
Abstract
Most theoretical and empirical studies of discourse marker multifunctionality do not approach it using a formal, systematic annotation model. Drawing on a domain-function taxonomy, this study examines 270 tokens of the discourse marker ni zhidao in Chinese media interviews. All values of the two-dimensional model designed for the whole category of discourse markers apply to ni zhidao, demonstrating its equally potent affordance on a particular discourse marker case cross-linguistically. By putting this model to the test, we found that “emphasis” needs to be added to the original 15 functions in the model, and that domains and functions need to be treated as dependent layers of pragmatic meaning. Functions determine domains, and domains need to be regarded as macro-functions to which specific functions are attributed. As such, we tentatively put forth an updated version that provides finer granularity and greater affordance, shedding new light on the pragmatic meaning of ni zhidao and the speaker’s underlying communicative intent. We propose that the sample be divided into uni-functional and multi-functional categories before being analyzed within the updated model to capture the multifunctional discourse markers in the same context-specific utterances. This study has implications for the need of more exhaustive, speech-friendly annotation models of DM multifunctionality and the cross-linguistic adaptation or refinement of established DM annotation models to cater to the unique traits of spoken DMs in different languages.
Keywords
Introduction
Discourse markers (DMs) belong to a “class of words with unique formal, functional, and pragmatic properties. […]. They […] are ‘overridden’ by pragmatic functions involving the speaker’s relationship to the hearer, to the utterance or to the whole text” (Aijmer, 2002, p. 2). Their nature and actual performance in some languages have been better understood through decades of research drawing on various theoretical frameworks and methodological approaches. Regardless of some unsettled controversies over their boundaries of categorization and terminologies (Kerstin, 2014; Liesbeth et al., 2013), they are regarded as polyfunctional items carrying little or no propositional content, which serve to structure discourse and manage interaction (Schourup, 1999).
As claimed by Crible and Degand (2019), DMs and their functions have been modeled through diverse frameworks, such as Schiffrin (1987a, 1987b, 2006), Redeker (1990), Hovy (1995), Brinton (1996), etc. These models are essentially qualitative and not meant to be applied to systematic corpus-based analyses. Considering that these studies fail to address DM multifunctionality systematically and formally (Petukhova & Bunt, 2009), some models, including Mann and Thompson (1988), Sanders et al. (1992), Prasad et al. (2008), Briz and Pons (2010), etc., focus on quantitative investigations of corpora. However, “most of these models target written language and the discourse relations that hold between sentences” (Crible & Degand, 2019, p. 3). Considering this research background, Crible and Degand (2019) proposed an innovative domain-function taxonomy model (DFTM) for annotating DMs rather than discourse relations, blazing the trail in exploring spoken DM polyfunctionality. The new model targets a highly reliable annotation taxonomy of the whole DM category rather than granular studies of specific DM cases, involving domains and functions applicable to both writing and speech. Proposing that discourse functions be categorized into three or four domains, viz. macro-functions roughly correlating with the communicative intent and involvement of the speaker (Cuenca, 2013; González, 2005; Maschler, 2009; Redeker, 1990), the DFTM is pioneering in its domain-function account of DM multifunctionality. In the model, “domains and functions are independent, thus vouching for an economical yet powerful model for systematic discourse analysis” (Crible & Degand, 2019, p. 4). The DFTM of independent semantic-pragmatic information provides granular analysis of the distribution of the DM category in a French speech corpus, enabling an adequate distinction between multi-domain and -function DMs. It has been successfully used to investigate diverse languages (French, English, Polish, and Spanish) and modalities (spoken, written, and signed), proving applicable to cross-linguistic studies (Crible et al., 2019).
Given that the “ideal granularity of the taxonomy is probably not universal but strongly depends on the goal of the annotation” (Cartoni et al., 2013, p. 81), the current research aims to put the DFTM to the test by applying it to the analysis of the DM ni zhidao in Chinese media interviews (“ni zhidao” hereinafter). This model can thus be substantiated for its rigor and operationality cross-linguistically and hopefully made “complemented by more fine-grained, DM-specific analyses of particular expressions” (Crible & Degand, 2019, p. 20) for better application to DM investigations in more languages. Specifically, our goals are threefold: to test the rigor and operationality of all values of the DFTM cross-linguistically; to demonstrate its affordance on a DM case study; and to provide new quantitative and qualitative findings concerning the distribution and combination of ni zhidao’s domains and functions, based on which we upgrade the DFTM if necessary.
Review of Literature
Studies of DMs
As reviewed in Shan (2021), DM studies have been conducted from five representative perspectives: (1) The coherence perspective (e.g., Schiffrin (1987a), Schiffrin (1994), Schiffrin (2003)) focuses on the part played by DMs in marking the semantic coherence holding discourse segments and discourse coherence modes; (2) the relevance perspective (e.g., Blakemore, 1987, 2002, 2011; Shan, 2014a) targets relevant inference to investigate the use of DMs to guide or restrict addressees to identify relevance holding between discourse segments; (3) the syntactic-pragmatic perspective (e.g., Akar & Öztürk, 2020; Fraser, 1987, 2015) explores the syntactic features and pragmatic functions of DMs, and proposes that DMs function to guide addressees to interpret the logical relationships holding between embedding discourse segments; (4) the grammaticalization or pragmaticalization perspective (e.g., Fedriani & Sanso, 2017; Maschler, 2009; Rhee, 2020; Tanno, 2022) deals with the evolution of DMs and the underlying factors; (5) the prosody-pragmatics perspective (e.g., Abuczki, 2014; Benuš, 2012; Gonen et al., 2015; Volin et al., 2017; Wichmann et al., 2010) takes prosody as an objective identifier of DMs or as a readily accessible characteristic to reveal the functions of DMs and how people understand them. Studies from these perspectives have examined various aspects of DMs, but they do not provide formal, systematic DM annotation models for reference.
Although most studies from these perspectives mainly investigated DMs in various languages other than Chinese, some (e.g., Liu, 2006; Shan, 2014a, 2014b, 2015, 2021, 2022; Tao, 2003; Wang, 2017) have examined Chinese DMs. Compared to DMs in other languages, many Chinese DMs have been relatively under-explored (Shan, 2021). Wang (2017) explores utterance-final dehua (“on condition that”) in Chinese as a conditional marker and a DM from the structural and semantic-pragmatic perspectives. Representative studies of ni zhidao have probed into its distinctive morphological features, and attention-arousing and communication-checking functions (Tao, 2003), its modes of attention-focusing, background-providing, and identification-seeking (Liu, 2006), its functions of constructing cognitive context, projecting attitudes, and manifesting inference (Shan, 2014a), its discourse-constructing functions and the internal mechanism and external motivation for its evolution (Shan, 2014b), and its prosody in different utterance positions (Shan, 2015). Shan (2022) is a comprehensive study, which explores the utterance positions, prosodic performances, semantic features, and pragmatic functions of ni zhidao, with an emphasis on the interaction between these four aspects. In Chinese spontaneous speech, ni zhidao has gradually become formally fixed, phonetically reduced, decategorized (i.e., syntactically detached and flexible, and deprived of syntactic capacities), desemanticized (i.e., semantically empty or bleached), and pragmatically functional (Enghels, 2018; Shan, 2022). These attributes of ni zhidao can be representative of the characteristics of typical Chinese DMs. Its communicative roles in spontaneous speech are characteristic of the interactive nature of the meta-pragmatic functions of DMs (Liu, 2006). As such, the study of ni zhidao can provide new insights into the studies of other Chinese DMs.
