
Abstract
This study aims to reveal the major risks faced by users in the insurance technology (Insurtech) sector and examine research and development trends in this field. This study employed the PRISMA protocol to screen 99 relevant records from the Web of Science database. Subsequently, the authors utilized RStudio and VOSviewer for data visualization analysis. First, the study identified the risks, including privacy risk, security risk, fraud risk, algorithmic bias, systemic risk, financial risk, regulatory risk, and claims risk. Second, scholarly attention to Insurtech risk began in 2006, reaching its peak in 2022. The cluster analysis shows that the core research includes risk and trust, technological fairness, blockchain, artificial intelligence, data security, cyber risks, and privacy concerns. There is also an observed evolutionary shift in theme from information security and privacy protection to algorithmic transparency and technological fairness. Further, this study suggests future research should strengthen cross-national collaboration, develop a “risk identification-assessment-response” framework, and pay attention to potential risks that may arise from emerging technologies such as generative artificial intelligence (GenAI) and Industry 5.0. All in all, this study systematically maps Insurtech risks from the user perspective, thereby overcoming the limitations of previous research, which primarily focus on corporate and regulatory viewpoints. Lastly, the findings provide industry practitioners with references for risk governance, while also expanding the theoretical framework of Insurtech risk for the academic community.
Keywords
Introduction
The insurance industry plays a vital role in the financial system, providing protection for the smooth operation of the social economy while supporting economic development through risk diversification and compensation. The advent of cutting-edge technologies such as artificial intelligence (AI), big data, and blockchain, has accelerated the integration of technology into insurance technology (Insurtech). Compared to traditional insurance, Insurtech offers distinct advantages, including enhanced operational efficiency, improved customer experience, and promoting larger market accessibility. For instance, machine learning (ML) optimizes claims processing by reducing errors and improving data accuracy (Komperla, 2021), while blockchain-based smart contracts automate business processes, boosting efficiency and transparency (Borselli, 2020). Additionally, big data analytics enables personalized risk assessment and dynamic pricing, facilitating more flexible insurance services (Van Anh & Duc, 2024). However, the rapid rise of Insurtech, while presenting innovative opportunities, has triggered significant academic concerns regarding its associated risks.
Insurtech’s risk threats stem from the aspects of data security, algorithmic fairness, and technical transparency. From users’ perspective, vulnerabilities such as hacking and data breaches threaten personal information security and also erode their trust in Insurtech (Ali Albasheir, 2023). The technological complexity and opaque decision-making process, particularly in algorithm-driven pricing and claims, can lead to discriminatory outcomes, placing users in disadvantaged situations (Lee et al., 2024; Paul, 2024). This opacity is especially pronounced in technology-dependent areas (such as credit assessment based on big data), where users often struggle to understand the algorithm’s decision-making logic and perceive a lack of reliability, fostering to skepticism and unease. Notably, these risks often intertwine. Data privacy concerns, unfair algorithms, and technological opacity may occur simultaneously, compounding user apprehension toward Insurtech.
Moreover, the integration of technology into insurance introduces new challenges. Small and medium-sized insurers, constrained by limited financial and technological capabilities, risk being eliminated from the market due to difficulties in adapting to digital transformation. Even among highly digitized insurance firms, system failure or cyberattacks threaten the security of user data and affect normal business operations (Aivazpour, et al., 2022; Ali Albasheir, 2023). This intensifies pressure on insurance companies to maintain their brand reputation and attract new users. Additionally, the occurrence of negative events related to technology may prompt stricter regulatory requirements and higher compliance costs for the insurance industry, potentially hindering the widespread adoption of Insurtech.
Despite growing academic attention on Insurtech risk, existing research still has some limitations. First, while existing research predominantly focuses on specific risk types, the exploration of multidimensional risk perspectives remains limited (Baboo, 2025; Celestin & Vanitha, 2022). Hence, this paper aims to bridge this gap by assessing eight risks users face while utilizing Insurtech services. In relation, the study provides actionable insights to researchers and industry practitioners in addressing Insurtech-related risks that threaten user experience. Second, regional explorations of Insurtech risks are fragmented and lack comprehensive analysis. In response, this paper presents an overview of research trends in the field from a global perspective, reviewing existing studies from several countries. Third, although the existing landscape of Insurtech risk research, such as Cappiello (2018), has been explored mainly from the perspective of insurance companies, this research focuses on examining the risks of Insurtech from a user’s perspective. This is based on the concerns raised by past scholarly bodies, such as Hassan et al. (2023), who pointed out that if Insurtech is perceived as carrying high risk, user adoption willingness may be inhibited. This suggests that high perceived risks, if left unaddressed, could become barriers to the widespread adoption of Insurtech.
To bridge these identified gaps in the existing body of research, this study systematically analyzes the literature related to Insurtech risk and focuses on answering the following research questions:
This paper begins with an introductory section, followed by a review of the literature related to Insurtech risk. Next, this study introduces the data collection process and bibliometric methodology. Subsequently, this paper presents the results and findings, and proposes future research directions.
Theoretical Background of the Research
The primary objective of this study is to investigate the major types of risks that users may encounter when utilizing Insurtech services. Past scholarly research has been conducted based on various theoretical perspectives. Theories such as the Technology Acceptance Model (TAM) and the Unified Theory of Technology Acceptance and Use (UTAUT) have often been employed to explain how risk influences users’ decisions in the adoption of Insurtech (Hassan et al., 2023; Shah et al., 2026). However, these theories were used to justify users’ adoption and use of Insurtech rather than in identifying what constitutes its associated risk. To better capture the risk factors, this paper draws on the Perceived Risk Theory as its theoretical foundation. This is based on the justification that Perceived Risk Theory focuses on individuals’ risk perceptions in uncertain and potential loss situations. Thus, it is suitable for identifying the various risk categories faced by users in Insurtech contexts.
