
Abstract
We aimed to develop an item bank of computerized adaptive testing for eating disorders (CAT-ED) in Chinese university students to increase measurement precision and improve test efficiency. A total of 1,025 Chinese undergraduate respondents answered a series of questions about eating disorders in a paper-pencil test. A total of 133 items from four well-validated Chinese-version scales of eating disorders were used to construct the item bank of CAT-ED with the following analysis. First, unidimensionality, model fit, local independence, item fit, discrimination and differential item functioning (DIF) were tested. Then, two simulation studies were applied to test the CAT-ED’s effectivity and rationality by calculating concurrent criterion-related validity, sensitivity and specificity. The final item bank comprised 77 items, which met the requirements of local independence, item fit, high discrimination and no differential item functioning in CAT. The mean number of administered items in CAT with the stopping rule fixed at SE ≤ 0.3 was 11 items. The obtained results showed that CAT-ED had acceptable reliability, validity, sensitivity and specificity.
Keywords
Introduction
Eating disorders (EDs) are a group of mental disorders characterized by various abnormal eating behaviors and attitudes, which are correlated with the interaction of environmental events with an individual’s biological and developmental characteristics (Treasure et al., 2010). In the Diagnostic and Statistical Manual of Mental Disorders (Fifth Edition), EDs primarily include anorexia nervosa (AN), bulimia nervosa (BN), binge eating disorders (BEDs), avoidant/restrictive food intake disorder (ARFID), ruminant/reflux disorders, and pica. In recent years, many studies on EDs have been published, such as epidemiological studies (e.g., Mitchison & Mond, 2015; Udo & Grilo, 2018), clinical medical studies (e.g., Yang et al., 2018), and psychological studies (e.g., Marzilli et al., 2018), which indicate that researchers have long been concerned about EDs. By summarizing and contextualizing the reviews of recent epidemiologic data on EDs in Asia and the Pacific, Thomas et al. (2016) found that regions with EDs are transnational in distribution and that the prevalence rate of eating disorders is very high. As a group of severe and disabling conditions, EDs have a negative effect on individuals and their families and cause sufferers to take both mental and physical blows (Erskine et al., 2016).
For EDs, conducting an effective evaluation is a critical step before treatment. Therefore, based on different disciplinary perspectives, many different methods have been applied to assess eating disorders by researchers or clinical practitioners (Chowdhury & Lask, 2001; Fairburn & Beglin, 1994; Rosen, 1996; Schaefer et al., 2020; Smyth et al., 2001). For researchers in the field of psychology, patients’ self-report is usually regarded as an important reference to assess the severity of EDs. Thus, based on classical test theory (CTT), several self-report scales about EDs have been developed by psychometrics researchers, such as the Eating Attitudes Test (EAT-26; Garner et al., 1982), the SCOFF Questionnaire (Morgan et al., 2000), the Eating Disorders Inventory (EDI; Garner et al., 1983), the Eating Symptoms Checklist-21 (ESC-21; Leung & Mak, 2003), the Eating Disorders Inventory-3 (EDI-3; Garner, 2004) and the Eating Disorders Examination Questionnaire (EDE-Q; Fairburn & Beglin, 1994). For decades, these scales have been effectively validated by researchers and have played an important role in diagnosing or measuring ED. However, these scales have some shortcomings. First, the performance estimation for the entire test heavily depends on the specific samples under CTT. For example, when the same test is administered to different groups of subjects, the test performance may be different; thus, the interpretation of test outcome is inconsistent. Second, using CTT to estimate measurement error is inaccurate, and sometimes reliability and validity may vary with different groups of subjects. At the same time, we could only obtain the average measurement accuracy of a single test group and could not give the measurement accuracy of the subjects under different trait levels. Third, all participants had to answer the exact same items for scores to be comparable. If the scale contains too many items, it will increase the subject’s burden, and sometimes some subjects even lose their patience due to the long test time. Therefore, based on the abovementioned three points, it is necessary to identify a new measurement mode to increase measurement accuracy and improve test efficiency.
