
Abstract
In the evaluation of engagement in occupation, it is important to access the qualitative data, including the client context. However, there are no tools capable of quantifying such data. The purpose of this study is to develop a Classifier of Engagement in Occupation with Machine Learning (CEOML) that is capable of quantifying context and evaluating engagement in occupation through the application of Natural Language Processing (NLP) and to validate the model performance. A supervised machine learning approach was adopted in this study for the development of clinical artificial intelligence, and it was conducted based on the Minimum Information about Clinical Artificial Intelligence Modeling. The research object was the Twitter data comprising 1,542 tweets posted over a one-week period, beginning on April 1, 2020. Bidirectional Encoder Representations from Transformers, an NLP model, was fine-tuned to learn a dataset labeled for the status of engagement in occupation. The model performance was validated using indicators (sensitivity, specificity, positive predictive value, negative predictive value, F-measure, and area under the curve of receiver operating characteristic curve), Cohen’s weighted kappa coefficient, and the attention level of the model to the text. The CEOML demonstrated suitable model performance, on par with the Canadian Occupational Performance Measure. High interpretability of the CEOML was also confirmed based on its level of attention. The developed CEOML can quantify and classify problems of engagement in occupation based on the client context.
Keywords
Introduction
Occupational therapy, one of rehabilitation, is a client-centered health profession concerned with promoting health and well-being through occupation (World Federation of Occupational Therapists [WFOT], 2019). To achieve this objective, occupational therapists seek to support engagement in occupation (WFOT, 2019). In addition, Occupational Therapy Practice Framework fourth edition (American Occupational Therapy Association, 2020) states that it is important for clients to engage in their desired occupation and indicates factors such as the client’s occupational performance and context for gauging this. Therefore, it is necessary to determine the client’s occupational situation through occupational performance and context to evaluate engagement in occupation.
The Canadian Occupational Performance Measure (COPM) is a standardized tool to evaluate occupational performance (Law et al., 2019). The COPM is the most widely used gold standard rating scale in occupational therapy and is available in 36 languages in over 40 countries (Law et al., 2019). With the COPM, a semi-structured interview is administered to the client, and their performance and satisfaction rated on a ten-point scale are determined and can not scale context.
Context comprises various elements: client, task, socio-cultural, temporal, geopolitical, and physical or social environmental. In evaluating client context, informal dialogue is an effective strategy for gathering context information (Fisher & Marterella, 2019). COPM evaluations also require gathering and interpreting information about the client’s context during the interview (Law et al., 2019). Owing to its complex relationship with occupation and context (Fisher & Marterella, 2019), it cannot be expressed as quantitative data in most cases and is described as qualitative data. Therefore, occupational therapists cannot use standardized tools to assess context and must use their subjective interpretations. Occupational therapy outcome measures should be scorable (Department of National Health and Welfare and Canadian Association of Occupational Therapists, 1987), similar to the COPM. Thus, it is necessary to develop a scorable tool for context. In addition, if there is an outcome that quantitatively assesses engagement in occupation of clients from context, it would help build evidence for occupational therapy and rehabilitation through its use in intervention studies.
Natural Language Processing (NLP) is a method of converting qualitative data into quantitative data. NLP is a set of techniques adopted to quantify human’s daily language (natural language) and process it using a computer. NLP is used in artificial intelligence for text classification, text generation, summarization, and translation tasks. Through NLP, it may be possible to directly quantify client context obtained through qualitative data and evaluate the status of client engagement in occupation.
Accordingly, this study aims to develop a Classifier of Engagement in Occupation with Machine Learning (CEOML) that evaluates the status of engagement in occupation-based on context through the application of NLP and validates the model performance.
Materials and Methods
Part 1: Study Design
This study adopted a supervised machine learning approach to develop a clinical artificial intelligence model. The CEOML was developed based on Minimum Information about Clinical Artificial Intelligence Modeling (MI-CLAIM; Norgeot et al., 2020), incorporating guidelines for developing clinical artificial intelligence models according to the protocol in Figure 1. MI-CLAIM was developed to achieve two goals: (a) to enable a direct assessment of clinical impact, including fairness and bias, and (b) to allow rapid replication of the technical design MI-CLAIM is structured from Part 1 to Part 6. In addition, since MI-CLAIM did not have a section on the data collection process, a Data collection section was added to Part 2 of this study.
