
Abstract
Deductive coding is a common discourse analysis method widely used by learning science and learning analytics researchers for understanding teaching and learning interactions. It often requires researchers to manually label all discourses to be analyzed according to a theoretically guided coding scheme, which is time-consuming and labor-intensive. The emergence of large language models such as GPT has opened a new avenue for automatic deductive coding to overcome the limitations of traditional deductive coding. To evaluate the usefulness of large language models in automatic deductive coding, we employed three different classification methods driven by different artificial intelligence technologies, including the traditional text classification method with text feature engineering, BERT-like pretrained language model and GPT-like pretrained large language model (LLM). We applied these methods to two different datasets, the annotation dataset and the discussion dataset, and explored the potential of GPT and prompt engineering in automatic deductive coding. By analyzing and comparing the accuracy and Kappa values of these three classification methods, we found that GPT with prompt engineering outperformed the other two methods on both datasets with a limited number of training samples. By providing detailed prompt structures, the reported work demonstrated how large language models can be used in the implementation of automatic deductive coding.
Plain Language Summary
It is important to annotate learning materials, so that people can understanding what is going on while students are conducting their learning. Such annotating work is usually labor intensive. With the development of generative artificial intelligence technology (such as GPT), we tried to finish this work automatically in this paper. In specific, we tried out three different artificial intelligence methods and compared their pros and cons. The three different methods were evaluated with two different datasets. In short, the paper showed the new possibility of using GPT in the field of learning analytics to save researchers precious time.
Introduction
Discourse analysis investigates the functional use of language to perform actions and construct identities, focusing on the meaning conveyed rather than the structural aspects or surface features of the language (Hjelm, 2021). Discourse analysis can be performed on both written text and spoken voice data. In the learning sciences, it is used to understand teaching and learning interactions in class or after-class tutoring (C. P. Rosé, 2017), providing valuable insights for scaffolding and facilitating the learning process (Meyer, 2023; Wang et al., 2015).
One common method for discourse analysis is deductive coding, which allows discourse analysis to analyze qualitative data in a quantitative way (Love & Corr, 2022). In deductive coding, researchers first code each segment of discourses according to a predefined coding schema and then apply statistical methods to analyze the coded results. This makes discourse analysis easy to follow and more reproducible. However, conducting deductive coding is quite time-consuming because researchers need to manually label all discourses according to a theory-informed coding schema.
To overcome the disadvantage of deductive coding, researchers started using Natural Language Processing (NLP) technologies to automate the coding process, thereby saving precious research time (C. Rosé et al., 2008). This shift toward automated deductive coding not only addresses the time constraints but also enhances efficiency in data analysis. We consider such methods of using natural language processing to code discourse as automatic deductive coding.
This analysis technique also facilitated mining the sentiments embedded in the discussion discourses. Researchers are able to track the learning sentiments embedded in huge discussion data with the help of natural language processing technology. Additionally, beyond the immediate benefit of saving research time, developing and refining such technology serves as a foundational step toward the creation of dialog-based intelligent tutoring agents (C. P. Rosé & Ferschke, 2016).
From a technical perspective, automatic deductive coding shares many similarities with automatic grading of students’ answers to open-response questions, which have been studied extensively (L. Zhang et al., 2022). They both aim to classify students’ plain text into several predefined classes. This is a classical text classification task in natural language processing. The classes can be either coding labels for deductive coding tasks or grades for auto-grading tasks. Automatic grading has been studied for decades. With the advent of advanced natural language processing methods such as Long Short Term Memory (LSTM) and Bidirectional Encoder Representation from Transformers (BERT), auto-grading accuracy has significantly improved. In contrast, while learning analytics researchers use text classification techniques in emotion and sentiment analysis, these techniques do not seem to have a widespread impact on traditional discourse analysis. Researchers still often need to manually code all text instead of referring to automatic coding or text classification techniques. This is probably because such text coding tasks often cannot provide enough training data.
The recent achievement in large language models, particularly Generative Pre-Trained Transformer (GPT) made by OpenAI, has opened up a new way for automatic deductive coding. GPT demonstrates remarkable performance on general classification tasks with few examples, known as few-shot learning, or even without any samples, which is called zero-shot learning. Some recent studies have begun to explore the use of Large Language Model (LLM) like GPT for tasks related to qualitative discourse analysis, specifically focusing on deductive coding (L. Zhang et al., 2025). However, while these studies have illustrated LLM’s potential, they also highlight some significant limitations, especially concerning the design of prompts that could improve model performance in specific tasks.
Our study seeks to build upon this foundational work by addressing these challenges and gaps. Unlike previous research that relied primarily on expert-developed codebooks, we explore the integration of fine-tuning techniques and Retrieval-augmented Generation (RAG) to enhance the model’s performance and understanding in deductive coding. RAG is a technique that combines large language models with external knowledge retrieval to enhance the model’s ability to generate accurate and contextually relevant responses. By introducing these advanced methods, we aim to improve the adaptability of LLM in qualitative research, reducing reliance on rigid codebooks and providing more flexibility in coding diverse data sets. Moreover, our comparison across traditional text classification, BERT-like models, and GPT-based LLM offers new insights into the relative performance of these models in different qualitative data environments, highlighting areas where LLM can outperform traditional methods. The qualitative data used in the experiments are the annotation dataset and the discussion dataset. The annotation dataset allows for the analysis of relatively straightforward student responses, while the discussion dataset captures interactions that involve deeper cognitive and social processes. By testing the classification models on the two datasets, we aim to investigate how they perform in different educational contexts.
By conducting the exploration and classification methods comparison, the study aims to answer the following two research questions:
(1) How do the three classification methods perform with the two given datasets?
(2) How many improvements can we make by integrating the LLMs related techniques, such as fine-tuning and RAG?
Building upon these questions, we propose the following hypotheses:
The rest of the paper first briefly reviews the existing works regarding sentiment analysis and educational assessment. These are two fields in learning analytics where text classification algorithms have proven successful. Then we describe two different data sets of our experiments. Third, we introduce the three different text classification approaches with an emphasis in the GPT approach. Fourth, we report the results for all the different settings. Finally, we conclude with remarks.
Related Work
Automatic Deductive Coding for Sentiment Analysis
In the field of learning analytics, text classification technology is often employed for the analysis of students’ emotions in participatory learning processes. Participatory learning, different from rigid teacher-controlled instruction, underscores the active involvement of students in collaborative learning processes. The key to successful participatory learning is to create positive experiences that enhance children’s cognitive engagement and awareness (Vartiainen et al., 2020). Emotion refers to a multi-componential construct of psychological subsystems, including affective, cognitive, motivational, expressive, and peripheral physiological processes (Pekrun, 2006). With the support of advanced technology, research on emotions and their role in cognitive processes within technology-rich learning environments has been gaining more attention (e.g., Huang et al., 2022). In technology-supported learning contexts, emotions can be expressed through emotional tones in the form of verbal or textual output, which refers to the vocal expression or dialog of emotion that conveys a student’s affective states (Chang et al., 2023; Ishii et al., 2003). Emotions and sentiments interpreted from expressed emotional tones are associated with students’ engagement, social interactions, and knowledge-sharing behaviors (Dang-Xuan et al., 2017; Näykki et al., 2014; Rapisarda, 2002), thereby shaping learners’ overall learning experience. Automatically detecting learners’ emotions forms the foundation for understanding what keeps their learning experience positive and how to sustain it. Therefore, it is important to automatically assess students’ emotions and sentiments in real-time learning procedure with the assistance of machine learning and large language models.
