
Abstract
In psychology, researchers are often interested in the predictive classification of individuals. Various models exist for such a purpose, but which model is considered a best practice is conditional on attributes of the data. Under certain conditions, linear discriminant analysis (LDA) has been shown to perform better than other predictive methods, such as logistic regression, multinomial logistic regression, random forests, support-vector machines, and the K-nearest neighbor algorithm. The purpose of this Tutorial is to provide researchers who already have a basic level of statistical training with a general overview of LDA and an example of its implementation and interpretation. Decisions that must be made when conducting an LDA (e.g., prior specification, choice of cross-validation procedures) and methods of evaluating case classification (posterior probability, typicality probability) and overall classification (hit rate, Huberty’s I index) are discussed. LDA for prediction is described from a modern Bayesian perspective, as opposed to its original derivation. A step-by-step example of implementing and interpreting LDA results is provided. All analyses were conducted in R, and the script is provided; the data are available online.
In psychology, researchers are often interested in predicting the classification of individuals. For example, accurately predicting who will drop out of a program can make it possible to avoid fruitless expenses, and predicting the severity of an illness can aid appropriate referral to treatment. Such prediction typically involves a set of predictor variables (e.g., demographics, condition-related covariates) and a categorical outcome with two or more mutually exclusive groups (e.g., people who survive to a certain date vs. those who do not; patients with mild, moderate, or severe depression). Several parametric and nonparametric methods for making predictive classifications are available. Classic parametric methods include linear discriminant analysis (LDA) and quadratic discriminant analysis (QDA), whereas nonparametric methods include variants of the K-nearest neighbors algorithm, support-vector machines, random forests, and neural networks. Notably, Hastie, Tibshirani, and Friedman (2009) stated that, in comparison with more modern nonparametric methods, “both LDA and QDA perform well on an amazingly large and diverse set of classification tasks. . . . It seems that whatever exotic tools are the rage of the day, we should always have available these two simple tools” (p. 111). The purpose of this article is to provide an introduction to the application of LDA for prediction in a Bayesian framework, review best-practice recommendations, and detail an example of the method’s application. Note that although LDA may also be used for description, our focus is on the application of LDA for prediction.
Disclosures
All the analyses for the example application of LDA were conducted in R (R Core Team, 2018). The syntax is provided in Appendix A and is available at the Open Science Framework (https://osf.io/6bk24/files/). The data are available online (UCLA Institute for Digital Research and Education, 2017).
Two Purposes of LDA
Fisher (1936) originally developed LDA as a method for finding linear combinations of variables that best separated observations into groups, or classifications. Using these linear combinations, researchers can learn which of the variables contribute most to group separation and the likely classification of a case with unobserved group membership. For example, clinical psychologists may be interested in associations between their clients’ psychological characteristics at intake (e.g., stress tolerance, anxiety, and self-confidence) and their compliance with treatment (e.g., missing most sessions, missing a few sessions, or missing no sessions); LDA can be used to identify which psychological characteristics contribute most to treatment compliance, as well as to formulate a model for using these characteristics to predictively classify treatment compliance among future clients. Fisher used the same method for both purposes, but LDA was subsequently modified for use in prediction. Given this differentiation between two purposes—description (also termed discrimination or separation) and prediction (also termed classification or allocation; Johnson & Wichern, 2007)—some researchers have named the two methods differentially as well.
When LDA is used to describe group differences on a set of variables, the method is often referred to as descriptive discriminant analysis (DDA). More specifically, DDA is used to describe which of a set of variables contribute most to group differentiation. It is suitable, for instance, as a follow-up to a statistically significant multivariate analysis of variance (Enders, 2003; Warne, 2014). The researcher estimates linear discriminant functions (LDFs), each of which is used to create discriminant scores explaining variability between groups. Plotting the linear discriminant scores can help researchers visualize the data in a lower-dimensional space, and plotting the coefficients of the LDFs can help researchers understand the dimensions that best separate the groups.
Alternatively, when LDA is used to develop classification rules for predicting group membership of new cases with unknown classification, it is often referred to as predictive discriminant analysis (PDA; e.g., Huberty & Hussein, 2003; Huberty & Olejnik, 2006). In this approach, a separate linear classification function (LCF) is derived for each group. (Although Hastie et al., 2009, called LCFs linear discriminant functions, we follow the terminology of Huberty and Hussein, 2003.) The data for a case with unknown classification are submitted to these LCFs, and the results are used to predict classification. For example, a sample of adolescents who have experienced a traumatic event may be classified into groups of low, medium, or high severity of posttraumatic stress disorder (PTSD) symptoms. A predictive model (set of LCFs) derived using these cases with observed group membership may then be used to predict the classification of symptom severity for a child who experiences a similar traumatic event. 1 LDA for prediction, our focus in this article, is the same as PDA; these terms can be used interchangeably in this context.
