
Abstract
English textbooks are the most pivotal learning materials in the EFL context. However, in Vietnam, English textbooks for general education are randomized by schools, which arouses a problem of whether they are equivalent for students to gain the same proficiency. This study attempts to report the differences in lexical demands and features, including length, sophistication, and diversity, of these textbooks. To this end, the researchers compiled a corpus of 54,566 tokens extracted from their listening transcripts. Results profiled by AntwordProfiler showed that 1,000, 2,000 to 3,000, and 3,000 to 4,000 word families in the BNC/COCA wordlist plus four supplementary lists of proper nouns (PNs), marginal words (MWs), transparent compounds (TCs), and acronyms were necessary to comprehend 85%, 95%, and 98% of listening in all the textbooks, correspondingly. Moreover, the results of pairwise comparisons run by Jamovi indicated significant differences in text length and lexical diversity between the textbooks but not in sophistication. In short, these grade-10 textbooks could support students in learning English vocabulary although they impede students from using them randomly. Hence, the study heightens the roles of teachers in the classroom and paves the way for researchers who are fond of vocabulary and English textbooks.
Introduction
In the Vietnamese context, English is a mandatory subject for ten-year education from Grade 3 to Grade 12 (Vu & Peters, 2021). Therefore, the foreign language programs for these grades have been particularly concerned, which leads to the compilation of series of textbooks as an instruction for English teaching and learning (Hoang, 2018). Due to the lack of language environments, textbooks hold a preeminent status far outstripping other sources in the English language classroom (Nu, 2018). They provide language lessons for students and guide teachers on how to build a course through its framework (Lau et al., 2018; Richards, 2001; To, 2018). To release new English textbook series, the Vietnam Ministry of Education and Training (hereafter MoET) has been collaborating with several well-known domestic and international publishers, listed as Pearson Education, National Geographic Learning, Oxford University Press, Cambridge University Press, Express Publishing, and Garnet Publishing. Despite having various series of textbooks, they are all designed to contain major themes relating to humans and lives (Hoang, 2018).
In 2020, the MoET stipulated the textbook selection process. Firstly, general education establishments propose a list of textbook series. Afterward, Provincial Departments of Education synthesize and send them to the Council to create practical textbook lists. Finally, the results are transferred to local administrations to approve suitable textbook series from the list. Therefore, many series of textbooks have been brought into use and permitted at random in different provinces and schools, depending on the local education syllabus. For various series of textbooks to be applicable to the same student population, one crucial hypothesis must be met. They should be equal in difficulty and maintained at an adequate level so as not to take much of students’ time or affect their lesson planning. Moreover, these series should have a similar range of vocabulary to prevent differences in the input for incidental vocabulary learning. On the contrary, students will face a disparity in qualification, making the MoET’s Project deviate from their initial goal for the national general education.
To the best of the researcher’s awareness, studies on English textbooks in Vietnam attempt to examine the sociolinguistic and pragmatic contents (Dang & Seals, 2016; Ton Nu & Murray, 2020) and teaching method or framework (Bui & Newton, 2022; To, 2018). Most of them have been conducted at the primary level although the upper secondary level is more decisive to the education path of general students in Vietnam. Since Grade 10 is the initial grade for upper secondary level in preparation for the national general English proficiency evaluation, the listening component in their textbooks is opted to get the corpus for investigation. Also, among the four main language skills, listening skill is the least researched despite its plentiful materials (Matthews & Cheng, 2015). To date, no published research has investigated and compared the spoken vocabulary in the new series. To fill in these gaps, the objective of this study is to evaluate the lexical demands, lengths, and lexical richness of grade 10 English textbooks in Vietnam. These textbook series, moreover, are compared to figure out whether they are of the same difficulty. Although the scope of this study is confined to Vietnamese Grade-10 textbooks, it can be beneficial to stakeholders from other EFL settings. Its findings will shed light upon the textbooks’ lexical features for teachers, curriculum designers, and students to plan for appropriate vocabulary teaching and learning strategies as well as for textbook writers to revise their future products. In this regard, the present study attempts to address the two research questions below:
How much vocabulary is required for grade-10 students to achieve 85%, 95%, and 98% coverage of listening sections in the eight English textbook series?
To what extent do the listening sections in these eight grade-10 English textbook series differ in terms of text length, lexical diversity, and lexical sophistication?
Literature Review
Vocabulary Knowledge and Listening Comprehension
Vocabulary is intimately involved with the listening skill (Nation, 2022). In specific, the degree to which learners can gain proficient listening comprehension is driven by their vocabulary knowledge (Ha, 2022a, 2022b; Matthews & Cheng, 2015; Trang et al., 2023). To estimate the adequate comprehension level in listening, lexical demand and lexical coverage are the two mostly used concepts in relation to vocabulary knowledge (Ha, 2021; Nation, 2022). It is commonly assumed that the strong correlation between lexical coverage and listening comprehension is reflected through the appropriate range to achieve moderate comprehension. In accordance with the results of van Zeeland and Schmitt (2013), 95% coverage is minimal, and 98% coverage is better for optimal comprehension of listening texts. In addition, high-frequency words play a crucial role in comprehension as learners can effortlessly recognize them in listening tasks (Matthews & Cheng, 2015).