Kastrati et al. (2020) devised a weakly supervised aspect-based sentiment analysis framework. Given student comments, they employed Convolutional Neural Network (CNN) for sentiment classification and Long Short Term Memory (LSTM) for aspect category recognition. Experiments were conducted using a substantial real-world education dataset, encompassing approximately 105K students’ reviews gathered from Coursera, along with a dataset comprising 5,989 students’ feedback in traditional classroom settings. CNN sentiment classification was applied for the binary classification of aspect sentiment, achieving an 82.1% F1 score, while LSTM aspect category recognition was employed for identifying four aspect categories, achieving an 86.3% F1 score. Dahiya et al. (2020) performed sentiment and emotion analysis on textual messages with emoticons. Employing a CNN model, they trained a classifier to categorize 29,939 unique statements, which were acquired from Kaggle, into six distinct emotions and gave an average accuracy of 72.9%. Klünder et al. (2020) integrate sentiment analysis with traditional natural language processing techniques to automate sentiment classification in text-based communication. They utilized three machine learning methods—random forest, Support Vector Machine (SVM), and Naive Bayes—to categorize each text segment as positive, neutral, or negative. The efficacy of this approach is substantiated through an industrial case study in software development. The case study comprises 1,947 messages extracted from a group chat within the Zulip communication tool, encompassing a total of 7,070 sentences. The ultimate classification results, reaching an accuracy of 62.97%, exhibit a level of effectiveness comparable to human ratings (Klünder et al., 2020).
Generally, datasets used for sentiment analysis are large and need a lot of human labeling for training. Even traditional methods such as random forest and SVM can sometimes satisfy the requirements. However, certain limitations may exist, such as the inability to integrate contextual information from the dialog for assessment.
Deductive Coding in Educational Assessment
In educational assessment, both deductive coding and grading aim to categorize responses. Deductive coding involves categorizing qualitative data based on predefined codes, where coders analyze responses and assign them to specific categories based on the content. Similarly, grading of open-response questions involves assigning a score or grade based on the evaluation of a student’s answer, which is also based on predefined criteria. Thus, grading can be considered as a form of deductive coding, where the “codes” are scores or categories that reflect the quality or correctness of the answer. Both processes rely on predetermined criteria to interpret responses and classify them into structured categories. Based on these similarities, automatic grading of open-response questions can be viewed as a form of automated deductive coding.
The grading of open-response questions requires a balance between subjective evaluation and the need for efficient, scalable, and consistent grading methods. It involves the assessment of students’ answers to questions that require free-form responses, as opposed to multiple-choice or other closed-ended formats. This context often demands more flexible and subjective grading methods. So the traditional approach involves manual grading by educators or domain experts. To reduce repetitive human work and support personalized learning (Erickson & Botelho, 2021), recent research has focused on the development of automatic grading methods with machine learning and natural language processing technologies.
Erickson et al. (2020) employed tree-based machine learning approaches, including random forest and XGBoost, as well as deep learning methodologies such as LSTM and the Rasch Model, to assess and analyze open-response questions in mathematics. The dataset utilized in their study comprised a total of 141,612 student responses to 2,042 unique problems from 25,069 students. Wilson et al. (2022) conducted a comparative analysis employing three machine learning models: logistic regression, random forest, and K-nearest neighbors. These algorithms are used to classify 2,450 student responses to open-ended questions in the Physical Measurement Questionnaire into four classes. L. Zhang et al. (2022) utilized the continuous Bag-of-words model (CBOW) to integrate the domain-general and domain-specific information in the process of feature engineering. Then they built the classifier model using LSTM and evaluated it with seven reading comprehension questions with over 16,000 labeled student answers. Compared with other traditional automatic grading models, their proposed model significantly improved the automatic grading performance on semi-open-ended questions.
LLM-Based Models for Deductive Coding
Building on the advancements in emotion and sentiment analysis, as well as the development of automatic grading systems for open-response questions, there has been growing interest in applying LLM to more complex tasks such as deductive coding in qualitative research. To offer new possibilities for handling large-scale qualitative data sets more efficiently, researchers have begun exploring how these models can assist or automate parts of this process. Previous research has applied NLP techniques to deductive coding tasks, particularly for determining whether existing codes are applicable to a given text. For example, Katz et al. (2024) proposed a novel method based on LLMs to classify student evaluations of teaching (SETs) and demonstrated that this approach could identify the themes within a set by extracting, embedding, clustering, and generalizing information, ultimately generating the corresponding codebook. Similarly, Morgan (2023) explored the effectiveness of ChatGPT for data analysis by investigating two qualitative datasets that had already been manually coded. His results showed that ChatGPT excelled at identifying concrete descriptive themes but was limited in detecting subtle interpretive themes. Xiao et al. (2023) explored the use of LLM in supporting deductive coding, a major category of qualitative analysis, and found that combining LLM with expert-drafted codebooks achieves fair to substantial agreements with expert-coded results. Their study utilized an expert codebook to construct prompts, and although it provided transparency and explicit control, it limited the performance of the model and was not effective in understanding. Tai et al. (2023) propose a methodology using LLM to support traditional deductive coding in qualitative research. They compared the performance of a large language model with traditional human coding in identifying five conceptual codes in three narrative texts, providing a systematic and reliable platform for code identification and offering a means of avoiding analysis misalignment. They also pointed out that there is a lack of validated research examining the use of LLM in qualitative analysis. Chew et al. (2023) provide a holistic approach for performing deductive coding with LLM, and aim to assess the effectiveness of GPT-3.5 across a range of deductive coding tasks through an in-depth case study and empirical evaluation on four publicly available datasets. The study notes several limitations, including the need for extensive prompt engineering and the assessment of coding performance across a wide variety of LLMs. Hou et al. (2024) explored the use of LLM to assist in deductive coding of social annotation data, achieving fair to substantial agreement with human raters in context-independent dimensions and moderate agreement in context-dependent dimensions. They claimed that there were still some challenges in including original text in the prompt engineering or fine-tuning models for context-dependent dimensions. Despite progress in applying NLP to deductive coding, particularly in generating codebooks from existing frameworks, it still faces limitations, especially when creating new codebooks without predefined frameworks (Katz et al., 2021). This suggests that while NLP demonstrates strong capabilities for specific tasks, further improvement is needed for handling more flexible and complex qualitative analysis tasks.
In summary, existing works regarding text classification adoption in education mainly focus on sentiment analysis in participatory learning and automatic grading on student answers. Both of these works required considerably large data set for training the supervised machine learning models, so that satisfactory results can be achieved. Only a few studies have attempted to use LLM for deductive coding in content analysis. Our study aims to verify that generalist models such as GPT, combined with other technologies, can be helpful in deductive coding tasks with few labeled items. In particular, we took two different datasets to conduct our experiments.
Datasets
To conduct our study and evaluate the three automatic deductive coding techniques, we used two datasets that were obtained from a Chinese poetry appreciation literary course at a university in central China. The course was open for science and engineering students, aiming to improve their literacy ability and cultivate their esthetic ability. The course adopted a face-to-face collaborative teaching mode and the classroom students were divided into groups. Some pre-class or in-class tasks require students to complete through a collaborative annotation system developed by our research team. Before class, the teacher assigned reading tasks, requiring students to read learning materials on the platform and highlight and annotate the materials. This formed the annotation dataset. During class, students used the chat function of the system to interact within groups based on in-class tasks and collaborate to solve problems. This formed the discussion dataset. We described the two datasets and the coding schema in detail below.
Each dataset was split into training and testing sets using an 8:2 ratio. The training set was to train the machine learning models or tune the prompts. The testing set was to evaluate the performance of different automatic coding techniques. In this way, all the automatic coding models used the exact same dataset for model calibration and evaluation. Note that the GPT approach only used several items in the training set and the other machine learning approaches used the entire training set. However, these settings allowed for a fair comparison of all the models.
Deductive Coding Framework
Learning activities can take on various forms and categories, with corresponding observable behaviors that influence cognitive engagement processes and drive distinct pathways of knowledge transformation. Chi and Wylie (2014) proposed the ICAP theoretical framework after decades of empirical investigation. This framework classifies and characterizes learning activity participation modes based on observable external behaviors. It delineates four levels of cognitive engagement: Passive, Active, Constructive, and Interactive. The relationship between these modes and their effects on learning outcomes follows a hierarchical structure, with Interactive engagement associated with the highest level of learning, followed by Constructive, Active, and Passive, as represented by the ordering I (Interactive) > C (Constructive) > A (Active) > P (Passive).
Based on the ICAP framework and taking into account the distinct characteristics of students reflected in the annotation and discussion datasets, we developed the coding framework for each dataset after adjustment and validation. The coding framework for the annotation and discussion dataset is presented in Tables 1 and 2 respectively.
The Coding Scheme of the Annotation Dataset.