Perceived Risk Theory
Perceived risk, first proposed by Bauer in 1960, highlights consumers’ subjective perception of potential losses when facing uncertainty (Trinh et al., 2020). Kaplan et al. (1974) later refined it into five dimensions: performance, financial, social, psychological, and physical. However, the importance of these five dimensions varies in different contexts, and the priority changes within different application scenarios. In Insurtech, users’ concerns are typically centered on the potential impact of risk on various aspects, including performance, financial, and psychological aspects. For example, some scholars explained that users’ concerns stem from anxieties about system stability, financial losses, and privacy issues (Talesh & Cunningham, 2021; Umran et al., 2025).
In contrast, further studies revealed that social and physical aspects are not the main concerns of Insurtech users. This perception may stem from the notion that Insurtech, being a human-computer interaction (individuals and platforms), does not rely on social interactions and is not directly related to physical health or personal safety (de Andrés-Sánchez & Gené-Albesa, 2024). Hence, the social and physiological dimensions of perceived risk are not attributable in this context.
In this study, in line with the established risk areas, Insurtech’s user-perceived risk is explored in terms of the dimensions of psychological, performance, and financial aspects. The psychological dimension reflects users’ anxiety and uneasiness when the outcome is uncertain, and information is difficult to grasp, specifically including concerns about privacy risks, security risks, and regulatory risks (Bruce et al., 2018; Xu & Zweifel, 2020). The performance dimension refers to the user’s concern about the ability of technical systems and service processes to function consistently in line with their expectations. This encompasses three common manifestations: system risk, algorithmic bias, and claims risk (Infantino, 2025; Umran et al., 2025). On the other hand, regarding the financial dimension, the related risks primarily concern issues that could lead to actual financial loss, mainly in terms of financial risk and fraud risk (Shah et al., 2026). These major risks form the underlying framework for identifying user-perceived risks in the Insurtech sector.
Risks Faced by Insurtech Users
Based on the existing body of scholarly literature, it can be inferred that privacy risk is one of the most significant concerns in the Insurtech sector (Braun & Jia, 2025). According to the concept of perceived risk theory, privacy risk can be categorized under psychological risk. This is reflected in users’ experience anxiety and unease over potential leakage or misuse of their sensitive personal information (Solove & Citron, 2017). Basil et al. (2022) argue that users are cautious about storing and sharing sensitive information, such as personal health records and behavioral tracking data. This caution arises from the possibility of data misuse or unauthorized access by third parties, which could result in invasion of privacy or financial loss.
Moreover, some studies have raised concerns about the risks to data security that users face when using Insurtech services (Celestin & Vanitha, 2022; Manes, 2020). The frequent hacking incidents encountered by users have further eroded public trust in the technology platforms (Vukotich, 2023). Despite operators’ continuous enhancement of data encryption and privacy protection measures, the opacity of algorithmic decision-making and centralized data storage exacerbates users’ anxiety (Zerilli et al., 2019). This causes users to be uncertain about the effectiveness of their information protection.
Data breach extends beyond privacy and users’ information security by creating new operational space for financial fraud. According to the perceived risk theory, users’ subjective concerns about this potential economic loss are categorized as financial risk. In Insurtech, users’ perceptions of financial risk are mainly characterized by the fear of actual economic losses resulting from inappropriate monetary expenditures and the fraudulent loss of funds from accounts (Stoeckli et al., 2018). Thus, uncertainty associated with the expenditure or loss of money constitutes an essential component of the user’s perceived financial risk.
In terms of the fraud risk in Insurtech services, phishing scams occur when fraudsters disguise themselves as legitimate entities, trick users into clicking on fraudulent links, and manipulate users into performing malicious actions (Ali et al., 2018; Stojnic et al., 2021). Clicking on sham links causes fraudulent entities to access people’s data and extract their sensitive information. Illegally obtained information, such as insurance records, contact information, and payment details, can be used for transactions and activities that can put the owners at high risk. In these scam cases, users often find it difficult to recognize the transactions’ authenticity, causing them to suffer financial losses without even realizing it.
Moreover, prior research, such as Kim and Kim (2025), notes that users’ concerns about the operational stability of Insurtech platforms are reflected in their perceptions of systemic risk (Kim & Kim, 2025). An important consideration is that the complexity of Insurtech’s technical architecture and its dependence on platform-based services have heightened users’ expectations for higher levels of technical management and system integration. Imperfections in technology management and internal system integration can lead to disruptions in platform services, resulting in problems such as interrupted user transactions and data loss (George et al., 2024). Hadan et al. (2024) supported this notion by arguing that frequent platform instability or technical failure erodes users’ confidence in system predictability and controllability, which raises concerns about its reliability.
Furthermore, existing studies indicate that users’ concerns about Insurtech services also stem from claims risk (Braun & Haeusle, 2024; Joginipalli, 2022). This includes uncertainties such as low transparency in the claims process and the possibility that claims outcomes may not be successfully approved. Within the theory of perceived risk, this is typically regarded as a performance risk. That is, users worry that the product or service may not function as effectively as expected or fulfill its promised capabilities. The opacity of automated claims systems in Insurtech exacerbates the occurrence of risks. While algorithm-driven standardized rules reduce the probability of making manual errors to some extent, once users’ data input is biased, they may still be at risk of being denied a claim, even if the claim request is reasonable.