Most studies of DMs in Chinese or other languages have described their evolution from various syntactic categories (e.g., Rhee, 2020; Tanno, 2022), their typical utterance locations (e.g., Degand & Fagard, 2011; Estelles & Bordería, 2014), and their functions in different domains of discourse structure (e.g., Crible & Degand, 2019; Redeker, 1990). Although relevant to DM functions, these studies do not explore DMs using a formal, systematic annotation model. In this state of research, a formal, systematic annotation model is urgently needed to shed fresh light on the pragmatic meaning of DMs and the speaker’s communicative intent. The analysis of ni zhidao using such a model is likely to contribute to an evolving conversation around DM multifunctionality, especially in Chinese studies. Such an analysis can promise to provide high replicability in future DM studies, hopefully, better revealing the meta-pragmatic awareness underlying the use of DMs.
Discourse Coherence and DM Function Taxonomies
Discourse Coherence Models
The tripartition of discourse into the representation of ideas, expression of the speaker, and appeal to the listener dates back to Bühler (1934). The tripartite distinction has some variants, the most representative of which is the distinction of the linguistic structure of discourse from its intentional structure and attentional structure (Grosz & Sidner, 1986). Mann and Thompson’s (1988) Rhetorical Structure Theory describes a significant aspect of the natural text organization. It characterizes the relations binding parts of natural texts and applies to many written and spoken languages. Inspired by the distinction between propositional content and communicative functions, Redeker (1990) puts forth another tripartition: Ideational relations entail the speaker’s commitment to the existing logical relations between two discourse units; rhetorical relations target the relations between two discourse units rather than between the states of affairs described in the two units; sequential relations concern those relations other than apparent ideational or rhetorical relations between two discourse units.
More recently, there was the advent of quadruple taxonomies in the literature. Building upon Redeker (1990), González (2005) focuses on a quadruple taxonomy of ideational, rhetorical, sequential, and inferential structures. The ideational structure establishes logico-semantic argumentative relations; the rhetorical structure signals the intentions and objectives of the speaker and facilitates conveying the illocutionary force; the sequential structure delimits boundaries between discourse segments and maintains the discourse network; the inferential structure links the cognitive domains of the interlocutors. Although involving the role played by DMs in marking discourse structure, González’s (2005) and Redeker’s (1990) models are meant to explore the pragmatic discourse structure. Identifying with Redeker (1990) and González (2005), Cuenca (2013) assumes that discourse functions can be grouped into three or four domains roughly corresponding to the speaker’s intention of and involvement in ongoing discourse. To give a theoretically satisfying account of discourse coherence relations, Sanders et al. (1992) propose a taxonomy (Cognitive approach to Cognitive Relations or CCR) that decomposes coherence relations into four cognitively salient binary primitives: basic operation (additive and causal relations), source of coherence (semantic and pragmatic relations), order of the segments (basic and nonbasic order in relations), and polarity (positive and negative relations). The model aims at “the psychological salience of the taxonomic primitives and their relevance to the understanding of coherence relations” (Sanders et al., 1992, p. 1) rather than at the descriptive adequacy of the taxonomy (Sanders et al., 1992, p. 4). Hovy’s (1995) quadruple model comprises semantic information, interpersonal information, stylistic considerations, and interpretation guidance. It describes discourse to address the individual functions of these four structures, their interaction, and their textual expression rather than DM multifunctionality.
The tripartite and quadruple taxonomies above aim at describing discourse coherence relations rather than explicitly marking these relations with DMs. These models, by design, only consist of discourse relations, without including additional DM functions. They are not DM annotation models proper, most unlikely to account for the characteristics and multifunctionality of DMs in specific utterance contexts in the corpus.
Distinct from the models above, Prasad et al.’s (2008, 2018) Penn Discourse Treebank (PDTB) versions are hierarchical annotation taxonomies of discourse relations and their arguments in the corpus. PDTB-2.0 (Prasad et al., 2008) describes all aspects of the annotation, including the argument structure, sense annotation, and attribution of discourse relations. PDTB-3.0 (Prasad et al., 2018) involves four semantic categories: TEMPORAL, CONTINGENCY, COMPARISON, and EXPANSION, which are further distinguished into two or more sub-classes with specific values. The PDTB has been used to analyze written data in many languages and spoken data in only a few languages (e.g., Tonelli et al., 2010, in Italian; Demirșahin & Zeyrek, 2014, in Turkish) (Crible & Degand, 2019). PDTB-2.0 and PDTB-3.0 are designed to capture discourse relations and diversified marking forms of these relations comprehensively rather than DM multifunctionality. This is true for other models reviewed above.
DM Function Models
Different from the aforementioned models, some taxonomies are intended for ascertaining the relationship between the structure of discourse and the functions of spoken DMs. By putting DMs within a heuristic discourse model with different domains, Schiffrin (1987a) proposes a quintuple distinction: the information state relating to the speaker’s and hearer’s organization and management of knowledge and meta-knowledge; the participation framework targeting the speaker’s and hearer’s identities, alignments, and relationships to each other and to what they are saying; the action structure concerning the organization of and constraints on speech acts; the exchange structure referring to interactional contingencies partially unique to the distribution of speaking/hearing rights; and the ideational structure dealing not only with propositions but also with topic/comment and information status (Schiffrin (1987a, 2006)). Relationships within and between these domains provide the system within which DMs function as indexicals (Schiffrin, 1987a, pp. 322–325) or contextualization cues (Schiffrin, 1987b), establishing coordinates within their context by indexing utterances to the participants or the text (Schiffrin, 1987a, pp. 316–317). Applying DMs to ongoing discourse expands their domains and creates multifunctionality, that is, one DM contributing to more than one discourse domain (Schiffrin, 2006). Brinton (1996) divides DMs into two categories: those belonging to the textual mode of language and those belonging to the interpersonal mode of language. In the textual mode, the speaker structures meaning as text, thus creating cohesive discourse; the interpersonal mode expresses the speaker’s attitudes, evaluation, judgments, expectations, and demands, the nature of the social exchange, the role of the speaker, and the role assigned to the hearer (Brinton, 1996, p. 38). Maschler (2009) exclusively examines Hebrew DMs in conversations, revolving around the interpersonal realm, the textual realm, the cognitive realm, and between realms. Similarly, Briz and Pons (2010) advocate interpersonal, textual, or modal DM functions. According to them, the functions of DMs depend on the types of their embedding discourse units (discourse, dialog, exchange, turn alternation, intervention, turn, act, and subact) and their positions (initial, medial, or final) in such units. In the models reviewed in this section, DMs tend to be initial, medial, or final in discourse units, functioning interpersonally, textually, or modally according to their specific positions. According to these models, unit and position may constrain the functions of DMs, for example, a final DM being most likely interpersonal (Crible & Degand, 2019). The functional distinctions of DMs in these models can serve their designing purposes, but these DM function taxonomies may not be sufficiently fine-grained for other research questions (Crible & Degand, 2019). They demonstrate that the variation of DMs may not necessarily be predictable and systematic all the time, as claimed by Crible and Degand (2019).
Unlike the DM function taxonomies discussed above, Petukhova and Bunt’s (2009) model of multiple dimensions aims at distinguishing and annotating semantic units to investigate the semantic functions of DMs in dialog empirically. This model is specially designed to rely on utterance surface features of prosody, word occurrence, and collocations automatically extracted from transcripts and sound files for the automatic identification of the multiple functions of DMs through machine-learning techniques. It is not suitable for the manual analysis of multi-functional DMs.
The models reviewed in Sections 2.2.1 and 2.2.2 are either essentially qualitative and unsuitable for systematic corpus-based DM multifunctionality analyses in formal, systematic manners (Petukhova & Bunt, 2009), for example, Schiffrin (1987a, 1987b, 2006), Redeker (1990), Hovy (1995), Brinton (1996), among others, or designed for quantitative investigations of written language and the discourse relations holding between sentences (Crible & Degand, 2019), such as Mann and Thompson (1988), Sanders et al. (1992), Prasad et al. (2008), Briz and Pons (2010), etc. Till now, the review of literature in Sections 2.1 and 2.2 has revealed the lack of annotation models specially constructed for DMs in speech.
