
Abstract
This study systematically reviewed 5,465 research articles related to data business and data value from 2010 to 2024. The sample literature was analyzed using Bradford’s Law, Price’s Law, and CiteSpace to identify and extract the core elements influencing the realization of data business value. Based on the sample literature, the multiple value forms of data resources and their inherent logical relationships were deeply explored. It aims to clarify the creation mechanism, circulation mechanism and value-added mechanism in the process of data value transformation centered on data assetization, commercialization and capitalization, and provides an in-depth analysis of the commercial value transformation process from the perspective of technology, market and institutional dimension. The results of the study show that data, as a new resource, presents unique value forms at various stages of development, it corresponds to different value generation mechanisms at different stages of its conversion process. The contribution of the study is two-fold. First, it systematically reviews the research in the field of data commercial value, clarifying the three value forms of data and proposing the three transformation stages of data value. Second, it does not only reflect the multi-dimensional characteristics of value generation in the process of data commercialization but also points out the importance of data asset management. These research results have far-reaching theoretical significance and practical implications for the in-depth understanding of the commercial value of data as well as the promotion of the process of data assetization, data commercialization and data capitalization.
Introduction
In recent years, governments and international organizations around the world have undertaken a series of top-level planning and policy formulation for the development strategy of the digital economy, which has had a broad and far-reaching impact on the development of the global digital economy. In June 2021, Japan released its Comprehensive Data Strategy, which aims to “establish a structure for the safe and efficient use of data by ensuring trust and public welfare,” and in September of the same year, the Digital Agency was established to implement the strategy. In October 2021, South Korea’s Council of Ministers passed the Basic Law for the Promotion of the Revitalization and Utilization of the Data Industry, which is aimed at promoting the development of the data industry and revitalizing the data economy. On May 16, 2022, the Council of the European Union approved the adoption of the Data Governance Act, which is going to be formally implemented by September 2023. The Data Governance Act aims to address three issues: (1) the reuse of public data in the hands of the government; (2) companies refuse to share data because they fear that sharing data means the loss of competitive advantage and risk of misuse; and (3) individuals are not sharing data because they fear that the data will not be secured. A report published by the Research Center for Technological Innovation, Tsinghua University, DAMA, & GLO Global Law Office (2023) expects the global data trading platform market to be valued at $19,750 million by 2028, growing at a CAGR of 15.9% during the forecast period.
The continuous introduction of data-related policies and regulations signifies that data is gradually becoming a new business competitive resource and production factor (Zeng & Glaister, 2018). Early research on data as a critical element primarily unfolded within the context of database systems, where scholars conceptualized data as a supplementary asset. These studies emphasized investigating methodologies for data acquisition, storage, and integration (Cappiello et al., 2003; Chowdhury et al., 1999; Lee & Strong, 2003), with the overarching objective of generating high-quality information resources to enhance organizational decision-making and operational efficiency (Parssian et al., 2004; Porter & Heppelmann, 2014). This foundational work established data management as a strategic enabler for optimizing institutional knowledge infrastructure and value creation processes. With the rapid development of digital, information and communication technologies, the digital transformation of traditional industries such as manufacturing, medical and healthcare, and finance has accelerated significantly, new forms and modes such as data-driven generative big model native applications are emerging (Alt et al., 2018; Sjödin et al., 2020). The realization of data value and data transformation in the contexts of digital industrialization and industrial digitalization has increasingly emerged as a frontier research area of common concern among management, law, and information systems disciplines (Gregory et al., 2022; Sun et al., 2024; Wenz et al., 2023). Currently, scholars have mainly studied data commercialization from the dimensions of data technology, data marketization, data value form and data value transformation. For example, scholars are focusing on the field of data technology which mostly concentrate on the cutting-edge management of data and technological tools, which promote the efficient use of data; while scholars focusing on data marketization describe and analyze the problems encountered in the process of data marketization from the perspectives of data ownership (H. Chen et al., 2012; Hummel et al., 2021), circulation (Bharadwaj et al., 2013; Yoo et al., 2010) and sharing (Jones & Tonetti, 2020); scholars focusing on the data value form describe and analyze the connotations and extensions of data assets (Jarvenpaa & Essén, 2023), data commodities (Aaltonen et al., 2021) and data capital (Gebauer et al., 2020; Hamilton & Sodeman, 2020). And some scholars who focus on data value form have discussed the connotation and extension of data assets, data commodities and data capital; another scholars are concerned about the transformation of data value, which involves the process of assetization (Wamba et al., 2015), commoditization (Buckley, 2020; Mikalef & Krogstie, 2020), and capitalization of data (Farboodi & Veldkamp, 2020).
This paper adopts bibliometric techniques to sort out the current status of data commercial value research, and finds that the existing research mainly focuses on a specific stage or dimension in the process of data commercial value, such as data technology, data marketization, and data value form, but lacks a systematic understanding of the whole process of data commercial value. Based on this, this paper compiles the research results of scholars in this field, clarifies the core author groups, journals and research hotspots on the topic of data commercial value, systematically explores the evolution of different value forms of data and the mechanism of value transformation, and tries to construct a theoretical framework of data commercial value that covers the process of data assetization, commoditization and capitalization. The main contribution of this paper is to construct a logical relationship diagram between the three value forms of data and develop an integrated research framework for the data value transformation process in order to provide theoretical guidance for the realization of data commercial value.
Research Method and Bibliometric Analysis
Study Identification
This study refers to previous studies and adopted a systematic literature review method to determines the scope of literature through elements such as journals and keywords (Merigó & Yang, 2017; Zupic & Čater, 2015), and the specific process that includes the following two steps. Firstly, we determine the source of literature. The database is mainly Web of Science, which covers international journals in the fields of social sciences such as management and economics. The reasons for selecting SSCI as the database are as follows: (1) The Web of Science (WoS) is widely used and recognized globally as an authoritative indicator, ensuring that research results are more representative and persuasive; (2) WoS offers a detailed content classification system, enabling more convenient and accurate retrieval of the necessary data; (3) WoS covers a longer time span and provides more comprehensive data, making it more suitable for scientific research; (4) WoS provides powerful citation tracking tools and various analytical tools, allowing researchers to understand the impact and dissemination of a particular research outcome within the academic community (Cheng et al., 2023; Geng et al., 2024; Geng & Maimaituerxun, 2022).
Secondly, we determine the search strategy. To thoroughly investigate the issues centered on data value and commercialization, this study employs keywords such as “Data commerc*”“Data valu*”“Big data commerc*”“Big data valu*” to conduct a search of SSCI journals literature based on titles, abstracts, and keywords. Contents which are faintly related to data technology such as blockchain, scientific data, and libraries are excluded by reviewing the abstracts of the preliminary search results individually, whereas contents that are highly related to data value and commercialization are retained. Since Industry 4.0 was first proposed at the Hannover Messe in Germany in 2011, the concept of intelligent manufacturing has spread rapidly across the globe. The data as a core resource that enables intelligent manufacturing, has become increasingly important and has emerged as a multidisciplinary research focus. Meanwhile, the collection and utilization of data play a critical role in fostering innovation systems across industries and enhancing competitive advantages (D. Li et al., 2021). Therefore, this study takes 5,465 eligible literatures from 2010 (the year before Industry 4.0 was officially proposed) to 2024 as the analysis object of this paper. Based on the extracted literatures, this study conducts a series of bibliometric analyses.
Bibliometric Analysis
Bibliometric analysis is a quantitative statistical method that utilizes mathematical and statistical techniques to study the distribution of scientific papers and authorship patterns. Firstly, this paper reviews the publication timeline of the sample literature, followed by a detailed analysis using Citespace software on co-cited journals, collaborating authors, co-citation authors, co-citation articles, publishing institutions, keywords co-occurrence and keywords time-zone. The aim is to help readers gain a deeper understanding of the current research advancements in data value and the business field. Furthermore, this paper draws upon Bradford’s Law and Price’s Law from the field of library and information science to statistically analyze the core journals and authors on this research topic.
