
Abstract
Despite ongoing efforts to standardize foreign language (L2) speaking assessment, the validity and reliability of human ratings remains contested due to their inherent subjectivity and the limited transparency of underlying judgment processes. While prior quantitative research has explored correlations between rater scores and measures of complexity, accuracy, fluency, and pronunciation (CAFP), relatively few studies have examined why particular linguistic features carry more weight than others. Addressing this gap, the present study employed a multilayered mixed-methods approach to investigate the relationship between CAFP indices and holistic ratings in an opinion-based, monologic English-speaking test at a Malaysian university. Quantitative analysis of 76 L2 speakers’ performances revealed that global accuracy, intelligible pronunciation, fluency (characterized by fewer pauses and repairs), and lexical sophistication (use of academic vocabulary) were strong predictors of higher scores, whereas syntactic complexity, lexical density, lexical diversity, and speech rate exerted no influence. Qualitative data from think-aloud protocols, interviews, and observation notes showed raters tended to prioritize perceived communicative effectiveness and relied on salient features under cognitive load, often overlooking less prominent aspects. The findings underscore the need to refine rater training and rubric design to mitigate judgment bias and cognitive fatigue, thereby supporting fairness and validity in L2 speaking assessment. At a broader level, these results offer an evidence base to enhance rater calibration and scoring consistency in L2 speaking assessment worldwide.
Introduction
Foreign language (L2) assessment, particularly of speaking, has long been a complex and evolving area of applied linguistics. As speaking is a spontaneous, real-time skill involving multiple linguistic and cognitive processes (Wang & Li, 2022), assessing it reliably and validly has posed persistent challenges. Conventionally, speaking performance in tests, whether standardized or institution-based, has been evaluated by trained human raters using established rubrics, often focusing on holistic scales (which assign a single overall score representing general communicative proficiency) or analytic scales (which provide separate scores for discrete aspects) of linguistic features such as complexity, accuracy, fluency, and pronunciation (CAFP), as well as discourse-related elements such as coherence, idea development, and task fulfillment (Onal, 2022; Sundqvist & Sandlund, 2024). These rubric-based assessments have the advantage of capturing overall communicative proficiency and allowing experienced raters to exercise professional judgment. However, these assessments are not without limitations, as subjectivity, potential rater bias, and inter-rater variability can undermine the consistency and transparency of the evaluation process (de Jong, 2023; Feng & Guo, 2022).
To address these concerns, there has been growing interest in using linguistic analyses to complement human judgments, with one such approach involving the measurement of analytic CAFP indices, which are objective, quantifiable dimensions derived from spoken language samples (Housen, 2022; Michel, 2017; Pallotti, 2021). These indices are typically calculated based on specific linguistic forms and provide a detailed account of how learners produce language in terms of syntactic and lexical complexity; morphological, syntactic, and lexical accuracy; temporal fluency, as indicated by speech rate, pause phenomena, and self-repairs; and pronunciation, as evidenced by features such as word intelligibility.
Building on this development, a growing body of research has sought to correlate CAFP measures with human ratings (i.e., scores assigned by trained evaluators based on their judgment of a performance) to investigate the extent to which rater judgments align with objective performance features, aiming to examine the validity and reliability of human ratings and identify key linguistic features influencing these judgments (Alshalan, 2024; Chen, 2025; Hu et al., 2025; Miyamoto, 2019; Ogawa, 2022). While such studies offer valuable insights into the statistical relationships between linguistic features and rater scores, especially in contexts where holistic rating scales are used to capture overall communicative proficiency (Kunnan, 2024), they fall short of uncovering the cognitive, interpretive, and contextual factors that shape how raters make sense of spoken performance, particularly in explaining why certain features influence scoring decisions in subtle or less readily articulated ways. This deficiency has prompted calls for “future studies [to] benefit from a mixed methodology … to better understand [raters’] perceptions” shaped by test-takers’ linguistic features during the scoring process (Ogawa, 2022, Discussion section, para. 12).
This call forms the foundation of our study, which is situated within a standardized, institutionally developed English-speaking test featuring opinion-based monologic tasks and assessed using holistic rating rubrics. We aim to answer the following research questions: (1) To what extent do analytic CAFP indices correlate with human ratings in the English-speaking test? and (2) How do examiners interpret and justify their rating decisions in candidates’ spoken performance? The study seeks to offer an integrated lens for interpreting rating behaviors in relation to linguistic performance. Beyond providing a locally grounded account of the speaking assessment process, it also contributes to broader theoretical and methodological discussions on how best to capture the complex interplay between measurable language features and human evaluative judgment.
Literature Review
Operationalizing CAFP
Complexity
Speaking complexity can be categorized into three types: developmental complexity (the sequence in which linguistic forms emerge and are mastered in L2 acquisition), cognitive complexity (the learner’s perception of the difficulty of language use), and linguistic complexity (the structural properties of the language itself; Bulté & Housen, 2012). While developmental and cognitive complexity are relative to individual learners, linguistic complexity is typically measured at an absolute level in research. Following this approach, the present study adopts Ellis’s (2003) definition of complexity as “the extent to which the language produced in performing a task is elaborate and varied” (p. 340), encompassing both syntactic and lexical dimensions.
Using the Analysis-of-Speech-unit (AS-unit; i.e., a main clause along with any subordinate clauses and associated material) and the clause (i.e., a subject-predicate unit) as the underlying units of analysis, syntactic complexity, defined as the structural elaboration and sophistication of syntactic forms used in speech (Michel, 2017), is measured by:
Mean length of AS-units (MLAS): the number of tokens divided by the number of AS-units.
Mean length of clauses (MLC): the number of tokens divided by the number of clauses.
Ratio of subordination based on AS-units (RSAS): the number of clauses divided by the number of AS-units.
These metrics respectively capture the length, sub-clausal, and subordination dimensions of syntactic elaboration and offer a comprehensive view of structural complexity in speech. Although T-units tends to be more commonly employed in syntactic complexity research, we prioritize AS-units due to their greater suitability for capturing clause structure and coordination in spontaneous spoken discourse.
Lexical complexity refers to the varied and sophisticated use of lexical items in an utterance and reflects the speaker’s ability to access and deploy a wide range of vocabulary (Bulté & Housen, 2012). It is typically examined through three dimensions: lexical density (the proportion of content words relative to the total number of words as an indicator of information richness), lexical diversity (the range of different lexical items used), and lexical sophistication (the use of low-frequency, advanced, or academic vocabulary). In empirical research, lexical complexity is often measured using specialized software programs that allow for consistent analysis across large datasets of speaking transcripts. Accordingly, the present study employs the following indices:
Proportion of content words (PCW) for lexical density, calculated using the VocabProfile program by dividing the number of content words by the total number of words in each sample (Cobb, 2002, as cited in Knoch et al., 2014).
