
Abstract
Data sharing promotes scientific progress by permitting replication of prior scientific analyses and by increasing the return on the human and financial investments made in data collection. The costs of data sharing can be reduced through the implementation of best practices in data management across the research life cycle; this article provides specific guidance on these practices. The benefits of data sharing will be reaped when researchers who share their data are rewarded with citations and recognition of the intellectual value inherent in producing new scientific data.
Data sharing is garnering increasing support across the social and natural sciences, including within the field of psychology. As the Data Sharing Working Group of the American Psychological Association (2015) recently noted, sharing data not only has the straightforward, key benefits of increased openness, accountability, and scientific progress, but also allows geographically dispersed individuals and those with limited resources to investigate scientific questions of interest, enables replication of analyses for verifying empirical findings, and opens extant data to analysis with new, more powerful, or integrative techniques than were available at the time of collection. (paragraph 2)
Several other benefits have been extolled for decades. Data sharing encourages multiple perspectives, saves money through reuse, promotes new research, leads to many more publications based on the data than would result if they were not shared, and protects against “fabrication, falsification, or distortion” (National Research Council, 1985, p. 14; see also Pienta, Alter, & Lyle, 2010; Piwowar, Day, & Fridsma, 2007). Many governmental agencies (Holdren, 2013; National Institutes of Health, Office of Extramural Research, 2007; National Science Foundation, n.d.), charitable foundations (Bill & Melinda Gates Foundation, 2017; Wellcome, n.d.-b), professional associations (Lupia & Elman, 2014), and scientific journals (Data Access & Research Transparency, 2016; Nature, 2016; Silva, 2014) now formally recognize these benefits by encouraging or even mandating data sharing.
Data sharing is a boon not only to the scientific community, but also to the original investigator. Sharing encourages better data management, which improves the efficiency and quality of output (Academia Stack Exchange, n.d.). Sharing can provide credit and recognition, and extend a researcher’s reach, much as publication does. When a researcher shares via an established and trusted archive, sharing reduces busywork and information loss after a project is completed by transferring dissemination and user-support responsibilities to the repository.
Resistance to Sharing Data
Although the benefits of data sharing are numerous, the practice of data sharing is still not standard in many research communities, including the psychology community. One study, for instance, found that 73% of psychologists whose work was published in four top American Psychological Association journals did not share their data upon request, even though “all corresponding authors had signed a statement that they would share their data for such verification purposes” (Wicherts, Bakker, & Molenaar, 2011, Methods, paragraph 1; see also Wicherts, Borsboom, Kats, & Molenaar, 2006). Why the hesitation? Some researchers fear loss of control or being scooped. In practice, however, the original data producer has a first-mover advantage for publication, given his or her deep knowledge of the data. Sharing data increases the likelihood that they will make a significant impact through secondary analysis and makes possible future citations that increase the value of the data and publications related to them (LeClere, 2010).
Other researchers worry that their work will not be replicated—never mind that reproducibility is a core component of science. As the Open Science Collaboration (2015) has argued, “scientific claims should not gain credence because of the status or authority of their originator but by the replicability of their supporting evidence” (p. 943). It is not surprising, at an emotional or individual level, that researchers are loathe to take actions that would allow someone to find that they made a mistake, or that their claim does not hold up. However, this understandable fear undermines scientific progress. If researchers think their research is worth doing—that the knowledge is worth knowing, not just to advance careers or build curriculum vitae, but because humankind is better off with better knowledge, a better understanding of why the sun shines or people get sick or unhappy or find jobs—then they should share their data to ensure that the knowledge they produce is valid. CAVATICA, a data-analysis and -sharing platform for pediatric cancer research, illustrates this point; see http://www.cavatica.org/): When research is driven by cancer patients and their families (in this case, represented by CAVATICA’s funder, the Dragon Master Foundation), concerns about data sharing are set aside in the interests of more rapid scientific discovery. 1 Rather than reinforce or reward tentative behavior, the academic and scientific community should acknowledge the social value of scientific progress by rewarding those researchers who accept the risk of being proven wrong by sharing their data.
