
Abstract
Foreign language (L2) learners’ speaking proficiency is often quantified using two dimensions: intuitive human ratings and analytical, linguistic complexity, accuracy, and fluency (CAF) indices. While previous research and assessment practices have predominantly focused on either the subjective approach to L2 speaking or the objective one, it is essential to establish an association between these two seemingly contradictory assessment methods to enhance and promote more credible assessment judgements. To this end, 160 recordings from a monologic task of a standardised English test in China were analysed to quantify CAF in the present study, and the scores were then compared with human ratings given by qualified examiners. Correlation and regression analyses demonstrated that human ratings were positively correlated with speaking fluency, with the number of pauses produced by a candidate being the most significant predictor of human-judged scores. Speaking complexity also positively predicted human ratings, with examiners tending to focus more on grammatical complexity than lexical complexity. In contrast, no correlations were found between human ratings and speaking accuracy. The findings of this study reinforce the possibility of “halo” effects on human raters in L2 assessment and suggest that rater training should focus on helping examiners recognise and mitigate such potential effects.
Introduction
In the literature on foreign language (L2) assessment and testing, the conceptualisation of L2 proficiency continues to expand and evolve. Accordingly, the notion of L2 speaking proficiency has undergone considerable changes, with researchers and educators continually reflecting on which core language skills should be evaluated and how they can be more effectively assessed. Today, analytical complexity, accuracy, and fluency (CAF) indices of L2 speaking proficiency underpin countless linguistic analyses. However, speaking is a complex process that is largely communication-oriented, and the extent to which a speaker has achieved the communicative goal cannot always be effectively measured by CAF indicators alone (Sundqvist & Sandlund, 2024). This limitation underscores the importance of subjective human ratings in complementing CAF analyses to provide further insights into L2 learners’ speaking proficiency (Alshalan, 2024; Ogawa, 2022). Although these two measurement methods have contrasting natures and application processes, and have rarely been employed together in previous research, the need to combine them is increasingly recognised, with initiatives to use human ratings to establish the concurrent validity of CAF analyses now being undertaken (H. Li & Zhang, 2021; Tran & Saito, 2021; Zeng, 2021). However, little is known about how CAF indices and human ratings correlate with each other. While it may seem commonsensical that moderate to strong correlations should exist between different language proficiency measurements of the same assessment task, the inherent subjectivity of human raters often leads them to unconsciously apply their expectations and experiences (Fernández et al., 2021; Green, 2021), creating potential scoring problems and necessitating efforts to mitigate the impact of subjectivity.
To address this, the present study, underpinned by a positivist paradigm, aims to identify possible correlations between objective measurements of speaking CAF and subjective ratings by qualified examiners in the same monologue tasks. Contextualised within China’s standardised English-speaking assessment system, namely the College English Test-Spoken English Test (CET-SET), this study responds to the call for local research on the effectiveness and reliability of assessment methods tailored to the Chinese educational context (Hu, 2022; Y. Jin et al., 2020), aligning with the global academic trend towards greater emphasis on context-specific assessment practices of CAF and subjective ratings (Sundqvist & Sandlund, 2024). The CET-SET, as part of the College English Test (CET) series, plays a crucial role in evaluating the English proficiency of university students across China. It is widely regarded as a benchmark for assessing spoken English skills among Chinese students and has a significant impact on their academic and professional futures (Q. Zhang, 2021). Despite its importance, there is limited research exploring how well this assessment captures the complexities of spoken English proficiency (L. Zhang, 2022), particularly when comparing the objective CAF measures with the more subjective human ratings provided by examiners. Given the influence of the CET-SET on educational outcomes in China, understanding the alignment—or lack thereof—between these two assessment approaches is essential. By situating this study within the CET-SET framework, the research not only addresses a gap in the literature but also contributes to the ongoing discourse on how best to assess L2 speaking proficiency in a way that is both scientifically robust and contextually appropriate.
Literature Review
CAF Indexes
In the 1980s, the development of second language acquisition (SLA) theories and research sparked a debate about the distinction between accurate and fluent oral language use in classroom contexts. Researchers such as Brumfit (1984) sought to differentiate accuracy-oriented L2 learning activities, which emphasised linguistic forms and grammatically correct language use, from fluency-centred activities that focused on spontaneous language production and meaning communication. However, it was not until the late 20th century that the original accuracy and fluency dichotomy was supplemented with complexity as another essential indicator of L2 learners’ speaking proficiency, leading to the proposal of the CAF triad as a model of L2 proficiency dimensions (Skehan, 1989). With the advancement of cognitive psychology and psycholinguistics, CAF has become a crucial variable in L2 research, and it is regarded “as principal epiphenomena of the psycholinguistic mechanism and processes underlying the acquisition, representation, and processing of L2 knowledge” (Housen & Kuiken, 2009, p. 462). Complexity and accuracy demonstrate an L2 learner’s current level of language proficiency, while fluency denotes their control of target language (TL) use. However, several controversial issues have arisen in CAF research, one of which is the differing views on what CAF imply and how they should be quantified (Byrnes, 2020; Housen et al., 2012; Leńko-Szymańska & Götz, 2022; Michel, 2017). This necessitates a clear identification of CAF definitions and measurement methods in what follows.
