
Abstract
This study evaluates how multimodal large language models translate Chinese culture-specific items by comparing GPT-4o, KIMI, DeepL, and Google Translate. Building on a curated dataset of 30 CSIs from The True Story of Ah Q, each paired with two human reference translations and culturally relevant images, we assess three dimensions of quality: Cultural Adequacy, Linguistic Naturalness, and Terminology Accuracy. GPT-4o and KIMI are tested under text only and image plus text conditions, while DeepL and Google Translate serve as unimodal baselines. Methods combine expert ratings with CLIP image–text alignment and post hoc qualitative analysis of cultural simplification. Results show that visual prompts significantly improve human-rated quality, with GPT-4o (image plus text) achieving the highest scores across all dimensions. CLIP analysis indicates a significant gain for GPT-4o with images, while KIMI’s CLIP gain is not statistically significant, mirroring but not fully matching human judgments. DeepL and Google Translate trail the multimodal systems on all human-rated dimensions and exhibit more frequent cultural simplification. The study contributes a replicable multimodal evaluation framework and underscores the importance of visual context for culturally sensitive translation in literary settings.
Plain Language Summary
Plain Language Summary Why was the study done? Languages often contain words and expressions that are deeply tied to culture, such as references to traditions, food, or historical figures. These culture-specific items (CSIs) are hard to translate, especially when using AI translation tools, because meaning can be lost or simplified. This study looked at whether new multimodal large language models (LLMs)—which can process both text and images—are better at handling cultural translations compared to traditional text-only systems. What did the researchers do? The team tested three AI translation systems: GPT-4o, KIMI, and Google Translate. They used 30 culture-specific items taken from the classic Chinese novel The True Story of Ah Q. Each item included a reference translation and an image to provide cultural context. The translations were evaluated on three aspects: (1) cultural adequacy, (2) natural flow of language, and (3) accurate use of terms. Both expert reviewers and an AI-based visual–linguistic tool were used to assess the quality. What did the researchers find? When models were given both text and images, their translations were more accurate and culturally appropriate. GPT-4o with text-plus-image input consistently produced the best results. In contrast, text-only systems, especially Google Translate, often failed to capture cultural meaning and sometimes oversimplified expressions. What do the findings mean? This study shows that adding images helps AI systems translate culture-rich content more effectively. It suggests that future translation tools should include visual context to preserve cultural meaning. The findings also provide a framework that other researchers can use to test multimodal AI translation in different languages and settings.
Keywords
Introduction
In the age of AI, translation has evolved from a purely linguistic process into a complex, context-sensitive activity involving multimodal inputs and outputs (Ai, 2022). Neural Machine Translation (NMT) systems—especially large multimodal models (LMMs) such as GPT-4o and KIMI—have demonstrated remarkable capabilities in generating fluent and contextually appropriate translations (Raunak et al., 2023; Shahriar et al., 2024). However, their ability to interpret and translate CSIs—terms embedded with historical, religious, social, and material meanings—remains an open and underexplored question, particularly when visual context is involved (El Zahra & Sahiruddin, 2023).
CSIs pose persistent challenges in translation studies. CSIs often resist direct equivalence, requiring not just lexical substitution but also cultural negotiation and contextual awareness (Rabiyatul Adawiyah et al., 2023). Human translators typically rely on cultural knowledge, pragmatic judgment, and contextual inference to mediate these terms. In contrast, AI-based translation systems—especially unimodal models like Google Translate—frequently struggle with CSIs, resulting in distortions, omissions, or semantic overgeneralizations (Bai, 2024). With recent advancements in multimodal AI, there is a growing possibility that image-grounded translation may assist in enhancing cultural fidelity (Lan et al., 2023)—yet this potential remains insufficiently examined within the domain of translation studies.
The present study seeks to address this gap by examining whether state-of-the-art multimodal translation models can utilize visual context to improve the translation of Chinese CSIs. The corpus is drawn from Lu Xun’s The True Story of Ah Q (Lu, 2001), a canonical Chinese novella characterized by rich cultural symbolism and social critique (Baek, 2022). A total of thirty CSIs were selected for their visual salience and cultural specificity. Each CSI was paired with a culturally relevant image and two human reference translations. The study compared translations produced by four systems: GPT-4o, KIMI, DeepL, and Google Translate. GPT-4o and KIMI were evaluated under two input modes—text-only and image-plus-text—while DeepL and Google Translate functioned as unimodal baselines without visual input.
To evaluate translation quality, both human expert judgments and automatic metrics were employed. Three expert raters assessed each translation across three dimensions: Cultural Adequacy, Linguistic Naturalness, and Terminology Accuracy. In addition, CLIP-based visual–textual similarity was applied to measure the degree of semantic alignment between translations and their corresponding cultural images. Qualitative analysis was further conducted to identify patterns of cultural simplification and loss in the AI-generated outputs.
To guide the investigation, the following research questions are posed:
Positioned at the intersection of translation studies, digital humanities, and artificial intelligence, this research aims to make three main contributions. First, it introduces a systematic framework for evaluating multimodal translation that integrates expert assessments, CLIP-based visual alignment, and qualitative interpretation. Second, it provides empirical evidence comparing multimodal and unimodal translation systems in the treatment of Chinese CSIs. Third, it underscores the significance of visual context in enhancing the cultural fidelity and interpretive depth of AI-assisted translation.
Unlike previous multimodal translation studies that have primarily focused on general or non-literary content, this research centers on Chinese literary texts characterized by high cultural density and symbolic meaning. Moreover, the integrated evaluation framework combining human and CLIP-based analyses for thirty CSIs represents a novel contribution to multimodal translation research within the literary domain.
Literature Review
CSI Translation Strategies
Culture-specific items (CSIs) have long represented a central challenge in translation studies, as they embody historical, social, religious, or material concepts that often lack direct equivalents in the target language (Rabiyatul Adawiyah et al., 2023). Translating CSIs requires more than linguistic substitution; it entails negotiating between semantic accuracy and cultural resonance, a process that involves interpretive, pragmatic, and ideological choices. As Nida’s (1964) theory of dynamic equivalence posits, translation should strive for equivalent effect rather than formal correspondence, yet achieving this balance becomes particularly complex when culturally bound expressions are involved. Similarly, Newmark (1988) distinguishes between semantic and communicative translation, where the former prioritizes fidelity to source meaning while the latter emphasizes target language acceptability. Both frameworks provide a conceptual basis for understanding how translators mediate cultural distance.
