
Abstract
Language competence, particularly in the national standard language ability (NSLA), constitutes a critical dimension of human capital. According to classical human capital theory and endogenous growth models, proficiency in NSLA enhances individuals’ capacity for information acquisition, social communication, and labor market integration, thereby improving employment outcomes and income levels. Drawing on data from the 2021 wave of the Annual Livelihood Survey of Farmers and Herders in Xizang in China, this study investigates the relationship between NSLA and household income among Tibetan farmers and herdsmen. Using an extended Mincerian earnings function, we find that: (1) NSLA has a statistically significant positive effect on household income; (2) among the four dimensions of language competence—listening, speaking, reading, and writing—speaking ability exerts the greatest impact; and (3) the income effect of NSLA varies considerably across income groups, with limited returns for low-income households and diminishing marginal returns for high-income households. These findings suggest that promoting NSLA among the rural Tibetan labor force can enhance income generation capacity and contribute to reducing income inequality. The study offers policy implications for advancing inclusive development and linguistic equity in multilingual, service-oriented economies like Xizang in China.
Introduction
Language is a vital medium for human communication and interaction. Beyond its social function, it also constitutes a crucial component of human capital (Chiswick & Miller, 2007). Individuals with stronger language skills often exhibit superior labor market performance, including better employment prospects, higher productivity, and enhanced social integration (Gao & Smyth, 2011). Accordingly, language competence holds significant social and economic value at both the individual and societal levels (Lo Bianco, 2010; Riera-Gil, 2019; Sanders & Nee, 1996). In the broader language competence framework, the national standard language—also known as Putonghua or Mandarin—forms the foundation, alongside dialects, foreign languages, and minority languages (Zhou & Sun, 2004).
The field of language economics dates back to Marschak (Marschak, 1965), who was among the first to propose that language possesses measurable economic characteristics. Since then, numerous scholars have incorporated language ability into human capital theory (Chiswick & Miller, 2007), with a growing body of empirical research demonstrating its positive effects on individual income (Blake et al., 2018; Dustmann, 1994; Lindley, 2002; Shields-Zeeman & Smit, 2022). This line of inquiry has established a widely accepted consensus: language competence enhances workers’ earnings potential (Boyd & Cao, 2009; Chiswick & Miller, 1995, 2015).
However, three important gaps in the literature remain. First, there is limited research on national language proficiency in ethnic minority regions, where data accessibility and structural complexity often hinder empirical inquiry (Beckett & Postiglione, 2013). Yet, these regions are of high research value due to their linguistic diversity and sociohistorical context. Second, existing studies tend to treat language ability as a unidimensional construct, with few analyses distinguishing between listening, speaking, reading, and writing skills and their respective income effects (Mancilla-Martinez et al., 2011). Third, there is insufficient understanding of income heterogeneity, especially how language competence interacts with income level and source (Aktuğ et al., 2021). To what extent does National Standard Language Ability (NSLA) influence the income levels of farmers and herdsmen in Xizang, and through what mechanisms does this relationship operate?
To answer this question, we analyze data from the 2021 Annual Livelihood Survey of Farmers and Herders in Xizang, the most comprehensive dataset currently available on rural Tibetan households. Situated within the context of China's evolving “dual circulation” economic strategy, this study highlights the strategic role of NSLA as a form of human capital for improving labor market access, reducing information asymmetry, and enhancing mobility among Tibetan farmers and herdsmen. In doing so, it contributes to the literature on rural development, minority language policy, and economic inequality in multilingual regions.
Theoretical Framework
Language Competence and Human Capital
Language is increasingly recognized as a meta-institution that shapes social and economic behavior across contexts (Zierhofer, 2005). Examining the development and use of language through an economic lens has become a core component of interdisciplinary research on language and development (Block, 2017). According to endogenous growth theory, language competence enhances individual human capital, which in turn contributes to long-term income growth through improved labor productivity and knowledge acquisition (Hanushek, 2012; Kuzminov et al., 2019; Škare & Lacmanović, 2015). In the Tibetan context, where ethnic language use is dominant, strengthening NSLA among farmers and herdsmen is not only a means of improving labor returns but also a key strategy to consolidate poverty alleviation achievements and promote rural revitalization.
