
Abstract
This study advances research on second language (L2) Chinese development by identifying linguistically grounded metrics capable of reliably capturing writing complexity, a central dimension of the widely adopted CAF framework (Complexity, Accuracy, Fluency) for evaluating learner development. While previous work has largely examined the correlation between traditional complexity (lexical, syntactic, and topic–comment–based) features (TCFs) and complexity using statistical inference, the present study adopts a predictive perspective and develops a new set of Dependency Construction–based Complexity Features (DCFs). Built upon well-established insights from Construction and Dependency Grammar, DCFs provide a linguistically informed framework consisting of 52 features that quantify both the diversity and the sophistication of learners’ syntactic constructions. Using a corpus of 6,975 graded compositions spanning three complexity levels, we trained machine learning models (logistic regression and random forest) to predict complexity. Comparative experiments show that DCFs consistently yield stronger predictive performance than traditional TCF measures, with random forest achieving an accuracy of 91.61%. These results demonstrate that DCFs offer a substantially more effective representation of L2 Chinese writing complexity, underscoring their value for automated assessment and for empirical research on L2 Chinese development.
Plain Language Summary
In second language acquisition, a key challenge is how to objectively assess a learner’s level of language development. A common framework for this task is CAF-complexity, accuracy, and fluency. Among these components, complexity receives particular attention because it reflects a learner’s ability to use advanced and sophisticated linguistic structures. Since complexity cannot be measured directly, it must be inferred from textual features, and features that capture deeper linguistic patterns should, in principle, provide better predictions. However, previous research has relied heavily on surface-level features such as sentence length or lexical diversity—features not grounded in modern linguistic theory and based on a simplistic divide between vocabulary and syntax. These measures often fail to capture what teachers observe in practice: the sophistication of writing is less about long sentences and more about natural, idiomatic combinations of words. To address these limitations, we draw on linguistic theories that integrate lexis and grammar, especially the concept of Construction Grammar and the collocational insights provided by Dependency Grammar. Based on these ideas, we develop a new feature set called Dependency Constructions based Features (DCFs). We compare DCFs with traditional complexity feature sets (TCFs) using both linear and nonlinear prediction models on a three-level learner corpus (low, medium, and high). The results show that DCFs consistently outperform TCFs, and nonlinear models outperform linear ones. These findings suggest that linguistically informed features and models offer clear advantages in complexity prediction. This study validates the scientific robustness of Construction Grammar by fundamentally shifting our perspective on linguistic complexity. Furthermore, it provides new evidence and a superior methodology for enhancing the automated assessment of writing complexity in second language education.
Keywords
Introduction
Complexity has long been a central concern in second-language (L2) writing assessment and has been widely used to trace learners’ developing proficiency (Bulté et al., 2025; Cheng, 2022; Hao et al., 2024; Jiang et al., 2019; Lu, 2011; Norris & Ortega, 2009; Ortega, 2003; Pallotti, 2015; Paquot, 2019; Spina, 2025). A wide range of syntactic, lexical, and phrasal measures have been developed and examined, followed by the application of statistical methods to validate them. This validation process typically involves quantifying the strength of the statistical association between these measures and text-level complexity, thereby assessing their effectiveness as indicators of linguistic complexity.
Features used in previous studies were predominantly drawn from the syntactic and word level, whereas recent studies have shifted their focus to phrasal features (Bulté & Housen, 2012; Hu et al., 2022; Paquot, 2019). Syntactic complexity measures were predominantly coarse-grained ones, taking the form of length (e.g., mean length of T-unit), frequencies or ratio. As limitations of these coarse-grained metrics became apparent (e.g., limited explanation), researchers began pursuing more fine-grained indices with better interpretability, such as dependency distance (Ouyang et al, 2022; Zhu & Xiong, 2025) and phrase-level features (Hu et al., 2022; Jiang et al., 2019; Paquot, 2019; Paquot & Naets, 2025). Among these, phrase-level measures have gained significant attention and have been proven highly advantageous. Studies based on English-language corpora have typically examined a limited range of phrasal types. For instance, Biber et al. (2011) developed phrase-level measures involving adverbials and noun modifiers, discovering these were more effective than clause-level features in measuring complexity of academic texts. Subsequent researches expanded the variety of phrases analyzed. Kyle and Crossley (2018) constructed 66 phrase-level measures based on 17 types of phrase structures, finding phrase-level measures superior to clause-level ones. Similar findings have been confirmed in Chinese texts. Jiang et al. (2019) confirmed the effectiveness of fine-grained features by systematically comparing the performance of clausal and phrasal features. Similarly, Wu (2021) found that measures of noun phrase complexity were better predictors of writing complexity than topic–comment–unit–based measures. In contrast to syntactic complexity, lexical complexity measures are fewer, primarily focusing on lexical diversity and lexical sophistication (Lu, 2010, 2011). A review of these studies reveals that research during this period heavily emphasized syntactic complexity, and the construction of syntactic and lexical complexity indices was often treated separately, likely influenced by the traditional linguistic dichotomy between lexis and syntax. Even in the construction of phrase-level indicators, the methodological approach primarily rested on the analysis of phrasal features rather than on phrasalogical ones.
A significant shift was marked by Paquot (2019), who moved towards a phraseological complexity feature construct. Grounded in phraseological theory, she argued that linguistic knowledge is not merely a combination of “grammar rules + a word list” but rather a vast inventory of phrases and constructions. Based on this perspective, she treated the word combination as the fundamental unit of text analysis, developed phraseological complexity features, and empirically validated their effectiveness. It is important to note that the phraseological indices introduced by Paquot (2019) considered not only the type of phrase but also lexical information within the phrase, such as the use of low-frequency collocations. She found strong associations between phraseological indices and complexity. Concurrently, Hu et al. (2022) conducted a similar investigation in L2 Chinese writing, in which they constructed 21 phraseological complexity measures. Based on 101 timed essays by L2 Chinese learners, they compared phraseological features with topic-comment-unit-based features in distinguishing text complexity, finding phraseological complexity features more effective. This approach of these two studies represents a significant advancement over previous methods, aligning with theoretical frameworks like Construction Grammar. These theoretical developments represent a paradigm shift in the understanding of language, marking a decisive move away from a lexicon-centric view toward one that is centered on word combinations. This perspective is well-founded and, crucially, provides a solid theoretical foundation for constructing complexity features based on word combinations.
While previous studies have provided us with valuable insights, they also exhibit certain limitations. Previous studies have predominantly focused on examining the correlation between individual or specific categories of features and text complexity, rather than investigating the relationship between the overall feature system and the text.
How can we quantify the correlation between a specific complexity features and text complexity? To address this issue, previous research has primarily relied on statistical approaches, such as correlation analysis and regression models, to examine the relationships between individual linguistic features and text complexity. While these methods are computationally straightforward and easy to interpret, their results can be unreliable and often produce “incoherent findings” (Norris & Ortega, 2009), indicating that isolating individual features to estimate their association with complexity is fundamentally flawed. One key limitation is that such methods implicitly treat language as a linear system, whereas language is inherently a complex adaptive system (Larsen-Freeman & Cameron, 2008), in which linguistic features interact in mutually reinforcing or inhibiting ways. Consequently, approaches that examine features in isolation fail to capture these interactions, limiting the validity and explanatory power of the resulting complexity measures.
To summarize, while the aforementioned studies have established complexity feature systems and initiated important exploration at the word-combination level, two critical challenges remain in existing research. First, the phraseological complexity feature systems constructed in previous studies are fragmented, failing to provide a comprehensive account of text complexity and thus hindering a global understanding. This fragmentation is evident in two ways: the types of word combinations covered are limited, as exemplified by Paquot (2019), who examined only three types; and the constructed features lack comprehensiveness, as illustrated by Hu et al. (2022), who, despite developing a richer set of relation types, primarily focused on frequency while neglecting crucial features such as association strength. Second, the predominant reliance on linear statistical methods fundamentally conflicts with the complex, nonlinear nature of language systems (Ortega, 2003). Conventional techniques, such as correlation and regression analyses, examine relationships between individual features and text complexity in isolation (Bi & Jiang, 2020; Ouyang et al., 2022; Paquot, 2019; Zhu & Xiong, 2025). They do not account for the intricate interactions among multiple linguistic features that collectively shape text complexity profiles. This methodological simplification may systematically obscure important patterns in the data.
In response to these challenges, the current study makes the following contributions. First, regarding construction-based features, we develop a comprehensive text complexity feature set based on Dependency Constructions (DCs) to provide a more thorough representation of textual complexity. A “Dependency Construction” is defined as a triplet consisting of two words in a syntactic dependency relationship and their dependency relationship (Yin, 2022). We adopt 44 dependency relationships, corresponding to the complete set of the Chinese Stanford Dependencies. From these constructions, we extract multi-dimensional complexity features that quantify both diversity and sophistication. These features incorporate not only commonly used frequency measures but also association strength metrics, the latter of which are rarely applied in current research on Chinese texts. Second, regarding evaluating methodology, we employ machine learning models to evaluate the predictive power of the feature set, leveraging their ability to capture nonlinear relationships between features and text complexity.
Using a corpus of approximately 6,975 Chinese compositions, this study conducts text complexity prediction with both traditional complexity features (TCFs) and the proposed Dependency Construction-based Features (DCFs), employing logistic regression and random forest models. The prediction performance of these models is then used to assess the effectiveness of each feature set. The present study aims to address the following questions:
Dependency Construction-Based Language Complexity Features
The development of a complexity feature system is fundamentally a process of textual analysis. In this section, we first establish the dependency construction as the fundamental unit of textual analysis and provide theoretical justification for this perspective. Subsequently, we present a detailed introduction to the Dependency Construction-based Complexity Features developed in this study.
Dependency Constructions as the Unit of Text Analysis
Word combinations are vital in theoretical linguistics, language acquisition, and natural language processing. Various terms like phraseological units, collocations, chunks, formulaic sequences, constructions, or collostructions reflect the linguistic community’s focus on word combinations. This emphasis is evident in data-driven linguistic research theories and in corpus linguistics, where phraseology has become a key area of study (Granger & Paquot, 2008). Corpus-based researches on word sequences show that meaning resides not in individual words but in phrases formed by word combinations and grammatical structures (Hunston, 2010). Sinclair and Carter (2004) expanded the concept of meaning units to multi-word units, which we broadly refer to as phrases.
Since word combinations are considered elements of language, a complexity feature set should be constructed based on word combinations (Hu et al., 2022; Paquot, 2019; Wu & Lu, 2024). In previous studies, word combinations are termed phraseological units (Paquot, 2019) or collocations (Hu, 2021). Hu et al. (2022) directly use “word-combination-based measures” in her L2 Chinese complexity research. Though employing varied terminologies to describe word combinations, they essentially refer to the same concept: word combinations used in syntactic dependency relationship, which we refer to as “Dependency Construction” (DC). This concept was notably elucidated by Yin (2022), which focuses on the automatic readability assessment of Chinese texts. A DC refers to a triplet comprising two words in a syntactic dependency relationship, which can be formally represented as (like, nsubj, I) [(喜欢, nsubj, 我)] (like, dobj, coffee) [(喜欢, dobj, 咖啡)] (like, advmod, really) [(喜欢, advmod, 特别)] (coffee, amod, hot) [(咖啡, amod, 热)]
The sentence contains four DCs of four types: nsubj, dobj, advmod, and amod. The four DCs in the sentence represent all the words and the relationships between them, with each word being in some kind of dependency relationship. In this way, we can describe and characterize text complexity based on DCs.

