
Abstract
This study investigates the effectiveness of teacher, AI-generated, and hybrid teacher-AI feedback on university students’ English writing performance in Hong Kong. Using a mixed-methods approach, the research examines the impact of different feedback types on student motivation, feedback quality, and essay revisions. A total of 1,267 students participated in an experimental design, with essays evaluated across three groups: human feedback, AI feedback, and hybrid feedback. Quantitative findings indicate that human feedback led to the highest essay score improvements, followed by hybrid feedback, with AI feedback showing the least improvement. Thematic analysis of student interviews revealed preference for human feedback, citing personalisation, specificity, and trust as key advantages. While hybrid feedback showed some benefits, students were less motivated by it compared to human feedback. The study highlights opportunities and limitations in integrating AI into feedback practices, emphasising the need for structured human-AI collaboration rather than full automation. These findings offer valuable insights for educators, policymakers, and AI developers seeking to enhance feedback mechanisms in English language learning contexts.
Introduction
Background
The advent of widely available text-based GenAI models such as Generative Pre-Trained Transformers (GPT) have transformed the potential to use computers to create human-like text (Sedkaoui & Benaichouba, 2024). The application of GenAI to education has been marked both with optimism about its capacity to assist in student learning (Slagg, 2024), as well as consternation about its consequences for critical thinking, research and writing skills, and academic integrity (Kenright, 2024). In the field of English Language Teaching (ELT), GenAI has been highlighted as a tool with the potential to assist English language learners (ELLs) acquire improved skills in written and spoken English as well as English comprehension (Kadaruddin, 2023).
Within education, the role that feedback plays towards learning has been well-established across research (Graham et al., 2015). Feedback has been associated with increased student motivation (Lipnevich et al., 2021), as well as improved revision on assessed academic work (Gnepp et al., 2020). However, students often complain about poor-quality feedback (Madigan & Kim, 2021), inconsistencies between professors (Meadows & Billington, 2005), and difficulties in accessing teacher feedback in good time (Dommett et al., 2019). Meanwhile, marking and feedback is frequently cited by teachers as a significant contributor towards workload and work-related stress (Hahn et al., 2021). There is thus the potential for GenAI to reduce workload on teachers, make feedback more readily available to students, and ensure consistent quality feedback on assessable work (Gao et al., 2024).
Rationale
Prior to the rise of GenAI in the 2020s, studies had already highlighted the potential for automated writing evaluation (AWE) to transform the ways in which feedback is generated and provided to students (Crossley et al., 2022; Fleckenstein et al., 2023). Since this time, a number of studies have emerged exploring the effects of GenAI feedback on student experience (Simon et al., 2024; Wood & Moss, 2024), motivation (Jose et al., 2024), and performance (Abd-Alrazaq et al., 2024; C. Chan & Hu, 2023). Likewise, a number of studies have emerged comparing teacher and AI feedback, though review studies disagree as to whether there is consensus on their comparative efficacy (Bond et al., 2024; Ruwe & Mayweg-Paus, 2023). Furthermore, much of this research is highly task-related or subject specific (Ramesh & Sanampudi, 2022), whilst comparisons of teacher and AI feedback typically omit hybridised models combining teacher and AI content.
This highlights the need for further research into the broader efficacy of GenAI towards providing effective feedback on written work as compared with alternative means. Undertaking research into such areas where data is scant and where consensus remains elusive can help towards clarifying the utility that AI has to offer in supplementing and enhancing university education. Research targeted in these areas can thus advance knowledge in this topic area and guide policymakers, institutions, and educators towards making best use of available AI resources when planning feedback on student work.
Aims and Objectives
This study is aimed at establishing the effects of AI feedback on written work as compared with human teacher and hybridised methods for providing feedback. Among its specific objectives is to uncover through research how AI can affect student motivation, justified by previous research demonstrating that feedback can have a positive effect on student motivation (Mohamed et al., 2025). Additionally, the study aims to evaluate the quality and consistency of AI feedback as compared with teacher feedback, contributing to the extant body of literature by adding the model of hybrid human-AI feedback to its comparison. The study also seeks to ascertain the effect of AI feedback upon written work produced by students, exploring specifically its effect on revisions to written essays and comparing this effect with human feedback. Situating these objectives within the field of ELT in Hong Kong also assists towards producing findings relevant to both English language learning at the university level and the reception of AI feedback on behalf of students within the context of Hong Kong.
Research Questions
In order to achieve the above aims and objectives, three research questions have been developed to direct the study’s design and methodology:
What is the effect of AI-generated feedback on the motivation of university students as compared with human-generated feedback? How does AI-generated feedback compare with human feedback and mixed human-AI feedback in terms of its quality and consistency? How far can AI-generated feedback improve students’ performance when undertaking revisions on written work when compared with human and mixed AI-human feedback?
As is documented in the methodology section below, the study employs a mixed-methods design in order to answer these research questions, combining statistical analysis of quantitative data derived from student essay scores and questionnaire responses with automated thematic analysis of data gathered from interviews with students.
Literature Review
AI-Generated Feedback
Research into AI feedback has a strong body of literature behind it, though the majority of it prior to the advent of GenAI focused on AWEs designed to evaluate specific tasks (Mertens et al., 2022). The comparative advantage of GenAI based on large language models (LLMs) is that they are more able to respond sensibly to unanticipated data, drawing on a massive pool of training data to provide tailored responses to new prompts (Bowman, 2023). This renders GenAI flexible in terms of the evaluative tasks to which it may be put, adapting towards diverse instructions, learning objectives, and marking criteria (Bressane et al., 2024).
