
Abstract
Rater variation has been a persistent concern for rater-mediated writing assessments. Instead of treating rater variation as an undesired source of measurement error, the method of comparative judgment (CJ) uses pairwise comparisons to elicit relative judgments from raters and statistical estimation to construct a measurement scale to rank object items, offering a viable approach to accommodate rater-associated heterogeneity of judgment making on the one hand and obtain reliable and valid outcomes on the other hand. The current study systematically examined the utility and quality of CJ as an assessment tool in the context of second language writing. A group of 16 raters (8 experienced and 8 novice) performed the CJ assessment on 94 pieces of English writing texts in the absence of rubric criteria. Despite raters’ varying expertise and rating experiences, raters were able to deliver judgments consistent with the shared consensus, yielding a CJ rank order of the writing texts with a moderate reliability. The analyses of raters’ justifications for judgment making showed that raters varied substantially in terms of evaluation criteria, but the collective expertise derived from the iterative CJ process presented a close alignment with the established scoring rubric. Additionally, inconsistencies were explored when raters and texts significantly deviated from the consensus of judgments, and practical implications were discussed. The results provide empirical evidence for the construct validity of CJ and add a novel perspective to the discussion of rater variation in second language writing assessment.
Keywords
Introduction
Human judgment plays a vital role in rater-mediated performance assessments, such as assessments of second language (L2) writing. Just as L2 writing by itself is a highly complex language skill, assessing L2 writing is further complicated by raters’ idiosyncratic criteria and subjective judgments (Weigle, 2002) that introduce undesired variation and consequently pose a threat to the reliability and validity of assessment outcomes (Messick, 1995). Research on rater behaviors in writing assessment contexts has demonstrated that raters differ to a large extent in how they interpret rubric criteria to translate their evaluation of text quality into scores, regardless of the analytical or holistic nature of rubrics (Eckes, 2012; Elliott, 2017; Wolfe, 1997). Although optimizing rubrics and rater training are widely implemented to reduce rater variability, the effectiveness of those practices has been shown to be less than expected (Bloxham, 2009; Eckes, 2008; Knoch, 2011; Lumley & McNamara, 1995). Raw scores are often adjusted using statistical modeling techniques like many-facet Rasch measurement (MFRM) to account for rater biases (Myford & Wolfe, 2003, 2004). Rater variation, as undesired sources of error in the measurement, remains a persistent concern for language writing assessment.
However, given the multidimensional nature of the language writing construct and the variability of human judgment, any single, uniform way of conceptualizing and evaluating writing skills seems insufficient to fully capture this inherent complexity (Cumming, 1990; Elliott, 2017; Lumley, 2002). Instead of limiting raters to predefined rubric criteria, raters’ divergent points of view may seem more agreeable to the diversity embedded in writing performance. The question that follows, then, is how to apply an assessment method that can incorporate this rater-associated heterogeneity in a systematic way so that concrete samples of L2 writing performance can be assessed with validity, reliability, and efficiency.
Innovation in educational assessment has drawn attention to the method of comparative judgment (CJ; Thurstone, 1927). The method simply requires raters to select the better out of two works through repeated pairwise comparisons and applies statistical estimation to construct a measurement scale to rank the works. Previous research has shown raters obtain highly reliable evaluations using CJ, advocating for its wider implementation in assessment domains (Bartholomew & Yoshikawa-Ruesch, 2018; Hartell & Buckley, 2021). However, prior studies have primarily focused on the implementation of CJ and its reliability in assessment, leaving construct validity, a crucial aspect of CJ less securitized. It has not been well examined what criteria raters use to compare works to establish CJ’s validity claim with divergent rater judgments; whether and how rater expertise and experiences affect judging behaviors during CJ remain to be addressed. Moreover, compared with other research fields, the investigation of CJ in the context of L2 writing assessment has been rather limited; particularly, how CJ can be used to incorporate rater variation has yet to be explored.
The purpose of this paper is to illustrate the utility of CJ as a promising approach to rater variation embedded in the conventional rubric-based L2 writing assessment, through examining consistency and judgment making of experienced and novice raters during a CJ assessment. The following sections briefly review common approaches used to address rater variation in the writing assessment research, and then introduce the rationales of the CJ method, followed by an empirical application in an English as a foreign language (EFL) writing assessment context. With the application, the reliability and validity of the CJ assessment are examined, and how CJ presents a viable approach to challenges such as rater variation, as well as some implications, is discussed.
Approaches to Rater Variation in Language Writing Assessment
Rater variation refers to the systematic variation in ratings or scores that is not associated with examinees’ performance per se, but with rater characteristics, such as reading styles (Wolfe, 1997), rater types (Eckes, 2008), raters’ cognitive, and meta-cognitive processing (Cumming et al., 2002; Vaughan, 1991; Zhang, 2016), rating experience (Crisp, 2013), fatigue and across-session drift (Palermo et al., 2019). These inconsistencies between and within raters present a challenge to measurement precision and a potential threat to the validity of decisions based on those judgments (Lumley & McNamara, 1995; Myford & Wolfe, 2004). Different approaches have been undertaken in extensive research attempting to mitigate the impacts of rater variation in language writing assessment, but yielded mixed results.