Syntactic parsing of “I really like hot coffee” (“我特别喜欢热咖啡”).
The utilization of Dependency Constructions (DCs) as the basic unit for text analysis offers significant advantages, which are primarily manifested in the following dimensions:
First, practical necessities. The concept of a DC is clear and largely self-explanatory, referring to a word combination composed of two words in a dependency relationship. This concept conveys two key pieces of information: (1) a DC is a binary combination, consisting of exactly two words, thereby excluding combinations of three or more words from the scope of this study; and (2) the two words must be syntactically linked by a dependency relationship, which distinguishes DCs from word combinations formed based on co-occurrence, such as “lexical bundles” commonly used in corpus linguistics (Biber & Conrad, 1999). It is important to note that DC focuses on whether two words have a dependency relationship, without restrictions on other factors, such as whether the words are adjacent or non-adjacent, thus eliminating many redundant explanations. Additionally, DCs have certain advantages in terms of representation. Formally represented as
Dependency Construction-Based Complexity Feature Set
Drawing on existing L2 complexity studies that derive features along the dimensions of diversity and sophistication (Hu, 2021; Paquot, 2019), this study develops a Chinese text complexity feature set based on DCs, referred to as DC-based complexity features (DCFs). DCFs quantify text complexity along two dimensions: diversity and sophistication. This feature set comprises 52 linguistic features, as summarized in Table 1.
DCs-Based Complexity Features (DCFs).
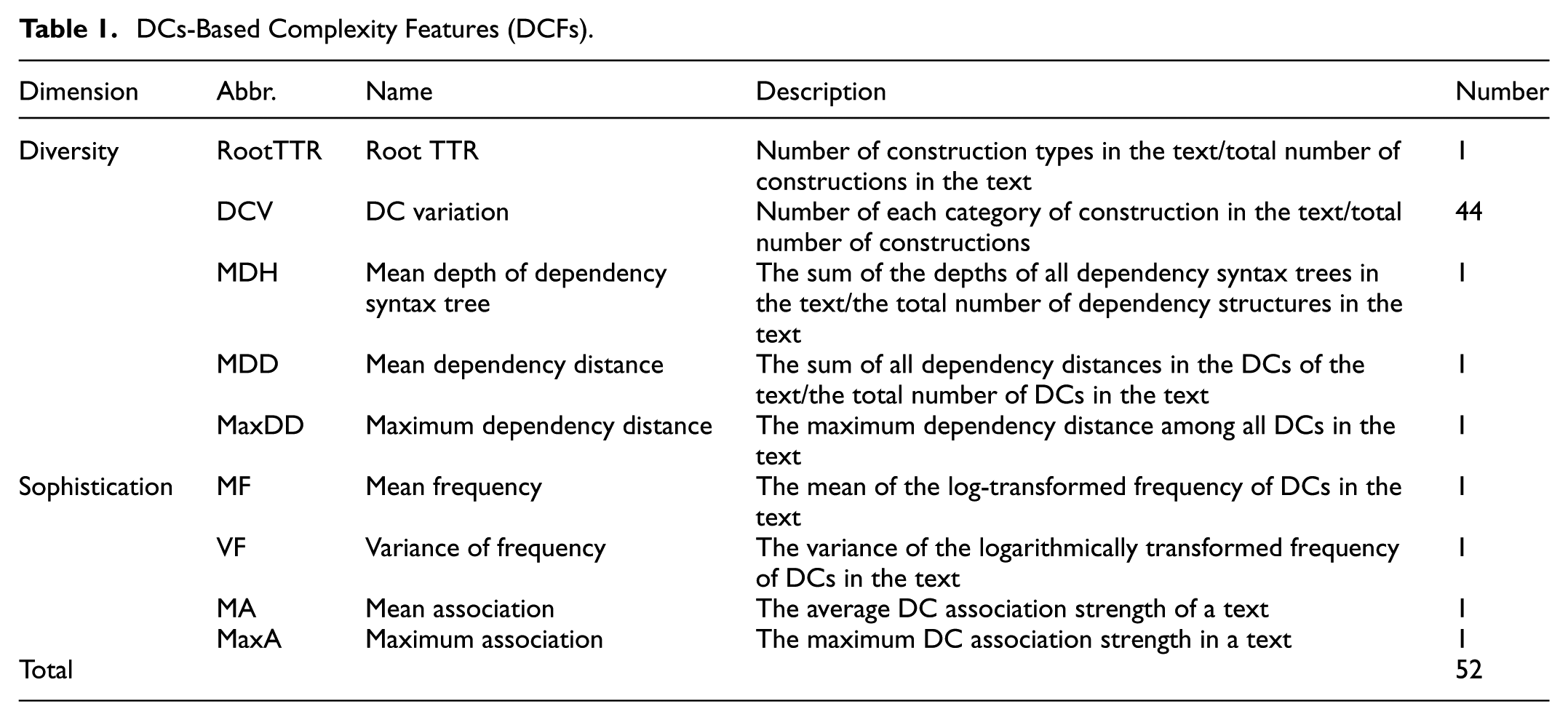
As shown in Table 1, the diversity features are organized into five categories, comprising a total of 48 features. Specifically, Root TTR is adapted from lexical richness measures to assess the variety of dependency structures. The Dependency Construction Variation (DCV) feature is calculated as the proportion of each type of Dependency Construction (DC) relative to the total number of DCs in the text. Since there are 44 relation types defined, this yields a set of 44 distinct features. MDH functions as a measure derived from the depth of the dependency tree. The dependency-distance features include MDD and MaxDD. Dependency distance refers to the linear distance between the two words in a DC. Previous studies have shown a strong correlation between MDD and language complexity in English texts (Jiang et al., 2019; Ouyang et al., 2022). The sophistication features is statistical in nature, an approach grounded in usage-based linguistic theory. Accordingly, they are referred to as usage features in the literature (Kyle & Crossley, 2018). Frequency-based measures represent the most widely adopted approach within this category. In our framework, these are operationalized through two specific metrics, which are denoted in Table 1 as mean frequency (MF) and variance of frequency (VF). As phrase-level frequencies are more difficult to obtain than word-level frequencies, prior research often uses the proportion of low-frequency collocations as a proxy. For example, Paquot (2019) employed the Academic Collocation List as a low-frequency phrase set in her study of L2 English writing, considering the proportion of academic collocations in a text as a sophistication feature. Similarly, Hu et al. (2022) defined a set of low-frequency Chinese collocations based on a Wikipedia-derived reference corpus and constructed features reflecting their proportion. In contrast to previous studies, the present research seeks to comprehensively capture the frequency profile of DCs in texts. To this end, a Chinese reference corpus comprising over 370 million words was compiled from compositions by learners at various educational levels. The size and coverage of this corpus ensure the reliability of the resulting frequency estimates. Based on this resource, as shown in Table 1, two frequency-related sophistication features were constructed: MF (the mean DC frequency) and VF (variance of DC frequency). In addition to frequency-based features, the association strength of DCs also constitutes important statistical property, which association strength quantifies the cohesion between word A and word B within a DC.
Advantages of the DCF-Based Approach
The DCF-based approach offers several distinct advantages over traditional methods of analyzing language complexity. These advantages can be summarized in two dimensions: a holistic perspective that integrates lexical and syntactic information, extensive coverage of dependency types and features and it provides a holistic framework that integrates lexical and syntactic information. Ortega (2003) and Norris and Ortega (2009) argued that research on language complexity should not be restricted to syntax alone. Although most existing studies focus on syntactic complexity, and some examine lexical complexity, these dimensions are often studied separately. DCs, which encode both lexical items and inter-word syntactic relationships, provide a holistic means of examining language complexity from the perspective of the language system as a whole. The DC-based complexity features developed in this study integrate both lexical and syntactic information. Second, the approach is characterized by its comprehensiveness. The DCs analyzed in this study encompass 44 types, representing the largest set reported in comparable research (e.g., 3 types in [Paquot, 2019]; 8 types in [Hu et al., 2022]). Including a wider range of dependency types allows for a more detailed and fine-grained analysis of texts, improving the reliability of the results. Furthermore, the complexity feature set was expanded to include measures such as dependency distance, dependency tree height, and association strength, resulting in a total of 52 features—the most extensive set reported in previous studies.
Evaluating Dependency Construction-Based Complexity Features (DCFs)
This chapter evaluates the predictive performance of the Dependency Constructions–based Complexity Features (DCFs) introduced in Chapter 2. The assessment of student essay complexity is framed as a text classification task, allowing the predictive power of the DCFs to be quantified through classification accuracy. Machine learning models are trained using both the DCFs and a comprehensive set of traditional complexity features (TCFs) to compare their relative effectiveness in predicting essay complexity levels. To ensure the robustness of the results, two algorithms—logistic regression and random forest—are employed. The TCF set includes standard syntactic and lexical features, as well as topic–comment–unit-based measures that capture discourse-level patterns in Chinese texts, providing a reasonable baseline for comparison. The experiments examine whether the DCFs demonstrate superior predictive performance relative to the TCFs and whether non-linear machine learning models offer advantages over previous statistical-inference-based approaches.
Graded Corpus and Reference Corpora
This study employed two corpora. The first, the Graded Corpus (GC), was used for training and evaluating the machine learning models. The second, the reference corpus (RC), provided reference data for extracting statistical language information.
Graded Corpus
The Graded Corpus (GC) consists of compositions produced by learners from diverse national backgrounds, categorized into three proficiency (complexity) levels: beginner (low), intermediate (medium), and advanced (high). The corpus comprises 6,975 texts, including 2,355 at the low level, 1,805 at the medium level, and 2,815 at the high level. A corpus encompassing multiple proficiency levels is essential for machine learning applications, as it directly affects the effectiveness of model training. High-quality data is ensured by three key criteria: authenticity, scale, and representativeness. Authenticity requires that compositions accurately reflect the writers’ language proficiency, with exam compositions completed without external references being ideal. Scale refers to the size of the corpus, as larger datasets provide richer information and improve model performance. Representativeness encompasses both a balanced distribution of texts across proficiency levels and a diversity of learner backgrounds, including varying native languages.
To meet these criteria, standardized examination compositions, especially those from large-scale assessments, were selected as primary data sources. For intermediate and advanced proficiency levels, the study drew on the HSK Dynamic Composition Corpus (Zhang, 2003; 2021), which provides a substantial number of compositions from learners at these levels. These compositions were organized into intermediate and advanced groups for the purposes of this study. Beginner-level compositions were not available in the HSK corpus, as the corresponding exams did not include composition tasks. Consequently, beginner-level texts were collected from the institution where the study was conducted, spanning the years 2015 to 2021. This collection comprised weekly classroom assignments, mid-term examinations, and final examinations, all produced by first-year learners at the beginner level. The sources included both paper-based and electronic submissions, with electronic texts primarily derived from online exams administered during the COVID-19 pandemic. All paper-based compositions were manually digitized, with only obvious typographical and punctuation errors corrected during transcription.
All compositions were reviewed by experienced Chinese instructors. Texts that were unintelligible due to excessive errors or did not correspond to the intended proficiency level were excluded. Minor typographical and punctuation errors were corrected to reduce their impact on computational parsing. The finalized corpus has the following properties: (1) all texts were produced in exam settings under closed-book, time-limited conditions, independently by the students, and (2) the original content and structure of the texts were largely preserved, with only minimal corrections applied.
Finally, a corpus of compositions was compiled and labeled into three proficiency levels: low, medium, and high. The dataset was randomly split into training and test sets at an 80:20 ratio, with the training set used for model development and the test set used for performance evaluation. The detailed distribution of compositions across proficiency levels is presented in Table 2.
Distribution of the Graded Corpus.

