
Abstract
Although multitasking is a common everyday activity, it is often challenging. The aim of this study was to evaluate the effect of noise attenuation during an audio-visual dual task and investigate cognitive resource allocation over time via pupillometry. Twenty-six normal hearing participants performed a dual task consisting of a primary speech recognition task and a secondary visual reaction-time task, as well as a visual-only task. Four conditions were tested in the dual task: two speech levels (60- and 64-dB SPL) and two noise conditions (No Attenuation with noise at 70 dB SPL; Attenuation condition with noise attenuated by passive damping). Elevated pupillary responses for the No Attenuation condition relative to the Attenuation and visual-only conditions indicated that participants allocated additional resources on the primary task during the playback of the first part of the sentence, while reaction time to the secondary task increased significantly relative to the visual-only task. In the Attenuation condition, participants performed the secondary task with a similar reaction time relative to the visual-only task (no dual-task cost), while pupillary responses revealed allocation of resources on the primary task after completion of the secondary task. These findings reveal that the temporal dynamics of cognitive resource allocation between primary and secondary task were affected by the level of background noise in the primary task. This study demonstrates that noise attenuation, as offered for example by audio devices, frees up cognitive resources in noisy listening environments and may be beneficial to improve performance and decrease dual-task costs during multitasking.
Introduction
Multitasking is a common activity in human everyday life and can be defined as the process of managing and executing more than one task at the same time. Several multitasking situations involve processing spoken information and, at the same time, solving a task visually, for example engaging in a conversation while navigating the environment, talking with a friend while watching television, listening to a podcast while driving, or reading e-mails while talking on the phone. These multitasking situations can take place anywhere and anytime, whether in a private or professional context. Despite being a common situation, multitasking is often challenging, and one may need to prioritize one task over the others to ensure satisfactory performance on the main task. The challenge with multitasking is posed by the need to concurrently use cognitive processes and resources when performing two or more tasks in parallel (Koch et al., 2018). One key principle of cognitive theories is that the amount of processing resources that a person has available is limited in capacity (Kahneman, 1973). According to Kahneman's capacity model, each individual has a single pool of limited resources that can be allocated flexibly and consciously among perceptual and mental activities (Wingfield, 2016). Once the total amount of resources is exceeded, the individual can choose to focus on one task at the expense of the other(s) or can divide the available resources among tasks causing some kind of interference (Kahneman, 1973; Wingfield, 2016). The amount of interference among tasks depends on the nature and the demands of the individual tasks (Pashler, 1994). Hence, the assumption is that there are both structural constraints in terms of capacity limits as well as flexible adaptations to task requirements (Kahneman, 1973; Koch et al., 2018). Although other theories of multitasking have been postulated to understand task interference and resource allocation (e.g., Allport et al. 1972; McLeod, 1977; Salvucci & Taatgen, 2008), a consensus has emerged to interpret listening effort in terms of Kahneman's capacity model (Pichora-Fuller et al., 2016), or an adaptation of it. The Framework for Understanding Effortful Listening (FUEL; Pichora-Fuller et al., 2016) is, in fact, an adaptation of Kahneman's capacity model. According to the FUEL model, the amount of effort required to achieve or maintain performance on a task depends on both the demands imposed by the task and the individual's motivation. The FUEL model defines effort as the deliberate allocation of resources to overcome obstacles in goal pursuit when carrying out a task (Pichora-Fuller et al., 2016). Listening effort is then defined more specifically as the effort allocated in performing listening tasks (Pichora-Fuller et al., 2016), where task demands may increase, for example, with increasing level of background noise.
Dual-task paradigms are often used in the laboratory to study human multitasking and to evaluate how two tasks performed simultaneously may interact and interfere causing a decrease in performance or efficiency (Gagné et al., 2017; Koch et al., 2018). In a dual-task paradigm, two tasks (a primary and a secondary one) are performed alone and simultaneously. The assumption behind using these paradigms is that if the cognitive resources required to perform both tasks simultaneously exceed the total resources available (Kahneman, 1973), the participant is expected to prioritize the primary task and a decrease in performance will be observed on the secondary task. This reduction in performance is referred to as dual-task cost and reflects the need to (consciously) allocate more resources on one task at the cost of the other task. For those experimental paradigms where the primary task is a speech recognition task and task demands are increased, for example, by increasing the level of background noise, the increase in cognitive resources needed to understand speech in a higher level of noise (i.e., listening effort; Pichora-Fuller et al., 2016) can be inferred by a decrease in performance on the secondary task. In other words, the dual-task cost can be considered a behavioral estimator of listening effort (Desjardins & Doherty, 2014; Gagné et al., 2017). Sarampalis et al. (2009) developed a dual-task paradigm consisting of a speech recognition task in background noise and a visual reaction-time task, and showed that listeners with normal hearing reacted faster in the visual reaction-time task when the background noise was attenuated. This finding suggests that noise attenuation can free up cognitive resources that would otherwise have been needed for recognizing speech, to be used for other tasks (i.e., to react faster in the visual task). While Sarampalis et al. (2009) provided evidence that noise attenuation was responsible for diverting cognitive resources from speech understanding to react faster in the visual task, their study did not clarify the timing of this process, i.e., when cognitive resources are diverted from one task to the other during the dual task.
This study aims to gain a deeper understanding of the temporal dynamics of cognitive resource allocation during a dual task and how noise attenuation affects these dynamics. Although dual-task costs and reaction-time can be used to explore cognitive processes and task interference, they cannot reveal the time course of resource allocation. Hence, pupil dilation was evaluated in this study as a measure of cognitive resource allocation over time to address the yet unresolved question about the temporal dynamics of the task conflict emerging in a dual-task paradigm consisting of a speech recognition task and a visual reaction-time task (Sarampalis et al., 2009). A similar approach tracking the temporal changes of pupil dilation to explore cognitive processes over time, task conflict, and reveal chronological priorities of tasks was used in previous studies (Hershman et al., 2021, 2023; Hershman & Henik, 2019, 2020). As emerged in those studies, the temporal analysis of pupil dilation seems to be a promising measure in cognitive research (Hershman et al., 2023). Task-evoked pupil dilation reflects activation of the autonomic nervous system, where the sympathetic and parasympathetic nervous systems interact and affect pupil size (Steinhauer et al. 2004). It is generally assumed that the biggest contributor to task-evoked pupil dilation is the sympathetic nervous system (via activation of the dilator muscle in the iris), but the inhibition of the parasympathetic nervous system can also contribute to the dilation (via relaxation of the sphincter muscle in the iris), especially in cognitively demanding situations and in light conditions (Steinhauer et al. 2004). The resulting pupil response indexes a complex mechanism underlying cognitive resource allocation (Kahneman & Beatty, 1966; see Zekveld et al., 2018 for a review). In hearing research, pupillary responses have been recorded during speech intelligibility tasks with varying task demands and have been shown to be a reliable physiological indicator of listening effort (Koelewijn et al., 2012, 2014; Ohlenforst et al., 2017, 2018; Winn et al., 2015; Wendt et al., 2017; Zekveld et al., 2010, 2014). Additionally, pupillometry has been shown to reflect cognitive resource allocation in a variety of other tasks, from memory load (Kahneman & Beatty, 1966), to mathematical problem solving (Bradshaw, 1968), selective attention (Hillyard et al. 1973), Stroop task interference (Hershman et al., 2021; Hershman & Henik, 2019, 2020; Laeng et al., 2011), audio-visual task (Wang et al., 2017; Wendt et al., 2016), and as an indicator of visual target recognition (Privitera et al., 2010). A few studies recorded pupillary responses while participants performed an audio-visual dual task and revealed that pupil dilation can reflect dual-task costs (e.g., Karatekin et al., 2004; Padilla et al., 2019; Tapper et al., 2021). However, these studies did not investigate dual-task costs and resource allocation over time. In this study, pupil dilation is used to track the timing of the cognitive resources allocated to perform a visual reaction-time task performed in isolation (visual-only task), as well as within a dual task. Behavioral, physiological, and subjective measures of listening effort were combined to offer supplementary insights into the allocation of cognitive resources over time and the impact of noise attenuation during a dual task.
