
Abstract
English Language MOOCs (LMOOCs) employ multimodal resources to enhance second language learners’ engagement and motivation. This study examined the multimodal instructional discourse in English LMOOCs in a Chinese MOOC platform, focusing on the rhetorical relations between the linguistic mode, termed verbiage, and two non-linguistic modes, namely facial expressions and gestures. Employing Rhetorical Structure Theory (RST) as its theoretical framework, this study involved a multimodal discourse analysis of 12 English LMOOCs. Specifically, it analyzed and compared the distribution of facial expressions and gestures, and rhetorical relations between verbiage and facial expressions and between verbiage and gestures in six nationally accredited quality LMOOCs and six regular LMOOCs without such national accreditation. The results revealed a significant association between course type and the use of the two non-linguistic modes. In addition, Elaboration, Emphasis, and Preparation were the three relations identified in two types of modal synergy: Verbiage + Facial expressions (i.e., V + FEs) and Verbiage + Gestures (i.e., V + Gestures), the latter also containing Restatement relation. A significant association between course type and the distribution of rhetorical relations was only identified in the V + Gestures but not in the V + FEs. This study contributes important insights into how linguistic and non-linguistic modes work together for meaning-making in LMOOCs and provides evidence for the applicability of RST in analyzing multimodal online teaching. Implications for practitioners are finally addressed.
Plain language summary
This study explored how English language courses that are taught online—known as LMOOCs—use various ways of communication, such as video and text, spoken words, facial expressions, and gestures, to support student learning. We used a method called Rhetorical Structure Theory, which helps analyze how diifferent parts of a message relate to each other, to examine the structure of communication in these courses. We compared nationally accredited English LMOOCs in China with regular ones that do not hold the same accreditation. We found that there was a connection between the type of course and modes of communication. Our study identified different ways that verbal and non-verbal communication worked together, such as providing more information, emphasizing important points, and preparing students for upcoming content. Interestingly, we observed a unique way that verbal and non-verbal communication worked together, called “restatement,” which only appeared in regular English LMOOCs. Our findings offer a novel understanding of how different forms of communication are used in online language courses and demonstrate that Rhetorical Structure Theory is a valuableframework for analyzing instructional discourse.
Keywords
Introduction
In the modern era of widespread internet accessibility, individuals have an array of options to acquire skills and knowledge in specific fields, one of which is through Massive Open Online Courses (MOOCs). MOOCs are online courses that offer open access, allowing individuals to enroll by registering an account and enabling learning to take place at any time and from any location (Bárcena et al., 2014). The content of MOOCs is typically organized into systematic and well-structured sections, encompassing various resources such as instructional videos, electronic book materials, and interactive discussion forums. Moreover, these open online courses offer services akin to offline courses, including homework feedback, regular assessments to monitor progress, and even certificates upon successful completion. The rapid development of MOOCs has brought about both advancements and concerns. While MOOCs offer numerous benefits, including flexibility and accessibility (Buhl & Andreasen, 2018; A. D. Ho et al., 2014; Za et al., 2014), several issues have been raised by researchers. Some of these concerns include learners’ difficulties in comprehending course materials (Hew & Cheung, 2014), the absence of peer-to-peer interaction (Choudhury & Pattnaik, 2020), ambiguities in assignment instructions (Young, 2013), high dropout rates (A. D. Ho et al., 2014), and limited opportunities for interaction (Motzo & Proudfoot, 2017).
Given that “interaction, both written and oral, was key to the course design” (Bárcena et al., 2014, p. 13), a lack of communication and interaction between the instructor and learners is an obvious shortage of MOOCs. Possibly, this is attributed to the inherent asynchronous characteristics of MOOCs, and specifically, the teaching and learning activities in MOOCs which take place asynchronously in different spatial situations. This is particularly salient in the case of Language MOOCs (LMOOCs), which are MOOCs for learning second languages, often using the target language as the medium of MOOC instruction (Bárcena & Martín-Monje, 2014). This lack of simultaneous communication and interaction during online lessons makes MOOC learners easily feel lost, especially when studying English and other related courses in LMOOCs, the lesson content of which is difficult and often delivered in English. Take the teaching of vocabulary in an English LMOOC as an example. It is difficult to tell the subtle and delicate differences between two synonyms without enough communication between the instructor and learners. Communication in LMOOCs is often one-way in nature, which is directed from instructors to learners. Therefore, instructors must utilize multimodal resources such as facial expressions and gestures to sustain learners’ attention, facilitate learners’ comprehension of lesson content, and enrich their learning experience in LMOOCs. Instructors should teach in a more lively and interesting way, given the frequent complaints from learners about instructors’ teaching style characterized as lacking liveliness and relying solely on reading from PowerPoint slides (Peng & Jiang, 2022).
