
Abstract
The International English Language Testing System (IELTS) has served as one of the most reliable proofs of people’s English language proficiency. There have been rumors about the discrepancy in difficulty between the two modules of IELTS, namely Academic (AC) and General Training (GT); however, there is little empirical evidence to confirm such a myth. This research directly compares the lexical demands, diversity, and sophistication between the reading passages in three sections of the two IELTS Reading test modules. 345 IELTS reading passages from 115 IELTS Reading tests were analyzed in terms of length, lexical diversity, sophistication, and demands. Results from the pairwise comparisons show significant differences between the three reading passages of the AC module and the first two reading sections of the GT module in terms of length and lexical sophistication. However, research findings also demonstrate insignificant differences between the AC passages and the last GT passage. In addition, results from lexical demand analyses confirm these findings by indicating that, for the AC reading passages and the last GT passage, learners need to be familiar with the most frequent 4,000 and 9,000 word families in the BNC/COCA lists to achieve 95% and 98% coverage, respectively. On the other hand, the first and second sections in the GT module only require a vocabulary knowledge at 3,000 to 6,000 levels for 95% and 98% coverage, correspondingly. Ultimately, implications for IELTS teaching and learning will be discussed.
Plain Language Summary
This study was designed to compare the needed vocabulary knowledge, level of word diversity, word complexity, and length between the reading passages in three sections of the two IELTS Reading test modules. A collection of 345 IELTS reading passages from 115 IELTS Reading tests was investigated in detail. Results showed significant differences between the three reading passages of the Academic (AC) module and the first two reading sections of the General Training (GT) module in terms of length and word complexity. It also addressed the number of words needed to achieve acceptable and optimal comprehension of AC reading and GT passages. Accordingly, implications for IELTS teaching and learning were also discussed.
Keywords
Introduction
For decades, the International English Language Testing System (IELTS) has been utilized as a reliable tool for English proficiency reference. Those who want to pursue higher education and global migration usually choose the IELTS test to be certified. The rationale for this common choice is that the test result reveals an analysis of a test-taker’s “indivisible body of language knowledge”; subsequently, every test-taker will be rated and, more importantly, a person’s IELTS’ performance is assumed to be generalized to the real world (Dastpak et al., 2021, p. 3). According to the report from the British Council, with an astounding number of over 3 million tests taken every year especially, roughly 3.5 and 3.7 million tests were delivered in 2018 and 2019, IELTS is believed to be the most popular English proficiency test globally (Read, 2022). This more than 40-year-old test not only serves the purpose of the aforementioned but also offers the foundation stone for further research.
The former version of today’s IELTS was the English Language Testing Service (ELTS) which was developed in 1980 by the collaboration of the British Council (BC) and the University of Cambridge Local Examination Syndicate (UCLES). The BC had a leading role in the ELTS’ development, particularly in the commitment to a more “accessible and affordable” version of the test (Dastpak et al., 2021, p. 4). At first, ELTS merely paid attention to assess the English proficiency of the British Government’s award recipients for their future studies in the United Kingdom. Consequently, the ELTS’ designers built its content based on the two “inter-related” trendy approaches in the 1970s, which were the communicative approach to language teaching and the growth of courses in English for Specific Purposes (ESP) (Read, 2022). In detail, the first was designed to simulate “real-life uses of the English language,” while the second focused on the “specific language needs” of test takers. Furthermore, the second entailed the formation of different tests based on their major academic fields of study (Read, 2022, p.4).
In 1989, a major revision was made to ELTS, which created a single test of academic language proficiency and the name of the test was changed to International English Language Testing System (IELTS). Regarding test design, significant changes to IELTS included: (1) the introduction of the GT module, (2) the reduction of the academic module from six to three sections, (3) the introduction of the independent four macro skills: Listening, Reading, Speaking and Writing (Read, 2022). Besides, since this milestone, IELTS in its current form has some outstanding features. Firstly, real life uses of English are tested, as originally identified. Secondly, there are networks of language centers globally and Speaking and Writing tests are graded by locally hired staff. Thirdly, the nine-level band scale is used as an instrument to measure language proficiency level. Finally, the test’s face validity is given higher value due to its wide acceptability of IELTS to test takers, IELTS trainers, university admission officials as well as decision makers in immigration, Government, and other professional organizations. This time also marked when Australia got involved as a partner of IELTS and the International Development Program (IDP) was set up. IDP acknowledged that IELTS was a lucrative tool for the marketing of higher education in Australia and started to recruit both degree-level students as well as those studying at university language centers.
