
Abstract
Current cochlear implant (CI) strategies carry speech information via the waveform envelope in frequency subbands. CIs require efficient speech processing to maximize information transfer to the brain, especially in background noise, where the speech envelope is not robust to noise interference. In such conditions, the envelope, after decomposition into frequency bands, may be enhanced by sparse transformations, such as nonnegative matrix factorization (NMF). Here, a novel CI processing algorithm is described, which works by applying NMF to the envelope matrix (envelopogram) of 22 frequency channels in order to improve performance in noisy environments. It is evaluated for speech in eight-talker babble noise. The critical sparsity constraint parameter was first tuned using objective measures and then evaluated with subjective speech perception experiments for both normal hearing and CI subjects. Results from vocoder simulations with 10 normal hearing subjects showed that the algorithm significantly enhances speech intelligibility with the selected sparsity constraints. Results from eight CI subjects showed no significant overall improvement compared with the standard advanced combination encoder algorithm, but a trend toward improvement of word identification of about 10 percentage points at +15 dB signal-to-noise ratio (SNR) was observed in the eight CI subjects. Additionally, a considerable reduction of the spread of speech perception performance from 40% to 93% for advanced combination encoder to 80% to 100% for the suggested NMF coding strategy was observed.
Keywords
Introduction
Cochlear implants (CI) are electrical devices that help to restore hearing to the profoundly deaf. The main principle of CIs is to stimulate the auditory nerve via electrodes surgically inserted into the inner ear. With the development of new speech processors and algorithms, CI users benefit more and more from their implants (Wilson & Dorman, 2007; Zeng, 2004), and many of them are even able to communicate via telephone. However, average speech perception performance of CI users is still far below that of normal-hearing (NH) listeners, especially in the presence of background noise. This may occur because there are information transmission bottlenecks (Olshausen & Field, 2004), both in the CI device itself and in the impaired auditory system, which limit acoustic information transmission to auditory neurons (Greenberg, Ainsworth, Popper, & Fay, 2004). Examples of such bottlenecks include the smaller dynamic range of CIs, relative to NH, and the limited number of electrodes.
There are currently two main ways by which speech processing algorithms aim to improve CI performance: one focuses on noise reduction preprocessing by trying to enhance speech and suppress noise (Hendriks & Martin, 2007; Hussain, Chetouani, Squartini, Bastari, & Piazza, 2007; Mauger, Arora, & Dawson, 2012; Mauger, Dawson, & Hersbach, 2012; Roberts, Ephraim, & Lev-Ari, 2006; Wouters & Berghe, 2001); the other focuses on redundancy reduction using different coding strategies (Buchner, Nogueira, Edler, Battmer, & Lenarz, 2008; Buechner et al., 2011; Li, 2008; Li, Lutman, Wang, & Bleeck, 2012; Loizou, Lobo, & Hu, 2005; Nie, Drennan, & Rubinstein, 2009) to make better use of the limited transfer capacity in the CI electrical-auditory system. Speech has a high degree of redundancy (Cooke, 2006; Kasturi, Loizou, Dorman, & Spahr, 2002), and humans can understand speech based on partial information and in difficult environments. This phenomenon has been explored and modeled using, for example, glimpsing (Cooke, 2006) or binary masking (Wang, Kjems, Pedersen, Boldt, & Lunner, 2009). Existing CI strategies, such as continuous interleaved sampling (Wilson et al., 1991), spectral peak (Seligman & McDermott, 1995) and the advanced combination encoder (ACE; Clark, 2003; Patrick, Busby, & Gibson, 2006), already take advantage of the redundancy properties of speech by selecting only few channels or only using envelope information for stimulation. Li and colleagues (Li, 2008; Li et al., 2012) demonstrated that these strategies deliver stimulation in a sparse representation of the speech and they introduced a SPARSE strategy, in which an algorithm based on independent component analysis is applied to the spectral envelope. Their results were promising, showing that the SPARSE strategy improved speech intelligibility for some CI users even with very limited familiarity with the stimulation strategy (Li, 2008; Li et al., 2012). The redundancy properties of speech were further investigated in Hu et al. (2011) by introducing an enhanced SPARSE strategy. Both objective measures and subjective listening tests with vocoder CI simulation in NH showed that the SPARSE strategy is a potential candidate for a future stimulation algorithm (Hu et al., 2011; Li, 2008; Li et al., 2012).
Nonnegative matrix factorization (NMF) (Lee & Seung, 1999, 2000) is an alternative algorithm that produces a sparse representation. It has recently attracted interest across many scientific and engineering disciplines, such as image processing, speech processing, and pattern classification (Cichocki, Zdunek, Phan, & Amari, 2009; Mohammadiha, Gerkmann, & Leijon, 2011; Potluru & Calhoun, 2008; Shashanka, Raj, & Smaragdis, 2008; Smaragdis & Brown, 2003; Spratling, 2006; Wang, Cichocki, & Chambers, 2009). NMF is useful for transforming high-dimensional data sets into a lower dimensional space (Potluru & Calhoun, 2008). Moreover, instead of developing holistic representations, NMF usually conducts parts-based decomposition and reconstruction using nonnegativity constraints (Lee & Seung, 1999). A nonnegative approach is suitable for envelope representations, which cannot be negative.