These arguments collectively demonstrate that the issue of algorithmic bias in systems used by Insurtech users is a topic of significant academic interest today. Specifically, many Insurtech platforms rely on big data or third-party data sharing to assess users’ credit ratings or insured risks (King et al., 2021). Digital platforms may misjudge users’ information due to reasons such as inaccurate data, algorithm design flaws, or algorithmic bias (Lee et al., 2024). Users struggle to understand the assessment mechanisms of digital platforms, resulting in a lack of clarity about the reasons behind their credit ratings dropping or claims being denied. Thus, they also lack sufficient information to lodge effective appeals against unfavorable decisions. In the context of inadequate or ineffective regulation, algorithmic bias may lead to unfair insurance pricing or claims decisions, thereby infringing on users’ rights and interests (Paul, 2024).
Finally, there is one type of risk that is often overlooked, but it is one that Insurtech users always face. This is the regulatory risk. Insufficient regulatory compliance and poor platform performance often erode users’ trust in Insurtech. However, the refinement of regulatory policies often lags behind the pace of technological innovation, as legal frameworks must strike a balance between promoting technological development and maintaining market discipline (Crandall & Flamm, 1989; Ranchordás, 2014). Some studies have noted that imperfections in the regulatory system have led some insurance platforms to utilize legal loopholes to evade contractual obligations. Examples include designing ambiguous clauses or arbitrarily adjusting rules to avoid making claims payments. Therefore, due to the lack of effective legal protection and rights defense mechanisms, users often struggle to obtain legal aid when their rights and interests are violated.
While these issues are intertwined, any of them could become a barrier to the adoption of Insurtech. Hence, based on the Perceived Risk Theory and the discussion above, Table 1 presents a summary of common risk types encountered by Insurtech users.
Risks Faced by Insurtech Users.

Source. Compiled by the authors.
Methodology
Review Methods
This study uses the bibliometric approach to analyze literature in the field of Insurtech risk. Bibliometric analysis, which is a scientific research method based on quantitative data, can systematically sort out the research status of a specific field through a structured review (Donthu et al., 2021). Unlike the traditional literature review, bibliometric analysis prioritizes objectivity and reproducibility of data, effectively reducing subjective bias. Moreover, it’s widely used to identify research hotspots, key themes, and research trends.
The Web of Science was selected as the database for this study due to its global recognition as a platform for high-quality academic peer-reviewed research. It contains authoritative journals and research results in a wide range of subject areas (Birkle et al., 2020), thereby providing comprehensive and reliable data support for this study. For the data analysis process, RStudio and VOSviewer were employed in this study. RStudio is an integrated development environment for the R programming language, as reflected in its wide usage by academics and scholars in data analysis, statistical computing, and data visualization (Derviş, 2019). VOSviewer excels in visualizing literature data and is widely used for co-occurrence analysis and cluster analysis in academic research. Combining these two tools, this study visualizes and presents the current research status in the Insurtech risk field. The visualization includes the research distribution, author collaboration methods, and keyword clusters. Moreover, the extensive data mining and analysis strategy adopted in this study is presented in Figure A1. This comprises three components: search strategy, scholarly filtering, and bibliometric analysis.
Data Collection and Processing
Designing a comprehensive and rigorous search strategy is essential to ensuring the reliability of data for bibliometric analysis. This study followed the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) process for data collection and processing to achieve satisfactory academic standardization and rigor, as presented in Figure 1.

PRISMA flowchart.
This study’s search time range in the Web of Science database was set from 2000 to 2024 to comprehensively cover the academic research in the field of Insurtech. The search string design used was based on keywords and synonyms related to Insurtech and its main risks. The search was performed by concatenating the keywords into search strings using Boolean operators. A total of 1,326 literature works were initially obtained. To prepare the data for analysis, the author performed comprehensive data cleaning and screened the results. This helps in including only relevant papers in the dataset. This was achieved by identifying and deleting duplicates. Regarding language, only English-language publications were retained. For the literature type, only research papers were included. The non-research materials, such as conference papers, book chapters, editorial content, review articles, and conference abstracts, were excluded.
Subsequently, the author preliminary assessed the literature based on titles and abstracts, excluding studies unrelated to the research topic; studies related to insurance technology risks from the user perspective were included. To ensure consistency in the literature screening process, two researchers independently performed this operation using uniform criteria. Cohen’s Kappa coefficient was used to assess the consistency between the two researchers’ screening results, yielding a value greater than 0.6, which indicates that the screening possesses good consistency (Li & Yu, 2022). Finally, the authors identified 99 articles related to this study.
Results and Findings
Annual Scientific Production
The trend in annual scientific research production on Insurtech risk-related topics between 2000 and 2024 is illustrated in Figure 2. The years from 2000 to 2016 recorded sparse publications of annual research and slower growth rates. The trend in this Insurtech’s early period reflects that the topic was at its exploration stage, and its associated risk warranted limited scholarly attention. The number of studies in this area started growing in 2017, peaking in 2022, which recorded the year with the highest number of scientific research productions. Thus, although research in Insurtech has been ongoing for decades, acceleration was recorded during the era of emerging technologies. This indicates that the past decade’s integration of artificial intelligence and blockchain in the insurance industry has influenced Insurtech risks to gain preeminence within the academic research landscape. Interest in Insurtech’s risks has also been amplified by the COVID-19 pandemic push toward increased digital adoption of insurance (Pauch & Bera, 2022). However, despite the rise in Insurtech’s research, the body of literature focusing specifically on its risks remains limited, and the field is still in its infancy.