The Domain-Function Taxonomy Model
Informed by the notion of discourse domains proposed by Redeker (1990), and the notion of discourse domains and functions put forth by González (2004, 2005) and Cuenca (2013), Crible (2017) developed an annotation taxonomy for DMs in spoken French and English to allow for comprehensive, quantitative studies of DMs, with broad coverage of their categories and functions. The taxonomy, however, entails a problem: the semantic links between similar functions in different domains are invisible due to the distinct functional labels they receive. To address the problem, Crible and Degand proposed a revised model in which domains and functions are two independent layers of pragmatic information, and any domain can freely combine with any function (Crible & Degand, 2019, p. 10). Established, tested, and refined through a corpus-based study, this model can meet the need for giving a quantitative account of the specific features and multifunctionality of spoken DMs across languages. It consists of 15 functions and 4 domains (Crible & Degand, 2019, pp. 11–13) listed below:
The rhetorical domain corresponds to subjective relations between two discourse events and the speaker’s attitude and reasoning;
The sequential domain corresponds to the signaling of the progressing steps of speech and thought;
The interpersonal domain corresponds to the interactive management of the exchange and the speaker-hearer relationship.
Each function can be combined with each domain, allowing for 60 (15 × 4) potential domain-function distributions and combinations to analyze DMs. This model “aims at accounting for the meaning and function of the DMs, as well as for the speaker’s communicative intention when using them” (Crible & Degand, 2019, p. 10). Unlike other models, it provides concrete guidelines on how to systematically apply domains and functions to DMs. As claimed by Crible and Degand (2019), this framework has already been successfully applied to some languages, including French, English, Polish, and Spanish, and to spoken, written, and signed modalities, therefore proven well suitable for cross-linguistic studies (e.g., Crible et al., 2019; Degand et al., 2018). Given its systematic and operational nature and methodological replicability, the current study uses it as a reference model for analyzing ni zhidao, although it is likely to “be complemented by more fine-grained, DM-specific analyses of particular expressions” (Crible & Degand, 2019, p. 20).
Data and Methodology
Data
Data provide the texts and contexts (slots and sequences more specifically) where ni zhidao tokens occur and are analyzed. The data were collected from interview programs staged on mainland China TV and Internet channels, including CCTV, Dragon TV, Hunan Satellite Television, and MSN website, and on Hong Kong Phoenix Satellite Television, as shown in Table 1. 70 interview conversations were selected, in which 270 DM tokens of ni zhidao were identified, because the multiple structural, semantic, and conversational uses of DMs become apparent only with a relatively large number of tokens (Schiffrin, 1982, p. 1). The overall number of speakers is 173, including 86 interviewers and 87 interviewees. Although 11 interviewers hosting 9 interviews were involved, they were counted as 86 because they interviewed different guests in different interviews in the same program. Both the interviewers and interviewees are native Chinese speakers. The conversations cover topics concerning almost all aspects of life, characterizing talk shows in China and the actual use of ni zhidao in media interviews.
270 ni zhidao Tokens in 70 Interview Conversations.

Methodology
The analysis of the actual uses of the 270 ni zhidao tokens followed a five-step procedure. First, 536 occurrences of DM and non-DM ni zhidao were identified in the data. Then, a distinction was made between 490 DM tokens and 46 non-DM tokens according to the defining characteristics of DMs: being syntactically optional, appearing at clause peripheries, having a procedural/core meaning, indexing discourse relations, marking topic and turn boundaries, managing interpersonal relationships, and expressing the speaker’s subjectivity (Blakemore, 2002; Crible, 2017; Schourup, 1999). Subsequently, the 490 DM tokens were verified following sequential and distributional accountability (Schiffrin, 1987a, pp. 69–71) in their immediate contexts. Step 4 attributed the 16 functions in the DFTM to the 490 tokens. In this process, the function attribution to 120 tokens was controversial among the annotators, so these tokens were excluded from the final analysis. In the last step, the remaining 370 tokens were assigned to the four domains in the DFTM, and 100 tokens were removed due to disagreement on their domain attribution. As a result, 270 tokens were finally analyzed in the current study.
The five steps were manually conducted. The function and domain assignments of all tokens were disambiguated in their immediate contexts by considering contextual cues in their interpretation. The identification of all DM ni zhidao tokens and their domains and functions “relies partly on identifying their distributional patterns in a full range of discourse environments” (Schiffrin, 1982, p. 1). Focusing on specific discourse environments through sequential and distributional accountability allows for more accurate identification, “avoiding the risk of missing generalizations and misidentifying functions” (Schiffrin, 1982, p. 21).
Results and Discussion
Results
Distributions and Combinations Uni-Function and -Domain ni zhidao
Of the 270 tokens, 210 were found to fulfill one single function and belong to one single domain. These tokens fall into 12 categories of functions (see Table 2). “Topic,” “specification,” “cause,” “consequence,” “addition,” and “contrast” are the top six functions performed by 46, 38, 32, 28, 25, and 23 tokens, respectively. The number of tokens serving these six functions totals 192, accounting for 91% of the 210 uni-function tokens. “Condition,” “hedging,” and “agreeing” are not represented by any of these 210 tokens. The other six functions are served by a maximum of five tokens, respectively.
Distribution of the 210 Uni-Function Tokens.

From Table 2, ni zhidao is primarily used to fulfill the functions of initiating, changing, or returning to topics (“topic”), elaborating on preceding discourse segments (“elaboration”), and marking logical relations (“cause,” “consequence,” “addition,” and “contrast”) between discourse segments. These functions roughly align with the three types of relations between ideas (cohesive, topic, and functional relations) proposed by Schiffrin (1987a, p. 26). The “topic” function of ni zhidao is concerned with the “organization of topics and subtopics” (Schiffrin, 1987a, p. 26). The “elaboration” function of ni zhidao is meant to convey one of the functional relations, that is, to “provide specific instances to illustrate a generalization” (Schiffrin, 1987a, p. 26). In the logical relations of “cause,” “consequence,” “addition,” and “contrast,”ni zhidao conveys the “semantic relationships underlying a text,” that is, cohesive ties in which the interpretation of an element in one clause presupposes information from a prior clause (Schiffrin, 1987a, p. 26). These three categories of relations fall into the ideational structure of the discourse coherence model put forth by Schiffrin (1987a), but they have been found to belong to the sequential, rhetorical, and ideational domains, respectively, in our study. This difference may point to the inapplicability of Schiffrin’s discourse coherence model to the cross-linguistic analysis of ni zhidao. As Crible and Degand (2019, p. 4) claimed, Schiffrin’s (1987a) model, though influential and widespread, is not specifically intended for systematic corpus application and is thus qualitative in nature. The analysis of ni zhidao calls for a corpus-oriented annotation model that can “provide operational guidelines on how to systematically apply domains and functions to corpus data” (Crible & Degand, 2019, p. 9).
The 210 uni-functional domain-specific tokens operate in four domains (see Table 3). 117 (56%) were found in the ideational domain, followed by 53 (25%) and 38 (18%) in the sequential and rhetorical domains, respectively. Merely 2 (1%) fall under the interpersonal domain. Such domain distribution suggests that the 210 ni zhidao tokens were primarily used to express objective discourse relations (ideational), to structure topics and turns (sequential), and to communicate the speaker’s reasoning and attitude (rhetorical), rather than to manage the exchange and the relationship between interlocutors (interpersonal). The distribution of ni zhidao in the ideational domain (56%) in our study does not fit with that in Crible and Degand (2019), in which DMs are not mainly used to express factual discourse relations (ideational). This divergence calls our attention to the cross-linguistic differences between Chinese and French. However, our finding of 1% of ni zhidao in the interpersonal domain is roughly consistent with the finding of Crible and Degand (2019), who also found a low frequency (around 10%) of French DMs in the interpersonal domain. This consistency can imply that DMs are not primarily used for “the interactive management of the exchange and the speaker-hearer relationship”Crible and Degand (2019, p. 12) in Chinese and French.
