
Abstract
Published investigations (n = 29) in which a dual-task experimental paradigm was employed to measure listening effort during speech understanding in younger and older adults were reviewed. A summary of the main findings reported in the articles is provided with respect to the participants’ age-group and hearing status. Effects of different signal characteristics, such as the test modality, on dual-task outcomes are evaluated, and associations with cognitive abilities and self-report measures of listening effort are described. Then, several procedural issues associated with the use of dual-task experiment paradigms are discussed. Finally, some issues that warrant future research are addressed. The review revealed large variability in the dual-task experimental paradigms that have been used to measure the listening effort expended during speech understanding. The differences in experimental procedures used across studies make it difficult to draw firm conclusions concerning the optimal choice of dual-task paradigm or the sensitivity of specific paradigms to different types of experimental manipulations. In general, the analysis confirmed that dual-task paradigms have been used successfully to measure differences in effort under different experimental conditions, in both younger and older adults. Several research questions that warrant further investigation in order to better understand and characterize the intricacies of dual-task paradigms were identified.
Introduction
In clinical settings, speech understanding is typically measured by calculating the proportion of keywords that can be identified correctly under a given listening condition (e.g., in quiet or in noise). One aspect of speech understanding that is underevaluated is listening effort. Listening effort refers to ‘the amount of processing resources (perceptual, attentional, cognitive, etc.) allocated to a specific auditory task, when the task demands are high (adverse listening conditions) and when the listener strives to reach a high-level of performance on the listening task. Under ideal listening conditions, listening to speech is relatively effortless (Rönnberg et al., 2013; Rönnberg, Rudner, Foo, & Lunner, 2008). Processing speech may become more effortful when the quality of the signal is degraded (e.g., due to noise or if the listener has hearing loss), when the language structure used is complex, or when the content of the message is less familiar.
There is no direct relationship between performance level in terms of proportion (or percent) of correct responses obtained on a listening task and listening effort. A person may obtain the same proportion of correct responses on two different tasks but report that performing one task was substantially more effortful than the other one. For example, a listener may be able to fully understand a spoken message in a challenging background noise but the amount of listening effort required to process the message in this situation may be considerably greater than when the same signal is processed in a quiet background setting. Likewise, persons with hearing loss often report that in some environments (especially noisy ones) listening requires substantially more concentration and attention than listening under ideal (quiet) environments (e.g., Desjardins & Doherty, 2013; Picou & Ricketts, 2014; Rakerd, Seitz, & Whearty, 1996; Xia, Nooraei, Kalluri, & Edwards, 2015). Measuring listening effort may be particularly well suited to comparing performance between two listening conditions when the speech recognition scores obtained on two tasks have reached ceiling levels. For example, the use of two hearing aids with different signal-processing algorithms may both yield the maximum correct recognition score on a given speech task administered in noise. However, the results of a behavioral listening effort task may reveal that performing the speech recognition task with one of the devices is more effortful than with the other one.
Presently, there is not a standardized test procedure to measure listening effort. Three broad categories of procedures have been used to measure listening effort: self-report, psychophysiological, and behavioral measures. A comprehensive review of these different approaches is beyond the scope of the present article but can be found in McGarrigle et al. (2014). In the present report, the analysis is limited to behavioral approaches. Measuring response times (RTs) is one approach that has been used to measure listening effort. However, this report will focus exclusively on the application of dual-task paradigms to measure listening effort during speech understanding. The decision to focus on this type of experimental paradigm was made because dual tasking (and even multitasking) is often required when processing speech in many real-life situations. This observation provides a form of ecological validity to the experimental procedure. Also, an informal literature search indicated that many investigators have used a dual-task paradigm to investigate listening effort.
The classic dual-task paradigm requires a participant to perform two tasks concurrently. One task is the primary task. In hearing research, this is usually the experimental listening task of interest (e.g., a task of speech recognition in noise). The other task, the secondary task, is used as a competing task. The tasks are administered to a participant under three experimental conditions: (a) the primary task is administered alone (primary-task baseline condition), (b) the secondary task is administered alone (secondary-task baseline condition), and (c) both the primary task and the secondary task are administered (dual-task condition). Typically, listening effort is calculated as the difference in performance on the secondary task between the baseline condition and the dual-task condition. Almost always, the listener is instructed to optimize performance on the primary task regardless of whether it is administered alone or under the dual-task condition. It is expected that performance on the primary task will be the same whether it is performed under the single-task condition or under the dual-task condition (Figure 1).
Illustration of the classic method used to measure listening effort.
The theoretical assumption underlying the use of a dual-task paradigm to measure listening effort is that the total processing resources that a person has available to perform tasks are limited in capacity and speed (Broadbent, 1958; Kahneman, 1973). If the attentional and the other cognitive resources required to perform the primary and the secondary tasks concurrently are less than the total resources available, then the person will be able to perform both tasks optimally. However, if the total resources required to perform both tasks exceed the maximum resources available, the person’s processing system will prioritize one of the tasks under the dual-task testing condition. If instructed to optimize performance on the primary task, then a decrease in performance will be observed on the secondary task.