Evaluation and Feedback
The literature highlights both the potential for GenAI to be used to evaluate and score student work, as well as the lack of consensus about the best programmes and methods for achieving such ends (Ferrara & Qunbar, 2022; Shetty et al., 2022). Studies tend to focus on comparing the accuracy of AI grading with teacher grading, often with a view to improving feedback on work through accurate evaluation (Johnson & Zhang, 2024). The internal consistency of AI scores has been well-established (Tate et al., 2024), though studies differ on their assessment of inter-rater reliability between human and AI scorers (Almegren et al., 2024; Bui & Barrot, 2025). Within ELT, GenAI programmes have noted to be more effective at detecting errors in written work than human evaluators (Mirzaeian, 2025), though few studies explore the capacity for AI to assess the quality of written student work in ELT.
The contributions of GenAI towards generating effective feedback for students have been discussed across the literature. One examination into the use of AI feedback in independent study found that students who utilised GPT feedback on their work developed better thinking, critical and reflective skills than students who did not (Essel et al., 2024). Another study that measured improvements in scores after revisions completed following GenAI feedback found that secondary-level EFL students performed better when receiving AI-feedback than those who received no such feedback (Meyer et al., 2024). There is therefore some support for using GenAI to provide feedback on student essays to assist with the improvement of student skills and performance.
Some have highlighted the need to develop mediating programmes to interact with GenAI to help students clarify feedback and scoring of work (Hong et al., 2024). Increasingly, studies seek to explore the effects of AI feedback on revision of material itself. For instance, one study explored hybrid peer-AI feedback and its effect on Chinese ELLs’ essay revisions, noting a number of different strategies for application of feedback (Guo et al., 2025). One experimental study carried out in Hong Kong noted that students performed better than a control group when receiving GenAI feedback on essays (S. Chan et al., 2024). However, more research is required to confirm such findings.
Comparisons With Human Feedback
Concerns about the efficacy of GenAI towards these purposes have been raised. For one, there are concerns about the quality of AI feedback when compared with human feedback given that GenAI is prone to making factual errors (Lee et al., 2024). Some have also raised concerns that AI feedback is comparatively generic and lacks specificity in its feedback, giving general tips that may or may not apply to a specific piece of work (Knoth et al., 2024). A related concern is that GenAI does not ‘know’ students as there are limitations to the body of active data it can draw upon, meaning that its perspective on student work is more atomised than is the case with teachers who come to know their students and their work (K. Li & Wong, 2023).
Studies offer mixed assessment on the capacities of GenAI to provide feedback of a comparable quality to human evaluators. One study found that GenAI offered feedback that broadly cohered with the positive or negative assessments of student work offered by teachers (Dai et al., 2023). A study comparing AI and human feedback provided to English as a foreign language (EFL) students found that AI tools offered more detailed feedback than human graders, but noted that its feedback was also more negative (Almegren et al., 2024).
There is increasing interest in the prospect for AI to inform human feedback or be edited or mediated by human intervention to provide hybridised human-AI feedback. One study of 124 Chinese EFL students found that GenAI feedback enhanced the quality of feedback provided by teachers (Guo et al., 2024), whilst another explored the effects of AI feedback on peer feedback (Guo et al., 2025). However, there is no clear model for providing hybridised or mixed human-AI feedback and more research is required to explore the potentials for this to combine and build upon the strengths of human and AI insight.
Student Experience and Motivation
Much contemporary research on motivation focuses on how interventions can enhance student motivation and thereby performance (Ahmadi et al., 2023). Studies into the use of GenAI for the purposes of offering feedback on student work have reported positive evaluations on behalf of students and teachers alike (Jacobsen & Weber, 2023; Steiss et al., 2024). Students report finding that GenAI supports their emotional well-being by offering guidance on their written products (C. Li & Xing, 2021), whilst some studies show that students report feeling more engaged with their work when I receipt of AI feedback (Aslan et al., 2024). Students tend to rate AI feedback as a valuable supplement to existing avenues for receiving feedback (Al Shloul et al., 2024). However, students appear to be more sceptical when faced with GenAI feedback as an alternative to teacher feedback (S. Chan et al., 2024).
Student motivation is thus potential subject to the ways in which AI is applied and how this relates to teacher feedback. One mixed-method experimental study involving 118 students found that conversational AI agents were useful for enhancing student motivation, but only when combined with scheduled access to teacher feedback rather than as an alternative (Neji et al., 2023). Another study using student interviews found that on-demand GenAI feedback could improve student motivation but had negative effects on attendance and engagement with in-person classes (Fahmy, 2024). A study carried out in the United States with 123 high-school students found that whilst GenAI feedback satisfied a need for autonomous learning, it did not satisfy the need for relatedness to the extent that teacher support provided (Chiu et al., 2024).
Research Gaps
The above section notes that GenAI holds significant potential owing to its flexibility as compared with other automated forms of scoring and providing feedback on work, highlighting especially the internal coherence of GenAI scoring, its utility as compared with receiving no feedback, as well as support for AI among students as part of an integrated framework incorporating human feedback from teachers. However, the review also notes some inconsistency across the literature as to the accuracy of AI scoring when compared with human feedback, as well as reluctance among students to ‘replace’ human feedback with AI feedback. Whilst hybrid systems show promise, there is little research into their efficacy or reception among students. This study may therefore build upon these gaps in the research literature to better inform future policymakers, educators, and students on the best uses of GenAI when offering feedback on academic work.
Methodology
Research Design
This study uses an experimental design that compares across three groups of student: one receiving AI-generated feedback; one receiving human (teacher) feedback; and one receiving mixed human-AI feedback. An experimental design was selected in order to support determination of causality through using the type of feedback received by the participants as an independent variable. The design of the research allows for several different outcomes to be compared, such as the scores awarded to student work after revisions had been completed. The design of this aspect to the study was influenced by the methods of previous research undertaken in this area (Wetzler et al., 2024). Furthermore, the design allows for student experiences and evaluations of the quality of feedback to be compared through statistical analysis of questionnaire data – an approach again influenced by previous research in this field (S. Chan et al., 2024).
