
Abstract
This study develops a Judicial Vocabulary List (JVL) based on the United States Supreme Court Decision Corpus (SCDC) from 1999 to 2023, addressing the lack of specialized vocabulary resources for legal English. Using Python, we analyzed the SCDC through statistical measures such as normalized frequency, range ratio, dispersion, and frequency ratio to identify high-frequency lemmas. The final JVL comprises 943 lemmas, primarily nouns, verbs, adjectives, and adverbs, covering 22.15% of Supreme Court decision texts. These vocabulary items are essential for understanding American case law. Data collection involved downloading Supreme Court decisions from the official website and cross-referencing them with the LexisNexis database to ensure accuracy. Text processing and cleaning were performed using Python libraries, and the corpus was analyzed using the Spacy library for lemmatization and part-of-speech tagging. Harvard Law Corpus (HLC) and Black’s Law Dictionary served as a reference to validate the relevance of JVL.
The JVL is designed to assist legal English learners, particularly non-native English speakers, in mastering core legal concepts. It also provides educators with a resource to design targeted teaching materials and aids researchers in categorizing and analyzing Supreme Court decisions by legal domain or specific issues. The findings underscore the importance of domain-specific vocabulary in legal education and practice, offering a valuable tool for legal professionals and scholars to study Supreme Court decisions effectively. This research contributes to legal linguistics by providing a detailed, corpus-based vocabulary list that reflects the unique lexical features of Supreme Court decisions.
Plain Language Summary
This study delves into the Supreme Court decisions between 1999 and 2023 to create a list of the most commonly used legal terms, making it easier for students and legal professionals to understand American law. Using advanced computer techniques to analyze official court documents, researchers identified the key words that appear frequently in these rulings. The final list includes 943 essential words like nouns, verbs, and legal terms that often come up in Supreme Court cases. This list is not only a tool for better understanding legal documents but also helps in teaching and studying law more effectively. By knowing these terms, learners can quickly grasp the complex language of legal rulings and better prepare for legal education and practice.
Keywords
Introduction
The formulation, interpretation, and enforcement of law in all societies are fundamentally mediated through language (Goody, 1986, p. 132; Maley, 2014). Legal language, often termed “legalese,” is characterized by its distinctive lexical and structural patterns, setting it apart from conventional forms of communication (Bashir et al., 2018). As Mellinkoff (2004) notes, “The law is a profession of words” (preface), and its language serves as the customary medium for legal professionals in common law jurisdictions where English is the official language.
The study of legal language has a rich academic history, beginning with the foundational work of Mellinkoff (1963), which remains a classic in the field. This body of research has been further developed by scholars such as Tiersma (1999) and Solan et al. (2015), who have expanded the scope of legal language studies by incorporating interdisciplinary insights from fields such as law, linguistics, literature, and history. Solan (1995) notes that the legal profession has a uniquely long-standing tradition of refining language outside academic settings. Bhatia (1987) categorizes legal language into spoken and written forms, with the latter further divided into academic, legislative, and judicial texts. This classification has remained influential and continues to be widely referenced in the field. Extensive research has been conducted on legal language, focusing on its definition, characteristics, functions, and discourse analysis (Alasmary, 2024; Barabucci et al., 2010; Conley et al., 2019; Gibbons, 1999; Lai et al., 2024; Maley, 2014). Tiersma (2006) argues that “legal language is itself a myth … it is a sublanguage of English” (p. 29), often praised for its precision yet criticized for its ambiguity (Mellinkoff, 2004, p. 21). The technical vocabulary of legal English poses significant challenges for learners, particularly in the context of English for Legal Purposes (ELP) and English for Specific Purposes (ESP) education (Bancroft-Billings, 2020; Northcott, 2012).
As Conley et al. (2019) emphasizes, “language is not merely the vehicle through which legal power operates—in many vital respects, language is legal power” (p. 16). The Supreme Court, as the highest judicial authority in the United States, not only adjudicates cases but also shapes and maintains the legal order and constitutional framework of the nation. Its rulings are pivotal in understanding the U.S. legal system and its operations. Judges frequently interpret statutes and legal documents, relying on established legal principles and precedents (Solan, 2010, pp. 13–14). This process often involves linguistic indeterminacy, which can create uncertainty in legal outcomes (Solan, 1986). Therefore, acquiring domain-specific vocabulary is essential for learners to understand and engage with legal knowledge (Baumann & Graves, 2010).
Given that Supreme Court decisions are binding on lower federal and state courts, these rulings are central to legal education, providing students and scholars with critical resources for learning legal principles and analyzing legal issues (Solan, 2010, p. 14). As Mellinkoff (2004) asserts, “To be of any use, the language of the law (as any other language) must not only express but convey thought” (preface). Understanding legal cases is crucial for learners to grasp the deeper meanings of legal principles (Tiersma, 1999).