Complexity
Complexity appears to be the most intricate construct within the CAF triad, and this complication arises from the various aspects it encompasses. According to Michel’s (2017) review, complexity is categorised into developmental complexity (i.e. the order of the emergence and mastery of linguistic forms in SLA), cognitive complexity (i.e. a learner’s perception of the difficulty of the TL), and linguistic complexity (i.e. the linguistic properties related to the TL). Developmental and cognitive complexity remain at a relative level, whereas linguistic complexity, at an absolute level, has been the focus of most SLA research, popularising the definition that complexity concerns “the extent to which the language produced in performing a task is elaborate and varied” (Ellis, 2003, p. 340).
The notion that complexity involves “the number of discrete components that a language feature or a language system consists of and the number of connections between the different components” (Bulté & Housen, 2012, p. 24)—that is, the number of word strings in language structures and the degree to which these structures can form word strings—has brought the measurement of lexical and linguistic complexity into focus. Popular methods for measuring lexical complexity include calculating the Type-Token Ratio (TTR) (i.e. dividing the number of word types in a discourse by the number of words in the same sample) or the Mean Segmental TTR (i.e. calculating the mean of TTR in segments of a given size). However, the former is believed to be influenced by corpus size, and the latter may produce invalid results due to inefficient data segmentation (Fidler & Cvrček, 2018). In response, a computer-calculated D score has been proposed and utilised in analysing lexical richness, which offers a complex adjustment to overcome the limitations of traditional measurement methods “by taking 100 random samples of 35 to 50 tokens (without replacement), calculating D using the original formula for TTR, and then calculating an average D score” (Siskova, 2012, p. 30).
Regarding grammatical complexity, earlier studies (see, for example, Markee, 2000; Mhundwa, 2004), particularly those conducted over two decades ago, primarily employed T-unit and C-unit as the basis for measuring unit length and clausal density. However, it has been argued that T-units do not capture the multifaceted nature of spoken data, especially when pauses and repairs are involved, and that the C-unit, as an adjustment of the T-unit, remains poorly defined. Therefore, the concept of the AS-unit has been proposed to measure unit length and clausal density in grammatical complexity at three levels: length, sub-clausal, and subordination. The corresponding indicators are Mean Length of AS-units (MLAS), Mean Length of Clauses (MLC), and Ratio of Subordination (RS), respectively (Foster et al., 2000; Norris & Ortega, 2009).
Accuracy
Regarding accuracy, classic interpretations have also made it a controversial issue within the applied linguistics community. According to Ellis (2009), accuracy is “the ability to avoid error in performance, possibly reflecting higher levels of control in the language as well as a conservative orientation, that is, avoidance of challenging structures that might provoke error” (p. 475). From this perspective, accuracy seems to be more closely associated with communication strategies—referring to the purposeful and planned use of language to achieve specific information-conveying goals—than with language utilisation itself (Pratama & Zainil, 2020). In contrast to this viewpoint, accuracy is also simply considered to be the error-free state of one’s output in the TL, or one’s ability to produce error-free speech (Housen et al., 2012), and this stance appears to be the prevailing definition underlying most CAF research (González-Robaina & Larenas, 2020).
The measurement of accuracy has focused on two dimensions: global accuracy, which accounts for all the errors in speech, and specific accuracy, which examines only the errors of particular linguistic forms (Iwashita et al., 2008). However, the latter can be problematic because different research instruments, such as speaking tasks or tests with varying formats and topics, may prompt the use of contrasting linguistic forms, making it difficult to establish a clear understanding of L2 learners’ specific accuracy. Consequently, global accuracy, which encompasses errors in syntax, morphology, and lexis, has been adopted in the present study. A common method for quantifying global accuracy is to calculate the number of errors per 100 words (Ellis & Barkhuizen, 2005), although this approach may be simplistic and susceptible to the influence of speech length. In response, researchers have proposed two more sophisticated variables: the percentage of error-free clauses (PEC) and the percentage of error-free AS-units (PEA), suggesting that these could provide a more precise and valid account of an L2 learner’s speaking accuracy (Ellis & Barkhuizen, 2005).
Fluency
Although fluency is a long-established variable, researchers have divergent interpretations of it. Some (e.g. Ghufron, 2017; Hussein et al., 2020; Samifanni, 2020) adhere to the broad layman conception described by Lennon (1990) as the ability to use the TL smoothly and spontaneously, while others prefer a narrower but more sophisticated understanding that fluency concerns “the production of language in real time without undue pausing or hesitation” (Ellis & Barkhuizen, 2005, p. 139). An even broader perspective is proposed by González-Robaina and Larenas (2020), who suggest that communication fluency involves the interplay of personal factors, prosodic elements, and educational and cultural levels, defining it as “a multifactorial construct which demands cognition, aptitude, motivation, and experience” in TL processing and performance (p. 3). Though this view is reasonable, the classical interpretation that fluency symbolises real-time language processing has underpinned most previous studies and the measurement of fluency.