In addition, it is worth discussing the launch of IELTS General Training here. IELTS was originally designed and introduced as an English test for academic purposes and then additionally recognized as a test for migration applicants at which GT module was introduced. The IELTS GT’s use is nowadays extended to employment requirements. The response to the versatile use has also redefined the GT module’s design. Its original purpose was to test the English proficiency of candidates coming to the United Kingdom for non-degree studies or training, and thus, it required a lower level of language proficiency (Read, 2022). As IELTS officially announces on its website, IELTS GT is a requirement for some specific migrant categories in four countries and GT “features everyday English language skills that you will need in social and workplace environments” (www.ielts.org). In other words, the GT module is primarily for use by non-academic migrants.
Indeed, there have been popular rumors among IELTS learners and test-takers that the GT is easier than the AC module. According to official guidelines from IELTS (https://www.ielts.org/), AC differs from GT modules in Reading and Writing skills. Besides, as aforementioned, IELTS AC is widely recognized as the requirement for entering higher education as well as any program taught in English. For IELTS GT, test takers are usually those who would like to complete their high school level and are in search of immigration (https://www.ielts.org/about-ielts/ielts-test-types), which in turn requires a lower level of language proficiency. When it comes to Reading, a clearly distinct skill between the two modules, passages/texts in GT are deemed “easier” than those in the AC module. Nonetheless, there is still a lack of strong empirical evidence of which is really more difficult and its extent.
When conducting research on Reading, some past scholars compared reading with “a guessing game” in combination with “relevant background knowledge” (Dinh & Dinh, 2019, p. 2). However, as for getting a high band score in IELTS reading, there is a need to assess readers’ reading commands such as how well they read to get main ideas, details, inferences, writer’s opinions, or the development of arguments; consequently, these weaken candidates’ efforts to “conquer the lengthy and nerve-wracking IELTS reading passages” (Dinh & Dinh, 2019, p. 3). In addition, as Dinh & Dinh argued, to deal with the requirements in IELTS Reading, candidates must have the ability to “identify key words, and paraphrase, to expand vocabulary” (Dinh & Dinh, 2019, p. 3). As a result, accentuating the importance of vocabulary in IELTS Reading is a potential field of study. Since only Reading and Writing sections are different for the two modules of IELTS and the most distinct skill is Reading, it is necessary to investigate how Reading of the two modules differ from each other. Among a few studies comparing the two versions of IELTS, in their studies, Ha et al. (2022) concluded that the two IELTS Reading modules were comparable in terms of difficulties. However, Ha et al.’s (2022) study has some limitations that warrant further explorations, which include (1) focusing on a single metric of lexical demand, (2) using a bias dataset, and (3) lacking statistical testing.
Despite the fact that IELTS assigns the distinct purposes to the two test modules and gives obvious advantages to the marking criteria in IELTS AC Reading (details could be found at https://www.ielts.org/for-organisations/ielts-scoring-in-detail), suggesting that the GT reading test is easier, questions remain concerning what this compensation is intended to address. In addition, as the IELTS is an English proficiency test (Read, 2022), its two test modules should be parallel and equivalent in this regard. In other words, regardless of whichever test module a person takes, the IELTS result should always reflect their English proficiency in a reliable way.
Therefore, in need of an in-depth and evidence-based understanding of the differences and levels of difficulty between the two IELTS modules, this study aims to shed light on differences in terms of length, lexical demands, diversity and also sophistication of the passages in the two IELTS Reading modules. Furthermore, this research points out how many words learners need to be familiar with in order to comprehend reading passages thoroughly when completing different reading sections of the two modules. This amount of knowledge is of great help to IELTS test-takers and trainers alike.