The coding scheme of the discussion dataset.

The Annotation Dataset
In the fall semester of 2021, we collected a dataset comprising 607 student annotations. This dataset was divided into a training set containing 484 items and a testing set containing 123 items. Seventy-three students participated in the course, representing diverse majors such as artificial intelligence, history, psychology, physics, etc.
Students were asked to read and annotate a Chinese article titled “The Image of Plum in Ancient Chinese Literature” on the system developed by our research team. The annotation reading interface of the system is shown in Figure 1.

The annotation reading interface of the system.
After collecting the data, two researchers manually analyzed and coded the annotation data based on the annotation coding framework (Table 1), which was adapted from the ICAP model. A random sample of 200 items from the annotated data was selected, and the two researchers obtained a Kappa value of 0.752, indicating good reliability.
The Discussion Dataset
The discussion dataset, comprising a total of 404 items, was gathered in the fall semester of 2022. This dataset was subsequently divided into a training set containing 320 items and a testing set containing 84 items. Seventy-two students, voluntarily enrolled in the course, participated in this dataset. The students had an average age of 20 and came from various non-literary majors. The students were grouped based on the Kolb Learning Style Questionnaire (Manolis et al., 2013), resulting in a total of 10 groups with 6 to 7 students in each.
Students worked in groups to select one of the five poets and analyzed their representative works of chrysanthemum poems through text communication using the same system. The discussion interface of the system is shown in Figure 2.

