
Abstract
Psychological science relies on behavioral measures to assess cognitive processing; however, the field has not yet developed a tradition of routinely examining the reliability of these behavioral measures. Reliable measures are essential to draw robust inferences from statistical analyses, and subpar reliability has severe implications for measures’ validity and interpretation. Without examining and reporting the reliability of measurements used in an analysis, it is nearly impossible to ascertain whether results are robust or have arisen largely from measurement error. In this article, we propose that researchers adopt a standard practice of estimating and reporting the reliability of behavioral assessments of cognitive processing. We illustrate the need for this practice using an example from experimental psychopathology, the dot-probe task, although we argue that reporting reliability is relevant across fields (e.g., social cognition and cognitive psychology). We explore several implications of low measurement reliability and the detrimental impact that failure to assess measurement reliability has on interpretability and comparison of results and therefore research quality. We argue that researchers in the field of cognition need to report measurement reliability as routine practice so that more reliable assessment tools can be developed. To provide some guidance on estimating and reporting reliability, we describe the use of bootstrapped split-half estimation and intraclass correlation coefficients to estimate internal consistency and test-retest reliability, respectively. For future researchers to build upon current results, it is imperative that all researchers provide psychometric information sufficient for estimating the accuracy of inferences and informing further development of cognitive-behavioral assessments.
In essence, it is as if I-P [information-processing] researchers have been granted psychometric free rein that would probably never be extended to researchers using other measures, such as questionnaires.
The central argument of this article is that psychological science stands to benefit greatly from adopting a standard practice of estimating and reporting the reliability of behavioral assessments. Behavioral assessments are commonly used in psychological science to examine cognitive processing, yet they rarely receive sufficient psychometric scrutiny. Here, we outline how reporting basic psychometrics will improve current research practices in psychological science. We use an example from experimental psychopathology showing that early adoption of such a practice would have avoided years of research using measures unsuited to individual differences research. More generally, our recommendations apply to any approach that relies on behavioral measures of cognitive functions, which we refer to as cognitive-behavioral measures. We echo the concern Vasey et al. (2003) expressed 16 years ago in the passage we quoted to open this article. Our impression is that although pockets of information-processing researchers have begun to appreciate the importance of measure reliability, little has changed in practice. We hope that this article helps to spark the small changes required to achieve a conceivably significant improvement in the quality and practice of research in experimental psychopathology, as well as psychological science more generally.
All measures, and therefore all analyses, are “contaminated” by measurement error. Reliability estimates provide researchers with an indication of the degree of contamination, enabling better judgments about the implications of their analyses. Various authors have stressed the importance of measurement reliability. For example, Wilkinson and the Task Force on Statistical Inference (1999) wrote that “interpreting the size of observed effects requires an assessment of the reliability of the scores” (p. 596), and LeBel and Paunonen (2011) recommended that researchers “calibrate their confidence in their experimental results as a function of the amount of random measurement error contaminating the scores of the dependent variable” (p. 578; also see Cooper, Gonthier, Barch, & Braver, 2017; Hedge, Powell, & Sumner, 2018). Psychometric consideration is usually afforded to self-report measures, but we argue that such consideration is equally important for cognitive-behavioral measures.
Reliability is not an inherent property of a task. Therefore, neither the term reliability nor obtained estimates of reliability should be ascribed to the task itself; reliability refers to the measurement obtained and not to the task used to obtain it. Many authors have made this same point (for a few examples, see Appelbaum et al., 2018; Cooper et al., 2017; Hedge et al., 2018; LeBel & Paunonen, 2011; and Wilkinson & Task Force on Statistical Inference, 1999). Nonetheless, it is warranted to emphasize that reliability is estimated from the scores obtained with a particular task performed by a particular sample under specific circumstances (we use measure and measurement throughout this article to refer to the measurements obtained, and not the task used). One cannot infer that a reliability estimate obtained for a certain measure in one sample, or reported in a test manual, will generalize to other study samples performing the same task. (Assuming that one’s measure is reliable, solely on the basis of other researchers’ reliability estimates, has been described as “reliability induction”—Vacha-Haase, Henson, & Caruso, 2002). Thus, researchers cannot assume a level of reliability in their measures without examining the psychometric properties of those measures in their particular study sample. It is, therefore, not surprising that psychological researchers are expected to report reliability and validity evidence for self-report questionnaires (e.g., the American Psychological Association’s reporting guidelines—Appelbaum et al., 2018). However, recent evidence has demonstrated that evidence for scale validity and reliability is severely underreported (Flake, Pek, & Hehman, 2017), and that crucial validity issues—such as lack of measurement invariance—remain hidden because of this underreporting (Hussey & Hughes, 2018).
This article is specifically concerned with the psychometrics of cognitive-behavioral tasks. Unfortunately, appraising the psychometrics of the measures obtained with these tasks is the exception rather than the rule (Gawronski, Deutsch, & Banse, 2011; Vasey et al., 2003). One reason for this may be that these tasks—unlike standardized questionnaires, for example—are often adapted to the research question, such as by modifying the task stimuli. In the absence of a standard practice of reporting the psychometrics of cognitive-behavioral measures, it is (a) difficult to determine how common or widespread it is for them to have reliability problems; (b) nearly impossible to assess the validity of previous research using these measures; (c) challenging to verify if changes to them result in improved reliability or validity; and (d) difficult, if not impossible, to compare effect sizes between studies. Cumulative science rests on the foundations of measurements, and building a sound research base is possible only when researchers report measurement psychometrics for all studies. Therefore, we recommend that psychological researchers estimate and report measurement reliability as standard practice, whether their work uses questionnaires or cognitive-behavioral measures.
This article is split into two parts. In the first part, we discuss the implications of measurement reliability for results, and the fact that these implications are often hidden because of lack of reporting. We then discuss an example from our field of experimental psychopathology to highlight some of these issues more concretely. In the second part of this article, we provide practical guidance on implementing the routine reporting of internal consistency and test-retest reliability estimates. We also provide example code to obtain reliability estimates, using simple commands in the R environment 1 to analyze publicly available Stroop-task data (Hedge et al., 2018). Finally, we make suggestions for the transparent and complete reporting of reliability estimates.
Disclosures
The code used to generate the reliability estimates in this article is available at the Open Science Framework (OSF), at https://osf.io/9jp65/. The files at OSF also include a copy of the data provided by Hedge et al. (2018), the submitted version of this manuscript, and the R Markdown script used to generate it.
On the Importance of Measurement Reliability
In this section, we highlight two areas of research where reliability plays an important role: statistical power and comparisons of results. For the impact of reliability in both areas to be evaluated, a standard practice of reporting reliability estimates will be necessary.
Reliability and statistical power
Low statistical power is an ongoing problem in psychological science (e.g., Button, Lewis, Penton-Voak, & Munafò, 2013; Morey & Lakens, 2016). Statistical power is the probability of observing a statistically significant effect for a given alpha (typically .05), sample size, and (nonzero) population effect. An often-overlooked fact is that low power, in addition to resulting in a low probability of observing effects that do exist (i.e., a high probability of committing Type II errors), increases the likelihood that any observed statistically significant effects are false positives (Ioannidis, 2005; Ioannidis, Tarone, & McLaughlin, 2011). Overlooking the influence of measurement reliability on statistical power means that its possible influence on the precision of statistical tests is unknown. In this section, we explore the relationship between statistical power and reliability in the case of both group-differences and individual differences designs.