Time Distribution of Publications
The Figure 1 shows the time distribution of research in the field of data value and data commercialization from 2010 to 2024. Since 2017, it has shown a rapid upward trend overall. Although it declined after 2021, it has been on the rise since 2023. It indicates that with the increasing maturity of big data applications, the value and commercialization of data have begun to receive more and more attention.
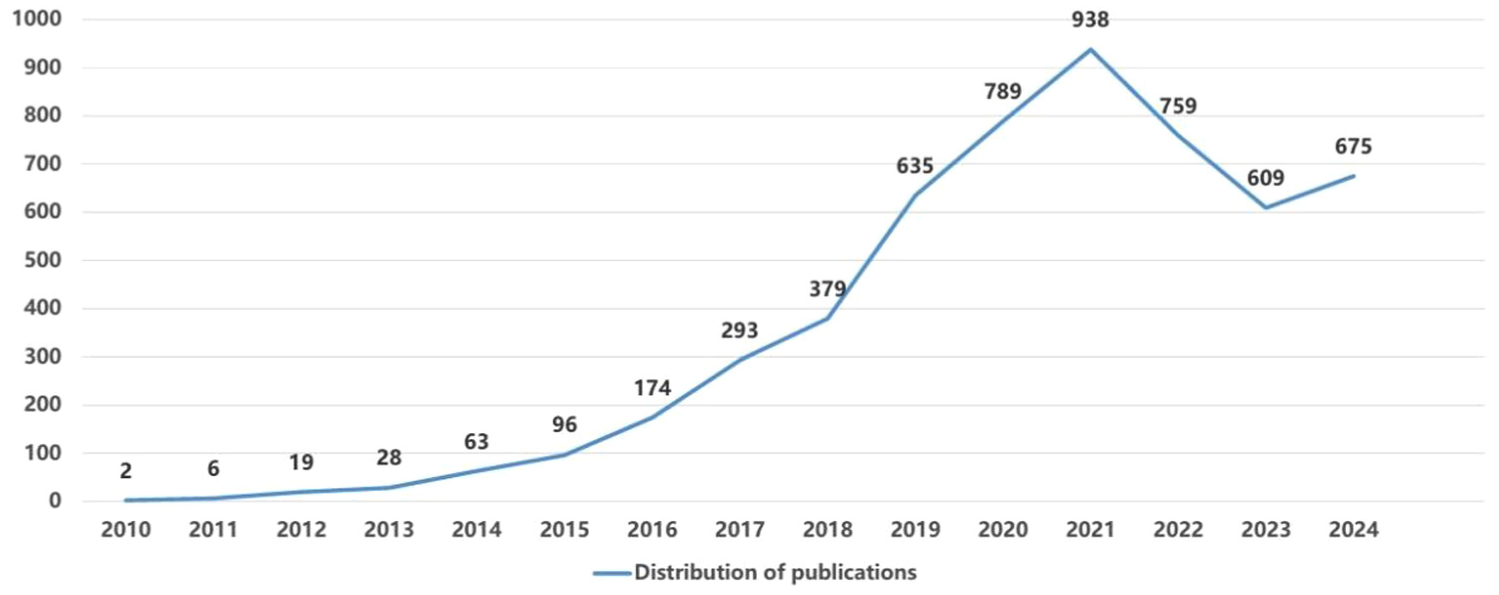
Time distribution of publications.
Journal Distribution Analysis
On the one hand, this paper carries out statistics on the sample literature published journals of WOS database respectively, and the top five journals in terms of the number of publications are Sustainability (344), Technological Forecasting and Social Change (102), Journal of Enterprise Information Management (88), Business Process Management Journal (80), Journal of Business Research (71), Management Decision (71), with a total of 756 articles published, accounting for 13.83% of the total. In addition, we used Citespace to conduct a statistical analysis of the top 10 co-cited journals in this field (Table 1). The Journal of Business Research (1,627), MIS Quarterly (1,349) and International Journal of Information Management (1,289) were cited the most frequently. For specific details, please refer to the Figure 2.
Table of Co-Cited Journals.

Clusters view of co-cited Journals.
On the other hand, this paper draws on Bradford’s study and uses Bradford’s Law to identify core journals that are closely related to the topic of this study (Bradford, 1985). The law divides journals into three regions according to the number of papers in descending order, that is, core region n1 containing a small number of high-productivity journals, n2 with a larger number of medium-productivity journals, and n3 with a large number of low-productivity journals. The three regions have similar number of papers, and the ratio of the number of journals is n1:n2:n3 = 1:α:α2 (α is a constant).
As shown in Table 2, the distribution of journals does not conform to the traditional Bradford’s law, but the number of articles carried is positively correlated with the degree of journal specialization, and most journals have published only 1 to 3 documents (77.17% of the total number of journals). Therefore, according to Bradford’s dispersion law R0 = 2ln(eE×Y) = 2ln(1.8×344)≈13(12.86) (Y represents the number of articles published in the journal with the largest number of articles), there are 85 journals in the core area which have satisfied the conditions and published 2,746 articles, accounting for 50.25% of the total publications.
English Literature Journal Partition Table.

Core Author Analysis
This paper applies Price’s law to statistically analyze the authors of the literature on the topic of this study to identify the core authors. Price’s law defines the level of research at which a scholar is recognized as outstanding in his or her field of expertise (Peterson, 1974). Price’s law determines the minimum number of publications to be achieved by a scholar in his/her field of study through a specific formula to rate his/her outstanding contribution.

Where nmax is the total number of papers published by the one research scholar with the highest number of publications in a research field, and m is the minimum number of publications required for the field to be recognized as a distinguished scholar.
The study counted 15,168 authors in the literature, of which 84.26% of the authors have published only one paper (12,780), as for Akter, the most prolific author, have published 29 papers. By Price’s law, authors who have published more than 4 (3.02) articles are considered core authors in their fields. The 442 core authors published 2,750 articles, which is 18.13% of the total number of articles.
Analysis of Collaborating Authors
To achieve a more comprehensive and in-depth analysis of this field, this paper examines the leading collaborating authors. Statistical analysis shows that, except for a very small number of scholars who have formed a stable group of co-authors, other scholars in this field have not yet formed a stable group of co-authors and cited authors.
An analysis of author collaboration was conducted using Citespace, revealing that the centrality of each author was recorded as 0.00, indicating an overall low intensity of collaboration among authors. The reason for this could be that the data on collaborating authors did not form a complete network, indicating that the collaborative relationships between authors were not closely knit or that there were a large number of isolated nodes within the data. This study suggests that enhancing collaboration among authors could promote resource sharing and collective efforts to advance research on data value and commercialization. Akter contributed 29 collaborative articles, it is the highest number among the authors. Additionally, each of the nine authors contributed more than 10 dozen collaborative articles (Table 3 for details).
Table of Collaborating Authors.

As shown in Figure 3, there is relatively strong collaboration among Akter, Wamba, and Gupta. Other research teams, such as Mikalef, Dwivedi, Gunasekaran, Wang, Luthra, Krogstie, and Dubey, have also been collaborated 10 or more times in this field. However, except for a very small number of research teams that cooperate relatively closely, the vast majority of research teams in this field have not yet established frequent cooperative networks, and the research clusters or hotspots of various scholars have not yet converged into a unified direction. The figure reveals that author collaboration in this field is relatively weak, indicating a need for broader resource sharing and collective efforts.

Collaborating authors.