The mixed-method design also allows for a qualitative approach to complement the analysis of quantitative data. Mixed-methods designs have the benefit of supporting the triangulation of findings (Heale & Forbes, 2013), as well as utilising the benefits of phenomenological data not always possible through narrowly quantitative analysis (Carter & Little, 2007). Whilst reducing data down for quantitative analysis can be useful for spotting correlations across data, the nuances of individual perspectives can be lost through this process (DeCarlo et al., 2020). The study therefore includes interviews with participants, subjected to thematic analysis in order to denote the most prevalent and emphatic themes raised by the participants (Fereday & Muir-Cochrane, 2006). Further details of the specific methods of data collection and analysis involved are given below.
Context
The cohort utilised in this study is comprised of 1,267 students participating in the second year of an English language course at a university in Hong Kong. The students involved were enrolled on an intermediate-level ‘English for Academic Purposes’ (EAP) module designed to assist students for whom English is a second language with acquiring better English for use in education and academia. The vast majority of students are undertaking degrees in the Humanities and Social Sciences, though some students were on other courses for which English academic communication is considered essential. The intermediate level assumes a certain degree of competency with English, broadly equivalent to a 6.0 to 7.0 in IELTS band score, or a B2 or C1 level on the Common European Framework of Reference CEFR. Although not all students possess these specific credentials, all students admitted onto the module have passed at least a first-year beginners’ course, whilst some may have also passed a foundational course in General English.
As the module brings in students from a variety of disciplinary areas and is compulsory for study in many subjects, the nature of its teaching and assessment is broader than is the case in English for Specific Purposes modules. Students are typically set written assessments where they are asked to select from a number of subject-specific questions as well as more general questions pertaining to general knowledge or current affairs. Students are asked to write an academic essay on these topics under both coursework and test conditions. As with similar studies on AI feedback (Q. Li et al., 2023), it was resolved to utilise a task similar to those that students might face in actual assessment and to attempt to recreate test conditions for the duration of the experiment.
The students were split into three groups: 431 receiving AI feedback only; 425 receiving teacher feedback only; and 411 receiving hybrid feedback. Students were not informed as to which group they belonged in. Of the students admitted into the study, a further 18 were recruited to take part in one-to-one interviews with the researcher regarding their experience of the task and their opinions on AI feedback. Six students were recruited from each group in accordance with research suggesting that six is an ideal minimum number for use with thematic analysis (Galvin, 2015).
Data Collection
Students were tasked with completing the task over the course of two 50-min tutorial sessions, though only students who completed consent forms had their data included in the study. The students were asked to complete an essay in a computer lab, receiving instructions via their university email, including an essay prompt, learning objectives, and marking rubric. The prompt was as follows:
Should employers be required to offer workers a four-day week to improve their work-life balance? Support your answer with reasons and examples.
The students were given 30 min to complete the task. The sessions were supervised by the class teacher and a supervisor, who oversaw classes of between 20 and 40 students – suitable numbers to ensure that test conditions could be recreated and students supervised to ensure no cheating or plagiarism (Ross & Morrison, 2004). Students submitted their completed essay via email to the researcher ahead to be marked and returned.
Feedback was provided by email some 2 weeks later to allow time for marking and grading. In the human feedback group, papers were marked and graded as normal according to the rubric provided, though interlinear comments were eschewed in favour of a prose response exceeding no more than 500 words. In the AI group, papers were submitted to GPT 3.5 because of its reputation as an advanced, popular, and free-to-use LLM of the kind that students might have ready access to (Mahapatra, 2024). The essay was submitted to the programme preceded by the following instructions:
A number of students of English studying at the undergraduate level at a university in Hong Kong have been tasked to write an essay on the following question: Should employers be required to offer workers a four-day week to improve their work-life balance? Support your answer with reasons and examples. They have been tasked with meeting the following four learning objectives through completion of the assignment: 1. Engage critically with the question, meeting the criteria set out in the instructions. 2. Argue convincingly towards a clear thesis, drawing on existing research or evidence where possible. 3. Employ academic vocabulary and formal English in your answer. 4. Ensure accurate spelling and grammatical coherence throughout. Based on these learning objectives, please provide no more than 500 words of feedback designed to help the student improve their essay and raise their grade, giving both general and specific guidance as to areas and means for potential improvement. You may reproduce the text and use superscript to offers specific notes on sections of the text. Neither the reproduced essay nor these notes need count towards the 5000-word limit. The essay in question follows below.
Hybridised feedback involved teachers receiving the output from this and then amending the text according to their own opinion on how the student work might be improved. This is in keeping with previously observed teacher use of AI-generated content in their feedback (Guo et al., 2024). Amended feedback that lay outside 20% to 80% similarity ranges when compared to the original AI feedback were discounted on the basis of being insufficiently hybridised. Samples of the essays submitted and feedback received may be found in appendices A through D.
Students received their feedback via email in a tutorial session 2 weeks after the original task and were given half an hour to revise their original paper. Returned again via email, student essays were subject to manual grading on behalf of class teachers and doctoral students. Difficulties in establishing consistency in grading between AI and teacher grades meant recommended manual scoring and grading in this case (Lee et al., 2024; Misiejuk et al., 2024). Inter-rater reliability was calculated to ensure consistency across human grading, resulting in an intraclass correlation coefficient (ICC) of .815, falling within 95% confidence intervals of 0.778 and 0.828 (Koch, 1982). Papers were scored out of 100 and were double-marked, with an average of the two grades comprising the mark used in analysis.
Quantitative Analysis
Students were asked following the revision task to complete a questionnaire on their experience of and opinion on feedback. The questionnaire asked students to rate various aspects to their experience, including their motivation to complete revisions and quality of the feedback received. The students provided scalar responses on a 10-point Likert scale. In addition to this, the difference between the original and revised average scores awarded to each paper by markers was recorded in order to compare the effect of feedback on performance in numerical terms. The data for the questionnaire responses and essay scores was entered into a database and analysed using IBM’s Statistical Package for the Social Sciences (SPSS) 29.0 (Salcedo & McCormick, 2020).
