
Abstract
Processing texts of multiple knowledge areas is a hard task. This article presents an Information Science contribution to natural language processing based on artificial neural networks through data arrangement. An extended concept of Information architecture was used, aggregating a multimodal view of organizing data. The Multimodal Information Architecture definition served as foundations for a five-step procedure to design, analyze and transform data used for artificial neural networks training and learning methods, complementing gaps identified by authors focused on Computer Science implementations. The proposal was validated with three datasets formed by texts coming from 16 knowledge areas. Results obtained through the usage of pre-processed data and raw data where compared. In each of the three datasets, the method identified arrangements which led to better and worst results, separating which corpus samples are more susceptible for knowledge extraction.
Keywords
Introduction
Organization and knowledge are two concepts with intimate relation within Information Science. Hjørland (2008) proposes two intersection points on these concepts, which can be divided into a technician view and scientific view. As the author said: In the narrow meaning Knowledge Organization (KO) is about activities such as document description, indexing and classification performed in libraries, bibliographical databases, archives and other kinds of “memory institutions” by librarians, archivists, information specialists, subject specialists, as well as by computer algorithms and laymen. KO as a field of study is concerned with the nature and quality of such knowledge organizing processes (KOP) as well as the knowledge organizing systems (KOS) used to organize documents, document representations, works and concepts. Library and Information Science (LIS) is the central discipline of KO in this narrow sense (although seriously challenged by, among other fields, computer science). (Hjørland, 2008, p. 86).
The increasing use of artificial intelligence models in daily activities of information processing and classification adds a new variable to a long discussed question. Taking Hjørland (2008) as one of its firsts definitions, Knowledge Organization as an scientific field would place Information Science and Librarianship as its central parts, however, being seriously challenged by Computer Science.
At the time this statement was made, Hinton et al. (2006) architectural implementation of artificial neural networks overcame a historical obstacle faced by Computing, placing it a step further on the applied Knowledge Organization leading role race.
Until Hinton et al. (2006) discovery, Artificial Neural Networks (ANN) developments suffered from lack of depth in layer implementation. Notoriously, the human brain, basis for intelligence models, has several layers of analysis, which makes it possible to deal with more complex problems. After this proposal, the number of treatment layers surpassed 2 or 3.
Overcoming computational limitation gave rise to a great variety of technological implementations, leading to innumerable neural networks designs that apply multiple mathematical algorithms to obtain a measure of intelligence through pattern verification.
Although some goals on Computer Science were achieved, data arrangement and knowledge organization still exists characterized by many separated communities working with different technologies, lacking researches about basic assumptions, relative merits and weak sides. As Hjørland (2008) stated, the problem is not just to formulate a theory, but to uncover theoretical assumptions in different practices and formulate them as clearly as possible in order to enable comparative approaches.
Taking a data driven point-of-view on the problem, Kar and Dwivedi (2020) state that Computer Science aims at new algorithms implementations, but Information System researches have spawned from pure mathematical and algorithm validation toward data collection and analysis on how these activities reflect findings. Authors expand the discussion beyond Hjørland (2008) questions inserting a multi-modal context, where data can be provided from multiple sources in a wide variety of formats.
In this article, Multimodal Information Architecture (MIA) is presented as an Information Science initial contribution to Artificial Intelligence (AI) models, figuring as a theoretical counterpart based on Knowledge Organization, specifically in Natural Language Processing—NLP.
Methodological Procedures
Aiming a structured analysis of MIA impacts on NLP problems, this work adopts a methodological approach developed by VanGigch and Pipino (1986) called World View
It considers the construction of knowledge along three stages that keep close relationship between them: a metaphysical level, prior to the formalization of the object of knowledge; a level of the object of knowledge itself; and a level of application of constructed knowledge. In this sense, this article will adapt such methodology as follows:
At the metaphysical level: identify the fundamental issues of NLP current development stage;
At the knowledge object level: propose ways of applying MIA in NLP problems;
At the knowledge application level: generate MIA products for implementation in NLP.
Making an extension on one of the conclusions made by Kar and Dwivedi (2020), where the authors suggest that multi-modal data analysis (where multiple data types would be involved, like text, images, networks, and links) would be enriching on model construction, this article will explore how to enrich a single data type (text on the case) through arrangement of data sets based on Kuroki (2018) Multimodal Information Architecture.
Deep Learning: Usage and Challenges in NLP
Foundations of artificial neural networks design were developed throughout the 60s and 90s. On the rise of years 2000s and the overcoming of shallow architectures by Hinton et al. (2006), a new wave of implementations started to make use of analysis layers depth, a practice that originated the term Deep Learning (DL) (Arel et al., 2010).
Wason (2018) proceeded with a survey of initiatives on the use DL in semantic problems identified significant results compared to human performance. Throughout the research it is possible to confirm that machine learning initiatives grew particularly well in effectiveness from 2006 (more precisely after shallow architectures limitations were overcame). Since then, ANN has been massively used in a wide range of domains such as voice recognition (no matter the sound source), Recurrent Neural Networks (RNN), handwriting recognition, deep belief networks, auto-encoders, acoustic modeling, classification feature detectors, calligraphy synthesis, language modeling, improvement and development of models among others. Considering the variety of applications, three major issues can still be commonly classified as challenging:
Data volume: quantity of data necessary to obtain satisfactory learning would be up to 10 times the amount of parameters (neurons) of the network design;
Overfitting: as larger the network gets, in terms of the number of parameters, greater the probability that learning is oversized, resulting in poor generalization (small changes on input objects leads to unsatisfactory results);
Brittle nature: neural networks tend to be specialized, so that when trained in a certain task, performance in another task is extremely unsatisfactory.