Still other researchers worry about freeloading: “Why should I go to the effort to obtain grants and collect my own data if I am then required to share my data with others?” (Firebaugh, 2007, p. 207). Researchers need to be willing to make costly investments in collecting primary data, but there are ways to reward them that are consistent with scientific advance. The U.S. patent system is based on the principle that the original inventor gets credit in return for transparency. The scientific community should approach researchers’ concerns regarding individual “property rights” over data in the same way. We acknowledge that researchers want to receive credit as well as to advance knowledge, and that research subjects want their confidentiality to be protected as well as to advance knowledge. The interests of both researchers and subjects are completely consistent with sharing data, as long as confidentiality protections and requirements for data citation are implemented. It is those citations that provide researchers with the individual incentive, beyond the intrinsic value of advancing science, to produce and share data.
Incentivized Data Sharing
Important changes in institutional, disciplinary, journal, and funder practices are necessary to support individual researchers in sharing their data and incentivize them to do so. Academic organizations—departments, colleges and universities, disciplinary associations such as the Association for Psychological Science—should treat data sharing (or published documentation or description of data) as a productive, scientific contribution in and of itself, equivalent to a refereed academic publication. The sharing of data should be considered explicitly in tenure and promotion decisions. Doing so would both provide increased incentive for sharing and contribute to the social validation of sharing.
Journals should require, rather than simply recommend, data archiving. One recent study found that the odds of finding the data online increase almost 1,000-fold when journals mandate data archiving, compared with when they have no archiving policy (Vines et al., 2013). The same study found archiving rates to be “only very slightly higher” (p. 1304) at journals that recommend (but do not require) archiving than at journals with no policy. Without mandates, data simply are not shared. Journals should also require data citation, so that those researchers who do share their data receive credit. Data sets should be cited just as publications are, so that the data producers receive comparable credit for their contribution.
Similarly, funders should require data sharing by awardees who are producing valuable new data resources, and they should provide funding for sustainable access to data that are shared. Although the requirement to submit data-management plans has increased awareness of the value of data in the research community, the returns to funders’ investments in the creation of new data can be fully realized only by taking the next step by requiring, enforcing, and funding sustainable plans for sharing data, and funders should withhold funding until sharing is verified. The National Institutes of Health in the United States and the Wellcome Trust in the United Kingdom already withhold a portion of funding when researchers do not make their publications publicly available (van Noorden, 2014). The Wellcome Trust, for instance, withholds the final 10% of the total grant funding if publication-sharing requirements are not met (Wellcome, n.d.-a). The result of this policy change was a marked increase in compliance with Wellcome’s open-access policy: The compliance rate rose to 91% in 2016, a significant improvement from 74% in 2015 (Wellcome, n.d.-c).
Increasing Researchers’ Capacity for Data Sharing
Two common data-sharing concerns we hear from our own community of users at the Inter-university Consortium for Social and Political Research (ICPSR) at the University of Michigan involve the level of effort required of researchers and disclosure risk. The first concern is that data sharing is a lot of work. The second concern is that data cannot be shared because they are confidential or the study’s subjects are identifiable. The latter is a particular concern when the data come from detailed, longitudinal surveys or administrative or other naturally occurring data. Solutions to each of these concerns are available and straightforward to implement.
As regards the first concern, it is true that data sharing does take effort. As one scientist-blogger (and, it should be noted, open-science enthusiast) wrote in exasperation, preparing data for sharing can be “a major pain in the ass and is really expensive, in terms of both the money and amount of time required” (Bruna, 2014, paragraph 5). Yet, with sufficient preparation, the effort needed to share data can be built into the standard data workflow, so that the eventual data sharing is nearly painless. As one data-sharing advocate noted, “Collecting data is a bit like cooking a good meal. If you clean as you go, when you are full and sleepy you will have much less to do” (LeClere, 2010, paragraph 12).