Lexical diversity score (D-score) for lexical diversity, generated using the computerized language analysis (CLAN) program (McKee et al., 2000). This method draws 100 random samples of 35 to 50 tokens from each transcript, computes type-token ratio for each sample, and calculates an average D-score that minimizes the influence of sample length.
Proportion of advanced words (PAW) for lexical sophistication, also calculated using VocabProfile, by dividing the number of advanced words (based on the Academic Word List) by the total number of words (Cobb, 2002, as cited in Knoch et al., 2014).
These measures together provide a multidimensional and computationally robust picture of learners’ lexical performance in spoken discourse.
Accuracy
Although accuracy has been defined as “the ability to avoid error in performance … [with] higher levels of control in the language as well as a conservative orientation” (Ellis, 2009, p. 475), this definition tends to align more closely with strategic communication, where learners deliberately select language forms to achieve communicative goals, rather than reflecting actual language use. Thus, speaking accuracy is more commonly understood as the extent to which a speaker’s output is free from linguistic errors in the target language (TL; Michel, 2017). Accuracy is typically assessed in terms of two categories: global accuracy, which encompasses all types of linguistic errors, and specific accuracy, which focuses on particular grammatical forms (Pallotti, 2021). However, measuring specific accuracy poses methodological challenges, as the linguistic structures elicited can vary across speaking tasks, topics, and test formats (Housen, 2022). For this reason, the present study adopts a global approach, incorporating errors across syntax, morphology, and lexis to provide a holistic picture of learners’ language control. Rather than relying on simplistic measures, such as errors per 100 words, which can be distorted by sample length, this study utilizes more refined and task-appropriate indicators of global accuracy (Ellis & Barkhuizen, 2005):
Percentage of error-free clauses (PEC): the number of error-free clauses divided by the total number of clauses.
Percentage of error-free AS-units (PEAS): the number of error-free AS-units divided by the total number of AS-units.
These measures provide a more reliable indication of learners’ overall accuracy in spontaneous spoken production, capturing how consistently they produce linguistically correct utterances across structurally varied units.
Fluency
Fluency is defined as “the production of language in real time without undue pausing or hesitation” (Ellis & Barkhuizen, 2005, p. 139), emphasizing the temporal dimension of speech and the speaker’s ability to maintain flow under time constraints. Accordingly, fluency is commonly operationalized through temporal variables that capture different aspects of speech production. These include speed fluency (the rate at which speech is delivered), breakdown fluency (pausing patterns that interrupt the flow of speech), and repair fluency (observed disruptions in speech flow) (Michel, 2017). These dimensions are typically measured by the following indices (Skehan, 2009):
Speech rate (SR): the number of words divided by the speaking time (in seconds).
Number of pauses (NP): the total number of filled and unfilled pauses longer than 250 ms, divided by the speaking time (in seconds).
Number of repairs (NR): the total number of repairs—including repetitions, reformulations, replacements, and false starts—divided by the speaking time (in seconds).
Pronunciation
Pronunciation is often defined in terms of how closely speech approximates TL norms and how easily it can be processed by listeners. Scholars have acknowledged pronunciation encompasses several interrelated components, most notably intelligibility (the extent to which a listener can correctly recognize the words a speaker produces), comprehensibility (the listener’s perception of the ease or difficulty of understanding the speaker), and accentedness (how much a speaker’s pronunciation deviates from target-like norms; Thomson, 2017). However, measuring comprehensibility and accentedness poses methodological challenges, as they heavily rely on subjective judgments, such as standardized Likert-style scales (Saito et al., 2020), and can be influenced by listener bias, familiarity with the speaker’s accent, or sociolinguistic expectations (Ma et al., 2018; Yan & Ginther, 2017). Therefore, the present study focuses specifically on intelligibility as the operational definition of pronunciation, which can be assessed more objectively through a transcription-based method (Hustad, 2006):
Intelligibility rate (IR): the number of accurately transcribed target keywords in a spoken response divided by the total number of keywords.
While this method may also be influenced by factors such as the transcriber’s familiarity with accented speech (Koffi, 2021), it nonetheless offers a relatively objective and replicable approach to capturing pronunciation performance compared with more interpretive measures of comprehensibility or accentedness.
Human Ratings and Rater Factors
In L2 assessment, human ratings represent the scores or judgments assigned by trained evaluators who assess a candidate’s TL performance based on predefined criteria or rubrics. In speaking, these ratings can be holistic—capturing overall communicative effectiveness—or analytic—evaluating discrete linguistic features (Sundqvist & Sandlund, 2024). As mentioned, one major concern of human ratings is their inherent subjectivity, which can introduce variability across raters due to individual differences in perception, experience, and expectations (de Jong, 2023; Feng & Guo, 2022). As such, many studies seek to determine the extent to which human judgments align with quantifiable aspects of learner speech for assessment validity and reliability. For example, Alshalan (2024) investigated the relationship between human ratings and complexity, accuracy, and fluency (CAF) indices in a task-based speaking test involving Saudi university English as a foreign language (EFL) learners. The study found the average CAF score positively correlated with holistic human ratings (i.e., overall scores reflecting a rater’s global impression of communicative proficiency rather than separate analytical categories), suggesting broad alignment. However, by treating CAF as a single combined metric, the study provided only a limited view of how each linguistic dimension contributed to scores, especially when compared to research exploring individual indices.
In contrast, Ogawa’s (2022) study with Japanese university EFL learners employed a self-developed, opinion-based monologic speaking task to examine the predictive power of individual CAF measures. Results showed fluency was the most significant predictor of holistic human ratings, while complexity and accuracy contributed minimally to score variance. This pattern is partially echoed in Miyamoto’s (2019) study in a similar context but using an interview-style test. Although fluency remained a strong predictor, Miyamoto’s (2019) findings placed greater emphasis on the role of speaking complexity in holistic human ratings. Chen’s (2025) research with Chinese EFL learners in an opinion-based test confirmed the predictive value of CAFP measures. In this study, all four dimensions significantly correlated with holistic human ratings of communicative adequacy; however, consistent with Hu et al. (2025), fluency and pronunciation were found to contribute more strongly than complexity or accuracy. These mixed findings, though they could be explained by differences in the specific CAFP indices used, task types, and sociolinguistic contexts (Housen, 2022), underscore the need for deeper investigation into not only what linguistic features influence human ratings but also why—as quantitative inconsistencies tend to be common in applied linguistics research, but qualitative insights serve to enrich interpretation and offer contextualized understandings that complement and clarify statistical results (Bang, 2025).