Item response theory (IRT) was proposed as an alternative to CTT to overcome abovementioned shortcomings (Hambleton et al., 1991; van der Linden & Hambleton, 1997). With the popularization of personal computers and the internet, computerized adaptive testing (CAT) is probably one of the most valuable new perspectives in the application of IRT (Wainer, 2000). As a novel type of test technology, CAT is a type of test method that uses IRT to build the item bank, employs the computerized algorithm to automatically select the most appropriate items to answer for different participants, and finally accurately estimates their trait levels (Wainer, 2000). In fact, it will create tests of different lengths for subjects at different levels of traits. Furthermore, we could also fix the short length of the test for every subject; thus, the test time can be also reduced. Since its appearance, CAT has shown considerable application prospects and has gradually become a research topic that has received widespread attention. To date, CAT has been successfully applied in earlier studies to diagnose or measure psychological illnesses such as personality disorder (Simms et al., 2011), depression (Gibbons et al., 2012), and anxiety (Gibbons et al., 2014).
To our knowledge, the application of CAT in EDs has not yet been formally discussed in the literature. Based on the limitations of traditional psychometric scales in measuring EDs and the advantages of computerized adaptive testing in assessing mental health and psychiatric illnesses, we consider applying CAT technology to measuring EDs. Therefore, in this study, we hope to address the abovementioned issues by developing an efficient and accurate item bank for EDs; then, we show the psychometric researchers, potential users or readers interested in applying CAT technology to measuring ED the complete theoretical and technical details on the development of CAT-ED as detailed as possible. At the same time, we also hope that this research can promote the application of computerized adaptive testing technology in the fields of mental health and psychiatry. More specifically, this article mainly involves the following three parts. First, we show the detailed development steps of the CAT-ED item bank, which meets the psychometric requirements of CAT, using four well-validated psychological scales for EDs as examples. Second, two simulation studies are conducted to evaluate the psychometric properties, efficiency, reliability, and validity of the CAT-ED item bank. In this part, we will verify the performance of the developed item bank by various accuracy indicators. Of note, there is a certain degree of difference between the two simulation studies. The first simulation study is conducted under a wider range of trait levels to show the test performance for simulated subjects at various trait levels. The second simulation study aims to test the performance of CAT-ED in a test environment close to reality. Finally, we list the limitations of this study and provide directions for future research.
Method
Participants
Data collection began in December 2018 and was completed in March 2019. In the process, considering the convenience of sampling and the representativeness of the samples, in this study, a total of 1,168 college students were recruited from seven colleges in 10 Chinese provinces including Shandong, Hebei, Jiangxi, Sichuan, Liaoning, Hunan, Hubei, Henan, Guangdong and Anhui. These samples represent Chinese college students from North, South, East, Central and Southwest China. To protect personal privacy, each respondent was assigned a unique code number for identification. To screen out individuals who could randomly respond, three lie detection items that were designed as opposite meanings were embedded in this survey. For example, “Facing pressure makes me feel powerful.” Its corresponding lie detection item was “The stressful scene makes me feel helpless.” Participants who responded to any one of the three pair items using the same answer were eliminated in this study. In addition, subjects with missing answers on any item about demographic information will also be eliminated. Finally, 1,025 respondents whose average age was 19.7 years (SD = 2.2, ranging from 17 to 24 years) were retained for the follow-up analyses. Detailed demographic information about these samples can be found in Table 1. All participations were voluntary and anonymous. The present study was carried out following the recommendations of psychometrics studies on mental health at the Research Center of Mental Health, Jiangxi Normal University. Informed consent was obtained from all participants in accordance with the Declaration of Helsinki.
Demographic Characteristics of Subjects (N = 1,025).

Instruments
Taking into account the localization, reliability and validity of the eating disorder scales, we identified the currently commonly used Chinese versions by searching the Chinese literature database. Finally, four well-validated psychological scales (Chinese Versions) measuring EDs were carefully selected and applied to construct the initial item bank. The four scales are the Eating Attitudes Test (EAT-26; Garner et al., 1982), the Eating Symptoms Checklist-21 (ESC-21; Leung & Mak, 2003), the Eating Disorders Inventory-3 (EDI-3; Garner, 2004), and the Eating Disorders Examination Questionnaire (EDE-Q; Fairburn & Beglin, 1994). A psychological scale named The SCOFF Questionnaire will be applied to test the concurrent criterion-related validity of CAT-ED in addition to the abovementioned four scales. Due to space limitations, these scales’ basic information such as reliability, validity and quantity of items of original and Chinese version, is only shown in the online supporting information, and it could be found in Table S1 in Supporting Information.