L2 fluency is typically assessed on three dimensions: speed, breakdown, and repair (Skehan, 2009). However, the first dimension, represented by speech rate or articulation rate, may be questionable for several reasons. First, speech speed is subject to individual characteristics and even an L2 learner’s first language (L1) rate; for example, Bradlow et al.’s (2017) and Shrosbree’s (2020) regression analyses have shown that L1 speech rate can be a strong predictor of L2 rate. Second, a high speech or articulation rate may be accompanied by numerous pauses, as Aas and Nacey (2019), referencing Hieke et al.’s (1983) work, suggest that these two variables may be negatively correlated. Third, those who are inclined to use simple words may exhibit a higher level of fluency than those who use complex polysyllabic words, an assumption consistent with Wanzek et al.’s (2019) inference from their classroom studies that students may display a slower speech rate when reading polysyllabic words. Therefore, only breakdown, which refers to the average length of filled and unfilled pauses over 250 milliseconds, and repairs, which include repetitions, reformulations, replacements, and false starts, are used in the present study. Fluency is thus indicated by the number of pauses (NP) and the number of repairs (NR) (Skehan, 2009).
Human Ratings
CAF measurement has been commonly used in speech data analysis, as it allows researchers to capture an objective and detailed picture of L2 learners’ speaking proficiency from various angles. However, its disadvantages—such as time-consuming processes, the inability to determine whether learners have achieved the required communicative goals, and a lack of ecological validity—have discouraged educators and even researchers from employing this approach. Instead, they have often relied on human evaluation, a long-established educational practice in L2 assessment. In most speaking assessment tasks, particularly in standardised tests or those intended for summative purposes, examiners typically follow preset marking rubrics to evaluate a candidate’s performance from either a holistic or an analytic perspective (Koizumi et al., 2020). Although this practice has been criticised for lacking objectivity and clarity and being susceptible to personal biases, researchers argue that using speaking rubrics not only engages learners in the assessment process (Özdil & Duran, 2023) but also provides students and teachers with valuable information, such as whether students have achieved the communicative goals of the tasks (Alaamer, 2021).
Research on the individual investigation of human rating and CAF is abundant, but the studies that have combined these two measurement methods warrant particular attention. Although such research is limited, the need to “compare subjective estimates of [L2] proficiency with its objective measures” has been recognised for some time (Aydoğan & Akbarov, 2018, p. 135). The available body of research can be broadly divided into two streams. The first stream includes studies in which CAF scores and human ratings have been used simultaneously to complement each other. For example, a study we are currently conducting analyses Chinese university students’ oral English proficiency under different pedagogical approaches using CAF measurements to gain linguistic insights, as well as human ratings, which are compared with China’s Standards of English Language Ability, a national framework that identifies Chinese English as a foreign language (EFL) learners’ proficiency levels. This design has been largely inspired by Fernández et al.’s (2021) research, where CAF analyses were employed to examine EFL learners’ language proficiency in detail, in conjunction with human ratings linked to the Common European Framework of Reference for Languages (CEFR). However, this type of research remains rare, and researchers suggest that the CAF triad offers advantages over marking rubrics or established proficiency frameworks “to benchmark and assess foreign language production, as it employs multiple indicators underlying each aspect,” the quantification of which allows comparisons of learners’ L2 development over time (Wang & Han, 2021, 1.3 Measurement of foreign language production, para. 2).
The second stream of research focuses on exploring the relationships between CAF scores and human ratings or human-judged proficiency levels, with most previous studies attempting to establish a predictive link between these two constructs. For instance, Yan et al.’s (2018) study examined data from the Aptis speaking test and compared various CAF features across different CEFR levels, revealing distinct CAF characteristics between lower and higher proficiency levels, as well as a moderate to strong relationship between most CAF indices and CEFR levels. This finding is similar to that of a later study by Yan et al. (2020), which used the same test corpus but focused on fluency and CEFR proficiency levels, as well as Kang and Yan’s (2018) study, where CAF indices varied significantly across certain CEFR levels. In comparison, Inoue’s (2016) study emphasised speaking complexity and accuracy. By analysing data from EFL learners at different CEFR levels, the researcher concluded that grammatical complexity might not necessarily correlate positively with human-judged proficiency levels, in contrast to the moderately high correlation between accuracy and human ratings. Ogawa’s (2022) recent research has been particularly influential in this field. By comparing human ratings of Japanese university students’ performance in a monologic oral English test with CAF measures, the researcher found that human ratings were primarily correlated with speaking fluency, as measured by the mean length of pauses, duration of syllables, mean length of run, and phonation time ratio. Additionally, speaking complexity (i.e. MLC, RS, and computer-calculated textual lexical diversity) and accuracy (i.e. PEC) indices also contributed to human ratings, although they explained a smaller portion of the variance compared to fluency measures.
Although this category of studies is not the mainstream of research and may not be at the core of L2 assessment development, researchers have generally praised the reliability of CAF indices while highlighting the ecological validity of human ratings as an indicator of the impressionistic judgement formed in communication. However, with previous research presenting heterogeneous findings in different educational contexts—a principal reason being the use of divergent CAF indices without a consensus on standardised quantification of CAF (Leńko-Szymańska & Götz, 2022)—the disagreement over how intuitive human ratings by examiners can be correlated with objective CAF measures remains unresolved. This necessitates the gathering of more empirical evidence to enrich this body of knowledge, which was also the primary purpose of the study presented below.