Reference Corpus
A reference corpus (RC) is generally large-scale, balanced, and representative, and is used to derive statistical information about language (Yin & Shao, 2023). In this study, the DCFs incorporate both diversity and sophistication features. Diversity features are extracted directly from the composition texts, while sophistication features rely on statistical measures derived from the RC. For example, the frequency of a DC reflects its prevalence in actual language use and is computed from its occurrence counts in the reference corpus. Similarly, association strength, which measures the degree of cohesion between words within a DC, is obtained from the same corpus.
To serve its purpose, the reference corpus must be sufficiently large and linguistically compatible with the target composition corpus. For this study, the RC comprises high-quality Chinese compositions written by primary and middle school students, collected through book scanning and web crawling, totaling over 370 million words. Student compositions were chosen because they cover multiple proficiency levels, exhibit balanced content and stylistic variety, and align closely with the language used by learners in GC. Compared with the 66-million-word L2 research paper corpus used by Paquot (2019) and the 138-million-word Chinese Wikipedia corpus employed by Hu et al. (2022), this reference corpus is both larger and more representative of the target language domain. The linguistic similarity between GC and the RC, particularly regarding the range of complexity levels in student compositions, enhances the reliability of statistical feature extraction.
Traditional Complexity Measures (Baseline)
For comparison with the proposed DCF framework, a baseline set of traditional complexity features (TCFs) are constructed. Drawing on the lexical and syntactic measures employed in Paquot (2019), this study further incorporates topic–comment–unit–based measures that capture discourse patterns characteristic of Chinese (Hu et al., 2022; Jin, 2007; Yu, 2021). The resulting TCF set consists of 14 lexical complexity measures and 9 syntactic complexity measures, as summarized in Table 3.
Traditional Complexity Features (TCFs).