Guidance about good data-management practice is plentiful. Several data repositories have provided step-by-step instructions, including ICPSR’s (2012b) “Guide to Social Science Data Preparation and Archiving” and DataONE’s “Data Management Guide for Public Participation in Scientific Research” (Wiggins et al., 2013). Recent publications have condensed the guidance into easily digestible rules of thumb, such as “Ten Simple Rules for the Care and Feeding of Scientific Data” (Goodman et al., 2014). This guidance typically addresses four primary components of data management:
Planning: Many federal agencies now require that formal data-management plans be submitted with research proposals. A good plan “describes the data you expect to acquire or generate during the course of a research project, how you will manage, describe, analyze, and store those data, and what mechanisms you will use at the end of your project to share and preserve your data” (Stanford Libraries, n.d., paragraph 1). Planning streamlines your workflow, prepares you for what to expect, and helps you avoid problems. ICPSR (2012a) provides step-by-step guidelines for creating a data-management plan (see Table 1 for a summary).
Standardization: A well-prepared data collection includes all information that secondary users will need to make sense of the data. The simplest way to meet this goal is to standardize documentation as it is created. Make sure to document everything! This includes labels, values, code, and the process used to generate the final data product. Workflow managers such as the Open Science Framework (https://osf.io/), GitHub (https://github.com/), and SEAD (http://sead-data.net/) can help you manage active projects. Table 2 presents useful questions to consider when planning how to standardize data.
Description: Create a codebook or user guide explaining the overall data collection, including the purpose, format, and methodological details (ICPSR, 2011). Good descriptions help answer questions about “the why, who, what, when, where, and how of the project” (Wiggins et al., 2013, p. 7). This information will help secondary users understand how to use the data, including how to replicate the study. That same information can be useful when creating an online finding aid for other researchers who are studying areas covered by the data and searching for relevant data. Table 3 summarizes the different elements you should make sure to include in your codebook.