First issue addresses a problem originally identified by Bellman (1954), discovered while producing a technical report on the Theory of Dynamic Programing, which aimed mathematical problems endowed with multiple decision scenarios. At certain point, the author made the following statement: We have a physical system whose state at any time t is determined by a set of quantities which we call state parameters, or state variables. At certain times, which may be prescribed in advance, or which may be determines by the process itself, we are called upon to make decisions which will affect the state of the system. These decisions are equivalent to transformations of the state variables, the choice of a decision being identical with the choice of a transformation. The outcome of the preceding decisions is to be used to guide the choice of future ones, with the purpose of the whole process that of maximizing some function of the parameters describing the final state. Examples of processes fitting this loose description are furnished by virtually every phase of modern life, from the planning of industrial production (Bellman, 1954, p.1).
At the other hand, second problem points out that proportionality between network size and data volume is required in order to achieve balance between known and unknown situations. Otherwise, the algorithm will only correctly predict scenarios which reproduce cases previously analyzed.
Even attending both cases, neural networks tend to be task-specialized, that is, an image recognition algorithm is likely to perform poorly in speech recognition problems, due to the brittle nature mentioned on the third issue.
To achieve a certain configuration of data that meets all three constraints tends to be a difficult task, specially in text processing activities, depending on how specific the use of language is on the concrete case.
According to Minaee et al. (2021), latest attempts to obtain better results in NLP are based on Transformers and Pre-Trained Models (PTMs). Since the earliest implementations of NLP Neural Networks, such as Convolutional Networks (CNNs), Recurrent Networks (RNNs), and Long Short-Term Memories (LSTM) networks, difficulty in capturing relationships between words within a sentence has been noticed.
After the development of Attention Mechanisms Models described by Bahdanau et al. (2014), NLP neural networks began to distinguish textual objects through word sets. Departing from this concept, a new architecture called Transformers developed by Vaswani et al. (2017) brought two relevant innovations: assignment of attention scores that indicates how influential one word is on another and improvement of parallelization methods, reducing training time. After 2018, usage of PTMs based on Transformers has grown, endowed with deeper architectures and pre-trained on large volumes of textual data, which, together, leads to better contextualization of words and sentences. Following this innovation, Qiu et al. (2020) researched the most used PTMs and divided them into four categories:
Representation type: how language is represented and which techniques are used to capture implicit linguistic rules and common sense knowledge, which are hidden in text data;
Model architecture: how contexts are identified, if by sequence models (word by word) or non-sequence models (though syntactic structures or pre-defined semantics)
Pre-training task: the main goal along training. Supervised learning aims to learn a function that maps an input to an output based on training data consisting of input-output pairs; unsupervised learning aims to find some intrinsic knowledge from unlabeled data, such as clusters, densities, latent representations; self-supervised learning (SSL) is a blend of of supervised and unsupervised learning. The procedure of learning is the same as in supervised learning, but the labels of training data are generated automatically
Extentions: PTMs usually learn universal language representations for general purpose applications. Data assembled for basic training is composed of a vast variety of contexts: legal, technological, romance, fiction, and many others. Therefore, to execute properly (and with higher degree of assertiveness) some specific tasks, model enrichment is not only desirable, but needed.
Qiu et al. (2020) also divided PTMs into generations according to their objectives. First generation models search good word mapping models, obtaining hierarchical word classification at the expense of language modeling. They are also context-independent. Mikolov et al. (2013a)’s Word2vec, Pennington et al. (2014)’s GloVe as well as Mikolov, Sutskever et al. (2013)’s CBow and Continuous Skip-Gram are examples. Second generation models seeks to produce vectors of words at sentence level, taking into account the context in which words are found. McCann et al. (2017)’s CoVe, Peters et al. (2018)’s ELMo, Radford et al. (2018)’s OpenAI GPT, and Devlin et al. (2018)’s BERT are examples. Considering how vast PTMs models are, Minaee et al. (2021) produced an article suggesting a five-step procedure for choosing a NLP Neural Network:
PTM Selection;
Domain adaptation;
Task-specific model design;
Task-specific fine tuning;
Model compression.
After reviewing over 150 DL models for text classification and more than 40 data sets, Minaee et al. (2021) concluded that even though great progress was achieved, some questions still challenging to the field:
Absence of datasets for more complex tasks: although a number of large-scale datasets have been collected for common text classification tasks in recent years, there remains a need for new datasets for more challenging TC tasks such as QA with multi-step reasoning, text classification for multi-lingual documents, and TC for extremely long documents;
Commonsense knowledge models: Incorporating commonsense knowledge into DL models has a potential to significantly improve model performance, pretty much in the same way that humans leverage commonsense knowledge to perform different tasks. Using widely held beliefs about everyday objects or concepts, AI systems can reason based on “default” assumptions about the unknowns in a similar way people do;
Memory Efficient Models: most modern neural language models require a significant amount of memory for training and inference. These models have to be compressed in order to meet the computation and storage constraints of edge applications. This can be done either by building student models using knowledge distillation, or by using model compression techniques;
Few-Shot and Zero-Shot Learning: most DL models are supervised models that require large amounts of domain labels. In practice, it is expensive to collect such labels for each new domain.
Advances made by pure Computer Science researches in NLP are notorious both in implementation diversity and technological scope. However, specific knowledge representations (also addressed as commonsense knowledge by Minaee et al., 2021) still an open issue to discuss.
MIA: Contributions on DL Development
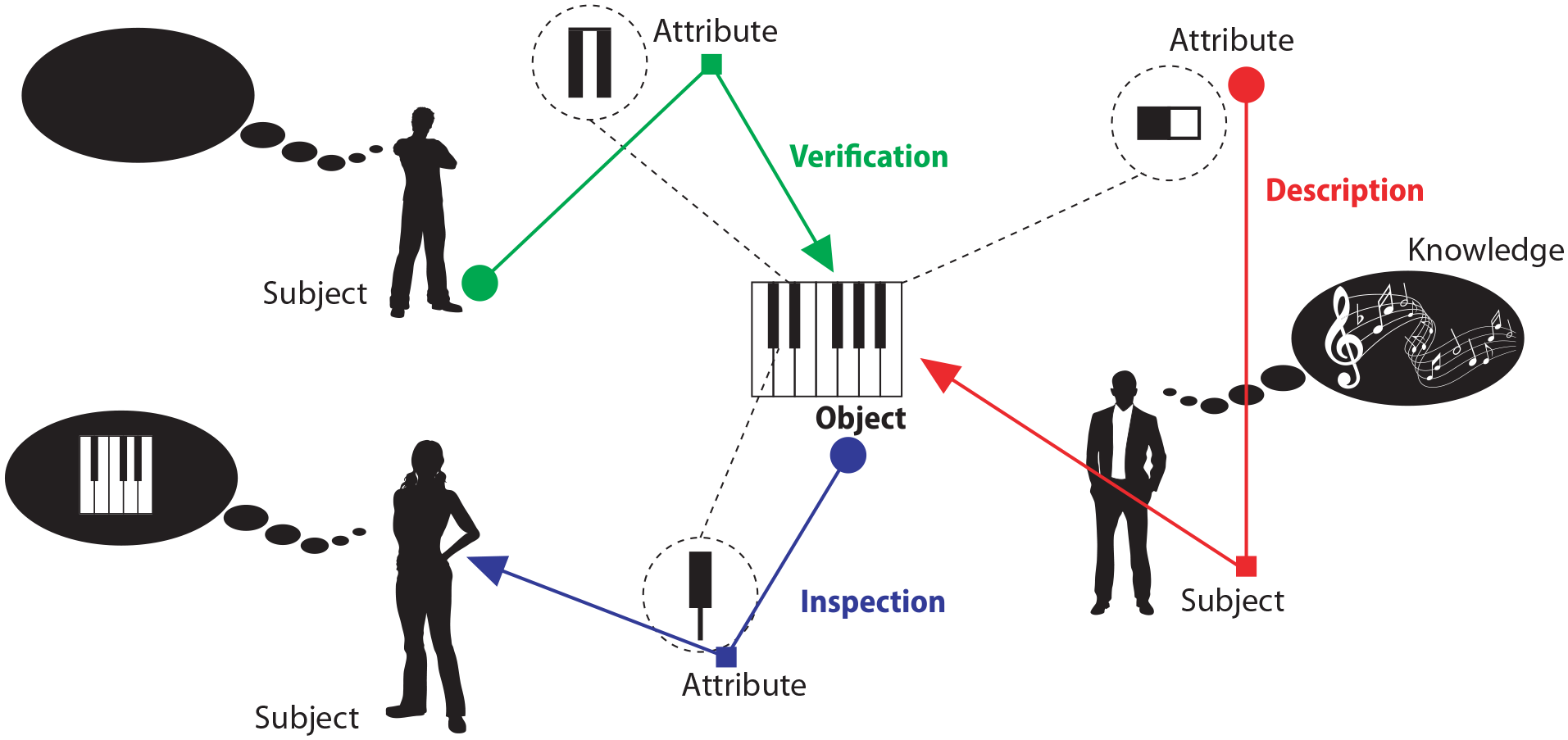
According to Kuroki (2018), MIA can be defined as the distinction and construction of architectural worlds through assumption of Relational Models, grouped by Space-Time contexts of Information states correlated or not. This definition was constructed by gathering properties coming from the concepts of architecture and information, according to Figure 1.