Originally, there were 149 items in the initial item bank of CAT-ED in addition to The SCOFF Questionnaire (containing five items), which was used to test criterion-related validity. However, in these items, 32 pairs of items (e.g., I think people are happiest when they are children vs. Childhood is the happiest period of life; I think my hip circumference is too large vs. I think my hips are too big.) are considered to have a similar meaning by the following review process. First, we invited four third-year master’s degree students; two of them were from the Chinese language and literature, and the others were from psychology. They were asked to identify the pairs that had the same or similar meaning in the original item bank. When there were different opinions, they needed to negotiate until they finally reached an agreement. Next, we invited another four third-year master’s degree students; two of them were from the Chinese language and literature, and the others were from psychology. They were asked to answer the same question of whether the pairs obtained from the abovementioned step had the same or similar meaning. In this step, we selected the pairs in which all invited evaluators thought there were the same or similar meanings. Finally, we randomly deleted an item from each chosen pair. Ultimately, 133 items made up the initial item bank.
Statistical Analysis
Data analysis is divided into three steps: construction of the item bank, simulation studies and validation of the effectiveness of CAT-ED. All details of data processing will be described next. Data analysis and simulation of administering items were mainly carried out via the R package mirt (Version1.3; Chalmers, 2012) and R package catR (Version 3.16; Magis & Barrada, 2017). The former was used for item bank construction and parameter calibration, and the latter was applied to simulate the process of administering items to participants.
Construction of Item Bank for CAT-ED
Step 1: Test the unidimensionality of the item bank
Unidimensionality is a crucial assumption in IRT, and an item bank will be regarded as unidimensional if the person’s latent trait level of the item measures, rather than other factors, resulted in the person’s response. This implies that responses to each item are affected by a single latent construct of test takers. In this study, the method for testing the assumption was recommended by Andrich (1996) and Reckase (1979) under the framework of IRT. If the ratio of the first eigenvalue explanatory variance to the second eigenvalue explanatory variance is greater than 4 and the variance of the first factor interpretation is greater than 20% (Reckase, 1979), the data can be considered to basically conform to this assumption (Reeve et al., 2007). Some researchers (Wu et al., 2019; Zhang et al., 2019) have tested this assumption according to the abovementioned standards when developing a unidimensional CAT item bank. In this part, we evaluate the dimensionality of our item bank using exploratory factor analyses via the SPSS 20.0 software by the following procedure. Principal component analysis (PCA) is used in this part, and no rotation is required. First, according to the EFA results, the items whose factor load on the first factor was less than 0.3 were removed. Then, a test for unidimensionality will be conducted again until the factor load of all items in the item bank is more than 0.3 (Reeve et al., 2007).
Step 2: Conduct the model selection
Selecting an appropriate IRT model for data analysis is the premise to ensure the accuracy of parameter estimation in IRT. In this research, the graded response model (GRM; Samejima, 1970), partial credit model (PCM; Masters, 1982) and generalized partial credit model (GPCM; Muraki, 1992) will be used as candidate models to fit the items in the CAT-ED item bank. The formula of these models are as follows:
(a) Graded Response Model (GRM). GRM assumes that there are

where
The probability of choosing a response category is not calculated directly from equation (1); it can be calculated using the following formula:

In this formula,
(b) Generalized partial credit model (GPCM) and partial credit model (PCM)
Assuming there are a total of

where
The selection of the optimal fitting model is based on test-level model-fit indices including −2log-likelihood (−2LL; Spiegelhalter et al., 1998), Akaike’s information criterion (AIC; Akaike, 1974) and Bayesian information criterion (BIC; Schwarz, 1978). The smaller the value of −2LL, AIC and BIC, the better the model fitting. Model selection is conducted via the flexMIRT software (Version 3.51; Cai, 2017).
Step 3: Evaluate local independence
IRT assumes that when subjects with the same ability respond to a question, they will not be affected by any other question on the same test, or it will violate the assumption. Yen (1984) proposed the Q3 statistic to test the local independence between items. Cohen (1988) holds the opinion that if the Q3 value between two items in a pair is higher than 0.36, the item will be considered to be locally dependent. He also suggests that among these pairs whose Q3 value is higher than 0.36, the item with the larger accumulated amount of Q3 in any pair will be deleted. In this part, we calculate the Q3 statistic using the function called residuals in the R package mirt.
