
Abstract
STEN (Standard Ten) is the most frequently preferred score generating method among the norm reference scores (e.g., percentile rank, STANINE) However, it is usually misleading because of the skewness presented with the data. In this study, rather than STEN, GRiSTEN (Golden Ratio in Statistics) approach is proposed to generate relatively fair outcomes. The GRiSTEN method acknowledges the effects of skewness by accounting for the contribution of each data element to the center point based on its specific location in the data stack. Generating norms using the GRiSTEN approach enables us to mark “the most capable” or “the least capable” scores regarding the test without involving too many arithmetic operations. In order to verify the applicability of the psychometric tests based on System Sigma run by Mevasis IT Consultancy in Turkey, a watch test, which is designed to observe respondents’ estimation of velocity, is carried out with a pilot group consisting of 407 male respondents aged between 30 and 50. By using GRiSTEN approach, it is shown that consistent outputs can be obtained without changing, ignoring, or transforming any elements regardless of the number of elements, skewness, distribution, and values of the data array.
Introduction
Numerous behavioral assessments (Shea et al., 2014) rely heavily on normative samples to make comparisons between people. A group of scores from the respondents assessed is obtained and then compared with each respondent’s score to form a normative sample or norm (Reznick, 1989).
This norm provides a context, that is, an established frame of reference, allowing for a meaningful interpretation of the results. Raw scores obtained from normative samples can be turned into percentile ranks with a conversion table, which offers a researcher two options, that is, raw scores or percentile ranks, in a statistical analysis. The percentile rank in respect to the raw score technique mentioned here is developed due to the skewness appearing in the real data (Bornmann, 2013). However, it has some shortcomings to be considered by test users (Thompson, 1993). The first most important of these flaws is that the norm referenced percentile ranks are not clear. The highest could be taken as either 5% or 10%, depending on the analyst’s choice. The second most important flaw is that norm score ranges are variable.
Consequently, small raw score differences are associated with large percentile differences at the center of the distribution. On the contrary, large raw score differences are associated with small percentile differences at the extremes of the distribution. (Brown, 1976). The raw scores between 51 and 87 may indicate the top score 10, but the raw scores between 42 and 50 may indicate 9. However, conversion of the raw scores into percentile ranks results in a change in the distribution pattern and cannot maintain the difference between scale units (Crocker & Algina, 1986). Moreover, arithmetic operations such as addition, subtraction, or multiplication cannot be applied to percentile ranks (Rodriguez, 1997). Thus, statisticians hesitate to make use of raw scores with respect to percentile ranks and opt for parametric approaches such as STEN in general.
The indicator of a respondent’s relative position as a range of values in context of the population is a STEN score (Canfield, 1951). STEN scores divide a score scale into 10 units, with STEN 2, 3, 4, 5, 6, 7, 8, and 9 covering a range of a one-half standard deviation (0.5σ) for each, and STEN 1 and 10 covering the remaining scores in the left and right tail, respectively. In other words, when STEN scores are used, most of the respondents fall into the average range making about 2% of them fall into the outliers of 1 or 10 in the Bell curve. Individual STEN scores are defined in reference to a standard normal distribution (see Figure 1; Coaley, 2010).