Research Questions and Hypotheses
The research questions (RQ) addressed in this study, along with the hypotheses (HYP) regarding the study outcomes, are provided below.
What is the effect of noise attenuation on performance in the primary speech recognition task? Based on previous studies using a similar paradigm to evaluate the effect of noise reduction on speech recognition (Ohlenforst et al., 2017; Wendt et al., 2017), it was hypothesized here that noise attenuation would increase speech recognition. What is the effect of noise attenuation on performance in the secondary visual task, in terms of reaction time and accuracy to press the correct response key? Based on the outcomes of Sarampalis et al. (2009), it was hypothesized that attenuating the background noise during the dual task would free up cognitive resources from recognizing speech in noise (primary task), allowing for faster reactions in the secondary visual task. What is the dual-task cost of adding an auditory task to a visual task, in terms of performance in the secondary visual task, i.e., the cost on reaction time and accuracy to press the correct response key? It was hypothesized that if the cognitive resources required to perform simultaneously an auditory and a visual task exceed the total resources available (Kahneman, 1973), the participant would prioritize the primary speech recognition task and a decrease in performance would be observed in the secondary visual task (i.e., longer reaction time and potentially lower accuracy when pressing the response key in reaction to the visual stimulus). What is the effect of noise attenuation on pupil dilation (RQ 4a) and subjective ratings of effort (RQ 4b) while performing the dual task? Based on previous studies observing a significant decrease in pupil dilation during a speech recognition task when applying noise reduction (Ohlenforst et al., 2017; Wendt et al., 2017), it was hypothesized here that noise attenuation would lead to a decrease in pupil dilation also when performing a speech recognition task and a visual task simultaneously (HYP 4a). Based on previous studies observing an increase in subjective ratings of listening effort when task demands on a speech recognition task increased (Koelewijn et al., 2012, 2018; Picou et al., 2011; Seeman & Sims, 2015; Zekveld et al., 2010, 2011), it was hypothesized here that noise attenuation would decrease the subjective ratings of listening effort also when participants are engaged in a dual task (Seeman & Sims, 2015) (HYP 4b). Does pupil dilation reflect the dual-task cost, i.e., is there a difference in pupil dilation between the visual-only task and the dual task? It was hypothesized that if pupillary responses during the dual task reflect the combined effort of performing a speech recognition task (Ohlenforst et al., 2017, 2018; Wendt et al., 2017; Zekveld et al., 2010, 2014) and a visual reaction-time task (Privitera et al., 2010), pupil dilation would increase in the dual task as compared to the visual-only task, i.e., pupil dilation can reveal a dual-task cost (Padilla et al., 2019). Does the timing of the dual-task cost observed via pupil responses, together with the reaction time to the secondary task, reflect when cognitive resources are allocated on the primary vs. secondary task? If a dual-task cost is observed in the pupillary responses (HYP5; Padilla et al., 2019), its timing and morphology will reflect when additional cognitive resources are allocated on the primary speech recognition task (in addition to the resources allocated to the secondary task). Additionally, reaction time to the secondary visual task will indicate when the visual task is completed and whether there is a need to divert cognitive resources from the secondary visual task to prioritize the primary task (Gagné et al., 2017). Hence, it was hypothesized that the relative timing of these two outcome measures would reflect when additional cognitive resources are allocated on the primary vs. secondary task (Hershman et al., 2021, 2023; Hershman & Henik, 2019, 2020).
Material and Methods
Participants
Twenty-six adult participants (15 males; 11 females) with self-reported normal hearing were included in this study. The mean age of the participants was 35 years (range: 23–51 years; standard deviation, SD = 9.2 years). All participants were native Danish speakers with no history of eye diseases or eye surgery, no history of neurological/psychiatric disease or usage of psychoactive drugs, no current outer ear pathology, and no confirmed or self-reported cognitive impairment. All above-mentioned inclusion and exclusion criteria were collected by means of a response sheet filled out for each participant. The sample size was determined based on two previous studies: one study using the same dual task (25 participants in Sarampalis et al., 2009) and another using the same temporal analysis of pupillary responses (26 participants in Hershman et al., 2021). A waiver for the study was obtained from the Research Ethics Committees of the Capital Region of Denmark (reference number: H-22057341).
Experimental Setup
The participants were seated in a double-walled audiometry booth (background noise within the limits of ISO 8253-2), with a keyboard placed in front of them, and were instructed to look forward at a fixation cross. Lighting in the room was adjusted to be soft (Zekveld et al., 2010) and the light intensity was measured for each participant with a luxmeter placed next to the participant's eyes (average luminance was 120 lux). All sound stimuli were controlled by a PC using MATLAB (R2021a, MathWorks, Natick, MA) and played through a pair of headphones (Sennheiser HD280 pro, Wedemark, Germany). The stimuli of the visual task (i.e., digits) were presented on a 32-inches screen mounted on the room's wall at 2.5 m in front of the participants. The digits were 512 points in size (18.1 cm). The pupillary responses were recorded using an eye-tracker (iView X RED, Senso-Motoric Instruments, Teltow, Germany) with a sampling frequency of 60 Hz, which was placed at 60 cm distance from the participant's eyes.
Experimental Paradigm
An adaptation of the dual task described in Sarampalis et al. (2009) was used in this study. The speech recognition task (primary task) was adapted for use with pupillometry (Winn et al., 2018), by adding an initial 3 s of noise before sentence onset and a 3 s retention interval after sentence offset before allowing for sentence repetition (Figure 1). Pupil dilation was recorded while the participants performed the dual task, from 2 s before the onset of the noise and until the participants completed the repetition of the sentence, as well as during the visual task performed in isolation pre- and post-test (Figure 2). The participants were given written and oral instructions before the visual task performed in isolation and before the dual task.

Illustration of one trial of the auditory task (primary speech recognition task) and the visual task (secondary reaction-time task). The dual task consisted of both tasks presented concurrently, while the visual-only task consisted of the visual reaction-time task presented in isolation. Time 0 marked the start of the sentence and the appearance of the digit on the screen.

Diagram of the experimental design and test procedure.
Primary Speech-In-Noise Recognition Task
Target sentences of a male speaker (Danish Hearing in Noise Test, HINT; Nielsen & Dau, 2011) were presented over headphones in a four-talker (4T) babble noise. The HINT sentences consist of simple and natural sentences in Danish, typically containing five words and with a mean duration of 1.5 s (Nielsen & Dau, 2011). The 4T babble noise had the same long-term average frequency spectrum as the HINT sentences and was created by recording two female and two male speakers reading newspaper passages (Wendt et al., 2017). For each trial, a random mixture of the four audio files was used as background noise. The noise started 3 s prior to each sentence and continued for 3 s after sentence offset (Figure 1). The participant's task was to verbally repeat the target sentences as accurately as possible after the offset of the 4 T babble. Speech recognition was calculated based on the percentage of words that were correctly repeated. The participants were instructed to prioritize the speech recognition task (i.e., the primary task) over the visual task by means of both oral and written instructions.