Multimodal Information Architecture concept construction.
The widely used definition of Information Architecture is expanded to address the concept of Mode coming from Kress and VanLeeuwen (2001) and Kress (2009), defined as any resource socially shaped and culturally given to construct meanings. Inserting this perspective impacts how the many forms of meaning expression can be perceived and classified. The definition of Mode endeavors to separate the agreement on use of language within a certain group of subjects from pure general grammar and semantics of the whole population that share the same language. This phenom appears as a driving force toward considering the existence of mode speak apart from mode write, even though both be materialized through an idiom, like Brazilian Portuguese or English. This theory goes along with recent NLP researches conclusions that points out the need for specialized representations of language through, as an example, model enrichment.
Taking apart from what Kar and Dwivedi (2020) cited on their conclusion on Information System researches with big data, MIA would try to enrich context where only one type of data is presented, through the union between what Kress (2009) defined as mode and Portner (2009) modal logic.
But aiming to model social phenomena through a technique capable of computational implementation is not an easy task. To exemplify the statement, consider a population that agreed on the use of English as their idiom to communicate on innovative technologies. This population is formed by people coming from different backgrounds as computer science, social sciences, engineering, mathematics and several others. Although all subjects have access to the corpus that forms the idiom English, there are some words that have different meanings to each subject. Taking the word system as an example, for social sciences it could have a positive value on analysis (meaning that indeed, system can be a sign of innovation), contrasting with computer science which could assume it as an negative value. Considering that not only the word system can assume different values, several Modes can be distinguished. According to Kuroki (2018), MIA addresses this defining that an architectural world is a Mode where meaning can be expressed.
So far, a fast but not practical solution to the proposed scenario would be implementing one model for each identified group of person, as a different mode can be formed. On the other hand, restricting to a single mode leads to dealing with inconsistency of values, culminating in models that will never be objectively accurate. A balance is needed to properly deal with the question as social Multimodality is a reality that cannot be cast aside.
Economy and relevance are two concepts that guide all decision-making situations. A traditional definition of both terms comes from the Ockham Razor which Abbagnano (2015) described as: “Pluralitas non est ponenda sine necessitae” (plurality shall not be taken without necessity, which leads to relevance) and “Frustra fit per plura quod potest fieri per pauciora” (unproductive is doing with more what can be done with less).
Recognizing that information contexts are socially multimodal (any arrangement will potentially lead to multiple modes) and some sense of order needs to be applied so that an information architecture can be effective, MIA uses Carnielli and Pizzi (2008) and Portner (2009) modal logic Frames, based on the modal operators of possibility and necessity. In resume, a logical proposition is necessary if it is true in all possible worlds (which links to a mode on MIA’s concept). Otherwise, it would be possible if it is true in at least one world.
Architectures produced through this concept can be applied on different meaning designation processes, a multimodal form of interpretation. On practical matters, it could produce data viewings or groupings able to express more effectively an information context, facilitating pattern recognition (or mitigating errors and incompleteness of data) by neural networks. An architectural world is a context formed by relationships between subjects and objects, that is, a semantic domain.
The following sections detail a five-step procedure to obtain a new informational domain configuration focused on NLP, figuring as a phase prior to traditional data pre-processing performed on artificial neural networks.
Identify Context Entities
For NLP and PTMs implementations, a context can be simply viewed as a collection of textual data categorized by similar characteristics on linguistic, semantic, factual, commonsense or any other. That is not the case on MIA. For a context to be classified as an architectural space, it necessarily has to consider at least one subject’s point of view on at least one object. On the other hand, the same object can be classified differently by multiple subjects, as well as a certain text sequence can express divergent meanings on different contexts. NLP neural networks try to overcome this barrier through voluminous data samples which, according to Minaee et al. (2021), is a characteristic more frequently found on complex tasks.
Before any distinction, everything is an entity. A context can only exist when some kind of restriction is imposed, some ruling that separates what belongs to the context from what is apart of it. Therefore, this notion of order needs to be imposed by some kind of special rational entity, a subject, capable of altering this informational space. Consequently, entities that fit the subjects’ criteria need to be differentiated from the others—the objects. Therefore, MIA’s first intervention aims to identify subjects and objects within a context, defining them as:
Once subjects of a context are identified, the set of actions taken to manipulate objects until a certain point in time defines the configuration of an observed moment. Every time a new observation is done, a different configuration can be perceived. This statement is grounded on Kuroki (2018)’s concept of correlations: fundamental unit of connection between one subject and one object. Even though different subjects have an agreement on the fundamental characteristics that define an object, their correlations with this objects are totally distinct, making plausible to assume the existence of intrinsic differences not observable at the time of analysis.
Identify Entities Correlations
On MIA, relations connect instances within a context or contexts between themselves. In this sense, a correlation is a special type of relation that occurs when a pair subject-object is formed. As each correlation tends to be unique, describing exactly how the connection was made is a hard task. It would be more suitable to aim a description as close to reality as possible. In this sense, four correlation modeling methods are proposed:
Through these operations, impressions of a subjects’ actions within a context regarding a group of objects attributes are collected. It is important to emphasize that only through modal logic models, multiple Modes in which entities are aggregated differently can be dealt in the same context. Getting back to the aforementioned example of the word system being issued divergent values on modes social sciences and computer sciences. To accommodate both of them, the informational space must be subdivided into smaller units and then describe relationships (not correlations, which refer to subjects and objects) between these units.
Domain Distinctions
When applying MIA a domain is defined as a set of attributes, extracted from objects, which are commonly recognized by a group of subjects through similar correlations. Therefore, subjects and objects can be part of multiple domains. Three point-of-views for domain establishment are possible:
When subsets produced on this stage are distinguished, MIA’s informational cycle is complete: “information states” scope is defined (coming from Identify context entities and Identify entities correlations) and verified whether these states are “correlated or not” (coming from Domain distinctions). A graphical representation of these point-of-views is presented on Figure 2.
Domain-establishment point-of-views.
Proposition of Relationship Between Domains
First three steps aimed on identifying entities, their correlations and domains to obtain a model of the informational space to be treated. After the problem scope is divided into distinguished domains, a multimodal view of it surmise a configuration where two or more domains can co-exist maintaining a logical coherence. Revisiting the steps taken up to this point, each mode has subjects that agreed on some social use of a corpus, correlated with objects and defined their attributes which can be grouped into domains. Therefore, to produce a multimodal view would be to discover how connect them, being guide by the principles economy and relevance.
Domain relations represent the architectural part of MIA. By proposing them, a new configuration of the informational space can be produced. The main issue is how to connect domains considering all the mentioned conditions. MIA also stands for an adequate measure of order, stating that relations have rules that restrict them. Its where modal logic appears as the path for solution. Considering this basis, three type of domain relations can be applied:
Not only the type of relations can be determined, but also their extensions. Its the ruling needed to restrict how broad the connection is. Modal logic Frames definitions are adopted by MIA as relationship rules:
A relation description comes from identifying both type and extension applied. For example, considering domains A = [1,3,4], B = [1,3,5], and C = [1,2,3,4,5]:
A → C is an IDENTITY SERIAL relation, as all attributes in A can be found in C;
B → C is another IDENTITY SERIAL relation, as all attributes in B can be found in C;
A ↔ B ↔ C are PROXIMITY SYMMETRIC relations, as at least one attribute can be found in all domains.
Space-Time Context-Based Groupings
Applying as much rules as possible to a domain or set of domains is not the purpose of AIM. Economy of relations must be taken into account, otherwise any configuration would tend to map objective reality as closely as possible. On the other hand, a static model would leave knowledge development aside. Whenever subjects correlate with other objects or modify their existent correlations, a new domain relation can be identified as well as previously proposed ones maybe reclassified into other types and extensions.
On modal logic, space-time distinctions can be identified through deontic structures, which express obligations and permissions. These are distinguished from epistemic structures, which deal with knowledge. The main difference resides on the impossibility of deontic structures to assume absolute truth: they only consider the possibility of an occurrence. According to Portner (2009), a simple example would be the moral rule “no murder”. Even though being viewed as necessary (it must exist in all possible contexts), murders still occur.
On MIA, the deontic view of relations and its restriction of possibility of occurrence affect how real world problems are modeled. As not all objective reality relations are assumed (which would hinder to meet economy principle), inevitably some characteristics of it are discarded. The same applies to relations and correlations. Taking as basis the initial example of obligations, suppose that a certain correlation
But social agreements and cultural acceptance are not obligatory immutable. If the mode that
Up to this point, all rules address spatial issues of an information architecture: how comprehensive a model is in terms of the relationships, objects and attributes. Time becomes, in fact, a limiting factor for any static model, which leads to the need for a cyclic model, as illustrated on Figure 3.