Distribution of the 210 Uni-Domain Tokens.

The corpus-based models of domain categorizations proposed by Redeker (1990), González (2004, 2005), and Cuenca (2013) are informative for our study, but they are not designed as annotation models per se. Like Schiffrin’s (1987a) model, they equally fail to provide specific guidelines on the systematic application of domains and functions to corpus data (Crible & Degand, 2019, p. 9) to guide the analysis of ni zhidao. This state of research justifies the choice of the DFTM as the only available reference model for the annotation of the specific characteristics and multifunctionality of ni zhidao. Given that there is no function annotation model available for Chinese DMs, this pilot study can advance the studies on ni zhidao and inform the research on other Chinese DMs. By proposing an operational model based on this analysis, we can address the unavailability of specifically-designed models for DMs rather than discourse relations in speech (Crible, 2017) in Chinese.
Table 4 gives an overview of the function-domain combinations of the 210 uni-function and -domain tokens. Twelve categories of combinations were identified. The ideational domain is combined with seven functions, involving 117 tokens. Ideational addition, ideational cause, ideational consequence, and ideational contrast represent the highest frequency in this domain, accounting for 25, 32, 28, and 23 tokens, respectively; ideational alternative, ideational concession, and ideational temporal occur only once, five times, and three times, respectively. The sequential domain is combined with three functions (“topic,” “monitoring,” and “quoting”), involving 46, 3, and 4 tokens, respectively. Encompassing 38 tokens, rhetorical specification occurs most frequently among the 12 classes of function-domain combinations. The interpersonal domain is combined only with two tokens of “disagreeing”ni zhidao. The top six function-domain combinations are sequential topic (46 tokens), rhetorical specification (38 tokens), ideational cause (32 tokens), ideational consequence (28 tokens), ideational addition (25 tokens), and ideational contrast (23 tokens), jointly constituting 91% of all combinations. There seems to be a certain association between domain distribution and function distribution: 98% of ni zhidao tokens were detected in the ideational, rhetorical, and sequential domains, which corresponds with 98% of tokens functioning to structure discourse through displaying discourse relations, discourse elaboration, and turn management. Thus, the frequency of a domain depends on the functions of the tokens.
Function-Domain Combinations of the 210 Uni-Function and -Domain Tokens.
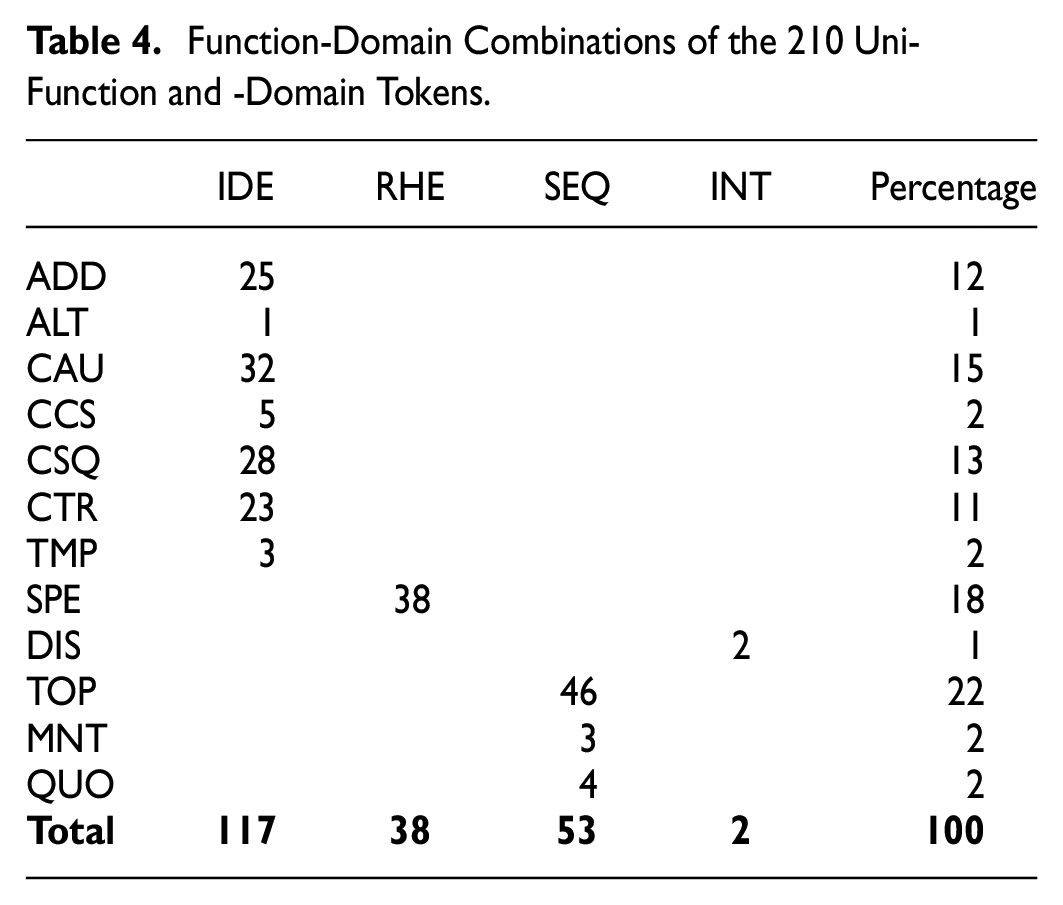
Like Crible (2017), we classified the 12 identified functions of ni zhidao across González’s (2005) four domains. In Crible (2017), the ideational domain encompasses “cause” and “temporal,” which is in tune with our finding, but her ideational “condition” has not been identified in the uni-function and -domain ni zhidao tokens. The ideational “addition,” “alternative,” “cause,” “concession,” “consequence,” “contrast,” and “temporal” attested in our study align well with those found by Crible and Degand (2019), but the rhetorical “specification” in our study contrasts the ideational “specification” in Crible and Degand (2019). Our sequential “topic,” “monitoring,” and “quoting” confirm those of Crible (2017) and Crible and Degand (2019). Our interpersonal “disagreement” also conforms to Crible and Degand’s (2019). It follows that Crible’s (2017) model and particularly Crible and Degand’s (2019) DFTM are highly operational on ni zhidao. As such, we may propose the application of these models to the analysis of other Chinese DMs to further test their operationality and affordance.
In (1) to (4), ni zhidao performs one single function in one single domain. In (1), ni zhidao elicits the reason why “The real fear is the shock afterward,” and this “cause” function falls into the “ideational” domain, conveying the consequence-cause relation between the two discourse events preceding and following ni zhidao. The “specification”ni zhidao in (2) introduces a segment that provides more detailed information to elaborate on the previous utterance segment, indicating the speaker’s judgment of the previous elusive segment and the need for explanation. It belongs to the “rhetorical” domain, which negotiates the speaker’s point of view on the content of a proposition (Traugott, 2014). In (3), the “topic”ni zhidao elicits a new topic at the beginning of a turn, falling into the “sequential” domain intended to structure discourse. The “quoting”ni zhidao in (4) introduces reported speech into the current speaker’s discourse. This ni zhidao appeals to the addressee for cooperation and understanding-checking (House, 2009) in the “interpersonal” domain.
(1) Zhenzhèng de hàipà qíshí shì guòhòu de nà zhǒng zhènhàn, huò yǒurén gàosù nǐ shuō liǎng gè xiǎoshí zhīhòu hǎixiào huì zài huílái.
