
Abstract
Focusing efficiently on potential weaknesses in the validity argument of writing assessments—such as writing subjectivity, content coverage, criteria vagueness, and raters’ incompetence—has been shown to positively enhance teachers’ overall writing assessment competence (AC). In this study, we propose a computational bootstrapping model of validity argument in L2 writing assessment and compare it to argument-based models such as Practical Reasoning (PR), Assessment Use Argument (AUA), and Rubric Use Argument (RUA). Specifically, this computational model gradually improves the validity argument by addressing subtle deficiencies in previous assessment competence and constructing a bootstrapping process for the validity argument. We collected data from the Chinese English Teachers’ Writing Assessment Competence Corpus (CETWACC), which includes texts from a total of Chinese L2 teachers in higher education. The corpus comprises six levels and 60 items detailing how these teachers perform in: (i) construction, (ii) reflection, (iii) externalization, (iv) internalization, (v) enhancement, and (vi) reconstruction. The findings suggest that the Cognitive Bootstrapping Model (CBM) significantly enhances teachers’ assessment competence through reasoned arguments and more scientific measures of validity arguments using computational algorithms. Overall, this study emphasizes the computational evidence of validity arguments and explores the subtle process of micro-changes in L2 writing assessment, transitioning from argument-based approaches to algorithmic methods. The results have implications for discussions on the role of validity argument bootstrapping in current writing assessments, offering a universally applicable and operationally feasible model for validating writing assessments.
Plain language summary
We found that when teachers address potential issues in writing assessments, such as subjectivity and unclear criteria, their overall assessment skills improve. In this study, we propose a computer-based model designed to enhance the validity of writing assessments and compare it with other argument-based models. Data were collected from Chinese English teachers in higher education to evaluate the model’s effectiveness. The findings reveal that our model, which systematically improves assessment by identifying and correcting past mistakes, significantly enhances assessment skills. By integrating reasoning with computational algorithms, it makes the assessment process more scientific. This study demonstrates how small, iterative changes in writing assessment can lead to substantial improvements, shifting from theoretical arguments to practical algorithms. The results suggest that our approach could be beneficial for enhancing writing assessments universally.
Introduction
In today’s educational assessment landscape, the significance of the validity argument in writing assessments for L2 (second language) teachers is well-recognized (Correnti et al., 2022; Cronbach, 1988; Kunnan & Jang, 2009). This recognition is due to the inherently unpredictable and subjective nature of L2 writing assessment (Bachman & Palmer, 1996; Taylor, 2023). In the context of an education system driven predominantly by examinations, it is believed that L2 teachers gradually acquire knowledge about validity arguments in writing assessment through either formal training or self-directed learning (Cronbach, 1988; Ferrara & Qunbar, 2022). This gradual exposure is considered a crucial factor in developing a robust understanding of validity arguments (Cronbach, 1988), with particular attention given to the quality of these arguments. However, existing studies on L2 writing rating standards tend to focus primarily on abstract and theoretical assessments. This approach provides limited insight into the development of assessment practices among L2 teachers in countries like China, Japan, and Korea, where teachers often prioritize form-focused writing assessments in preparation for significant exams such as the National College Entrance Examination (NCEE) in China (Bachman, 2000; Pan, 2019).
To address these assessment disparities, there is an increasing interest in researching ways to enhance L2 teachers’ validity arguments in writing assessments across different teaching levels and experiences. Many studies conducted in China (e.g., He & Jiang, 2023; Shu, 2023; Xu & Zang, 2023), as well as similar contexts in Japan (e.g., Ahmed et al., 2021) and Korea (e.g., Kim, 2020), have examined the validity of language assessments in static and horizontal terms rather than dynamic and longitudinal terms. Nonetheless, our understanding of how indicators such as teaching levels and teaching experience affect the development and impact of validity arguments in complex L2 assessments remains limited. Consequently, more research and innovative methods are required to explore the gradual cognitive development of validity arguments in writing assessments (e.g., Bachman, 2005; Chan et al., 2015; Ferrara & Qunbar, 2022).
While most studies on teacher competence focus on teaching abilities using frameworks such as Practical Reasoning (PR; Toulmin, 1958, 2003), the Assessment Use Argument Framework (AUA; Bachman & Palmer, 2010), and the Rubric Use Argument (AUA; Fulcher, 2010), cognitive bootstrapping offers a dynamic approach to quantifying indicators of validity arguments in L2 writing assessments. This approach addresses the call made by Chapelle (2012, p. 41) and Wollenschläger et al. (2016, p. 11). The Cognitive Bootstrapping Model (CBM), based on these frameworks, provides a visible continuum for monitoring the simultaneous process of validity argument development. It enables teachers to explore a progressive range of schematism and to advance from initial assessment competence to a dynamic validity argument continuum through computational algorithms (Panadero & Jonsson, 2013). CBM offers a novel cognitive pathway and a nuanced perspective on teaching levels and experience in validity arguments for writing assessments.
Given the importance of advancing and refining L2 teachers’ validity arguments in writing assessments, this study aims to analyze the model fit of CBM across different teaching levels and experiences using computational analysis (Kunnan, 2000; Larsson et al., 2021, 2022). By conducting a comprehensive self-report, we seek to assess teachers’ cognitive development in relation to their teaching experience. Ultimately, this research will propose effective strategies for applying CBM to enhance formative assessment practices and offer a new approach to accurately measuring and improving assessment validity.
Theoretical Framework
This study is grounded in frameworks such as Practical Reasoning (PR; Toulmin, 1958, 2003), the Assessment Use Argument Framework (AUA; Bachman & Palmer, 2010), and the Rubric Use Argument (RUA; Fulcher, 2010). These frameworks delineate the validity argument in the assessment process, which depends on data derived from reasoning arguments and the dimensions of writing ratings (Piantadosi et al., 2016). As an emerging field, research on teachers’ cognitive beliefs about the validity of writing assessment—specifically regarding the reasoning behind scoring consequences, feedback, and the interpretation of scoring elements (such as scoring rubrics)—has expanded over the past decade (Fulcher, 2010; McNamara & Knoch, 2019).
Regarding the evaluation of teachers’ assessment processes, Sawaki and Koizumi (2017) examined the appropriateness of raters’ scoring based on teachers’ cognition in writing assessment. While some studies have successfully addressed straightforward assessment issues with static writing standards (Dechter et al., 2013), other areas provide a more mixed or incomplete picture of teachers’ cognition. These include the dynamic influence on teachers’ interpretation of numerical beliefs (Wollenschläger et al., 2016), writing target setting (Knoch, 2009; Knoch & Chapelle, 2018), and the representativeness, integrity, and generalization of scoring elements (Bachman & Palmer, 2010; Lallmamode et al., 2016). Additionally, the effectiveness and fairness of scoring feedback (Arter & McTighe, 2001; Ghaffar et al., 2020; Panadero & Jonsson, 2013) and the rationality of writing target setting (Bachman & Palmer, 2010; Lallmamode et al., 2016) are areas of concern.
According to PR, AUA, and RUA, numerous studies have reported positive outcomes in validity arguments (e.g., Bachman & Palmer, 2010; Castillo et al., 2023; Fulcher, 2010; Jonsson & Svingby, 2007; Saeli & Rahmati, 2023; Toulmin, 1958, 2003). However, some studies have highlighted limitations in the qualitative analysis of validity arguments, particularly in text-oriented educational environments rather than quantitative computing and cognitive bootstrapping. These qualitative results may be attributed to the macro-level illustration of validity arguments that teachers prioritize statically. For instance, Toulmin (1958) and Jonsson and Svingby (2007) measured writing assessment in terms of facts, evidence, reasoning, and claims, while Chan et al. (2015) and Piantadosi et al. (2012) focused on teachers’ cognitive biases in validity arguments. Research methods also play a role; some emphasize interpreting and illustrating writing rating standards with argumentative power (e.g., Bachman & Palmer, 2010; Castillo et al., 2023; Correnti et al., 2022; Fulcher, 2010; Hannah et al., 2023). Ferrara and Qunbar (2022) discussed the limitations in evidence and validity arguments for scores generated by automated scoring engines, noting concerns related to teacher development concerning teaching levels and age.