The discussion interface of the system.
After all the data was collected, two researchers manually coded and analyzed the discussion data using a modified version of the ICAP framework, referred to as the discussion data coding framework (Table 2). In the initial phase, the researchers independently coded 84 samples from both groups, achieving an inter-rater reliability of 0.69. Following this, the researchers refined the coding framework and reviewed the initial coded data through discussion. Through consultation and consensus-building, we performed a second round of pre-coding. In a subsequent round, the researchers randomly selected 69 samples from both groups, resulting in an increase in inter-rater reliability to 0.80.
The three automatic coding techniques were evaluated by following the procedure shown in Figure 3. The manually coded results were divided into training and testing datasets. The three automatic classification methods, including the traditional text classification method, BERT-like pretrained language model, and GPT-like pretrained language, were applied to classify the annotation and discussion data. The classification methods are described in detail in the next section.
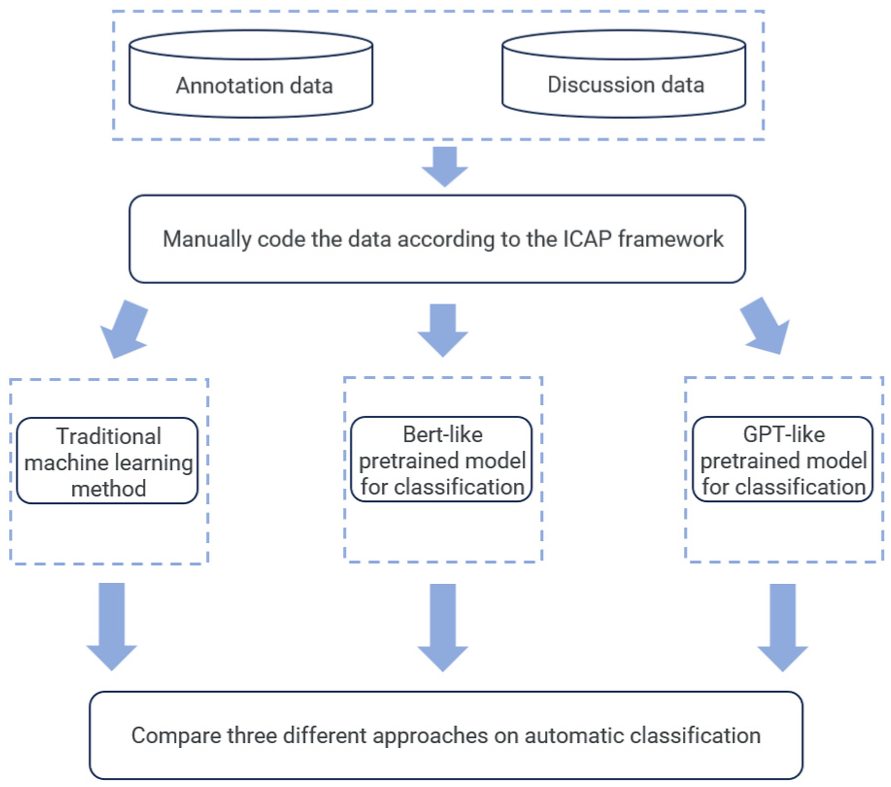
The experiment procedures.
Methods
This section briefly introduced the three different approaches of text classification for automatic deductive coding. In this study, we examined two distinct types of discourse. One is students’ reading annotations, the other is students’ discussion dialogs. Since the purpose of the comparison is to explore the power of large language models, we respectively selected one representative model for traditional machine learning and BERT-like methods. The rest of the section describes these two models and how we used GPT in deductive coding.
Traditional Machine Learning Method
We selected Random Forest (RF) as the representative model for traditional machine learning methods, because it has performed well in many related tasks (Schonlau & Zou, 2020). Figure 4 illustrates the process of using a traditional machine learning method for classification. The first step is to conduct word segmentation, which transforms each student’s sentence into a set of words. We used jieba library to perform this step. Note that such a transformation would lose the sequential information of the original sentence as well as the grammatical structures (Qader et al., 2019). After splitting the sentences into word sets, we calculated the frequency of each word and used these frequencies as inputs for the Random Forest model. This kind of feature engineering approach is called Bag-of-Words (BoW). Random Forest is essentially a group of decision trees. Each decision node of the decision trees comprised word frequency and a threshold. We used RandomForestClassifier in scikit-learn to perform the implementation. There were two hyper-parameters of this algorithm, which were the estimator and the random seed. The estimator defines the upper bound of the number of decision trees in the forest, and the random seed decides the initial values of the parameters. The estimator was set to 100, and the random seed was set to 42.