The differentiation between DDA and PDA is more than semantic. In DDA, the original method presented by Fisher (1936) is used to estimate LDFs, whereas in PDA, the LCFs are derived with the additional influence of prior information, within a Bayesian framework. Welch (1939) formally incorporated this use of prior information in conjunction with Fisher’s (1936) original derivation to achieve optimal predictive classification (Hastie et al., 2009).
Though Welch (1939) did not expressly describe his work as Bayesian, the procedure is the same. The Bayesian derivation of LDA for classification provides posterior probabilities of a case’s membership in the groups under consideration. A single case will have a posterior probability of membership for each group (e.g., .10 for Group 1, .24 for Group 2, and .66 for Group 3), and these probabilities will sum to 1.00 across groups. Each posterior probability is the probability that the case in question, given the observed data for that case, is a member of the given group, characterized by the data of the group’s members. Posterior probabilities may be useful when the classification of a case is less than clear-cut (Johnson & Wichern, 2007). A Bayesian derivation of LDA for classification utilizes prior probabilities of group membership—in conjunction with the observed variables—to produce these posterior probabilities. Prior probabilities, for example, can be based on what is already known about the population distribution. If there are two possible classifications (e.g., successful or unsuccessful treatment), and one classification group has contained only 5% of cases in the past, the analyst would want to classify a case into that low-occurrence group only when the evidence for doing so is very strong (Klecka, 1980). In this case, the prior probability for the low-occurrence group could be set to .05, and the prior probability for the other group could be .95, to reflect the known population distribution. When the prior probability of group membership is equal across groups and the assumptions of LDA (discussed later) are met, Fisher’s and Welch’s derivations will yield the same results for classification (Huberty & Hussein, 2003).
Whereas our focus in this article is on the Bayesian application, readers who are interested in the original approach may want to consult Fisher (1936) or Johnson and Wichern (2007) for more detail. Kruschke has provided explanations of applied Bayesian estimation with t tests (Kruschke, 2013) and regression (Kruschke, Aguinis, & Joo, 2012), and an explanation of applied Bayesian estimation with multilevel modeling is available in Boedeker (2017). Appendix B provides more technical details on the derivation of LCFs.
Overview of LDA for Prediction
LDA can be used for allocating new observations to previously defined categories through the creation of a classification rule (Huberty, 1994; Huberty & Barton, 1989; Klecka, 1980). First, data for which group membership is known (training data) are used to derive LCFs. LCFs are similar to unstandardized regression equations; the sum of an intercept and the products of weights and observed variables produce a single classification score. LCFs are derived using Mahalanobis distance and prior probability. Mahalanobis distance is a single value describing the distance between two points in multivariate space. In classification, these two points are the location of a case’s data and a given group’s centroid, that is, the group’s average for each variable used for classification within that group. A Mahalanobis distance can be calculated for each case for each group. The group with the lowest Mahalanobis distance from a case is the group to which the case is most similar in multivariate space.
A case’s observations are submitted to each group’s LCF to calculate a classification score, and the case is assigned to the group for which it has the highest score. Posterior probabilities are also derived from these classification scores by using Bayes theorem. Posterior probabilities of membership in the groups and typicality probabilities—values representing how “typical” a case’s data are for each group—are used to evaluate the assigned classification.
The overall accuracy of prediction can be evaluated for the training data using hit rates and effect size (Huberty’s I index). Hit rate is the percentage of cases correctly predicted using the LCFs. Higher hit rates indicate more accurate prediction of group membership. Ultimately, if a set of LCFs is found to be accurate (i.e., the hit rate and Huberty’s I are high), it can be used to predict classification for a different set of cases for which group membership is unknown.
Specification of prior probability
In this section, we briefly describe four methods for specifying prior probabilities: (a) assuming equality across groups, (b) assuming equality to the data distribution, (c) using a known population distribution, and (d) using the cost of misclassification. The first method essentially admits no prior information about differences in group membership. In the two-group case, the prior probability of membership in Group 1 and the prior probability of membership in Group 2 would both equal .50 (i.e., 50%). With this method, the data entirely determine the posterior probabilities of group membership. Alternatively, the researcher may assume that the sample reflects the distribution of cases in the population and set the prior probabilities to reflect the percentages of group membership in the data. For instance, when this second method is used, if 30% of patients in the training data were classified as treatment seeking, then the prior probability for membership in the treatment-seeking group would be set to .30. If the analyst has prior knowledge of the distribution in the population, the third method can be used. That is, the assigned prior probabilities can reflect this knowledge. For example, prevalence of current PTSD is estimated at 3.5% in the general population (Kessler, Chiu, Demler, Merikangas, & Walters, 2005), so a researcher interested in evaluating a predictive model for identifying PTSD might set the prior probability of membership in a “current PTSD” group to .035. Finally, prior probabilities may be based on the cost of misclassification. Cancer diagnoses provide an example of when this approach is useful. Inaccurately classifying a tumor as benign is more lethal than inaccurately classifying it as malignant. If it is possible to numerically determine the costs of misclassification, then this information may be utilized in the prior probability.