Given the complexity of teaching levels and teaching age, applied linguistics has presented various definitions and operationalizations (Castillo et al., 2023; Fulcher, 2010). The dynamic observation of validity arguments is often described as a nuanced process that must address a diverse audience, linking concepts, evidence, social and personal consequences, and values with factors such as teaching age and length (Cronbach, 1988). For example, Kane (2006) defines it as an argument-based approach that requires stating the claims being made and evaluating their credibility from a longitudinal perspective. Scholars have proposed various validation frameworks to guide the development of validity arguments (Bachman & Palmer, 2010; Fränken et al., 2022; Kane, 2006, 2013). Recent studies have recognized the importance of teachers’ assessment in developing validity arguments, especially regarding AI-based validity arguments within writing assessments using cognitive bootstrapping models (Correnti et al., 2022; Ferrara & Qunbar, 2022; Hannah et al., 2023). Therefore, it is crucial to observe formalized bootstrapping perspectives of validity arguments in relation to teaching age and levels longitudinally—a topic rarely discussed in previous studies.
As depicted in Figure 1a (formalized bootstrapping), there has been extensive research on static and horizontal assessments, formative assessments, and valid assessments in recent years (Fladung et al., 2023; Hartwell & Aull, 2023). Updating validity arguments and validity enhancement with assessment competence (AC) and real-time validity (RV) is essential. Cognitive bootstrapping of validity arguments involves progressively upgrading assessment competence (AC) from “existing assessment knowledge” to real-time validity (RV) (Piantadosi et al., 2012; Zhao et al., 2022). This process is reflected in the constant, gradual feedback through teaching, testing, assessing, and rating (Razavipour, 2023). Additionally, assessment feedback promotes the transition from the initial AC status to a new status (R′V′), thereby enhancing the influence of teaching, testing, assessing, and rating.

Cognitive bootstrapping model of validity argument: (a) the upgradation of static assessment and (b) construction computing of CB.
As illustrated in Figure 1b, progressive cognitive bootstrapping is assessed based on cumulative testing washback. The transition from Assessment Competence (AC) to Real-Time Validity (RV) is depicted through six distinct teaching levels: construction, reflection, externalization, internalization, enhancement, and competence. These levels vividly highlight the gap between AC and RV. Building on the work of Lallmamode et al. (2016), this study refines the validity argument by integrating elements of assessment enhancement at each level. The argument system encompasses both foundational assessments and argument enhancement, with weights assigned according to their validity argument (Ghaffar et al., 2020). Developing an argument that addresses all six levels is crucial in current writing assessments, given the inherent subjectivity and variability in writing ratings (McNamara & Knoch, 2019; Woods et al., 2023). These teaching levels can be broadly classified into stages of bootstrapping: the construction of AC and self-reflection represent the initial stage for L2 teachers; externalization and internalization of AC constitute the intermediate stage; while enhancement and advanced bootstrapping of AC mark the superior stage.
To address our research questions, we employed the Cognitive Bootstrapping Model (CBM; Zhao et al., 2022) and utilized a measured visualization of its cognitive bootstrapping mode. This mode is depicted as a circular motion originating from computer-assisted testing and converging with real-time validity (RV) (see Figure 1a; Griffiths et al., 2015). The CBM is a foundational concept in learning and development theories, explaining the gradual mechanisms of cognitive models. While CBM techniques can be scaled up to accommodate latent, unmeasured variables in advanced models (e.g., Larsson et al., 2022), this study focuses on modeling measured variables within a bootstrapping analysis of validity arguments.
This technique allows us to test our hypotheses regarding the effects of independent variables on dependent variables. Assessment competence (AC) is represented by circles and randomly positioned spaces, while real-time validity (RV) in writing assessment is symbolized by a stick composed of diverse-shaped units. The attribute values across the AC model range from 0 to 6. An algorithm was used to determine the final number of units for RV in writing assessment, expressed as R′V′′ ← circle (AC) × RV − space (AC). The assessment materials are detailed in Figure 1a. For generalization, any segment number between 0 and 6 could be selected, resulting in a nominal assessment performance level of 1/6 = 16.67%. The generalization trials were chosen using an entropy-minimizing approach, enabling an effective bootstrapping method to distinguish between hypotheses favored by the assessment mode. This information can be accessed at (https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN2FKLQVPC&version=DRAFT).
Against this backdrop, several unanswered questions remain regarding the construction and bootstrapping of validity argument, including, but not limited to, establishing teachers’ cognitive, quantifiable, bootstrapping standards within validity-argument frameworks (Tabari et al., 2023). Such assessments may fail to evaluate the depth and breadth of content and logic, leading to ambiguity for raters during the rating process (see Fulcher, 2010). As noted by Hannah et al. (2023), one reason why teachers may not be conscious of validity argument in writing assessment is due to the limited techniques available to quantify the rating system.
Therefore, this study incorporates the indicators of the teaching levels and teaching age into monitoring teachers’ cognitive bootstrapping in validity argument. The specific research questions are formulated as follows:
Research Question 1: What is the developmental trend of model fitting of CBM in validity argument?
Research Question 2: To what extent are there indicators of the teaching age and teaching levels that influence on teachers’ CBM in validity argument?
These questions expand our understanding of the various factors that contribute to the CBM in validity argument in writing assessment among L2 teachers. By examining the influence of teaching age, teaching levels, we can identify effective strategies for enhancing and promoting teachers’ validity argument in educational assessment with exactness and promote the reform of current simple, invalid and vague assessment in overall education.
Data and Method
Data Collection
The data for this study were sourced from the Chinese English Teachers’ Writing Assessment Competence Corpus (CETWACC; Ke, 2023). CETWACC is a writing-based assessment tool with standardized instructions designed to evaluate the assessment competence of early L2 teachers in relation to their teaching age and levels. The corpus comprises texts from 224 Chinese L2 teachers, representing various ages and teaching levels, and includes a total of 60 sub-dimensions. These sub-dimensions are categorized into seven age groups and six teaching levels, each coded from 0 to 3, resulting in a maximum total score of 100. At each testing site, a blinded assessor—trained to ensure consistency—administered the CETWACC. Higher scores on the CETWACC indicate a greater ability to construct valid arguments in writing assessment. The CETWACC has demonstrated strong inter-rater reliability, with a Cohen’s kappa of 0.92, and moderate accuracy in predicting the validity of writing assessments. All CETWACC assessments were based on self-reports and necessary surveys, with recordings coded by the assessor. To assess inter-rater agreement, 40% of self-reports and surveys were randomly selected and additionally coded by an assessor at a different study site. This double coding process showed good inter-rater agreement, with an Intraclass Correlation Coefficient (ICC) of .84.
Coding Process of Cognitive Bootstrapping of Validity Argument
Validity argument is a key measure of teachers’ assessment competence within a specific context. It has been extensively used in writing assessments and has been shown to predict teachers’ writing assessment competence effectively (Crossley et al., 2014). One common and straightforward measure for validity argument is the scoring degree of a writing assessment item. However, a notable limitation of current validity arguments is the vagueness and randomness that can arise from the writing propositions to the raters’ assessments for coding. To address these issues, various quantifying measures have been developed to enhance validity arguments in writing assessments. In this study, we utilize a corpus named CETWACCA for coding the data. Unlike previous validity argument models (e.g., PR, AUA, RUA), CETWACCA employs two independent coders to categorize teachers’ self-reports and records. The first coder classifies all semi-structured responses, while 15% of these classified self-reports are cross-examined by the second coder to ensure agreement.
