
Abstract
Bilateral cochlear-implant (BiCI) users are less accurate at localizing free-field (FF) sound sources than normal-hearing (NH) listeners. This performance gap is not well understood but is likely due to a combination of compromises in acoustic signal representation by the two independent speech processors and neural degradation of auditory pathways associated with a patient’s hearing loss. To exclusively investigate the effect of CI speech encoding on horizontal-plane sound localization, the present study measured sound localization performance in NH subjects listening to vocoder processed and nonvocoded virtual acoustic space (VAS) stimuli. Various aspects of BiCI stimulation such as independently functioning devices, variable across-ear channel selection, and pulsatile stimulation were simulated using uncorrelated noise (Nu), correlated noise (N0), or Gaussian-enveloped tone (GET) carriers during vocoder processing. Additionally, FF sound localization in BiCI users was measured in the same testing environment for comparison. Distinct response patterns across azimuthal locations were evident for both listener groups and were analyzed using a multilevel regression analysis. Simulated implant speech encoding, regardless of carrier, was detrimental to NH localization and the GET vocoder best simulated BiCI FF performance in NH listeners. Overall, the detrimental effect of vocoder processing on NH performance suggests that sound localization deficits may persist even for BiCI patients who have minimal neural degradation associated with their hearing loss and indicates that CI speech encoding plays a significant role in the sound localization deficits experienced by BiCI users.
Introduction
Cochlear implants (CIs) are used at increasing rates to provide hearing to individuals with severe-to-profound hearing loss. Many patients receive bilateral cochlear implants (BiCIs) in an effort to improve spatial hearing abilities, such as sound localization and speech understanding in noisy environments, relative to the single-CI listening mode. Numerous free-field (FF) studies have established that compared with unilateral CI use, bilateral CIs improve sound localization accuracy along the horizontal plane (Grantham, Ashmead, Ricketts, Labadie, & Haynes, 2007; Litovsky, Parkinson, & Arcaroli, 2009; Majdak, Goupell, & Laback, 2011; Nopp, Schleich, & D’Haese, 2004; Seeber, Baumann, & Fastl, 2004; Van Hoesel, 2004; Seeber & Fastl, 2008). For example, Litovsky et al. (2009) reported that root mean square (RMS) errors along the horizontal plane for 17 postlingually deafened adult BiCI users were overall 30° lower for bilateral implant use compared with unilateral use. Other studies have also shown similar effect sizes. Despite the added benefit of having two implants, BiCI users still demonstrate large deficits in spatial hearing performance compared with normal-hearing (NH) listeners (Grantham et al., 2007; Litovsky, 2011; Litovsky et al., 2012). For example, Grantham et al. (2007) reported that overall errors for adult BiCI users were on average 29° compared with the 7.6° observed for NH listeners, demonstrating that bilateral stimulation alone does not restore sound localization abilities.
Such a gap in localization performance could arise from a number of fundamental differences between NH listeners and BiCI users; however, investigating possible sources for these localization deficits has been complicated by the variability in performance across BiCI patients due to numerous factors. Variable periods of auditory deprivation can result in differing amounts of neural degeneration (Coco et al., 2007; Leake, Hradek, & Snyder, 1999), and human temporal bones studies have demonstrated that the extent of auditory nerve survival can vary significantly among cochleae (Hinojosa & Marion, 1983; Nadol, Young, & Glynn, 1989; Otte, Schunknecht, & Kerr, 1978). For BiCI patients, such issues are further complicated by the likelihood of asymmetrical neural degeneration between the two ears, as many patients may undergo hearing loss at different rates between the two ears. Despite extensive research on horizontal-plane sound localization in BiCI users, little is known about the relative contributions of degraded neural circuitry.
Another important factor is the manner in which acoustic signals are encoded and presented to the implanted patient’s auditory system. The work presented here focuses on exploring possible ways in which degraded auditory signal representation may account for differences in performance between NH listeners and BiCI users. It is generally thought that certain acoustical cues necessary for sound localization are not adequately provided to BiCI users. For example, asymmetries in microphone characteristics (Van Hoesel, Ramsden, & Odriscoll, 2002), variable electrode insertion depths (Kan, Stoelb, Litovsky, & Goupell, 2013), uncoordinated stimulation between the bilateral devices (Laback, Pok, Baumgartner, Deutsch, & Schmid, 2004; Seeber et al., 2004; Seeber & Fastl, 2008), and spread of electrical current across adjacent electrodes (Fu & Nogaki, 2005; Landsberger, Padilla, & Srinivasan, 2012; Van Hoesel & Tyler, 2003) could all affect acoustical cue presentation to the auditory system. In NH listeners, sound localization along the horizontal plane requires the binaural processing of acoustical cues. These cues include interaural time differences (ITD) in the acoustic temporal fine structure (TFS) of low frequencies (<1.5 kHz), interaural level difference (ILD) at high frequencies, and ITDs in the slowly varying amplitude modulations of the acoustic envelopes (ENVs). In general, ITDs in the low-frequency TFS have been shown to be the dominant cue (Blauert, 1997; Macpherson & Middlebrooks, 2002; Middlebrooks & Green, 1991; Wightman & Kistler, 1989).
Previous FF studies in BiCI users have demonstrated that these listeners predominantly use ILDs with limited use of ITD information (Laback, Pok, et al., 2004; Litovsky et al., 2009, Litovsky, Jones, Agrawal, & van Hoesel, 2010; Seeber & Fastl, 2008; Van Hoesel, 2008). These results are not surprising because CI signal processing discards acoustic TFS and encodes the acoustic ENVs. However, studies using research processors that bypass the clinical CI speech processors and deliver tightly controlled binaural cues via coordinated stimulation have shown that many BiCI users exhibit sensitivity to ILDs, as well as ITDs presented at low pulse rates (Litovsky et al., 2010, 2012; Van Hoesel, 2007; Van Hoesel, Jones, & Litovsky, 2009). It is noteworthy that ITD sensitivity in BiCI users is generally worse than that seen in NH listeners (see Litovsky et al., 2010, 2012). Many BiCI users also exhibit sensitivity to ITDs contained in the ENVs of high-rate stimuli that are amplitude modulated at low rates (Laback, Pok, et al., 2004; Seeber & Fastl, 2008; Van Hoesel & Tyler, 2003; Van Hoesel et al., 2009), and sensitivity is often comparable to that seen with ITDs in low-rate stimuli (Majdak, Laback, & Baumgartner, 2006; Van Hoesel, 2007; Van Hoesel et al., 2009). For modulated signals such as speech, ITDs extracted from the ENVs of the high-rate stimulation could be potentially useful for BiCI sound localization (Loizou, 1999; Wilson & Dorman, 2008). The aforementioned studies have identified similarities between BiCI and NH listeners, as well as gaps in performance under ideal conditions in which binaural cues are presented with precision. However, in a clinical setting when patients listen in the FF with their processors, the technical features listed earlier are not taken into consideration.