Assumptions
Two assumptions of LDA for prediction are multivariate normality of the distribution of variables within classifications and equality of variance-covariance matrices across classifications. Both of these assumptions are reflected in Appendix B’s derivation of LCFs, which specifies that the data follow a multivariate normal distribution and pools the variance-covariance matrices across classes. Multivariate normality is particularly important for the utility of computed posterior probabilities and in calculating the intercept term of each LCF (Hastie et al., 2009). When multivariate normality is violated, the probabilities are not exact and must be interpreted with caution (Klecka, 1980; Lachenbruch, 1975). However, LDA results have been shown to be robust to violations of multivariate normality (Khondoker, Dobson, Skirrow, Simmons, & Stahl, 2016; Sherry, 2006), particularly when groups are approximately equal in size (Lachenbruch, 1975). The assumption of equal variance-covariance matrices is what makes LDA linear instead of quadratic (Huberty & Curry, 1978). In LDA, the LCF for each group is found using the pooled variance-covariance matrix, whereas in QDA, each group’s LCF is calculated using the group’s unique variance-covariance matrix (Huberty & Barton, 1989; Joachimsthaler & Stam, 1988).
When to use LDA for prediction
As we mentioned earlier, there are many methods for predictive classification. Recent simulation studies point to which methods perform best under various conditions. 2 For example, Khondoker et al. (2016) conducted a simulation comparing random forests, support-vector machines, LDA, and the K-nearest neighbor algorithm and found that none of these options performed uniformly best. However, when the number of predictors was less than half the sample size and the predictors had relatively high correlations (> .6; though not so high as to cause multicollinearity issues), LDA was the method of choice. Khondoker et al. provided further recommendations as to which classification method performs best in other data conditions as well, and we encourage readers who find themselves with data that are not well suited for LDA to consult that work. In another comparison of classifiers—including random forests, support-vector machines, and the K-nearest neighbor algorithm—LDA was shown to perform well when class membership was highly unbalanced (Brown & Mues, 2012).
Additionally, LDA may be preferable to logistic regression and multinomial logistic regression for group classification. More specifically, LDA can be used for classification of three or more groups (unlike logistic regression) and does not require specification of a reference group (unlike multinomial logistic regression). LDA also has the advantage that it can be used to estimate model parameters under conditions of separability (Hastie et al., 2009), that is, when a single predictor is able to perfectly separate cases into classes. If such separability occurs, the maximum likelihood estimator in logistic and multinomial logistic regression will fail to converge and will not produce accurate parameter estimates.
There are certain instances in which LDA may not perform optimally. For example, when data are not multivariate normal and the variance-covariance matrices are not approximately equal, LDA will not be optimal for classification. Either parametric or nonparametric classification methods that do not require explicit specification of data distributions may be more appropriate under such circumstances. Explanation of each of the alternative classification methods and why they may outperform LDA under various data conditions is beyond the scope of this Tutorial but is available in other sources (e.g., Hastie et al., 2009).
Model Evaluation
Case classification
A model’s case classification is evaluated using posterior and typicality probabilities. A case’s posterior probability for a given group indicates the certainty of that case’s classification in that group. For instance, if there are two groups (i.e., Group 1 and Group 2), and the posterior probabilities for a case belonging to those groups are .01 and .99, respectively, the evidence is strong that the case is a member of Group 2. If instead the posterior probabilities are .49 and .51, then the case’s membership in Group 2 is questionable. Such a case is considered a fence rider; its classification is in doubt because it has approximately equal posterior probabilities for multiple groups (Huberty & Olejnik, 2006). In LDA, fences are the thresholds that determine which cases get classified into which groups. As the observations closest to these fences, fence riders are the cases whose classification is most likely to be affected by outlier data, the inclusion or exclusion of new predictor variables, or failure to meet assumptions. Additionally, the presence of a large number of fence riders may suggest the possibility of another level of the grouping variable (e.g., a third group between two identified groups; Huberty & Olejnik, 2006). For example, a large number of fence riders between a “mild substance use” group and a “severe substance use” group may indicate the presence of a “moderate substance use” group in the training data.
The typicality probability is the “probability that a case that far from the centroid would actually belong to [the] group” (Klecka, 1980, p. 45); it indicates how typical an individual’s score is for a given group. Typicality probability is based on the right tail of the chi-square distribution; the chi-square value is equal to the Mahalanobis distance, and the degrees of freedom is equal to the number of predictors (Klecka, 1980). Generally, a larger distance indicates that an individual is less typical of the group (and has a lower typicality probability); conversely, a shorter distance indicates that a case is more typical of the group (and has a larger typicality probability). However, it is important to note that a small typicality probability for a given group does not necessarily mean that an individual should not be assigned to that group. Rather, the individual is potentially an outlier in the data set.