The comparison of norm-referenced scores and their relationship with the normal distribution.
The midpoint of STEN scoring system is the value 5.5. The STEN scoring system is normally distributed and then divided into 10 parts by letting 0.5 standard deviations correspond to each point of the scale. The STEN scores are demarcated by −2, −1.5, −1, −0.5, 0, 0.5, 1, 1.5, and 2.0.
Each of these numbers can be assumed as z-scores in the standard normal distribution. The remaining tails of the distribution are equivalent to the 1st and 10th STEN scores. So less than −2 corresponds to a score of 1, and greater than 2 corresponds to a score of 10. STANINE and t score are the transformed z scores like STEN. STANİNE score is divided into nine points and produces a normal distribution whose mean is 5, and whose standard deviation is 1 (Clark-Carter, 2005). T score produces a normal distribution whose standard deviation is 10 and whose mean is 50 (Coaley, 2010).
Despite being commonly preferred, STEN has some drawbacks. It is based on standard scoring principles and makes one think within score ranges rather than absolute scores. The ranges formed with STEN are not sufficient to indicate important differences among respondents. In addition, the analysts cannot interpret the minute differences between the scores as required. Another limitation of STEN scoring is that it presents scores by processing non-normally distributed data as if it were distributed normally. Skewness is of great of importance here. It refers to a lack of symmetry in data distribution. The values are concentrated in the left or right tail. Every data array does not show normal distribution in nature. Thus, it does not have to be symmetrical. It can be positively or negatively skewed. Therefore, skewness plays an important role in obtaining significant outputs. However, scaling approaches like STEN neither take these outliers stemming from skewness into consideration nor yield a symmetrical distribution curve.
Outliers that “skew” (Doane & Seward, 2011) the mean either up or down will overstate one side of the average and understate the other. Therefore, the number of scores above and below the mean value should be approximately equivalent. Exclusion of data (Pleace, 2016) from the sample results in a higher or lower mean. Another consequence of data exclusion is the perception of scores. They may be perceived as below or above the mean when the opposite is true. The spread of results appears narrower, offering a smaller apparent standard deviation with the culling of data (Tummaruk et al., 2009) from one or both ends of the distribution. Accordingly, a respondent’s scores may appear further from the mean and more extreme than they actually are.
False “floor-effects” (Whitaker & Wood, 2008) are introduced with the exclusion of usually low scores, which serve to “unbalance” the distribution. A resulting positive skewness:
Overstates the scores of those below the true mean Understates the scores of those above the true mean Yields inordinate scores in the mean range (within 1 standard deviation of the mean)
The normal distribution function has been most frequently used in assessing continuous data, which is not commonly observed in nature (Pearson, 1920). This raises concerns since a lot of the observable data around us tends to be skewed. Misleading effects of skewness can be dealt with by the GRiSTEN (Golden Ratio In Statistics; Gunver et al., 2018) method, which considers the contribution of each data element to the center point as well as its specific location in the data stack. STEN explains negative and positive skewness with a single parameter, whereas GRiSTEN shows it with two different parameters. To illustrate, the former makes the output stretch by 5 units in both tails while the latter makes it stretch by 7 units in the right tail and by 3 units in the left tail. Thus, GRiSTEN can overcome skewness by differentiating the parameters in right and left tails.
There are deficiencies in norm scoring assessment in skewed data. Can a different method of norm scoring assessment be tried on skewed data and give a better result? Could GRIS, which was previously developed by Gunver et al. (2018), be an alternative in this regard?
The aim of this study is to evaluate STEN, which is a standard method for norm score assessment, and GRISTEN, a new method, in skewed data.
Materials and Methods
Materials
A pilot study was carried out to validate Turkish psychometric tests conducted by Mevasis Bilisim Danismanlik (Mevasis | HPC Çözüm Ortağı, 2015), which are developed with System Sigma (Alfa-electronics, 2018). Snowball sampling method was used for sampling. Web site Public announcment by Mevasis Bilisim Danismanlik was applied (Mevasis | HPC Çözüm Ortağı, 2015). All people who wanted to participate were included in the sample. A total of 407 male respondents aged 30 to 50 are included in a Watch test. All respondents were provided written consent prior to having the tests.
The watch test is a psychometric test which aims to define velocity-distance abilities. By measuring the reaction time, the watch test aims to show how precise a respondent can be when they react to an event and whether they can demonstrate their reaction with or without creating a time lag.
The vane moves toward 12 with a constant velocity and disappears at a specified point keeping its move hidden. The respondent is asked to hit 12 when he assumes the vane has arrived at 12. There are three selections of velocity and each are repeated six times (see Figure 2).