For part-of-speech–related measures, 10 major word classes were examined: nouns, verbs, adjectives, pronouns, quantifiers, numerals, adverbs, conjunctions, prepositions, and modal particles. In the WV category, the proportion of each of these 10 classes was computed independently, yielding 10 separate features. In the LWV category, lexical words include nouns, verbs, adjectives, numerals, quantifiers, pronouns, state words, and distinguishing words.
Procedure
Dependency Parsing
Given that large-scale, data-driven research is contingent upon efficient linguistic annotation, a reliance on exclusively manual corpus annotation is therefore not a viable approach. With recent advances in natural language processing (NLP), a variety of tools now support automatic text annotation and syntactic analysis. This study employs HanLP as the core processing toolkit. HanLP integrates a suite of models and algorithms, with word segmentation as its foundational component. Its segmentation model is trained on a corpus of approximately 99.7 million words—one of the largest publicly documented Chinese segmentation corpora. HanLP supports multiple part-of-speech (POS) tagsets, including CTB, PKU, 863, and NPCMJ. This study adopts the Chinese Treebank (CTB) tagset by default (Xue et al., 2005), which defines 33 POS categories, including punctuation. In addition to segmentation and POS tagging, we rely on HanLP’s syntactic parsing module. Parsing analyzes the grammatical relations among words and represents them in a tree structure. HanLP provides several dependency annotation schemes such as SD, UD, and PMT. As previously noted, this study adopts the Chinese Stanford Dependencies (CSD) framework. HanLP’s dependency parser is used to automatically extract all dependency constructions (DCs) required for the computation of DCFs.
Feature Extraction
The feature extraction methodology outlined in this chapter begins with the preprocessing of the graded learner corpus, followed by the parallel preprocessing of the reference corpus. The processed data subsequently enables the extraction of two distinct feature sets: the novel Dependency Construction-based Features (DCFs) and the Traditional Complexity Features (TCFs). The ensuing discussion will detail each of these stages in sequence.
All learner compositions in the graded corpus were first segmented into individual sentences, resulting in over 17 million sentences in total. HanLP was then applied to each sentence to conduct word segmentation, part-of-speech tagging, and dependency parsing. The processed proficiency corpus contains more than 1.34 million tokens and over 1.06 million dependency constructions (DCs). Figure 2 presents the distribution of syntactic DC types in this corpus. As illustrated, advmod (adverbial modifier) is by far the most frequent dependency relation. Sentence-level dependency information was retained to calculate dependency distances. Following Liu (2008), the dependency distance between a governor and its dependent is defined as the linear difference in their word positions within the sentence. This study adopts the same approach. For illustration, consider the sentence “我特别喜欢热咖啡” (I really like hot coffee), where each word is numbered sequentially according to its position in the sentence (Figure 3). The dependency distance of the subject relation (喜欢, nsubj, 我) is calculated as 3 − 1 = 2. The distances for the other dependencies—(喜欢, dobj, 咖啡), (喜欢, advmod, 特别), and (咖啡, amod, 热)—are 2, 1, and 1, respectively. The maximum dependency distance (MaxDD) in this sentence is 2, and the mean dependency distance (MDD) is (2 + 2 + 1 + 1)/4. Using this method, MaxDD and MDD can be computed at the text level. The results for texts of different proficiency levels are summarized in Table 4.