The instructional discourse in LMOOCs is multimodal but has been scarcely analyzed using multimodal discourse analysis (MDA), and most existing MDA studies have overwhelmingly focused on the analysis of the functions of other multiple modes such as images or gestures, with the mode of language being overlooked (Kim, 2021; Sallam et al., 2020; Zappavigna, 2019). Language is undeniably the fundamental mode in human communication and classroom teaching because teachers primarily convey messages and knowledge to students through language. The subtle, logical relations that exist between language and other semiotic modes within a multimodal discourse warrant exploration in order to enhance knowledge communication in asynchronous teaching contexts such as LMOOCs. Rhetorical Structure Theory (RST), initially proposed by Mann and Thompson (1988), is a linguistic theory that aims to describe discourse structure by analyzing rhetorical relations between different parts of a discourse, such as clauses and paragraphs. A considerable amount of work (Bateman, 2008; Feng et al., 2016; P. Zhang & Feng, 2018) in the last few years has focused on revealing the rhetorical relations between language and other modalities, such as visual, audio, or combined forms (Taboada & Habel, 2013). In the context of LMOOC teaching, challenges can arise when language and other modalities are not effectively integrated into the instructional discourse (Choudhury & Pattnaik, 2020; Motzo & Proudfoot, 2017). Therefore, analyzing how language and other modes are integrated into the instructional discourse of LMOOCs should become a key focus for researchers in both rhetoric relations and multimodality.
By analyzing various modes used in LMOOCs, this study aimed to explore and summarize the characteristics of multimodal synthesis employed in English LMOOCs. Specifically, this study drew on RST as the analytical framework and conducted an MDA of English LMOOCs, focusing on LMOOC instructors’ language, (termed verbiage), gestures, and facial expressions. Furthermore, this study compared the two types of English LMOOCs, which are quality LMOOCs accredited by the Ministry of Education of China (2017, 2019) and regular LMOOCs without such national accreditation. This study set out to answer the following research questions:
RQ1. Are there significant differences in the length of facial expressions and gestures between the quality English LMOOCs and regular English LMOOCs? Are course types significantly associated with the distribution of the non-linguistic modes?
RQ2. What are the relations frequently occurring in two types of modal synergy (Verbiage + Facial expressions; Verbiage + Gestures)? How are course types associated with the frequencies of the identified relations?
Literature Review
Research on LMOOCs
The fast-growing trend of LMOOCs (Bárcena & Martín-Monje, 2014; Sallam et al., 2020) has inspired LMOOC-related research worldwide. A systemic review of published literature (2012–2018) regarding LMOOCs showed that conference papers were initially the most popular type of publication on LMOOC research, and Spain and China were the leading countries in LMOOC research (Sallam et al., 2020). Existing LMOOC literature could be grouped into eight facets, which include introductory facets, conceptualizations of LMOOCs, case studies of LMOOCs, educational theory related to LMOOCs, technology used in LMOOCs, LMOOC participants, LMOOC providers, and others (Sallam et al., 2020). Studies on LMOOC participants (n = 22, 30.98%) and LMOOC providers (n = 16, 22.53%) collectively accounted for a large proportion (n = 38, 53.52%) of the existing LMOOC-related literature.
Research on participation in MOOC learning, based on Hill’s (2013) holistic classification of MOOC learners, has focused on the degree of learners’ participation in LMOOCs (Martín-Monje et al., 2017). Hill (2013) reported five types of MOOC learners: (1) “no-shows” (people register but never log in); (2) “observers” (learners log in and may read content or browse discussions, but do not take any form of assessment); (3) “drop-ins” (learners perform some activities but do not attempt to complete the entire course); (4) passive participants (learners view a course as content to consume, but generally do not engage with the assignments); (5) and active participants (learners fully intend to participate in the MOOC). The most prominent learner type in LMOOCs was found to be the second category, that is, “observers,” as they often “access the learning materials but do not submit tasks or engage in online interaction actively” (Martín-Monje et al., 2017, p. 1), and this could be one of the reasons to explain the low completion rates of LMOOCs. In addition, learners’ pre-existing language proficiency can affect their learning effectiveness. A lower pre-existing language proficiency may result in greater difficulties in completing course tasks and assignments, which in turn can lead to lower completion rates for the course. It has been reported that many learners do not meet the language entry standard before they begin their language learning in LMOOCs (Martín-Monje & Castrillo, 2016).
Studies concerning LMOOC providers have mainly focused on instructors and course producers in terms of instructional design (e.g., Fang, 2018) and multimodal affordances for language teaching (e.g., Gilliland et al., 2018). Castrillo (2014) proposed a framework for teaching language in MOOCs, in which the role of the LMOOC instructor is “content facilitator” in short subtitled videos (p. 72). Another reason that weakens learners’ willingness to complete LMOOCs could be related to the instructor’s presence. It was reported that there was a strong association between instructor presence and higher completion rates (Sallam et al., 2020). However, despite the substantial findings on both learner types and LMOOC providers’ course design, there remains a lack of research on the videos that present instructors’ lecturing process to learners.
Videos are the most effective materials preferred by male and female learners alike in LMOOCs (Chun & Plass, 2000; Martín-Monje et al., 2017). This may be because LMOOCs largely follow the xMOOC instructional model that uses prepared videos as the main material (Sedano Cuevas, 2017). MOOCs are generally divided into cMOOCs and xMOOCs based on their course design style (Downes, 2012; Teixeira & Mota, 2014). The cMOOCs usually adopt a connectivist approach that requires learners to “construct and traverse” the knowledge network on their own (Downes, 2012, p. 9), while the xMOOCs follow an instructivist approach (Ferguson & Clow, 2015) which is usually syllabus-based and presented as “pre-recorded instructor lecture videos” (Hew et al., 2018, p. 72). The optimal video length should be 10 to 15 min, since “students’ attention maxes out at around ten or fifteen minutes” (Khan, 2012, p. 30). In addition, the role of subtitles in LMOOC videos is especially crucial since offering comprehensive subtitles allows students to easily follow the contents (Castrillo, 2014).
