
Abstract
This study investigated the role of ChatGPT4o as an AI peer assessor in English-as-a-foreign-language (EFL) speaking classrooms, with a focus on its scoring reliability and the effectiveness of its feedback. The research involved 40 first-year English major students from two parallel classes at a Chinese university. Twenty from one class served as speech sample providers; and the other 20 served as human peer assessors. In addition, ChatGPT4o served as an AI peer assessor. The study employed univariate and multivariate generalizability (G-) theory to compare the consistency and reliability of holistic and analytic scoring between ChatGPT4o and human peer assessors. The results demonstrated that ChatGPT4o provided significantly more consistent and reliable scores across domains such as accuracy, fluency, and complexity. Moreover, ChatGPT4o delivered more comprehensive and effective feedback, offering clear guidance for improvement. However, interviews with human peer assessors revealed concerns about ChatGPT4o’s limitations in capturing the subtle aspects of spoken language, such as emotion and cultural context, and the potential over-reliance on ChatGPT4o in EFL assessments. The findings suggested that while ChatGPT4o as an AI peer assessor can enhance the reliability and quality of peer assessments, its adoption should be carefully managed to complement, rather than replace, human judgment, ensuring a balanced approach in EFL speaking classrooms.
Introduction
In recent years, the incorporation of artificial intelligence (AI) into language education has attracted considerable attention as both educators and researchers investigate its potential to improve teaching, learning, and assessment processes (Guo & Wang, 2023; Link, Mehrzad, & Rahimi, 2022; Shermis & Hamner, 2013). AI has brought about new methods that are transforming instructional practices and assessment approaches, with particular emphasis on its ability to deliver efficient and personalized educational experiences (Ansari et al., 2023; Barrot, 2023; Creely, 2024; Farazouli et al., 2024; Tate et al., 2024). Among these AI advancements, OpenAI’s ChatGPT has gained recognition as a significant tool, especially for its role in evaluating English-as-a-foreign-language (EFL) tasks (Kasneci et al., 2023; Lu et al., 2024).
In the context of EFL writing, assessments demand considerable expertise and resources to ensure they are both accurate and fair (Huang, 2012, Li & Huang, 2022). As a result, there has been increasing interest in utilizing AI to enhance both peer and teacher assessments in EFL writing classrooms (Li et al., 2024; Zhang, 2023a, 2023b). Research indicates that AI tools like ChatGPT can automate evaluation processes, deliver immediate feedback, and customize learning experiences to meet the needs of individual students (Lu et al., 2024; Praphan & Praphan, 2023; Zou & Huang, 2023a, 2023b). For instance, Lu et al. (2024) found that ChatGPT could effectively complement traditional teacher evaluations in undergraduate academic writing by providing consistent and prompt feedback.
Although much research has concentrated on EFL writing assessments, assessing EFL speaking skills presents similar challenges, requiring extensive expertise and resources to produce reliable results (Belmamoune, 2022; de Jong, 2023; Huang et al., 2020; Khusnia, 2015; Wu et al., 2022). Human raters often face difficulties in maintaining consistency and objectivity when evaluating speaking proficiency (de Jong, 2023; Wu et al., 2022). Despite the similarities between writing and speaking assessments, raters must evaluate accuracy, fluency, and complexity, much like they assess language, content, and organization in writing (Li et al., 2024; Wu et al., 2022). These similarities create challenges in ensuring consistent and objective evaluations, whether in speaking or writing tasks. AI tools like ChatGPT4o could help mitigate these challenges by offering consistent evaluations across both modalities. However, the application of AI technologies like ChatGPT4o in EFL speaking assessment has been underexplored. This lack of research is particularly significant in countries like China, where the population of EFL learners is the largest globally (Christou et al., 2024).
This study aimed to fill the research gap by exploring the potential of ChatGPT4o, an advanced iteration of ChatGPT, as an AI peer assessor in Chinese EFL speaking classrooms (Murad et al, 2024; Shahriar et al., 2024). The decision to focus on AI as a peer assessor stems from the growing interest in peer assessment in educational contexts, which allows students to engage actively in the assessment process, receive feedback from multiple perspectives, and contribute to a more personalized learning environment (Li et al., 2022). In large classrooms, where individual feedback from teachers may be limited (Li et al., 2022; Wu et al., 2022), peer assessment supported by AI tools like ChatGPT4o can significantly enhance the efficiency and effectiveness of evaluations. By integrating AI, this study attempted to explore how peer assessment, traditionally a time-intensive process, can be refined through AI’s consistent scoring capabilities, while still benefiting from human judgment in key aspects such as emotional tone and cultural context.
Therefore, this study explored the reliability of ChatGPT4o’s scoring of EFL speech samples and the effectiveness of its feedback. It provided crucial insights into the integration of AI in peer assessment in EFL speaking classrooms to help deliver consistent and effective feedback to EFL students
Literature Review
Unlike the assessments of EFL receptive skills (i.e., listening and reading), the assessments of EFL productive skills (i.e., writing and speaking) require subjective judgments from raters on different aspects of writing and speaking samples (Li et al., 2024; Li et al., 2022; Wu et al., 2022). Much research on EFL assessments of productive skills has concentrated on writing; the speaking domain has received comparatively less attention; furthermore, EFL writing and speaking assessments share similarities. Therefore, this section reviews literature on both EFL writing and speaking assessments.
Reliability and Feedback in EFL Writing and Speaking Assessments
Reliability is a fundamental principle in effective EFL writing and speaking assessments, ensuring consistent measurement outcomes across different instances of the assessment process. According to the Standards for Educational and Psychological Testing (AERA, APA, & NCME, 2014), reliability is defined as the extent to which scores are free from random error, highlighting the need for consistent results across raters and occasions. The similarities between EFL writing and speaking assessments pose challenges in maintaining reliable and consistent assessments across raters and occasions. Just as writing assessments often struggle with biases in scoring, speaking assessments also encounter issues of inconsistency, especially when evaluating the speech samples of EFL speakers (Li et al., 2022).