Annual scientific production.
Most Productive Authors
The most productive authors in the Insurtech risk field are listed in Table 2. Among them, eight authors produced two articles, representing the highest number of articles published in this field. In terms of academic impact, Tanwar’s study has the highest number of citations (206), followed by Sharma (97) and Cheng (85), indicating that their studies are influential in the field. It can be observed that the Insurtech risk field has not yet formed a pattern dominated by prominent scholars, and the research team is still relatively decentralized.
Most Productive Authors.

Source. Compiled by the authors using RStudio.
Note. Times cited are based on Google Scholar as of February 2025.
Figure 3 shows the annual distribution of the scientific productions of these authors; the size of each node indicates the number of articles published in a certain year, with darker indicating higher citation frequencies of the articles. In terms of annual distribution, the studies by these productive authors were mainly conducted between 2017 and 2022. A period coinciding with the rapid development of Insurtech, and with it, the issue of potential risk began receiving academic attention. However, it is noteworthy that this research trend did not sustain growth after 2023. This shift may indicate that the current academic focus on Insurtech risks has yet to establish a long-term, stable research team.

Most productive authors over time.
Most Productive Countries
The potential threats of Insurtech to users have become a topic of concern around the world. However, there are differences in scientific productivity in this field across countries. The dataset analysis indicates that studies with high scientific production are mainly concentrated in a few countries. These publications by countries are presented in Figure 4. The result interprets that countries with darker colors indicate higher scientific productivity. The analysis reveals the United States as the country with the highest production in Insurtech risks, with 17 articles. Next are China and India with 15 and 13 publications, respectively. This pattern indicates these countries are more active in contributing to academic research on Insurtech risks. The higher publication pattern may also reflect their population, as these three countries are the three most populous countries globally.

Geographical locations of the reviewed studies.
Aside from the top three contributors, other countries that have significantly contributed to the Insurtech risks research field are mainly located in the continents of North America and Asia. Whereas the research productions in South America and Central Africa regions are relatively limited. This phenomenon highlights regional gaps in insurance technology risk research and reflects the uneven distribution of global academic resources and policy attention.
Although research in this field has reached a certain scale, the current mode of research collaboration is still dominated by single country publications (SCP), with fewer multiple country publications (MCP), as shown in Figure 5. This trend indicates that the mode of research cooperation in this area is mainly within a nation, with less international cooperation. Thus, there is still much room for the development of internationalized collaboration among multiple countries in this field. The lack of multinational collaborative research not only undermines the development of theories with a global perspective but also hinders the formulation of governance recommendations applicable across diverse market environments. To advance knowledge diversity and ensure sustainable practices in this field, future research urgently requires strengthened transnational cooperation.
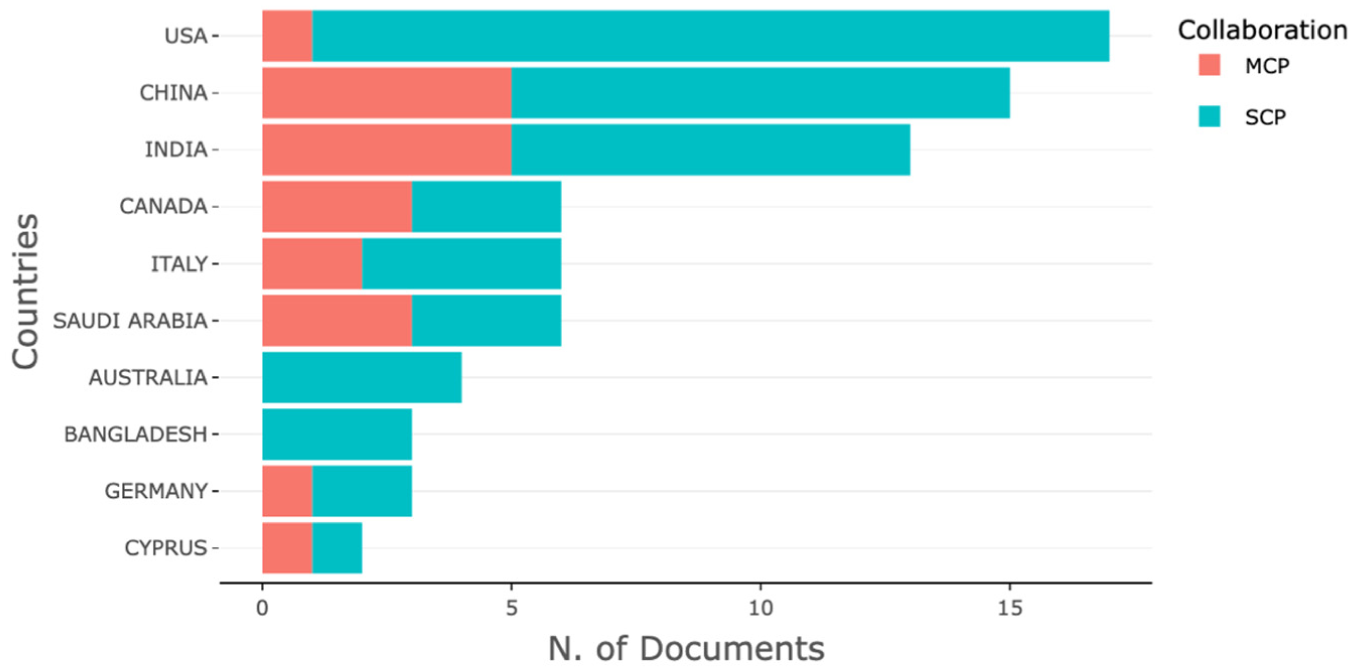
Most productive countries.
