
Abstract
This study examines the capacity of ChatGPT (GPT-4o), a large language model-based AI system, to evaluate architectural design competition projects. It investigates how jury input shapes the model’s assessments and how effectively it integrates multimodal data (text + visuals). The analysis focuses on eight awarded projects (three prizes and five honorable mentions) from the 2025 Kadıköy Municipality New Service Building National Architectural Design Competition. ChatGPT assessed the projects under two scenarios: with access to jury reports (jury-influenced) and without any jury data (independent evaluation). In both cases, the projects were scored on a 0 to 5 scale across six thematic categories defined in the competition brief. The findings show that when jury reports were available, ChatGPT’s evaluations aligned strongly with those of the human jury (r ≈ 0.87). Without jury input, project rankings and thematic emphases shifted, indicating the model’s capacity to generate alternative interpretations based on textual and visual information. This study contributes to architectural evaluation research methodologically by introducing a dual-scenario framework, theoretically by revealing how AI mirrors or diverges from human judgment, and practically by demonstrating its potential as a decision-support tool. While AI can enrich evaluation processes, human expertise remains essential for nuanced, context-specific decision-making.
Keywords
Introduction
Architectural design competitions have become an integral part of the discipline of architecture, as they promote creativity, contribute to the advancement of the profession, and offer alternative visions for public buildings (Chupin, 2011; Li et al., 2023). These competitions provide a platform for global architectural discourse, open not only to professional architects but also to academics, students, and various urban stakeholders (Dinçer et al., 2022; Lipstadt, 2003; Önal & Özbudak, 2018). However, the process of selecting winning proposals in architectural competitions is inherently subjective. A growing body of literature highlights persistent concerns regarding fairness, transparency, and consistency in the jurying process (Ford, 2014; Strebel & Silberberger, 2017). This subjectivity often stems from the heterogeneity of jury composition, the clarity (or lack thereof) of evaluation criteria, and the manner in which those criteria are applied (Berčič et al., 2024; Volker, 2010). This growing concern highlights the urgent need for alternative or complementary evaluation mechanisms that can enhance transparency and consistency without replacing human judgment. AI-powered systems, particularly multimodal models, are increasingly seen as promising tools in this regard.
In architectural competitions, final awards are determined by a selection committee—referred to as the jury—whose decisions are shaped by their expertise, professional experiences, and aesthetic judgments (Cucuzzella, 2020; Tempestini, 2025). This subjectivity becomes even more critical in large-scale public competitions where architectural outcomes have long-term urban implications (Białkiewicz, 2020; Strong, 1996), a fact that remains a key point of debate in the discourse on architectural competitions (Müştak Sevindik, 2024). The issue of consistent and transparent decision-making becomes particularly important in large-scale competitions involving public buildings and multiple stakeholders (Bahtiyar & Yaldız, 2024; Shin et al., 2025). In response, various methods and support systems have been developed in recent years to make architectural jury processes more objective, systematic, and transparent (Özeren & Qurraie, 2022). Multi-Criteria Decision-Making (MCDM) tools such as the Analytic Hierarchy Process (AHP), Multi-Attribute Utility Theory (MAUT), and DEX have emerged as notable approaches in this regard (Berčič et al., 2024; Chen et al., 2010; Pujadas et al., 2017). These models aim to reduce subjectivity in traditional jury evaluations and support decision-making through quantitative analysis (Su et al., 2024). However, these tools mostly rely on predefined criteria and lack the ability to interpret projects as holistic architectural narratives. This represents a critical gap in current scholarship, especially in leveraging AI for qualitative judgment in competitions.
Unlike classical decision support models, large language models can operate directly on textual and visual narratives, enabling richer interpretation and potentially revealing alternative evaluative perspectives. Against this backdrop, the question of whether AI-based systems can be integrated into architectural evaluation processes has gained increasing relevance. Large language models (LLMs), which have evolved rapidly in recent years, are not only generative tools but are also being recognized as catalysts for architectural thinking (Horvath et al., 2024). With capabilities spanning text-to-text, text-to-image, and image-to-image generation, LLMs offer a new dimension to thematic evaluation of architectural competition projects. Their ability to reproduce the visual and conceptual layers of architectural narrative positions them as potential alternative agents in critical analysis. However, the tendency of these tools to assess projects in a context-independent manner raises the question of how closely their evaluations align with the intuition-based judgments of human juries.
Artificial intelligence (AI) has increasingly been adopted in the field of architecture, encompassing a broad range of applications from design automation and building performance analysis to process simulations and aesthetic decision support (Burry, 2011; Gallo et al., 2020). One of the most prominent developments within this trajectory is the emergence of large language models (LLMs), which offer capabilities for interpreting architectural texts, analyzing design projects, and performing thematic evaluations (Franch et al., 2022).
Specifically, this study employs ChatGPT to examine how an LLM behaves as an architectural evaluator under different conditions (Cob-Parro et al., 2024; OpenAI, 2023). This study focuses on the role and potential of AI in architectural criticism. Specifically, it investigates whether an AI model can evaluate architectural competition projects in a manner comparable to human juries, and to what extent its assessments align with or diverge from those of expert panels. A central inquiry also concerns whether such evaluations rely solely on textual data or effectively integrate both textual and visual content. Framing this inquiry within Human–Computer Interaction and “AI as Critic” perspectives provides a theoretical basis to understand how machine-generated judgments might align with or diverge from established human evaluative discourses.
Based on this theoretical positioning, the study poses the following guiding research questions and hypotheses regarding alignment, divergence, and thematic weighting in AI-based evaluations of architectural competitions. To explore these questions, the research focuses on the “Kadıköy Municipality New Service Building National Architectural Design Competition,” held in Turkey in 2025 (Konkur, 2025). This competition was selected as the case study because the authors actively participated in the design process and observed the competition closely from its inception. In total, eight awarded projects (three prize-winning entries and five honorable mentions) were evaluated by ChatGPT under two distinct scenarios. In the first scenario, the AI model was given access to the official jury reports, allowing its evaluation to be shaped by jury influence. In the second scenario, ChatGPT assessed the projects independently, using only project texts and presentation visuals, with no information from the jury.
