
Abstract
This study examines the development of the ChatGPT-4o model developed by OpenAI to solve university-level probability problems over 8 months. The study is a descriptive study based on the general screening model. Within the scope of the study, 38 probability problems with four different grades and different difficulty levels [easy, medium, and hard] were modeled, and the answers of ChatGPT-4o were evaluated in terms of accuracy and consistency of the process steps at 8-month intervals. The difference in success between the problem-solving measurements of ChatGPT-4o was not only statistically significant but also practically remarkable. The problem-solving skill of ChatGPT-4o exhibited a statistically significant performance increase at different difficulty levels over time. Furthermore, when all levels were considered collectively, the general success rate improved substantially. The findings reveal that the model significantly increased performance, especially in problems with conditional probability and union/intersection events. At the same time, improvements were observed in the model’s ability to present the solution process in a more explanatory and systematic way. The results reveal ChatGPT-4o’s potential for reasoning during problem-solving processes and demonstrate how this capability has evolved over time. Overall, the integration of ChatGPT-4o models into mathematics education may support students’ fundamental problem-solving skills and enable teachers to allocate classroom time to more complex tasks. However, the model’s limitations should not be overlooked. In this context, further comprehensive research is needed to examine the effects of artificial intelligence–based systems on instructional processes, ensuring their effective, reliable, and pedagogically appropriate integration into mathematics teaching.
Introduction
Nowadays, artificial intelligence (AI) is increasingly coming to the forefront with its potential to exert significant impacts across various disciplines, particularly in the field of education (Sposato, 2025). In the context of mathematics education, AI technologies bring with them various advantages, such as personalized teaching, interactive learning environments, and real-time feedback, but also important problems such as being misleading, weakening creative thinking and problem-solving skills, opacity of reasoning processes, algorithmic biases, lack of emotional intelligence, and data privacy and security (O. A. Opesemowo & Ndlovu, 2024). However, over the last year, ChatGPT-4o, a model developed by OpenAI, has emerged as an artificial intelligence tool that continuously improves its mathematical problem-solving skills and can provide more efficient solutions in new areas (O. A. G. Opesemowo et al., 2024).
The concept of “intelligence” in AI refers to a machine that can solve mathematical problems. This means that the machine can produce its own solution instead of having pre-coded solutions. Therefore, AI investigates methods that enable computers to acquire the thinking, learning, and self-development abilities that can be achieved by human intelligence, aiming to design machines that can solve problems considered difficult by humans (Noster et al., 2024). One of these purposes, mathematical thinking, involves considering the world from a mathematical perspective, which entails modeling, using symbols, and applying mathematical concepts to various situations (Yazgan, 2007). For mathematicians, mathematics is a unique way of thinking that leads us to truth and definitive knowledge. For thought to occur, a problem must first be defined. To solve the problem, connections are established between concepts, a solution is sought, and thinking plays a role in this process. The ability to think mathematically develops in the problem-solving process (Ersoy & Guner, 2015). In other words, problems should be a starting point for mathematical thinking.
Artificial intelligence can support students’ problem-solving and mathematical thinking skills in mathematics education (Pinheiro & Santos, 2025). In understanding complex topics, it can provide personalized feedback that guides students’ cognitive processes and helps them identify their learning gaps. In this way, students gain opportunities to apply mathematical concepts in different contexts and to develop logical solutions to multi-step problems (Luong et al., 2025). Artificial intelligence tools, such as ChatGPT-4o, can support these processes and enhance the learning environment in mathematics education (İnci Kuzu, 2026).
Identifying the development of problem-solving skills supported by artificial intelligence is crucial for understanding the effectiveness of AI-assisted tools that can enhance students’ learning processes in mathematics education. Such an evaluation reveals the role artificial intelligence plays in students’ problem-solving processes across problems of varying difficulty levels and enables a more informed and effective use of AI in education. Therefore, monitoring progress in problem-solving skills facilitated by artificial intelligence is crucial for enhancing the effectiveness of teaching and learning processes in mathematics education.
Theoretical and Conceptual Framework
With the acceleration of digital transformation, artificial intelligence–based applications are becoming more visible and influential in the field of education (Kuzu & Erdoğan Kayabaşı, 2025). While the capacity of these technologies to transform teaching and learning processes is noteworthy, claims suggesting that the possibilities offered by artificial intelligence are unlimited should be approached with caution. Although AI tools present significant opportunities, their potential should be evaluated within realistic boundaries and in alignment with pedagogical requirements (Zhang & Aslan, 2021).