To best facilitate vocabulary learning, learners should set their own long-term goal to measure the number of vocabulary needed (Nation, 2022). In the light of Nation (2022), vocabulary demand is known as a certain range of words to which a learner understands a text. From the perspective of lexical demand for learners, there is a question about the number of vocabulary needed to reach minimal and optimal comprehension of a text. Over the past decade, a large volume of published research has claimed three common thresholds for readers or listeners to comprehend a text, which are 85%, 95%, and 98% (Laufer & Ravenhorst-Kalovski, 2010; Laufer, 2013; Schmitt et al., 2011; van Zeeland & Schmitt, 2013). For language-focused instruction, students are suggested to cover no less than 85% (McLean, 2021). For acceptable comprehension, Laufer and Ravenhorst-Kalovski (2010) confirmed that the threshold should be 95%. In case the instruction focuses on meaning, 98% is the optimal threshold (Nation, 2022). It is transparent that there will be a lower density of unknown words at higher thresholds. In detail, if learners reach 95% and 98% coverage, they are just unable to identify 1 word in every 20 or 50 words.
The notion of word frequency is conceptualized relying on the occurrence of words in a certain corpus. Specifically, the present study refers to the British Nation Corpus/Corpus of Contemporary American English (BNC/COCA). This wordlist was introduced by Nation in 2012 and was described as a “better indication of word frequency” (Schmitt et al., 2017, p. 7). It is composed of 25 1,000-word-family levels and four supplementary lists including Proper Nouns (PN), Marginal Words (MW), Transparent Compounds (TC), and Acronyms (Trang et al., 2023). In the BNC/COCA wordlist, words are divided into three degrees: high-frequency, mid-frequency and low-frequency. Research on high-frequency words by Schmitt and Schmitt (2014) suggested that high-frequency levels are the first three 1,000-word levels in the BNC/COCA wordlist. These high-frequency levels are composed of function words (e.g., the, a, for, etc) and familiar content words (e.g., access, brand, century, etc). Aside from that, they make up the highest proportion of running words in almost all texts (Nation, 2022; Yang & Coxhead, 2022). Accompanied by the four supplementary lists, they aid learners in approaching even 95% of text comprehension. Following high-frequency levels are the next 6,000 mid-frequency word families spreading across the fourth to the ninth 1,000-word levels. These levels include words of medium occurrence. Words beyond the ninth level, from the tenth level onward, are classified into low-frequency words. These words account for the greatest number of word families compared to the two others. However, they take a limited percentage of a text due to their infrequency. Thus, learners do not need to care about them for the purpose of comprehension (Laufer, 2013).
The Impact of Text Length on Listening Comprehension
According to Miller (1956), because listeners have to consecutively deal with phoneme sequences, longer texts can exhaust their capacity for attention. It is apparent that the length of a text can strongly impact one’s comprehension through their memory and attentional skills (Forrin et al., 2018; Forrin et al., 2020). For readers, a text can put them in a state of distraction if it is too long to remember and understand. Similar to readers, listeners also face these problems when listening to a lengthy text. Additionally, listeners cannot deal with a passage several times as readers, therefore, they have to strive to maximize their memory and decode the content in a short time (Wolf et al., 2018). Besides, listeners are also limited in their consciousness as they simultaneously receive and process too much information while suffering the pressure of given time in listening tasks (Csikszentmihalyi, 1990). As a result, text length is a factor that has an intense influence on students’ listening comprehension.
Lexical Richness and Lexical Diversity
Lexical richness has been termed as a measurement of the variety of words in a certain sample or text (Daller et al., 2003). To the present, it is considered one of the most common terms to estimate learners’ vocabulary (Kim et al., 2018). This notion was equated with the other term lexical diversity for a long time although they had been defined distinguishingly (Jarvis, 2013). However, many researchers have recently adopted a broader notion of lexical richness. The research of Read (2000) says that lexical richness includes, but not only, lexical diversity, along with lexical sophistication.
Lexical diversity is influenced by the proportion of types or unique words in a text and their repetition (Jarvis, 2013). It is recognized as linguistic complexity, which is a useful gauge for assessing language proficiency, vocabulary knowledge, and so forth. Lexical sophistication, in the same vein, helps predict the difficulty of words and reflects the level of vocabulary knowledge in accordance with frequency levels (Jarvis, 2013). It relates to advanced words whose levels are at low frequencies (Laufer & Nation, 1995; Kim et al., 2018). In the present study, lexical sophistication is defined by the traditional notion and is measured on the basis of the frequency-based approach, which is to estimate low-frequency words from 4,000 to 25,000 word families in the BNC/COCA wordlist.