Based on Bhatia’s (1987) classification of legal language, this research, focusing on the judicial texts of U.S. Supreme Court decisions, seeks to generate a high-frequency vocabulary list, that will serve multiple purposes. First, it will assist legal language learners, particularly those for whom English is a second language, in understanding core legal concepts and principles. Second, it will enable educators to design more targeted teaching materials, enhancing instructional effectiveness. Third, the vocabulary list will facilitate the categorization and archiving of Supreme Court decisions by legal domain (e.g., criminal law, civil law, constitutional law, administrative law) or specific issues (e.g., equal protection, free speech), aiding researchers in efficiently locating and analyzing relevant cases and legal principles.
Literature Review
Academic Vocabulary
Academic vocabulary refers to lexical items that are frequently used across a wide range of academic texts but are relatively uncommon in non-academic contexts (Coxhead & Nation, 2001). Academic vocabulary has sometimes been called sub-technical vocabulary because it does not contain technical words but rather formal vocabulary (Nation, 2001). These words are essential for organizing scientific discourse and building the rhetoric of academic texts (Paquot, 2010). Academic vocabulary is considered the most important factor in increasing learners’ lexical competence, critical thinking, and making decisions (Khalilova, 2023). It can be categorized into general academic vocabulary, which is common across various disciplines, and domain-specific academic vocabulary, which is closely related to particular fields of study (Baumann & Graves, 2010).
General academic vocabulary refers to words that appear frequently across multiple disciplines or academic domains (Baumann & Graves, 2010). These words “are used across content areas, have abstract definitions, and are a challenge to master” (Townsend, 2009, p. 242). For instance, terms such as “analyze,” “distribution,” and “indicate” are essential for higher education, regardless of the specific field of study. Coxhead (2000) termed these words academic words and defined them as “lexical items [that] occur frequently and uniformly across a wide range of academic material” (p. 218). Based on college-level academic reading materials published in New Zealand and Britain, Coxhead compiled a corpus of 3.5 million running words and created a word list consisting of 570 word families. This list “provides educators and researchers with a sound, empirically based set of words” (Baumann & Graves, 2010, p. 7).
Domain-specific academic vocabulary, also referred to as technical vocabulary (Fisher & Frey, 2008) or content-specific vocabulary (Hiebert & Lubliner, 2008), encompasses terms and expressions commonly found in content area textbooks and other technical writing. This specific academic vocabulary is widely recognized as the most prevalent form within academic contexts, comprising highly specialized and context-dependent terms such as “kinetic energy” in physics or “periodic table” in chemistry.
Academic vocabulary has been a focal point of extensive scholarly research over the past decades, with numerous studies highlighting its critical role in various language skills and academic success (Gardner & Davies, 2014; Nagy & Townsend, 2012). Mastery of academic vocabulary is essential for non-native English speakers, particularly learners of English for Academic Purposes (EAP) and English as a Medium of Instruction (EMI), as it enables them to navigate complex academic texts, lectures, and seminars, which are integral components of university study (Dang et al., 2017; Hyland & Tse, 2007; Nation, 2001). Furthermore, vocabulary knowledge is strongly correlated with academic achievement, as it allows learners to comprehend discipline-specific materials, contribute effectively to the construction and dissemination of knowledge, and express their ideas clearly and persuasively (Masrai & Milton, 2021; Nagy & Townsend, 2012; Nation, 2001).
Nagy and Townsend (2012) emphasize that academic vocabulary is a core component of academic language, and the ability to read and understand texts across various disciplines is deeply tied to students’ vocabulary knowledge. They also highlight the pivotal role of educators in supporting learners’ understanding and application of discipline-specific language. Nation (2001) further stresses that acquiring English vocabulary is one of the most critical tasks for English learners, as insufficient vocabulary knowledge can lead to significant challenges in both academic and professional contexts. For instance, a medical student’s misunderstanding of key terms such as “analysis” could have serious consequences. Additionally, Harmon et al. (2005) point out that students may struggle to grasp fundamental concepts in their subjects if they lack adequate vocabulary knowledge. Thus, academic vocabulary serves as a foundational element for both language acquisition and academic success in higher education contexts. As a critical component of written and spoken discourse across disciplines such as science, history, and literature, academic vocabulary enables scholars and students to engage in meaningful learning and critical thinking within their respective fields.
Learning academic vocabulary presents significant challenges for non-native students, as these words appear less frequently in every language and are difficult to acquire incidentally. Research has demonstrated that learning academic words enhances learners’ ability to comprehend academic texts far more quickly than acquiring low-frequency general vocabulary (Coxhead, 2000; Nation & Waring, 1997; Nation & Webb, 2011). Unfortunately, the mechanisms underlying the learning of vocabulary through written production remain largely unexplored (Silva et al., 2024). University students often fail to master academic words even after years of study at English-medium universities (e.g., Knoch et al., 2015; Zhang & Lu, 2014). Consequently, researchers have developed various academic word lists to assist students in learning these words more effectively.