This justifies the present study’s purpose of using qualitative data from human raters to supplement quantitative findings on the correlations between CAFP indices and human ratings. By contextualizing language assessment within a constructivist paradigm, which views assessment as an interpretive act shaped by raters’ perceptions and professional judgment (Kunnan, 2024), we adopt a socio-psychological perspective to examine rater behaviors and perceptions in this study. This perspective aligns with the view that human judgment is influenced not only by observable linguistic features but also by raters’ internal schemas, cognitive heuristics, and socially embedded expectations about what constitutes proficient TL use (Yan & Ginther, 2017).
Within this perspective, cognitive load theory (Sweller, 1988), which emphasizes human working memory has limited capacity, is particularly relevant. As raters process extended streams of spoken input while attending to multiple linguistic dimensions, their working memory can become overburdened and lead to a reliance on more salient or accessible features. Dual-Process Theory (Kahneman, 2011) also offers insight into the cognitive mechanisms underlying these judgments. According to this theory, raters may rely on fast, intuitive evaluations (System 1) when salient speech features are immediately apparent, while more deliberate, analytic processes (System 2) may be reserved for less perceptible dimensions. These dual processes help explain why certain CAFP features may disproportionately influence scores, even when rubrics are designed to weight features equally. The Halo effect (Thorndike, 1920) further accounts for how salient strengths in one observable dimension can influence judgments in unrelated areas and create an inflated overall evaluation. This perceptual bias is widely acknowledged across cognitive psychology and educational measurement, particularly in holistic performance assessments where raters must integrate multiple criteria into a single score (Noor et al., 2023; O’Grady, 2023). In such contexts, we hypothesize that certain CAFP dimensions has the potential to shape holistic human rating decisions, as illustrated in Figure 1, albeit to varying degrees depending on its perceptual salience and the cognitive conditions under which raters are operating. This potential pattern, together with its underlying mechanisms, forms the focus of the present study, with a mixed-methods approach adopted for its investigation.

Potential influence pathways of CAFP dimensions on holistic human rating decisions.
Methodology
Research Context
The present study was conducted at a Malaysian university, which had seen a steady increase in the number of international students from non-English-speaking countries in recent years. In response to the linguistic and academic needs of this growing population, the university developed a standardized academic English proficiency test to serve both admission and placement purposes. The focus of this study was the speaking component of the test, which was designed to evaluate students’ ability to articulate ideas, organize arguments, and communicate effectively in academic contexts. The speaking test took the form of an opinion-based monologic task, in which candidates were given a prompt and 2 min to prepare, followed by a 3-min monologue during which they were expected to express and justify their opinions. For the specific test administration in this study, the topic prompt was: “Discuss why more people are pursuing higher education, and why some are not. Provide at least three reasons.”
Research Design and Data Collection
This study adopted a multilayered mixed-methods research design, in which quantitative and qualitative approaches were not only combined but also embedded across multiple, interlinked stages of data collection and analysis to yield a more comprehensive understanding of the research problem (Headley & Clark, 2019). At the first layer, quantitative linguistic analyses were conducted through a coordinated process involving transcription, detailed coding of linguistic units, and computation of CAFP indices, which provided a statistical map of performance features. At the second, concurrent layer, holistic human ratings were obtained alongside think-aloud protocols, observational notes, and follow-up interviews, generating qualitative accounts of rater decision-making as the ratings were being assigned. The integration occurred both within and across layers: quantitative patterns, such as the strength of particular CAFP predictors, were used to guide the focus of qualitative probing, while qualitative insights from think-alouds and interviews informed the interpretation of why certain features carried more weight or were overlooked. This iterative, layered structure moved beyond simple confirmation, allowing each method to shape and deepen the other, and ensuring that the analysis captured not only the “what” of statistical relationships but also the “why” behind them (Ary et al., 2019).
Using census sampling, which ensured inclusion of the entire population of interest and eliminated sampling bias (Wu & Thompson, 2021), we analyzed all 76 audio-recorded speaking performances from the most recent test administration. Written informed consent was obtained from all test-takers in advance, outlining the study’s purpose, voluntary nature of participation, and the right to withdraw without penalty. The design minimized potential risks by using non-invasive procedures and analyzing performance data collected as part of a routine, high-stakes speaking test, thereby avoiding any additional burden or discomfort to participants. The potential benefits to participants included generating empirical evidence that could inform fairer, more valid speaking assessment practices. Specifically, most test-takers were Chinese (n = 58), with additional participants from Indonesia (n = 10), Bangladesh (n = 5), and Pakistan (n = 3). All participants were between 19 and 21 years old and were EFL learners. The test was taken for the purpose of admission into undergraduate programs, which spanned disciplines such as business, engineering, and computer science.
Each recording corresponded to the task prompt described earlier. The duration of the recordings ranged from 2.03 to 3.00 min. As mentioned, data collection firstly proceeded through two concurrent processes:
Transcription and Linguistic Coding A team of eight transcribers, including six EFL speakers and two native speakers, all holding PhD degrees in linguistics or related fields, transcribed the recordings, with each transcriber assigned approximately 10 recordings. The transcriptions were coded for linguistic analysis using standardized procedures. The units identified and coded were: AS-units, clauses, errors (lexical, morphological, syntactic), pauses, repairs, and intelligible words. These coded elements were tallied by the transcribers and used as the basis for calculating the CAFP indices. A pre-research training session was conducted to ensure consistent understanding and application of the coding definitions. A pilot study, in which all transcribers coded the same set of 15 recordings, yielded Fleiss’ kappa values above .80, indicating a high level of reliability. Another team of three professionals, all PhD holders with research interests in computational linguistics, further processed the speaking transcripts using the CLAN and VocabProfile programs. Their tasks included calculating the number of tokens and keywords, measuring speaking time, and analyzing lexical density (PCW), lexical diversity (D-score), and lexical sophistication (PAW). The raw data from all these professionals were returned to the test administration team, who organized them into an Excel spreadsheet with built-in formulas for the aforementioned CAFP measures. While the statistics for lexical complexity were already computed, the team’s primary task was to use the counts of identified linguistic units to calculate indices of syntactic complexity (MLC, MLAS, RSAS), accuracy (PEC, PEA), fluency (SR, NP, NR), and pronunciation (IR).
