
Abstract
Review popularity is similar to awareness and information accessibility components: Both have a profound effect on customer purchase decisions. Therefore, this study proposes a new method for predicting online review popularity that combines the extreme gradient boosting tree algorithm (XGBoost), to extract key features on the bases of ranking scores and the skip-gram model, which can subsequently identify semantic words according to key textual terms. Findings revealed that written reviews had higher review popularity than non-textual reviews (reviewer and product factors). Moreover, the proposed method achieved higher prediction accuracy than the traditional ridge regression technique of Root Mean Squared Logarithmic Error (RMSLE). The main factors affecting review popularity and key reviewers for specific textual terms were also identified. Findings could help vendors identify key influencers for their product promotion and then support the design of word-suggestion systems for online reviews.
Keywords
Introduction
In recent years, together with the rapid growth of the internet and web 2.0 applications, numerous online products related to word-of-mouth (WOM) communities have emerged that provide user-generated content (e.g., online product review) conveniently and at low cost (Ghose & Ipeirotis, 2010). Hence, customer reviews have become today’s electronic WOM (eWOM) for the current generation of customers and business managers. Reviewers on these online platforms devote time and energy to writing reviews and sharing useful information with prospective consumers to help them evaluate products and make purchase decisions (Zhao et al., 2013; Zhu & Zhang, 2010). Online reviews are therefore particularly important in the purchase of products and services, as a source of advice for consumers to narrow the information gap and reduce uncertainty in their decisions (Dimoka et al., 2012). Service providers and manufacturers value these online reviews because they may reveal genuine concerns of online customers and provide useful market intelligence (Forman et al., 2008; A. H. Huang et al., 2015).
Online consumer reviews are accessible to many readers online; readers often perceive online reviews as more credible and more trustworthy than traditional advertising (L. Huang et al., 2007). Based on these advantages, prior studies on online reviews have focused on the effect of reading reviews on readers’ attitudes (Doh & Hwang, 2009; M. Lee et al., 2009). These studies serve as conceptual antecedents of some decision and behavioral outcomes of interest (e.g., purchasing a laptop computer, movie, or camera).
The number of readers who have been attracted to reading an online review is called review popularity; a review with high review popularity is considered attractive, similar to awareness components (awareness and knowledge on the product, favorable attitudes or feelings toward the product, and action on the acquisition of the product) and information accessibility components (ambiguous information and nonambiguous information; J. Wu, 2017). Therefore, obtaining high review popularity is critical for driving sales; a review with many readers means potential for more reviewers who will create further online reviews—an effective strategy for promoting products (R. Huang & Sarigollu, 2012; Luan et al., 2019). Moreover, to inspire other people to read a review, the review content written by a reviewer is a crucial factor. However, optimal selection of key reviewers from many reviewers must still be answered (Y. M. Li et al., 2011). Therefore, investigating what factors influence review popularity and how to select key reviewers are relevant questions for research scholars and online marketers.
A few studies in the existing literature on eWOM analyze factors of online review popularity, mostly focused on helpfulness prediction based on helpfulness votes (Chua & Banerjee, 2016; Ghose & Ipeirotis, 2010; Hu & Chen, 2016; S. Lee & Choeh, 2016; Z. Liu & Park, 2015; Mudambi & Schuff, 2010; Siering et al., 2018; Yang et al., 2020). To evaluate the helpfulness of reviews, these studies selected famous websites, such as Amazon and Trip Advisor, where online readers can submit review helpful votes. However, review helpfulness cannot be determined if the voting mechanism is ineffective, or without a helpful vote function; furthermore, there may be cases where new reviews are yet to receive votes, which would mean that their level of helpfulness could not be determined (Singh et al., 2017). In these cases, the review popularity can be used to estimate the helpfulness evaluation, as the two are closely related favorable attitudes toward product (J. Wu, 2017). In addition, previous studies analyze the effectiveness of online reviews using many aspects, such as sentiment factors, review extremity, review length, review depth, product type, review title, and review content for helpfulness prediction. However, a combination of reviewer characteristics, product description, and the nature of the words used in the reviews have not been extensively investigated in these studies.
This study predicts online review popularity for cosmetics using a new method that combines the extreme gradient boosting tree algorithm (XGBoost) and the skip-gram model to analyze the effect of non-textual reviews (reviewer and product-related factors) and textual reviews. It has been observed in previous investigations that the type of reviewer, product features, and review content contribute the most to the prediction of reviewer popularity. Taiwan’s cosmetics industry accounted for 0.7% of the global cosmetics market, valued at approximately US$4 billion. Skincare products accounted for 52.4% of the value (Taiwan Cosmetic Market, 2018). The beauty market’s heaviest consumers are also the most likely to engage in online reviews, with more than 70% saying that comment posts motivate them to buy products (Stargage, 2017). By proposing a new method to investigate the factors that affect online review popularity, this study addresses four research questions:
The study primarily aims to predict online review popularity, where the popularity level is defined based on the total number of users who read the review. Two types of popular machine learning methods were used for the experiment: ridge regression and XGBoost. An effective prediction model for review popularity is built using the XGBoost method. Theoretically, the results of this study contribute to prior research in eWOM by highlighting the influential role of textual reviews and their contribution to review popularity. More specifically, the research sheds light on the strong relationship between important textual review terms and their semantic words in the comments and review popularity. The practical contribution is based on the study’s proposed model: Online vendors can analyze customers’ online reviews to identify important terms that are then recommended to reviewers for use to achieve high review popularity, which will increase company sales. The findings could also help vendors to identify key influencers for their product promotion. The major contributions are summarized as follows:
The study highlights the importance of certain textual terms and semantic words for review popularity.
The study builds an effective model to predict the popularity of online reviews using a combination of the XGBoost and skip-gram models.
It employs two different machine learning methods to study prediction models.
It extracts the important values of non-textual and textual review features and determines the key factors that increase review popularity.
It helps online retailers to develop online marketing strategies and word-suggestion systems to support reviewers in achieving high review popularity. In addition, the study identifies key reviewers for product promotion.
The rest of the article is structured as follows: The “Literature Review” section reviews the related literature and is followed by the methods of data collection and analysis in the “Research Methodology” section. The results are presented in the “Results” section. Next, the “Discussion” and “Implication” sections presents the discussion and implications. The “Conclusion” section provides the conclusion. Finally, the “Limitations and Future Research” section outlines the study’s limitations and directions for future research.
Literature Review
eWOM
WOM is a consumer-dominated channel of marketing communication where the sender is independent of the market (Brown et al., 2007). The development of network technology and the ubiquitous distribution of the internet have transformed traditional face-to-face WOM communication into eWOM communication. Consumers now use the internet to share experience and options by writing their product experience and reading peer consumers’ product evaluation on different platforms, such as retailers’ websites, brand communities, independent websites, customer blogs, and so on (M. Lee & Youn, 2009). Online customer reviews therefore affect consumers’ purchase decisions (Zhao et al., 2013), company product sales (Zhu & Zhang, 2010), and online helpfulness evaluations (Malik & Hussain, 2018; Singh et al., 2017). Online customer reviews are a type of eWOM: Customer reviews are more reliable than the information provided by sellers because they offer noncommercial, detailed, experiment-based, and up-to-date information (Hennig-Thurau et al., 2004; Yoo & Gretzel, 2011). Moreover, online reviews influence consumers and businesses considerably because they transcend spatio-temporal limitations by enabling simultaneous communication among numerous people (Bickart & Schindler, 2001).