Step 4: Check the item model fit of the remaining items
When conducting IRT-based analysis, testing the goodness of item fit is considered to be an important step. If the item has a low degree of fit to the selected model, it will affect the measurement accuracy to some extent (Köhler & Hartig, 2017). The test for item fit is applied to examine whether the item fits the IRT model well. In our research, we followed the suggestion of Orlando and Thissen (2003) and used the S-χ2 statistic to check each item’s degree of fit. When the P value of the S-χ2 of an item is less than the critical value of .01, it indicates that this item poorly fits the IRT model and should be excluded from the item bank (Flens et al., 2017). To test the goodness of fit for each item, the function called itemfit in the R package mirt is used.
Step 5: Choose items with high discrimination parameters
Discrimination is an essential indicator and is related to the quality of the single item and even the total test. In IRT, the discrimination parameter is closely related to the information of items and even the whole test. The greater the discrimination parameter, the higher the information. Therefore, item discrimination has shown a significant impact on measurement accuracy and it is usually used to determine whether the items could be preserved in the CAT item bank in IRT (Wainer, 2000). Baker and Kim (2004) pointed out that to estimate the person parameters effectively, the discrimination parameter is generally required to be between 0.5 and 2. Therefore, whether the value of discrimination is less than 0.5 will be taken as the criterion for the retention or deletion of the item. Using the functions coef and mirt in the R package mirt, we obtained each item’s discrimination parameter based on the response data.
Step 6: Test Differential Item Functioning (DIF)
DIF is used to identify systematic differences caused by demographic variables such as gender and age (Gaynes et al., 2002); therefore, it is closely related to the fairness of the test. Adaptive testing may be more susceptible to the impact of DIF on validity than fixed testing because DIF may have a greater impact on short CAT evaluation (Reeve et al., 2007; Wainer, 2000). To build a nonbiased item bank, logistic regression (LR) is used for the DIF test in this study, specifically using McFadden’s pseudo R2 method (Choi et al., 2011). The change in McFadden’s pseudo R2 is used to evaluate the effect size, and the hypothesis of no DIF is rejected when the R2 change reaches a critical value. This indicates that there is a deviation in the item when the variation in R2 is greater than .02; then, it should be deleted (Choi et al., 2011). Referring to existing IRT-related and CAT-related studies (Gaynes et al., 2002; Liu et al., 2020; Tan et al., 2018), we selected two demographic variables, which have been the focus of DIF detection in these studies: region (rural, city) and gender (male, female). In this study, we conducted DIF analysis using the R package lordif (Version 0.3-3; Choi et al., 2011).
Psychometric Properties of CAT-ED
Two parts are mainly involved in the psychometric properties of CAT-ED: the algorithm of CAT and its performance evaluation.
Algorithm of CAT-ED and evaluation
The core of ensuring the implementation of CAT is the algorithm, which allows the computer to automatically select an appropriate item for the subject and give them the test results. It mainly involves four steps: initial item selection, parameter estimation, item selection algorithm and stopping rule (Chen & Cook, 2009).