The development of artificial intelligence began in the 1960s, when Skinner’s “teaching machines” project introduced programmed lessons and automatic feedback, marking a significant milestone in the application of artificial intelligence in education (Watters, 2023). The 1970s saw a focus on research and development in artificial intelligence, student modeling, and adaptive learning systems (Kolhatin, 2025). In the 1980s, expert systems began to be utilized in education, providing information and guidance in specific areas (Gülleroğlu & Coşkun, 2021). The rapid development of the Internet, wireless network communications, and computer technologies has also accelerated the use of AI-supported classroom applications (Koukaras et al., 2025). The rise of the Internet in the 1990s provided new access channels and multimedia content for learning. In comparison, virtual learning environments and online courses gained widespread adoption in the 2000s, offering students greater flexibility in terms of time and space (Zhai, 2022). In the 2010s, big data and learning analytics began to be used for personalized learning experiences and adaptive assessments. Additionally, 2020 is viewed as a period during which the use of artificial intelligence-supported chatbots and virtual assistants in education increased, and research on student interaction and participation was also conducted (İşler & Kılıç, 2021). Released in its third version in 2022, ChatGPT-4o has paved the way for a new era in mathematics education, necessitating a reconsideration of instructional approaches in this field. This artificial intelligence-based tool has influenced the way mathematical problems are addressed, thereby demonstrating significant transformative potential in educational processes (Weßels, 2023).
Nowadays, AI applications are frequently used in education studies (Arslan, 2020). ChatGPT-4o, one of the most widely used applications, has attracted considerable attention, particularly in education. ChatGPT-4o is an AI-based chatbot developed by OpenAI (Birer, 2023). Cooper stated that ChatGPT-4o has numerous applications in education, including the potential to assist teachers in creating exams and evaluations (Cooper, 2023). In addition, algorithms can calculate the probability of students failing or dropping out of the course (Bahadir, 2016) or help continuously analyze student success (Zawacki-Richter et al., 2019). Such skills of artificial intelligence have enabled it to become an integral part of the educational vision in many countries in recent years (Wang et al., 2024). Artificial intelligence has been widely utilized to develop educational content, intelligent tutoring methods and systems, assess students, and enhance teacher-student interaction (Suárez, 2025). Artificial intelligence, which is likely to be discussed in the 21st Century, can be defined as an intelligent tutor that differs from other educational technologies. In addition, instead of providing learners with the same content within the program, it will continue to develop a model that enables all individuals to perform the learning function appropriately (Karabıyık, 2024).
Luckin and Holmes grouped AI applications in education into three categories: personal tutors, intelligent support for collaborative learning, and intelligent virtual reality (Luckin & Holmes, 2016). Baker and Smith classified AI tools for students, teachers, and systems (Baker & Smith, 2019). Alam stated that AI can help in education in terms of the educational process (assistance to routine tasks in the educational process and changes in this process) and the educational environment and content (what kind of education is needed for a subject; Alam, 2021). Today, education has evolved into a comprehensive process that incorporates teaching, measurable goals, and results both in and out of the classroom, rather than merely having students memorize specific pre-prepared texts (Kurtuluş & Gece, 2025). These reasons have led us to follow the development of AI.
In addition, examining the procedural development of problem-solving skills in recent years through AI-based modeling and systems such as ChatGPT-4o is important for revealing the potential increase in AI’s success rates over time, particularly in problems of varying difficulty levels. This perspective supports the study’s aims and provides a necessary framework for understanding the effects of artificial intelligence applications in education on learning processes and reasoning.
Review of Literature
The literature reviews conducted indicate that the number of studies addressing the problem-solving capacity of artificial intelligence has been steadily increasing. In particular, the competencies of ChatGPT-4o -based models in mathematical and scientific domains have been thoroughly examined across various research contexts. These studies demonstrate that, when provided with appropriate prompts, ChatGPT-4o is capable of performing advanced mathematical tasks such as integration, executing linear algebraic operations, and solving partial differential equations (Helfrich-Schkarbanenko, 2023). However, such achievements do not imply that the model can independently, consistently, and flawlessly solve mathematical problems under all conditions. It has been reported that ChatGPT-4o can solve many questions included in nationally administered mathematics examinations; nevertheless, this performance is often dependent on explicit instructions, and correct results are not always produced on the first attempt (Korkmaz Guler et al., 2024). In a study comparing the problem-solving performances of ChatGPT-4o and Google Bard across different levels of difficulty, it was reported that both systems yielded more reliable results, particularly in tasks involving simple arithmetic operations and basic logical reasoning (Plevris et al., 2023). Although ChatGPT-4o can be considered a powerful problem-solving tool, its success has been shown to largely vary depending on the complexity of the problem and the specific mathematical domain to which it belongs (Dao & Le, 2023).
Frieder et al. examined ChatGPT-4o’s performance on problems drawn from advanced mathematics textbooks used at elite universities, its ability to detect errors in mathematical proofs, and its performance on Mathematics Olympiad-level problems. Although the findings were noteworthy in certain respects, the researchers concluded that ChatGPT-4o can produce inconsistent and unreliable results when confronted with tasks requiring advanced mathematical reasoning (Frieder et al., 2023).