The Most Common Metrics of Lexical Diversity
Among numerous indices of lexical diversity (LD), the type-token ratio (TTR) is “the simplest and most widely used LD index” (Zenker & Kyle, 2021, p. 1), determined by dividing the number of unique words by the total number of words in a text (Daller et al., 2003; Jarvis, 2013). Nonetheless, this index is strongly affected by text length. In an attempt to seek the lexical diversity indices that are the least impacted by text length, Zenker and Kyle (2021) compared conventional and modern indices on texts of different lengths. The authors drew line graphs to present the raw lexical diversity values and z-scores of the indices, and conducted the binned analysis of Pearson correlation. The results suggested that Moving Average Type Token Ratio (MATTR), Vocab-D (HD-D), and Measure of Textual Lexical Diversity (MTLD) were the three most stable lexical diversity indices having negligible correlations with text length (r < .100).
Moving Average TTR (MATTR or MATTR50) is an adjustment of simple TTR to decrease the effect of text length (Covington & McFall, 2010). MATTR cuts the text into each 50-word segment by moving up to 1 word unit, so it is also known as MATTR50. Afterwards, each segment is averaged, and finally, all of the results are re-averaged for the output of the last MATTR.
The hypergeometric distribution diversity (HD-D) index is a metric calculated through probabilities (McCarthy & Jarvis, 2010). HD-D computes the probabilities of encountering all tokens of a type in a sample of 42 words in a text. After that, the sum of all probabilities of all types is the final value of lexical diversity.
Measure of Textual Lexical Diversity (MTLD) is a metric calculating the average of token strings reaching a certain TTR value following two directions: forward and backward (Koizumi, 2012; Zenker & Kyle, 2021). In each direction, MTLD cuts the text into different segments with the last word reaching TTR value under or equal to 0.72. If the string is under 10 words, it is not counted. In case a text impossibly reaches 0.72 at the end of the text, the remainder of the text is proportionately calculated contingent on the trajectory from 1.00 to 0.72 (Koizuimi, 2012). Later on, the total tokens of the text are divided by the times that TTRs value 0.72 or below, plus the decimal of the remainder (i.e.,
Studies on the Vocabulary of English Textbooks in EFL Contexts
In the Indonesia context, Aziez and Aziez (2018) examined English textbooks for junior and senior high-school students to clarify three aspects: (a) their lexical coverage by the BNC list; (b) their lexical variety calculated by the TTR index; and (c) the number of academic words and words beyond 2,000 high frequency words. For the question about lexical coverage, the study found that at 95%, students needed 4,000 word families at the junior level and 5,000 word families at the senior level. The finding for the second question addressed the TTR scores of all levels of textbooks which was equal to 0.23. In terms of academic words, for the junior level, the percentage of academic words and those beyond the 2,000-word level in the textbooks both equaled 1.75%. In the meantime, as to the senior level, these words covered 3.56% and 11.87% of the textbooks. All these findings pointed out that the vocabulary level of those textbooks was too high for the competence of the students. Therefore, Indonesia should adjust their textbooks to be compatible with the students’ knowledge.
Interested in Chinese secondary schools, Yang and Coxhead (2022) investigated the corpus from Books 3 and 4 of the New Concept English Textbook Series (NCE). In order to analyze a total of 40,895 tokens, the two researchers operated RANGE program 1.0.0 (Heatley et al., 2002) and adopted the BNC/COCA lists accompanied by the four supplementary lists. The results showed that learners needed 3,000 and 5,000 with the four supplementary lists to respectively achieve 95% and 98% coverage of Book 3, and 4,000 to 6,000 word families plus the supplementary lists for 95% and 98% coverage of Book 4. In addition, more than 85% of the textbooks fell to high-frequency words in the first three levels of the list. Focusing on the same country, Sun and Dang (2020) conducted a study on 265 voluntary high school students who used Yilin textbooks in their curriculum. For the application of the study, the researchers accumulated a corpus of 273,094 tokens from written and listening transcripts and ran the data on RANGE with the BNC/COCA wordlist. The results exhibited that to reach 95% and 98% coverage of the Yilin textbooks, learners needed to know 3,000 and 9,000 word families along with the four supplementary lists. The finding also disclosed that the Yilin textbooks were a big pressure on Chinese high school students.
To the best of the researchers’ awareness, Nguyen (2020) was one of the pioneers in analyzing the vocabulary of the new high school English textbooks published in 2020 for Vietnamese students, namely Tieng Anh 10, Tieng Anh 11, and Tieng Anh 12. 422 high school students were recruited from the entire country and the three corresponding grades were tested by the Vocabulary Levels Test (VLT; Webbbalance et al., 2017) to identify their vocabulary knowledge. Then, reading passages in the textbooks were processed by the Vocabprofilers on the Lextutor.ca website using the BNC/COCA wordlist and compared with the results of VLT. The findings pointed out that as the student’s knowledge covered the first two high-frequency levels in BNC/COCA, they could comprehend 87.1% of these textbooks. To gain the coverage of 95% and 98% of these textbooks, they were expected to possess the vocabulary knowledge of the third and fifth 1,000-word lists in BNC/COCA. As can be seen from the study of Nguyen, although the study adopted BNC/COCA, it was not accompanied by the four supplementary lists including PNs, MWs, TCs and acronyms. Therefore, the results of lexical demand could be misleading and the difficulty of the textbooks, if these lists had been counted, might have been different. Two years later, Le and Dinh (2022) investigated the edited version of the grade 10 textbook in the study of Nguyen (2020). To gain the lexical demand and coverage of high-frequency words of the textbook, they developed a corpus of 41,137 words extracted from written texts and audio transcripts and processed them on Vocabprofilers with the BNC/COCA lists. The finding indicated that Vietnamese students needed 3,000 to 5,000 word families to achieve 95% and 98% coverage of the textbook, which was challenging for them to learn without support. This finding seemingly resonated with Nguyen’s study (2020), however, the outcome did include the supplementary lists. Moreover, the researchers found that although the textbook covered the first high-frequency level, just over half of the second 1,000-word list was encountered. Thus, teachers are encouraged to adapt the textbook for teaching effectively.