Given the importance of both linguistic and non-linguistic modes in LMOOCs, as demonstrated by the effectiveness of videos and the role of subtitles, it is essential to explore the multimodal instructional discourse further. Following the social semiotic approach to multimodality (Kress & van Leeuwen, 2006) and maintaining that signs are always meaningful (Kress, 2003), W. Y. Ho (2018) conducted a multimodal observation on two online learners who self-directed their Chinese learning. She pointed out that learners could choose apt resources to facilitate their language learning. In this case, instructors’ use of multimodality, including both linguistic mode and non-linguistic modes should also be explored, as non-linguistic modes play “an equally important part as that played by language in the learning process” (W. Y. Ho, 2018, p. 248).
Multimodal Discourse Analysis of Instructional Discourse
Given the rising interest in multimodality over the past decades (Kress, 2003; Kress & van Leeuwen, 2006), a new trend of discourse analysis has emerged, which is MDA. This may be ascribed to the development of new scientific technologies such as the widespread of the Internet and highly smart electronic devices, which provide new ways for people to receive and exchange messages utilizing multimodal resources. MDA refers to the analysis of multimodal discourse in which other modes or semiotic resources (e.g., gestures, images) besides language are taken into consideration (Lim, 2019; D. Zhang & Wang, 2010). A mode is a semiotic resource such as verbal language, written texts, images, and multimodal discourse usually contains more than one mode. The application of MDA in educational contexts has often focused on the teacher and students’ multimodal communication in classrooms, such as English language classrooms (Veletsianos et al., 2015). Royce (2002) analyzed multimodal texts in a science textbook in high school, examining the ideational meaning encoded in an extract from an introductory environmental science textbook. His study explored the complementarity of different modes in the multimodal discourse and the synergies of modes in multimodal instruction texts. Royce’s (2002) analysis identified five types of meaning relations that describe how the visual and verbal modes complement each other in conveying ideational meanings in a multimodal text: intersemiotic synonymy (similarity relations), intersemiotic antonymy (opposition relations), intersemiotic hyponymy (class-subclass relations), intersemiotic meronymy (part-whole relations), and intersemiotic collocation (expectancy relations).
Recent years have also witnessed a growing body of research showing that gestures, postures, and other modes contribute to the interaction between instructors and students and the interaction among students (Bezemer, 2008; Fasel Lauzon & Berger, 2015; Morell, 2018). Teachers’ facial expressions, movements, videos, and PPTs have been found to promote students’ motivation to communicate in class (Buckingham & Alpaslan, 2017). Kendon (2004) suggested that gesture is integrally related to speech and should be recognized as intrinsic to human language, challenging the view of body language as a substitute for speech. Sime (2006) found that learners of English as a foreign language (EFL) perceived teachers’ gestures as having cognitive, emotional, and organizational functions in the EFL classroom, playing a key role in the language learning process. Hood (2011) reported that in face-to-face teaching discourse, hand gestures relate to interpersonal meaning by indicating whether the teacher “expands or contracts space for other voices” through palms-up or palms-down positions (p. 11). Erfanian Mohammadi et al.’s (2019) study indicated that students majoring in Teaching English as a Foreign Language interacted with both human and nonhuman semiotic resources, using gestures and gaze to express mental processes, convey positive attitudes, and develop classroom materials on food for intercultural competence. Although research on multimodal instructional discourse analysis was extensive (e.g., Abousnnouga & Machin, 2011; Lim, 2019; Xiong & Quek, 2006), studies have seldom explored the subtle, logical relations realized between clauses and between language and other semiotic modes within the multimodal instructional discourse.
Exploring Visual Rhetoric Relations in Multimodal Discourse
RST is a discourse analysis theory proposed by Mann and Thompson (1988). Its primary objective is to elucidate text organization and coherence by continually identifying relationships between different text spans, ultimately outlining the rhetorical structure of the entire discourse. Wang and Dong (1995) pointed out that most of these rhetorical relations are compatible with the metafunctions in Systemic Functional Grammar (SFG; Halliday, 1994); specifically, the semantic, pragmatic, and textual relations correspond to the ideational, interpersonal, and textual metafunctions, respectively.
RST has been widely applied in discourse analysis (Chik & Taboada, 2020; Matthiessen & Pun, 2019; Taboada & Mann, 2006; Trnavac et al., 2016), but has only recently been employed in MDA of multimodal texts (Bateman, 2014; Feng et al., 2016; Taboada & Habel, 2013; P. Zhang & Feng, 2018). Bateman (2014) discussed the visual style of multimodal discourse by applying RST. Feng et al. (2016) extended RST to analyze the multimodality embedded in TV advertisements. P. Zhang and Feng (2018) further applied RST to analyze the Corpus of Public Health Posters and introduced the use of gem-tool, which is professional software that generates the diagram of rhetorical relations automatically. However, there are few attempts to apply RST to analyze multimodal instructional discourse. Analyzing the integration of language and other non-linguistic modes into instructional discourse is essential for understanding how different modes of communication collaborate to enhance meaning-making and learner engagement in language teaching. These insights are especially valuable for improving teaching and learning in LMOOCs, where the combination of linguistic and non-linguistic modes can significantly influence learner engagement and content comprehension.