The focus of the present article is on the use of dual-task paradigms to measure listening effort during speech understanding. First, a summary is provided of the main findings reported by investigators that have employed this type of experimental paradigm to measure listening effort for speech among younger and older adults. Then, some unresolved issues related to the use of dual-task paradigms to measure listening effort during speech understanding are discussed.
Methods
In early 2015, a scoping search was undertaken to retrieve all studies that had used a dual-task paradigm to investigate listening effort for speech understanding. The review procedure did not strictly follow the guidelines for systematic reviews, such as the PRISMA guidelines (http://www.prisma-statement.org/). For example, no exact records were kept of the number of publications initially retrieved from each of the searched databases. Furthermore, an evaluation of the quality and strength of the reviewed studies was not undertaken. Nonetheless, a structured approach was applied to retrieving, including, and reviewing the publications. First, PubMed was queried for publications containing the keywords effort, ease of listening, cognitive load, or processing load in combination with hearing, listening, speech recognition, speech understanding, or speech perception, and additionally in combination with behavioral, dual task, response delay, or response time, resulting in approximately 80 search results. Furthermore, Google scholar was queried with some of the above listed keywords to browse for publications not detected in the initial PubMed search. In total, approximately 90 publications were identified as potential articles for the review. From this initial list, studies were excluded if they were not peer reviewed, did not include the use of a dual-task paradigm to investigate listening effort, or if the primary task was not a speech-understanding task. Inclusion or exclusion of articles was based on information provided in the title and abstract. If these sources of information were inconclusive, the whole article was scanned for fulfilment of the aforementioned requirements. Each article was rated by one of the authors of the present review. In cases of uncertainty, consensus about the article’s suitability was reached by all authors of the current article. Throughout the review process, the reference sections of the included articles were scanned for additional relevant articles.
Summary of Published Articles in Which a Dual-Task Experimental Procedure Was Used to Measure the Listening Effort Expended to Perform a Speech-Understanding Task.

Note. AOSPAN = automatic operation span task; AV = audiovisual; BIN = binaural; BTE = behind the ear; C−/+ = cognitive function good (+) or, cognitive function poor (−); CST = continuous speech test; DIR = directional; DM = directional microphone; DPRT = Digital pursuit Rotor Tracking; DT = dual task; DSST = digit symbol substitution test; ENH = spectrally enhanced; ENHC = spectrally enhanced with compression; FF = talker at front; F-RF = talker at right-front; H−/+ = hearing sensitivity good (+) or, hearing sensitivity poor (−); HA = hearing aid; HI = hearing impaired; HRV = heartrate variability; LDT = lexical decision task; LNS = letter number sequencing test; NAL-R = National Acoustics Laboratory-revised version; MF = monaural far; MME = modified direct magnitude estimation; MN monaural near; N = number of participants; NC = near coding; NH = normal hearing; NoP = no processing; NR = noise reduction; NRDM = noise reduction and directional microphone; NV-hi = vocoded, high intelligibility; NV-lo = vocoded, low intelligibility; OHI = old, hearing impaired; ONH = old, normal hearing; OSLA matrix = Oldenburg sentences matrix test; P = primary task; pDTC = proportional -task; R = reverberation; Rspan = reading span; RSPIN = revised speech in noise test; RT = response time; S = secondary task; SIN = sentences in noise; SNR = signal to noise ratio; SPIN = speech in noise; SSN = speech spectrum noise; TLX = text load index; TVM sentences = closed-set sentence recognition test; TTB = 2-talker babble; V-AP = visual-with concurrent auditory processing; VCV = vowel consonant vowel; VRT = visual response time; WAIS = Wechsler Adult Intelligence Scale; WM = working memory; WMC = working memory capacity; WMS = working memory span; YNH = young, normal hearing.
Unilateral hearing loss was simulated by the use of an earplug with inserted into one ear during testing, resulting in a gradually sloping 4 dB per octave conductive hearing loss of approximately 30 dB HL at 500, 1,000, and 2,000 Hz.
In basic mode, the hearing aid microphone was omnidirectional, and all advanced features, except for feedback management, were disabled, including directional processing and DNR. In advanced mode, the manufacturer’s default settings for different listening environments were used. This included multichannel automatic directivity and algorithms designed to reduce reverberation, general background noise, and wind noise. The background noise level in this study (55 dBA) was not high enough to activate the devices’ directional processing or noise-reduction algorithms. Thus, regardless of the aid setting (basic or advanced), the hearing aids were functioning in omnidirectional mode with no DNR active during testing. The interest was whether continuous access to advanced signal processing during daily activities would reduce cognitive processing demands and listening effort such that differences would be apparent when tested on the study’s cognitively demanding dual task completed at the end of the day.
Note on group labels: H+C+ = mild hearing loss, better cognitive function; H−C+ = moderate hearing loss, better cognitive function; H+C− = mild hearing loss, poorer cognitive function; H−C− = moderate hearing loss, poorer cognitive function
Note that the study by Wild et al. describes a dual task and provides behavioral results for it, but the study did not examine listening effort or dual-task cost. Performance was only assessed for attended stimuli.
