
Abstract
The article offers an in-depth lexical analysis of the listening sub-test of the famous International English Language Testing System (IELTS). The vocabulary profile of 239 listening transcripts from 60 IELTS official practice tests were analyzed. The results showed that, 3,000 most frequent word families in the British National Corpus/Corpus of Contemporary American English (BNC/COCA) word list were necessary to safely gain 95% coverage of all four sections in the test. Meanwhile, a vocabulary knowledge at the 5,000 level would secure the 98% coverage. The study also reveals that, with the support of 570 word families from the Academic Word List (AWL), learners only need to be familiar with 2,000 word families to achieve 95% coverage of the first, second, and third listening sections, equaling 75% of the IELTS listening test. The differences in lexical demands between listening sections were also highlighted.
Introduction
In the age of globalization, English language proficiency could be seen as a key for people’s success in most aspects of life including education, employment and even immigration (Fernandez, 2018). For English-medium universities, the English language proficiency level of international applicants is viewed as the second most important admission criterion, only after academic performance (Phakiti, 2016). Evidence for English language proficiency could be obtained by taking the International English Language Testing System (IELTS) which was jointly developed and managed by the British Council and IDP Australia (Pearson, 2019). In the four sub-tests of the IELTS, the listening comprehension subtest have been viewed as intensive and overwhelming for test takers due to its one-time and read-listen-write format (Alavi et al., 2018; Field, 2005). Taking the listening part in such format means that test takers have to focus simultaneously on three language skills: listening, reading, and writing, which is really demanding in terms of cognitive processing (Aryadoust, 2012; Alavi et al., 2018).
Among several factors affecting listening comprehension, vocabulary knowledge could be deemed as the decisive element (Nation, 2013; Newton & Nation, 2021). Over decades, lots of efforts have been put into the investigation of the correlation between vocabulary and listening comprehension, and for most of the time, all discussions came down to the same conclusion that larger vocabulary knowledge generally leads to better listening comprehension (Ha, 2021b; Lange & Matthews, 2020; Cheng & Matthews, 2018; Stæhr, 2008, 2009; Van Zeeland & Schmitt, 2013). Researchers have also spent years to examine the number of words needed to understand various types of spoken texts (Nation, 2006; Nurmukhamedov, 2017; Nurmukhamedov & Sharakhimov, 2021; Webb & Rodgers, 2009a, 2009b). However, when it comes to the question concerning the number of words needed to understand the listening recordings in an IELTS test, it would be really hard to receive a specific, detailed, and evidence-based answer.
Realizing the dire need for an answer for such questions, the present study was conducted to offer an in-depth analysis into the vocabulary profile of the listening sections in the IELTS test. Such analyses would give scientific information regarding the amount of words needed to successfully comprehend different parts of the IELTS listening comprehension subtest. The research’s results would not only benefit English learners who are preparing for the once-in-2-year test, but would also support teachers of IELTS preparation courses in their material design and lesson planning.
Literature Review
Lexical Coverage and Listening Comprehension
Studies in the field of vocabulary have indicated that the lexical demand of texts is determined by calculating the number of words which learners need to know for an adequate comprehension (Laufer & Ravenhorst-Kalovski, 2010; Nation, 2006; Stæhr, 2008, 2009; Webb & Rodgers, 2009b). Although there are a number of elements affecting the ability to understand text genres, lexical coverage is likely to be the most powerful factor as it decides whether people can understand the texts or not (Nation, 2013). Researches in the field of vocabulary study have proven a linear and strong relationship between lexical coverage and listening comprehension (Matthews & Cheng, 2015; Ha, 2021b; Lange & Matthews, 2020; Cheng & Matthews, 2018; Van Zeeland & Schmitt, 2013). Discussions concerning such relationship normally came to the same conclusion that learners should be familiar with at least 95% and preferably 98% of the running words in the text in order to gain adequate comprehension, with little or even zero controversy (Hu & Nation, 2000; Laufer, 1989; Nurmukhamedov & Webb, 2019; Schmitt et al., 2011; Webb, 2020).
However, it should be noted that the “adequate” threshold of one text type cannot be simply applied to another (Cheng & Matthews, 2018; Stæhr, 2009). For reading comprehension, 95% and 98% coverage are required for minimal and optional threshold of understanding, respectively (Laufer & Ravenhorst-Kalovski, 2010). Meanwhile, for listening comprehension, Van Zeeland and Schmitt (2013) demonstrated that though 98% coverage may give learners with a high level of understanding, grasping 95% of words may be adequate for pleasurable comprehension of informal narratives.
