
Abstract
The abstract is an integral part of a scientific paper. Despite the importance of abstracts, very little research has investigated the vocabulary size needed to read abstracts in scientific papers. This present study analyzed the lexical profile of 26 million words from approximately 100,000 scholarly abstracts across 10 major subjects of science. The results showed that the vocabulary size of the most frequent 7,000 and 15,000 word families in the British National Corpus/Corpus of Contemporary American English (BNC/COCA) word list plus proper nouns, marginal words, transparent compounds, acronyms were needed to gain 95% and 98% coverage of the abstract corpus, respectively. However, data from cross-disciplinary analyses demonstrated significant differences in the lexical demands between abstracts of different fields of study. The 570 word families in the Academic Word List were found to make up for 13.77% of the words in the corpus. Implications for the use of abstracts in language classrooms were discussed.
Introduction
The abstract is a brief summary of the research paper, recognized as “an abbreviated, accurate representation of a document” (Weil, 1970, p. 352), and serves the purpose of highlighting major points of the research (research subject, methodology, and findings of the research) and explaining why the scientific work is of special value. In addition to the title, the abstract is the first part of the article that readers know about, and with subscription-based journals, this is the only part that readers can access. As a result, according to Nicholas et al. (2003), the abstracts tend to be read frequently among sections of research papers. Therefore, it would be more than safe to say that the abstracts play an important role in capturing the attention of editors and readers. Readers’ judgment of whether the document is relevant to the topic of interest and the recognition of a research paper are largely influenced by the information contained in the abstract. Consequently, accessible and readable abstracts are necessary for not only scholars for academic purposes, but especially non-specialist readers.
Moreover, when examining the availability of abstracts in teaching and learning English, these abstracts can be assumed to offer a large amount of academic vocabulary and authentic input. Although abstracts are very helpful in learning vocabulary, being able to understand the knowledge contained in the abstract can be challenging for L2 learners. Therefore, using scholarly abstracts to teach language raises the question of how much vocabulary size learners need to obtain to understand abstracts?
There have been many studies conducted to investigate the lexical coverage of academic writing on different types of texts, such as Hyland and Tse (2007), Li and Qian (2010), Hsu (2011), . . . but few studies have paid attention to the lexical demands of the abstracts in research papers. However, most research on academic writing is more than 10 years old and needs revisiting to provide the latest understanding of the lexical demands of academic written English. Consequently, the current research aims to shed light on the vocabulary knowledge needed for second language (L2) learners to reach 95% and 98% coverage of abstracts of research papers in various scientific fields. Besides, many researchers have argued that the lexical demands of texts, both in spoken and written, of different fields are disparate (Dang & Webb, 2014; Hajiyeva, 2015). As a result, this study not only shows the lexical demands of abstracts but also examines and compares them within many different scientific fields, and then goes on to give an overview for lexical coverage of academic writing. In addition, the study indicates the distribution of the Academic Word List in scholarly abstracts. Finally, with the results obtained, the present study will provide teachers with guidelines for employing scholarly abstracts as teaching materials in language classrooms.
The Definition of “Lexical Coverage” and its Relationship to Comprehension
Research have been conducted on the proportion of words learners have to know to gain adequate comprehension of a particular text. In these studies, the lexical demands have been approached in terms of lexical coverage. The phrase “lexical coverage” is used with the meaning of “the percentage of running words in the text known by the readers” (Nation, 2006, p. 61). Figures of 95% and 98% are deemed necessary to reach reasonable (Laufer, 1989) and optimal (Hu & Nation, 2000) comprehension, respectively.
The concept of comprehension, according to Ha (2021), was a “matter of judgment and each researcher had his or her justification when setting a threshold for reasonable comprehension, which, in most cases, was the minimum passing grade in the testing system of the institution or country where they worked or conducted the study” (p. 17). For example, Laufer (1989) investigated the mutual relationship between lexical coverage and reading comprehension and found that with a minimum of 95% lexical coverage, L2 readers would achieve a passing score of 55%, which represented the lowest passing score at the Haifa University, or higher. More than two decades later, Laufer and Ravenhorst-Kalovski (2010) employed the strict score of 134/150, which was nearly 90%, on the Psychometric Entrance Test created by the National Institute for Testing and Evaluation (NITE) in Israel and re-confirmed the two thresholds of lexical coverage (95% and 98%) needed for reading comprehension. It is interesting that although different criteria were used to define reading comprehension, either 55% (Laufer, 1989), 70% (Hazenberg & Hulstijn, 1996; Stæhr, 2009) or even 90% (Laufer & Ravenhorst-Kalovski, 2010), these studies all agreed with the relationship between the above-mentioned lexical coverages and reading comprehension. In an influential study that examined the link between vocabulary knowledge and listening comprehension, van Zeeland and Schmitt (2013) emphasized that 95% coverage was the coverage for “good but not necessarily complete comprehension,” while 98% was the ideal coverage for “very high comprehension.” These findings were later revisited and supported by the results of a myriad of studies (Ha, 2021; Nurmukhamedov & Webb, 2019; Webb, 2020).