Analysis of Co-citation Authors
To identify the core authors in this field, we conducted an analysis of co-cited authors. Among them, the articles by Wabmba were cited the most, with a co-citation count of 592. The centrality score were 0.32, respectively, significantly higher than those of other authors. This indicates that Wabmba has a substantial influence in this field and has made outstanding contributions (Table 4 for details).
Table View of Co-Citation Authors.
The CiteSpace calculates author co-citation counts by tallying the co-citations of the first author, where multiple citations of the same author within a single document are counted only once. As shown in Figure 4, the co-cited author network reveals the relationships among scholars within a specific research field.

Clusters view of co-citation authors.
Co-Citation Analysis of Articles
To reveal the research themes and the knowledge structure of the research field, this paper conducted a co-citation analysis of the sample articles (Geng et al., 2024; Hu et al., 2020). Co-citation refers to the phenomenon where two or more documents are cited together in the reference list of a third document. When different authors cite the same set of documents in their research, these co-cited documents form an implicit association. The analysis revealed that no highly cited documents have yet emerged in the field of data value and business. The overall trend suggests that many viewpoints and perspectives in this field have not yet reached a consensus (Figure 5 for details).

Clusters view of co-citation articles.
As shown in Table 5, the six articles co-cited the most are by Wamba SF, Hair JF, Mikalef P and Gandomi A, each having been cited over 120 times. From a dynamic capabilities perspective, Wamba et al. (2017) empirically demonstrate that big data analytics capabilities significantly enhance firm performance by improving organizational responsiveness and innovation. Hair et al. (2019) systematically elaborates the theoretical foundations and practical applications of multivariate statistical methods—including factor analysis, regression analysis, and structural equation modeling—in empirical research. Building on the resource-based view, Wamba et al. (2015) reveal how big data analytics functions as a strategic resource to optimize supply chain performance through information sharing and process optimization. Gandomi and Haider (2015) comprehensively review the conceptual framework and technical architecture of big data, systematizing key methodologies from data acquisition and storage to advanced analytics along with their typical application scenarios. The research of Mikalef et al. (2020) proposed that the ability of big data analysis enables enterprises to generate insights that help enhance their dynamic capabilities, which in turn has a positive impact on marketing and technical capabilities. From a production economics lens, G. Wang et al. (2016) examine the mechanisms through which big data analytics improves operational efficiency and cost-effectiveness in manufacturing systems.
Table of Co-Citation Articles.
Analysis of Publishing Institutions
Analyzing publishing institutions provides deeper insights into current research progress and the specific issues these institutions prioritize within the field. Statistical analysis indicates that scholars from the Chinese Academy of Sciences (CAS), Hong Kong Polytech Univ (PolyU), and Wuhan Univ (WHU) are particularly focused on issues related to data value and commercialization (Table 6 for details). However, the data results indicate that the centrality of the top 10 research institutions is zero, suggesting that the research in this field has not yet established a high-output, close-knit collaboration (Geng et al., 2024). It is hoped that in the future, efficient inter-institutional cooperation can be formed to collectively advance the development of this field.
Table of Publishing Institutions.

Analysis of Research Hotspots
On the basis of the statistical analysis of core authors and core journals mentioned above, this paper uses CiteSpace software statistics to conduct keyword co-occurrence analysis (as shown in Figure 6 and Table 7). The results show that: scholars in related fields mainly carry out research on the value of data from the following two dimensions: from the dimension of assisted decision-making, in the face of the emergence of massive amounts of data, how to prompt enterprises to make effective use of visualization and analysis tools to carry out in-depth processing and accurate interpretation of such data, with a view to achieving the goal of enhancing the efficiency and accuracy of corporate decision-making; from the technology-related dimension, non-Chinese scholars pay more attention to data-driven machine learning, information systems, information technology, digitization, and data analysis. This shows that overseas scholars are not only concerned about the application and value realization of data as a new resource, but also have an in-depth inquiry into the mechanism and source of data generation. Especially in the technical fields of information technology and data analytics, as the application of these technologies can generate a large amount of data, the research and application of these technologies have become an important direction in the study of the commercial value of data.
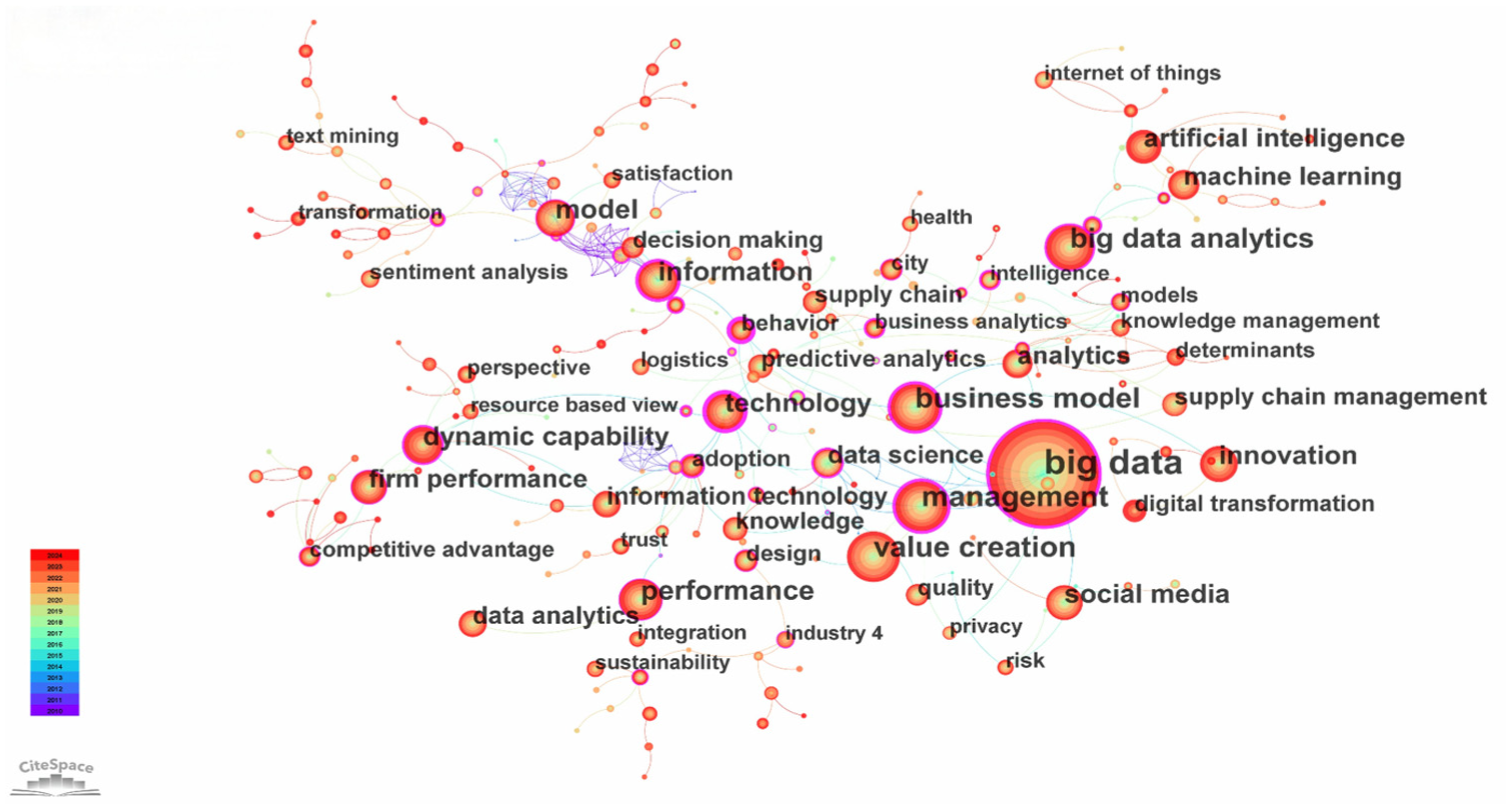
Keyword co-occurrence graph for Citespace sample literature.