Evaluations in both scenarios were conducted using six thematic categories derived from the official competition brief: (1) Urban Context and Site Integration, (2) Spatial Organization and User Diversity, (3) Social Function and Public Life, (4) Sustainability and Resilience, (5) Structural and Technological Solutions, and (6) Aesthetic Quality, Representation, and Presentation. All projects were scored on a scale of 0 to 5 under each category. The resulting scores from both scenarios were then compared using statistical metrics including ranking deviation, mean absolute error (MAE), root mean square error (RMSE), and Pearson correlation coefficient. The scientific contribution of this study is threefold.
(1) Methodological contribution: It introduces a novel dual-scenario evaluation model (jury influenced vs. independent) that systematically examines how a large language model interprets architectural competition entries through multimodal inputs.
(2) Theoretical contribution: It provides a critical analysis of the alignment and divergence between AI-generated and human jury evaluations, thereby expanding ongoing debates on the epistemology of architectural judgment in the age of AI.
(3) Practical contribution: It demonstrates the potential of AI to function as an alternative pre-jury decision-support tool, offering structured, transparent, and pluralistic perspectives that can complement but not replace human evaluation in architectural competitions.
In doing so, this research not only explores the integration of AI into architectural evaluation practices but also opens up a broader discussion on whether such systems can replace or merely support human judgment—particularly in areas involving subjective interpretation, intuitive reasoning, and contextual sensitivity.
The following sections situate this contribution within the broader technological and disciplinary context, outlining how AI tools are currently intersecting with architectural evaluation practices.
The Interface Between Artificial Intelligence and Architecture
To situate this study within the broader discourse on AI in architecture, the following sections review the intersection of AI technologies and architectural evaluation. In recent years, artificial intelligence (AI) technologies have rapidly gained a foothold within the architectural discipline, significantly transforming a variety of subfields (Kumar et al., 2024). This transformation extends far beyond design automation, encompassing areas such as planning optimization (Zhao et al., 2024), urban analytics (Roy et al., 2024), building energy modeling (Ali et al., 2024; Heidari et al., 2024), and aesthetic decision support systems (Hamdy, 2024). With advancements in machine learning and deep learning algorithms, it has become increasingly feasible to process and interpret architectural data in textual, visual, and spatial forms (Liu et al., 2024).
Accordingly, the ways in which AI is utilized in architectural practice and education have become more diverse. Płoszaj-Mazurek and Ryńska (2024), for instance, explored AI’s role in reducing carbon emissions. Xu et al. (2024) demonstrated how AI algorithms can be applied to analyze spatial networks. Chandrasekera et al. (2025) emphasized the potential of AI to provide rapid feedback mechanisms that influence early design decisions. This perspective is further expanded in a study by Horvath et al. (2024), in which generative AI models—spanning text-to-text, text-to-image, and image-to-image capabilities—were integrated into a conceptual architectural design process. Their research revealed that AI-generated texts, trained on competition briefs, offered conceptual theme suggestions to designers, while AI-generated images derived from these texts contributed to formal diversity in design exploration.
Despite these developments, questions remain as to how effectively such tools can be applied within the context of architectural competitions. Given the inherently interpretive nature of these competitions, which rely not only on technical accuracy but also on aesthetic and contextual sensitivity, the role of AI in this evaluative space is still not clearly defined.
Evaluation Potential of ChatGPT and Large Language Models
Building on their capacity to process complex textual narratives, LLMs have recently been adapted to architectural discourse, where their analytical potential is increasingly explored for evaluative purposes. Models like ChatGPT, with their ability to interpret unstructured texts, identify thematic patterns, and establish contextual associations, have emerged as promising tools for evaluative processes (Huang et al., 2024; OpenAI, 2023).
Recent studies (Belaroussi, 2025; Jin et al., 2025) demonstrate that ChatGPT exhibits a certain degree of competence in analyzing architectural project narratives, evaluating thematic coherence, and generating critical discourse. However, when it comes to visual data analysis, the model’s performance has been noted to be more limited. The development of models capable of processing both visual and textual inputs in an integrated manner represents a significant step toward overcoming this limitation.
In this context, it is not only the model’s ability to evaluate design competition entries that matters but also the extent to which its assessments align with or diverge from human jury priorities. Investigating how the model behaves under different conditions particularly whether it is influenced by jury data or operates independently offers a unique opportunity to test whether AI can truly function as an autonomous “critic” within architectural discourse. This dual capacity for textual and visual interpretation underpins the present study’s experimental design.
Methodology
Research Design
This study adopts a comparative and explanatory research design to evaluate the capacity of an artificial intelligence-based language model (ChatGPT) to assess architectural competition projects. The methodology is structured around a two-stage experimental analysis model and employs a mixed-methods approach that integrates both qualitative and quantitative data analysis (Figure 1).