The pedagogical implications of lexical coverage have also been the research topic of several scholars (McLean, 2021). Stoeckel et al. (2021, cited in McLean, 2021) and Schmitt et al. (2011) suggested that, for a reading passage to be considered for language-focused instruction activities, learners need to be familiar with at least 85% of the running words in that text. If the purpose of including abstracts in lessons involved reading comprehension, then a 95% coverage would be required (Laufer, 1989; Schmitt et al., 2011). For meaning-focused and extensive reading activities, teachers should make sure their learners know at least 98% of the words in their reading materials (Nation, 2007; Webb & Nation, 2017). For speed reading or fluency development, Nation (2007) suggested that the reading passage contained no unknown words to readers, emphasizing a 100% lexical coverage.
Lexical Demands Across Text Genres—How Many Words Do Learners Need to Understand Different Types of Texts?
In language research, besides identifying the lexical demand, researchers also mind about whether lexical demands differ between various types of spoken and written text.
Webb and Rodgers (2009a, 2009b) investigated the lexical profiles of American and British movies, as well as TV programs. They found that, coupled with proper nouns and marginal words, the vocabulary knowledge of 6,000 and 7,000 word families in the British National Corpus (BNC) word list (Nation, 2006) provided 98% coverage of movies and TV programs, respectively. Al-Surmi’s (2014) research partially replicated Webb and Rodgers’s (2009a, 2009b) studies and investigated the lexical coverage of both soap operas and sitcoms. The results showed that knowledge of the most frequent 2,000 word families including proper nouns and marginal words was necessary to reach 95.49% and 95.05% coverage for soap operas and sitcoms, correspondingly. The lexical demands were different when it came to 98% coverage. The vocabulary size of the most frequent 5,000 word families provided 98.19% coverage of soap operas, while the vocabulary size of the most frequent 7,000 word families accounted for 98.07% of the running words in sitcoms.
In a recent attempt to provide a methodological update for the lexical profile of informal spoken English, Ha (2022a) employed Nation’s (2017) British National Corpus/ Corpus of Contemporary American English (BNC/COCA) to analyze a mega-corpus consisted of 122,000 transcripts of soap operas (100 million words), TV programs (325 million words), and movies (200 million words). His findings found that, together with proper nouns (PN), marginal words (MW), transparent compounds (TC), and acronyms (AC), 2,000 and 4,000 most frequent word families in Nation’s (2017) British National Corpus/ Corpus of Contemporary American English (BNC/COCA) wordlist accounted for 95% and 98% of the running words in soap operas, respectively (Ha, 2022a). For movies and TV programs, Ha (2022a) also pointed out that the word knowledge of 3,000 and 5,000 most frequent word families in the BNC/COCA lists plus PN, MW, TC, AC would help learners to reach 95% and 98% coverage, correspondingly. Basing on the same methodology, Nurmukhamedov and Sharakhimov (2021) examined the lexical coverage of podcasts—the growing popular spoken English resource. The results of this study indicated that the vocabulary size of 3,000 most frequent word families in the BNC/COCA word list plus PN, MW, TC, AC accounted for 96.75% coverage, and knowledge of the most frequent 5,000 word families was sufficient to gain 98.26% coverage.
For non-academic written texts, Nation’s (2006) influential study showed that 4,000 and 8,000 to 9,000 most frequent word families in the BNC lists plus proper nouns would cover 95% and 98% of the words in newspapers and novels, respectively. 16 years later, Ha (2022b) revisited the topic by using Nation’s (2017) BNC/COCA lists and analyzing Davies’s (2016/2021) News On the Web (NOW) mega-corpus that contained 12.5 billion tokens from online newspapers and magazines. While findings of the replication study showed significant variations in the vocabulary knowledge needed for 98% coverage between newspapers from different countries, in general, vocabulary knowledge of 3,000 to 4,000 word families in the BNC/COCA lists plus PN, MW, TC, and AC would be required for 95% coverage (Ha, 2022b).