After identifying the general purpose of the study, the four research questions are raised:
Do reading passages from different sections and test modules differ significantly in terms of length?
Do reading passages from different sections and test modules differ significantly in terms of lexical diversity?
Do reading passages from different sections and test modules differ significantly in terms of lexical sophistication?
Do reading passages from different sections and test modules differ significantly in terms of lexical demand?
Literature Review
Lexical Diversity
Lexical Diversity (LD) could be understood as the range, variation, or diversity (Crystal, 1982; Malvern et al., 2004; Wolfe-Quintero et al., 1998) of vocabulary used in a text. Carroll (1938) probably made one of the earliest attempts to address this variation in word use. He introduced the term “Diversity of Vocabulary” and defined it as “the relative amount of repetitiveness or the relative variety in vocabulary” (Carroll, 1938, p. 379). Due to its simple nature, the index of LD has been applied in textual and lexical assessments in a variety of research fields, including stylistics, neuropathology, (applied) linguistics, and data mining. In applied linguistics, values of LD are often linked to learners’ productive vocabulary size, which can in turn be used to predict the quality of speaking or writing (McCarthy & Jarvis, 2007, 2010). Larger values of LD in a text may also suggest that readers are more likely to encounter new and unfamiliar words.
One of the most widely known indices of lexical diversity is Type-Token Ratio (TTR; Johnson, 1944; Templin, 1957). TTR can be calculated by simply dividing the number of unique words (type) by the total number of running words in a text. Despite its wide range of applications, this metric of LD suffered from its sensitivity to text length (McCarthy & Jarvis, 2007; Zenker & Kyle, 2021). It would be obvious from the formula that as the total number of tokens increases, the value of TTR automatically decreases. This inverse proportion would be a great issue for text comparisons. When LD and text length correlated, it was impossible to determine whether any statistical differences were due to the actual diversity of word use or simply to differences in the number of tokens. This resulted in a number of possibly misleading findings because the researchers were unaware of this issue (Ertmer et al., 2002; Miller, 1981), and a number of researchers who were aware of this problem had limited their analyses to a very narrow range of text lengths (Biber, 1989). Early attempts to restrict the influence of text length on LD included several transformations of the original TTR formula. Table 1 below offers a brief summary of these transformations. However, none of the mentioned formulas managed to constrain the impact of text length to a satisfactory level (Kyle et al., 2023; McCarthy & Jarvis, 2007; Zenker & Kyle, 2021).
Mathematical Transformations of Type-token Ratio.

Other improvements in LD measures that venture beyond simple transformations of the original formula and involve complicated computational estimations include Mean Segment TTR (MSTTR, Johnson, 1944), Moving Average TTR (MATTR, Covington & McFall, 2010), the Hypergeometric Distribution Diversity index (HDD, McCarthy & Jarvis, 2007) and the Measure of Textual Lexical Diversity (MTLD) and its variants (McCarthy & Jarvis, 2010). A full discussion of these rather complicated computational measures is beyond the scope of this paper. Readers can see Zenker and Kyle (2021), Kyle et al. (2021) and Kyle et al. (2023) for details. Briefly, these measures offer robust estimations of LD with better resistance to the effect of text length. Among those, MTLD original and MATTR have been proven to be the most reliable (Kyle et al., 2023; Zenker & Kyle, 2021). In the present study, MATTR was selected as the metric of LD.
Lexical Sophistication
Lexical sophistication (LS) is defined as “the proportion of relatively unusual or advanced words in the learner’s text” (Read, 2000, p. 203). Most researchers agree that LS measure is related to the proportion of frequent or infrequent vocabulary in a text (Hao et al., 2023; Hyltenstam, 1988; Laufer, 1994; Laufer & Nation, 1995; Lu, 2012; Linnarud, 1986). The definitions of frequent and infrequent words are often based on the objective frequency ranking of the words in an authentic corpus. As a result, one word could have different frequency rankings when different corpora were taken into account. The assumption is that as words appear infrequently in real-life language, their chances of being encountered and acquired by language learners are smaller. As a result, learners are less likely to be familiar with the words and are nearly certain to have difficulties understanding them when reading or listening (Laufer & Nation, 1995; Read, 2000).
