
Abstract
The article presents a lexical study that investigates the lexical demands of academic written texts at different levels of writing. By employing the British National Corpus/ Corpus of Contemporary American English (BNC/COCA) word list and the Academic Word List (AWL), the present study analyzed data from the British Academic Written English (BAWE) corpus, which contained 2,761 student assignments, and the Public Library of Science One (PLOS ONE) corpus which included 4,000 scholarly articles. Results from the analyses demonstrated significant differences in lexical difficulty between students’ assignments and scholarly publications. The proportion of academic vocabulary in written texts was also found to increase as the writers’ levels went up. Cross-discipline comparisons highlighted the difference in lexical difficulties between scientific disciplines.
Plain Language Summary
The present study was designed to find an answer to the question concerning the number of words needed to understand academic writing. Two corpora of students’ assignments and research articles which contained papers from a range of disciplines were analyzed. The results from the analyses showed the number of words needed to gain acceptable and optimal comprehension of academic written texts for different scientific disciplines and levels of writing. The findings also provided evidence for the differences in lexical difficulty between academic texts at various levels and of different disciplines.
Introduction
For decades, the field of writing research have long acknowledged the significance of lexical complexity to the quality of writing and the proficiency of the writers (Barrot & Agdeppa, 2021; Biber et al., 2016; Bulté & Housen, 2014; Casal & Lee, 2019; Crossley & McNamara, 2014; Taguchi et al., 2013). The relationship between complexity and writing quality have been investigated through a wide range of research methodologies, from the comparison of noun phrase and clausal elaboration (Bider & Gray, 2010) to the examination of the occurrence of complex structures Casal (2020) and Lu et al. (2020), to the degree to which complex and difficult words were used (Choemue & Bram, 2021; H. S. Ha, 2019; Maamuujav, 2021; Zhang et al., 2021). These examinations of complexity in academic writing have, in Casal and Lu’s (2021, p. 96) opinion, opened “a novel scholarly space” and raised “important questions regarding the ways in which academic writing can be called syntactically complex.”
Among several factors determining writing quality, vocabulary, or the words used in a text, is believed to be the most crucial one (Choemue & Bram, 2021; H. S. Ha, 2019; Maamuujav, 2021; Zhang et al., 2021). Research conducted by Breeze (2008), Choemue and Bram (2021), Fairclough and Belpoliti (2016), Maamuujav (2021), and Zhang et al. (2021) demonstrated that texts produced by more advanced writers contained a wider range of less frequent and academic words compared to those written by less proficient learners. Corpus-driven, wordlist-based studies on the lexical profile of various text genres also showed that different types of text may have different lexical demands (Tegge, 2017, Table 7). In other words, it has been found that different types of texts require readers to know different amounts of vocabulary to adequately understand them, and larger lexical knowledge would be needed to comprehend more difficult texts.
An undeniable strength of lexical profiling studies based on word-frequency lists is that they provide readers with concrete, quantified indications of text difficulty rather than statistical evidences of associations or significant differences. For example, while a lexical knowledge of 3,000 word families in Nation’s (2006) British National Corpus were required to adequately comprehend informal spoken English (Al-Surmi, 2014; Nation, 2006; S. Webb & Rodgers, 2009a, 2009b), a vocabulary knowledge of 4,000 word families would be needed for acceptable comprehension of academic spoken discourses (Dang & Webb, 2014; Nurmukhamedov, 2017). These indications serve as a universal guideline for researchers to compare the difficulty of different types of texts as well as for English teachers and learners to select the suitable reading and listening materials (Nurmukhamedov & Sharakhimov, 2023, Table 1; Tegge, 2017, Table 7).
Although there have been a number of studies on the vocabulary profile of academic written texts (Cobb & Horst, 2004; Hsu, 2011, 2014, 2018, 2022; Hu et al., 2021; Hyland & Tse, 2007; Rahmat & Coxhead, 2021; Sun & Dang, 2020; Yang & Coxhead, 2022), most of them focused on the vocabulary loads of textbooks. The only paper that could be said to have examined the vocabulary profile of research articles was Hsu (2011). However, Hsu (2011) only tapped into the lexical demands of research papers of one discipline (Business). In addition, Hsu’s (2011) study employed Nation’s (2006) BNC wordlist which is believed to be relatively bias and outdated (Schmitt et al., 2017).
Therefore, to the best of our knowledge, no research has really provided insights into the vocabulary profile of academic texts at different levels of writing from a multidisciplinary perspective. More importantly, while there has been evidences for statistically significant differences between texts produced by writers at different levels, the degree of these differences has not been depicted in a way that could be easily understood by general readership. Realizing the need to fill in such a methodological gap in the field, the present study employed the British Academic Written English (BAWE) which included written assignments of undergraduate and post-graduate students from three universities in the UK, and the PLOS ONE corpus which consisted of scholarly articles from a top-tier scientific journal to tap into the lexical differences of academic writing at different levels. The study would also attempt to shed light on the variation in lexical demands between papers of different scientific disciplines. As the research utilized Nation’s (2017) comprehensive, up-to-date British National Corpus/Corpus of Contemporary American English (BNC/COCA) and Coxhead’s (2000) Academic Word List, its findings contribute to the AWL- and BNC/COCA-based universal guideline of lexical profiles of texts.
Literature Review
Lexical Coverage, Word-Frequency List, and the Indication of Text Difficulties
The field of applied linguistics have long recognized the significance of vocabulary. Most, if not all of the findings suggested that a rich lexical resource is fundamental to the operation and development of various aspects of language such as language skills (Cheng & Matthews, 2018; H. T. Ha, 2021b; Lange & Matthews, 2020; Laufer & Ravenhorst-Kalovski, 2010; Qian & Lin, 2020; Schmitt et al., 2011; van Zeeland & Schmitt, 2013) and even the knowledge of grammatical structures (Barcroft, 2007; Guo & Roehrig, 2011; Lewis, 2002; Zhang, 2012; Zhang & Koda, 2013).