Several studies conducted on academic spoken and written texts have shown that academic texts have higher lexical requirements than non-academic spoken and written texts (Hsu, 2018, 2022; Liu & Chen, 2019; Nurmukhamedov, 2017). For example, Hsu’s BNC/COCA-based studies on subject-focused textbooks presented the lexical demands of 5,000 and 10,000 word families plus supplementary words (PN, MW, TC, AC) for 95% and 98% coverage, in the order given (Hsu, 2018, 2022). Liu and Chen (2019) also showed that learners would need up to 5,000 to 7,000 word families in the BNC/COCA list plus supplementary words to understand 98% of the words in TED talks, depending on disciplines. It could be seen that, compared to non-academic discourses, academic written and spoken English would require an additional knowledge of 1,000 to 2,000 word families to gain corresponding coverage thresholds.
Several studies have been conducted to examine the distribution of the AWL’s 570 word families in written academic texts (Cobb & Horst, 2004; Coxhead, 2000; Hyland & Tse, 2007). The results indicated that there was a relatively similar proportion of AWL items: 10.0% (Coxhead, 2000), 11.6% (Cobb & Horst, 2004), 10.6% (Hyland & Tse, 2007), 10.46% (Li & Qian, 2010).
Why is Abstract Important?
Scholarly abstracts contain the most integrated information of the research article. It is responsible for providing an executive summary of what the research paper contains such as research objectives, research questions, methodology, results, and implications. If the abstract is written effectively and comprehensively, it can represent clearly the value of the scientific work that stands behind it. The abstract is also considered a helpful tool for helping readers access information more easily and find specific information without spending time reading the entire paper. The abstract, as an overview of a research paper, will provide scholars and non-specialist readers with a general understanding of a particular study and help them form their first opinion on that research project.
Besides, the abstract is the first content that catches the reader’s eyes, so the abstract should be ensured to be attractive and concise enough. A good abstract would help potential readers determine the relevance of the research paper to their interests and convey key findings to those who do not have time to read the entire article. Some researchers believe that the abstract is the part that the vast majority of people read before deciding whether to continue reading or not. Lu et al.’s (2019) study revealed that high-impact scholarly abstracts presented a really high degree of lexical complexity, leading to the assumption that the use of uncommon, academic or technical terminologies would not pose great challenges to the readers’ comprehension. In contrast, such practice was believed to reflect a positive image of the research quality, and therefore, make scholars feel more interested and eager to read and cite the research paper (Lu et al., 2019). However, not every researcher shares the same perspective, Jin et al. (2021) argue that scholarly writers should be mindful of their non-expert readers and aim for a greater variety of readership. Their study even pointed out that the readability of a paper’s abstract had a significant impact on its online attention (Jin et al., 2021).
Abstracts are not only the essential part of research papers but also play an important role in teaching and learning English. Similar to podcasts, novels, or TED Talks, abstracts provide readers with authentic inputs on a variety of scientific disciplines, ranging from vocabulary to grammar points. With the Internet and the rise of search engines, the abstract became more accessible and a free source of data for learning for all readers. It can be argued that abstracts are a useful resource that provides a wealth of lexical knowledge to the reader. If the abstracts are included in courses in the right way and to the right audience, it will bring a lot of pedagogical benefits. For example, the inclusion of subject-specific abstracts as reading materials for English as Academic Purposes (EAP) or English as Specific Purposes (ESP) students not only offers a rich source of subject-related, academic vocabulary, but also up-to-date knowledge on the field of study.
Given the importance of abstracts to research papers and the lack of evidence-based answers concerning the number of words needed to understand these executive summaries. A thorough investigation of the lexical profile of scholarly abstracts of different research disciplines is not just guaranteed but rather essential.
The Present Study
The present study investigates the lexical coverage of approximately 100,000 abstracts from about 100,000 research articles. This research paper examined abstracts but not the whole research papers because they are short, only about 200 words in length but can represent the important contents of the whole study. Besides, if we were to use the full paper, probably our maximum sample size could only reach 10,000 papers as each paper can be up to more than 10,000 words. Furthermore, the focus of the study was on the breadth of academic writing, aiming to cover as many disciplines as possible, to review abstracts from a variety of subjects in academic written English. This study used an extensive corpus, covering all the major subjects of science: Biology and life sciences (BLS), Computer and information sciences (CIS), Earth sciences (ES), Ecology and environmental sciences (EES), Engineering and technology (ET), Medicine and health sciences (MHS), People and places (PP), Physical sciences (PS), Research and analysis methods (RAS), Social sciences (SS).