Academic Vocabulary List
The development of academic word lists has a long history, beginning with the University Word List (UWL) created by Xue and Nation (1984). The UWL was compiled by combining several earlier lists and included 836 word families that were deemed essential for university-level study. However, the UWL was criticized for its lack of consistent selection principles and the small size of the corpora used for its compilation (Coxhead, 2000).
In response to these criticisms, Coxhead (2000) developed a major UWL, using a 3.5 million word text corpus to create a more systematic version of the Academic Word List (AWL), which has since become a standard resource for EAP learners and educators. The AWL was created using a larger and more balanced corpus of academic texts, and it introduced a more rigorous methodology for word selection, including criteria for frequency, range, and uniformity (Coxhead, 2000). The AWL has been widely used in EAP curricula and has influenced the development of other academic word lists, such as the Academic Vocabulary List (AVL) by Gardner and Davies (2014) and the Academic Spoken Word List (ASWL) by Dang et al. (2017).
The AVL, for example, was developed using a 120-million-word academic subcorpus of the Corpus of Contemporary American English (COCA) and includes 3,000 word families that are highly frequent and widely distributed across academic texts (Gardner & Davies, 2014). The AVL addresses some of the limitations of the AWL by including general high-frequency words that have special meanings in academic contexts and by providing a more comprehensive coverage of academic vocabulary.
The need for discipline-specific academic word lists has led to the development of several specialized lists, such as the Business Word List #1 (BWL#1; Konstantakis, 2007), the Pharmacology Word List (Fraser, 2007), the Medical Academic Word List (MAWL; Wang et al., 2008), the Science Word List (SWL; Coxhead & Hirsch, 2007), the Computer Science Word List (CSWL; Minshall, 2013), the Chemistry Academic Word List (CAWL; Valipouri & Nassaji, 2013), the Nursing Academic Word List (NAWL; Yang, 2015), the Accounting Academic Word List (AAWL; Khany & Kalantari, 2021), the Medical Academic Vocabulary List (MAVL; Lei & Liu, 2016), the Science Academic Word List (SAWL; It-ngam & Phoocharoensil, 2019), the Economics Academic Word List (EAWL; O’Flynn, 2019), and the Computer Science Academic Vocabulary List (CSAVL; Roesler, 2021). These lists are designed to meet the specific vocabulary needs of learners in particular fields and provide a more targeted approach to vocabulary learning.
Research on legal academic vocabulary lists has made significant strides over the past few decades, particularly in the fields of legal linguistics, legal informatics, and legal education. The earliest study on legal vocabulary list can be traced back to McIlhenney (1954) and her work, The Most Frequently Used Legal Words and Phrases. Her study aimed to provide a core legal vocabulary list for legal secretaries and stenographers to support their work in legal dictation and transcription. McIlhenney extracted six lists of high-frequency legal words and phrases by analyzing a sample of cases from the 13 western states comprising the Pacific District of the United States Circuit Court of Appeals, with the total number of running words slightly exceeding 600,000. The study emphasized the importance of these words in legal documentation. Although its primary purpose was to support the training of legal secretaries, its methodology laid the groundwork for subsequent research on legal vocabulary lists (McIlhenney, 1954).
In recent years, corpus-based research on legal vocabulary has gradually become mainstream. Alasmary (2019) proposed the Written Academic Legal Vocabulary list (WALV) by analyzing a corpus of academic legal texts. Using criteria such as frequency, range, and keyness, the study identified 298 core word families and found that nouns dominate legal academic texts. This vocabulary list provides an important reference for teaching legal English (Alasmary, 2019). Additionally, Bancroft-Billings (2020) focused on spoken technical vocabulary in law school classrooms. Kemp (2022) expanded the scope of legal vocabulary research by concentrating on academic vocabulary in the field of international law. By constructing a corpus (DSVC-IL) encompassing 12 domains of international law, the study extracted 1,026 core word families and demonstrated their representativeness in international legal texts. This research not only supports the improvement of reading skills for international law students but also offers new perspectives on methodologies for studying legal vocabulary (Kemp, 2022).
Research on legal academic vocabulary has evolved from early frequency-based analyses to multidimensional, corpus-based studies, achieving significant progress in the field of international law. However, existing studies still have limitations, such as the restricted coverage of vocabulary lists and their focus on general legal vocabulary or specific legal genres, leaving a notable gap in the study of judicial vocabulary, particularly in the context of U.S. Supreme Court decisions. The primary research gap identified in this study is the lack of a detailed, corpus-based judicial vocabulary list that captures the unique lexical features of U.S. Supreme Court opinions. This study aims to address this gap by constructing a Judicial Vocabulary List (JVL) based on Supreme Court decisions. Our research fills an important gap in the learning and teaching of JVL. The research questions guiding this study are as follows:
To answer RQ1, we constructed the Supreme Court Decision Corpus (SCDC) by collecting all U.S. Supreme Court decisions issued between 1999 and 2023 from the official Supreme Court website and cross-referencing them with the LexisNexis database to ensure accuracy and consistency. The corpus was processed and cleaned using Python libraries, and lemmatization and part-of-speech tagging were performed using the Spacy library. We then analyzed the corpus using quantitative metrics, including normalized frequency, range ratio, dispersion, and frequency ratio, to identify the most frequently used lemmas and their distribution across different parts of speech (e.g., nouns, verbs, adjectives, adverbs). This approach allowed us to systematically extract high-frequency lemmas that are representative of the unique lexical features of Supreme Court decisions, ensuring that the resulting JVL captures the core vocabulary essential for understanding judicial texts.