Methods
Context and Participants
This study was part of a larger research project on the development trajectory of Chinese EFL learners’ speaking proficiency. The present study adopted a quantitative approach in line with the stated research objective. Eighty students from a comprehensive Chinese higher education institution were recruited for the study with informed consent. In the original research, the participants were evenly allocated to a comparison group and an experimental group, but for the purposes of the present study, they were considered as a single cohort. The sample consisted of 42 males and 38 females, with an average age of 21 years. While the participants were enrolled in different programme streams, they all took College English, a compulsory EFL unit for undergraduates at the research site.
Data Collection
Data were collected from monologic tasks included in a mock CET-SET Band 6 (CET-SET6), a standardised test in China designed to assess university students’ proficiency in spoken English with established validity, reliability, and fairness (Lu et al., 2016). The test comprises two types of tasks: dialogue and monologue. The monologue tasks were specifically chosen for this study because they provide a more controlled and focused environment for assessing individual speaking proficiency, allowing for a clearer analysis of the CAF measures in isolation from the interactive dynamics that are present in dialogue tasks (Ogawa, 2022). The test booklets used in the study were adapted from authentic test batteries by a group of CET experts (Liu et al., 2020) and had been used in our previous study, where their validity—particularly face validity—was established. This meant that the booklets had been reviewed by a group of experts who believed the test accurately measured what it was intended to measure. In the test, candidates were required to discuss a specific topic (e.g. the advantages or disadvantages of online learning/public transportation) provided by the examiner for approximately 2 min after 1 min of preparation, with their responses recorded for further analysis. The test was organised by two qualified examiners who adhered to the administration requirements of the CET-SET6. In the original study, the speaking test was administered both before and after the study to examine development patterns. The present study utilised the already collected data, with 160 speech samples from 80 students available for analysis.
Data Analysis
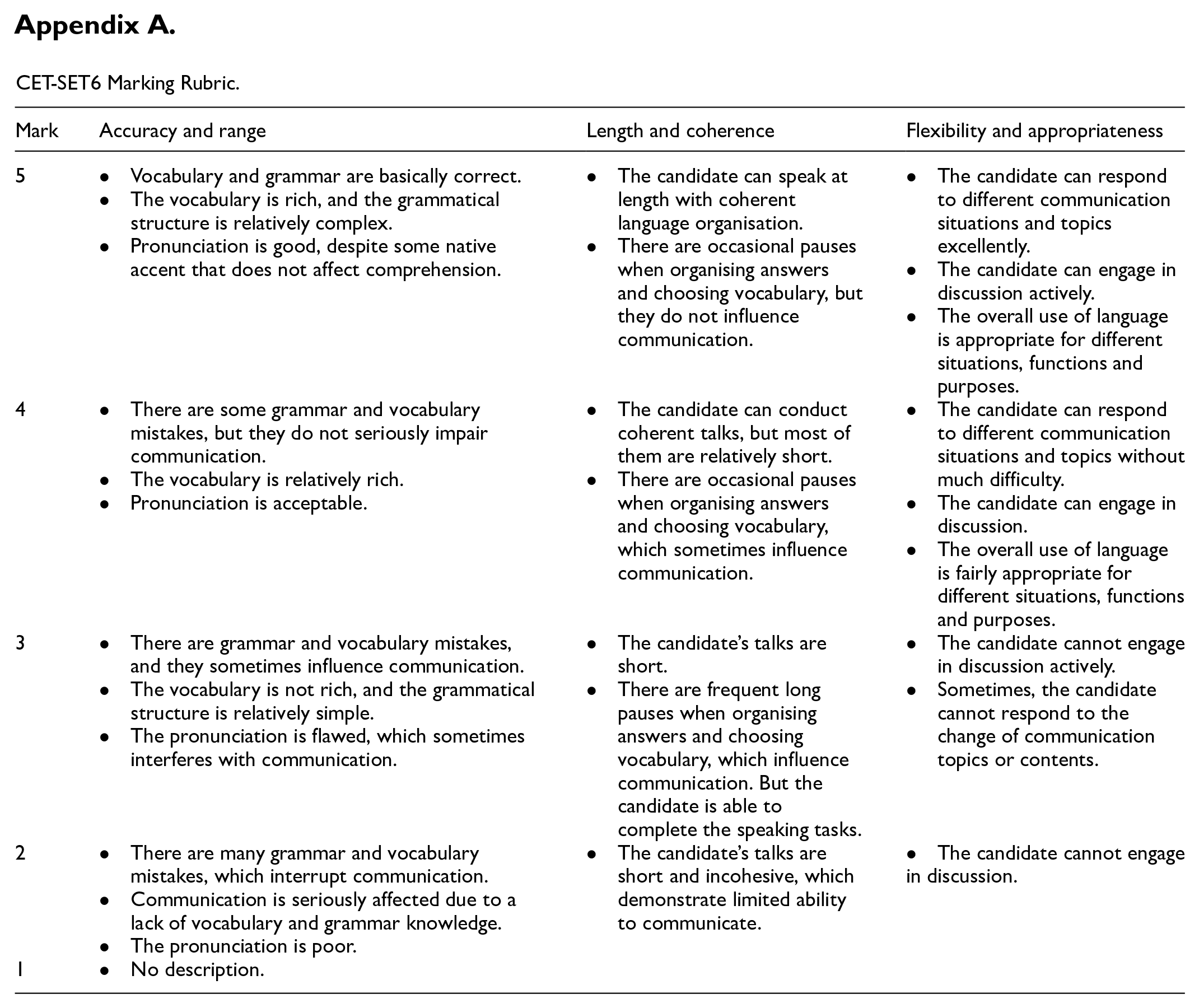
Based on the authentic marking rubric of CET-SET6 (Committee of CET Band 4 and Band 6, 2016) (see Appendix A), the participants’ responses were scored by two qualified raters. The rubric evaluates English speaking proficiency from three perspectives: Accuracy and Range, Length and Coherence, and Flexibility and Appropriateness, each of which is weighted with a maximum of five marks. However, only holistic scores, serving as an indicator of global proficiency, were analysed in this study because the original CET-SET6 does not report a candidate’s sub-scores for each criterion. Furthermore, operationalising and analysing global proficiency tends to be more straightforward than other measurement methods (Colantoni et al., 2015), and it is common practice in research contexts to adopt an analytical approach to scoring but only report holistic scores for research and educational purposes (Xiao & Wang, 2017).