Our study found an inter-coder agreement level of 91.37%. Moreover, CETWACCA has been shown to generate six identified levels, which are labeled as follows: (i) Construction: This code corresponds to the teachers’ assessment level or startup in each item. For example, “Space is multiplied by the number of codes, and then the number of their teaching length is subtracted.” (ii) Reflection: This code corresponds to the assessment self-reports. For example, “The spaces are subtracted from the units by their number, and the number of codes is multiplied by the number of units of their teaching length.” (iii) Externalization: This code represents an unclear or implicit description of how two sub-progressive assessments should be externalized. For example, “The codes multiply the units of teaching length, and codes subtract them.” (iv) Internalization: This code involves adding two units of spaces to the RV (dependent variable) under the assumption that nothing happens if the value of the assessment competence feature is 1. For example, “Adds two units of spaces only if there are two or more codes with their teaching length.” (v) Enhancement: This code signifies that one feature of the assessment competence (AC) multiplies the RV. For example, “The number of codes multiplies the number of units of teaching length.” (vi) Competence: This code indicates that one feature of the RV acts as a subtractor to the revised variable (R′V′). For example, “Each space on the AC removes one RV.” Overall, CETWACCA provides a comprehensive and detailed framework for assessing teachers’ writing evaluation competence, addressing the limitations of previous validity argument approaches. The texts have been manually cleaned, and all scoring and annotations in the self-reports have been corrected. This cleaning process enhances the accuracy of computing statistics. An overview of the data used in the present study is provided in Table 1.
Descriptive Statistics Based on Teachers’ Self-Reports.
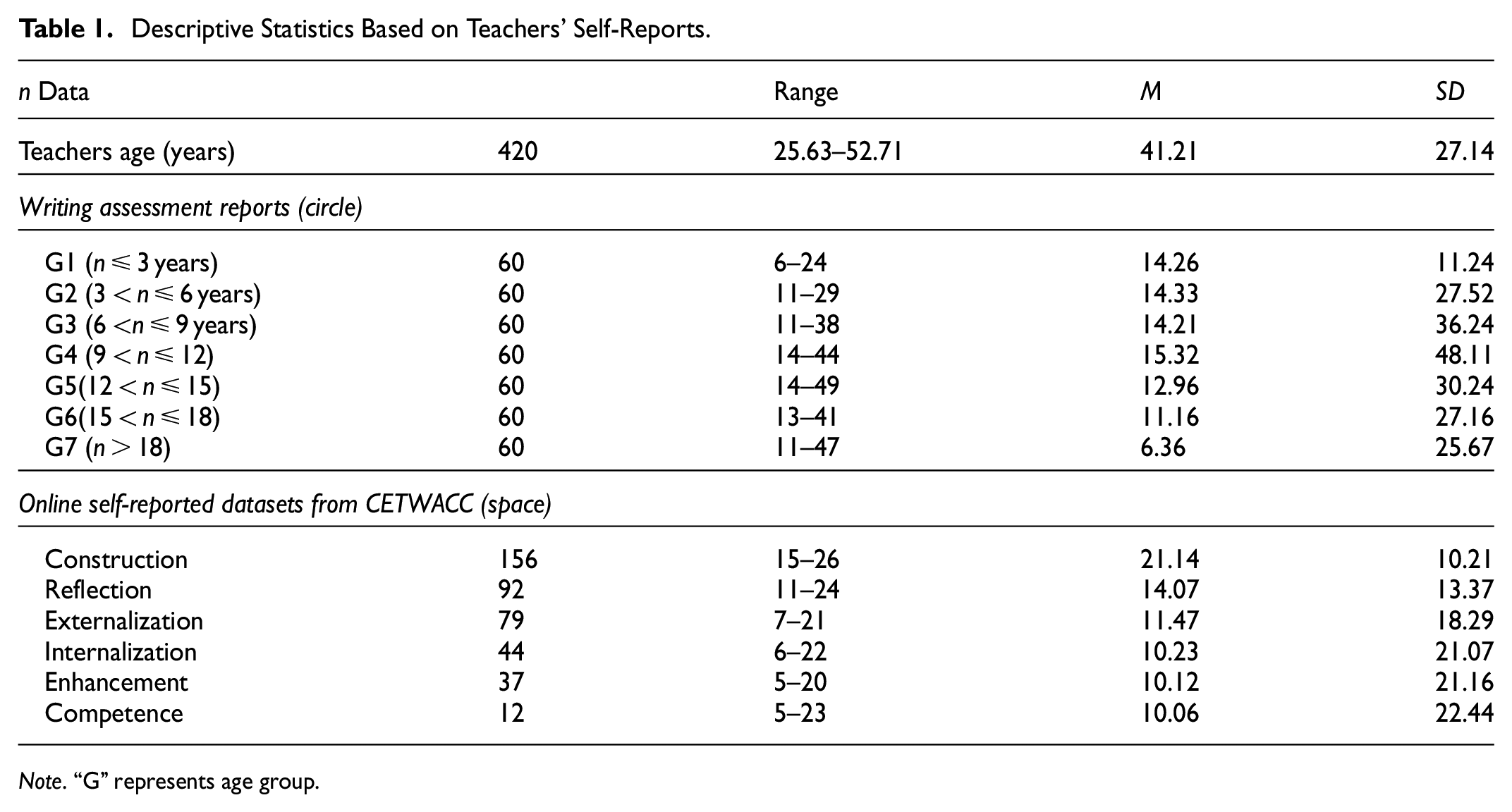
Note. “G” represents age group.
As shown in Table 1, a distinguishing feature of CETWACCA is its inclusion of self-reported data and survey information recorded by teachers across six levels of initial assessment competence (AC) within a dynamic continuum: (i) Construction (156), (ii) Reflection (92), (iii) Externalization (79), (iv) Internalization (44), (v) Enhancement (37), and (vi) Competence (12). This distribution indicates a decrease in the number of teachers from the lowest teaching level (Construction, 156) to the highest level (Competence, 12). The mean scores of teachers across different teaching ages vary significantly. For example, teachers in the age range 9 < n ≤ 12 achieved the highest mean score (15.32) across the levels from Construction to Competence, with scores decreasing from 21.14 at the Construction level to 10.06 at the Competence level. This diminishing trend in scores is evident. The performance of the self-reported information across these six levels is illustrated in Figure 2 (see Ke et al., 2023).