Motivated by the nonnegativity feature of the signal envelopes in CI channels and the positive firing rate of auditory neurons, a sparse coding strategy based on NMF is proposed in the current study, and we investigate whether it can improve the performance of CI users in noisy environments. Considering the computational complexity of NMF and an envisaged real-time implementation, a basic NMF method with a sparse constraint λ (Hoyer, 2002) is applied. The choice of λ to deal with the trade-off between sparseness and intelligibility, and thus to maximize the performance of the whole algorithm, is a substantial challenge.
The proposed algorithm is evaluated in eight-talker babble noise with both objective measures and experimental listening tests, using specific λ values to assess the effect of λ on the algorithm output. The article is organized as follows: First, the sparse NMF algorithm is presented after a short introduction to NMF. The ACE strategy and how the proposed sparse NMF strategy is embedded are described. Second, the objective evaluation methods and subjective tests for both NH and CI subjects are described. Subsequently, the evaluation results are provided. Finally, a discussion and the conclusions are presented.
Algorithm
NMF is a method to factorize a nonnegative matrix

Principle of Sparse NMF in Envelope Domain
In our application,
Problem formulation
Let


The sparseness constraint λ in equation (1) is an important parameter that handles the compromise between the NMF approximation and the sparsity. One goal of the current study is to choose λ to maximize the performance of the algorithm, assessed in objective evaluation and subjective psychophysical experiments in the following sections.
Algorithm description
As proposed by Hoyer (2002, 2004), an iterative algorithm is implemented to minimize the cost function in equation (1), in which the basis matrix Initialize basis matrix Iterate until convergence:
Rescale each column of
The variable μ is the step size, a small positive constant, which should be set appropriately to achieve reasonable optimization time and good resolution in obtaining the optimal values of
Sparse NMF Strategy for CIs
The suggested sparse NMF strategy was integrated with a research ACE strategy which served as a comparison framework. It was implemented in the Nucleus MATLAB Toolbox (NMT) v4.20 (Cochlear Technology, 2002; Swanson, 2008). NMT is a set of MATLAB scripts provided by Cochlear Limited and allows researchers to derive or modify speech processing strategies either at the speech processing strategy level or at a lower level to create sequences of electrode stimulation patterns and programmatically stream the patterns directly to Nucleus devices or simulators.
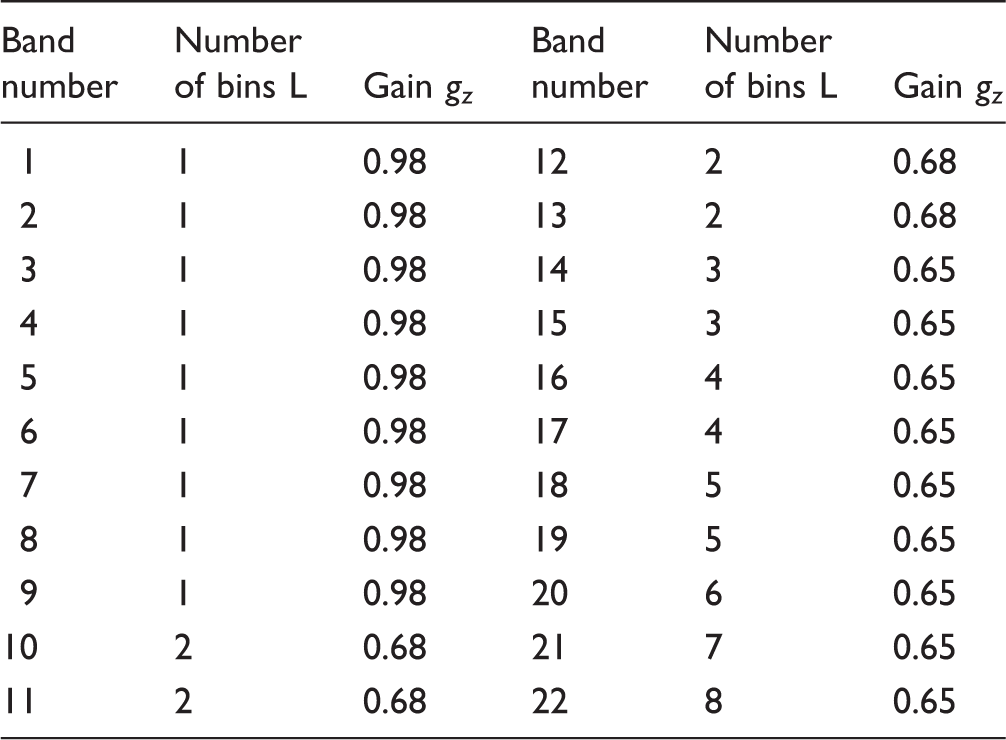
Figure 1a illustrates a basic block diagram of the research ACE strategy. Flowcharts of the ACE strategy and the proposed sparse NMF strategy: (a) illustrates the research ACE strategy, (b) shows the flowchart of the proposed sparse NMF algorithm and how it is integrated with the research ACE strategy. Number of FFT Bins and Weightings 

In the channel selection block, a subset of envelopes with the largest amplitudes is selected for stimulation. In the vocoder simulation block, the noise vocoder in the NMT is used for the generation of the vocoded speech. The extracted envelopes from 22 channels after the maxima selection process are used to modulate pink noise signals, which have been band-pass filtered by fourth-order Butterworth filters corresponding to the analysis channels. Finally, all the modulated channels are summed to produce the vocoded stimuli (Dorman, Loizou, Spahr, & Maloff, 2002; Swanson, 2008). Although the simulations cannot model individual CI users’ performance perfectly, it has been shown that these simulations are still useful tools for evaluation new algorithms in their initial stages (Loizou, 2006).