The importance of vocabulary is most highlighted with the concept of lexical coverage, the proportion of words (also known as tokens or running words) a learner need to be familiar with to gain adequate comprehension for a text. The lexical coverage required for adequate understanding has been the subject of several studies and researchers have provided evidence-based answers to the question concerning the number of words required for adequate comprehension. According to Laufer (1989), 95% coverage was considered to be the lower boundary required for a sufficient understanding of a text. Namely, the remaining 5% means that one word in every 20 words or two lines would be unfamiliar to the readers (Hu & Nation, 2000). For learners who want to read for pleasure, 98% coverage was advised as the upper boundary (Hirsh & Nation, 1992; Laufer & Sim, 1985). With this threshold, one out of each 50 words would be unfamiliar to the reader, the degree considered acceptable for unassisted reading comprehension (Hu & Nation, 2000) as well as ideal coverage for the written text (Laufer et al., 2004). In the studies of listening comprehension, it was also proven that learners could attain adequate listening comprehension if 95% coverage was known, whereas 98% coverage may help learners reach a high level of understanding (van Zeeland & Schmitt, 2013).
Another breakthrough in vocabulary research could be said to be the creation of word-frequency lists. These lists rank words in accordance with the number of time they occur in a corpus that reflects the use of real-life English, and from which offer an indication of word-frequency level. The idea was simple: words that occur more frequently in real-life English would have higher chances to be acquired than less frequent ones. Moreover, as less frequent words are less likely to be known than higher-frequency words, they are perceived to be “more difficult” and therefore should be ranked at higher “levels.” Evidence-based arguments that support the relationship between word-frequency and word-difficulty were provided in the recent discussion between Hashimoto (2021) and Stewart et al. (2022). Supportive evidences for the association between frequency and difficulty of words were also strongly documented in validation studies of vocabulary tests that based on word-frequency lists (H. T. Ha, 2021a; McLean et al., 2015; S. Webb et al., 2017) and research that used these vocabulary tests to examine the vocabulary knowledge of leaners (Dang et al., 2022; H. T. Ha, 2021b; Noreillie et al., 2018; Stæhr, 2009).
Typical examples of the most popular and widely-referred word-frequency lists in the field are Nation’s (2006) BNC and Nation’s (2017) BNC/COCA wordlists. In 2006, Paul Nation created the BNC word-frequency list based on the British National Corpus (BNC). The BNC is a 100-million-token corpus composed of texts from various genres (e.g., spoken, fiction, magazines, newspapers, and academic). The BNC word list contained the fourteen 1,000-word-family levels ordered by the range, dispersion, and frequency of English terms found in the BNC to approximate a text’s vocabulary level. The list came with two supplementary lists of proper nouns (PN) and marginal words (MW). Despite being a methodological basis for a great number of lexical profiling studies (Tegge, 2017, Table 7; Nurmukhamedov & Sharakhimov, 2023, Table 1; Nurmukhamedov & Webb, 2019), the BNC wordlist is often viewed as bias and outdated since it contains texts in the 1980s—early 1990s which only reflect British English (Davies, 2008; Schmitt et al., 2017). Several years later, in 2012, Paul Nation create the BNC/COCA word lists from the British National Corpus and the Corpus of Contemporary American English. The inclusion of the COCA introduced the representation of American English to the lists, extended the range of word-frequency levels from 14 to 25, and also added two new supplementary lists of transparent compounds (TC), and acronyms (AC) (Nation, 2017, 2020). As Nation keeps updating the lists (Nation, 2020), the BNC/COCA could be seen as a more comprehensive and up-to-date version of the BNC and may serve as a “better indication of word frequency” (Schmitt et al., 2017, p. 218). The word list was also shown to outperform other wordlists (Dang et al., 2022; Dang & Webb, 2016).
Another wordlist worth mentioning is Coxhead’s (2000) Academic Word List (AWL). The AWL consists of 570 word families generated from a 3.5-million-token corpus containing academic texts from four disciplinary sub-corpora: Arts, Commerce (including economics, marketing, and management), Law, and the Sciences (including biology, computing, mathematics, etc.). The AWL was originally created in support of General Service List (GSL). This means that the 570 word families in the AWL were not included in West’s (1953) 2,000-word-family GSL, so that the two wordlists could stack and the AWL would provide additional coverage for learners who have mastered 2,000 most frequent word families in the GSL (Coxhead, 2000). The AWL was found to accounted for approximately 10% of the running words in academic written texts (Cobb & Horst, 2004; Hyland & Tse, 2007) and 4% to 5% in academic spoken discourses (Dang & Webb, 2014; Nurmukhamedov, 2017; Phung & Ha, 2022).
The Lexical Coverage as an Indication of Text Difficulty
The values of word-frequency levels, together with lexical coverage thresholds, have been providing researchers with valuable insights into the amount of words learners need to know to reasonably comprehend a particular type of text. Moreover, as texts at higher levels of difficulties often contain “high-level” vocabulary and more “academic” texts are usually made up of larger proportion of academic words (Phung & Ha, 2022), these lexical coverage values could also be used as an indication of lexical difficulty of a text. Over decades, research based on Nation’s (2006) BNC wordlist have documented a strong lexical profile of different types of texts (see Tegge, 2017, Table 7; Nurmukhamedov & Sharakhimov, 2023, Table 1; Nurmukhamedov & Webb, 2019). Recent BNC/COCA-based lexical profiling studies have also managed to map out the vocabulary demands of certain text genres. Table 1 provides a summary of recent literatures concerning the differences in lexical demands between various types of texts. Besides the conclusion that a knowledge of 5,000 most frequent word families in the BNC/COCA wordlist would safely secure 98% coverage of most spoken texts, it could be observed that soap operas were less lexically demanding compared to Movies, TV programs, and Podcasts. In addition, the four mentioned representatives of informal English were also proven to be easier to understand compared to TED talks which usually represented more academic spoken discourse. Phung and Ha (2022) also provided really useful data regarding the differences in the level of lexical difficulty and “academic” between different sections in the IELTS listening test. More interestingly, as all listed studies were based on the same wordlist (BNC/COCA), researchers and teachers can link the levels of difficulty as well as see and “feel” the degree to which a certain type of text is more difficult or easier to understand compared to various types of texts in a quantified way, whether they are spoken or written, academic or non-academic.
Coverage Provided by the BNC/COCA Lists and the AWL Among Various Text Genres.

