Probably Wrong, but Which Coefficient Omega Is Right?: A Tutorial on Using R to Obtain Better Reliability Estimates
Supplemental material, Flora_AMPPSOpenPracticesDisclosure for Your Coefficient Alpha Is Probably Wrong, but Which Coefficient Omega Is Right?: A Tutorial on Using R to Obtain Better Reliability Estimates by David B. Flora in Advances in Methods and Practices in Psychological Science
Footnotes
Acknowledgements
I would like to thank Reviewer 3 for detailed and constructive guidance across several drafts of this manuscript.
Transparency
Action Editor: Mijke Rhemtulla
Editor: Daniel J. Simons
Author Contributions
D. B. Flora is the sole author of this manuscript and is responsible for its content.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.