Power, reliability, and group differences
Reliability has an indirect functional relationship with statistical power, which we illustrate here using a simple group-differences test as an example. Statistical power is dependent on both group sizes and measurement variance: Lower variance yields higher statistical power. As defined by classical test theory, observed-score variance (X), or total variance, is the sum of true-score variance (T) and error variance (E; i.e., X = T + E). Power depends on the total variance, that is, the sum of true-score and error variance. Measurement reliability (R), on the other hand, is defined as the proportion of variance attributed to true-score relative to total variance (i.e., R = T/T + E). As Zimmerman and Zumbo (2015) demonstrated mathematically, the relationship between reliability and power can be observed by holding either true-score variance or error variance constant and leaving the other to vary. By adding true-score or error variance, one increases the total variance and can observe the ensuing relationship between reliability and power. Briefly, when true variance is fixed, increases in error variance result in decreases in reliability and decreases in statistical power. In contrast, fixing error variance and increasing true variance leads to increases in reliability, but with decreases in power.
Visualizing these relationships can be helpful for understanding the conceptual difference between reductions in power due to increased error variance and reductions in power due to increased true variance. Figure 1 presents a visual representation of the relationship between variance and reliability. In the left graph, true-score variance is constant, whereas in the right graph, error variance is constant. Note the resulting reliability (T/T + E) on the y-axes and consider the impact of increasing total variance in both graphs. As total variance increases (i.e., as the width of the error bars increases), the observed effect size,
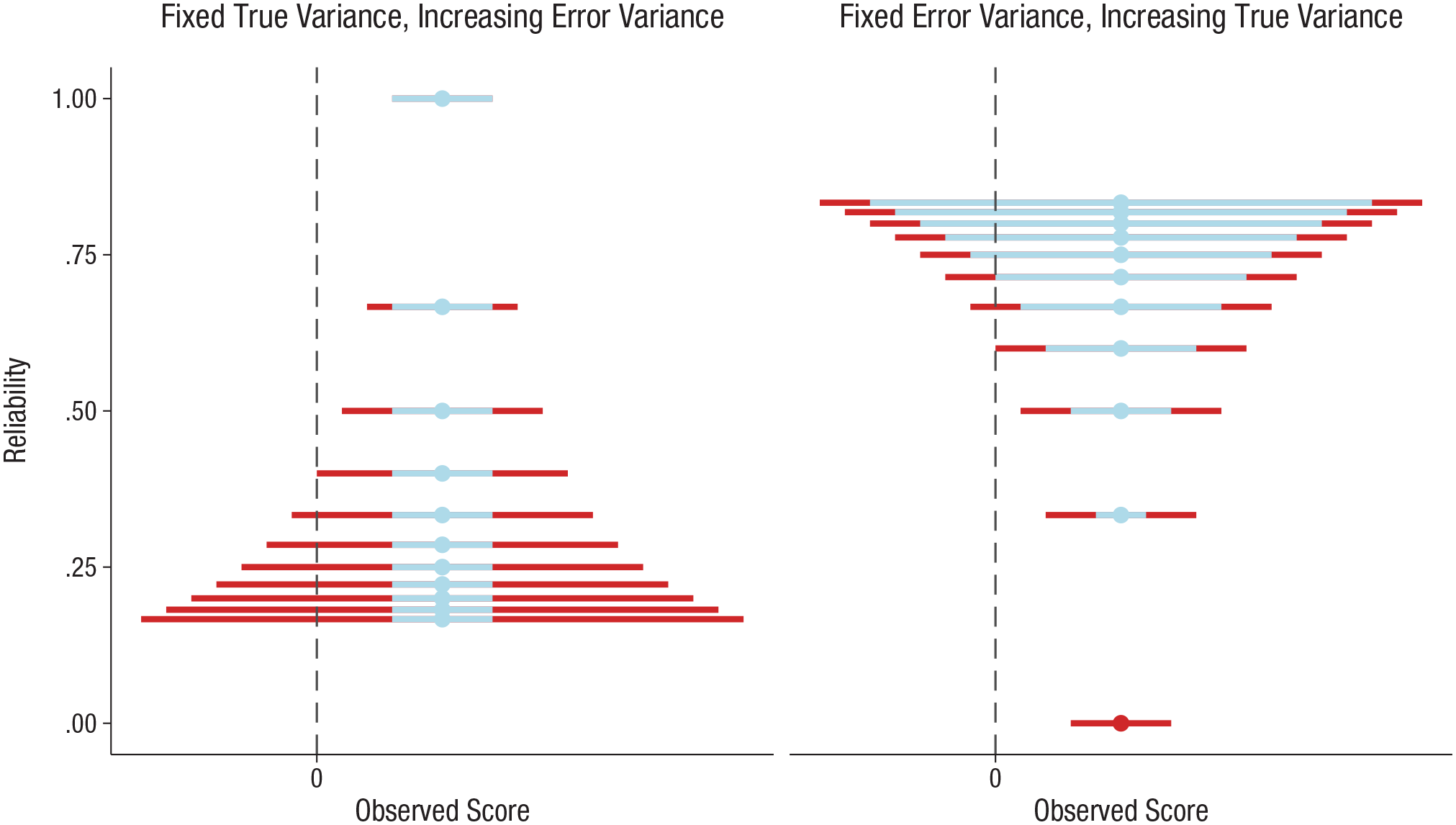
The relationship between reliability and variance. Both graphs show comparisons between observed measurement distributions and a reference value of zero (the dashed vertical lines). The blue sections of the distributions represent the true-score variance (T), and the red sections represent the error variance (E); the total width indicates the total variance. The corresponding reliability estimates (T/T + E) are indicated on the y-axis. The left-hand graph illustrates the decrease in reliability and increase in total variance that occurs when error variance increases while true-score variance remains constant. Thus, power changes despite no change in the true effect. The right-hand graph illustrates the decrease in both reliability and total variance that occurs when true-score variance decreases while error variance remains constant. Thus, power is reduced when the size of the true effect is smaller.