Watch test. In the watch test, there is a screen displaying a clock and a stop button. The respondent is asked to tap the button on the screen when he assumes that the vane has hit 12.
Low velocity watch test: The velocity of vane is 6.25°/s. In the low velocity Watch test, the vane appears at 11:45 and disappears at 11:53. The respondent is expected to estimate the velocity of the vane from the moment it appears until it disappears, and by taking the velocity into account, to respond to it when he assumes it is 12 sharp.
Medium velocity watch test: The velocity of vane is 8°/s. In the medium velocity watch test, the vane appears at 11:40 and disappears at 11:50. The respondent is expected to estimate the velocity of the vane from the moment it appears until it disappears, and by taking the velocity into account, to respond to it when he assumes it is 12 sharp.
High velocity watch test: The velocity of vane is 16.6°/s In the high velocity watch test, the vane appears at 11:20 and disappears at 11:40. The respondent is expected to estimate the velocity of the vane from the moment it appears until it disappears, and by taking the velocity into account, to respond to it when he assumes it is 12 sharp.
All time lags in six tests for each respondent are tallied up to form the respondent’s total score, which is called “a performance score.” If the respondent fails to hit 12 on any event, absolute time lag is set to 1,500 ms. The watch performance score is the average of low, medium, and high velocity performance scores. Short time lags are defined as high norm scores while high performance scores refer to low norm scores.
The histograms of these scores, which are developed by Percentile bin (Pb) method (Gunver et al., 2017) are given below. Standard deviation is taken into account to create the histogram divisions according to Scott’s normal reference rules. However, the standard deviation is unnecessarily large, especially with skewed data. Therefore, an alternative method is proposed to create histograms. The narrowest area containing 4% of the data stack is sought. It is expected to be around the median, especially in symmetrical data heaps. The reason why the percentiles are increased by four is it is the smallest divider that divides 100 but not 50. If the data stack contains more than 4% repeating members in time, the Sequential Difference (SeDi) can be zero. However, since the histogram bin cannot be equal to zero, a correction column is set up, and when the percentiles are increased by four at a time, all zeros are replaced by the maximum consecutive difference between percentiles. When the percentiles are increased by four at a time, the narrowest distance greater than zero is determined as the histogram division (

Low velocity watch test.

Medium velocity watch test.

High velocity watch test.

Watch performance score.
Methods
The performance scores of the mentioned tests are converted to both STEN scores and GRiSTEN scores. The GRiSTEN scores are calculated based on the approach of GRIS. (Gunver et al., 2018) due to the skewness of the scores. This approach proposes calculations of G (coefficient of skewness), O (GRiSTEN mean), and DLeft and DRight (GRiSTEN deviations), which are performed with a Matlab code (GRiS Matlab, 2018). A calculator (Goldenratioinstatistics.com., 2020) has been developed so that these calculations can be made easily by the users.
Coefficient of skewness (G): “In addition to the other skewness measurement formulas, the coefficient of skewness allows calculating the skewness independently of the sample size.

GRiSTEN mean (O): A linear new mean (O), which takes the large value of the golden ratio in the median and the small value of the golden ratio at the outliers, is designed.
GRiSTEN Deviations (DLeft and DRight): The most remarkable point about GRiSTEN deviation is that it allows calculating two independent deviations for each side of the GRiSTEN Mean.
The calculations are presented in Table 1.
Calculation of the Scores Presented by STEN and GRiSTEN.