The publications that had been judged to be eligible for the current review were read by at least one of the authors to extract the following information incorporated into a Master Table (see Table 1): participant characteristics (e.g., age, hearing status, other relevant factors), research question addressed in the study, primary task used, secondary task used, test conditions applied, other relevant dependent variables measured, main findings reported from the dual-task data, other related findings reported by the investigators, and any other relevant comments related to the article.
Results
The reviewed articles were evaluated regarding their findings on listening effort during speech understanding on the one hand and regarding methodological issues connected to dual-task paradigms on the other hand.
Summary of Findings
Effects of age
Several studies compared the amount of listening effort expended by younger and older adults when performing a speech-understanding task (Anderson-Gosselin & Gagné, 2011a, 2011b; Desjardins & Doherty, 2013; Helfer, Chevalier, & Freyman, 2010; Rakerd et al., 1996; Tun, McCoy, & Wingfield, 2009; Tun, Wingfield, & Stine, 1991). Generally, the results of these studies indicate that older adults (with normal or near-normal pure-tone detection thresholds) expend a greater amount of listening effort to recognize speech in noise than younger adults. This finding holds both for when the primary and the secondary tasks are administered under identical conditions (e.g., at the same signal-to-noise ratio [SNR]) to the two age-groups and when both groups are tested at the same level of performance by adjusting the SNR at which a given participant performs the speech task (Anderson-Gosselin & Gagné, 2011a, 2011b).
Effects of the hearing status
In some studies, a dual-task paradigm was used to investigate the effects of hearing status on listening effort among adult participants (Desjardins & Doherty, 2013; Helfer et al., 2010; Neher, Grimm, & Hohmann, 2014; Picou, Ricketts, & Hornsby, 2013; Tun et al., 2009; Xia et al., 2015). In general, the results of these investigations revealed that listeners with hearing loss deploy more listening effort than their age-matched counterparts with normal hearing acuity, especially when the speech-understanding task is administered in noise.
Effects of the perceptual modality in which the speech is presented
Some investigators compared the listening effort expended by participants as a function of whether the speech stimuli were presented audiovisually or in an auditory-alone modality (Anderson-Gosselin & Gagné, 2011a; Fraser, Gagné, Alepins, & Dubois, 2010; Picou, Ricketts, & Hornsby, 2011, 2013).
The results reported by Gagné and his collaborators revealed that when the speech stimuli were presented at the same SNR in both perceptual modalities, the listening effort expended to understand speech was greater in the auditory-alone modality (Anderson-Gosselin & Gagné, 2011a; Fraser et al., 2010). However, when both modalities were tested at the same primary-task performance level (i.e., poorer SNR in the audiovisual condition), speech understanding was more effortful in the audiovisual condition than in the auditory-alone condition. In contrast, Picou and coworkers (Picou et al., 2011, 2013) found that the provision of visual cues did not significantly increase listening effort for speech stimuli. Moreover, Picou et al. (2013) observed that better lip readers were more likely to derive benefit from the provision of visual cues and show a reduction in listening effort relative to an auditory-only condition. Clearly, more research is needed to account for the different findings reported by these two groups of investigators. One possible explanation may be the dual-task paradigm used; one group of investigators used a concurrent dual-task paradigm (Anderson-Gosselin & Gagné, 2011a, 2011b; Fraser et al., 2010), whereas the other group used a sequential paradigm (Picou et al., 2011, 2013).
Relationship between dual-task outcomes and cognitive abilities
The relationship between the amount of listening effort expended during speech understanding and measures of cognitive abilities was assessed in several studies. For example, in some of the studies reviewed, the participants also performed a test of working memory capacity (WMC; Choi et al., 2008; Desjardins & Doherty, 2013; Neher et al., 2014; Neher, Grimm, Hohmann, & Kollmeier, 2014; Picou, 2011, 2013; Tun et al., 2009, 1991).
Desjardins and Doherty (2013) reported a significant correlation between outcomes on the Reading-Span test and listening effort in a group of participants who had hearing loss and who were fitted with hearing aids. Similarly, Tun et al. (1991) reported that WMC was a good predictor of listening effort. Picou et al. (2011) investigated listening effort for a speech recognition task administered in two modalities: auditory alone and audiovisual. The authors reported that participants who were good speech readers and who had a large WMC deployed less effort to perform the speech-understanding tasks. However, in other studies, the investigators failed to demonstrate that WMC was correlated to the listening effort displayed by adults with hearing loss who used hearing aids (Desjardins, 2016; Desjardins & Doherty, 2014; Neher et al., 2014; Neher, Grimm, Hohmann, et al., 2014). Furthermore, no associations with listening effort in listeners with a hearing loss were observed for a Stroop test of selective attention (Desjardins & Doherty, 2013) or the Digit Symbol Substitution Test for processing speed (Desjardins, 2016; Desjardins & Doherty, 2014). In summary, current results are inconclusive concerning the relationship between dual-task cost during speech understanding and WMC or other cognitive abilities.
Relationship between dual-task outcomes and self-report measures of listening effort
Questionnaires incorporating Likert-like rating scales have been used to assess self-report listening effort. Two examples of such questionnaires are the Quality of hearing subscale of the “Speech, Spatial, and Qualities of Hearing” Scale (Gatehouse & Noble, 2004) and the Device-Oriented Subjective Outcome (Cox, Alexander, & Xu, 2014). Also, some investigators have used a unidimensional rating scale (e.g., ranging from no effort to an extremely high level of effort) to quantify the perceived listening effort during a listening task (Anderson-Gosselin & Gagné, 2011a, 2011b; Desjardins, 2016; Desjardins & Doherty, 2013, 2014; Fraser et al., 2010; Neher, Grimm, Hohmann, et al., 2014; Picou et al., 2011).