Research Gaps and the Present Study
The researches reviewed above have contributed a valuable property to the literature on the vocabulary of EFL textbooks. Notwithstanding their contributions, they still expose some gaps that need addressing. Firstly, the way to evaluate textbooks in the previous studies unveils two methodological issues. With regard to lexical demand, only Sun and Dang (2020) considered the first three 1,000-word levels as high-frequency words while the others accepted the first two 1,000-word levels. Additionally, these studies were based on frequency to gauge the depth of textbooks instead of other lexical features except for the work of Aziez and Aziez (2018) measuring lexical diversity. This study, however, relied on the TTR index which is significantly sensitive to text length. To gain a more accurate insight, the present study works on the 3,000 level and takes into account the other features including length, sophistication, and diversity.
Secondly, the studies of Nguyen (2020) and Le and Dinh (2022) were conducted solely on one new English textbook series. Nonetheless, to date, there have been nine textbook series widely applied to grade 10. In spite of the emergence of other English textbook series, attempts to research them are almost nil. Accordingly, no evidence or investigation has proven the validity of these textbooks. As a result, the present study aims to bridge this gap by comparing all the series for a more comprehensive view of grade 10 English textbooks in Vietnam.
Methodology
Research Design
In this research, the quantitative method was employed to measure the lexical coverage and lexical richness of the English textbook series. The AntwordProfiler version 2.1.0 (Anthony, 2023) accompanied with BNC/COCA lists created by Nation (2017) was run to respond to Research question 1. Then, Research question 2 was answered by calculating a sort of lexical diversity indices with Tool for the Automatic Analysis of Lexical Diversity (TAALED; Kyleet al., 2021). The study also employed Jamovi version 2.3.28 to examine whether these textbooks significantly varied through pairwise comparisons.
Data Collection
In the period of 2022 to 2023, the MoET released nine new English textbook series for grade 10 students. Unfortunately, the authors’ survey on the selection of textbooks indicated that very few provinces have opted for Macmillan Move On, and it was also unavailable for download. Thus, it was excluded from the data source of this study. As mentioned earlier, the key data was the listening sections in those English textbooks. The corpus included a total of 54,566 tokens. The size of units and passages were different from each other. Information relating to the eight series of English textbooks is presented in Table 1.
Information of the Eight Textbook Series.

CC: Culture Corner; CLIL: Content and Language Integrated Learning; PC: Progress Check.
Source: author.
Data Preparation
The listening transcripts were mostly taken from teacher’s books of these series. Some of them were collected from the subtitles of the audios. Then, a data extraction tool from Microsoft named PowerToys was applied to convert raw texts from the data sources into text files. However, there were some spelling errors due to the unoptimized function of the tool. It could be seen that the characters “m” and “rn” were quite similar, which caused some misinterpretations in the scanning process of the tool. Besides, some uppercase characters such as “I” and “O” were converted as the numbers “1” and “0.” Thus, the researcher retyped the errors manually, removed redundant words, and re-added missing words to the corpus.
Data Analysis
The AntWordProfiler (Anthony, 2023) was utilized to process all of the text files. The program used the BNC/COCA list (Nation, 2017) to classify words into their frequency levels, count their occurrences, and calculate their sums and percentages. Tokens were arranged in 25 levels and four supplementary lists, moreover, outlying tokens would be put in “Not in the list.” Then, those not-in-the-list words would be returned to their correct positions in the four supplementary lists. The updated data would be processed to report the coverage of each full textbook, and each unit in each textbook was further analyzed independently.
Research question 2 could be answered based on the results of each unit in terms of length, sophistication and diversity. Length was counted by the total tokens of each unit. At the same time, lexical sophistication was calculated according to the sum of word families from the 4,000 to 25,000 levels (
Results
RQ1: How Much Vocabulary Do Grade-10 Students Need to Achieve 95% and 98% Coverage of Listening Sections in the Eight English Series of Textbooks?
Table 2 illustrates the lexical coverage of each level in two cases whether learners have the awareness of the four supplementary lists of PNs, MWs, TCs and Acronyms or not. Learners who could understand these lists just needed 2,000 or 3,000 word families to reach 95% of the textbooks. In contrast, learners without recognition of them had to double, triple, or even more their vocabulary knowledge to comprehend 95% of the textbooks.