Research Gap and the Present Study
While various studies have been conducted to investigate the lexical coverage of various types of written and spoken texts, the lexical demands of academic research articles have been examined to a very limited extent. Moreover, to date, the extent to which academic writing differs according to scientific disciplines and levels of writers have not been shed light upon. The only study that could be said to have tapped into the disciplinary difference in academic discourse was Dang and Webb (2014). In their study, the four disciplinary sub-corpora of the British Academic Spoken English (BASE) was examined. By using Nation’s (2006) BNC lists, Dang and Webb (2014) have proven that Social Sciences and Arts and Humanities were the least lexically demanding disciplines and Life and Medical Sciences was the most difficult-to-understand branch of science. However, as their study only examined academic spoken English, the investigation into disciplinary difference in academic written English remains warranted.
By analyzing the BAWE corpus which included 2,761 student’s written assignments and the PLOS ONE corpus which consisted of 4,000 published scholarly articles, the research aim to shed light upon the lexical differences between various scientific disciplines and levels of writers. In particular, the research aims to answer the following questions:
To what extent does the coverage of high- mid- and low-frequency words differ according to different scientific disciplines and levels of writers?
To what extent does the vocabulary size needed to reach 95% and 98% coverage differ according to different scientific disciplines and levels of writers?
To what extent does the proportion of AWL items differ according to different scientific disciplines and levels of writers?
Methodology
The Corpora
For the present study, two corpora were compiled. The British Academic Written English (BAWE) corpus, a collection of texts produced by undergraduate and Master students in various scientific disciplines in the UK, was employed. The BAWE corpus is available online at Coventry University (http://www.coventry.ac.uk/bawe) and through the Sketch Engine corpus query interface (http://www.sketchengine.co.uk/). The BAWE corpus consisted of 2,761 proficiently graded student assignments collected at the Universities of Warwick, Reading, and Oxford Brookes with ESRC funding as part of the project entitled “An investigation of genres of assessed writing in British Higher Education” between 2004 and 2007. This 6.5-million-token corpus was made up of four broad disciplinary sub-corpora: Arts and Humanities (including 705 assignments), Life Sciences (including 683 assignments), Physical Sciences (including 596 assignments), Social Sciences (including 777 assignments), across four levels of study (Year 1, Year 2, Year 3 undergraduate, and taught Masters). The BAWE corpus were made up of different types of students’ assignments, ranging from essays, case studies, reviews, methodology recounts, research reports, proposals to empathy writing. However, as the main purpose of the corpus creators was to reflect academic writing from different levels and disciplines (Alsop & Nesi, 2009), the number of assignments were unevenly distributed, with essays contributing to nearly half of the papers in the corpus.
Two considerations led to the selection of the BAWE corpus. First, since it was a corpus created from graded university assignments, BAWE represented academic writing at students’ levels, which made a optimal comparison to academic writing at publication level. Second, as one of the study’s objectives was to see if the disciplinary differences in academic spoken discourse (Dang & Webb, 2014) could be found in academic written texts, the fact that BAWE contained students’ essays from the four academic disciplines presented in Dang and Webb (2014) made it the best choice for such purpose.
The second corpus, Public Library of Science (PLOS) ONE, was additionally used in this study to examine the lexical demands of academic written English at the expert level. The present study collected 4,000 scholarly articles from PLOS ONE via AntCorGen software, a freeware corpus generation tool searching for documents in the PLOS ONE research database (Anthony, 2019). Since 2006, the Public Library of Science (PLOS) has introduced PLOS ONE, a peer-reviewed open access scientific journal. PLOS ONE covers preeminent research from any discipline of science. In advance of publication, each submission must be evaluated by a PLOS ONE Editorial Board member and then went through a rigorous peer-review process. Estimates suggest that by 2010, PLOS ONE has become the most prominent journal globally (Morrison, 2011). Therefore, the application of PLOS ONE corpora was hugely significant in examining the lexicon at the expert level, through which a fascinating contrast could be conceived between the lexical needs of the student and the professional academic written texts. It was essential to notice that the Arts and Humanities sub-corpora was included in the Social sciences sub-corpora in the PLOS ONE corpus. Therefore, in the present study, 19,636,598 tokens would be derived from three disciplinary sub-corpora, including Biology and Life Sciences, Physical Sciences, and Social Sciences. Each sub-corpus included 1,000 texts, except for Social Sciences, which included 2,000 texts.
The Level-of-Writing Hypothesis
The present study operationalizes its analysis basing on a hypothesis that the levels of academic written texts could be reflected in (1) the writers’ level of study and (2) the rigorousness of the examination that the papers had to go through. For the first assumption, the authors considered Year 1, Year 2, Year 3, and Masters to be four different levels of writers as students would benefit from additional training and their academic writing would be improved accordingly. This was also in line with the purpose of Alsop and Nesi (2009) when creating the BAWE corpus.
The second assumption was made in an attempt to set up another threshold of writing level that goes beyond taught Masters students’ papers. These papers must be comparative in number of texts, variation of disciplines, be consistent in evaluation criteria, and of course, represent higher quality of writing compared to these taught Masters assignments. For a corpus of academic written texts that could tick all these boxes, the PLOS ONE corpus generated by AntCorGen (Anthony, 2019) appeared to be an optimal choice for certain reasons. First, it is arguably the only time-efficient way to collect a number of academic written texts that are comparable to the BAWE corpus’s 2,761 written assignments. Second, as PLOS ONE is a mega multidisciplinary journal that publishes research articles from all branches of science, it offers the possibility to collect scholarly articles from all the disciplines covered in the BAWE corpus. Third, as each journal had relatively different criteria for paper acceptance, which sometimes depend on the editors, reviewers and even the ranking of the journal, it was necessary, if not crucial, to collect data from the same journal to ensure that articles were evaluated using relatively similar criteria. As all of the papers in the PLOS ONE were collect from the same journal, they were assumed to be evaluated using relatively similar evaluating criteria. The last and also the most important, PLOS ONE was one of the highest ranked and regarded scholarly journal which set really strict criteria for paper acceptance, we would assume that these criteria for acceptance represented higher standards of writing quality compared to the acceptance standards of the raters/lecturers for Masters’ papers in the BAWE corpus.