Power, reliability, and correlation: correcting for reliability
The reliability of measures constrains the maximum observable correlation between two measures: One cannot observe an association between two variables that is larger than the average reliability of those variables. Thus, greater measurement error and reduced between-subjects variance reduces the ability to observe associations between cognitive processes (also see Rouder, Kumar, & Haaf, 2019). To estimate this impact, one can begin with Spearman’s (1904) formula (also known as the attenuation-correction formula) to correct for the influence of measurement error on correlational analysis:
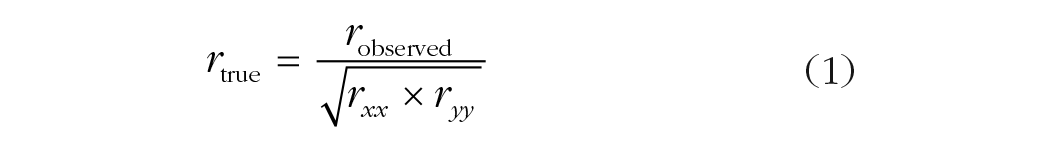
Reliability estimates are estimates of variables’ autocorrelations (i.e., rxx and ryy in Equation 1). In other words, Spearman’s formula says that the true correlation between the true scores of x and y is the observed correlation divided by the square root of the product of the autocorrelations for both measurements. The formula can be rearranged to the following:
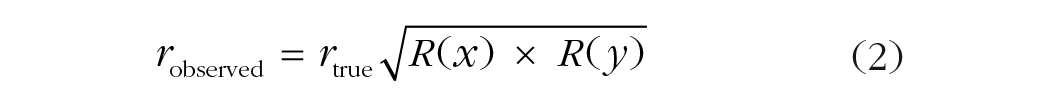
Using the rearranged formula, one can calculate the expected observed correlation and hence the power to detect a correlation in a study that has been powered at 80% to detect a correlation of at least the size of the expected true correlation. For example, if the expected true correlation between two measures in a study is .50 and both measures have reliability of .90, the observable correlation drops to .45:
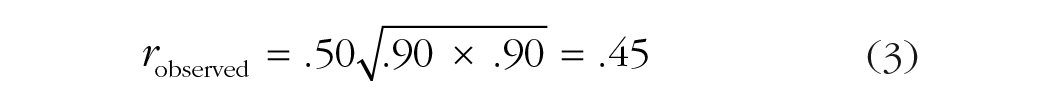
If 28 subjects were recruited to achieve 80% power to detect a correlation of .50, the fact that each measure had a reliability coefficient of .90 means that the study’s actual power (to detect an r of .45) was 69.5% rather than 80%. To regain the desired 80% power, a sample of 36 subjects would be required. Given that .90 reliability for both measures would be considered quite excellent, this example shows the large impact that measurement reliability has on power. Further illustrating this point, Figure 2 presents the required sample size to achieve 80% statistical power to detect true correlations of .3, .5, and .7, across a range of reliability estimates for both measures. Note that Hedge et al. (2018, Table 5) presented a similar argument.
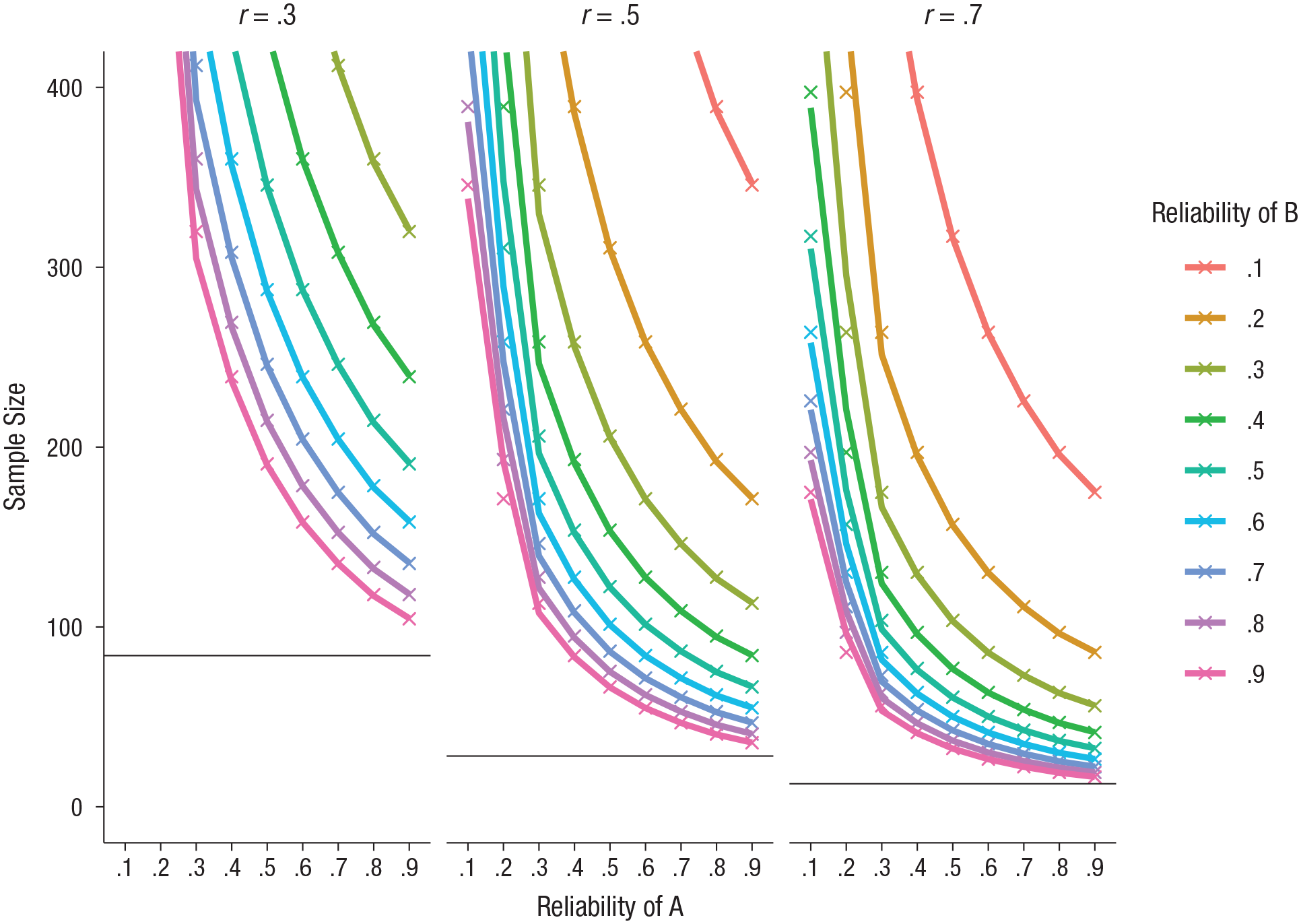
Required sample size for 80% power to detect true correlations of .3, .5, and .7 between measures A and B after correction for their reliability. The horizontal lines indicate the sample size required assuming perfect reliability of the two measures. For readers who may have a gray-scale version of this figure, the left-to-right order of the lines in the graphs matches the bottom-to-top order in the color key.
Readers who are interested in applying multilevel modeling to correct for the influence of measurement error may want to consult two recent publications exploring the use of hierarchical models to account for one source of error variance, namely, trial-level variation (Rouder & Haaf, 2018b; Rouder et al., 2019). None of the models tested by Rouder et al. (2019) performed well enough to accurately recover the simulated effect size. But these trial-level hierarchical models did outperform Spearman’s attenuation-correction formula (which can be unstable). The authors argued that error variance (measurement noise) may render the true-variance relationship between measures unrecoverable, and render it nearly impossible to answer questions about individual differences for certain measures. Yet hierarchical models are likely the best available tool to account for error. Hierarchical modeling including trial-level variation could routinely account for error in measures. However, in our experience, it is not yet standard for hierarchical models to be used to analyze data from behavioral tasks. We hope that the use of these models will become standard in the upcoming years. To help bridge this gap, we advocate efforts to promote a greater, more widespread understanding of the importance of the psychometrics of behavioral measurements and a greater focus on a standard practice of reporting estimates of their internal consistency and test-retest reliability.