A pilot study was conducted prior to the main study, involving 34 students from the same research context, with the sample size deemed acceptable (Julious, 2005). The raters for the main study also participated in the pilot study. They received professional training provided by the official CET board, familiarised themselves with the assessment criteria, practised rating by viewing taped performances and setting cut scores according to seven levels—A+ (14.5–15), A (13.5–14.4), B+ (12.5–13.4), B (11–12.4), C+ (9.5–10.9), C (8–9.4), and D (below 7.9)—and explained and discussed the rationale behind the scores awarded. This process ensured the validity and reliability of the human ratings (Luoma, 2010). Consequently, the pilot study indicated that adequate inter-rater reliability had been achieved for the instrument and each of the aforementioned criteria (see Table 1). Similarly, the statistics used in the subsequent analysis also demonstrated satisfactory reliability of the instrument in the main study.
Kappa Values of Instrument.

In addition to human ratings, the participants’ responses were transcribed and coded with the identification of AS-units, clauses, errors, pauses, and repairs for the CAF analysis. The data was initially transcribed by the first author of this paper and an English expert together. They then coded the transcripts individually, following the CAF measures. To ensure intercoder reliability, they compared and discussed their transcriptions through three rounds of coding. The final agreement for each code exceeded 90%, which is well above the minimum intercoder agreement threshold of 75% (Mackey & Gass, 2005). Numerous methods exist for measuring CAF (see the compilation by Koizumi, 2005), but the ones used in this study (see Table 2) were those identified as appropriate in the literature review. After data collection, Pearson correlation and multiple regression analyses were performed using Statistical Package for the Social Sciences 25.0. The assumptions for correlation (i.e. normality, linearity, and homoscedasticity of data) and regression (i.e. a reasonable ratio of cases, normality, linearity, and homoscedasticity of data, no significant outliers or multicollinearity) tests were not violated in this study.
Computation Methods of CAF Indices.

Findings
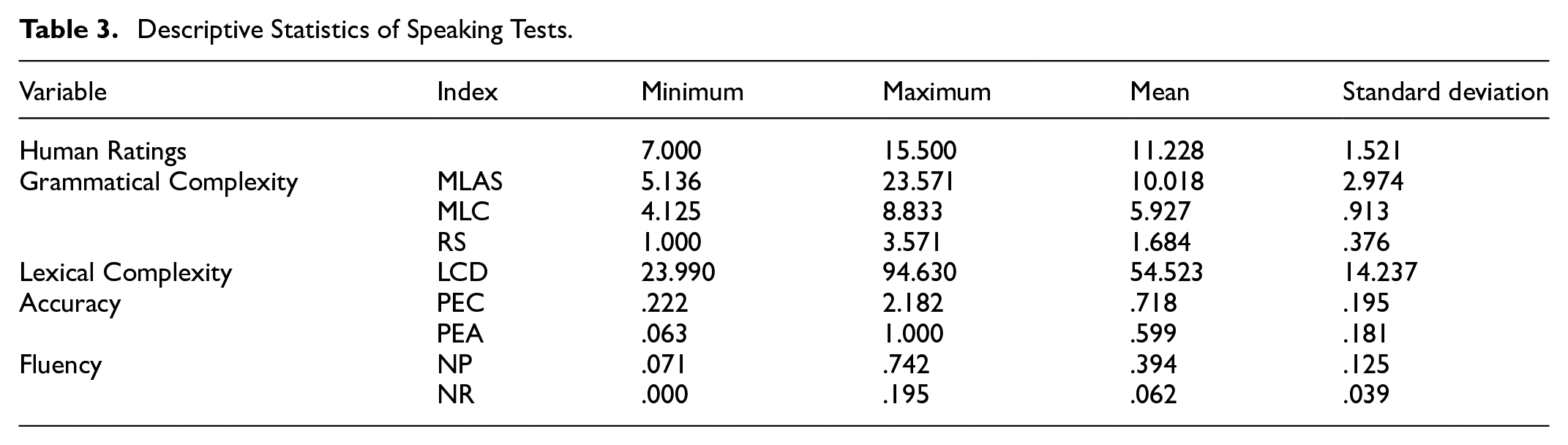
Despite the descriptive statistics presented in Table 3, the correlation statistics between the variables were particularly noteworthy. As shown in Table 4, a bivariate Pearson’s product-moment correlation coefficient was calculated to determine the size and direction of the linear relationship between human ratings and CAF indices. Significant correlations were found between human ratings and the MLAS, MLC, RS, and D-score (p < .05), which are indices of syntactic and lexical complexity. However, according to the rule of thumb regarding the Pearson correlation coefficient (Pallant, 2016), the linear relationship between human ratings and speaking complexity could only be considered weak (0 < r < .3), although changes in complexity indices led to changes in human ratings in the same direction. Conversely, there was a strong negative correlation between human ratings and the indicators of speaking fluency (−.5 < r < .0), namely the NP and the NR. This suggested that the lower the NP and the NR, the higher the human ratings. Nevertheless, no correlations were found between human ratings and the PEC and PEA (p > .05), indicating that changes in speaking accuracy did not result in any change in human ratings.