In an online WOM environment, while some consumers provide experience-based product information (reviewers), others read product information provided by peer consumers (readers). Researchers have examined the effect of online reviews from different perspectives. For instance, online reviews influence e-commerce sales and people’s awareness of products (Álvarez et al., 2007; Chevalier & Mayzlin, 2006; Godes & Mayzlin, 2004); a study by Cheng and Ho (2015) indicated that readers considered reviews more practical and useful when written by reviewers with many followers, a high level of expertise in review writing, and high image and word counts. Other studies have investigated the effect of online reviews on consumers’ purchase decisions and evaluations (Hung, 2017; Kumar & Benbasat, 2006; D. Yin et al., 2014; Zhao et al., 2013). Another stream of research has explored the moderating role of product and consumer-related characteristics in the effect of online reviews, including product involvement and reviewer self-disclosure (Zhu & Zhang, 2010). In the advertising field, most studies have focused on exploring the effect of online reviews and their influence on product attitudes (Zablocki et al., 2019) and brand awareness (Zhao et al., 2015). Other research has investigated factors that influence online review readers’ evaluation of review helpfulness, for instance, the rating of a product based on the sentiment score of a review (F. Wang & Karimi, 2019) or on the linguistic category features of the text (Krishnamoorthy, 2015). These studies have concluded that online product reviews increase interaction among customers, customer ties, and the frequency and amount of time customers spend on a website (Mudambi & Schuff, 2010).
This study analyzes the effect of experience goods (cosmetics) reviews on review popularity; the use of influential review content, reviewer variables, and product factors in the prediction model offer robust results.
Online Non-Textual Reviews
Reviewer-related factors
Online retailers increasingly seek to understand reviewer factors’ influence on online reader trust, usefulness evaluation, review popularity, and purchase decisions (Y. Liu et al., 2008; D. Wang et al., 2013), and how to strategically utilize these factors to drive business. Previous literature on online reviews has focused on reviewer self-disclosure (e.g., name, photo, location, and gender); the literature describes disclosure in various ways: as communication of personal information, thoughts, and feelings to other people (Srivastava & Kalro, 2019); cultural background, gender, age, and personality (Gao et al., 2017); reviewer information display on the website (Racherla & Friske, 2012); reviewer characteristics, such as nicknames, hobbies, and interests (Ghose & Ipeirotis, 2010); and disclosure of personal identity, expertise, and reputation (Z. Liu & Park, 2015). Hu and Chen (2016) demonstrated that the time a reviewer published a review, the number of days that the review remained visible, and the number of reviews with the same rating at the time of the review all had an impact on the evaluation of the helpfulness of the review. In addition, another study considers user information, venue, and content factors to predict the popularity of micro-reviews (Vasconcelos et al., 2014).
One reason that reviewer characteristics have an impact on online consumers is that they are an indicator of the credibility of the review source (X. Wu et al., 2020). Both online reviews and retailer websites provide a variety of information about reviewers, including rankings, summaries of past contributions, and special badges, such as top 50 or 100. Based on that information, consumers infer credibility, and this affects their evaluation of the reviews (Ghose & Ipeirotis, 2010). In addition, online review system characteristics and informant characteristics have an influence on the perceived informativeness and trustworthiness of review popularity, from the perspective of readers: These factors ultimately affect readers’ intention to use the related service (Johanes et al., 2016). In this study, we extend the reviewer factors of online WOM communication by analyzing reviewer factors’ effect on review popularity; the factors include reviewer gender, age, active index on the website, reviewer star sign (e.g., Leo, Aries, Taurus), reviewer’s related topics, number of articles written by a reviewer, review publishing date, and how a reviewer experiences products.
Product-related factors
Given that potential consumers often lack experience with products due to physical distance (Kim, 2014), they usually compare alternative products based on information found in reviewers’ product evaluations in the comments, such as appearance, quality, and practical value of a product (X. Li et al., 2019; D. H. Park et al., 2007). Product uncertainty refers to consumer’s difficulty in evaluating product attributes and predicting how a product will perform in the future, which is a major impediment to online markets (Dimoka et al., 2012). When consumers consider buying products online, they often read online reviews about the products to understand the features of the products. Each product has multiple features, and consumers have different preferences for each feature of each product. Therefore, it is necessary to solve the problem of product feature extraction based on online reviews (Fan et al., 2020).
Many scholars have pointed out the importance of product feature extraction from different perspectives. For instance, a study conducted by Zhu and Zhang (2010) considered product categories and consumer characteristics in relation to consumers’ evaluation of online review helpfulness. D. Wang et al. (2013) proposed the SumView technique, which is a web-based review summarization system for automatically extracting the most representative expressions and customer opinions on various product aspects. This method can lead to more user satisfaction than the results without summaries. Mudambi and Schuff (2010) adopted a linear regression model to investigate the characteristics of helpful online reviews on Amazon.com. Their findings revealed that review extremity, review depth, and product type were prominent factors with respect to helpfulness.
The current study proposes a new method to analyze the dimension of product factors such as brand, rating, attribute, and pictures in a review. In our proposed method, these factors are ranked based on their relative importance in contributing to increase review popularity.
Textual Review
Understanding the factors of a review that attracts popularity is crucial for both vendors and reviewers (Liang, 2016). Vendors invest substantial resources in content engineering and are constantly seeking optimal means of managing and improving the digital content in their portion of cyberspace. Therefore, knowing what makes a review attractive is critical to effective content engineering and the overall success of their internet marketing efforts. Empirical research has indicated that two main components influence the value of reviews: review content of the review itself and sentiment of review (Al-Natour & Turetken, 2020). The first component has been investigated in previous studies to assess the value of a review by analyzing its content, such as review depth (Bjering et al., 2015; S. Lee & Choeh, 2016), review length (Eslami et al., 2018), writing style and timeliness of the review (S. Park & Nicolau, 2015), and signals expressed in the review content and basic text characteristics (Huffaker et al., 2011; Siering et al., 2018).
The second component affecting readers in their evaluation of a review’s content is the sentiment of the review or text readability (Korfiatis et al., 2012; F. Wang & Karimi, 2019). Previous literature has shown that a message generated by a person with high credibility is more persuasive, leading to greater behavioral compliance (Butler & Wang, 2012; Crisci & Kassinove, 1973; Pavlou & Dimoka, 2006) and a higher level of acceptance of the suggestions offered by the person (Suzuki, 1978). Ghose et al. (2012) proposed a new ranking system for hotel search engines that mine consumer reviews and considered the readability of the review as a major factor. Their study found that content was the most critical aspect of a review. To present effective information, a review should be precise or easy to understand and without ambiguity, which refers to how easily a text can be understood by readers (Klare, 1974). Recently, a study by Yang et al. (2020) indicated reviews with similar text in title and content as more helpful; title sentiment positively affects review helpfulness and negatively moderates the relationship between text similarity and review helpfulness. In addition, informativeness, as a variable for identifying helpful reviews, significantly improves the accuracy of predicting review helpfulness compared with review length (Sun et al., 2019). Reviewers’ linguistic styles (e.g., shouting, immediacy, and evidence-based) are significantly important for product search and for product experience capitalization, and are evidently positively correlated to their helpfulness ratings (T. S. Li et al., 2019; Ludwig et al., 2013).
In line with our objective, the study used XGBoost to extract the important word features that reviewers use in their reviews based on importance score ranking. It then employed the skip-gram model to identify semantic words according to these important features to predict review popularity; key reviewers were identified based on the frequency of using important words in their reviews.
Research Methodology
Based on the objective of the study, the proposed method has five major stages, as presented in Figure 1. Following data collection from the website Urcosme (https://www.urcosme.com/), preprocessing was performed to eliminate redundancies, irrelevant information, and punctuation. Term frequency–inverse document frequency (TF-IDF) was then utilized to assign a weight to each word for input to the prediction model, depending on its value as an independent variable. To predict review popularity, two machine learning algorithms, XGBoost (T. Chen & Guestrin, 2016) and ridge regression (Y. R. Chen et al., 2018), were used to construct two classifiers individually for comparison. Furthermore, a fivefold cross-valid strategy was applied to train and test classifiers. In the fivefold cross validation, the original data set was randomly partitioned into five equal-size subsamples. Four folds were merged to form a training data set. The fifth fold was used as the testing data set. This process was then repeated five times. The outcomes of the above prediction models were compared with the objective function of the Root Mean Squared Logarithmic Error (RMSLE) to select the model with the optimal performance and minimal values of RMSLE. We next selected the model with the best performance in feature selection to identify key features from textual and non-textual variables that significantly contributed to creating review popularity. We used the skip-gram model (W. Zhang et al., 2018) to determine semantic words related to the crucial textual reviews and to identify key reviewers based on frequently used words in their reviews.