Simulations using vocoders can be powerful in that some effects of CI processing can be evaluated in the healthy auditory system of NH listeners while bypassing subject-dependent factors associated with hearing loss and cochlear implantation (Dorman, Loizou, Fitzke, & Tu, 1998; Dorman, Loizou, & Rainey, 1997; Goupell, Majdak, & Laback, 2010; Qin & Oxenham, 2003; Shannon, Zeng, Kamath, Wygonski, & Ekelid, 1995; Wilson et al., 1991). Another advantage of using vocoders with NH listeners is the reduced across-subject variability, in contrast to the ubiquitous high variability in CI users. Vocoders simulate CI speech encoding by processing acoustic signals in a similar manner as clinical speech processors. Present day CI speech encoding strategies filter incoming acoustic signals into a small number of discrete frequency bands (typically 12–22 channels between 150 Hz and 8 kHz) corresponding to the number of electrode contacts used by the particular device. The acoustic ENV within each channel is extracted and transmitted via high-rate electrical pulse stimulation on electrode contacts spaced along the tonotopically organized cochlea, while the TFS of the signal is discarded (Loizou, 1999). In traditional vocoders, the ENVs of the acoustic signals extracted from the frequency bands can be used to modulate narrowband noise or sine tone carriers, to stimulate specific places along the cochlea. Recently, Gaussian-enveloped tone (GET) carriers have also been used to simulate CI sound processing (Goupell et al., 2010; Goupell, Stoelb, Kan, & Litovsky, 2013).
In GET vocoders, a Gaussian-shaped temporal envelope modulates a sine tone to generate a brief acoustic pulse that is replicated and delayed to create a pulse train. As GET pulses excite a larger frequency spectrum compared with a sine tone (van Schijndel, Houtgast, & Festen, 1999), the GET vocoder simulates in some ways the spread of electrical current along the basilar membrane, in addition to presenting pulsatile stimulation. Noise (Bingabr, Espinoza-Varas, & Loizou, 2008; Fu and Nogaki, 2005) and sine (Crew, Galvin, & Fu, 2012) vocoders can also simulate current spread and have been commonly used to probe acoustic features necessary for speech reception in various listening environments (Dorman & Loizou, 1997; Dorman, Loizou, & Fitzke, 1998; Qin & Oxenham, 2003); however, the GET vocoder has been argued to better simulate the electrical stimulation in clinical CI devices (Goupell et al., 2010, 2013). A recent study comparing lateralization of ITDs and ILDs showed that NH subjects listening to GET pulse trains performed similarly to BiCI subjects (Kan et al., 2013). Additionally, Goupell et al. (2010) used GET vocoders to process VAS stimuli and showed that localization performance along the median plane in NH listeners deteriorated with decreased number of channels. Results using the GET stimulation also suggested that current CI encoding strategies should have a sufficient number of channels for vertical-plane sound localization capabilities. To date, the effect of CI speech encoding on sound localization abilities along the horizontal plane in NH listeners has not been previously tested.
The present study created a realistic BiCI simulation in NH listeners by combining virtual acoustic space (VAS) and vocoder techniques, and then directly compared this NH performance with that tested in BiCI users in the same FF testing environment. We measured head-related transfer functions (HRTFs) for each NH subject, and individualized VAS speech stimuli were created for localization testing to ensure comparable localization performance in the control condition. Each subject’s VAS stimuli were then processed using either a noise or GET vocoder, and localization performance was measured. The baseline data from this work have the potential to lead to investigations of the numerous additional factors that might affect BiCI sound localization, such as electrode mismatch and spread of current (see Fu & Nogaki, 2005; Kan et al., 2013) while circumventing the confounding variable degrees of neural degradation associated with BiCI users.
Methods
Participants
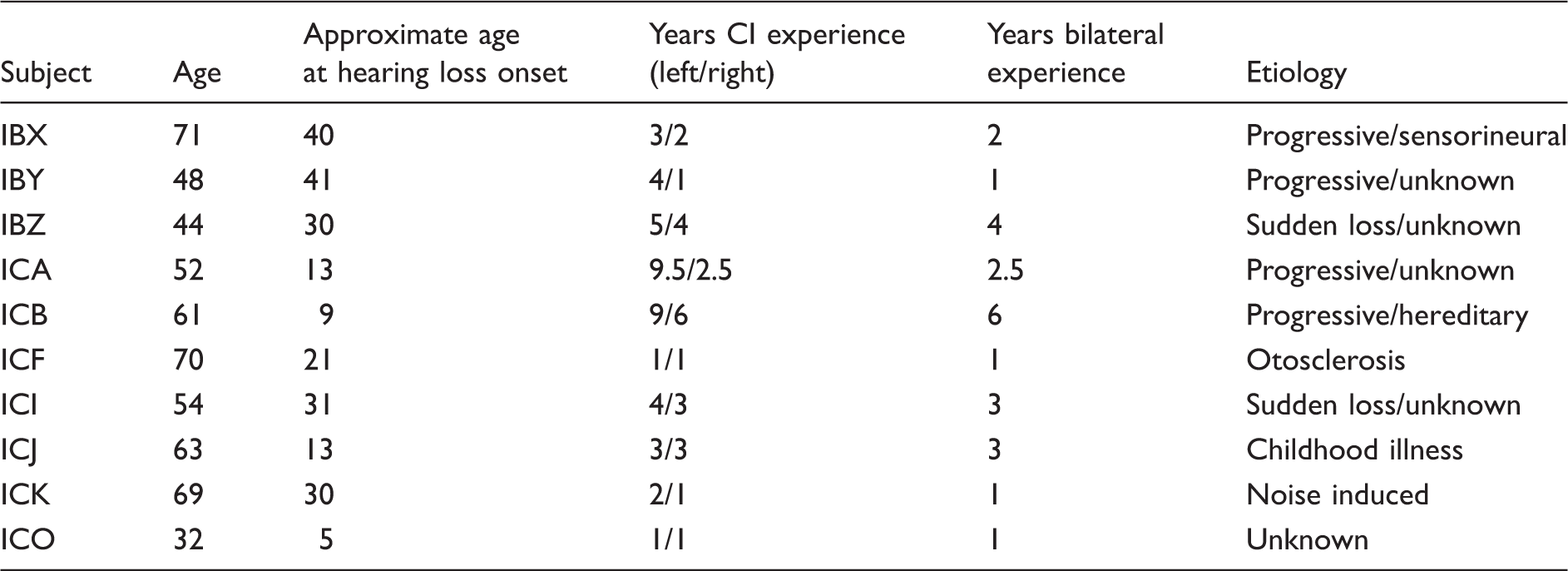
Profile and Etiology of BiCI Subjects.