As a specific form of human capital, language competence requires deliberate investment—time, financial resources, and effort—but yields considerable economic returns through skill upgrading and social mobility (Erosa et al., 2010; Grubel & Scott, 1966; Rastogi, 2000). Compared to local dialects or minority languages, NSLA holds higher market value in accessing public services, vocational training, and formal labor markets (Liu, 2015; Sasaki, 2017). First, NSLA facilitates the learning and dissemination of agricultural technology and employment-related skills (Arcury et al., 2010), thereby enhancing labor productivity. Second, it expands the social and informational networks of rural populations, fostering greater economic participation and demand responsiveness (Humphrey & Sneath, 1999).
H1: NSLA has a significant positive effect on the income of Tibetan farmers and herdsmen.
Language Competence and Income
Language competence also plays a differential role across income sources and income levels. Prior research has found that operational income (e.g., self-employment or small-scale entrepreneurship) is more sensitive to language skills, due to the need for negotiation, communication, and market engagement (Chiswick & Miller, 1995; Nima, 2019). In contrast, wage income and transfer income depend less directly on communication ability and are thus less influenced by language competence. Furthermore, income heterogeneity effects are evident: language skills may exert diminishing marginal effects at higher income levels, but may also exhibit a strong Matthew effect by reinforcing advantages among the already well-off (Yang et al., 2022). Conversely, improved NSLA may yield particularly strong gains for low-income groups by enhancing basic labor market access (Alobo Loison, 2015; Gollin, 2023; Ozgen et al., 2010).
H2: The effect of NSLA on income varies significantly across income types and income levels, exhibiting heterogeneous impacts.
In addition to the general income-enhancing effect and income heterogeneity across income levels, prior literature also suggests that the impact of language ability may differ significantly across income sources, particularly between operational income and other types of income, such as wages or transfers (Chiswick & Miller, 1995; Nima, 2019). Operational income typically involves higher demands for communication, negotiation, and information processing—all of which rely heavily on language competence. In contrast, wage and transfer incomes tend to be more institutionally stable and less dependent on individual language skills. Therefore, language ability is expected to have stronger income-enhancing effects among those engaged in self-employment or agricultural production activities, relative to those primarily reliant on wage or public transfer income.
H3: The effect of NSLA is more pronounced for farmers and herdsmen whose primary income source is operational income, compared to those reliant on wage or transfer income.
Methods
Data
This study is based on data from the Xizang Livelihood Development Research (XLDR), an annual household survey conducted by the Livelihood Research Center at Xizang University. The 2021 wave, which forms the basis of this study, is currently the only round that includes detailed and multidimensional information on language competence, covering listening, speaking, reading, and writing skills. Earlier waves (2018–2020) lacked complete language variables, while subsequent rounds (2023) significantly reduced language-related questions, making the 2021 dataset the most comprehensive and usable microdata for analyzing NSLA among Tibetan rural populations to date.
The survey employed a multi-stage, stratified sampling design to ensure geographic and economic representativeness. Six prefecture-level cities in Xizang were included (excluding the Ali region due to logistical challenges), covering 59 agricultural and pastoral counties. In the first stage, 17 sample counties were selected: 7 from Lhasa, 3 from Nyingchi, 3 from Nagqu, 2 from Shigatse, and 1 each from Shannan and Chamdo. In the second stage, 72 villages were sampled based on agro-pastoral economic structure. In the final stage, 12 households per village were selected using systematic random sampling from official household registries. In some cases, the number of sampled households was reduced due to extreme geographic or weather conditions; however, village-level representativeness was retained.
The original sample included 834 rural households. For the purpose of this study, we limited the analysis to households whose head was between 18 and 65 years old—reflecting the working-age population—and excluded observations with missing values on key variables such as income or language competence. This yielded a final valid sample of 666 households. Importantly, the language competence data pertain specifically to the household head, who also serves as the primary income earner in the vast majority of Tibetan farming and herding families. Therefore, we treat language competence at the individual (household head) level as representative of the household’s overall linguistic capital, aligning it with the household-level income variable.