A growing body of literature has explored strategies and challenges in translating CSIs, particularly in audiovisual and literary contexts. Halim et al. (2024) conducted a qualitative analysis of subtitle translations in the Indonesian documentary Perempuan Tana Humba using Aixelá’s (1996) taxonomy of CSI strategies. They found that repetitive use, absolute universalization, and glossing were common techniques for balancing cultural retention with audience comprehension. However, the need to adjust strategies based on context highlighted the ongoing tension between fidelity and accessibility.
Similarly, Nematullayev and Yodgorov (2024) examined conceptual metaphors and idiomatic expressions in the Uzbek–English translation of Saodat Asri Qissalari through Newmark’s (1988) framework. Their study revealed that conveying the emotional and cultural depth of CSIs often required hybrid strategy combinations that bridge literal and adaptive renderings. They emphasized the translator’s interpretive role in negotiating between cultural resonance and linguistic intelligibility, echoing Nida’s dynamic equivalence.
In another study, Chai et al. (2022) analyzed the English subtitles of a Chinese documentary on paper-cutting art, identifying three recurring challenges: technical (subtitle timing constraints), cultural (absence of target-language equivalents), and linguistic (syntactic differences). Based on Tomaszkiewicz’s (2010) model, they found that omission, direct transfer, and adaptation were the most frequent strategies, though each entailed trade-offs in meaning retention.
In the literary domain, Leonavičienė and Inokaitytė (2023) investigated the English and French translations of Lithuanian author Ričardas Gavelis’s Vilnius Poker. Applying Chesterman’s (2016) strategy taxonomy, they discovered that the English version leaned toward foreignization, preserving Soviet-era allusions, while the French version adopted a domestication approach to better align with target cultural expectations. This contrast, consistent with Venuti’s (1995) theory of domestication and foreignization, illustrates how translation strategies vary not only by text type but also by sociocultural norms and ideological orientation.
Other studies also underscore the impact of linguistic gaps and cultural asymmetry. Šiukštaitė (2022) evaluated the Lithuanian dubbing of Memoirs of a Geisha, showing how Japanese CSIs such as honorifics and ritual practices challenged target-language rendering. Makaoui (2023), drawing on both Newmark (1988) and Aixelá (1996), highlighted the need to balance semantic precision with contextual adaptation in Arabic–English translation. Similarly, Ali et al. (2023) explored Kurdish–English translations of compliments, noting that insufficient cultural literacy often led to literal or unnatural renderings that distort pragmatic meaning.
Taken together, these studies highlight three persistent challenges: (1) the absence of direct cultural equivalents in the target language; (2) the tension between preserving source culture and maintaining target readability; and (3) the need for context-sensitive decision-making that reflects both semantic fidelity and cultural appropriateness.
These theoretical and empirical insights—grounded in the works of Nida (1964), Newmark (1988), Venuti (1995), and Aixelá (1996)—form the conceptual foundation for evaluating how contemporary AI translation models handle CSIs, particularly under multimodal input conditions that integrate both linguistic and visual context.
Multimodal NMT Developments
The evolution of machine translation has shifted from rule-based systems to NMT, with increasing interest in incorporating visual context through multimodal approaches. As Chen (2023) outlines, this trajectory has seen advances from RNN-based models to the dominance of Transformer architectures, which significantly enhanced translation fluency and contextual understanding. However, challenges such as overfitting, low-resource language performance, and model interpretability persist.
Nair et al. (2023) introduced the core principles of multimodal NMT (PMPO), demonstrating how combining textual and visual data improves translation quality across diverse applications including e-commerce and healthcare. Their work highlighted the use of convolutional and recurrent neural networks with attention mechanisms to integrate multiple input modalities.
Xuewen (2024) demonstrated that transformer-based multimodal gated networks could significantly improve BLEU and TER scores in complex English-to-Chinese translation tasks by dynamically weighting visual and textual information. Similarly, Yuasa et al. (2023) used latent diffusion models to generate synthetic images more closely aligned with source sentences, resulting in measurable BLEU improvements and stronger CLIP alignment.
A parallel development is the use of visual annotation and multi-modal consistency to simulate future linguistic contexts, as shown by Huang et al. (2023). Their model enhanced generation coherence by integrating visual cues into target-side decoding. These findings affirm the potential of visual-text integration for improved semantic understanding in translation.
Nevertheless, concerns remain regarding whether MNMT systems truly utilize visual data. Li et al. (2021) found that when real images were replaced with unrelated or noisy ones, model performance did not significantly degrade—suggesting visual information was underutilized. They proposed strategies like back-translation and word dropout to force reliance on visual input, which improved gender accuracy and BLEU scores in ambiguous contexts.
Tian et al. (2024) further advanced the field with the DSKP-MMT framework, which integrates enhanced knowledge distillation and contrastive learning to support MMT even in the absence of images. Their model achieved superior BLEU and METEOR scores across language pairs, highlighting robustness and scalability.
Overall, these studies reflect growing consensus that multimodal translation models can improve performance—but only when their architecture and training data explicitly encourage attention to visual information. The current study builds on this line of inquiry by evaluating how image-text pairing affects the translation of Chinese CSIs, a culturally dense and low-resource context.
Prompt Engineering and Evaluation Frameworks
With the rise of LLMs, prompt engineering has become a key strategy in enhancing AI performance in translation and evaluation (Marvin et al., 2024). Recent research emphasizes the growing potential of multimodal prompting to improve translation quality and evaluation validity.
Yang et al. (2024) proposed a multimodal multilingual NMT framework using contrastive learning and conditional vision-language memory. Their results showed that visual prompts improved BLEU scores by nearly 4 points across 102 languages. Similarly, Liu (2023) demonstrated that multimodal prompts in systems like Opal and 3DALL-E enhanced user efficiency and creative output, suggesting their value in guiding generative translation systems.
Lu et al. (2023) introduced an error analysis prompting method combining chain-of-thought and structured evaluation. They found that ChatGPT, when guided by well-designed prompts, could produce human-like translation assessments. However, limitations such as score variability and translation bias remained.
Tian et al. (2023) developed the Partitioned Multimodal Multi-prompt (PMPO) model, which integrates hierarchical context from vision encoders. This model outperformed conventional prompting techniques, particularly in domain generalization and new category recognition, supporting its applicability in AI translation assessment.
Other works focused on improving control and flexibility in prompt-driven NMT. Li et al. (2022) proposed Prompt-NMT, a model that supports multiple prompt types for constrained translation tasks. Jiao et al. (2024) introduced the T3S prompt classification framework, showing that richer prompt design improved accuracy and fluency. Wang et al. (2023) also showed that domain knowledge embedded as prompts significantly enhanced terminology matching and translation robustness across noisy domains.