Equipment
Measurement of HRTFs and behavioral sound localization testing were conducted in the same sound booth. The booth had internal dimensions of 2.90 × 2.74 × 2.44 m (IAC, RS 254 S), and additional sound-absorbing foam was attached to the inside walls to reduce reflections. A Tucker-Davis Technologies (TDT) System 3 was used to select and drive an array of 19 loudspeakers (Cambridge SoundWorks) arranged on a semicircular arc of 1.2 m radius. Loudspeakers were positioned in 10° increments along the horizontal plane between ± 90° and were hidden behind a dark, acoustically transparent curtain. Subjects sat in the center of the array with their ears at the same height as the loudspeakers. For FF localization testing, stimuli were calibrated to output at 60-dB sound pressure level (SPL) using a digital precision sound level meter (System 824, Larson Davis; Depew, NY) placed at the center of the arc where the subject’s head would be positioned. The VAS stimuli were presented via in-ear headphones (ER-2, Etyomtic Research) using the TDT System 3 with a 48-kHz sampling rate and were calibrated so that the perceived output level of the headphones matched that of the FF presentations. Headphone calibrations were made using the sound level meter and an artificial ear coupler (2-cc coupler, G.R.A.S.; Larson Davis, Depew, New York). All stimulus presentations and data acquisition were done using custom MATLAB software (Mathworks, Inc., Natick, MA). All analyses were carried out using R software version 3.0.2.
HRTF Measurements
For each NH subject, individual HRTF measurements were made for the 19 loudspeaker locations, using a blocked-ear technique (Møller, 1992). Subjects were asked to face the front (i.e., speaker position 0°) and to remain stationary during each stimulus presentation. Golay codes (200 ms long, five repetitions) were used as probe signals for HRTF recordings, and the in-ear responses were recorded by a blocked-meatus microphone pair (HeadZap binaural microphones, AuSim, Mountain View, CA) placed in the entrance of each ear canal. Microphone output signals were amplified (MP-1, Sound Devices) and recorded using a TDT RP2.1 at 48 kHz. Traditionally, HRTFs are defined with reference to the sound pressure in the middle of the head with the listener absent (Møller, 1992). To obtain an HRTF for a particular source location, the microphone recordings at the ears can be divided by the response measured with only the microphone at the location in the center of the loudspeaker array. This effectively removes the loudspeaker frequency characteristics in HRTFs. However, in this experiment, the loudspeaker characteristics were not removed from the digital filters used to synthesize the VAS stimuli because we were interested in preserving these characteristics for a direct comparison of FF localization performance to headphone presentations. Thus, the loudspeaker frequency characteristics were not removed from the HRTFs.
It should also be noted that the HRTF recording procedures used in the current study may not be representative of the BiCI condition for most patients, as the majority of CI processors use microphones that are placed behind the ear. However, the aim of the present study was to exclusively investigate the effect of CI speech encoding on NH sound localization. As such, the HRTF measurements made with microphones placed in the ears ensured that individual-specific acoustical cues for each subject were intact prior to vocoder processing. Additionally, the acoustical cues captured by microphones in the ear should be natural for NH listeners, so no adaptation to these cues or training was required for the VAS stimuli.
Stimuli
Nonvocoded stimuli
NH listeners were tested with stimuli consisting of 10 monosyllabic consonant-nucleus-consonant (CNC) words spoken by a male talker. Each speech token (beam, cape, car, choose, chore, ditch, dodge, goose, knife, and merge) was filtered by the HRTF measurements to create VAS stimuli for each spatial location. These stimuli provided a control condition for comparison to performance measured with the vocoded stimuli. To make comparisons of sound localization performance between nonvocoded and vocoded stimuli, test stimuli were low-pass filtered to match the bandwidth of the vocoder. A fourth-order Butterworth filter with an 8-kHz cutoff frequency was applied to the original speech stimuli prior to HRTF-filtering for VAS presentation. Subjects confirmed that the perceived loudness of the VAS stimuli presented through the headphones matched the loudness of FF stimuli presented from the loudspeaker array. For the BiCI listeners, FF sound localization performance was measured using four bursts of pink noise each with a 10-ms rise–fall time and 170 ms in duration. These stimuli and parameters were chosen to optimize the FF localization performance in the BiCI listeners (Litovsky et al., 2009; Van Hoesel & Tyler, 2003).
Vocoded stimuli
Frequency Allocation for the Vocoder Channels Used in This Study.

The carriers used in this experiment were chosen to simulate different aspects of cochlear implant stimulation. The NHN0 and NHNu stimuli were intended to simulate the presence and absence of coordinated binaural stimulation, respectively, while preserving level and envelope cues imposed by the HRTF filtering of the stimuli. Wideband noise carriers were generated independently for each channel, and prior to envelope modulation, were band-pass filtered with the same analysis filters described earlier. For the NHN0 stimuli, the same noise carrier was used for both ears. For the NHNu stimuli, different noise carriers were used for each ear. The NHGET pulse trains were used to simulate CI electrical stimulation. A 100-Hz GET pulse train centered at each of the center frequencies in Table 2 was generated in a manner similar to that described in Goupell et al., (2010), where the bandwidth of the Gaussian pulse was equal to the bandwidth of the corresponding band-pass filter. The left and right signal envelopes were used to modulate the GET pulse train. It should be noted that the same GET pulse train was used to carry the left and right signal envelopes, which means the timing of the envelope and TFS of the GET pulses were synchronized between the left and right ears before modulation with the speech envelope. Hence, the left and right ear signals varied only by the envelope cues extracted from the VAS stimuli.