The development of a clear rubric lays out an essential first step to reliable scorings, which clearly specifies the attributes to be assessed and provides detailed descriptions or exemplar responses to differentiate levels of performance (Eckes, 2008; Wilson, 2006). Although a well-designed rubric can serve as a regulatory means to guide the way in which raters evaluate each writing performance, raters were found to use rubrics with varying foci on and broadness of scoring criteria (Eckes, 2008; Wolfe, 2004), and score texts on the given criteria more severely or more leniently based on their own internal standards (Elliott, 2017; Lumley, 2002; Rhead et al., 2016). Moreover, individual raters tend to perceive differential relevance of criteria depending on the quality levels of writing performance (Humphry & Heldsinger, 2019), or shift their focus over a long rating session and across multiple sessions (Elliott, 2017; Lumley, 2002; Palermo, 2022; Wang et al., 2017). These idiosyncratic interpretations and applications of rubric criteria observed in scoring sessions highlighted the importance and necessity of rater training.
Implementing rater training offers another mode to minimize rater variation. Along with a specific rubric, rater training is assumed to facilitate a shared understanding of the standards among raters, leading to more agreement and reliable scoring decisions (Elliott, 2017; Lumley, 2002). Improved between-rater agreement and within-rater scoring consistency after training have been reported (e.g., Davis, 2016; Weigle, 1998), and the effects were more prominent for novice or excessively severe/lenient raters (Yan & Chuang, 2022). For established raters, on the other hand, (additional) training or feedback showed little or limited further effect on their rating consistency (Davis, 2016; Knoch, 2011). Researchers also questioned the validity and effectiveness of rater training, as training may result in raters agreeing on only superficial aspects of writing rather than more substantive features (Charney, 1984).
Alternatively, researchers turned to statistical models aiming to detect, measure, and correct for potential rater effects on scoring performance, among which two most frequently used frameworks are generalizability theory (G-theory; Brennan, 2001) and the many-facet Rasch measurement approach (MFRM; Linacre, 1994). The G-theory helps improve the assessment reliability by disentangling multiple sources of error variance, including rater variation, from the total error of the observed scores, and by estimating the optimal numbers of tasks and/or raters per task that minimize the impact from error components. The MFRM approach incorporates influences of additional characteristics (i.e., facets) into the measurement model and estimates the extent to which these facets affect ratings. More recently, innovative statistical approaches from other disciplines have been explored, such as the hierarchical rater model and its extensions (DeCarlo et al., 2011; Patz et al., 2002) and social network analysis (Lamprianou, 2018). Each of those statistical approaches has its benefits and drawbacks, which is beyond the scope of this paper.
Despite divergent results regarding the effectiveness of reducing rater variation, all those practices treat rater variation in decision-making process as undesired error components, impairing the precision of performance evaluation. However, as L2 writing entails a multidimensional latent construct and a creative product, any single set of rubric criteria may fail to fully capture the underlying complexity. The emphasis on high reliability by training raters to conform to a “consistent” decision-making pattern outlined by a specific rubric also denies the possibility of “more than one ‘correct’ reading of a text” (Weigle, 1994, p. 199). As human judgment is an indispensable element of L2 writing assessment, the expertise and experiences raters bring into the assessment should constitute an integral part of their scoring decisions (Huot, 1990). Therefore, instead of treating rater variation as a nuisance to reliable scores, we argue that an alternative approach to rater variation, can be adopted, allowing raters to employ their expertise and experiences on the one hand and systematically modeling the resulting heterogeneity to produce reliable and valid outcomes on the other hand.
Comparative Judgment: A Relative Judgment Approach
When awarding scores, raters are essentially required to judge the absolute quality of individual writing performances in isolation; however, humans are rarely good at making absolute judgment (Laming, 2004; Thurstone, 1927). In practice, raters either decide on a score by comparing each text against the predefined standard (Elliott, 2017), or gauge (sometimes adjust) scores after comparing the current text with ones that have been previously evaluated (e.g., Elliott, 2017; Lumley, 2002), rendering their judgments relative. In light of these decision-making behaviors, researchers explored a relative judgment approach—comparative judgment—to enable direct comparisons of performances in relation to each other.
The method of comparative judgment (CJ; Thurstone, 1927), instead of evaluating and assigning a score to individual performance one at a time, requires raters to directly compare pairs of performances and judge holistically which one in each pair is of better quality under assessment. The binary judgments from repeated pairwise comparisons are used to construct a ranking scale that orders students’ performances from lowest to highest quality. Advances in computer technology have greatly promoted applications of the CJ procedure (S. Bartholomew & Yoshikawa-Ruesch, 2018; Hartell & Buckley, 2021), showing its potential for producing valid and highly reliable results in open-ended and performance-based assessments, such as essay questions (Walland, 2022; Whitehouse, 2013; Whitehouse & Pollitt, 2012), academic writing (Bouwer et al., 2018; van Daal et al., 2019), engineering design (S. R. Bartholomew et al., 2018; Strimel et al., 2021), mathematical problem-solving (Jones et al., 2015), and within an interdisciplinary university program (Baniya et al., 2022).
The Rationales for Using Comparative Judgment
Previous studies using CJ for student assessment often reported superior reliability ranging from 0.67 to 0.99 with the majority greater than 0.80 (see e.g., Steedle & Ferrara, 2016; Verhavert et al., 2018 for an overview). Though some very high values (0.95 or above) were challenged by the potential inflation with an adaptive algorithm (Bramley, 2015; Bramley & Vitello, 2019), the average CJ reliability reported is often higher than can be obtained by conventional rubric scoring. The high reliability and validity of CJ are claimed to be underpinned by the key features of relative judgments and a shared consensus based on collective expertise.