Cumulative Coverage With and Without the Four Supplementary Lists in the BNC/COCA.

In the situation of not being aware of these lists, learners could only reach a maximum of around 97%. Therefore, learners were required to understand PNs, MWs, TCs and Acronyms so that they just needed about 3,000 to 4,000 word families to achieve 98% coverage.
Figure 1 demonstrates the vocabulary demand to understand 85%, 95%, and 98% of listening parts of the eight textbook series. It has been shown that all of these series just needed the first frequency level to achieve 85% of the words in the series. In terms of the 95% threshold, except C-21 Smart requiring 2,000 to 3,000 word families, all the remaining series were at 1,000 to 2,000 levels of the BNC/COCA lists. Regarding 98% coverage, Bright, Friend Global, Global Success and THiNK needed from 2,000 to 3,000 word families while the others needed more than 1,000.
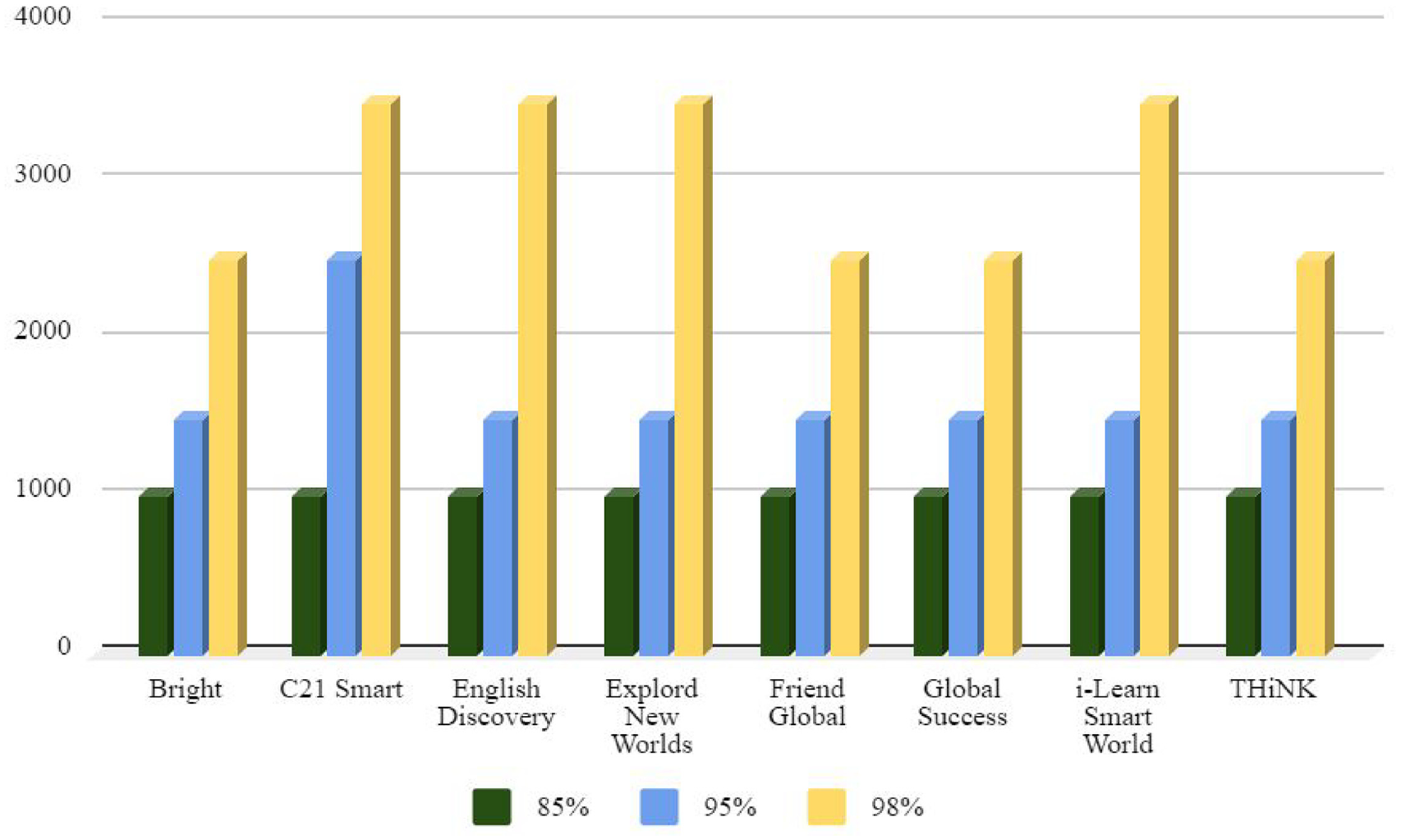
Vocabulary needed to understand 85%, 95% and 98% listening parts of the eight textbook series.
RQ2: To What Extent Do the Listening Sections in These Eight Grade-10 English Textbook Series Vary?