Archiving: Some repositories will help review and enhance a data collection prior to publication. A trusted archive should provide a landing page with a persistent, globally unique identifier so that other people can find and cite your data, and provide the long-term digital support needed to preserve and disseminate the data well beyond the end of your formal research project. For example, Figure 1 shows a standard study home page at ICPSR. In addition to the study’s title, the names of individuals responsible for the production of the data, and links to the data and other information, it provides a standard data citation, so that any secondary users know how the data should be cited. There are now available many data repositories that will preserve and share data from individual researchers. These include general data repositories, such as Dryad (http://datadryad.org/), figshare (https://figshare.com), and Zenodo (https://zenodo.org ), as well as disciplinary archives, such as ICPSR, and local institutional repositories typically run by a university library (Vitale et al., 2017).
Elements of a Data-Management Plan
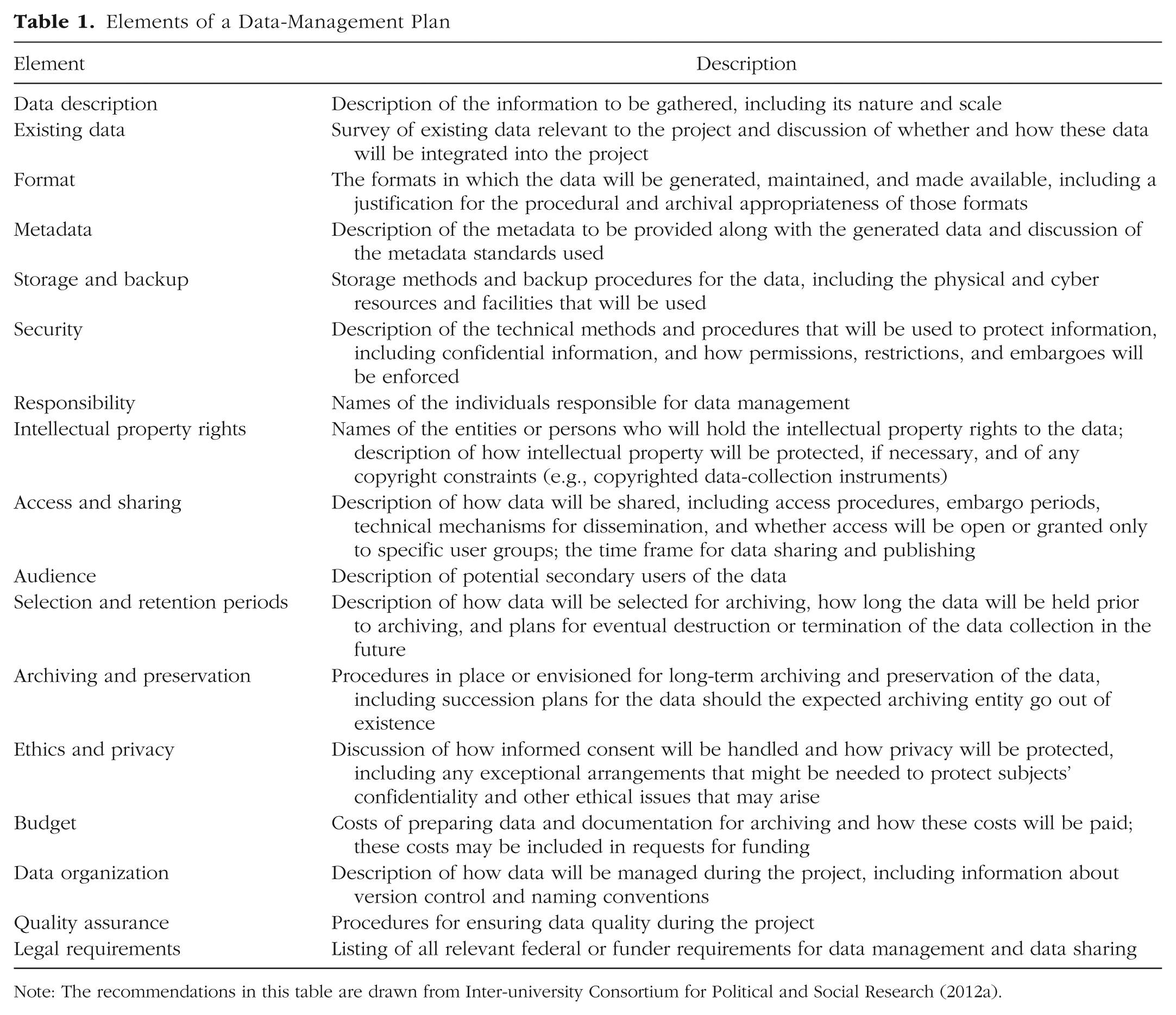
Note: The recommendations in this table are drawn from Inter-university Consortium for Political and Social Research (2012a).
Questions to Consider When Planning to Standardize Data

Note: This table was adapted with permission from Research Connections (2017, p. 5).
Guidelines for Describing Data

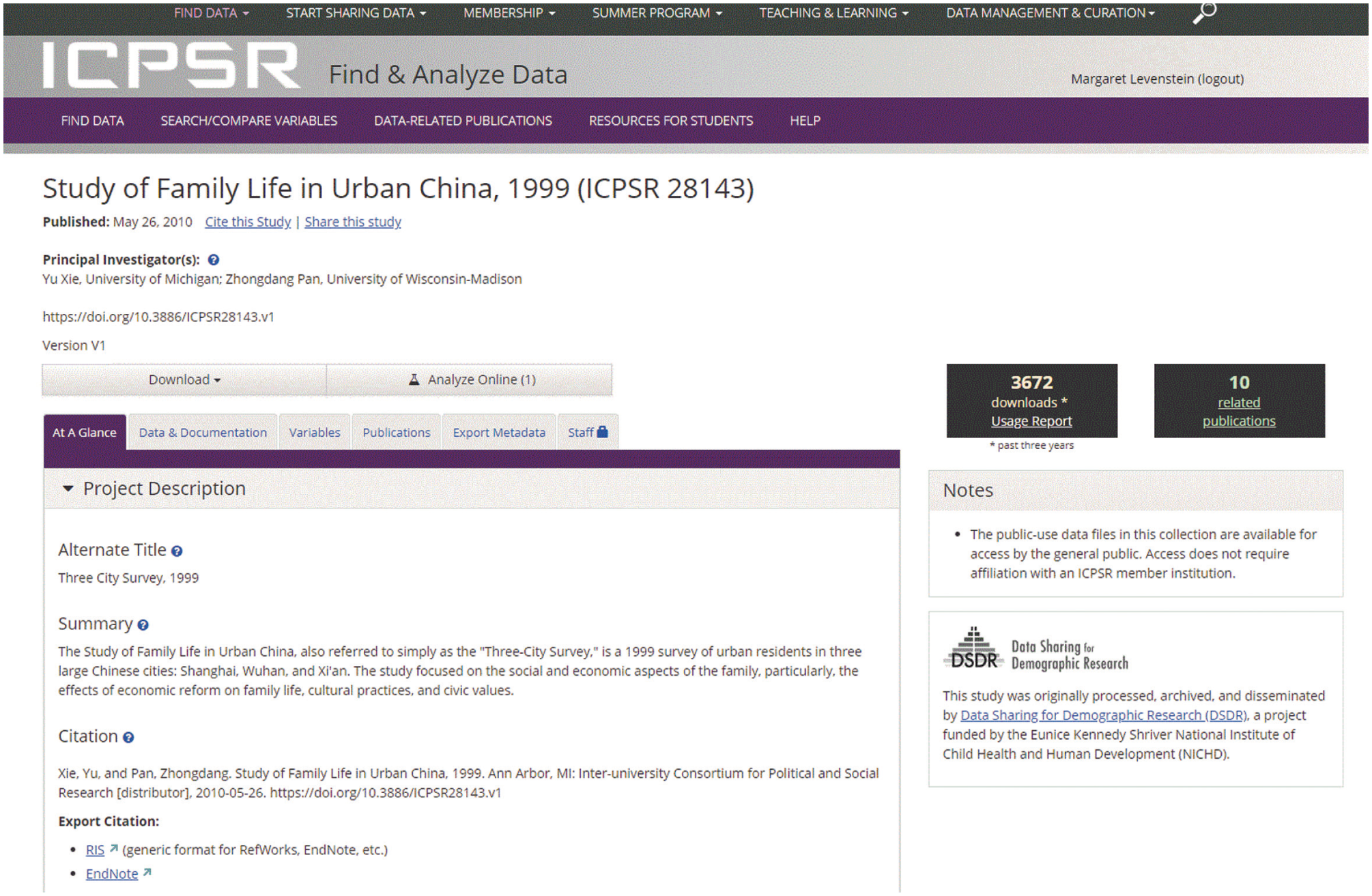
Example of the study home page for a data collection archived at the Inter-university Consortium for Political and Social Research.
Effective data management takes practice, but the payoff is rewarding. That same scientist-blogger who complained about data sharing being “a major pain in the ass” later wrote, “It’s also important for me to remember that it will get cheaper and cheaper every time I do it (e.g., preparing metadata was a snap this time because I used the template from my prior submissions . . .)” (Bruna, 2014, paragraph 5).