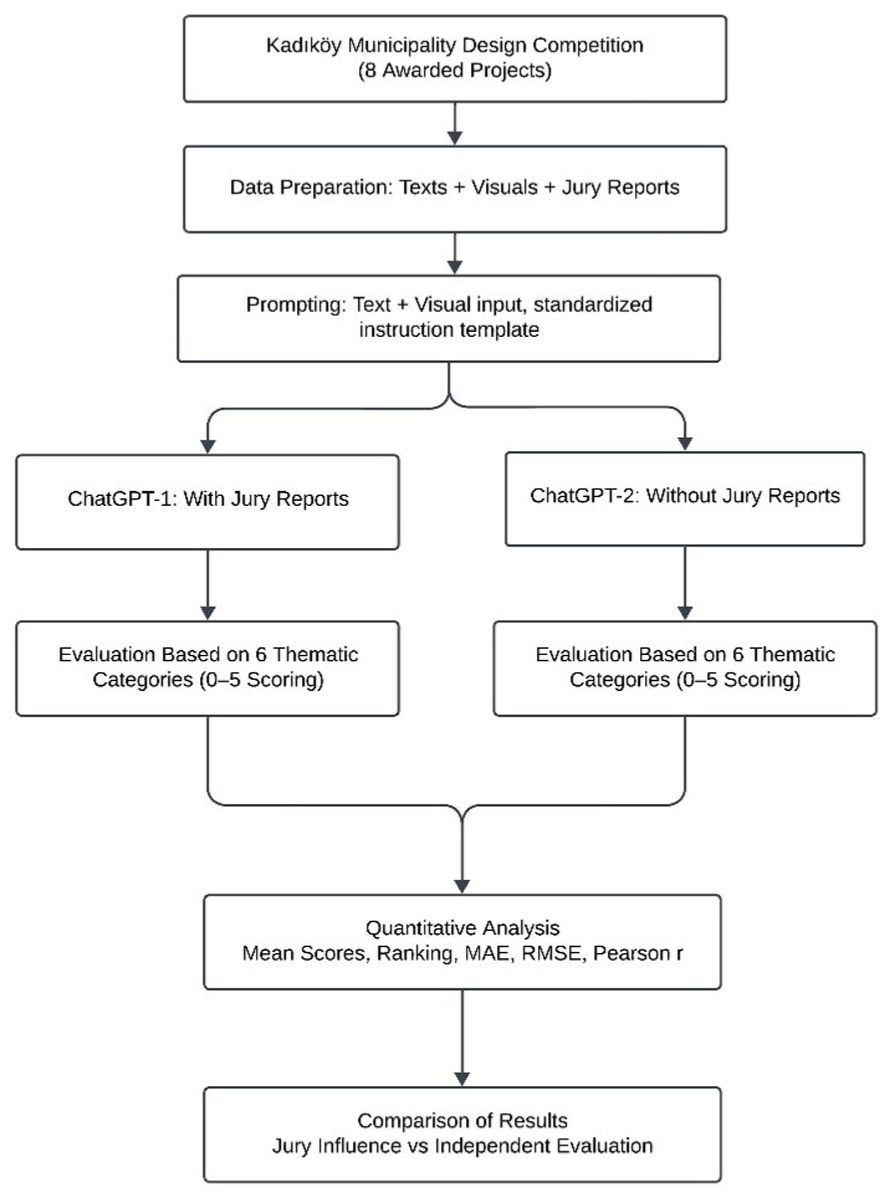
Figure 1 illustrates the operational workflow of the study, including standardized data preparation (text + visuals), model input and prompt design, dual-scenario evaluation (jury-influenced vs. independent), thematic scoring, and statistical analysis.
The primary aim of the study is to reveal the differences between evaluations produced by ChatGPT under the influence of jury reports and those conducted entirely independently. Moreover, the study seeks to identify in which thematic categories these differences are most pronounced, using statistical indicators to support the analysis.
This dual-scenario evaluation model is, to the best of our knowledge, the first to be systematically applied in the field of architecture. It offers a novel approach for testing the reliability of AI-assisted critiques and for examining whether the AI replicates human jury decisions or generates its own interpretive judgments.
All evaluations were performed using GPT-4o (June 2025 version), which supports multimodal input. For each project, textual and visual data were uploaded simultaneously, allowing the model to interpret both modalities in an integrated manner. Textual content was provided as plain text, while visual content was attached as high-resolution .jpeg files representing project panels and diagrams. The model was explicitly instructed to evaluate both data types together within the defined thematic framework.
Sample and Data Set
The study focuses on eight awarded projects from the 2025 Kadıköy Municipality New Service Building National Architectural Design Competition. These include three prize-winning entries (first, second, and third prizes) and five honorable mentions. This competition was selected due to its multi-stakeholder public program, the availability of comprehensive jury reports, and open access to a rich project dataset. Two types of data were used for each project:
Textual data: Project explanatory reports, conceptual framework texts, and descriptive notes on presentation boards.
Visual data: Presentation panels, site plans, elevations/sections, diagrams, and render images.
All data were retrieved from the Kadıköy Municipality competition archive and publicly available digital platforms. Documents were standardized and compiled in .pdf and .jpeg formats for consistent input into ChatGPT.
To ensure consistency across projects, all text files were stripped of any identifying jury remarks or team names, and all images were standardized to 300 dpi resolution. Each project’s data was presented in the same order (text first, then visuals) to control for prompt sequence effects.
Thematic Coding Categories
Project evaluations were structured around six thematic categories derived from the competition briefly and frequently referenced in the jury reports. These categories served as the shared evaluation framework for both the human juries and the AI model:
Urban Context and Site Integration
Spatial Organization and User Diversity
Social Function and Public Life
Sustainability and Resilience
Structural and Technological Solutions
Aesthetic Quality, Representation, and Presentation
Each category included specific sub-criteria, and all evaluations were scored on a scale from 0 (very weak) to 5 (very strong). This framework ensured consistency in evaluation and enabled measurable, comparative analysis.
Evaluation Procedure
Stage 1: Evaluation with Jury Influence (ChatGPT-1): In this scenario, ChatGPT was provided with the project texts and visuals along with the official jury reports. The aim was to observe whether the model’s assessments mirrored the jury’s rankings and comments, indicating susceptibility to external evaluation cues.
Stage 2: Independent Evaluation (ChatGPT-2): Here, the same projects were presented to ChatGPT without access to jury data—only textual and visual project information was supplied. The goal was to determine whether the model could generate original assessments independently, free from jury influence.
In both scenarios, the evaluations followed the same thematic structure and scoring system. Fixed prompt formats were used to standardize responses, and comparable scores were produced for each project across both stages.
To ensure replicability, a fixed prompt format was used in both scenarios. Below is an example from the independent evaluation stage:
You are acting as an architectural competition jury. Evaluate the project across the six predefined thematic categories used in this study (Urban Context and Site Integration, Spatial Organization and User Diversity, Social Function and Public Life, Sustainability and Resilience, Structural and Technological Solutions, Aesthetic Quality, Representation and Presentation). Consider both the textual explanation and the visual materials provided. Assign a score from 0 (very weak) to 5 (very strong) for each category and provide a short justification for each. Base your judgment only on the provided materials; do not use external knowledge or prior jury decisions.