Table 3 sheds a light on the correlation of text length to lexical sophistication and diversity. It is apparent that the relationship between text length and sophistication were negligible. In terms of diversity, there were three indices commended by Zenker and Kyle (2021), including MATTR, HD-D and MTLD. These are the three most reliable metrics to measure lexical diversity across different text lengths.
Correlations Between Length, Lexical Sophistication, and Lexical Diversity Indices.

In Table 3, the result of MATTR50 (r = −0.029) showed the lowest correlation, indicating that it would show the lexical diversity of the textbooks the most accurately and reliably with the lowest text length effect. In addition, the p-value of MATTR50 was equal to .795 which was far larger than .05. It could be seen that the result was insignificant, in other words, there was no correlation between text length and lexical diversity.
In Table 4, the Skewness and Kurtosis values were reported to identify the distribution and shape of the histogram for the purpose of choosing one among the three central tendencies (i.e., mean, median, and mode). There was outlying data out of the interval of [−2; 2] (Curran et al., 1996). Due to the asymmetric histogram, different distribution and outlying figures, the data was somewhere not normally distributed. Therefore, a non-parametric test represented by the median was run to make pairwise comparisons of the eight textbooks.
Descriptive Statistics of Listening Transcripts in the Eight English Textbooks Series on Length, Sophistication, and Diversity.

In Table 5, the Shapiro-Wilk test was run to determine the normality of statistics. While the Shapiro-Wilk of Sophistication, W = 0.973, reflected that the assumption of normality was not violated (p = 0.072), the statistics of Length and Diversity, W = 0.945 and W = 0.936 respectively, showed departures from normality (p = .001 and p < 0.001). Hence, the Kruskal-Wallis test was reported.
Shapiro-Wilk test of Normality.

Due to the violation of normality, a non-parametric test called Kruskal-Wallis was performed on the three constructs including length, sophistication and diversity. Then, multiple comparisons were conducted on the medians of the three constructs. As observed in Table 6, the results of length and diversity indicated significant divergence with p-values being smaller than 0.001 (p < .001).
Results of the Kruskal-Wallis Test.
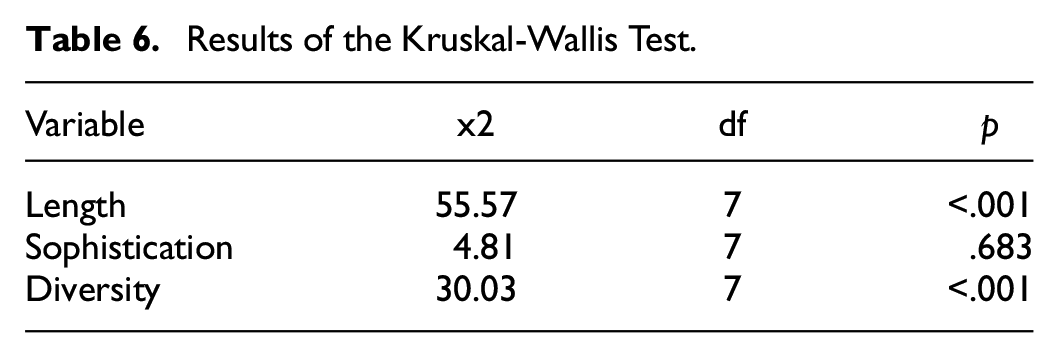
The ANOVAs were significant for length and diversity, then, Dwass-Steel-Critchlow-Fligner post-hoc results were reported in Table 7. Of all the textbooks, regarding Length, D (Explore New Worlds), E (Friends Global), F (Global Success), G (i-Learn Smart World) and H (THiNK) were the five most noticeable series. The trinity of D, E and F were significantly different from A, B and C. Besides this trinity, both G and H had a statistically significant difference with B and E. In addition, there were also two other pairs showing significant differences in length, including D versus E and E versus F.
Pairwise Comparisons Between the Listening Transcripts in the Eight English Textbooks.

With regard to diversity, H draws great attention by virtue of its difference to most of the series. H was significantly different from three of seven textbooks involving A, F, and G. Aside from that, D was the only textbook that showed a significant difference with F and G. It can be seen from the results that H was the most special textbook in terms of length as well as diversity. In respect of diversity, the trinity of D, E, and F were the three most noteworthy.
Discussion
It can be seen from the analysis that the eight English textbook series had a comparatively equivalent lexical demand for 85%, 95% and 98% of the listening transcripts. Detailedly, these three strands could represent three kinds of instructions in language learning. All of these textbooks appropriately facilitated students’ language-focused learning at around the 1,000 level. Comparing this result with that of Nguyen (2020), which showed that students could understand 87.1% of textbooks with words at the 2,000 bands, the new series were adjusted to be more suitable and less difficult than the previous ones. In comparison with the study of Yang and Coxhead (2022), the NCE textbooks in China needed the first three high-frequency levels for 85% coverage. It is transparent that the textbooks in China were more difficult than the new textbooks in Vietnam.