Some researchers believe that the listening or phonological form of language would be more challenging to process and understand compared to the written or orthographic form (Cheng & Matthews, 2018; Ha, 2021b; Milton & Hopkins, 2006). Cheng and Matthews (2018) hold that the written form of a word is temporally stable and therefore would be available for revisiting, just like how we can read and re-read a sentence or a word when we have problem understanding it. However, the same does not go for the phonological form of a word, which is temporary and does not support unlimited re-examination. While it might be irritating to ask our interlocutors or professors to repeat themselves more than two times, it is still feasible and most people would be happy to provide such supports. However, the same convenience would not be available in any listening component of a standardized English proficiency test. In a study that examined the relationships between students’ vocabulary knowledge and their performance on the IELTS listening and reading tests, Ha (2021b) showed that, despite being far less lexically demanding, the IELTS listening test witnessed inferior mean scores compared to the IELTS reading test. It seemed that learners performed better in the reading component of the IELTS even though these reading passages demanded far larger vocabulary size than the IELTS listening recordings (Ha, 2021b).
It is also worth noting that listening and trying to understand conversations and presentations in the IELTS listening sub-test could be even more challenging than those in real life situation. A reason for this is because the test takers can only listen to the recording once, which should be deemed one of the major factors (Alavi et al., 2018; Field, 2005). Another reason for that is due to the lack of supportive non-verbal clues like facial expression, gestures or lip movements, which are considered to be crucial for the processing of aural input (Harris, 2003). The proportion of academic and low-frequency words are also considered to be the elements that make spoken discourses in academic contexts more difficult to comprehend than those in informal situations (van Zeeland & Schmitt, 2013).
The Lexical Demands English Spoken Discourses
For decades, researchers have documented a comprehensive lexical profile of English spoken discourse, both in general and academic contexts.
In Meara (1991) studied the lexical profiles of BBC radio broadcasts and indicated that the 2,500-word level made up around 90% coverage of the broadcasts. In an influential paper, Nation (2006) told us that it took 3,000 and 7,000 most frequent word families in the British National Corpus (BNC) word list plus proper nouns (PN) to understand 95% and 98% of the words in daily conversations. Webb and Rodgers (2009b) conducted a study analyzing the vocabulary in 88 English language television programs. They discovered that knowing the 3,000 most frequent word families in Nation’s (2006) BNC word list plus proper nouns and marginal words (MW) might help audiences acquire 95% coverage of TV shows. The figures were similar to the findings of Webb & Rodgers’ (2009a) study regarding the 95% coverage threshold of movies. To achieve 98% coverage of movies, audiences must be familiar to 6,000 word families plus proper nouns and marginal words, while the vocabulary knowledge at the 7,000 level was required for the TV programs. In an attempt to continue Webb & Rodgers’ works, Al-Surmi (2014) indicated that the most frequent 2,000 word families in the BNC lists plus proper nouns and marginal words made up 95% of the running words in soap operas and sitcoms. The results also showed that while it only took audiences 5,000 word families to understand 98% of the words in soap operas, a vocabulary knowledge at the 7,000 level would be required for watching sitcoms with relaxation (Al-Surmi, 2014). In her study in 2017, Tegge examined the lexical demand of pop songs derived from Billboard charts and teacher-selected songs for language teaching purposes. The findings suggested that being familiar with 3,000 and 6,000 word families in the BNC lists plus proper nouns, transparent compounds (TC) and marginal words might help learners attain 95% and 98% coverage of the Wellington Corpus of Popular Songs (WOP), correspondingly. On the other hand, to reach 95% and 98% coverage of the Wellington Corpus of Popular Songs in English Teaching (WOPET), learners only needed to know 2,000 and 4,000 word families, in the order given. The most recent attempt to examine the lexical profile of general spoken discourse is Nurmukhamedov and Sharakhimov (2021). Using the British National Corpus/Corpus of Contemporary American English (BNC/COCA) word list, they pointed out that 3,000 and 5,000 most frequent word families plus proper nouns, marginal words, transparent compounds, and acronyms made up of 96.75% and 98.26% of the tokens in podcasts.
If we were to take things more seriously and look at the lexical demands of academic spoken English, then it would not be so hard to find the answers.
In 2010, Horst looked at the lexical coverage of in-class instructions focused on English as a second language (ESL) learners and studied the extent to which it may support the accidental acquisition of freshly encountered words. The results showed that learners needed to comprehend 4,000 word families to achieve 98% coverage of teachers’ discourses. It also gave a proof that ESL instructors teaching in the classroom context provides little possibilities for accidental vocabulary acquisition (Horst, 2010). Two years later, Coxhead and Walls (2012) assessed the vocabulary coverage of TED Talks to study whether the AWL was contained in TED Talks in the same way as it was in written academic texts. The results showed that, coupled with proper nouns, the knowledge of 4,000 and 9,000 word families in the BNC word list was sufficient for 95% and 98% coverage of TED Talks, respectively. In 2017, Nurmukhamedov revisited the issue and confirmed that together with proper nouns and marginal words, 4,000 word families were necessary to attain 95% coverage, and 8,000 word families offered 98% coverage of TED Talks presentations. Making use of the British Academic Spoken English (BASE) corpus, Dang and Webb’s (2014) study investigated the lexical demands of academic lectures and seminars. Their analyses showed that learners were required to know around 4,000 word families in the BNC lists plus proper nouns and marginal words to acquire 95% coverage of academic spoken discourses (Dang & Webb, 2014). In addition, their results also emphasized that if learners mastered the AWL, they would only need the knowledge of 3,000 word families to cover 95% of the words in academic spoken English (Dang & Webb, 2014).