Data Analysis Techniques
The collected score data were analyzed using descriptive statistical techniques to examine the relationship between jury-influenced (ChatGPT-1) and independent (ChatGPT-2) evaluations.
First, thematic mean analysis was used to calculate average scores for each thematic category across projects, allowing for a category-level comparison. Second, Mean Absolute Error (MAE) and Root Mean Square Error (RMSE) were employed to quantify the magnitude of numerical differences between the two scenarios. MAE provides a straightforward measure of average deviation, while RMSE is more sensitive to larger discrepancies.
Third, Ranking Consistency Analysis assessed variation in project rankings between ChatGPT-1 and ChatGPT-2. Finally, the Pearson Correlation Coefficient (r) was calculated to evaluate the degree of linear association between ChatGPT’s assessments and the original human jury decisions. These indicators were selected to capture the consistency, magnitude of deviation, and directional alignment between evaluation scenarios. Given the small sample size (N = 8) and the exploratory scope of the study, inferential statistical tests were not applied.
Ethical Considerations
Only publicly available architectural competition materials were used in this study. No personal data were processed, and all analyses were conducted in accordance with principles of research ethics and data confidentiality. All analyses were performed using GPT-4o (June 2025 release), and the model was used exclusively within the constraints of its publicly available functionalities.
Findings
This section presents a comparative analysis of the eight awarded projects (three prizes and five honorable mentions) from the Kadıköy Municipality New Service Building Architectural Design Competition. The analysis includes both the human jury evaluations and the assessments produced by ChatGPT under two distinct conditions:
ChatGPT-1: AI evaluations conducted after being exposed to the official jury reports, reflecting potential influence from jury comments and rankings.
ChatGPT-2: Independent AI evaluations based solely on the textual and visual materials of each project, without any access to jury data.
Overall Average Score Comparison
The comparative results highlight a clear divergence between AI assessments under jury influence and independent conditions, both in mean scores and ranking positions. For each project, average scores were calculated across the six predefined thematic categories. These scores were then systematically compared to identify patterns, differences, and overlaps between human and AI assessments. The results of ChatGPT evaluations conducted with jury influence are presented in Table 1.
ChatGPT-1 Evaluation Scores (With Jury Influence).
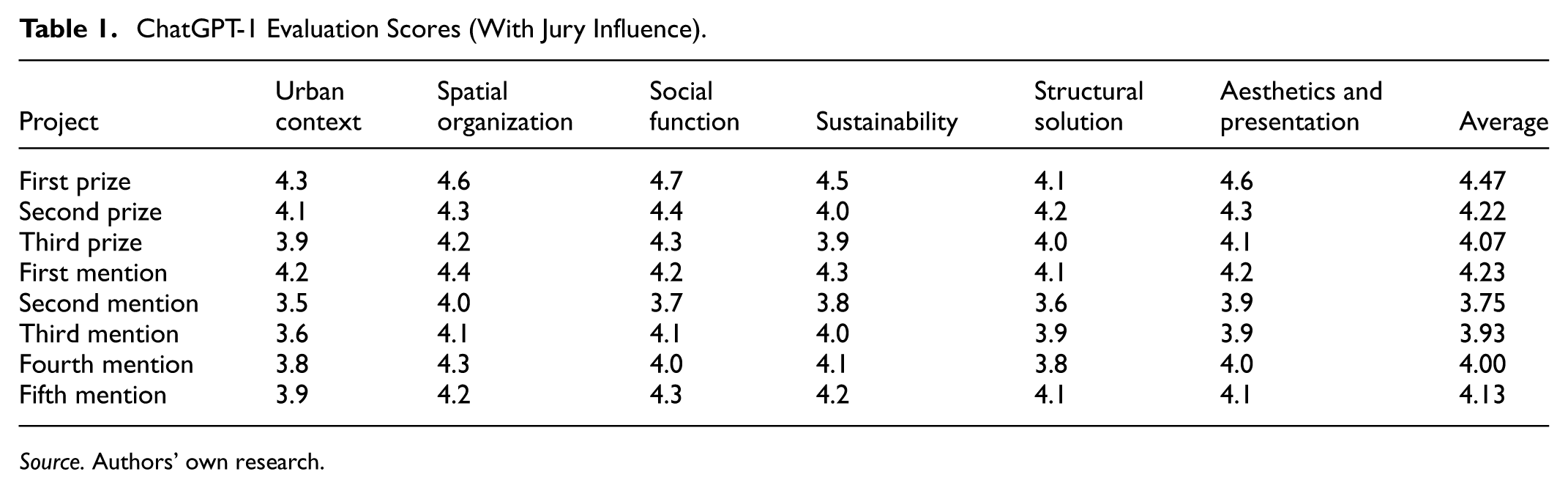
Source. Authors’ own research.
In contrast, the results of independent ChatGPT evaluations—conducted without access to jury inputare shown in Table 2. The goal of these comparisons is twofold: (1) to evaluate the objectivity and consistency of AI-based assessment systems, and (2) to explore how exposure to human jury data may influence the AI model’s scoring tendencies and thematic focus.
ChatGPT-2 Evaluation Scores (Independent Assessment).