A variety of statistical tests were carried out on the data submitted. Pearson’s product-moment correlation coefficient was used to identify numerical relations between sets of data – useful here because of its capacity for exploring linear relationships with respect to revision scores (Kombrot, 2005). The student’s t-test was used also to compare between group scores, such as those pertaining to motivation and feedback quality. Linear regression tests were also carried out to explore how specific variables might impact test scores. Furthermore, ANOVA tests combined with post-hoc tests have been used to identify how the groups align or differ from each other.
Qualitative Analysis
The interview data for this study was subject to transcription and thematic analysis. One-to-one interviews were carried out within 48 hr of the second task and lasted no more than half-an-hour each. Open-ended questions were developed in order to allow detail in participant response and to avoid leading them towards certain answers (Silverman, 2013; Supplemental Appendix E). Questions were posed in a semi-structured manner so as to allow the interview to remain on the topics more relevant to the research questions without overly steering responses (Wethington & McDarby, 2015). The interviews were transcribed using digital software and then manually corrected ahead of analysis (Supplemental Appendix F).
Thematic analysis was carried out on the transcribed data using ATLAS. Thematic analysis is an approach to qualitative analysis that focuses on discovering what ‘themes’ are most prevalent or emphatic across data (Braun & Clarke, 2006). It is useful especially for generating rich insights from relatively small cohorts of data, as is often the case in interview studies (Nowell et al., 2017). ATLAS allows for the coding process to be digitised and for the themes to be categorised and displayed using visual graphics (Hecker & Kalpokas, 2014). Likewise, it permits the use of automated coding according to terms that have linguistic or thematic similarity, reducing factors such as researcher bias from intruding into the analysis process (Mackieson et al., 2018). The findings of this process are detailed in the relevant section below.
Findings
Quantitative
Effect on Performance
The essays completed by the participants were scored by lecturers before and after revisions in order to compare how far different feedback types affected student performance. The intraclass correlation coefficient (ICC) was carried out to ensure consistency among these graders. To accomplish this, the markers were all asked to grade a number of identical papers. A two-way random effects model with single measures was employed, with absolute agreement defined to factor in any outlying scores. An ICC of .815 was observed, falling within the 95% confidence intervals of 0.778 and 0.828.
As Table 1 demonstrates, though initial average scores were within 0.12 marks between all groups, there were substantial differences between mean scores. The AI feedback group saw an average improvement of 2.575 after revisions, but both the mixed and human feedback scores saw larger improvements: mixed feedback scores increased by 5.399 after revisions on average, whilst those in the human feedback group saw improvements of 7.28. The biggest differences were therefore between the human and AI groups, with the average score of the human feedback group improving by some 4.705 more than the AI group after revisions. This suggests that although AI feedback can result in improved student performance, it is not as effective as human feedback to this end.
Average Scores for Essays Across Experimental Groups and Differences Between Groups.

To test whether these results were statistically significant, normality for the data was checked. The Kolmogorov-Smirnov test was applied to check normality because of the large dataset (Daniel, 1990). The test was applied to each group separately to compare data against a normal distribution (Table 2). The null hypothesis of normality had to be rejected for the mixed feedback group according to the results. Skewness coefficients were calculated to try to account for this. It was found that the mixed group had a strong rightwards skew, indicating perhaps that some participants had much larger score improvements than others.
Normality Test Results for Performance Data.
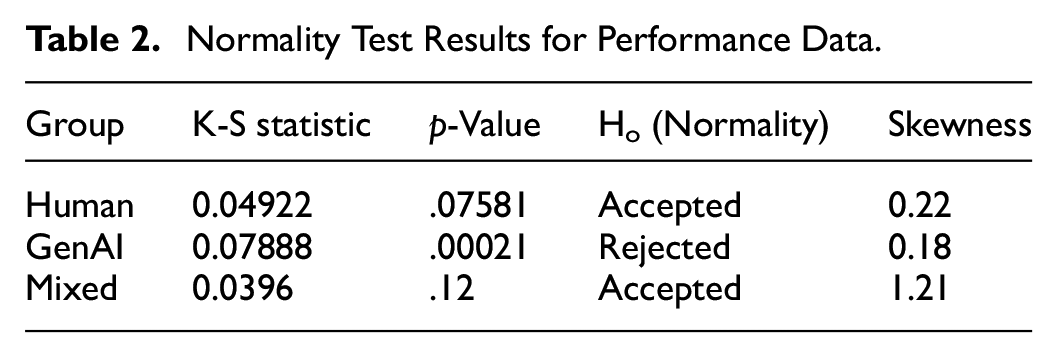
Although the null hypothesis of normality had to be rejected for the mixed feedback group, the large dataset means that it may still remain robust enough for ANOVA (Vanbrabant et al., 2015). Levene’s test for homogeneity of variances was therefore carried out in order to establish whether the variances of the groups are roughly equal. A statistic of 1.97 and a p-value of .115 indicates that that null hypothesis of equal variances should not be rejected. For this reason, the data is suitably normal to be subjected to a one-way ANOVA.
A one-way ANOVA was carried out on the experiment groups to establish whether any group has a statistically significant different mean improvement score to any other group (Table 3). The large F-statistic here (25.47) indicates that the between-group variation is substantially larger than the variation observed within groups, implying that the feedback type employed did indeed have a significant impact on revision scores. This is reflected in the large difference between the mean squares between (95.13) and within (0.271) groups. The low p-value (.0001) confirms that these findings are statistically significant. For this reason, it may be assumed that the differences between the averages observed above do indeed reflect the different feedback approaches administered.
ANOVA Output for Comparison of Experimental Groups.

A post-hoc test was carried out to test the differences between groups themselves. Tukey’s Honest Significant Difference (HSD) was carried out to identify which of the groups differ from each other (Table 4). This recalculates the mean differences in Table 1, adjusting for the standard error of the difference between he means in order to account for in-group variability. The comparisons between the human and AI score differences show that the mean differences observed remain substantial and likewise demonstrate that they are statistically significant. The human feedback group saw the biggest average improvements in scores, followed by the mixed group, and then the AI feedback group.