How Much Vocabulary Is Needed to Understand Listening Components in Standardized Tests?
For the purpose of assessing learners’ English proficiency, a wide range of international tests were born and widely recognized. In response to the question of how much vocabulary knowledge learners need to know to achieve high results on the test, numerous studies in the field of vocabulary have been conducted.
Chujo and Oghigian (2009) proved that learners may not be compulsory to have vocabulary knowledge larger than the 10,000 level to comprehend the Test of English as a Foreign Language (TOEFL) test. They considered the vocabulary level needed for two forms of the TOEFL test: TOEFL Paper-based Test (PBT) and Internet-based Test (iBT). In six TOEFL PBT practice tests, it was discovered that the most common 6,242 lemmas or 5,000 word families were required to reach 95% coverage. They also discovered that the top 4,719 lemmas or 4,000 word families accounted for 95% of the words in the iBT practice test. Masaya Kaneko (2015) examined the vocabulary size necessary for the TOEFL iBT listening sections. He pointed out that that the most frequent 3,000 word families plus proper nouns and marginal words provided 95% text coverage, and the most frequent 6,000 word families yielded 98% coverage for the TOEFL listening passages (Kaneko, 2015).
Another significant test is the Test of English for International Communication (TOEIC). It is specifically developed to assess the English proficiency of people involved in an international environment on a daily basis. Chujo and Oghigian (2009) utilized 95% text coverage as a criterion for determining how much words are required to achieve this coverage level on the TOEIC test. According to their findings, about 3,000 word families in Nation’s (2006) BNC word list were demanded to yield 95% coverage on the current TOEIC test. Revisiting Chujo and Oghigian’ (2009) findings, Kaneko (2017) looked at the lexical demand of the TOEIC listening test. His work indicated that the second most frequent 1,000 word families yielded an average coverage of 94.74% and the third most frequent 1,000 word families accounted for 97.57% of the running words in the listening components. It was also proven that the vocabulary size from 3,000 to 4,000 word families was required reach the level of 98% coverage in the TOEIC listening tests (Kaneko, 2017).
With regard to the International English Language Testing System (IELTS), Kaneko’s (2020) is one of the few papers examining the lexical coverage of this test. He suggested that the most frequent 2,000 to 3,000 in the BNC/COCA word list were sufficient to reach 95% coverage in the listening passages, respectively. Kaneko (2020) also pointed out that 98% coverage for the listening sections could be achieved if leaners knew the most frequent 3,000 to 5,000 word families.
Research Gap and the Present Study
Although being informative, the earlier researches mentioned in the previous parts have some limitations. Firstly, to date, IELTS has been increasingly appreciated within both domestic and international colleges, universities and organizations as it comprehensively assesses four English skills for academic purposes—Listening, Speaking, Reading, and Writing. However, most of the research papers examining the relationship between lexical coverage and international tests have tended to favor TOEIC (Chujo & Oghigian, 2009; Kaneko, 2017, 2020) or TOEFL (Chujo & Oghigians, 2009; Collins, 2017; Kaneko, 2014, 2015, 2020) over IELTS (Kaneko, 2020). The second research gap lies with the sample size. As the only reviewed research paper that looked at the lexical profile of the IELTS reading and listening passages. Kaneko’s (2020) study only reported data from two official practice tests, which was far from sufficient to yield any reliable results. This limited sample size severely restricted the generalizability of his findings. Moreover, he did not separate four sections in the IELTS listening test and researched to what extent the vocabulary knowledge affects the learners’ ability to comprehend each of these sections. In fact, the listening passages involved in four listening sections deal with various contexts and the language features utilized in one section is relatively distinct from others. Therefore, combining texts from various sections of the IELTS listening test into one corpus and calculating coverage profile of the mixed text may not lead to the accurate results. This mistake may make the findings ungeneralizable and inconclusive.
Another area that demands attention is the support AWL could provide for BNC/COCA. Dang and Webb (2014) discovered the distribution of the AWL (Coxhead, 2000) in the first three most frequency 1,000-word levels in Nation’s (2006) BNC and the support offered by the AWL for learners who had different levels of vocabulary consisted in the BNC. Meanwhile, there are no research papers examining to what extent the AWL can help learners to acquire the reasonable comprehension of texts when they know the different levels of frequent words offered by the BNC/COCA (Nation, 2017).