Overall, it is observed that ChatGPT-4o’s mathematical performance is highly sensitive to variables such as problem type, difficulty level, and mathematical domain. However, a notable limitation of much of the existing literature is that the types of tasks examined have not been systematically classified.
Within the datasets on which ChatGPT-4o is trained, the extent to which specific mathematical domains (e.g., algebra, analysis, or topology), problem types, and levels of difficulty are represented can directly influence the model’s knowledge structure and problem-solving proficiency. Moreover, this data composition may shape ChatGPT-4o’s problem-solving strategies, such as favoring particular numerical methods for differential equations or directing users toward specific digital tools during the solution process. However, the scope and effects of such tendencies have not been clearly established in the literature (Spreitzer et al., 2024).
In conclusion, ChatGPT-4o can be considered a tool capable of solving mathematical problems at different levels with a certain degree of success. Studies comparing ChatGPT-4o versions generally indicate that ChatGPT-4.o outperforms GPT-3.5. This suggests that, when used within appropriate pedagogical frameworks, ChatGPT-4o can serve as a powerful resource to support students’ mathematical understanding. Nevertheless, as ChatGPT-4o has become an integral part of classroom environments, this technology must be integrated into mathematics education, not in an unplanned manner, but through a conscious, systematic, and critical approach. As previously noted, evaluations of ChatGPT-4o’s mathematical performance vary depending on the mathematical level, problem type, and target audience. Therefore, it is of great importance for both teachers and students to accurately comprehend the opportunities and limitations offered by ChatGPT-4o across different mathematical contexts.
Purpose and Importance of the Study
In mathematics education, probability is one of the areas where conceptual difficulties and misconceptions are most frequently encountered (Memnun, 2008). Understanding probability requires deeper and more careful thinking than many other mathematical topics, as well as critical and intuitive reasoning, making logical estimations, and the effective use of a strong mathematical language (İnci Kuzu & Uras, 2018). Probability knowledge, which is widely applied in everyday life and across various professional fields, plays a crucial role in enabling individuals to make sound decisions in situations involving uncertainty (Konold et al., 2011). Despite its importance, probability instruction remains one of the most challenging topics in mathematics for both students and teachers (İnci Kuzu, 2021).
In recent years, with the widespread adoption of artificial intelligence–based large language models in the field of education, the role of tools such as ChatGPT-4o in mathematical problem-solving processes has attracted increasing scholarly attention. Existing studies indicate that ChatGPT-4o demonstrates high performance on basic and routine mathematical problems; however, as problem complexity increases, particularly in multi-step tasks and questions requiring a high cognitive load, its accuracy rates tend to decline (Karabıyık, 2024). Nevertheless, a review of the literature reveals that longitudinal studies examining how the problem-solving abilities of ChatGPT-4o or similar large language models change and develop over time are quite limited. The majority of current research evaluates model performance at a single point in time, thereby overlooking process-oriented development and changes in cognitive consistency.
The primary aim of this study is to address the gap in the literature by examining the process-oriented development of the problem-solving ability of the ChatGPT-4o model developed by OpenAI over an 8-month period. Within the scope of the study, changes over time in the model’s abilities to understand fundamental rules, execute multi-step operations, draw accurate inferences under conditions of uncertainty, and generate consistent solutions across problems of varying difficulty levels were analyzed. In this respect, the research not only describes the current performance of artificial intelligence but also provides empirical evidence on how the mathematical reasoning capabilities of large language models evolve.
In this context, the main research problem was formulated as follows:
How does the problem-solving ability of the ChatGPT-4o model developed by OpenAI change over an eight-month period with respect to questions of varying difficulty levels?
In line with this overarching problem, the following research questions were addressed:
How did ChatGPT-4o’s problem-solving performance across different difficulty levels change over 8 months?
How do the types of errors made by ChatGPT-4o in incorrectly solved questions, and the underlying causes of these errors, change over the 8-month period?
How does development over time affect the model’s consistency and cognitive performance, particularly in multi-step problems and those with a high level of difficulty?
In this respect, the study makes an original contribution to the literature by addressing the mathematical problem-solving processes of artificial intelligence-based large language models from a temporal development perspective, thereby enabling more robust and informed evaluations of the potential use of such systems in mathematics education.