Proposed research model framework.
Data Collection
The data in this study were collected from urcosme.com, which is one of the most famous cosmetics and skincare product review websites in Taiwan. The website provides user-generated content regarding experiences using the products, product opinions, as well as a shopping cart. Skincare products are chosen as the focal items in our study as it takes up the highest percentage rate with 52.4% in the total Taiwan Cosmetic Market (Taiwan Cosmetic Market, 2018). Web crawler and R programming were selected to scrape data. Data scraping is a technique performed by a computer program to extract data from the human-readable output from a platform. A total of 540 reviewers who wrote reviews on the product name WHITIA lotion in the category of skincare products were chosen, yielding 127,135 valid reviews in total. The TF-IDF algorithm produced columns of 50,000 variables of preprocessed words.
User information published on the website includes reviewer gender, skin type, age, star sign, topics, index, article type, and article number. We distinguished between two types of review features: features of the review text and non-textual variables related to user and product information. Table 1 lists the details of our study’s review features. We investigated the effects of these factors on review popularity, that is, the dependent variable measures the number of people with access to read the review content; high popularity indicated that the review content comprised helpful information and consequently attracted relatively many viewers (J. Wu, 2017).
Study Review Features.

Data Processing
Chinese word segmentation
Chinese word segmentation is a key step to improve the accuracy of various types of Chinese text processing, such as speech recognition, machine translation, and language understanding (H. Li & Yuan, 1998). This study utilized “Jieba” for Chinese word segmentation. To the best of our knowledge, “Jieba” is the most general, stable, and easy-to-use technique for segmenting Chinese words.
Stop word removal
Stop words are frequently used in descriptions, such as “the,” “are,” “and,” and “a.” These words have little or no relevant meaning and thus limit the efficiency of information retrieval (IR). The Sklearn package in Python was used to eliminate such words.
TF-IDF
TF-IDF is often used in IR and text mining to determine the significance of a word in a corpus of documents (Ramos, 2003). In our data framework, we defined the TF-IDF weight
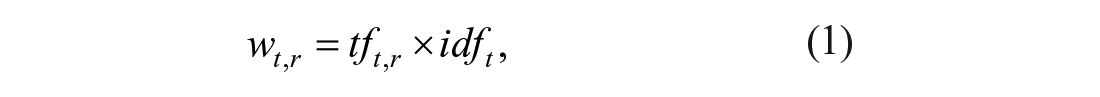
where
N-gram
We used the n-gram model to evaluate “n” continuous words in a review text and predict the subsequent item in a sequence. In sentiment analysis, the n-gram model helps analyze the sentiments of texts or documents. Unigram refers to an n-gram of size 1; bigram refers to an n-gram of size 2; trigram refers to an n-gram of size 3; any higher n-gram term refers to some n-gram of size 4 or higher. Examples of unigrams include “the,” “food,” “is,” “not,” and “delicious,” where a single word is considered, and its bigrams are “the food,” “food is,” “is not,” and “not delicious,” where word pairs are considered.
Prediction Model
Among various machines learning methods, we selected ridge regression and XGBoost for predictive model as a robust and effective machine learning method in prediction. XGBoost is a boosting algorithm belonging to supervised learning, which is an ensemble algorithm based on gradient boosted trees. It integrates the predictions of “weak” classifiers to achieve a “strong” classifier (tree model) via a serial training process, and it can avoid overfitting by adding a regularization term. Parallel and distributed computing hastens the learning process to enable a quicker modeling process (T. Chen & Guestrin, 2016). Ridge regression was used to enhance extreme learning machine as proposed by G.-B. Huang et al. (2006), which is a novel single hidden layer feed forward neural network, where the input weights and the bias of hidden nodes are generated randomly without tuning and the output weight is determined analytically. It is also an extreme learning machine as it owns an extremely fast learning algorithm and good generalization capability (G. Li & Niu, 2013).
Ridge regression is a statistical method for modeling a linear relationship between a dependent variable and independent variables. This technique plays a major role in various machine learning algorithms, especially in the field of e-commerce, in which ridge regression is utilized to analyze a data set on the basis of user profiles and comments; and it summarizes them in a compact form to investigate item relevance for users (Y. R. Chen et al., 2018). Researchers recently conducted a study on the basis of feature selection in document retrieval. Findings showed that the ridge regression model has given the same or even better performance results compared with logistic regression and support vector machine algorithm (Aseervatham et al., 2011; T. Zhang & Oles, 2001); those methods are extensively adopted in previous research to assess the effect of online reviews.
The boosting method has been remarkably successful in terms of predictive performance (Zięba et al., 2016). For the XGBoost model parameters, we used xi and yi as independent variables to represent a total of 50,000 words, with k features and n observation values. Next, following the method of another study (T. Chen & Guestrin, 2016), a tree ensemble mode was constructed using m additive functions to establish the regression model for the current study and predict review popularity