These findings affirm that prompt design—especially when incorporating visual elements—is essential for enhancing both translation generation and evaluation. In this study, prompt-based input variation forms a central part of the experimental design, allowing comparison between text-only and image-text conditions. Additionally, the evaluation approach draws on structured human assessment and automatic metrics, building on these recent advances in prompt-enhanced translation research.
Therefore, this study contributes new empirical evidence on how multimodal inputs influence the translation of literary CSIs. It also introduces a replicable framework that combines human cultural evaluations with automated multimodal alignment metrics, which has not been systematically applied to CSI translation in previous research.
Methods
Research Design
This study adopts a comparative, product-oriented, and mixed-methods research design to evaluate the effectiveness of multimodal input in translating Chinese culture-specific items (CSIs) using contemporary AI translation systems. The design was selected because it allows for systematic comparison of translation outputs across systems and input modes, thereby providing a comprehensive perspective on both cultural fidelity and linguistic quality.
The research compares the performance of four translation systems, namely GPT-4o, KIMI, DeepL, and Google Translate, to investigate how visual context influences translation quality. GPT-4o and KIMI were tested under two input conditions, text-only and image-plus-text, whereas DeepL and Google Translate served as unimodal baselines without image input.
A mixed-methods analytical framework integrating quantitative and qualitative approaches was employed. Quantitatively, translation quality was assessed across three human-rated dimensions: Cultural Adequacy, Linguistic Naturalness, and Terminology Accuracy. One-way ANOVA and Tukey’s HSD post hoc tests were used to determine statistically significant differences among systems. To complement human evaluation, Contrastive Language–Image Pretraining (CLIP) was used to compute visual–textual similarity scores, providing an objective indicator of semantic alignment between translated text and culturally relevant images.
This design builds upon recent multimodal translation evaluation studies such as Motlagh et al. (2024) and Vijayan et al. (2024), which developed quantitative frameworks for assessing image utilization and multimodal coherence in machine translation. Motlagh et al. (2024) introduced the CoMMuTE benchmark to test how translation systems use visual cues for lexical disambiguation, while Vijayan et al. (2024) proposed a multi-dimensional evaluation protocol combining text-only and multimodal datasets to capture real-world complexity. Unlike these model-centric studies that focus primarily on disambiguation or general caption translation, the present study extends the multimodal evaluation paradigm to culturally embedded literary contexts, emphasizing cultural fidelity and pragmatic interpretation in AI-mediated translation.
In addition, the research design explicitly acknowledges potential cultural bias in human ratings and the interpretive limitations of CLIP metrics in capturing nuanced cultural meaning. To mitigate these concerns, multiple bilingual raters were employed to ensure inter-rater reliability, and CLIP scores were triangulated with human judgments and qualitative analyses to ensure interpretive validity.
Finally, selected translation samples were examined qualitatively to identify recurring patterns of cultural simplification, metaphor distortion, and semantic generalization. This process enriches the interpretation of quantitative results and illustrates how visual grounding shapes the treatment of CSIs in AI-generated translations.
Data Collection and Dataset Construction
From an annotated corpus of 200 CSIs in The True Story of Ah Q, a subset of 60 items was selected for this study. The selection was based on three criteria:
Cultural specificity: Items were chosen if they embodied significant cultural, historical, religious, or social meanings as defined by Aixelá (1996) and Newmark (1988).
Visual salience: Each CSI must have a tangible, photographable referent or an associated cultural image that could be found in public-domain image repositories. Visual salience was operationalized as the degree to which an image could directly depict the concept or object referenced by the CSI, aiding disambiguation in translation.
Coverage of CSI categories: The selected 60 items were balanced across several CSI types, including material culture (e.g., objects, clothing), social culture (e.g., gestures, rituals), and religious references, ensuring diversity in the test set.
For each CSI, a dataset was compiled comprising the original Chinese sentence containing the CSI, a culturally relevant image, and two human-translated reference sentences. The two reference translations used in this study were produced by Yang Hsien-yi and Gladys Yang (Lu, 2001), who are known for their domestication strategies aimed at improving readability for Western readers, and by Julia Lovell (Lu, 2009), whose work maintains closer fidelity to Chinese linguistic and cultural nuances and reflects a more foreignization-oriented approach. Both translators are highly experienced and widely cited in sinological studies, making their translations a reliable benchmark for evaluating the fidelity of Chinese CSIs.
Each CSI was translated by six systems, namely GPT-4o (image plus text), GPT-4o (text only), KIMI (image plus text), KIMI (text only), DeepL (text only), and Google Translate (text only). All translations were generated in May 2025. GPT-4o outputs were obtained through ChatGPT Plus with image upload enabled. KIMI translations were produced using the KIMI Web interface, while DeepL and Google Translate translations were retrieved from their official online platforms. All outputs were standardized and formatted prior to evaluation to ensure consistency across systems.
Prompting Strategy
The design of the prompts was informed by the instructional prompting framework proposed by Zhou et al. (2023), which emphasizes the effectiveness of task-specific, English-framed, zero-shot prompts in guiding large language models during machine translation tasks. In accordance with these principles, two prompt templates were employed to align with the two input conditions.
For the text-only condition, the following standardized prompt was used across all models: “Translate the following Chinese sentence into English. Only provide one fluent sentence, and do not include explanation.”
For the image-plus-text condition, the prompt was revised to explicitly reference the visual input and establish its relevance to the cultural-specific item. To this end, the following format was applied, with each instance dynamically adapted to the specific CSI under examination: “Translate the following Chinese sentence into English. The image provided is relevant to the term ‘X’ mentioned in the sentence. Only provide one fluent sentence, and do not include explanation.”
This two-prompt strategy was designed to ensure semantic consistency across input conditions while allowing visual input to contribute to cultural interpretation where applicable.
Evaluation Metrics
Human Expert Evaluation
Five bilingual translation experts independently rated all machine-generated outputs across three dimensions, adapted from established translation quality assessment frameworks (House, 2015; Rico, 2017):
Cultural adequacy: The extent to which the translation preserves the culture-specific meaning and contextual nuance of the CSI, drawing on the notion of covert/overt translation and cultural transfer (House, 2015; Newmark, 1988).
Linguistic naturalness: The fluency, syntactic smoothness, and idiomaticity of the target text, based on principles of target language acceptability (Rico, 2017).
Terminology accuracy: The correctness and specificity of culture-bound or technical terms, in line with translation evaluation rubrics such as DAETS (American Translators Association, 2006) and ISO 17100 (International Organization for Standardization, 2015).
A five-point Likert scale was used, where 1 indicated “poor” and 5 indicated “excellent.” Scores were averaged across raters to generate mean ratings for each dimension. Inter-rater reliability was confirmed using Cronbach’s alpha (α ≥ .90), indicating strong consistency across evaluators.