In the CI stimulation block, the electrical stimulation pulses are modulated by the envelopes of the signals in the corresponding frequency bands. In addition, the pulse trains are separated in time and interleaved in order to minimize electrical interaction among the electrodes.
Figure 1b shows the flow chart of the proposed sparse NMF algorithm using a modified ACE strategy framework. The new modules are highlighted by the dashed frame of Figure 1b. The sparse NMF algorithm is applied to the envelopogram on a block-by-block basis by buffering a certain number of continuous frames in each channel. The envelopes are reconstructed from the modified sparse NMF components. The same maxima selection process as used in the research ACE strategy is applied on the reconstructed envelopogram after sparse NMF processing.
Each column of Example sounds (Din, Tin) in the time and envelope domains: (a) waveforms of the words with x-axis is time in samples with a sample rate of 16 kHz (b) envelopogram of the corresponding words with x-axis and y-axis being time in frames and channel number, respectively. Decomposition and reconstruction by sparse NMF of the envelopogram of the words “Din” and “Tin”: (a) component matrices Reconstruction of sparse NMF envelopograms in babble noise. The bottom left and bottom middle panels are waveform and envelopogram of noisy speech “Bin” (SNR = 5 dB). The top left and top middle panels are the corresponding subplots of the clean speech. The top right and bottom right panels are the reconstructed noisy envelopograms for (a) Optimum λ values as a function of the SNR. The brown dotted curve shows the optimum values obtained from NCM of vocoded speech using sparse NMF strategy. The blue curve shows a fitted exponential decay function. (b) Optimum λ values and two alternatives, one for a higher sparseness constraint and one for a lower sparseness constraint.
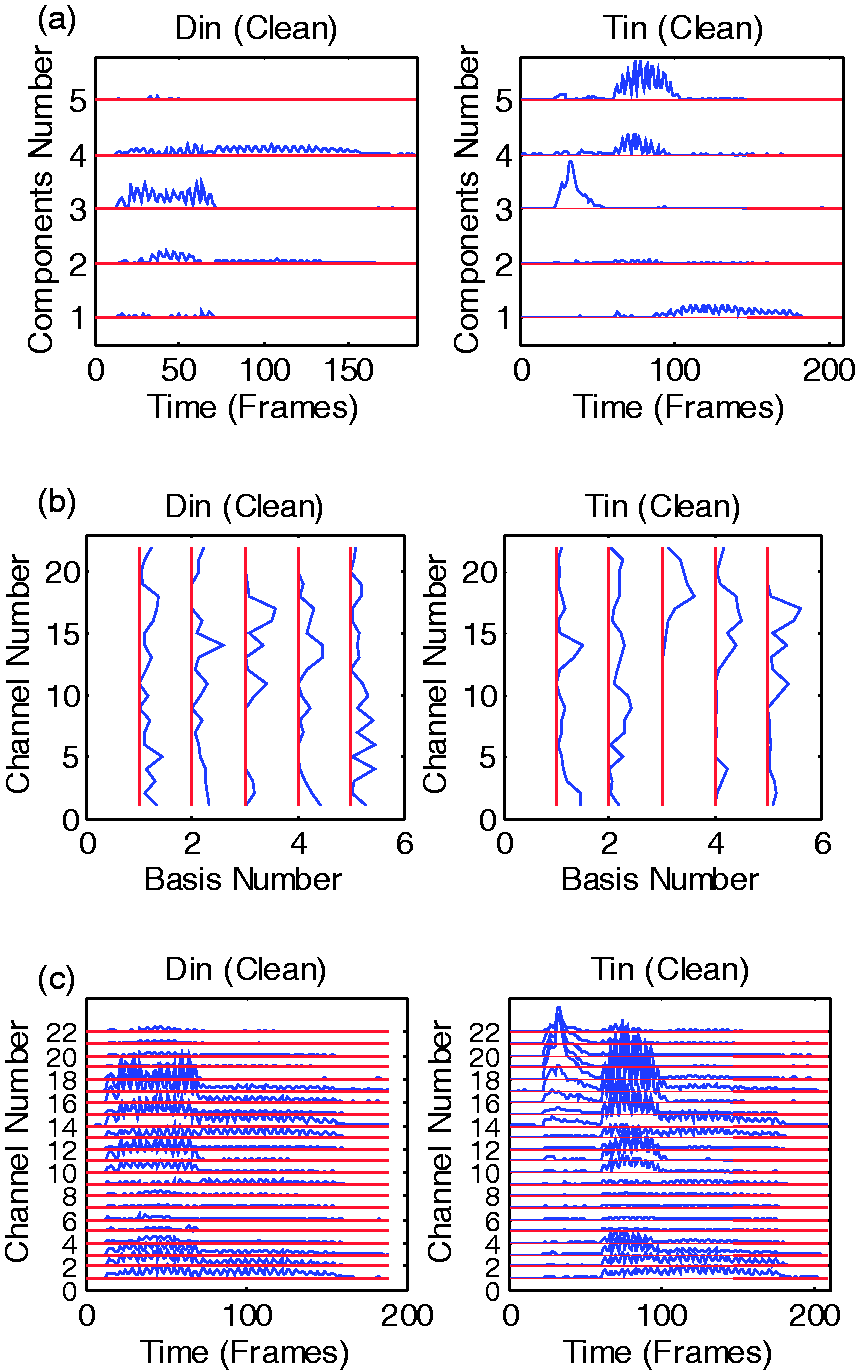


To visualize the NMF decomposition of the envelopogram of both clean and noisy speech signals, monosyllabic words taken from Foster and Haggard (1979) as used in Lutman and Clark (1986) were assessed. The block length was the length (L in samples) of the corresponding word. The total short-time frame number for each individual word is
Figure 3 shows the decomposition and reconstruction of the envelopogram with
For noisy signals, it can be assumed that the factorization of the envelopogram into the basis and component matrices yields some components that mainly correspond to the speech source while others are mainly produced by the noise source. The application of sparse NMF can be interpreted by assuming either that the smaller NMF components correspond to the noise basis vectors, or they do not contribute significantly to the intelligibility of speech. By normalizing each basis vector to unit norm and by applying different sparseness constraint λ to the factorization, the small NMF components will be removed and hence a more sparse signal will be obtained while effectively performing noise reduction and reducing redundancy. The sparseness of the reconstructed signal can be controlled via tuning λ.