The last but not the least, there is a methodological issue in a few studies. Ishida’s (2004) and Chujo and Oghigian’s (2009) blended texts originated from both reading and listening parts of the practice TOEFL tests into one corpus and measured the coverage for the blended text. In fact, in measuring lexical demands of standardized international tests, it is suggested that researchers investigate listening and reading tests separately (Taylor, 2014; Webb & Paribakht, 2015), and to focus only on reading tests (Green et al., 2010; Khalifa & Schmitt, 2010), or only on listening tests (Matthews & Cheng, 2015; Stæhr, 2009). Kaneko (2014, 2015, 2017, 2020) separately examined the coverage figures of the reading and listening sub-tests involved in the international tests. However, it should be noted that each section within a sub-test may deal with a different context and therefore may utilized different language features, especially for the IELTS. Hence, it is crucial that each section in the IELTS listening test should be investigated in isolation.
Given the aforementioned drawbacks in some previous researches, it seems reasonable to revisit the lexical demands for the IELTS listening test. By collecting a wider range of samples from the IELTS tests and making use of the most optimal word-frequency lists, this paper is in response to questions that the previous studies were not able to clarify.
In general, the core purpose of the present study is to seek the answers to the following questions:
How much vocabulary is necessary to acquire 95% and 98% coverage of each section in the IELTS listening test?
How does the AWL distribute in each section of the IELTS listening test?
To what extent the AWL could support learners who have limited vocabulary knowledge in the IELTS listening test?
Methodology
Materials
Fifteen IELTS Authentic Practice Tests books—Official Cambridge Exam Preparation (UCLES, 1996, 2000, 2002, 2006, 2009, 2011, 2013, 2016a, 2016b, 2017a, 2017b, 2018a, 2018b, 2019, 2020) were examined in the present study. Including a total of 168,370 tokens, this corpus was established based on four sections in the IELTS listening tests. Table 1 presents the number of texts and tokens included in each section.
General Information about the Corpus.

It should be noted that these four corpora were at the approximately similar size. Compared to Kaneko’s (2020) study which also investigated the lexical coverage of IELTS listening tests, the corpus used in the present study were 33 times larger in term of size.
The reason for choosing four sections as four main sub-corpora instead of combining all the four sections is that the present study aims to analyze the vocabulary coverage of each section and then compare the coverage figures among them. Four sections analyzed in the present study include: conversation in general context (CG), presentation in general context (PG), conversation in academic context (CA), and presentation in academic context (PA). Information regarding the format of IELTS test is available on its official website: https://www.ielts.org/for-test-takers/test-format.
Data Analysis
Listening transcripts were collected from Cambridge official IELTS practice tests series, which is published yearly by the University of Cambridge Local Examination Syndicate (UCLES). Since the IELTS listening component is the same regardless of the IELTS test modules (e.g., Academic or General Training), materials from both test modules were collected. The collected transcripts were then classified according to their sections in the IELTS tests, details could be found in the Materials section.
After being collected, hyphens in hyphenated words were substituted by spaces so that the words creating these hyphenated words could be classified based on their own frequency. In fact, the reason for this replacement was that lexical profiler programs cannot read hyphenated items. For example, the hyphens in the items such as black-and-white or south-west were removed and then each single word (black, and, white, south, west) was reclassified based on their frequency levels. After that, the lexical profile of the modified corpora was then analyzed by a lexical profiler program.
The computer program utilized to investigate the lexical profile of these corpora was RANGE (Heatley, Nation, & Coxhead, 2002). RANGE is a lexical profiler program that measures how frequent a word occurs according to a word list.
Nation’s (2017) BNC/COCA lists were used with RANGE to indicate the frequency levels at which the words in each text occurred. The BNC/COCA lists contains twenty-five 1,000-word levels and four supplementary lists of proper nouns, marginal words, transparent compounds, and acronyms. Words that do not belong to these lists would be classified as “Not in the lists.” In addition, to calculate the proportion of academic words in each sub-corpus, the GSL-AWL lists that contain 2,570 word families (Coxhead, 2000; West, 1953) were analyzed with RANGE.
Result
Table 2 presents the coverage of each section in the IELTS listening sub-test provided by Nation’s (2017) BNC/COCA. The most frequent 1,000 word families covered most of the running words for all corpora with the difficult level decreased as the word frequency went down.
Coverage of each Corpus Provided by the BNC/COCA (%).

As shown in the table, the first 1,000 word families accounted for 85.35% and 86.24% of the running words in Section 1 and Section 2, respectively. These figures were relatively higher than those of Section 3 (83.74%) and Section 4 (79.71%). On the other hand, by the level of 4,000 word families, the coverage of Section 1 and Section 2 were under 1%. Meanwhile, the word-level at which the coverage of Section 3 and Section 4 got lower than 1% was the fifth level, signaling a potential difference in the levels of difficulty among sections.