Holistic Rating by Raters A panel of five professionally trained raters—comprising three EFL speakers and two native speakers, all holding PhD qualifications in applied linguistics or related fields—independently assessed the 76 speaking performances using a holistic rating rubric (Appendix A), with each rater assigned approximately 15 recordings. The rubric, developed and validated by the university’s assessment team, included a 5-point scale (ranging from “1 = very limited command” to “5 = near-native proficiency,” with 0.5-point increments allowed) and emphasized speaking CAFP and the development of arguments. A pilot study with these raters, who evaluated the same set of 15 recordings, demonstrated satisfactory reliability, with Fleiss’ kappa exceeding .80. Once the test-takers’ scores were finalized, they were returned to and compiled by the administration team. During the rating process, raters were asked to verbalize their thought processes using a think-aloud protocol, which had been developed and refined based on expert feedback. Sample guiding prompts included: “What are you focusing on as you listen to this speaker?”“What makes this speaker more or less effective in your judgment?”“Which features stood out most in your scoring decision?” and “What was your reason for assigning this score?” While think-aloud protocols could introduce potential limitations (e.g., social desirability bias or the possibility that verbalizing thoughts may alter natural cognitive processes) (Sensing, 2022), we sought to mitigate these risks by using neutral, non-leading prompts, conducting practice trials to increase rater comfort, and assuring participants that there were no “right” or “wrong” responses. These sessions were video-recorded and transcribed for qualitative analysis, and observational notes on rater behaviors (e.g., hesitation, audio replay, note-taking) were taken to triangulate verbal data with non-verbal cues.
After completing all ratings, each rater participated in a semi-structured in-depth interview guided by a protocol designed to elicit deeper reflections on their scoring criteria, perceptions of speech features, and challenges encountered during assessment. The interviews were conducted face-to-face in English, each lasting between 40 and 60 min. Sample interview questions included: “Can you describe what you typically prioritize when scoring speaking performances?”“Were there moments when your initial impression of the speaker changed? Why?” and “To what extent do you think certain linguistic features influence your judgment?”Figure 2 briefly shows the quantitative and qualitative data collection process.

Data collection process.
Data Analysis
To examine the relationships between human ratings and CAFP indices, the data were processed using the R programming environment for Pearson correlation and regression analyses, with assumptions generally met. The rule adopted to interpret correlational strength (r) was: very weak (±0.00–0.19), weak (±0.20–0.39), moderate (±0.40–0.59), strong (±0.60–0.79), and very strong (±0.80–1.00; Cohen, 1988). Qualitative data from think-aloud, observation, and interview transcripts were analyzed thematically following Braun and Clarke’s (2021) six-phase framework: familiarization with the data through repeated reading of transcripts and observation notes; generation of initial codes that captured salient features related to raters’ perceptions and judgment criteria; searching for broader themes by collating codes across transcripts; reviewing themes to ensure representativeness; and defining and naming themes to reflect their analytic essence.
Particularly, we adopted an inductive coding approach, which was appropriate given the exploratory nature of the study (Saldaña, 2021). For example, initial codes such as “noticing pauses over grammar,”“giving credit for academic words,” and “flow matters more than structure” surfaced repeatedly during early coding cycles. These were derived from raters’ think-aloud comments and were refined as analysis progressed across data sources. Through iterative coding, these initial labels were consolidated into broader themes. One such theme, “Perceived Communicative Effectiveness Matters Most,” captured raters’ emphasis on accuracy, fluency, intelligibility, and message clarity over grammatical or lexical complexity. Throughout the qualitative analysis, we ensured trustworthiness by engaging in analyst triangulation: multiple researchers independently coded a subset of the transcripts and then compared and refined codes through iterative discussions to reach consensus. Additionally, we maintained a detailed audit trail documenting analytic decisions, code definitions, and theme development, which enhanced the transparency and replicability of our approach. We also conducted member checking by inviting the raters to review and comment on the preliminary thematic findings, which helped to validate that our interpretations resonated with their actual experiences during the rating process.
Findings
Quantitative Findings
Table 1 presents the descriptive statistics for holistic human ratings and CAFP indices, while Table 2 summarizes their correlation coefficients. In this study, holistic human ratings showed no significant correlation with syntactic complexity indices, including MLAS, MLC, and RSAS (p > .05), suggesting that human raters might not prioritize the length, sub-clausal, and subordination dimensions of syntactic elaboration when evaluating speaking performance. Lexical complexity yielded mixed results. Lexical density (PCW) and diversity (D-Score) were not significantly correlated with human ratings. However, a strong, positive correlation was found for lexical sophistication, namely PAW (r = .69, p = .004), indicating that the use of more advanced vocabulary was associated with higher human ratings. Regarding accuracy, both PEC (r = .95, p < .001) and PEAS (r = .93, p < .001) showed very strong and significant positive correlations with human ratings, which demonstrated that syntactic, morphological, and lexical accuracy substantially influenced raters’ perceptions of speaking quality. In terms of fluency, SR did not correlate significantly with human ratings, whereas NP (r = –.76, p = .001) and NR (r = –.79, p < .001) were both strongly and negatively correlated, suggesting that fewer pauses and self-repairs were associated with higher scores. Finally, pronunciation, measured by IR (r = .81, p < .001), demonstrated a strong and positive correlation with human ratings, indicating that intelligibility played a crucial role in overall speaking assessment.
Descriptive Statistics Human Ratings and CAFP Indices.

Note. MLAS = mean length of AS-units; MLC = mean length of clauses; RSAS = ratio of subordination based on AS-units; PCW = proportion of content words; D-score = lexical diversity score; PAW = proportion of advanced words; PEC = percentage of error-free clauses; PEAS = percentage of error-free AS-units; SR = speech rate; NP = number of pauses; NR = number of repairs; IR = intelligibility rate.
Correlational Statistics of Human Ratings with CAFP Indices.

Note. MLAS = mean length of AS-units; MLC = mean length of clauses; RSAS = ratio of subordination based on AS-units; PCW = proportion of content words; D-score = lexical diversity score; PAW = proportion of advanced words; PEC = percentage of error-free clauses; PEAS = percentage of error-free AS-units; SR = speech rate; NP = number of pauses; NR = number of repairs; IR = intelligibility rate.
Regression analyses were conducted to identify which CAFP indices best predicted holistic human ratings of speaking performance. According to Table 3, the strongest predictors were the two speaking accuracy indices: PEC (R2 = .90, p < .001) and PEAS (R2 = .87, p < .001). Pronunciation, measured by IR, was also a strong predictor (R2 = .66, p < .001), suggesting that clearer, more intelligible speech was consistently associated with higher human ratings. Fluency indices, NP (R2 = .57, p = .001) and NR (R2 = .63, p < .001), were moderate predictors, indicating that smoother delivery and fewer self-corrections positively contributed to perceived speaking quality. Lastly, lexical sophistication, as measured by PAW, also accounted for a significant portion of the variance in human ratings (R2 = .48, p = .004), though to a lesser extent than other indices. These results collectively highlight the central role of linguistic accuracy in shaping raters’ judgments, with pronunciation, fluency, and lexical sophistication serving as meaningful, but secondary, indicators.
Regression Statistics.