Figure 4 shows simulation results of the application of NMF on the envelopogram of the word “Bin” in noisy situations for two sparsity levels (
Methods
Three experiments were designed to evaluate the proposed sparse NMF algorithm with a specific λ and to compare the results with the research ACE strategy. To mimic a more realistic (and more difficult) scenario, eight-talker babble noise instead of Gaussian noise was used in this study. In Experiment I, a wide range of values for λ was selected for objective evaluation in order to narrow down the λ range for the subjective listening tests with NH and CI subjects. In Experiment II, speech reception thresholds (SRT) were assessed (Hu et al., 2012) in NH subjects. Noise vocoder simulated signals produced with the NMT software (shown in Figure 1) were used in Experiments I and II. In Experiment III, CI subjects were recruited to evaluate the proposed algorithm.
Experiments for both NH and CI subjects were performed at the Institute of Sound and Vibration Research, Southampton, and were approved by National Health Service ethics committee (ref 09/H0504/116) and Institute of Sound and Vibration Research Human Experimentation Safety and Ethics Committee (ref 2346).
Experiment I: Objective Measures
Objective measures were applied to assess the effect of λ on the algorithm output as a preselection stage. A wide range of λ values between 0.01 and 0.2, with a step size of 0.01 was used. The objective measures aimed to evaluate the sparsity and to predict speech intelligibility. As applied by Li (2008), kurtosis was used to assess sparsity. Since it is unclear which objective evaluation method better predicts speech perception for vocoded speech, a two-step parameter selection procedure was developed based on Hu et al. (2012), where the results of the objective measures were used to set a smaller range of λ for a further SRT (Plomp & Mimpen, 1979) experiment for NH listeners. Results from Hu et al. (2012) showed that both the normalized covariance metric (NCM) and short-time objective intelligibility (STOI) could predict the performance of intelligibility for noise vocoded speech in some instances. This finding is consistent with Chen and Loizou’s (2011) study, where it was demonstrated that the coherence-based and speech transmission index-based measures are good tools for modeling the intelligibility of vocoded speech. Therefore, kurtosis, NCM, and STOI were all used here to explore the possible effect of λ on the speech perception prior to the subjective listening tests.
Speech material
Bamford-Kowal-Bench (BKB) sentences (Bench, Kowal, & Bamford, 1979) were used. BKB sentence lists are standard British speech materials with 21 lists. Each list contains 50 keywords in 16 sentences. Eight-talker babble noise was added to the speech material at three different long-term SNRs (0, 5, and 10 dB). The noise vocoder as described in Figure 1 was applied to the whole sentence corpus, on their output envelopes either from the ACE strategy (baseline condition) or from the sparse NMF strategy.
Kurtosis
Kurtosis based on equation (2) was used as a measure of sparseness (Li, 2008):

Normalized Covariance Metric
The NCM measure was used as one of the objective measures for speech intelligibility. NCM is similar to speech transmission index (Steeneken & Houtgast, 1980), which is based on the covariance between the input and output envelope signals. It is expected to correlate highly with the intelligibility of vocoded speech due to similarities in the NCM calculation and CI processing strategies: Both use information extracted from the envelopes in a number of frequency bands while discarding fine-structure information (Chen & Loizou, 2010; Goldsworthy & Greenberg, 2004). For computing the NCM value, the stimulus was first band-pass filtered into
Short Time Objective Intelligibility
The STOI is based on a correlation coefficient between the temporal envelopes of the clean and the degraded speech in short-time overlapping segments (Taal, Hendriks, Heusdens, & Jensen, 2011). The input of STOI is the clean and the processed signal in the time domain, and the output is a scalar value which has a monotonic relation with the average intelligibility of the processed signal (Taal et al., 2011). In our case, since vocoded speech signals were the test materials for NH subjects, the first input is the vocoded NMF processed signal and the second is the corresponding vocoded ACE clean speech.
Experiment II: SRTs for NH Subjects
In this experiment, NH subjects were recruited to evaluate the sparse NMF strategies in different combinations of SNR and λ values.
Subjects
A total of 10 NH subjects (with NH thresholds between
Speech material
The NH Subjective Experiment Conditions.

Equipment and procedures
All experiments were performed in a sound-isolated room with diotic sounds presented through Sennheiser HDA 200 headphones using a Creek OBH-21SE headphone amplifier. The vocoded BKB sentence lists of a female speaker were used. A two-up one-down adaptive procedure was used to find the SNR required for 70.7% correct recognition in each condition. The speech presentation level was fixed, while the SNR was varied adaptively with a 1-dB step size by changing the noise level (Dahlquist, Lutman, Wood, & Leijon, 2005). The sentence list was randomized for each participant. A sentence was classified to be correctly identified when at least two keywords were correctly repeated. The participants were trained for a few minutes with noise vocoded clean BKB sentences to become familiar with the test procedure.