However, that frequency-to-difficulty relationship has been a topic for discussion in recent years (Hashimoto, 2021; Stewart et al., 2021). While maintaining their agreement on the role that frequency plays in word difficulty, Hashimoto and Egbert (2019), Vitta et al. (2023), and Ha et al. (2024) pointed out that there are other characteristics of words that are of equal or even greater weight in deciding the difficulty of a word. Some of those include form-related variables, orthographic regularity, phonotactic regularity, morphological regularity, word length, polysemy and homonymy, range and dispersion, word neighborhood density, contextual distinctiveness and age of acquisition (Hashimoto & Egbert, 2019, pp. 843–847). Still, in all the reviewed studies, frequency was found to be one of the strongest predictors of word difficulty. Therefore, in the present study, frequency was employed as the primary metric of lexical sophistication.
Applied linguists also have different views regarding the dimensionality of the two metrics of lexical sophistication and diversity. While some linguists view the two constructs as unidimensional and incorporate them into a single formula (Daller et al., 2003), others treat them as separate lexical estimates (Lu, 2012; Read, 2000). The researchers hold a multidimensional view toward the lexical richness construct and consider lexical diversity and sophistication as separate measures. In the present research, frequency was selected as an indication of lexical frequency. The researchers used the proportion of mid- and low-frequency vocabulary, the words that are ranked from level 4000 and above in the BNC/COCA lists (Nation, 2022), as an estimate of unusual or advanced words in a text.
Lexical Demand
The concept of lexical demand is grounded in lexical coverage, an influential finding that learners can achieve adequate and optimal text comprehension when they are familiar with 95% and 98% of the running words in a text in the order given (Hu & Nation, 2000; Laufer, 1989; Schmitt et al., 2011). Based on these thresholds, the next natural question would be what level or amount of vocabulary knowledge learners would need to achieve 95% and 98% coverage for a particular text or text genre. An answer to such research questions is called the lexical demand of a text or text genre.
Lexical demand operates based on word frequency lists. These lists classify words into frequency bands or levels according to their frequency rankings. A typical example of these wordlists is Paul Nation’s (2017) British National Corpus/Corpus of Contemporary American English (BNC/COCA) wordlist which contains 25 1000-word levels plus 4 supplementary lists of proper nouns, marginal words, transparent compounds and acronyms. Several researchers have employed this list to estimate the lexical demands of several text genres. For example, Ha (2022a) found that learners would need 5,000 most frequent word families in Nation’s (2017) BNC/COCA lists to obtain 98% coverage of TV programs and movies. In a parallel study, Ha (2022b) indicated that learners are required to be familiar with at least 4,000 word families in the BNC/COCA lists to gain 95% coverage of online newspapers and magazines. For standardized tests, Phung and Ha (2022) showed that, it generally takes 3,000 and 5,000 word families in the BNC/COCA to achieve 95% and 98% coverage of the four sections in the IELTS listening tests, respectively. However, if learners knew 570 word families in the Academic Word List (Coxhead, 2000), they would only need a word knowledge of 2,000 word families to understand 95% of the words in sections 1, 2 and 3 (Phung & Ha, 2022).
The lexical demands of reading or listening passages in standardized tests of English have received some attention over the past decades (Kaneko, 2014, 2015, 2017, 2020; Webb & Paribakht, 2015). However, these studies only reported the mean lexical demands of the whole test, leaving the variance between sections untouched. Ha et al. (2022) was among the few attempts to uncover the differences in lexical difficulty between various reading passages in the IELTS reading test. In their study, reading passages in the tests were treated individually, leading to the classification of 03 AC passages and 05 GT passages. Ha et al. (2022) conducted lexical demand analysis on the 8 types of passages using the BNC/COCA lists and found a large gap between the two groups: (1) passages in the AC test module and the last paragraph in the GT module and (2) the remaining 4 passages in the GT module. Despite being informative Ha et al. (2022) only based their conclusions on the measures of lexical demands and did not conduct any statistical tests of significance. In addition, Ha et al.’s sample size for the GT corpus was relatively small, containing only data from 12 tests, all of which together make their findings superficial and ungeneralizable.