Methodology
Research Model
This study aims to investigate the development of ChatGPT-4o’s performance in solving university-level probability-related questions of varying difficulty levels over an 8-month period. Accordingly, questions categorized as easy, medium, and difficult were presented to ChatGPT-4o, and the accuracy of the responses was evaluated by comparing the results obtained at two different time points separated by 8 months. This research is a descriptive study based on the general screening model. The research described the success of an artificial intelligence-based language model (ChatGPT-4o) in solving questions with different difficulty levels. The difficulty levels of the questions were predetermined. The answers given by the model to these questions were evaluated in terms of accuracy, and the success rates were statistically analyzed.
Study Group and Data Collection
The research study group consists of 38 questions, divided into four grades with varying difficulty levels (easy, medium, and hard) at each level. The questions are coded as L1E1 (Level 1, Easy, 1st question), L2H3 (Level 2, hard 3rd question) according to their grade and difficulty levels.
The 38-item question set used in this study was developed within the framework of a descriptive research design aimed at characterizing ChatGPT-4o’s performance in solving probability problems across different levels of difficulty, rather than making statistical generalizations. The primary objective of this study is to examine the accuracy of the model’s responses to questions aligned with a specific curriculum and to compare changes in performance over time. In this context, limiting the number of questions is consistent with the exploratory and descriptive nature of the research.
The relatively small number of questions within subgroups (e.g., specific grade levels and difficulty categories) may be considered a factor limiting statistical power. Nevertheless, in this study, each question was treated as an independent unit of measurement, and the analyses were conducted by administering the same set of questions to ChatGPT-4o at two different time points. In this way, the potential variance effects arising from small subgroup sizes were partially mitigated through the use of a repeated-measures design and non-parametric statistical methods, specifically the Wilcoxon signed-rank test.
Probability Problems—Classification in Four Different Levels
Level 1: Basic Concepts
Goal: Understand the basic concept of probability.
Easy: A die is rolled. What is the probability of rolling a 6?
Medium: What is the probability of rolling an odd number when rolling a die?
Hard: A die is rolled twice. What is the probability of rolling a five on at least one of the rolls?
Required Knowledge: Have knowledge about simple fractions and ratios.
Level 2: Joint Events
Goal: Independent events and joint probability.
Easy: A coin is rolled twice. What is the probability that both roll heads?
Medium: A die and a coin are rolled together. What is the probability that the die rolls a four and the coin rolls tails?
Hard: What is the probability that the sum of the numbers rolled when two dice are rolled is 8?
Required Knowledge: To have knowledge about independence, multiplication, and addition rules.
Level 3: Conditional Probability Objective
Goal: The probability of one event occurring after another event has occurred.
Easy: There are three red and two blue balls in a bag. If the first one is red, what is the probability that the second one is blue?
Medium: Three red and two blue balls are drawn from the bag, one after the other, without replacement. What is the probability that the second ball drawn is red?
Hard: If person A tests positive, what is the probability that they are sick? (A preliminary probability is given.)
Required Information: Conditional probability formula, prior knowledge
Level 4: Combinatorial Probability Objective
Goal: Calculating probability with permutations and combinations.
Easy: In how many different ways can three different books be arranged on a shelf?
Medium: Six different people are to be lined up side by side. In how many different arrangements are possible such that people A and B do not sit next to each other?
Hard: Seven people are to be arranged side by side in a row. People A and B will sit next to each other, while person C will not sit next to either of them. How many different seating arrangements are possible?
Required Information: Combinations, permutations, and regular grouping.
The first data of the study were obtained on 15.10.2024, and the last data were collected on 15.06.2025 from the paid version of ChatGPT-4o. These questions were classified based on expert opinions, ensuring content validity. The questions were directed to ChatGPT-4o at two different time points (first application and re-application 8 months later). The answers provided by the model were scored within the framework of predetermined true/false criteria, and the solution’s success was evaluated accordingly. In this way, the differences that may occur between the answers given by the model to the same questions in the 8 months were made statistically comparable (Table 1).
Level, Difficulty, and Success Distributions of Questions.