Experiment III: Word Identification Tests for CI Subjects
In this experiment, CI subjects were recruited to evaluate the sparse NMF strategies in babble noise with different combinations of SNR and λ values.
Subjects
A total of 10 participants were recruited from the University of Southampton Auditory Implant Service database. Two (one male, one female, aged 65 and 55) underwent the pilot experiments for fine-tuning of the experimental setup and parameters, and the other eight (two males, six females, aged between 30 to 87 years) took part in Experiment III formal tests. Only the data from these eight participants are included and analyzed in the results. All of them were native English speakers and unilaterally implanted (four left sided, four right sided) with a Nucleus 24 CI. The hearing threshold levels of their unimplanted ears were at least 90 dB (as established by pure tone audiometry between 500 Hz and 8 kHz). They all had been implanted for more than 1 year (ranged 3–12 years) and had BKB sentence scores in quiet
Speech material
Considering that the participants might have experienced the BKB sentences previously as a part of their CI assessment and rehabilitation process and to avoid learning effects, an alternative sentence set known as IHR sentence lists (Faulkner, 1998) was used in these experiments. Again, eight-talker babble noise was used as masker. Both the IHR database and BKB database have the same structure and same talker; they contain a similar level of complexity in both vocabulary and syntax. Eighteen sentence lists were used, each containing 15 sentences, with 3 keywords each. One sentence list was used for each condition. The sentence list used in each condition was randomized across participants. BKB sentences were used for practice.
Sparsity parameter λ
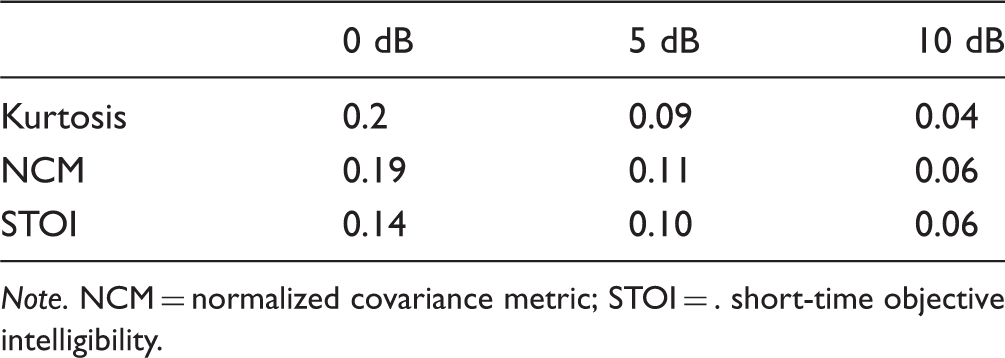