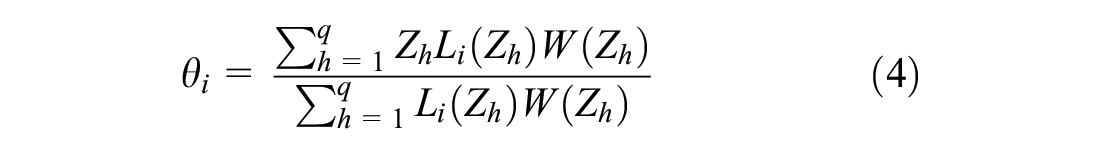
where
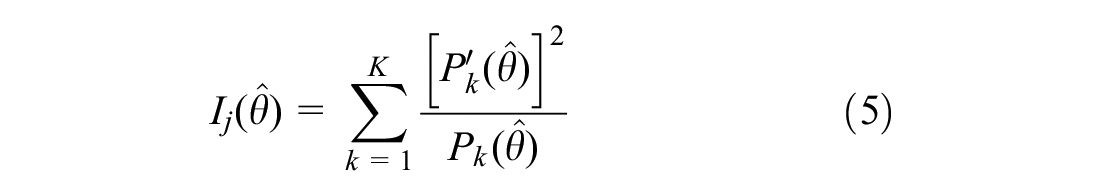
where
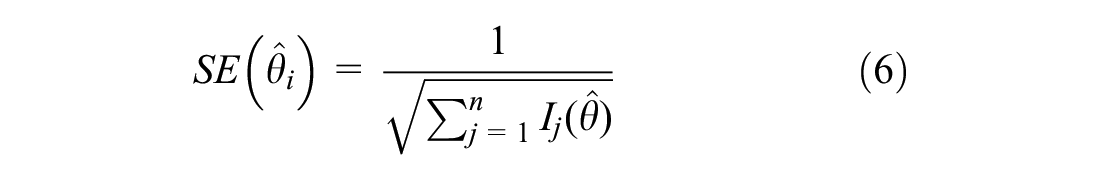
where SE stands for standard error of test, and
Design on exploring psychometric properties of CAT-ED
To evaluate the effectiveness of the CAT-ED algorithm, the authors designed two simulation studies. The first simulation is conducted based on the simulated latent trait value (regarded as each simulated subject’s true trait value) and simulated response patterns. The second simulation is called a post-hoc simulation, that is, item responses that are not randomly drawn but picked from a given real response pattern. In the post-hoc simulation, the real responses of paper and pencil test based on the real subjects are used to simulate the adaptive administration process. The largest difference between the two simulation studies lies in the source of the subjects and the response patterns. Apart from that, the item parameters used in the simulation study and the post-hoc simulation study are completely the same, and these item parameters are estimated with the functions coef and mirt in the R package mirt by maximum likelihood estimation (MLE) method based on 1,025 real subjects’ response data.
The simulation study aims to show the measurement accuracy for simulated subjects at different trait levels between −3.5 and 3.5. Thus, different trait levels of EDs for subjects are simulated and deemed their true levels of EDs in this study. Specifically, within the values of the ED trait (

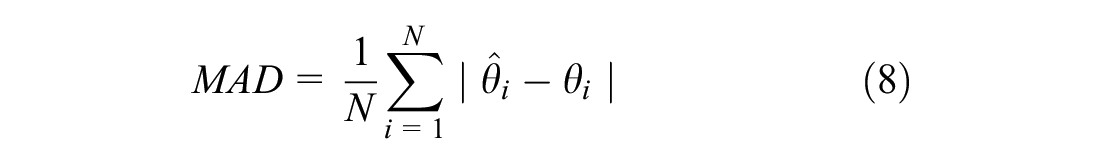

where N is the number of subjects; the estimated trait level of test taker i is represented by
Then, based on the real item parameters of CAT-ED and the real response pattern of each real subject for each item, the adaptive administration process is simulated in the post-hoc simulation study. The administration process in the post-hoc simulation is the same that in the simulation study other than the source of respondents and their response data. According to Magis and Barrada (2017), in post-hoc simulations, when the true trait level of each subject cannot be provided, it is common to treat the estimated latent trait with the full vector of responses as the best guess of the true trait level. Therefore, we estimated the true trait level of each real subject with the function thetaEst in the R package catR using the EAP method. Similarly, to explore the rationality and effectiveness of the algorithm in an environment close to reality, the correlation coefficients between the true theta and the estimated theta of each real subject under each stopping rule will be determined. Then, we calculated the average test length and the standard error of measurement of 1,025 participants on CAT-ED. In the post-hoc simulation study, the standard error is derived from the second derivative of the likelihood function based on the item parameters and estimated trait levels. In addition, the average saving ratio (it is equal to the proportion of items in the item bank that are not administered) of the CAT-ED item bank under each stopping rule is also calculated.
Performance Evaluation of CAT-ED
The main purpose is to explore the accuracy of trait estimation, concurrent criterion-related validity and predictive utility (sensitivity and specificity) of CAT-ED. Of note, the data used in this analysis were drawn from real subjects.
Accuracy of trait estimation
According to Kolen et al. (1996), conditional standard errors of measurement (SEM) are an effective indicator reflecting measurement error in IRT. Therefore, this indicator is frequently used in many IRT-related applied studies such as by Ferrando (2003) and Irwin et al. (2012). In this study, conditional SEM was calculated to test the accuracy of trait estimation under different stopping rules.