Reliability and comparability
Cooper et al. (2017) illustrated two potential pitfalls when comparing effect sizes without considering reliability, using data derived from the AX-CPT, a variant of the computerized continuous performance task, as an example. To illustrate a potential pitfall when comparing correlations between samples taken from different populations, they used AX-CPT data, including reliabilities, originally reported by Strauss et al. (2014). Cooper et al. noted that the observed correlations between AX-CPT performance and another task measure (performance on the relational and item-specific encoding task) were greater in the schizophrenia sample than in the control sample. Also, the AX-CPT measure had greater variance, and greater test-retest reliability across all trial types, in the schizophrenia sample compared with the control sample. Therefore, it cannot be ruled out that the differences between the samples in the correlation between performance on the two tasks was the result of differences in variance and reliability between the samples.
Cooper et al. (2017) next illustrated a potential pitfall when comparing findings of largely identical studies, which one might expect to have produced the same results: Differences in psychometric properties lead to incomparable effect sizes. For this demonstration, they used data from two studies (Gonthier, Macnamara, Chow, Conway, & Braver, 2016; Richmond, Redick, & Braver, 2016) that recruited separate samples from the same population to examine the relationship between AX-CPT performance and a measure of working memory capacity. Although both studies found a correlation between performance on one AX-CPT trial type and working memory capacity, only one of the studies found a correlation between performance on two other AX-CPT trial types and working memory capacity. Reliability of the measures also differed between the studies. Therefore, it is unclear whether the difference in correlations reflects a genuine difference in associations or is a by-product of psychometric differences. Taking a step further, other researchers have proposed that effect-size estimates should be corrected for measurement error by default, as arguably psychological research is typically concerned with the relationships between actual traits or constructs, rather than between measures of traits or constructs (Schmidt & Hunter, 1996). Correcting for error would enable direct comparisons between the effect sizes Cooper et al. reported, for example. Thus, adopting a standard practice of reporting reliability would allow for better generalizability of effect-size estimates as well as more accurate comparisons of effect sizes (including aggregation of effect sizes, as in meta-analyses).
An example from the field of experimental psychopathology: the dot-probe task
To build on the previous sections, we discuss an example from experimental psychopathology relating to selective attentional processing of emotional information (for reviews of this field, see, e.g., Cisler & Koster, 2010; Gotlib & Joormann, 2010; Yiend, 2010). We focus on a task frequently used to assess (and often, attempt to modify) selective attentional bias: the emotional dot-probe task (C. MacLeod, Mathews, & Tata, 1986). In a typical dot-probe task, two stimuli are presented simultaneously for a set presentation duration (e.g., 500 ms). Usually, one of the stimuli is emotional (e.g., threat related), and the other is neutral. Immediately after the stimuli disappear, a probe is presented, and subjects press a key to report the identity of the probe (e.g., whether it is the letter E or F). The outcome measure indexes attentional bias, calculated by subtracting the average response time (RT) for trials in which the probe appeared in the location of the emotional stimulus from the average RT for trials in which the probe appeared in the location of the neutral stimulus. Dot-probe studies have used many variations of the task, differing in the number of trials, the stimulus presentation duration, the stimulus sets, the type of stimuli used (e.g., words or images), the type of probes (and how easily they can be perceived), and even whether the task is to identify the probe or just the location of the probe.
The use of the dot-probe methodology has grown considerably over the past decade (Kruijt, Field, & Fox, 2016, Fig. S1), and the number of published studies now likely numbers in the thousands. Unfortunately, in a recent study, Rodebaugh et al. (2016) were able to identify only 13 studies for which the reliability of the dot-probe task was reported. This growth in use of the task occurred despite two early publications that highlighted its reliability problems (Schmukle, 2005; Staugaard, 2009). When reliability estimates for the dot-probe task are reported, they tend to be unacceptably low (as low as –.12 in Waechter, Nelson, Wright, Hyatt, & Oakman, 2014). It is important to note that the reported estimates range widely (e.g., r = .45 in Bar-Haim et al., 2010; r = −.23 to .70 in Enock, Hofmann, & McNally, 2014; r = .15 to .59 in Waechter & Stolz, 2015). Since 2014, there has been growing concern about the reliability of the task, and several articles have directly examined its psychometric properties (H. M. Brown et al., 2014; Kappenman, Farrens, Luck, & Proudfit, 2014; Price et al., 2015; Sigurjónsdóttir, Sigurðardóttir, Björnsson, & Kristjánsson, 2015; Waechter et al., 2014; Waechter & Stolz, 2015). Alongside widespread calls to develop more reliable measures (e.g., C. MacLeod & Grafton, 2016; Price et al., 2015; Rodebaugh et al., 2016; Waechter & Stolz, 2015), various recommendations have been made to improve the stability and reliability of the dot-probe task (e.g., Price et al., 2015). Yet a recent study found that a number of these recommendations did not lead to consistent improvements in reliability, and no version of the task (or strategy for processing its data) was found to have adequate reliability (Jones, Christiansen, & Field, 2018).
Had the psychometric properties of dot-probe data been investigated early on—and had it already been known that individual differences studies using measures with high noise are doomed to fail (Rouder et al., 2019)—extensive resources might never have been invested in individual differences research using this task. Similarly, early psychometric examination might have led to a different understanding of the meaning of dot-probe-derived attentional-bias indices and to powerful theoretical insights regarding attentional bias, perhaps heavily altering the trajectory of the field. For example, Rodebaugh et al. (2016) recently compared the reliability of dot-probe bias indices calculated using traditional difference scores with the reliability of dot-probe indices treating attentional bias as a dynamic process. They found that difference scores yielded low reliability, whereas scores that treated attentional bias as a dynamic process led to much-improved reliability estimates. This puts doubt on the theoretical position that attentional bias is stable over time and raises serious questions about the typical use of the dot-probe measure and the decades of previous research using it—including the research in which many variants of the dot-probe task were intended to modify attentional bias. Rodebaugh et al. convincingly argued that, even aside from the fact that low reliability raises questions about the robustness of previous results, the lack of reporting reliability threatens theoretical understanding of attentional bias. Although it is a problem that the dot-probe task tends to yield unreliable data, the more pressing barrier is the consistent failure to estimate and report the psychometrics of behavioral measures in the first instance.
It is not our intention to unduly attack the dot-probe task. We use this task, as one of many potential examples, to demonstrate how taking “psychometric free reign” (Vasey et al., 2003, p. 84) with behavioral measures is detrimental to cumulative science. Evidence demonstrating the dangers of taking such liberties continues to mount; poor reliability is detrimental to making sound theoretical inferences (Rodebaugh et al., 2016), psychometric information is commonly underreported (Barry, Chaney, Piazza-Gardner, & Chavarria, 2014; Flake et al., 2017; Slaney, Tkatchouk, Gabriel, & Maraun, 2009), and this lack of reporting may hide serious validity issues (Hussey & Hughes, 2018). The purpose of this article is not to quash any discussion or research through a generalized argument that the measures in psychological research are not reliable, but rather to convince researchers that the field stands to benefit from improved standards for reporting psychometrics.