Keyword Co-Occurrence Table for Citespace Sample Literature.

The “time-zone” analysis of co-occurring keywords is crucial, as it helps to delineate the stages of academic research, reveal the evolution of research hotspots, assess the maturity of research fields, and identify emerging research directions (Cheng et al., 2023; Liu et al., 2015). The “Time-zone” view of keywords in this study positions nodes from left to right based on the year of publication. Utilizing the time-zone view function provided by CiteSpace, the distribution frequency and intensity of keywords are calculated on an annual basis. The larger the circle, the more frequently the keyword appears and the stronger its intensity; conversely, smaller circles indicate less frequent and weaker occurrences. As shown in Figure 7, research hotspots have evolved from an early focus on value creation, decision making big data and management (2010–2013) to business model, technology, big data analytics and machine learning (2014–2017) by gradually shifting, followed by artificial intelligence, sustainability, firm performance and deep learning (2018–2020), and eventually concentrated on circular economy, digital transformation, industry 4.0, digital economy and innovation performance (2021–2024). Furthermore, the temporal analysis of keyword co-occurrence reveals that value creation, firm performance, data management, and business model innovation have consistently been research hotspots of scholarly attention.

“Time-zone” view of keywords.
It can be seen from the above bibliometric analysis that the commercialization process of data resources and its value creation mechanism have become an important interdisciplinary research hotspot. Since the advent of big data technologies, academic exploration into data commercialization pathways (e.g., intelligent manufacturing, precision marketing) and value realization models (e.g., user profiling, smart decision-making) has maintained sustained momentum, evidenced by exponential growth in scholarly outputs. Empirical findings demonstrate that data-driven innovation over the past decade has transcended mere technological dimensions (such as machine learning algorithm optimization and data analytics model development) to fundamentally reshape economic practices, including business ecosystem reconstruction and industrial value chain upgrading. However, it is noteworthy that despite prolific research efforts from technological and business model perspectives, three critical theoretical gaps persist: (1) insufficient conceptualization of data’s multidimensional value forms (data assets, data commodities and data capital); (2) inadequate understanding of dynamic conversion mechanisms (data assetization, data commodification and data capitalization); (3) absence of systematic frameworks integrating commercialization pathways. This theoretical fragmentation substantially hinders the effective unlocking of data’s commercial potential across industrial applications. To address these knowledge gaps, this study synthesizes cross-disciplinary research spanning 2010 to 2024 to achieve two primary objectives: first, to delineate the intrinsic value manifestations of data resources through their lifecycle; second, to model the dynamic conversion processes that transform raw data into commercial value. The proposed theoretical framework aims to advance scholarly discourse by establishing systematic linkages between data value generation mechanisms and practical commercialization strategies, thereby providing conceptual foundations for future research in data value and data commerce.
The Value Form of Data Resources and Its Internal Logic
Data is a new type of special resource, which refers to facts or information collected, organized and assembled from multiple sources (Janssen et al., 2017) which has greater scale, high speed, diversity, accuracy, and value as a resource (Barbet & Coutinet, 2001; Gantz & Reinsel, 2011). Among all those characteristics, data is highly recognized by its scale, high speed, diversity, and accuracy, which help enterprises generate business insights with high value and improve their innovation ability in order to further increase the value of enterprise data resources (Dubey et al., 2019). Existing literature mainly discusses and analyzes the value form of data from the perspective of data assets, data commodities and data capital. It is widely recognized within the academic community that data represents a novel factor of production, distinct from land, capital, and intellectual outputs, and possesses its own unique attributes. However, there is still no consensus on the precise understanding of these unique attributes. Nonetheless, most scholars agree that the distinctive attributes of data can at least be categorized and analyzed from the perspectives of technical and economic attributes (Kitchin, 2021; Yoo et al., 2012; Zuboff, 2015).
Data Assets
The concept of data assets, originating from Peters’ thesis (Peterson, 1974), has gained significant traction with the rise of the digital economy. As recognition of data’s intrinsic value has grown, data assets have emerged as the new “oil” of the digital era. While scholars and institutions offer various definitions, there’s a consensus on the fundamental role of data assets in driving the digital economy.
From a management perspective, data assets are defined as data resources owned or controlled by an organization that are expected to generate future economic benefits, demonstrating significant financial value for enterprises (Grover et al., 2018). Within the information systems domain, data assets encompass structured or unstructured data systematically collected, stored, and managed to create economic value or strategic advantages for organizations (Xu et al., 2024; LaValle et al., 2010). Core characteristics include quantifiability and reusability, which underpin their capacity to drive organizational innovation and decision-making (Trabucchi & Buganza, 2019; Shahid & Sheikh, 2021). From a legal standpoint, scholarly discourse emphasizes the delineation of property rights and compliance boundaries for data assets. The EU’s General Data Protection Regulation (GDPR) classifies personal data as “information relating to an identifiable natural person,” mandating data controllers to adhere to principles such as informed consent and data minimization during assetization processes (European Union, 2016). Furthermore, the allocation of data asset ownership necessitates balancing control rights and economic efficiency, while aligning legal frameworks with societal welfare considerations (Birch et al., 2021).
Data assets possess a unique ability to foster value creation and innovation. Wamba et al. (2017) illuminate how these assets catalyze business model innovation, streamline processes, and spur product development, ultimately generating value for enterprises. The fluid nature of data assets, as noted by Witschel et al. (2019) and Wamba et al. (2020), allows their value to fluctuate over time and across different contexts. This inherent flexibility empowers organizations to swiftly adapt to market shifts and evolving customer needs.
The multifaceted nature of data assets further enhances their utility. Grover et al. (2018) highlight the diverse types of data encompassed by these assets, ranging from customer information to transaction records and social media interactions. This variety offers a rich tapestry of insights for business analysis and decision-making. Moreover, as Birch et al. (2021) point out, the reusability of data assets allows for their application across various business processes, maximizing value realization. These characteristics render data assets invaluable in business development, digital economy, and market dynamics (refer to Table 8 for details).
Data Asset Characteristics.
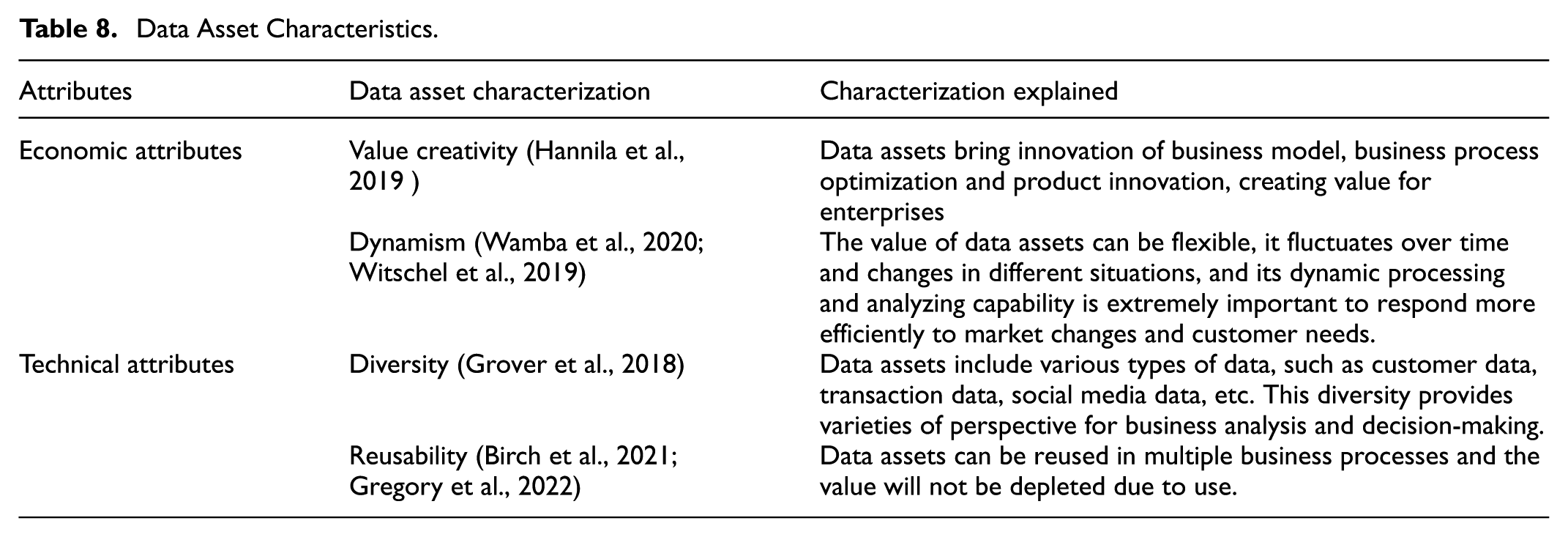
In the banking sector, for instance, data assets might comprise basic customer information, business data such as account records and investment histories, and behavioral data like transaction patterns. These assets form the cornerstone of a bank’s data-driven operations and strategic decision-making processes.