Process of the Random Forest classification method.
BERT-Like Pretrained Model for Classification
For BERT-like pretrained models, we used RoBERTa, an advanced version of BERT, enhanced through training on a larger corpus (Shaheen et al., 2020). Notably, Qasim et al. (2022) demonstrated the superior performance of the RoBERTa model in various classification tasks compared to other pre-trained language models. However, they also highlighted that RoBERTa exhibits stronger linguistic bias.
Figure 5 shows the process of using RoBERTa for classification. The initial step involves loading the dataset and tokenizing it using RoBERTa’s tokenizer. This process converts the text into numerical representations suitable for machine learning. Specifically, we utilized the chinese_roberta_wwm_ext_pytorch pre-trained model. Different pooling strategies, including CLS pooling, mean pooling, and max pooling, are implemented to extract features from the hidden states of the RoBERTa model. These strategies contribute to capturing essential information from the input sequences. A linear classifier head is incorporated into the model to translate the extracted features into target categories. The model is trained using the Adam optimizer with a learning rate of 2e−5 and a weight decay of 1e−4. The training is conducted over five epochs. A batch size of 16 is employed during the training process. The maximum sequence length for tokenization is set to 200. Sentences exceeding this length are truncated, while shorter sentences are padded with spaces to ensure uniform input dimensions.
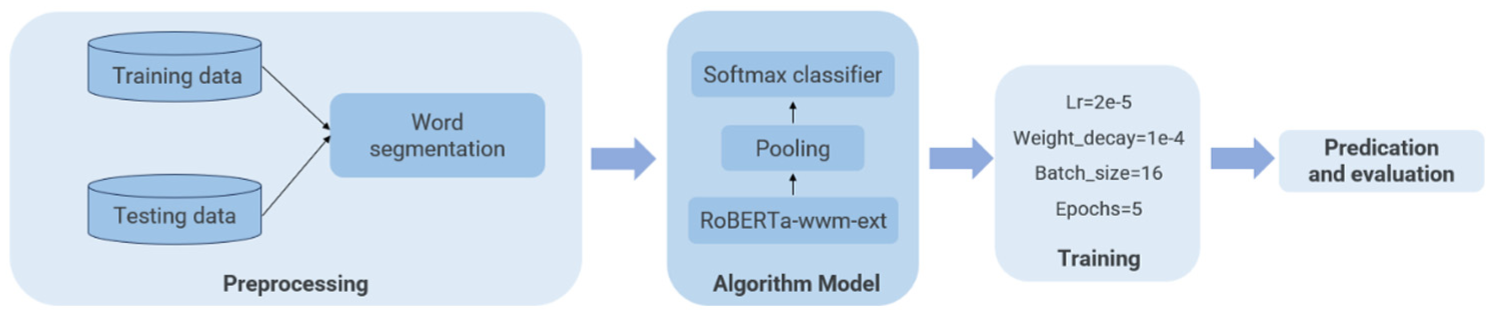
Process of RoBERTa classification method.
GPT-Like Pretrained Model for Classification
Despite the proliferation of various generative artificial intelligence models, OpenAI’s GPT stands out as the most representative and proficient in multiple aspects. In many cases, GPT can perform well with only the instructions given in the prompts. To better instruct GPT, researchers often need to go through a process called prompt engineering. Prompt engineering is the means by which GPT is programed using prompts (White et al., 2023). Few-shot learning, and chain of thought (CoT) are two well-known and useful techniques in prompt engineering. Few-shot learning aims to enable models to learn and adapt to new tasks from a limited number of samples (Brown et al., 2020), while CoT achieves this by breaking texts into continuous segments and utilizing them as model inputs (Wei et al., 2022). Recently, a technique called Retrieval-augmented Generation has emerged, which integrates domain knowledge into general large language models, improving the quality and effectiveness of the generated results (Gao et al., 2023). Besides prompting engineering, fine-tuning is another method of calibrating the large language models to fit the downstream tasks (Touvron et al., 2023). But this method required many more labeled samples for training the models.
In this study, we considered all the techniques mentioned above, including few-shot learning, CoT, RAG, and fine-tuning. In addition, we combined traditional natural language processing techniques with GPT for further improvement.
In terms of the foundation model, this study mainly employed GPT-4, recognized as one of the most powerful generative AI models. The fine-tuned foundation model was GPT 3.5 because OpenAI did not support fine-tuning GPT-4. To optimize the prompts, we used GPT4′s playground for prompt formulation and refinement. Once researchers were satisfied with the prompt’s performance in the playground, the final version was used to build the backend code, which went through all the discourse data and called OpenAI’s API to process it. We used four different settings in the GPT approach to explore the usefulness of the techniques. Because the dataset we used was in Chinese, all prompts were also written in Chinese in our actual program no matter the setting. We translated them into English for ease of reading.
Prompt Only
In this method, we exclusively employed prompts and GPT-4 for deductive coding. During the prompt tuning process in the playground, we drafted a prompt based on the dataset characteristics. Through iterative refinement, our final prompt consisted of the five parts below (a full version sample prompt is attached in the Appendix):
Introduction to the Course Background
Issuance of Instructions
Detailed Introduction to Encoding Rules
Output Structure and Examples
Input data
At first, the prompt introduced the background of the course where the student discourse was generated. Then the prompt described what GPT needed to do (i.e., the conduction of deductive coding). In the third, the prompt provided the detailed codebook. In the following, the prompt described the desired format of the output. Several coding examples were also provided here as the implementation of a few-shot learning techniques. Specifically, we manually selected three representative student discourse examples and told GPT the corresponding human labels. In the last part of the prompt, we gave the input data that needs to be coded. This method was only used for the annotation dataset. So, the input data comprised the annotation along with its highlighting text.
Regarding GPT settings, we used the gpt-4-1106-preview version with a temperature value of 0, a maximum text length of 4,096, and both frequency_penalty and presence_penalty set to 0.
Finetuning
We performed fine-tuning based on the GPT-3.5-Turbo model. The basic idea of fine-tuning is to use many labeled examples as the training data to calibrate the foundation model, so that the fine-tuned model can adapt to the specific downstream task, which is deductive coding in our case. As the documents of GPT suggested, around 100 training samples would be sufficient for the fine-tuning task of GPT. This method was applied to both annotation and discussion datasets.
For the annotation dataset, we used the same prompts as those in the previous setting (i.e., prompt only). We used 90 entries to build a fine-tuned model and evaluated its performance. The training epoch was set to 3.
For the discussion dataset, because we had 10 sets of dialogs generated by 10 groups of students with 404 dialog turns in total, we asked GPT to consider the dialog turns independently without the context and did fine-tuning. We used 100 entries to build a fine-tuned model. The training epoch was set to 3 as well.
Prompt + Traditional NLP
Following the suggestion of Do et al. (2024), we integrated prompt-based LLMs with traditional NLP technologies to improve overall performance. In specific, we built a reference database including the original reading material and the corresponding online reference information. During the process of automatic coding, instead of handing over the entire task to GPT, we did similar sentence checking at first. It means that for each input sentence of students’ annotations, we wrote a program to find out the most similar sentence in the reference database. The similarity between two sentences is defined as follows:
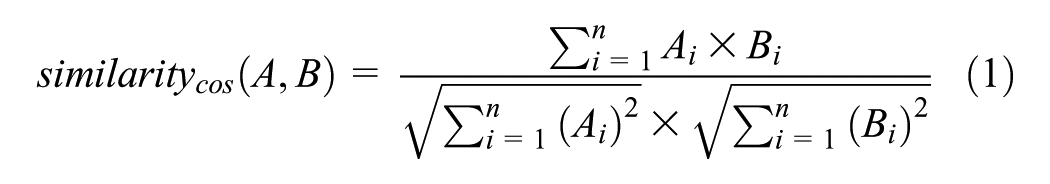
If the similarity score between a student’s annotation and the most similar sentence in the reference database exceeded a threshold, the program coded the annotation as “A,” otherwise, the program asked GPT to make a further judgment. The structure of the prompt for the further judgment remained the same, except for the absence of the introduction to the code “A.”
Prompt With Context Knowledge + Traditional NLP
At last, we further included context knowledge in the prompt. We used different strategies for the two different datasets. We used RAG with the reference database mentioned in the previous section for the annotation dataset. We injected the full dialog context for the discussion dataset. We respectively described the two strategies in the following.
For the annotation dataset, we retrieved two relevant sentences of the input annotation from the reference database based on their sentence similarities. We used the retrieved information to augment the generated results of GPT, in which RAG was implemented. Note that the traditional NLP technique was used again in the calculation of sentence similarity. Different from the prompts introduced previously, the prompts here were constructed dynamically based on the reference sentences. The contents of the prompts were also slightly different because we asked GPT to break the deductive coding process into two steps inspired by CoT. Specifically, GPT needed to first consider the relation of the student’s annotation to the two reference sentences, then make the coding decision. Figure 6 illustrated how traditional NLP and context knowledge were integrated in the workflow of the automatic deductive coding with GPT. Traditional NLP was integrated mainly through similarity calculation, and context knowledge was integrated through RAG. The resulting framework of the classification prompt for this experiment is outlined below:
Introduction to the Course Background
Issuance of Instructions
Detailed Introduction to Encoding Rules
Output Structure and Examples
Comment
Highlight
Reference1
Reference2