For quantitative analysis, paired-sample t-tests were conducted to compare the text-only and image-plus-text conditions for GPT-4o and KIMI. A one-way ANOVA followed by Tukey’s HSD post hoc tests was used to examine significant differences among the six translation systems (GPT-4o image + text, GPT-4o text-only, KIMI image + text, KIMI text-only, DeepL, and Google Translate).
CLIP-Based Visual-Linguistic Alignment
To objectively assess the semantic alignment between translations and reference images, CLIP scores were computed. The ViT-B/32 model from Open CLIP was used to calculate image-text similarity. Higher scores indicate stronger alignment. Each translation was paired with its corresponding image, and CLIP scores were computed across all five systems. Paired t-tests and ANOVA were used for statistical comparison.
Qualitative Analysis of Cultural Simplification
Drawing from Newmark (1988) and Aixelá (1996), cultural simplification is operationalized as the omission, generalization, or misinterpretation of CSIs in translation. Four representative examples were selected to illustrate this phenomenon, focusing on cases where GPT-4o (image + text) produced culturally rich renderings while other systems exhibited simplification. Each example includes the source text (ST), image, and all six translations (TT1-TT6), accompanied by interpretative commentary.
Ethical Considerations
This study involved the prospective recruitment of human participants to evaluate the quality of AI-generated translations. Ethical approval was obtained from the Ethics Committee of Wuhan University of Engineering Science under approval number WUOES20250203.
The recruitment period began on March 28, 2025 and ended on May 3, 2025. All participants were professional bilingual translators who were fully informed about the study’s purpose and procedures. Written informed consent was obtained from all participants prior to their involvement.
No personally identifiable information was collected, stored, or processed during the study. The research was conducted in full compliance with institutional and international ethical guidelines for research involving human participants.
Results
Multimodal Input Effects on Human Judgments and Visual-Linguistic Alignment
This section reports the findings from human evaluation and CLIP-based visual-linguistic similarity analysis, aiming to assess the effectiveness of multimodal input (text + image) in translating Chinese CSIs. Two strands of evidence were analyzed: expert scores across three evaluation dimensions—Cultural Adequacy, Linguistic Naturalness, and Terminology Accuracy—and CLIP similarity scores, which measure the semantic alignment between translated text and corresponding reference images.
Human Evaluation Results
To examine whether multimodal input enhances the translation quality of culture-specific items (CSIs), human evaluations were conducted for GPT-4o and KIMI under both text-only and image+text conditions, alongside two baseline systems (DeepL and Google Translate). The results are visualized in Figure 1, and the descriptive statistics are presented in “Table 1”. Statistical comparisons via paired sample t-tests are reported in “Tables 2 and 3.”
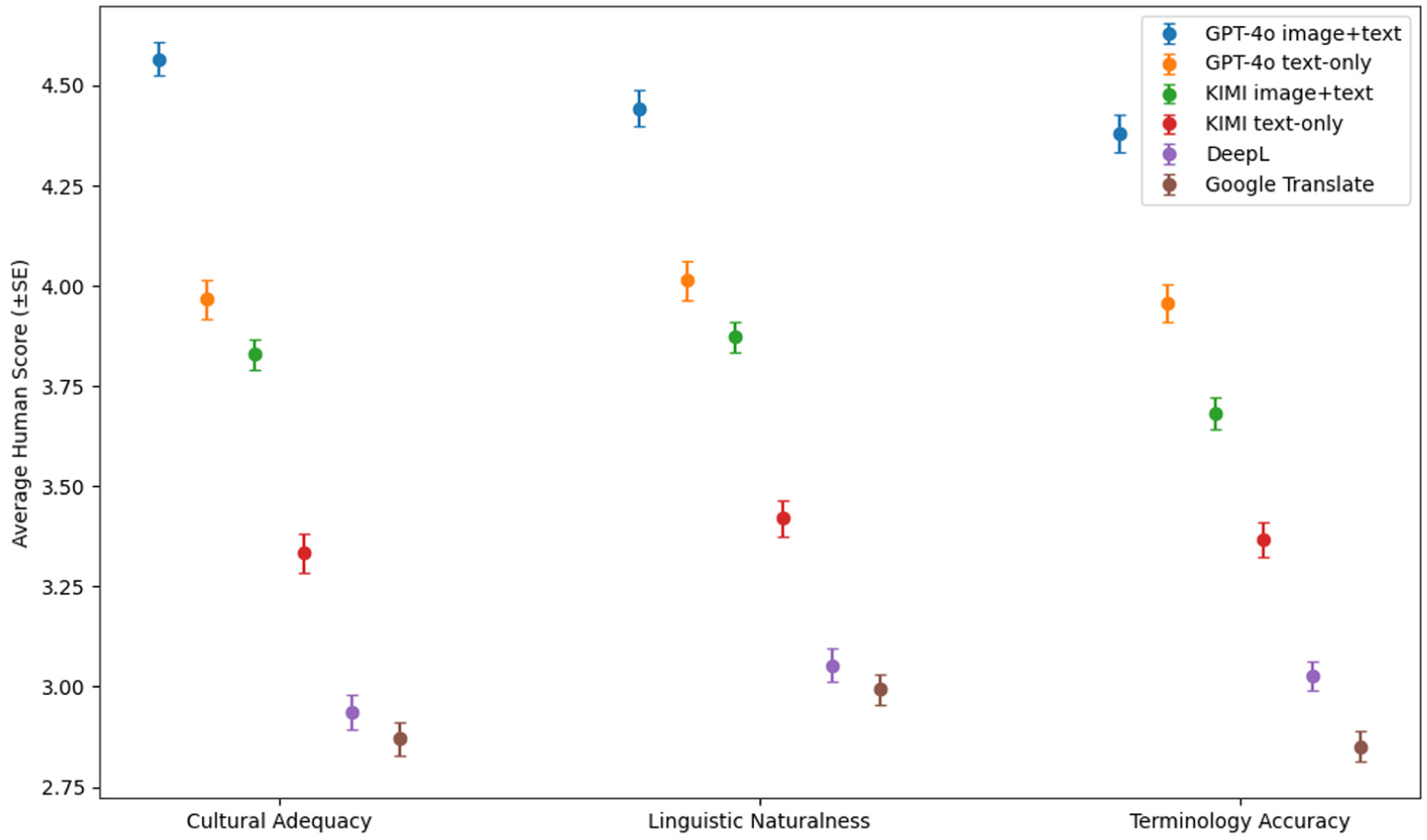
Average human scores by system and evaluation dimension.
Mean and Standard Deviation of Human Evaluation Scores by Translation System and Input Mode.

Paired Sample t-Test Results for GPT-4o: Text-Only Versus Image + Text Inputs.