Several investigators have examined the relationship between behavioral and self-report measures of listening effort (or ease of listening; which can be considered the opposite of listening effort). In general, no associations between the two types of measures were observed (Anderson-Gosselin & Gagné, 2011a, 2011b; Desjardins, 2016; Desjardins & Doherty, 2013, 2014; Feuerstein, 1992; Fraser et al., 2010; Hornsby, 2013; Neher et al., 2014; Pals, Sarampalis, & Baskent, 2013; Picou et al., 2013). This consistent finding suggests that dual-task experimental paradigms may not measure the same attributes of listening effort as the concepts used by listeners when asked to rate the effort that was required to perform a specified speech-understanding task. Accordingly, Lemke and Besser (2016) have suggested that the term listening effort should be used as an umbrella term for processing effort (in terms of resource allocation) during listening on the one hand and for perceived effort (self-reported experience) on the other hand. McGarrigle et al. (2014) suggested that the term dual-task cost be used to describe the results obtained when a dual-task paradigm is used as a measure of listening effort.
Relationship between dual-task outcomes and other independent variables
This section summarizes how dual-task outcomes for listening effort are influenced by the characteristics of the masking signal, the SNR at which the speech task is administered, linguistic characteristics of the speech signal, and amplification or specific signal-processing algorithms incorporated into hearing aids.
Characteristics of the masker
In most of the studies reviewed, the speech material was presented in the presence of an interfering signal. In some of the studies, the interfering signal consisted of a masking noise (Anderson-Gosselin & Gagné, 2011a, 2011b; Fraser et al., 2010). In two other studies, cafeteria noise was used as an interfering signal (Neher et al., 2014; Neher, Grimm, Hohmann, et al., 2014). Other investigators used speech as an interfering signal (e.g., Baer, Moore, & Gatehouse, 1993; Ng, Rudner, Lunner, & Rönnberg, 2015; Picou et al., 2011, 2013; Xia et al., 2015). In one of the studies, the interfering signal consisted of backward speech (Helfer et al., 2010). A thorough discussion on the advantages and disadvantages of using nonspeech signals as an interfering signal (i.e., purely energetic masking) versus speech stimuli (which includes both energetic and semantic or informational masking) is beyond the scope of the present review. Several investigators have discussed these two types of masking signals in relation to performance on speech-understanding tasks (Brungart, Simpson, Ericson, & Scott, 2001; Freyman, Balakrishnan, & Helfer, 2004; Kidd, Mason, Richards, Gallun, & Durlach, 2008; Rosen, Souza, Ekelund, & Majeed, 2013).
Desjardins and Doherty (2013) found that the type of the masking signal had an influence on listening effort but the effect was different for younger and older listeners. Helfer et al. (2010) found that listening effort is influenced by the spatial configuration of the masking source relative to the target speech. Xia et al. (2015) reported that the availability of spatial separation cues or voice-difference cues also has an effect on listening effort.
SNR at which the speech task is administered
In some studies, the effect of the SNR on dual-task outcomes was tested (Baer et al., 1993; Neher et al., 2014; Neher, Grimm, Hohmann, et al., 2014; Sarampalis, Kalluri, Edwards, & Hafter, 2009). In all of these studies, it was found that performance on the secondary task improved (i.e., the dual-task cost decreased) when the SNR was improved. However, it is noteworthy that in those studies, performance on the primary task also improved as the SNR improved. Hence, it is not possible to rule out the possibility that the reduction in dual-task cost on the secondary task was attributable to the fact that the primary task became less difficult as the SNR was improved.
A related issue is the SNR at which the speech-understanding task is administered. In most of the studies reviewed, the SNR selected was such that it yielded a high-level speech-understanding accuracy score (e.g., 80% correct), while avoiding ceiling effects. In a recent study Wu et al. (2016) used a dual-task paradigm to investigate listening effort as a function of the SNR at which the primary speech recognition task was administered. For each experimental condition of the primary task, RTs to both an easy task (i.e., visual probe detection) and a difficult task (i.e., a color Stroop test) were used to measure performance for the secondary task. Three different (but related) experiments yielded a similar pattern of results concerning the secondary task. Specifically, RTs for the secondary task had a maximum duration when the SNR was set so that the primary-task performance level yielded speech recognition scores that were in the range of 30% to 50% correct (i.e., at SNRs of −2 and 0 dB). RTs for the secondary task were shorter when the SNR was set to yield either lower or higher speech recognition scores. The unexpected finding in these experiments is that the maximum duration RT was not observed under the experimental condition in which the sentences were presented at the poorest SNRs. The findings reported by Wu et al. (2016) suggest that the experimental condition under which listening effort is most likely to be revealed occurs when the primary speech-perception task is designed to results in a performance level that gives a percent correct response rate between 30% and 50%.