Overall classification
The overall accuracy of prediction (hit rate) in the training data is used to evaluate the utility of the prediction model (LCFs). However, the hit rate for LDA models is inherently biased—in most cases, artificially inflated. This bias comes from using LCFs to reclassify the same data set from which they were derived, a process known as internal classification. Methodologists have suggested that LDA hit rates should be calculated using external classification, that is, by calculating LCFs in one data set and then using those functions to classify cases in another data set (Hsu, 1989; Huberty, 1994; Huberty & Barton, 1989).
When external classification is not possible, cross-validation (CV) methods can be used to give an unbiased estimate of the hit rate. Three options are leave-one-out (LOO) CV, k-fold CV, and repeated k-fold CV. LOO CV is a jackknifing methodology. The classification functions are estimated with one observation held out, and then the held-out observation is classified (Lachenbruch & Mickey, 1968). This process is repeated for all cases. In the k-fold CV procedure, the sample is randomly divided into k subsets. The classification functions are derived using all but one subset, and the cases in the held-out subset are then classified. This is repeated for each of the subsets, and the hit rates are averaged across repetitions. In repeated k-fold CV, the k-fold procedure is repeated a specified number of times, each time with a different division of the sample into k subsets. The results over repetitions are averaged.
Hit rates obtained using CV methods are typically lower than the original hit rates, but are less biased estimates of classification accuracy and, therefore, are the hit rates that should be reported and interpreted. Rodriguez, Perez, and Lozano (2010) recommended using (a) k-fold CV with 5 or 10 folds in preference to LOO CV and (b) repeated k-fold CV in preference to k-fold and LOO CV. This recommendation was based on their simulation, in which LOO CV, though least biased, had the greatest variance in error estimation as well as the greatest computational cost. Though computational cost may not be an issue in applications in psychology, Hastie et al. (2009) recommended the k-fold procedure with 5 or 10 folds as a compromise between reducing estimator bias and reducing variance. In a simulation that varied sample size, Braga-Neto and Dougherty (2004) found that repeated k-fold CV with 10 folds performed well with as few as 20 cases. After CV, the final set of LCFs to be applied to data with unknown classification are the LCFs derived using the entire training data set.
Interpreting the hit rate without providing some context for the likelihood of accurate classification by chance can be misleading. For example, a hit rate of 80% may appear impressive at face value, but if 90% of the data were observed within one group, a hit rate of 80% would be less accurate than classification based solely on chance. Huberty and Lowman (2000) proposed Huberty’s I index as a measurement of improvement over chance. The chance hit rate, Hc, is calculated as follows:

where qi is the prior probability for group i, ni is the number of cases in group i, and N is the total number of cases in the sample. In LDA for prediction, Huberty’s I index is considered the “gold standard” measure of effect size and is highly correlated with other measures of effect size (e.g., η2; Huberty & Lowman, 2000). Huberty’s I is calculated as follows:

where Ho is the observed hit rate and Hc is the chance hit rate (Equation 1).
It is noteworthy that LDA differs from other methods with regard to the additive influence of new predictors. In other methods (e.g., multiple regression), the addition of a predictor will always lead to equal or greater accuracy in prediction. In LDA, that is not always the case; the addition of unrelated variables, or variables with extremely high collinearity, can reduce correct classification (Henson, 2002). Therefore, variables should be carefully selected and justified.
Example
In this section, we detail how to use LDA for classification in R. Annotated syntax for this example is available in Appendix A. The data were collected from a large international airline company and can be found online (UCLA Institute for Digital Research and Education, 2017). The data come from a project undertaken by industrial-organizational psychologists who were interested in whether three job classifications (Customer Service, Mechanic, and Dispatcher) appealed to different personality types. Possible predictive personality variables were assessed in 244 airline employees using a brief battery that asked questions about outdoor skills, social skills, and conservativeness.
Assumptions
Within each job classification, we assessed multivariate normality with scatterplots showing the association between squared Mahalanobis distance and associated chi-square quantiles (Fig. 1; Henson, 1999). For multivariate normality, plotted values are expected to fall generally on a diagonal. All three plots indicated some deviation from multivariate normality. The deviations of the Mechanics group were the greatest, although they did not appear to be extreme for the vast majority of cases. Additionally, we used Mardia’s (1970, 1974) skewness and kurtosis tests to evaluate multivariate normality (see Table 1). Combining the evidence from the plots and the null findings of the statistical tests, we determined that it was acceptable to assume that the distributions within each class were approximately multivariate normal. We assessed the equality of variance-covariance matrices with Box’s (1949) M and comparison of log determinants and their 95% confidence intervals (Cai, Liang, & Zhou, 2015). Box’s M was not statistically significant, based on the recommended lower criterion for statistical significance with this test (i.e., p < .001; Tabachnick & Fidell, 2013). A log determinant is essentially a single-value summary of the total variability within a matrix. Near equality between log determinants indicates that variability across matrices is similar (Tabachnick & Fidell, 2013). The log determinants across the three groups were similar, and their 95% confidence intervals overlapped (see Table 1). These findings indicated that the data did not violate any testable assumptions to an extent that would be concerning.