Paired Sample t-Test Results for KIMI: Text-Only Versus Image + Text Inputs.

As illustrated in Figure 1, GPT-4o with image + text input achieved the highest scores across all three evaluation dimensions. The most substantial improvement occurred in Cultural Adequacy (from 3.97 to 4.57), followed by Terminology Accuracy and Linguistic Naturalness. All improvements were statistically significant (p < .001; see Table 2), confirming that the inclusion of visual cues markedly enhances GPT-4o’s ability to interpret cultural nuances and convey contextually appropriate meanings.
KIMI displayed a similar trend, albeit with slightly lower overall performance. The addition of images led to significant gains in all dimensions, most notably in Cultural Adequacy (from 3.33 to 3.83; p < .001), underscoring the value of multimodal contextual information for improving semantic fidelity (Table 3).
By contrast, DeepL and Google Translate, both unimodal systems without image conditioning, received the lowest human scores across all categories, particularly in Cultural Adequacy (below 3.0 on average). This suggests that traditional neural machine translation systems still struggle to render culturally embedded meanings and stylistic subtleties in Chinese literary contexts.
Collectively, these findings provide robust support for Hypothesis 1—that incorporating relevant visual information into LLM input significantly improves human-perceived translation quality, especially in conveying cultural and contextual meaning.
CLIP-Based Similarity Results
To complement the human evaluation, this section examines the visual–linguistic alignment of translations using Contrastive Language–Image Pretraining (CLIP) similarity scores. The CLIP metric quantifies how closely each translated sentence corresponds semantically to its associated cultural image, thereby providing an objective multimodal perspective on translation quality beyond human judgment.
The descriptive statistics of CLIP scores are shown in Table 4, while Figure 2 visualizes the mean similarity scores across translation systems with error bars representing standard errors. To assess whether image input enhances model alignment, paired t-tests were performed comparing text-only and image + text conditions for both GPT-4o and KIMI (see Table 5).
Mean and Standard Deviation of CLIP Scores by Translation System and Input Mode.

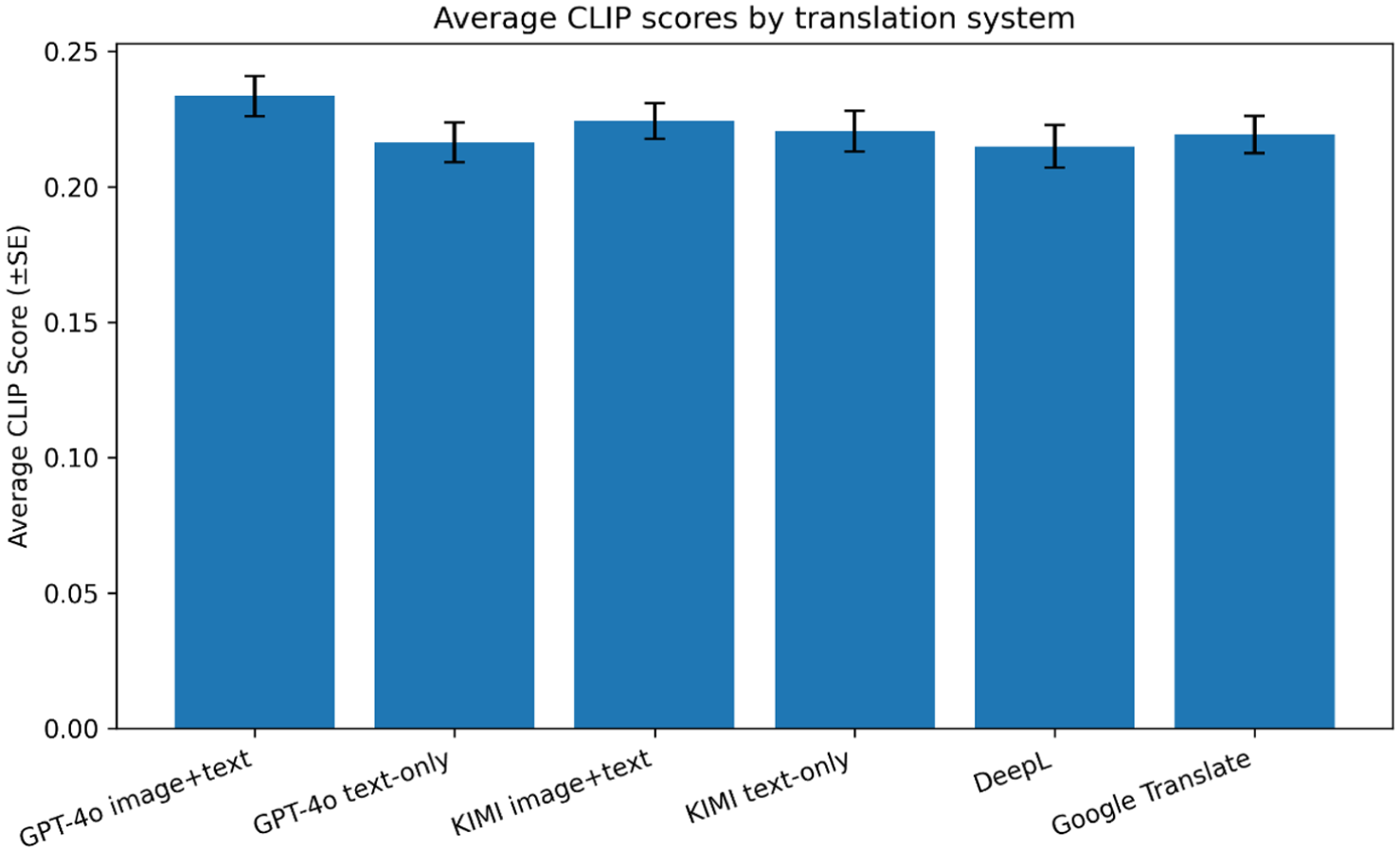
Average CLIP scores by translation system.
Paired Sample t-Test Results for CLIP Scores.

Table 4 indicates that GPT-4o image + text achieved the highest mean CLIP score (M = .2334, SD = .0576), followed by KIMI image + text (M = .2243, SD = .0508). Text-only variants of both models produced slightly lower scores (GPT-4o M = .2164; KIMI M = .2205), while the unimodal baselines DeepL (M = .2149) and Google Translate (M = .2193) yielded the lowest alignment performance overall.
The inferential results in Table 5 confirm that GPT-4o benefited significantly from multimodal input, t(59) = −4.46, p < .001, indicating stronger semantic consistency between its translations and the corresponding cultural imagery. In contrast, KIMI showed a smaller, statistically non-significant increase (t[59] = −1.07, p = .288), suggesting a limited advantage from visual grounding in its current architecture.