Although the data are cross-sectional and limited to a single year, they represent the most detailed, large-scale, and recent survey available on Tibetan rural NSLA. Given the structural stability of language competence—as a form of long-term human capital—and the absence of any major policy or demographic shocks related to language or migration since 2021, the findings retain relevant analytical and policy value.
Measures
The dependent variable in this study is the logarithm of total annual household income. This variable is drawn from the TLDR survey question asking respondents to report their family’s total income in the past year. A logarithmic transformation is applied to mitigate the effects of skewness and potential heteroscedasticity in the distribution of household income.
The core explanatory variable is the NSLA of the household head, measured through four dimensions: listening, speaking, reading, and writing. These components are assessed via self-reported Likert-type items in the TLDR questionnaire. Respondents rate their ability on a five-point scale ranging from 1 (“very poor”) to 5 (“very good”). A composite NSLA index is constructed by averaging the scores across all four dimensions. Given that household heads are typically the main income earners in Tibetan rural families, their language ability serves as a proxy for household linguistic capital. While self-assessment may involve some degree of subjectivity, such self-rated scales have been widely used and validated in previous language economics studies (Chiswick & Miller, 2007). Unfortunately, due to data constraints, we are unable to apply objective language tests or differential weights across dimensions. Nevertheless, the equal-weighted average provides a balanced and interpretable measure of NSLA across respondents.
Following relevant literature (Chen et al., 2023; Sieg et al., 2023), control variables are grouped into three categories: Individual characteristics: gender (male = 1), age (in years), marital status (1 = currently married), education level (ordinal), and self-reported health status (1 = healthy, 0 = otherwise). Household characteristics: total number of family members, and family-level social capital, proxied by whether any household member holds a position in village or township-level governance. Village characteristics: type of agro-pastoral economy (agricultural/pastoral/mixed) and religious environment, measured by the presence of religious landmarks (white stupas or temples) in the village. All control variables are included to account for observable heterogeneity at the individual, household, and community levels that may influence income outcomes.
Analytical Strategies
Given that language ability constitutes a form of human capital, this study adopts a modified Mincer earnings function to examine its income effect among Tibetan farmers and herdsmen (Abbas & Foreman-Peck, 2008). The Mincer model remains a widely applied and parsimonious framework in human capital literature due to its clarity, interpretability, and compatibility with earnings data. The baseline regression model is specified as follows:

Where ln yi is the dependent variable, representing the annual income of the labor force in farmer and herder families (extreme values and logarithmic transformation are applied to address heteroscedasticity); NSLAi represents the composite language ability measurement, denoting the comprehensive score of the farmers and herdsmen's national standard language listening, speaking, reading, and writing abilities; α1 is the coefficient for the core explanatory variable, indicating the impact of the enhancement of comprehensive language ability on income effect; Xki includes a series of control variables that encompass individual characteristics, family characteristics, and village characteristics as specified in the model; εi is the random error term. After testing, the VIF values between the variables in the model are all less than 2, and the average VIF value is only 1.17, based on which it is judged that the model does not have multicollinearity (Kim, 2019).
However, estimation using cross-sectional data introduces potential biases. Specifically, (1) endogeneity bias may arise from omitted variable bias or reverse causality, where higher income may enhance access to language learning opportunities; (2) sample selection bias and unobserved heterogeneity, given the stratified sampling across diverse village types. (3) measurement error, due to the self-reported nature of language ability scores.