Evaluation of CAT-ED’s validity
Concurrent criterion-related validity
In this study, concurrent criterion-related validity is expressed as Pearson’s correlations between the estimated trait value in CAT-ED and the standard scores of the criterion scale (The SCOFF questionnaire). Then, we calculated it out.
Predictive utility (sensitivity and specificity)
In this study, sensitivity means the possibility that a respondent with ED is correctly diagnosed with ED, while specificity refers to the possibility that a normal subject is correctly diagnosed with no ED. The higher the quantity of sensitivity and specificity, the better the effect of the diagnosis. The receiver operating characteristic curve (ROC) is a composite indicator reflecting sensitivity and specificity (Hand, 2010), which takes sensitivity as the ordinate and 1—specificity as the abscissa, and is often used for the evaluation of diagnostic effect (Lusted, 1960) and some studies in CAT (Gibbons et al., 2014; Tan et al., 2018). In ROC analysis, the area under the curve (AUC), which refers to the area under the ROC curve, is often considered an important indicator to evaluate the diagnostic effectiveness of the developed clinical tool. In general, the larger is the AUC, the higher is the diagnostic accuracy. In other words, the closer the AUC is to 1, the better the is diagnostic effect.
To conduct ROC analysis, subjects were divided into two groups including subjects with and without EDs, according to the following three criteria. (1) Generally, a score of ≥4 for an individual item was applied to indicate clinical significance (Keane et al., 2017). At the same time, there are 22 items in total of EDE-Q; hence, the authors would regard a total score greater than 88 (22 times 4 is 88) of EDE-Q (Chinese version) as the screening criteria. (2) A total score of ≥2 in the SCOFF Questionnaire is applied to indicate that subjects are likely to have EDs (Morgan et al., 2000). (3) We also included an additional question (Have you been diagnosed with an eating disorder including anorexia, bulimia or atypical eating disorder by a professional clinician?) in the questionnaire during this collection process. Of note, only when the subjects’ responses on the paper questionnaire met all these criteria simultaneously can the subjects be considered as patients with EDs, or they will be assumed to be people without EDs. The calculated results showed that a total of 31 of 1,025 subjects were identified as patients with EDs. Next, we obtained the dichotomous data for each participant with or without EDs. Then, we used both the estimated ED trait score in CAT-ED under different stopping rules and the obtained dichotomous data collectively to conduct ROC analysis via the SPSS 20.0 software. Finally, we determined the sensitivity, specificity and AUC under chosen stopping rules in the post-hoc simulation study.
Results
Construction of Item Bank for CAT-ED
Unidimensionality
A total of 23 items were removed from the initial item bank due to their factor loading on the first factor being less than 0.3. Consequently, 110 items were retained from the initial item bank of CAT-ED at this step. Then, EFA was reconducted out, and the results showed that the first eigenvalue of factor analysis was 38.273; the second characteristic value was 6.167, and the variance explained of the first factor was 34.793%, which satisfied the assumption of unidimensionality.
Model selection
We conducted test fit analysis using the models including GRM, PCM and GPCM. The obtained results suggested that GRM fitted the data better than GPCM and PCM because its indices of −2LL, AIC and BIC were smaller than those of the other two models. Thus, GRM was used for the follow-up analysis. Detailed calculated results of these indices can be found in Table S2 in the Supporting Information.
Local independence
In this step, according to Cohen (1988), 12 items were deleted from the item bank because they were locally dependent on other items after conducting the Q3 statistic. After the deletion, the hypothesis of local independence is also satisfied.
Item fit
The findings indicated that the P values of the S-χ2 value of 19 items were less than the critical value of .01 (Flens et al., 2017); therefore, they were removed from the item bank.
Discrimination parameters
The obtained results show that an item’s discrimination parameter is less than .5 (Baker & Kim, 2004), and then it is deleted from the remaining item bank during this step.
Differential item functioning (DIF)
There was significant DIF between males and females on an item whose value of R2 change was .0262 and was beyond the critical of .02 (Choi et al., 2011). Apart from that, no DIF items are found on the level of region. Ultimately, this item was removed from the item bank during this step.