Inter-rater reliability, which evaluates the degree of agreement among different raters scoring the same responses, has been extensively studied in EFL writing and speaking assessments (Han & Huang, 2017; de Jong, 2023; Zhang et al., 2023b). For example, research by Han and Huang (2017) and de Jong (2023) has explored strategies to improve inter-rater reliability in EFL writing and speaking assessments, respectively, emphasizing the importance of rigorous training and calibration for assessors.
Beyond reliability, providing qualitative feedback is crucial in EFL writing and speaking assessments, as it helps students identify their strengths and areas for improvement (Carless et al., 2011; Hattie & Timperley, 2007; Hu & Zhang, 2014). Effective feedback should be clear, understandable, and constructive to support students’ progress in language proficiency (Li et al., 2022; Wu et al., 2022; Hu & Zhang, 2014). Recent research has emphasized the importance of delivering feedback that addresses language accuracy, fluency, and complexity in speaking assessments, calling for more systematic approaches to feedback delivery (Li et al., 2022).
Applying Univariate and Multivariate G-Theory in Scoring EFL Writing and Speaking
Generalizability (G−) theory, developed by Cronbach et al. (1972), goes beyond classical test theory (CTT) by allowing for the analysis of multiple sources of error simultaneously, provides a more powerful framework than CTT for evaluating the reliability of scoring in EFL writing and speaking assessments, where subjective judgments are common (Brennan, 2001a; Shavelson & Webb, 1991). Unlike other frameworks, such as many-facet Rasch measurement, G-theory provides a comprehensive approach by offering a robust understanding of assessment reliability (Brennan, 2001a; Shavelson & Webb, 1991).
Many studies have adopted the G-theory approach in EFL writing assessments (e.g., Zhao and Huang, 2020; Li and Huang, 2022; Li et al., 2024; Han, 2017; Whipple, 2016). For example, Whipple (2016) and Zhao and Huang (2020a) employed G-theory to examine how a single-rater system impacts the score reliability of EFL writing assessment. The findings of both studies indicated that the current single-rater system cannot achieve an acceptable reliability coefficient. Later, Han (2017) and Li and Huang (2022) used G-theory to investigate the impact of essay quality on the holistic score reliability of EFL essays. Both studies reported that the scores assigned to high-quality essays demonstrated higher reliability than those assigned to low-quality essays. The rater interview results indicated that most raters only considered language or content while marking low overall quality essays but considered language, content, and organization while marking high overall quality essays. Recently, Li et al. (2024) employed G-theory to evaluate the role of ChatGPT4 in enhancing EFL writing assessment in classroom settings and reported that ChatGPT4 achieved consistently higher scoring reliability than the teacher raters.
While G-theory has been widely used in EFL writing assessments, it is equally beneficial for examining the reliability of EFL speaking assessments, which often involve more subjectivity. It allows for the simultaneous analysis of various sources of error, such as raters, tasks, and linguistic complexity. It provides a more comprehensive approach to assessing the consistency of scoring, which is especially crucial in EFL speaking assessments where evaluations can vary widely (Li et al., 2022).
Software programs like GENOVA (Crick & Brennan, 1983) and its multivariate version, mGENOVA (Brennan, 2001b), have been critical in conducting G-studies that assess the impact of various sources of variance, such as raters and tasks, on overall assessment outcomes. These tools have been used to ensure both holistic and analytic scoring reliability in EFL writing and speaking assessments, thereby improving the quality and fairness of these evaluations (Gao & Brennan, 2001; Li et al., 2022; Wu et al., 2022). The present study used both univariate and multivariate G-theory frameworks to assess the reliability of ChatGPT4o’s scoring in EFL speaking assessments, aiming to provide a thorough analysis of its potential as an AI peer assessor.
Peer Assessments in EFL Writing and Speaking
Extensive research has demonstrated the benefits of peer assessments in EFL writing and speaking, showing its effectiveness in improving students’ writing and speaking skills and fostering learner autonomy (Fathi et al., 2019; Li et al., 2020; Lee & Evans, 2019; Liu & Carless, 2006; Matsuno, 2009; Shen et al., 2020; Su et al., 2023; Wu et al., 2022). Shen et al. (2020) found that peer assessments significantly enhanced learner autonomy, reduced dependence on teachers, and increased students’ confidence. Matsuno (2009) used multifaceted Rasch modeling to compare peer and self-assessments with teacher assessments in writing classes, revealing the beneficial role of peer assessments. Similarly, Sun et al. (2023) employed multifaceted Rasch modeling to examine the impact of peer assessment in college English writing classes, noting its effectiveness despite some limitations compared to teacher feedback, particularly in terms of depth and solution-oriented comments.
Research comparing the reliability of peer assessments and teacher assessments has shown that, when peers are adequately trained, their reliability can match that of teachers. Wu et al. (2022) used G-theory to compare the reliability of holistic scores from peer and teacher assessors, finding that the reliability of scores from three peer assessors matched that of one teacher assessor. Peers were comparable to teachers in evaluating the content and organization of EFL essays. Similarly, Li et al. (2022) applied G-theory to compare the reliability of holistic scores from peer and teacher assessors in EFL speaking classrooms, reporting that the reliability of up to two peer assessors’ holistic scoring is equivalent to that of one teacher assessor’s scoring.
Effectiveness of AI-Generated Feedback
AI tools like ChatGPT have transformed the delivery of feedback in educational settings by providing immediate, detailed, and personalized feedback that aids students in improving their language skills and increasing their confidence (Cao & Zhong, 2023; Guo et al., 2022; Yan, 2023). Research has shown that such feedback can significantly enhance students’ learning outcomes by promoting self-directed learning and complementing classroom interactions (Lu et al., 2024; Pang et al., 2024). Moreover, AI-driven feedback systems improve the efficiency and reliability of assessments, offering secure testing and a personalized learning experience that is often more effective than traditional methods (Song & Song, 2023; Su et al., 2023; Zhai, 2023).