Methodology
Data Collection and Annotation Tool
In this study, the data consisted of 12 transcribed and annotated English LMOOCs obtained from two prominent MOOC platforms in China: China University MOOC (https://www.icourse163.org/) and Xuetang Online (https://www.xuetangx.com/). With the increasing popularity of MOOCs, the Ministry of Education (MOE) of China accredited a total of 490 and 801 national-level quality MOOCs in 2017 (Ministry of Education of China, 2017) and 2018 (Ministry of Education of China, 2019), respectively. To differentiate between the MOOCs, the high-quality courses accredited by the MOE were categorized as quality English LMOOCs (n = 6), while the remaining online courses not receiving such accreditation were designated as regular English LMOOCs (n = 6) in this study.
The present study utilized EUDICO Linguistic Annotator (ELAN; Max Planck Institute for Psycholinguistics, T. L. A, 2019), which is a tool for annotating, analyzing, and documenting multimodal data within the context of language teaching discourse. ELAN utilizes tiers as the fundamental level of annotation. Researchers can process files in annotation, transcription, and segmentation modes. ELAN allows for the creation of multiple tiers to capture different modalities such as verbiage, facial expressions, gaze, and gestures. Synchronization, visualization, and annotation tools aid in analyzing and understanding multimodal data efficiently (Zheng & Peng, 2022).
Similarly, the rhetorical relations between verbiage and the two non-linguistic modes (facial expressions and gestures) were analyzed in ELAN 5.8. It should be noted that the rhetorical relations in “V + One mode” were coded according to the rhetorical relations between each non-linguistic mode at its occurrence and the verbiage sounding therein.
Analytical Frameworks for Multimodal Rhetorical Relations
Drawing on Taboada and Habel’s (2013) RST, we treated both linguistic and non-linguistic modes as integral components of meaning-making resources in the multimodal discourse of LMOOCs. In RST, a text span, which can be of any length, serves as the elementary discourse unit. The term “span” encompasses both simple units of discourse, such as an independent or dependent clause, and complex units, such as a combination of sentences (Stede et al., 2017). Adjacent text spans in RST can combine to form larger text spans, progressively building the entire discourse. These text spans assume two distinct roles: Nucleus and Satellite. A span in a dominant position is called the Nucleus (N), while a span in a non-dominant position is known as the Satellite (S). A rhetorical relation is visually represented by an arrow originating from the Satellite and pointing toward the Nucleus. Figure 1 illustrates an annotated rhetorical relation formed by a nucleus and a satellite.

A sample RST analysis.
The types of relations between text spans in RST can be categorized into two groups: nucleus-satellite relations and multinuclear relations. For example, as can be seen in Figure 1, the first clause “Dragon has various symbols in western and eastern cultures” functions as the nucleus, presenting the central theme of the sentence. The second clause “it represents good luck and great honor in eastern culture” functions as the nucleus, and the third clause “while symbolizing evil and darkness in western culture” functions as a satellite constructing an Antithesis relation with the second clause. Together, the second clause and third clause serve as the satellite, constructing an Elaboration relation with the first clause, providing details about a dragon’s symbolism in both cultures. In cases where two adjacent spans both assume a dominant position, they form a multinuclear relation. These nucleus-satellite and multinuclear relations can be repeatedly identified at higher levels of text spans until the rhetorical structure of the entire discourse is adequately described. In other words, RST can be employed to analyze the relations between clauses, sentences, and even paragraphs to describe the rhetorical structure of a discourse.
The RST framework empowers this study to elucidate how various modes communicate meaning and interact with the linguistic mode (i.e., verbiage) to construct online instructional discourses. The major modes explored in this study were verbiage, facial expressions, and gestures. The scheme for coding gestures was based on Norris (2004), which identified four types of gestures: iconic, metaphoric, deictic, and beat, whose definitions are shown in Table 1. In addition, during the analysis, we found a typical gesture prevailing in the English LMOOCs, which involves the teacher using a remote mouse to switch PPT slides. This type was added as the fifth one and termed as the performative gesture, aligning with the terminology proposed by Lim (2019). The coding scheme of facial expressions was adopted from He (2018) who conducted a multimodal discourse analysis of online foreign language mini-lectures. He (2018) divided facial expressions into two types: face smile and face serious. In practice, we found it difficult to define serious facial expressions since instructors in English LMOOCs may maintain a calm facial expression without showing explicit emotions, which may be perceived as serious facial expressions. Hence, this type was further defined as showing observable features such as frowning. The coding scheme of facial expressions and gestures in this study is presented in Table 1.
The Coding Scheme of Facial Expressions and Gestures Adapted from He (2018) and Norris (2004).

This study took Taboada and Habel’s (2013) sets of rhetorical relations as the analytical framework for analyzing multimodal rhetorical relations. Their study was built on a large corpus of multimodal documents, which explored nine rhetorical relations including Elaboration, Evidence, Motivation, Preparation, Circumstance, Summary, Restatement, Enablement, and Contrast (Taboada & Habel, 2013). Additionally, based on our previous observation, this study found that a relation of Emphasis needed to be added to explain the relations between verbiage and other modes such as beat gestures. Beat gestures can signal “the temporal locus in the speech of something the speaker feels is important concerning the larger discourse, the equivalent to using a yellow highlighter on a written text” (McNeill, 2005, pp. 40–41). Therefore, this study adopted a total of 10 types of rhetorical relations as the scheme for coding the relations between verbiage and other non-linguistic modes (see Table 2).