Questions of experimental differences and of individual differences
The distinction between experimental research (e.g., research on the effects of manipulations) and individual differences research (e.g., correlational research) is worth briefly discussing (e.g., Borsboom, Kievit, Cervone, & Hood, 2009; Cronbach, 1957, 1975). Experimental analyses benefit from precision (e.g., Luck, 2019), which is necessarily paired with low between-individuals variance (De Schryver, Hughes, Rosseel, & De Houwer, 2016), and this is perhaps reflected in a desire for groups that are as homogeneous as possible (Hedge et al., 2018). However, low variance may be due to lack of sensitivity in a measure, and low variance within a homogeneous group may result in difficulties rank-ordering the individuals within the group. Regardless of the cause of low between-individuals (true) variance, when it is paired with any amount of error variance, low reliability can easily result. Many tasks clearly display robust between-group or between-condition differences, but they also tend to have suboptimal reliability for individual differences research (Hedge et al., 2018). One such task is the Stroop (1935) task. It has been asserted that the Stroop effect can be considered universal (i.e., one can safely assume that everyone is subject to the Stroop effect; C. M. MacLeod, 1991; Rouder & Haaf, 2018a). Yet the task does not demonstrate sufficient reliability to be useful for investigating questions about individual differences (Hedge et al., 2018; Rouder et al., 2019).
Thus, robust experimental effects should not be interpreted as an indication of a measure’s high reliability or validity, nor do they provide sufficient information on the applicability of the measure for individual differences research (Cooper et al., 2017; Hedge et al., 2018). Unfortunately, it is common for tasks developed for experimental settings to be used in individual differences research with little attention paid to their psychometric properties. As Rouder et al. (2019) recently demonstrated, the use of tasks with low reliability in studies focusing on individual differences is doomed to fail. Regardless of the research question and the analytic method used, high measurement error will be detrimental to the analysis and the inferences that can be drawn from it (e.g., Kanyongo, Brook, Kyei-Blankson, & Gocmen, 2007).
Barriers to a standard practice of reporting reliability
We see two main barriers to implementing a standard practice of estimating and reporting the reliability of cognitive-behavioral tasks. First, it may not even be possible to estimate reliability for some measures. Perhaps the task or the data processing required is too complex, or perhaps another characteristic of the task, sample, context, or data collected leads to difficulties in estimating reliability. In cases such as these, the authors might consider stating that to their knowledge, there is no appropriate procedure to estimate the reliability of the measure. This would have the benefit of transparency. Further, a consideration of reliability in the absence of a reliability estimate would help in tempering interpretations of results, if only by preempting an implicit assumption that a measure is perfectly reliable and valid. Second, there is a lack of education and—in some instances—tools needed to implement a practice of estimating and reporting reliability for cognitive-behavioral measures. Psychometric training in core psychology courses is often limited to calculating Cronbach’s alpha for self-report data, but this statistic, and similar reliability estimates, may not apply to cognitive-behavioral measures. If a suitable procedure to estimate reliability does not exist or is inaccessible, then it would be foolhardy to expect researchers to report reliability as standard practice. A similar argument was made regarding the use of Bayesian statistics and sparked the development of JASP, a free, open-source software that is similar to SPSS but has the capacity to perform Bayesian analyses in an accessible way (Love et al., 2019; Marsman & Wagenmakers, 2017; Wagenmakers et al., 2018). It is important to ensure that the tools required to estimate reliability are readily available and easy to use. Therefore, the second part of this article forms a brief tutorial (with R code, examples, and recommendations) on estimating and reporting reliability.
A Brief Introduction to Estimating and Reporting Measurement Reliability
In this section, we outline approaches to estimating and reporting the reliability of one’s task measurements. Figure 3 presents our core recommendations for estimating internal consistency and test-retest reliability in flowchart form. Before presenting our recommendations in detail, we discuss some general considerations for estimating and reporting reliability.
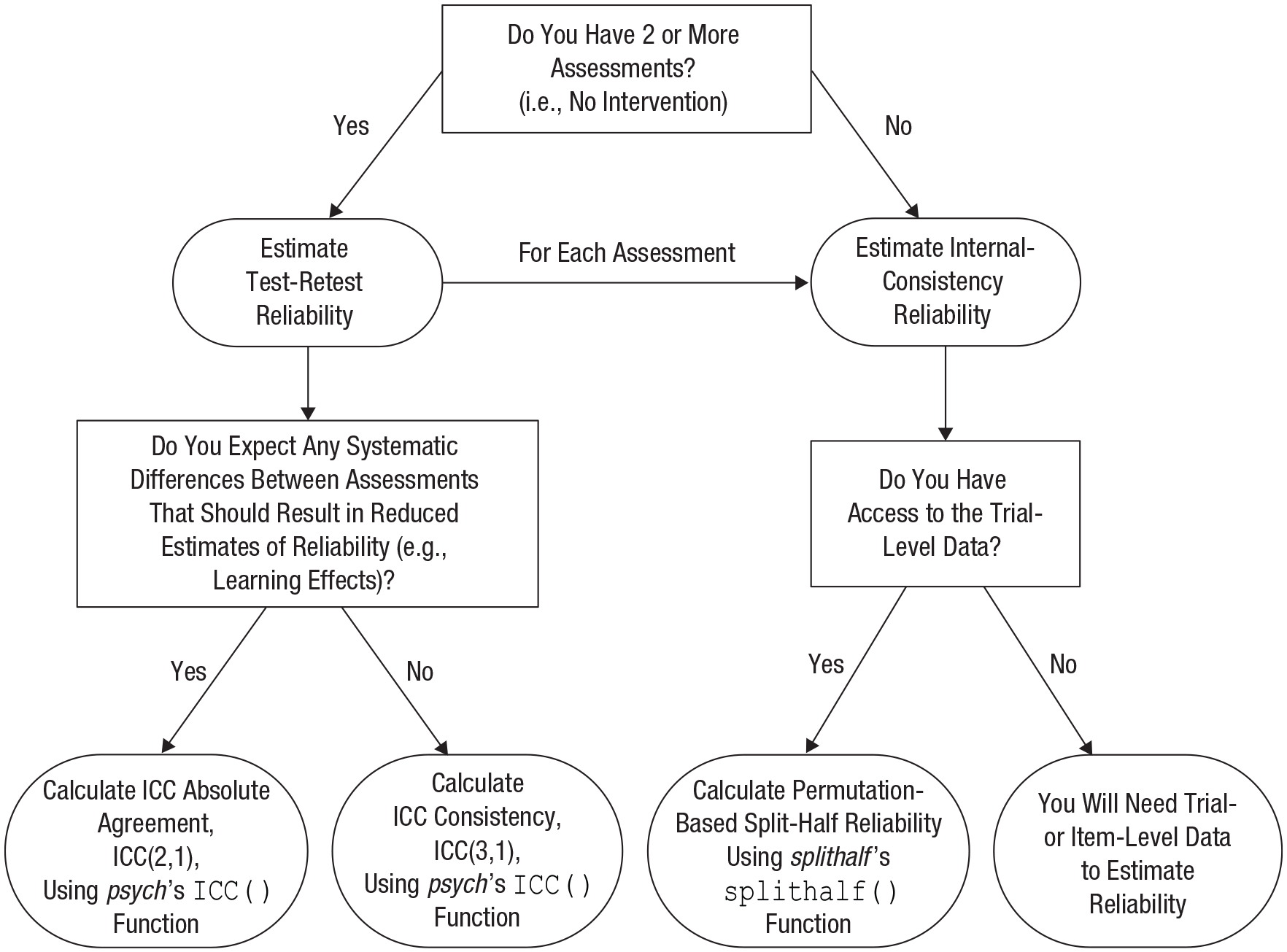
Flowchart of our core recommendations for reporting internal consistency and (if multiple measurements are available) test-retest reliability. ICC = intraclass correlation coefficient.