MIA development cycle.
Implementing MIA
Following the adopted methodological procedures, applying MIA in a NLP task is suggested as the knowledge application level. The problem selected is a text classification task based on the Brazilian Portuguese idiom. Difficulty lies both in absence of sufficient data for learning and the semantic scope of the available data. In short, it is a positive or negative trend analysis of texts meeting legal requirements for taxes incentives on research, development and innovation. Annually, more than 10,000 projects are submitted and classified into 16 knowledge areas. Up to 2022, only texts from 2014 and 2015 were evaluated and reached a final decision. Table 1 presents the results of those years with a value 0 for rejected texts and of value 1 for approved texts.
2014 and 2015 Approval Rate.

NLP Training With Data Not Treated by MIA
Analyzed projects from 2014 and 2015 were used for training, validation and testing in a text classification neural network. The transformer based model BERTimbau developed by Souza et al. (2020) for Brazilian Portuguese was used. This algorithm was pre-trained with Wagner et al. (2018)’s brWaC corpus as language reference, which is formed by 3.5 million documents and 2.68 billion tokens. Selected neural network separates data into three parts: Training, Validation, and Testing. For each set, two variables were observed. Loss represents the difference between expected and obtained results. This value is used for weight adjustment, which makes it possible to advance in learning throughout the experiment. Lower loss values indicate better network learning. Accuracy represents the correct answers percentage obtained in each stage of the experiment. This variable represents model assertiveness given the input data.
To isolate impact produced by MIA products from any interference arising from techniques linked to computer science (database enrichment, learning algorithm configuration, increased scope of analysis), no improvement procedure will be applied either to the environment nor to the set of original data, which guarantees that any change on results comes solely and exclusively from MIA.
In order to validate MIA full cycle, three data grouping where generated: 2014, 2015, and 2014/2015. Each of them were submitted to 10 experiments of 20 epochs with 50 training rounds each. Table 2 shows average results obtained on each of the 10 experiments using 2015 data. Last line of the table expresses overall average of the 10 experiments, therefore, an expected result considering 200 training cycles.
Average Results of Training Rounds for Non-treated Domain—2014 and 2015.
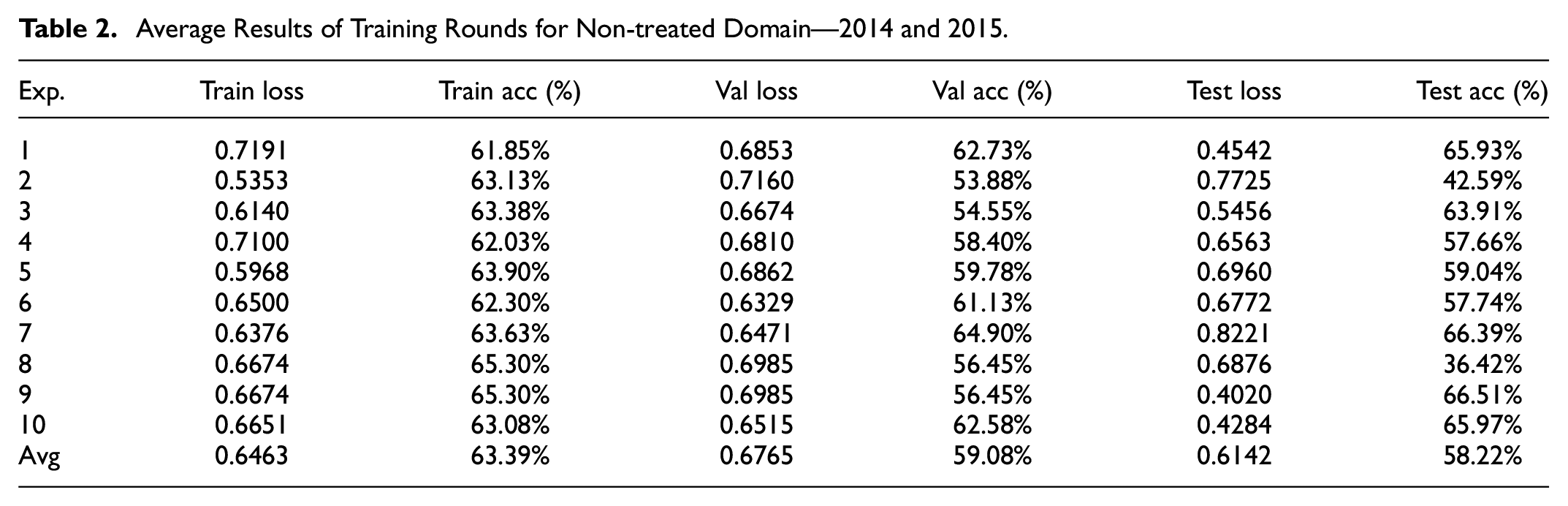
For 2015 results reached only 77.57% on accuracy average, with max value on 80.67%. Only three experiments broke 80 plus result and on two opportunities average test loss reached one plus point. As much as it can be considered a low-valued score, it is not the worst on the given dataset. Table 3 shows result from the same 10 experiment procedure using 2014 data.
Average Results of Training Rounds for Non-treated Domain—2014.