The conducting of this research helps to create a lexical profile for scholarly abstracts in 10 major subjects of science. Besides, this study will also provide comprehensive comparisons and discussions on various disciplines in science, thereby filling the research gap in academic written English. The research is conducted with the objective of providing insights into academic writing in its fullest picture. Its findings play an important role in providing teachers and learners of English for Academic Purposes (EAP) courses with new insights into academic written English, so that improvements in teaching and learning could take place in the right direction.
Research Questions
The review revealed the obsolescence and research gaps in studies of academic written English. Therefore, this research is conducted with the aim of providing up to date and comprehensive knowledge of academic written English in its fullest picture.
In particular, the present study seeks answers to the following research questions:
How many word families do learners need to know to reach 95% and 98% coverage of abstracts in academic written English?
How many word families do learners need to know to reach 95% and 98% coverage of each subject sub-corpus?
How much coverage does the AWL provide for abstracts in academic written English?
How much coverage does the AWL provide for each subject sub-corpus?
Methodology
Data Collection
This study used a corpus consisting of approximately 100,000 abstracts in research articles, totaling 26,843,833 words. For each register, the number of analyzed texts is roughly equal to ensure comparability as well as representativeness. Table 1 shows the composition of the corpus. To collect this number of abstracts, the researcher used a free software called AntCorGen (Anthony, 2019). Laurence Anthony’s AntCorGen is a “discipline-specific corpus creation tool” with data taken from the open science journal, PLOS ONE. PLOS ONE is a multidisciplinary, open - access mega journal with a large number of published scientific works. The creation of such a large, broad, and comprehensive corpus is a necessity to meet the stated purpose of the study.
General Information About the Corpus.

Data Analysis
The present study used RANGE to analyze the lexical profile of the abstract corpus. Heatley et al. (2002) introduced a computer program called RANGE. RANGE can help researchers to list words based on their occurrence in word lists and show the number of times the word is used in the target text. It can be used with GSL/AWL list, BNC word list and BNC/COCA word list.
The present study employed the GSL/AWL list and BNC/COCA word list to examine the vocabulary in the texts.
The abstract corpus was analyzed by the BNC/COCA word list to investigate the vocabulary knowledge necessary to gain 95% and 98% coverage threshold. Besides twenty-five 1,000-word-frequency lists, there are other additional wordlists such as Proper nouns (list 31), Marginal words (list 32), Transparent compounds (list 33) and Acronyms (list 34). Words in these word lists were assumed to be known by the learners (Nation & Webb, 2011; Nurmukhamedov & Sharakhimov, 2021; Tegge, 2017). Hyphens in hyphenated words were also removed and replaced with spaces as they could not be read by RANGE. The hyphenated words, then, will be reclassified based on the frequency of their single-word items. Words that were not found in the above lists will be listed as Not in the Lists. The study also used RANGE with the GSL/AWL list to determine the frequent degree of academic words in the abstract corpus and each subject.
Results
Table 2 shows the frequency and distribution of the AWL and GSL in the abstract corpus and each subject sub-corpus. The AWL made up 13.77% coverage of the abstract corpus. This coverage is 3 times larger than the coverage of the AWL in the BASE corpus (4.41%, Dang & Webb, 2014, Table 2) and 3.5 times larger compared to TED talks (Coxhead & Walls, 2012; Nurmukhamedov, 2017). In addition, along with the 2,000 word families in GSL, the AWL provided 77.22% coverage of the abstract corpus. It is interesting to note that the coverage provided by AWL is more than twice the coverage of the second 1,000 word families from the GSL in the abstract corpus.
Coverage of the Corpus and Each Sub-Corpus by the General Service List and the Academic Word List.