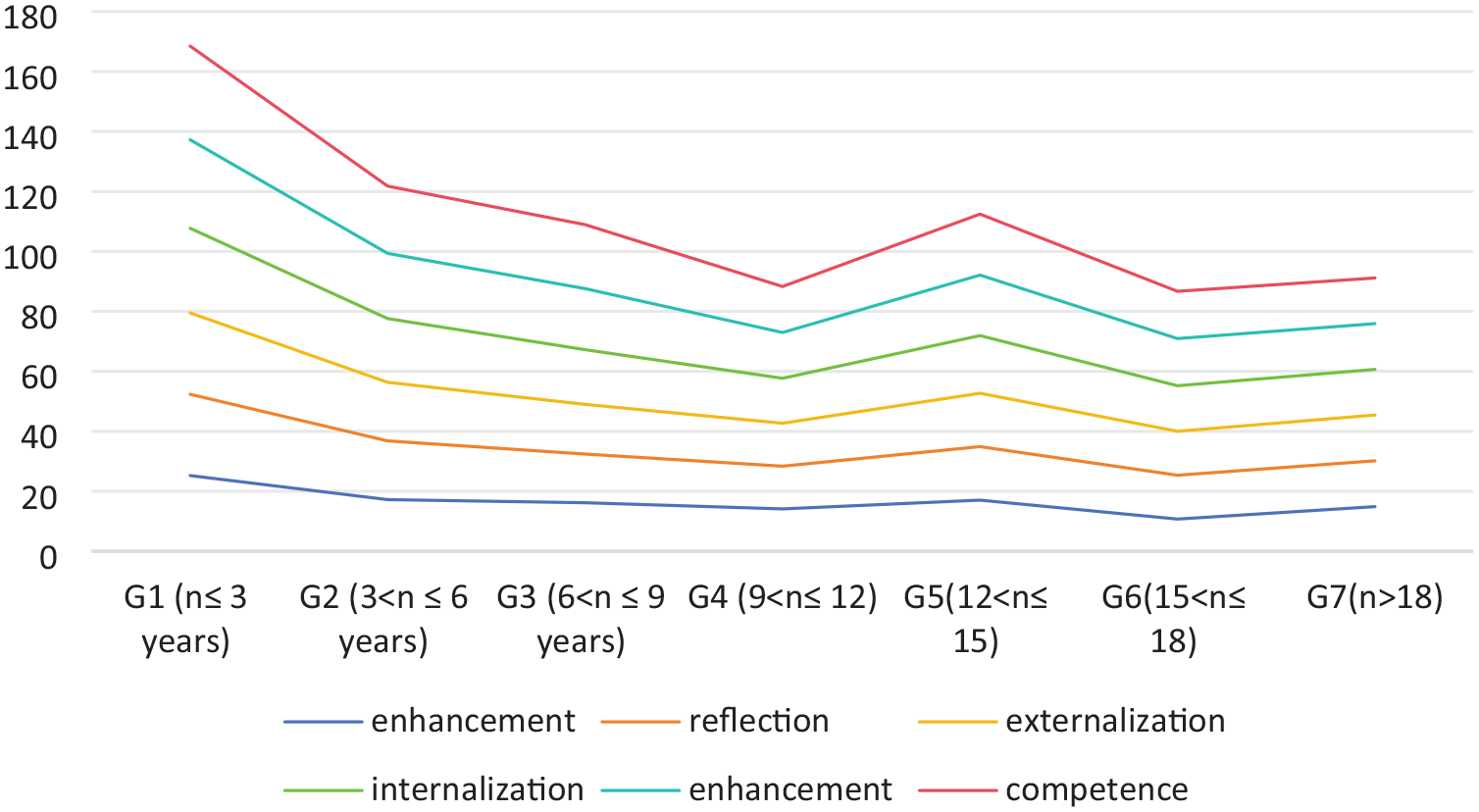
Teachers’ performance throughout the six levels.
In addition to the six levels previously mentioned, we also analyzed data across seven different teaching experience categories: G1 (≤3 years), G2 (3 < n ≤ 6 years), G3 (6 < n ≤ 9 years), G4 (9 < n ≤ 12 years), G5 (12 < n ≤ 15 years), G6 (15 < n ≤ 18 years), and G7 (>18 years). The statistical data for these categories across the six levels are presented in Figure 2. The results indicate that teachers with less than 3 years of experience (G1) are perceived as more competent compared to those in the G7 category (>18 years). There are two main reasons for this observation. First, G1 consists of newly hired employees who often meet high entry requirements, such as holding a master’s degree or higher. They have typically received systematic training in language assessment and other professional areas. In contrast, many members of G7, who have been in the profession for a longer period, are diploma or undergraduate graduates with less specialized training in language assessment. Additionally, although teachers in G7 have substantial teaching experience, it is often exam-oriented. Their engagement with quality education and assessment practices is generally lower than that of the G1 group. G7 teachers may also have less confidence and motivation in developing and evaluating language tests, particularly those incorporating digital technology.
Chinese L2 college teachers can be categorized into two groups: those who major in English and those who do not. Teachers from English-major programs are required to assess writing based on both content and tools, while teachers from non-English major programs use English primarily as a tool. This distinction results in different writing assessment competencies, as illustrated in Figure 3.
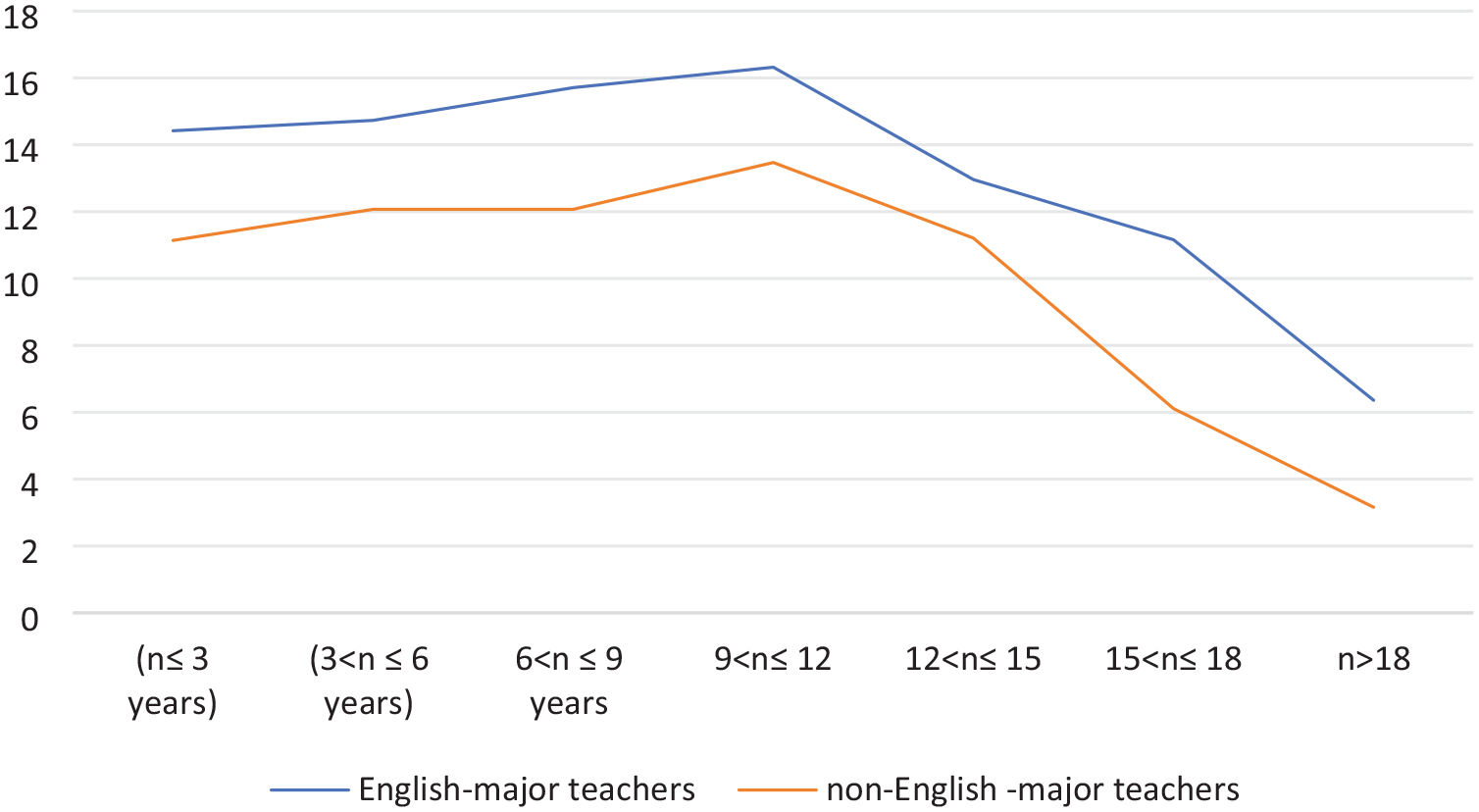
The scores for different teachers across teaching age.
Additionally, we examined whether teachers in both categories exhibited similar trends in their assessment competencies. For instance, the highest peak in competency levels is observed within the G4 category (9 < n ≤ 12). This analysis considers whether teachers were aware that their writing propositions and rating standards might differ. Such awareness could potentially influence the assessment competence requirements for L2 teachers.