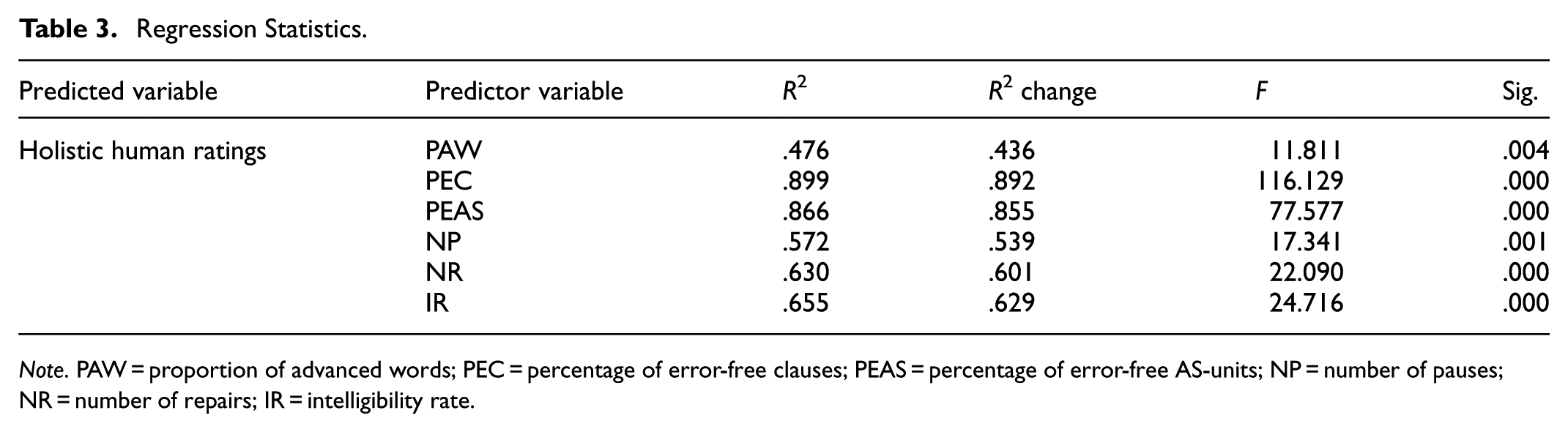
Note. PAW = proportion of advanced words; PEC = percentage of error-free clauses; PEAS = percentage of error-free AS-units; NP = number of pauses; NR = number of repairs; IR = intelligibility rate.
Qualitative Findings
Perceived Communicative Effectiveness Matters Most
We defined communicative effectiveness as the listener’s perception of the speaker’s ability to convey their message, capture attention, and communicate clearly (Littlemore, 2023). In line with existing literature, we found raters primarily judged a speech to be “good” when it featured accurate and fluent TL use (Jiang, 2023; Saeed, 2023) alongside intelligible pronunciation (Ma et al., 2018), making the message easy to understand. Accurate use of syntax, morphology, and vocabulary, for example, made it easier for raters to follow the speech. During the marking process, raters often responded positively to performances where meaning was conveyed with grammatical structures and word choices supporting clarity. In contrast, when grammatical inaccuracies or awkward lexical choices interfered with comprehension, raters paused more frequently, replayed audio, or expressed doubt about their scoring decision. In interviews, raters reaffirmed that message clarity was one of their main priorities. While rubric criteria were acknowledged, most raters recalled making scoring decisions based on how well the speaker “got the point across” and whether the speech “made sense as a whole.” Performances that caused confusion or disrupted understanding—often due to inaccurate or unnatural language use—were rated more critically.
Okay, this part is very clear … correct use of vocabulary and grammar … [which] helps me follow the argument easily. I don’t need to rewind anything here. It’s what I’d consider a strong response. (Think-aloud) The grammar is messy here … I’m struggling to understand it. Because it’s unclear, I don’t feel confident giving a higher score. The meaning just doesn’t come through well. (Think-aloud) What I usually focus on is whether I can understand the speaker without effort. If the language makes sense, I tend to give a higher score. But if I struggle to understand what they’re trying to say, that affects the overall impression. (Interview)
Similarly, we observed that when test-takers demonstrated smooth fluency characterized by minimal pausing and limited self-repairs, alongside intelligible pronunciation, raters often perceived the speech as more coherent and effective, even when minor grammatical errors or the use of relatively simple vocabulary and sentence structures were present. In the think-aloud, raters frequently commented that fluent delivery with intelligible pronunciation helped sustain their engagement and reduced the effort required to process the message. Several raters expressed that, in such cases, they were more inclined to assign higher scores because the speech “sounded natural” and “kept the momentum”. Likewise, in the interviews, raters emphasized the importance of delivery in shaping their scoring decisions. Many noted fluency and clear pronunciation gave the impression of greater communicative confidence and competence, which positively influenced their overall evaluation.
This part flows really well. I didn’t notice any awkward stops or repairs, and pronunciation is clear. Although the vocabulary is quite basic, it feels like a strong performance because I can follow it easily. (Think-aloud) When someone speaks fluently and I don’t have difficulty understanding them, I’d score them higher …. It shows they’re competent. If they pause too much or mispronounce words, even if the content is okay, it disrupts the impression. (Interview)
Interestingly, during the think-aloud, we observed varied levels of SR across test-takers; however, raters seldom commented on this feature and appeared more attuned to fluency markers such as pauses and repairs. One typical scenario involved a test-taker who spoke slowly but steadily, with clear articulation and minimal pausing. Instead of offering a critique, the rater responded: It’s quite easy to follow … no stops or stumbles, so it works for me. (Think-aloud)
In contrast, another test-taker spoke at a noticeably faster pace but produced frequent self-repairs and pauses. For instance, in one segment they said: “People, um, they want, I mean, they go to university, uh, because … because, like, opportunities … job opportunities.” Our observation notes captured the rater’s reaction: The rater leaned forward and replayed the segment twice. They frowned, tapped the pen, and muttered, “Too many restarts … I can’t keep track of the point.” Despite the fast pace, the frequent repairs interrupted clarity. (Think-aloud Observation)
Therefore, we brought the issue of SR to the interviews. Raters emphasized a higher SR did not necessarily reflect strong speaking proficiency. In fact, several noted that fast-paced speakers often lacked accurate TL use, produced disfluent speech filled with frequent pauses and repairs, or had unclear pronunciation that undermined intelligibility (Feng & Guo, 2022). Rather than perceiving fast delivery as a strength, raters described it as a potential red flag, especially when it masked underlying issues in grammar, vocabulary control, or clarity.