Test accuracy values varied from 48.94% to 58.78%, with average of 54.79%. A high drop of 22.78% on average comparing to 2015. It is noteworthy to observe that 2014 data scored 9.84% high/low gap, a small difference from 2015 data that presented 8.62% gap. Even though results variance had similar values on both datasets, test accuracy had major differences. These results lead to testing both years combined with the same procedure, which results are shown on Table 2.
When joining both datasets, values lean toward 2014 results, with a 15.52% worsening compared to 2015 results, meaning that the characteristics coming from 2014 data contaminated 2015 on the merge. High/low gap had a huge drop to 30.09%. These effects needs to be explored and explained. Therefore, starting from the same datasets provided, the objectives to be achieved through MIA-based data treatment will be:
(i) Find domain grouping configurations that increase test accuracy, using the same NLP algorithm, with no technical-computational interventions;
(ii) Identify domains which data present greater or lesser potential for learning extraction.
Step 1: Identify Context Entities
First step to transform the information environment in question is to identify entities from the original contexts. Active subjects (natural persons) in the initial configuration analyze texts submitted according to 16 knowledge areas and classify them as approved or non-approved. As the classification is given through judgment of several individuals, when applying MIA, this collective knowledge expressed in each area can be considered as a subject, thus obtaining 16 subjects.
Reflexively, objects are also defined by this distinction of subjects, given that there is a semantic agreement between people who analyzed texts in each area. Difference resides in the fact that each knowledge area has a binary value—Approved or Non-approved—with three semantic groupings—Innovative Element, Technological Barrier, and Methodology—resulting in 96 semantic contexts. In this sense, given that objects are expressed through attributes, only nouns are eligible as entities, considering their ability to absorb attributes through other semantic terms that modify them. Figure 4 shows the amounts obtained by context for 2015.

Objects identified by context—2015.
Step 2: Identify Entities Correlations
The second stage for producing a MIA model is to identify correlations between subjects and objects in the domain. For this step, a technique proposed by Jones (1973) called Inverse Document Frequency (IDF) was used. It is a logarithmic measure of a term relevance considering a set of documents: lower the incidence of a given word in a text, greater the probability of its relevance.
This technique was also used on Lim and Maglio (2018) with similar implementation for smart service system through text mining.
Entity selection procedure must identify words that are relevant to the model, maintaining relationship relevance between the potential entity and original context. In this sense, five stages of analysis are proposed:
1. Obtain the IDF value of each entity within each of the 96 semantic domains;
2. Calculate IDF average of each entity considering all 96 semantic domains;
3. Calculate K value, expressed by the standard deviation of IDF averages;
4. Select all entities that IDF value is greatest than K value;
5. Identify objects through DEFINITION, COMPARISION, FUSION, or DECOMPOSITION.
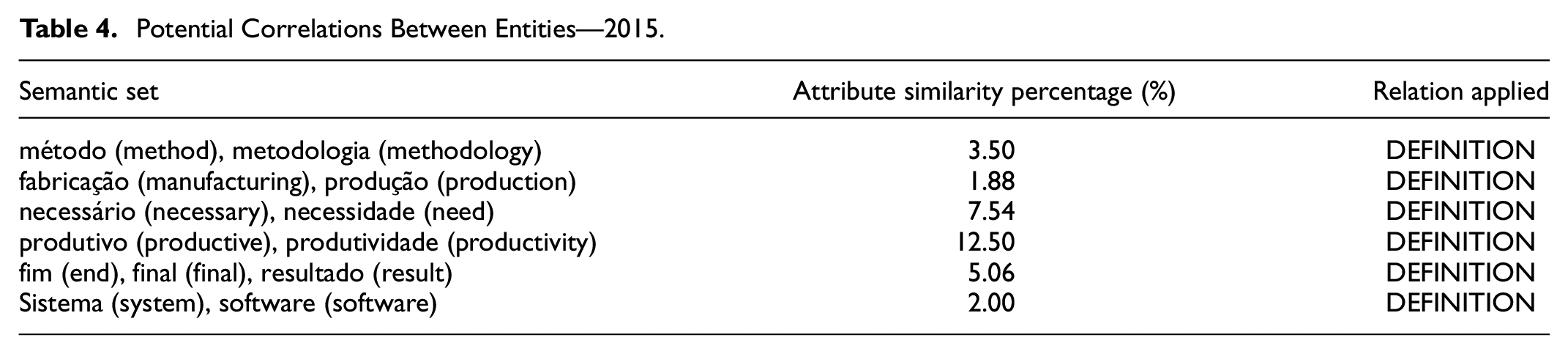
For 2015, 21,142 potential entities were identified. When applying steps 1 to 4 this number decreases to 513. Among potential entities, semantic sets [method, methodology], [manufacturing, production], [necessary, need], [productive, productivity], [end, final, result], [system, software] were identified. Attributes of these sets were analyzed through COMPARISON, in order to verify the need for DEFINITION of two terms or for FUSION in just one term. Table 4 presents the results of these potential relationships in question. As similarity percentage is lower than 50%, all 513 entities obtained throughout the initial four steps are then recognized and correlated as domain objects.
Potential Correlations Between Entities—2015.
Step 3: Domain Distinction
Once 16 active subjects and 513 recognized objects were identified on the original context, its informational space configuration can be modified through description, inspection or verification. Since the path to obtain this configuration began with natural persons analyzing and classifying a set of texts, verification procedure seems the most assertive choice for domain distinction. As stated before, this can be done through three steps:
Inquire a group of subjects;
Identify common attributes;
Group objects that have these attributes.
First step was carried out prior to Step 1: Identify context entities, when text data were analyzed by natural persons. In other words, when the original dataset was obtained, classified by knowledge area and had an approval/disapproval assessment, subjects inquiry was fulfilled. Part of second step was carried out in Step 2: Identify entities correlations, where 513 objects recognized by the 16 subjects. To complete all three steps for this phase, three actions are proposed:
1. Object relevance calculation for the 16 subjects: each knowledge area has a binary value (approved/reproved) for three semantic contexts (Innovative Element, Technological Barrier, and Methodology), resulting in six sub-domains. IDF values of each object are transformed into six parameters, obtaining the object’s relevance value for each of the 16 subjects, as shown in Table 5. This value represents how relevant objects are for the subjects;
2. Subject’s environment adherence index: endowed with all objects relevance value, the sum of all these values represents the adherence level of the subjects scope of knowledge to the analyzed context, as shown in Table 6.
3. Obtain the informational context dispersion index: given by the standard deviation of the adherence indexes calculated in the previous procedure, as a measure of how uniform the informational environment is.
4. Domains conception, based on the dispersion index of the informational environment: greater the dispersion index, greater the number of data clusters, observing the need for balance between the subjects’ adherence rates to the environment.
For 2015 data, dispersion index calculated based on was 562.38, which divides the spectrum of values in Table 6 into four ranges:
Example of Object Relevance Calculation.