Secondary Visual Reaction-Time Task
As soon as the target sentence began, a digit from 1 to 8 would appear on either the right or left side of the screen. The participant's task was to quickly press the keyboard's arrow key in the direction of the digit if it was even, and in the opposite direction if it was odd (Sarampalis et al., 2009). The correct response (i.e., accuracy in pressing the correct arrow key) depended on both the parity of the digit (even or odd) and its location on the screen (right or left). The participant had to press the arrow key as fast as possible and before the end of 4T babble. Reaction time was monitored using Psychtoolbox and it was calculated as the time from the appearance of the digit on the screen to the moment the arrow key was pressed. As soon as the arrow key was pressed, the digit disappeared. Changes in luminance were minimized by displaying the digits in a dark red color on a black screen (as shown in Figure 1).
Experimental Conditions
During the dual task, a total of four conditions were tested: two speech levels at 60 dB SPL and 64 dB SPL, and two noise conditions, namely the No Attenuation condition and the Attenuation condition. The No Attenuation condition consisted of unprocessed 4T babble noise at 70 dB SPL, yielding signal-to-noise ratios (SNRs) of −10 dB and −6 dB. The two SNRs of −10 and −6 dB were selected based on the outcomes of a pilot study, where the SNR was adaptively varied to achieve about 50% and 80% correct word recognition with unprocessed noise, which was the range of performance also tested in Sarampalis et al. (2009). Before the start of the study, the unprocessed 4T babble noise was played from four loudspeakers in an anechoic room. The sound was recorded in the ear canals of a Head and Torso Simulator with and without headphones to estimate the attenuation achieved through passive damping. Based on the measured transfer function, a filter was estimated (see the frequency response of the measured response and the estimated filter in Figure 1 in the Supplemental Materials). The obtained filter was applied to the 4T babble noise to obtain the noise used in the Attenuation condition, simulating the passive damping that is obtained when wearing headphones. Overall, the noise in the Attenuation condition was 13 dB lower than the sound pressure level measured in the No Attenuation condition, resulting in 57 dB SPL and leading to SNRs of + 3 dB and + 7 dB.
The visual reaction-time task was also performed in isolation before and after the dual task, as a baseline condition. Evaluating the performance on the visual reaction-time task alone was also necessary to calculate the dual-task cost on reaction time and accuracy of button press. Note that the speech recognition task was not performed in isolation due to the constraint of a limited number of HINT lists available in Danish.
Subjective Ratings of Listening Effort and Performance
Self-reported ratings of listening effort, performance, and tendency to quit were collected using a questionnaire (Koelewijn et al., 2012, 2018; Zekveld et al., 2010) that the participants completed after each condition of the dual task (see Figure 2). The questionnaire consisted of three questions that the participants had to rate on a visual analog scale ranging from 0% to 100% with numerical markers every 10% and descriptive markers (at 0%, 25%, 50%, 75%, 100%). The first question was related to invested listening effort (“How much effort did you invest to hear the sentences?”) and was rated from 0% (“no effort”) to 100% (“very high effort”), with intermediate markers of low, moderate, and high effort. The second question on self-perceived performance in speech recognition (“How many words do you think you understood correctly?”) was rated from 0% (“none”) to 100% (“all”), with intermediate markers “less than half,” “half,” and “more than half.” The third question on tendency to quit (“How often did you have to give up understanding the sentences?”) was rated from 0% (“never”) to 100% (“always”), with intermediate markers “less than half of the time,” “half of the time,” and “more than half of the time.”
Experimental Procedure
Figure 2 illustrates the experimental procedure, which overall took less than 2 h. The session started with a first training on the visual-only task (25 trials) to get acquainted with the visual task and button press. This was followed by a training on the dual task with unprocessed noise (two lists of 25 HINT sentences; i.e., 50 trials in total). The first list (25 trials) was presented using an adaptive procedure to achieve 50% correct, where the 4T babble was fixed at 70 dB SPL, and the speech level was adjusted based on the participant's response, in order for the participant to become familiar with a wider range of SNRs. The second list (25 trials) was presented with the level of the 4T babble fixed at 70 dB SPL and the level of the sentences fixed at 64 dB SPL (SNR = −6 dB).
After training, the test started with the secondary visual task performed in isolation as a baseline condition (25 trials; visual-only pre). This was followed by the dual task, which consisted of 50 trials (two lists of 25 HINT sentences) for each of the four tested conditions (two speech levels and two noise attenuation conditions; 200 trials in total). The participants were blinded to the four tested conditions. The noise attenuation conditions were presented in a block design: all 100 trials with noise attenuation in one block and all 100 trials without noise attenuation noise in another block. The block design was chosen to minimize influencing expectations about trial difficulty based on the initial baseline with noise. Using a cross-over counterbalanced design, half of the participants started with the block with noise attenuation, and half of the participants started with the block without noise attenuation. The order of the speech levels was randomized within blocks (i.e., 50 trials with one speech level and 50 trials with the other speech level, as illustrated in Figure 2). Following each dual-task condition (50 trials), participants completed the questionnaire with three questions, assessing listening effort, self-perceived performance, and tendency to quit. After the dual task, the secondary visual task was performed in isolation as an additional baseline condition to evaluate training effects (25 trials; visual-only post).
Pre-Processing of Pupillary Responses
Due to a technical failure to record pupillary responses for the last participant, pupil data were collected and analyzed for 25 out of the 26 participants. Pupil traces were pre-processed using the same procedure for de-blinking and smoothing as described by Wendt et al. (2018). The first five trials for each condition and participant were excluded from further analysis. The mean pupil dilation and standard deviation were calculated for the remaining 20 trials. Pupil dilations lower than three times the standard deviation of the mean were coded as eye-blinks. Eye-blinks were removed by first expanding the gap of missing data (from about 80 ms before to 150 ms after the blinks) to remove the transient excursions and then using linear interpolation to fill the gap (Winn et al., 2018). Trials with more than 15% eye-blinks were disregarded. The eye with most valid trials was chosen for each subject. A moving average filter with a symmetric rectangular window of 117 ms length was used to smooth the de-blinked trials and to remove any high-frequency artifacts. The mean baseline value, calculated for the 1-s time window before sentence onset, was subtracted from each trial. For each participant and condition, the mean pupil trace was then calculated by averaging all valid pre-processed trials after de-blinking, smoothing, and baseline subtraction. Pre-processing of pupillary responses was performed in MATLAB (R2021a, MathWorks, Natick, MA).