Matching reliability and outcome scores
Reliability estimates should be drawn from the same data as the outcome scores. For example, removal of outlier trials, subjects with high error rates, and so on, must be performed before reliability is estimated; indeed, data-reduction pipelines can have a surprising influence on reliability estimates. Similarly, if the outcome of interest entered into the analysis is a difference score, the reliability of the difference score (and not its components) should be determined. Likewise, if the sample has been divided into several groups, it follows that reliability should be estimated for each group. Reliability should be estimated for the actual outcome measures to be analyzed.
Reporting p values
We do not recommend that p values be reported alongside reliability estimates. In our view, it is often unclear what the p value adds or indicates in this context, and reporting this value opens the way for a potential misinterpretation that when a reliability estimate differs significantly from zero, one can be confident in the reliability of the measurement. On several occasions, we have observed statements describing a measurement’s reliability as being statistically significant even though the magnitude of the estimate is small (e.g., < .3); avoiding this misunderstanding by simply not reporting p values is preferable. Confidence intervals for reliability estimates, on the other hand, are informative, and we recommend reporting them.
Thresholds for reliability
We refrain from making specific recommendations for what should be considered “adequate” or “excellent” reliability. Reliability estimates are continuous, and using arbitrary thresholds may hinder their utility. Other researchers have suggested that .7 or .8 is a suitable threshold for reliability or have used labels for specific intervals (e.g., .50–.75 = “moderate” reliability, .75–.90 = “good” reliability, and > .90 = “excellent” reliability; Koo & Li, 2016). These labels should not be considered thresholds to pass, but rather should be considered another means to assess the validity of results based on these measures (Rodebaugh et al., 2016). A benefit of widespread reporting of reliability is that it would be possible to describe a task’s normative range of reliability estimates generated across samples, conditions, and task versions. Researchers would then have an almost metapsychometric reference point to compare with their estimates. Such comparisons are likely to be more useful than merely claiming that one’s measure has achieved “adequate” reliability.
Negative reliability estimates
It is possible for reliability estimates to be negative. At first sight, such a finding might seem to indicate that those individuals who scored highest on the first half of the task, scored lowest on the second, and vice versa (a conclusion that is mind-boggling in many contexts). However, negative reliability estimates can arise spuriously for at least two reasons. The first is that the data may violate the assumption of equal covariances among half-tests (Cronbach & Hartmann, 1954). The second cause of spurious negative reliability estimates is specific to difference scores (e.g., bias indices or gain scores). When the components of a difference score correlate highly, the variance of the difference score will approach zero. At zero variance, reliability is also zero, but because of imprecision in the estimate, the correlation between two assessments may appear to be negative. In such cases, it appears as if the data have an impossible covariance structure, with the total proportion of variance explained by the difference score plus its component scores surpassing the maximum value of 1 (all variance observed). In cases when an unlikely negative reliability estimate is obtained, we recommend reporting that negative estimate but interpreting it as equaling zero reliability (indeed, the value of 0 will typically be included in the estimate’s confidence interval).
Reporting the complete analysis
Even when ostensibly the same measure of reliability is used, different procedures for calculating the estimate may result in different estimates. For example, using a split-half approach, one could split trials into odd- and even-numbered trials or into the first half and second half of trials. Therefore, we recommend that authors report not only the reliability estimates themselves, but also the analysis procedures used to obtain those estimates. Such full reporting will facilitate transparency and reproducibility (providing analysis code would be ideal). Relevant details include if and how data were divided, the estimation method used, and the number of permutations or bootstraps, if applicable. Additionally, we recommend that confidence intervals be reported (e.g., Koo & Li, 2016) and note that reporting both corrected and uncorrected estimates (e.g., in the case of split-half reliability) can be useful to ease comparisons of estimates across studies.
Recommended methods for estimating reliability
For the following examples, we used Stroop-task data from Hedge et al. (2018). The data and code (see the R Markdown script) to re-create these analyses can be found on our project page at OSF (https://osf.io/9jp65/). Briefly, in Hedge et al.’s Stroop task, subjects made key-press responses to report the color of a word presented centrally on-screen. In congruent trials, the word’s meaning was the same as the font color. In incongruent trials, the word’s meaning was different from the font color. Subjects completed 240 trials of each trial type. For these examples, we focus on RT cost as the outcome measure; this cost is calculated by subtracting the mean RT in congruent trials from the mean RT in incongruent trials. Subjects completed the Stroop task twice, in sessions approximately 3 weeks apart. These separate sessions were useful for our purposes, because they allowed us to investigate both the internal consistency of each measurement separately and the test-retest reliability. Hedge et al. reported Stroop data from two separate studies; for simplicity, we have pooled these data. We followed their data-reduction procedures, and exact details can be found in the R Markdown version of our submitted manuscript at OSF (https://osf.io/9jp65/).
Internal consistency: permutation-based split-half correlations
Various statistical software programs offer the option to compute Cronbach’s alpha, yet many of these use an approach that is unlikely to be suitable for cognitive-behavioral tasks. The most commonly used approach amounts to averaging the correlations between each item’s score and the sum score of the remaining items. This approach assumes that Item 1, Item 2, Item 3, and so forth, have been identical for all subjects. It appears that to apply this approach to data from behavioral tasks, researchers often resort to creating bins of trials, each to be treated as an individual “item” or minitest. However, unless trial stimuli and conditions are presented in a fixed order, Cronbach’s alpha derived with this approach will not be a valid estimate of reliability. If one bins by trial number, then the stimuli within each bin will differ between subjects. If the same set of trials (same stimuli, etc.) have been presented to all subjects, with presentation order randomized for each subject, one could bin by stimulus (e.g., by specific pairing of word content and color in the Stroop example), yet each bin would contain trials from different stages of the task, which might reduce the obtained reliability estimate. We also note that although omega has been advocated as a robust estimate to replace alpha (Dunn, Baguley, & Brunsden, 2014; Peters, 2014; Sijtsma, 2009; Viladrich, Angulo-Brunet, & Doval, 2017), the same assumption that each bin is identical across subjects applies. Thus, the most common approach to obtaining alpha and omega is unsuitable for most task designs, except when a fixed trial and stimulus order was used.