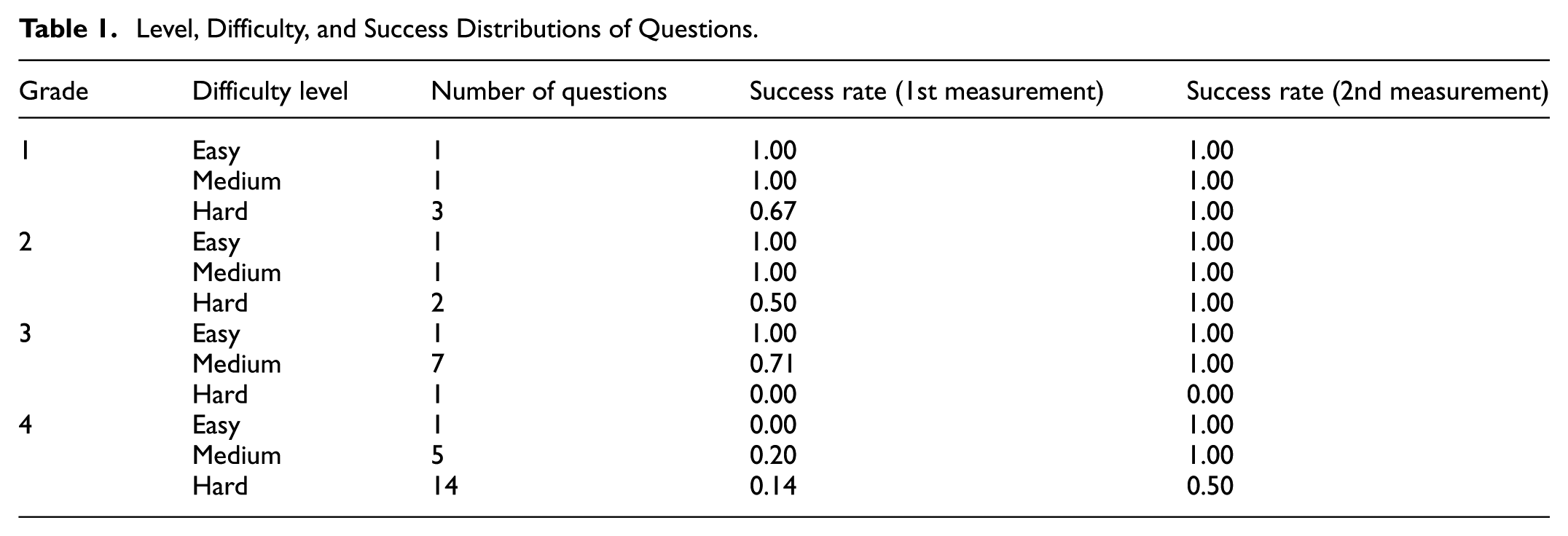
In the study, the correct answer rates of 38 questions classified at different difficulty levels were compared by ChatGPT-4o at two different time points (first and second measurements). The general success rate average in the first measurement was 0.60, and its standard deviation (Esdeira, 2017) was calculated as 0.42. In the second measurement, the success rate average was found to have increased significantly to 0.88. The SD value of the second measurement was 0.31. When Table 1 is examined, it is noted that the success rates generally reached 100% in the second measurement for all easy and medium level questions, and that there was a significant increase in the success rate of especially hard questions. For example, while the success rate in the 4th level, which included 14 hard questions, was only 0.14 in the first measurement, this rate increased to 0.50 in the second. Similarly, the success rate of the seven medium difficulty questions in the 3rd level was 0.71 in the first and reached 1.00 in the second. These findings suggest that ChatGPT-4o can provide more accurate answers to the same questions over time, indicating consistency and improved cognitive outcomes.
Data Analysis
Descriptive statistics were used to analyze the data obtained within the scope of the research. The success rates in the first and second measurements of 38 questions classified by difficulty level using ChatGPT-4o were calculated, and the mean and standard deviation values were determined.
The Wilcoxon signed-rank test was applied to determine whether the success rates between the two measurements contained a statistically significant difference, as the data did not meet the assumption of normal distribution. All analyses were performed using the SPSS 25.0 package program. Then, the solutions to each incorrectly made problem were subjected to content analysis by the researchers, and the reasons for the errors were examined.
Results
Within the scope of the research, difference-in-difference analyses were conducted for each grade and question with different difficulty levels at these grades, as well as for the total number of questions. First, difference-in-difference analyses were conducted on measurements of different grades and the total number of questions. To evaluate the success of ChatGPT-4o in answering questions classified at different difficulty grades over time, statistical comparisons were made between the two measurements. In this direction, the non-parametric Wilcoxon signed-rank test was applied to determine whether the success rates changed significantly over time. Analysis results are presented in Table 2.
Comparison of Success Rates by Grade.

According to Table 2, no statistically significant difference was found in the comparisons made for the questions at the first, second, and third grades (Grade 1: Z = −1.00, p = .317; Grade 2: Z = −1.00, p = .317; Grade 3: Z = −1.00, p = .317). These findings reveal that the responses given by ChatGPT-4o to the questions at these levels did not show any significant difference over time. Despite the increase in success rates at the fourth grade, the statistical significance limit was not reached (Z = −1.61, p = .109). However, as a result of the Wilcoxon test conducted at the total level (when all questions were considered together), the difference between the first and second measurements was found to be significant (Z = −2.20, p = .028). This situation reveals that ChatGPT-4o showed a statistically significant development in the general success level over time. Additionally, the effect size calculated to evaluate the impact of this difference was η2 = .13. According to Cohen’s classification, this value indicates a medium effect size (Cohen, 2013). In other words, the difference in success between the measurements is statistically significant and practically remarkable. These findings show that large language models can give more accurate and consistent answers to the same questions over time, and that learning processes or model updates contribute to increased performance. Figure 1 summarizes the change in ChatGPT-4o’s success in answering questions classified at different levels over 8 months.