where
Key Feature and Word Feature Weight of the Fractional Mode
After creating the basic XGBoost regression tree hypothesis, we can define the loss function as Equation 3 for the regression model of this study.


The loss function Equation 3 is set to a differentiable function, and the first term of Equation 3 is used to estimate the difference between the predicted review popularity
We added the regression model to the regression tree of the previous

The second-order approximation identified in a study conducted by Friedman et al. (2000) was then used to implement the Taylor series from Equation 5 and obtain

After removing the constant term, Equation 7 is obtained:

Expanding the penalty term enables the calculation of Equations 8 and 9.

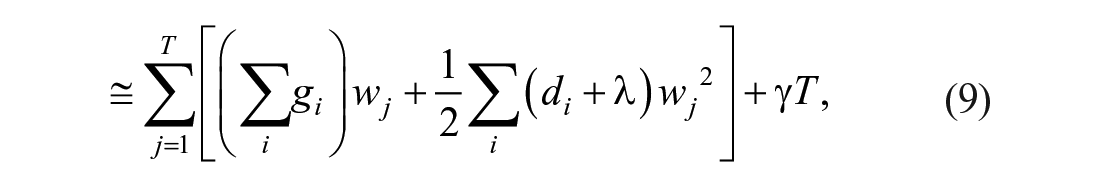
where j is the branch of each regression tree. By letting

Then, we differentiated the weight

Weight

Next,

Additional accurate predictions are produced when the value of



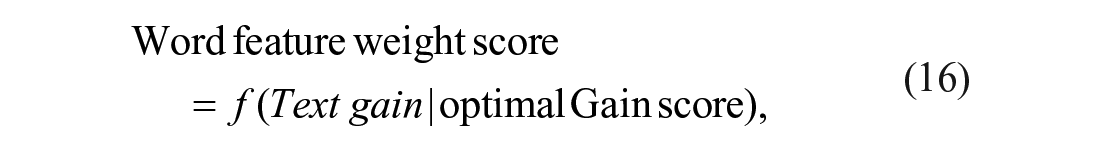

For example, identifying the right split (R: word-skincare) and left split (L: word-moisturizer) branches as optimal for minimizing the undivided branch and leaf scores relative to other variables, as in Equation 18, would indicate that the weight score of R in Equation 19 is greater than that of L in Equation 20. We can then obtain the word feature using Equation 21 with word-skincare and word-moisturizer as the first and second features selected.