Furthermore, the data from CETWACCA were collected from a total of 420 L2 teachers (256 male) with a mean age of 41.21 years. These teachers were recruited from 48 universities across 11 provinces. The sample size was determined based on an assessment competence analysis involving three between-subject conditions, with the goal of achieving a statistical power of at least 0.95 to detect a medium-sized effect (≈0.41). Participating teachers received a base payment of RMB 50. On average, completing the writing assessment task in CETWACCA took 10.18 ± 3.27 min. It is important to note that all teachers who participated in the study were included in the analysis.
Bootstrapping Construction
Quantifying Bootstrapping Items
In addressing the modular reflection and reuse of writing assessment fragments, we propose the formalization of items in writing logic of progressive items which effectively resolves the subjective and random problems in generating writing items (Hannah et al., 2023). Additionally, our work aligns with recent research by Piantadosi et al. (2016), who argues that language logic serves as a unified coding system for representing teachers’ writing assessment. To put it simply, there are mainly four steps for us to quantify the progressive items. Initially, we commence by defining a basic set of writing rating standard (s) necessary for the writing assessment, allowing for explanatory convenience while maintaining the flexibility to accommodate more subtle and computational assessment standard (s). Additionally, in the designing of writing rating, each rating item, denoted as i, is treated as a function and is bounded by its input domain assessment and output co-domain assessment, represented as iAC ⇒ iRV. Furthermore, following the exactness of quantifying writing rating, we introduce several basic rating items (performance assessment:grammatical errors, sentence structures, language logic, diction; after-effects:functions, usability, durability, value and impact; educational context :content assignment, validity argument, assessment difficulty) within our validity argument (Bachman & Palmer, 2010). These include getspace, getcircle, and getcode, all having the assessment transformation in the target of writing assessment (sub ⇒ obj). Finally, we include the rating item (getcode) with the assessment (e.g., sub ⇒ quantify ⇒ obj), as well as the rating operator (e.g., add, sub, and mult), each having the quantifying assessment (e.g., sub ⇒ operate ⇒ quantify ⇒ obj). Here get(space) means the teachers’ cognitive bootstrapping of validity argument in space or distance from argument to algorithm, get (circle) represents the status or position of AC, and get (code) stands for the basic assessment items established that promotes teachers assesseing writing from subjective evaluation to objective quantification.
For example, the term getspace (sub ⇒ obj) takes a unit of AC input through the corresponding reflection with self-report (value) representing the number of spaces on that validity argument into an additional footstep of RV. Similarly, the operator “add” takes two footsteps as the enhancement of assessment competence whereas the operator “sub” takes one footstep as the weakening of assessment competence and rating operator “mult” represents the speed of enhancement during the AC bootstrapping. Alongside these types of rating items, we also consider six progressive enhancements: 1, 2, 3, 4, 5, and 6 as they appear in the assessment levels.
To simplify the algorithm of validity argument in AC, we adopt the annotation (a), where a (getspace) represents the distance of the process of sub ⇒ obj. The algorithm incorporates four dimensions of validity arguments (i.e., illustration, evidence, content, assessment, I, E, C, and A), which play a role in the construction bootstrapping in validity argument. These four dimensions of validity argument form structures of the validity argument [framework, AC, RV]. For instance, the dimension (I) applies first level of the present AC and reflections (self-report), to the data collection of AC first, and subsequently feeds the result into the progressive proficiency into another level, RV. This is executed as AC (RV (x)). Similarly, the dimension (E) sends the statistical analysis (i.e., externalization and internalization) to the demonstration of teachers’AC, while the dimension (C) presents the designing of the rating scope, styles, and standards (i.e., content or rubric) for both teachers and students. Finally, the dimension (A) acts as an identity function that returns the new R′V′ as is. When dealing with AC variables, we concatenate the corresponding dimensions in the stratum sequence.
Item Testing Generation
We employ a tail-recursion approach, akin to Dechter et al. (2013), to effectively compose assessment items while meeting cognitive constraints. As delineated in algorithm procedure, when given a target assessment code c = co ⇒ … ⇒ tk and a set of assessment variables X = {x0, …, xn}, the algorithm progresses to the construction level with a probability of β1. Subsequently, with a probability of β2, the algorithm generates a term with the assessment progression (p) and incorporates it into the reflection level. This step is labeled as the “reflection” in algorithm procedure. The construction step commences by selecting CETWACC aligning with the externalization and internalization assessment of i (i.e., tAC(i)). Here, in our default configuration, the last element of an assessment is considered the enhancement assessment.
Inference of Validity Argument
Given the probabilistic nature of validity argument in writing assessment, effectively approximating a cognitive distribution over latent item testings poses a challenge. We employ established methods for sampling from Pitman–Yor processes (Pitman & Yor, 1997) to enable teachers to make appropriate inferences for more appropriate writing rating, conditioned on the item response testing (IRT) at any given moment. This can be accomplished through Gibbs sampling (Geman & Geman, 1984) at each iteration. Based on the progressive assessment from the previous iteration Gi − 1, an updated assessment Gi is sampled and added to the collection of writing samples.
During each iteration of Gibbs sampling, while seeking writing ratings consistent with assessment data, we employ an online progressive AC questionnaire under cognitive constraints. As the assessment space expands exponentially with depth, we hypothesize that teachers are more inclined to assess deeply rather than shallowly. Hence, we generate assessment argument (a ∝e−md), where m is a parameter controlling the depth of the assessment items.
Due to cognitive constraints, we were only able to enumerate enhancement scopes up to the depth of writing rating. However, this can result in deeply nested assessments due to iterated construction and reflection. To determine the progressive AC in e−ma, we conducted an assessment standard over enhancement indicators (0–6) alongside other procedures. With m = 0, assessment arguments 1 and 2 are equally likely, while increasing m makes the validity argument (a = 1) more preferred. The best-fitting value of m found to be 6, indicating a stronger preference for the validity argument (a = 1).
Thanks to the comprehensive bootstrapping procedure, we anticipate that our mode accurately and efficiently approximates the true assessment distribution about the teachers’ AC in the validity argument. Extensive Gibbs sampling can be computationally expensive, and running more than a few steps may not yield significant additional value. Therefore, we assume that teachers conduct only limited bootstrapping in writing assessment within each level. To approximate the population-level system distribution, we conducted 500 simulations for chains of rating depth (d). During mode fitting, we compared simulations for chains of rating depth (d = 1, 2, 3, 4, 5, 6). The analysis revealed that the best-fitting mode operates on a d = 3 chain (along with an enhancement argument). This finding strongly suggests that teachers have a bounded use of AC for bootstrapping in writing assessment. Through the cognitive bootstrapping discussed, we fit a linear regression model after each level of the AC with formula:

We made generalization predictions using fitted parameters and the requisite generalization validity argument’s bootstrapping values. Specifically, we rounded the RV segment to the two nearest integers to match the dynamic R′V′.
Mode Generalizations
By utilizing sampled sets of writing items, we employ the generative procedure of assessment competence (AC) to approximate the coding distribution over latent progressive rating items. This approach allows us to make model predictions about generalizations for new, partially observed assessment data, resulting in a concurrent distribution over these generalizations. To ensure a fair comparison between our model and three other significant models (PR, AUA, RUA), we performed a bootstrapping process over time. This procedure provided an assessment predictive model that reasonably represents the population for practical applications. It is important to note that generating the simultaneous AC model is computationally intensive. However, this level of analysis is necessary only for approximating a population-level distribution and is not required for individual participants. For data visualization and analysis, we used R version 4.2.2. All statistical analyses were conducted using the “rstatix” package version 0.7.2 with default settings. The following section describes the construction of the validity argument model.