As illustrated in Figure 2, the pattern of CLIP similarity closely mirrors the human evaluation trends reported in Section 4.1.1: models receiving image input—particularly GPT-4o—consistently achieve higher multimodal alignment than purely text-based systems. Although the absolute differences appear modest (≈.02–.03), they are meaningful in high-dimensional embedding spaces, where small numerical gains correspond to notable improvements in semantic correspondence.
Collectively, these CLIP findings reinforce the human evaluation results, providing convergent evidence that multimodal input enhances both linguistic and cultural adequacy. The results therefore substantiate Hypothesis 1, demonstrating that incorporating visual context improves translation quality for culture-specific content by aligning linguistic representations more closely with cultural imagery.
Cross-System Comparison: GPT-4o Versus KIMI Versus Google Translate Versus DeepL
This section compares the overall performance of GPT-4o, KIMI, DeepL, and Google Translate across the three evaluation dimensions, namely Cultural Adequacy, Linguistic Naturalness, and Terminology Accuracy. A one-way ANOVA was conducted to determine whether significant differences existed among the systems. As shown in Table 6, the results revealed statistically significant differences in all three human-rated dimensions (p < .001), with F-statistics ranging from 236.71 to 304.13. These findings indicate that both the translation model and the input mode (text-only vs. image plus text) have a significant effect on translation quality in terms of cultural and linguistic performance. In contrast, there was no significant difference among systems in the CLIP-based visual–linguistic similarity scores (F = .438, p = .7808), suggesting that all models exhibited a comparable level of multimodal alignment according to the automated metric.
ANOVA Results on Human and CLIP Evaluation Scores.

To explore these differences further, Tukey’s HSD post hoc tests were conducted for each dimension. The detailed outcomes are presented in Tables 7 to 9 and illustrated in Figures 3 to 5.
Post Hoc Test Results on Cultural Adequacy.

Post Hoc Test Results on Linguistic Naturalness.
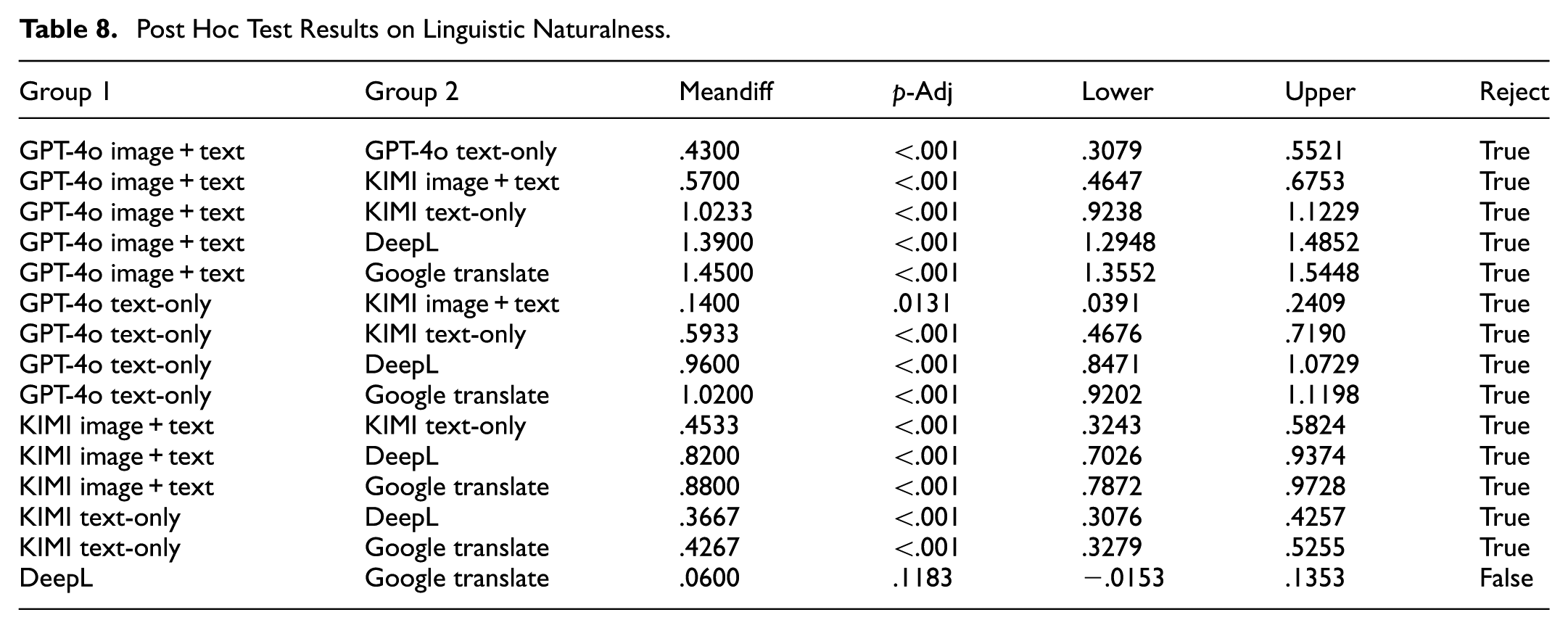
Post Hoc Test Results on Terminology Accuracy.


Tukey post hoc heatmap for cultural adequacy.