The workflow of automatic deductive coding with GPT for annotation data, illustrating the integration of traditional NLP and RAG.
For the discussion dataset, we included the entire dialog of the discussion group as the context knowledge and asked GPT to code each dialog turn. GPT was instructed to consider the surrounding dialog turns while determining the encoding categories. The framework of the classification prompt for this dataset is as follows:
Introduction to the Course Background
Issuance of Instructions
Detailed Introduction to Encoding Rules
Output Structure and Examples
Student dialogs
Evaluation Metrics
We used accuracy, precision, recall, F1 score, and Cohen’s kappa to evaluate and compare the performances of the models. The first four metrics are widely used in computational-related journals, and the last one is used widely in psychology journals.
Accuracy represents the ratio of correctly predicted instances to the total instances in the dataset. It provides an overall measure of the model’s correctness. Precision is the ratio of correctly predicted positive observations to the total predicted positives. It measures the accuracy of positive predictions. Recall, also known as sensitivity or true positive rate, is the ratio of correctly predicted positive observations to the actual positives in the dataset. It assesses the model’s ability to capture all relevant instances. The F1 score is the harmonic mean of precision and recall. It provides a balanced measure that considers both false positives and false negatives. Cohen’s Kappa is a statistic that measures the agreement between the predicted and actual classifications, considering the possibility of the agreement occurring by chance. It corrects for the chance agreement inherent in accuracy. High accuracy, precision, recall, and F1 score values all indicate effective classification performance. Kappa values indicate the amount of agreement between the predicted results and the ground truth. Values close to 1 indicate substantial agreement, while 0 suggests no agreement. This comprehensive set of evaluation metrics enables a thorough analysis of the classification methods, shedding light on their efficiency in handling annotation and discussion datasets.
Results and Discussion
In this section, we report the results of the three different approaches for automatic deductive coding and discuss the findings. For each approach, we report the coding results of the annotation and discussion datasets respectively. We make a summary of the three approaches by the end of this section. Among the three approaches, we focus on the GPT-based one.
Traditional Machine Learning (Random Forest)
For the annotation dataset, the random forest classification method achieved an overall accuracy of 0.56. The Kappa value was found to be 0.28. We calculated precision, recall, and F1-score for each type of code. The results were reported in Table 3.
Performance Metrics for Annotation Data.

As for the discussion dataset, the random forest classification method exhibited a lower overall classification accuracy of 0.48. The Kappa value for the discussion data was 0.32, indicating slight agreement beyond chance. This discrepancy in accuracy between the two datasets emphasizes the method’s varying performance when applied to different types of data. Similarly, precision, recall, and F1-score were reported in Table 4.
Performance Metrics for Discussion Data.

The results clearly showed that the random forest classifier did not provide good performance in general and had quite different performance on different coding categories. This approach exhibited an especially bad performance in the Interaction (I) coding category in the discussion dataset. This was not surprising because this approach simply treated all discourses as bags of words and made deductive coding decisions solely based on the frequencies of occurrences of these words.
BERT-Based (RoBERTa)
For the annotation dataset, the overall accuracy was determined to be 0.59, with a Kappa value of 0.36. Precision, recall, and F1-score for each coding category were reported in Table 5.
Annotation Classification Metrics Using RoBERTa.

For the discussion dataset, the automatic coding results indicate an overall accuracy of 0.67, accompanied by a Kappa value of 0.54, showcasing a robust performance. The class-specific coding results are presented in Table 6.
Discussion Classification Metrics Using RoBERTa.

As a more advanced NLP technique, RoBERTa demonstrated improved performance in both annotation and discussion datasets. However, this approach seemed to produce biased results more easily. For example, the trained automatic coder did not identify any M or I code. Probably because the training data itself is biased, and the trained model is over fit.
GPT-Based
Results of the Prompt-Only Method
The overall accuracy was quite low, only 0.37. Given that it was essentially a threefold classification problem, the performance was just a little bit better than chance. The Kappa value was only 0.005. So, using the prompt alone was not enough for accomplishing the deductive coding task. Table 7 provides more details of the results for each coding category.
Annotation Classification Metrics of the Prompt Only Experiment.

Results of the fine-tuning method
The performance of automatic deductive coding is significantly improved when the model is fine-tuned, even with a weaker GPT-3.5-Turbo version. The accuracy was improved to 0.54 with a Kappa of 0.28. The precision, recall, and F1-score for each coding category were detailed in Table 8.
Results of the Fine-tuning Model for Annotation Classification of the Prompt Only.

Results of the prompt + NLP method
Once the active coding category was identified through sentence similarity calculation, the performance of prompt + NLP method improved compared to the prompt-only method. The overall accuracy was 0.46 and the Kappa was 0.164. Table 9 provides the performance details for each coding category. We also combined the NLP technique here with the fine-tuned model. As a result, the overall accuracy was 0.63 and the Kappa was 0.43.
Annotation Classification Metrics with an NLP Method.

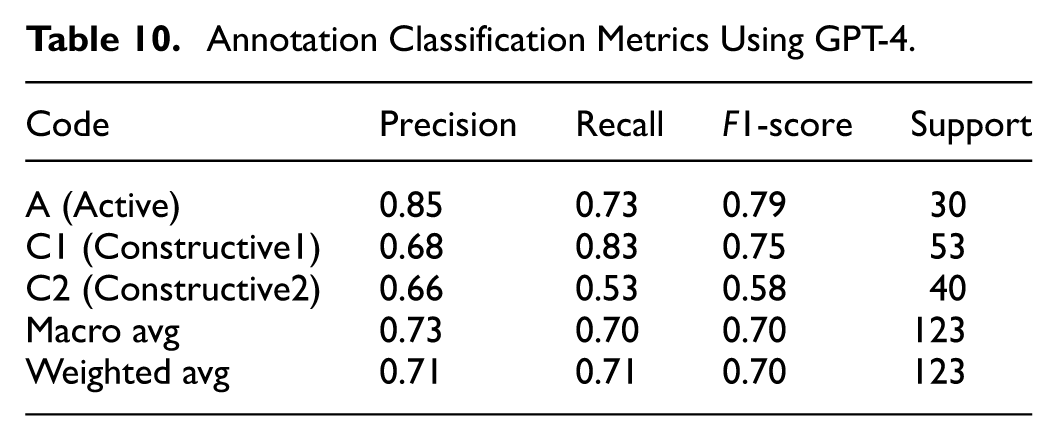
Results of prompt with context + NLP method
The performance of automatic deductive coding achieved the best result when the context and NLP were both involved. The overall accuracy was 0.71 and the Kappa was 0.54. Detailed performance for each coding category was presented in Table 10.
Annotation Classification Metrics Using GPT-4.
Results of fine-tuning method
Remind that the fine-tuned model considered each turn in the dialogs independently. Without such dialog context information, the corresponding automatic coding performance can still achieve an accuracy at 0.73 and the Kappa was 0.64. The detailed results of precision, recall, and F1 score for each coding category were described in Table 11.
Results of the Fine-tuning Model for Five-class Classification of Discussion Data.