Testing Procedure
Listeners sat on a chair in the center of the loudspeaker array and were asked to remain still with their gaze fixated on a visual marker at 0° during all stimulus presentations. Localization stimuli were presented from either the loudspeaker array (FF) or through headphones (VAS and vocoded conditions) at 60 dB SPL. Additionally, ± 4 dB level roving was applied to the stimuli prior to presentation to minimize the use of monaural level cues. Spectral roving was also applied to the pink noise stimuli by dividing the energy spectrum of stimulus into 50 critical bands and assigning a random intensity ( ± 10 dB) to each band (Wightman & Kistler, 1989). Listeners were aware of the azimuthal range of loudspeakers (−90° to 90°) and that sounds were presented only from frontal source locations within this range; however, the loudspeakers remained hidden behind an acoustically transparent curtain. Each condition was presented twice as a separate block of 95 trials (5 stimulus presentations × 19 locations), each typically lasting ∼20 min. The CNC words were randomly presented once from each of the target locations. Sound localization testing was conducted in three 2-hr sessions.
Trials were self-initiated by pressing a button on a touch screen monitor placed in front of the subject and positioned such that it had a minimal effect on the acoustic stimuli. Following stimulus presentation, a graphical user interface (GUI) with an image of an arc representing the arc of loudspeakers was displayed on the touch screen monitor. Subjects indicated their response by placing a digital marker anywhere on the arc image corresponding to the perceived sound source location. To facilitate perceptual correspondence between the spatial locations in the room and the arc image on the touch screen, visual markers were placed at 45° increments both along the curtain in the room and on the GUI.
Results
For comparisons with previous BiCI FF studies, sound localization performance was evaluated by computing the overall RMS error for all 190 trials per condition. Assuming a uniform distribution of random responses (i.e., guessing), chance performance was calculated to be 75.6° within the full range of responses and 39.7° for responses that were within the correct left or right hemisphere. The VAS techniques employed here were validated by comparing NHFF and NHVAS performance. The average RMS error was slightly smaller for the FF condition than the VAS condition (NHFF: 8.2 ± 1.9°; NHVAS: 11.2 ± 1.7°); this is consistent with previous findings that localization of FF sounds is generally better than for virtual sounds (Middlebrooks, 1999). Additionally, the average RMS error for the NHVAS condition here was comparable to the average lateral RMS error (12.4 ± 2.2°) recently reported for NH subjects listening to VAS stimuli (Majdak et al., 2011). These findings indicate that the VAS techniques reported here provided an adequate representation of FF stimulus presentation.
Figure 1 shows the across-subject average RMS error (bar, mean) and standard deviation (error bars, ± SD) for NH subjects in the four conditions tested as well as the BiCI subjects. There was a clear increase in the average RMS error between the NHVAS (11.2 ± 1.7°) and the three vocoded conditions, NHNu (36.4 ± 6.0°), NHN0 (40.6 ± 11.0°), and NHGET (34.2 ± 7.7°). A one-way, repeated-measures analysis of variance (ANOVA) of the RMS errors measured for the NH subjects on the four listening conditions showed a significant main effect, F(3, 9) = 89.62, p < .001. Scheffe’s post hoc analyses revealed significant differences between the VAS and all the vocoder conditions (p < .05), indicating that vocoder processing of VAS stimuli significantly increased localization errors. However, there were no significant differences between the three vocoder conditions. For BiCI subjects, the average RMS error, BiCIFF (27.9 ± 12.3°), was consistent with previously reported data (Grantham et al., 2007; Litovsky et al., 2009). Independent samples t tests were conducted to test for differences in RMS errors between each of the NH conditions and the BiCIFF data. Pairwise test with Bonferroni correction revealed that the RMS errors in the BiCIFF condition were significantly larger than the NHVAS condition, t(18) = −10.693, p < .001. Additionally, the NHNu and NHN0 conditions had significantly larger RMS errors than the BiCIFF condition—NHNu: t(18) = 3.561, p = .002; NHN0: t(18) = 3.378, p = .003. The comparison between BiCIFF and NHGET approached significance but was non-significant following the p-value adjustments for multiple comparisons, t(18) = 2.232, p = .039. Thus, the BiCI subjects performed worse than the NH listeners listening to VAS stimuli. However, BiCI subjects generally outperformed NH listeners, following vocoder processing of the VAS stimuli.
Summary of localization performance. The average RMS error (bars, mean) and standard deviation (error bars, ±SD) for NH and BiCI subjects are plotted. The asterisk indicates statistically significant results for comparison of the average RMS across subjects for each listening condition and post hoc analysis (see text for details).
Although the group analysis revealed no difference in RMS errors between the vocoder conditions, we wanted to explore whether differences in response distributions and localization error patterns across target locations existed. For this analysis, localization errors were calculated as the absolute difference between target and response angles. The absolute error measure better represents localization accuracy, that is, the systematic error as measured by the bias, whereas the RMS error measure better represents localization precision, that is, the error variability across all locations (Majdak et al., 2011). The average absolute errors for the NH subjects were VAS (9.4 ± 2.3°), VCNu (28.4 ± 4.6°), VCN0 (31.3 ± 8.2°), and VCGET (27.0 ± 6.4°). For BiCI subjects, the average absolute error (21.4 ± 3.6°) was consistent with the absolute lateral error (19.3 ± 2.3°) recently reported for BiCI users listening to VAS stimuli (Majdak et al., 2011). To observe target location effects, the average absolute error (bar, mean) and standard error (error bars, ± SE) as a function of target angle is plotted in Figure 2(a) for each condition. Additionally, subject responses were binned into 10° increments, and counts were average across subjects for each target location (Figure 2(b), mean and ± SE). Varying patterns in the average RMS errors and response distributions across target locations were observed for the different listening condition. For example, the VCN0 condition on average resulted in small RMS errors at target location 0° and large errors for target locations ± 90° (Figure 2(a), VCN0 panel). However, the lower RMS errors seem to be a result of more target sounds being heard from the front locations (Figure 2(b), VCN0 panel). Given that distinct patterns were observed for the different vocoder conditions, we wanted to investigate whether any of the vocoders produced a similar localization error pattern as those measured in the BiCI users.