Table 3 presents the cumulative coverage excluding proper nouns, marginal words, transparent compounds and acronyms for each corpus. It could be seen from the table that PN, MW, TC, and AC made up a relatively large proportion in Section 1 and Section 3. Without these lists, neither Section 1 nor Section 3 achieved 95% and 98% coverage. The level of 3,000 most frequent word families was sufficient to reach 95% coverage of Section 2. However, 98% coverage of this sub-corpus could not be achieved if four additional lists were unknown. For Section 4, to reach 95% and 98% coverage without the support of PN, MW, TC, and AC, learners needed to be familiar with 4,000 and more than 11,000 word families, correspondingly.
Cumulative Coverage Without Proper Nouns (PN), Marginal Words (MW), Transparent Compounds (TC), and Acronyms (AC) for Each Corpus (%).

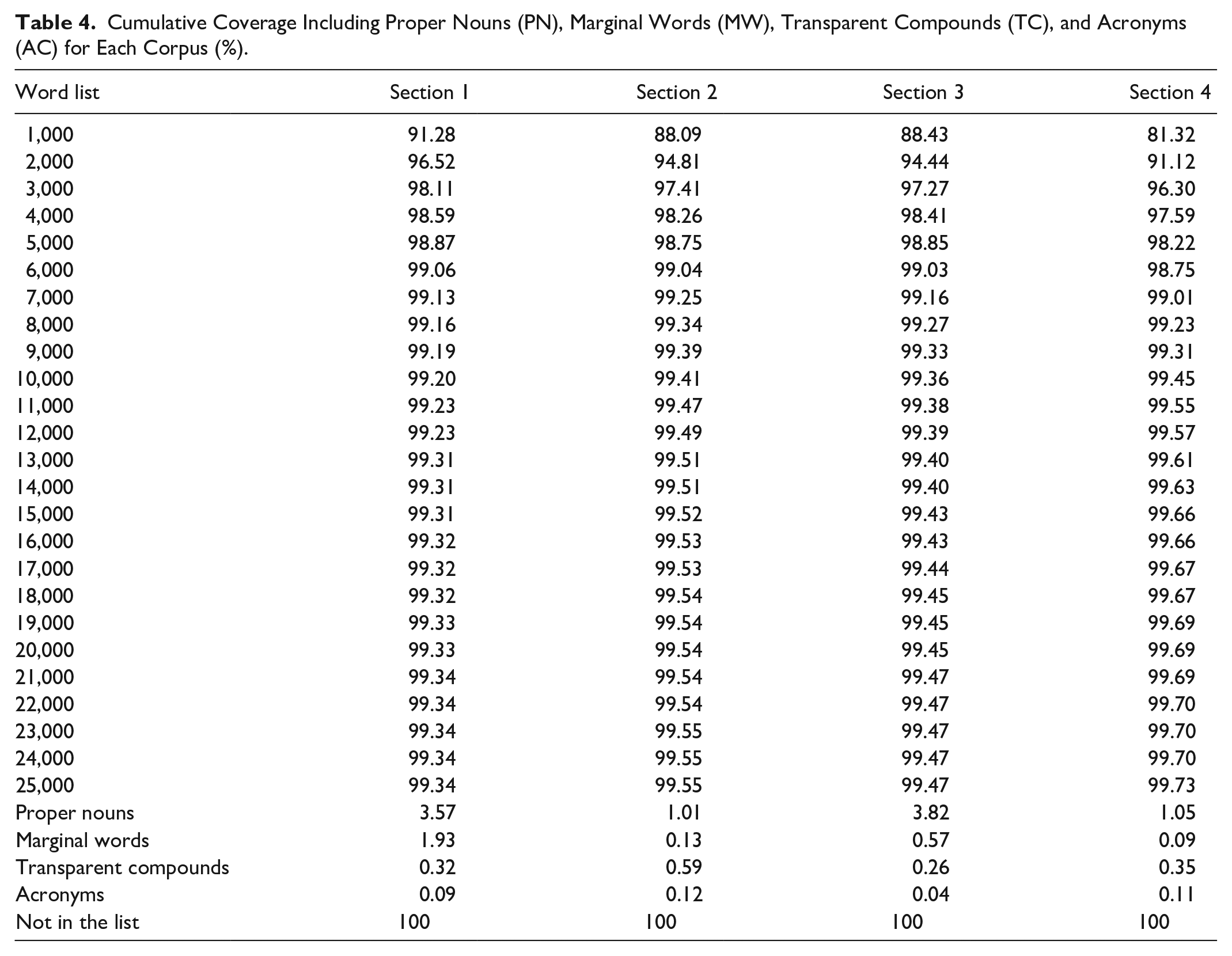
Table 4 shows the cumulative coverage coupled with proper nouns (PN), marginal words (MW), transparent compounds (TC), and acronyms (AC) for each corpus. Coupled with proper nouns, marginal words, transparent compounds and acronyms, learners needed to know 2,000 and 3,000 word families to achieve 96.52% and 98.11% coverage of Section 1 in IELTS listening practice tests, respectively. Knowledge of the most frequent 3,000 word families in BNC/COCA plus PN, MW, TC, and AC could provide the coverage of 97. 41% and 97.27% for Section 2 and Section 3, correspondingly, which went beyond the level of 95% coverage. According to Nation & Hu (2000), at the level of 95% coverage, 1 in 20 tokens is unknown, however, at the 97% coverage threshold, the number of unknown words drops to 1 in 31. This means that the 97% coverage may offer learners nearly twice as many opportunities to understand the texts as the 95% coverage may. In addition, the table also described that if learners were familiar with the most frequent 4,000 word families plus PN, MW, TC, and AC, they would be able to reach the threshold of 98% coverage of both Section 2 and Section 3 in the IELTS listening tests. Similar to those two sub-corpora, the word knowledge necessary to achieve 95% coverage of Section 4 is 3,000 most frequent word families. However, for Section 4, the vocabulary knowledge required to achieve 98% coverage is one-level higher than that of Section 2 and Section 3. The vocabulary knowledge of 5,000 word families accounted for 98.22% of the token found in Section 4. The findings pointed out that Section 1 and Section 4 were the least and most lexically demanding, in the order given. Section 2 and Section 3 were relatively similar in terms of lexical demand.