Measures of lexical demands play a special role in the field of vocabulary studies because their estimation can be related to the results of vocabulary tests that sampled their test items from the same word lists. For instance, research findings from BNC/COCA-based lexical profiling studies could inform psycholinguistic studies that use vocabulary tests that are also made from the BNC/COCA lists such as the Updated Vocabulary Levels Test (Webb et al., 2017) and the Listening Vocabulary Levels Test (McLean et al., 2015).
It is worth noting that there are two major assumptions underlying the concept of lexical demands. On the one hand, some researchers believe that it is reasonable to assume proper nouns can be easily recognized and understood by readers or listeners (Dang & Webb, 2014; Nurmukhamedov & Sharakhimov, 2021; Tegge, 2017; Webb & Rodgers, 2009a, 2009b). On the other hand, there are scholars who are pushing forward empirical evidence against such practices (Klassen, 2022a, 2022b; Nicklin et al., 2023). However, without assuming the automated recognition of proper nouns, it would be difficult to reach conclusions on 98% or even 95% coverage thresholds as proper nouns, together with words that do not belong to any lists, would make up from 2% to 5% of the running words (Ha, 2022b). At the same time, basing lexical demand estimation of any text genre on that assumption might produce misleading findings (Nicklin et al., 2023). In the present study, since lexical demand was employed as an indication for text difficulty, results from both assumptions were reported. However, readers are encouraged to interpret these lexical demand estimates with a grain of salt.
Text Length
The literature offers little discussion on the relationship between text length, reading comprehension and/or test difficulty. There is, however, empirical evidence that lengthy texts might make readers mind wander (MW), a state of mind in which the content of thought is shifted away from an on-going task or an event of focus due to self-generated thoughts or feelings (Forrin et al., 2021). Researchers suggested that extensive text length may appear more demanding to readers and therefore make them more likely to disengage their attention (Forrin et al., 2018, 2019, 2021). Other researchers hold that longer texts may put more pressure on readers’ working memory compared to shorter ones (Andreassen & Braten, 2010). In a standardized test where test takers have to read and answer questions against the clock, lengthy texts could be critical to readers as they require more time to read and understand. Given the same number of questions and amount of time, tests that involve significantly longer texts would pose greater challenges to learners.
Methodology
Data Collection and Analysis
The researchers gathered reading passages from all IELTS practice tests that Cambridge University Press, one of the IELTS creators, has officially published in the current study to ensure the representativeness of the data. Moreover, to ensure the meaningfulness of the analyses, reading texts were divided into test sections, rather than isolated passages as Ha et al. (2022) did. The purpose of this is to make the sub-corpora align well with how they were designed according to IELTS (more details at: https://www.ielts.org/how-to-use-ielts-results/four-skills/general-training-reading/format). Reading passages from 115 IELTS reading tests, including 68 from the AC module and 47 from the GT module, were collected for analysis. The reading passages were extracted from the officially published Cambridge Practice Test for IELTS (UCLES 1996, 2000, 2002, 2005, 2006, 2007, 2009, 2011, 2013, 2015, 2016a, 2016b, 2017a, 2017b, 2018a, 2018b, 2019a, 2019b, 2020a, 2020b, 2021a, 2021b, 2022a, 2022b). By the time this research was conducted, these materials accounted for all the available official IELTS Practice tests published by Cambridge University Press. Collected texts were then divided according to their modules and sections. Table 2 gives information on the IELTS reading corpus.
General Information About the Corpus.

Text files were first processed using AntWordProfiler 2.1.0 (Anthony, 2023) based on the Nation’s (2017) BNC/COCA wordlist. The data was then imported into an Excel spreadsheet for the calculation of lexical demands and sophistication. For the lexical difficulty, Tool for The Automatic Analysis of Lexical Diversity (TAALED, Kyle et al. (2021) was utilized. Moving Average Type Token Ratio (MATTR) was employed as a measure of lexical diversity for the present study following the recommendations of Zenker and Kyle (2021) and Kyle et al. (2023). The researchers considered frequency as the primary indication of lexical sophistication and used the proportion of words that belong to the 4th to 25th levels in the BNC/COCA lists as a metric of lexical sophistication for the present study. Text length was found to correlate at a very small degree with 4-25k (%) (r = .167) and MATTR (r = .014).