Results of prompt with context + NLP
When the entire dialog was included in the prompt, the accuracy of automatic deductive coding reached 0.77, with a Kappa value of 0.72. This overall performance is acceptable for inter-agreement. The detailed results for each coding category are presented in Table 12.
Discussion Classification Metrics Using GPT4.

Based on the reported results above, the same method had quite different performances on the two different datasets. It is probably because the writing annotation is more complex than discussing in-class tasks within groups. Students usually do not think too much before writing down their opinions and can even have many casual talks during discussions. In addition, contextual information in discussion is easy to obtain. This refers to the discourse of adjacent turns in the dialog. In contrast, while students are making reading annotations, they need to first select and highlight one or two sentences that they think are interesting in the reading material. Then, the students may integrate the highlighted information with their own thoughts to make the annotations. Some students may even search the web for external knowledge to improve the quality of their annotations. Indeed, some students tend to simply copy and paste the information they searched. We found that we could easily identify these cases using sentence similarity calculation, which is a widely used NLP technique.
We summarized and illustrated the performances of four different settings of the classification model for the annotation dataset in Figure 7. It can be noticed that fine-tuning, the combination of NLP, and providing context information all benefit the automatic coding performance. This highlights an important limitation of prompt-only methods, which rely solely on pre-written instructions and are less effective when dealing with complex content. Our experiments show that the prompt-only method fails to adequately address the intricacies of annotation tasks. However, when we incorporated contextual information, such as the surrounding discourse or additional background knowledge, the performances were significantly improved. These results suggest that contextual information is essential for improving automatic deductive coding performance. So, it seems necessary to integrate all suitable techniques to dynamically construct prompts for automatic deductive coding instead of only relying on LLMs with static prompts.
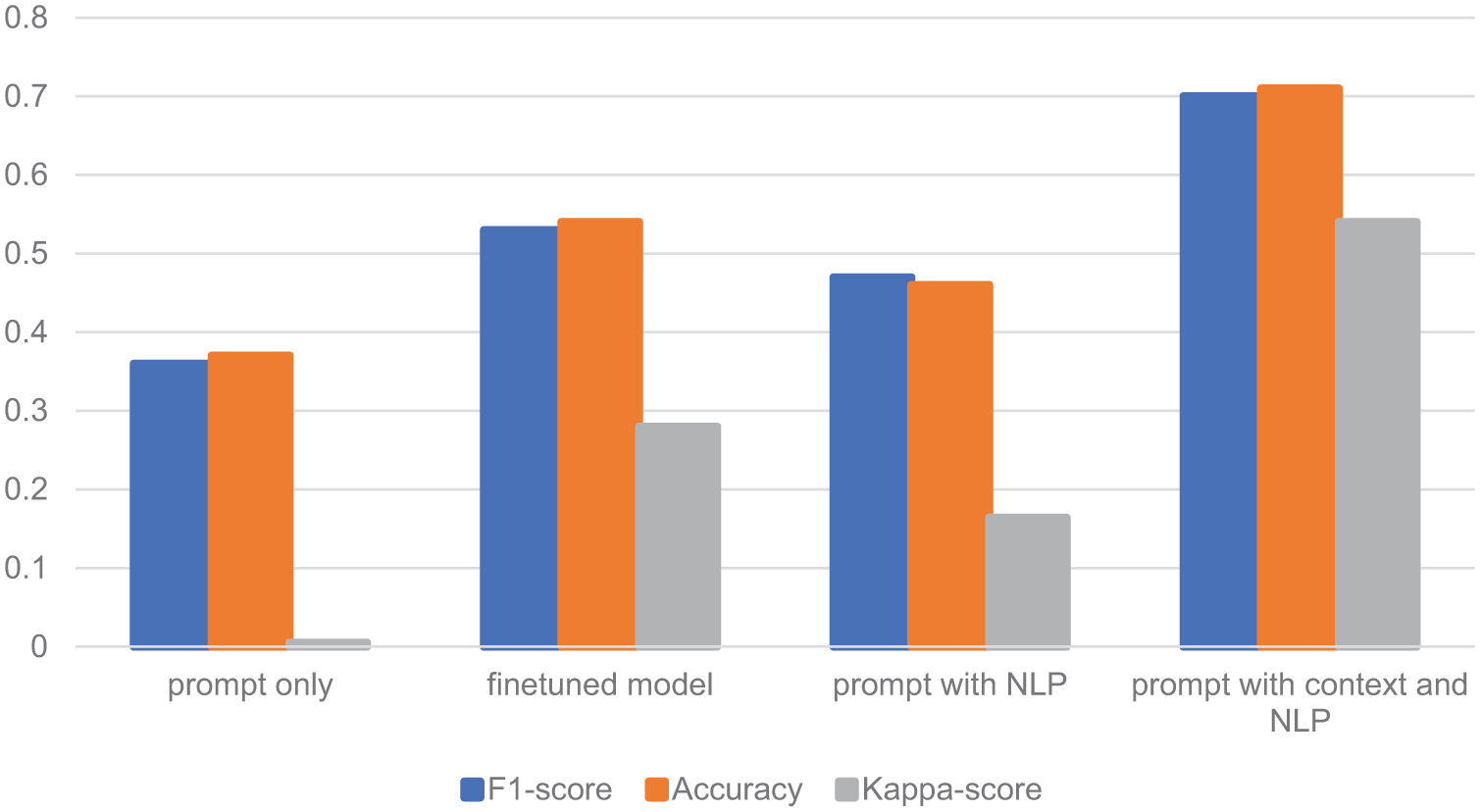
While the annotation dataset provided some valuable insights into model performance, the discussion dataset presented additional challenges, particularly with the classification of the “Interactive (I)” category. As the results indicated, all models struggled to accurately identify this code.
Based on our codebook, one dialog turn is “Interactive” when the content of this turn is built upon the content of one or several previous turns. The relation among these turns is not obvious and hard to catch even by experienced human coders. People can easily get confused between “Interactive” and “Constructive” because they both provide new information in the discourse, and it is subtle to decide whether this new information is built upon other discourse (i.e., Interactive) or not (i.e., Constructive). In other words, the bad performance on this specific coding category is due to the difficulty of the task itself.
Summary of the Results
In this section, we summarize the results of all three automatic deductive coding methods on annotation and discussion datasets. Because we used several different settings in the GPT-based approach, we selected the best-performing one with context information and NLP integrated. The Kappa and the accuracies of the three approaches are listed in Tables 13 and 14 respectively.
Comparison of Kappa Values for Three Classification Methods on Two Datasets.