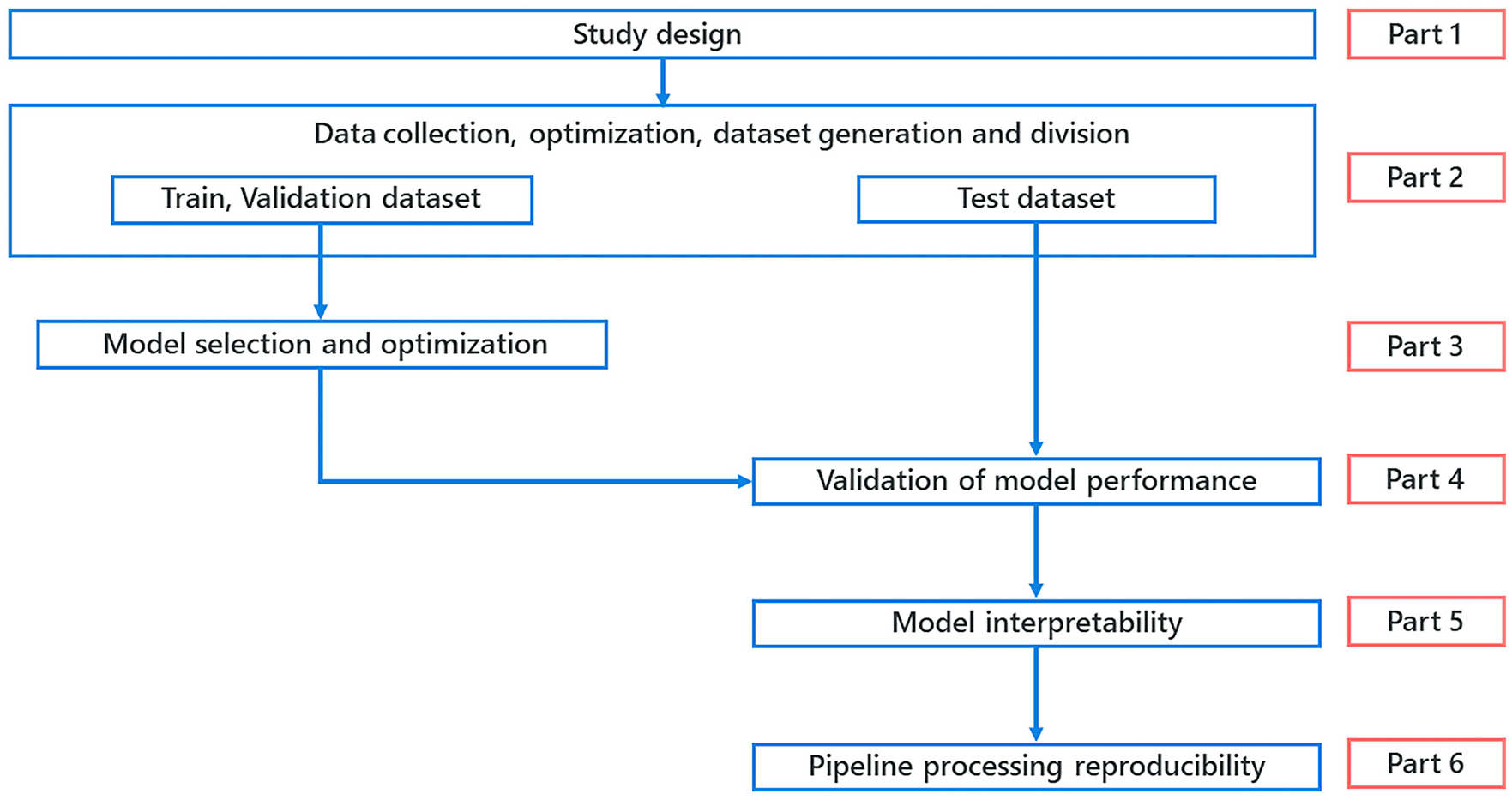
Process of this study by the MI-CLAIM protocol.