Results
Table 3 offers descriptive information on the length, lexical diversity and lexical sophistication of the six sections. Overall, while the values of Skewness were within the range of ±2, which showed some degree of symmetry, a certain degree of leptokurtic could be observed.
Descriptive Statistics on Length, Lexical Diversity, and Lexical Sophistication.

Three sets of ANOVAs plus post-hoc tests were conducted to examine the statistical differences in Length, Lexical Diversity and Lexical Sophistication between different sections. The Shapiro-Wilk test of normality signaled a significant deviation from normality for Length (W = 0.957, p < .001), Diversity (W = 0.992, p = .046) and Sophistication (W = 0.978, p < .001). As a result, Kruskal–Wallis tests were utilized. The ANOVAs were significant for Length, χ2(5) = 135, p < .001, ε2 = .393 and Sophistication, χ2(5) = 80.8, p < 0.001, ε2 = .235, but were insignificant for Diversity, χ2(5) = 5.98, p = .308, ε2 = .0174. Table 4 presents the results of the Dwass-Steel-Critchlow-Fligner post-hoc tests. As multiple tests of significance were conducted, Bonferroni correction was applied to control the inflation of α.
Dwass-Steel-Critchlow-Fligner Pairwise Comparisons.

Indicates statistical significance after Bonferroni correction.
In terms of Length, results from the analyses showed insignificant differences between A1, A2, A3, and G3. Significant results were found between AC reading passages (A1, A2, A3) and G1 and G2. G1, G2, and G3 were also found to be significantly different.
When it comes to lexical sophistication, A1, A2, A3, and G3 were once again found to be insignificantly different, with the A3-G3 comparison as the only exception. In this round, G1 and G2 were insignificantly different. The two sections differed significantly with A1, A2, A3, and G3, with A3-G1 being the only exception. Lexical diversity observed no statistical differences between the sections.
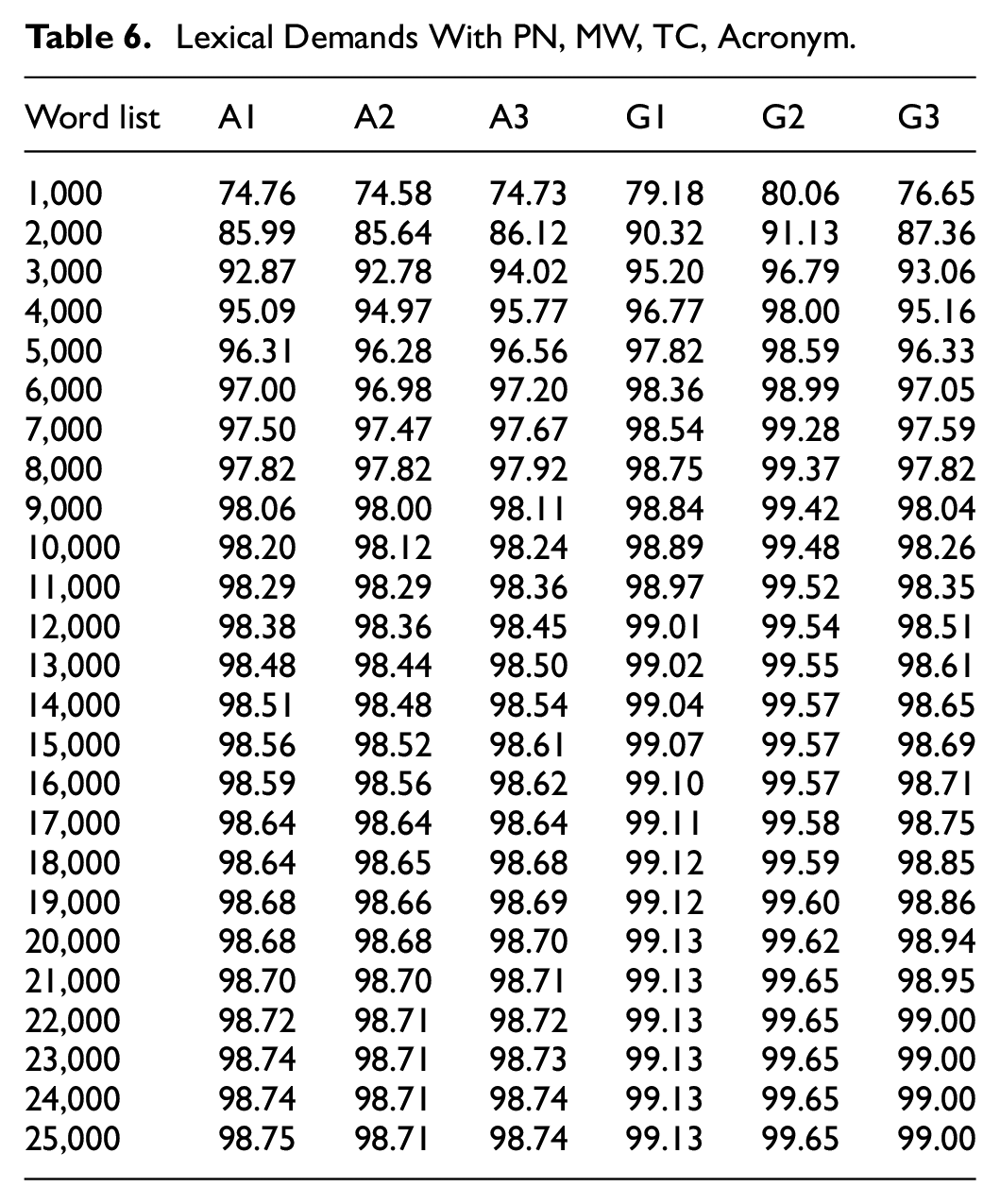