In EFL settings, automated scoring systems, such as those used in TOEFL or IELTS, have long been used to assess language proficiency. These systems, however, are generally limited in the depth and adaptability of the feedback they provide, as they rely on fixed, rule-based algorithms (Shadiev & Feng, 2024; Taskıran & Goksel, 2022; Xi, 2010). In contrast, AI-based feedback, such as that from ChatGPT, can deliver more context-sensitive, detailed, and individualized suggestions that cater to the learner’s specific areas of improvement (Evenddy, 2024; Khasawneh, 2024; Li et al., 2024). These differences are particularly significant in language learning, where personalized feedback is crucial to the development of writing, speaking, and listening skills. Studies have shown that AI-generated feedback can supplement or even surpass traditional methods in some areas, providing more immediate and comprehensive support to learners (Evenddy, 2024; Li et al., 2024).
Comparative studies have examined the effectiveness of AI-generated feedback compared to traditional feedback. Traditional feedback typically refers to teacher-provided assessments, such as written comments, verbal feedback, and corrections (Ishchenko & Verkhovtsova, 2019; Mak, 2019). While this form of feedback is personalized, it is often limited by the time constraints teachers face and may lack the immediacy or consistency required for optimal learning. Comparative studies have shown that AI-generated feedback, such as that provided by ChatGPT, offers distinct advantages in areas like vocabulary development and coherence in writing. For example, Cao and Zhong (2023) found that AI-driven feedback significantly improved students’ vocabulary and inter-sentence cohesion. Similarly, research by Song and Song (2023) suggested that EFL learners who received AI-generated feedback outperformed their peers in writing skills and motivation. These results highlight how AI feedback not only compares favorably with traditional feedback but also enhances students’ engagement and performance in assessments.
Research Gaps and Questions
While substantial research has explored the benefits of ChatGPT in EFL writing assessments, the use of ChatGPT4o in assessing EFL speaking proficiency remains unexplored. Existing studies on AI-driven EFL speaking assessments are limited, and the potential of ChatGPT4o in peer assessment contexts has not been fully examined. This study aimed to bridge this gap by investigating the reliability and effectiveness of ChatGPT4o in EFL speaking classrooms, focusing on its ability to provide consistent and effective feedback compared to human peer assessors.
The following key research questions guided this study: (a) how does the reliability of ChatGPT4o’s scoring of EFL speech samples compare with that of human peer assessors when both apply the same course-validated rubric? (b) How does the qualitative feedback produced by ChatGPT4o differ from that of human peers in terms of clarity, accuracy, and actionable usefulness? And (c) what are human peer assessors’ perceptions of, and willingness to use, ChatGPT-4o as an AI peer assessment tool in their EFL speaking classrooms?
Methodology
Participants
This study involved 40 first-year English major undergraduate students from a university in China. The sample consisted of two groups: 20 students who provided speech samples and 20 students who acted as human peer assessors. The speech sample providers participated in a final English speaking examination as part of their regular coursework, and the peer assessors were recruited from a parallel class. To further understand human raters’ perspectives on AI feedback, four of the human peer assessors were selected for follow-up interviews.
The participants were informed about the voluntary nature of their participation and data privacy concerns. Informed consent was obtained from all students prior to data collection. Both the speech sample providers and peer assessors were selected from the same cohort of first-year English majors, which ensured that they shared similar levels of language proficiency.
Materials
EFL Speech Samples
The EFL speech samples used in this study were drawn from the students’ final English speaking examination, where each student was required to give a one-minute oral presentation on the topic “Describe a person whom you like most.” The presentations were recorded individually using audio recording devices in a controlled classroom environment. The speech samples selected for this study were diverse, reflecting a range of proficiency levels.
ChatGPT4o
For the AI peer assessor, ChatGPT4o was employed to evaluate the EFL speech samples. ChatGPT4o was selected for its advanced capabilities in processing oral language, offering a more sophisticated analysis than previous versions of ChatGPT (Murad et al., 2024; Shahriar et al., 2024). The AI’s scoring was based on the same assessment criteria used by human raters, ensuring that it evaluated accuracy, fluency, and complexity in the same way that human assessors would. ChatGPT4o was trained to refine its scoring algorithms to match the assessment framework, ensuring alignment with the human peer assessment criteria.
Data Collection Procedures
Speech Sample Collection
The speech samples were collected during a final English speaking examination, where each student was required to provide a one-minute oral presentation on a specific topic. The recordings were collected using audio devices during a controlled exam session, ensuring that the assessment was consistent for all participants.
Human Peer Assessors
The human peer assessors underwent training to ensure they understood the scoring criteria and could apply them consistently. The training was delivered through a series of online workshops, where assessors were introduced to the scoring criteria (course-embedded and validated by the program’s testing committee). The workshops included a discussion of the key aspects of fluency, accuracy, and complexity, followed by the practice of scoring three sample speech recordings. The peer assessors were asked to assign holistic scores first and then proceed with analytic scoring for accuracy, fluency, and complexity after a one-week interval between scoring phases to minimize potential bias.
To ensure consistency, discussion sessions followed each practice session to allow assessors to compare their decisions and reconcile any discrepancies. The one-week interval between the holistic scoring and analytic scoring ensured that human raters could focus on different aspects of the speech samples independently, without the influence of prior assessments.