Data Commodities
The notion of data commodities can be traced back to J.W. Tukey’s 1962 paper, which explored data commodity visualization (Tukey, 1962). Since then, this concept has evolved significantly, with scholars and organizations offering various perspectives on its definition and analysis.
From the view of management science, data commodities refer to standardized and processed data products or services capable of market transactions, which enhance data liquidity and facilitate broad application and value creation (Kitchens et al., 2018). These commodities possess well-defined market value and can be commercialized through data trading platforms or direct sales. Through an information systems lens, data commodities are defined as digitally packaged datasets exchangeable in markets, with their value realization contingent upon technological infrastructure and supply-demand matching efficiency (Driessen et al., 2022). From a legal standpoint, the legitimacy of data commodities must satisfy three requirements: (1) Clarity of Rights: Transaction parties must explicitly define data entitlements, including ownership and usage rights (Ponta & Catana, 2023); (2) Regulatory Compliance: Transaction content must adhere to privacy protection regulations (e.g., GDPR) and national security laws (Corrales et al., 2019); (3) Contractual Standardization: Transaction transparency and traceability should be ensured through technologies like smart contracts (Buterin, 2014).
Data commodities possess a remarkable ability to transcend traditional market constraints. As Yoo et al. (2010) observe, these commodities can circulate and be traded in the market, unhindered by conventional limitations of geography, space, and time. This fluidity significantly amplifies their market value. Jones and Tonetti (2020) shed light on another intriguing aspect of data commodities—their non-competitive nature. This characteristic facilitates data sharing, yielding benefits such as economies of scale, network effects, and collaborative innovation.
The malleable nature of data commodities further enhances their utility. Bechtsis et al. (2022) note that flexible data systems can accommodate varying data volumes and formats, enabling companies to rapidly address changing customer requirements and market dynamics. This adaptability is complemented by customizability, as highlighted by Ghoshal et al. (2020) and Kitchens et al. (2018). Data commodities can be tailored to meet diverse user needs, offering targeted insights and solutions. These unique attributes—adaptability, circulation, non-competitiveness, customizability, and continuous innovation—define the essence of data commodities (refer to Table 9 for details).
Data commodity characteristics.
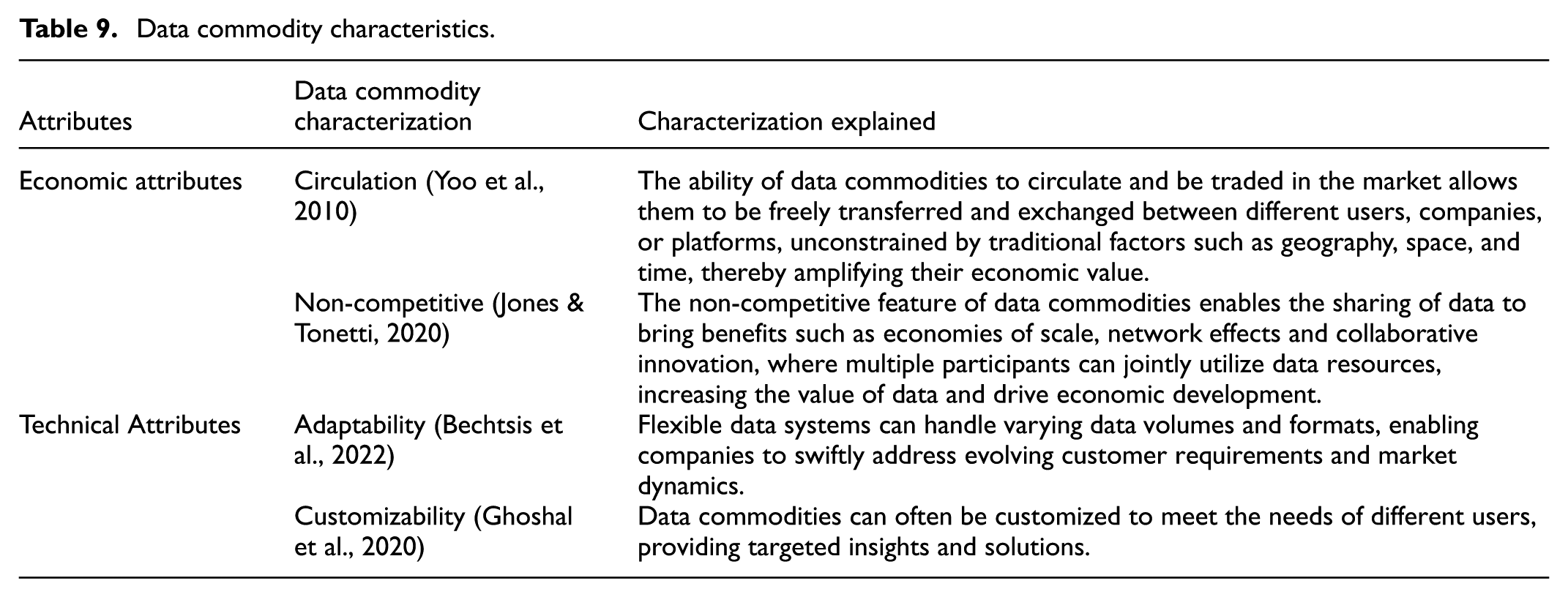
A prime example of this transformation occurs when banks convert their internal data assets into external commodities. By desensitizing and standardizing data, they create tradable products for the data market, effectively bridging the gap between internal resources and external market demand.
Data Capital
The concept of data capital first emerged in a working paper by the Central Statistics Office of Norway (Nordbotten, 1967), where it was considered the reserve stock of data collection and computation central to statistical documentation systems. Contemporary definitions, such as that proposed by Brynjolfsson et al. (2021), view data capital as the value embodied in structured and unstructured data, both within and outside an organization, driving business decisions, innovation, and competitive advantage.
In the field of management, data capital is regarded as a strategic asset of enterprises, endowing data with financial value and driving long-term competitive advantages and innovation capabilities (Aaltonen et al., 2021; Contreras Pinochet et al., 2021). Data capital encompasses not only the current value of data but also its future potential for appreciation in financial markets. From the Information Systems viewpoint, data capital refers to the accumulated data resources that organizations utilize over time for decision-making, innovation, and organizational development, with its value manifested in enhanced predictive capabilities and improved decision-making efficiency (Tang, 2021). From the Law perspective, the development of data capital faces two major legal obstacles: (1) ambiguous data ownership, characterized by fragmented rights among multiple stakeholders (e.g., users, enterprises, governments) (Xiao et al., 2020); and (2) data monopolies by large platforms that restrict market competition, necessitating legal interventions for regulation (Ma, 2022).