Tables 5 and 6 offer data on the cumulative lexical coverage of the BNC/COCA lists for the sub-corpora without and with the added knowledge of four supplementary lists, respectively. These figures show the proportion of running words that learners would cover when they reach a certain level of vocabulary knowledge. For example, as Table 5 suggests, when the automatic recognition of PN, MW, TC and Acronym were not assumed, learners with the vocabulary knowledge of the most frequent 3,000 word families in the BNC/COCA lists would be familiar with 95.14% of the reading passages in the second section of the IELTS GT test and around 71% to 72% of the running words in the IELTS AC Reading test.
Lexical demands without PN, MW, TC, Acronym.

Lexical Demands With PN, MW, TC, Acronym.
Without assuming the knowledge of four auxiliary lists, G2 was the only section that can reach 98% at 21,000 level coverage due to its low proportion of proper nouns. A2 and G3 managed to reach 95% coverage at 11,000 and 12,000 levels, respectively. A3 and G1 reached 95% coverage at the same level of 7000. A1, the section with the largest proportion of proper nouns, did not really reach the 95% threshold even at 25,000 level. The results from Table 4 suggest an order of lexical demand from high to low as A1 > A2 ∼ G3 > A3 ∼ G1 > G2.
When knowledge of PN, MW, TC and acronym was assumed (Table 5), the differences caused by the supplementary lists were removed. In this scenario, we can see that A1, A2, A3, and G5 reached 95% and 98% coverage at roughly the same levels of 4,000 and 9,000, correspondingly, holding their places as the most lexically demanding sections. G1 then came next, achieving 95% and 98% coverage at 3,000 and 6,000 thresholds, in the order given. G2 was the least lexically demanding section, reaching 96.79% and 98% at 3,000 and 4,000 levels, respectively. Data from Table 5 indicates an order of lexical demands that is similar to Ha et al.’s (2022) findings.