In Algorithm VA (i, m), Each term i is treated as a function and is constrained by its two types: input and output domain type, expressed in the form cinput → coutput, with right association by Construction of present AC. Furthermore, we default the last type cn in a type c1 → … → cn to be the output type. Letting agent and recipient objects be variables with type G , we consider basic terms “Get a code, for instance, enhance,” each with type α → α|m|, term “Get a reflection, for example, RV,” with type c(GM) → i, and terms “Bootstrap AC (externalization),” each with type m′ = r (m) when i > 0, do. Additionally, The term “Enhancement variables (internalization)” → i′ = t (m′) → t (GM)i − 1 takes an object as “Assessment enhancement.” The term “Combine recursively” takes two integers VA (r′, m′) as input and returns their sum as output; and likewise for the other terms above. We also consider (i ′ ← i − 1), because these are the quantities presented in the algorithm VA (i, m). For n input variables we get RV assumption (competence) in corresponding order.
Results
Firstly, we compare the fit of our CBM to address our first research question. Secondly, we delve deeper into the best-fitting model to answer our second research question. Thirdly, we provide a summary of the computational model comparison of validity argument.
Model Fitting of CBM with Teaching Levels
To address our first research question regarding the relative effects of the CBM and three previous models, we examine the model fit for each of the competing models. Table 2 provides a summary of the fit indices for these models. In our study, we utilized several commonly-reported fit indices to assess the goodness-of-fit of the models. These include Chi-square (χ2), Comparative Fit Index (CFI), Root Mean Square Error of Approximation (RMSEA), and Standard Root Mean Square Residual (SRMR). Additionally, we also considered the Akaike Information Criterion (AIC) as a means to compare the relative fit of the models.
Model Comparison.
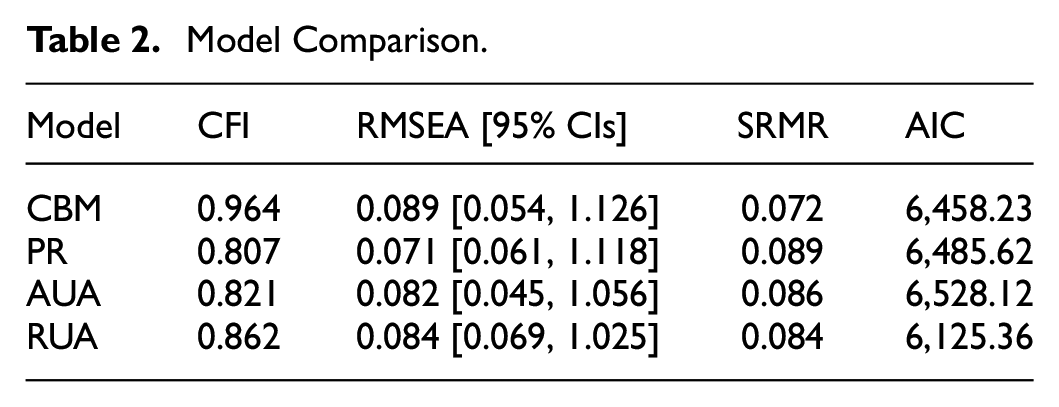
As shown in Table 2, the CBM model stands out as the best-fitting model according to all three fit indices. It also has the lowest AIC value (6,458.23). This model not only demonstrates the best fit among the four models but also shows an acceptable to good overall fit, as indicated by a CFI value exceeding 0.964 and an SRMR value of 0.072. Although the RMSEA value slightly exceeds the recommended threshold of 0.06, this is typical for models with a small number of variables.
The construction level followed the structure depicted in Figure 1b, while the reflection level focused on the roles of the circles and spaces of the RV. The externalization level maintained the initial structure of the construction level but kept circle (AC) = 1 throughout the assessment bootstrapping process, making the combination of circle (AC) × RV and RV − space (AC) clear and scientifically computable. We anticipated seeing the expression R′V′ = circle (AC) × RV − space (AC) more frequently than R′V′ = circle (AC) × (RV − space (AC)) if L2 teachers processed during the enhancement level with the reflected validity argument from the initial level. Similarly, the roles of the circles and spaces of RV were conducted differently, with key results replicating robustly over time. For simplicity, the subtle changes observed across the six levels are reported in our analysis.
Firstly, a significant difference was observed in the initial level of assessment bootstrapping between the construction and reflection levels, as presented in Table 3. Teachers at the reflection level achieved an accuracy of 4.87%, which was significantly higher than the 18.41% accuracy observed at the construction level (t(1,110) = 7.54, p < .001, Cohen’s d = 0.31, 95% CI [0.08, 0.19], chance accuracy 1/14 = 7.14%). The substantial standard deviations indicate a wide range of individual differences in progressive bootstrapping in validity argument, highlighting the subjectivity and variability in how teachers validate progressive consciousness in writing assessment. These differences are further illustrated by the self-reports in CETWACCA.
Model Fits.

Additionally, our analysis of CETWACCA records revealed intriguing findings regarding the externalization and internalization levels. Specifically, under the internalization level, 26.29% of teachers accurately demonstrated their writing assessment competence, while 27.83% did so under the externalization level (p < .001, 95% CI [0.02, 0.21]). Notably, among the teachers who believed that one feature multiplied at the assessment level, there was a strong correlation with their self-reported assessment competence under the externalization level, indicating a significant upgrading effect. Self-reports were coded based on content matching the teachers’ assessment competence, involving operators (such as multiply, subtract, or add), and incorporating appropriate reasoning patterns based on conditionals, feature positions, or relative quantities across the six levels.
Furthermore, as depicted in Figure 4, we observed that 51.61% accuracy under the enhancement level reflected a strong necessity for validity argument classified as “exactness” in assessment competence. This robust bootstrapping effect resulted in significantly higher accuracy compared to the four previous levels (p < .001, 95% CI [0.06, 0.29]). The influence of earlier bootstrapping levels on the enhancement level of the experiment was evident.

The simultaneous bootstrapping across six levels.
Lastly, at the highest level (competence), after being exposed to simpler examples, 81.38% of teachers initially provided accurate assessment reconstructions and even expanded upon their initial ideas, resulting in 81.38% accuracy at this level. Additionally, only 13.21% of teachers reported a slowness in writing assessment (p = .01, 95% CI [0.09, 0.28]). These results suggest that L2 teachers eventually reach the assessment bootstrapping stage, where their initial accurate assessments facilitate their achievement of assessment competence. This pattern supports the hypothesis that teachers reconstruct their initial levels to successfully bootstrap assessment at the highest level.
Item Adjustment in Reconstruction Bootstrapping Based on Assessment Literacy
We will now present and discuss the item adjustments made in the CBM model to examine the process of reconstruction bootstrapping and address our second research question: To what extent do indicators of teaching age influence teachers’ validity arguments? Given that CBM demonstrated an acceptable fit, we can analyze the path coefficients for each variable. The model fitting of CBM supports the idea that L2 teachers’ prior constructions of validity arguments in their writing assessments are influenced by their teaching age. Generally, this suggests that many teachers remain at the construction level, which makes it challenging for them to advance to subsequent levels. To address these issues, it is crucial to consider “item adjustment” and enhance the CBM to address the urgent need for validity arguments, especially for teachers in groups 4 through 7.
As shown in Figure 4, we observed item adjustments at two levels (reflection and internalization). At the reflection level, teachers often reused validity arguments from the initial level, focusing on classroom instruction rather than on how to propose and rate writing. This level requires teachers to stimulate their assessment competence and improve their AC bootstrapping (i.e., R′V′ = circle (AC) × (RV − space (AC))), which was not sufficiently addressed at the construction level. Additionally, if teachers predominantly used addition as their assessment mode, it was expected that they would continue to favor their original assessment competence at the reflection level.
Regarding our second research question, we found that teachers favored their assessment competence less frequently at the internalization level compared to the reflection level. The assessment bootstrapping accuracy at the internalization level was 26.29%, compared to 27.83% at the externalization level, with no significant changes between the two levels. This suggests that there are factors affecting teachers’AC as they move from the externalization to the internalization level.