The real fear is the shock afterward, or someone telling you that the tsunami will come back in two hours.
(2) Lìdù yěshì zhǐ de biǎoxiàn chūlái de zhānglì,
Strength also refers to the tension expressed.
(4) Tāmen shuō
They said
Distributions and Combinations of Multi-Function and -Domain ni zhidao
The “emphasis” function is not included in the DFTM, but it is represented in our data. It is accordingly incorporated into the taxonomy of the multi-function and -domain tokens. Sixty tokens were found to perform more than one function simultaneously in the same context-specific utterances, with 45 types of function combinations and 77 pairs of functions attested, as shown in Table 5. “Consequence” and “specification” combine with 11 functions. “Addition” and “cause” combine with nine functions. “Contrast” and “topic” each combine with eight functions. The remaining 10 functions are all combined with five or fewer functions. “Concession” is combined only with “addition,” “condition” is combined only with “consequence” and “specification,” and “temporal” is combined only with “addition” and “consequence.”
The Number of the 60 Multifunctional Tokens in Function Combinations.


Note. The diagonal splits the table into two parts. The figures in blue above the diagonal refer to the same function combinations as the figures in black below the diagonal. Each figure means the number of function combinations.
Among the 45 categories of function combinations, the most frequent one is “cause-specification,” occurring seven times. Each of the eight types of combinations, including “addition-specification,” “addition-topic,” “cause-contrast,” “cause-topic,” “disagreeing-topic,” “consequence-specification,” “contrast-specification,” and “specification-emphasis,” appears three times. Ten classes of combinations show up twice each, and the remaining 26 combinations each make their presence once, as shown in Table 5. Although claiming the improved methodological replicability and theoretical adequacy of the DFTM, Crible and Degand (2019, p. 11) “refrain from using double labels,” such as “consequence-topic.” Since the DFTM has been only applied to data in spoken French and English, our Chinese data provided a new testing ground for this model for its cross-linguistic replicability. Our application of it to ni zhidao proved it applicable to the function combinations of ni zhidao, although Crible and Degand (2019, p. 11) assert that double labels are “complex to handle quantitatively.” We found it essential to apply double labels to ni zhidao while they believe double labels are no longer needed in efficient annotation and quantitative analysis (Crible & Degand, 2019, p. 11).
Table 6 shows the function-domain combinations of the 60 tokens assigned to more than one domain and function. “Emphasis” is added to the 15 functions composing the DFTM. The 60 tokens were attested in two, three, or four domains simultaneously, similar to most French DMs investigated by Crible and Degand (2019). Besides, we have not identified domain-specific functions while Crible and Degand (2019) detected domain-specific ones, though in a limited number. This difference may be attributed to cross-linguistic variation, for Crible and Degand’s (2019) model has not been applied to Chinese previously. The 60 ni zhidao tokens present 54 different function-domain combinations, compared with 42 found by Crible and Degand (2019) in their French and English data, showing more diversified combinations of ni zhidao. This confirms Crible and Degand’s (2019) claim that more combinations could be found in other languages. Nine functions (“addition,” “cause,” “consequence,” “contrast,” “specification,” “hedging,” “quoting,” “monitoring,” and “topic”) are represented in all four domains, in contrast to four functions (“addition,” “alternative,” “concession,” and “consequence”) having variants in all four domains (Crible & Degand, 2019). “Temporal,” “agreeing,” “disagreeing,” and “emphasis” are present in three domains. “Alternative,” “concession,” and “condition” are embodied in two domains. The ideational domain coincides with all 16 functions. The rhetorical, sequential, and interpersonal domains coincide with 15, 14, and 9 functions, respectively. No domain-specific functions or function-specific domains were attested in our data. Nor were the combinations of “sequential alternative,” “interpersonal alternative,” “rhetorical concession,” “interpersonal concession,” “sequential condition,” “interpersonal condition,” “interpersonal temporal,” “interpersonal agreeing,” “interpersonal disagreeing,” and “interpersonal emphasis.” There is no apparent connection between the frequency of tokens in each function and the number of domains where the tokens are expressed: “specification” is the most frequent function, having ideational, rhetorical, sequential, and interpersonal variants, while “hedging,” though considerably less frequent, is also represented in the four domains. Therefore, the diversity of domains does not necessarily mean the diversity of functions, as shown in Table 6. This finding aligns well with Crible and Degand (2019).
Function-Domain Combinations of the 60 Multi-Function and -Domain Tokens.

Note. “★” indicates a combination between a specific function and a specific domain. The reason why the total number of tokens (139) is far more than 60 is that a token may perform two, three, or even four functions simultaneously in a specific utterance.
Crible and Degand (2019, p. 16) “cannot think of ideational or rhetorical uses” of “monitoring,” but we did capture these combinations. Besides, we identified “ideational cause,” “ideational emphasis,” and “ideational condition” that Crible and Degand (2019, p. 16) did not attest in French and English DMs. However, we did not find such combinations as “sequential alternative,” “interpersonal alternative,” “rhetorical concession,” “interpersonal concession,” “sequential condition,” “interpersonal condition,” “interpersonal temporal,” and “interpersonal agreeing” that Crible and Degand (2019) captured in their data; we did not discover such domain-specific functions while Crible and Degand (2019) ascertained three cases, “quoting” and “topic” specific to the sequential domain and “disagreeing” to the interpersonal domain. These different cases of domain-function combinations show the cross-linguistic variations in DM multifunctionality and the cross-linguistic operationality and affordance of the DFTM. This finding encouraged us to adopt and develop this model to cater to the annotation of ni zhidao to fill the gap in the literature.
In (5) to (6), ni zhidao expresses the same “specification” in different domains, rhetorical, ideational, sequential, or interpersonal. In (5), the segment following ni zhidao elaborates on the segment preceding it rhetorically, showing the speaker’s attitudes to and reasoning of the discourse events under discussion. Meanwhile, it is a prelude to a cause of the foregoing result or a brand new topic, functioning ideationally or sequentially, respectively. Ni zhidao in (6), though indicating “specification,” quotes reported speech interpersonally.
(5) Suǒyǐ wǒ jīngcháng jǐ rénjiā sòng zhè zhāng zhuānjí de shíhòu, wǒ dū jiā shàng yījù: Bàituō nǐ, yī dìng yào tīng. Yīnwèi
So when I often gave people this album, I always added a word: Please, do listen to it. Because
(6) Tā dì yījù huàshuō fànbīngbīng zhè nǚrén gòu hěn de, wǒ shuō zěnme gòu hěn. Tā shuō
He first said that Fan Bingbing is a ruthless woman, and I said how ruthless. He said,
Ni zhidao in (5) and (6) could receive entirely different treatments within other frameworks discussed in the Review of Literature section. Within the PDTB-2.0 (Prasad et al., 2008) and the PDTB-3.0 (Prasad et al., 2018), Example (5) would be Cause + Belief, but (6) could not be represented due to the lack of appropriate labels for it in these models. Other discourse coherence relation models, including Mann and Thompson (1988), Sanders et al. (1992), Briz and Pons (2010), etc., equally failed to capture the multifunctionality of ni zhidao in (5) and (6) among many other tokens because of their designing purposes of quantitative analyses of discourse relations between written sentences (Crible & Degand, 2019). Similarly, qualitative models, such as Schiffrin (1987a, 1987b, 2006), Redeker (1990), Hovy (1995), and Brinton (1996), could not annotate multi-function and -domain ni zhdiao, because they are not fit for corpus-based formal, systematic analyses of DM multifunctionality (Petukhova & Bunt, 2009). A taxonomy model is needed to describe multifunctional ni zhidao and other Chinese DMs systematically and in detail. The DFTM answers this call, but it avoids using double-function labels, which makes it unsuitable for describing multi-function and -domain ni zhidao. We, therefore, further developed the DFTM by applying double-function labels, capturing multi-function and -domain ni zhidao and giving them a fine-grained description.