ChatGPT4o’s Training
ChatGPT4o underwent a similar process for training. The model was fine-tuned using a set of sample speech data and assessment criteria, which allowed it to align closely with human-based ratings. This process involved refining its scoring algorithms to focus on specific aspects of accuracy, fluency, and complexity in oral production. This procedure was based on existing language assessment frameworks and aligned with the criteria used by human raters. ChatGPT4o was trained on the same speech samples provided to the human peer assessors, ensuring it evaluated them according to the same standards.
Follow-up Interviews
After the assessment phase, four human peer assessors were selected for follow-up semi-structured interviews. The interviews aimed to understand the peer assessors’ experiences using ChatGPT4o and their perceptions of the AI’s effectiveness as a peer assessor. Before the interviews, the peer assessors were provided with the AI-generated scores and feedback for the speech samples. They were asked to review the feedback, and the interviews explored how ChatGPT4o compared to their own assessments and feedback in terms of clarity, accuracy, and actionability. Sample interview questions included “what is your current stance on the use of ChatGPT4o for assessing English major students’ English speaking in classroom settings?”“Do you believe ChatGPT4o-generated feedback is effective? Why or why not?”“What are your major concerns regarding the acceptance of ChatGPT4o-generated scores and feedback for classroom English speaking assessments?”And “what factors would increase your trust in ChatGPT4o-generated scores and feedback for classroom English speaking assessments?”
Data Collection Timeline
Data collection took place over several weeks. Human assessors worked in two phases, each lasting about one week. ChatGPT4o assessed the same set of 20 speech samples in four separate sessions, spaced three days apart, to minimize bias. The entire process was designed to allow for comprehensive analysis of both human and AI-generated feedback.
Data Analysis
Scoring Reliability
To address the first research question, the scoring reliability of ChatGPT4o and human peer assessors was analyzed using univariate and multivariate G-theory frameworks. The software programs GENOVA and mGENOVA (Brennan, 2001b; Crick & Brennan, 1983) were used to estimate variance components and assess their impact on scoring reliability within balanced designs. This involved performing random effects univariate and multivariate G-studies and decision (D)-studies for both ChatGPT4o and human peer assessors, focusing on the variability and reliability of holistic and analytic scoring, respectively. These analyses provided insights into the consistency and robustness of the scoring systems utilized.
Feedback Effectiveness
The effectiveness of the qualitative feedback provided by both ChatGPT4o and human peer assessors was analyzed using a combination of quantitative and qualitative methods. The feedback was categorized into the domains of accuracy, fluency, and complexity using a color-coding system. The effectiveness of feedback was then measured for each domain by the first two researchers using a 0-3 holistic rubric covering clarity, accuracy, and actionability, with Cohen’s κ = .82. Descriptive statistics (e.g., mean and standard deviation) were used to compare the quantity of effective feedback provided by each assessor group.
Follow-up Interview Data
The interview data from the human peer assessors were analyzed thematically, focusing on how ChatGPT4o’s feedback compared to human-generated feedback and its integration into their assessments. The first two researchers independently coded the interview transcripts and discussed discrepancies to ensure consistency in theme identification (Creswell & Creswell, 2023). Key themes were identified and used to explore human peer assessors’ perceptions of and willingness to use ChatGPT4o as an AI peer assessment tool in the EFL speaking classes.
Results
Findings for the First Research Question
Reliability of Holistic Scoring
To evaluate the consistency and reliability of the holistic scoring for the 20 EFL speech samples, univariate G-theory was applied, incorporating both G-studies and D-studies. The G-studies focused on identifying the proportion of total score variance attributable to each variance component, while the D-studies further analyzed these components to assess the reliability of the scoring process (Brennan, 2001a). The results of these analyses are displayed in Tables 1 and 2.
Results for Univariate Person-by-Rater Design G-Studies.

Results for Univariate Person-by-Rater Design D-Studies.

Table 1 presents the G-study results for both ChatGPT4o and human peer assessors. For ChatGPT4o, the variance due to the object of measurement (i.e., person, p), which reflects the students’ English speaking abilities, accounted for 59.4% of the total variance. The residual variance, which includes variability from interactions between facets and other unmeasured errors, comprised 39.03% of the total variance. The variance component related to rater differences, indicating variations in scoring leniency among raters, contributed only 1.57% of the total variance. In the G-theory framework, variance associated with the object of measurement is considered desirable variance, whereas variance related to the rater and residual components is viewed as undesirable variance (Brennan, 2001a; Shavelson & Webb, 1991). In contrast, the holistic scoring by peer assessors showed significantly less desirable variance and more undesirable variance, with the object of measurement accounting for only 35.63% of the total variance, the rater variance component representing 36.54% of the total variance, and the residual variance comprising 27.83%.
The D-studies further explored these variance components to calculate the reliability (i.e., phi-coefficients for criterion-referenced interpretations in classroom assessment settings) of holistic scoring by ChatGPT4o compared to human peer assessors. Reliability coefficients were calculated under various conditions, ranging from one to ten assessors, with a sample size of 20. The results are shown in Table 2 and Figure 1.

Comparison of holistic scoring reliability by ChatGPT4o and human peer assessors.
As seen in Table 2, ChatGPT4o demonstrated significantly higher reliability compared to human peer assessors. For example, for a single rating, the reliability coefficient was .59 for ChatGPT4o, whereas it was just .36 for human peer assessors. Increasing the number of ratings to two would achieve substantially improved reliability, with coefficients rising to .75 for ChatGPT4o and .53 for human peer assessors.
In summary, the G- and D-studies revealed that holistic scoring by ChatGPT4o exhibited considerably less variability and higher reliability compared to the scoring by human peer assessors. These findings suggested that ChatGPT4o could serve as a reasonably reliable AI peer assessor to complement holistic scoring conducted by human peer assessors in English speaking classrooms.