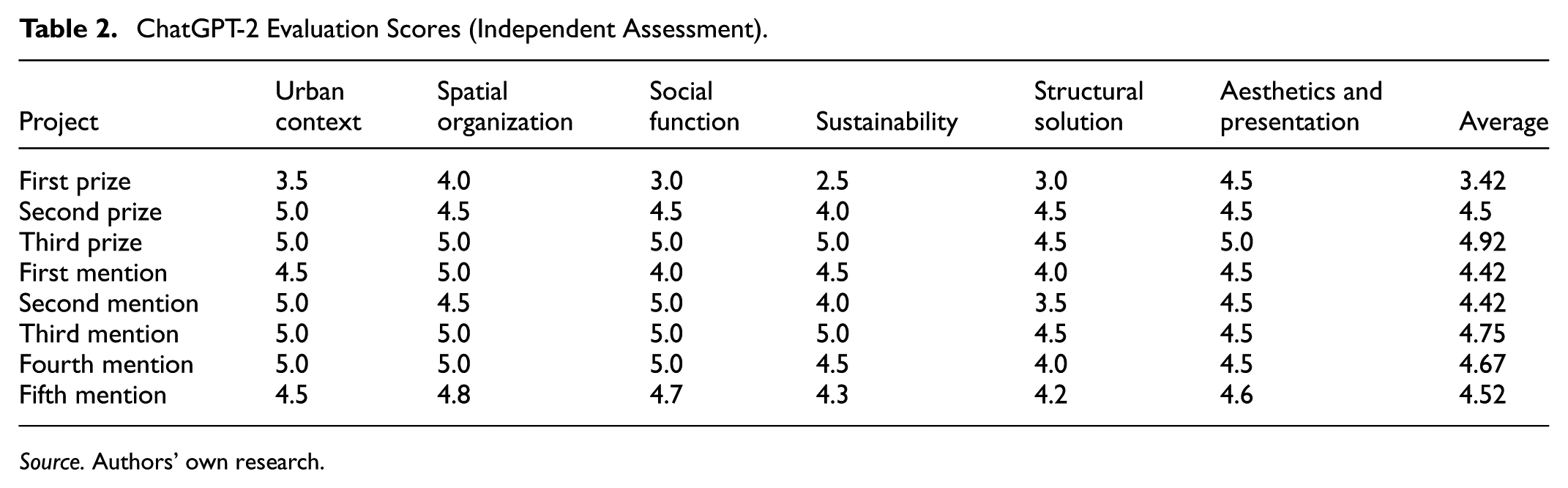
Source. Authors’ own research.
The thematic analysis reveals that ChatGPT provided more consistent scores in some categories, while showing greater variability in others. Lowest deviation: Aesthetic Quality, Representation, and Presentation. Highest deviation: Sustainability and Resilience
The thematic analysis reveals clear differences between categories. The largest deviation between the two scenarios was observed in Urban Context and Site Integration (MAE = 0.98), while the smallest deviation occurred in Structural and Technological Solutions (MAE = 0.38). Intermediate levels of deviation were observed in Social Function and Public Life (MAE = 0.79), Sustainability and Resilience (MAE = 0.63), Spatial Organization and User Diversity (MAE = 0.61), and Aesthetic Quality, Representation and Presentation (MAE = 0.46). These results indicate that ChatGPT was more stable when evaluating technical-functional aspects and more variable when interpreting urban and contextual factors.
These results suggest that ChatGPT can make strong inferences based on visual presentations and conceptual narratives. However, in technically and strategically complex areas such as sustainability, the model appears to rely more heavily on the explicit articulation of such aspects within the project documentation.
The comparative overview of both ChatGPT evaluation modes, including Δ, MAE, RMSE, and correlation values, is summarized in Table 3.
Comparative Overview of ChatGPT’s Evaluations Conducted with Jury Influence and Independent Assessment (text + visual).

Source. Authors’ own research.
Note. The mean difference (Δ), Mean Absolute Error (MAE = 0.615), and Root Mean Square Error (RMSE = 0.677) were calculated to quantify the variations. Average ranking position difference = 3.375; Pearson correlation (r) ≈ .87 between ChatGPT-1 and jury, ≈ 0.42 between ChatGPT-2 and jury.
These values indicate that ChatGPT, when provided with jury data, produces evaluations that closely align with human judgments. In contrast, when operating independently without access to jury input generates more original and differentiated assessments.
The First Prize project, which received the highest score under jury-influenced evaluation, experienced a significant drop in the independent assessment (–1.05 mean difference), suggesting a strong likelihood of jury influence on the AI's judgment.
Conversely, the Third Prize project rose to the top in the independent evaluation, achieving the highest overall score (+0.85 mean difference), indicating that it was potentially undervalued by the jury.
All honorable mention projects received higher scores in the independent analysis. Notably, the third and fourth honorable mentions showed substantial positive shifts in scoring.
Overall, ChatGPT-2 employed a wider scoring range and offered more differentiated evaluations across projects.
These findings suggest that when ChatGPT operates free from jury influence, it tends to engage in more critical and technically driven analysis, offering unique perspectives that may differ from consensus human judgment. A visual comparison of the evaluation mean differences and trends between ChatGPT-1 and ChatGPT-2 is presented in Figure 2.
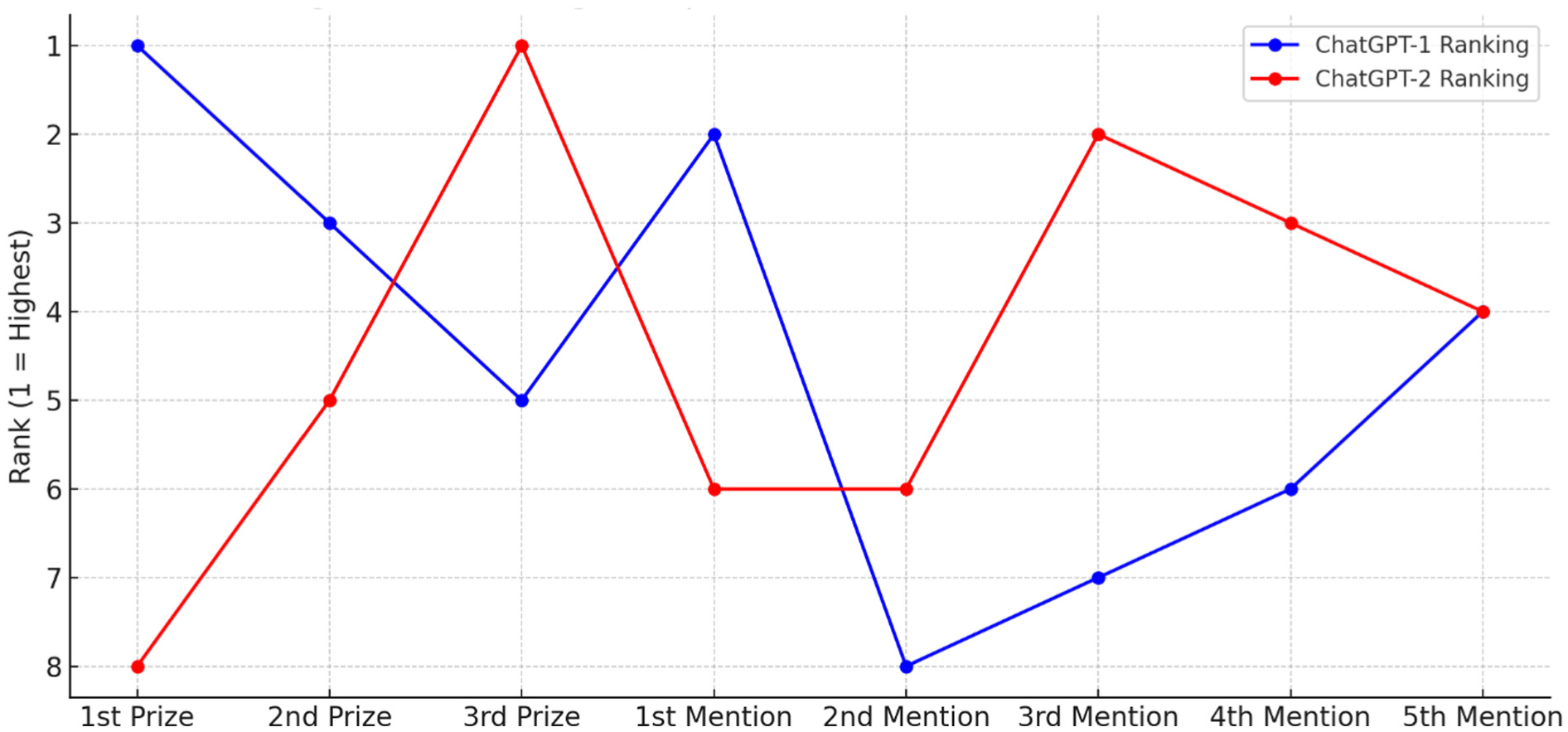
Comparison of Ranking Positions between Jury-Influenced (ChatGPT-1) and Independent (ChatGPT-2) Evaluations of Awarded Projects.
This Figure 2 compares average project scores under two AI evaluation conditions. When influenced by jury reports, the First Prize project ranked highest, but it scored lowest in the independent assessment. Conversely, some Honorable Mentions scored higher without jury input, underscoring the strong impact of jury language on AI evaluation.
Comparative In-Depth Analysis of Awarded Projects
First Prize: This project, despite receiving the highest score under jury-influenced evaluation, was among the lowest-rated in the independent analysis. This sharp decline suggests that the jury reports may have created a positively skewed perception of the project. According to ChatGPT-2, while the topographic resolution is compelling, the project lacks strength in sustainability, public continuity, and technical detailing. Visual materials were interpreted as lacking user scenarios and inclusiveness. This highlights the significant influence of jury knowledge on the initial AI assessment.