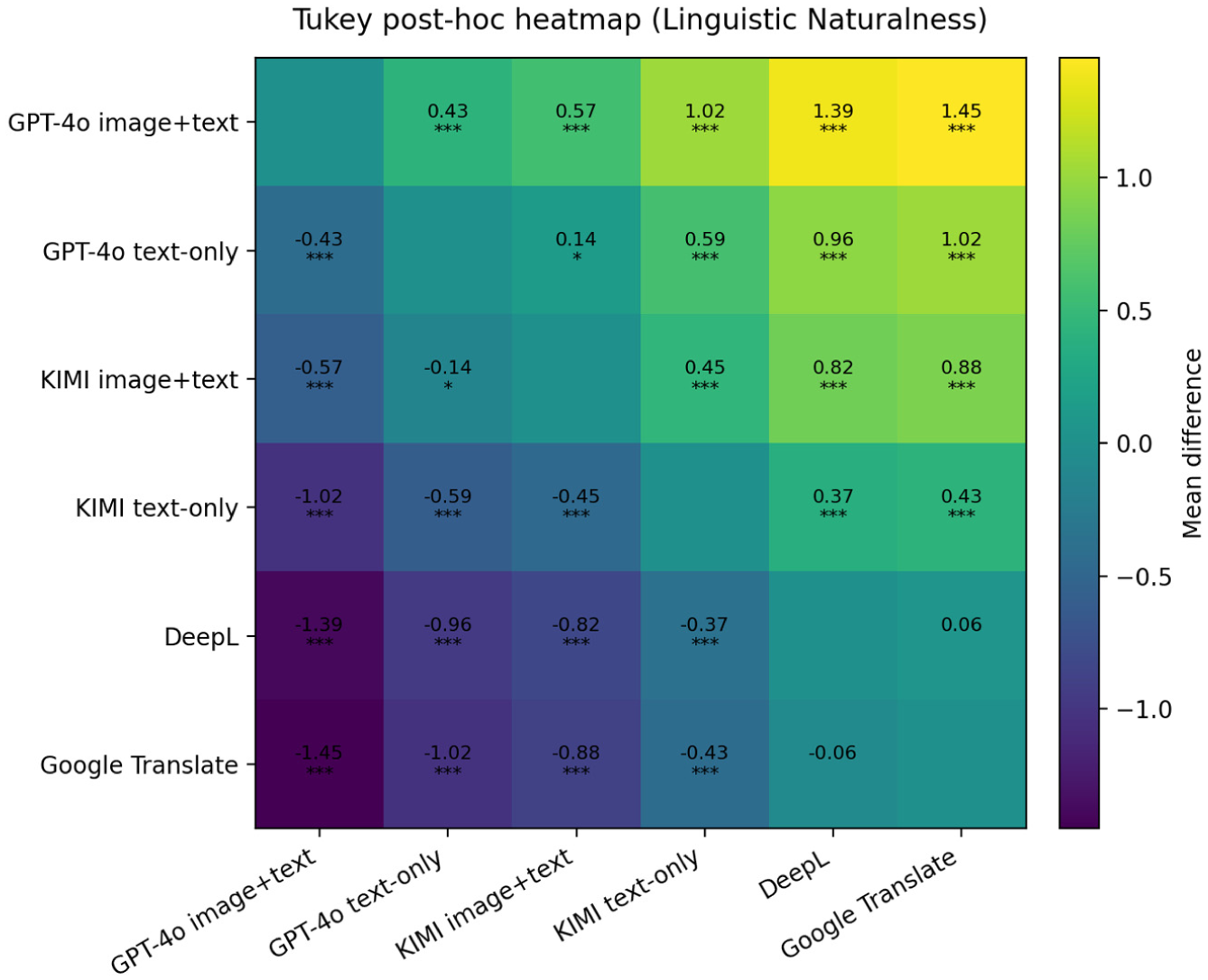
Tukey post hoc heatmap for linguistic naturalness.

Tukey post hoc heatmap for terminology accuracy.
In terms of cultural adequacy, GPT-4o with image input achieved the highest mean score and significantly outperformed all other systems (p < .001). The largest mean difference was observed when compared with Google Translate (mean diff = 1.70) and DeepL (mean diff = 1.63). Even the text-only version of GPT-4o performed significantly better than most systems, except KIMI with image input, which showed moderate improvement through multimodal enhancement (Table 7).
For Linguistic Naturalness, GPT-4o with image input again obtained the highest mean scores (Table 8). Pairwise comparisons showed significant improvements over all other systems (p < .001), while KIMI with image input ranked second and outperformed its text-only variant (p < .01). DeepL and Google Translate consistently received the lowest ratings, and the difference between them was not statistically significant (p = .118).
Regarding Terminology Accuracy, the results presented in Table 9 indicate a similar pattern. GPT-4o with image input produced the most accurate terminology translation, followed by KIMI with image input, KIMI text-only, DeepL, and Google Translate. All pairwise comparisons involving GPT-4o with image input reached statistical significance (p < .001), confirming its superior ability to preserve domain-specific terms. KIMI also showed a notable multimodal advantage over its text-only version (p < .001).
The three Tukey post hoc heatmaps (Figures 3–5) provide a visual summary of these comparative results. Each cell in the heatmap represents the mean difference between two systems, with warmer colors indicating higher mean scores and asterisks denoting significant differences (p < .05, *p < .01, **p < .001). The consistent dominance of GPT-4o with image input across all three dimensions highlights its superior performance in achieving both cultural fidelity and linguistic precision. In contrast, Google Translate displayed the weakest results in every category.
Evidence of Cultural Simplification in AI Translations
Drawing from cultural translation theory (Aixelá, 1996; Newmark, 1988), this study defines cultural simplification as the tendency of translations, particularly those generated by AI models, to neutralize, generalize, or omit culture-specific items (CSIs), thereby reducing their cultural richness, specificity, and semantic depth. This section compares six translations per example: TT1: GPT-4o (image + text), TT2: GPT-4o (text-only), TT3: KIMI (image + text), TT4: KIMI (text-only), TT5: Google Translate, and TT6: DeepL.
The culturally rich term “
Example 1 of Cultural Simplification.

The term “
Example 2 of Cultural Simplification.

The phrase “
Example 3 of Cultural Simplification.

The euphemism “
Example 4 of Cultural Simplification.

These examples reveal a consistent pattern. GPT-4o (image + text) demonstrates the strongest capacity for cultural contextualization, consistently producing translations that align with the source text’s symbolic and pragmatic intent. DeepL (TT6) performs relatively well in preserving linguistic fluency and partial meaning, though it remains less attuned to cultural nuance. KIMI (both modes) shows moderate fidelity but occasional semantic flattening, while Google Translate (TT5) exhibits the most pronounced simplification, frequently defaulting to generic or literal renderings that obscure cultural connotation.
Overall, the findings confirm that visual grounding significantly enhances semantic and cultural retention in AI translation, supporting the view that multimodal input helps mitigate cultural simplification and enriches contextual fidelity.
Discussion
This study examined how multimodal input, particularly the integration of images, influences the translation of culture-specific items (CSIs) by four AI translation systems: GPT-4o, KIMI, DeepL, and Google Translate. Using expert evaluation and CLIP-based alignment metrics, the research provides new empirical evidence on how visual grounding affects cross-cultural translation quality. Unlike previous studies that primarily explored strategy choice in human translation (Halim et al., 2024; Nematullayev & Yodgorov, 2024), this work focuses on how multimodal architectures replicate or diverge from human cultural reasoning.
First, in addressing RQ1, the findings confirm that visual context significantly improves translation quality across all three dimensions—Cultural Adequacy, Linguistic Naturalness, and Terminology Accuracy. These results extend previous multimodal NMT research (Xuewen, 2024; Yuasa et al., 2023) by demonstrating that image-text pairing benefits not only syntactic fluency but also cultural fidelity. While earlier studies achieved higher BLEU or TER scores through vision-language fusion, they rarely examined how visual prompts influence the rendering of culturally dense expressions. The current findings show that visual grounding enables models to activate perceptual semantics and pragmatic inference, which supports Nida’s (1964) dynamic equivalence and Venuti’s (1995) balanced domestication-foreignization perspective. By contrast, unimodal systems tend to rely on lexical probability, which restricts their ability to reconstruct culture-bound meaning.