Identify Semantic Words
After obtaining keyword features with

We predicted word

Mechanism of the Skip-gram model for identifying key words and semantic words.
The skip-gram model defines
Negative sampling is suggested by W. Zhang et al. (2018) in solving the problem to calculate
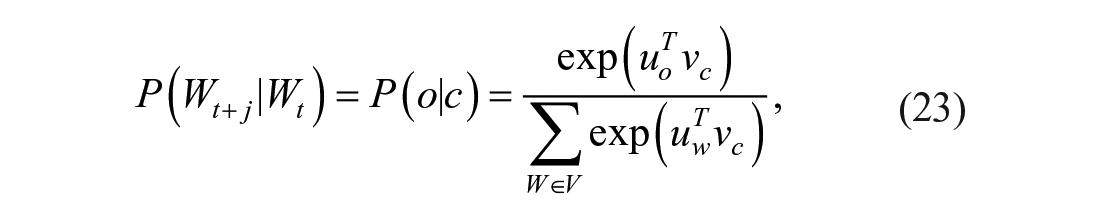
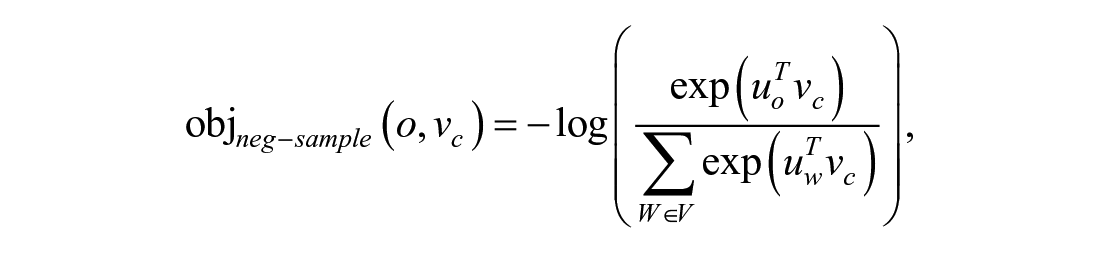
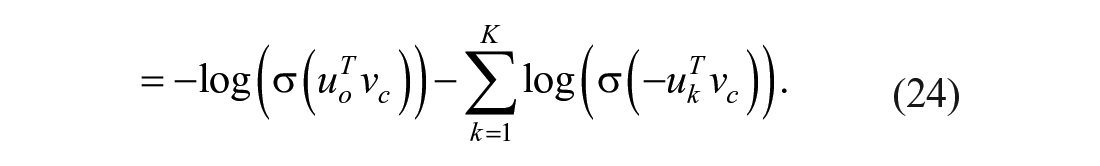
Finally, cosine similarity was used to identify semantically related words through every word

Key Reviewer
Key reviewers were identified on the basis of the frequency in which they used keywords and semantic words in their reviews. For example, the word “effect” and its semantic words have a highly important ranking; the user who has frequently used effect and its sematic words in their comment is a key reviewer related to these important terms.
Results
Prediction Model
After eliminating the stop words and calculating the word vector for each word, we used these word vectors as inputs in training the models to predict review popularity. To develop the prediction model, we used 80% of the data as the training set and the remaining 20% as the test set. The trained model was then tested on the test set to evaluate its performance.
We compared the performance of the two approaches, the ridge regression and XGBoost methods, using RMSLE as the optimization metric. The goal was to identify which model produced minimal error prediction; that is, the model with the lower RMSLE. The results revealed that the XGBoost model with 50,000 predictors achieved an RMSLE value of 1.168, outperforming the ridge regression model, which had an RMSLE of 1.471. Thus, the XGBoost model demonstrated high prediction accuracy relative to the ridge regression model.
Textual and Feature Selection Analysis
XGBoost is selected to extract important non-textual and textual reviews based on their importance ranking scores. After deriving 501 features extracted from textual and non-textual feature variables, we selected the top 18 textual review features and the top 10 non-textual feature variables according to the contribution of key terms and weighted rankings of these features to review popularity. In the comparison of weight contribution, the analysis results indicated that review textual features obtained a majority at the top of key features that contributed to review popularity. Therefore, the textual review showed a higher contribution to review popularity than the non-textual variables. Figures 3 and 4 display the weightings of significance.

Top 18 key text review feature words.

Top 10 key non-textual review features.
Figure 3 presents the details of textual features and the contribution of its significance weighting to review popularity. These top 18 key features were as follows: makeup, feeling, effect, skin, starting, moisturizing, product, sense, like, color, time, recommend, suitable for, repurchase, concealer, basic maintenance, acne, and refreshing. High weightings indicate that a term contributed highly to the review popularity. For example, the term “makeup” contributed a value of 0.039 to review popularity, and the term “feeling” contributed a value of 0.026 to popularity concerning textual terms.
Accordingly, non-textual variables with significant weightings to review popularity were selected, with the author_age variable contributing the highest value of 0.023 to review popularity creation. Non-textual variables with the next highest values were as follows: comment_exp_real product refers to reviewer experience regarding the real product, author_index measures the frequency of user activity on the online platform, attribute_lotion represents the contribution of lotion quality to the product review, author_skin_combination measures the combined skin type of the reviewer, author_article_num measures the number of reviews written by the reviewer, comment_exp_sample is user experience of sample products provided by the supplier, attribute_butter is related to the contribution of the butter factor to the product review, attribute_essence measures the contribution of the essential factor to the product review, and attribute_cream is the influence of the cream factor on the product review. Figure 4 presents the weightings of these features.
After selecting key terms, the skip-gram model was employed to predict the semantic terms surrounding the key feature words. Table 2 presents the results.
Semantic Terms Identified From Selecting Key Features.