Absolute localization error and response distribution across target angles. (a) The across-subject average absolute difference between target and response angles (bars, mean) and standard deviation (error bars, ± SD) for each target location. (b) The average binned responses for each target angle across subjects, with responses placed in the nearest 10 bin.
To compare localization performance patterns between NH and BiCI listeners, a multilevel regression analysis (Mirman, 2014) was used to model and analyze the data. The pattern of errors (Figure 2(a)) and distribution of responses (Figure 2(b)) across target locations for each condition exhibited a rough symmetry moving from the central to lateral target locations on either side. Due to this observation, the absolute localization errors were collapsed as a function of target deviance from the center speaker (0°), that is, the absolute target angle. Figure 3 plots the absolute error as a function of absolute target angle (mean and ± SE) for all NH and BiCI localization data. These patterns of error across azimuth were modeled with third-order orthogonal polynomials (i.e., linear, quadratic, and cubic components) and fixed effects of listening condition (i.e., interactions on the intercept component) on all absolute target terms. The FF BiCI errors are plotted on the far left, and the model fit of the BiCIFF data are also plotted in each panel (Figure 3, solid red line). The model fit of the BiCIFF data were treated as the baseline model for comparison and parameters were then estimated for the vocoder conditions (see Table 3 for detailed information).
Observed data and multilevel regression model fits for effect of listening condition on absolute error across azimuthal locations. For each listening condition (panels), the across-subject average absolute error (point, mean) and standard error (error bars, ± SE) are plotted as a function of the absolute target angle with the solid line representing the model fit. The BiCIFF model fit was treated as the reference and is plotted (thin line) on each of the panels displaying the NH listening conditions for visual comparison. Parameter Estimates for Analysis of Listening Condition Effects on Localization Error Patterns Across Azimuth. Note. The baseline model of the BiCIFF localization data was used as a reference for comparison to the model fits of the data collected for the different vocoder conditions. p < .05. **p < .01. ***p < .001.
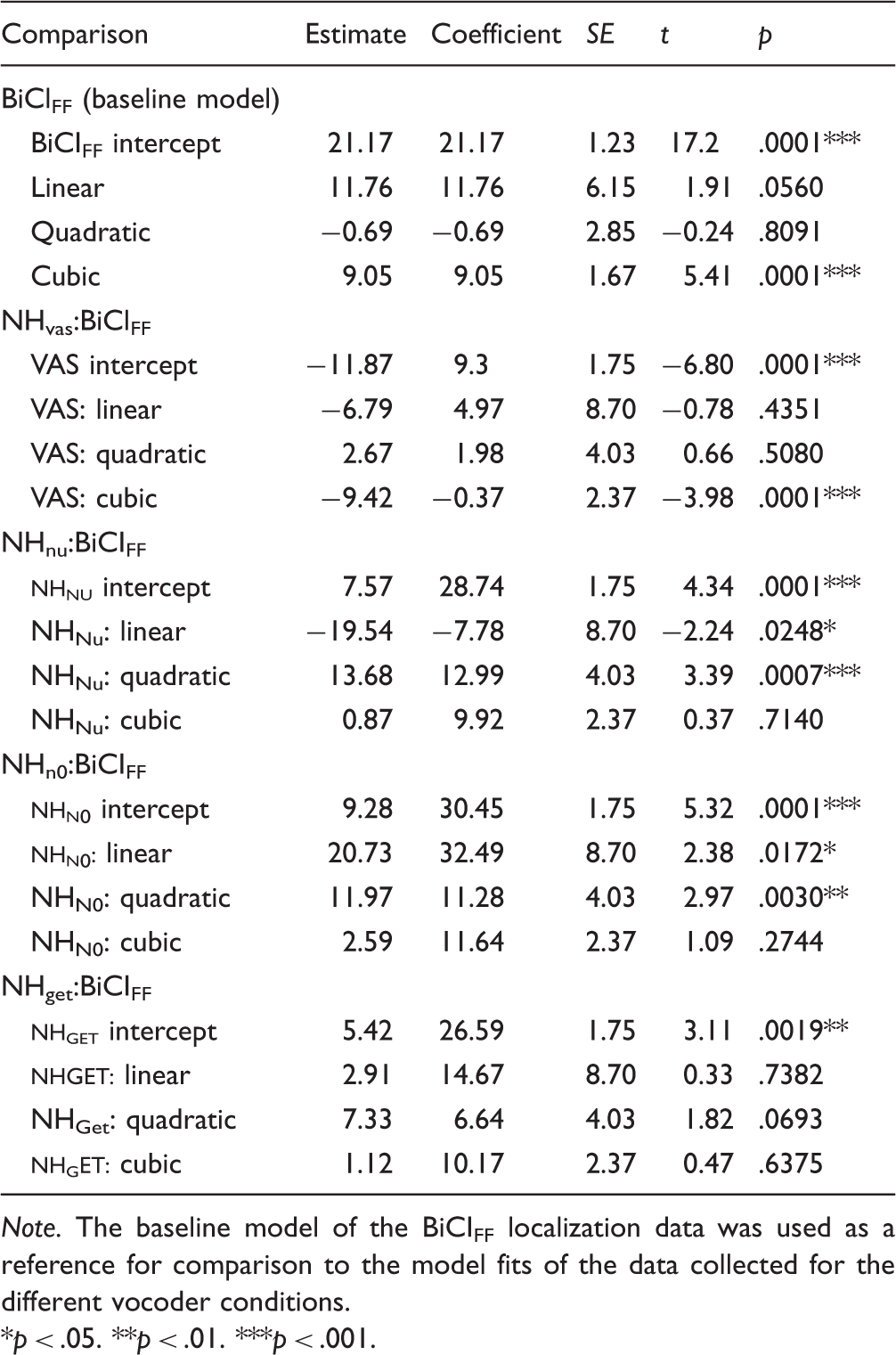
For statistical analysis using orthogonal polynomials, the intercept component corresponds to the overall average of the measure of interest (Mirman, 2014), which in this study was the absolute error. First, there was a significant effect of the BiCIFF condition on the intercept component, indicating that this condition resulted in an absolute error (21.17°) that was significantly different from an absolute error of 0°(see Table 3). Next, the intercept components were compared across conditions. Conceptually, this is roughly like a t test comparing the tested conditions to the baseline model (Mirman, 2014). For example, the average absolute error for the NHVAS condition was 11.87° less than the BiCIFF condition, which was found to be significant, and the average absolute error for the NHNu condition was 7.57° greater than the BiCIFF condition, which was also significant (see Table 3). All the NH listening conditions resulted in significant intercept effects, which indicate that the average absolute error for the NH conditions was significantly different than the BiCIFF condition. That is, the average absolute localization error in BiCI users was significantly higher than the NHVAS condition and significantly lower than all three of the NH vocoder conditions.