Statistical Analysis
Linear mixed effects (LME) models were implemented in R (R Core Team, 2021) using the statistical package lmerTest (Kuznetsova et al. 2017). A LME model was carried out for each outcome of interest (i.e., percentage of correctly repeated words, reaction time, accuracy to press the correct response key in the visual task, dual-task cost in reaction time, dual-task cost in accuracy). The ANOVA function was used on the LME model outcomes. The initial models used speech level, noise attenuation, and repetitions as fixed effects and test participant as a random effect (random intercept). The factor of repetition was not significant and was, thus, eliminated from the model using a backwards elimination process. The final models used speech level and noise attenuation as fixed effects and test participant as a random effect (random intercept). The degrees of freedom were calculated using the Satterthwaite's method of approximation as implemented in the lmerTest package (Kuznetsova et al., 2017). Effect sizes are reported using partial eta-squared (η2p). Posthoc analysis was carried out via contrasts of least-square means using the package emmeans in R (Lenth, 2016) and multiplicity adjustments were carried out using the Tukey method when comparing families of more than two estimates. Pupillary responses were analyzed in MATLAB (R2021a, MathWorks, Natick, MA) using temporal Bayesian analysis of pupil responses (Hershman et al., 2021, 2023), which consists of a series of Bayesian t-tests across the time range of the trial and allows to reveal clusters of samples differing between conditions. This analysis was chosen to clarify the temporal dynamics of the cognitive processes behind the dual task (Hershman & Henik, 2019, 2020), which cannot be analyzed using traditional statistical methods for pupillometry (e.g., mean or peak dilation). The Bayesian analysis provides Bayes factors (BF; Jeffreys, 1961), where BF10 means evidence in favor of the alternative hypothesis over the null hypothesis. BF10 values above 3 are considered moderate evidence supporting the alternative hypothesis (i.e., a meaningful difference in pupil dilation between two conditions), values above 10 are considered strong support, and values above 30 are considered very strong support (Hershman et al., 2021, 2023).
Results
Speech Recognition in the Dual Task (RQ 1)
Figure 3 depicts speech-in-noise recognition performance (i.e., percentage of correctly repeated words) for the four dual-task conditions. In the No Attenuation condition, the mean speech recognition performance was 51.6% when the speech level was 60 dB SPL (SNR = −10 dB) and 84.4% when the speech level was 64 dB SPL (SNR = −6 dB). In the Attenuation condition, speech recognition performance increased up to 99.8% and 99.9%, for speech levels of 60- and 64-dB SPL (SNRs of +3 and +7 dB), respectively. The linear mixed model revealed a significant main effect of noise attenuation [F(1,179) = 1346.28; p < .0001; η2p = 0.88] and speech level [F(1,179) = 359.72; p < .0001; η2p = 0.67] on speech recognition, as well as a significant interaction between speech level and noise attenuation [F(1,179) = 353.03; p < .0001; η2p = 0.66]. The posthoc analysis indicated that the effect of speech level was significant only for the No Attenuation condition (estimated effect: 32.8 percentage points; p < .0001, indicated with *** in Figure 3), while it was not significant for the Attenuation condition (p = .90), where performance was at ceiling at both speech levels. The effect of noise attenuation was significant at both speech levels (estimated effect at 60 dB SPL: 48.2 percentage points, p < .0001; estimated effect at 64 dB SPL: 15.5 percentage points, p < .0001; indicated with *** in Figure 3), resulting in increased speech recognition, in agreement with HYP 1.

Speech recognition performance during the dual task, for the two noise conditions (Attenuation, No Attenuation) and speech levels (60- and 64-dB SPL). For each box, the median is depicted with a bold line, the bottom and top edges of the box indicate the 25th and 75th percentiles, respectively, the whiskers extend to the most extreme data points not considered outliers, and the outliers are plotted individually using circles. ***Depicts p < .0001, as obtained by posthoc analysis.
Reaction Time and Accuracy: Visual-Only Task and Dual Task (RQ 2, RQ 3)
Figure 4(a) shows the mean reaction time (RT) for each test condition of the dual task, as well as during the visual task performed in isolation pre- and post-test as baseline condition. When performing the visual task alone, participants reacted rather quickly by pressing the arrow key, on average, 0.71 s after the visual stimulus presentation (visual pre: RT = 0.73 s; visual post: RT = 0.7 s), with no significant difference between pre- and post-test conditions (Wilcoxon signed-rank test, p = .073). When performing the dual task, reaction time for the Attenuation condition was, on average, 0.68 s and 0.7 s, at 64 and 60 dB SPL, respectively, while it was longer for the No Attenuation condition (on average, 0.90 s and 1.0 s, at 64 and 60 dB SPL, respectively). The linear mixed model for the four dual-task conditions revealed a significant main effect of noise attenuation [F(1,179) = 100.48; p < .0001; η2p = .36, indicated with *** in Figure 4(a)] and speech level [F(1,179) = 4.98; p = .027; η2p = .03] on reaction time, while the interaction between speech level and noise attenuation was not significant [F(1,179) = 2.80; p = 0.096]. The estimated effect of attenuation on reaction time, averaged across speech levels, was 258 ms, while the estimated effect of speech level, averaged across attenuation conditions, was 57 ms.

Behavioral results for the visual task, when performed in isolation (visual-only task, pre and post) and as a secondary task during the four dual-task conditions. (a) Reaction time (i.e., time of button press from the appearance of a digit on the screen). (b) Accuracy of button press (% of correctly pressed response key). Asterisks indicate significant differences across conditions (*p < .05; **p < .01; ***p < .001).
Accuracy on the visual task (i.e., pressing the correct arrow key) was high for all conditions (Figure 4(b)), on average ranging from 97.2% when the visual task was performed in isolation (both for pre- and post-conditions) to 98.4% when the visual task was performed within the dual task (both in the Attenuation and No Attenuation conditions). The linear mixed model for the four dual-task conditions revealed no significant main effect of noise attenuation [F(1,179) = 0.01; p = .907] nor of speech level [F(1,179) = 0.01; p = .907] on accuracy, as well as no significant interaction between speech level and noise attenuation [F(1,179) = 0.34; p = .560].
Overall, these results show that applying noise attenuation during a dual task comprising an auditory primary task and a visual secondary task led to faster reaction times on the secondary task (in agreement with HYP 2) without any compromise on accuracy.
Dual-Task Cost on Reaction Time and Accuracy
To evaluate the cost of adding a speech recognition task to the visual task, a linear mixed model was performed on the difference in reaction time and accuracy between dual task and visual task performed in isolation (averaged between pre- and post-conditions). The least-squares means were calculated for each factor of the linear model (noise attenuation and speech level) and were then tested against zero to evaluate whether there was a significant cost of dual tasking (i.e., a significant difference in behavioral performance between the visual-only task and the dual task). The outcome of this analysis showed that there was a significant cost of dual tasking on reaction time only for the No Attenuation condition (estimated cost at 64 dB SPL: 183 ms, p = .0001; estimated cost at 60 dB SPL: 283.5 ms, p < .0001; indicated with *** in Figure 4(a)), i.e., a significantly slower reaction time when the visual task was performed as secondary task within the dual task than when performed in isolation (in agreement with HYP 3). There was no significant cost of dual tasking on reaction time for the Attenuation condition (64 dB SPL: p = .470; 60 dB SPL: p = .692).
The analysis of dual-task cost on accuracy showed that there was a small but significant benefit of dual tasking on accuracy for the Attenuation condition at 64 dB SPL (estimated benefit: 1.23 percentage points, p = .037) and No Attenuation condition at 60 dB SPL (estimated benefit: 1.31 percentage points, p = .027). There was no significant cost (nor benefit) for the other two conditions (p = .067). In other words, accuracy was significantly higher when the visual task was performed as the secondary task within the dual task than when performed in isolation (for two of the four dual-task conditions, irrespective of noise attenuation). This was in contrast to initial expectations (HYP 3) and is further addressed in the discussion.