Second Prize: This project was rated strongly under both evaluation modes, with a slight increase in its score during the independent analysis. Notably, its spatial configuration including the integration of an urban garden, permeability, and the effective placement of social amenities was more prominently recognized in the visual-text analysis. This demonstrates the AI model’s potential to assess architectural contexts independently and insightfully.
Third Prize: A remarkable positive shift was observed in the Third Prize Project. Initially scored relatively lower in the jury-influenced evaluation, it achieved near-maximum scores in independent analysis based on text and visuals. This divergence suggests that either the jury report did not fully highlight the project’s strengths, or ChatGPT’s original interpretation provided a more comprehensive critique. The project was particularly praised for its participatory design approach, public space configuration, and aesthetic-technological integration.
Honorable Mentions: Across all five honorable mention projects, noticeable score increases were recorded in the second round of evaluation. This indicates that strengths not emphasized in the jury reports were more systematically analyzed by the AI in the independent assessment.
First Mention: A modest increase was observed. The project was positively evaluated in both scenarios, especially for its transition between public and institutional space, natural lighting strategy, and modular massing system.
Second Mention: This project showed a significant increase. While the jury highlighted its technical infrastructure shortcomings, ChatGPT-2 focused on the project's strong integration with the urban context, continuity of open spaces, and conceptual depth.
Third Mention: This project exhibited the largest scoring leap. The AI praised its socio-cultural contextual sensitivity, sustainability strategies, and ecological awareness—elements that may have been underemphasized in the jury report.
Fourth Mention: ChatGPT-2 awarded higher scores for this project, especially in terms of conceptual coherence and interaction with public life. The effective representation of spatial flexibility and user scenarios in the visual materials contributed to this result.
Fifth Mention: This project also showed a meaningful increase in score. Its aesthetic consistency, programmatic clarity, and fragmented mass organization were clearly conveyed through strong visual representation.
Summary of Key Findings
Although the prize-winning projects performed well in the jury-influenced evaluation, some experienced significant score reductions in the independent analysis, most notably the First Prize project. This indicates that the AI model is capable of prioritizing different evaluative criteria than those emphasized by the human jury. In contrast, the Honorable Mention projects consistently received higher scores in the independent assessment, with several reaching performance levels comparable to the officially awarded entries. These findings underscore the AI's potential to reveal alternative strengths that may not have been fully recognized by the jury. The role of jury influence is evident in the first evaluation, where the AI aligned closely with the conceptual language, rankings, and framing found in the jury reports. However, in the second, jury-independent evaluation, the model focused more on aspects such as design expression, visual coherence, and thematic clarity, indicating a clear shift in evaluative emphasis. Despite this divergence, the ranking similarity between the two assessments is noteworthy: all three prize-winning projects were also ranked in the top three by the AI in the independent scenario. This consistency suggests that certain architectural qualities or “codes” are broadly recognizable, whether assessed by human juries or advanced AI models.