Second, regarding RQ2, the cross-system comparison reveals clear performance stratification that resonates with and expands earlier research on multimodal prompting. Yang et al. (2024) and Tian et al. (2023) showed that multimodal memory and partitioned prompting can improve contextual coherence. Our results empirically validate these claims in a literary translation setting: GPT-4o (image + text) consistently outperformed all other systems, while DeepL and Google Translate, both unimodal, showed limited ability to retain culture-specific nuance. The superiority of GPT-4o can be attributed to its vision–language embedding mechanism, which aligns visual features with textual semantics. This finding deepens the observations of Li et al. (2021), who found that earlier MNMT systems often ignored visual input. By contrast, GPT-4o demonstrably utilizes visual cues to disambiguate symbolic references, confirming that newer multimodal architectures have begun to overcome this long-noted limitation.
Third, in response to RQ3, the qualitative analysis of cultural simplification offers insight into why AI systems still distort culturally loaded expressions. Earlier descriptive studies (Chai et al., 2022; Makaoui, 2023) emphasized how human translators negotiate semantic loss through adaptive strategies. Our evidence shows that, without visual or pragmatic anchoring, AI models exhibit a similar but unregulated simplification process, often neutralizing metaphors or ritual terms. Literal renderings such as translating “
Comparatively, this study differs from prior CSI-focused research in three main ways. First, whereas previous works (Halim et al., 2024; Leonavičienė & Inokaitytė, 2023) analyzed human strategies using Aixelá or Chesterman’s taxonomies, this research quantifies how AI systems approximate those strategies through multimodal processing. Second, unlike earlier multimodal NMT experiments that concentrated on BLEU improvement, this study evaluates cultural and linguistic dimensions through human scoring and CLIP alignment, thereby integrating both qualitative and quantitative evidence. Third, the inclusion of four systems (two multimodal and two unimodal) enables a clearer attribution of improvement to multimodality itself rather than to model size or training corpus, addressing the methodological concerns raised by Li et al. (2021) and Tian et al. (2024).
The findings therefore bridge two previously separate strands of research: cultural translation theory and computational multimodality. They substantiate the theoretical view that cultural meaning is partly embodied and thus benefits from multimodal encoding (Barsalou, 2008). Practically, they suggest that multimodal prompts can be integrated into translator-training environments and computer-assisted translation (CAT) tools to raise awareness of visual–cultural associations. By empirically linking traditional translation theories with current AI modelling, this study contributes to redefining the scope of translation studies in the age of generative multimodality.
Conclusion
This study provides a comprehensive evaluation of how multimodal AI translation systems handle culture-specific items (CSIs) in Chinese literary texts. By combining human expert assessments, CLIP-based visual–text alignment analysis, and qualitative examination, the findings provide robust evidence that the inclusion of visual context significantly improves both the cultural fidelity and linguistic quality of AI-generated translations. Specifically, image-based input enhanced translation performance across all three evaluated dimensions: Cultural Adequacy, Linguistic Naturalness, and Terminology Accuracy.
Among the four systems evaluated, GPT-4o with image-plus-text input consistently achieved the highest overall performance. It demonstrated a superior ability to preserve cultural meaning, ensure terminological precision, and produce linguistically natural expressions. KIMI also benefited from multimodal input, although its performance remained slightly below that of GPT-4o. DeepL and Google Translate, which operate as unimodal systems without visual grounding, achieved comparatively lower scores. Google Translate in particular frequently exhibited cultural simplification, omitting or generalizing culturally embedded meanings that require contextual sensitivity. These findings collectively validate the hypotheses proposed in this study and confirm that multimodal input provides a measurable advantage in translating culturally rich and semantically nuanced content.
Theoretically, this research extends the current understanding of multimodal machine translation by empirically demonstrating how visual grounding supports semantic disambiguation and cultural contextualization. It contributes a replicable methodological framework that integrates quantitative and qualitative evaluation, thereby enhancing the analytical rigor of translation technology research. From a pedagogical perspective, the results suggest that multimodal translation models can serve as valuable educational tools for translator training, enabling students to connect linguistic expression with visual and cultural context.
Practically, the study highlights the potential of integrating multimodal mechanisms into future translation systems to achieve more culturally resonant and contextually accurate outputs. As artificial intelligence becomes increasingly integrated into professional translation, education, and intercultural communication, ensuring that models maintain both linguistic precision and cultural integrity will be critical to responsible AI deployment in the humanities and social sciences.
Despite these contributions, several limitations should be acknowledged. The dataset consisted of 60 CSIs extracted from a single Chinese novella, The True Story of Ah Q, which may limit the generalizability of the findings to other genres or languages. Moreover, only two multimodal systems (GPT-4o and KIMI) and two unimodal baselines (DeepL and Google Translate) were examined. Future research could include a broader selection of AI models and a more diverse set of texts, allowing for stronger cross-linguistic and cross-genre comparisons. Expanding multimodal inputs beyond static images to include audio and video could further improve context modeling and pragmatic understanding. Additionally, the development of culturally sensitive automatic evaluation metrics capable of capturing figurative language, metaphor, and pragmatic intent remains a promising direction for future work.
In conclusion, this study demonstrates that multimodal AI translation systems, particularly GPT-4o, hold substantial potential for advancing the cultural and linguistic quality of machine translation. By integrating textual and visual information, these systems move closer to human-level cultural awareness, marking an important step toward more contextually intelligent and culturally inclusive translation technologies.
Footnotes
Ethical Considerations
This study involved human expert evaluation of machine-translated outputs. All expert participants were professional bilingual translators who voluntarily participated in the study. Prior to data collection, informed consent was obtained from all participants. The evaluation process was anonymous, and no personally identifiable information was collected. The study protocol was reviewed and approved by the [Ethics Committee of Wuhan University of Engineering Science] under approval number [WUOES20250203].
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
All data supporting the findings of this study are publicly available on Zenodo at [ANONYMIZED]. The dataset includes the complete set of 60 culture-specific items (CSIs), reference translations, system-generated outputs, associated images, and statistical analysis tables used in this research.
AI Disclosure Statement
The authors declare that the language polishing for this manuscript was assisted by DeepSeek, a language enhancement tool. All other aspects of the research process, including data gathering, manuscript preparation, research design, and conceptualization, were independently completed by the author.