The Framework of Rhetorical Relation Analysis (Adapted from Taboada & Habel, 2013).

Procedures to Answer Research Questions
To answer the first research question, the lengths and frequencies of the two non-linguistic modes (facial expressions and gestures) were counted using SPSS to enable a comparison of the use of modes between quality and regular English LMOOCs. Mann-Whitney U test was employed to test the difference in the lengths of these two modes between the two types of English LMOOCs. Mann-Whitney U test is the non-parametric equivalent of the independent-samples t-test used to examine the differences between two samples (Field, 2009). For the frequency data, a Chi-square test was used to check whether there was a significant difference between quality and regular English LMOOCs. The Chi-square test is a non-parametric statistic suitable for comparing the distribution of frequencies of categorical data (Field, 2009). Similarly, to answer the second question, the frequencies of the rhetorical relations realized in the synergy of verbiage and each of the two non-linguistic modes were calculated respectively, labeled as Verbiage + Facial Expressions (henceforth, V + FEs) and Verbiage + Gestures (henceforth, V + Gestures). A Chi-square test was performed to examine the association between course types and the frequencies of rhetorical relations.
Results
The Distribution of Non-linguistic Modes in English LMOOCs
The results show that the duration of the use of the two modes was longer in the quality English LMOOCs than in the regular English LMOOCs. Tables 3 and 4 display the length and frequency of facial expressions and gestures in the two types of LMOOCs. The most frequently appearing mode in these 12 MOOCs was gesture. The frequency of facial expressions was slightly higher (223 − 214 = 9) in the quality English LMOOCs, and the frequencies of gestures (1,494 − 616 = 878) were much higher in the quality English LMOOCs than in the regular English LMOOCs. This means that the instructors of the quality English LMOOCs seemed to employ more facial expressions and gestures than those of the regular English LMOOCs.
The Length and Frequency of Modes in the Quality English LMOOCs.

The Length and Frequency of Modes in the Regular English LMOOCs.

To examine the difference in the length of these modes between the quality and regular English LMOOCs, the percentage of each mode’s length in the whole length of each English LMOOC was calculated and then multiplied by 100 to obtain a larger value for easier comparison. Since only 12 English LMOOCs were analyzed in this study, a Mann-Whitney U test was conducted. It was found that the length of gesture was significantly greater in the quality LMOOCs than in the regular English LMOOCs (z = −2.082, p = .04, r = .37). However, no significant differences were found in the length of facial expressions between the two types of English LMOOCs. In addition, the Chi-square test showed that there was a significant association between course type and the distribution of modes, χ2(2) = 64.44, p < .01. Regarding the first research question, we concluded that there was a significant association between course types and the distribution of the non-linguistic modes, favoring more frequent use of these modes in the quality LMOOCs.
Rhetorical Relations Between Verbiage and Non-linguistic Modes
Results show that the rhetorical relations with the highest frequency in V + FEs in the quality English LMOOCs were Elaboration, Preparation, and Emphasis, while the top three rhetorical relations in regular English LMOOCs were Preparation, Elaboration, and Emphasis. Table 5 shows the relations with frequencies of five or above, while those with frequencies below five were grouped under the category of “Others.”
The Distribution of the Rhetorical Relations of V + FEs and V + Gestures.

As seen in Table 5, Elaboration appeared most frequently in both modal synergies. These figures show that Elaboration was the most frequently used rhetorical relation in both V + FEs and V + Gestures. A Chi-square test was conducted and showed that there was no significant association between course types and the distribution of rhetorical relations realized in the synergy of V + FEs, χ2(3) = 7.426, p > .01. However, the Chi-square test showed that there was a significant association between course types and the distribution of rhetorical relations realized in V + Gestures, χ2(4) = 60.046, p < .01. This result suggests that instructors of the quality English LMOOCs used more synergies of verbiage and gestures when teaching online courses than those of the regular English LMOOCs.
Figure 2 illustrates an example of Preparation in the V + FEs synergy. It should be noted that video screenshots in this paper were substituted with simplified sketches to protect privacy. As seen in Figure 2, the first unit is the instructor’s smiling face, which was annotated as the mode of Facial expressions, and the second unit is the instructor’s verbiage (“Today, we are going to learn a new lesson”). The facial expression functioned as the satellite and its rhetorical relation with the nucleus was Elaboration since the lecturer’s smiling face was a greeting as well as a hint which served to prepare learners for this lesson.

An example of preparation relation in the V + FEs synergy.
It was also found that V + Gestures synergy was more frequently used in the quality English LMOOCs, which mainly consisted of rhetorical relations of Emphasis, Elaboration, and Preparation with verbiage (i.e., the nucleus). In particular, the Emphasis relation in V + Gestures was usually realized by beat gestures. Beat gestures were performed in a short and quick rhythm and were often used in conjunction with verbiage by instructors when emphasizing the words or content they were talking about. Figure 3 shows an example of the Emphasis relation realized in the V + Gestures synergy. As can be seen in this figure, the lecturer’s verbiage (“As a result, people may refer crow to death.”) was accompanied by his left hand moving up and down quickly, which indicated that he was using the beat gesture to emphasize his conclusion about what he had just said.