Overall, the independent assessment scenario highlighted ChatGPT’s evaluative autonomy, demonstrating that the model can independently identify and reward architectural merit even in the absence of jury guidance, while occasionally offering interpretations that diverge meaningfully from human judgment. The comparative results reveal clear and measurable divergences between the two evaluation scenarios. Jury-influenced scores exhibited a strong alignment with the official competition results, with a high Pearson correlation (r ≈ .87), indicating that the model closely mirrored human jury tendencies when exposed to jury language. In contrast, the independent evaluation produced more differentiated scores and rankings (r ≈ .42), suggesting a greater degree of critical autonomy. The most pronounced deviation was observed in the First Prize project, which experienced a mean score decrease of –1.05 between the two scenarios, while the Honorable Mention projects consistently showed notable score increases. Among the thematic categories, Urban Context and Site Integration emerged as the most variable dimension (MAE = 0.98), reflecting the model’s sensitivity to contextual and narrative cues in the absence of jury influence
Jury Influence and ChatGPT’s Independence
These findings provide significant insight into the potential integration of AI into architectural evaluation processes. Particularly through its ability to analyze multiple data types (text + visuals), the AI model demonstrates the capacity to generate comprehensive and nuanced architectural critiques occasionally offering insights that go beyond those expressed in jury reports. While ChatGPT’s assessments largely aligned with jury decisions in certain cases, it also introduced notable ranking changes for other projects. This indicates that AI can serve both as a supportive evaluation tool and as an alternative interpretive platform, capable of offering distinct perspectives within design competitions.
These findings not only reveal the influence of jury language on AI judgments but also demonstrate the model’s potential to operate as an autonomous critical agent, setting the stage for the broader theoretical implications discussed in the following section.
Discussion
The primary aim of this study was to examine the evaluative potential of large language models (LLMs) in architectural design competitions, particularly in terms of their alignment or divergence from human jury assessments. The findings reveal that when ChatGPT has access to jury reports, its evaluations closely align with those of the jury. However, in the absence of such information, significant differences emerge in project rankings and thematic emphases. These results open up a broader debate on whether AI in architectural critique functions primarily as a reproducer of existing discourses or as an independent interpreter capable of generating original perspectives.
ChatGPT Evaluations Guided by Jury Input
In the ChatGPT-1 evaluations, the conceptual frameworks, terminology, and ranking information embedded in the jury reports directly shaped the AI’s evaluative outputs. The fact that the top three projects received the highest scores in exactly the same order as the jury rankings demonstrates the model’s strong tendency to internalize the evaluative language and content priorities of human juries. In this context, the AI functions less as an autonomous critic and more as a discursive agent that mirrors existing evaluative structures rather than challenging or expanding them.
As Tempestini (2025) emphasizes, architectural evaluation processes are shaped not only by objective criteria but also by social dynamics—such as professional norms, ethical assumptions, and disciplinary habits. Jury reports, therefore, serve not merely as analytical documents but also as discursive constructs that reflect and reinforce the normative boundaries of the architectural discipline. ChatGPT’s mimicry of this discourse effectively transforms it into a synthetic interpreter that replicates dominant value systems rather than challenging or expanding them.
Similarly, Broady (2017) draws attention to the transdisciplinary and pluralistic nature of architectural knowledge production, noting that the frameworks generated through jury deliberations may suppress alternative viewpoints. When exposed to such frameworks, ChatGPT appears to reproduce the existing epistemic order rather than diversify architectural critique. This raises concerns about AI-driven conformity, which may conflict with the pluralism that is central to a healthy architectural criticism culture.
From this perspective, the fact that jury reports function as a form of “training data” for the model presents a limitation. It potentially inhibits the generation of alternative perspectives. While the low MAE (0.20) and RMSE (0.25) values confirm a high level of alignment between the model and the jury, they also suggest that the model’s capacity for critical depth and original analysis may be constrained. The high alignment (r ≈ .87) and low error metrics (MAE = 0.615) in this scenario further demonstrate how closely the model mirrors jury discourse. This dependence on jury discourse also frames the boundaries within which the model operates, shaping its critical behavior. This finding aligns with the ‘AI as Critic’ perspective, in which the model acts less as an autonomous designer and more as a discursive agent embedded within human-defined evaluative frameworks (Horvath et al., 2024).
Originality and Limitations of Independent ChatGPT Evaluations
In the ChatGPT-2 scenario, the model had no access to jury reports and relied solely on project presentation texts and visuals. When this external reference is removed, the model’s evaluative behavior shifts markedly. This is consistent with the quantitative results, which showed lower alignment (r ≈ .42) and higher MAE values in the independent evaluation scenario. Under these conditions, the AI produced more original, diverse, and technically differentiated evaluations. The shifts in rankings and score increases—particularly among the honorable mention projects—indicate that the model developed a degree of autonomy based on its multimodal interpretation. This aligns with the findings of Price and Nicholson (2019), who emphasize both the potential and the limitations of AI in architectural evaluation tasks.
However, this independence also comes with certain limitations. When deprived of contextual data, the AI may struggle to accurately interpret the social, cultural, or economic references embedded in a project. Additionally, strategies implicitly suggested in the competition brief or intuitive design decisions may be overlooked. This limitation was particularly evident in the thematic category of Sustainability and Resilience, which showed the highest variance between the two evaluations.
Thematic Alignment and Deviation: Strengths and Constraints of the Model
The thematic comparison revealed that ChatGPT produced more consistent evaluations and showed closer alignment with jury decisions in specific categories. Notably, the Aesthetic Quality, Representation, and Presentation category exhibited the lowest deviation across both evaluation scenarios, indicating a stable evaluative pattern in this area.
This outcome suggests that large language models perform more effectively when criteria emphasize visual communication, conceptual clarity, and graphic presentation. In other words, AI demonstrates stronger evaluative capacity when judgments are anchored in formal representations and presentation-based aesthetics.
Conversely, performance declined in more abstract, technically informed, and context-sensitive categories such as Sustainability and Resilience. In these areas, the AI's reliance on external guidance (e.g., jury input) becomes more pronounced, and the absence of such cues leads to higher variability in assessment. As Nishant et al. (2020) argue, while AI systems may excel in modeling aesthetic language, they struggle to independently evaluate design quality in terms of environmental performance, technical adequacy, and contextual responsiveness. This disparity underscores the limitations of the model’s contextual memory and its ability to address complex, multi-layered design themes.