Linguistic characteristics of the speech signal
In some studies, the revised Speech in Noise Test (Bilger, Nuetzel, Rabinowitz, & Rzeczkowski, 1984; Wilson, McArdle, Watts, & Smith, 2012) was used to assess listening effort using a dual-task paradigm (Desjardins & Doherty, 2013, 2014; Feuerstein, 1992; Sarampalis et al., 2009). The results of these investigations showed that listening effort was greater for the low-predictability sentences than for the high-predictability sentences.
Amplification or specific types of signal processing
A number of investigators have reported the effects of amplification or specific types of signal-processing algorithms on listening effort. Overall, regardless of the type of dual-task paradigm used, listening effort appears to decrease with the use of (a) amplification (Baer et al., 1993; Downs, 1982; Hornsby, 2013; Picou et al., 2013), (b) dynamic-range compression (Baer et al., 1993), (c) noise-reduction algorithms (Desjardins & Doherty, 2014; Sarampalis et al., 2009), (d) directional microphones (Wu et al., 2014), (e) advanced compared with basic hearing-aid settings (Hornsby, 2013), and (f) combinations of directional microphones and noise reduction (Desjardins, 2016). However, it should be noted that sometimes, changes in listening effort were observed only for some of the experimental conditions tested. In fact, in two studies, it was found that the use of an aggressive noise-reduction algorithm resulted in an increase in listening effort (Neher et al., 2014; Neher, Grimm, Hohmann, et al., 2014). At the present time, it is not clear whether the differences in findings across the studies are due to differences in the noise-reduction algorithms used, differences in the dual-task paradigms employed, differences in other components of the experimental procedures, or differences in the characteristics of the participants.
Methodological Issues and Design Considerations
While analyzing the studies retained for the present review, it became evident that several decisions made during the design stage of investigations incorporating a dual-task paradigm may influence the results obtained. This section reviews some of the identified methodological issues.
Type of dual-task paradigm (concurrent vs. sequential)
Under the dual-task condition, within a single test trial, the primary task and the secondary task may be administered concurrently or sequentially. With concurrent stimulus presentation, the participant is required to process the stimuli of both tasks at the same time, such as in the studies by Desjardins and colleagues (Desjardins, 2016; Desjardins & Doherty, 2013, 2014). The secondary task in those studies, initially described by Kemper, Schmalzried, Herman, Leedahl, and Mohankumar (2009), consisted of the digital pursuit rotor task, a visual motor tracking task performed with a computer mouse. Under the dual-task condition, the participants had to listen to and repeat the primary-task sentences they heard while performing the digital pursuit rotor task.
In sequential dual-task paradigms, a period of time separates the presentation of the primary- and the secondary-task stimuli, such as described by Rakerd et al. (1996). In that study, a list of digits appeared on a computer monitor. The participants were instructed to memorize the list for later recall. Then, the participants heard a short text of connected discourse that was approximately 1 minute in duration and answered questions about the information presented. Afterwards, the participants were asked to recall the list of digits initially presented to them. More recently, a similar sequential dual-task paradigm was employed in some studies reported by Picou et al. (2011, 2013).
Among the studies conducted with adult participants, an overwhelming majority of the studies used a concurrent experimental paradigm. In fact, only one of the studies reviewed included a sequential design (Rakerd et al., 1996). It would appear as though there is a strong bias to use concurrent dual-task paradigms to investigate listening effort for speech. One of the reasons for this tendency may be that investigators wish to capitalize on the fact that requesting a participant to perform two tasks concurrently holds a high level of ecological validity because multitasking is something that persons are often required to do as part of their everyday life activities. Furthermore, concurrent dual tasking taps into more processing resources than merely memory functions.
Primary tasks of dual-task paradigms
In most of the studies reviewed, the primary task was sentence recognition (Anderson-Gosselin & Gagné, 2011a, 2011b; Baer et al., 1993; Desjardins, 2016; Desjardins & Doherty, 2013, 2014; Feuerstein, 1992; Fraser et al., 2010; Helfer et al., 2010; Neher, Grimm, Hohmann, et al., 2014; Pals et al., 2013; Sarampalis et al., 2009; Wild et al., 2012; Wu et al., 2014). However, in one study, the primary task was syllable recognition (Rigo, 1986), and in other studies, the primary task was recognition of words presented in isolation (Downs, 1982; Hornsby, 2013; Picou & Ricketts, 2014; Picou et al., 2011, 2013; Tun et al., 2009). In two studies, the stimuli used were spoken passages, and the task consisted of a speech-comprehension response (Rakerd et al., 1996; Tun et al., 1991). Some studies used a closed-set response task, whereas other investigators used an open-set speech recognition task. One advantage of using a closed-set recognition task is that it makes it easy to determine the when the participant initiates response (i.e., key-stroke or finger response on a touch screen monitor) and thus to assess the RT as well as accuracy.
Secondary tasks used
List of Types of Secondary Tasks That Were Used in the Reviewed Dual-Task Studies on Listening Effort for Speech.