Discussion
The present research was conducted to offer insights into the lexical factors affecting the difficulty of the two modules of the IELTS test. By examining length, lexical diversity, sophistication and demands of the reading sections, results from the analyses not only confirmed but also extended the findings of Ha et al. (2022). One of the key conclusions that we now feel confident to make is that reading passages in the AC module are significantly longer and more lexically challenging than at least 2 sections in the GT module, which accounts for approximately 67% of the IELTS reading test. In their discussion, Ha et al. (2022, p. 13) took the differences in band score calculation between the two test modules into consideration and concluded that “two reading modules in the IELTS tests are comparable in terms of difficulty.” It is true that AC test takers would have the advantage of one band score compared to their GT counterparts. For example, answering correctly 15 out of 40 questions would give an AC test taker a band score 5.0, but a 4.0 band score for a GT test taker. The same goes for band scores 6.0 and 7.0, then the scoring system becomes less favorable toward AC test takers. The tolerance reduces to two correct answers when it comes to band score 8.0. At band score 9.0, the difference is only one correct answer between the two modules. Readers can find more details at https://ielts.co.nz/newzealand/results/ielts-band-scores/reading-band-score. However, when the significant differences in length is added to the equation, even with the one-band-score advantage, we would say that those who took the IELTS AC reading test would have to face a significantly greater challenge compared to their counterparts who took the GT module.
Differences in length and lexical sophistication may have significant impact on the difficulty of the test as they affect the amount of information test takers would have to process, the amount of time needed to look for the answers to the questions, and the probability of being distracted and selecting incorrect answers (Grabe & Yamashita, 2022; Jeon & Yamashita, 2022). Furthermore, lexical coverage literature suggests that learners would have near-zero chances of adequately comprehending a text if they fail to understand 95% of the running words (Schmitt et al., 2011). This means that while learners with vocabulary knowledge at 3000 level would be able to deal with 32% or 67.5% of the IELTS General reading test without or with the supplementary lists assumption correspondingly, their chances of adequately comprehending the AC reading passages would be 0%. Similar examples can be found in Tables 4 and 5. This leads us to the question of whether the two reading modules are really parallel in terms of difficulty. In other words, we wonder if the same learners would receive similar band scores for their reading proficiency if they take both the versions of the reading tests.
Besides raising a theoretical question, the present study’s findings offer practical implications for research and teaching. As the lexical demands of the reading passages were measured using the BNC/COCA lists, teachers of IELTS preparation courses can use a BNC/COCA-based vocabulary test such as the Updated Vocabulary Levels Test (Webb et al., 2017) or New Vocabulary Levels Test (McLean & Kramer, 2015) to assess and monitor their learners’ progress. English learners can employ the same strategy to see if they are really ready. However, since empirical research has shown that these tests are vulnerable to irrelevant constructs such as local item dependence and testwiseness (Ha, 2022c; Stoeckel et al., 2021), using the meaning-recall version of these tests for precise estimation is highly recommended (Stewart et al., 2021; Stoeckel et al., 2021). Researchers who are looking for a standardized reading test for their studies can use the lexical profiles of the IELTS sections provided in this research as a guideline to select appropriate materials for their participants.
Conclusion
With greater sample sizes and more thorough analyses, the present study offers an extended yet more valid answer to the research questions proposed by Ha et al. (2022). Reading passages from the AC module of the IELTS test were found to be significantly longer and more complicated than most of their GT counterparts. This may cause substantial gaps in the difficulty between the two versions of the IELTS reading test, which is likely to result in significant differences between test takers’ reading band scores. Although IELTS have given their measures to tackle this, we doubt the compensation would be justified.
However, as the present study did not include learners’ scores as well as reading time on the two reading tests, any claims on the test takers’ performances are hypothetical and therefore not reliable. We acknowledge this as a limitation of the research. Future research into this issue should include learners’ performance and the time needed to complete the two modules of the IELTS Reading test. That is when the myth is truly uncovered.
Footnotes
Acknowledgements
We would like to acknowledge the funding of University of Economics Ho Chi Minh City (UEH).
Ethical Considerations
The studies involving human participants were reviewed and approved by University of Economics Ho Chi Minh City (UEH).
Consent to Participate
The present study does not involve human participants.
Authors’ Contribution
All authors listed have made significant, direct and intellectual contributions to the paper. All the authors read and approved the manuscript for publication.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research is funded by University of Economics Ho Chi Minh City (UEH).
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.