At 95% coverage, the eight English textbook series were relatively equal. All of them just required nearly 2,000 word families, except for C21 Smart which required upwards of 2,000 word families. In the research of Nguyen (2020) and Le and Dinh (2022), the previous textbooks required students to master 3,000 word families. In essence, the Tieng Anh 10 textbook was apparently more difficult than the eight new textbooks. In comparison with the vocabulary demands in the two studies of Sun and Dang (2020) and Yang and Coxhead (2022), Chinese students had to achieve 1,000 to 2,000 more word families than the students using the eight textbooks in Vietnam. All of these findings shine a light that the vocabulary demands of the textbooks in Vietnam are less laborious than those in the other EFL countries, particularly in China.
As regards optimal comprehension, the eight series fell into the range of 3,000 to 4,000 word families. To be more specific, two main tendencies could be noticed: (1) four textbooks (i.e. Bright, Friends Global, Global Success, and THiNK) did not exceed 3,000 word families, whereas (2) the others were close to the fourth levels. The results stand out that some series reached mid-frequency levels when it comes to the coverage of 98% of running words. Compared to the vocabulary demands of the textbooks in Nguyen’s research (2020), and more recently in Le and Dinh’s research (2020), which were up to 5,000 word families, the preceding series were 1.25 to 1.7 times higher than the new series. Similarly, Book 3 and Book 4 in the NCE textbooks in China correspondingly demanded 5,000 and 6,000 word families, and the Yilin textbooks had an unexpected vocabulary demand escalating to around 8,000 to 11,000 word levels. It can be deduced that the new series of English textbooks in Vietnam are less lexically demanding than these textbooks.
As seen from the three thresholds above, the new series of English textbooks in Vietnam necessitated moderate vocabulary compared to the textbooks in the other contexts. The gap of 3% from 95% to 98% of the textbooks in Vietnam is also more realistic than that of the other textbooks, which helps lessen the time and difficulty for students in learning vocabulary. In spite of that, the lexical coverage of these textbooks is still profoundly difficult for grade-10 students. Researching the receptive knowledge of university students in Vietnam, Dang (2020) pointed out that about one-half of the students had not approached the first high-frequency word level and just one-tenth of them could master a maximum of 2,000 words. Her research focused on university students whereas the present study targeted grade-10 students. Therefore, it would be seemingly impossible for grade-10 students to comprehend textbooks that are even beyond the knowledge of university students. Consequently, textbook writers and administrators should realise the shortcomings of these new series of textbooks so as to adjust them. One of the feasible solutions is to apply a profiling program to control the vocabulary load of these textbooks. Furthermore, the level of English proficiency is different among students, therefore, they should conduct investigations and empirical studies to offer an appropriate range of vocabulary for students across the country. Moreover, they also have to modify the difficulty of these textbooks to guarantee the equivalent outcome among students.
As remarked above, the four supplementary lists would be a decisive factor in the coverage of the textbooks since they can reduce the word levels and the number of words that students actually need to learn. The reason for this is that even if these words are unfamiliar to students, they can be easily predicted. For instance, PNs can be recognized by capital forms (e.g., Jayden, Nguyen Thi Dinh, Phong Nha, Kyoto, China, Nestle, Facebook, Instagram, etc). Aside from PNs, students can also recognise MWs (e.g., eww, err, haha, uh, uhm, etc.), familiar TCs (e.g., smartphones, ballgame, mindmap, etc.) and acronyms (e.g., CCTV, BTS, USB, etc.). Hence, the four supplementary lists support much for the students. Besides, most PNs were relevant to Vietnamese places or names, therefore, students could easily identify them owing to their familiarity. This finding is entirely in line with that of Le and Dinh (2022). As a result, supplementary lists have great benefits for students to comprehend the listening parts in the eight textbooks.
Other important findings on the lexical features of these textbooks were also detected. First, the most noticeable feature was the different text lengths between these textbooks. As reported in Tables 4 and 7, there were some texts containing even less than 100 words, whereas some transcripts could be at least 1,900 running words. These dramatic differences can make students learning different textbooks diverge in knowledge acquisition (Mesmer & Hiebert, 2015). Detailedly, longer texts will take students more time and more effort to comprehend. So, they will be under more pressure and less productive in class. Moreover, longer texts will distract students’ attention from the main idea of the text and make them unable to remember messages while listening.
The next feature to be compared is the lexical sophistication of the textbooks. Thanks to their insignificant differences, the number of advanced words in the textbooks was equal. In both studies in Vietnam, advanced words accounted for 3.4% of Tieng Anh 10 (Le & Dinh, 2022; Nguyen, 2020;). Meanwhile, the lexical sophistication scores of the present study fluctuated from 1.7 to 2.3. The new series, hence, partially solves the problem of Tieng Anh 10 by substantially cutting off the number of advanced words and mostly focusing on high-frequency words. Also, in the statement of Nation (2022), the percentage of around 2% is the most effective for students’ vocabulary absorption and retention. In comparison with the studies in the Chinese context, the vocabulary demand of the Yilin textbooks stretched to the 11,000 word level and the percentage of words in 4,000 to 25,000 levels took up just 2.74% (Sun & Dang, 2020). It can be noticed that there was a slight disparity in the proportion of sophisticated words in the Yilin textbooks and those in the present study. One more interesting finding is that the sophisticated words in the Tieng Anh 10 textbook put an end to the 16,000- or 17,000-word level while some of the textbooks in the eight new series can spread to the 25.000-word level. In such a case, even though the new series of textbooks cut down the number of sophisticated words, the occurrence of rare and extraordinary words seems to be more than that of advanced words. Accordingly, the new textbooks still hinder students’ vocabulary learning.