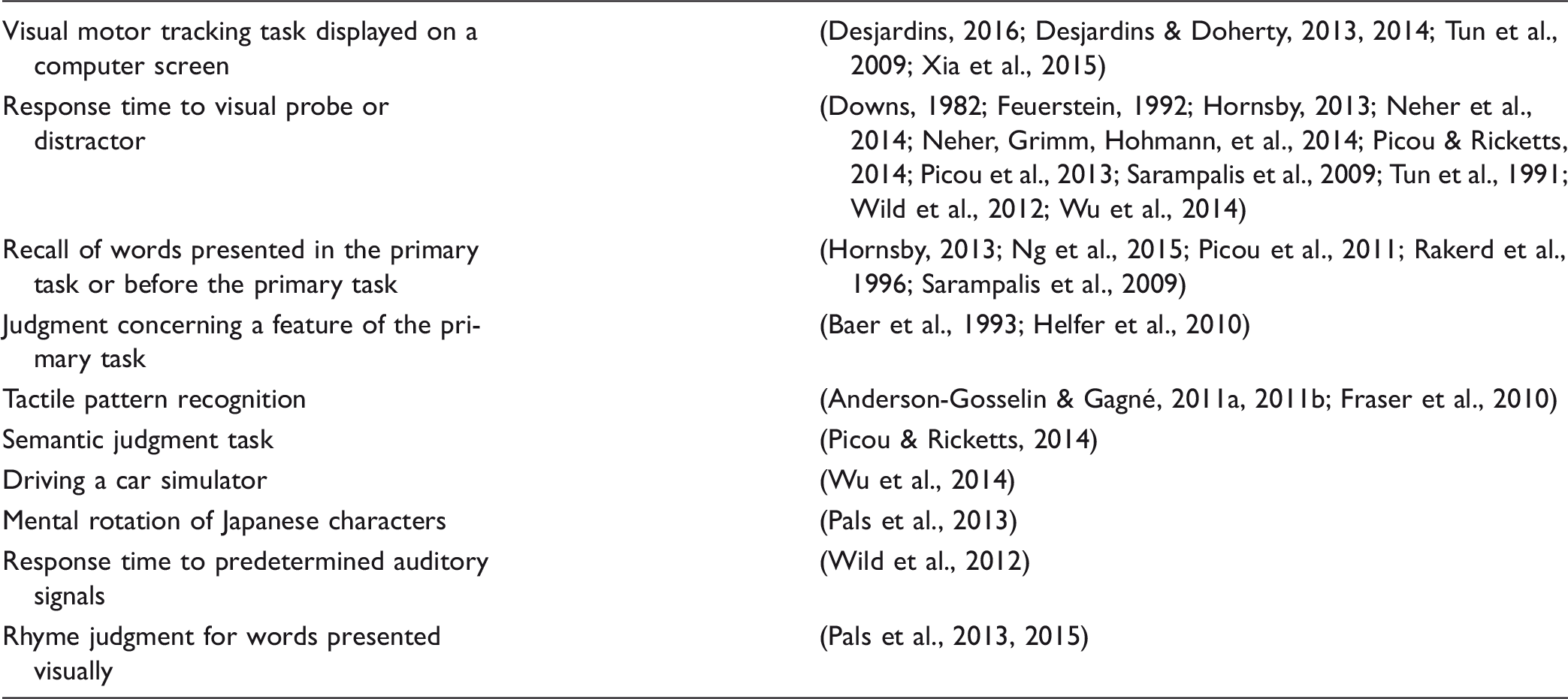
Presently, no specific category of secondary task has been shown to be the most appropriate for measuring listening effort using a dual-task paradigm. Picou and Ricketts (2014) reported two experiments in which the goal of the study was to evaluate the effects of the secondary task on listening-effort outcomes. In each experiment, three different secondary tasks, based on RT measures, were compared: (a) simple visual probe, (b) complex visual probe, and (c) category of word presented. The results of Experiment 1 (conducted with participants with normal hearing) and Experiment 2 (conducted with participants with a mild-to-moderate hearing loss) revealed that only the secondary task that required a word-category recognition response was sensitive to changes in the primary task. According to the investigators, word-category recognition required deeper processing than the two visual-probe tasks. It is difficult to determine whether the secondary task that consisted of the word-category recognition task was more sensitive to listening effort because it involved processing linguistic information (just as the primary task did) or because it was cognitively more demanding in other respects. Nevertheless, the results of the investigation do suggest that the type of secondary task used may have an influence on whether or not listening effort can be measured.
In another study (Wu et al., 2014), different secondary tasks were used in two companion experiments in which the same participants were involved. In one experiment, the secondary task consisted of driving a vehicle in a driving simulator, and in the other study, it consisted of a visual-pattern recognition task. In both experiments, performance on the secondary task revealed a significant effect of listening effort. Moreover, the performance levels on both tasks were found to be significantly correlated with each other. This finding supports the idea that different categories of secondary tasks may be equally appropriate to measure listening effort using a dual-task paradigm. Notwithstanding these observations, at the present time it would be unwise to conclude that any secondary task can be used to investigate listening effort for speech understanding and that all secondary tasks are equally sensitive to differences in listening effort. In summary, further research may be required to identify which type of secondary task or which combination of primary and secondary tasks are best suited for investigating listening effort for speech understanding.