To answer RQ2, we compared the coverage of JVL with other established academic vocabulary lists, including AWL, AVL, and WALV. We standardized all vocabulary lists to the lemma level using tools such as Familizer/Lemmatizer and the Oxford English Dictionary to ensure comparability. We then calculated the coverage of each list in both the SCDC and the Harvard Law Corpus (HLC), a reference corpus comprising 5 million words. By analyzing the coverage rates of these lists in legal corpora and cross-referencing with Black’s Law Dictionary, we were able to assess the relative effectiveness of the JVL in capturing the specialized vocabulary of U.S. Supreme Court decisions. This comparative analysis highlighted the superior coverage of the JVL in judicial texts, demonstrating its relevance and utility for legal language learners and researchers.
By addressing these questions, this study seeks to provide a valuable resource for non-native English-speaking law students and international legal practitioners who speak English as an additional language, legal English teachers and scholars studying Anglo-American law, enhancing their understanding and mastery of the specialized vocabulary used in U.S. Supreme Court decisions.
Methodology
This section outlines the methodology used to construct SCDC and compile the JVL. The process is divided into four main steps: (1) data collection, (2) data processing and cleaning, (3) data analysis and vocabulary selection, and (4) validation and comparison. Each step is described in detail to ensure clarity and rigor.
Data Collection
The research data for this paper were sourced from the official website of the U.S. Supreme Court (see https://www.supremecourt.gov/opinions/opinions.aspx). We downloaded all the opinions of the Supreme Court issued between 1999 and 2023 from the website to ensure the completeness of the dataset and the inclusion of recent decisions. The 25-year span (1999–2023) was selected to capture both historical and contemporary linguistic patterns in Supreme Court decisions, ensuring that the vocabulary list reflects both enduring legal terminology and recent developments.
To ensure data accuracy and consistency, we cross-referenced the Supreme Court opinions with the LexisNexis database (https://www.lexisnexis.com/en-us). Since the Supreme Court website provides decisions in PDF format, which can yield low accuracy during text extraction, we manually extracted citation information from the PDFs and used these citations to download the corresponding cases in Microsoft Word format from LexisNexis. This process ensured the reliability of the data for subsequent text processing and analysis.
Additionally, we utilized HLC, a reference corpus comprising 5 million words from the Caselaw Access Project (https://case.law/), to validate the coverage and relevance of the JVL in a broader legal context.
Data Processing and Cleaning
The collected data were processed and cleaned using Python libraries to prepare the corpus for analysis. The steps included:
(1) Text extraction: We used the python-docx library to extract text from the Microsoft Word documents.
(2) Text cleaning: Headers, footers, footnotes, and whitespace characters were removed to ensure the text was clean and ready for analysis.
(3) Tokenization and lemmatization: The cleaned text was processed using the Spacy library (https://spacy.io/usage/linguistic-features) for sentence segmentation, tokenization, lemmatization, and part-of-speech tagging. This step standardized the text by reducing words to their base forms (lemmas) and tagging them with their respective parts of speech (e.g., nouns, verbs, adjectives, adverbs).
(4) Corpus formatting: The final corpus was stored in the Corpus Workbench format, with one word per line. The surface form of each word was placed in the first column, and token-level annotations (e.g., lemma, part of speech) were added as additional TAB-separated columns.
Ultimately, we created the SCDC (1999–2023). As shown in Table 1, over a 25-year span, the distribution of text numbers, types, and tokens per year is relatively uniform. The total word count of the corpus exceeds 15 million.
Overview of SCDC.

We conducted a study on the characteristics of the most frequently used lemmas in SCDC. As illustrated in Figure 1, the frequency of legal words is roughly inversely proportional to their rank in the frequency table, which aligns with Zipf’s Law (Zipf, 1949). Furthermore, when the frequency rank is low, the additional coverage is also limited. It is also evident that acquiring the first 10,000 lexical units can achieve 95% coverage, but it falls short of reaching 98% coverage.

Cumulative Percentage of High-Frequency Words in SCDC.
Data Analysis and Vocabulary Selection
This study relies on quantitative indicators to determine the judicial vocabulary list. The metrics used include normalized frequency, range ratio, dispersion, and frequency ratio. Each metric is defined and illustrated with an example to demonstrate its application in the selection process.
(1) Normalized frequency refers to the occurrence of a word or lemma per million words or lemmas in a corpus. This metric standardizes word frequency across corpora of different sizes, enabling meaningful comparisons.
In the SCDC, the lemma “deem_verb” appears 1,644 times, which means “deem_verb” occurs 108.87 times per million words in the SCDC (1,644/15,100,089 × 1,000,000 = 108.87).