Most Relevant Affiliations
Most Relevant Affiliations is usually measured by the number of publications or citations and is used to identify influential institutions in a particular research area. The academic institutions most relevant to this research area, are presented in Table 3. The institutions are mainly located in India, China, the United States, and Saudi Arabia. Among them, Thapar Institute of Engineering and Technology tops the list with three articles, followed by nine research institutions such as Nirma University, Wuhan University, and the University of Missouri System, with two articles each. In terms of academic impact, Nirma University is the most cited (206 times), followed by Thapar Institute of Engineering and Technology (171 times) and Wuhan University (80 times). This finding indicates that the research field has not yet formed a research pattern dominated by a single institution but rather is driven by multiple academic institutions. Moreover, most of these institutions are located in countries with more active Insurtech development.
Most Relevant Affiliations.
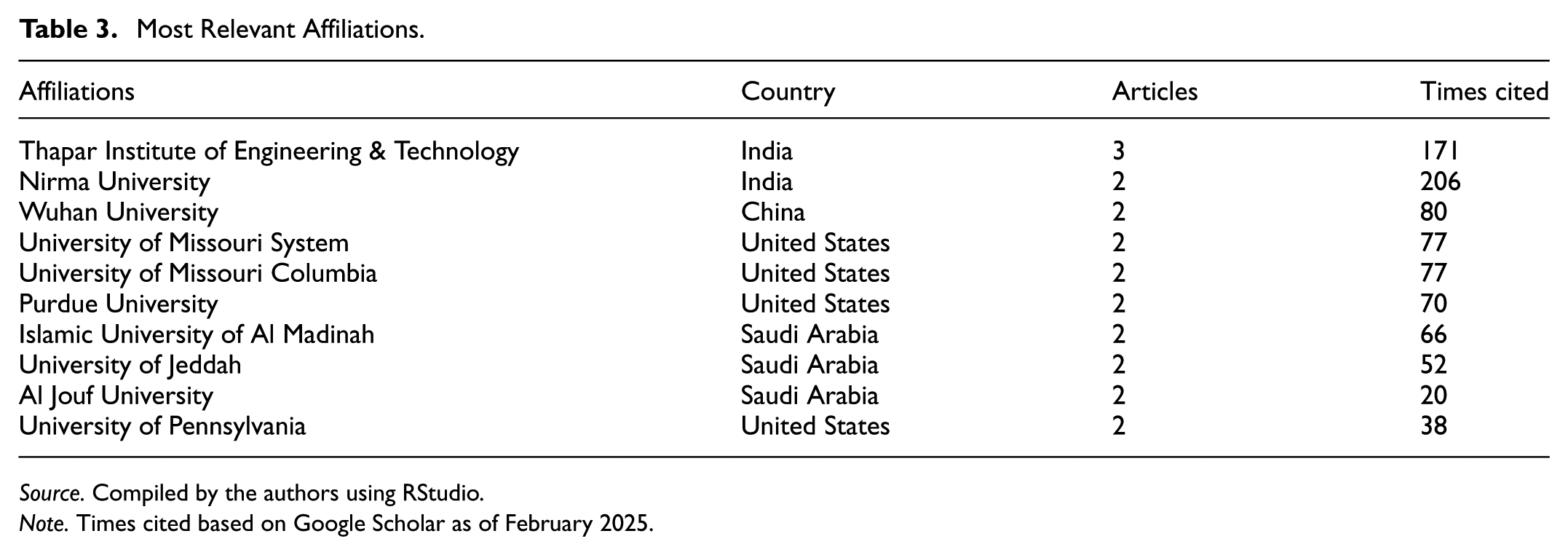
Source. Compiled by the authors using RStudio.
Note. Times cited based on Google Scholar as of February 2025.
Relationship Among Authors, Keywords, and Sources
The three-field-plot visualization, which shows the association between the authors (AU), keywords (DE), and sources (SO), is depicted in Figure 6. The length of each column indicates the number of research productions, with longer columns indicating more productions. Further, the number and the thickness of the connecting lines indicate the degree of association with the topic, with more and thicker lines indicating a stronger connection between the author, journal and the particular research topic. According to Figure 6, the keyword analysis reveals popular research themes in the field, including blockchain, security, insurance, and privacy. Obviously, these themes are closely related to the application of Insurtech in the digital environment and the risk issues faced.

Relationships among authors, keywords, and sources.
In addition, the Figure 6 shows that the academic pattern in this field is relatively decentralized, with multiple authors conducting research mainly independently around their respective research themes. Meanwhile, these studies are mainly published in journals such as IEEE Access, International Journal of Bank Marketing, and Journal of Medical Internet Research. These journals cover the fields of engineering, medical informatics, and marketing, reflecting the diversity of research directions and cross-disciplines in this field. Given that a robust collaborative network among current researchers has yet to be established, future studies could further promote interdisciplinary teamwork and joint publications to explore the multidimensional issues of Insurtech risks more comprehensively.