Comparison of Accuracy Values for Three Classification Methods on Two Datasets.

RQ1: Performance of the Three Classification Methods
Random Forest is the earliest AI algorithm for automatic discourse analysis among the three approaches and GPT is the most cutting-edge one. In general, the more advanced AI approaches produce better performance. Another thing that needs to be noted is that the GPT-based approach, except for the fine-tuned method, only used several labeled samples for writing up the prompt, although we allocated hundreds of labeled training samples for the sake of fair comparison. So, the biggest advantage of the GPT-based approach is not its higher accuracy and kappa, but the low requirement of training samples. This advantage can make the GPT-based approach valuable in practice.
While the GPT-4 model demonstrated superior accuracy in classifying the data, it comes with certain practical challenges, notably API costs and computational resource requirements (Yenduri et al., 2024). For large-scale datasets or budget-conscious projects, more accessible models like Random Forest or RoBERTa may offer a more cost-effective and resource-efficient solution. Random Forest, in particular, requires fewer computational resources and can be implemented on local machines (J. Zhang & Zong, 2024), making it a viable option for some special cases. Researchers should carefully weigh these trade-offs when selecting a method, balancing the need for high accuracy with the practical constraints of available resources.
RQ2: The Power of Prompt Techniques for Automatic Deductive Coding
We need to note that the GPT-based approach is not just plug-and-play for automatic deductive coding. Indeed, ChatGPT provides an easy-to-use interface for all. Even people without any programing experience can use ChatGPT to accomplish some sophisticated tasks, such as article summarization and data analysis. However, as we showed in the results of the different methods of the GPT-based approach, the performance can be significantly improved when techniques such as RAG are included because GPT needs contextual information to make more accurate decisions. We also showed that we may need to figure out some rules with traditional NLP techniques like discourse similarity calculation to identify some discourse code, instead of having GPT take over all the tasks. The reasons behind such integration are probably because we, as human experts, know more contextual information and guidance than LLMs, and we should describe them as much as possible by using all kinds of LLM-related techniques such as RAG, CoT, few-shot, and so forth.
Beyond methodological contributions, our findings hold broader implications for educational research and practice. Automated deductive coding methods can streamline research workflows, allowing scholars to analyze large volumes of discourse data that would otherwise be infeasible to code manually (Bryda & Sadowski, 2024). For educational researchers, the integration of GPT-based models may facilitate more efficient formative assessment by providing timely insights into student participation and reflection (Na & Feng, 2025). This, in turn, may empower students by offering rapid feedback and opportunities for self-reflection, thereby fostering greater agency in the learning process.
Conclusion
In conclusion, this study aimed to assess and compare three distinct text classification methods applied to automatic deductive coding. The methods we adopted encompassed traditional text classification with feature engineering, BERT-like pre-trained language models, and GPT-like pretrained language models, representing generative language models.
The traditional text classification method, which relies on feature engineering, struggled to adapt to student-generated content in both annotation and discussion datasets. On the other hand, the BERT-like model exhibited improved accuracy, leveraging its contextual understanding of language. However, its reliance on tokenized input and the need for substantial data size and computational resources limit its practicality. The standout performer in our study was the GPT-based approach. This approach showcased remarkable adaptability and effectiveness in classifying both annotation and discussion data, outperforming other methods in terms of accuracy and Kappa values. The generative language model, with its inherent ability to consider word order and context, demonstrated promising results even with a limited dataset.
While the findings of this study are promising, it is important to acknowledge the limitations of the specific context in which it was conducted. The performance of LLMs is often influenced by language and domain factors. For instance, X. Zhang et al. (2023) noted that LLM performance can vary across different linguistic environments, particularly in non-English settings with limited training data, leading to suboptimal results. The dataset used in this study is restricted to Chinese students in a Chinese poetry course, which may affect the generalizability of the results. Therefore, applying this approach to English datasets may yield better outcomes.
To strengthen the robustness and generalizability of these findings, future research should expand the scope of dataset. This could include students from diverse linguistic, cultural, and academic backgrounds, as well as testing in different study domains. Larger datasets with more varied student content would provide deeper insights into how these models perform across different educational contexts and disciplines. Additionally, integrating multilingual datasets could shed light on how well generative models like GPT can handle cross-lingual text classification tasks in educational technology.
Despite these limitations, the comparison highlighted the potential of generative language models. The GPT-like model, in particular, presents a compelling avenue for further exploration in educational technology, showcasing promising results in the context of student participatory learning. As the field evolves, leveraging such models could bring more efficient and accurate ways to assess and engage with student-generated content, ultimately enhancing the quality of educational processes.
Supplemental Material
sj-docx-1-sgo-10.1177_21582440251390054 – Supplemental material for Automatic Deductive Coding in Discourse Analysis: An Application of Large Language Models in Learning Analytics
Supplemental material, sj-docx-1-sgo-10.1177_21582440251390054 for Automatic Deductive Coding in Discourse Analysis: An Application of Large Language Models in Learning Analytics by Lishan Zhang, Han Wu, Tengfei Duan and Hanxiang Du in SAGE Open
Footnotes
Acknowledgements
We thank the students who participated in the experiments that formed the datasets.
Ethical Considerations
The ethical approval for this research came through Central China Normal University IRB#202209026 on Sep 26, 2022. Verbal consents of the participants were obtained.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This material is based upon work supported by the National Natural Science Foundation of China (NSFC) under Grant Nos. 62377017 and 62293551.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
All the prompts used for automatic deductive coding were included in the supplemental material.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.