Ways of quantifying listening effort
Proportion correct responses versus RT measures of listening effort
In some studies, the dependent variable used to quantify listening effort consisted of the proportion of correct scores, while in other studies, it consisted of a RT measure (refer to Table 1 for an overview of dependent measures used across studies). At the present time, there is no clear indication concerning which of the two approaches is the most appropriate to characterize listening effort. However, it is noteworthy that Whelan (2008) claims that in some experiments, the RT data collected may not meet some of the assumptions required to use an analysis of variance to test for significant effects.
Some investigators have chosen to compute both proportion correct scores and RTs for the secondary task (Anderson-Gosselin & Gagné, 2011a, 2011b; Fraser et al., 2010). For example, Gagné and his colleagues (Anderson-Gosselin & Gagné, 2011a, 2011b; Fraser et al., 2010) used a two-element tactile pattern recognition task as their secondary task. The four possible response alternatives were displayed on a touch screen computer monitor. The participants were instructed to respond as quickly as possible by selecting their choice of response from the alternatives shown on the monitor. Both accuracy and RTs were assessed. As a first approximation, both methods used to quantify performance on the secondary task led to a similar pattern of results.
The metric used to measure listening effort
The classic method used to quantify listening effort consists of calculating the difference score (DS) between the baseline and the dual-task performance on the secondary task (i.e., Listening effort = Secondary taskbaseline−Secondary taskdual-task). However, a simple DS should not be used if there is a large difference between groups in the baseline secondary-task performance. For example, a DS of 30 ms should be interpreted differently, when the baseline RT was 540 ms (i.e., 540 ms−510 ms = 30 ms) compared with when the baseline RT was 80 ms (i.e., 80 ms−50 ms = 30 ms DS). One way to circumvent this issue is to use a proportional DS. For example, Fraser et al. (2010) computed a proportional dual-task cost (pDTC) as their measure of listening effort, where pDTC = Secondary-taskbaseline−Secondary-taskdual-task/Secondary-taskbaseline × 100.
Similarly, there may be a difference in a participant’s performance level on the primary task when it is administered under the baseline condition and when it is administered concurrently under the dual-task condition. In such cases, it may be appropriate to compute a pDTC for the primary task in addition to a pDTC for the secondary task. Significant differences in pDTC for either the primary task or the secondary task could be interpreted as an indication of a significant effect of listening effort (e.g., Fraser et al., 2010). Moreover, when pDTCs are computed for both the primary and the secondary tasks, it is justified to compute an aggregate listening effort index by combining the listening effort scores (e.g., pDTC) obtained for both the primary and the secondary tasks. For example, one may choose to report the pDTCtotal score (whereby, the pDTCtotal = pDTCprimary task + pDTCsecondary task). Notably, an aggregate listening effort index was not reported in any of the studies included in the present review. However, a rationale in support of using an approach similar to the one described here was recently provided by Plummer and Eskes (2015). The investigators claim that the magnitude and direction of dual-task interference may be influenced by the interaction between the two tasks and by how individuals spontaneously prioritize their attention. The authors demonstrate that this approach to measuring dual-task cost takes into account the trade-offs in performance that the participant may attribute to the primary and the secondary tasks.
Same experimental condition versus same level of performance
When a study is designed to compare listening effort across different groups of participants, the investigator must decide whether the speech-understanding task should be administered under the same conditions across groups (e.g., at the same SNR) or at equal speech-understanding baseline performance (e.g., using a different SNR for each group). Both options may be appropriate, depending on the research question that is being addressed. The same issue also applies when different experimental conditions (e.g., Amplification System A vs. Amplification System B) are administered to the same group of participants, that is, when the study consists of a within-subject design. One alternative could be to incorporate both experimental setups in the same study, as was done in some of the reviewed studies (e.g., Anderson-Gosselin & Gagné, 2011a, 2011b; Fraser et al., 2010). This latter alternative makes it possible to address the results from both an ecological (everyday life situation) as well as a conceptual (measuring listening effort at the same level of performance) standpoint.
Other methodological considerations
For a secure interpretation of differences in secondary-task outcomes in terms of listening effort, it is required that the listener is motivated to aim at high levels of performance in both primary task and secondary task, as well as that the tasks are challenging enough to draw on the full investment of required processing resources available in the listener’s processing system. Otherwise, when no difference in secondary-task outcome is observed, one does not know whether there was no difference in effort for the different primary-task conditions or whether there were sufficient resources left for performing a more effortful primary task without compromising performance on the secondary task. This methodological requirement is hard to ensure, given that we have no means to assess the general individual capacity available.
Another methodological concern is that priority should be given to the primary task by the listener under all circumstances for an easy interpretation of the experimental results. However, it may not always be possible to monitor whether this condition is satisfied. For example, a dual-task study conducted with children revealed that instructions given to participants on how to prioritize the two tasks were ineffective (Choi et al., 2008).
Discussion and Conclusions
The current article presents an overview of previous studies that have used dual-task paradigms to assess listening effort during speech understanding. We would like to stress that while we strove to perform a scoping review, the review was not performed according to guidelines for a systematic review and did not aim to evaluate the quality of the included studies in any way. Rather, the purpose was to thoroughly describe the previous publications to provide an overview of what has been done so far, given that dual tasks for measuring listening effort are a relatively new field within hearing research. Specifically, the aims of this review were to (a) describe the large variety of methodological approaches that have been applied, especially the plenty of secondary tasks; (b) provide a broad summary of the results that have been obtained, especially regarding effects of listener age, hearing status, and signal processing; (c) discuss a number of methodological considerations that need to be taken into account when designing a dual-task study.