Cumulative Coverage Including Proper Nouns (PN), Marginal Words (MW), Transparent Compounds (TC), and Acronyms (AC) for Each Corpus (%).
The coverage of the AWL (Coxhead, 2000) in four sub-corpora is exhibited in Table 5. It is obvious from the table that the distribution of the AWL was not even among the four sections. This list increased gradually its coverage from Section 1 to Section 4. This is because the conversation and presentation in academic contexts contain more academic vocabulary than those in general contexts. This list had the lowest coverage in Section 1 corpus (1.89%) and the highest coverage in Section 4 corpus (5.85%). The coverage of the AWL in Section 2 and Section were 2.92% and 3.39%, in the other given.
The Coverage of the AWL in Each Corpus in the IELTS Listening Practice Tests (%).

Dang and Webb’ (2014) study indicated that a large proportion of the AWL appeared in the BNC’s most frequent 1,000 and 2,000-word level. However, the present study used the BNC/COCA and the first two word levels of the list were based on spoken discourse. Therefore, at these two levels in the BNC/COCA, the AWL should not appear as much as in the BNC. When examining the coverage of the BNC/COCA lists on 570 word families in the AWL, the results revealed that the AWL accounted for 3.70%, 24.14%, 56.16%, 9.42%, 3.26%, and 1.12% in the first six 1,000-word levels in the BNC/COCA list, in the order given. The rest of this list had the proportion under 1%. It is obvious that most of the words in the AWL appeared in the most frequent 2,000 and 3,000 levels, which means that the AWL had the strongest contribution to the first and second 1,000-word levels.
As mentioned above, more than half of the AWL was at the most frequent 3,000-word level onward. Therefore, Section 2, Section 3, and Section 4 might get the greatest benefit from the AWL as the 2,000-word level of Section 2 and Section 3 were approaching the 95% threshold. The 2,000 level of accounted for 91.12% of the words in section 4, which was quite far away from the 95% threshold. However, since the AWL made up a relatively large proportion (5.85%) of the tokens in the section 4, the analysis was still worth trying.
Table 6 shows the degree to which the AWL items occurred in the second, third and fourth sub-corpora were distributed in the BNC/COCA lists. Section 1 was excluded from this analysis due to two reasons. The first one was because of the limited occurrence of the AWL, which was less than 2%. Another reason was that Section 1 reached the two consecutive thresholds of 95% and 98% at levels 2,000 and 3,000, correspondingly, which means that this type of analysis would barely make any added value.
The Distribution of the AWL in the BNC/COCA Lists for Section 2 and Section 3.

The result revealed that, for the three corpora, a large majority of the AWL items were placed in 2,000 and 3,000-word levels in the BNC/COCA lists. At the 2,000 level of Nation’s (2017) BNC/COCA lists, the AWL items accounted for 1.23%, 1.51%, and 2.83% of the words in the Section 2, Section 3, and Section 4, respectively. Meanwhile, at the most frequent 3,000-word level, 1.06%, 1.46%, and 2.32% of the words in the BNC/COCA lists for Section 2, Section 3, and Section 4 were made up by the AWL items, in the given order. By the fourth 1,000-word level, vastly few words of the AWL occurred, and the coverage at these word lists were <0.1%.
Table 7 illustrates the extent to which the AWL support learners who had different vocabulary sizes. The accumulative coverage of the AWL words in the BNC/COCA lists for Section 2, Section 3, and Section 4 are displayed in the second and third columns. The fourth and fifth columns give the remaining coverage of the AWL items after being subtracted by the total AWL coverage. For instance, for learners who are familiar with the first 1,000 BNC/COCA word families and the AWL, their knowledge of the AWL would provide 2.92 − 0.60 = 2.32% additional coverage of Section 2.