Part 2: Data Collection and Optimization, Dataset Generation, and Division
Problems of engagement in occupation can arise even when there are no issues of illness or disability (Akiyama & Kyougoku, 2010; Miyake et al., 2018; Wilcock, 2006). Thus, the authors considered tweets posted on Twitter as typical examples of qualitative data related to context or engagement in occupation and, accordingly, collected data from Twitter. In addition, CEOML was developed in Japanese in this study. The reasons for developing the Japanese version of CEOML first were (a) the number of tweets in Japanese is smaller than in English, and (b) the development cost is higher in Japanese because, unlike English, Japanese requires tokenizing. Therefore, we thought that if the model performance of the Japanese version of CEOML were high, the development of other language versions of CEMOL, such as English, would be prepared.
The target data were 2000 tweets in Japanese-language, including the negative verb conjugation “nai” in Japanese, randomly selected from the tweets posted on Twitter in Japan over the 1 week from April 1, 2020, to April 7, 2020. First, tweets were collected using the Application Programming Interface (API) Twitter, Inc. provided. Next, the collected tweets underwent preprocessing to remove character strings containing content that could be used to identify individuals (e.g., account name and personal name), symbols, and emojis and convert alphanumeric characters into lowercase, single-byte characters. Lastly, tweets containing excessively political, sexual, and redundant content by the same account were excluded as data inappropriate for learning.
In supervised learning, preparing a dataset with assigned true labels is necessary. In the present study, in order to classify problems of engagement in occupation, the first and second authors labeled the data using a positive label if a problem of engagement in occupation was identified and a negative label, if there was no such problem identified, based on context information obtained from the content of the tweet. The authors who participated in the labeling were researchers in engagement in occupation and experienced qualitative research. Furthermore, to further improve the quality of the labeling, if Cohen’s weighted kappa coefficient (kappa coefficient)-an index of inter-rater reliability-was less than or equal to Landis and Koch’s (1977) criterion of a substantial agreement rate (.61), the authors discussed the decision criteria and performed the labeling again under blind conditions. Lastly, the dataset was divided into training, validation, and test datasets in the proportion of 8:1:1. The training and validation datasets were used for learning. In contrast, the test dataset was used to validate the model performance and was thus used as a dataset separate from learning.
Part 3: Model Selection and Optimization
It is considered effective in NLP to fine-tune a pre-trained model—a language model trained on a large body of data—for a specific task one intends to accomplish using a small body of data of a few thousand (Brown et al., 2020; Devlin et al., 2019; Raffel et al., 2020). In this study, we fine-tuned the pre-trained model known as Bidirectional Encoder Representations from Transformers (BERT; Devlin et al., 2019). BERT is designed to pre-train deep bidirectional representations from the unlabeled text by jointly conditioning on both left and right contexts in all layers. As a result, the pre-trained BERT model can be fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inference, without substantial task-specific architecture modifications (Devlin et al., 2019). We used the generated dataset discussed in Part 2 and adopted a model that outputs binary values (positive and negative) through linear regression. The pre-trained model used in this study is the pre-trained Japanese BERT model of Tohoku University (https://github.com/cl-tohoku/bert-japanese). The hyperparameters during fine-tuning (learning rate, weight decay, warm-up steps, epoch, and batch size) used the automatic hyperparameter optimization framework Optuna and were tuned through 100 trials.
Part 4: Validation of Model Performance
The model performance was validated using the test dataset. The following performance indicators were calculated: accuracy, sensitivity, specificity, positive predictive value (PPV), negative predictive value (NPV), F-measure that the harmonic mean of sensitivity (or specific) and PPV (or NPV), and area under the curve (AUC) of the receiver operating characteristic (ROC) curve and its 95% confidence interval (95% CI).
Part 5: Model Interpretability
When developing clinical artificial intelligence models, it is essential to develop highly interpretable models (Norgeot et al., 2020). Therefore, the CEOML’s interpretability was evaluated from three perspectives: cut-off value calculation, inter-rater reliability confirmation, and model inferences visualization.