An example of emphasis relation in the V + Gestures synergy.
It was found that the relation of Elaboration in V + Gestures was mainly fulfilled by metaphoric gestures which were used to refer to the abstract concept or concrete things at a distance. Figure 4 shows an example of Elaboration realized in the V + Gestures synergy, in which a metaphoric gesture as the satellite formed an Elaboration. Relation with the nucleus (the instructor’s verbiage) in a quality English LMOOC. As seen in this figure, when uttering the sentence (“For example, the repetition of beginning parts is called anaphora.”), the instructor’s right palm was facing down, which was meant to elaborate on the abstract concept “the repetition of beginning parts”. According to Wang and Dong (1995), Elaboration is a representation of the ideational function, one of the three metafunctions in SFG proposed by Halliday (1994).

An example of elaboration telation in the V + Gestures synergy.
While Figures 1 –3 exemplify the RST analysis of “V + One mode”, Figure 4 provides a more comprehensive depiction of multimodal rhetorical relations analyzed in our study.
As is shown in Figure 5, there are three text spans (T1–T3) and two modes (FEs and Gestures) shown in three pictures (P1–P3). Picture 1 is a picture of the teacher’s face smile accompanying T1, that is, the teacher’s verbiage (“In different countries, there are different meanings for…or imaginary one”). Face smile in P1 functions as a Preparation for the teacher to start his class. Preparation refers to the textual function that the writer uses to organize the texts in its discourse (Stede et al., 2017), and here this relation means that the teacher used facial expressions to help organize the instructional discourse of this English LMOOC. Picture 2 is a picture of the teacher’s beat gesture, which was used to emphasize the key point (“ominous or bad luck”) in T2 (“Crowing, China is associated with something ominous or bad luck”). The rhetorical relation in this synergy of beat gesture and verbiage is Emphasis, which belongs to semantic relations, which means that the gesture helps realize the ideational function of language (see Section 2.3.1). P3 shows the teacher’s metaphoric gesture, which was used to elaborate the abstract concept “the voice of crow” in T3 (“Superstitious hold that if one heard the Voice of crow, one would suffer from misfortune”). This metaphoric gesture was used here to represent the abstract symbol of “the voice of crow” and thus complemented the meaning that verbiage mode was expressing, forming an Elaboration relation.
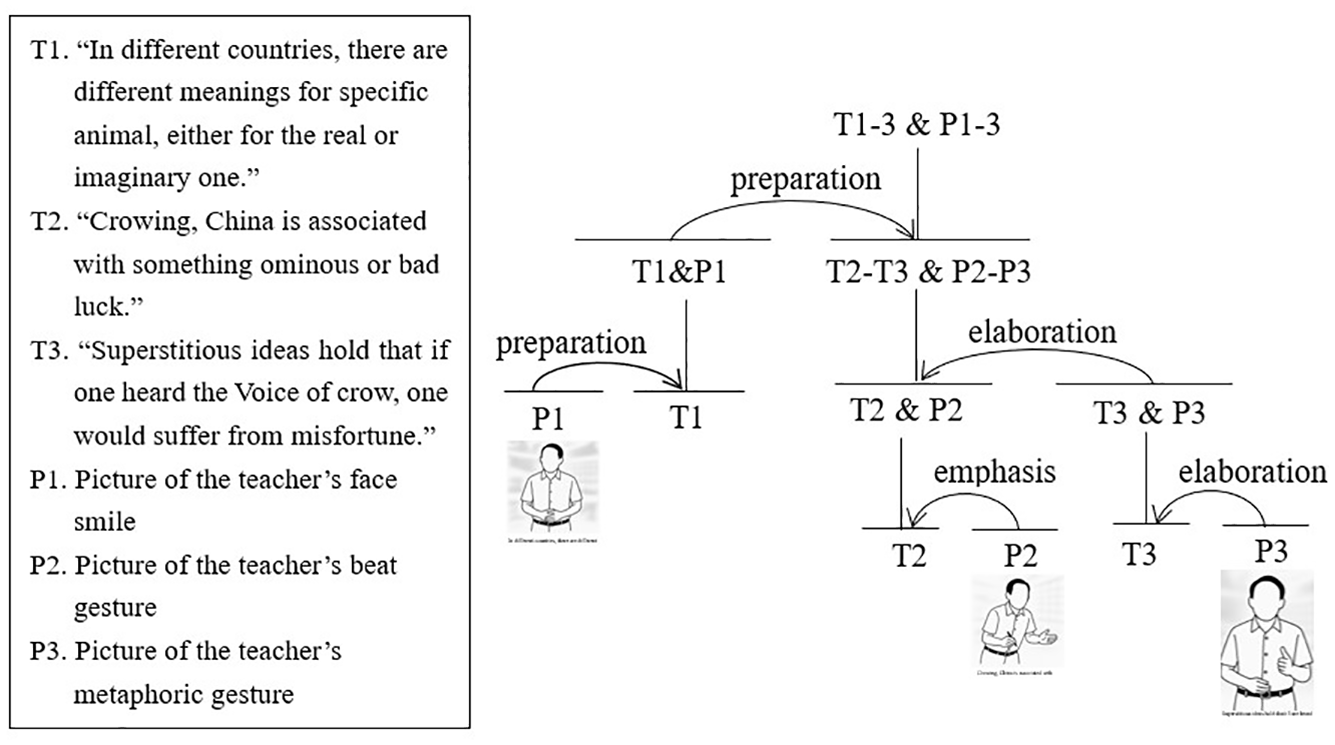
A sample of multimodal rhetorical analysis in our study.