Tukey’s HSD Output Comparing Experimental Groups.
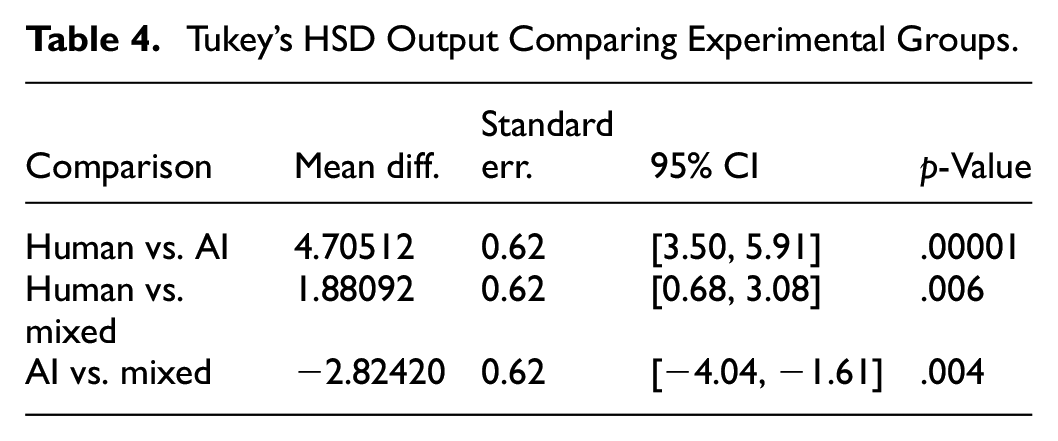
Taking the ANOVA and Tukey’s post-hoc test into account, it is prudent to consider the effect size and difference strength. Calculating eta squared through dividing the sum square between groups by the total sum of squares indicates that feedback type has a large effect on score improvements (η2 = 0.32). Converting this into Cohen’s f by finding the square route of η2 divided by 1−η2 provides a score of 0.686 – again, indicating a medium-to-large effect size. It is worth noting that the confidence intervals of the post-hoc test do not include 0, indicating also statistical significance, as confirmed in the p-value. There is therefore strong statistical support for assuming that whilst AI feedback can improve student performance on written essays, its implementation in the experiment was inferior to that of human feedback.
In order to examine whether discrepancies observed in the mixed group might owe to the proportion of content written by GenAI versus humans, a test was carried out to establish whether score improvements correlated with increasing proportions of GenAI feedback text rewritten by teachers. First, Pearson’s correlation coefficient was carried out to measure the direction and strength of any correlation. The output suggested a weak to moderate correlation between the proportion of GenAI feedback rewritten by the human teacher and the improvement score (r = .35, p = .047). This would suggest that student scores in the mixed group improved more when teachers rewrote more of the AI feedback.
However, it may be recalled that normality scores for the mixed group were called into question by the normality tests carried out (Table 2). For this reason, Spearman’s rank correlation was also carried out to test the correlation between the proportion of mixed feedback attributable t humans/AI and the differences between original and revised essay scores. The test produced a Spearman’s rho of 0.29, falling within 95% confidence intervals of 0.02 and 0.56 and admitting a p-value just within the bounds of statistical significance (p = .04). This indicates a weak correlation that is both broadly in line with Pearson’s coefficient (r = .35) and is likewise statistically significant. It may be concluded, then, that there is a weak relationship between the proportion of AI feedback rewritten by teachers and the improvements made to original essays through student revision.
Student Motivation
Students were provided with a short questionnaire following completion of revision, whereafter they were asked to rate their level of motivation to complete revisions in the session. Students were also asked how motivated they would be to receive feedback of the same kind on their work in future.
The students reported various levels of motivation with respect to how motivated they were to complete revisions. Students in the human feedback group were 1.03532 points on average more motivated to complete the revision task than those in the AI group and 1.25294 points more motivated than the mixed feedback group. These differences became more pronounced when asked to rate how motivated they would be to receive the same type of feedback in future (human, AI, or mixed). The students in the human feedback group were considerably more motivated to receive AI feedback than in either other group and the difference in motivation between human and mixed group students also increased (Table 5). This suggests that students were least likely to prefer to mixed feedback to any other type and most likely to prefer human feedback (Table 6).
Self-Reported Motivation Across Experimental Groups.

Normality Statistics for Student Responses to Questions About Motivation.

Normality tests revealed that the data was not normally distributed for motivation to undertake revisions (Table 5). On the basis of Kolmogorov-Smirnov tests, it was established that whilst the distribution for the AI group was normal, the human and mixed feedback groups both showed strong deviations from normality that were statistically similar. However, questions about motivation to receive the same feedback type in future were within normal distributions ranges (Table 5). Thus, the student’s t-test was carried out to compare motivation to receive future feedback (because of their normal distribution), whilst Welch’s t-test was used to compare motivation to complete revision because it does not assume normal distribution (Ruxton, 2006).