Descriptive Statistics of Speaking Tests.
Correlations Amongst Human Ratings and CAF Indices.

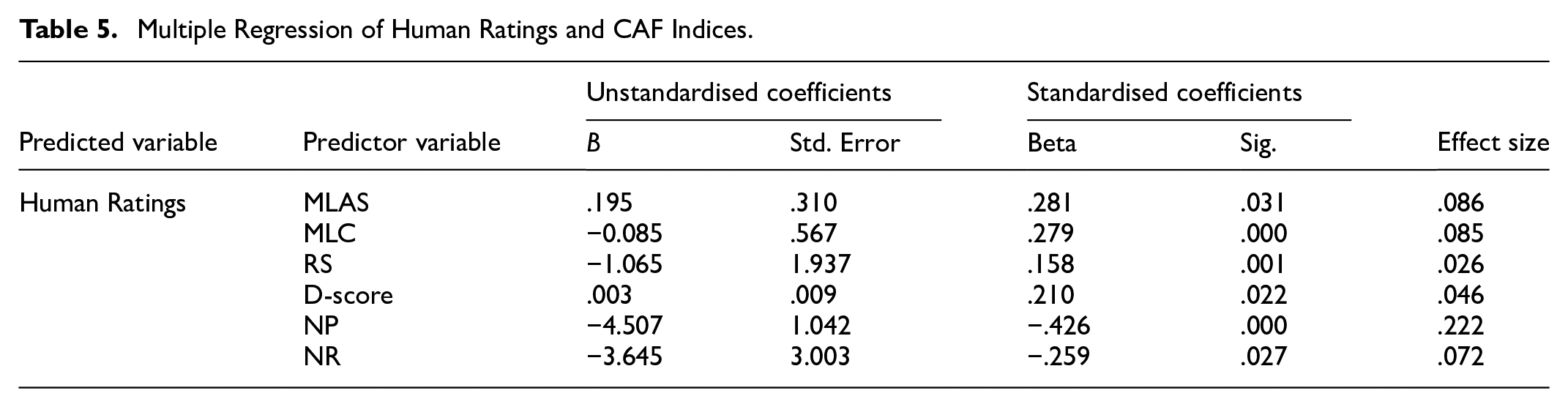
Then, standard multiple regression analyses were conducted to estimate the proportion of variance in human ratings that could be accounted for by the CAF indices. The multiple regression model, with all eight predictors, produced R2 = .25, F(8, 159) = 6.43, p < .001. As shown in Table 5, speaking complexity, as measured by the MLAS, MLC, RS, and D-score, had significant positive regression weights (p < .05), suggesting that EFL learners with higher scores on these scales were expected to receive higher human ratings, after controlling for the other variables in the model. Conversely, the NP and NR scales, which are typical of speaking fluency, had significant negative weights (p < .05), indicating that, after accounting for the other predictors, students with lower NP and NR scores were anticipated to receive higher human ratings. In contrast, the predictor variables related to speaking accuracy did not contribute significantly to the regression model (p > .05). Considering the absolute values of the beta coefficients, NP had the largest predictive effect on human ratings, with the other predictors having a less pronounced effect on the dependent variable.
Multiple Regression of Human Ratings and CAF Indices.
Discussion
Overall, the present study has indicated that human ratings of a standardised test could be associated with certain CAF indices. Notably, speaking fluency emerged as a substantial predictor of subjective human ratings, with higher levels of fluency corresponding to increased scores. This finding aligns with previous studies that have similarly demonstrated a strong tendency for human ratings of L2 speaking to be predominantly influenced by fluency measures (de Jong, 2016; Ginther et al., 2010; T. Jin & Mak, 2013; Ogawa, 2022; Révész et al., 2016), suggesting that examiners might award higher scores to candidates who can speak an L2 fluently with fewer pauses or repairs. Specifically, human ratings were correlated with speaking fluency as quantified by the NP, which emerged as the most significant predictor variable among the others. This finding is consistent with Tonkyn’s (2012) research, which noted that “pause clusters appeared to be strong influences on judges’ assessments of level” (p. 239). Although there are abundant findings linking subjective scores with objective fluency indices, one should be cautious about drawing robust conclusions on speaking fluency. According to de Jong (2016), if examiners are instructed to focus on certain aspects of speaking fluency, their ratings may become closely aligned with the objective measures of those specific fluency aspects, potentially overlooking other important features of fluency. Thus, the finding that the NP was the most significant predictor of human ratings is logical, as the marking rubric used in the present study specifically highlights the NP as a key measure of speaking fluency (Q. Zhang, 2021).