(2) Range ratio measures the proportion of sub-corpora in which a lemma appears at least once, with a frequency of at least 20% of its expected frequency in each sub-corpus (Gardner & Davies, 2014). The SCDC is divided into 25 sub-corpora by year, and the range ratio ensures that a lemma is distributed across multiple time periods.
For example, if the lemma “fairness_noun” is distributed across all 25 sub-corpora, its range ratio is 25/25 = 1; if “punitive_adj” is distributed in 19 sub-corpora, its range ratio is 19/25 = 0.76.
(3) Dispersion (Juilland’s D; Juilland & Chang-Rodriguez, 1964) measures the evenness of a lemma’s distribution across a corpus. It ranges from 0.01 to 1.00, where 0.01 indicates a highly concentrated distribution and 1.00 indicates a perfectly even distribution. Dispersion D uses the proportion of lemmas rather than raw frequency counts, thus not requiring uniform sub-corpus sizes. Dispersion provides valuable information on whether a word is evenly distributed or concentrated within the corpus, offering insights into its distribution pattern. In contrast, range ratio primarily reveals the proportion of a corpus a word exists in but does not provide information on the uniformity of its distribution.
For instance, if a lemma appears in all 25 sub-corpora with a frequency above or equal to 20% of the expected frequency, its range ratio is 1, but it might appear far more frequently in some sub-corpora than in others. In such cases, the dispersion might be low, and the lemma might be excluded from the final judicial vocabulary list. For example, the lemma “partial_adj” has a range ratio of 1 but a low dispersion, thus failing to meet the selection criteria and not included in the final judicial vocabulary list.
(4) Frequency ratio is the ratio of a word’s normalized frequency in the target corpus to that in a reference corpus (Gardner & Davies, 2014). This study uses COCA as the reference corpus, representing contemporary American English with a diverse genre and substantial corpus size (Davies, 2009). Since COCA is dynamically updated with new content annually, the size of the corpus accessed at different times may vary. The COCA corpus used in this study, up to 2019, contains approximately 783 million words after removing sentences with “@” symbols.
If the frequency ratio is less than 1, it indicates a lemma is more inclined to appear in the reference corpus, that is, more common in general English; a frequency ratio equal to 1 suggests a lemma is used similarly in both legal and general contexts; a frequency ratio greater than 1 indicates a lemma appears more frequently in legal settings.
For example, the lemma “liable_adj” has a normalized frequency of 61.33 in SCDC, while it has a normalized frequency of 4.0 in COCA, thus the frequency ratio is 15.29, indicating its prevalence in legal contexts. The lemma “faith_noun” has a frequency ratio of 1.08 in both the SCDC and COCA, suggesting similar usage in legal and general contexts, thus it is not included in the judicial vocabulary list.
We used the NumPy package to implement these four metrics, allowing the vocabulary list to be reproducible and comparable with other studies using the same quantitative metrics but different corpora or threshold standards. Additionally, these metrics provide researchers, teachers, and learners with useful information about word usage in the corpus.
It should be noted that when using quantitative metrics to compile a vocabulary list, the setting of thresholds does not have recommended values and is determined through repeated adjustments by scholars, a process known as parameter optimization (Gardner & Davies, 2014; Lei & Liu, 2016).
In the process of developing JVL, parameter tuning played a critical role in determining the appropriate thresholds for key statistical measures such as frequency ratio, range ratio, and dispersion. Previous studies in corpus-based vocabulary list development have often relied on iterative experimentation to establish these thresholds. For instance, Gardner and Davies (2014) conducted extensive trials, testing frequency ratio values ranging from 1.2 to 2.0, and observed how adjusting these values affected the inclusion or exclusion of words in their academic core list. Similarly, Lei and Liu (2016) employed a trial-and-error approach to determine optimal thresholds, ensuring that the resulting vocabulary list accurately reflected the lexical characteristics of their target corpus.
In this study, we adopted a similar methodology, iteratively testing and refining threshold values for each statistical measure to ensure the JVL captured the most representative and high-frequency lemmas in Supreme Court decisions. For normalized frequency, we explored values ranging from 25 to 40, increasing in increments of 1, while range ratio was tested within 0.5 to 1, with 0.1 increments. Additionally, dispersion values were evaluated across 0.5 to 0.8, increasing by 0.1 at each step. Frequency ratio was set between 1.2 and 2.0, with increments of 0.1 applied at each step. This process involved analyzing how changes in thresholds influenced the composition of the vocabulary list, balancing precision and coverage to create a resource that is both comprehensive and domain-specific. By leveraging insights from prior research and applying a systematic approach to parameter tuning, we ensured the robustness and reliability of the JVL.
Validation and Comparison
To validate the JVL, we compared its coverage in the SCDC and the HLC with other established academic vocabulary lists, including AWL, AVL, and WALV. The AWL and AVL are academic vocabulary lists applicable across various disciplines, while the WALV specifically targets legal academia.