Reliability of Analytic Scoring
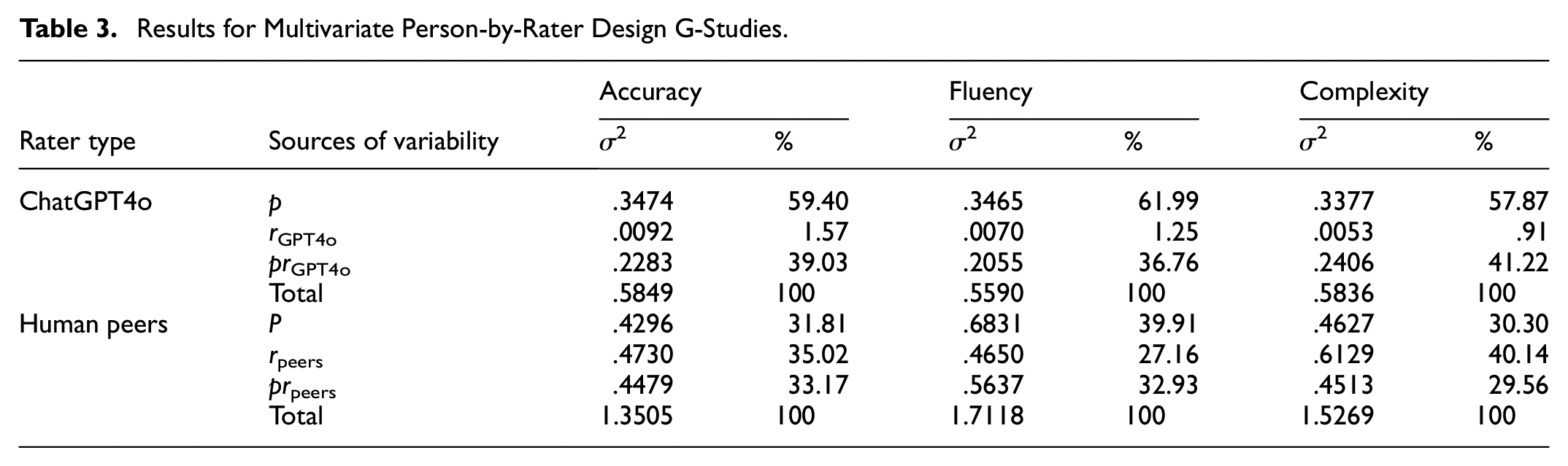
To assess the variability and reliability of analytic scoring for the 20 EFL speech samples, multivariate G-theory was utilized, involving both G-studies and D-studies (Brennan, 2001a). The results of these multivariate G- and D-studies are presented in Tables 3 and 4.
Results for Multivariate Person-by-Rater Design G-Studies.
Results for Multivariate Person-by-Rater Design D-Studies.

Table 3 details the outcomes of the multivariate G-studies, which examined the variability in analytic scoring by ChatGPT4o and human peer assessors across the three domains of accuracy, fluency, and complexity of the speech samples, respectively. For ChatGPT4o, the largest variance component was the person variance (59.4% for accuracy, 61.99% for fluency, and 57.87% for complexity), followed by the residual variance (39.03% for accuracy, 36.76% for fluency, and 41.22% for complexity), with the rater variance contributing minimally (less than 2% of the total variance) across all three domains.
Conversely, for human peer assessors, the person, residual, and rater variance components explained relatively similar amounts of total variance across the domains of accuracy, fluency, and complexity. Specifically, the object of measurement accounted for 31.81%, 39.91%, and 30.30% of the total variance in the accuracy, fluency, and complexity domains, respectively. The residual variance accounted for 33.17%, 32.93%, and 29.56% of the total variance across the three domains, respectively. The rater variance component contributed 35.02%, 27.16%, and 40.14% of the total variance in the three domains, respectively.
These variance components were further analyzed through multivariate D-studies to calculate reliability coefficients (i.e., phi-coefficients for criterion-referenced interpretations in classroom assessment settings) for the analytic scoring by ChatGPT4o compared to human peer assessors across the domains of accuracy, fluency, and complexity. Reliability coefficients for all three domains were calculated under various conditions, ranging from one to ten assessors, with a sample size of 20. The results are shown in Table 4 and Figure 2.

Comparison of analytic scoring reliability by ChatGPT4o and human peer assessors.
For a single rating by ChatGPT4o, the reliability coefficients were .59 for accuracy, .62 for fluency, and .58 for complexity. Increasing the number of assessors to two would significantly improve the reliability across all three domains, with coefficients rising to .75 for accuracy, .77 for fluency, and .73 for complexity.
For a single human peer assessor, the reliability coefficients were only .32 for accuracy, .40 for fluency, and .30 for complexity. When the number of assessors was increased to two, reliability increased to just .48 for accuracy, .57 for fluency, and .47 for complexity.
In conclusion, the multivariate G- and D-studies indicated that the analytic scoring conducted by ChatGPT4o exhibited considerably less variability and higher reliability across the three domains of accuracy, fluency, and complexity than human peer assessors. These results suggested that ChatGPT4o could also be a reasonably reliable AI peer assessor to assist EFL students with analytic scoring in English speaking classrooms.