Distribution of DC types in the graded corpus.

Word order of “我特别喜欢热咖啡” (“I particularly like hot coffee”).
Distribution of Dependency Distance Measures by Proficiency Level.

The reference corpus was first segmented into sentences, after which each sentence was processed with HanLP for word segmentation, part-of-speech tagging, and dependency parsing. From this corpus, we extracted nearly 2 billion dependency constructions. Word-level and DC-level frequency counts were computed for each sentence and aggregated to derive the overall frequency distributions of the reference corpus. These statistics were then stored as the background word-frequency database and background DC-frequency database. Mutual Information (MI) was adopted as the metric for quantifying the association strength between linguistic units. Introducing MI into the workflow enables the automatic measurement of structural cohesion within dependency constructions using large-scale corpus evidence. This method provides an objective estimate of the degree of lexical association and structural tightness between the two components of a given dependency relation, thereby reducing reliance on subjective linguistic intuition. In essence, the procedure operationalizes syntactic relations by converting them into statistically measurable indicators of association strength. Through this computation, the system can automatically identify high-frequency, tightly bound constructions that may function as prefabricated chunks. Finally, MI values were calculated for all dependency constructions in the reference corpus and stored in a DC association-strength database. For each construction (word A, dependency, word B)—where dependency denotes the specific relation type—its association strength was computed using the following MI formula:



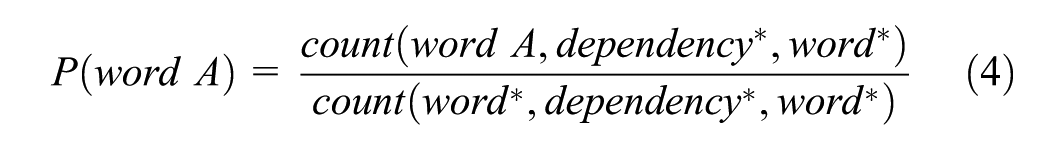

Note that in the formula above, the asterisk (*) denotes a wildcard, representing any word.
Regarding the extraction of DCFs, calculations were performed for the metrics defined in Table 3. At the text level, using the information obtained from the aforementioned preprocessing steps, the type-token ratio (TTR) of dependency constructions, the proportion of each DC type, and the mean dependency distance (MDD) were computed, as summarized in Table 4. Frequency-related features, including the mean and variance of DC frequency, were derived by retrieving background frequency information from the DC frequency database. Additionally, association strength values for each DC were extracted from the DC association-strength database. From these, the maximum dependency distance (MaxDD) was obtained, and overall syntactic association strength metrics were calculated at the text level. Table 5 presents the association-strength-related features of composition texts across different proficiency levels.
Distribution of Dependency Construction Association Strength by Proficiency Level.