Daller et al. (2003) deemed that lexical sophistication affects the ratio of lexical variety in a text, in other words, they are proportional to each other. It is somewhat surprising that lexical diversity was inverse to sophistication in this study and had the same tendency as length in that the lexical diversity was significantly varied between the eight textbooks. The finding proves that although the eight textbooks offer an equivalent amount of advanced vocabulary, old types also repeat regularly. This can be explained by the presence of conversations in listening sections. The study of Kim (2002) clearly demonstrated that repetition is a mechanism that enables speakers to maintain the talk. Therefore, the number of new types will decrease as the conversation proceeds. Nonetheless, the fact that textbook writers cannot control the equivalence in lexical diversity between the eight textbooks will be detrimental to students’ vocabulary uptake and learning. It will also cause differences in students’ proficiency.
Due to these lexical problems, textbook writers should re-measure the level of words in these textbooks. They can refer to some frequency lists like the BNC/COCA lists to limit the occurrence of rare words. Especially for listening sections, students will be extremely confused as they aurally encounter rare words. Not only that, textbook writers should balance text lengths to cope with the case that students are distracted during long listening. Besides, teachers also hold a keynote position in the classroom. They should consider and be aware of the target proficiency to plan for teaching methods and adapt the textbooks more effectively. A common advice is that the Updated Vocabulary Levels Test (Webb et al., 2017) should be applied to evaluate the vocabulary size of students. Moreover, Younas and Dong (2024) have proven that animated movies are considerably effective for linking vocabulary with its use in the real world through visual and auditory skills. Hence, teachers can browse through some movies having a similar range of vocabulary with these textbooks to increase their student’s exposure to newly acquired words. Apart from teaching the written and oral forms of vocabulary and context-based instruction, metaphorical competence, which is the ability to identify and interpret metaphors in listening and reading, is also recommended to train vocabulary for learners (Zhou et al., 2022). Additionally, the teachers should also be flexible in teaching by eliminating redundancy in listening sections of each unit or textbook and focusing mostly on key lessons.
Conclusion
This study is undertaken to compare the vocabulary in the eight English textbook series in Vietnam. It has provided insights into the soundness of randomising EFL textbooks, with a particular focus on the lexical features of their listening texts. The findings showed that at 85% coverage, students needed approximately 1,000 word families; for adequate comprehension at 95%, the figure stretched to 2,000 to 3,000 word families; and for optimal comprehension at 98% coverage, 3,000 to 4,000 word families were required. Certainly, this vocabulary demand included the four supplementary lists in the BNC/COCA lists and they were applicable to all of the textbooks. Furthermore, although the differences in lexical sophistication of those textbooks were insignificant, their lengths and lexical diversity were significantly varied. In conclusion, despite their equivalence in lexical demands and sophistication, the significant differences in length and diversity will be a considerable impediment to using these textbooks randomly. Besides, the lexical demands of these textbooks were still high, which hampers students’ vocabulary learning.
Limitations and Directions for Future Research
Despite a number of evident contributions, there are some limitations that need to be addressed in future research. First, the data source of this study excluded Macmillan Move On due to its limited access. Therefore, the researcher could not compare it with the other new textbooks to give suggestions for students or teachers who use this textbook. Future research can focus on this series to extend the literature on the vocabulary of Grade 10 English textbooks in Vietnam. Secondly, the study just explored the vocabulary coverage of the eight textbooks but did not test the vocabulary knowledge of students to identify the proper number of words needed. This opens the opportunity for research on examining the alignment between the lexical demands and levels of the textbooks with the student’s knowledge using The Updated Vocabulary Levels Test (Webb et al., 2017) or The New Vocabulary Levels Test (McLean & Kramer, 2015). Another research direction, which is the most concerning to the researcher, is the lack of an investigation into the knowledge advancement in textbooks across grades and levels. The lexical difficulty of textbooks for the following grades should gradually increase to guarantee students’ progress. Future studies can aim at comparing the vocabulary in EFL textbooks of different grades.
Footnotes
Acknowledgements
The authors would like to sincerely thank Mr. Hung Tan Ha, Victoria University of Wellington, New Zealand for his great support to this research project.
Authors’ Contribution
The authors declare that this is their original work, except where proper citations are made. It is not considered for publication anywhere else.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research is funded by University of Economics Ho Chi Minh City, Vietnam.
Ethical Approval
Ethical approval is not applicable for this article.
Statement of Human and Animal Rights
This article does not contain any studies with human or animal subjects.
Statement of Informed Consent
There are no human subjects in this article and informed consent is not applicable.