Because of large individual differences in speech perception performance in quiet among CI users, the same sparsity level might not be appropriate for different CI users. Thus, three different sparsity levels were generated in the CI experiments. First, the “optimal” λ values were obtained in the same way as in Experiment I (Figure 6). According to the results of Experiment I, the λ values obtained with the NCM and the STOI at 5 dB SNR (Table 4) are similar; they are equally good in predicting the speech recognition performance of the NH participants in Experiment II (Figure 7). Since NCM gives a larger optimal λ at Kurtosis, NCM, and STOI of vocoded speech reconstructed from different strategies at three SNRs: 0, 5, and 10 dB. Top left panel: Kurtosis. Bottom left panel: NCM. Bottom right panel: STOI. Red dash-dotted line: SNR = 0 dB from ACE. Green dashed line: SNR = 5 dB from ACE. Black dotted line: SNR = 10 dB from ACE. The corresponding marked curves are from sparse NMF (“□,” “o,” “+”). In the top left panel, the brown solid line is the kurtosis of vocoded clean speech using ACE; the values marked with blue dots are those with the same kurtosis as observed for clean vocoded speech of ACE. In the bottom panels, the blue dots indicate the maximum values of each objective measure under different SNR conditions. SRTs of the 10 NH participants for ACE and the 3 NMF strategies with different sparsity levels. (a) Individual SRTs of the 10 NH participants (S1–S10). The category is the participant index and the vertical axis shows the SRT in dB. (b) Boxplot of the results (median, inter-quartile ranges, and overall range). Here, the category axis indicates the algorithms (ACE, NMF008, NMF010, and NMF013).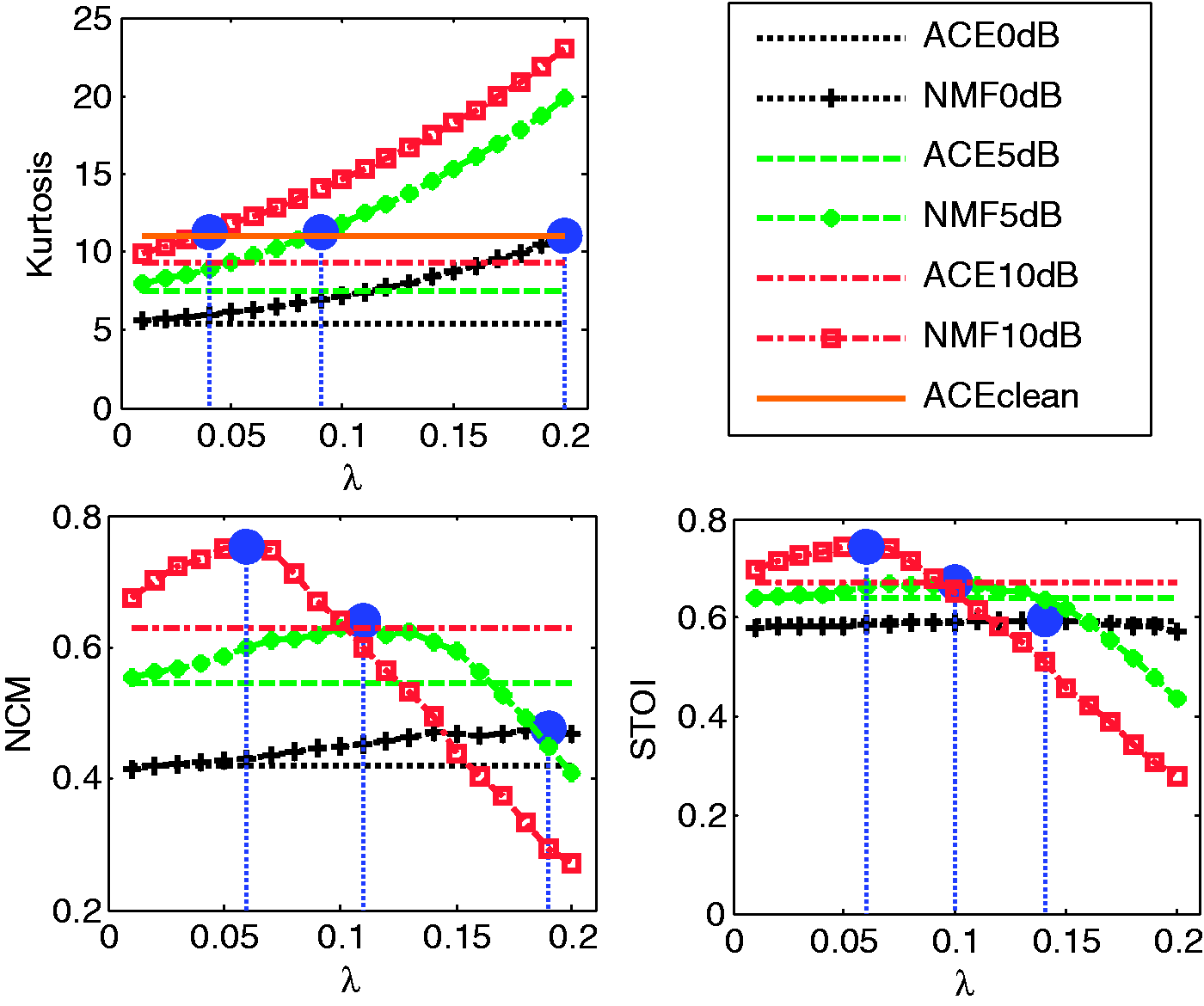
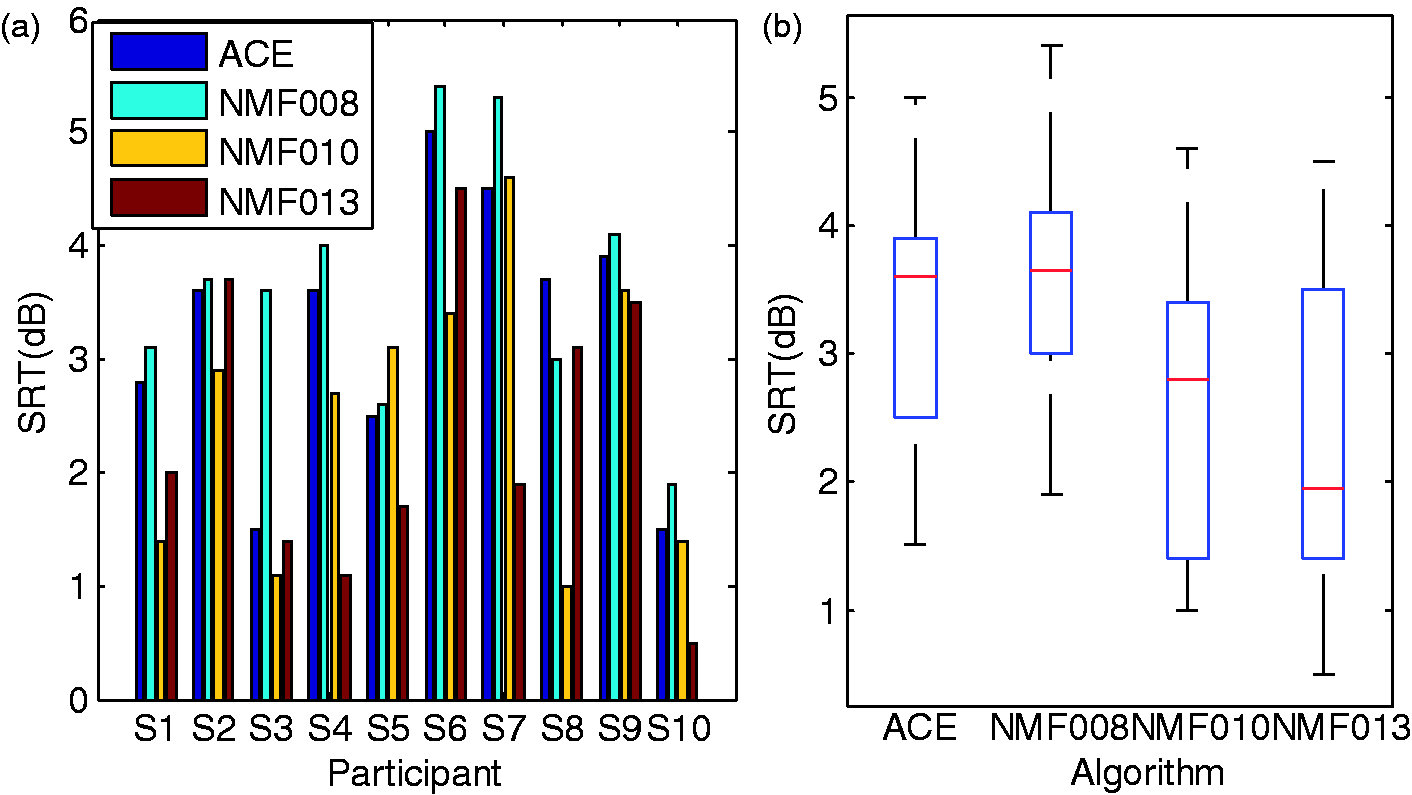
Figure 5a shows λ for different conditions obtained from NCM. The SNR was in the range from 
The Sparsity λ Used in the CI Experiments for Each Condition.