The first-order polynomial is the linear component and describes the slope of the relationship between absolute target and absolute error. There were significant linear effects for all of the vocoder conditions, except for the NHNu condition, meaning that as the absolute target angle increased, the absolute error increased. The NHN0 condition had a significantly larger linear effect compared with the BiCIFF model, as can be observed in the steeper slope (Figure 3, NHN0 panel). The linear components of the NHVAS and NHGET fits were not significantly different than the linear component of the BiCIFF fit (see Table 3, Condition:Linear for statistical summary).
Apart from the differences in slope, there were differences in the degree of curvature which were captured by the second-order polynomial. This is the quadratic component and describes the degree of slope change (i.e., single inflection) in the data. The quadratic components of the NHNu and NHN0 conditions were significantly different than those from the BiCIFF data. The NHVAS, NHGET, and BiCIFF conditions were similar in that they all lacked a significant quadratic effect (see Table 3, Condition:Quadratic for statistical summary).
One of the more interesting findings of this study was that the BiCI and vocoder conditions exhibited an additional inflection that was not observed in the NHVAS model. This is captured by the cubic component (i.e., third-order polynomial) and indicates the degree of a second inflection in a curve. Specifically, the cubic component describes the dip in the response curve around the 60° target angle, which did not emerge in the NHVAS condition (Figure 3, NHVAS panel compared with all other panels). This indicates that the error rates proximal to 60° were smaller for both NH listeners (vocoded conditions) and BiCI users. Overall, the main finding of the multilevel regression analysis was that the NHGET condition produced localization performance that was most similar to that measured in BiCI users.
Interestingly, there was noticeable intersubject variability with regard to how NH subjects performed on the same vocoder conditions. To illustrate the various patterns of response distributions observed for different subjects, we show the NHGET condition, which was found to be most comparable to BiCIFF performance (see earlier). Figure 4 compares individual localization data for six BiCI subjects (Figure 4(a) to (c)) and six NH subjects (Figure 4(d) to (f)). The overall RMS error for each condition is shown inside each plot (see bottom right), where smaller values indicate better localization performance. Qualitatively, responses falling on the positive sloping diagonal are indicative of accurate localization. For visual comparison between NHGET and BiCIFF response distributions, response histograms are plotted on the right of each figure. Data from these subjects were chosen to depict the variability observed in performance across NH subjects for the vocoded stimuli (see NHGET, Figure 4(b)) that coincided with the variability observed in BiCIFF response distributions. Similar response distributions are plotted in each column. For example, the two BiCI subjects (Figure 4(a)) and the two NH subjects (Figure 4(b)) in the first column distributed responses to more central locations. The center column (Figure 4(b) and (e)) shows subjects whose majority of responses were grouped around spatial locations on either side. The column on the far right (Figure 4(c) and (f)) shows distribution patterns in which the majority of responses grouped into three spatial locations (i.e., left, center, and right). The similar variability in response distributions for both NH subjects listening to NHGET stimuli and for BiCI subjects listening in the FF suggest that individuals distribute responses differently given degraded auditory input whether the signal is acoustically degraded or presented via electrical stimulation.
Localization data and response distributions. Responses were binned to the nearest 10° and data point size reflects the number of responses within each bin (bottom left). The number at the bottom right corner of each plot is the RMS error. The small bar graphs next to each localization plot display a histogram of responses binned to the nearest 10°. (a–c) Localization data measured in BiCI users who responses varied by grouping around different spatial location. (d–f) Localization data in NH subjects who exhibited similar patterns of response distributions listening to VCGET stimuli as the BiCI users in the column above them.
Discussion
The experiments reported here tested the ability of NH listeners to localize VAS stimuli that were processed through noise and GET vocoders for sounds varying in location along the horizontal plane. The present study demonstrates that NH localization performance along the horizontal plane can be degraded to levels observed in BiCI patients using a combination of VAS and vocoder techniques. The results showed that sound localization performance was significantly worse for all vocoded stimuli compared with virtual FF stimuli (Figure 1); thus, a detrimental effect on NH performance occurs with vocoders and degrades performance of individuals with healthy auditory systems to similar levels of horizontal-plane localization observed in BiCI users. In particular, the GET vocoder provided the best simulation of BiCI FF performance across the population of NH subjects tested here (Figure 3). An additional interesting finding is that NH listeners exhibited a similar range of intersubject variability and error patterns as was observed in BiCI subjects (Figure 4). These observations suggest that human listeners vary in how they process and localize degraded auditory inputs, regardless of whether the cause of degradation in the signal is due to the signal processing imposed on acoustic signals or due to the numerous factors that impact signals when they are provided electrically. Although both BiCI listeners and NH subjects listening to the vocoded stimuli exhibited variable response distributions, there was an observable inflection point around the ±60° in the average error patterns across locations for each of these groups (Figure 3). This inflection can also be observed in the lower errors (Figure 2(a)) and the increase in responses for these locations (Figure 2(b)), such that we speculate listeners may be responding to these locations when they are unsure of the exact source location but are confident that the sound originated from a location somewhere in that particular hemifield.