Success rates by grades.
After examining the difference between the two measurements according to different grades, the success rates of both measurements according to different difficulty levels were compared, and the findings are given in Table 3. Table 3 shows no significant difference between the success rates in the first and second measurements for easy questions (Z = −1.00, p = .317). Similarly, no statistically significant difference was observed between the measurements for medium (Z = −1.34, p = .180) and hard (Z = −1.61, p = .109) questions. These results show that the model’s performance remained consistent in each category, regardless of the difficulty level, and did not significantly improve.
Comparison of Success Rates Across Difficulty Levels.

Figure 2 summarizes the change in ChatGPT-4o’s success in answering classified questions of different difficulty levels over 8 months. On the other hand, when all questions were considered together, when compared at the general success rate level, a significant difference emerged (Z = −2.20, p = .028). It was determined that the success level of ChatGPT-4o in the second measurement was significantly higher than in the first. This finding shows that the model can provide more successful answers to the same questions at a general level over time. As a result, it can be said that ChatGPT-4o showed a performance increase over time at different difficulty levels, although not statistically significant, and that the general success rate improved significantly, especially when all levels were considered collectively.

Success rates according to difficulty levels.
The example presented in Figure 3 provides clear evidence of a temporal improvement in ChatGPT-4o’s problem-solving performance, particularly in terms of accurately interpreting probability questions and employing more coherent and effective solution strategies over time. When Figure 3 is examined, ChatGPT-4o, in its first solution, perceived the odd dice as 1-1, 3-3, and 5-5. However, there are also situations of 1-3, 1-5, 3-1, 3-5, 5-1, 5-3. Therefore, the solution was incorrect. However, in the second solution, it understood the question correctly. First, it calculated the probabilities of the dice not being odd and removed them from the probability calculation, thus arriving at the correct result.

Comparison of ChatGPT-4o’s solutions to problem G1H1 8 months before and after.
Qualitative Findings on ChatGPT-4o’s Problem-Solving Performance: A Comparison of Initial and Final Assessments
Table 4 summarizes the qualitative analysis results regarding ChatGPT-4o’s performance in solving probability problems, presenting a comparison between the initial and follow-up measurements conducted over an 8-month period and highlighting the observed developments in terms of accuracy, reasoning, solution strategies, and problem-solving consistency.
Qualitative Findings on ChatGPT-4o’s Problem-Solving Performance Over 8 Months.
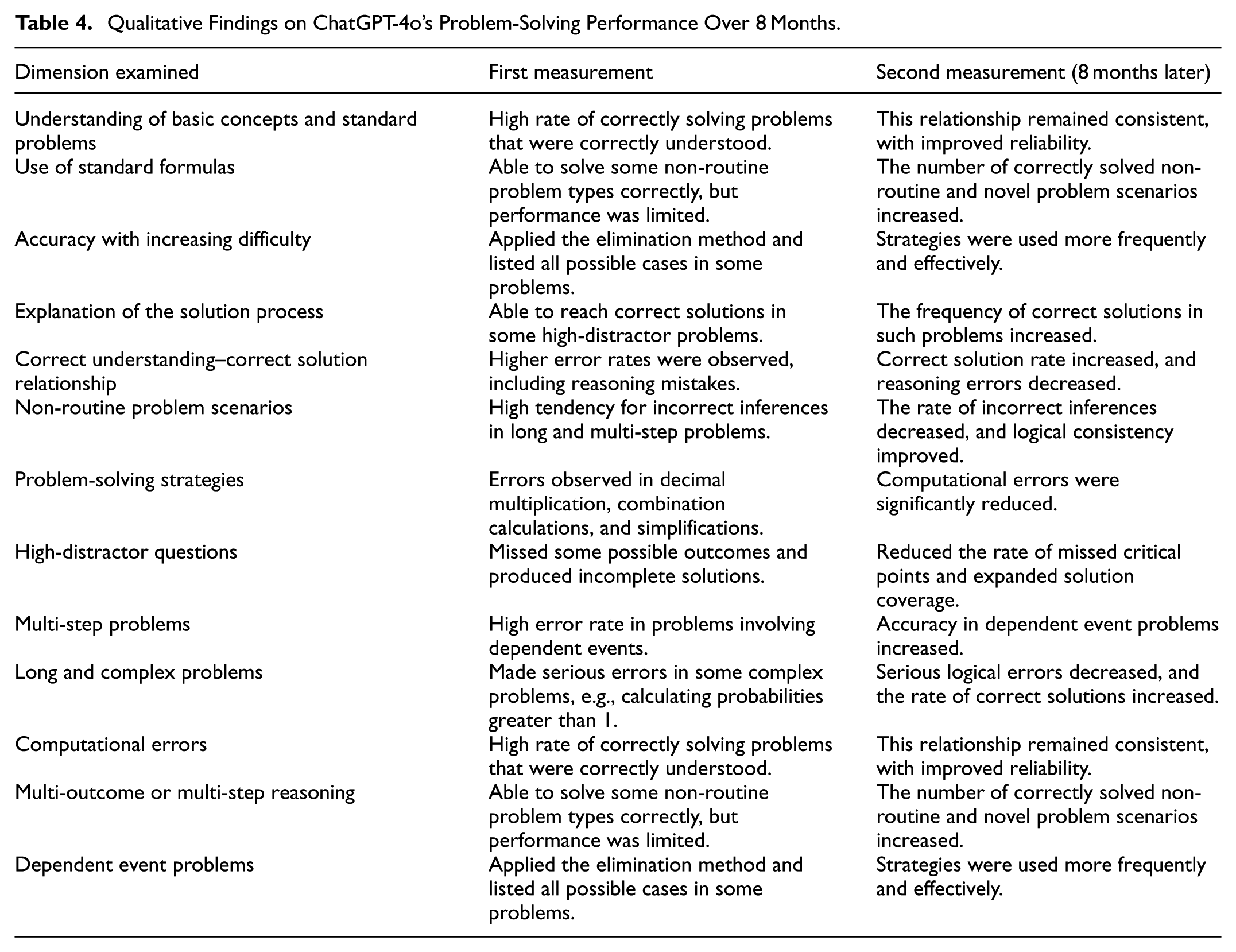