The second concern we hear from ICPSR users is more complicated, but still manageable. There is justifiable reason to guard against disclosure of confidential or potentially identifiable data, particularly when the data are detailed or longitudinal. Even if basic identifying information is suppressed, the large amount of information now available at low cost in public and commercial data sets makes re-identification easier than in the past (Bradley & Sweeney, 2004). Researchers often want access to data (e.g., detailed geographic information) that makes other data easily re-identifiable, or to personally identifiable information itself, for linkage to, for example, electronic health records or administrative records on health-care expenditures (e.g., records from the Centers for Medicare & Medicaid Services). Other data, such as videos of children, simply lose too much value for many studies if noise is added to obscure recognition (Gilmore & Adolph, 2017). Researchers often assume that the interest of the individuals participating in a study is best protected by not sharing. But participants share their time and personal information because they want scientific progress. Researchers owe it to study participants, and to the taxpayers and foundations that support research, to extract as much scientific knowledge as possible from the support that they have given to these research endeavors.
There are now multiple straightforward, accessible ways to address concerns about sharing data that contain sensitive and confidential information. In some cases these issues are best addressed with the assistance of a qualified data archive. Here, we describe several of the steps that you can take to address these concerns at different stages of a research project:
Use appropriate consent protocols: At the beginning of a study, it is important to make use of consent protocols that explicitly permit sharing, with confidentiality protection, for research purposes. Although it is essential that confidentiality is maintained, proper informed-consent language should not unduly restrict eventual data sharing. For example, avoid language that promises to limit data access to a particular research team or indicates that the consent will expire after a period of time. ICPSR (2017c) maintains an online resource of recommended informed-consent language for data sharing (see Table 4).