Findings for the Second Research Question
Usefulness of Qualitative Feedback
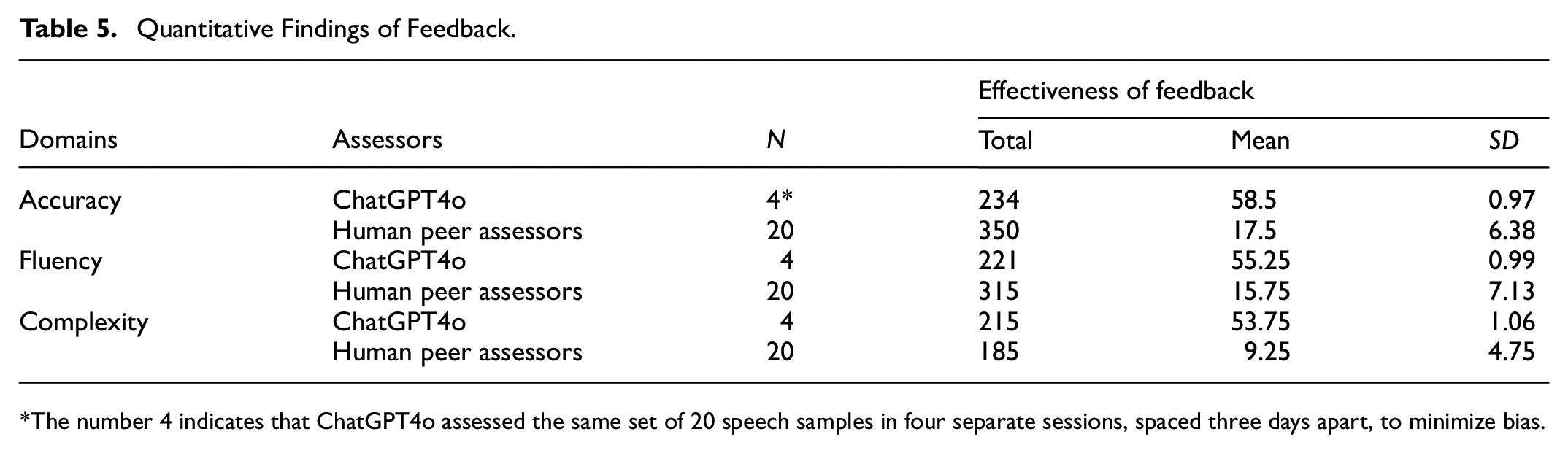
The qualitative feedback provided by both ChatGPT4o and human peer assessors on the 20 speech samples was analyzed using a combination of quantitative methods, such as descriptive statistics, and qualitative techniques, including coding, categorization, and thematic analysis, to determine its usefulness. In this study, effective feedback is defined as feedback that clearly identifies issues in any of the three domains—accuracy, fluency, or complexity—of an EFL speech sample and offers understandable and constructive suggestions for improvement in the specified area (Carless et al., 2011; Hattie & Timperley, 2007). The results of these quantitative and qualitative analyses are presented in Tables 5 and 6, respectively.
Quantitative Findings of Feedback.
The number 4 indicates that ChatGPT4o assessed the same set of 20 speech samples in four separate sessions, spaced three days apart, to minimize bias.
Qualitative Findings of Feedback.

Table 5 summarizes the descriptive statistics regarding the effectiveness of feedback comments provided by ChatGPT4o compared to those given by human peer assessors. The findings indicated that ChatGPT4o consistently delivered more useful feedback than human peer assessors, offering more than three times the feedback on accuracy (mean for ChatGPT4o = 58.5, mean for human peer assessors = 17.5) and fluency (mean for ChatGPT4o = 55.25, mean for human peer assessors = 15.75), and approximately six times the feedback on complexity (mean for ChatGPT4o = 53.75, mean for human peer assessors = 9.25). Additionally, the standard deviation values for ChatGPT4o were significantly lower than those for human peer assessors, indicating that ChatGPT4o provided more consistent feedback across the domains of accuracy, fluency, and complexity, whereas human peer assessors showed greater variability in their feedback.
These descriptive statistical results suggested considerable differences in the quantity and consistency of effective feedback on accuracy, fluency, and complexity between ChatGPT4o and human peer assessors. The findings implied that ChatGPT4o could be a valuable AI peer assessor to support human peer assessment by providing comprehensive qualitative feedback in EFL speaking classrooms.
To better understand and classify the effective feedback provided on EFL speech samples by ChatGPT4o and human peer assessors, the feedback was analyzed to identify and consolidate major themes within the domains of accuracy, fluency, and complexity (see Table 6). This thematic analysis clarified the specific areas where students’ English speaking showed weaknesses and needed improvement.
The qualitative analysis of feedback revealed eight major themes across the domains of accuracy, fluency, and complexity. In the accuracy domain, the feedback primarily highlighted issues related to (a) pronunciation accuracy, (b) vocabulary accuracy, and (c) grammar accuracy. In the fluency domain, the feedback concentrated on (a) speed fluency, (b) breakdown fluency, and (c) repair fluency. In the complexity domain, the feedback focused on (a) lexical complexity and (b) grammatical complexity.
However, the foci on these themes varied significantly between the feedback provided by each assessor group. For instance, ChatGPT4o was able to provide comprehensive feedback that addressed nearly all the identified themes within a single speech sample. In contrast, the feedback from human peer assessors often included numerous positive comments, particularly related to accuracy or fluency themes, which may not have directly contributed to improving speaking performance. To illustrate this, specific feedback provided by ChatGPT4o and one human peer assessor on the accuracy, fluency, and complexity domains of EFL speech sample #12 is discussed below.
“
(Feedback provided by ChatGPT4o)
“
(Feedback provided by one human peer assessor)
In summary, the feedback themes identified recurring issues in accuracy, fluency, and complexity across the 20 EFL speech samples assessed by ChatGPT4o and human peer assessors. The feedback stressed the need for targeted instruction and practice, suggesting that addressing these areas with specific strategies could significantly enhance the quality of students’ English speaking.
Findings for the Third Research Question
Human Peer Assessors’ Acceptance of ChatGPT4o as an AI Peer Assessor in EFL Speaking
The analysis of interview data with four human peer assessors uncovered distinct themes and differences in their acceptance of ChatGPT4o as an AI peer assessor in English speaking classrooms, particularly reflected in their responses to the five interview questions.