Based on the procedures described above, all complexity features were automatically extracted and computed.
Following the automated extraction of DCFs, traditional complexity features (TCFs) were also extracted. While DCFs capture dependency-level structures, TCFs focus on more surface-level and statistical aspects of language. Unlike DCF, TCF extraction does not require dependency parsing; instead, it relies on lexical, part-of-speech, and discourse-level information. The extraction process includes three categories of features: lexical richness (e.g., word frequency, lexical diversity), syntactic complexity (e.g., sentence length), and topic-chain coherence (e.g., referential continuity, topic persistence). Methods for computing lexical and syntactic features were adapted from Yin (2022), which employs statistical and sequence-based models to quantify text complexity without deep syntactic analysis. Topic-comment-unit-based features were extracted following Hu et al. (2022), which track topic continuity across sentences using anaphora resolution and entity coherence metrics.
Machine Learning Modeling for Text Complexity Prediction
To evaluate the predictive capacity of dependency construction (DC) features in text classification, this study conducted automated prediction experiments using two machine learning algorithms: logistic regression (LR) and random forest (RF). The LR model applies a sigmoid function to map the linear model outputs to the [0,1] interval, providing probabilistic predictions. As a linear model, LR is relatively simple and widely used. In contrast, the RF model is an ensemble learning method that constructs multiple decision trees as base learners. RF inherently captures non-linear relationships, demonstrates high predictive accuracy, exhibits robustness to outliers and noise, and is less prone to overfitting. Selecting these two distinct model types allows for a comprehensive assessment of the predictive value of the proposed features. Model training was evaluated using 10-fold cross-validation. Hyperparameter optimization was performed through a randomized grid search, with the best parameters applied for final model training on the training set. Based on this setup, four automated text complexity prediction experiments were conducted, as detailed below:
Configuration 1: Prediction with LR using TCFs.
Configuration 2: Prediction with RF using TCFs.
Configuration 3: Prediction with LR using DCFs.
Configuration 4: Prediction with RF using DCFs.
These experiments allow for a systematic comparison of feature sets (TCFs vs. DCFs) and different models (linear vs. non-linear) in predicting text complexity.
Assessing model performance is a critical component of any natural language processing task. In this study, prediction models were evaluated using standard performance metrics, including accuracy, precision, recall, and F1 score. Among these, the F1 score provides a balanced measure that combines precision and recall, offering a comprehensive indication of overall model performance. These metrics are employed to compare the predictive effectiveness of models based on different feature sets and algorithms.
Results
RQ 1 Performance Comparison Between DCFs and TCFs
Using two machine learning models (LR and RF), this study conducted four text complexity prediction experiments to examine how different feature sets influence classification performance. Across all evaluations—accuracy, precision, recall, and F1—the Dependency Construction–based Features (DCFs) consistently outperformed the traditional complexity features (TCFs) in both models. This pattern indicates that DCFs provide a more informative representation of learner writing for automatic proficiency prediction.
Overall Prediction Performance Across All Proficiency Levels
As shown in Table 6, the Dependency Construction–based Features (DCFs) deliver markedly stronger performance than the traditional complexity features (TCFs) across all four evaluation metrics—accuracy, precision, recall, and F1-score—in both LR and RF models. Although TCFs already achieve solid results (83.87% accuracy with LR and 89.39% with RF), such performance largely reflects the broad and well-established coverage of the TCFs employed in this study.
Results of DCFs and TCFs in LR and RF models.

In contrast, DCFs exhibit consistently superior results in both classifiers. In the RF model, the accuracy and F1-score of DCFs exceed 91%, a level that approaches the overall grading consistency typically observed among human experts. When directly comparing the two feature sets, the advantage of DCFs becomes more evident. With the LR classifier, DCFs improve upon TCFs by 3.23%, 3.51%, 3.32%, and 3.21% in accuracy, precision, recall, and F1, respectively. A similar pattern emerges with the RF classifier, where DCFs yield gains of 2.22%, 2.32%, 2.22%, and 2.22% in the corresponding metrics.
Taken together, these findings demonstrate the clear superiority of DCFs over TCFs in overall prediction performance. This improvement likely stems from the structure of DCs, which encode lexical information alongside inter-word combinational relationships—capturing phrasal-level organization that aligns with the view that multiword constructions constitute fundamental units of language.
Level-Wise Prediction Performance
From the perspective of individual proficiency levels (low, medium, high), the DCFs consistently achieved higher performance than the TCFs across both machine learning models. Given that the RF model outperformed the LR model overall, the following discussion focuses on the RF results. Figures 4 and 5 present the three-class confusion matrices for the TCFs and DCFs under the RF model, where the labels 0, 1, and 2 correspond to low, medium, and high proficiency levels, respectively. The horizontal axis indicates the model’s predicted classes, and the vertical axis represents the actual labels, with each cell showing the number of texts falling into that prediction–actual pair.
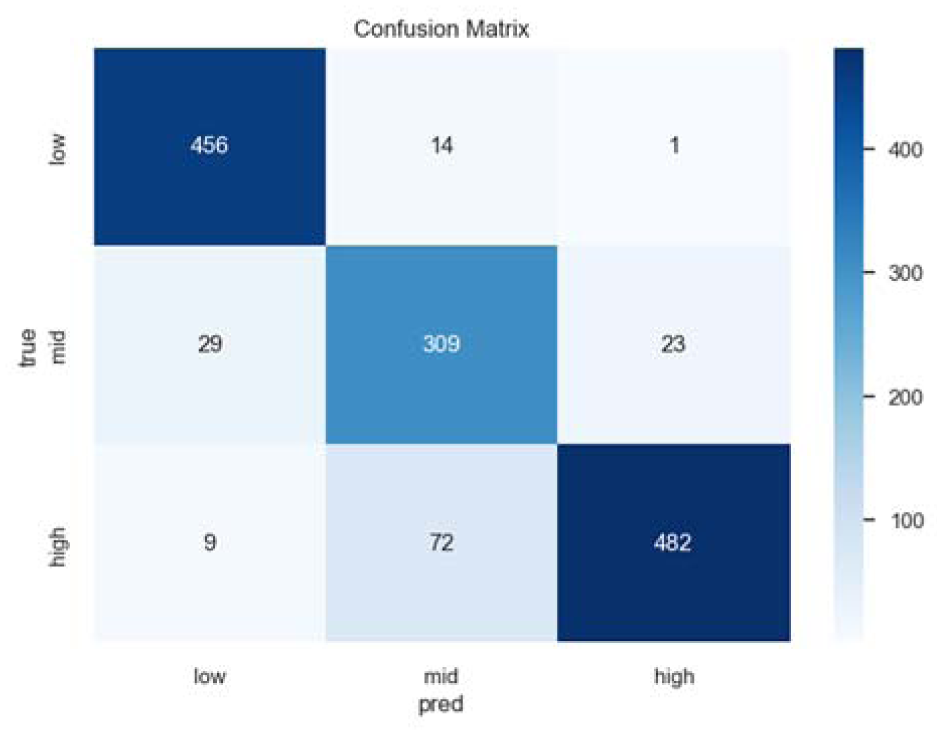
Confusion matrix for the three-class prediction using TCFs with LR.