The results indicate that ChatGPT-4o demonstrated a marked improvement in problem-solving performance over the 8-month period, particularly in probability problems involving dependent and conditional events. While the initial measurement revealed high error rates and incomplete reasoning in such problems, the final measurement showed that ChatGPT-4o more accurately identified dependencies between events, consistently established conditional probability relationships, and consequently achieved higher rates of correct solutions. Furthermore, whereas the initial measurement exhibited various types of errors, including computational errors (e.g., decimal multiplication, combination calculations, and simplifications), logical and reasoning errors, incomplete solutions or omitted possible cases, incorrect inferences in multi-step problems, and errors arising from susceptibility to distracting elements, these error types were substantially reduced in the final measurement. In addition, solution strategies were applied in a more effective and systematic manner, and the explanations provided became more coherent and pedagogically robust.
Discussion
In this study, the ChatGPT-4o model was analyzed over an 8-month period with respect to its capability to solve probability problems, and variations in its performance were systematically examined. The results indicate a gradual improvement in the model’s performance over time. According to the first research question, increases in correct response rates were observed for problems at medium and great difficulty levels. Nevertheless, the model continues to exhibit limitations in tasks involving conditional probability, dependent events, and multi-step reasoning processes. Occasional logical inconsistencies and inaccurate inferences were also identified. These findings suggest that while artificial intelligence–based language models may demonstrate performance improvements over time, they still face challenges when addressing highly complex and cognitively demanding problem scenarios. Comparable results have been reported in earlier studies (Sabzalieva & Valentini, 2023; Wang et al., 2024).
According to the second research question, it was determined that ChatGPT-4o makes errors when multiplying decimal numbers; it also makes mistakes in combination calculations in some problems and, in some cases, simple simplification errors. These findings indicate that ChatGPT-4o is prone to making operational or arithmetic errors. Furthermore, a one-way examination of the solution steps provided by ChatGPT-4o was insufficient to verify their accuracy. This shows that each step in ChatGPT-4o’s problem-solving process should be evaluated not only for whether the problem is correctly interpreted, but also for whether the mathematical operations are performed correctly. Similarly, Wang and colleagues also determined that ChatGPT-4o produces computational errors (Wang et al., 2024).
In problems involving dependent events, where the outcome of one event affects the occurrence of another, ChatGPT-4o produced incorrect solutions in multiple instances. This issue suggests that ChatGPT-4o’s performance in such problem types warrants more in-depth investigation. In a study examining ChatGPT-4o’s problem-solving abilities, Marinosyan (2024) reported that although ChatGPT-4o demonstrates a relatively strong level of conceptual understanding, it falls short in areas requiring rigorous mathematical proofs and consistent logical reasoning. While the model exhibits high performance on questions that can be solved using standard formulas, it still requires further development in tasks that demand the interpretation of special cases and multi-step logical reasoning (Alibrahim, 2024; Wardat et al., 2023).