Given that each vocabulary list uses different basic units, we standardized all lists to the lemma level for comparison. A word family is composed of a headword along with its derived and inflected forms that can be comprehended by learners without the necessity of learning each form independently (Bauer & Nation, 1993; Nation, 2001). A lemma represents a type of word family where the members include the headword and its inflected forms, all belonging to the same part of speech (Bauer & Nation, 1993; Hirsh & Nation, 1992). Conversely, a flemma is a broader category of the word family, encompassing a headword and its inflected forms across different parts of speech (Nation, 2016; Pinchbeck, 2014). Flemmas generally encompass a greater number of members compared to lemmas.
We utilized Familizer/Lemmatizer Tools V2.5 (see https://www.lextutor.ca/familizer/) to convert headwords into word families and then transformed these into flemmas. Lastly, we used the Oxford English Dictionary to convert flemmas into lemmas.
Results
We set the threshold for normalized frequency at 32, the range ratio at 0.6, the dispersion at 0.7, and the frequency ratio at 1.5. Ultimately, 943 lemmas that met these threshold conditions collectively form the JVL.
Selected Lemmas and Their Distribution by Part of Speech (Addressing RQ2)
The lemmas are categorized according to parts of speech, as shown in Table 2. The results indicate that the vocabulary is predominantly nouns (including pronouns), accounting for about 52.2% of the list. This is followed by verbs, adjectives, and adverbs in decreasing order. Additionally, the vocabulary includes some abbreviations.
Part-of-Speech Distribution in JVL.
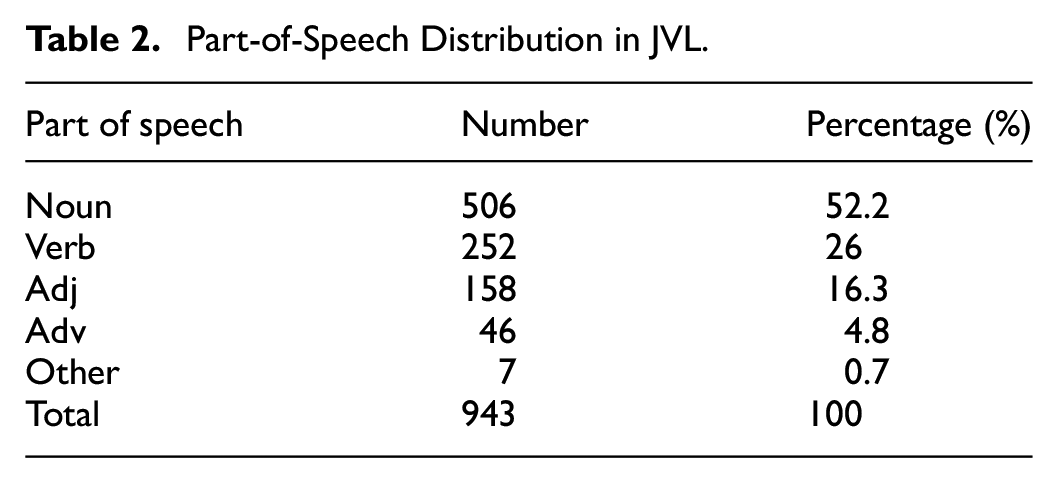
Nouns
As seen from Table 2, it is evident that the frequent use of nouns, particularly those related to law, cases, regulations, procedures, and rights, is a prominent feature of judicial vocabulary. Some nouns appear capitalized at the beginning of sentences in court decisions, in lowercase within the text, and in all caps when emphasizing the opinion of the court. This indicates that the same word can have different forms depending on its position in the text, yet it does not affect the fact that it represents the same word. For instance, the noun “court” appears in the corpus in three forms: “court” appears 57,025 times, “Court” 86,794 times, and “COURT” 1,721 times. Despite the variation in form, these represent the same word and should be aggregated as a high-frequency word in the SCDC.
Additionally, the opinions contain a substantial number of nouns representing legal jargon (such as “victim,” “review,” “decree,” “habeas,” “abuse,” “damages,” “immunity,” “felony,” “plea,” “remedy”), case descriptions (“plaintiff,” “defendant,” “petitioner,” “respondent,” “appeal,” “issue,” “judge,” “dissent,” “motion”), and regulations (“tort,” “regulation,” “clause,” “legislature,” “ruling”). This illustrates the Supreme Court justices’ seriousness and precision in their choice of words in decisions.
Verbs
Verbs, appearing second most frequently in the vocabulary list, underscore the legal force and binding nature of the decisions, with terms like “verdict,” “dissent,” “concur,” “deny,” “reject,” “prohibit,” and “demonstrate. “ However, there are many instances where verbs are used as nouns, indicating a nominalization process in judicial texts (Williams, 2004), such as “sentence,” “permit,” “leave,” “count,” “file,” “address,” “act,” “issue,” “order,” “record,” “notice,” etc.