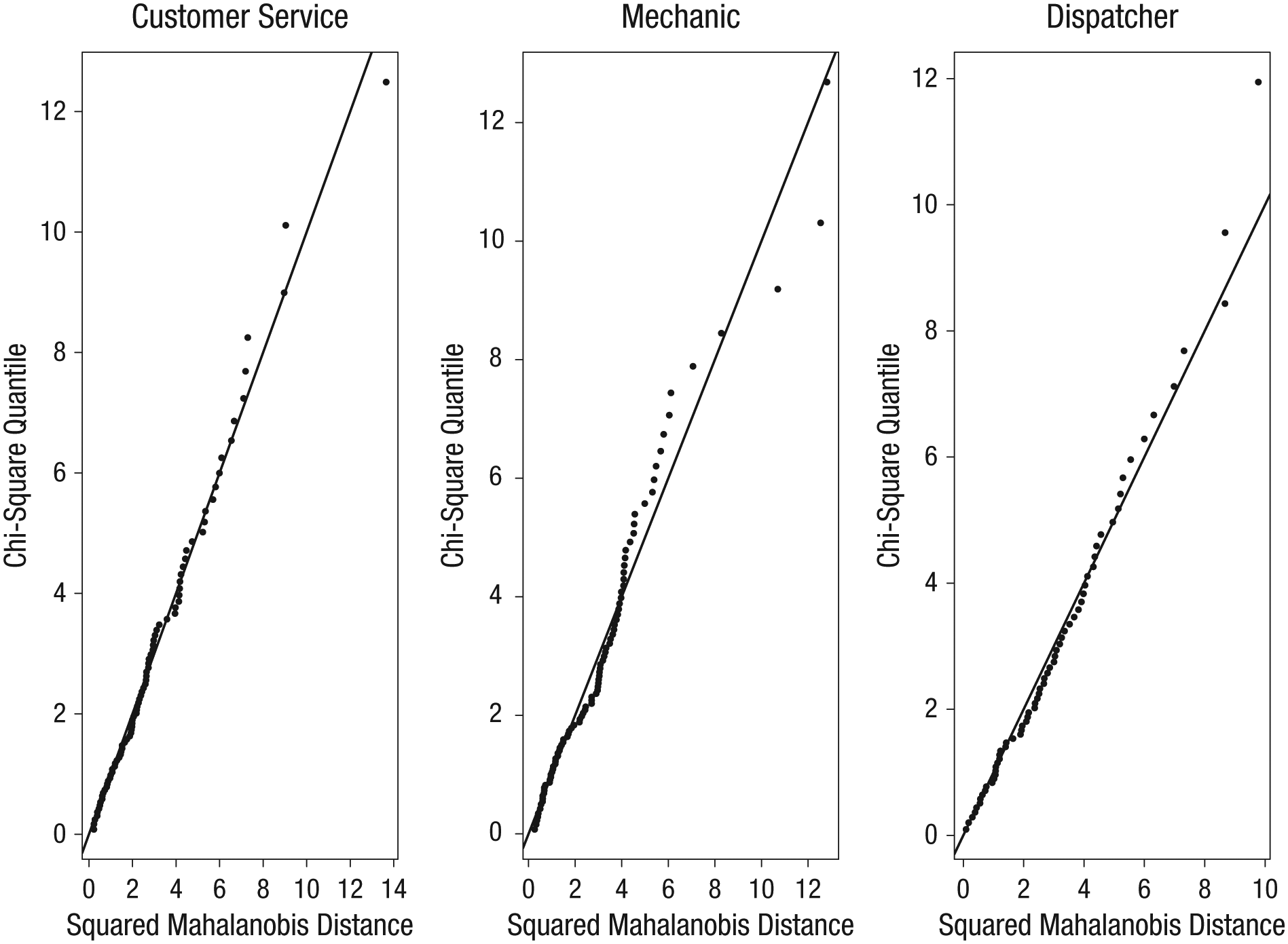
Scatterplots for assessing the multivariate normality of the predictor variables within each job classification (from left to right): Customer Service, Mechanic, and Dispatcher. The horizontal axis is the squared Mahalanobis distance, or multivariate distance, of the case from the centroid of the respective group, and the vertical axis is the case’s expected quantile in the chi-square distribution with degrees of freedom equal to the number of predictors.