According to the third research question, in some complex or high-difficulty problems, ChatGPT-4o attempted to generate alternative solution approaches but failed to arrive at the correct result. In certain cases, its logical reasoning process appeared to break down to such an extent that the model produced probability values greater than one. ChatGPT-4o primarily relies on algebraic equations and formulas to obtain correct solutions and is not particularly effective in employing other problem-solving strategies, such as estimation, verification, and refinement, resulting in inconsistent accuracy in its responses (Getenet, 2024; Marinosyan, 2024). These findings are consistent with the work of Frieder et al., who argue that mathematical and contextual complexity constitute a critical determinant of ChatGPT-4o’s performance (Frieder et al., 2023). Similarly, other studies indicate that mathematical and contextual complexity may significantly influence outcomes and that performance may remain limited in complex tasks (Dao & Le, 2023; Wardat et al., 2023).
The study found that ChatGPT-4o produced more consistent and accurate results in probability problems (Ray, 2023). These observed performance improvements are related to developer updates, expansion of training data, and improvements in model architecture; they are not the result of organic learning in a pedagogical sense and cannot be directly compared to human learning. In mathematics education, students can use ChatGPT-4o as a supplementary tool in basic modeling and standard problem-solving tasks; the model provides reliable results for simple calculations and basic logical reasoning, allowing teachers to focus on more complex problems. The possibility of incomplete or incorrect answers in intermediate or multi-step problems highlights the importance of critical evaluation and teacher supervision. It draws attention to the risk of student over-reliance (İnci Kuzu, 2026). Analyzing ChatGPT-4o’s solution errors presents a pedagogical opportunity, contributing to the development of both the use of AI-based tools and the ability to identify and correct incorrect solutions. Therefore, the model should be used as a supplementary educational tool, not a primary problem-solving tool, and traditional teaching methods and teacher supervision remain critical in complex tasks.
In summary, the rapid development exhibited by ChatGPT-4o models over a relatively short period, along with improvements in their problem-solving capabilities, offers significant potential for the integration of artificial intelligence into mathematics education. Furthermore, while supporting students’ basic problem-solving skills, it allows teachers to allocate classroom time more effectively to tasks that require greater complexity and interpretation. However, given the model’s current limitations, students need to continue developing their critical thinking and independent problem-solving skills. Maintaining this balance while leveraging ChatGPT-4o’s strengths is critical to students’ academic and professional success.
Conclusion and Recommendations
To enable more effective use of ChatGPT-4o in mathematics education, certain precautions and enhancements are required. Teacher supervision is of critical importance in the use of the model, particularly for problems that are open to interpretation, multi-step in nature, or of great difficulty. Enhancing ChatGPT-4o’s performance necessitates training processes enriched with mathematical data and the further development of its ability to generate step-by-step solutions. Artificial intelligence tools should be employed as complementary resources that support students’ fundamental problem-solving skills, and excessive student dependence on such tools should be avoided. Moreover, analyzing the model’s solution errors can be leveraged as a pedagogical strategy to foster students’ logical reasoning and problem-solving abilities. In the future, artificial intelligence systems are expected to improve their performance by minimizing problem-solving errors. However, from a pedagogical perspective, whether such systems can independently manage students’ learning processes remains a distinct and important topic for further research.
Limitations
The 38-item question set used in this study was developed within the framework of a descriptive research design aimed at characterizing ChatGPT-4o’s performance in solving probability problems across different levels of difficulty, rather than enabling statistical generalization. This limited dataset may be statistically insufficient for drawing broad conclusions. In addition, the exclusive focus on probability limits the extent to which a general evaluation of artificial intelligence performance can be made. External factors such as the timing and context in which the questions were administered, system load, internet connectivity, or the operational state of the platform at the time may have influenced the model’s performance. The findings obtained in this study are therefore likely specific to the particular model examined and the questions posed. Similar results may not necessarily be observed with different artificial intelligence models or across other disciplinary domains.
During the design phase of the study, the use of the existing artificial intelligence model (ChatGPT-4o) was planned. However, when evaluating the performance of ChatGPT-4o, the rapid advancement of artificial intelligence models, particularly the emergence of next-generation systems such as ChatGPT-5, may influence the interpretation of the findings. It is anticipated that ChatGPT-5, supported by more advanced algorithms and substantially larger datasets, may achieve higher levels of accuracy. This advancement could lead to a pronounced performance difference compared to ChatGPT-4o, especially in the context of complex probability problems. Future research may therefore be required to examine in greater detail the potential educational impacts of newer models such as ChatGPT-5. Accordingly, the findings of the present study should be interpreted with the understanding that they may change as more advanced artificial intelligence models become available.
Footnotes
Author Contributions
The authors have contributed equally throughout all stages of this work.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Karabuk University Scientific Research Project Unit supported this study within the scope of project number KBÜBAP-25-YL-033.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
There are no datasets associated with this research.