One of the defining features of data capital is its capacity for value addition. W. C. Li et al. (2019) illuminate how the ability to extract valuable and operational insights from vast amounts of data fuels data capital operations and facilitates continuous value growth. This characteristic is closely tied to the cumulative nature of data capital, as emphasized by Aaltonen et al. (2021). As more data is collected and analyzed over time, organizations gain increasingly profound insights into market trends, customer behavior, and operational efficiency, thereby enhancing the overall value of their data capital.
The versatility of data capital is another key attribute. Contreras Pinochet et al. (2021) explore how data capital can be seamlessly integrated with various financial instruments, creating specific operational modes that promote value circulation and appreciation. This integration capability is complemented by the circulatory nature of data capital, as noted by Ghoshal et al. (2020). Data can be shared and circulated in the market through standardized means, allowing for the full realization of its value. These characteristics—value-addedness, circulation, integration, accumulation, and profitability—position data capital as a crucial driver of contemporary socio-economic development (refer to Table 10 for details).
Data Capital Characteristics.
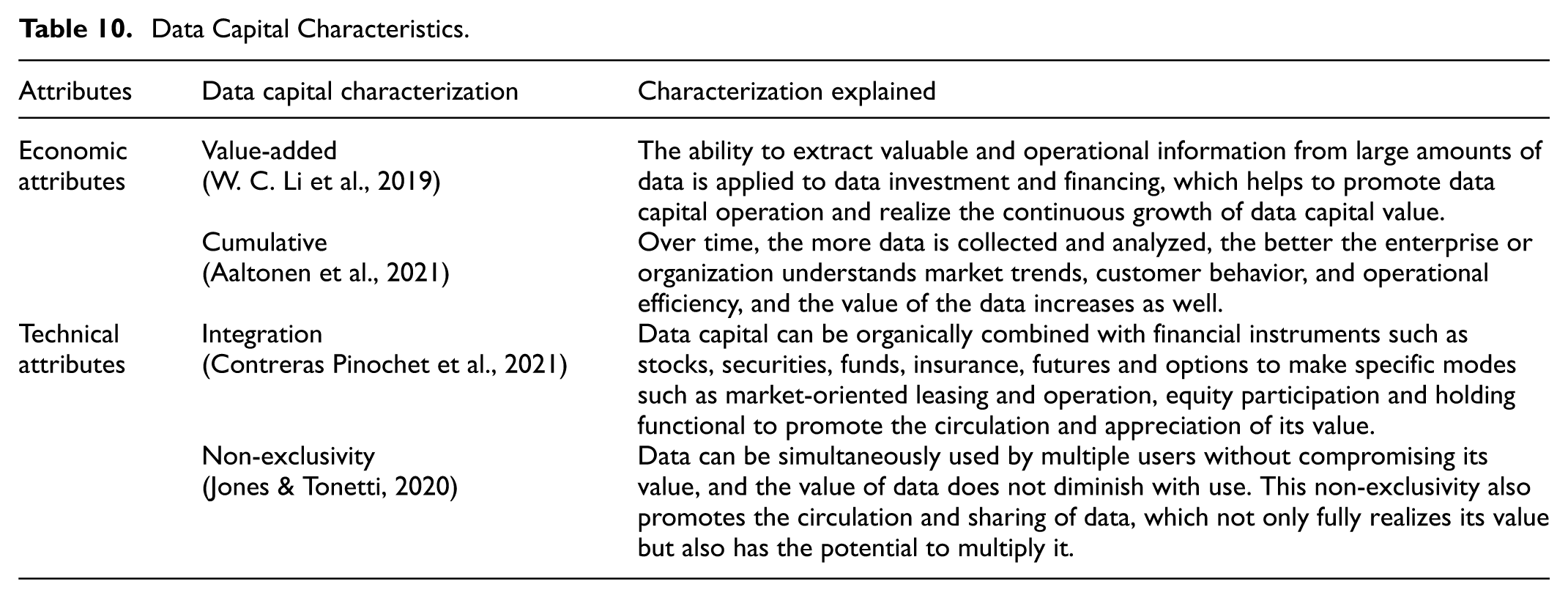
A compelling illustration of data capital in action can be seen when banks securitize their data assets. By packaging customer and contextual data into data asset-backed securities for trading in the capital market, banks effectively revitalize their stock data assets and unlock new financing avenues. This process transforms data into a form of capital capable of generating tangible cash flow, underscoring the pivotal role of data capital in modern financial ecosystems.
Intrinsic Logic
Under the wave of digital economy, the interaction and transformation among data assets, data commodities, and data capital have become the focus of attention in both academic and business circles. Data asset is the basic value form of data resources, which is the cornerstone of data commodity and data capital. Data commodities are processed data outputs, such as reports and models. Data capital is the economic value formed by the long-term accumulation of data assets and commodities, reflecting the ability of enterprises to utilize data to gain advantages and benefits.
Hannila et al. (2022) emphasized the importance of data assets in portfolio management, which are not only a collection of information but also the basis for supporting enterprise decision-making and innovation. Chakrabarti et al. (2016) explored how to transform data assets into data commodities through a case study, showing that data assets can be transformed into data commodities of practical value to the enterprise through analysis and application. Meanwhile, Fleckenstein et al. (2023) point out that data commodities optimize the application management of data assets by integrating and analyzing different data sources and transforming data assets into business insights. The study by Bryan et al. (2017) argues that data capital is the ability of an enterprise to transform its assets and products into corporate competitive advantages and profitability. Data capital also plays a positive role in data assets and products. For example, Jones and Tonetti (2020) point out that the development of data capital boosts the application and management of data assets in organizations; Brinch (2018), Grover et al. (2018), and Sadowski (2019) show that data capital empowers the enhancement of the investment and financing ability of data financial products due to value-added and integrated characteristics. In summary, data assets, data commodities and data capital form a logical system of mutual influence and circular promotion. Data assets are the foundation, data commoditization is the way of value realization, and data capital is the result of value accumulation. Clarifying the three value forms of data can help the industry better unleash the value of data and enhance competitiveness (as shown in Figure 8).

A schematic diagram of the logical relationship between the value forms of data resources.
Value Transformation Process of Data Resources
Data Value Creation Mechanism
Data assetization is the process of transforming data resources into assets that can bring economic benefits or enhance decision-making support capabilities, which includes data collection, integration, processing, storage, analysis, fusion, application, value assessment, and ownership confirmation, etc., with the aim of unleashing and creating the potential value of data (R. Y. Wang & Strong, 1996). Data value creation relies on enterprise data strategy, technical capabilities and market opportunities, and the core lies in accurate and reliable data pricing, while facing challenges such as data fragmentation, islanding, pricing difficulties and privacy protection (Alazab et al., 2022; Ge et al., 2022; Sookhak et al., 2014). In this paper, we have explored the value creation mechanism in data assetization in technical, market and institutional dimensions.
Technical Dimension. Data collection, storage, security, and standardized processing technologies are the key technical elements of data assetization. The continuous development of data collection, storage and security technologies provides technical guarantee for the process of data assetization (Brinch, 2018). In addition, data standardization processing is also one of the core elements in the process of data assetization. Data standardization not only improves the quality of data circulation and usability, but also is the key of insurance of data consistency and comparability. In addition, standardized processing enhances interoperability between different systems, improving compatibility and usability of data resources and providing a solid foundation for data analysis and business decision-making. As standards continue to evolve, organizations also need to continuously adapt their data processing strategies to accommodate these changes to better unlock the value of data resources.