Data Preparation
After downloading, the BAWE corpus comprises a collection of XML and text files. The BAWE text files were delivered to each specialized folder according to disciplines such as Arts and Humanities, Life Sciences, Physical Sciences, and Social Sciences, and each subject was separated into levels ranging from Y1 to Masters. The process was done by Windows command lines. The researcher re-checked the data several times during the data collecting procedure and occasionally repeated the process for perfect accuracy. Following their placement in the folders, the files were tallied and confirmed equivalent to the number of assignments submitted in 2008. The initial subjects were the same as those included in the BAWE corpus, including four broad disciplines: Arts and Humanities, Life sciences, Physical sciences, and Social sciences. However, according to the PLOS ONE corpus, Arts and Humanities were included in Social Sciences since they shared many characteristics in common. Accordingly, the Arts and Humanities sub-corpus was combined with the Social Sciences in this research. As a result, there were three broad disciplines, including Life sciences, Physical sciences, and Social sciences, in the BAWE corpus discussed in the present study. PLOS ONE corpus was collected using AntCorGen software (Anthony, 2019) in accordance with the three disciplines and the number of assignments of each BAWE subject sub-corpus. The PLOS ONE corpus collected the same amount of texts in Life Science and Physical Science. Since Arts and Humanities sub-corpus was included in the Social Science sub-corpora, the number of texts collected was doubled. Table 2 below shows the components of the BAWE and PLOS ONE corpora.
General Information About the Two Corpora.

Data Analysis
The BAWE and PLOS ONE corpora were analyzed using the RANGE software (Nation & Heatley, 2002). A computer algorithm classifies text vocabulary according to the word lists that are utilized. It can be downloaded from Paul Nation’s website: http://www.vuw.ac.nz/lals/staff/paul-nation/nation.aspx. The Range comes with free downloadable word-frequency lists such as the General Service List (GSL)/AWL, the British National Corpus (BNC), and the BNC/Corpus of Contemporary American English (COCA). Nation’s (2017) 25-word-family BNC/COCA lists were used with RANGE. The range and frequency of words’ occurrence in the BNC/COCA were used to construct these lists. The RANGE software categorized less common terms that did not belong to the first 25,000 word families as proper nouns, marginal words, acronyms, transparent compounds, or not in the lists. Three other base word lists were used with RANGE to assess the percentage of academic terms in the BAWE, PLOS ONE corpus. Baseword lists 1 and 2 comprised the first and the second 1,000 words of GSL, and baseword list 3 was Coxhead’s (2000) AWL. Since RANGE could not read hyphenated words, hyphens in hyphenated items would be removed and replaced by spaces, and the frequency then reclassified these words according to their frequency in the BNC/COCA wordlists. The hyphens in terms such as “life-saving” and “early-onset” were deleted, and the words were categorized based on the frequency of their single-word components, such as life saving and early onset.
Results
Research Question 1: Variation in the Coverage of High- Mid- and Low-Frequency Words
Table 3 presents the lexical coverage of the PLOS ONE and BAWE corpus at each level in BNC/COCA word lists. It is obvious that the most frequent 1,000 word families made up most of the tokens in the corpora. It can also be observed that the proportion of words covered decreased as the frequency levels went down. To be more specific, for the BAWE corpus, the first 1,000-word level accounted for 67.93% of running words, while only 12.43% coverage was covered at the second 1,000-word level. There was an equivalent in the coverage at the first 1,000 word families between disciplines of the BAWE corpus. For the Life Sciences and Physical Sciences sub-corpus, the first 1,000-word level accounted for 67.07% and 67.67% of the tokens, respectively. There was a slight improvement in the Social Sciences sub-corpus at 68.31% coverage compared to the other two sub-corpora. At the 2,000-word-family level, only 12.60%; 12.73%, and 12.27% were reached in Life Sciences, Physical Sciences, and Social Sciences sub-corpora, respectively. This demonstrated the importance of recognizing the most well-known word families. The percentage of words that occurred in the BAWE corpus was <1% (0.74%) by the sixth 1,000 word families. This sixth 1,000-word level was also applied to Life Sciences (0.85%) and Physical Sciences (0.71%) sub-corpora, in which the percentage of words was <1%, while in the Social Sciences sub-corpus, its coverage was under 1% (0.99%) by the fifth level.
Coverage at Each Level in BNC/COCA Word Lists.

With texts at publication levels in the PLOS ONE corpus, the coverage at each level was altered. If the first 1,000 word families accounted for 67.93% of running words in the BAWE corpus, then at the PLOS ONE corpus, only 59.75% of running words was covered by the first 1,000-word level. The first 1,000 word families covered 56.52% and 56.66% coverage in the Life Sciences and Physical Sciences sub-corpora of the PLOS ONE corpus, respectively. In the Social Sciences sub-corpus yet, there was a rise at 63.31% coverage compared to the other two sub-corpora, same as in the BAWE corpus. Compared to the BAWE corpus, the table showed that lexical coverage at the first 1,000-word level of the PLOS ONE corpus was lower. Specifically, if the first 1,000-word level in the BNC/COCA list accounted for 67.07%, 67.67%, and 68.31% of the words in the three sub-corpus of the BAWE, including Life Sciences, Physical Sciences, and Social Sciences, respectively, then, in the PLOS ONE corpus, the figures were 56.52%, 56.56%, and 63.31%, respectively. By the seventh 1,000 word families, the percentage of words that occurred in the PLOS ONE corpus was <1% (0.64%), one level lower compared to the BAWE corpus (by the sixth 1,000 word families). This seventh 1,000-word level was also applied to Life Sciences (0.75%) and Physical Sciences (0.88%) sub-corpus, in which the percentage of words was <1%, while in the Social Sciences sub-corpus, its coverage was under 1% (0.64%) by the sixth level.
The results indicated that at the first 1,000 most frequent word families, the coverage was covered in the PLOS ONE corpus would be pared down compared to the BAWE corpus, and the word level in which the coverage was <1% in the PLOS ONE corpus was also lower than in the BAWE corpus. At both the BAWE and PLOS ONE corpora, Social Sciences sub-corpora were less lexically demanding than the other two sub-corpora.