Co-Occurrence of Keywords Analysis
In this study, VOSviewer was used to perform keyword co-occurrence analysis of the 99 articles screened. A total of 597 keywords were extracted from the keyword field. Among these, 497 keywords appeared only once, accounting for 83.24%. Including all terms would fragment the network and compromise visualization quality. Drawing on keyword distribution patterns and recommendations for medium-scale data processing, this study sets the minimum keyword co-occurrence frequency threshold at 2 (Yang, 2025). This effectively eliminates low-frequency noise while preserving representative research themes. Subsequently, a total of 100 keywords met the criteria and were screened. As a result, 70 keywords that were highly relevant to the research topic were retained, and 30 irrelevant keywords were excluded. The top 20 high-frequency keywords in the co-occurrence analysis are listed in Table 4. Among them, “insurance” and “blockchain” rank first with 17 occurrences, reflecting the core status of these topics in the field. These are followed by “privacy,”“risk,” and “trust” with 14, 12, and 10 occurrences, respectively. In addition, the total link strength of a keyword reflects the degree to which a particular term is closely associated with other keywords in the research network (Alsharif et al., 2020). A higher value of total link strength indicates a higher degree of association of the term with other keywords. “Insurance” has the highest total link strength in this study, reflecting its high relevance to the topic of Insurtech.
Co-Occurrence of Terms.

Source. Compiled by the authors using VOSviewer.
Cluster Analysis of Co-Occurrence of Keywords
The co-occurrence network is a visualization of the distributions and connections of research themes based on the frequency of keyword co-occurrences. In the co-occurrence network structure, keywords with high co-occurrence frequency and total link strength are in the center of the network; while keywords with low co-occurrence frequency and low total link strength are distributed at the edge of the network (Lozano et al., 2019). In addition, the co-occurrence network classifies research themes by nodes of different colors, where nodes of the same color are categorized as a cluster (McAllister et al., 2022). Moreover, the size of the node reflects the frequency of the keyword’s occurrence in the literature, with larger nodes indicating more frequent keyword occurrences.
In this study, VOSviewer generated the keywords into seven clusters in the co-occurrence network, as portrayed in Figure 7. The figure shows that the field consists of multiple interrelated but differently focused research themes. Within the network structure, core keywords (such as “risk,”“trust,”“privacy,” and “blockchain”) occupy the central region of the network, forming dense connections with other secondary themes through numerous links. This indicates that these concepts possess high interconnectivity and centrality within insurance technology research, serving as vital bridges linking diverse research topics. In contrast, themes like “security,”“cyber risk,”“artificial intelligence,” and “smart contracts” are also frequently mentioned. However, the connections between their keywords are weaker, and their frequency of appearance is relatively low. This indicates that their development in current research is not as mature as the former themes. Subsequently, the authors categorized and analyzed themes based on the keywords covered by each cluster.

Keywords co-occurrence network.
Cluster One (Red): Risk and Trust
Cluster one focuses on perceived risk and trust in technology, with keywords including “risk,”“trust,”“perceived risk,”“information technology,” and “disruptive technology.” The crisis of trust has become a major barrier to the promotion of emerging technologies (Li et al., 2008). This indicates that in the insurance technology context, users’ acceptance and adoption of emerging technologies are often accompanied by risk perception and trust considerations. Based on the risk categories identified earlier, this cluster is closely linked to privacy risks, data security risks, and financial risks (Celestin & Vanitha, 2022; Chatzara, 2020), as these pose the most direct threats to users’ trust in the Insurtech. In Perceived Risk Theory, perceived risk manifests as users’ cognitive assessment of potential losses and their tendency to avoid them. Therefore, how to enhance user trust while reducing perceived risks has become a controversial topic in this field.
Cluster Two (Green): Fairness in Technology
The second cluster is related to fairness in the areas of Insurtech, with keywords including “attitude,”“discrimination,”“personalization,”“disclosures,”“life insurance,” and “financial literacy.” With the increasing usage of algorithm-driven personalization services in the insurance industry, the potential ethical and fairness issues have been receiving increasing academic attention. In practice, Insurtech relies on algorithms for key processes such as underwriting, pricing, risk assessment and claims review. However, algorithmic biases may make unfavorable judgments for certain groups. Examples include disparities in insurance pricing based on health records, and specific age or occupational groups being set up for automatic exclusion (Xin & Huang, 2024). In addition, algorithmic opacity restricts users’ right to clarity in information (McKinlay, 2020). However, algorithmic bias and insufficient information disclosure reveal, to some extent, the regulatory risk users may face (Johnson, 2019; Suijs & Wielhouwer, 2019). Meanwhile, disparities in financial literacy heighten the likelihood of fraud and financial risks for low-literacy groups (Wei et al., 2025). As a result, the diffusion of Insurtech may also inadvertently exacerbate social inequality. To mitigate these technology-driven inequities, future efforts must enhance regulatory effectiveness to promote algorithmic transparency and compliance.
Cluster Three (Blue): Blockchain and Smart Contracts
Cluster three focuses on the applications of blockchain and smart contracts in the insurance sector. Emerged keywords include “insurance,”“blockchain,”“smart contracts,”“contracts,” and “management.” This reflects that the blockchain’s data tamper-resistance and smart contracts’ automated enforcement of claims have improved the transparency and efficiency of insurance services (Lavanya & Kavitha, 2022). However, the high degree of automation of blockchain and smart contracts makes handling complex or ambiguous cases challenging, which may lead to misjudgments in claiming (Jin et al., 2024). Currently, academics are still exploring and optimizing the application of blockchain and smart contract technology in the insurance industry. This effectively reveals the claims risks users face when utilizing insurance technology. Claims outcomes may deviate from expectations, and rigid rules may even compromise user rights (Madhala, 2025). Within a risk management framework, establishing a balanced mechanism that integrates automation with human intervention could serve as one approach to mitigating claims risks.