First, relative comparisons help reduce inter-rater variation. Raters may differ significantly in determining the absolute quality of performances, but they are more likely to agree on which one out of a pair is better. The relative quality of two performances is then irrespective of the absolute standards of individual raters involved, canceling out differences in rater severity and leniency (Kimbell, 2022; Pollitt, 2004). Second, relative judgments help reduce within-rater variation. While raters’ evaluation standard and focus tend to drift over time (Lumley, 2002; Pollitt, 2012a; Wang et al., 2017), their judgments of “the better” in a pair would be more likely to be consistent. By bringing more consistency in raters’ judgments, the reliability is assumed to improve. Next to that, unlike conventional rubric scoring where each writing performance is usually assessed by only one or two raters before receiving a final score, CJ demands that each writing be compared in several different pairings and evaluated by multiple raters independently. Pooling together all the comparative judgments creates a shared consensus among raters of the perceived quality, resulting a rank order of performances that is more reliable (Pollitt, 2012a). Researchers have shown that the reliability of CJ is largely determined by the number of comparisons per text received (Bramley, 2015; Kimbell, 2022). On average 10 to 14 comparisons per text are needed to obtain a reliability of 0.70, and 26 to 37 comparisons per text for a reliability of 0.90 (Verhavert et al., 2019).
Apart from excellent reliability, the result of CJ benefits from the collective expertise from all the raters. While the use of rubrics may compel raters to adopt a specific conceptualization of good writing (Weigle, 1994), CJ does not impose predefined criteria on raters and allows raters to fully tap into their expertise to base their judgments on whichever aspect(s) of the writing construct they value. This “freedom to exercise discretion” (Humphry & Heldsinger, 2019, p. 11), however, invites questions regarding the validity and objectiveness of raters’ comparative judgments. While the validity of CJ has not been adequately investigated, Whitehouse (2013) and van Daal et al. (2019) explored the criteria raters used to make CJ decisions, and found that those criteria were highly construct-relevant, not only relating to but extending beyond the criteria specified by the assessment objectives or attainment targets. Thus, by allowing raters to employ their collective expertise, CJ is assumed to produce a more comprehensive conceptualization of the writing competence that embraces various dimensions and elements than a single rubric, and is therefore said to improve not only reliability but validity of the assessment (Chambers & Cunningham, 2022; Lesterhuis et al., 2018).
Comparative Judgment in L2 Writing Assessment
Compared with burgeoning research into utilizing CJ in other subject domains, studies on CJ in the context of L2 writing assessment have been relatively limited. Sims et al. (2020) examined the performance of novice and experienced raters with two rating methods, rubric rating with MFRM and CJ, and found that two groups of raters produced reliable ratings in both settings, and that rating disparity between novice and experienced raters was less prominent with CJ than with the commonly used rubric rating with MFRM approach. One intriguing line of research extends this idea and explores the use of CJ in combination with crowdsourcing (i.e., soliciting contribution from a large group of dispersed participants) to generate reliable and valid evaluations for writing texts in L2 learner corpora. These studies included either expert linguists from the applied linguistic community (Paquot et al., 2022; Thwaites, Kollias, & Paquot, 2024) or judges of more diverse backgrounds recruited from an online crowdsourcing platform (Thwaites, Vandeweerd, & Paquot, 2024), and demonstrated evidence for high levels of reliability and concurrent validity of the crowdsourced CJ evaluations with rubric-based assessment approaches.
One issue that has not been addressed in those studies is the construct validity of CJ used for L2 writing assessment (Thwaites, Vandeweerd, & Paquot, 2024). While the overall CJ reliability was satisfactory, previous studies nevertheless showed indications that systematic differences may exist between groups of judges in their judging performance, possibly associated with judge characteristics, such as professional expertise, and rating experiences. The sources and the extent of rating variation are yet to be investigated. More fundamentally, what criteria judges relied on when comparing texts and to what extent these criteria delivered a valid construct representation of L2 writing should be carefully inspected before CJ results can be used with confidence (Kelly et al., 2022). A small number of studies examining the validity of CJ provided support for construct relevance and full construct representation in judges’ comparative decisions with L1 writing assessment (Chambers & Cunningham, 2022; Lesterhuis et al., 2022; Walland, 2022), but these findings cannot, and should not, be assumed to apply to the L2 context without empirical underpinning.
The Present Study
With high reliability of CJ generally found in large-scale assessments and in other various subject domains, the present study evaluates the utility and quality of the CJ method with a relatively small group of raters in the context of L2 writing, with the aim to incorporate rater variation on the one hand and obtain reliable and valid outcomes on the other hand.
More specifically, it is of interest whether the claimed advantage of high reliability in large-scale CJ assessments can also be obtained in L2 writing assessment with relatively a small group of teachers as raters, and whether any raters (or texts) deviate from the shared consensus in the comparative judgment making. Second, as CJ employs a holistic approach without predefined rubrics, which text features raters attend to when delivering a judgment of “the better” are crucial for CJ to claim validity, and what are similarities and differences in raters’ judgment making processes. Furthermore, when raters (texts) deviate significantly from the shared consensus, referred to as misfitting, where the inconsistency lies conveys valuable diagnostic information for future learning and instruction. The investigation of these issues leads to the following research questions (RQ).