Promotion Offered by the AWL for Learners Who Know Different Amounts of Vocabulary as Defined by the BNC/COCA Word Lists (%).

It was found that more than half of the AWL items appeared in the 2,000 level in the BNC/COCA word list for Section 2 (1.83%), Section 3 (1.86%), and Section 4 (3.41%). As a result, at this word level, the AWL could contribute 1.09%, 1.53%, and 2.44% for Section 2, Section 3, and Section 4, in the order given. Meanwhile, by the third 1,000-word level, learners were no longer supported by the AWL as the coverage of this list at these levels was getting closer to the total coverage of it in each sub-corpus.
The potential support for learners who have limited BNC/COCA vocabulary knowledge but know 570 word families provided by the AWL is demonstrated in Table 8. The potential coverage at a given word level for both corpora was calculated by adding the cumulative coverage at that word level including PN, MW, TC, and AC to the additional coverage of AWL items. For example, at the most frequent 1,000-word level, learners may get 88.09 + 2.32 = 90.41%, 88.43 + 3.04 = 91.47%, and 81.32 + 5.27 = 86.59% coverage of Section 2, Section 3, and Section 4, correspondingly, if they know the AWL. Similarly, at the level of 2,000 word families, the AWL can help learners acquire the potential coverage of 95.90% for Section 2 and 95.97% for Section 3. It is noticeable that at the 2,000-word level, coverage increases from the level at which learners are not be able to sufficiently comprehend IELTS listening Section 2 (94.84%) and Section 3 (94.44%) to the point at which they may acquire reasonable comprehension if they have knowledge of the AWL. It is also worth noting that, despite being given the largest additional coverage by the AWL, Section 4 was not able to reach the 95% threshold at the 2,000 level.
Potential Coverage with and Without the AWL Knowledge at Different Word Levels.

Note: Bold indicates 95% coverage.
Discussion
In response to the first research question, the vocabulary knowledge necessary to reach 95% coverage of four corpora ranged from 2,000 to 3,000 word families in the BNC/COCA word list plus PN, MW, TC, and AC. To achieve 98% coverage of these corpora, learners needed to know 3,000 to 5,000 word families. In general, there are no great gaps between the vocabulary demands for 95% and 98% coverage of four corpora, except for the last corpus where the difference was 2,000 word families between two thresholds.
These findings suggest that the recordings in the IELTS listening tests may be relatively less demanding than TED Talks presentations (Nurmukhamedov, 2017) and podcasts (Nurmukhamedov & Sharakhimov, 2021). Nurmukhamedov (2017) indicated that learners should know a vocabulary of 4,000 and 8,000 word families in the BNC list plus proper nouns and marginal words to reach 95% and 98% coverage of TED Talks presentations, respectively. These lexical demands were almost twice as much as those of the present study. A study investigating the lexical coverage of English podcasts (Nurmukhamedov & Sharakhimov, 2021) described that 3,000 word families in the BNC/COCA list plus PN, MW, TC, and AC covered more than 95% while 5,000 word families accounted for 98% of the running words in podcasts. A common point of the previous and present studies is that both of them uses the BNC/COCA lists to analyze the coverage of target corpora. Therefore, the comparison in terms of lexical demands between these two papers will be reasonable and less lame than comparing with papers using BNC lists. When compared with the present study, podcasts had the equal lexical demands to Section 4 corpus. This means that with the vocabulary knowledge of 5,000 word families plus PN, MW, TC, and AC, learners can not only deeply understand various podcast categories but also be more likely to get acceptable scores on the IELTS listening test.
Moreover, the vocabulary size required to achieve 95% of Section 2, Section 3, and Section 4 in the IELTS listening tests is similar to that of English movies and TV programs (Webb & Rodgers, 2009a, 2009b). However, viewers would have to add on 1,000 to 2,000 word families if they wished to understand 98% of the words movies and TV programs. Section 1 in the present study share a similarity with the Wellington Corpus of Popular Songs (WOP) corpus (Tegge, 2017) in terms of the lexical demand for 95% coverage. These two corpora require the knowledge of 2,000 word families plus relatively the same additional word lists to achieve 95% coverage. On the other hand, 98% coverage the WOP demands the vocabulary size of 1,000 additional word families compared with Section 1 corpus in this paper.
It should be noted that vocabulary knowledge to reach 95% and 98% coverage are different among genres. However, for the present study, the results recommend that learners should rather have a good comprehension of 3,000 words families plus PN, MW, TC, and AC to acquire 95% coverage of all corpora in the IELTS listening tests. As 98% coverage is suggested for great level of listening comprehension (van Zeeland & Schmitt, 2013), being familiar with the most frequent 5,000 word families or more would support learners to achieve the higher score in the IELTS listening tests.