Results of Assumption Checks for the Example Application of Linear Discriminant Analysis
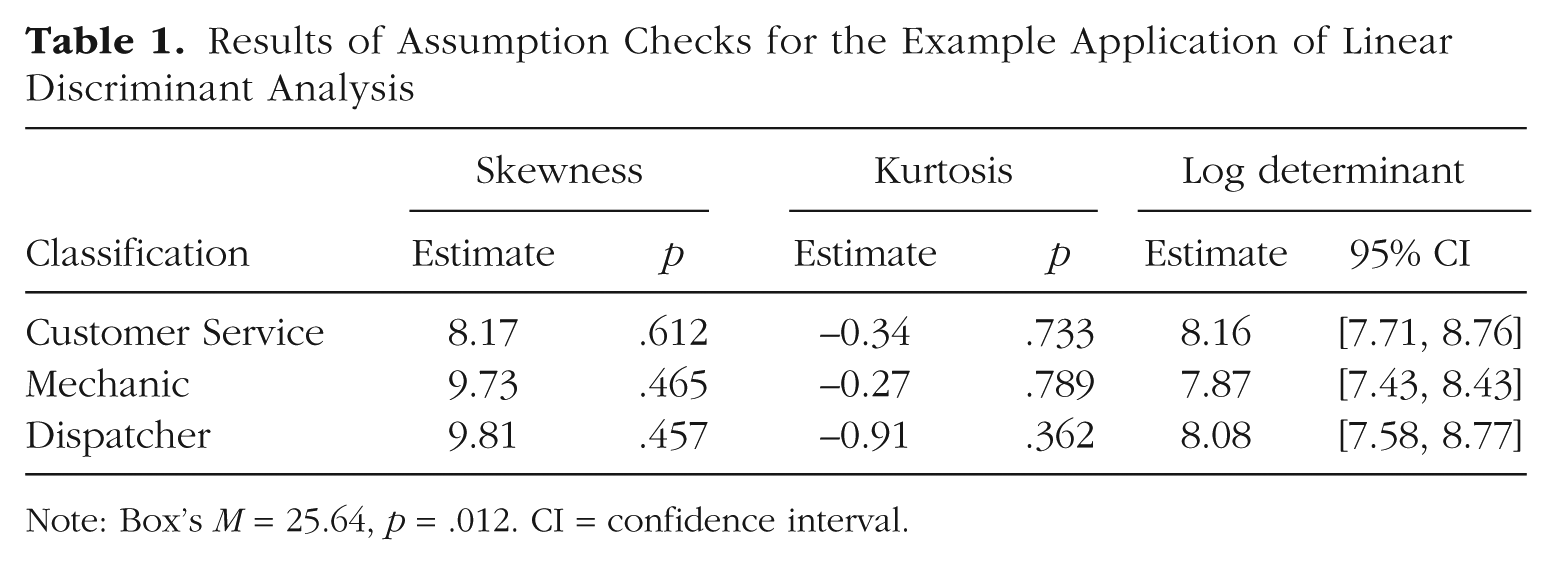
Note: Box’s M = 25.64, p = .012. CI = confidence interval.
Case classification
Running the syntax for the example produced a data set that contained the observed predictors and actual classification of cases, along with the predicted classification, the posterior probabilities, and the typicality probabilities for each case (see Table 2 for sample results).
Results for Six Cases in the Example Application of Linear Discriminant Analysis
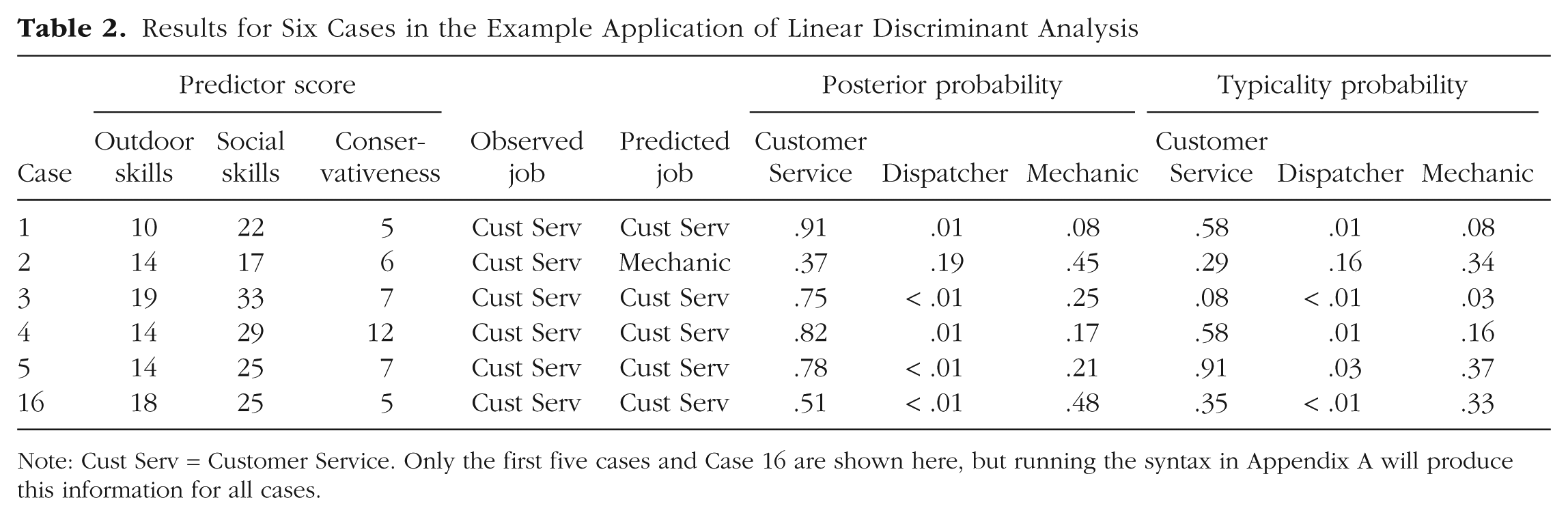
Note: Cust Serv = Customer Service. Only the first five cases and Case 16 are shown here, but running the syntax in Appendix A will produce this information for all cases.