It is not meaningful for the CAT-ED item bank to measure ED until all abovementioned procedures are completed. After deleting 56 items through the abovementioned steps, the remaining 77 items effectively satisfied the basic assumptions of IRT. Therefore, these items make up the final CAT-ED item bank and will be used for further analysis. In addition, the item parameters and item fit of the item bank are also shown in Table S3 in the Supporting Information due to space limitations.
Psychometric Properties of CAT-ED
Algorithm of CAT-ED and its evaluation
Results of simulation study
The deviation, recovery and correlation coefficient (r) between the true value and the estimated value of the simulated subjects’ EDs trait scores are shown in Table 2. Table 2 indicates that regardless of which stopping rule is chosen, the correlation coefficient (r) is greater than .95, which indicates that there is a high consistency between the true value and the estimated value of subjects’
Recovery of ED Trait Estimation Under Each Stopping Rule in the Simulation Study.

Note. The r stands for Pearson product-moment correlation coefficient. MAD = mean absolute deviation; RMSE = root mean squared error.
Shows the discrepancy on .01 levels notable.
Results of the post-hoc simulation study
After calculation, the results of the number of items used, standard error of measurement and the Pearson product-moment correlation coefficient (r) under each stopping rule are displayed in Table 3. As shown in Table 3, the average number of items used was reduced by more than 60% regardless of which stopping rule was chosen, which shows the great advantage of CAT in improving test efficiency, and the mean SE in each stopping rule was acceptable. Although the subjects were only administered a small part of the items, there were still high correlations between the CAT
Psychometric Properties of CAT-ED Item Bank in the Post-hoc Simulation Study.

Note. The r stands for the Pearson product-moment correlation coefficient of estimated latent trait levels of subjects between the CAT
Shows the discrepancy on .01 levels notable.

Number of administered items and test information at different trait levels under different stopping rules.
Performance Evaluation of CAT- ED
Accuracy of trait estimates
For the CAT-ED item bank, the conditional SEM estimation at different trait levels under each stopping rule are shown in Figure 2. According to Ferrando (2003), if an S.E.M. value of 0.5 (an S.E.M. value of 0.5 corresponds to a reliability of 0.80) is considered to be the maximum error acceptable for practical purposes, from Figure 2, we can conclude that conditional SEM under each stopping rule is acceptable. Additionally, it is easy to see that the full CAT-ED item bank shows the highest accuracy, and SE ≤ 0.6 has the lowest accuracy. The accuracy will decrease as the stopping rule gradually becomes looser because the stricter is the stopping rule, the more items the subject has to answer. The conditional SEM shows the smallest when the subject’s trait score is close to 1.5, which means that the CAT-ED item bank showed the highest measurement accuracy in the trait score of 1.5.

The conditional SEM at different trait levels under each stopping rule.
Concurrent criterion-related validity
The obtained results show that the Pearson product-moment correlation coefficients of CAT-ED in each chosen stopping rule and the SCOFF questionnaire are all higher than 0.6 (p < .001), which illustrates that the concurrent criterion-related validity of CAT-ED is good and acceptable. If the reader is interested, the detailed results can be found in Table S4 in the Supporting Information.
Predictive utility (sensitivity and specificity)
The result of ROC analysis is listed in Table 4. As shown, CAT-ED performs well in the diagnostic accuracy of ED. Regardless of each stopping rule, the specificity and sensitivity of CAT-ED are all within a reasonable range. The AUC values under all stopping rules are also higher than the critical value of 0.7, which is universally used as the lower bound for moderate predictive utility (Forkmann et al., 2013). Thus, all stopping rules in this research are acceptable in predictive utility. Moreover, the AUC values can even reach 0.8 in the stopping rule of SE ≤ 0.3. These results also suggest that although the test length of subjects has been greatly shortened, it results only in a smaller drop in prediction precision. Given space constraints, we only show the AUC, sensitivity and specificity, and the ROC curve is not shown there. If the reader is interested, this information is shown in Figure S1 in the Supporting Information.
The Diagnostic Effects of CAT-ED for the Post-hoc Simulation Study.