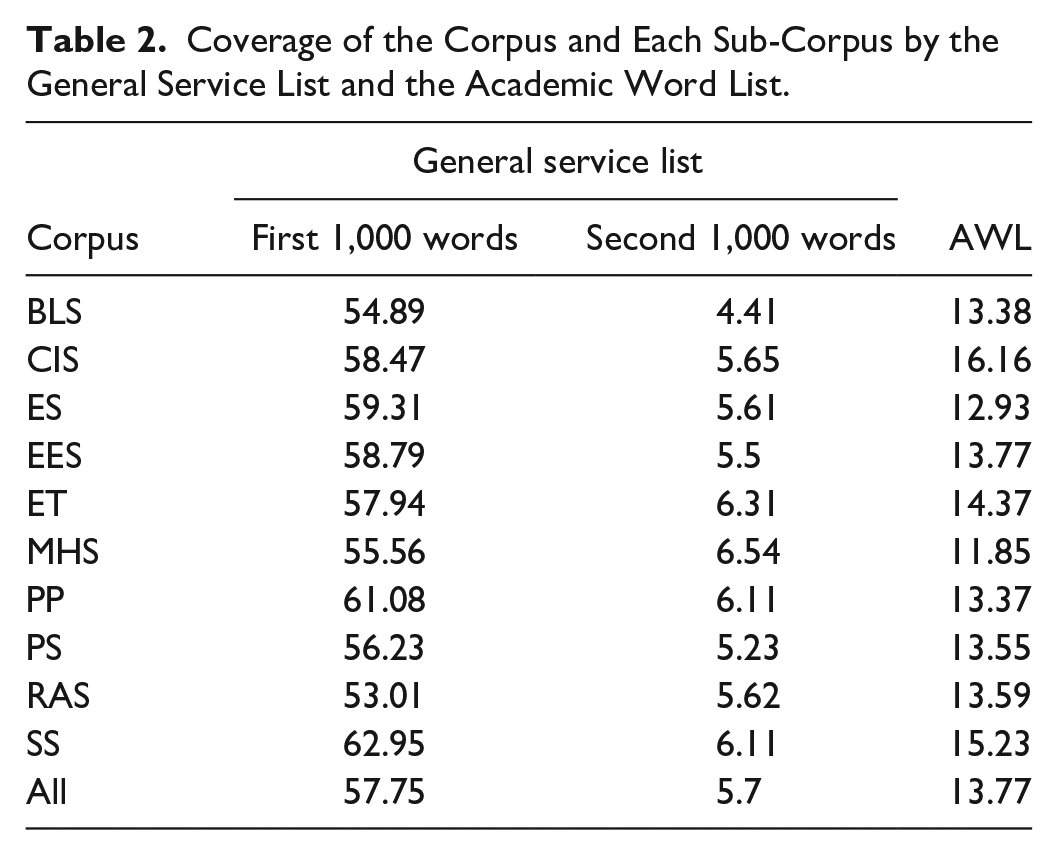
Table 2 also shows the variation in the coverage of AWL across 10 subject sub-corpora. The lowest and highest coverages were 11.85% and 16.16% in the MHS sub-corpus and the CIS sub-corpus, respectively. The distribution of the AWL on the remaining sub-corpora was relatively similar. Besides, the distribution of the first 1,000 word families in the GSL list across the 10 subject sub-corpora is also noteworthy. The highest coverage was 62,95% in the SS sub-corpus, far exceeding the lowest coverage in the RAS sub-corpus (53.01%).
The second column of Table 3 shows the coverage of each word level for the abstract corpus provided by the BNC/COCA word list (Nation, 2017). The first three 1,000-word-family lists covered a large proportion of the running words in the abstract corpus. The first, second, and third 1,000 most frequent word families in the BNC/COCA word list accounted for 55.30%, 14.22%, and 14.81% of the tokens in the corpus, correspondingly.
Coverage of the Corpus by the BNC/COCA List.

While these results indicate the importance of recognizing and knowing the first 3,000 word families for reading comprehension, the most frequent 1,000 word families’ coverage percentage is quite low. Its coverage, 55.30%, is much less than the coverage provided by the most frequent 1,000 word families in corpora of non-academic, written English such as online newspapers and magazines (72.48%, Ha, 2022b, Table 1). However, such coverage is comparable to the findings of lexical studies on subject-focused academic textbooks (57.75%, Hsu, 2022, Table 2). In addition, it is also much less than the coverage of the first 1,000 word families in corpus taken from general, spoken English like movies (85.47%, Ha, 2022b, Table 3), television programs (84.74%, Ha, 2022b, Table 3) and soap operas (83.21%, Ha, 2022b, Table 3). In the podcast corpus, the first 1,000 word families accounted for 82.80% of the tokens (Nurmukhamedov & Sharakhimov, 2021, Table 3).