Adjectives and Adverbs
Adjectives and adverbs, while less frequent than nouns and verbs, play a crucial role in judicial texts by adding precision, nuance, and emphasis to the language used in court decisions. Adjectives are often employed to describe case details, legal principles, or the characteristics of the parties involved. Common adjectives include “equal,” “potential,” “basic,” “initial,” “legitimate,” “valid,” “essential,” and “qualified.” These terms help to clarify the nature of the legal issues at hand, such as whether a claim is “valid” or whether a party has a “legitimate” interest in the case.
Adverbs, on the other hand, are used to modify verbs, adjectives, or other adverbs, often indicating the manner, degree, or frequency of an action or condition. Examples include “clearly,” “directly,” “explicitly,” “generally,” “reasonably,” and “sufficiently.” These adverbs are particularly important in judicial texts because they help to convey the court’s reasoning and the strength of its conclusions. For instance, a court might state that a law “clearly” violates constitutional rights or that a decision is “sufficiently” supported by the evidence.
Others
The vocabulary also includes abbreviations, which are critical for students to learn and understand when studying cases. Without proper explanation, these could cause misunderstandings. The Supreme Court decisions utilize a variety of abbreviations to simplify complex legal expressions. These abbreviations can be categorized into three types: (1). Case Compilation Abbreviations: for example, Atlantic Reporter (A.), Federal Reporter (F.). (2). Legal Citation Abbreviations: for example, Federal (Fed.), Republic (Rep.), Confer (Cf.). (3). Court and Litigation Related Abbreviations: for example, Court (Ct.), Judge (J.), Judges (JJ), Versus (V.). Understanding these abbreviations and their uses is essential for effectively navigating and interpreting judicial texts.
Comparison With AWL, AVL, and WALV (Addressing RQ2)
As presented in Table 3, the AWL comprises 570 word families, which encompass 3,107 distinct word forms. Subsequently, 2,071 flemmas were identified from these word forms. These flemmas were then converted into 2,453 lemmas using the Oxford English Dictionary. Similarly, the WALV list, containing 498 headwords, was transformed into word families, resulting in 386 word families comprising 2,646 word forms. Following this, 1,667 flemmas were extracted from these word forms and subsequently converted into 1,967 lemmas through the Oxford English Dictionary.
Coverage of Vocabulary Lists in Legal Corpora.
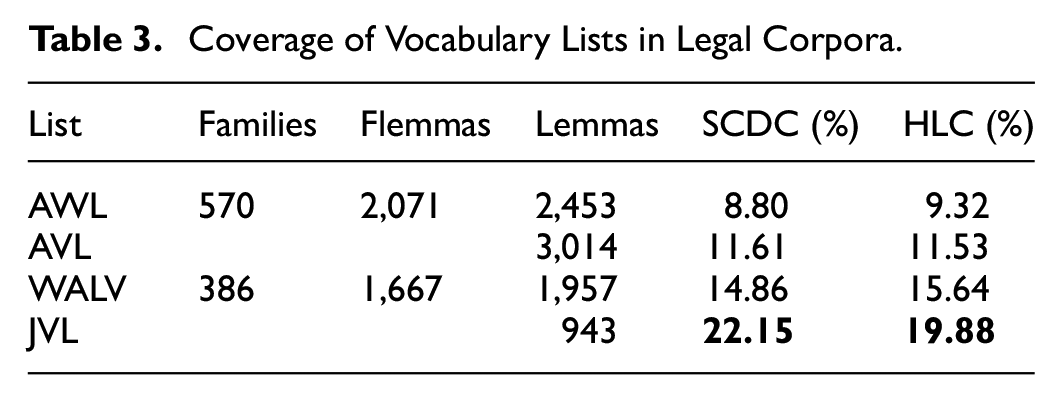
Table 3 presents several noteworthy findings regarding the coverage of vocabulary lists across different corpora. The AVL initially comprised 3,015 lemmas, but during the deduplication process implemented through a Python program, a duplication of the lemma “disproportionately_adv” was identified. Following the removal of this duplicate entry, the final list was reduced to 3,014 lemmas, ensuring data integrity for subsequent analyses.
The comparative analysis reveals significant insights into the performance of various vocabulary lists. The AWL demonstrates consistent coverage across two different corpora, with percentages of 8.8% and 9.32%, closely mirroring Coxhead’s (2000) reported coverage of 9.4% in a legal sub-corpus. Similarly, the AVL exhibits coverage rates of 11.61% and 11.53% in the SCDC and HLC corpora respectively, slightly lower than the approximately 14% coverage reported by Gardner and Davies (2014) in the BNC and COCA academic corpora. The WALV outperforms these lists with higher coverage rates of 14.86% and 15.64% in the examined corpora, exceeding the 13.9% coverage reported in its source corpus by Alasmary (2019).