Confusion matrix for the three-class prediction using DCFs with RF.
As shown in Figure 4 (TCFs) and Figure 5 (DCFs), the level-wise accuracies of the RF model exhibited a consistent pattern. With TCFs, the accuracy for the low, medium, and high levels were 92.31%, 78.23%, and 95.26%, respectively; With DCFs, these accuracies increased to 94.11%, 80.85%, and 97.80%, respectively.
A stable tendency across feature sets is that prediction accuracy is highest for high-level texts, followed by low-level texts, with medium-level texts being the most difficult to classify. This trend aligns with the intuition that intermediate texts often exhibit mixed characteristics, making boundary distinctions less clear.
The confusion matrices further reveal that misclassifications predominantly occurred between adjacent levels. For instance, the most frequent error type was high-level texts misclassified as medium, with 72 cases in Figure 4 and 69 cases in Figure 5. In contrast, non-adjacent misclassifications were rare; for example, as shown in Figure 6, no low-level text was incorrectly classified as high, indicating that the models maintained strong discrimination between the extremes of the proficiency spectrum.

Accuracy of DCFs and TCFs using LR.
RQ 2 Performance Comparison Between LR and RF Models
Across both feature sets, the random forest model consistently outperforms logistic regression. As shown in Table 6, when using DCFs, random forest exceeds logistic regression by 4.51% in accuracy, 1.35% in precision, 4.51% in recall, and 4.32% in F-score, demonstrating a clear overall advantage.
The confusion matrices further illustrate these differences. Figures 4 and 5 show the three-class results of logistic regression under TCFs and DCFs. Compared with random forest, logistic regression displays a much higher rate of misclassification between non-adjacent proficiency levels. For example, with TCFs, logistic regression mislabels high-level texts as low-level 15 times and low-level texts as high-level 10 times—substantially more than the errors made by random forest.
This pattern suggests that logistic regression struggles to accommodate the non-linear relationships present in linguistic feature interactions. As a linear classifier, it has limited expressive capacity. In contrast, random forest—an ensemble of decision trees—naturally captures non-linear patterns, reduces variance through aggregation, and ultimately provides stronger generalization in this prediction task.
Discussion
The results of this study indicate that the DCFs consistently outperform the TCFs in predicting L2 writing complexity. This advantage is observed across multiple evaluation metrics and different models, demonstrating the robustness of DCFs for text complexity assessment. These findings provide strong empirical evidence supporting a construction-based approach, highlighting its capacity to capture both lexical and syntactic interrelations. Beyond methodological validation, the results offer valuable insights into the developmental patterns of text complexity in L2 writing, suggesting that dependency constructions-based features can more accurately reflect learners’ language development.
The Superiority of DCFs Over TCFs: Theoretical Explanations and Their Empirical Basis
As shown in Figures 6 and 7, DCFs consistently achieve higher prediction accuracy than TCFs under both logistic regression (LR) and random forest (RF) models, demonstrating their clear, robust, and substantially superior predictive performance.

Accuracy of DCFs and TCFs using RF.
Theoretical and Empirical Basis for DCFs’ Superiority
DCFs outperform TCFs not because of model-specific artifacts but because they encode a genuinely richer representation of linguistic complexity in L2 writing. This pattern converges with prior arguments that phrase- and construction-level features capture critical aspects of complexity that traditional lexical- and syntactic-level metrics often miss (Kyle & Crossley, 2018; Paquot, 2019). In addition, the present study provides a more rigorous test of this claim than earlier work. The TCF baseline was intentionally constructed to be comprehensive, encompassing 23 well-established features drawn from lexical, syntactic, and topic-comment–based dimensions. By contrast, reference feature sets in studies such as Hu et al. (2022) were comparatively narrower, focusing primarily on topic–comment units. The fact that DCFs consistently surpassed this broad and methodologically robust TCF baseline strengthens the interpretation that their advantage reflects a substantive improvement in how linguistic complexity is operationalized, rather than a byproduct of limited comparisons or restricted benchmarks.
Superiority Supported by Construction Grammar
The theoretical foundation of DCFs explains why they consistently outperform traditional feature sets. Their advantage lies in their ability to encode linguistically complete units. Whereas TCFs treat lexical and syntactic features as separate, atomized elements, DCFs represent the patterned co-occurrence of words within their syntactic environments, thereby capturing constructions as integrated form–meaning pairings. This modeling choice is theoretically motivated: Construction Grammar posits that constructions, rather than isolated words, constitute the basic building blocks of language (Goldberg, 2006).
By operationalizing constructions as measurable units, DCFs translate a construction-based view of grammar into a computationally tractable framework. The empirical success of this approach reinforces the theoretical move away from lexical-centric metrics and underscores the explanatory value of construction-based representations. Beyond methodological implications, these findings also speak to language pedagogy, highlighting the need to foreground the teaching of constructions as central units of linguistic knowledge.
The Superiority of RF Over LR: Alignment with Language as a Complex Adaptive System
As shown in Figures 8 and 9, RF consistently and substantially outperforms LR on both the DCFs and TCFs. This advantage is not purely algorithmic but theoretical: RF better accommodates the defining properties of language as a complex adaptive system (CAS), particularly the non-linear interactions that arise among linguistic features.