Researchers should inspect the typicality probabilities for outliers and fence riders. Huberty and Wisenbaker (1992) suggested that a case with a typicality probability less than .10 for its assigned class should be considered an outlier. For example, in our output, Case 3 had a typicality probability of .078 for its assigned class (Table 2). Although this case was correctly classified, the inclusion of such an outlying data point can influence the coefficients of the LCFs. Huberty and Wisenbaker recommended removing such cases from the analysis, although caution should be taken in doing so because of the potential for overfitting the model or redefining the population of interest. Case 16 would be considered a fence rider, with posterior probabilities of .510 for Customer Service and .483 for Mechanic (Table 2). Because there were only a small number of outliers and fence riders in our output, we did not remove any cases.
Overall classification
After considering the potential influence of outliers and fence riders, we evaluated the overall classification of cases by examining hit rates and Huberty’s I index. Given the bias inherent to internal classification, we used CV methods to determine hit rates. The hit rates were .746 for LOO CV, .738 for k-fold CV (with k = 10), and .741 for repeated k-fold CV (with k = 10 and repetitions = 20). These hit rates should be considered in light of the chance hit rate. The chance hit rate was calculated by substituting into Equation 1 the prior probability of each occupation (e.g., .333 for each), sample size (85, 93, and 66), and total sample size (244). The chance hit rate was .333. Although the hit rates (i.e., .738–.746) appeared to be relatively large compared with a chance hit rate of .333, the final step was calculating Huberty’s I index. We used the LOO-CV hit rate in Equation 2 and found that Huberty’s I was .619. 3 Huberty and Lowman (2000) suggested that an I index of .35 is a general and conservative threshold for a high (or large) effect. Thus, the I index for this example is considered a large effect.
Overall, this analysis indicates that the industrial-organizational psychologists working for the airline could conclude that the three job classifications did, in fact, appeal to different personality types. The LCFs derived from measures of outdoor skills, social skills, and conservativeness correctly classified approximately 75% of the participants in the study—a marked improvement over chance, evidenced by a large effect size.
Classifying a new case
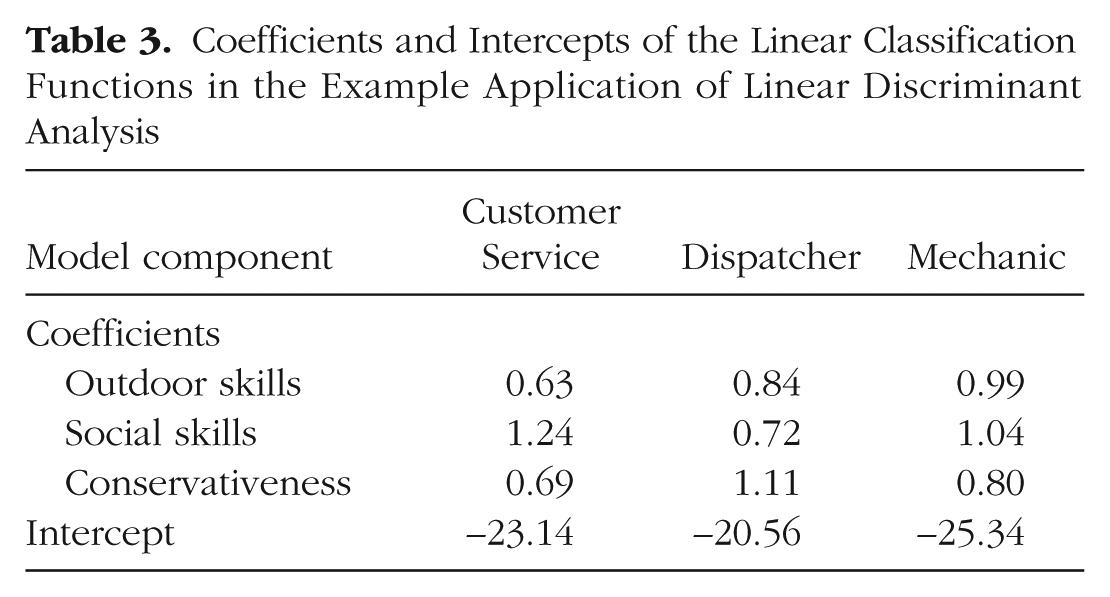
The coefficients and intercepts of the LCFs derived in the training data set, shown in Table 3, can be applied to an unclassified case to predict classification. As an example, we applied the LCFs to a case with a score of 18 for outdoor skills, a score of 10 for social skills, and a score of 8 for conservativeness, substituting these values in to the LCF for each classification. The results, including posterior probabilities and typicality probabilities, are presented in Table 4. According to the results, the new example case belongs with the Dispatcher group because of the high posterior probability and comparatively large typicality probability for that group. Psychologists working for the airline could be confident that the assignment is likely correct for this case because the cross-validated classification with the training data was favorable.