Pupillometry
Visual-Only Task
Figure 5(a) shows the mean pupil curves for the visual-only task, which was performed in isolation before the dual task (visual pre, dashed line) and after the dual task (visual post, solid line). Both curves show a first small peak around 0.7 s, coinciding with the mean reaction time (button press) for the visual-only condition. This first peak might reflect the mental load of performing the visual task and/or the change in display color (or contrast) that occurred when the digit appeared on the screen (Privitera et al., 2010). A larger second peak is observed around 2 s, which is likely to reflect the motor response of pressing a key on the keyboard (Zénon et al., 2014). The temporal Bayesian analysis (Figure 5(b)) did not reveal any meaningful difference in pupil dilation between pre- and post-conditions (BF10 < 3), suggesting that there was no training effect throughout the experimental procedure. All further analyses will consider the mean pupil dilation for the visual-only condition, averaged between pre- and post-conditions.
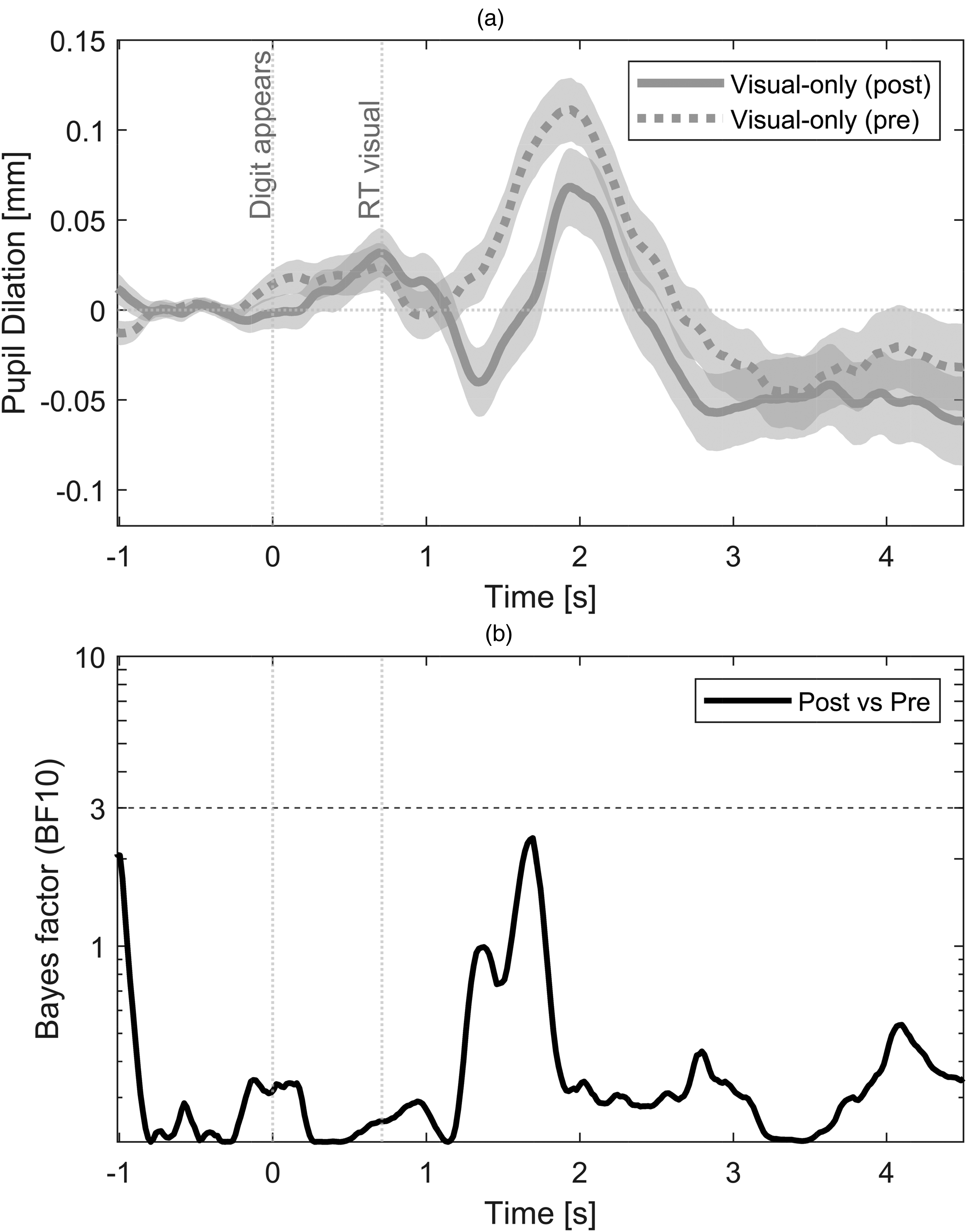
(a) Mean pupil dilation for the visual-only task (pre and post). The shaded area depicts the standard error of the mean. The vertical line at 0 depicts the appearance of the digit on the screen, the vertical line at 0.71 s depicts the mean reaction time (RT) for the visual-only task (i.e., time of button press averaged across participants and between pre- and post-conditions). (b) Bayes factor across time. BF10 lower than 3 indicates no meaningful difference in pupil dilation between pre- and post-conditions.
Dual Task vs Visual-Only Task (RQ 4a, RQ5)
Figure 6(a) shows the mean pupil curves for the Attenuation (dashed black curve) and No Attenuation (solid black curve) conditions of the dual task, as well as for the visual task performed in isolation (gray curve). The visual-only condition depicts the average dilation across pre- and post-conditions, since no meaningful differences were detected in the pupil curves between pre- vs. post-conditions (BF10 < 3, Figure 5(b)). The Attenuation and No Attenuation conditions depict the average dilation across the two speech levels, since no meaningful differences were detected in the pupil curves between speech levels (BF10 < 3, Figure 2 in Supplemental Materials). The horizontal bars in Figure 6(a) indicate meaningful differences (i.e., BF10 ≥ 3) between conditions (e.g., the horizontal solid and dashed black lines indicate meaningful differences between the No Attenuation and Attenuation conditions), as revealed by the temporal Bayesian analysis presented in Figure 6(b).

(a) Mean pupil dilation for the dual task conditions (Att: attenuation; No Att: no attenuation) and for the visual-only task. The shaded area depicts the standard error of the mean. The vertical line at 0 depicts the start of the sentence and the appearance of the digit on the screen, the vertical line at 1.5 s indicates the end of the sentence, the vertical lines at 0.69 s, 0.71 s, and 0.95 s depict the mean reaction time (RT) for the attenuation condition (RT Att.), the visual-only task (RT Vis.), and the no attenuation condition (RT No Att.), respectively. The horizontal lines represent meaningful differences in pupil response (i.e., BF10 ≥ 3) between conditions. (B) Bayes factor across time. BF10 ≥ 3 indicates a meaningful difference in pupil dilation between conditions.