Research Question 2: Variation in the Vocabulary Knowledge Needed to Reach 95% and 98% Coverage
Table 4 shows the cumulative coverage with and without proper nouns (PN), marginal words (MW), transparent compounds (TC), and acronyms (AC) for the BAWE and PLOS ONE corpora. Data from the analyses demonstrated the importance of supplementary words to text comprehension. To be more specific, without the assistance of PN, MW, TC, and AC, it was not possible to reach 98% coverage for students’ assignments and readers would need to know 10,000 word families to understand 95% of the words in the BAWE corpus. More notably, if all the supplementary words were assumed to be unknown, then it would be impossible for reader to reach any of the mentioned thresholds for comprehension.
Cumulative Coverage (%) Excluding and Including Proper Nouns (PN), Marginal Words (MW), Transparent Compounds (TC), and Acronyms (AC) for the BAWE and PLOS ONE Corpora.
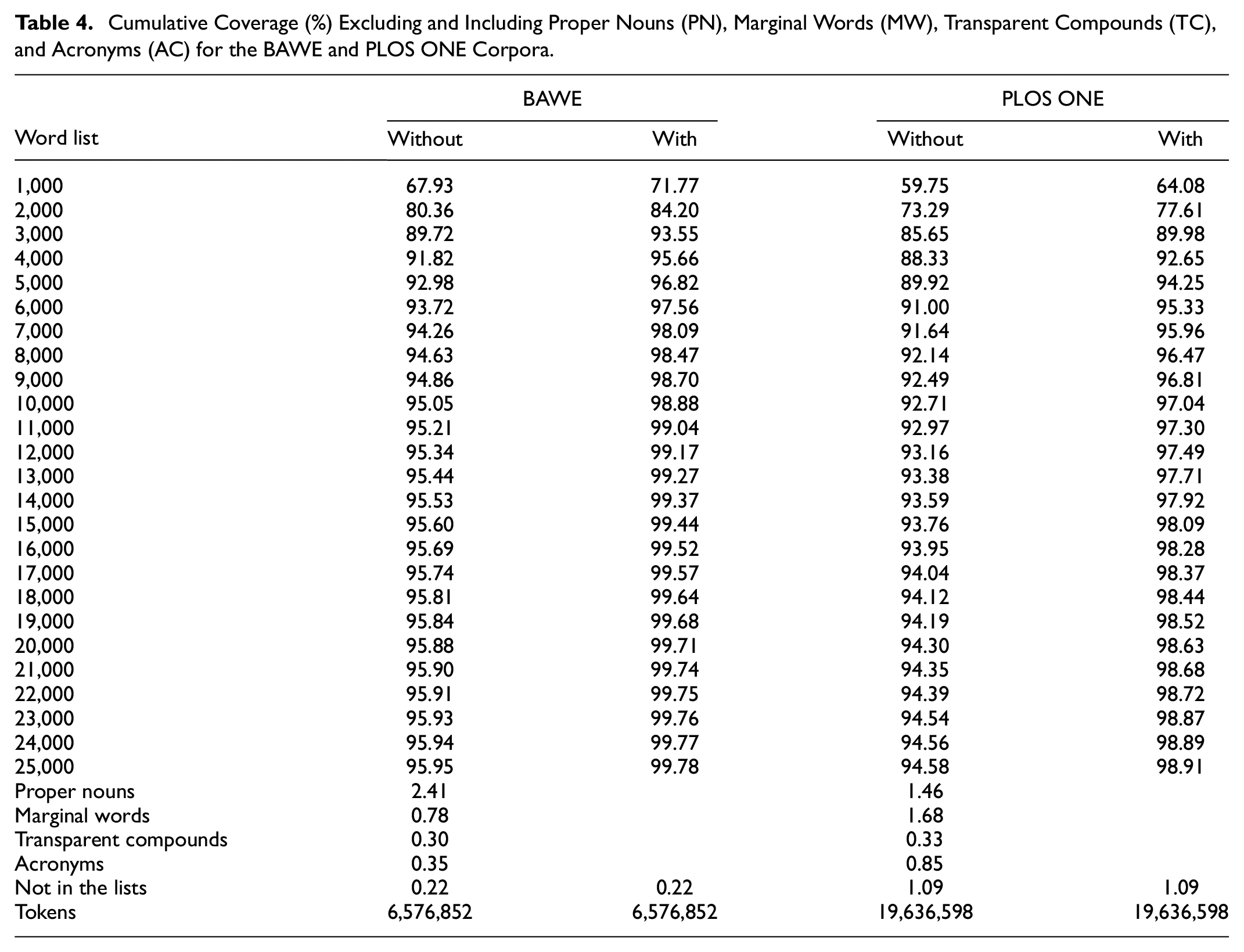
In contrast, with the help of PN, MW, TC, and AC, only 4,000 word families was necessary to reach 95.66% coverage for the BAWE corpus, almost three times lower than the 10,000-word-family threshold (without the support of the four auxiliary lists). To reach 98% coverage for the BAWE corpus, a learner should know 7,000 word families plus PN, MW, TC, and AC. There were remarkable differences in the vocabulary necessary to reach 95% and 98% coverage between the BAWE and the PLOS ONE corpus. Providing that 4,000 word families was necessary to reach 95.66% coverage of the BAWE corpus, a vocabulary of the most 6,000 word families plus PN, MW, TC, and AC was required to reach 95.33% coverage of the PLOS ONE corpus. To attain 98% coverage of the PLOS ONE corpus, knowledge of 14,000 word families plus PN, MW, TC, and AC was expected. It is worth nothing that the number of words required to reach 98% (14,000) coverage of PLOS ONE was twice as much as the number of words required to reach 98% (7,000) coverage of the BAWE corpus.
Table 5 shows the cumulative coverage (%) including proper nouns (PN), marginal words (MW), transparent compounds (TC), and acronyms (AC) of the Life Sciences sub-corpus in the BAWE and the PLOS ONE ranging from Year 1 to Master (in the BAWE corpus) to Publication (in the PLOS ONE corpus). As shown in the Table, there was a similarity in the lexical demands to reach 95% coverage of the corpus at Year 1, Year 2, and Year 3 levels. Coupled with PN, MW, TC, and AC, a vocabulary size of 5,000 word families provided 96.16% (Year 1), 95.95% (Year 2), and 95.36% (Year 3) coverage. However, at the Master and Publication levels, a larger amount of lexicon was demanded to attain 95% coverage. Specifically, 6,000 word families were required to reach 95.83% coverage at the Master level, while 8,000 word families were required to achieve 94.92% coverage at the Publication level.