In addition, speaking complexity, both grammatical and lexical, was correlated with and could predict human ratings, though its effect was less pronounced compared to speaking fluency. This finding is consistent with previous research, which has also shown that candidates’ complex utterances and use of extensive vocabulary can positively influence examiners’ judgements during the marking process (T. Jin & Mak, 2013; Ogawa, 2022; Révész et al., 2016). Tonkyn’s (2012) study produced similar findings regarding grammatical complexity but suggested that lexical complexity was not correlated with examiners’ assessments, particularly for learners of adjacent proficiency levels (see also Inoue, 2016). We attempt to explain this by speculating that human raters might consciously or subconsciously emphasise and tally words during a speaking test. This assumption is plausible, as human raters are inevitably “influenced (often unconsciously) by their previous experience, expectations, knowledge, preferences, and subjective interpretation of assessment scales and their categories and descriptors” (Taylor & Galaczi, 2011, p. 211). Nevertheless, the seemingly unavoidable influence of subjectivity also raises the possibility that human raters could be “heavily influenced by the occurrence of just a few, judiciously placed, infrequent words and expressions” (Milton et al., 2010, p. 93). In this regard, we justify the correlation between grammatical and lexical complexity with human ratings observed in both the present study and previous ones. We speculate that this correlation stands out not only due to the marking descriptors that emphasise the use of rich vocabulary and complex sentence structures but also because of examiners’ expectations and preferences for the diversity and density of a candidate’s linguistic features.
Regarding accuracy, the present study, in line with some others (e.g. Ogawa, 2022), suggested that the ability to produce error-free utterances might not be as influential as complexity and fluency measures in obtaining higher scores from human raters. This finding contradicts previous research, which indicated that speaking accuracy tends to be a critical factor in judges’ assessments, as errors can disrupt speech and make it less comprehensible or coherent (Inoue, 2016; Tonkyn, 2012). However, Yan and Ginther (2017) highlighted an interesting scenario where, if human raters are overwhelmed with the identification and assessment of certain aspects of speaking performance, they might become more tolerant of other aspects that are also considered important. Based on this perspective, we speculate that the examiners in the present study might have paid less attention to speaking accuracy compared to fluency and complexity. Another possible explanation could lie in the contradictory nature of focussing on form versus focussing on meaning, which might lead examiners to concentrate on only one at a time (McNamara, 1996). This view aligns with Duijm et al.’s (2018) finding that raters might not simultaneously attend to both fluency and accuracy. Therefore, although the marking rubric used in the present study “covers not only Accuracy and Range at the grammatical (and lexical) level but also Length and Coherence and Flexibility and Appropriateness at the textual and pragmatic level” (Q. Zhang, 2021, p. 8), the communicative aspect of the rubric and the participants’ speaking performance might have received more attention from the examiners, emphasising meaning-focused output and fluency rather than the proper use of linguistic forms.
Admittedly, there is a lack of clear compatibility between the findings of the present study and existing research. One plausible explanation could be that different CAF measures have been used by researchers to quantify L2 speaking proficiency, with the long-standing debate on the efficacy of these heterogeneous CAF indices still unresolved. For instance, in Ogawa’s (2022) research, speaking fluency was related not only to pauses and repairs made by an L2 speaker but also to the mean length of run, phonation time ratio, and mean duration of syllable. However, measures concerning speech rate were excluded from the present study due to concerns that a speaker’s L2 fluency is highly correlated with their L1 fluency (Bradlow et al., 2017; Shrosbree, 2020). Although the study has reached the same conclusion as Ogawa’s (2022)—that is, analytical measures of fluency tend to be significantly predictive of human ratings—the adoption of the same analytical indices would undoubtedly invite a closer comparison. However, what is clear is that speaking requires the use of different skills, and some tend to be more influential than others in human ratings, potentially leading to a “halo” effect, where one characteristic of L2 production overshadows the judgement of the entire text (Knoch, 2009). Various factors (e.g. different interpretations of marking rubrics, a rater’s confusion or overemphasis on certain criteria, the high cognitive load of scoring a candidate’s performance) may exert this effect, directing a rater’s principal attention to complexity, accuracy, or fluency, and thereby influencing the overall rating process (Bijani et al., 2022; Hsieh, 2020). While the reasons behind these findings remain unclear given the design of the present study, this scenario highlights the importance of incorporating analytical CAF measures when quantifying speaking proficiency, ensuring the validity and reliability of assessment outcomes.
For reasons of authenticity and validity, many language testers still prefer to use performance assessments to evaluate L2 learners’ productive abilities, which is understandable given the complexity and difficulty of decoding assessment data and conducting quantitative CAF analyses. Even so, such complications do not necessarily equate to the impracticability of CAF measures, which could be adopted through collaboration between L2 researchers and examiners. That means, by working together, researchers can provide the necessary expertise in CAF analysis, while examiners bring practical insights from the testing field. This collaboration could lead to the development of more refined assessment tools that incorporate both subjective human ratings and objective CAF measures, offering a balanced approach to evaluating L2 speaking proficiency.