Furthermore, it is should be noted that the coverage of the third 1,000 word families was 0.59% more than that of the second 1,000 word families. This is quite a special feature when analyzing this abstract corpus. In most other studies, the coverage gradually decreased as the word level increased. This means that, typically, the coverage of the second 1,000 word families should be larger than the coverage of the third 1,000 word families. Meanwhile, in this study, the opposite was found. In addition, most coverage provided by the first 2,000 word families and 3,000 word families were below 10% (Ha, 2022a, 2022b). However, in the present study, the second and the third 1,000 word families provided significant coverage of 14.22% and 14.81%, respectively. When comparing this data with data from academic spoken English studies such as lectures (Dang & Webb, 2014) or TED Talks presentations (Nurmukhamedov, 2017), the difference is also significant. In Dang and Webb’s (2014) study, the first 2,000 and 3,000 word families accounted for a very little percentage of running words, 2.07% and 1.76% respectively. Similarly, in Nurmukhamedov’s (2017) study, the second 1,000 word families provided 6.07% and the third 1,000 word families accounted for only 2.16% of running words. These differences are significant even though the comparisons were made between studies using different wordlists (BNC and BNC/COCA).
The coverage at the fourth, fifth and sixth 1,000 levels were 2.99%, 1.83%, and 1.54%, respectively. This is an interesting finding as for most corpora, coverage at the 5,000 level was less than 1%. To be specific, for the NOW corpus, the most frequent 5,000 word families accounted for 0.98% of the running words (Ha, 2022b). For movies, TV program, and soap operas, the fifth 1,000 word families provided 0.66%, 0.70%, and 0.35% coverage, respectively (Ha, 2022a). However, in the abstract corpus, at the 5,000 level, the coverage was still quite high, 1.83%. Coverage only dropped to 0.87%, below 1% when reaching the 7,000 level. These figures are well in line with those of academic textbooks (3.31%—fourth level, 2.02%—fifth level, 1.00%—sixth level, Hsu, 2022, Table 2). These findings emphasized the occurrence of low-frequency vocabulary in academic writing.
Words from the 7,000 level onward only made up for less than 1% of running words in the corpus. There was a downward tendency in lexical coverage as the word level went up. However, at the twenty-third 1,000 word families, the percentage coverage was slightly increased, 0.40% of running words in the corpus. With the 23rd word level, a low-frequency word level, this coverage was quite high and only 0.15% away from the coverage of the 8,000 word families.
The last two columns of Table 3 show the cumulative coverage with and without proper nouns, marginal words, transparent compounds, and acronyms. If learners did not understand proper nouns, marginal words, transparent compounds, as well as acronyms, they must know 23,000 word families to understand 95.25% of running words. Besides, reaching 98% coverage of the abstract corpus was impossible. Conversely, the knowledge of 7,000 word families provided 95.46% coverage and the knowledge of 15,000 word families was necessary to achieve 97.99% coverage of the corpus if proper nouns, marginal words, transparent compounds, acronyms were assumed to be known. It indicates that learners must have knowledge of additional 8,000 word families to move from 95% to 98% coverage.
Table 4 presents the coverage of each word level for each subject sub-corpus by the BNC/COCA word list. The most frequent 1,000 word families in the BNC/COCA word list shared relatively similar coverage across 10 subject sub-corpora. Coverage ranged from 51.45% (the RAS sub-corpus) to 58.95% (the PP sub-corpus). On most subject sub-corpus, the coverage of the third 1,000 word families was greater than that of the second 1,000 word families (six out of 10 sub-corpora). The largest difference recorded was 2.8% in the BLS sub-corpus. The twenty-third 1,000 word families across all sub-corpora provided significant coverage, for such a low-frequency level, with the lowest and highest coverage of 0.32% (the BLS sub-corpus) and 0.47% (the PS sub-corpus).
Coverage of the BNC/COCA List for Each Sub-Corpus.

Table 5 shows cumulative coverage of each subject sub-corpus without proper nouns, marginal words, transparent compounds and acronyms. It seems that the mere knowledge of 25,000 word families from the BNC/COCA list were not enough to understand 98% of running words across 10 subject sub-corpora. Even in two sub-corpora, MHS and RAS, reaching 95% coverage was not possible.
Cumulative Coverage of Each Subject Sub-Corpus Without Proper Nouns, Marginal Words, Transparent Compounds, and Acronyms.