Discussion
Since there is a lack of physical presence in the virtual class, viewers of English LMOOCs mostly rely on visual and auditory channels when comprehending multimodal instructional discourse in English LMOOCs. Therefore, besides the subtitles in LMOOC videos, instructors’ facial expressions and gestures would constitute important semiotic resources for learners’ making meaning of lesson content. The current analysis indicated that the instructional discourse of quality LMOOCs was characterized by the instructors’ greater use of facial expressions and gestures accompanying their verbal speech. Experienced teachers using gestures can build positive rapport with students, enhancing communication, comprehension, and memory retention (Peng et al., 2017). Gestures can complement verbal instructions, ease language barriers, and create an engaging classroom atmosphere. The modal synergy of gestures and verbiage was evident in our study, which constituted various rhetorical relations proposed in RST (Taboada & Habel, 2013). Our findings support the application of RST by demonstrating that non-verbal cues, such as gestures and facial expressions, could enhance message transmission.
In addition, the two non-linguistic modes are all related to the visual channel, which may influence learners’ perceptions of English MOOCs. Peng (2019) found that the teacher’s facial expressions and gestures could either encourage or intimidate students’ communication intentions. In the same vein, it may be inferred that LMOOC instructors’ use of facial expressions and gestures may more or less affect the learners’ preference for the class and finally influence their evaluation of the LMOOCs.
Coincidently, gestures were also the most frequently used mode in terms of length and frequency for both the quality and regular English LMOOCs in this study. Instructors of the quality English LMOOCs may also have a good sense of how to use gestures to maintain learners’ attention and interest during the class. In Hood’s (2011) analysis of gestures, palms up were found to construct an expansion of heteroglossic space in the class, while in this study, palms up were a metaphoric gesture that was used to manifest abstract content. The finding of more frequent gestures used in quality LMOOCs in this study is consistent with He’s (2018) research, which identified gestures (e.g., hand beats) and images as the most commonly used modes in high-quality micro-lectures. In addition, this study found that beat gestures were frequently employed to realize Emphasis relation with verbiage, which confirmed Lim’s (2019) study that gestures with rhythmic beats can function to express the teacher’s emphasis on teaching content. Besides, the deictic gestures analyzed in this study were similar to the gestures used to point at a particular student, the whole class, or the screen, as reported by Lim (2019). This study found that lecturers used deictic gestures to point at PowerPoint slides, enhancing the effectiveness in conveying the intended message to the audience.
It was found that the two types of English LMOOCs differed in the use of facial expressions only in terms of frequency but not in terms of length. This may imply that the quality English LMOOCs exhibited more flexibility in employing facial expressions than the regular English LMOOCs. Appropriate use of facial expressions such as smiles can convey positive emotions (Sime, 2006) and thus boost learners’ willingness to communicate (Peng, 2019). A smiling face toward the audience could build rapport with the views and suggest the viewers “enter into some kind of imaginary relation” with the represented persons in images (Kress & van Leeuwen, 2006, p. 118), and in the current case, with the English LMOOC instructors. On the other hand, a lack of facial expressions may not be able to sustain learners’ attention or interest in the teaching, which could not enhance learners’ situated experience of class. Gu (2013) proposed a principle known as “the congruity of one’s speech, thinking, emotion and gesture” (p. 2), which concerns people’s feeling of situated communication. In addition, gestures refer not only to hand gestures but also movement of any body part (Kendon, 2004), and the latter type of movement could be referred to as body gesture. In this sense, facial expressions belong to the category of body gestures, a lack of which may affect learners’ experience of situated classroom communication.
The frequency and length of V + Gestures in the quality English LMOOCs were significantly higher than in the regular ones. Simultaneous use of both language and non-linguistic modes would help to draw learners’ attention and thus keep their motivation to engage in English LMOOC learning. Peng (2019) found that there was a nuanced association between Chinese students’ willingness to communicate in English and visual modality in the English language classroom. It may be inferred that lecturers of quality English LMOOCs may have an awareness, albeit possibly an implicit one, of the functions of multiple modes in maintaining learners’ attention, and motivation to learn English LMOOCs. Human communication and interaction are multimodal (O’Halloran, 2011), and so is classroom communication. MOOC classrooms are virtual in which students cannot receive immediate help from teachers and teachers have to speak to “imagined students” when recording the lessons. Using the verbal modality alone is not sufficient to promote classroom engagement, especially to elicit interaction among learners, as they naturally construct interpersonal meanings using not only language but also other semiotic resources (Erfanian Mohammadi et al., 2019). This is particularly the case for learners of English LMOOCs, for many of them learn English as a foreign language and thus will rely on multiple modes, including but not limited to language, to comprehend lesson content, and to sustain their attention and motivation to persist in their learning.