The cut-off value for prediction by CEOML was calculated based on the Yoden Index (Schisterman et al., 2005). Subsequently, to validate the association between the test dataset and prediction by CEOML based on the cut-off value, a chi-squared test was performed at a significance level of 0.01. CEOML inter-rater reliability was evaluated by the kappa coefficient between the predictions based on the CEOML cut-off value and the labels in the test data set. The model inferences were evaluated using the attention head mechanism of BERT that outputs the portion of the text the model was attending to at the time of prediction. Attention is a method for learning the correspondence between input strings and output strings, indicating where in the string the model has Attention (Vaswani et al., 2017). BERT incorporates 12 Multi-Head Attentions that use the Attention mechanism (Devlin et al., 2019). In this study, the mean output obtained from the twelve attention head mechanisms was visualized for three bodies of data—maximum, minimum, and around cut-off CEOML prediction values—to evaluate the model inferences.
Part 6: Pipeline Processing Reproducibility
All processes of this study were performed in a single notebook using Google Colaboratory. The programming language used was Python 3.7.12. The libraries used were Transformers 4.15.0, including BERT pre-trained models, and Optuna 2.10.0, a library for hyperparameter tuning. Japanese tokenization used the Transformer’s tokenizer and was based on the Mecab ipadic-Neologd dictionary. The datasets, models, and codes used in this study are publicly available on Zenodo and can be accessed by anyone (https://doi.org/10.5281/zenodo.6586116).
Ethical Considerations
This study was conducted in accordance with the Declaration of Helsinki. There are no ethical considerations because this study does not use human subjects or living organisms, only tweets, which are open data. Data collection followed the Twitter API user guidelines and the Twitter policies stipulated by Twitter Inc. Tweets are considered open data; however, some of the tweets collected might contain content from which individuals could be identified. Therefore, in the present study, personal information such as personal names, Twitter IDs, and addresses were deleted, and utmost care was taken to ensure the inability to identify individuals from the content of the tweets. Note that there were no conflicts of interest to disclose concerning this study.
Results
Ultimately, 448 data points were excluded, and 1,554 were used for the dataset. The kappa coefficient representing inter-rater reliability for dataset labeling was .651. The dataset was divided into a training dataset of 1,223 data points (79%), a validation dataset of 185 data points (11%), and a test dataset of 124 data points (10%).
CEOML performance indicators using the test dataset are shown in Table 1. The accuracy was 0.763. The sensitivity was 0.759, the specificity was 0.771, and the mean was 0.766. The PPV was 0.719, the NPV was 0.806, and the mean was 0.768. For the F-measure, the positive was 0.739, the negative was 0.788, and the mean was 0.767.
CEOML Performance Indicators Using the Test Dataset.

Note. PPV = positive predictive values; NPV = negative predictive values; — = blank cells.
The CEOML cut-off value, AUC-ROC curve, and violin plot illustrating the distribution of prediction values for the test dataset are shown in Figure 2. The violin plot is an extension of the box plot, representing the density distribution of data. Prediction values for the positive test dataset were as follows: minimum −2.649, first quartile 0.188, median 1.660, third quartile 2.223, and maximum 2.877. Regarding the distribution, the amount of data tended to increase as the positive value increased. When the test dataset was negative, the prediction values were as follows: minimum −2.784, first quartile −2.276, median −1.37, third quartile 0.052, and maximum 2.785. Regarding the distribution, the amount of data tended to increase as the negative value increased. The AUC-ROC curve was 0.825 with a 95% CI of [0.748, 0.902].