To address these concerns, the study employs the following identification strategies: (1) Instrumental Variable (IV) estimation, to correct for endogeneity, we use the survey question “Do you intersperse national standard language words when speaking your ethnic language?” as an instrument for NSLA. This variable, ranging from “never” to “always,” affects NSLA by reflecting exposure and usage frequency, but is unlikely to directly affect household income, satisfying the exclusion restriction. While acknowledging the empirical difficulty of proving perfect exogeneity, this IV is widely used in language economics and grounded in sociolinguistic behavior (Chiswick & Miller, 2007); (2) robustness via Propensity Score Matching (PSM), to address sample selection bias and observable heterogeneity, we apply PSM to compare households with “high” versus “low” NSLA scores. This allows estimation of average treatment effects under more balanced covariate distributions; (3) binary transformation for measurement robustness, to mitigate measurement errors stemming from self-assessment bias, we construct a binary version of NSLA by classifying responses of “average” and below as low language ability, and “good” or “very good” as high ability. This approach follows the “strict definition” technique (Thompson et al., 1999), enhancing the robustness of variable construction.
Results
The descriptive statistics presented in Table 1 outline the key socio-economic characteristics of Tibetan farming and herding households included in the 2021 survey. The overall income level reflects a modest earning group, while the substantial range of income values indicates notable economic heterogeneity within the sample. Household sizes are relatively large, consistent with traditional rural household structures. A high proportion of respondents report the presence of religious landmarks within their villages, reflecting the strong role of cultural and spiritual practices in local communities. Regarding NSLA, self-reported proficiency across listening, speaking, reading, and writing remains moderate on average, suggesting room for improvement in overall NSLA. Among the four dimensions, oral language proficiency appears slightly stronger than other aspects. These descriptive features provide essential context for understanding how individual and household characteristics relate to income outcomes, and serve as the empirical foundation for the econometric analysis that follows.
Descriptive Statistics of All Analytical Variables.

Table 2 presents the OLS regression results examining the effect of NSLA on household income. Across all model specifications, the coefficient for NSLA remains positive and statistically significant at the 1% level, confirming its robust association with income enhancement among Tibetan farmers and herdsmen. Model (1), without controls, yields a relatively inflated coefficient, likely due to omitted variable bias. In Model (2), after accounting for individual-level characteristics, the coefficient for NSLA decreases by 0.045 but remains significant, indicating partial mediation by individual traits. Gender, marital status, and health status are positively associated with income, suggesting their independent contributions to economic outcomes. Model (3) incorporates family-level controls. The NSLA coefficient further declines by 0.045, highlighting the role of household size and social capital in explaining income variation. Both variables are positively associated with income, underscoring the importance of household context in labor returns. In Model (4), village-level factors are added. While the NSLA coefficient remains stable and significant, only a marginal change (–0.01) is observed, indicating limited explanatory power of village-level variation. Notably, religious landmarks at the village level are negatively associated with income, suggesting possible structural constraints linked to social norms or mobility. Overall, the stepwise model enhancement confirms the robustness of the income-enhancing effect of NSLA, even after controlling for multilevel heterogeneity.
OLS Models Predicting Household Income of NSLA.

Notes: Standard deviations are in parentheses; 95% confidence intervals in brackets.
p < .0.1, **p < .05, ***p < .01.
Table 3 reports the regression results for the four components of NSLA—listening, speaking, reading, and writing—estimated separately to examine their individual effects on household income. All four dimensions exhibit positive and statistically significant coefficients at the 1% level, indicating that each aspect of NSLA contributes to income enhancement among Tibetan farmers and herdsmen. Among them, speaking ability demonstrates the largest effect, with a coefficient of 0.125, suggesting that a one-level improvement in speaking proficiency is associated with a 12.5% increase in household income. Listening, reading, and writing abilities also show positive and comparable effects, but with slightly smaller magnitudes. These findings underscore the pivotal role of oral communication in facilitating labor market access, social interaction, and information acquisition in the regional context.
OLS Models Predicting Household Income of Each Dimension of NSLA.

Notes: Standard deviations are in parentheses; 95% confidence intervals in brackets.
p < .0.1, **p < .05, ***p < .01.
Table 4 presents the two-stage least squares (2SLS) regression results addressing potential endogeneity. The first-stage F-statistic exceeds the conventional threshold, confirming the strength of the instrument. In the second stage, the coefficient for NSLA remains positive and statistically significant at the 1% level, consistent with the baseline OLS results. These findings suggest that endogeneity does not bias the main conclusion and reinforce the robustness of the income-enhancing effect of NSLA.