The present review revealed a large variability in the experimental paradigms used to behaviorally measure listening effort during speech understanding, in terms of the primary and secondary tasks applied as well as the experimental manipulations for which effects on effort were assessed, and the listener groups. While most of the applied paradigms were able to detect changes in listening effort related to an experimental manipulation, this large variability in applied settings makes it difficult to draw any firm conclusions about the most suitable dual-task paradigm for assessing listening effort or about the sensitivity of specific paradigms to different types of experimental manipulations. Overall, systematic evaluations of the applied paradigms, including psychometric properties, are lacking and would be highly desired.
Specifically, the relationship between dual-task cost and the following factors should be examined. First, in the vast majority of the studies, the SNR for the primary speech-understanding task was set in such a way that the participants obtained a high level of baseline accuracy performance, often in the range of 80% correct or better. It would be of interest to examine the relationship between the level of performance on the primary-task baseline measure and the dual-task cost. For example, is there a linear relationship between primary-task baseline and dual-task cost on the secondary task, such that doubling accuracy on the primary task leads to halving dual-task costs on the secondary task?
Second, it is not known whether the additivity of different sources of listening effort is linear or nonlinear. For example, the dual-task cost of performing a speech recognition task in noise for individuals with a moderately severe hearing loss may be equal to the dual-task cost of performing the same speech task for persons with normal hearing who perform the task in a nonnative language. What is the dual-task cost expected for individuals with a moderately severe hearing loss who perform the speech recognition task in their nonnative language?
Third, whereas some investigators (Picou & Ricketts, 2014; Wu et al., 2014) have compared the effects of using different secondary tasks when assessing listening effort, to date there is no general understanding of the suitability and sensitivity of the different types of secondary tasks. Is a secondary task that calls upon the use of short-term memory as sensitive as a secondary task that calls upon the use of visual attention skills? Recently, Kahneman’s (1973) capacity model of attention has been adapted to the specific case of listening effort, resulting in the framework for understanding effortful listening (FUEL; Pichora-Fuller et al., 2016). The FUEL framework consolidates the general assumptions of the Kahneman’s model that resources are limited and shared between tasks and illustrates how effort is influenced by interactions of external task demands and internal motivation. Accordingly, the FUEL framework confirms the theoretical assumptions underlying the dual-task approach. However, to our knowledge, neither the FUEL framework nor any other model of cognitive resources (cf. Wingfield, 2016) provides information that would theoretically motivate the choice of a specific type of secondary task. For example, it may seem obvious that a secondary task in the same modality (auditory) as the primary task or the same processing domain (verbal) would compete more with speech understanding than other tasks. Nonetheless, as described in the present review, dual-task costs during speech understanding have also been found for secondary tasks such as motor tracking and tactile pattern recognition. It has been described that multitasking leads to an increased activation of and demand for executive functions (Diamond, 2013). Possibly, the reallocation of resources toward executive functions in dual tasking is more important than the domain or modality of the secondary task and potentially also than the specific design of the secondary task.
Fourth, both sequential and concurrent dual-task paradigms can be used to measure listening effort. At the present time, it is not known if these two approaches measure the same dimensions of listening effort. If not, then which approach is best suited to measure listening effort for speech-understanding tasks?
Finally, the participant is generally instructed to optimize performance on the primary task rather than on the secondary task. Data obtained from children suggest that this simple instruction may not be sufficient to ensure that the participant will optimize performance on the primary task (Choi et al., 2008; Irwin-Chase & Burns, 2000). It would be of interest to examine the same issue in adults. Also, in a previous section, it was suggested that perhaps one way of overcoming this issue may be to compute an aggregate dual-task cost. However, at the present time, there are no empirical data available to support the use of this strategy.
In sum, the present review provides a comprehensive and critical analysis of investigations in which a dual-task paradigm was used to investigate aspects of speech understanding among younger and older adults. Generally, the results of the analysis suggest that this type of experimental procedure appears to be sensitive to a number of differences in experimental conditions, both across groups of participants as well as within the same group of listeners. At the same time, systematic evaluations of the existing paradigms are needed for making informed design decisions. Given the importance of attentional and other cognitive processes involved in speech understanding, it would be of interest to pursue investigations that contribute to the development of a clinical procedure that will make it possible to quantify the listening effort during speech understanding. In the long term, the use of dual-task experimental paradigms may constitute a good approach toward achieving this goal.
The review also revealed that at the present time, there does not appear to be a consensus on the type of dual-task experimental paradigm that is most appropriate to investigate listening effort for speech understanding. Several differences in experimental procedures were apparent across investigations. Also, several issues that warrant further investigations were identified. The present review should be of interest to investigators who are interested in applying dual-task experimental paradigms to investigate issues related to listening effort. Finally, several research questions that warrant further investigation in order to better understand and characterize the intricacies of dual-task paradigms were proposed.
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.