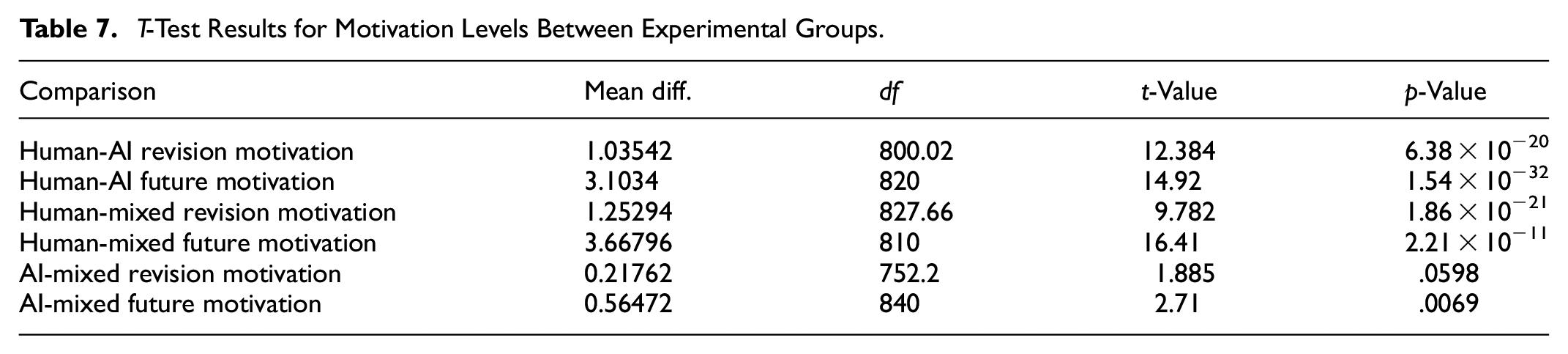
The results show there are indeed significant differences when comparing the human and AI feedback groups and the human and mixed feedback groups when it came to completing revisions (Table 7). However, the differences between the AI and mixed group could not be established as statistically significant (p = .0598). This indicates that the small score difference of 0.21762 between these two groups was not statistically significant. The t-tests carried out to compare students’ self-reported motivation to receive the same type of feedback in future indicate strong, statistically significant differences for all comparisons excepting that between AI and mixed feedback. Although statistically significant, the mean difference here was smaller, indicating that students’ motivation to receive similar feedback in future only differed slightly between the AI and mixed feedback groups.
T-Test Results for Motivation Levels Between Experimental Groups.
Finally, calculations were determined to compare whether motivation might have had an impact on score improvements following revisions to papers. A linear regression model was used, employing the essay score improvement as the dependent variable and motivation as the predictor variable. The output suggests that for every point increase in motivation, essay improvement increases by 0.68 points on average across the entire dataset (Table 8). This implies that differences in motivation levels between groups may account for differing improvement levels noted also when comparing improvements to marks awarded after revisions.
Regression Analysis Comparing Motivation With Essay Improvement Scores.

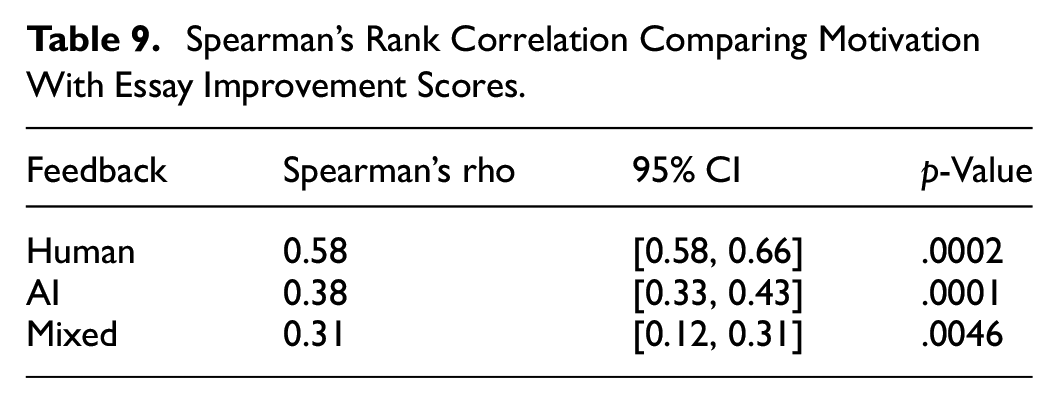
As data was not normally distributed, Spearman’s correlation was used to calculate any potential correlation between motivation to complete revisions and improvement scores (Table 9). Correlations were indeed found, with a weak-to-moderate correlation for the AI and mixed groups and a moderate-to-strong correlation for the human feedback group. This suggests that though motivation had something of an effect on performance, this effect was more pronounced among the human group, for which motivation was by the highest. This suggests that the human feedback group were not only more motivated to complete revisions but their motivation was more effectual in terms of improving their performance.
Spearman’s Rank Correlation Comparing Motivation With Essay Improvement Scores.
Qualitative
The interviews were uploaded to ATLAS and subject to AI coding powered by OpenAI. As Hecker and Kalpokas (2024) observe, ATLAS is a leading tool for automating thematic analysis and is particularly powerful as it allows for editing of codes by the human researcher also. The AI was provided a prompt including the research’s aims, context, and research questions and then generated codes inductively through analysing the interviews.
As Figure 1 shows, there were a number of themes raised by the participants pertaining to feedback, with specific features relevant to EAP in ELT (e.g., grammar, structure, arguments, etc.) falling among the most frequently cited terms and themes raised. The themes were sorted into three main thematic groups: themes pertaining to feedback comparison, themes pertaining motivation impact, and themes pertaining to performance improvement. The most prevalent themes for each group were then selected for further exploration (see Figure 2). These groups and their constituent themes are discussed in more depth below.

Concepts cloud for interviews generated in ATLAS.

Prevalence of interview themes generated in ATLAS.
Motivation Impact
The main themes mentioned by the participants in the study described a mixture of positive and negative impacts of feedback on motivation. As Figure 3 demonstrates, positive assessments of the effects of feedback and motivation were distributed across all groups, whilst negative impacts were more focused across the AI and mixed feedback groups. Some participants from these groups were overwhelmingly negative, as may be evinced from the Sankey chart (Figure 3), where AI Participant 6 and Mixed Participant 4 account for large chunks of the negative feedback; conversely AI Participant 1 is almost wholly positive about its effect on motivation.

Sankey chart for main themes relating to motivation impact.
The contrast may be seen in the comments pertaining to these themes. For instance, Human Participant 1 argued that they preferred teacher feedback because of its depth, noting that they found in-depth feedback to be the most effective approach. By contrast, AI Participant 6 argued that the feedback they received was ‘shallow’ and concentrated largely on grammar. This was a common complaint, with multiple respondents across the AI group referring to their feedback as ‘superficial’. One participant from the mixed group argued that seeing where the AI feedback ended and that of the teacher began demotivated: ‘[My feedback] was literally just some AI jumble with my teacher’s remarks clearly tacked onto the end. I didn’t appreciate that. There’s very little gone into it’ (Mixed Participant 4). Whether or not the feedback was comprehensive and targeted towards the individual’s work appears to be what ‘counts’ according to the participants interviewed.