However, averaging the correlations between each item’s score and the sum score of the other items is only one way to estimate alpha, which is defined as the average of all possible correlations between subsets of items. It is also possible to calculate alpha as the average of a sufficiently large number of split-half reliability estimates (Spearman, 1910) when each split-half reliability is based on a different random division of the items. In the split-half method as it is commonly applied, the data for a measure are split into two halves, typically into either the first and second half or the odd- and even-numbered items or trials. The Pearson correlation between these halves is then calculated as an estimate of the measure’s internal reliability. The Spearman-Brown (prophecy) formula (W. Brown, 1910; Spearman, 1910) is often subsequently applied to this estimation. This correction accounts for the underestimation resulting from splitting the number of observations in half to enable calculating a correlation. The Spearman-Brown corrected estimate is calculated as follows:

When applied to tasks, standard split-half reliability estimates tend to be unstable. For example, reliability estimates obtained from splitting the data into odd- and even-numbered trials have the potential to vary greatly depending on which trials happened to be odd and even (Enock, Robinaugh, Reese, & McNally, 2012). Therefore, Enock et al. advocated estimating measurement reliability with a permutation approach, in which the data are repeatedly randomly split into two halves and the reliability estimate is calculated for each split (also see Cooper et al., 2017; J. W. MacLeod et al., 2010). The estimates are then averaged to provide a more stable estimate of reliability. It is important to note that Cronbach’s alpha can be defined as the average of all possible split-half reliabilities (Cronbach, 1951). Permutation-based split-half reliability, therefore, approximates Cronbach’s alpha, while avoiding the concerns we have discussed regarding estimating the internal consistency of cognitive-behavioral data. We recommend that researchers estimate and report permutation-based split-half reliabilities for their measures as estimates of internal-consistency reliability.
The R package splithalf (Parsons, 2019b) was developed to enable researchers with minimal programming experience to apply this method to (trial-level) task data with relative ease. Full documentation of the package, with examples, can be found online (Parsons, 2019a). Note that the online documentation will be the most up-to-date; for the examples in this article, we used Version 0.5.3, and future package versions may use a format different from the one in this article.
The permutation split-half approach can be performed on Hedge et al.’s (2018) Stroop data using the following code:
The first line of code loads the splithalf package. The command
Running this code will produce the output shown in Figure 4. The output includes two rows, one for each testing session (the

R output showing estimated permutation-based split-half reliabilities for the data from Hedge, Powell, and Sumner (2018). See the text for details.
The output for this example might be reported as follows: Permutation-based split-half reliability estimates were obtained, separately for each time point, using the splithalf package (Version 0.5.3; Parsons, 2019b). The results of 5,000 random splits were averaged. Reliability estimates were as follows: Time 1: rS = .61, 95% confidence interval (CI) = [.40, .76] (uncorrected: r = .45, 95% CI = [.25, .62]); Time 2: rS = .50, 95% CI = [.26, .69] (uncorrected: r = .34, 95% CI = [.15, .52]).
Test-retest reliability: intraclass correlation coefficients
Whereas the random-splits split-half method provides an estimate of the stability of a measure’s outcome within a single assessment, test-retest reliability provides an indication of the stability of a measure’s scores over time. The time frame for the retest is an important consideration in the interpretation of test-retest estimates. For example, consider the intuitive difference between test-retest reliability assessed over 1 hour versus a much longer period, such as 1 year. These variations of test-retest reliability have been described as indexing dependability and stability, respectively (Hussey & Hughes, 2018; Revelle, 2018), although the exact timings that correspond to either description are not agreed upon.
When interpreting a test-retest estimate, it is important to consider the extent to which one would expect the construct of interest to remain stable over the time elapsed between the two assessments. One should take into account, for example, the extent to which task performance is expected to vary as a result of random processes, such as mood fluctuations, and more systematic processes, such as practice or diurnal effects. Most indices of test-retest reliability are not affected by systematic changes between assessments, provided that all subjects are affected to the same extent (a notable exception is the intraclass correlation coefficient, or ICC, variation that estimates agreement, which we discuss later in this section). Yet, in practice, systematic processes affecting performance affect individuals to varying degrees, thereby reducing test-retest reliability. It follows that the extent to which low test-retest reliability of a measure should reduce confidence in analytic results based on that measure will depend greatly on the study design and the assumed characteristics of the construct being measured. Low test-retest reliability might be considered more problematic for a trait construct than for a state construct, for instance. Low estimates of internal reliability may be theorized to be due to the construct fluctuating so rapidly that it cannot be measured reliably, but when a construct by its very nature cannot be measured reliably, it seems to follow that it also cannot be reliably studied or even verified to exist.
Test-retest reliability is often calculated as the Pearson correlation between two assessments of the same sample using the same measure. The summary data provided by Hedge et al. (2018) were collated into a single data frame,
The output indicates a test-retest reliability of .73, 95% CI = [.62, .81].
The Pearson correlation is an easily obtained indication of the consistency between two measurements, and its value tends to be close to the value that would be obtained if the data were analyzed more extensively using a method called variance decomposition. In variance decomposition, which is closely related to analysis of variance, the variance of the outcome measure is divided into true variance (within, between, or both) and error variance, and test-retest reliability is calculated as the true variance divided by the total variance (true variance/true variance + error variance).
ICCs, first introduced by Fisher (1954), are correlation estimates obtained through variance decomposition. An ICC taking into account only the decomposition into true and error variance reflects what is called consistency, that is, the extent to which the individuals are ranked in the same order or pattern at the two assessments. However, it has been argued that test-retest reliability should reflect agreement, rather than consistency, between measurements (Koo & Li, 2016). For example, a perfect correlation between scores at two time points may occur when there is a systematic difference between the time points (i.e., a difference that is about equal for all subjects). Despite the perfect consistency, if the measure has a predefined boundary value, some or all subjects may be classified differently at the two assessments because their score ended up on different sides of the boundary value. Imagine a scenario in which the second of two measurements is simply the first measurement plus a fixed amount (e.g., all subjects improved by 10 points on the fictional measure). This change may be a result of practice effects, development, or perhaps some other systematic difference over time. It is up to the researcher to determine the importance—and relevance to the research question—of these kinds of potential systematic changes in scores, and to use this determination to guide the decision of which ICC approach is most applicable. In this case, the consistency (and the correlation) would be extremely high, whereas the absolute agreement would be lower because agreement takes into account the difference between sessions.