Cluster Four (Yellow): Artificial Intelligence
Cluster four focuses on the applications of artificial intelligence, with keywords including “artificial intelligence,”“machine learning,”“health,” and “healthcare.” In the health insurance industry, artificial intelligence relies on the ability of big data and machine learning to deeply analyze users’ health status and behavioral habits for the purpose of providing a more accurate risk assessment and rational insurance pricing (Zhang & Xu, 2024). However, the application of artificial intelligence is also accompanied by black-box algorithm issues (Adadi & Berrada, 2018; Williams, 2024), which have triggered extensive discussions among scholars on technical transparency. These phenomena not only reveal potential algorithmic biases in AI applications but also highlight compliance risks stemming from lagging regulatory frameworks. When users detect potential discrimination in algorithms or find regulatory mechanisms insufficient to protect their rights, their trust in the technology is inevitably eroded (Ali Albasheir, 2023).
Cluster Five (Purple): Data Security
The fifth cluster focuses on data security issues in technology, with keywords such as “security,”“data breach,”“big data,”“medical services,” and “private data.” Compared with traditional offline insurance business, the whole business process of Insurtech relies on the collection, transmission, storage and analysis of user data. The widespread application of big data in Insurtech and the continued expansion of the scale of user data have increased the risk of data security and privacy breaches (Xia et al., 2017). Particularly in the health insurance sector, the multi-party engagement and information sharing between the insurance industry and the healthcare industry makes it easier for private information such as medical records to face the possibility of unauthorized use on Insurtech platforms. Currently, data security remains one of the issues to be addressed in the insurance industry. Therefore, Insurtech can enhance data security and traceability through encryption technology, blockchain-based evidence storage, and multi-factor authentication mechanisms.
Cluster Six (Gray): Cyber Risk
Cluster six focuses on the issue of cyber risk in technology, with keywords including “cyber risk,”“internet,”“health insurance,”“challenges,” and “usage-based insurance.” Due to the application of big data, artificial intelligence, and cloud computing to optimize business processes, insurance companies face serious cybersecurity threats and have become key targets for hacker attacks. Attackers use phishing attacks, ransomware, and data tampering to steal user information, insurance contract data, and corporate operational data (Alkhalil et al., 2021; Reshmi, 2021). From an insurance technology risk perspective, cyberattacks highlight systemic risks stemming from insufficient system stability (Welburn & Strong, 2022). On the other hand, data breaches caused by cyberattacks create conditions for illegal exploitation, thereby increasing the likelihood of users encountering financial risk (Jimmy, 2024). As cyberattacks continue to escalate, there is still a need for constant attention and optimization defense system for securing users’ data.
Cluster Seven (Orange): Privacy Concern
Cluster seven focuses on the privacy issue in technology, with keywords such as “privacy” and “Internet of Things (IoT).” Privacy risks are also one of the primary risks identified in this study. Privacy issues, which have always been a topic of discussion among many scholars in the Insurtech field, mainly stem from the increased risk of personal data exposure and the potential threat of data misuse. Insurance companies utilize IoT devices (e.g., wearables and internet-connected cars) to collect and store user information (Ritz & Knaack, 2017), extending data access from online to everyday life. Users’ sensitive data are continuously monitored and recorded, including biometrics and location information. While this data tracking enhances business accuracy, it also exposes personal privacy to more serious security risks. In the theory of technology acceptance, privacy concerns undermine users’ trust in insurance technology (Dekkal et al., 2024), thereby reducing their willingness to adopt it. Within the risk management framework, establishing robust data protection mechanisms is regarded as a key approach to mitigating privacy exposure risks.
Thematic Evolution
The thematic evolution of Insurtech risk research shows a clear phase change, as shown in Figure 8. Before 2018, the research focused primarily on insurance service management. The more active terms include “management,”“word-of-mouth,” and “quality,” indicating that research in the early stage focused on business management, customer word-of-mouth, and service quality assessment. In the phase from 2018 to 2020, the research focus shifted to technology trust. Terms such as “trust,”“internet,” and “information technology” became popular, indicating the insurance industry’s increased focus on user trust during digital transformation. In the phase from 2021 to 2024, recent research trends moved from trust to risk management, privacy protection, and the integration of Insurtech with emerging technologies. Terms such as “perceived risk,”“risk,”“blockchain,”“discrimination,” and “personalization” received more attention. This finding indicates that in recent years, scholars have become increasingly concerned about the potential risks of Insurtech, as well as exploring aspects of data privacy, personalization, and algorithmic discrimination.

Trend topics.
The thematic map analysis helps to identify the emerging research themes and future research directions (Singh et al., 2022). This study reveals the structure and trends of Insurtech risk research through a thematic map, as shown in Figure 9. Of the four quadrants, the upper-right quadrant represents the motor themes in Insurtech risk research that dominate the field. The motor themes have not only matured but also occupy a central position within the research network, forming the mainstream of research in this field. The bottom-right quadrant represents basic themes that are not yet mature but possess development potential. These basic themes exhibit strong connections with multiple other themes and may evolve into research hotspots in the future. The upper-left quadrant represents niche themes characterized by in-depth research but limited research scope. These niche themes have relatively weak connections to mainstream research directions. The themes in the bottom-left quadrant are not yet mature or are on the periphery, with their future development paths still uncertain. These themes may either evolve into emerging trends or gradually become marginalized (Hussain et al., 2023).

Thematic map.