Practically, the gap between human-judged L2 proficiency and analytic measures highlights the importance of acknowledging and integrating rater perceptions into both marking scales and rater training. This integration should focus on deepening raters’ understanding of the nuances of CAF measures and their relationship to overall language proficiency. It is crucial that rater training also includes strategies for maintaining objectivity in assessment, ensuring that raters are aware of potential biases and are equipped to mitigate them effectively. With a shared understanding among test designers and examiners of why a specific sample surpasses another and how certain aspects of subjectivity may influence scoring, the construction and interpretation of verbal descriptors in assessment criteria can be greatly improved. In this context, reliability could be considered “not a problem” in L2 speaking assessment (Bachman, 1988, p. 150).
For further research, a broader agenda should be explored. Jeon et al.’s (2022) latest research has revealed human raters’ sensitivity to different types of lexical complexity (e.g. diversity, density, sophistication) corresponding to learners’ varying levels of linguistic competence. Hence, there is a possibility that human ratings based on relevant scales could better identify changes in L2 proficiency than objective measures. This interesting finding suggests that considering individual differences in comparing human ratings with CAF indices would enhance the understanding of the complex nature of L2 assessment. That being said, it is also necessary to account for learner heterogeneity, particularly differences in language proficiency, when quantifying speaking CAF. It seems to be a rule of thumb that research with well-justified choices of CAF measures is credible in its own right, whereas the output features of L2 learners at different language levels can vary significantly, with nuances that can only be captured by corresponding CAF indices—for example, complexity by coordination and subordination (Hasnain & Halder, 2022). Finally, in light of the idea of full utilisation of research data (Chen et al., 2022), an extension of the study could focus on the correlations among CAF, the statistics of which have already been tabulated above, to establish evidence for the debate between the Limited Attention Capacity Hypothesis (Skehan, 1998) and the Cognition Hypothesis (Robinson, 2001). With the former highlighting a trade-off effect on CAF and the latter suggesting that the attentional resources allocated to a specific dimension of L2 output do not clash with those assigned to others, the disagreement remains unresolved and requires more empirical evidence (S. Li, 2022).
Conclusion
This study examined the relationships between analytical CAF indices and intuitive human ratings within China’s EFL context. The analyses of data collected from a standardised test demonstrated that speaking fluency, particularly the NP and NR in speech, significantly predicted human ratings. Similarly, speaking complexity, focussing on grammatical and lexical dimensions, was also a meaningful predictor, although its effect was less pronounced than that of fluency. In contrast, human ratings were not associated with speaking accuracy, despite previous research establishing a link between the CAF triad and human-judged L2 proficiency levels.
Admittedly, this study is not without limitations. Firstly, the reliance on a positivist paradigm, while valuable, may lack the depth of insight that a mixed-methods approach could offer, such as by exploring examiners’ real-time perceptions of assessment. Additionally, concerns may arise regarding the reliability of the human ratings analysed in the study, despite the professionalism and expertise of the examiners involved. This underscores the need for more systematic research, potentially incorporating many-facet Rasch measurement, to explore the various components of rater-mediated assessment. Nevertheless, the findings presented here are significant as they highlight the potential gap between objective CAF measures and subjective human ratings, suggesting that addressing this gap could enhance the contextual and scoring validity of the specific test employed in the study.
Footnotes
Appendix
CET-SET6 Marking Rubric.
| Mark | Accuracy and range | Length and coherence | Flexibility and appropriateness |
|---|---|---|---|
| 5 | • Vocabulary and grammar are basically correct. • The vocabulary is rich, and the grammatical structure is relatively complex. • Pronunciation is good, despite some native accent that does not affect comprehension. |
• The candidate can speak at length with coherent language organisation. • There are occasional pauses when organising answers and choosing vocabulary, but they do not influence communication. |
• The candidate can respond to different communication situations and topics excellently. • The candidate can engage in discussion actively. • The overall use of language is appropriate for different situations, functions and purposes. |
| 4 | • There are some grammar and vocabulary mistakes, but they do not seriously impair communication. • The vocabulary is relatively rich. • Pronunciation is acceptable. |
• The candidate can conduct coherent talks, but most of them are relatively short. • There are occasional pauses when organising answers and choosing vocabulary, which sometimes influence communication. |
• The candidate can respond to different communication situations and topics without much difficulty. • The candidate can engage in discussion. • The overall use of language is fairly appropriate for different situations, functions and purposes. |
| 3 | • There are grammar and vocabulary mistakes, and they sometimes influence communication. • The vocabulary is not rich, and the grammatical structure is relatively simple. • The pronunciation is flawed, which sometimes interferes with communication. |
• The candidate’s talks are short. • There are frequent long pauses when organising answers and choosing vocabulary, which influence communication. But the candidate is able to complete the speaking tasks. |
• The candidate cannot engage in discussion actively. • Sometimes, the candidate cannot respond to the change of communication topics or contents. |
| 2 | • There are many grammar and vocabulary mistakes, which interrupt communication. • Communication is seriously affected due to a lack of vocabulary and grammar knowledge. • The pronunciation is poor. |
• The candidate’s talks are short and incohesive, which demonstrate limited ability to communicate. | • The candidate cannot engage in discussion. |
| 1 | • No description. | ||
Consent to Participate
Informed consent was obtained from all participants in the study.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Center for Research and Instrumentation Management (CRIM) and Faculty of Education, Universiti Kebangsaan Malaysia (UKM).
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The datasets used during the current study are available from the corresponding author upon reasonable request.