Localization performance measured here for the BiCI subjects was comparable to previously reported BiCI data (Grantham et al., 2007; Grieco-Calub & Litovsky, 2010; Litovsky et al., 2009; Majdak et al., 2011; Nopp et al., 2004). Grantham et al. (2007) reported an average overall error of 29.1 ± 7.6° for 22 BiCI users localizing speech stimuli. Similarly, Litovsky et al. (2009) reported overall localization errors of 28.4 ± 12.5° for 17 postlingually deafened BiCI users. More recently, localization of virtual sound sources has been reported for five BiCI users with an average precision error of 23.4 ± 2.3° for noise stimuli roved at a similar level ( ± 5 dB) to our study (Majdak et al., 2011). The average across-subject RMS error and response variability measured in BiCI subjects in the present study (27.9 ± 12.3°) is consistent with these previous findings. Interestingly, despite all the disadvantages that BiCI users face (i.e., independently functioning devices, reduced spectral information, current spread, electrode mismatch, varying etiologies, and amounts of neural degeneration), the average RMS for these listeners was lower than the NH average RMS for all three vocoder conditions. One possible reason for these lower RMS errors could be the stimuli used to test BiCI localization. The pink noise stimuli may have provided additional directional information, and were repeated four times, providing multiple looks. Another reason for the lower overall RMS error in BiCI users may be because these listeners had more experience with degraded auditory input, as all the BiCI subjects had a minimum of 1 year of listening experience with their CIs, whereas NH subjects were tested acutely. Goupell, et al. (2010) demonstrated that NH localization along the median plane while listening to GET-vocoded VAS stimuli significantly improved with training, although the performance was not as accurate as listening to unprocessed stimuli. Thus, it is reasonable to hypothesize that with more experience, the NH subjects in this study could possibly exhibit performance that would be similar to the overall RMS errors measured in the BiCI subjects.
The large increase in overall localization errors for NH subjects listening to vocoded stimuli occurred whether the original signal’s acoustic TFS was replaced with uncorrelated (NHNu), correlated (NHN0), or synchronized-pulsatile (NHGET) stimulation. Replacing the acoustic TFS during CI speech encoding creates binaural stimulation in which the TFS-ITDs that are presented to the auditory system do not correspond with the ILDs presented, and results in conflicting acoustical cues (i.e., each cue points to a different location). Studies show that when presenting the NH auditory system with conflicting ITD and ILD cues via VAS techniques, both the neural representation of these cues (Delgutte, Joris, Litovsky, & Yin, 1999; Slee & Young, 2011; Sterbing, Hartung, & Hoffmann, 2003) and localization performance (Macpherson & Middlebrooks, 2002; Middlebrooks, 1999; Middlebrooks, Macpherson, & Onsan, 2000; Wightman & Kistler, 1992) become altered compared with when the cues are consistent with how they are naturally experienced. In the present study for instance, the acoustic carriers in the vocoder stimuli would still activate the neural circuitry responsible for extracting ITDs; however, as they do not contain the acoustically appropriate ITD information, a neural representation of inconsistent ITD/ILD cues is more than likely to be encoded. In fact, binaural interference may occur in which the acoustically inappropriate low-frequency ITDs would dominate an individual’s perceived lateral position (Best, Gallun, Carlile, & Shinn-Cunningham, 2007; Best, Laback, & Majdak, 2011) and may be responsible for the inaccurate localization observed in both BiCI users and NH subjects listening to vocoded stimuli. Although auditory deprivation has been shown to result in degraded sound localization (Noble, Byrne, & Lepage, 1994), the extent to which degraded neural circuitry in BiCI users is responsible for poor localization has not been previously studied. Because we observed similar localization deficits in individuals with intact auditory systems listening to BiCI simulations (Figure 4), we posit that horizontal-plane localization deficits are attributable to the signal processing in CIs more so than the compromised auditory systems of BiCI users.
The experimental approaches reported here aimed to simulate the effects of various aspects CI speech encoding and bilateral stimulation on horizontal-plane sound localization. One issue may be that the independent signal processing, variable channel selection, and high-rate electrical stimulation introduces interaural decorrelation into the signals presented to the auditory system, in addition to impeding the ability to deliver ITD information (Seeber & Fastl, 2008). A likely consequence is that the spectrotemporal representations of acoustic signals are not being presented at the two ears with a high amount of binaural coherence. Several studies in NH listeners have reported that a reduction in the interaural correlation is perceived by the listener as a broadening of the sound image (Bernstein & Trahiotis, 1992; Durlach, Gabriel, Colburn, & Trahiotis, 1986; Gabriel & Colburn, 1981; Goupell & Hartmann, 2006; Jeffress, Blodgett, & Deatherage, 1962). The NHNu stimuli in the present study simulated this potential reduction in interaural correlation due to independent signal processing and variable channel selection. Additionally, the NHN0 stimuli tested whether localization could be improved by creating of a more punctuate sound image via the temporal synchronization of the spectrally random carriers across the ears.
Comparing the performance between the two noise-vocoded conditions (Figure 3, NHNu and NHN0 panels), the NHNu stimuli resulted in extremely poor localization across all azimuthal locations. In contrast, localization of the NHN0 stimuli was biased toward the speaker location at 0° (Figure 2(a) and (b)) and rapidly decreased at more lateral positions. The NHNu data are in agreement with previous psychoacoustical studies, which have demonstrated that as the signal correlation between the ears decreases, the perceived sound image becomes more diffused and lateralization abilities deteriorate (Bernstein & Trahiotis, 1997; Goupell & Hartmann, 2006; Goupell & Litovsky, 2013; Jeffress et al., 1962; Trahiotis, Bernstein, Stern, & Buell, 2005). In addition to this, neural ITD encoding of broadband signals, such as speech, depends critically on a high amount of binaural coherence in the spectrotemporal features of the acoustic signals (Egnor, 2001; Saberi et al., 1998). Saberi et al. (1998) investigated the effects of binaural decorrelation on neural spatial coding and behavioral responses to spatial cues in the barn owl. Localization performance in barn owls for noise burst containing ITDs (and no ILDs) rapidly deteriorated as the interaural correlation of the signals presented was decreased (Saberi et al., 1998). Furthermore, responses of ITD sensitive neurons in the owl’s optic tectum declined rapidly as interaural decorrelation increased, thus these neurons exhibited less ITD tuning to the decorrelated stimuli. Similar findings have been shown in human cortical imaging studies (Zimmer & Macaluso, 2005, 2009). Zimmer and Macaluso (2005) found that activity in Heshl’s gyrus increased with increasing interaural correlation of white noise stimuli and that posterior auditory regions also showed increased activity for the high coherence stimuli, primarily when sound localization was being performed. Thus, the lack of interaural correlation in the NHNu stimuli may explain why these stimuli were difficult to localize.