According to the information presented in Figure 9, the motor themes of Insurtech risk research focus on trust, privacy protection, personalization, and data disclosure. These themes have driven the academic field’s extensive exploration of data security and privacy protection. Meanwhile, basic themes such as big data, information technology, online, and healthcare form an important underpinning of the field; despite the low research density, these themes are likely to be future research directions in the field. In addition, niche themes such as financial literacy are deeply researched. Although they depict a relatively limited scope of influence, yet, they have important practical implications in research. Financial literacy can affect an individual’s ability to perceive and judge Insurtech risks, which in turn affects their decision-making behavior (Wei et al., 2025). Finally, there are emerging or declining themes such as the internet, governance, and management, which may decline or evolve into new themes in the future as technology or the environment changes. Therefore, future research still needs to focus on the dynamic evolution of these themes.
Conclusion
This study identifies eight types of risks users face in the insurance technology environment, based on Perceived Risk Theory. The findings reveal the urgent need for industry practitioners to establish a systematic “risk identification–assessment–response” framework to detect potential hazards early, quantify their severity, and develop differentiated management measures for different risk types. Among these risks, privacy risks remain a central concern in insurance technology risks. This necessitates the need for Insurtech companies to elevate privacy protection to a strategic priority. Additionally, the research reveals an expansion of Insurtech risks beyond traditional privacy and information security to encompass algorithmic transparency and fairness. This means regulators cannot merely focus on data protection, but also compel them to mitigate discriminatory pricing and claims resulting from algorithmic bias. This can be achieved through establishing algorithmic audits and mandating model disclosures. This insight equips researchers with a deeper understanding of the current research status and research trends in Insurtech. It will also support efforts to protect users’ legitimate rights from infringement. Thus, promoting a sustainable Insurtech innovation.
Despite these contributions, this study has some limitations. First, its reliance on the Web of Science database for data retrieval restricts the data scope. The non-inclusion of other databases, such as Scopus and institutional databases limits the number of publications analyzed by this research (Al-Khoury et al., 2022). This gap can be addressed by subsequent research. Thus, the dataset can be expanded to cover all related papers in Insurtech. Second, the language filter is restricted to English-language literature, potentially overlooking significant findings in non-English contexts and thereby limiting the diversity of international perspectives. Third, the interdisciplinary nature of the research topic increases uncertainty in literature identification. For instance, cross-application scenarios such as artificial intelligence, health insurance, and blockchain are often categorized under different disciplinary fields. Relying solely on abstract screening may result in inadequate coverage of relevant literature. Finally, while bibliometric methods help reveal macro trends, they remain limited in uncovering causal mechanisms. Future research could validate the actual impact of different risk factors on users’ adoption of insurance technology.
Based on the above discussion, it is necessary to propose a future research agenda as a response to the current research gap and limitations. First, future research should not only expand the scope of database coverage but also adopt multi-method approaches to systematically assess and address Insurtech risks. Quantitative methods (such as surveys and experimental designs) can reveal how different risk dimensions influence user adoption behavior (Chatzoglou & Vraimaki, 2010). While qualitative methods (such as interviews and focus groups) help dissect risk generation mechanisms and user perception differences (Peng et al., 2016).
Second, cross-national comparative research urgently requires strengthening. Different institutional and cultural contexts may lead to variations in users’ perceptions and tolerance levels regarding risks such as privacy and regulation (Keh & Sun, 2008). For instance, in European and American countries subject to stringent regulations like GDPR, privacy and regulation become core concerns. Whereas in emerging markets, systemic risks tend to be more heavily emphasized (Rughiniş et al., 2021). Strengthening international collaboration not only enhances the diversity of research perspectives but also provides more universally applicable references for policy formulation.
Third, future research should develop a “risk identification-assessment-response” framework to provide practitioners and regulators with actionable tools. During the risk identification phase, risk types can be clarified through big data mining or questionnaire surveys (Shi et al., 2017). In the risk assessment phase, a quantitative indicator system should be established, such as measuring risks based on both occurrence probability and potential losses (Rot, 2008). During the risk response phase, differentiated management measures need to be proposed for different risks.
Finally, future research should focus on how emerging technologies are reshaping the risk landscape of Insurtech. For instance, while GenAI can enhance the intelligence of claims processing and pricing, it also carries risks of deepfakes and information manipulation (Ferrara, 2024). Similarly, human-machine collaboration in Industry 5.0 may strengthen personalized services but could exacerbate uncertainties surrounding data sharing and liability attribution (Bertolini, 2016). Striking a balance between innovation and risk will become a critical issue for both Insurtech research and regulation.
Overall, this study bridges the gap in previous systematic analyses of insurance technology risks. Based on the above findings, this study visualizes the research results, as shown in Figure 10. From a user perspective, the authors categorize major risk types based on perceived risk theory. In addition, the findings also provide industry practitioners and policymakers with a comprehensive risk landscape. This enables them to systematically grasp the existence of multidimensional risks and their dynamic evolution as technology advances. This study contributes to balancing the development of Insurtech with the protection of user rights and interests, as well as promoting in-depth industry attention to the negative impacts of Insurtech. These are necessary actions toward ensuring a sustainable digital insurance ecosystem.

Science mapping of Insurtech risks.
Footnotes
Appendix
Acknowledgements
The authors would like to thank all researchers, participants, and others who were involved directly or indirectly during data collection and reviewed this manuscript.
Ethical Considerations
This study is a review of previously published work; no new human data were collected and therefore did not require ethical approval.
Consent to Participate
There are no human participants in this article and informed consent is not required.
Author Contributions
The authors declare that they contributed equally to the preparation of this manuscript and that all authors have reviewed and approved the final version of the manuscript for submission.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.*