For example, the key textual feature “feeling” was predicted from semantic words: smell, look, clean, feel, obvious, skin, absorb, refresh, same, and effect. For the term “product,” the list of semantic words are brand, series, ingredients, merchandise, skincare product, lotion, effect, stuff, loose powder, and sunscreen. These semantic words are highly correlated to important words and contribute highly to review popularity.
Key Reviewer Detection
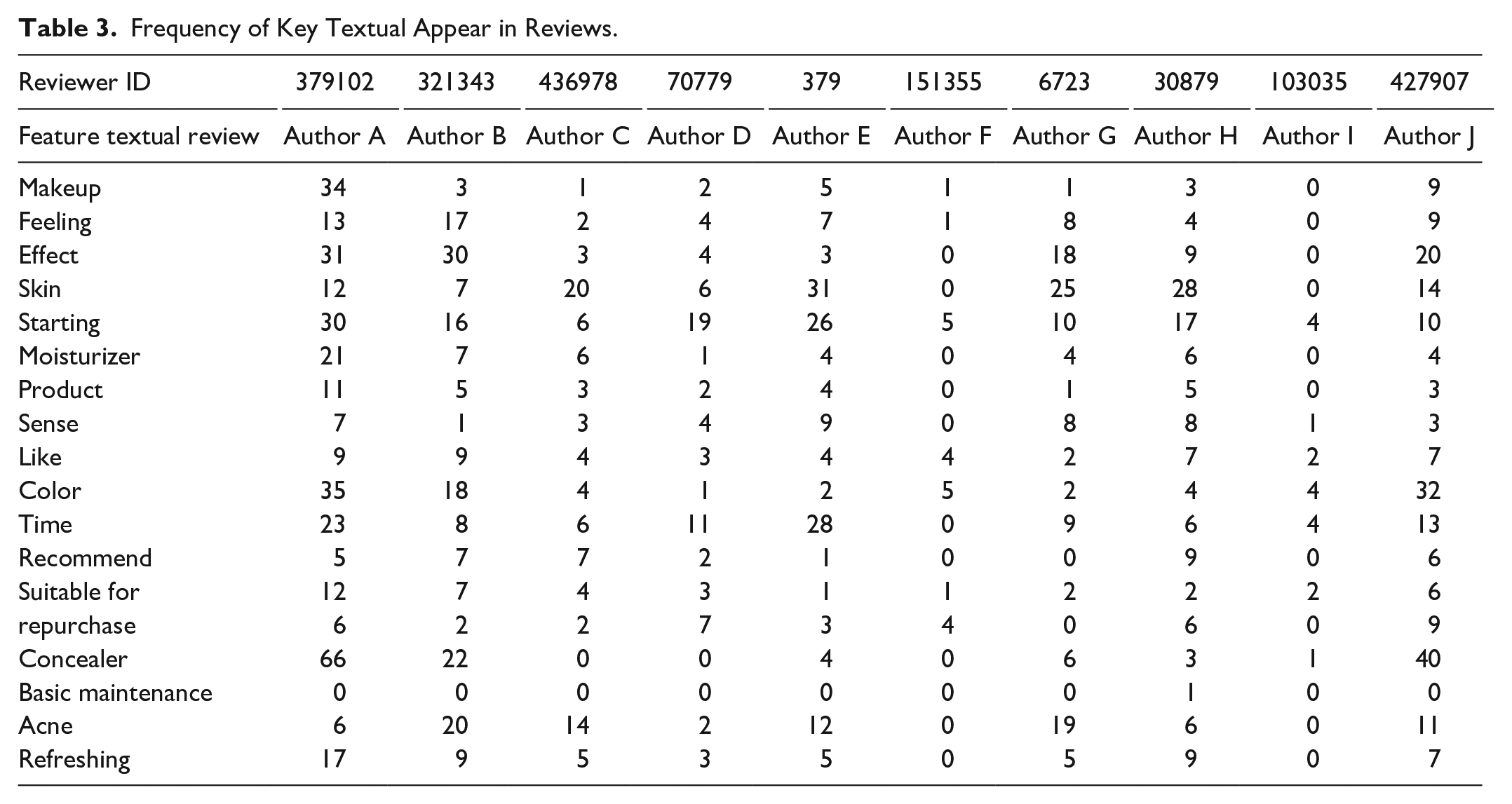
Key authors were selected based on the frequency with which they used key or semantic words in their reviews according to the ranking of significance in our proposed method. In Table 3, we randomly selected 10 reviewers to determine the frequency with which terms occurred in the text of their reviews. For example, when reviews included the term “effect” or its semantic words, Author A with ID 379102, who used “effect” has the highest frequency of 31 counts of “effect” compared with other authors. Therefore, Author A was selected as the first key author for the term “effect.” However, for the term “feeling,” Author B used it 17 times in reviews, which are several times more than other author used the term. Therefore, Author B was considered the key reviewer for the term “feeling.”
Frequency of Key Textual Appear in Reviews.
Evaluating Prediction Model
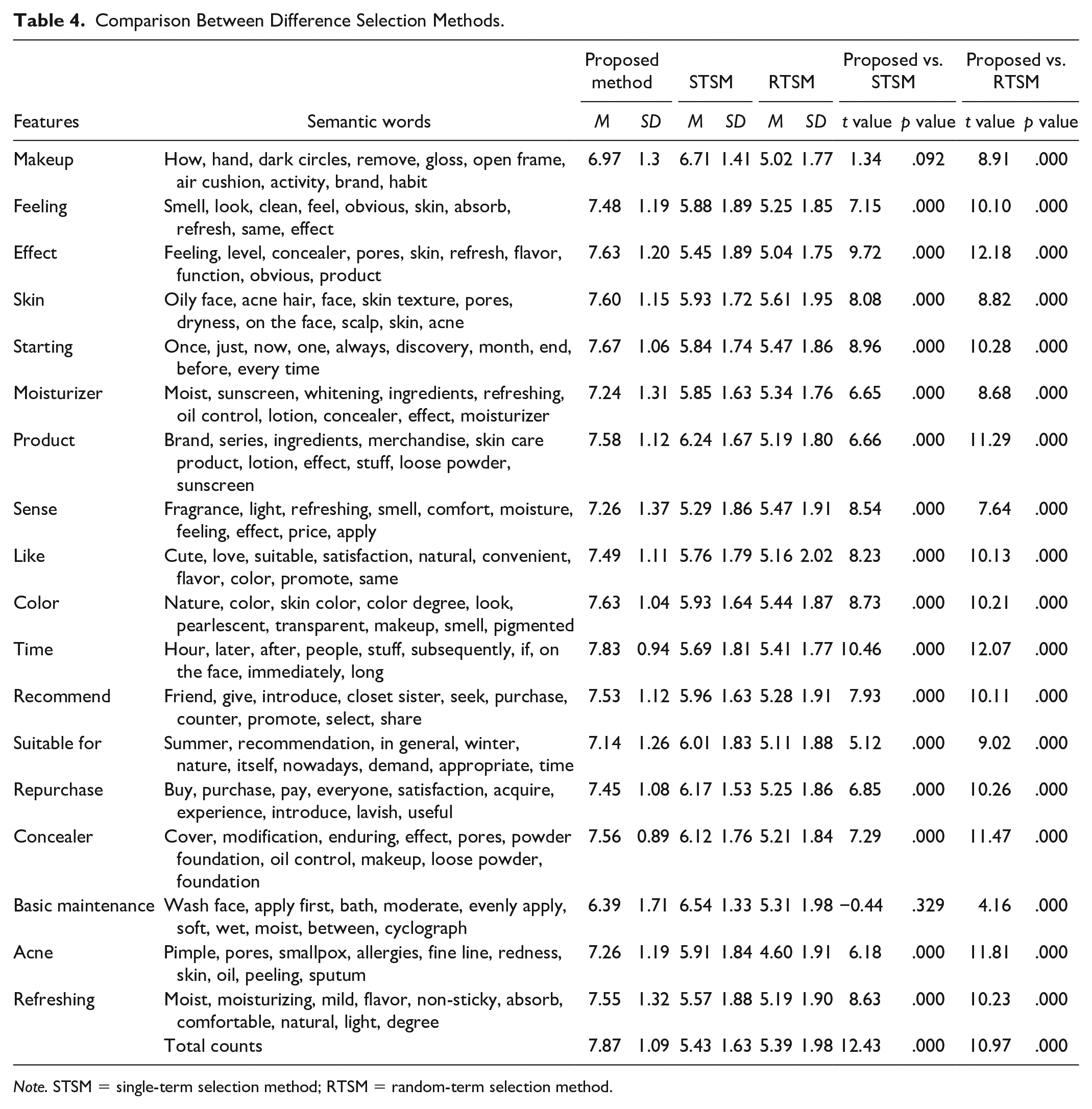
To increase the reliability and effectiveness of the proposed method in selecting keywords for predictions, we randomly selected 100 reviews to predict the review popularity measure for a WHITIA lotion product. Our proposed method was designed to select key features according to their weighted ranking in terms of their contribution to review popularity by using the XGBoost algorithm and the skip-gram model for the selection of semantic words in textual terms. The single-term selection method (STSM) and the random-term selection method (RTSM) were used for comparison with our proposed method concerning review popularity prediction. Table 4 presents the statistical details of this comparison.