Discussion
In the past, researchers developed various self-reported scales for measuring ED, however, they were constructed by classical test theory. Therefore, there were inevitably some drawbacks in these instruments. A recent approach is to reanalyze the psychometric characteristics of established fixed-length instruments using IRT and convert it to a computer adaptive version (Childs et al., 2000). In this study, the authors adopted IRT to complete the construction and calibration of the item bank of CAT-ED and conducted a series of simulation studies to explore its performance using a Chinese sample. Additionally, the complete theoretical and technical details on the development and validation of CAT-ED are carefully introduced. The final results showed that CAT-ED had acceptable psychometric characteristics that were embodied in the following aspects: all remaining items were strictly consistent with the hypothesis of unidimensionality; there was no strong local dependence for all items; the discrimination parameters for all items were above 0.5; no DIF was found in the item bank; the entire item bank showed a high degree of concurrent criterion-related validity (e.g., r = .707 and .688 when SE ≤ 0.2 and SE ≤ 0.3 respectively); and the diagnostic accuracy (AUC = 0.837 for the full test) of CAT-ED was ideal. In addition, the authors also concluded that SE ≤ 0.3 was suggested to be optimal after comprehensively considering the conditions including the length and measurement accuracy of CAT-ED under different stopping rules.
Previous studies have shown that, compared with the scales developed by CTT, CAT could significantly improve the measurement accuracy (Gibbons et al., 2012; Simms et al., 2011), which was also confirmed in this study. Additionally, the subjects’ trait level of ED can be quickly and accurately estimated with little loss of measurement accuracy even though they only answered a small number of items (such as 6 items), which was nearly impossible under the framework of CTT. To be precise, the main contributions of this work are shown in the following points: (a) convert existing ED measurement tools frequently applied in China to a CAT version for the first time and develop a well-calibrated item bank for CAT-ED; (b) establish the theoretical and technical premises for potential practitioners to use computerized adaptive testing to measure ED in a clinical environment; (c) offer a new perspective for ED measurement and effectively improve the measurement accuracy and test efficiency.
However, there are several limitations while the results of the research are encouraging. The authors believe that these limitations will set up directions for follow-up research. The shortcomings of the article are as follows. First, because the MFI item selection strategy is used in both two simulation studies, it could cause some well-validated items to have a very low usage rate in the administered process. From an economic point of view, this is most likely not conducive to saving the cost of developing an item bank. Therefore, in the future, it is necessary to adopt a more optimized item selection strategies under the premise of ensuring measurement accuracy to achieve an equal utilization rate of each item. Second, based on the preset screening criteria, we found that only 31 subjects were finally identified with EDs, which is only approximately 3% of the total number. According to an epidemiologic study of ED in China, the results showed a prevalence rate of 1.05% for AN, 2.98% for BN, and 3.53% for BED among female university students in Wuhan, China (Tong et al., 2014). Compared with the results of this study, it seems that the percentage of patients with EDs is relatively small. This may have the effect of skewing the results presented for sensitivity and specificity. Therefore, in the future work, in order to ensure the good predictive performance of the proposed item bank, it is necessary to correct the performance of CAT-ED in sensitivity and specificity through a more comprehensive investigation. Finally, we only evaluated the performance of CAT-ED in a simulated CAT environment rather than a real CAT administration. To evaluate the real effects of CAT-ED in the clinical environment in detail, it is necessary to establish a real CAT test system and use it in the administration of ED patients.
Conclusion
Data analysis results suggest that the performance of CAT-ED is good. CAT-ED meets the requirements of CAT development in IRT and performs well in accuracy, reliability, validity, sensitivity and specificity. CAT-ED can be used as an effective tool for measuring individuals’ ED traits, and it promises to offer a brand-new perspective for measuring ED traits with psychological scales.
Supplemental Material
sj-docx-1-sgo-10.1177_21582440221141273 – Supplemental material for Developing an Item Bank of Computerized Adaptive Testing for Eating Disorders in Chinese University Students
Supplemental material, sj-docx-1-sgo-10.1177_21582440221141273 for Developing an Item Bank of Computerized Adaptive Testing for Eating Disorders in Chinese University Students by Kai Liu, Longfei Zhang, Dongbo Tu and Yan Cai in SAGE Open
Footnotes
Acknowledgements
Thanks for the participation of all the subjects in this research. Sincere gratitude goes to YZ, FH, MY for assistance in data collection.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China (Grant No. 62167004 and 32160203).
Ethics Statement
This work was approved by Research Center of mental health, Jiangxi normal university. The project name is psychometrics studies on mental health. The project code is HM20200150030.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.