Performance Improvement
The Sankey chart for performance improvement demonstrates how differing assessments of improvement levels were present depending on feedback group (Figure 4). The theme ‘limited improvement’ was prevalent in five of the six AI participant interviews, but only one from the human feedback group. ‘Limited effectiveness’ is most associated with the mixed feedback group, whereas ‘improvement’ is most associated with the human feedback group, with no AI group participants emphasising this theme.
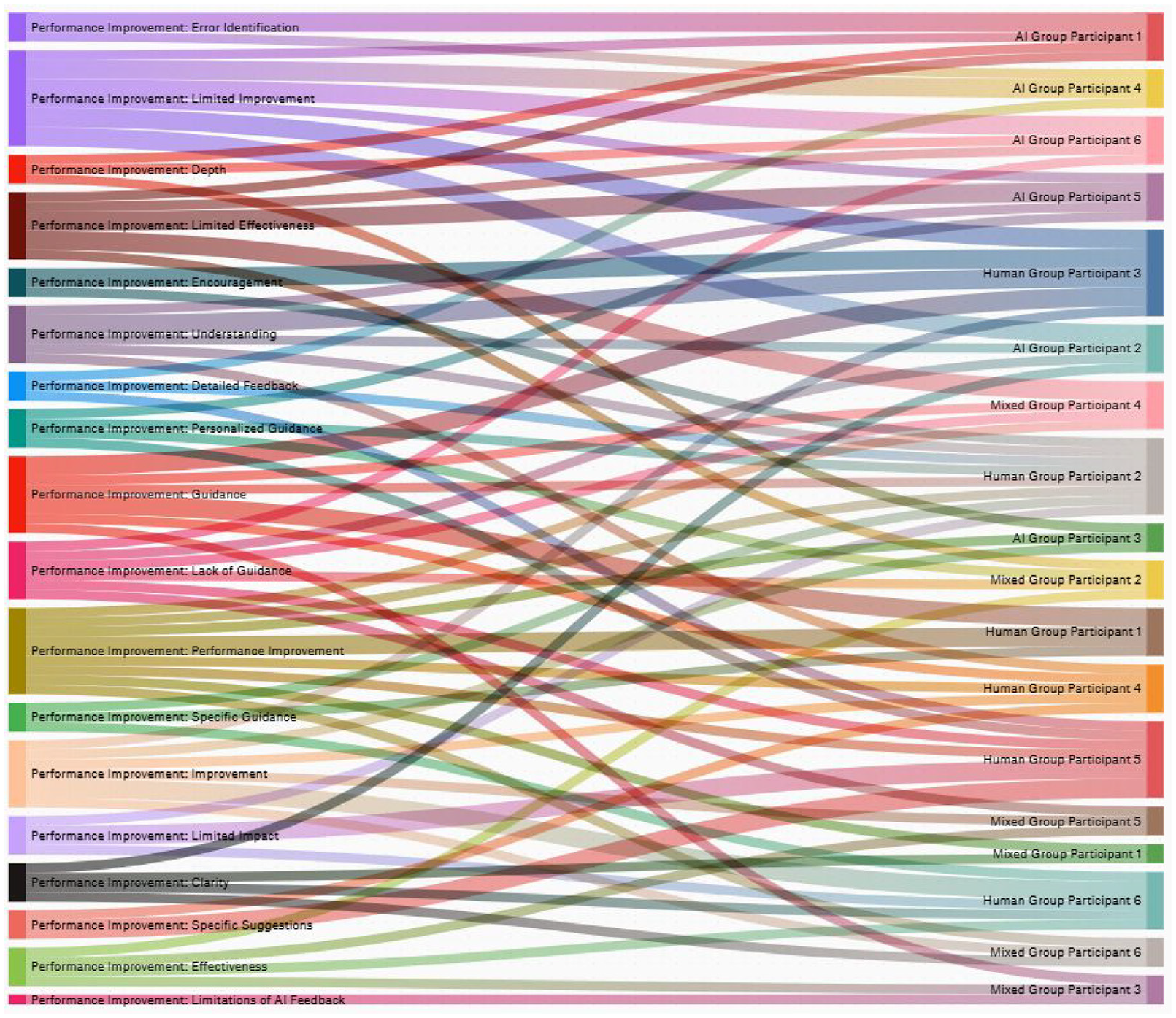
Sankey chart for main themes relating to performance improvement.
The themes associated with performance improvement potentially shed some light on how the participants felt their specific feedback type benefited them. Terms such as ‘depth’ and ‘detail’ are more associated with the AI participants, though not always in a positive light, as Figure 2 illustrates. AI Participant 6 stated that ‘I felt that [the feedback received] made some good general points and observations, but there was not enough detail or guidance’. A lack of guidance was also a frequent complaint among the mixed group participants.
Within the human groups, specific guidance and suggestions were highlighted in a positive light: ‘The feedback I received quoted specific lines of text back at me and basically said, “okay, here is what you do”. That’s helpful, I need to see what areas require improvement’ (Human Participant 1). Themes such as personalisation, clarity, and understanding were also prevalent across the human and mixed feedback groups, highlighting some areas of crossover between the two groups and what aspects to the feedback were deemed most impactful towards performance.
Feedback Comparison
The Sankey chart in Figure 5 illustrates the most important themes that participants ranked when asked about how they viewed various forms of feedback. Consistency and quality were the two most prevalent themes and more or less every participant raised these as important. Notable also, depth was mentioned frequently – especially among participants who had received AI feedback, whilst other themes such as having detailed explanations, clarity, reliability, and specificity were more diffuse.

Sankey chart for main themes relating to feedback comparison.