Market Dimension. Asset pricing is a key step in unleashing value in the data assetization process and a core aspect of the market-based allocation of data elements. Data asset pricing involves the quantitative assessment of its value, and its considerations including the scarcity and availability of data and many other characteristics (Huang & Rust, 2018). Currently, the most mainstream pricing methods include cost-based pricing (Azcoitia & Laoutaris, 2022), market comparison pricing (Koutroumpis et al., 2020), value-based pricing (Ingenbleek, 2007) and income method (Barbet & Coutinet, 2001). Elia et al. (2020) proposed a framework for assessing the value of data assets, that is, considering factors such as data quality, data integrity, and data relevance, and determining its value by combining the using conditions. Another pricing method based on machine learning has also begun to rise. L. Chen et al. (2024) use deep learning algorithms to construct a pricing model by training historical transaction data, which can automatically generate pricing based on data characteristics. However, the asymmetry, uncertainty and dynamic change of data assets still make data asset pricing a complicated challenge.
Institutional Dimension. The ambiguous definition of data ownership constitutes a key institutional barrier to data marketization, and only by clarifying data ownership can the process of data assetization be better promoted and the value of data be truly unleashed. This is not only a legal and ethical issue, but also involves technical and economic dimensions, and balancing data tenure, privacy and commercial utilization needs is the key to the data assetization process (Martin et al., 2017).
Data Value Circulation Mechanism
Data commercialization is the process of transforming data assets or resources into data commodities, aiming at realizing the commercial and functional value of data by the means of technology and management. This process covers the whole process from data collection and processing to final product development and marketable circulation, and relies on advanced technologies such as deep learning data mining and an accurate grasp of target market demand (Crain, 2018). Data commercialization not only improves the availability and value of data, but also promotes the process of new product development and innovative decision-making (Canellopoulou-bottis & Bouchagiar, 2018). At the current stage, the realization of data value in the process of data commoditization benefits from its ability to interact freely in the market, including the open circulation and sharing of data (Šlibar et al., 2021). The formation interaction and compliance of data commodities in the process of data commoditization are issues of concern, involving three different dimensions: technological, market, and institutional.
Technical dimension. The development of data commodities is an important part of data commoditization, including multiple steps such as data collection, cleaning, integration, analysis, and processing. Data commoditization has to face different challenges in data collecting such as the diversity and varying quality of data and has to ensure the accuracy and availability of different data (Becker et al., 2015). In addition, efficient data commoditization adapts to changing amount of data and types, helping organizations to be prepared for responding to different customer needs and market changes timely (Liang et al., 2018). Quality management at the data processing stage is the key to success, while standardization of data formatting needs to be handled at the transformation stage (Wook et al., 2021). This helps in the exchange and circulation of data commodities. In the analysis phase, accurate customer analysis and behavioral prediction provide strategic insights for the enterprise (Kitchens et al., 2018). In the application phase, choosing the right methods and tools is the key to improving speed of delivery and cost reduction (Yoo et al., 2010).
Market Dimension. In the process of data commoditization, the circulation and sharing of data commodities is the key to realizing the value of data. By using the data efficiently, data commodities can promote innovation of product and service, improve operational efficiency, optimize supply chain, accurate pricing, keep customers closer and optimize decision-making process, helping data resources realize their value in a more efficient way (Günther et al., 2017; Richter et al., 2017). The circulation, transparency and sharing of data commodities are the key elements of today’s digital economy, and the accurate measurement of data value is an important prerequisite for realizing the effective circulation and sharing of data commodities in the market. Therefore, establishing an effective pricing system for data commodity value is of great significance for promoting data circulation, transparency and sharing. Data transparency promotes the marketization of data commodities, provides a platform for sharing and collaboration, and leads to in-depth processing and innovative use of data. With the development of big data and cloud computing, enterprises can response quickly to market changes and improve the efficiency of decision support systems. Cross-industry data flows lead to new business models and innovation opportunities, promote collaboration and knowledge sharing, and increase the value of data and economic growth (Jones & Tonetti, 2020).
Institutional Dimension. Compliance management of data is crucial in the process of data commoditization and is a core aspect of facilitating data circulation and realizing the value of data resources. It is not only related to data quality and security, but also to regulatory requirements and business decision-making effectiveness (Kwon & Johnson, 2013). Comprehensive measures are required to achieve compliance, such as the development of data protection strategies, legal requirements and risk management, and the customization of compliance requirements to business and regulatory needs. Legal definitions and guidelines have a central guiding role in the field of data compliance, such as the European General Data Protection Regulation (GDPR) and the U.S. Health Insurance Pass-through and Accountability Act (HIPAA) for example, which set clear rules for data compliance and protection in their contents (Dong et al., 2018).
Data Value Enhancement Mechanisms
Data capitalization is the process of upgrading data commodities or resources into data capital, and achieving data value appreciation through input-output management by market-based means. This process includes a full range of transformation from data collection, analysis and processing to commercialization and application, and relies on advanced data processing and analysis technologies, while taking into account the balance between market demand and data privacy protection. Data capitalization aims at transforming data into circulating capital, combining with financial instruments to achieve market-oriented operation, and promoting the value enhancement and utilization of data resources. Liquidity and value-addedness are its key factors, which help promote the circulation and sharing of data in the market (Wook et al., 2021). Through the extraction of valuable information and in-depth analysis of market and consumer data, data capitalization provides enterprises with new business insights and strategic directions, enhances the investment and financing capabilities of financial products, and promotes business model innovation. The construction of data credit systems and institutions strengthens trust in data financial products and ensures the stable and healthy development of data capital (Dong et al., 2018).
Technology Dimension. The development of big data financial technology and digital infrastructure promotes the process of data capitalization, and big data promotes the innovation of value proposition business processes and revenue models through the instrumental use of resources and technology, as well as the reconstruction of the external relationship network, which provides the basis for the innovation of business models. And advanced data infrastructures and digital perception tools (e.g., pattern recognition, data mining, machine learning, etc.) significantly enhance the service performance of financial products, for example, providing personalized and customized financial services (Gomber et al., 2018). The improvement of data analytics plays a key role in business model innovation and the enhancement of financial product investment and financing capabilities. It not only influences data collection and trading strategies in the financial market, for example, the application of demand analysis and data-intensive trading strategies to help companies to be able to finance their businesses more efficiently (Tambe, 2014); it also fuels banks and fintech companies to launch new business models and financial products to meet customer needs through cooperation or technological upgrades.
Market Dimension. Cappa et al. (2021) emphasized the capitalization path of big data industry development in the process of data capitalization, including the use of a variety of financial instruments and market mechanisms to support the financing and development of big data projects, indicating that the big data industry is not only a field of technology and information processing, but also an important field of economic and financial activities. Data capitalization empowers diversified investment and financing strategies and market mechanisms to promote the mature development of data projects. From the perspective that data capitalization facilitates a better allocation of capital, Benaroch points out in his study that as more investment risks are scrutinized by the financial markets, decision makers can draw on technical benchmarks and information from the financial markets in order to align their investment decisions with the market and to make capital allocations and investments that best fit the market conditions, which is critical to understanding the role of data in capital allocation. The use of data not only helps firms more accurately assess investment risk, but also facilitates more scientific capital allocation strategy development.
Institutional Dimension. The need to reshape the credit system drives the process of data capitalization. The rise of Internet finance and the application of big data have promoted the development of a new type of credit assessment system, and the construction of an effective credit indicator system is essential. Since the 1960s, the amount of price information in the financial market has increased and the trust of investors has risen, indicating that the improvement of the financial data credit system has a high degree of credibility, which has an important impact on the efficiency of the market information (Bai et al., 2016). The research of Dong et al. (2018) shows that multiple data sources are crucial for the improvement of the credit system. The research of Courtney et al. (2017) on the asymmetric information in the field of crowdfunding reveals that signaling and reputation endorsement are crucial for the establishing an effective credit system are critical.