Cumulative Coverage Including Proper Nouns (PN), Marginal Words (MW), Transparent Compounds (TC), and Acronyms (AC) of the Life Sciences Sub-corpus in the BAWE and PLOS ONE Corpus.

Likewise, there was also a resemblance in the vocabulary sizes to reach 98% coverage in Year 1 and Year 2 in the BAWE corpus. 9000 word families plus PN, MW, TC, and AC, were adequate to attain 98.24% coverage (Year 1) and 97.99% coverage (Year 2). In order to attain 98% coverage at Year 3 and the Master level, there was a slightly higher vocabulary volume required. For the Year 3 level, 98.06% coverage could be covered by knowing the most frequent 10,000 word families, while 11,000 word families were expected to reach 98.15% coverage at the Master level. On the other hand, to gain 98% coverage at the Publication level, the number of words demanded reached 20,000 word families. This number was almost three times higher than the lexical amount needed to achieve 95% coverage at the Publication level (8,000), approximately or more prominent than twice the number of words needed to achieve 98% coverage from Year 1 to Master level (Year 1 and Year 2: 9,000; Year 3: 10,000, and Master: 11,000).
Table 6 shows the cumulative coverage (%) including proper nouns (PN), marginal words (MW), transparent compounds (TC), and acronyms (AC) of the Physical Sciences sub-corpus in the BAWE and the PLOS ONE ranging from Year 1 to Master (in the BAWE corpus) to Publication (in the PLOS ONE corpus). It indicated the inconsistencies between the vocabulary amount required to approach 95% and 98% coverage of the Physical Sciences sub-corpus. It displayed a significant discrepancy in the amount of lexicon needed to reach 95% and 98% between the Publication level and the remaining levels. Vocabulary knowledge of 4,000 word families plus PN, MW, TC, and AC was sufficient to assist learners in reaching 95% coverage from Year 1 to Master level. Precisely, the most 4,000 most frequent word families provided 95.59% (Year 1), 94.93% (Year 2), 95.20% (Year 3), and 96.24% (Master) coverage, as shown in the table. Nevertheless, learners were expected to grasp a vocabulary size of up to 9,000 word families to achieve 95.17% corpus coverage at the Publication level, nearly twice as much as the other four levels.
Cumulative Coverage (%) Including Proper Nouns (PN), Marginal Words (MW), Transparent Compounds (TC), and Acronyms (AC) of the Physical Sciences Sub-corpus in the BAWE and PLOS ONE Corpus.

There were inconsistencies among the vocabulary demanded to approach 98% coverage from Year 1 to Master level. If knowledge of the most frequent 6,000 word families plus PN, MW, TC, and AC could provide 97.94% coverage of the corpus at the Master level, the vocabulary knowledge of 7,000 word families was demanded to cover 98.15% coverage in Year 1, whereas knowledge of 8,000 word families accounted for 98.18% and 98.32% of the running words in the Year 2 and Year 3 sub-corpora, respectively. On the other hand, to gain 98% coverage of the Physical Sciences sub-corpus at the Publication level, the number of words demanded reached 20,000 word families including PN, MW, TC, and AC, approximately or larger three times than the number of words needed to achieve 98% coverage from Year 1 to Master level (Year 1: 7,000; Year 2 and Year 3: 8,000; Master: 6,000). This number was similar to the lexicon demanded to gain 98% coverage of the Life Sciences sub-corpus at the Publication level (Table 4).
Table 7 shows the cumulative coverage (%) including proper nouns (PN), marginal words (MW), transparent compounds (TC), and acronyms (AC) of the Social Sciences sub-corpus in the BAWE and the PLOS ONE ranging from Year 1 to Master (in the BAWE corpus) and to Publication (in the PLOS ONE corpus). If the vocabulary amount required to approach 95% and 98% coverage of the Life Sciences sub-corpus and the Physical Sciences sub-corpus displayed some inconsistencies, the Social Sciences sub-corpus, in contrast, showed the relative sameness in the number of vocabulary demanded to reach the tune of 95% and 98% coverage. As shown in the table, the amount of lexicon required to reach 95% coverage of the corpus from Year 1 to Publication level was identical. In which, knowledge of the most frequent 4,000 word families including PN, MW, TC, and AC accounted for 96.47% coverage in Year 1, 96.16% coverage in Year 2, 96.23% coverage in Year 3, 96.31% at Master level, and 95.60% coverage at the Publication level.
Cumulative Coverage (%) Including Proper Nouns (PN), Marginal Words (MW), Transparent Compounds (TC), and Acronyms (AC) of the Social Sciences Sub-corpus in the BAWE and PLOS ONE Corpus.