Theme 1: Perceived Reliability of ChatGPT4o Scores
Regarding the reliability of scores generated by ChatGPT4o (Interview Question 2), most participants recognized the system’s potential, though some had reservations. Participant A expressed confidence in ChatGPT4o’s reliability, stating, “The reliability of ChatGPT4o’s scoring is consistently higher than that of students’ scoring across various domains,” suggesting a strong belief in the AI’s capability to deliver accurate and fair evaluations. Similarly, Participant C shared this view, noting that the AI evaluates “from a relatively professional angle,” which makes it useful for reliable assessments. However, Participant B voiced doubt, pointing out that “it may sometimes be inaccurate” due to its reliance on pattern recognition and the need for further research, particularly in the context of Chinese students. Participant D offered a balanced perspective, acknowledging the reliability of the scores “to some extent” but also expressing concerns about the AI peer assessor’s ability to fully grasp the subjective subtleties of speaking, such as emotions and intonation.
Theme 2: Effectiveness of ChatGPT4o Feedback
On the subject of the effectiveness of feedback generated by ChatGPT4o (Interview Question 3), participants generally found the feedback useful and effective, though their enthusiasm varied. Participant A was particularly positive, citing how students in a high school EFL program “responded positively to the specific, practical steps provided by the AI tool,” which led to measurable improvements in their speaking skills. Participant D also found the feedback useful and effective but stressed that its effectiveness depends on the quality of the input provided to the AI, stating, “If our input is not clear and specific, the AI might not provide sufficiently effective feedback.” In contrast, Participant B raised concerns about the AI’s limitations in understanding “language fluency, intonation, cultural appropriateness, or emotional subtlety,” indicating that while the feedback might be helpful for technical aspects like grammar, it may fall short in more subtle areas. Participant C offered a unique viewpoint, comparing the feedback’s utility to technological advancements, suggesting that while it may seem limited now, it could become more practical as technology progresses.
Theme 3: Concerns over acceptance and trust in ChatGPT4o
Concerns about the acceptance and trust in ChatGPT4o-generated scores and feedback (Interview Questions 4 and 5) were prominent among most participants. Participant B expressed concern that teachers might become overly dependent on AI, potentially diminishing “the importance of real human interaction in language learning.” This concern was echoed by Participant D, who feared that ChatGPT4o’s assessments could become standardized, leading to a “one-size-fits-all approach” that fails to account for individual student differences. On the other hand, Participant C worried about the impact of lower-than-expected scores on student motivation, noting that “the constant feedback might lead to student fatigue and increased pressure.” To build trust, Participant A recommended a collaborative approach, involving “ongoing input from students, educators, and AI specialists,” to ensure that the system remains responsive to classroom needs. Participant D suggested that authoritative teacher evaluations be compared with AI-generated feedback to validate the system’s reliability and increase student trust.
Theme 4: Stance on the Use of ChatGPT4o in Classroom Settings
Participants expressed varying opinions on using ChatGPT4o for assessing English speaking (Interview Question 1). Participant A was strongly supportive, noting that integrating ChatGPT4o into classroom assessments could provide “valuable benefits,” particularly in offering targeted support for improving speaking skills. In contrast, Participant B saw the AI as a supplementary tool rather than a replacement for teachers, emphasizing that “only human teachers can offer a more personalized understanding and guidance.” Participant C appreciated the professional perspective that ChatGPT4o offered, viewing it as a tool that could “better support student development” by helping identify weaknesses. Participant D emphasized the practicality of implementing ChatGPT4o, citing its low cost and ability to assist teachers in providing “targeted guidance” based on organized data.
In summary, while there is broad recognition of the potential benefits of ChatGPT4o as a peer assessment aid, the students’ responses reflect cautious optimism, weakened by concerns about reliability, effectiveness, and the essential role of human involvement in language learning. The findings suggested that while ChatGPT4o could be a valuable AI peer assessor in classroom assessments, its integration should be carefully managed to address these concerns and build trust among students.
Discussion and Conclusions
The findings of this study provide important insights into the potential of ChatGPT4o as an AI peer assessor in EFL speaking classrooms, highlighting both its strengths and limitations. These results contribute significantly to the existing body of research on AI-assisted EFL assessments, particularly in the unexplored area of using ChatGPT4o in assessing speaking proficiency.
Scoring Reliability
In terms of scoring reliability, this study demonstrated that ChatGPT4o offers a higher degree of consistency and reliability in both holistic and analytic scoring compared to human peer assessors. This finding is consistent with previous studies suggesting that AI models, when optimized for specific tasks, can significantly improve scoring accuracy and consistency (Li et al., 2024). The lower variability in ChatGPT4o’s scoring, as indicated by the G- and D-studies, supports the notion that AI tools like ChatGPT4o can serve as reliable assessment aids, especially in settings where consistency is critical (Brennan, 2001a).
However, it is important to address a potential concern: whether the AI’s consistency might stem from leniency. Some researchers have noted that AI might provide uniformly high scores, similar to human teachers who might be overly lenient in their grading (Tate et al., 2024). While ChatGPT4o’s consistent scoring can be seen as a strength, it could also indicate that the system might have built-in biases or algorithms that tend to favor higher scores, regardless of actual proficiency levels. Thus, while ChatGPT4o’s consistency is advantageous, further investigation into whether this reflects genuine scoring accuracy or an inherent leniency bias is essential. This adds an important layer to understanding the underlying mechanisms driving ChatGPT4o’s performance and highlights the need to assess whether consistent results translate into truly valid assessments.
Moreover, while ChatGPT4o demonstrated reliability in scoring, its inability to fully capture the subtleties of spoken language—such as emotional expression, tone, and intonation—suggests that AI cannot fully replace human judgment in these areas. These limitations reinforce the notion that while AI can complement human assessors, it should not replace them entirely. The nuanced elements of speech, including tone, emotional inflections, and cultural contexts, remain better evaluated by human assessors, who possess the ability to interpret these factors.