Discussion
A Better Understanding of ni zhidao
The analysis above confirms that ni zhidao does not appear arbitrarily and context-independently. They function through specific discourse segments constructed coherently using ideational, rhetorical, sequential, and interpersonal structures (Crible & Degand, 2019; González, 2005). Specifically, they are used not only “to segment, recover, organize, and reformulate the information provided to the hearer, but also to share common ground, assumptions, and presuppositions with him/her” (González, 2005, p. 53), as illustrated in (1) to (6). These ends are achieved inter-subjectively by establishing a rapport with the hearer using the “ni” (“you”) positioning to attract their attention. Therefore, a link can be established between utterance segments and ni zhidao, which is intended “to structure the interaction and to signal the structure and coherence of discourse” (González, 2005, p. 55). Helping to explicate the relationship between preceding and succeeding propositions (Schiffrin, 1987a, p. 318), ni zhidao cues “the speaker’s cognition, attitudes, and beliefs” and facilitates “the transmission of illocutionary force and intentions” (González, 2005, p. 53). The ideational, rhetorical, sequential, and interpersonal purposes of communication underlie the use of ni zhidao, and ni zhdiao, in turn, encodes and conveys these aims to the hearer, implying the appropriate interpretation of the utterance segments indexed. In other words, ni zhidao is purposefully used in specific contexts to facilitate conveying utterance intentions by establishing proximity, intimacy, and collaboration between interlocutors through confirming common ground, shared background knowledge, assumptions, and presuppositions, and checking the hearer’s understanding. As such, placing ni zhidao within ideational, rhetorical, sequential, and interpersonal domains can advance Shan’s (2022) analysis of ni zhidao. Although Shan (2022), the most systematic ni zhidao study in the literature, illustrates the interpersonal and textual functions of ni zhidao, which are approximate to the interpersonal and ideational domains, respectively, he has not analyzed ni zhidao within the sequential and rhetorical domains. This is most possibly because he does not intend to present a quantitative, exhaustive analysis of all ni zhidao tokens in his data, but to randomly exemplify the functions potentially performed by this DM, based on his research objective (Shan, 2022). Through corpus-based exhaustive examination, we did attest to sequential and rhetorical ni zhidao, therefore adding new findings to the literature on ni zhidao represented by Tao (2003), Liu (2006), and Shan (2014a, 2014b, 2015, 2022).
The relationship between utterance segments and DM functions allows for categorizing ni zhidao based on their macro roles in utterances. Ni zhidao can function ideationally, rhetorically, sequentially, and interpersonally in light of its different contextual effects of linking facts, meeting argumentative needs, signifying utterance continuity, and achieving collaboration between the interlocutors, respectively (Crible & Degand, 2019, p. 10). Ideational ni zhidao signals “logico-semantic argumentative relations” (González, 2005, p. 54) between utterance segments. Though characteristic of semantic bleaching (Shan, 2022), it is related to the referential discourse structure, signifying the objective relations between utterance segments and entailing the slightest degree of personal involvement (Crible & Degand, 2019). The rhetorical domain represents the speaker’s communicative intents and facilitates conveying the illocutionary force of discourse (González, 2005). It is the most productive breeding ground for ni zhidao, where ni zhidao guides the hearer through the world constructed in text, enabling them to know the speaker’s actions, thoughts, intents, beliefs, emotions, and attitudes (Crible & Degand, 2019). The sequential domain demarcates utterance boundaries, maintains the discourse network, and helps topic-shifting. It relates to the configuration of local and global discourse segments, including topics, turns, hesitation breaks, and filled pauses (Crible & Degand, 2019, p. 12). Thus, sequential ni zhidao orders ideas logically in the text world, elicits quotes, takes turns, and initiates, shifts, or rounds off topics, explicitly signaling “the progressing steps of speech and thought” (Crible & Degand, 2019, p. 12). The interpersonal domain bridges the speaker’s and the hearer’s cognitive domains. In this context, ni zhidao facilitates information sharing, negotiates shared common ground and implications, and appeals for cooperation. It engages the hearer in the text world, helping convey the illocutionary meaning of discourse. It is “linked to the interactive management of the exchange and the speaker-hearer relationship,” and plays “a phatic function to call attention or to manifest understanding” (Crible & Degand, 2019, p. 12). The sequential and rhetorical domains where we captured ni zhidao align not only well with those included in the DFTM (Crible & Degand, 2019), but also approximately with the exchange and action structures in Schiffrin’s (1987a) discourse coherence model. Our capture of ni zhidao in the ideational, interpersonal, rhetorical, and sequential domains, especially in rhetorical and sequential domains that failed to be captured in relevant studies (Liu, 2006; Shan, 2014a, 2014b, 2015, 2022; Tao, 2003), could contribute to the studies on the multifunctionality of ni zhidao. This finding can highlight the prominent function of domains in the pragmatic variations of MDs: what may vary includes not merely specific functions and discourse coherence relations expressed by DMs, but the types of DM-connected elements and the speaker’s intents as well (Crible & Degand, 2019).
The classification of the four domains above does not necessarily indicate that ni zhidao primarily serving ideational purposes cannot function rhetorically, sequentially, or interpersonally, but implies that each token plays a predominant role in a specific utterance context, as evidenced by the performance of the 210 uni-function and uni-domain tokens. Some tokens do fall under different functions and domains simultaneously, as demonstrated by the actual use of the 60 versatile tokens. What differentiates our study from previous studies (Liu, 2006; Shan, 2014a, 2014b, 2015, 2022; Tao, 2003), therefore, lies in our distinction of multi-function and -domain ni zhidao from uni-function and -domain ni zhidao before we made tailored analyses. This distinction made our analyses considerably more granular and exhaustive, ensuring the presentation of the full picture of ni zhidao in its actual use. As such, we attested to far more functions, like “hedging,” “agreeing,” “disagreeing,” “concession,” “quoting,” etc., as well as double functions and domain-function combinations, which have not been documented in Tao (2003), Liu (2006), and Shan (2014a, 2014b, 2015, 2022).
Whether uni-functional or multi-functional, ni zhidao predominantly performs ideational functions: 56% of the uni-functional tokens and 43% of the multi-functional ones play the roles of “addition,” “alternative,” “concession,” “condition,” “cause,” “consequence,” “contrast,” and “temporal” ideationally. This stands in stark contrast to 48.7% of sequential DMs in Crible and Degand (2019), who found merely 10.2% of ideational uses. Additionally, ni zhidao often seeks understanding rhetorically and structures discourse sequentially: 42% of the uni-functional tokens and slightly below 50% of the multi-functional tokens are thus used to indicate “specification,” “emphasis,” “hedging,” “monitoring,” “topic,” and “quoting.” Our ascertained percentages are relatively higher than those (30.3% of rhetorical uses and 48.7% of sequential uses) reported by Crible and Degand (2019). Only around 2% of the uni-functional tokens and 7% of the multi-functional tokens fall into the interpersonal domain to serve the functions of “agreeing” and “disagreeing,” compared with around 10% of interpersonal uses in Crible and Degand (2019). These figures show that ni zhidao in our data is primarily used to express facts (ideational), structure discourse (sequential), and convey speaker attitudes (rhetorical), rather than to directly address the hearer (interpersonal). This finding contrasts that of Crible and Degand (2019): French DMs are mostly used rhetorically and sequentially rather than ideationally and interpersonally. The considerably low percentage of interpersonal ni zhidao seemingly contradicts the highly interactive nature of media interview conversations. It may be explained by “the peripheral, emerging status of interpersonal variants of discourse relations” (Crible & Degand, 2019, p. 16) in spontaneous speech. This counter-intuitive finding gives us a better understanding of the elusive ni zhidao, which has been examined mainly in the interpersonal domain by Tao (2003), Liu (2006), and Shan (2014a, 2014b, 2015, 2022).