In answer to the second research question, it can be noted that the AWL was not allocated evenly among sections. This is in line with Cobb and Horst’s (2004), Hyland and Tse’s (2007), and Dang and Webb’s (2014) findings. In this paper, the lowest coverage was in Section 1 corpus (1.89%) and the highest coverage was in Section 4 corpus (5.85%). This should be inferred that Section 4 would be supported the most by the AWL while Section 1 would get the least benefit. The higher coverage of the AWL in Section 4 may be due to the high occurrence of vocabulary in the AWL that are popular to the presentation in academic context, for example, a university lecture.
Some research also discovered the distribution of the AWL in various types of text. According to Nurmukhamedov’s (2017) and Coxhead and Walls’s (2012) research, the AWL coverage in TED Talks ranged from 3.79% to 3.90%. These coverage data are roughly similar to academic spoken English, 4.41% (Dang & Webb, 2014) and university-based economics lectures, 4.90% (Thompson, 2006). The coverage of the AWL in the above-mentioned studies is comparative to those of Section 3 and Section 4 in the present study. However, it is highlighted that the AWL provides more coverage in written texts than in spoken data. This means that learners have less opportunities to acquire academic vocabulary from listening than reading.
In answer to the third research question, results from the analyses indicated that, with the support of the AWL, learners only need to have a comprehension of 2,000 word families to achieve 95% coverage of both Section 2 and Section 3, respectively. By the third 1,000-word level, the AWL had nearly zero influence on the coverage of Section 2 and Section 3. Hence, there was no significant changes in the coverage of these two corpora from that level onward. In other words, the AWL contributed the most to the second 1,000-word level at which the coverage of Section 2 and Section 3 increased from inadequate thresholds to the optimal ones. These findings could be significant if we were to consider 95% to be the coverage threshold for adequate comprehension, as van Zeeland and Schmitt (2013) suggested, 95% could provide “good but not necessarily complete” comprehension for spoken discourses (pp. 18, 19).
As the present study was based on Nation’s (2017) BNC/COCA lists and Coxhead’s (2000) AWL, English teachers can use tests of receptive phonological vocabulary knowledge that employed the AWL and BNC/COCA lists as the source for test items to predict their students’ performance on a real IELTS test. In fact, the Listening Vocabulary Levels Test (LVLT; Ha, 2021a; McLean et al., 2015) could be a great test for such purpose. The LVLT measures vocabulary knowledge of the AWL and the 5,000 most frequent word families in the BNC/COCA lists, and was found to strongly correlated with the IELTS listening test at 0.65 (Ha, 2021b). The present research’s findings were also strongly in line with Ha’s (2021b) study which investigated the relationship between test takers receptive phonological vocabulary knowledge and their performance on the IELTS listening test. Ha’s (2021b) analyses pointed out that learners with the vocabulary knowledge at 3,000 level were very likely to get an IELTS band score 5.0, and those who knew the 5,000 most frequent word families in the BNC/COCA word list could obtained the IELTS band score of 6.5 on the listening component.
English teachers of IELTS preparation courses are advised to help their students master the 2,000 most frequent word families in the BNC/COCA lists and 570 word families in the AWL as this was proven to help learners understand three out of four sections in the IELTS listening test. As Webb and Chang (2012) and Ozturk (2016) pointed out, L2 learners could add on to their existing lexical knowledge approximately 400 to 500 word families a year. This 2,570 word families learning burden could be achievable over the span of 5 to 6 years, theoretically. However, in actual practice, as Ha’s (2021b) findings revealed, most university students in EFL contexts had the vocabulary knowledge at the 2,000 level and above. Therefore, attaining the IELTS 6.5 band score in the listening comprehension test with appropriate learning strategies would be a feasible goal.
Conclusion
Following the methodology developed for the investigation of academic spoken discourse by Dang and Webb (2014), the present study seeks to shine light on the lexical profile of the IELTS listening sub-test with similar depth. In general, results from the analysis showed the difference in lexical demands between different sections, which might be deemed significant to a certain extent. However, with the importance of academic vocabulary revealed, teachers and learners of IELTS courses could use the study’s finding as a guideline for choosing the most efficient strategies for their IELTS preparation.
Although the present study provided a deep insight into the lexical demands of the IELTS listening test, it did not involve real students score on each section of the test. Besides, the results only showed the amount of vocabulary learners would need to achieve 95% and 98% coverage, we cannot say for sure whether learners could actually comprehend a text should these requirements be satisfied. Research did show that people could understand 100% of the running words in a text and still failed to understand the delivered message (Graham, 2006). Future researches are encouraged to examine the results found in this study from different perspectives. For example, it is still not clear how students with only the knowledge of the AWL and the most frequent 2,000 word families in the BNC/COCA list perform in a real IELTS listening test. The relationship between learners’ vocabulary knowledge, test questions types, test taking strategies and listening comprehension also deserves investigation.
Footnotes
Availability of Data and Materials
The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.