In summary, this section sums up the process of commercialization of data resources being experiencing the evolution from data assets to data commodities, and at last to data capital, and the value form has increased from potential value to use value to capital value. In this process of “internalization - externalization - capitalization,” data assets require corporate data governance capabilities, data commodities require desensitization, pricing and other processing, and data capital requires transaction scale and quantification of value-added benefits. The three elements of technological progress, legal system and market mechanism are intertwined and jointly drive the process of data commercialization, constituting the endogenous impetus, and guarantee for the transformation and value-addedness of data (as shown in Figure 9).

Mechanism diagram of data resource value transformation process.
Conclusion
After conducting an in-depth literature review, this study systematically examines the extant research on the commercial value of data resources, exploring three primary manifestations of data value—data assets, data commodities, and data capital—and analyzing the intrinsic relationships and underlying logic that connect them. Furthermore, it places special emphasis on the processes by which raw data resources realize their value, delineating in detail the value-transformation pathways of data assetization, data commoditization, and data capitalization. The findings offer important theoretical foundations and practical guidance for both policymakers and enterprises.
For policymakers, this study elucidates the distinctive value forms of data as an emergent resource and the mechanisms by which value is generated at different stages of its development. As big data applications mature, the value and commercialization of data have garnered increasing attention. To promote the efficient utilization and value transformation of data, policymakers should strengthen legislation and regulation concerning data circulation, sharing, and security, thereby ensuring that data yields maximal economic and social benefits within a lawful and compliant framework. In addition, policymakers ought to encourage and support innovation in data technologies, establish and refine data-trading platforms, and foster the healthy development of data markets. For example, the Japanese Comprehensive Data Strategy seeks to create a secure and efficient data ecosystem grounded in trust and public welfare; the Framework Act on the Promotion and Use of Data Industries in South Korea aims to advance the national data sector; and the Data Governance Act adopted by the European Union addresses public data reuse, corporate data sharing, and individual data protection.
For enterprises, this study provides valuable insights into the effective management and utilization of data assets. Data assets underpin both data commodities and data capital, and organizations must develop robust data-governance capabilities—including data collection, integration, processing, storage, analysis, fusion, application, valuation, and ownership confirmation—to fully unlock and generate the latent value of their data. Data commoditization serves as a critical pathway for realizing data value: through advanced analytical and technological approaches, firms can transform internal data into marketable products or services, thereby securing competitive advantage. Finally, data capitalization is essential for value enhancement, and enterprises should actively explore mechanisms that integrate data assets with financial instruments—such as data-asset-backed securitization—to boost the investability and financibility of their data holdings and facilitate the market operation of data capital. For example, banks can package customer and contextual data into securities backed by data assets, mobilizing dormant data inventories in capital markets and unlocking new financing channels.
However, this study also has several limitations. Firstly, although research on the commercial value of data has made considerable progress, there remains a lack of a comprehensive and systematic framework to guide future investigations. Secondly, existing studies have predominantly focused on discrete dimensions of the data–value realization process—such as technological, market, or policy aspects—without offering an integrated understanding of the end-to-end commercial value chain. Finally, because this analysis relies primarily on bibliometric methods, it does not delve deeply into the specific challenges and solutions encountered by industries or firms in practice.
Future Research
Based on this theoretical framework, this paper further proposes potential future research directions centered on the understanding of the plurality and dynamics of data value forms, value realization mechanism, value circulation mechanism and value distribution mechanism.
The first direction is to deepen the understanding of the diversity and dynamics of data value forms. (1) Future research endeavors could further elaborate on the classification of data value forms, delving deeply into distinct categories such as information value, decision-making value, and prediction value, while actively exploring their transformations and evolutions within various application contexts; (2)In conducting such research, the adoption of time-series analysis and dynamic modeling methods should be considered to dynamically analyze the evolution of data value, closely monitoring the impacts of technological advancements, shifts in market demand, and adjustments in the policy environment on data value; (3) This paper suggests that future considerations should include cross-disciplinary comparisons and integrations, contrasting data value forms across different industries and nations, thoroughly investigating their universality and specificity, and striving to facilitate the convergence and advancement of interdisciplinary theories on data value.
The second direction is to conduct in-depth study of data value realization mechanism. The process of realizing the value of data resources is affected by multiple factors, such as the source of data and application fields. (1) By in-depth analyzing of the key elements in the process of data value creation, transmission and capture, such as technological innovation, market structure, institutional environment, etc., to reveal its mechanism (Wu et al., 2024); (2) What are the unique features of data-driven value realization paths such as data-driven decision-making, product and service innovation, and business model development (Lafferty, 2019); (3) Future research could delve into the model innovations for realizing data value through various pathways, such as the platform economy and the sharing economy; (4) This paper suggests that future research should focus on exploring how to balance efficiency and fairness in the process of realizing data value, and on designing incentive mechanisms to facilitate efficient utilization and equitable distribution of data.
The third direction is to examine the data value circulation mechanism. Future research should be devoted to the development of data resource management strategies that not only reflect the multi-dimensional value of data, but also adapt to the needs of different industries. (1) Future research could embark from the examination of domestic and international data trading systems and policies, delving into the architecture, standards, processes, and regulatory mechanisms of the data trading market, with a particular emphasis on the security norms governing cross-border data flows (Jones & Tonetti, 2020); (2) Future research could place significant emphasis on optimizing data pricing mechanisms, particularly on developing more accurate pricing models for data products in complex transaction scenarios leveraging big data and machine learning technologies (Hasan et al., 2020; Sookhak et al., 2014); (3) How to innovate the data pricing model under the environment of new technologies, such as cloud computing and IoT (Alazab et al., 2022); (4) The similarities and differences of the data commercialization cases in different fields (Arshad et al., 2023); (5) Analyzing the mechanism and obstacles of data sharing and transparency, and designing strategies to promote data sharing and transparency, including data sharing models, open boundaries and regulatory rules (X. Li et al., 2023).
The fourth direction is to clarify the data value distribution mechanism. Comprehensively analyze the data value distribution mechanism from multiple dimensions, in line with the principle of “who invests, who contributes, who benefits,” establish the value orientation of social fairness, common wealth and economic efficiency, face the challenges at different stages of data value distribution, and solve the key issues faced by data value distribution. (1) Future research could employ qualitative comparative analysis and case studies to conduct a thorough analysis of the factors influencing the distribution of data value, examining aspects such as resource input, value contribution, and distribution subjects; (2) The data value distribution stage can be broadly divided into the initial distribution and re-distribution. Future research can take “contribution evaluation by the market and compensation determination by contribution” as the principle to study the strategy and realization path of data value distribution; (3) Using dynamic game theory and experimental analysis methods, focusing on compensation distribution based on value contribution and transfer payment based on resource input to study the strategy and realization path of data value redistribution.
Footnotes
Acknowledgements
I would like to express my sincere gratitude to my two collaborators, YuLin Liu and YiTing Hu, for their invaluable contributions to the research design, data collection, analysis, and manuscript preparation. Their expertise and dedication significantly enhanced the quality of this study. I am also grateful to the National Social Science Fund for their financial support (Grant No.24AGL011), which made this research possible. Additionally, I would like to thank all the colleagues and friends who provided support and encouragement throughout the research process.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Research on the Operating and Implementation Mechanism of Data Value System Project supported by the National Social Science Fund (24AGL011).
Declaration of Conflicting Interests
The authors declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: After carefully reading the conflict of interest statement, Haolang Qin, YuLin Liu, and YiTing Hu guarantee that this article has no direct or indirect interests related to the submission of Sage journals.