Ni zhidao is a “routinized expression” (Enghels, 2018, p. 107), through which the speaker (1) structures discourse (Crible & Degand, 2019) (sequential), (2) negotiates their viewpoint on propositional content (Traugott, 2014) (rhetorical), (3) appeals to the hearer for cooperation and understanding-checking (House, 2009) (interpersonal), and (4) asserts the probability of the truth of the state of affairs described (Nuyts, 2001) (ideational). In these domains, ni zhidao performs 16 context-specific functions. Our analysis of ni zhidao within the DFTM can not only relatively sufficiently describe the meanings and functions of ni zhidao in specific contexts, but also better reveal the speakers’ communicative intents when using it in different domains (Crible & Degand, 2019). However, Tao (2003), Liu (2006), and Shan (2014a, 2014b, 2015, 2021, 2022) are less likely to provide such detailed, fine-grained descriptions of ni zhidao due to their specific research objectives and their qualitative rather than quantitative nature, though they have enhanced our understanding of ni zhidao from different angles. This is the first study that has addressed the multifunctionality of ni zhidao within the DFTM. It has demonstrated the operationality and affordance of this taxonomy model cross-linguistically. Given the typical phonetic, syntactic, semantic, and pragmatic nature of ni zhidao as a representative Chinese DM (Shan, 2022), this study may promise to have a high degree of replicability to other Chinese DMs. Based on the present study of ni zhidao, investigations of other Chinese DMs could be conducted to better describe the challenging pragmatic category of DMs comprehensively and quantitatively, which could not be achieved from other perspectives adopted by existing studies of Chinese DMs.
Operationality and Affordance of the DFTM on ni zhidao
Based on Redeker (1990), González (2004, 2005), and Cuenca (2013), the DFTM incorporated into its framework four domains of discourse structure “targeted by DMs depending on the types of elements that are connected” (Crible & Degand, 2019, p. 9). This taxonomy model can provide operational guidelines for systematically applying domains and functions to corpus data. It applies to the analysis of ni zhidao, though needing to be upgraded to better suit this case study cross-linguistically.
In the DFTM, “functions and domains are independent” (Crible & Degand, 2019, p. 4). However, we found that domains and functions are closely related rather than independent planes of pragmatic information. As illustrated in Examples (1) to (6), the functions fulfilled by ni zhidao determine the domains it belongs to. When specifying a single relation between discourse segments (events) in a specific context, it falls into a single domain. This finding confirms Crible’s (2017) proposal that each function falls into only one domain, producing a given domain-function combination. When indicating different relations between discourse segments (events) simultaneously in a particular context, it falls into different domains simultaneously. In this case, any function can combine with any domain (Crible & Degand, 2019), making diversified domain-function combinations possible. Targeting the whole DM category in their data, Crible and Degand (2019) derived various domain-function combinations from different DMs rather than from each particular DM. As they refrained from using double-function labels (Crible & Degand, 2019), the DFTM failed to consider the multifunctionality of some individual DM cases in the same utterances. In this sense, the DFTM can not directly provide operationality and affordance that can be replicated in the analysis of ni zhidao tokens that simultaneously play various roles in the same contexts. However, informed by Crible and Degand (2019), we tentatively updated their model to cater to the analysis of multi-domain and -function ni zhidao to capture all ni zhidao tokens in our data and thus ensure better operationality and affordance of the upgraded model (to be described in the following subsection). Data analyses revealed that domains as generic macro-functions encompass specific functions, and the number of domains a ni zhidao token falls into depends on the number of functions a ni zhidao token performs in a specific utterance context. We, therefore, divided ni zhidao tokens into two categories, uni-functional and multi-functional, before examining them. We first identified all potential functions served by each token and then attributed each function to a corresponding domain. As a result, we detected ni zhidao tokens of single, double, triple, or quadruple functions, capturing one-domain, two-domain, three-domain, and four-domain tokens in our data. This shows that we need to consider the variation of languages when applying any linguistic model cross-linguistically, as implied by Crible and Degand (2019).
The 15 functions incorporated into the DFTM can explain French, English, Polish, and Spanish DMs, but they failed to explain some ni zhidao tokens in our data cross-linguistically. Some ni zhidao tokens in our study were attested to fulfill the “emphasis” function, highlighting the speaker’s attitude and reasoning. Adding this function to the DFTM, we managed to account for all ni zhidao tokens in the data by interpreting not only the meaning and function of ni zhidao, but the underlying communicative intentions of the speakers (Crible & Degand, 2019, p. 10). As Crible and Degand (2019, p. 19) predicted, “case studies on particular DMs may require a more fine-grained taxonomy of functions than our list of 15 labels.” Our list of 16 functions can provide improved operationality and affordance.
The analysis above reveals that “[t]he ideal granularity of the taxonomy is probably not universal” (Cartoni et al., 2013, p. 81) and the best taxonomy models are those that are “methodologically reliable and answer the given research question with the accurate degree of precision” (Crible & Degand, 2019, p. 19). In our study, the DFTM needs to be further modified to well capture the actual uses of ni zhidao in specific contexts, although it has been proven well suitable for the analysis of French, English, Polish, and Spanish DMs (Crible & Degand, 2019). The modified taxonomy model provided potent operationality and sufficient affordance on ni zhidao. This may contribute to our understanding that any established linguistic theory, though well serving its designing purpose, needs to be adapted cross-linguistically to varying degrees to provide methodological replicability and theoretical adequacy.
An Upgraded Version of the DFTM
To improve the operationality and affordance of the DFTM on ni zhidao, we tentatively propose an upgraded version of the DFTM (UDFTM), in which an extra function, “emphasis,” is added to the original 15 functions in the DFTM. “Emphasis” is meant to “reinforce the propositional value of the utterance” (González, 2005, p. 61). The 16 functions and 4 domains are interrelated in the UDFTM, where the functions of DMs determine the domains DMs belong to, and generic domains encompass specific functions. Moreover, we recommend that DMs be divided into uni-functional and multi-functional categories before being subjected to analysis within the UDFTM, to better capture the polyfunctionality of some individual DMs in the same utterance contexts. The UDFTM allows for 64 (16 × 4) possible domain-function combinations of DMs in specific contexts. Compared with the 60 (15 × 4) domain-function combinations in the DFTM, the 64 combinations in the UDFTM could provide a more granular taxonomy framework that is more likely to exhaust the DM category or DM cases in specific corpora.
Given the potential connection between domains and functions and based on the DFTM, this study argues in favor of attributing the 16 functions to the four domains (see Table 7) in the analysis of uni-domain and -function DMs that perform different functions in different discourse contexts (Crible, 2017). Such attribution was informed by González (2005), Crible and Degand (2019), Halliday (1970), and Hovy (1995). González (2005, p. 54) proposed that “logico-semantic argumentative relations (of cause, reason, result, concession, contrast, time, etc.)” are considered “ideational.”Crible and Degand (2019) asserted that “disagreeing” is specific to the “interpersonal” domain, and “topic,” “monitoring,” and “quoting” are “sequential.”Halliday (1970, p. 163) regarded the “manner of speaking” as a rhetorical choice. Hovy (1995, p. 3) looked on “stylistic preferability” as the rhetorical domain. As regards the multi-domain and -function DMs, we propose a variant annotation model, as shown in Table 8. This model proved to be highly operational on ni zhidao tokens that perform different functions simultaneously in the same discourse context (Crible, 2017). By applying the two variant models, we have embedded all ni zhidao tokens in particular discourse environments with sequential and distributional accountability, that is, specific coherence relations that they establish between preceding and succeeding utterance segments (Schiffrin, 1987b). The UDFTM features relatively finer granularity and greater affordance on ni zhidao. This upgraded model can be applied to case studies of other Chinese DMs and DMs in other languages to be further tested in its operationality and affordance.