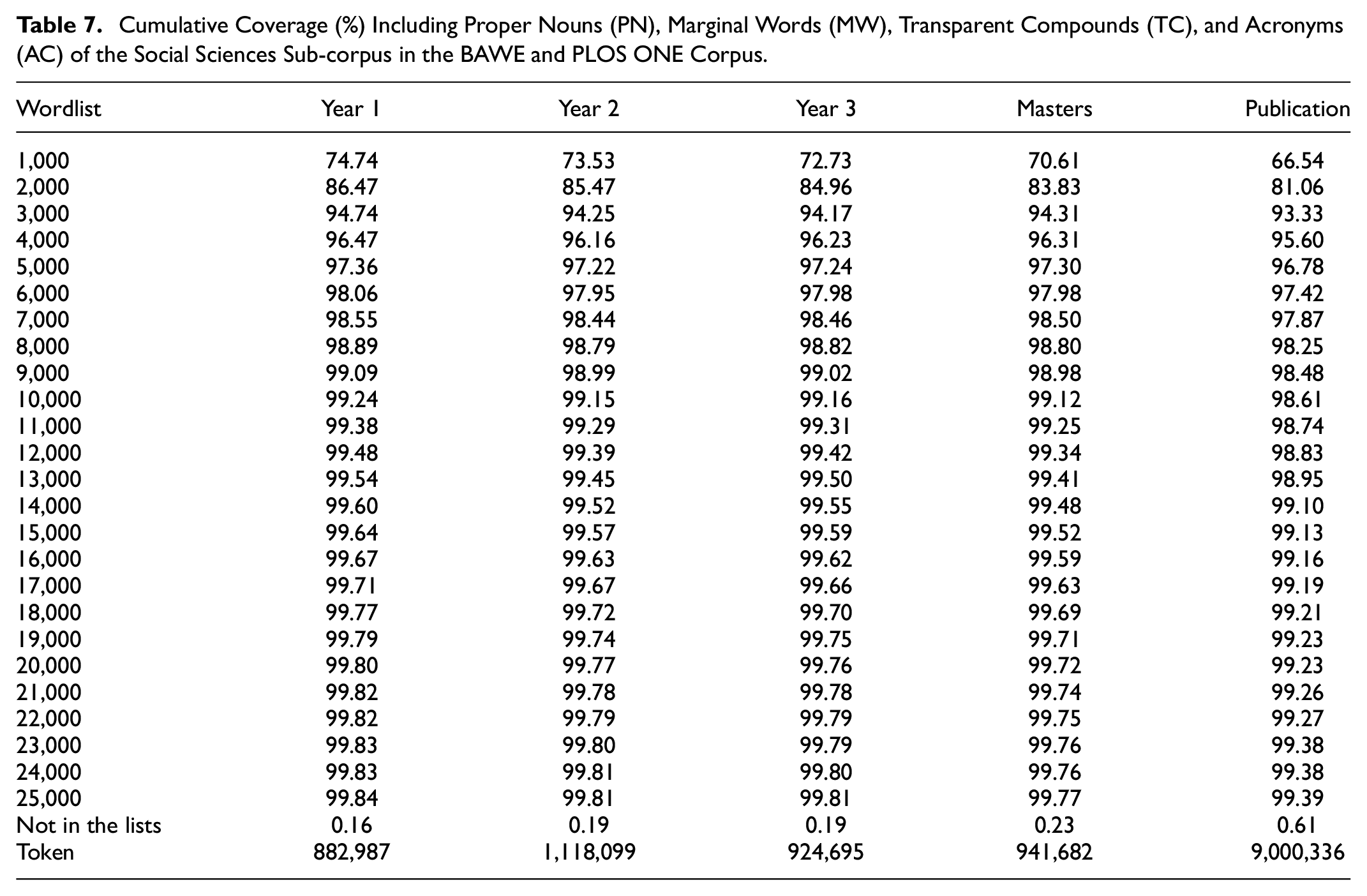
Similarly, to achieve 98% coverage of the Social Sciences sub-corpus from Year 1 to Master level, the vocabulary quantity needed did not differ. A vocabulary of the most frequent 6,000 word families plus PN, MW, TC, and AC was sufficient to reach 98.06%, 97.95%, 97.98%, and 97.98% coverage ranging from Year 1 to Master level, respectively. In order to attain 98% coverage at the Publication level, there was a slightly higher vocabulary volume required. 98.25% coverage could be covered by knowing the most frequent 8,000 word families plus PN, MW, TC, and AC. Compared to Life Sciences and Physical Sciences sub-corpus, the results indicated that the lexical demanded to reach 95% and 98% coverage of the Social Sciences sub-corpus at the Publication level did not yield an apparent discrepancy with other education levels.
Research Question 3: Variation in the Distribution of Academic Vocabulary
The distribution of the AWL in each sub-corpus presented in the BAWE and PLOS ONE corpus is shown in Table 8. Although the AWL was not evenly distributed across the level sub-corpora in each subject sub-corpora, we could generally observe an increasing tendency in the AWL coverage from Year 1 (8.53%) to Year 2 (9.44%), Year 3 (10.03%), Master (11.00%), and Publication (12.85%) levels.
Coverage of the BAWE and PLOS ONE Corpus and Each Sub-corpus by the GSL and the AWL (%).

For the PLOS ONE corpus, the highest coverage was covered in the Social Sciences sub-corpora (13.80%), and the lowest coverage was in the Physical Sciences (11.20%). Coverage of the AWL in the Biology and Life Sciences sub-corpus was 12.48%. The AWL was not evenly distributed across the three sub-corpora in the BAWE corpus and varied across four education levels from Year 1 to Master. In the Life Sciences sub-corpus of the BAWE corpus, the AWL ranged from 8.73% coverage to 9.85% coverage. In the Physical Sciences sub-corpus of the BAWE corpus, the AWL ranged from 8.84% coverage to 11.63% coverage. Similarly, the AWL ranged from 8.36% coverage to 11.66% coverage in the Social Sciences sub-corpus.
Discussion
Data from the analyses of the BAWE corpus showed that it takes readers 4,000 to 5,000 and 6,000 to 11,000 word families in the BNC/COCA list to understand 95% and 98% of the running words in students’ assignments, correspondingly, which could be said to be a little higher compared to the lexical demands of online newspaper and magazine articles found in H. T. Ha (2022b) and, to some extent, be comparable to Hsu’s (2018, 2022) findings concerning subject-focused textbooks. On the other hand, research articles published in PLOS ONE would require up to 9,000 and 20,000 word families to achieve 95% and 98% coverage, respectively. This signals that scholarly publications are much more difficult to understand compared to students’ assignments. Given that native English speakers and ESL learners can only increase their lexical resource by approximately 1,000 (Nation & Coxhead, 2021) and 500 (Ozturk, 2016; S. A. Webb & Chang, 2012) word families a year, in the given order, these differences in lexical demands between students’ assignments and scholarly articles could be deemed as significant.
Research findings also reveal the disciplinary differences in lexical difficulties. Table 9 compares the present study’s results to Dang and Webb’s (2014) findings. Although the two studies employed two different wordlists, certain similarities could be observed. The most noticeable observation is the fact that Social Sciences was the least lexically demanding branch of science, generally requiring only half of what was needed to understand texts in Life and Physical sciences. Although unable to spot significant difference in lexical difficulties between Physical and Life Sciences, research findings were in line with Dang and Webb (2014) that these two were the most lexically demanding scientific disciplines. It is interesting to see that papers in the field of Social Sciences, whether they were students’ assignments or scholarly articles, only required as much lexical knowledge as online newspapers and magazines (H. T. Ha, 2022b). While the present study did not offer evidence to support a scientific explanation for this similarity, we would hypothesize that it was to similarities in topics. As papers in the field of Social Sciences often deal with issue in the society including business, education, politics and other aspects of human, they share certain language features in common with online newspapers and magazines which often write about the same topics.