Note. SNR = signal-to-noise ratio; NCM = normalized covariance metric.
The Optimal λ of Different Conditions.
Note. NCM = normalized covariance metric; STOI = . short-time objective intelligibility.
Equipment and procedure
The Nucleus Implant Communicator (NIC) software (provided by Cochlear Corporation) was used to communicate with the Nucleus implant and to send stimulus sequences to the implanted electrodes through a research processor (L34) via the standard hardware. The NIC is a set of software modules and libraries associated with NMT, which allows encoding of the envelopogram to stimuli sequences of electrode stimulation and programmatically streaming these sequences to the L34 processor (Swanson, 2008). The L34 processor acts as hardware for communicating between the PC and the Nucleus implant and controlling transmission of radio frequency pulses to the subject’s implant. All stimulus sequence files were generated individually according to existing individual CI map settings and saved for each participant and each condition offline.
All experiments were performed in a sound proof room. During the experiment, participants were asked to repeat whatever they recognized after each presented sentence, and the correctly identified keywords were recorded by the experimenter. A percentage keywords correct rate (KCR) was then calculated and stored at the end of each condition. Participants were offered breaks after each condition or when they experienced any fatigue during the experiment. The duration of the break was determined by the participant. Five BKB practice sentences from each condition at 15 dB SNR were presented before the formal experiments to get used to the new stimulation pattern. This familiarization lasted around a minute, and it thus cannot be assumed that participants were fully acclimatized to the new sounds. The order of presentation of all the 16 conditions was randomized. Total testing time varied between participants between 1 and 2 hours.
Results
Results of Experiment I
Figure 6 shows the kurtosis, NCM, and the STOI outputs of the speech processed by the ACE strategy and the sparse NMF strategies with a range of λ at three SNRs (0, 5, and 10 dB). The x-axis represents λ and the y-axis shows the corresponding objective measure output value. Each value is the average across all
The top left panel in Figure 6 shows the kurtosis values of clean and noisy conditions at three SNRs, respectively. The average kurtosis values of the vocoded ACE noisy speech signals (
The bottom left and right panels in Figure 6 show the NCM and the STOI values of the clean and noisy conditions. The NCM and the STOI values of the ACE processed noisy speech signals (
According to Table 4, the λ obtained with the NCM and the STOI at 5 dB SNR are 0.11 and 0.1, respectively. They are very similar to each other and also close to λ (0.09) obtained from kurtosis analysis, where the NMF processed vocoded speech has a similar kurtosis as that of the clean ACE vocoded speech. But for 0 dB SNR, NCM-based optimal λ (0.19) is closer to the kurtosis (0.2). Overall, the optimized λ for
Results of Experiment II
Figure 7a shows the individual SRT of the 10 NH participants in four conditions (indicated by different colors). The results show large individual performance differences. Figure 7b shows the results as a box plot (median, inter-quartile ranges and overall range). On average, there was a 0.74 dB improvement for NMF010 and a 0.92 dB improvement for NMF013 compared with the ACE strategy. A one-way repeated measures ANOVA shows a significant effect of strategy,
In summary, the proposed algorithm with individually selected λ can outperform ACE for NH subjects listening to noise-vocoded speech. Objective measures at 5 dB SNR predicted a λ range between 0.08 and 0.13. This is in line with the results from the NH test. According to the NH data, λ can be slightly larger than 0.13, but this needs to be further evaluated in future, for example, by testing
Results of Experiment III
Figure 8a shows the results of the KCR speech of the eight CI participants for ACE, NMFlow, NMFncm, and NMFhigh (indicated by the different colors). The four subpanels in Figure 8a are the results for the four different SNR conditions 0, 5, 10, and 15 dB. The results show large variability between subjects, demonstrating that individual participants do not benefit equally from all NMF conditions; for different SNRs, a different NMF condition might be optimal for each participant. Figure 8b shows the boxplot of the KCR results for the different algorithms. Figure 8c shows the individual KCR improvement for the different algorithms compared with ACE averaged over all SNRs and Figure 8d shows the corresponding boxplot of the KCR improvement for the different algorithms compared with ACE averaged over all SNRs and participants.