The curves for the dual task show a much more pronounced first peak and generally a larger pupil dilation during the playback of the sentence, indicating the cost of adding a listening task to the visual task. In particular, the outcomes of the Bayesian analysis revealed both a meaningful effect of noise attenuation (i.e., BF10 ≥ 3 between the two dual-task conditions of No Attenuation vs. Attenuation, in line with HYP 4a) and a meaningful dual-task cost (i.e., BF10 ≥ 3 between each dual-task condition and the visual-only condition, in line with HYP 5), though in different time ranges. The meaningful effect of noise attenuation was present between sentence onset and 0.39 s, i.e., during playback of the first part of the sentence, as well as between 2.76 s and 3.43 s, i.e., during sentence retention and reconstruction, where a sustained pupillary response was observed for the No Attenuation relative to the Attenuation condition. A meaningful dual-task cost for the No Attenuation condition (relative to the visual-only condition) was observed between 0.41 s and 0.56 s, i.e., half-way through the playback of the sentence. A meaningful dual-task cost for the Attenuation condition (relative to the visual-only condition) was observed between 0.69 s and 1.11 s, and between 1.28 s and 1.46 s, i.e., just after button press and until sentence offset. Note that meaningful differences in pupil dilation between the No Attenuation and the Attenuation condition were already present at baseline before sentence onset (between −1 s and −0.86 s; between −0.34 s and −0.16 s).
Subjective Ratings of Listening Effort and Performance (RQ 4b)
Figure 7 shows the subjective ratings obtained for the three questions of the questionnaire administered after each dual-task condition. A linear mixed model was performed for each of the three questions. The linear mixed model for the first question (invested effort, Figure 7(a)) revealed a significant main effect of noise attenuation [F(1,75) = 617.49; p < .0001; η2p = 0.89] and speech level [F(1,75) = 11.64; p = .001; η2p = 0.13] on self-reported listening effort, as well as a significant interaction between speech level and noise attenuation [F(1,75) = 7.87; p = .006; η2p = 0.09]. The posthoc analysis indicated that the effect of speech level was significant only for the No Attenuation condition (p < .0001, indicated with *** in Figure 7), while it was not significant for the Attenuation condition (p = .669). The effect of noise attenuation was significant at both speech levels (p < .0001, indicated with *** in Figure 7), resulting in decreased perceived listening effort, in agreement with HYP 4b.

Subjective ratings for each of the three questions of the questionnaire (a) Invested effort, (b) perceived performance, (c) tendency to give up, filled out after each condition of the dual task, for the two noise conditions (Attenuation, No Attenuation) and speech levels (60- and 64-dB SPL). For each box, the median is depicted with a bold line, the bottom and top edges of the box indicate the 25th and 75th percentiles, respectively, the whiskers extend to the most extreme data points not considered outliers, and the outliers are plotted individually using circles. *** Depicts p < .0001, as obtained by posthoc analysis.
The linear mixed model for the second question (perceived performance, Figure 7(b)) revealed a significant main effect of noise attenuation [F(1,75) = 380.54; p < .0001; η2p = 0.84] and speech level [F(1,75) = 30.80; p < .0001; η2p = 0.29] on self-reported performance, as well as a significant interaction between speech level and noise attenuation [F(1,75) = 34.12; p < .0001; η2p = 0.31]. The posthoc analysis indicated that the effect of speech level was significant only for the No Attenuation condition (p < .0001, indicated with *** in Figure 7), while it was not significant for the Attenuation condition (p = .837). The effect of noise attenuation was significant at both speech levels (p < .0001, indicated with *** in Figure 7).
The linear mixed model for the third question (tendency to give up, Figure 7(c)) revealed a significant main effect of noise attenuation [F(1,75) = 241.40; p < .0001; η2p = 0.76] and speech level [F(1,75) = 39.13; p < .0001; η2p = 0.34] on perception of giving up, as well as a significant interaction between speech level and noise attenuation [F(1,75) = 40.62; p < .0001; η2p = 0.35]. The posthoc analysis indicated that the effect of speech level was significant only for the No Attenuation condition (p < .0001, indicated with *** in Figure 7), while it was not significant for the Attenuation condition (p = .934). The effect of noise attenuation was significant at both speech levels (p < .0001, indicated with *** in Figure 7).
Hence, applying noise attenuation led to a significant and perceivable decrease in listening effort, increase in performance, and decrease in tendency to give up.
Discussion
This study evaluated behavioral performance, cognitive resource allocation as reflected by pupillary responses, and subjective ratings while participants performed a dual-task paradigm consisting of a primary speech recognition task and a secondary visual reaction-time task.
Behavioral Performance: Effect of Noise Attenuation and Dual-Task Cost
The behavioral results obtained for the dual task showed that noise attenuation led to improved performance on both the primary and secondary tasks, namely significantly better speech recognition on the primary task (Figure 3), as well as faster reaction times on the secondary task without any compromise on accuracy (Figure 4). In terms of dual-task cost, significantly slower reaction time was obtained for the No Attenuation condition when the visual task was performed as secondary task within the dual task than when performed in isolation (Figure 4(a)). On the contrary, there was no significant cost of dual tasking on reaction time for the Attenuation condition (Figure 4(a)). These findings indicate that, during the dual task, additional cognitive resources needed to be diverted from the secondary visual task to the primary speech recognition task for the No Attenuation condition, leading to a longer reaction time. Differently, attenuating the noise in the Attenuation condition led to having enough cognitive resources available to perform both tasks at a very high level of performance (speech recognition at about 100% correct and similar reaction time as in the visual-only task). Interestingly, a dual-task benefit was also observed in terms of increased accuracy in button press relative to the visual-only task (Figure 4(b)). This finding may be explained by a higher predictability of the visual task when performed within the dual task, since the appearance of the digit on the screen was cued by the preceding 3 s of noise, while there was no auditory cue indicating the start of the trial for the visual-only condition. Hence, the participants might have been more prepared for the number to appear in the dual-task conditions. An alternative explanation could also be an increased engagement due to lower idle time when performing the dual task relative to one task in isolation.
Although the current study tested a similar range of behavioral performance as Sarampalis et al. (2009), i.e., word recognition scores around 50% and 80% for unprocessed background noise, the results of the current study revealed a significant main effect of noise attenuation on both speech recognition and reaction time, in contrast to Sarampalis et al. (2009) who obtained a significant effect of noise attenuation only for reaction time at the lowest SNR tested (i.e., at −6 dB SNR, corresponding to 50% correct word identification in their study). One explanation for this difference is that in the current study only the background noise was filtered with a dampening curve and not the target speech signal, simulating a situation where one is listening to the signal of interest via headphones while the background noise is attenuated by the passive damping obtained by wearing headphones. The overall attenuation achieved was 13 dB, yielding a strong improvement of SNRs in the Attenuation condition (i.e., SNRs of +3 dB and +7 dB vs. initial SNRs of −10 dB and −6 dB). In contrast, Sarampalis et al. (2009) simulated a different situation where both the target speech and the babble noise are captured and processed by a noise reduction algorithm for hearing aids, which might have offered the equivalent of a 4-dB SNR improvement, as suggested by the authors. Differences in the study design might have also affected the results, since the current study explicitly instructed the listeners to prioritize the primary speech recognition task during the dual task, while Sarampalis et al. instructed the participants to pay equal amount of attention to the two tasks. Instructing the participants to prioritize the primary task allows the decrease in performance on the secondary task to be interpreted as an increase in listening effort on the primary task (Gagné et al., 2017). In the current study, a decrease in performance observed on the secondary task for the No Attenuation condition can be interpreted as additional cognitive resources needing to be diverted from the secondary task to the primary task due the higher task demand imposed by the listening condition (i.e., higher noise level). When participants are not instructed to prioritize the primary task and no difference in performance is observed on the secondary task, one cannot conclude whether there was no difference in listening effort across primary-task conditions or whether the participant did not divert cognitive resources from the secondary to the primary task because not instructed to do so (Gagné et al., 2017).