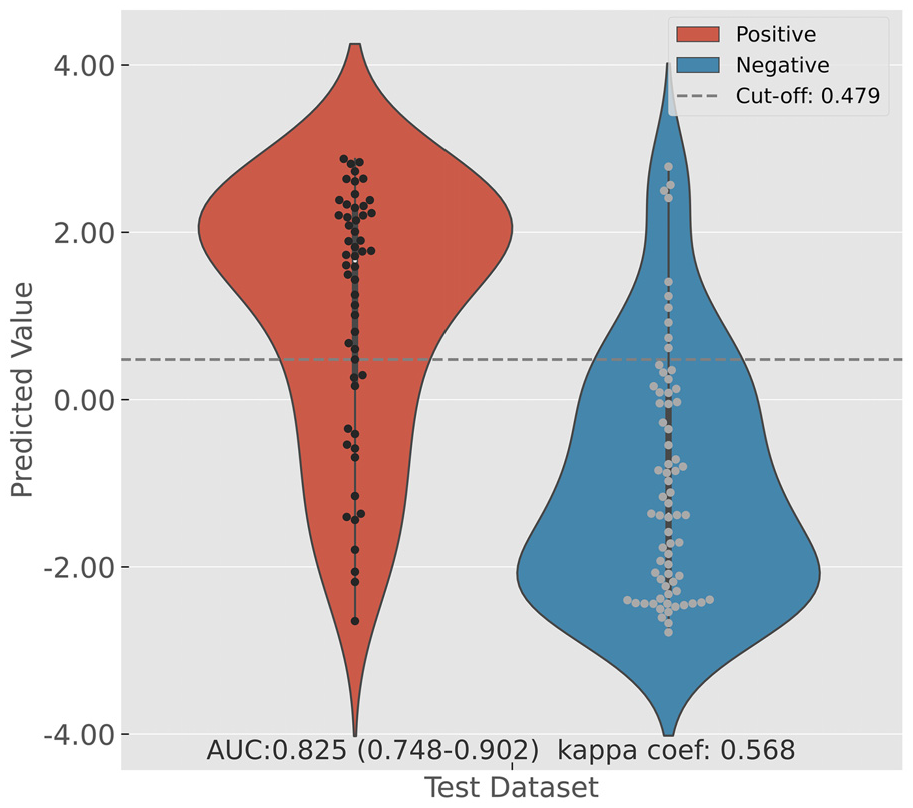
The CEOML cut-off value, AUC-ROC curve, and violin plot illustrate the distribution of prediction values for the test dataset.
The Youden index cut-off value for CEOML prediction was 0.479 (Figure 2). The chi-squared test of CEOML prediction based on the cut-off value and the test dataset confirmed a significant difference at p = .000000000677 (chi-squared value = 38.086). The kappa coefficient representing inter-rater reliability between the CEOML and the test dataset was .568 (Figure 2).
The attention CEOML focused on the test dataset is shown in Figure 3. At the maximum value for CEOML prediction, the test dataset and prediction label agreed on positive, and the level of Attention was higher in the overall text (Figure 3, top). The test dataset and prediction label disagreed around the cut-off value, and increased Attention was paid to approximately 80% of the overall words (Figure 3, middle). At the minimum value of CEOML prediction, the test dataset and prediction label agreed on negative, and less Attention was paid to only a portion of the text (Figure 3, bottom). Attention intensified when negative words such as “dekinai” (EN: nothing), “jikan” (EN: punctual), and “shatto auto” (EN: shut themselves off) appeared.

The attention CEOML focused on the test dataset. It shows the maximum (top), around cut-off values (middle), and minimum (bottom) attention of the CEOML predictions.
Discussion
CEOML Model Performance
Generally, excellent classifiers have high, well-balanced sensitivity (or specificity) and PPV (or NPV). From Table 1, sensitivity, specificity, PPV, and NPV are 0.719 to 0.801, suggesting a moderate classification performance level. In addition, the F-measure is a harmonic mean of these values; a higher F-measure indicates a more effective classifier. The F-measure for the CEOML is 0.767, suggesting that the CEOML demonstrated suitable classification performance. It is further supported by the accuracy value of 0.763.
Moreover, Hosmer et al. (2013) have stated that an AUC of 0.8 or greater but below 0.9 indicates excellent discrimination. In the study by Eyssen et al. (2011), the AUC of the COPM is 0.79–0.85. The AUC of the CEOML is 0.825 (95% CI [0.748, 0.902]), and it is therefore considered to demonstrate excellent classification performance on par with the COPM.
Based on these results, the model performance of the CEOML is confirmed to be appropriate and on par with the COPM. Furthermore, since COPM evaluates engagement in occupation from the perspective of occupational performance, whereas CEOML evaluates engagement in occupation from context, the combined use of these tools is expected to enable a high-quality assessment of engagement in occupation.
CEOML Interpretability
This study validated the model interpretability in the CEOML cut-off value, inter-rater reliability with the dataset, and Attention to the text.