Method
Text Materials
A total of 94 writing texts in English were collected using a writing task that was part of a practice test for the Test for English Major-Band 8 (TEM8) at a university in the eastern part of China. The TEM8 is a standardized English proficiency test targeted at the fourth-year undergraduate students majoring in English in China, which examines whether students have attained the proficiency level specified in the national curriculum (NACFLT, 2000). The writing task used in this study required students to construct an argumentative writing of a minimum of 300 words in response to a prompt (see Appendix 1) within 45 minutes, with a focus on content relevance, content sufficiency, organization, and language quality of the writing.
Raters
Sixteen raters with English as a foreign language were invited to participate in the CJ assessment. Eight of them were lecturers (two males and six females, aged between 36 and 57) at the university where the study was conducted, giving undergraduate English courses including English language and literature, academic writing, and second language acquisition. All the lecturers were proficient in English and English writing, with teaching experiences ranging from 2 to 20 years. The other eight raters were postgraduate students (one male and seven females, aged between 25 and 30) enrolled in the Master’s program of teaching English as a foreign language at the university. All the raters volunteered their time.
Except one lecturer who had attended TEM8 writing scoring sessions at the national test administration center, none of the lecturers had received any explicit training on assessing the TEM8 writing. Nevertheless, they needed to evaluate students’ assignment essays and/or exam papers during their years of teaching and thus were reasonably experienced in assessing L2 writing. They were referred to as experienced raters hereafter. None of the Master’s students had any prior experiences in assessing L2 writing, and thus were novice raters in the study, but they all had taken, and passed the TEM8 and were familiar with the writing task requirements.
Data Collection and Procedure
Each writing text was anonymized, scanned, and uploaded to the online platform No More Marking (www.nomoremarking.com), which is a web-based digital system that pairs and presents student works side by side for raters to compare. A webpage link to the online CJ assessment was sent to each rater via email, so that they could access and complete the CJ assessment on their computers within a time window of one week.
Prior to the CJ assessment, the raters were gathered for an information session about 30 minutes, which included brief introductions of CJ, the writing task, and performing CJ with the online system. In particular, neither a rubric nor competence descriptions of L2 writing were provided; instead, the raters were explicitly instructed to evaluate and compare the L2 writing based on their professional expertise and prior rating/writing experiences. With the online system, for each pair the raters needed to select the text judged with better writing quality, and were encouraged to input brief comments explaining why they considered one text better (or worse) than the other before submitting their decision. After that, a new pair would be generated. The procedure continued until all the raters completed their comparison quota.
Based on the findings of Verhavert et al. (2019), the number of comparisons per text was set to 14 to target a reliability of at least 0.70 that was deemed sufficient for low-stakes tests. This led to a CJ design of 658 paired comparisons in total (
Data Analysis
The binary judgment data of 601 pairwise comparisons were exported from the online system and modeled using the Bradley-Terry-Luce model (BTL model; Bradley & Terry, 1952; Luce, 1959) to determine the locations of the writing texts on a quality scale. More specifically, for each pair, the probability of text
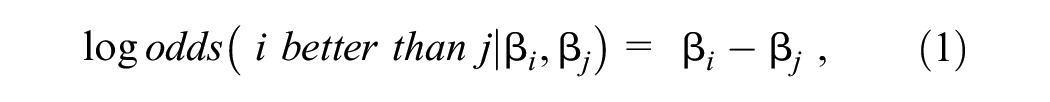
where
To examine reliability of the CJ scale (RQ1a), a scale separation reliability (SSR) statistic was calculated in an analogy to the separation index in the Rasch model (Rasch, 1960) literature as:

where
To investigate whether any raters or texts significantly deviated from the BTL model prediction (RQ1b), misfit statistics were calculated. The infit statistic, that is, information weighted mean square (Wright & Masters, 1982) was calculated for each text (rater) as the weighted average of the squared Pearson residuals

in which
Raters’ decision making (RQ2) was explored by analyzing their comments following the thematic analysis procedure (Brooks et al., 2006). Comments were first segmented into single arguments regarding a specific feature of writing (e.g., “richer in content,”“better structure,” or “providing specific supports”), leading to a total of 763 arguments. The initial coding scheme based on the framework by Cumming et al. (2001) was adjusted by merging some categories (e.g., grammar and spelling) or refining some into a generic text feature and a task specific one (e.g., paragraph development and argument development). The author and another EFL lecturer independently coded a proportion of the arguments, and yielded an inter-rater agreement of 0.91, suggesting satisfactory reliability of the coding. The author then completed coding of the remaining arguments, and grouped them into seven broader writing aspects. An overview of the final coding scheme and grouping can be found in Table 1. These arguments were compared with the established rubric used for TEM8 scoring (see Appendix 2). The relative uses of each writing aspect in judgment making were calculated in percentages for the whole group of 16 raters as well as for the experienced and novice rater groups separately. Significance of differences between the two rater groups in their judgment making was tested using the
The Coding Scheme, the Grouping, and Frequencies of Text Features, and the Percentages of Writing Aspects Raters Used for Comparative Judgment Making.

Note. The percentages, representing the relative uses of each broad aspect of writing in raters’ judgment making, were calculated for two rater groups separately and all the raters as a whole in NVivo. The numbers in bold denote the three aspects most frequently attended to by the corresponding rater groups.