Pupillary Responses and Cognitive Resource Allocation Over Time (RQ6)
By combining pupillary responses with behavioral findings, it was possible to infer the temporal dynamics of cognitive resource allocation during the dual task, depending on the cognitive demands imposed by the listening task. A higher level of background noise in the No Attenuation condition was associated with a significantly larger pupil response during the playback of the first part of the sentence relative to the Attenuation condition (0–0.39 s; Figure 6(a)) and to the visual-only condition (0.41–0.56 s; Figure 6(a)). Hence, the higher task demand imposed by adding a listening task to a visual-only task, as well as having a higher level of background noise required the participants to quickly allocate higher listening effort to process the sentence in noise. Additionally, an increase in reaction time was observed on the secondary task for the No Attenuation condition (average button press of 0.9 and 1 s, at 64- and 60-dB SPL, respectively; depicted by a vertical dashed line in Figure 6(a) “RT No Att.”). Together, these findings suggest that when task demands on the primary task increased, participants prioritized the speech recognition task by investing additional cognitive resources during the playback of the first part of the sentence and delaying the secondary task. It should also be noted that meaningful differences in pupil dilation between the No Attenuation and the Attenuation condition were already observed at baseline, before sentence onset, suggesting that the higher level of background noise during baseline in the No Attenuation condition might have also led to a greater arousal in anticipation of a more challenging task (Winn et al., 2018). While this effect was mitigated by baseline correction, it still resulted in a positive slope of dilation already noticeable before sentence onset. A positive slope of pupil dilation before sentence onset was also observed with a 4-talker babble noise in Wendt et al. (2018) despite the same level of background noise across conditions, suggesting that listeners can anticipate the difficulty of a trial by being exposed to the same SNR within a block. Hence, differences in pupil dilation observed between the No Attenuation and Attenuation condition during the playback of the first part of the sentence (0–0.39 s) were likely resulting from a combination of anticipatory effects of a more challenging task and reactionary effects to sentence encoding (after a physiological delay of around 0.3 s after sentence onset; Hoeks & Levelt, 1993; Wang et al., 2017). Additionally, the increased difficulty to process the sentence in the No Attenuation condition had also consequences after sentence offset. In fact, a sustained pupillary response was observed during sentence retention, suggesting that additional cognitive resources were allocated to reconstruct the sentence, eventually leading to mean word recognition scores between 51.6% (at −10 dB SNR) and 84.4% (at −6 dB SNR) for the No Attenuation condition. Note that this sustained pattern of pupillary responses in the No Attenuation condition was driven by the need to allocate extra cognitive resources to reconstruct the sentence (Winn & Teece, 2021, 2022) and did not reflect a higher state of arousal due to the higher level of background noise per se (see Figure 3 in Supplemental Materials, where a sustained response is only observed for the incorrectly repeated sentences in the No Attenuation condition). This “peak and sustain” pattern of pupillary responses has been previously observed in other studies, for conditions perceived by the participants as demanding or unsolved, for example for difficult unsolved arithmetic problems (Bradshaw, 1968), incorrectly repeated sentences (Zekveld et al., 2010; Bianchi et al., 2019), sentences with low spectral resolution content (Winn et al., 2015), sentences with low semantic context (Winn, 2016), and sentences that needed to be reconstructed (Winn & Teece, 2021, 2022). Hence, when the background noise was not attenuated, not only did extra cognitive resources need to be quickly allocated for understanding the speech signal, thereby delaying reaction time to the visual task, but also a more sustained use of cognitive resources was needed afterwards to reconstruct the sentence.
Pupillary responses to the Attenuation condition were very similar to the pupillary responses obtained for the visual-only condition for the first part of the sentence playback and until button press (Figure 6(a)), suggesting a similar initial investment of cognitive resources during the dual task and the visual-only condition. The lack of a dual-task cost in the pupillary responses for the first 0.69 s, combined with a similar reaction time between Attenuation condition (0.69 s; “RT Att.” in Figure 6(a)) and visual-only (0.71 s; “RT Vis.” in Figure 6(a)), suggests that in this time window the participants allocated cognitive resources primarily to solve the secondary visual task. One cannot exclude that a low-level encoding of auditory information was also performed in this time window without affecting pupillary responses, which are most likely evoked by higher level language processing (Winn et al., 2018). Only around button press, a dual-task cost emerged in the pupillary responses and was observed during the playback of the second half of the sentence (i.e., from 0.69 s until sentence offset). These findings suggest that just after solving the visual task, participants invested additional resources to process the sentence, perhaps exploiting a recency effect to retrieve the first part of the sentence and achieve about 100% correct in speech recognition. Hence, while behaviorally no dual-task cost was observed for the Attenuation condition (speech recognition at about 100% correct and similar reaction time as in the visual-only task), the analysis of pupillary dilation over time revealed a dual-task cost after the secondary visual task was completed. Finally, the pupillary responses showed a rapid release of effort for the Attenuation condition during sentence retention, suggesting that the sentence was fully understood and there was no need to allocate additional cognitive resources to reconstruct it (Bianchi et al., 2019; Zekveld et al. 2010).
Implications for Mechanisms of Multitasking
One of the key questions about multitasking is whether humans are truly capable of performing two tasks at once or are rather quickly switching between two tasks (Gazzaniga et al., 2013). In an imaging study, Dux et al. (2009) investigated connectivity patterns of participants performing an audio-visual dual task over the course of two weeks. Dux and colleagues showed evidence that the participants became more efficient in switching between the two tasks after 2 weeks of training, suggesting that humans are quickly alternating between two tasks rather than actually performing tasks at the same time (Gazzaniga et al., 2013). The current study was not specifically designed to disentangle different mechanisms of multitasking. However, it was assumed that an elevation of the pupillary responses during the dual task (relative to the visual-only task) was an indication that additional cognitive resources were needed to process speech in noise (primary task), in addition to the resources allocated on the visual task (HYP 5). If humans were truly performing the two tasks simultaneously without exceeding the total resources available, one could have expected an increase in pupillary responses during the dual task relative to the visual-only task throughout the whole trial and no difference in reaction time between dual task and visual-only task. Hence, humans could simply invest extra resources to understand speech, while also performing the visual task at the same time, without affecting performance on the visual task. The findings of this study for the Attenuation condition did not show a difference in reaction time, suggesting that there were enough resources to perform both the primary task (with speech recognition around 100%) and still react as fast as possible to the secondary visual task. This finding alone does not clarify whether the participants were able to perform both tasks at the same time or if they were rapidly alternating between them. However, the pupillary responses during the dual task were elevated relative to the visual-only task only after completion of the secondary task (i.e., from around button press until sentence offset), perhaps suggesting that the participants first completed the visual task and then allocated resources to process speech. On the other hand, the pupillary responses for the No Attenuation condition showed that additional cognitive resources were allocated on the primary task quickly after sentence onset (and already before sentence onset due to anticipatory effects), while the reaction time on the secondary task was delayed. Hence, the findings of the current study suggest that the additional resources required for the primary task were not distributed evenly throughout the trial. They were allocated during the playback of either the first half of the sentence (No Attenuation condition), causing a delay in completing the secondary task, or the second half of the sentence (Attenuation condition), suggesting that perhaps the participants switched between primary and secondary task rather than performing both tasks concurrently. This conclusion remains speculative due to the study design (lack of an auditory-only condition) and potential influences from other factors, such as heightened arousal at the beginning of the trial in the No Attenuation condition due to anticipatory effects. However, exploring dual-tasks costs over time via pupillometry is a novel and promising method to explore the timing of cognitive resource allocation. Further investigations are needed to better understand the mechanisms behind dual tasking and multitasking.