The CEOML cut-off value is 0.479, and statistical testing with the test dataset based on the cut-off value confirmed a significant difference. These results suggest that the classification of the test dataset based on the cut-off value is effective. Further, the kappa coefficient representing inter-rater reliability between prediction by the CEOML and the test dataset is 0.568. Based on the criteria of Landis and Koch (1977), the kappa coefficient of .41 or greater, but less than .60, is moderate, and the CEOML is confirmed to demonstrate moderate inter-rater reliability.
Figure 3 shows that when CEOML predicts positive, strong Attention is paid to the overall text (top), and conversely, when CEOML predicts negative, Attention is paid to only a portion of the text (bottom). For data around the cut-off value (Figure 3, middle), CEOML assessed a false positive and directed Attention in the same manner as that in the case of positive prediction. While this text (Figure 3, middle) has many words that CEOML considers positive, the subject of the Japanese text is unknown. Therefore, it is possible that CEOML replaced the subject of the text with the first person, resulting in false positives. Since there are many texts in Japanese in which the subject is omitted, it is conceivable that CEOML would detect such false positives. These results suggest that the prediction accuracy and interpretability may increase for the text with high or low prediction values and decrease when the text approaches the cut-off value.
Further, the Attention intensified for words such as “dekinai” (EN: nothing), “jikan” (EN: punctual), and “shatto auto” (EN: shut themselves off). These are considered negative words expressing the context of the person who posted the tweet and the problems of engagement in occupation. Thus, it can be confirmed that CEOML makes predictions by increasing Attention to words in the text related to problems of engagement in occupation and context.
Research Limitations
This study has three limitations: (1) dataset quality, (2) clinical applications of the model, and (3) available languages.
Dataset Quality
In this study, the kappa coefficient for labeling the dataset is .651, which is considered adequate (Landis & Koch, 1977), while not sufficient for use in machine learning. Further, while learning is possible with only a small dataset when fine-tuning, the training dataset in the present study consists of 1,233 data points, which may not be sufficient. However, since retraining is easy if the protocols of this study are followed, it is expected that a large research team building on this study will develop a high-quality data set of more than 5,000 points using the revised labeling method, which will improve performance.
Clinical Applications of the Model
The validation of model performance conducted in the present study considers only Twitter data; the data collected from actual clients have not been considered for validation. However, because problems of engagement in occupation can arise even without issues of illness or disability (Akiyama & Kyougoku, 2010; Miyake et al., 2018; Wilcock, 2006), occupational therapists may be able to use CEOML in their clinical practice by utilizing qualitative data on clients, such as the tweet data. Although CEOML has a classification performance comparable to COPM, the gold standard in occupational therapy, it is considered to have moderate performance based on measures such as Accuracy, F-measure, and AUC, and its performance may not be sufficient for operational use. Therefore, to confirm higher clinical applicability, a large amount of qualitative data of clients in different settings, such as inpatients and elderly facility users, should be collected to improve the model performance of CEOML further.
Available Languages
The CEOML can only be used in Japanese and is incompatible with other languages. However, Japanese is generally considered an extremely difficult target for NLP as a language with esoteric grammatical subjects, free word order, and no demarcation between words. Thus, the fact that the CEOML developed in this study demonstrates suitable performance in Japanese suggests that following the same protocol to generate an English version of the CEOML will yield improved performance than the Japanese version.
Conclusions
To assess engagement in occupation from context, the CEOML was developed, which quantifies context using NLP techniques to classify and quantify engagement in occupation issues. The model performance of the developed CEOML was moderate and comparable to the classification performance of COPM, the gold standard assessment tool in occupational therapy. Attention to text by the Attention head of CEOML was also confirmed, suggesting high interpretability of the model. In addition, because engagement in occupation issues can arise regardless of the presence or absence of illness, CEOML may be a tool that occupational therapists can use extensively in their clinical practice. However, since the CEOML was not validated with actual clients, caution should be exercised in its use, and further validation is needed in the future.
Footnotes
Acknowledgements
We thank Professor Norio Suzuki of the Department of Occupational Therapy, School of Nursing and Rehabilitation Sciences, for his advice on this study.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.