The BTL modeling of the binary judgments were performed using the BradleyTerry2 package (Turner & Firth, 2012) in R (R Core Team, 2023), the coding of judgment making comments using NVivo version 14 (2023), and all the other analyses in R. An overview of the study design and analysis framework is presented in the diagram in Appendix 3.
Results
RQ1a: Rank Order and Reliability
Figure 1 presents the scale of all the writing texts ordered by their quality scores derived from the BTL model. Each point denotes a text and the error bar the corresponding 95% confidence interval. The quality scores
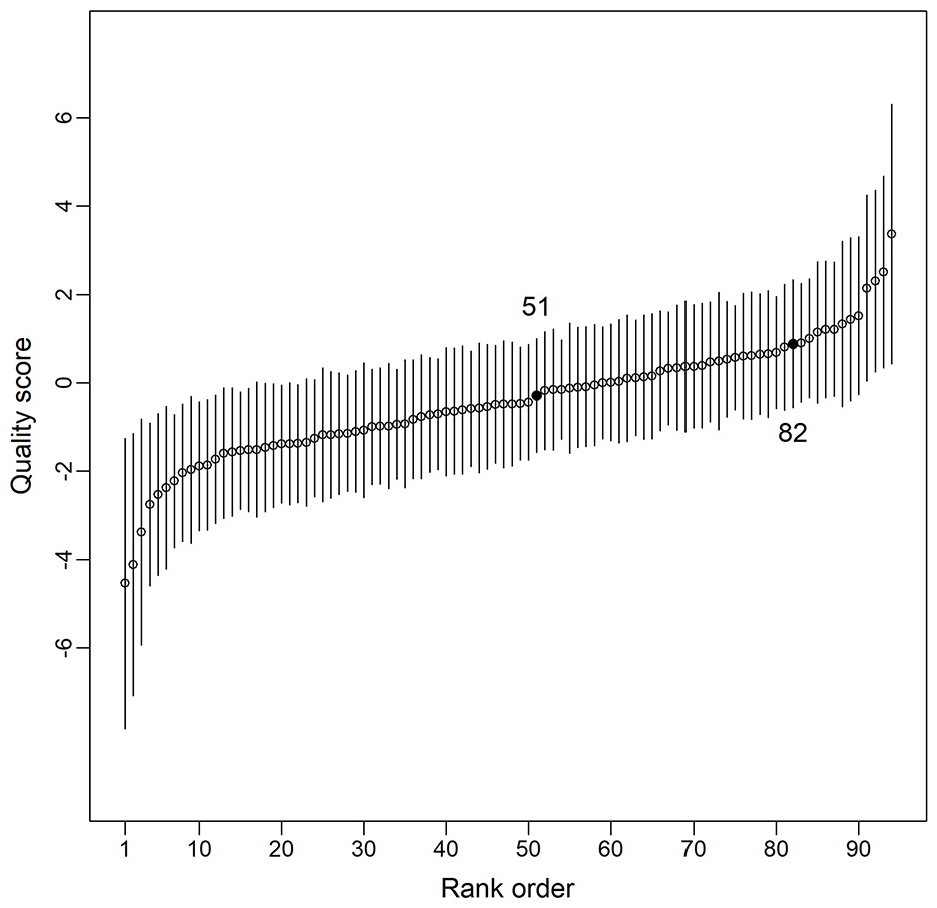
Rank order of the texts’ writing quality (ascending order) using comparative judgment.
RQ1b: Rater and Text Misfit
The infit statistics were calculated for each rater and plotted in Figure 2A to identify any raters whose judgments were relatively different from the other raters. The mean infit across all the raters was 0.91 (SD = 0.21); Rater 11 was identified as an “outlier” with an infit value of 1.37 that was marginally greater than the threshold of 1.32 for misfit. The deviation signals that this rater might compare the texts using different criteria from other raters’, leading to judgments not conforming to the shared consensus. In addition, the ANOVA test showed no significant difference in the misfit tendency between the experienced and novice raters at the significant level of 0.05 (F(1,14) = 3.03, p = 0.10).

Infit mean square statistics for raters (A) and texts (B).
The infit statistics were also calculated for each text, and the mean text infit was 0.84 (SD = 0.30). Figure 2B, which plots the distribution of text infit values, shows that Texts 77 and 82, with infit values of 1.63 and 1.53, respectively, exceeded the misfit threshold value of 1.43. The large infit values indicate that these two texts were “problematic” for the raters to reach mutual consistency regarding their quality. Given both the moderate reliability and misfitting rater and texts, it is therefore important to inspect how the raters made their judgments when comparing texts and the source(s) of the inconsistency.
RQ2: Text Features and Judgment Making
Raters’ judgment making was explored by analyzing their comments that justified their decisions when comparing text pairs. Table 1 gives the frequencies of text features provided by the raters and the percentages of use by grouping aspect. Among the total 763 arguments of all 16 raters, three writing aspects received the most attention (with bolded numbers in Table 1), namely, rhetorical organization (32.5%), English language use (18.6%), and task development (16.8%), accounting for two-thirds of all the justification arguments. Together with the aspects of idea contents (12.7%) and length production (3.0%), 83.6% of raters’ arguments can be directly related to all the assessment criteria components specified in the standard TEM8 scoring rubric (see Appendix 2). However, different from the TEM8 scoring rubric putting more weights on the content (ideas and argumentation), the raters in the study focused more on rhetorical organization.