Table 6 shows the cumulative coverage of each subject sub-corpus including proper nouns, marginal words, transparent compounds as well as acronyms. The knowledge needed to achieve 95% and 98% coverage across the five subject sub-corpora (CIS, ES, EES, ET, MHS) were mostly consistent at the 6,000 or 7,000 and 13,000 to 16,000 word levels, respectively. For the remaining subject sub-corpora, the vocabulary knowledge required to achieve 95% coverage ranged from 5,000 to 10,000 word families and a vocabulary size of 8,000 to 19,000 word families was needed to reach 98% coverage. The data indicate that SS required the least vocabulary size (5,000 word families accounted for 96.07% of the words and 8,000 word families made up of 98%) and RAS was the most lexically demanding (10,000 word families for 95.20% coverage and 19,000 word families for 97.97% coverage). There was a large variation in the vocabulary knowledge required to achieve reasonable and ideal comprehension between the SS sub-corpus and the RAS sub-corpus. Namely, the difference was 5,000 word families at 95% coverage threshold, and for the 98% threshold, the difference went up to 11,000 word families. Following the SS sub-corpus, the PP sub-corpus can be seen as the second easiest to understand. The PP sub-corpus needed knowledge of 5,000 word families to achieve 95% coverage and knowledge of 11,000 word families to achieve 98% coverage. The SS and PP sub-corpus required the same amount of knowledge to gain 95% coverage, but at 98% coverage, the PP sub-corpus needed more than 3,000 word families. On the contrary, the PS, RAS and BLS sub-corpora may pose relatively great challenges to readers. The vocabulary knowledge required to achieve 95% and 98% coverage were 10,000 and 18,000 to 19,000 word families, respectively. These findings suggest that SS and PP sub-corpora were significantly less difficult to understand than PS, RAS and BLS.
Cumulative Coverage of Each Subject Sub-Corpus With Proper Nouns, Marginal Words, Transparent Compounds, and Acronyms.

Note. The bolded figures indicate the level at which cumulative text coverages reached 95% and 98%.
Discussions
In answer to the first question, the knowledge of 7,000 word families plus PN, MW, TC, AC provided 95% coverage, meanwhile, a vocabulary size of 15,000 word families was necessary to reach 98% coverage of the abstract corpus. Compared with the vocabulary knowledge needed to achieve 95% and 98% coverage of other corpora such as university-based academic lectures (Dang & Webb, 2014), TED Talks presentations (Liu & Chen, 2019), informal spoken English (Ha, 2022a; Nurmukhamedov & Sharakhimov, 2021) and non-academic written English (Ha, 2022b), abstracts need a larger vocabulary size. For example, compared with the findings of Liu and Chen (2019), the result indicates that the abstract corpus needs additional 4,000 word families at the 95% threshold and 8,000 to 10,000 word families at the 98% threshold, generally highlighting the difference in lexical demands between academic spoken and written English. Data from the analyses also showed that, scholarly abstracts are more lexically demanding compared to subject-focused textbooks (Hsu, 2018, 2022). This might be because reading materials selected for pedagogical purposes have went through serious considerations made by textbook writers to make sure that they were not overly difficult for learners.
In answer to the second question, the results show a variation in the knowledge needed to reach the 95% and 98% thresholds across 10 subject sub-corpora. Given that PN, MW, TC, AC were known, the results indicated that SS was the least lexical demanding corpus while RAS was the most lexical demanding corpus. Namely, SS required the vocabulary size of 5,000 word families for 96.07% coverage and 8,000 word families 98% coverage while RAS needed the knowledge of 10,000 most frequent word families for 95.20% coverage and 19,000 word families for 97.97% coverage. The differences in the vocabulary size necessary at both 95% and 98% coverage of each subject sub-corpus confirmed Dang and Webb’s (2014) assumption that “different disciplines may have different lexical demands with some being more difficult to understand than others” (p. 18). But the aim of the present study is not only to confirm such assumptions, but to venture beyond that. The research findings show that the vocabulary sizes needed to achieve 95% and 98% coverage varied greatly across the 10 subject sub-corpora. Especially, considering the vocabulary demands of the two major groups of sciences, the distinction is clearer than ever. In the present study, Social sciences included SS and PP sub-corpora, while Natural sciences consisted of ES, EES, PS, and RAS sub-corpora. SS and PP were the least lexical demand sub-corpora and were considered legible for ESL learners. Meanwhile, the most lexically demanding abstracts came from ES, EES, PS, and RAS sub-corpus. These findings highlight the conclusion that Natural sciences require more complex vocabulary than Social sciences.
In answer to the third question, the AWL made up 13.77% coverage of the abstract corpus. This coverage is much greater than the coverage provided by the AWL in past academic written corpora: 10.0% (Coxhead, 2000), 10.6% (Hyland & Tse, 2007), 10.46% (Li & Qian, 2010) and academic spoken corpora: 4.41% (Dang & Webb, 2014), 3.79% (Nurmukhamedov, 2017). This result shows that the AWL list covers a significant amount of vocabulary in the abstract of research papers. As a result, it can be concluded that learners with knowledge of the 570 word families in the AWL might find it easier to read these abstracts, and these abstracts also make a useful contribution to the learning of academic vocabulary.