Instrumental Variable Results.

Notes: Standard deviations are in parentheses; 95% confidence intervals in brackets.
p < .0.1, **p < .05, ***p < .01.
Table 5 presents the results of the Propensity Score Matching (PSM) analysis used to address potential selection bias. Three matching algorithms—nearest-neighbor, radius, and kernel matching—are employed to estimate the Average Treatment Effect (ATE). The ATE coefficients for strong NSLA are 0.2041, 0.3974, and 0.2333, respectively, across the three methods, all statistically significant. These results consistently indicate that individuals with higher NSLA enjoy significantly greater income levels than those with weaker NSLA. The robustness across matching techniques reinforces the validity of the core finding: NSLA positively contributes to income among Tibetan farmers and herdsmen.
PSM Estimating Results.

To account for potential measurement error arising from respondents’ subjective self-assessment of NSLA, Table 6 reports the results of a robustness check using a binary classification of NSLA. Following established literature, NSLA is redefined under a stricter criterion, where only responses rated as “average” or above are classified as “good.” The regression results remain positive and statistically significant, closely aligning with the baseline OLS findings. This confirms the robustness of the core conclusion and provides further empirical support for Hypothesis 1—namely, that stronger NSLA is positively associated with higher household income among Tibetan farmers and herdsmen.
NSLA Corrected Estimate Error Base Regression Results.
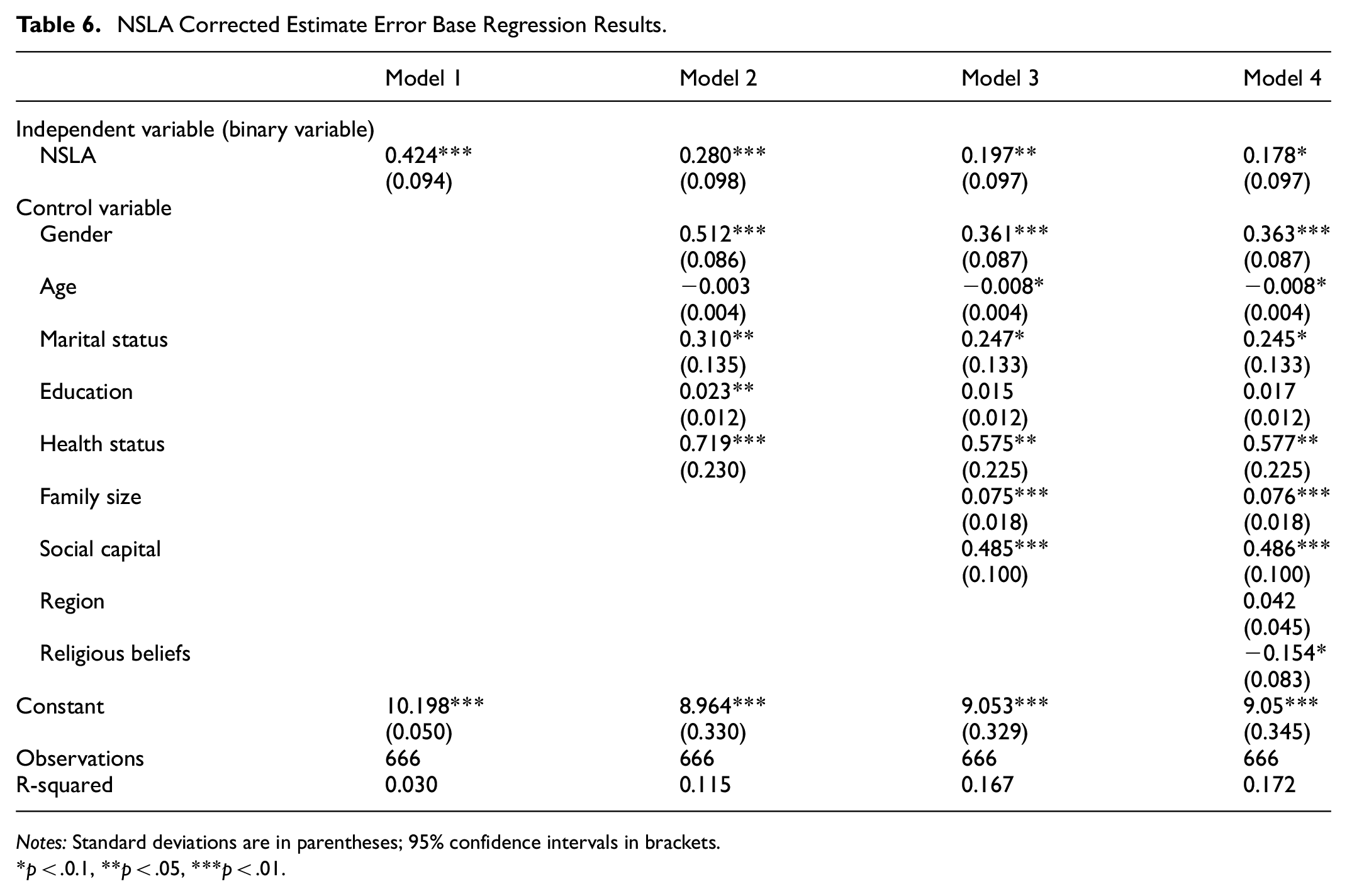
Notes: Standard deviations are in parentheses; 95% confidence intervals in brackets.
p < .0.1, **p < .05, ***p < .01.
Table 7 presents the quantile regression results of NSLA’s impact on income among Tibetan farmers and herdsmen. The analysis spans the 0.1, 0.25, 0.5, 0.75, and 0.9 income quantiles to capture heterogeneity across income levels. Results indicate that at the 10th percentile, NSLA does not have a statistically significant effect on income. However, from the 25th to the 90th percentiles, the effect is positive and significant at the 5% level. Notably, the coefficient of NSLA exhibits a declining trend approaching the 90th percentile.
Quantile Regression Results for Household Income.