Despite no group difference found in their misfit diagnostics, the experienced and novice raters demonstrated divergent patterns in how they arrived at their judgments, which is reflected in their relative uses of writing aspects, and text features in Table 1. Firstly, both groups considered rhetorical organization the primary criterion for comparisons (30.1% for the experienced group and 34.3% for the novice group), but the novice raters predominantly focused on the representation of an introduction-body-conclusion structure, whereas the experienced raters also addressed the development within and between paragraphs as well as cohesion-coherence. Secondly, next to rhetorical organization, the experienced raters informed their decisions by comparing students’ writing in terms of English language use (24.7%) and task development (22.9%), while the novice raters more frequently attended to layout (17.6%) and idea contents (15.1%). Thirdly, the style of writing was also one important aspect for the experienced raters (9.6%), but it was the least frequently considered aspect by the novice raters (3.0%). In addition, the experienced raters were barely affected by handwriting and the length of a text during comparisons. The
RQ3: Inconsistency of Misfitting Rater and Texts
Rater 11 was identified as misfitting, making judgments relatively more inconsistent from the other raters. An inspection into Rater 11′s profile and arguments for judgment making showed that Rater 11 was a lecturer, completed 35 comparisons, and provided 51 arguments for the decisions made. Compared with the non-misfitting raters, close to half of Rater 11′s arguments for a favorable judgment were based on English language use (44.2%, more specifically, vocabulary/expression and syntax), followed by rhetorical organization focusing exclusively on the introduction-body-conclusion structure (32.7%). Idea contents (13.5%) and argumentation (13.5%) were the other two frequently considered aspects. These patterns suggest that Rater 11 laid a heavy focus on basic writing aspects like linguistic elements and text structure, which made his/her judgments different from the other raters. One possible explanation could be that Rater 11 was teaching the language to non-English major students for functional purposes, and the other raters were all teaching English major students at more advanced and academic levels or they were English major students themselves.
Texts 77 and 82 were identified as misfit, meaning a lack of agreement among the raters’ comparative judgments regarding their qualities. A close examination of the CJ trails showed that both texts were compared with 13 different texts and received five unexpected decisions, that is, being judged better against a stronger opponent or inferior to a poorer one. Table 2 lists arguments from raters’ justifications for the comparative decisions involving the two misfitting texts. Text 77 seemed to have comparable features of organizational structure, handwriting, and idea contents, but its effective use of vocabulary stood out for some raters. On the other hand, Text 82 seemed to have an advantage in clear and logic reasoning, but might be mediocre at idea contents and linguistic performance. Given raters’ varying foci as reported above, it is possible that when the text presented an imbalanced performance with one outstanding feature, this unique characteristic was highly appreciated by some raters and attracted them to draw a favorable judgment on the overall quality of the text, delivering a judgment that deviated from the shared consensus.
Raters’ Justifications for Comparative Judgments Involving Two Misfitting Texts.

When the text was considered inferior, the justifications were made regarding the opponent text.
Discussion
Underpinned by the psychological law of comparative judgment (Thurstone, 1927), the method of CJ uses pairwise comparisons to elicit relative judgments without confining raters to a predefined rubric, and has been emerging as a viable alternative to rubric-based assessment. Given the persistent challenge of rater variation in L2 writing assessment, the present study evaluated CJ as an alternative assessment method for L2 writing with a group of raters with varying professional expertise and scoring experiences. The reliability, raters’ judgment making (validity), and misfit feedback of the CJ procedure were examined to shed light on the quality and applicability of CJ for L2 writing assessment.
How Reliable Are the CJ Results and to What Extent Were Raters (Texts) Consistent with the Shared Consensus?
In the study, no predefined rubrics nor general competence descriptions of L2 writing were provided to the raters. Yet, the CJ assessment yielded a moderate scale separation reliability (SSR) of 0.64, suggesting a relatively good internal consistency of the resulting rank order of the writing texts. Since the SSR statistic can also be interpreted as inter-rater reliability (Verhavert et al., 2018), the result suggests an adequate level of agreement among raters that is comparable with what might be expected in typical writing assessments with rubrics (Bramley & Vitello, 2019). This demonstrates the advantage of CJ over rubric scoring. Furthermore, the holistic nature of the CJ method also bears a resemblance to the frequently used holistic marking method, but rater variation due to differential interpretation and application of rubric criteria in the latter is replaced by relative judgments on comparing pairs of texts in the CJ procedure, leading to increased consistency of judgments made. The rater misfit diagnostics showed that all the raters (except one) in the study, despite their differences in professional expertise and rating experiences, were able to make comparative judgments conforming to the mutual consistency. In this sense, CJ provides an alternative approach to the challenge of rater variation, not by training raters to adopt a similar decision-making process with rubrics, but by canceling out differences in the absolute standards between and within raters to create a shared consensus.