Results of Subjects’ Adherence Index Calculations—2015.

Tier 4, from 0 to 562.38: gathering subjects Metallurgy, Pharmaceuticals, Paper and Cellulose, Mining, Furniture, Construction, Agroindustry, Telecommunications and Textile;
Tier3, from 562.39 to 1.12476: gathering subjects Petrochemical, Consumer Goods, ICTs, Food and Electronics;
Tier 2, from 1.12477 to 1.68714: gathering the subject Mechanics and Transport;
Tier 1, from 1.68715 to 2.24952: gathering the subject Others.
The smallest possible level of distinction/aggregation in the informational context, considering all 16 subjects, is the division into two domains. Such distinction must take subjects adherence to the informational context balance into account. Therefore, grouping [1, 4] and [2, 3] are the most balanced, giving rise to:
Potential domain 1, formed by subjects Metallurgy, Pharmaceuticals, Paper and Cellulose, Mining, Furniture, Construction, Agroindustry, Telecommunications, Textile, and Others;
Potential domain 2, formed by subjects Petrochemicals, Consumer Goods, ICT, Food, Electronics and Mechanics, and Transport.
Step 4: Relationship Between Domains
With two potential domains found in the previous step, we move on to establishing relationships between the knowledge areas and these domains, as well as between themselves. Figure 5 demonstrates Identity and Proximity relationships that originated both potential domains and relationship extension between them.

Relationships between knowledge areas and potential domains—2015.
Only potential domain 1 presents a Symmetric Identity relation, since the knowledge area “Others” is the only one that has all objects mapped on Mia Step 2: Identify entities correlations. All relationships identified while constructing potential domains 1 and 2 are reflexive, since this operation begins with common objects identification, which necessarily requires checking the existence of the object in the domain itself, and only then proceeding to verify the existence of the referred object in another domain.
Regarding the relationship between potential domains 1 and 2, there is a single symmetric relationship [1,2], given that all objects can be found in any possible configuration of both domains, which demonstrates that both coexist independently and are also micro-organizations of the original informational context.
Step 5: Space-Time Context-Based Groupings
As described in Step 1: Identify context entities, text data from 2015 was used to conceive the domain distribution obtained in Step 3: Domain distinction. In order to verify temporal impact on the proposed architecture over the years, MIA cycle exposed in Figure 3 was applied along with procedures described in Step 1: Identify context entities to Step 4: Relationship between domains on 2014 data, resulting on a different domain configuration.
For Step 2: Identify entities correlations the number of potential entities becomes 480 in detriment of 513 obtained in 2015. Subjects adherence rates for 2014 are shown in Table 7.
Results of Subjects’ Adherence Index Calculations—2014.

Informational context dispersion index for 2014 was 798.84. Been this value higher than 2015’s, it resulted in a slightly different aggregation of subjects:
Tier 3, from 0 to 798.84: gathering subjects Metallurgy, Pharmaceuticals, Paper and Cellulose, Mining, Furniture, Construction, Agroindustry, Telecommunications, and Textiles;
Tier 2, from 798.85 to 1.59768: gathering subjects Petrochemicals, Consumer Goods, ICTs, Food, and Electronics;
Tier 1, from 2.39653 to 3.19537: gathering subjects Mechanics and Transport and Others.
Most notable changes are: gathering of subjects Mechanics and Transports and Others into tier 1 level (extinguishing tier 2 level); downgrading Information and Communications Technology subject to tier 2, below dispersion index; reordering of subjects on tier 3 level. Although changes are apparently negligible, balance between the subjects’ adherence rates must be considered. Therefore, three potential domains are proposed for 2014:
Potential domain 3, formed by subjects Mechanics and Transport and part of tier 3 subjects: Agroindustry, Furniture, Paper and Cellulose, Pharmaceuticals, and ICTs;
Potential domain 4, formed by subjects Others and the remaining part of tier 3 subjects: Textile, Telecommunications, Construction, Mining, and Metallurgy;
Potential domain 5, formed by all tier 2 subjects: Petrochemicals, Consumer Goods, Electronics, and Food.
It demonstrates that the problem is highly sensitive to spatial-temporal distinctions: a MIA model used in 1 year cannot be assumed as applicable to a new temporal context. Confirmation comes when analyzing data from both 2014 and 2015. The number of potential entities identified turn to be 1.192 and subjects’ adherence rates are shown in Table 8.
Results of Subjects’ Adherence Index Calculations—2014 and 2015.

The informational context dispersion index increased to 10,243.65, creating three different potential domains from those previously identified:
Potential domain 6, comprising subjects Mechanical and Transport, Telecommunications, Construction, Paper and Cellulose, Pharmaceuticals, and Metallurgy;
Potential domain 7, comprising subjects Others, Textiles, Agroindustry, Furniture, Mining, and Consumer Goods;
Potential domain 8, comprising subjects Petrochemicals, Food, ICTs, and Electronics.
Results on NLP With MIA Modeled Data
As stated on section NLP training with data not treated by MIA, to produce a predictive model based on untreated data from the selected problem is precarious. Equipped with MIA products obtained from Step 1: Identify context entities to Step 5: Space-time context-based groupings, the data model will be validated.
For this purpose, 2014 and 2015 data were organized according to the potential domains 1 to 8 and trained for 10 times each, maintaining all conditions described no section NLP training with data not treated by MIA. Appendix Tables 17 and 18 presents results from potential domains 1 and 2, respectively, while Table 9 makes a resumed comparison.
Comparison of Results—2015 Data.