Feedback Effectiveness
The study also found that ChatGPT4o provides significantly more useful and consistent feedback across the domains of accuracy, fluency, and complexity compared to human peer assessors. This finding aligns with the growing body of research suggesting that AI-driven feedback systems can deliver detailed, personalized, and effective feedback, enhancing student learning more effectively than traditional methods (Cao & Zhong, 2023; Li et al., 2024). ChatGPT4o demonstrated the ability to cover a broad range of feedback themes within a single speech sample, which is often difficult for human peer assessors to achieve consistently due to human limitations, such as cognitive load and bias.
However, while ChatGPT4o excelled at providing consistent and comprehensive feedback, the feedback it offered was not without its limitations. Students raised concerns about the AI’s inability to capture the cultural nuances and contextual subtleties embedded in language use (Song & Song, 2023). For example, ChatGPT4o might miss cultural references or fail to interpret emotionally charged language effectively. This finding reinforces the idea that AI feedback, while valuable, should not replace human insights, especially when it comes to language subtleties that require deeper cultural understanding or emotional awareness.
AI Acceptance and Trust
A significant part of the study also focused on student acceptance and trust in ChatGPT4o as an AI peer assessor. The analysis of interview data revealed varying levels of acceptance among students, with some expressing concerns about over-reliance on AI and its potential to reduce human interaction in language learning. This is consistent with broader concerns in educational research about the integration of AI into teaching and assessment (Creely, 2024). While some students expressed trust in ChatGPT4o’s reliability and found its feedback to be useful, others were hesitant, fearing that AI might standardize assessments in ways that overlook individual student needs.
Interestingly, the interview data highlighted that students felt more comfortable with ChatGPT4o if it was seen as a complementary tool rather than a replacement for human assessors. For example, some students suggested that a collaborative approach—involving input from both AI and human assessors—might help address trust issues and ensure that the system responds appropriately to classroom needs. These insights align with previous studies recommending transparency in AI implementation and ongoing collaboration between students, educators, and AI developers (Creely, 2024). This collaborative approach would help build trust in AI tools and ensure that their role in education is optimized.
Conclusions
In conclusion, the findings of this study suggest that ChatGPT4o can be a reliable and effective AI peer assessor in EFL speaking classrooms. The AI demonstrated significant advantages in terms of scoring consistency and providing feedback, making it a potentially valuable tool for complementing human assessments. However, the study also highlighted several challenges, particularly the limitations of AI in understanding the emotional subtleties and cultural nuances of spoken language. These findings suggest that while AI tools like ChatGPT4o have the potential to significantly enhance language assessments, their use should be seen as complementary to, rather than a replacement for, human judgment.
Limitations and Future Research
Despite these advantages, the study’s limitations should be considered. First, the small sample size (20 EFL speech samples and 20 peer assessors) limits the generalizability of the findings. Further research with larger and more diverse populations will be necessary to confirm these results and explore the full potential of ChatGPT4o across different contexts and student groups.
Second, the study focused on first-year English majors at a single institution, which limits the applicability of the findings to other educational settings. Future research should expand the study to include different educational levels and institutions, as well as consider the impact of cultural differences on AI assessment.
Third, while this study compared ChatGPT4o’s assessments with those of human peer assessors, it did not include a comparison with professional teacher assessments, which are often considered the gold standard. Future research should compare AI-based assessments with teacher assessments to better contextualize the performance of AI tools in educational settings.
Lastly, ChatGPT4o may not be fully accessible to all learners and instructors in China, particularly in comparison to more widely used AI tools such as Doubao. It offers unique advantages in natural language processing and real-time assessment that make it an ideal candidate for exploring the future integration of AI in EFL speaking assessment (Murad et al., 2024; Shahriar et al., 2024). This study focused on ChatGPT4o’s potential to push the boundaries of what AI can achieve in EFL speaking assessment. The researchers acknowledge, however, that accessibility remains a significant challenge, and future research could explore how other AI tools like Doubao could also be used to support peer assessments in more practical contexts.
Pedagogical Implications
This study offers several pedagogical implications for EFL instructors and students. First, by improving the reliability of human peer assessments, ChatGPT4o can help ensure fairer and more consistent evaluations of students’ speaking performance. This enhanced reliability could help students trust the assessment process more and focus on improving their speaking skills.
Second, the ability of ChatGPT4o to provide detailed and effective feedback across domains such as accuracy, fluency, and complexity means that students can receive more specific and actionable suggestions for improvement. This targeted feedback can guide their language learning more effectively, particularly in self-directed learning environments.
Finally, integrating ChatGPT4o into classroom assessments could promote a more collaborative and autonomous learning environment. Students could use AI-generated feedback to reflect on their own performance and that of their peers, fostering deeper engagement with the learning material and promoting learner autonomy.
In summary, while ChatGPT4o can be a valuable tool for enhancing EFL speaking assessments, its use should be carefully managed to balance the strengths of AI with the irreplaceable contributions of human assessors. With ongoing research and collaboration, AI tools like ChatGPT4o have the potential to transform language learning and assessment practices, offering greater consistency, reliability, and personalized feedback.
Footnotes
Ethical Considerations
This study involving human participants was reviewed and approved by the Evidence-based Research Center for Educational Assessment (ERCEA) Research Ethical Review Board at Jiangsu University (Ethical Approval Number: ERCEA2404).
Consent to Participate
The participants provided their written informed consent to participate in this study.
Author Contributions
Jinyan Huang and Junfei Li made equal contribution to this article and share first authorship. Junfei Li: conceptualization, literature, methodology, data acquisition, data analysis, revision, and funding. Jinyan Huang: conceptualization, literature, methodology, data analysis, writing, and editing for submission. Thomas Sheeran: conceptualization, methodology, data acquisition, and revision.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was supported by the Shanghai Educational Sciences Research Program (C2024114) granted to Junfei Li.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The datasets generated during and/or analyzed during the current study are available from the corresponding author only on reasonable request.