For the NHN0 stimuli, although the signals were completely correlated between the ears, the dominant low-frequency TFS-ITD cues contained in each of the stimuli across all spatial locations pointed to the center. Thus, the pattern of errors (Figure 3, NHN0 panel) for this condition, that is, the higher degree of errors for more lateral locations, can be explained because subjects on average perceived the sound image to be coming from more central locations (Figure 2(b)). In the studies mentioned earlier (Egnor, 2001; Saberi et al., 1998; Zimmer & Macaluso, 2005, 2009), ITDs were applied to stimuli with various degrees of correlation between completely uncorrelated (Nu) and correlated (N0) noise tokens. Here, we were also able to investigate whether applying individualized HRTF filtering (i.e., containing all the natural acoustical cues) and physiologically meaningful temporal envelopes (i.e., speech) to the Nu and N0 noise carriers could produce accurate sound localization. Previous studies have investigated the contribution of envelope ITDs cues to intracranial lateralization in NH listeners (Bernstein & Trahiotis, 1996, 2002; Dietz, Ewert, & Hohmann, 2009, 2011; Laback, Zimmermann, Majdak, Baumgartner, & Pok, 2011). However, Dietz et al., (2011) also reported that auditory model predictions of localization accuracy based solely on envelope modulations were worse than the predictions based on fine structure. Our data are in agreement with this study, demonstrating that ITD cues in the envelopes of FF speech stimuli are not sufficient in moving the NHN0 sound image across the spatial locations.
The GET vocoder was used to simulate the electrical pulse trains delivered during CI stimulation. Similar techniques to those reported here have been used previously to test sound localization in the median plane (Goupell et al., 2010). Given the extensive literature on lateralization/discrimination of ITDs in amplitude-modulated stimuli (Bernstein & Trahiotis, 1985, 2002; Laback, Pok, et al., 2004; Laback, Zimmermann, et al., 2011; Seeber & Fastl, 2008; Van Hoesel et al., 2009), one could speculate that the temporal modulations of speech envelopes would provide an additional cue for sound localization in the horizontal plane. Although the ability of BiCI users to perform sound localization tasks based solely on envelope ITDs has not been investigated directly, their ability to discriminate and lateralize such stimuli has been studied (Ihlefeld, Kan, & Litovsky, 2014; Laback, Pok, et al., 2004, Laback, Zimmermann, et al., 2011; Van Hoesel et al., 2009). Laback, Pok, et al. (2004) showed that the best envelope ITD thresholds in BiCI users were on the order of 150 µs and that envelope ITDs could induce monotonic changes in the lateralization of the auditory image. It should also be noted that the ITD thresholds measured for click trains were significantly lower than for speech tokens. However, previous studies do not indicate that envelope ITD sensitivity will translate into accurate localization of FF sound sources.
Our study differs from previous amplitude-modulated ITDs studies in two ways. First, the listening task and spatial hearing assessments were different, as previous studies measured either ITD discrimination or intracranial lateralization of stimuli containing independent fine-structure and envelope-based temporal disparities. Second, prior studies used periodic carriers with periodic modulators and 100% modulation depths. For speech, however, signals are more complex with envelope modulations that are shallower and less temporally consistent relative to the modulators use in fixed-frequency stimuli. In addition, the filtering by HRTFs (i.e., the frequency-dependent ILDs) further affects the depths of the ongoing envelope temporal modulations between the ears. Reducing the depth of envelope modulations has been shown to result in poorer ITD thresholds (Bernstein & Trahiotis, 1996; Ihlefeld et al., 2014). Our findings lend support to this notion, as the temporal envelope cues available to the NH subjects listening to GET vocoder simulations did not appear to provide sufficient information to produce accurate sound localization (Figure 3, NHGET panel). However, the similar patterns in errors across azimuthal locations suggest that the NHGET stimuli produced the most comparable performance to BiCI localization in NH listeners.
The variability in performance observed for both BiCI and NH listeners (Figure 4) suggests that the localization strategies used by individuals are different, whether auditory signals are degraded acoustically or provided electrically. Recent studies involving sound source identification (i.e., ability of listeners to identify objects from the sound of impact) in quiet have shown that listeners regularly use different listening strategies that result in similar performance accuracy, but for different levels of variability in performance (Lutfi & Liu, 2007; Lutfi, Liu, & Stoelinga, 2011). The current study suggests a similar notion for sound localization of degraded auditory signals. For example, BiCI subjects ICF, ICO, and IBY (Figure 4(a) to (c)) had similar overall RMS error (∼ 25 – 26°), but very different response distributions. Although such intersubject variability is often attributable to the fact that these listeners used BiCIs for hearing, it was observed that NH listeners also exhibited similar variability when listening to vocoder processed stimuli. For instance, NH subjects STL and TAQ (Figure 4(d) and (e), respectively) had similar overall RMS errors (∼ 38 – 39°), but the errors were accounted for by very different error distributions. While subject STL responded to mostly central locations, TAQ distributed responses around left and right locations. Such observations indicate that the intersubject variability observed for BiCI users may not solely reflect factors that are often considered to be the root of localization errors, such as peripheral factors, but may be the result of individuals employing different strategies for making decisions about the location of a sound source when given degraded auditory input.
Conclusion
Simulated CI speech encoding resulted in large sound localization deficits in NH listeners, and overall errors were comparable with those measured in bilaterally implanted patients. Among the vocoders used to process free-field speech envelopes, the GET vocoder produced the most similar patterns of localization error across azimuth to those observed in BiCI users. Although these data were obtained with CI simulations, they nonetheless lend support to the notion that CI speech encoding in the present day bilateral listening mode contributes to sound localization difficulties in BiCI users. The crux of this finding assumes that the bilateral vocoder simulations described in this study approximate the interaural cues available to the binaural circuits of BiCI users; however, the integrity with which binaural cues are preserved at the level of binaural neural circuitry is currently unknown, and more than likely varies across patient and devices type. NH listeners exhibited a similar intersubject variability in error patterns to that observed in the BiCI users, suggesting that individuals employ different strategies when identifying a sound source location whether auditory signals are degraded acoustically or provided electrically. Future studies using the techniques presented here could efficiently investigate the potential success of novel sound encoding strategies aimed at improving spatial hearing abilities in bilaterally implanted patients.
Footnotes
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported by grants from the NIH-NIDCD (R01 DC003083 and R01 DC01049) and in part by a core grant from the NIH-NICHD to the Waisman Center (P30 HD03352).
Acknowledgements
We would like to thank all our listeners who participated in these experiments, Kyle Martel and Kate Landowski for all their help with data collection, and Amy Jones and Ann Todd for providing review and feedback on prior drafts of the manuscript. We would like to especially thank Dr. Matt Winn for providing assistance with coding the R software and his thoughtful discussions on data interpretation.