Performance of LR and RF using TCFs.

Performance of LR and RF using DCFs.
Linguistic Complexity from a CAS Perspective
Language complexity is inherently multidimensional (Bulté & Housen, 2012; Norris & Ortega, 2009), a view supported by the conceptualization of language as a CAS (Cameron & Larsen-Freeman, 2007; Liu, 2018). In the present study, features from DCF and TCF serve to characterize L2 learners’ compositions, which can be considered fundamental elements of the L2 language system. Crucially, these elements do not operate independently; rather, they interact, synergize, and constrain one another in dynamic, configuration-specific ways. From this perspective, isolating individual features and quantifying their separate contributions to complexity is inherently limited. Accordingly, we input the full feature set into machine-learning algorithms. To evaluate the empirical consequences of modeling these interactions linearly versus non-linearly, we systematically compare the predictive performance of linear models (e.g., LR) with that of non-linear models (e.g., RF).
From Linear Constraints to Non-Linear Modeling
As a generalized linear model, logistic regression (LR) is built on the assumption of a linear decision boundary. It separates complexity levels through a hyperplane derived from a weighted linear combination of features. This additive structure—where feature effects are simply summed—cannot adequately represent the complex interaction patterns characteristic of linguistic complexity, as such features are seldom independent or purely additive. Consequently, LR’s linear kernel is inherently constrained when faced with the intricate interdependencies among linguistic features. This limitation helps explain the instability and limited explanatory power frequently reported in studies that rely on linear models to link individual linguistic features with text complexity: the linear assumption simply cannot capture the genuinely non-linear nature of linguistic complexity.
In contrast, random forest (RF), as an ensemble learning method, is intrinsically suited to modeling complexity (Breiman, 2001). RF constructs multiple decision trees and aggregates their outputs—for example, through voting or averaging. Its key advantage lies in its ability to automatically capture non-linear relationships and higher-order feature interactions without requiring explicit specification. Through recursive partitioning of the feature space, RF learns decision rules far more flexible than a single hyperplane. This capacity to model intricate relational structures allows RF to better exploit the multi-dimensional linguistic information encoded in feature sets such as DCF. In essence, RF’s distributed, multi-pathway decision process aligns more closely with the behavior of language as a complex adaptive system.
The Role of Data
Large-Scale Data as a Prerequisite for Robust Modeling
The strong performance of machine learning models—particularly non-linear models such as random forest—relies fundamentally on the availability of large, high-quality datasets. The present study benefits from a substantial and well-balanced sample of 6,975 L2 compositions, with each proficiency level represented by more than 2,000 texts. This scale provides a sufficiently rich empirical basis for the model to learn stable, discriminative feature patterns. For multi-tree ensemble models, large-scale data is especially advantageous. It allows the model to capture a broad range of linguistic phenomena, including low-frequency but highly diagnostic features. Moreover, a dataset of this size increases statistical power, strengthens generalization, and reduces the risk of overfitting—issues that are difficult to avoid with small samples. This study’s dataset, comprising nearly 7,000 balanced essays, stands in stark contrast to the much smaller corpora used in earlier research, which often contained fewer than 1,000 texts, whether in studies of Chinese (e.g., Hu et al., 2022; Zhu & Xiong, 2025) or English (e.g., Kyle & Crossley, 2018). The markedly larger data foundation in the present work is therefore not merely a quantitative improvement but a methodological necessity for applying more powerful, non-linear models. Given this perspective, it is reasonable to infer that data scarcity was a primary factor limiting the adoption of non-linear machine learning approaches in previous studies. Recognizing the foundational role of large-scale data is thus essential for advancing methodological development in text complexity research.
Conclusion and Implications
This study presents a comprehensive analysis of dependency construction-based features (DCFs) and validates their utility using machine learning models on a graded large-scale L2 Chinese writing corpus. The findings challenge the traditional “vocabulary–syntax” dichotomy in L2 writing research, showing that dependency constructions, rather than isolated words, provide a more fundamental and effective unit for characterizing the development of writing proficiency. This evidence from L2 Chinese writing supports core tenets of the theory of Construction Grammar, emphasizing that linguistic knowledge is composed of prefabricated constructions, and encourages a paradigm shift in analysis from “words” to “constructions.”
Methodologically, the study establishes a rigorous, replicable framework. The use of a large, balanced corpus ensures reliability and generalizability, capturing low-frequency yet linguistically significant phenomena. The systematic construction of a feature set encompassing 44 types of dependency relations addresses the fragmentation issues often found in prior research. Furthermore, applying multiple machine learning models (e.g., LR and RF) allows robust cross-validation and leverages their ability to handle complex non-linear relationships, exceeding the capabilities of traditional linear methods. This approach provides model-agnostic evidence supporting the conclusions and offers methodological insights for future studies.
The implications extend to both pedagogy and technological applications. In L2 Chinese instruction, the results suggest shifting the focus from isolated vocabulary learning to explicit teaching of high-frequency, authentic constructions. For learners, cultivating “construction awareness” is essential for enhancing linguistic authenticity. Technologically, the validated DCF feature set and complexity prediction models can serve as core modules in next-generation automated essay scoring (AES) systems, demonstrating clear practical value.
Nonetheless, this study has limitations that offer directions for future research. Currently, the feature set focuses primarily on sentence-level phenomena; incorporating discourse-level features such as cohesion and coherence could yield a more comprehensive representation of text complexity. Additionally, exploring explainable AI methods to interpret the contributions of individual features would provide deeper insights into model decision-making and further enhance the interpretability and utility of the DCF framework.
Footnotes
Consent to Participate
Not applicable. This study is a corpus-based analysis of publicly available texts and does not involve human participants or primary data collection from individuals.
Author Contributions
Xiaojun Yin: Conceptualization, Methodology, Writing—original draft preparation. Zihao Zhang: Methodology, Data curation, Writing—original draft preparation, Writing—review and editing. Xi Ding: Writing—review and editing.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research project is supported by the National Social Science Fund of China: Research on Grammatical Typological Differences and Knowledge Base Construction for International Chinese Education (23BYY172).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
Data will be made available on request.