Comparison Between Difference Selection Methods.
Note. STSM = single-term selection method; RTSM = random-term selection method.
Apart from the 18 important word features and semantic words, the table also presents a total count, which combines the top 18 phrases to create a word group. The mean was calculated using a logarithmic transformation of popularity. Given that popularity had a right-skewed distribution of 17.76, it was logarithmically transformed into a normal distribution of 0.26. We used the t test to assess the performance of the proposed method, with t > 0 indicating that the proposed method exhibited superior prediction performance compared with the other methods. A significantly better performance by the proposed method was indicated by p < .05.
A comparison of the performance of the proposed method with the STSM in terms of the t statistic value revealed that only the term “basic maintenance” had t < 0. Thus, 95% of the feature terms using the proposed method outperformed those selected using the STSM. Only two features, “makeup” and “basic maintenance,” did not exhibit significantly better performance (p > .05), whereas the remaining terms did (p < .05). Therefore, 89% of the terms selected using the proposed method were more significant than those selected using the STSM. Figure 5 shows the performance comparison between the proposed method and the STSM in the term “makeup.” However, a comparison of our proposed method with the RTSM in terms of the t test and p values indicated that our model significantly outperformed the RTSM for all terms, and we could observe that the distributions of the proposed method compared with those of the RTSM were significantly different in the example for the term “makeup” shown in Figure 6. Thus, our proposed method was demonstrably more effective in predicting the review popularity for the WHITIA lotion product compared with the STSM and the RTSM.