On the other hand, with 12 to 17 (median = 13) comparisons per text, the SSR value of 0.64 obtained in the study was lower than the targeted level of 0.70 as suggested by Verhavert et al. (2019) as well as those reported in most of previous research using CJ (Steedle & Ferrara, 2016; Verhavert et al., 2018). This could be due to the varying expertise of the raters in the study. The results showed no differences between the experienced and novice raters in their misfit tendency, which is in line with the findings that novices, even students with subject knowledge, can perform CJ as reliably as experts (S. R. Bartholomew et al., 2018; Jones & Alcock, 2014). However, with relatively lower discriminating capability, it takes more rounds of comparisons for novice raters to reach the same reliability level as their experienced counterparties (Kimbell, 2022; Verhavert et al., 2019). Consequently, it is possible that with a similar amount of comparisons performed by the novice and experience raters in this study, the tentative consistency of the former could be lower than that of the latter, affecting the overall reliability achieved. Given that the number of comparisons per text is one key factor that affects the SSR (Bramley, 2015; Kimbell, 2022; Verhavert et al., 2019), a maximal level of reliability could be eventually achieved by increasing rounds of comparisons.
Another possible explanation for the moderate SSR could be the homogeneous characteristic of the writing texts. Based on teachers’ knowledge of the learning and classroom formative assessment activities, the students involved in the study had very similar levels of English writing proficiency. The narrow “gap” between two paired texts made it more difficult for the raters to distinguish the better one consistently (Kimbell, 2022). It could be beneficial to include a set of well-established threshold benchmarks from rubric-based assessment in CJ texts to facilitate mapping the CJ rank order to rubric ratings (See Limitations).
How Did the Raters Arrive at (In)consistent Judgments When Comparing L2 Writing?
The thematic analysis into raters’ judgment making arguments showed that raters, on the individual level, varied substantially in what text features they used as criteria to compare single pairs of texts, but collectively the representation derived from the iterative process of pairwise comparisons presented a close alignment with the established scoring rubric. All the criteria components of the scoring rubric were covered by the arguments justifying raters’ decisions, and more than 83% of the raters’ arguments directly related to the assessed criteria in the rubric, providing strong evidence for the construct validity of CJ. Next to that, raters in the study also attended to aspects that were not addressed by the established rubric but were rather relevant and important in terms of English writing in general, such as style and persuasiveness of the writing. This is consistent with previous studies in that CJ often accommodates an extended range of evaluation criteria over specific rubrics (S. R. Bartholomew et al., 2018; Lesterhuis et al., 2018; van Daal et al., 2019). Without the reference to (or limitation of) predefined criteria, raters can tap into their expertise, apply their own conceptualizations of writing to the reading of texts, and deliver a professional judgment. Thus, our results provide empirical support for the construct validity of CJ relying on raters’ expertise and experiences, which embraced a more comprehensive representation than a single rubric specification of what good L2 writing looks like.
Besides, the results add to the CJ literature by highlighting the differences between the experienced and novice raters regarding how they conformed to the shared consensus. The novice raters tended to compare texts in terms of more rule-applying lower-order aspects of writing (Cumming et al., 2001; text structure and layout) and idea contents, whereas the experienced raters informed their judgments mostly by higher-order aspects (rhetorical development, argumentation, and style), and were less affected by construct-irrelevant factors (handwriting or text length). These results are similar to the findings in the literature of rubric-based L2 writing assessment that raters evaluated texts with various foci (Cumming, 1990; Eckes, 2008) and at different levels (Wolfe, 1997; Zhang, 2016). While variations in raters’ criteria were assumed to produce inconsistent judgments in rubric scoring (Eckes, 2008; Huot, 1990), this study illustrates that CJ offered a feasible means to integrate these rater variations by aggregating all the judgments made on one text to produce a global evaluation of its quality. With varied judgment criteria, the novice raters contributed to the shared consensus in terms of what was contained in the texts, and the experienced raters in terms of how the messages were conveyed, whether in a logic, effective, or appropriate manner. Thus, it can be argued that rater variations are allowed, even welcomed, in CJ (van Daal et al., 2019), as long as the deviation is not due to construct-irrelevant factors or biases (see below).
Where Does the Misfit Lie?
Misfit indicates a pattern of raters making (or texts receiving) unexpected judgments consistently. In the study, one rater and two texts were identified as misfitting, demonstrating relatively more deviation from the shared consensus than the others. It should be noted that CJ accommodates the heterogeneity of judgment making processes by pooling together all the raters’ judgments, and thus the misfit statistics are better interpreted relatively rather than absolutely (Pollitt, 2012b). The misfitting rater was the only non-English major related judge, suggesting that current teaching level could be an important factor in promoting consistent judgments. This finding echoes the results by Whitehouse and Pollitt (2012) showing that raters teaching at a similar level were more likely to share a common set of standards to base their judgments on. A significantly misfitting rater may have some practical implications, as how raters conceptualize L2 writing can influence what and how they teach students to develop L2 writing skills. The study illustrates that raters’ misfit statistics in CJ may serve as a good indication to inform raters about their divergent conceptualization of the construct (or other skills), so that appropriate adjustments in their teaching can be made to ensure students to develop the competence according to criteria that are valued in general instead of a rater’s idiosyncratic standards.
It was also observed in the study that when a salient feature was present in a text, it tended to cause the raters to disagree more, leading to more divergent judgments. Text 77 had a prominent feature of good vocabulary and Text 82 fine logic reasoning; the appreciation of these particular features may lead some raters to draw a favorable but inconsistent generalizing conclusion about the overall quality of the texts. This judgment making behavior is commonly known as the halo effect (Thorndike, 1920). The finding suggests that raters in a CJ procedure could also be subject to the halo effect as often reported in rubric-based assessment (e.g., Engelhard, 1994; Myford & Wolfe, 2004). Since advocators of CJ sometimes claim that in the absence of a rubric, rater training on standardization meetings is unnecessary, the results in this study point out the importance of providing basic guidance to raters on assessing L2 writing prior to the CJ procedure.