Just because someone speaks quickly doesn’t mean they’re fluent. I’ve had cases where the speech was fast but full of mistakes and hard to follow. I’d rather hear slower, clearer speech with fewer errors and better structure—it shows more control. (Interview)
Cognitive Load and Salient Judgment Cues
At the beginning of the think-aloud sessions and during interviews, raters highlighted the core dimensions of CAFP in the preset marking rubrics were central to their scoring decisions. However, interestingly, as the think-aloud progressed, we noticed a gradual shift in rater behavior. Some raters began to rely more on apparent speech aspects rather than maintaining equal attention to all rubric criteria. This shift appeared to be influenced by the growing cognitive demands of sustained rating, especially when assessing multiple performances consecutively, leading to signs of rater fatigue (Sundqvist et al., 2020).
Honestly, I think I’m getting a bit tired now … I’m mostly going by how it sounds overall rather than picking apart every sentence. (Think-aloud) The rater sighed audibly, leaned back in their chair, and skipped replaying a segment that previously would have prompted review. Instead of taking notes as they had earlier, they quickly assigned a score without verbalizing justification. (Think-aloud Observation) After about the fourth or fifth recording, I noticed I wasn’t analyzing the same way—I stopped focusing as much on structure or grammar. I just listened for whether it felt fluent and understandable overall. It’s hard to stay fully sharp after marking so many in a row. (Interview)
Under such conditions, raters were less likely to closely examine more abstract or analytically demanding features (Yan & Ginther, 2017), instead favoring more salient cues that were noticeable and easier to process. Despite the aforementioned emphasis on accuracy, fluency, and pronunciation, lexical sophistication, typically reflected in the use of academic vocabulary, often served as an additional cognitive shortcut for judging overall language proficiency. These items were interpreted as signals of advanced language use, despite being only one aspect of broader lexical complexity. In contrast, the presence of less obvious features such as a diverse range of word types or content-word-heavy speech seldom prompted commentary or appeared to influence ratings strongly.
Oh, that’s a good word …“infrastructure”—not something you hear every day. Sounds more advanced. (Think-aloud comment made immediately after the test-taker used an academic term) I didn’t really notice how many different words they used, but the academic tone stood out—it makes the speech feel more sophisticated. (Think-aloud reflection while assigning a high score despite not mentioning lexical diversity) When I hear academic words, I get the impression that the speaker has a good command of English, even if the rest of the language is quite simple. (Interview)
By contrast, syntactic complexity was rarely foregrounded in raters’ decision-making unless it directly impacted message clarity. While these dimensions were often associated with advanced speaking proficiency, the think-aloud revealed raters seldom explicitly noted the presence of long or embedded constructions unless they caused confusion. In many cases, syntactic elaboration was either taken for granted or overlooked entirely, particularly when the overall delivery was smooth and understandable. In interviews, raters acknowledged this tendency, noting that unless complex syntax disrupted the flow or meaning of the speech, it often failed to register consciously in their scoring rationale. Instead, they admitted more immediately salient features, such as pronunciation, fluency, and lexical choices, tended to dominate their attention.
Scenario 1 from Think-aloud Observation:
“Although more people are going to university because they believe it leads to better jobs, some still choose not to because …”
“Hmm … the pronunciation is quite soft. I’m not sure I caught that word.” (The rater paused and replayed the audio, then commented on pronunciation without acknowledging the complex concessive structure.)
Scenario 2 from Think-aloud Observation:
“If students are supported by scholarships, they are more likely …”
“Nice pacing here… and a good word like ‘scholarships.’ I’ll give credit for that.” (The rater noted vocabulary but did not engage with the conditional clause structure.)
I don’t usually notice how complex the sentence structure is unless it’s confusing. If the speech flows and I get the message, I’m more focused on whether they sound fluent and if their vocabulary fits the topic. (Interview)
Holistic Rubrics Blur Component-Level Judgments
Although raters received detailed training and engaged in guided practice using the holistic scoring rubric, our data reveal the structure of the rubric itself, which required a single, unified score to represent multiple dimensions of CAFP, made it cognitively demanding to assess each component systematically (Sundqvist & Sandlund, 2024). Think-aloud protocols revealed that while some raters initially attempted to attend to specific aspects of performance, such as tense accuracy or sentence variety, they often revised their tentative scores as the speech progressed. In many cases, raters expressed uncertainty and recalibrated their judgments based on more salient impressions of the speaker’s overall communicative effectiveness. These impressionistic shifts became particularly evident toward the later stages of the think-aloud sessions, when raters increasingly relied on fluent and intelligible delivery or isolated instances of accurate language use or sophisticated vocabulary, rather than consistently referencing the full set of rubric criteria. This shift was also observed in rater behavior. Early in the rating process, raters frequently paused the audio, took notes, consulted the rubric, or replayed segments to scrutinize specific TL features. However, as the session progressed, these behaviors became less frequent. Raters tended to make quicker scoring decisions and verbalized fewer references to the CAFP components, suggesting a gradual move away from rubric-driven analysis toward more intuitive, impression-based judgments. Interview data echoed this pattern. While raters reiterated their commitment to rubric-based scoring, many acknowledged the difficulty of maintaining equal attention to all components within a holistic framework. Several noted that they tended to “mentally average” or weigh more visible cues, such as fluency and accuracy, over more abstract or effortful dimensions such as syntactic complexity. Raters also shared that, under time pressure or fatigue, they gravitated toward what they could remember most clearly, such as a fluent stretch, rather than conducting a balanced evaluation.
At first, I noted their sentence structure … but as it went on, I started focusing more on how well the message came across. I guess I’m leaning toward a higher score because overall it just felt fluent and clear, even if not all parts were strong. (Think-Aloud) In the first few recordings, the rater paused frequently, jotted down comments on grammar and vocabulary, and referred to the rubric printout several times. By the sixth recording, the same rater listened through the entire response without stopping, leaned back in their chair, and gave a score almost immediately, without verbalizing many specific language features. (Observation)
Discussion
This study is among the few to adopt a mixed-methods approach to investigate the relationship between holistic human ratings and CAFP indices in L2 speaking assessment. Quantitative findings indicate that speaking accuracy most strongly influences human ratings, followed by intelligible pronunciation, fluency (reflected in fewer pauses and repairs), and lexical sophistication. In contrast, syntactic complexity and SR appear to play a minimal role in shaping rater judgments. These results diverge slightly from earlier studies (Chen, 2025; Hu et al., 2025; Miyamoto, 2019; Ogawa, 2022), which often identified fluency, pronunciation, and lexis as primary predictors and suggested a modest role for accuracy and syntactic complexity. Furthermore, as previous research often relied on less comprehensive definitions of CAFP (Pallotti, 2021), this study provides more refined insights, showing that fluent delivery with minimal pauses and repairs, along with the use of academic vocabulary, tends to influence holistic scores, whereas speech rate, lexical density (reflected in content word use), and lexical diversity (based on type-token variation) appear to have limited impact.