Notes: Standard deviations are in parentheses; 95% confidence intervals in brackets.
p < .0.1, **p < .05, ***p < .01.
Table 8 reports the regression results examining the impact of NSLA on various income sources, categorized as wage income, operating income, property income, and transfer income. Given the differing primary income sources among Tibetan farmers and herdsmen, sample sizes vary across income types but remain sufficient for statistical analysis. The results reveal the distinct channels through which NSLA influences income composition.
Regression Results for Different Household Income Sources.

Notes: Standard deviations are in parentheses; 95% confidence intervals in brackets.
p < .0.1, **p < .05, ***p < .01.
The main sources of income of different families in the survey sample are different, so the observed values of the sample will show differences and will not affect the regression results.
Discussion
This study empirically examined the income effects of NSLA among Tibetan farmers and herdsmen using household survey data from the 2021 Xizang Livelihood Development Research (XLDR). Our findings offer nuanced support for the hypothesis that NSLA—especially oral proficiency—constitutes a significant form of human capital that enhances income, while also revealing heterogeneous effects across income sources and income levels.
The baseline regression results confirm a positive and statistically significant relationship between NSLA and household income. This finding is consistent with human capital theory (Becker, 1985; Mincer, 1981), which suggests that investment in skills such as language enhances individual productivity and economic outcomes. In the Tibetan context—where tourism, public services, and communication-based labor are major employment sectors—language skills serve as a critical tool for accessing labor markets and negotiating social capital (Chiswick & Miller, 2007; Lo Bianco, 2010).
Disaggregated analysis further suggests that oral NSLA has the most substantial effect among the four dimensions (listening, speaking, reading, writing). This highlights the central role of spoken communication in facilitating both employment and informal economic activities. Oral fluency reduces information asymmetry, broadens access to social networks, and enhances employability—effects that are particularly salient in rural and semi-formal labor markets (Sieg et al., 2023).