Probability density function plot of proposed method and STSM for the term “makeup.”

Probability density function plot of proposed method and RTSM for the term “makeup.”
Discussion
This study aims to investigate the impact of non-textual and textual reviews on online review popularity and to identify the most appropriate semantic terms and key reviewers in terms of key textual variables; the study employs a new method that uses a combination of the XGBoost and skip-gram models. The findings indicate that review textual features are the most significant parameters to determine review popularity (compared with the important scores in Figures 3 and 4). This outcome emphasizes the importance of review content and suggests that a customer who uses textual reviews for potential buyers and expresses them through meaningful and concise wording will contribute to increasing online review popularity. In line with previous studies, this study verifies the importance of textual characteristics (Ghose & Ipeirotis, 2010; Sun et al., 2019; F. Wang & Karimi, 2019; Yang et al., 2020) in customers’ evaluation of the effectiveness of online reviews.
Moreover, the results indicate the relevance of semantic words associated with textual reviews in the contribution to online review popularity. Consistent with previous studies, this study emphasizes the importance of information value (words used in textual review) in online product reviews; readers of product reviews do not merely count the number of stars but also read the corresponding reviews (Butler & Wang, 2012; Pavlou & Dimoka, 2006). Rich content of feedback text comments plays a significant role in building a buyer’s trust in a seller (Hennig-Thurau et al., 2004; Yoo & Gretzel, 2011). When writing an online review, like any other textual message, reviewers not only decide on what to write but also how to write it. These decisions define the content review and linguistic characteristics (Huffaker et al., 2011; Ludwig et al., 2013). In line with these suggestions, our study emphasizes the importance of key reviewers in creating the helpfulness of reviews that lead to high review popularity. Furthermore, through our model, we can identify key reviewers, who are those that consistently employ important textual terms in their reviews to attract review popularity.
Consistent with previous studies, the results regarding the non-textual review variables highlight the importance of reviewer age, reviewer experience with real products (Bickart & Schindler, 2001; D. H. Park et al., 2007), and the time they spent on websites (Hu & Chen, 2016) in creating online review popularity. In the cosmetic field, most consumers are young or middle aged; therefore, different age groups will have different styles of review, leading to different contributions to review popularity. Regarding product experience, reviewers who have used the real product will know more about its quality and effectiveness than customers who have only used suppliers’ sample products; their review will therefore attract more readers. Regarding product factors, previous studies have suggested that uncertain product information in a review leads to consumers’ difficulty in evaluating product attributes (Kim, 2014; T. S. Li et al., 2019). Hence, we suggest that a reviewer’s use of the most relevant product distribution in writing a review will significantly contribute to review popularity.
The review publish day is a variable frequently included in research on online reviews; some studies report contradicting results on its effect on customers’ evaluation of review helpfulness (Y. Liu et al., 2008; G. Yin et al., 2014). In this study, review publish day shows no significant contribution to the number of readers. A possible explanation for this contradiction is that reviews are not always equally visible to readers; to attract people to read the review, the reviewer should focus on content. In addition, previous studies have suggested that the review publish day affected the review effectiveness evaluation when the number of days of the review was shown on the first page and the number of reviews with the same rating at the time that the review was posted was included in the prediction model (Hu & Chen, 2016). Therefore, this research question is recommended for future research.
In contrast to a previous study by Malik and Hussain (2018) that used different machine learning methods to analyze review content and reviewer variables that contribute to review helpfulness, this study’s results indicate that the stochastic gradient boosting learning method yields the most accurate prediction of helpfulness. The current study not only applies the XGBoost to analyze non-textual and textual contents based on importance ranking but also incorporates the skip-gram model to identify semantic words related to key terms, which provides more robust results. Moreover, the XGBoost produces a more accurate prediction compared with the ridge regression model; our method reports better performance in selecting important texts and their semantic words compared with the STSM and the RTSM. Therefore, the study’s techniques are appropriate for estimating complex relationships among variables using multiple learning algorithms to obtain better predictive performance than can be achieved with any of the constituent learning algorithms (T. Chen & Guestrin, 2016).
Implications
The implications of this study can be explained from two perspectives: theoretical and managerial aspects. The research takes a major step toward identifying the factors that drive customers to read reviews. First, the findings highlight that the qualitative characteristics of the content of reviews (i.e., important texts used to describe products and their semantic words) contribute more to explaining review popularity than other characteristics, such as reviewers’ and product factors. Moreover, this study assesses a combination of all the factors related to online reviews, thus allowing for development of a comprehensive model to predict review popularity. In terms of the theory of eWOM communication, which refers to the extent to which consumers write online reviews to share experience and to support future customers in product evaluation (Godes & Mayzlin, 2004; T. S. Li et al., 2019; D. H. Park et al., 2007), online WOM affects review helpfulness assessment (S. Lee & Choeh, 2016; J. Wu, 2017; Yang et al., 2020) and product sales (Chevalier & Mayzlin, 2006; Zhu & Zhang, 2010). The findings of this research shed light on multiple aspects of online review that attract readers to reviews and lead to review popularity. In the online environment, where consumers have limited ability to assess the integrity of product information, especially with regard to cosmetic goods, the information reviewer uses review content, word description, experiences with real products, and messages related to product attributes to improve consumers’ perceived usefulness, which leads to high review popularity.
Electronic commerce merchants and sellers provide a platform for internet users to leave their opinions and post valuable feedback related to online product. This feedback by customers assists in building customer trust and supports customers’ purchase decisions. From a practical perspective, this study has several major implications for research on increasing product review readership and thus future sales (R. Huang & Sarigollu, 2012; Luan et al., 2019).
Online marketing could develop online marketing strategies. First, online vendors can use this method of analyzing customers’ online reviews to achieve high review popularity. Online retailers could generally advise their customers to describe product-related aspects while avoiding uncertain language, and to express their opinions using strong words. Similarly, online marketers need a word suggesting system to support online reviewers while writing product reviews. For instance, for the word “feeling” used in a review, the system would automatically suggest related semantic words, such as smell, clean, feel, obvious, skin, absorb, refresh, same, and effect, to describe the term, which would lead to increased review popularity. Online retailers might also automatically select key reviewers with high review popularity based on our study proposed model for corporate product advertising. Finally, these outcomes can also be effectively applied on websites to analyze customer reviews where the helpfulness vote system is ineffective or the system does not have the vote functionality at all. Online cosmetic marketers need to find reviews that attract readers and delight them, and that are easy to read, and regularly update them on the front pages.
Conclusion
The market for cosmetic products is highly competitive, which means that text mining research must comprehensively evaluate the online reviews of cosmetics users. We developed a new model to obtain important variables related to textual and non-textual features that contribute to review popularity. By considering keywords and semantic properties, online vendors can discern which features mentioned in reviews are more helpful, and users can learn how to write better reviews and subsequently attract more people to read their comments and provide helpful information for other buyers. In addition, the study also proposes a method of selecting a key reviewer based on the frequency with which important words and semantic words are used in their review; online vendors can select key specific textual reviewers for their promotional campaigns by identifying reviewers who frequently use key feature words.
Another important finding of this research is that the XGBoost performs better than the ridge regression technique. The RMSLE obtained when testing the review data on the WHITIA lotion product using the gradient boosting technique, a type of ensemble learning, is much less than that obtained using linear regression.
Limitations and Future Research
Despite its contribution to online review research, this study has certain limitations. First, many prior studies found bias in online review helpfulness ranking as affected by review publishing order. Owing to the Matthew effect, early posted most helpful reviews typically attracted a disproportionally large number of review popularity and votes than later posted reviews, thus defeating the original review popularity and reinforcing the sequential bias (Wan, 2015). This research did not address this sequential bias in popular prediction model development. Hence, future study can address this issue. Second, previous research employed different machine learning methods in predictive model (Malik & Hussain, 2018). The current study used XGBoost and ridge regression for review popularity prediction. Therefore, future studies can encompass the machine learning methods such as Deep Learning or Genetic Algorithm to further enhance the current findings.
Third, the data set used focused on words used in cosmetic product categories. Consequently, the generated results are only applicable to cosmetic products. Other fields might have different words emphasizing their product features. Therefore, the application of the study results is limited. Future research can replicate the method analysis in different product categories. Fourth, we measured review popularity only with respect to the number of people who accessed reviews and used it as the dependent variable in this study. However, users who are more active receive more feedback on their comments than their less active counterparts and thus interact more with other users, which leads to their increased review popularity. Therefore, a more detailed analysis is required to explain the findings of this research in the future. Finally, future investigation of review popularity in different product categories and of the relationship between review popularity and company product sales is warranted.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The authors wish to thank the Ministry of Science and Technology of Taiwan for providing financial support (MOST 106-2410-H-011-006).