However, despite these nuances, we argue that the quantitative findings of our study remain conceptually aligned with previous research: holistic human ratings are often influenced by specific speech features, which highlights the inherent subjectivity of L2 assessment (de Jong, 2023; Feng & Guo, 2022). Qualitative findings suggest raters tend to prioritize aspects of L2 speaking that either contribute to perceived communicative effectiveness (Jiang, 2023; Saeed, 2023) or stand out as salient features (de Oliveira Borges, 2024) during the marking process. These include accurate use of syntax, morphology, and lexis; fluent delivery with minimal pauses and repairs that seldom disrupt comprehension; intelligible pronunciation that facilitates listener processing; and the use of academic vocabulary that enhances lexical sophistication. While previous literature has also identified SR as a salient indicator of fluency that can shape initial impressions of speaking proficiency (Kunnan, 2024; Wang & Li, 2022), the current study found that raters were less attuned to SR per se but focused more on fluency markers (e.g., hesitation, pausing, self-repair) that directly affected message clarity.
This tendency not only explains the correlations found in the quantitative data but also reveals the mechanisms through which raters make judgments. Particularly under conditions of cognitive fatigue (Sundqvist et al., 2020), raters appear to rely on easily perceivable cues rather than distributing equal attention across all rubric dimensions. In such cases, less salient but equally important dimensions, such as syntactic complexity or lexical density and diversity, may be inadvertently overlooked. The cognitive demands of holistic scoring (Yan & Ginther, 2017), as demonstrated by our think-aloud and interview data, often lead raters to form impressionistic judgments based on isolated identifiable speech features rather than engage in fine-grained analysis of language form and structure. As a result, holistic rubrics, while designed for efficiency and ecological validity (Kunnan, 2024; Onal, 2022), may blur component-level judgments and privilege speech features that are more noticeable or intuitively processed. This pattern of selective attention may be understood through the Halo Effect (Thorndike, 1920), a cognitive bias wherein a rater’s positive impression of one salient trait can overshadow and positively skew their evaluation of other performance aspects. In the context of the study, this was evident when raters encountered fluent, intelligible delivery—often accompanied by the use of a few academic words—and subsequently assigned higher holistic scores, even when the speech might have been weaker in other dimensions, such as syntactic complexity.
Such a Halo effect is closely linked to rater cognition and can be further interpreted through the lens of cognitive load theory (Sweller, 1988), which posits that individuals have a limited capacity for processing information in working memory. During high-stakes assessment scenarios, especially when multiple performances are rated consecutively, raters may experience increased cognitive load (Dimova et al., 2020; Ghaemi, 2022). Under such conditions, they tend to focus on more salient, readily accessible cues while deprioritizing more abstract or less immediately noticeable features (Thai & Sheehan, 2022), which require deeper analytical processing. When cognitive resources are strained, raters may resort to heuristic processing (Davis, 2024), relying on intuitive judgments rather than systematic evaluation of each rubric component, which was also evident in our observation of raters who increasingly defaulted to surface-level features such as fluency and pronunciation as the rating sessions progressed. This behavioral shift aligns with the principles of Dual-Process Theory (Kahneman, 2011). As cognitive load accumulated, raters appeared to shift from the more effortful, rubric-driven processing, which was particularly evident at the beginning of the sessions, to the more automatic, impression-based judgments toward the end. This dual-process perspective offers a compelling explanation for why certain features, especially those perceived as communicatively effective or linguistically sophisticated, disproportionately influenced overall scores, even when rubric criteria required balanced attention to all aspects of performance.
However, we would like to caution readers when interpreting the research findings, as an important and growing area of inquiry in L2 speaking assessment concerns rater-related factors that can significantly shape scoring judgments. Prior assessment experience (Otsuki, 2025), familiarity with the linguistic and cultural backgrounds of test-takers (Al Mahmoud, 2020), and culturally influenced expectations of “proficient” speech (Qutub, 2023) have been shown in previous research to affect how raters attend to and weigh various performance features. Such factors may operate independently of, or interact with, measurable CAFP dimensions, potentially amplifying or attenuating their perceived contribution to holistic ratings. As these variables fall outside the scope of the present study, they were neither systematically controlled nor examined in our analysis. Consequently, the observed relationships between CAFP measures and holistic human ratings should be interpreted with the understanding that unexamined rater-specific influences may also account for some variance in judgment.
Implication and Conclusion
Theoretically, this study extends models of L2 speaking assessment by showing that CAFP components do not contribute equally to holistic ratings. It refines our understanding of holistic human ratings by revealing that raters privilege salient features under cognitive load, thereby supporting and expanding cognitive–process-oriented models that incorporate feature salience and attentional constraints. The findings of this study suggest several practical implications for enhancing the validity and reliability of L2 speaking assessment in settings that rely on holistic human ratings. To mitigate the cognitive overload that contributes to selective attention and heuristic judgment, institutions should consider implementing structured rater breaks and rotating scoring sessions to avoid decision fatigue. Introducing calibrated “anchor performances” at regular intervals can help reset rater attention and recalibrate judgments toward the rubric’s intended criteria. Also, rater training should move beyond rubric familiarization and incorporate cognitive strategies for maintaining analytic attention under load, such as teaching raters to consciously monitor for overlooked features such as syntactic complexity or lexical density and diversity. Integrating brief self-regulation checklists during scoring may also reinforce balanced evaluation. Furthermore, the design of rating rubrics should be reconsidered: while holistic rubrics offer practical efficiency, they may benefit from embedded prompts or semi-analytic scaffolds to remind raters of under-attended dimensions, particularly those less salient in natural processing.
Despite the methodological rigor of this study, several limitations must be acknowledged. Conducted at a Malaysian university using a locally developed English speaking test, the findings may not be generalizable to other institutional contexts, assessment formats, or broader learner populations. Although the sample size was adequate for mixed-methods analysis, both the participants and raters were demographically homogeneous—most test-takers were Chinese students, and rater linguistic backgrounds and prior assessment experiences were not systematically considered. This lack of cultural and linguistic diversity constrains the applicability of the results to contexts where such diversity is higher and may influence scoring behavior in ways not captured here. Additionally, the study focused solely on a monologic, opinion-based speaking task which, while standardized, may not reflect the complexity and interactional demands of more spontaneous or dialogic speaking tasks encountered in real-world communication. Future research should purposively recruit culturally and linguistically diverse participants and raters, consider a broader range of speaking tasks, and explicitly examine how rater backgrounds shape scoring orientations to strengthen the generalizability and relevance of findings across varied assessment and instructional contexts.
Footnotes
Appendix
Marking Rubrics.