Attribution of Functions to Domains for Uni-Domain and -Function DM Tokens.

Attribution of Functions to Domains for Multi-Domain and -Function DM Tokens.

“*” Indicates that the marked function has not been attested in a certain domain in this study, but it may be identified in such a domain in future studies.
Admittedly, the individual components of the UDFTM are not brand-new but are informed by relevant studies. When ascertaining the four domains, the UDFTM drew on the DFTM and other previous models, such as Schiffrin (1987a), Hovy (1995), Redeker (1990), González (2005), and Petukhova and Bunt (2009); when determining the 16 functions, the UDFTM referred to the DFTM and other previous taxonomies, including Schiffrin (1987a), Crible (2017), and Shan (2014a, 2014b, 2015, 2022). What makes the UDFTM innovative consists in the combination of these components in a unified, operational, speech-friendly, and exhaustive annotation model, which displays what differs among these components, how they are mutually related, and how they are applied to DMs (Crible & Degand, 2019, p. 19).
Conclusion
DMs are subjected to two types of studies: (i) those disentangling the intricate meaning and function network of DMs; and (ii) those tracing the DM status as the outcome of a long-term linguistic change in the form of pragmaticalization, lexicalization, subjectification, and grammaticalization (Enghels, 2018, p. 108). This study belongs to the first category, but it approaches ni zhidao using the DFTM. By putting this model to the test in the analysis of ni zhidao, we found that “emphasis” needs to be added to the original 15 functions in the DFTM and that domains and functions should not be treated as independent layers of pragmatic meaning. Instead, functions determine domains, and domains need to be regarded as generic functions to which specific functions are attributed. Accordingly, we proposed an upgraded version of Crible and Degand’s (2019) DFTM, which can provide finer granularity and greater affordance on ni zhidao.
Our study can contribute to the relevant literature and provide essential implications for future studies in two aspects. First and foremost, our study has enriched previous studies on ni zhidao (Liu, 2006; Shan, 2014a, 2014b, 2015, 2022; Tao, 2003), giving fresh insights into the actual performance of this DM in speech. Such a corpus-based exhaustive domain-function examination could shed new light on the investigations of other Chinese DMs and even DMs in other languages, especially considering the cross-linguistic replicability, operationality, and affordance of the DFTM and the UDFTM. Qualitative in nature, these studies drew on relevant models proposed in previous studies, like Schiffrin (1987a, 1987b, 2006), Redeker (1990), Hovy (1995), Brinton (1996), etc., to explore the multifunctionality of ni zhidao. They have not escaped from the analysis paradigm of primarily resorting to exemplification to fit or substantiate given function labels. As a result, they have not attested to some ni zhidao tokens that play other functions than those incorporated into some qualitative DM multifunctionality taxonomy models, like “hedging,” “agreeing,” “disagreeing,” “concession,” “quoting,” etc., not to mention double functions, like “cause-specification,” “addition-topic,” “specification-emphasis,” etc., and some domain-function combinations, like “sequential hedging,” “rhetorical disagreeing,” etc. In contrast, our study captured these fine-grained functional representations by exhausting the corpus of interview speech we established, expanding our understanding of the functional characteristics of ni zhidao. Informed by our study, DM researchers could gain a better understanding of other Chinese DMs and DMs in other languages by scrutinizing this challenging pragmatic category not only from the perspective of function (i.e., the pragmatic meaning of DMs) but also from the perspective of domain (i.e., the speaker’s communicative intents underlying the use of DMs). Such domain-function two-dimensional analyses can promise to substantively advance DM inquiries in general, therefore enabling us to approach the elusive nature of DMs. An implication drawn in this respect is that “more exhaustive, speech-friendly annotation models” (Crible & Cuenca, 2017, p. 149) of DM multifunctionality that are corpus-based are urgently needed to exhaustively account for the authentic uses of DMs as they are in specific corpora, especially considering that “most annotation frameworks are writing-based, thus partially unfit to be applied in spoken corpora” (Crible & Cuenca, 2017, p. 149), including the Rhetorical Structure Theory (Mann & Thompson, 1988), the PDTB (Prasad et al., 2008, 2018), etc. Despite the predominance of such writing-based taxonomy models, spoken and spoken-like corpora with large databases are increasingly accessible, like the Spoken BNC2014 project for English or C-Oral-Rom for Romance languages (Crible & Cuenca, 2017, p. 149). Under such paradoxical circumstances, there is a pressing need to consider the unique characteristics of spoken data to achieve descriptive adequacy and upgrade writing-based annotation models (Crible & Cuenca, 2017, p. 150). Only through such refined models, can we gradually approach the nature of the challenging category of DMs (Crible & Degand, 2019) in speech.
The second contribution of this study is that it can cast new light on the challenging DM attribute of multifunctionality (Crible & Cuenca, 2017, p. 156) and how to approach this elusive characteristic. We drew on a most relevant model and other closely associated models to tentatively produce an upgraded model that can best cater to our spoken data, rather than directly, mechanically applied established models. DMs are “restricted primarily to spoken discourse” (Biber, 2006, p. 66). The multidimensionality of verbal communication is especially prone to expressions that simultaneously work on diverse levels or macro-functions (Crible & Cuenca, 2017, p. 158). Spoken DMs, therefore, tend to display certain relative differences or tendencies (Crible & Cuenca, 2017, p. 152), compared with written DMs. As claimed by Crible and Cuenca (2017, p. 155), “[i]t thus appears that spoken DMs not only tend to take scope over large and distant segments (as in writing), but can also combine local and global scope simultaneously, making the annotation process quite complex and calling for specific function types at a higher level of discourse structure than what is included in local views of coherence (PDTB, CCR).”
Such unique features of spoken DMs underlie their challenging characteristic of multifunctionality, especially in speech (Crible & Cuenca, 2017, p. 156). To rise to this challenge, we distinguished two categories of ni zhidao: “a single member can perform different functions in different contexts” (uni-domain and -function tokens); “a single member can perform different functions simultaneously in the same context” (multi-domain and -function tokens) (Crible, 2017, p. 107). With the two categories in mind, we exhausted all ni zhidao tokens in our data. We, therefore, managed to “choose among many different possible senses for a single DM, including highly underspecified uses” (Crible & Cuenca, 2017, p. 159), presenting a fine-grained analysis of the multifunctionality of ni zhidao that could not have been achieved using available models. When finding tokens that could not be covered by the function labels in the DFTM and other established models, we relied on their specific embedding contexts to work out a new label, “emphasis.” An essential implication drawn here is that established DM annotation models need to be adapted or refined to cater to the unique traits of spoken DMs systematically and comprehensively (Crible & Cuenca, 2017), for better application to cross-linguistic DM studies. This is because spoken DMs are embedded in more varied structural configurations (Crible & Cuenca, 2017, p. 161) and multidimensionality (Petukhova & Bunt, 2009) at various discourse levels, compared with written DMs, making their multifunctionality potentially more complex to annotate. Established DM annotation models, especially writing-based ones, need to be extended or upgraded to capture the finer granularity of the comparatively larger functional range of spoken DMs in unplanned, spontaneous speech, just as we have done in this study. Informed by previous studies we reviewed, especially by our upgrading of the DFTM, we believe that it is such application, testing, and refinement in a cyclical manner that may most likely contribute to the increasing improvement and growing operationality and affordance of DM and other linguistic theories, paradigms, and models.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was funded by the National Office for Philosophy and Social Sciences of China (grant number: 21FYYB058).