In summary, the critical analysis capacity of models like ChatGPT varies according to thematic focus. While the model may deliver balanced and reliable evaluations for visually expressive projects, it falls short in replacing human intuition in more abstract and layered domains. This variability reinforces the necessity for human expertise in certain aspects of architectural assessment. These thematic patterns point to the kinds of evaluative spaces in which AI can either support or diverge from human judgment.
The Role of AI in Architectural Criticism Culture
The findings suggest that AI-based language models can contribute meaningfully to architectural evaluation not as autonomous critics, but as supportive tools that accelerate and diversify critique. ChatGPT demonstrates the ability to replicate jury decisions with high accuracy; however, this alignment often results more from discursive imitation than from genuine critical insight. In independent assessments, by contrast, the model exhibits greater originality, offering alternative rankings and interpretations. This behavior highlights AI's potential role as a rapid-feedback mechanism in early-stage evaluations, design studios, and public competitions. The study by Gökdemir and Kayan (2025) supports this proposition, identifying AI as a facilitator of iterative critique rather than a final arbiter.
Nevertheless, final decisions must still rely on human judgment grounded in intuition, contextual literacy, and cultural sensitivity. While AI can assist and enrich evaluative discourse, the layered and value-driven nature of architectural criticism necessitates a human-centered interpretive framework. This positions AI not as a replacement for human criticality, but as an extension of architectural discourse- an additional layer in what Carpo (2017) identifies as the ongoing transformation of critical reasoning through digital and computational media.
Conclusion
This study aimed to comparatively evaluate eight awarded projects (three prizes and five honorable mentions) from the Kadıköy Municipality Architectural Design Competition through both human jury assessments and two distinct AI-based analyses conducted using ChatGPT. The central research question focused on how architectural design critique can be generated using large language models (LLMs) and to what extent these critiques align with or diverge from human jury decisions.
One of the most critical findings is the clear influence of jury reports on ChatGPT’s evaluations. When provided with jury narratives, the model replicated the jury’s rankings with high fidelity, assigning the highest scores to the first, second, and third prize-winning projects in the same order as the original jury. This result demonstrates that conceptual framing, linguistic tone, and structured commentary embedded in jury reports are not merely “inputs” for LLMs but act as interpretive frameworks that shape their evaluative behavior.
The key contributions of this study can be articulated along three main dimensions. Methodologically, it introduces a pioneering dual-scenario evaluation model, providing a structured thematic coding framework that enables systematic comparison between jury-influenced and independent AI evaluations. Theoretically, it opens a critical dialogue on the role of AI in architectural critique by examining originality, discursive imitation, and the boundaries of AI’s critical autonomy. It challenges assumptions about AI’s neutrality and investigates how language models can both reinforce and deviate from dominant architectural discourses. Practically, the findings demonstrate the potential of AI-assisted evaluations in areas such as preliminary jury filtering, early-stage studio feedback, and generating diverse perspectives in large-scale competitions.
In the independent scenario, where the AI evaluated projects based solely on presentation texts and visuals, significant ranking shifts emerged. Honorable Mention projects, in particular, were reassessed more favorably, indicating that the model applied alternative evaluative criteria when not guided by jury discourse. This reflects the model’s capacity to operate as a semi-autonomous critical agent under multimodal input conditions.
At the thematic level, the lowest deviation occurred in Aesthetic Quality, Representation, and Presentation, while the highest deviation was observed in Sustainability and Resilience. This suggests that AI systems interpret visual and formal elements with greater stability, whereas categories requiring technical reasoning or contextual depth remain more ambiguous in the absence of explicit guidance.
Quantitative indicators further support these findings. Jury-influenced evaluations exhibited high alignment and low error (r ≈ .87; MAE = 0.615), while independent evaluations displayed lower alignment and higher variability (r ≈ .42; RMSE = 0.677). This confirms that ChatGPT can adopt a more critical and differentiated stance without jury data, but its reliability remains tied to the quality of textual and visual inputs.
Based on these results, three key conclusions can be drawn:
Jury-guided evaluations enable high alignment with official outcomes but restrict the model’s interpretive autonomy and critical diversity.
Independent evaluations allow the AI to surface alternative strengths and perspectives, making it a valuable supplementary assessment tool in design competitions.
The quality of input data both textual and visual plays a decisive role in determining the consistency and depth of AI-generated critiques.
These findings provide a methodological basis for integrating AI into architectural education, competition processes, and critical discourse. However, this integration must be approached cautiously to avoid undermining essential disciplinary values such as pluralism, critical reasoning, and contextual sensitivity.
In conclusion, while large language models can generate architectural evaluations with notable accuracy, especially when provided with multimodal input, they lack the subjective creativity, conceptual intuition, and socio-cultural interpretive depth necessary to fully replace human juries. Human evaluators consider not only thematic performance but also how a project situates itself within broader cultural and urban narratives. For this reason, ChatGPT should be understood not as a decision-making authority but as a tool for pre-evaluation, analytical acceleration, and diversification of architectural critique.
This study has certain limitations that should be acknowledged. The analysis was based on a single architectural competition with a relatively small number of projects (N = 8), which may limit the generalizability of the findings. Future research should expand this framework across multiple competitions, explore different AI models, and integrate more advanced multimodal analysis to assess how AI can complement or challenge human judgment in broader architectural contexts. In addition, this study acknowledges potential sources of bias inherent in both AI and human-based evaluations. On the AI side, model outputs may be influenced by pre-training data biases, prompt sensitivity, and limited interpretive capacity regarding complex visual information. On the human side, jury assessments can reflect subjective preferences, disciplinary norms, and implicit aesthetic assumptions. Recognizing these biases is essential for critically interpreting the findings and for positioning AI as a complementary—rather than neutral—actor in architectural evaluation.
Footnotes
Consent for Publication
The publication of this study has been approved by all authors.
Author Contributions
Conceptualization: ÖÖ, EBÖ; Methodology: EBÖ; Writing—original draft: ÖÖ; Writing—review & editing: ÖÖ. All authors read and approved the final manuscript.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statements
The data are available upon reasonable request.