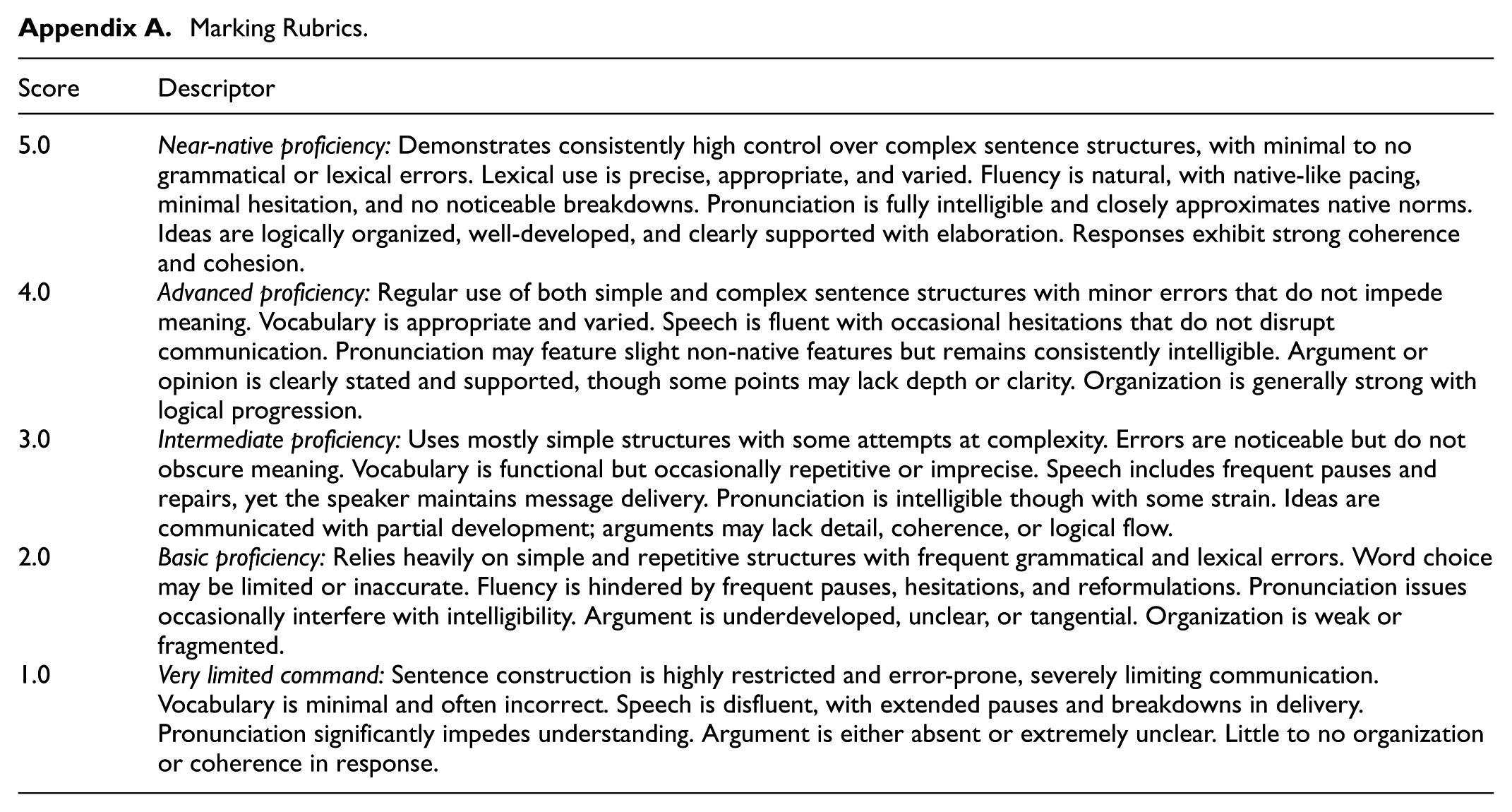
| Score | Descriptor |
|---|---|
| 5.0 | Near-native proficiency: Demonstrates consistently high control over complex sentence structures, with minimal to no grammatical or lexical errors. Lexical use is precise, appropriate, and varied. Fluency is natural, with native-like pacing, minimal hesitation, and no noticeable breakdowns. Pronunciation is fully intelligible and closely approximates native norms. Ideas are logically organized, well-developed, and clearly supported with elaboration. Responses exhibit strong coherence and cohesion. |
| 4.0 | Advanced proficiency: Regular use of both simple and complex sentence structures with minor errors that do not impede meaning. Vocabulary is appropriate and varied. Speech is fluent with occasional hesitations that do not disrupt communication. Pronunciation may feature slight non-native features but remains consistently intelligible. Argument or opinion is clearly stated and supported, though some points may lack depth or clarity. Organization is generally strong with logical progression. |
| 3.0 | Intermediate proficiency: Uses mostly simple structures with some attempts at complexity. Errors are noticeable but do not obscure meaning. Vocabulary is functional but occasionally repetitive or imprecise. Speech includes frequent pauses and repairs, yet the speaker maintains message delivery. Pronunciation is intelligible though with some strain. Ideas are communicated with partial development; arguments may lack detail, coherence, or logical flow. |
| 2.0 | Basic proficiency: Relies heavily on simple and repetitive structures with frequent grammatical and lexical errors. Word choice may be limited or inaccurate. Fluency is hindered by frequent pauses, hesitations, and reformulations. Pronunciation issues occasionally interfere with intelligibility. Argument is underdeveloped, unclear, or tangential. Organization is weak or fragmented. |
| 1.0 | Very limited command: Sentence construction is highly restricted and error-prone, severely limiting communication. Vocabulary is minimal and often incorrect. Speech is disfluent, with extended pauses and breakdowns in delivery. Pronunciation significantly impedes understanding. Argument is either absent or extremely unclear. Little to no organization or coherence in response. |
Acknowledgements
We would like to extend our thanks to the participants of the study and the examiners involved.
Ethical Considerations
The research was conducted in accordance with the Declaration of Helsinki and approved by the ethical committee of the Faculty of Education, Universiti Kebangsaan Malaysia. The research design minimized risks by using non-invasive procedures, with data collected in comfortable settings and under conditions of anonymity. Participants could withdraw at any time without penalty, and there were no foreseeable risks to participants in this study. The potential benefits to participants included generating empirical evidence that could inform fairer, more valid speaking assessment practices.
Consent to Participate
Informed consent was obtained through a written information sheet that clearly outlined the purpose, procedures, voluntary nature, and confidentiality of the study.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research was funded by the Faculty of Education, Universiti Kebangsaan Malaysia (Grant Number: GG-2024-030).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The data used in the study are available from the correspondence author upon reasonable request.