Heterogeneity analysis by income quantiles and income sources reveals a more complex picture. On one hand, the positive effect of NSLA is most pronounced among middle- and lower-middle-income households, supporting the idea of cumulative advantage or the “Matthew Effect” (Yang et al., 2022). On the other hand, the impact diminishes for the highest income quantiles, suggesting that income growth at the upper tail is increasingly driven by non-linguistic forms of capital such as education, assets, or entrepreneurship. More notably, NSLA appears to have little to no effect on income among the lowest-income households. This may reflect multiple constraints: limited labor mobility, low baseline education, and exclusion from networks or markets where language skills can be monetized. These structural limitations diminish the marginal utility of NSLA, suggesting that language interventions alone may be insufficient without broader social and economic inclusion.
Analysis by income type further differentiates the economic role of NSLA. The strongest associations are observed for wage income and transfer income, both of which involve interaction with employers, institutions, or public agencies. In contrast, operational (self-employment) income—largely derived from localized agricultural or herding activities—shows a weaker or non-significant association with NSLA. This is theoretically consistent: economic returns to language are conditional on the presence of market interaction and communication demands, which are more limited in localized subsistence sectors (Farrell et al., 2016; Gao & Smyth, 2011).
The study contributes to the growing literature on language economics and minority development in three important ways. First, it empirically validates the income-enhancing role of NSLA in a context where bilingualism and linguistic segmentation are socially embedded and economically consequential. Second, it distinguishes between different dimensions of language competence, highlighting the centrality of oral skills in low-literacy, high-context labor markets. Third, by analyzing heterogeneity in effects, it offers a more granular understanding of how and when language functions as economic capital, thus expanding the applicability of human capital theory to peripheral and ethnolinguistically diverse regions.
Several limitations warrant caution in interpreting the results. First, the study relies on cross-sectional data from 2021, which, while the most recent wave with comprehensive language indicators, constrains the ability to infer causal directionality or track dynamics over time. Although instrumental variable estimation mitigates some endogeneity concerns, panel data would offer stronger identification and robustness. Second, language proficiency is measured through self-assessed Likert scales, which may be prone to reporting bias. While this approach is commonly used in sociolinguistic and human capital studies, future work could benefit from integrating objective or standardized language testing. Third, NSLA is treated as the primary language competence variable, given the context of national policy and the structure of the TLDR survey. Other forms of NSLA—such as regional dialects, minority scripts, or foreign languages—were not systematically included due to data constraints. While preliminary checks showed limited variation in dialect use around Lhasa and low foreign language exposure among the target group, the exclusion of these dimensions limits the comprehensiveness of the linguistic capital framework. Fourth, the study uses the household head’s NSLA as a proxy for household-level NSLA, based on local labor division norms. While justified in the context of Tibetan agro-pastoral households—where male heads often represent the primary income earners—this approach may overlook intra-household variation, particularly among younger or female members.
Future studies could expand upon this work in several directions. First, with the expected release of newer survey waves, panel data analyses could offer longitudinal insights into how NSLA evolves and influences income trajectories over time. Second, research could investigate gender-specific effects, particularly given the gendered structure of labor and education in Xizang. Third, qualitative or mixed-methods studies could uncover the mechanisms behind the observed heterogeneity, exploring how language interacts with social identity, migration intentions, or institutional trust. Lastly, extending the analysis to other ethnic or peripheral regions in China and beyond could enhance the comparative generalizability of the findings.
Footnotes
Ethical Considerations
This study was conducted in 2021 to survey the socioeconomic conditions of farmers and herders in the Xizang. Formal ethics committee approval was not required, as the research involved non-invasive questionnaire data. Institutional approval was obtained from the Xizang Livelihood Research Center. Written informed consent was obtained from all participants prior to data collection. All procedures complied with the principles of the Declaration of Helsinki and relevant national guidelines.
Consent to Participate
The study posed minimal risk to participants, as all data were irreversibly de-identified and contained no sensitive personal information. The potential societal benefits outweighed any minimal risks. Written informed consent was obtained from all participants prior to data collection, including consent from legal guardians for minors and vulnerable groups.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: National Natural Science Foundation of China (71964031); National Social Science Fund of China (22BMZ126).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
Data are restricted for privacy but accessible via XLRC upon reasonable request.