In practice, there exists a multitude of ICC approaches. McGraw and Wong (1996) described 10 variations of the ICC, and Shrout and Fleiss (1979) described 6. The conventions used to describe the variations differed between these two articles, and in part because of this, it can be difficult to determine which variation is most appropriate in a given circumstance. Helpfully, Koo and Li (2016) have provided a comparison of conventions and the relevant formulas. We suggest that the two ICC variations most appropriate for assessing consistency and agreement in the data from cognitive-behavioral tasks are the ICCs labeled ICC(3,1) and ICC(2,1), respectively, in Shrout and Fleiss’s convention. Both are based on variance decomposition using a two-way mixed-effects model of the single-rater type. The primary decision for researchers is whether they are primarily concerned with the consistency (ICC3,1) or the absolute agreement (ICC2,1) of their measures, though we suggest that reporting both estimates is valuable because it allows for a comparison between the measures’ consistency and agreement. The equations for these two ICCs are as follows:
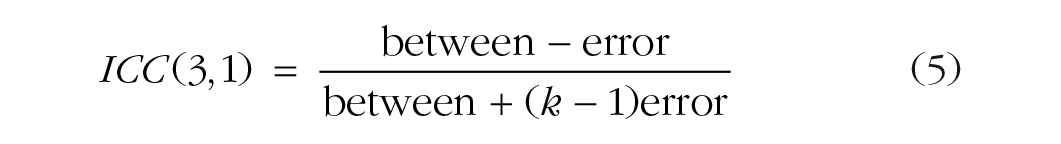
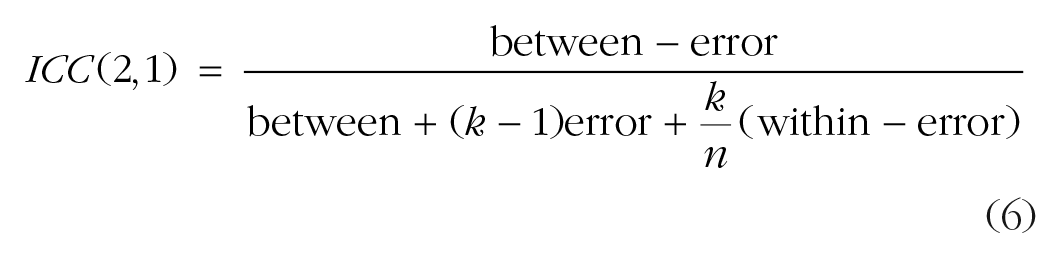
We have taken the liberty of replacing Koo and Li’s notation (distinguishing variance obtained within columns vs. within rows) with a between/within-subjects notation, in which “between” refers to between-subjects variance, “within” refers to within-subjects or between-sessions variance, and “error” refers to error variance; k is the number of measurements, and n is the sample size. Note that agreement (Equation 6) extends consistency (Equation 5) by including within-subjects variance (changes between tests) in the denominator. This causes the denominator to be larger if there is error associated with differences between sessions within subjects, which in turn results in a lower ICC estimate for agreement than for consistency.
ICCs (including 95% confidence intervals) can be estimated easily in R using the psych package (Revelle, 2018). The following code first loads the psych package before calling the ICC function. It selects the Stroop data from Hedge et al. (2018) from the two available time points:
The standard output, shown in Figure 5, includes six variations of the ICC and related test statistics. The second and third rows of the output correspond to the ICC(2,1) (absolute agreement) and ICC(3,1) (consistency). The

R output showing the estimated intraclass correlation coefficients (ICCs) for the data from Hedge, Powell, and Sumner (2018). See the text for details. Note that this output has been altered slightly to be more presentable here.
The agreement and consistency estimates in this output might be reported as follows: The Stroop task’s test-retest reliability between the first and second testing sessions was estimated with intraclass correlation coefficients (ICCs) using the psych package in R (Revelle, 2018). We report the results of two-way mixed-effects models for absolute agreement, ICC(2,1), and consistency, ICC(3,1). The estimated agreement was .64, 95% confidence interval (CI) = [.31, .80], and the estimated consistency was .72, 95% CI = [.61, .80].
Other recommendations
Our chief aim in this article is to argue for a culture change and to encourage researchers to adopt a standard practice of estimating and reporting the reliability of their measurements. There are several other related recommendations we would like to make.
First, we recommend that when developing novel computerized tasks (or adapting existing ones), researchers conduct validation studies for the new measures. This would greatly facilitate the development of reliable and valid measurements. Work such as this should be encouraged as an essential contribution to psychological science. Providing open data would further assist researchers in examining the reliability of cognitive measures whose reliability has not been reported and would provide opportunities to test different scoring approaches and examine any changes in the psychometrics of the outcome.
Second, we recommend that psychometric information be pooled so that researchers have access to a meta-archive tool. To adequately fill the current gap in knowledge, this pool would need to include psychometric information that has not yet been analyzed (or has gone unreported) in the existing literature. However, even collating already published psychometric information would allow researchers to compare, for example, the reliability estimate from a novel clinical sample with typically observed reliability estimates. Thus, researchers would not have to rely on thresholds for “adequate” or “good” reliability but would be able to directly compare their own reliability estimates with those typically observed for similar measures.
Finally, although most of our recommendations are aimed at researchers, it is the responsibility of journal editors and peer reviewers to request psychometric information on cognitive-behavioral tasks, just as they would for questionnaire measures. Extending current requirements for reporting effect sizes and confidence intervals, or precise p values, reviewers could request psychometric evaluations of all measures used, whether those measures are based on self-report or other behavioral data. Indeed, reporting the psychometric properties of measurements falls clearly within the American Psychological Association’s reporting standards (Appelbaum et al., 2018, p. 7).
Summary
We have argued that researchers using cognitive-behavioral measures should adopt a standard practice of estimating and reporting the reliability of these measures. We have discussed several issues that arise when a measure has low reliability, as well as difficulties in comparing effect-size estimates when reliability is unknown, and we have pointed out that reliability is so seldom reported that one cannot know the impact of these issues on the current state of knowledge. Beyond arguing that researchers need to report reliability estimates as standard practice, we have tried to help make this a reality by providing some assistance, in the form of a short tutorial and R code. Future researchers, especially those wanting to use a measure whose reliability in experimental settings has been tested only in their correlational research, will benefit if reporting reliability becomes standard. Today’s researchers have an obligation to future researchers to provide a sound evidence base, and this includes developing valid and reliable tools. For this to happen, psychological scientists must develop a research culture in which it is routine to estimate and report the reliability of cognitive-behavioral measures.
Supplemental Material
Parsons_AMPPSOpenPracticesDisclosure-v1.0 – Supplemental material for Psychological Science Needs a Standard Practice of Reporting the Reliability of Cognitive-Behavioral Measurements
Supplemental material, Parsons_AMPPSOpenPracticesDisclosure-v1.0 for Psychological Science Needs a Standard Practice of Reporting the Reliability of Cognitive-Behavioral Measurements by Sam Parsons, Anne-Wil Kruijt and Elaine Fox in Advances in Methods and Practices in Psychological Science
Footnotes
Acknowledgements
We would like to thank Craig Hedge for making the data used in our examples open and available. We would also like to thank all the people who provided feedback on the preprint version of this article. Their comments and critical feedback, and the articles they shared, have helped us develop this manuscript. In alphabetical order (apologies to anybody missed), we thank James Bartlett, Paul Christiansen, Oliver Clarke, Andrew Jones, Michael Kane, Jesse Kaye, Rogier Kievit, Kevin King, Mike Lawrence, Marcus Munafò, Cliodhna O’Connor, Oscar Olvera, Oliver Robinson, Guillaume Rousselet, Eric-Jan Wagenmakers, and Bruno Zumbo.
Action Editor
Pamela Davis-Kean served as action editor for this article.
Author Contributions
S. Parsons conceived and wrote the manuscript. A.-W. Kruijt provided crucial conceptual and theoretical feedback. All the authors provided critical input to develop the final manuscript, which they all agreed upon.
Declaration of Conflicting Interests
The author(s) declared that there were no conflicts of interest with respect to the authorship or the publication of this article.
Funding
This work was funded by the European Research Council under the European Union’s Seventh Framework Programme (FP7/2007-2013) and European Research Council Grant 324176.
Open Practices
Open Data: not applicable
Preregistration: not applicable
All materials have been made publicly available via the Open Science Framework and can be accessed at https://osf.io/9jp65/. The complete Open Practices Disclosure for this article can be found at http://journals.sagepub.com/doi/suppl/10.1177/2515245919879695. This article has received the badge for Open Materials. More information about the Open Practices badges can be found at ![]() .
.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.