Keyword correct rate (KCR) results for the CI participants: (a) Individual KCR for the eight participants with the different coding strategies (indicated by the colors) at the four SNRs (sub panels); (b) boxplot of KCR for the four coding strategies at the different SNRs in the same style as in (a). (c) KCR improvement for the three NMF coding strategies compared with ACE averaged over all SNRs. (d) boxplot of KCR improvement compared with ACE averaged over all SNRs and participants.
It appears that the CI users who show worst performance with ACE may benefit most. In fact, Participant 4 (who benefits least) is a top performing CI user (using ACE) at SNRs of 5 dB and above, while Participant 3 (who benefits most) has the lowest speech recognition score in 15 dB SNR and was so impressed with the sound quality that he asked if he could have our experimental coding strategy as his standard setting.
However, due to the variability of the individual results and the small number of participants, the overall effect of coding strategy is not statistically significant: a two-way repeated-measures ANOVA showed no significant effect of strategy,
Assuming CI users were allowed to choose the optimal coding strategy among the three NMF options and ACE in the fitting practice based on their performance, only Participant 4 would use ACE instead of NMFncm. In total, seven out of eight participants performed better with at least one of the NMF strategies than with the ACE strategy. However, it should be noted that such a result could occur by chance if all algorithms perform similarly, given that there are three NMF alternatives.
Although there is no significant effect of coding strategy, there is still a trend and reduced variability in the data, at least at the highest SNR (15 dB). While for ACE, there is considerable spread in the speech perception performance with a range of 40% to 93% (see Figure 8a), for NMFncm, all subjects perform in the range 80% to 100% with little spread and are on average 11 percentage points better than for ACE. Accordingly, the improvement of NMFncm over ACE may be largest for the participants with lowest ACE performance.
Discussion and Conclusions
A novel CI coding strategy has been proposed in which sparse NMF is applied to the envelopes of CI channels in order to improve the performance of CI users in noisy environments. Babble noise was used in both objective and subjective speech intelligibility assessments. Subjective listening experiments with 10 NH listeners and noise vocoder CI simulation demonstrated that the proposed sparse NMF strategy could significantly outperform the existing ACE strategy when using appropriate sparsity constraints. The objective measures of vocoded speech imply that an SNR-dependent sparsity constraint λ might produce better results.
The proposed sparse NMF algorithm also showed improved speech recognition performance for seven out of eight CI users in babble noise with at least one of the NMF strategies. However, the individual optimum NMF strategy varied strongly across subjects, and there was no significant improvement for any of the three NMF settings over ACE. As a trend, the highest KCR improvement averaged across all eight participants of 11 percentage points was observed for the NCM λ constraint at the highest SNR of 15 dB, with all subjects showing a speech perception performance in the range 80% to 100%. Note that this was the case, although there was minimal familiarization with the stimulus. The improvements are smaller at lower SNR, but we expect that acclimatization may lead to further improvement. This needs to be shown in a future study. It has been shown that listeners need acclimatization periods on the order of days if not weeks to get the full benefit of any new strategy. Our listeners had been listening to ACE for years, but had virtually no exposure to the new stimulation, which also changed every few minutes due to randomization of conditions.
The current trend of improved speech perception in near-quiet (+15 dB SNR) indicates that NMF might be suited to overcome the CI-auditory-nerve bottleneck by selecting crucial speech information. But there are large individual performance variations; possible reasons might be differences in the number of surviving spiral ganglion cells, variable brain plasticity, and ability to adapt to the coding strategy among participants. The smaller improvements in the noisy situations, however, indicate that the power of the proposed NMF strategy as noise reduction might be limited to higher SNRs. Therefore, further improvements might be achieved by combining NMF with noise reduction algorithms like beamforming or by developing more intelligent NMF component selection techniques instead of pure energy-based methods.
The power of the experiment including all participants was low (
Although there was no statistically significant improvement for any of the NMF conditions over ACE, nevertheless a particular sparseness condition (supported by the trend for improvement with NMFncm in the current data) might be best for each participant. If future results support this trend, for clinical applications, such an optimal coding strategy might have to be selected by comparing speech reception scores in quiet for the different NMF strategies and ACE.
Overall, the study shows that the NMF algorithm may have the potential to confer better real-world speech recognition performance for at least some CI users. It might be preferable to optimize the trade-off between the sparseness and reconstruction for each individual CI user in the future, perhaps under user control. This approach needs to be evaluated with more CI subjects using a real-time sparse coding system (Hu et al., 2013), which would allow individual parameter tuning, daily acoustic scenario training over prolonged periods, and online speech testing for CI subjects in real time.
Footnotes
Acknowledgments
The authors would like to thank Professor Arne Leijon, Nasser Mohammadiha, and Jalil Taghia for their collaboration on part of the work during the first author’s visit in Sound and Image Processing Lab, KTH, Stockholm, Sweden. They would also like to thank Prof Bastiaan Kleijn, Victoria University of Wellington, New Zealand, for the original suggestion to explore using NMF. We further appreciate the valuable comments and suggestions by the anonymous reviewers and by the editor Andrew Oxenham. The authors thank Cochlear Europe for providing the NMT software and NIC streaming application. They are very grateful to Frances Pedley and Falk-Martin Hoffmann for collecting some of the data and to their subjects for participating in these experiments.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the European Framework 7 project Digital Signal Processing in Audiology (PITNGA- 2008-214699) and Cochlear Europe. It is currently partly supported by EU FP7 under the Advanced Bilateral Cochlear Implant Technology (ABCIT: grant No. 304912) and DFG SFB TRR 31.