What is novel in this study is the exploration of the rhetorical relations in modal synergies of verbiage and the two non-linguistic modes, respectively. A salient finding is that a smiling face was usually presented to form a Preparation relation with verbiage, while it was found to be a part of the Solutionhood relation in Feng et al. (2016), who applied RST to explore the rhetorical relations in TV commercials. These different findings may be attributed to the distinct characteristics of the discourses. The instructional discourse of English LMOOCs naturally requires instructors to impart their knowledge to students while maintaining rapport with students. However, commercials reflect a promotional discourse to attract the audience’s attention and convince them to purchase merchandise. Therefore, facial expressions may also have other rhetorical relations, such as Evidence, since they can boost the audience’s confidence in what the protagonist introduced in the commercials, according to Coplan’s (2006) analysis of the role of facial emotions. In addition, this study found that Emphasis, Elaboration, and Preparation were three rhetorical relations appearing most frequently in the V + Gestures in quality English LMOOCs, which is consistent with some findings from previous research applying RST. For instance, Feng and Wignell (2011) also found that Elaboration was a common rhetorical relation appearing in TV commercials. Elaboration of V + Gestures corresponds to the primary and secondary reinforcement category relations in D. Zhang’s (2009) MDA framework, where the primary reinforcement refers to the dominant role of direct explanation, and the secondary reinforcement refers to the supportive role of emotional engagement. Gestures here served as a secondary mode while instructors’ verbiage served as the primary mode for instructing students in the class.
Emphasis is a newly identified relation in this study, since the taxonomy of rhetorical relation is open-ended (Mann et al., 1992). Emphasis refers to the speaker’s reinforcement of what he or she is talking about, which is similar to the Reinforcement relation in the Complementary category in D. Zhang’s (2009) theoretical framework of MDA. The Reinforcement relation refers to the relation in which there is a dominant mode in communication while other mode or modes functions to reinforce the dominant mode (D. Zhang, 2009). Gestures in this study were the reinforcement of what lecturers were talking about during the lessons. The current findings, along with existing literature, provide compelling evidence supporting the feasibility of applying RST theory in MDA research, especially in the research on instructional discourse. In brief, exploring the rhetorical relations embedded in various semiotic resources is of significance (Matthiessen & Pun, 2019).
Several implications for practitioners can be generated from this study. LMOOC instructors could consider using positive facial expressions such as smiles can serve as both a welcome and an opening announcement at the onset of an LMOOC teaching video, which can help their learners feel the authenticity of instructors’ presence in the virtual classroom. By grasping the role of different gestures in learners’ meaning-making of an online class, LMOOC lecturers can learn to use specific gestures during the class to effectively complement or emphasize the lesson content or the message they mean to convey to learners. Given the rhetorical relations identified in modal synergies in the LMOOC instructional discourse, practitioners could also use modal synergies, such as V + Gestures, as strategic teaching tools to express the rhetorical relations of Emphasis, Elaboration, and Preparation in virtual teaching in LMOOC contexts. The more frequent use of these modal synergies in the quality English LMOOCs implies the positive roles of these synergies. Therefore, practitioners can strategically integrate multimodal synergies to enhance lesson structure and learner retention, ensuring that key points are not only conveyed but also remembered by students. Finally, in this AI era, practitioners could harness insights into the role of multimodality unveiled in this study to explore the potential for weaving various non-linguistic modes into AI-mediated teaching or virtual reality teaching to promote immersive and authentic learning experiences among learners.
Conclusion
This study has attempted to answer the research questions concerning mainly two aspects of quality and regular English LMOOCs: the use of non-linguistic modes and the rhetorical relations in the synergy of linguistic mode and non-linguistic mode. The novelty of this study lies in its extending the use of RST in analyzing English LMOOCs, which has enriched the multimodal discourse analysis based on RST. Through this study, it could be concluded that instructors’ body language can form various rhetorical relations with instructional verbiage, which may create differing effects, as could be found in the differences between the quality and regular English LMOOCs. In the meantime, this study highlights the importance of recognizing language as the fundamental mode in MDA by treating language as the nucleus and other modes as its satellites. The exploration of rhetorical relations between verbiage and the two non-linguistic modes respectively in this study has provided empirical evidence that RST can be robustly applied to multimodal instructional discourse, particularly in online language courses. Due to the immense work involved in the annotation and analysis, this study only examined the rhetorical relations between verbiage and facial expressions as well as gestures, without considering other modes such as images, music, and videos. Future studies could explore the many other modes, such as images, audio or video materials, and their contribution to the rhetorical structure of instructional discourse. This study suggests that the RST theory is suitable for the multimodal discourse analysis of instructional discourses of English LMOOCs, and it can ultimately fulfill the metafunctions of language. Future research may also apply RST to explore other modes of such as images, videos, and music in English LMOOCs.
Footnotes
Acknowledgements
The study thanks to the support provided by the National Social Science Fund of China (Grant No. 19BYY197) and the 2023 Guangdong Philosophy and Social Science Planning- General Projects of Foreign Language Informationization Special Projects (GD23WZXC02-12).
Ethical Consideration
No human or animal involvement.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The study has been supported by the National Social Science Fund of China (Grant No. 19BYY197), and the 2023 Guangdong Philosophy and Social Science Planning- General Projects of Foreign Language Informationization Special Projects (GD23WZXC02-12).
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
Data sharing not applicable to this article as no datasets were generated or analyzed during the current study.