In answer to the fourth question, the distribution of the AWL list across the subject sub-corpora is uneven. Coverage on 10 subject sub-corpora is: 13.38% (BLS), 16.16% (CIS), 12.93% (ES), 13.77% (EES), 14.37% (ET), 11.85% (MHS), 13.37% (PP), 13.55% (PS), 13.59% (RAS), and 15.23% (SS). In this study, the lowest coverage is 11.85% in the MHS sub-corpus and the highest coverage is 16.16% in the CIS sub-corpus. This result indicates that learners who are interested in research papers from the CIS field should know the AWL list. Besides, learners major in courses from SS will also benefit from learning this list because the distribution of the AWL in the SS corpus is also significant, 15.23%.
From pedagogical perspectives, the use of scholarly abstracts as reading materials for EAP classes is still feasible despite the high lexical demands. Data from Table 6 shows that the knowledge of 3,000 most frequent word families in the BNC/COCA lists plus supplementary words would help learners achieve 85% coverage of all scholarly abstracts. This implies that the use of abstracts as form-focused instruction materials would be feasible for learners who know 3,000 words families in the BNC/COCA and above. As Ha’s (2021) study suggested, this level of word knowledge is common for most L2 university students and is equivalent to an IELTS band score of 5.0 in the listening and reading subtests. If the use of abstracts in a language classroom involved reading comprehension activities, then even the least lexically demanding discipline, Social Sciences, would require a word knowledge of 5,000 word families in the BNC/COCA lists. According to Ha (2021), this vocabulary knowledge can only be found in learners who obtained the band scores of 6.5 or above on the IELTS reading and listening tests, the level of English proficiency at which students would be accepted for admission in most English-speaking universities.
However, one of the upsides of having high lexical demands is the fact that scholarly abstracts contains a rich lexical resources of academic and less-frequent, subject-specific vocabulary. Teachers who wish to use scholarly abstracts for their language-focused or reading comprehension activities are advised to first analyze the vocabulary profile of their selected abstracts using the VP-Compleat program (at https://www.lextutor.ca/vp/) and then cherry-pick words that are beyond the 3,000 level for deliberate instructions. If this practice is applied to Social Sciences-related disciplines including Linguistics (applied), Business, Humanities and Education, then words at 3,000 level or above would account for only 8% to 9% of the total tokens (Table 6), approximately 16 to 18 words for a 200-word abstract. This means that a careful pre-teaching of these unknown words would lead to a successful reading comprehension session with scholarly abstracts, even for students with vocabulary at 3,000 level. The use of scientific abstracts in language classrooms could be seen as a one-stone-two-bird practice as we are providing learners with the language features and up-to-date knowledge that may both related and useful to their field of study.
Conclusion
Current research provided insights into academic written English through examining the lexical profile of abstracts in research papers. Its results demonstrated significant variations in lexical demands between abstracts of different scientific disciplines. The findings also pointed out that scholarly abstracts offer a rich lexical resources of academic vocabulary, and that the use of abstracts in language classroom can only be practical for learners with vocabulary knowledge at 3,000 level or above.
While the present study offers a comprehension insight into the vocabulary profile of academic writing, it’s power of analysis was limited by the use of a general wordlist (BNC/COCA) as the primary research methodology. As scholarly abstracts are subject-specific in nature, future studies on lexical profile of academic abstracts that utilize wordlists from both general and specialist corpora would be more than encouraged.
Footnotes
Abbreviations
BLS: Biology and life sciences; BNC: British National Corpus; CIS: Computer and information sciences; COCA: Corpus of Contemporary American English; ESL: English as a Second Language; ES: Earth sciences; EES: Ecology and environmental sciences; ET: Engineering and technology; TOEFL: Test of English as a Foreign Language; MW: Marginal Words; NOW: News on the Web; PN: Proper nouns; TC: Transparent Compounds; US: United States; UK: United Kingdom; MHS: Medicine and health sciences; PP: People and places; PS: Physical sciences; RAS: Research and analysis methods; SS: Social sciences; IELTS: International English Testing System.
Author Contributions
The first author was responsible for data collection and analysis. All authors contributed equally to the preparation of the manuscript.
Availability of Data and Materials
The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.