Disciplinary Differences in Lexical Demands in Academic Written and Spoken English.

Regarding whether the lexical profile of academic written English differs according to the writers’ levels, the present study suggests that it has an inconsistency. The distinction in vocabulary requirements across levels is particularly noticeable when analyzing the two sub-corpora containing Life Sciences and Physical Science. When comparing Year 1 to Master level in the Life Sciences and Physical Science sub-corpora, there is a typically trivial variation in the quantity of vocabulary required (approximately 1,000 word families to 2,000 word families). Still, as previously noted, the vocabulary demand at publication level is astonishingly higher (by two or almost three times). In the Social Sciences sub-corpus, the vocabulary required to achieve 95% coverage from Year 1 to Publication remains stable, while at the publication level, a higher vocabulary will be required to achieve 98% coverage but not exceedingly notable. These findings suggested that while the distinction in lexical difficulty between students’ assignments and scholarly articles was evident, the lexical differences between students’ writing at different levels were barely visible. Life Sciences could be said to be the only case where the hypothesized order of lexical difficulty was confirmed.
Concerning the coverage of the AWL in academic written English, the results showed that the AWL accounted from 8.53% to 12.85% of the running words. The coverage provided by the AWL in this study is considerably extensive compared with those in the studies of academic spoken English (Dang & Webb, 2014), university-based economics lectures (Thompson, 2006), TED Talks (Nurmukhamedov, 2017), which accounted for 4.41%, 4.90%, and 3.79%, respectively. It is conceivable that the AWL highlights words encountered in academic writing English rather than academic spoken discourse (Nurmukhamedov, 2017). The results in this study are consistent with other studies of academic written English such as Cobb and Horst (2004), Hyland and Tse (2007), Coxhead (2000), Martínez et al. (2009), which accounted for 11.6%, 10.6%, 10%, 9.06%, respectively. There is a 12.85% of the AWL distribution in the PLOS ONE corpus, the highest of any number reported. This figure reaffirms the high academic level and the massive vocabulary size required in the PLOS ONE corpus.
Different from the results concerning the 95% and 98% coverage, research findings on the coverage of AWL items seemed to support the proposed hypothesis about levels of writing. To be specific, the proportion of AWL became greater as the levels of writers went up, from Year 1 to Publication level: 8.53% (Y1) to 9.44% (Y2) to 10.03% (Y3) to 11.00% (M) to 12.85% (PLOS ONE). This could be said to align perfectly with Phung and Ha’s (2022) findings concerning the percentage of AWL items in the four sections of the IELTS listening test as illustrated in Table 1. Moreover, the results could be said to be well in line with Djiwandono (2016) which examined the differences in lexical richness between students’ and lecturers’ academic essays. Djiwandono’s study indicated that learners at the less advanced level use fewer academic words than those at a more advanced level. The findings of these studies generally provided further evidence for the assumption that more academic texts tend to contain more academic vocabulary, which was also supported by Choemue and Bram (2021).
Conclusion
This study has provided remarkable findings for the lexical demands of academic written English from a multidisciplinary perspective. Although the results did not show visible differences in lexical difficulties between different levels of students’ assignments, results from the analyses demonstrated a considerable difference in lexical demands between students’ assignments and published scholarly articles. Regarding the disciplinary differences in lexical demands, although we could not replicate the order of lexical of difficulty of Life Sciences > Physical Sciences > Social Sciences as presented in Dang and Webb (2014), data analysis of both the BAWE and PLOS ONE corpora supported the claim that Social Sciences is the least lexically demanding or the easiest-to-understand discipline.
Despite the helpful findings, several limitations should be noted in the present research. Although the current study contributes to the literature of lexical coverage and vocabulary demands in an academic written setting, the study has only examined the coverage of three disciplines, including Life Sciences, Physical Sciences, and Social Sciences. It should be noted that these disciplines made up <30% of the subjects covered in PLOS ONE journal, and other disciplines may be worth exploring beyond the focus of the current study. Moreover, while coverage may have the most significant impact influential factor, it is only one of several elements that might affect understanding, and that 100% coverage does not necessarily guarantee comprehension. There are other determinants such as learners’ background knowledge (S. A. Stahl et al., 1989, 1991; S. A. Stahl & Jacobson, 1986), the relevance of unknown words in context (S. Stahl, 1990) and individual differences (Mezynski, 1983; S. Stahl, 1990) that may affect comprehension of academic written discourse. Another limitation concerns the lack of variation in different types of academic writing. As the present study analyzed academic papers without a close examination of various text types (case study, critique, essay, review, proposal…), this led to the lack of sensitivity and variation in analyzed data. The assumption concerning writers’ levels used in this study was also a limitation worth mentioning. As scholarly publications could come from anyone with any academic background, some of whom might be taught postgraduate or even undergraduate students.
As a result, further studies into the issue are encouraged to dig deeper into the performance of specific groups of writers with different levels of language proficiency. It would be interesting to correlate the metrics of productive vocabulary knowledge of someone and his or her writing’s lexical coverage. Corpus-driven studies in the future should also examine the disciplinary differences in lexical difficulty from a wider range of disciplines. Currently, AntCorGen (Anthony, 2019) can collect more than 100,000 research articles from 11 different disciplines. It could be said that the present study did not exploit the maximum potential of this corpus generator program. Also, an in-depth investigation into the differences in lexical difficulties between various types of academic written texts would be a great addition that fill the gap of the present study.
Footnotes
Acknowledgements
The data in this study come from the British Academic Written English (BAWE) corpus, which was developed at the Universities of Warwick, Reading and Oxford Brookes under the directorship of Hilary Nesi and Sheena Gardner (formerly of the Centre for Applied Linguistics, Warwick), Paul Thompson (formerly of the Department of Applied Linguistics, Reading) and Paul Wickens (School of Education, Oxford Brookes), with funding from the ESRC (RES-000-23-0800). Details of how to access to the corpus via the Oxford Text Archive can be found at ![]()
Authors’ Contribution
The first author was responsible for data collection and analysis. All authors contributed equally to the preparation of the manuscript.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Ethics Statement for Animal and Human Studies
Not applicable.
Data Availability Statement
The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.