Potential domain 1 showed 7.31% of gain in test accuracy, opposed to a loss of 4.92% on potential domain 2. High/low variance, a measurement of the difference between lowest and highest test accuracy result, was 4.35% against 8.62% of 2015 original dataset. Another noteworthy observation is that the lowest test accuracy along domain 1 experiments was 82.10%, a value never achieved during raw 2015 dataset simulations showed on Table 10.
Average Results of Training Rounds for Non-treated Domain—2015.

On the other hand, domain 2 highest test accuracy reached only 78.96%, which is barely better than the average of results on 2015 non-treated data. What draws attention is the lowest score on this domain: 53.40%, a value that is 24.70% lower than the average.
Continuing with MIA validation, temporal impacts on domain modeling were addressed through running experiments with data pre-treated based on 2014 texts, as well as joining both 2014 and 2015 texts.
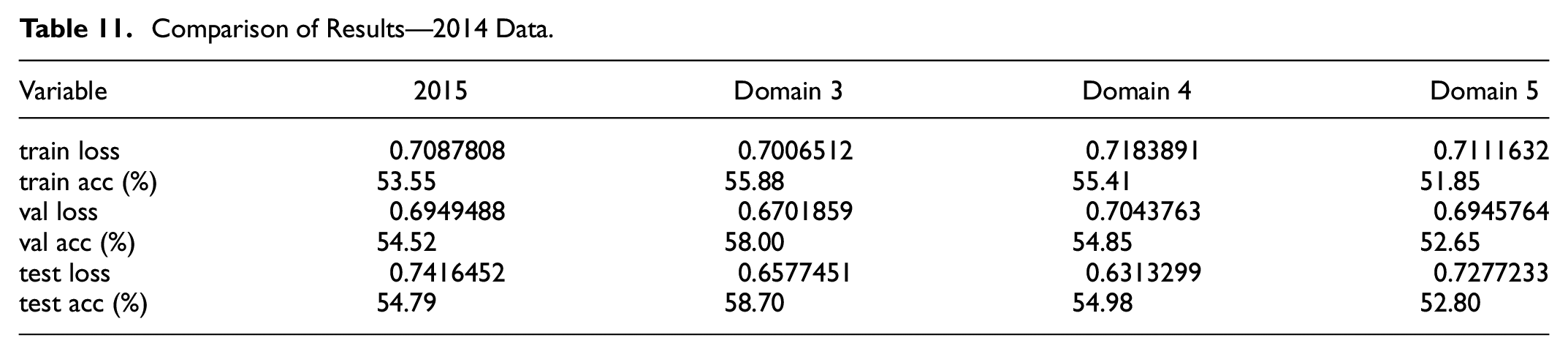
Analyzing 2014, three domains were modeled, one more than 2015. Appendix Tables 19 to 21 presents the results on potential domains 3 to 5 respectively. Comparison of results is presented on Table 11.
Comparison of Results—2014 Data.
During MIA construction procedure for 2014, there was a reduction in the number of potential entities compared to 2015 (513-480) and an increase in the informational context dispersion index (from 562.38 to 798.84). Such numbers lead to the following considerations on experiments results, which will guide analysis:
(i) Subjects who acted in the informational context of 2014 recognized fewer entities as relevant objects, with a great variation in their indices of environment adherence. There are subjects who have high adherence rate to the context (most of their recognized objects are listed as relevant on the global informational context), and others have low adherence to the context (most of their recognized objects are not listed as relevant on the global informational context);
(ii) The relevant informational context to be treated was more dispersed, requiring more subdivisions of the original context, going from two domains to three.
Domain 3 showed an improvement of 4.01% in test accuracy levels, a smaller gain than the one registered for domain 1 in 2015. High/low variance reached 7.23%, reducing the original dataset value of 9.84%. It is noteworthy that the average of test accuracy (58.70%) almost reached top value of raw 2014 dataset (58.74%).
Domain 4 remained practically unchanged if compared to the original context, presenting a discrete 0.19% improvement in average test accuracy. Nonetheless, two points of observation need to be addressed. First, high/low gap suffered a huge drop to 22.69% (12.85% more than 2014 raw dataset), characterizing this domain as highly unstable. Second, top result bested both domain 3 and 2014 raw dataset: 66.59% against 61.57% and 58.78% respectively.
Domain 5, in turn, showed a 1.99% drop in average test accuracy, reaching only 52.80%. High/low gap maintained levels observed on domain 3, scoring 7.30%. On absolute numbers, this domain presented the worst result on test accuracy.
As MIA products indicated, high data dispersion and low subject adherence affected 2014 relevant context: the dataset with more learning capacity becomes smaller and, even so, with little expressive gain. Some parts also presented high variance and results on accuracy sometimes are unpredictable.
Last scenario, joining 2014 and 2015 data, also was divided into three domains, which results can be seen on Appendix Tables 22 to 24, with comparison shown on Table 12.
Comparison of Results—2014 and 2015 Data.
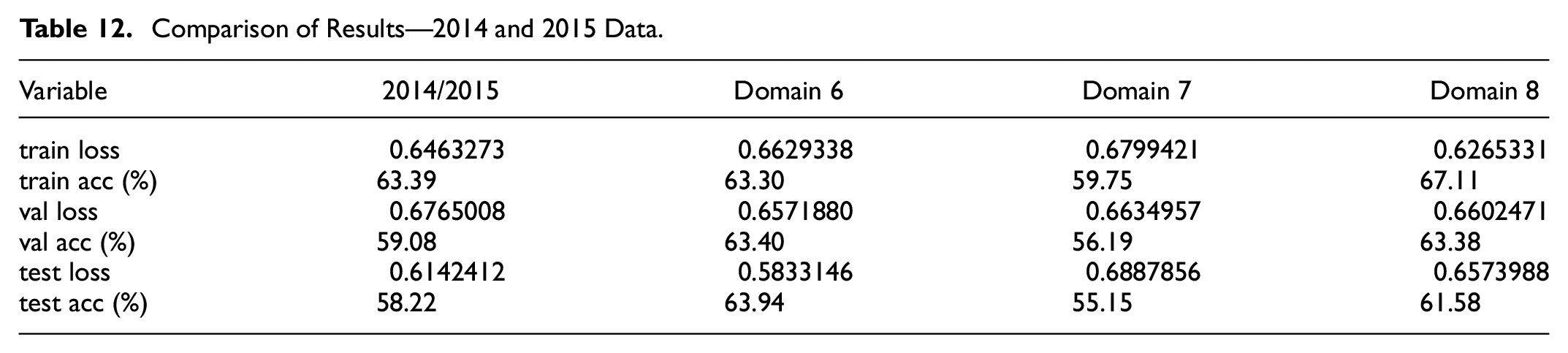
Even though the number of potential entities almost doubled to 1,192, informational context dispersion index grew more than 19 times, reaching 10,243.65. Again, a mismatch between subjects’ knowledge adherence to the relevant informational context lead to high variance on results.
Domain 6 had a gain on average test accuracy of 5.72% (63.94% against 58.22% on raw 2014/2015 data), with much better high/low variance of 7.78%, a 22.31% drop from the 30.09% obtained before.
Domain 7 got a drop on average test result of 3.07% with a high/low gap of 25.25%. It is important to highlight that on four opportunities test accuracy didn’t reached 50% (exp. 1 with 48.86%, exp. 5 with 41.12%, exp. 8 with 46.70% and exp. 10 with 46.07%). On comparative analysis (before MIA and after MIA), this domain can be taken as the worst result overall. Not only test accuracy suffered a fall, but also high/low variance got extremely high compared to previous results.
Domain 8 presented a shy gain of 3.07% on average test accuracy, but presented high/low variance of 18.28%. Even though better than the 30.09% presented on the original dataset, is 10.50% worst then domain 6, which also presented gain on test accuracy.
As an overall analysis based on average test accuracy values, from the eight proposed potential domains, four resulted in better values, three in worst, and one kept almost the same level with nearly insignificant gain. From these results, Table 13 was produced to present learning potential for knowledge area. Its a simple result based on whether the knowledge area belonged to a proposed domain that led to a gain on accuracy (issuing a+ 1 value on the domain year), had no relevant impact (issuing 0) or culminated on a loss of accuracy (issuing −1).
Knowledge Area Learning Potential Analysis.