Implications
The present study also has some implications for instructors and administrators of English major programs. It could be a great challenge to develop an effective scoring rubric for L2 writing that enhances consistency in evaluation and also promotes learning and instruction. High levels of reliability have primarily been sought with externally developed standardized assessments (Humphry & Heldsinger, 2020). This study has shown that CJ enables raters to utilize their professional expert and perform valid evaluations of texts at a satisfactory level of reliability, even with a small group of raters and without extensive negotiation. This offers instructors and program administrators a time-efficient and economic means to deliver reliable classroom- and program-based evaluations. Furthermore, studies of Humphry and Heldsinger (2020) and Marshall et al. (2020) demonstrated that if threshold benchmark texts from standardized tests or large-scale national assessments are to be anchored on the constructed CJ scale, CJ can inform raters to improve the quality and criterion validity of their program-based assessments.
Additionally, the process of actively comparing texts and reflecting on the reasons puts forward CJ’s potential pedagogical benefits in learning and instruction. For instance, when students engage in CJ as rater themselves, concrete examples of writing can help them better understand the abstract construct of writing competency and what it means by “good” and “better” (Kimbell, 2022). Thus, besides the advantages of improved psychometric properties as an assessment method, the potentials of CJ as a feedback tool and learning experience in L2 writing are also an interesting topic for future research.
Limitations
The first limitation of this study was the sample of L2 writing used for the CJ assessment, which can be considered a convenient sample. The practice test, from which the writing texts were collected, had been administered in an evening session one month before the actual TEM8 took place. It is possible that the students were insufficiently motivated or experiencing fatigue during the practice session, causing the quality of the writing to be relatively low in general. With limited “gaps” between text pairs, it might be consequently more difficult for the raters to discriminate the winner from a pair consistently.
The second limitation related to the investigation of the consistency of judgments between the two rater groups. The whole CJ assessment was carried out jointly by the two rater groups, making calculating SSR for each group less straightforward. Splitting the data would further reduce the number of comparisons per text and overlaps between text pairs, leading to even lower consistency of the results. A design with two rater groups completing the whole procedure independently would enable a direct comparison of their judgment consistency. Additionally, the small sample size of raters makes the results of this study less generalizable.
In the present study, no comparison was made between the CJ results and traditional rubric ratings, due to the unavailability of reliable rating scores and benchmark exemplars. Since the present study primarily aimed to focus on (in)consistency among raters/texts and raters’ comparative judgment making to establish CJ’s construct validity in assessing L2 writing, subsequent studies can include a set of established threshold benchmarks from traditional rubric rating as anchor points on the CJ rank order, comparing CJ results and rubric ratings to examine the criterion validity of CJ.
Lastly, the current study explored CJ for assessing L2 writing by focusing on psychometric properties. Another important aspect of how the raters experienced the novel method was not addressed in this study. As raters’ perceptions of and attitudes toward an assessment method can influence their use of the method and confidence in their judgments, future research should explore this perspective using methods such as survey and interview feedback.
Conclusion
Rater variation has been a persistent concern for language writing assessment. Instead of optimizing scoring rubrics and training practices, the current study evaluated the method of CJ as an alternative approach to rater variations, underpinned by relative judgments and a shared consensus of collective expertise among raters. With an iterative pairwise comparison process and statistical estimation, CJ holds promise for accommodating rater-associated heterogeneity of evaluation on the one hand, and obtaining a reliable and valid rank order of writing texts on the other hand. Despite the relatively small number of raters and their varying professional expertise in the study, the assessment outcomes were shown with a satisfactory level of reliability and validity. Meanwhile, the study also expressed the necessity of providing relevant guidance to raters, if not explicit training, to enable more valid evaluations. The intuitive rationale and simple procedure of CJ reduce the need for time-consuming rater training (S. R. Bartholomew et al., 2018; Pollitt, 2012a; Whitehouse, 2013), but information about targeted writing skills and common pitfalls like the halo effect can help raters avoid being affected by construct-irrelevant factors and judgment biases.
To the author’s knowledge, this is one of the first studies that systematically investigated what text feature(s) raters considered to deliver a comparative decision in the context of L2 writing assessment with CJ. It contributes to the existing literature by providing empirical evidence for the less examined construct validity of CJ in the context of L2 writing, and adding a novel perspective to the discussion of rater variation in the rater-mediated assessment literature. With the growing interest of CJ in the educational assessment filed, more elaborated investigations of the quality and effectiveness of CJ are needed to foster confidence in its use.
Footnotes
Appendix
Appendix 2
Ethical Considerations
The study was approved by the Research Ethics Committee of Shaoxing University (No.2023WGY06) on February 27, 2023. The participants provided their written informed consent to participate in this study.
Author Contributions
Qian Wu contributed to the Conceptualization, Methodology, Formal analysis, Investigation, Drafting and Revision, and Funding acquisition of the study. The author thanks Qi Luo for assisting in collecting, scanning, and uploading the text materials.
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the university research grant (NO. 13011002002/114) and the project grant (No. 2023SK008) from Shaoxing University.
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.