Favouring human feedback or doubting the capacity of AI feedback was widespread across the feedback, with many arguing that human feedback was simply superior: ‘AI just isn’t there yet … I’ve tried it, it’s not good enough’ (Mixed Participant 6). Others suggested that as their teachers were their markers, their feedback was naturally more useful than that of AI: ‘They know what they want to see. You can upload a rubric or whatever to AI but none of that matters if it can’t handle it or the lecturer marks to their own standards’ (AI Participant 2). As AI was not their grader, its opinion was valued less than that of teachers.
Discussion
The findings raise a number of points that warrant further discussion. First, human feedback saw the greatest essay score improvement after revisions, followed by mixed feedback, then AI. Whilst all groups saw improvement, human feedback thereby appeared to be associated with more improvement. Analysis of the mixed feedback group scores suggest that score improvements scaled with the proportion of text rewritten by teachers. Although the observed relationship here was weak, the results do suggest that teacher editing can enhance the efficacy of AI feedback, though AI-based feedback is generally inferior to that of human teachers. Previous studies have noted the potential for AI to improve teacher feedback (Guo et al., 2024), but not vice versa, representing a new finding with respect to hybridised feedback. An important caveat here is that the scores were based on double-mark averages with the teachers providing feedback being one of those markers. As such, it may be that teachers tended towards marking more favourably work they had provided feedback on despite broad consistency across the cohort according to the ICC.
The student interviews demonstrate that the students in the human and mixed groups appeared to view the quality of feedback with human input higher than that of AI feedback. This was reflected also in the statistical analysis of quality ratings offered by students. AI feedback group interviewees highlighted the limited improvements offered by the feedback they had received, whilst those in groups with human feedback providers mentioned themes such as personalisation, clarity, and understanding as instrumental in improving their performance. Concerns about the specificity of feedback provided by AI have been raised in past research (Knoth et al., 2024), situating this study’s findings within previous studies assessing student experience of and opinions on AI-generated feedback. However, concerns about a lack of detail provided by AI feedback – reflected in the experiences of those in the AI group – contradict the findings of past studies, which suggest a greater level of detail in AI feedback (Almegren et al., 2024).
It is worth noting that when questioned about the types of feedback they preferred, students broadly favoured human feedback and questioned the capabilities of AI feedback. This reflects the studies cited in the literature review, according to which students typically are sceptical of AI feedback and favour teacher feedback when faced with the choice (Bond et al., 2024). It is worth noting, however, that many of the participants in the AI feedback group suspected they had received AI feedback, indicating both a familiarity with AI content and accurate expectations about the kind of feedback it typically offers. A minority of mixed and human group participants were also confident and correct about the groups to which they had been assigned. It is possible that students’ evaluations of the feedback they received therefore may have been skewed by correctly guessing to which group they belonged and the intrusions of existing prejudices and bias into their evaluations of the feedback received.
The variable of motivation was investigated in the study, with students in the human and AI groups reporting higher motivation than those in the mixed group. This latter result was largely out of step with performance metrics, according to which the mixed group outperformed the AI feedback group. Normality for the mixed group responses on motivation could not be established and suitable tests likewise could not establish statistically significant differences between the AI and mixed groups with regards to motivation to complete revisions. However, the mixed group were by far the least motivated to receive similar feedback in future. This is somewhat against the trend observed in the interviews, wherein mixed group assessments of the feedback received was more positive than that of the AI feedback group. As the interviewees from this group were not sampled evenly on the basis of the proportion of human versus AI content provided, it possible that some discrepancy related to this may be to blame for these contradictory trends.
As for the effect of motivation upon performance, a linear regression analysis and Spearman’s rank correlation coefficient both suggested that motivation was positively correlated with score improvements. This effect was least pronounced among the mixed group and most pronounced among the human group. The higher rates of overall motivation and the increased efficacy in terms of marks per point of motivation among the human feedback group speak to the cumulative effect of human feedback on performance through increased motivation as compared with alternative feedback types. The low scores for mixed feedback suggests that the comparably superior essay score improvements observed when compared with pure-AI feedback cannot be attributed to increased motivation, which is less both in its total average and average effect on performance.
Conclusion
This study has compared the experiences and effects of various types of feedback based on source and has made several findings relating to the research questions. Human feedback was found to lead to the greatest essay improvements, followed by mixed human-AI then pure-AI feedback. Across the mixed group, there was a weak positive correlation between the proportion of human content and improvements to essay scores after revisions; however, mixed feedback group students reported the lowest motivation to complete revisions and demonstrated the lowest return on motivation scores in terms of effects upon essay scores. However, the abnormal distribution of motivation scores across the mixed group may call these discrepancies into question. Overall, students favoured human feedback over AI feedback on the basis of its clarity, depth, and specificity, and expressed doubts over whether AI had the capacity to offer feedback of an equivalent quality. This was reflected in evaluations of the quality of feedback received. However, it may be that students correctly inferred which group they belonged to, in which case pre-existing judgements about various types of feedback might have influenced their responses. Nevertheless, the research produces new insights into how comparably motivating and effective various forms of feedback generally are, producing insights particularly applicable into the context of ELT at the university level in Hong Kong.
Supplemental Material
sj-docx-1-sgo-10.1177_21582440251352907 – Supplemental material for Evaluating Teacher, AI, and Hybrid Feedback in English Language Learning: Impact on Student Motivation, Quality, and Performance in Hong Kong
Supplemental material, sj-docx-1-sgo-10.1177_21582440251352907 for Evaluating Teacher, AI, and Hybrid Feedback in English Language Learning: Impact on Student Motivation, Quality, and Performance in Hong Kong by Noble Lo, Sumie Chan and Alan Wong in SAGE Open
Footnotes
Ethical Considerations
All procedures performed in studies involving human participants were in accordance with the ethical standards.
Consent to Participate
Informed consent was obtained from all individual participants included in the study.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
Data will be made available on reasonable request to corresponding author.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.