Furthermore, the decrease in synthesizing teachers’AC at the externalization level was not primarily due to a shift in validity arguments about assessment competence. Instead, it was influenced by overall testing environment factors, where teachers had to accept the writing prompts, rating standards, or even the rating system as given. Teachers’ assessment bootstrapping seemed to be constrained by external factors such as an overload of teaching tasks, limited opportunities to participate in language assessment development, and the unquestioned authority of testing item allocation (e.g., Han & Liang, 2021; Shu, 2023). Additionally, nearly 76.45% of L2 teachers at the externalization level reported weaknesses in validity arguments related to assessment competence (1.29%) compared to those who enhanced their assessment competence (8.43%). This indicates that language testing remains a significant inductive problem, affecting sequential bootstrap assessment in reasoning tasks. In other words, teachers may naturally focus on external factors impacting their professional development rather than on the design and measures of writing assessments, potentially overlooking the necessity of accurate student performance.
In our CETWACCA datasets, teachers had access to all six levels of assessment examples through the assessment interface at the end of the initial level. They could freely scroll and revisit any earlier levels, which may have influenced the sequence of reflection and reuse beyond the coders’ original intentions for writing assessment. It is also important to note that we encouraged teachers to report progressive relationships across all six levels, which might have prompted intentional revisits over time.
Discussion
The current study aimed to examine the developmental trends in model fitting of CBM and the influence of teaching age on teachers’ validity arguments across six levels. We hypothesized that teachers might develop biased interpretations of assessment competence (AC) and be susceptible to test-oriented pitfalls, such as selective attention or assumptions related to randomness and subjectivity in vagueness-based writing rating standards. Previous research has suggested that varying interpretations of writing assessments arise from teachers’ differing prior beliefs (Knoch & Chapelle, 2018; Kunnan & Jang, 2009). However, our findings indicate that significantly different validity arguments can emerge among teachers due to the design of the writing assessment criteria, which may deviate from normative approaches to writing assessment. Our experiments focused on progressive assessment and quantification in abstract settings, rather than relying solely on subjective descriptions of macro-dimensions such as grammar, sentence structure, logic, and content completeness (e.g., Test for English Majors, Bands 4 and 8 in China). This approach highlights that a definitive interpretation is not guaranteed to be consistent, even among proficient teachers who critically analyze writing data using traditional rating methods. The following section will discuss the developmental trends in model fitting for CBM, while the subsequent sections will address item adjustments in reconstruction bootstrapping.
Developmental Trend of Model Fitting of CBM
The outcomes of our analysis on the teachers’ developmental trends in model fitting of CBM provide some support for potential causal relationships between L2 teachers’ development and their cognitive bootstrapping. Specifically, the status of teachers’ cognitive bootstrapping aligns with a pattern where teachers exhibit reduced attention during writing assessments, which may contribute to increased feedback for teaching and learning. This reduced attentiveness to language assessment and the educational environment may limit teachers’ opportunities to engage with the knowledge structure, leading them to focus more on teaching rather than on testing and assessment. Additionally, the CBM effect might reflect a disinterest in, or even a negative attitude towards, writing testing and assessment during language instruction, which could mirror the current state of language assessment literacy among these teachers.
These findings are consistent with previous research suggesting that teachers’ approaches to writing assessment impact the accuracy of their assessments of students’ learning status (Panadero & Jonsson, 2013; Stevens & Levi, 2005). The implications are significant, as teachers’ attentiveness and awareness regarding cognitive bootstrapping in writing assessment are known predictors of their proficiency in language assessment literacy (Knoch & Chapelle, 2018). Thus, the CBM analysis underscores the importance of examining how L2 teachers’ developmental trends in model fitting influence writing assessment. Our findings suggest that the difficulties L2 teachers face with CBM in writing assessment might be part of the broader educational influence on their daily teaching practices. However, conclusions about CBM should not be drawn with absolute certainty.
Although we observed a CBM construction linking parent distress with teachers’ cognition regarding writing assessment behavior, mediated by their attentiveness to writing assessment issues, it is possible that lower attentiveness originates from early learning and educational experiences of these teachers. Furthermore, the language assessment practices of these L2 teachers may contribute to misconceptions about language assessment (Crossley et al., 2014; Ghaffar et al., 2020; Saeli & Rahmati, 2023). These findings offer some statistical support for the mutual influence proposed by CBM and highlight that subtle cognitive changes involve considerable unexplained variance. Additionally, our data indicated that teachers placed less emphasis on their assessment competence at the internalization level. This finding aligns with previous research showing that consistent training in assessment education enhances cognitive bootstrapping (Shu, 2023; Zhao et al., 2022). This association is both novel and challenging to interpret. Future research should explore causal mechanisms with more detailed longitudinal data to more definitively assess the development of CBM.
Indicators of the Teaching Age That Influence on Teachers’ Validity Argument Across Six Levels
While L2 teachers demonstrated prior constructions of validity arguments in their writing assessments relative to their teaching age, indicators of teaching age were related to the cognitive bootstrapping model (CBM) without clear evidence linking teachers’ validity arguments through CBM variables. Greater challenges in language assessment were associated with more complex educational environments and weaker washback effects on teachers’ ability to develop validity arguments. Furthermore, our findings indicate that educational background, a rigid focus on “scores-promoting” educational policies, and higher levels of subjectivity and randomness in validating progressive consciousness in writing assessments were directly related to the development of CBM.
These findings align with previous research. For example, Chan et al. (2015) found that teachers often prioritized improving students’ scores over developing self-interactions in validity testing (see also Correnti et al., 2022). Cronbach (1988) outlined five perspectives of validity arguments but limited their application to the generation of writing test items without practical operations on large-scale texts. However, few studies have investigated the relationship between the development of indicators and the gradual nature of CBM in writing assessment. Previous research has primarily focused on the associations between teaching, learning, and testing washback, based on extensive writing manuscripts and student writing outcomes (Chapelle et al., 2008; Wollenschläger et al., 2016). These studies reported that washback effects in writing testing were linked to inadequate systematic training and cognitive bootstrapping among L2 teachers focusing on writing assessment.
Our findings, which associate teaching age with teachers’ outcomes, are consistent with prior research showing that teachers often exhibit subjectivity when scoring writing tasks due to the vague and subjective nature of the rating standards (Sawaki & Koizumi, 2017). This contrasts with past findings by Dechter et al. (2013), who addressed simpler assessment problems. The differences in findings may stem from the varying degrees of gradualness between the two studies. Dechter et al.’s research, based on a smaller sample of teachers’ static language assessment literacy, differs from the current study’s focus on the gradual and continuous nature of CBM. This comparison highlights the variability in study designs, particularly in terms of sample sizes and measures used.
To our knowledge, this study is the first to explore the association between teachers’ CBM and their evolving cognition regarding writing assessment relative to their teaching age across six levels. As such, these results provide novel insights into the relationship between these two variables.
Model Comparison
We conducted an analysis of CBM bootstrapping in comparison to three prominent validity argument models (PR, AUA, and RUA) to evaluate their effectiveness in observing teachers’ validity arguments during assessment bootstrapping. Initially, we utilized an assessment bootstrapping model based on the validity arguments described in the previous section.
There are three similarities between CBM and the three validity argument models. Firstly, validity issues. All four models address a series of validity claims and reasons that require substantial evidence to demonstrate the reasonableness of these quality attributes. Secondly, mode construction. All four models indicate that validity-inference effects and significant effects observed by teachers can be explained as outcomes of a reflection-and-construction mode that expands the capabilities of a bounded assessment mode. Thirdly, accuracy pursuit. All these models systematically achieve accuracy of writing validity because they assign equal assessment probability to the intended teachers’ assessment competence and equivalent-consistent assessment competence.