Real-Life Implications
The outcomes of this study revealed that reducing the background noise allowed participants to perform two tasks (simultaneously) without any decline in performance. These findings suggest that when time constraints in everyday life impose the need to perform more than one task at a time, one could consider reducing background noise with, for example, headphones or ear plugs. This might help free up cognitive resources and decrease the cost of multitasking. The current study used a noise attenuation algorithm simulating the passive damping obtained via headphones, which can be used in several contexts to effectively reduce unwanted surrounding noise. Although not in the scope of the current study, directionality and noise reduction algorithms in hearing devices were also shown to free cognitive resources and reduce the listening effort for processing speech in noise (Desjardins & Doherty, 2014; Ohlenforst et al., 2018; Sarampalis et al., 2009; Wendt et al., 2017).
Limitations
As a general consideration when designing a pupillometry study comprising a task that requires a behavioral response from the participant, it is recommended that the response window is delayed by some seconds after stimulus presentation (Winn et al., 2018). This is because the behavioral response, e.g., a verbal response or button press, can increase the pupil size by as much as 400% (Hoeks & Levelt, 1993; McCloy et al., 2017; Privitera et al., 2010; Winn et al., 2018), thus masking the sensory-evoked response. When recording pupil dilation during a speech recognition task, the response window is generally postponed by some seconds after sentence offset. This period is often called retention interval (see Figure 1). Retention intervals ranging from 5 to 1.5 s have been previously used in studies of listening effort (e.g., Koelewijn et al., 2015, 2017; Ohlenforst et al., 2017; Winn, 2016; Winn et al., 2015; Zekveld et al., 2010). In the current study, a 3 s retention interval was used (e.g., Koelewijn et al., 2012; Wendt et al., 2017, 2018), and participants were instructed to wait until the offset of the noise before giving a verbal response (primary task). Postponing the response window is possible in such paradigms where response time is not critical nor a variable of interest. However, when response time is used as an outcome measure to evaluate the speed of cognitive processing and participants should, hence, press a button as fast as possible, delaying the response window is not an option. This was the case for the secondary visual reaction-time task. As a result, a large pupillary response was observed around 2 s after stimulus onset—about 1.4 s after button press (see Figures 5 and 6). It is very likely that this large pupil response to the motoric button press might have masked or suppressed some differences in cognitive resource allocation across conditions around the end of the listening window and at the start of the retention period.
When using dual-tasks paradigms, it is often of interest to evaluate performance for each task in isolation, besides performance on the dual task, to evaluate the cost of performing two tasks at a time relative to each task alone (Gagné et al., 2017). In the current study, it was not possible to perform the speech recognition task in isolation because of the limited amount of available HINT lists in Danish. In fact, the 10 Danish HINT lists with 20 sentences each (Nielsen & Dau, 2011) have been modified for the use with pupillometry to create 8 HINT lists containing 25 sentences (Wendt et al., 2017). With 8 test lists available, and the necessity to run two lists per condition (Sarampalis et al., 2009), it was only possible to test speech recognition for the four conditions of the dual task and not to additionally test the primary task in isolation. Since participants were instructed to prioritize the primary speech recognition task, it was expected that performance would have been the same whether the primary task was performed in isolation or within the dual task (Gagné et al., 2017). However, this cannot be confirmed in the current study. Indications from a pilot test seem to suggest that performance on the auditory-only task was similar to that obtained in the dual task. In fact, an auditory-only pilot study was performed to find the speech levels to achieve 50% and 80% correct word recognition when the noise was fixed at 70 dB SPL (No Attenuation condition). The speech levels obtained in the pilot study were 60- and 64-dB SPL, which were then used in this study, yielding 51.6% and 84.4% correct recognition, respectively, in the dual task for the No Attenuation condition. Additionally, speech recognition in the Attenuation condition was about 100%. These findings seem to suggest that speech recognition performance during the dual task might have been very similar to, and at least not lower than, what was expected to obtain with these speech levels on an auditory-only task. Hence, it seems that participants were correctly prioritizing the primary task and diverting cognitive resources from the secondary task to the primary task when needed (i.e., in the No Attenuation condition).
Conclusion
In this study, a dual task consisting of a primary speech recognition task in background noise and a secondary visual reaction-time task was performed, while task demands of the primary task were varied by attenuating the background noise. By exploring dual-task costs behaviorally and via pupillometry, this study offers a novel and promising method to explore the timing of cognitive resource allocation. Behaviorally, performing a dual task in a higher level of background noise (No Attenuation condition) led to a dual-task cost in terms of significantly slower reaction time to perform the secondary visual task. However, once the background noise was attenuated (Attenuation condition), no dual-task cost was observed on reaction time, suggesting that there were enough cognitive resources to perform both the primary task with speech recognition around 100% and still react as fast as possible to the secondary visual task. Pupillary responses revealed that the level of background noise modulated the timing of the cognitive resources invested in the primary task. In the No Attenuation condition, higher listening effort was allocated quickly in the primary task while the completion of the secondary task was postponed. In the Attenuation condition, the secondary task was performed as quickly as possible, while higher listening effort was only observed after completion of the secondary task. These results may suggest that the participants switched between primary and secondary task rather than performing both tasks concurrently. Overall, these findings demonstrate that noise attenuation, as offered for example by audio devices, frees up cognitive resources in noisy listening environments and can be beneficial to improve performance and decrease dual-task costs during multitasking activities.
Supplemental Material
sj-docx-1-tia-10.1177_23312165251367630 - Supplemental material for Pupillary Responses During a Dual Task: Effect of Noise Attenuation on the Timing of Cognitive Resource Allocation
Supplemental material, sj-docx-1-tia-10.1177_23312165251367630 for Pupillary Responses During a Dual Task: Effect of Noise Attenuation on the Timing of Cognitive Resource Allocation by Federica Bianchi, Sindri Jonsson, Torben Christiansen and Elaine Hoi Ning Ng in Trends in Hearing
Footnotes
Acknowledgments
The authors thank Lorenz Fiedler at the Eriksholm Research Centre for the helpful discussion of the pupillometry results, Svend Feldt at EPOS Group A/S for creating the filtered noise, and the three anonymous reviewers for their helpful comments that greatly contributed to improve the manuscript.
Ethical Considerations
A waiver for the study was obtained from the Research Ethics Committees of the Capital Region of Denmark (reference number: H-22057341). The study did not present any potential risk for the test participants. One possible disadvantage could have been the fatigue that the participants may have experienced in connection to listening to speech in noise while also performing a visual task.
Consent to Participate
After receiving both written and verbal information about the study, all test participants signed an informed consent form. All participants gave consent to Oticon A/S for collecting, storing and processing all data necessary for the study.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by EPOS Group A/S.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.