Separate personally identifiable information: If a data set includes personally identifiable information, it is recommended that these variables be separated from the rest of the data set and multiple crosswalks between the files be created and encrypted in order to protect private information without having to destroy it. First, give each subject a study-specific unique ID. Second, create a crosswalk between the personally identifiable information and a new, otherwise completely meaningless, identification key. Third, create a second crosswalk between that “meaningless” identification key and your study’s IDs. Fourth, create a file that contains the personally identifiable information and the arbitrary IDs. Encrypt it. Finally, create a second file that contains the arbitrary IDs and the study IDs. Encrypt it. Keep your study data with the study IDs; keep the personally identifiable information separate. The file with your study data will be the basis for the research data sets that are shared with the general research community. The encrypted files should be kept in a secure computing environment where they may be accessed by qualified researchers who want to enhance and analyze the data with other information (e.g., data from subsequent waves of a survey or administrative data, such as those in the National Death Index).
Anonymize and desensitize the data: Public-use versions of the original data can be created by removing direct personal identifiers (e.g., names, identification numbers) as well as other variables that increase the likelihood of re-identification (e.g., home address or detailed geography, exact measures of income). This option provides secondary users with access to data, albeit data that are missing potential variables of interest. Rather than removing variables, it may be possible to recode them. Examples of recoding include converting exact birth dates to time intervals or exact income levels to income ranges (ICPSR, 2017a). Alternatively, you may use statistical methods of protecting confidentiality that “blur or disguise the data in such a way that individual data items cannot be uniquely associated with or attributed to a particular person or establishment” (American Statistical Association, 2008, p. 4; see also Federal Committee on Statistical Methodology, 2005).
Put the data behind a physical or virtual firewall: There are a number of alternative methods for providing researchers with access to confidential data for analytic purposes while still protecting it from disclosure. One option that works well for popular, well-documented data is software that permits on-line analysis and automatically checks the output for disclosure risk. Such software allows secondary users immediate analytic access to restricted-use data behind an interface that automates disclosure protections. For example, results with cell counts beyond a sensitivity threshold may be suppressed to protect against potential identification of subjects. Researchers cannot directly observe the underlying microdata. A second option is to make data available in a virtual data enclave. A virtual data enclave provides access to restricted data on a remote server, similar to a remote-desktop environment. Users cannot download or upload data, and all software needed for analysis is preinstalled in the secure environment. Output can be removed from the virtual enclave only by a third party and may be reviewed for disclosure risk before being moved. A researcher can see but cannot remove the microdata and also cannot combine the microdata with other data that might permit re-identification. Finally, data can be shared through a physical data enclave. In this case, approved users visit a physical location that is monitored and secured. They cannot bring electronic equipment into the enclave, and all output, notes, and other materials must be reviewed for disclosure risk before leaving the enclave (ICPSR, 2017b).
Model Informed-Consent Language for Data Sharing

Note: These examples are taken from the Model Language section of Inter-university Consortium for Political and Social Research (2017c).
Data-sharing concerns can be overcome with sufficient planning. Tools and processes to assist researchers are in place, especially through qualified data archives. Data sharing need not be overly burdensome, and confidential or identifiable data can be shared using appropriate access and control mechanisms. The benefits of data sharing far outweigh the costs. The research community can increase data sharing, and the benefits reaped, by implementing small changes in standard academic practice, including requiring citation of data sets and valuing data sharing as a scientific contribution comparable to publication. We owe it to research subjects and to the taxpayers and foundations that support research to extract as much scientific knowledge as possible from their support. Sharing data with other researchers is one way to achieve that.
Footnotes
Action Editor
Daniel J. Simons served as action editor for this article.
Author Contributions
M. C. Levenstein and J. A. Lyle jointly generated the ideas and text in this article. Their names are listed in alphabetical order.
Declaration of Conflicting Interests
The author(s) declared that there were no conflicts of interest with respect to the authorship or the publication of this article.