Particularly noteworthy is the performance of the JVL developed in this study, which demonstrates superior coverage in judicial texts. Compiled from a selection corpus 1.5 times larger than that used for the WALV and a reference corpus nearly tenfold in size, the JVL achieves the highest coverages in the SCDC and HLC corpora, reaching 22.15% and 19.88% respectively (in bold). This finding aligns with the results reported by Lei and Liu (2016) in their medical corpus study, where their medical academic vocabulary list also achieved around 20% coverage. The consistent performance of specialized vocabulary lists across different academic domains suggests that corpus size and domain specificity are crucial factors in developing effective academic vocabulary resources. These results not only validate the methodological approach adopted in this study but also highlight the potential of domain-specific vocabulary lists in enhancing academic language learning and research.
To further validate the effectiveness of the JVL, we compared it with Black’s Law Dictionary, “the most cited law dictionary in United States Supreme Court opinions” (Hellyer, 2005, p. 158). The results showed that 634 out of 943 lemmas (approximately 67.2%) were included in Black’s Law Dictionary. This finding aligns with the study by Kamrotov et al. (2022), who compared the Russian Economics Word List (REWL) with two economics dictionaries and found that 315 lemmas (62.1%) were mentioned in at least one of the dictionaries. This suggests that the JVL not only covers legal terminology but also includes high-frequency core vocabulary used in legal texts, providing essential reference material for learners of legal English.
Conclusion
This study developed JVL based on SCDC from 1999 to 2023, addressing the critical gap in specialized vocabulary resources for legal English. The findings of this research not only respond to the initial research questions but also contribute significantly to the field of legal linguistics and ESP education.
The first research question (RQ1) aimed to identify the most frequently used lemmas in U.S. Supreme Court decisions and their distribution across different parts of speech. Through rigorous corpus analysis using normalized frequency, range ratio, dispersion, and frequency ratio, we identified 943 high-frequency lemmas, predominantly nouns, verbs, adjectives, and adverbs. These lemmas cover approximately 20% of Supreme Court decision texts, reflecting the unique lexical features of judicial language. The second research question (RQ2) sought to compare the coverage of the JVL with other established academic vocabulary lists, such as AWL, AVL, and WALV. Our analysis demonstrated that the JVL provides superior coverage in judicial texts, capturing specialized vocabulary essential for understanding Supreme Court decisions. This comparative analysis underscores the relevance and utility of the JVL for legal language learners and researchers.
This research contributes new knowledge to the field of legal linguistics by providing a detailed, corpus-based vocabulary list that reflects the unique lexical features of Supreme Court decisions. Unlike previous studies that focused on general legal vocabulary or specific legal genres, the JVL specifically targets the judicial language of the U.S. Supreme Court, filling a notable gap in the literature. By leveraging advanced computational tools and methodologies, this study offers a systematic approach to identifying and analyzing domain-specific vocabulary, setting a precedent for future research in legal corpus linguistics. Furthermore, the JVL serves as a valuable resource for legal professionals, scholars, and educators, enhancing their ability to study and teach U.S. Supreme Court decisions effectively.
The JVL is a valuable tool for legal English instruction. Educators can use the JVL to design targeted vocabulary lessons, focusing on the most frequent words in Supreme Court decisions. As Coxhead (2011) notes, vocabulary instruction should align with learners’ needs. For non-native legal English learners, mastering the JVL enhances their ability to read and analyze complex texts. Strategies like meaning-focused input (e.g., reading judicial opinions) and language-focused learning (e.g., explicit instruction on word meanings) can help students internalize the vocabulary (Nation, 2007). The JVL can also be integrated into legal English curricula to develop reading exercises, writing tasks, and oral discussions centered on Supreme Court cases. Tongpoon-Patanasorn (2018) emphasizes the importance of frequency-based word lists in curriculum design, ensuring learners encounter relevant vocabulary. Additionally, the JVL can be used for assessments, such as vocabulary tests and quizzes, to measure progress and provide feedback. Coxhead (2011) highlights the role of formative assessment in identifying areas for improvement. Breeze (2015) helps students become familiar with legal vocabularies and expressions by creating exercises. By incorporating the JVL into teaching and assessment, educators can support learners in building the lexical competence needed for legal studies and practice.
While this study provides a comprehensive vocabulary list for Supreme Court decisions, it is not without limitations. First, the study focuses on written judicial texts and does not address spoken legal language, such as courtroom discourse or legal lectures. Incorporating spoken legal corpora could provide a more holistic understanding of legal vocabulary. Second, the JVL is limited to lemmas and does not account for multi-word expressions or collocations, which are often critical in legal language. Future studies could explore the development of a collocational or phraseological list to complement the JVL.
Footnotes
Acknowledgements
The authors would like to thank the editor and the anonymous reviewers for their insightful comments, which have greatly improved the quality of the manuscript.
Ethical Considerations
This article does not contain any studies with human or animal participants.
Author Contributions
G.H.: writing—original draft. L.L.: data curation, writing—original draft & review. J.G.: conceptualization, Writing—review & editing.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Planning Fund Project of the Ministry of Education of China (
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The datasets presented in this article are not readily available because they can be used for academic purpose only. Requests to access the datasets should be directed to the corresponding author.