After all the analysis and conclusions obtained, it is plausible to conclude that starting from the same data set, MIA pre-treatment allowed us to identify subdivisions with greater and lesser capacity for learning, demonstrated through test accuracy. It indicates that MIA can contribute on AI researches through finding relations that are underneath pure algorithm development.
Results Discussions: What’s Next?
Another implication that is up to discussion is inserting Portner (2009) logical frames on other NLP applications such as named entity recognition and relation extraction.
Considering that MIA treats relations through modal logic frames, semantically it would be possible to extend the spectrum of relations while summarizing them in to certain classes or concepts. For an initial development, rules listed on Table 14 were adopted.
Frames, Logical Definitions and Adopted Relations.

A SERIAL FRAME entails that if a relation necessarily exists
appliedTo: when an idea is applied to another idea modifying the original one.
inputTo: when a concept details another concept in terms of sub-components or parts that assemble a whole.
USE: when a concept needs another one to produce full sense on the given context.
A REFLEXIVE FRAME occurs when assuming that all objects presents this relation
HAVE: when all instances of a certain concept have another concept as attribute.
A SYMMETRIC FRAME occurs when given the existence of a relation (p), necessarily in all context the relation is possible (
canBe: when a concept can be taken as similar (having the same attributes) as another concept.
These relations were designed to connect objects and their attributes as well as to make semantic relation between objects themselves. As MIA considers objects as an special case of an entity, all definitions stated by Kuroki (2018) can be applied to named entity recognition practices:
Objects are defined by subjects, whom recognize them as part of a body of knowledge;
Objects have attributes, which characterize them;
Objects can be compared, analyzing their attributes and checking their similarity;
Objects are fungible between them and, sometimes, used as attribute by another object.
As an extension to Spacy’s labels, other entity classes were added to the model with a designated behavior (object or pure attribute). To test the use of these definitions, a small data set of 112 sentences with random knowledge area were analyzed by specialists, in order to test the approach. Classifications list and total entities found are demonstrated on Table 15.
Extended Entities Proposed Through MIA.

Along the 112 sentences analyzed, 96 relations were identified comprising the extended entities. Some logical inconsistencies with the rules presented on Table 14 were identified, therefore, needed correction. Table 16 list a small amount of relations not duly classified by experts.
Example of Identified Misclassifications According to Table 14 Rules.

These examples are only part of MIA modeling capacities on relation extraction and are based on 5.3. Possibilities can go beyond this simple application if more relations are described and duly classified into logic frames, therefore, creating a framework for entities and relations labeling, reducing biases coming from different specialists or tutors.
Conclusions
In this article it is intended to position Information Science (through Multimodal Information Architecture) as an active part on data arrangement for NLP, appearing as a scientific discipline that provides techniques which can be used prior to an artificial neural network formalization. Data pre-treatment provided through MIA can increase better accuracy probabilities by performing a rearrangement of the provided data, imposing a sense of dynamic organization according to space-time distinctions.
In section Deep Learning: usage and challenges in NLP current stage of NLP development was reviewed. A diverse range of algorithmic implementations were identified, however, most used training techniques (such as supervised learning) still require large volume of classified data, enhancements made by specific knowledge models (scientific, technical or any other specific use of language) or common sense models (oriented to questions about the real world). Furthermore, even when all these restrictions are surpassed, incomplete data still an issue to deal with.
Section MIA: contributions on DL development presents MIA and its treatment of Modes as resources to construct meanings, which can be modeled through modal logic structures called Frames. The use of MIA makes it possible to deal with different semantics in the same informational context, a common problem in NLP tasks. MIA’s approach to the issue is based on economy and relevance to provide the best information configuration possible. A 5-step procedure to construct multimodal information architectures was proposed, which can identify subjects and their correlations with objects, construct domains where subjects and objects can correlate and map relationships between these domains.
In section Implementing MIA, the five-step procedure for building MIA products was applied to a real problem of texts classification. Eight subdomains were designed without any enhancement or enrichment made based on computational techniques. Using a state-of-the-art NLP algorithm for Brazilian Portuguese, learning experiments were undertaken with the raw data and MIA-treated data.
Although the observed values were numerically discrete from accuracy prediction point of view, improvement potential can be seen in most of the distinguished domains. Considering that no data enrichment procedure nor linguistic model improvement have been carried out, it is plausible to conclude that MIA indicated the best possible data grouping at each temporal distinction, starting only from the records initially presented.
Finally, it is observed that in this article, the choice of the IDF technique proposed to obtain correlations between subjects and objects in Step 2: Identify entities correlations does not link the MIA to its use, it can be replaced by any other technique that provides a measure of object relevance for each subject. Investigation of other methods of obtaining this level of relevance is encouraged.
Footnotes
Appendix
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Ethics Statement
There was no usage of either animal or human studies.