Likewise, there are three differences between CBM and the three validity argument models. Firstly, inference promotion. The PR model highlights the process of drawing conclusions (claims) from factual information through deductive inference with adequate explanation and pertinent evidence for interpretation and validation. The AUA model emphasizes the “consequences” connected to writing decisions and the accuracy of these decisions influenced by our inference of assessment abilities. The RUA model emphasizes the value chain from scoring consequences to scoring inference (scoring metrics). In comparison, CBM, based on Goodman et al. (2008), assumes simultaneous validity argument as the previous assessment in previous modes but incorporates probabilistic assessing for prior assessment, as specified by the assessment standard in the Formalization (also described in the Methods section).
Secondly, logical routes. The PR model relies largely on the rational aspects of reliability of “evidence” and the validity of “rebuttals,” which provides the route for the utilization of argumentation in language tests for research examination paradigm validity originating from the practical reasoning model. The AUA model demonstrates a reasonable logical route of teachers’ AC that requires a scientific “assessment” of them, and the assessment methods and processes are inseparable from the sampling of assessment performance. The RUA model underlines that promoting assessment is the expected logic and purpose of grading, which improves assessment quality. In comparison, CBM foregrounds quantifying generalizations in the computing route, capable of generalization but without explicit logical guesses.
Thirdly, processing construction. The PR model emphasizes data, backing, warrant, qualifier, rebuttal, and claim. The AUA model emphasizes consequences, decisions, interpretation, and assessment, forming a systematic logical chain and constituting a logical inference requiring supporting evidence and demonstration for each argument clue. The RUA model reinforces rating scales of scoring consequences, scoring feedback, ability explanation, and scoring elements, forming a chain of argumentation. In comparison, CBM emphasizes the construction of bootstrapping construction, reflection, externalization, internalization, enhancement, and assessment with a computing route.
Overall, CBM provides a much more comprehensive explanation of teachers’ progressive patterns in the experiments compared to other considered modes. This indicates that both the validity-argument effects and the significant effects manifested by teachers can be explained as outcomes of a reflection-and-reconstruction system that expands the capabilities of a bootstrapping system. Importantly, the progressive bootstrapping can be accounted for by a simultaneous computing mode, underscoring the central role of a cognitive system for teachers’ inductive inference for validity argument.
Implications
These results carry significant pedagogical implications, particularly within the Chinese educational context. Teachers’ engagement with validity arguments presents both opportunities and challenges in educating and nurturing students while integrating ideological elements into classroom instruction. One notable challenge, as highlighted in the literature, is bridging the gap between focusing on educating “students” and improving “scores” (see, for example, Shu, 2023). To address this issue, Pan (2019), a prominent figure in Chinese language testing, proposed a pedagogical model known as “pedagogy ideology,” which incorporates a series of educational books by President Xi Jinping.
Regarding validity arguments, which pose specific difficulties for Chinese teachers, particularly in middle schools, initial guidance should ensure that teachers possess the requisite assessment skills and qualifications. This guidance should focus on issues related to writing, including writing targets, prompts, process assessment, rating criteria, rater training, and the application of writing assessments. The insights gained from examining L2 teachers’ cognitive bootstrapping in validity arguments for writing assessments provide valuable information about student performance, highlighting both strengths and areas for improvement. For instance, if many students consistently make grammatical errors or struggle with argument structure, teachers can identify specific aspects of writing that need additional focus in their instruction.
Firstly, cognitive bootstrapping methods (CBM) offer insights that can help teachers tailor their instruction to better address students’ needs. For example, if a class collectively struggles with thesis statements, a teacher might allocate more time to this aspect, incorporating targeted exercises and providing focused feedback. Additionally, cognitive bootstrapping enables educators to monitor student progress over time. By comparing assessments from various points throughout the year, teachers can observe skill development and adjust their teaching strategies accordingly.
Moreover, constructive feedback derived from cognitive bootstrapping in validity arguments helps teachers recognize and learn from their mistakes, promoting improvement in writing assessment practices. Teachers can use these results to set specific, measurable goals. For example, if a student aims to improve their use of transitions between paragraphs, the teacher might focus on enhancing critical thinking in writing assessments.
Furthermore, data from writing assessments can reveal gaps in the curriculum. If assessments indicate that students are lacking certain skills, educators can revise and enhance the curriculum to address these deficiencies, thus better supporting student learning. Cognitive bootstrapping also encourages students to reflect on their own work, aiding their development of critical thinking and self-regulation skills, which supports their overall academic growth.
Finally, analyzing cognitive bootstrapping in validity arguments ensures that all teachers, regardless of their background or ability, receive the necessary support. This approach helps address achievement gaps and provides additional resources or interventions where needed. By designing assignments that require analysis, synthesis, and evaluation, educators promote deeper learning and critical engagement with content. Therefore, the present study addresses assessment challenges, shapes, and enhances educational practices, providing valuable information that can lead to more effective teaching strategies, improved curriculum design, and better assessment outcomes.
Future Directions
Based on the main findings discussed, the trajectory of progress in our assessment bootstrapping through the testing environment suggests several intriguing future research directions. Firstly, Bachman and Palmer (2010) reviewed performance in writing assessment and highlighted that assessment competence (AC) is constrained by cognitive limitations. Instead of merely being passive recipients of information, it seems more plausible that teachers engage in validity argument-driven item testing, which influences their selection of an appropriate subset to form a comprehensive picture of AC. Future studies could build on our cognitive bootstrapping model (CBM) by exploring active assessment scenarios and investigating data-seeking assessment directions within the domain of validity arguments. Secondly, the recycling of reflection and regurgitation can enhance validity arguments by refining representations of AC. Future research should examine the extent to which scoring criteria are critical manifestations of various dimensions of language proficiency. Further investigation is needed to quantitatively explore scoring scales that reflect measurement features (Woods et al., 2023) and ensure that these scales align with the intended test constructs (Bachman & Palmer, 2010; Lallmamode et al., 2016). Thirdly, recent advancements in neuroscience related to writing assessment have begun to reveal how the brain engages in non-parametric computations and latent progressive inference, offering insights into representational status. A challenge in the assessment framework utilized here is the close link between our validity argument representations and their embodied sensory consequences. Future research could explore how computing operations assess images with such deeply embodied representations.
Limitations
Inevitably, this study has several limitations that could be addressed in future research. For example, our analysis relied on a deterministic likelihood model. Additionally, our model did not incorporate validity arguments from previous assessments involving conditionals, which limited its ability to account for all the “out-of-control” self-reports made by teachers when interpreting assessment competence. Future research could address this by either incorporating more foundational previous assessments or by adopting an if-else validity argument framework. Moreover, there are various alternatives to the writing logic used to evaluate our writing tasks. For instance, considering the quantification of validity arguments as fixed indicators might suffice for primary logic rating. To extend our quantification approach to lifelong assessment, it would be beneficial to incorporate a simultaneous assessment competence model where assessments are considered in conjunction with other factors.
Conclusion
We emphasize the central role of validity argument bootstrapping in enhancing teachers’ assessment competence and propose a computational approach to this process. Our study highlights the importance of cognitive inference algorithms, particularly the six teaching levels and teaching age, in parsing assessment competence (AC) within a fully subjective rating environment. Our findings reveal the critical role of item design, from qualitative to quantitative ratings, in addressing the challenges of writing assessment. We hope this research will not only advance the understanding of validity arguments in writing testing but also promote the development of data-driven writing assessments through computational methods.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: National Social Science Project of China (A Study on the Validity Argument Model of Digitally Empowered Foreign Language Writing Assessment, 23BYY162).
Ethical Approval
The authors assert that all procedures contributing to this work comply with the ethical standards of the relevant national and institutional committees on human experimentation and with the Helsinki Declaration of 1964 and its subsequent amendments.
Consent to Participate
Informed consent was obtained from all the participants.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation. All research data can be open-shared free in Dataverse.