Coefficients and Intercepts of the Linear Classification Functions in the Example Application of Linear Discriminant Analysis
Results for the New Case in the Example Application of Linear Discriminant Analysis

Conclusion
This Tutorial is meant to serve as a practical and applied overview of LDA for prediction of group membership. Though several classification methods exist, LDA has been shown to operate comparatively well when the number of predictors is fewer than half the number of cases, the correlations between predictors is greater than .60, and the assumptions of the model are approximately met. LDA also may be preferred over logistic and multinomial logistic regression when specification of a reference group is inappropriate or under conditions of separability. For evaluating overall classification, repeated k-fold cross-validation is recommended, when possible, and Huberty’s I index is the recommended effect size for determining whether the classification model performs better than chance. Posterior probabilities indicate the probability of group membership, and typicality probabilities are useful for identifying outliers or pointing to a potentially unnamed class. Psychological researchers interested in a more intricate understanding of LDA should consult Huberty’s (1994) or Huberty and Olejnik’s (2006) books concerning applied discriminant analysis, as well as the works we have cited throughout this article.
Supplemental Material
Boedeker_Open_Practices_Disclosure – Supplemental material for Linear Discriminant Analysis for Prediction of Group Membership: A User-Friendly Primer
Supplemental material, Boedeker_Open_Practices_Disclosure for Linear Discriminant Analysis for Prediction of Group Membership: A User-Friendly Primer by Peter Boedeker and Nathan T. Kearns in Advances in Methods and Practices in Psychological Science
Footnotes
Appendix A: Annotated R Syntax for the Example of Linear Discriminant Analysis Discussed in the Main Text
Appendix B: Derivation of Linear Classification Functions and Bayesian Posterior Probabilities
This appendix provides technical details regarding the derivation of linear classification functions (LCFs) in a Bayesian framework. The LCFs output a classification score for each group for a given case, and these scores can be used to derive the posterior probabilities of group membership.
The posterior probability is the probability that an individual with response vector
where Pr(X =
Assuming a multivariate normal distribution of predictors, the density of the predictors within a class k is estimated as follows:
where p is the number of predictors, and T indicates transposition. This estimate is equivalent to Pr(X =
Every term that does not depend on k will remain constant and can be written as a single constant, C′, such that
To maximize over k groups, we first take the log:
We note that log C′ does not vary by k. Therefore, to determine classification, we maximize only the variable terms over the k groups:
Expanding this final term and simplifying yields
However, the second term in this expression also does not depend on k. Therefore, to find the maximum over the k possible classes, we need only use the following:
The first term in Equation B2 is dependent entirely on the prior probability of membership in group k. The second term is a constant dependent on the mean of the predictor variables, or centroid, within group k. The sum of the first and second terms yields the LCF’s intercept for the kth group. The final term is the product of a case’s vector of observed responses to predictor variables and the coefficients of the LCF for the kth group. Substituting a single case’s response vector into Equation B2 produces a classification score from which the posterior probability of group membership may also be derived.
Action Editor
Frederick L. Oswald served as action editor for this article.
Author Contributions
N. T. Kearns wrote an initial draft of the manuscript. P. Boedeker substantially revised the manuscript and wrote the syntax for the data analysis. Both authors critically edited the manuscript and approved the final submitted version.
Declaration of Conflicting Interests
The author(s) declared that there were no conflicts of interest with respect to the authorship or the publication of this article.
Open Practices
Open Data: not applicable
Preregistration: not applicable
All materials have been made publicly available via the Open Science Framework and can be accessed at https://osf.io/6bk24/files/. The complete Open Practices Disclosure for this article can be found at http://journals.sagepub.com/doi/suppl/10.1177/2515245919849378. This article has received the badge for Open Materials. More information about the Open Practices badges can be found at ![]() .
.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.