Note.
Table 1 shows the scores that STEN and GRiSTEN present in certain cases. For example; if the respondent’s score is greater than the sum of
Results
The low velocity watch test (Figure 3), medium velocity watch test (Figure 4), and high velocity watch test (Figure 5) graphics are created by transforming the total time lags produced by the respondent into norm reference scores. The watch performance score graph (Figure 6) is created according to the total number of time lags produced by the respondent.
As this study is focused on skewness, which causes misleading results, Table 2 demonstrates the effects of skewness on the descriptives.
Descriptives.
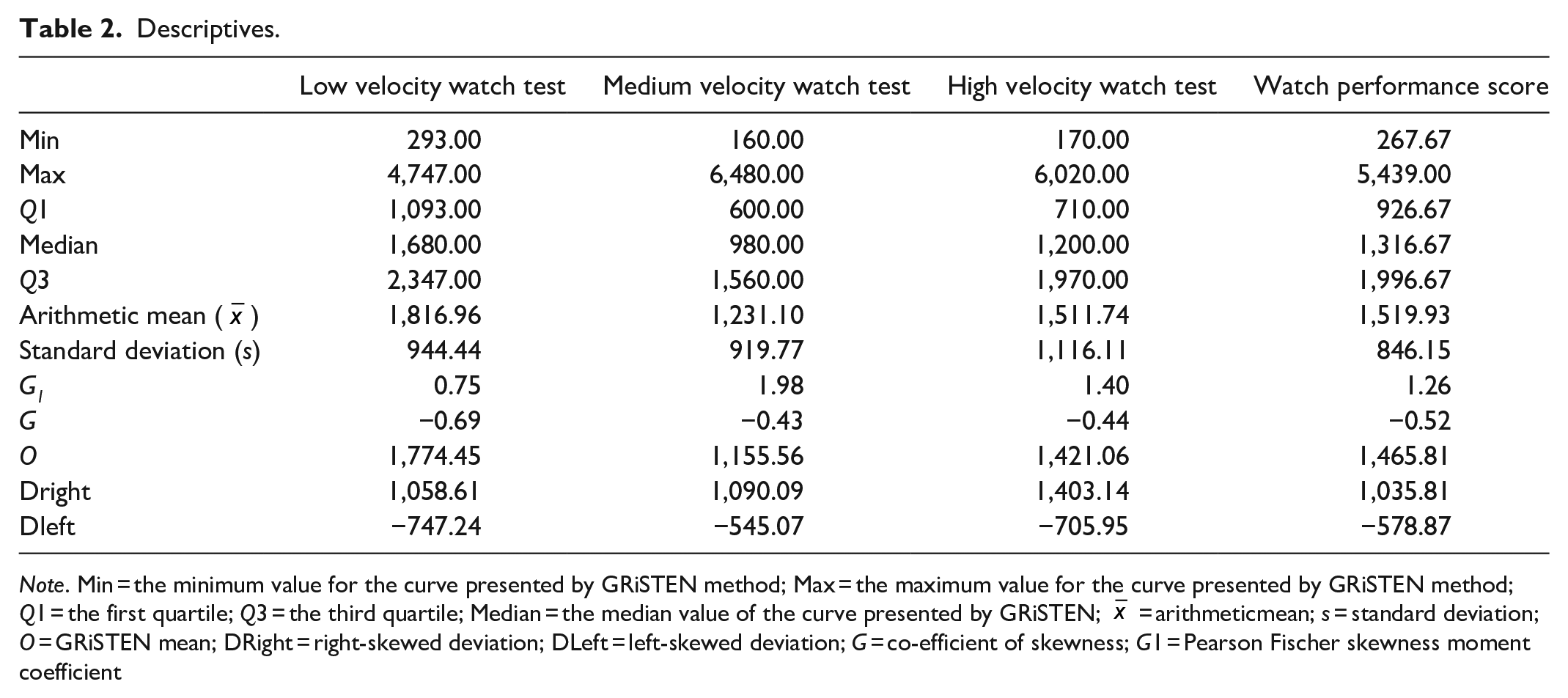
Note. Min = the minimum value for the curve presented by GRiSTEN method; Max = the maximum value for the curve presented by GRiSTEN method; Q1 = the first quartile; Q3 = the third quartile; Median = the median value of the curve presented by GRiSTEN;
In Table 2, G and G1 show that the distribution is not normal. Considering these values, it can be inferred that GRiSTEN should be used in non-normal distribution.
The scores of STEN, which overlooks skewness, and the scores of GRiSTEN, which takes skewness into account, are presented in Table 3.
STEN and GRiSTEN Scores.

Note. @: represents the respondent’s score.
Table 3 shows the score value ranges presented by GRiSTEN and STEN on the basis of milliseconds for the watch test. Based upon this table, it is seen that STEN yields negative scores. However, it is impossible for time to have negative values. Table 3 shows clearly that while STEN is inconvenient due its shortcomings, GRiSTEN provides acceptable outputs, which highlights the efficacy of GRiSTEN.
The number of respondents’ scores with STEN and GRiSTEN norms are demonstrated in Figures 7 to 10; STEN yields non-normal distribution of scores as if it were normal while GRiSTEN processes a non-normal distribution as it is. Thus, the scores provided by STEN and GRiSTEN differ. The horizontal axis in figures shows the STEN and GRiSTEN scores and the vertical axis shows the number of respondents with those scores.
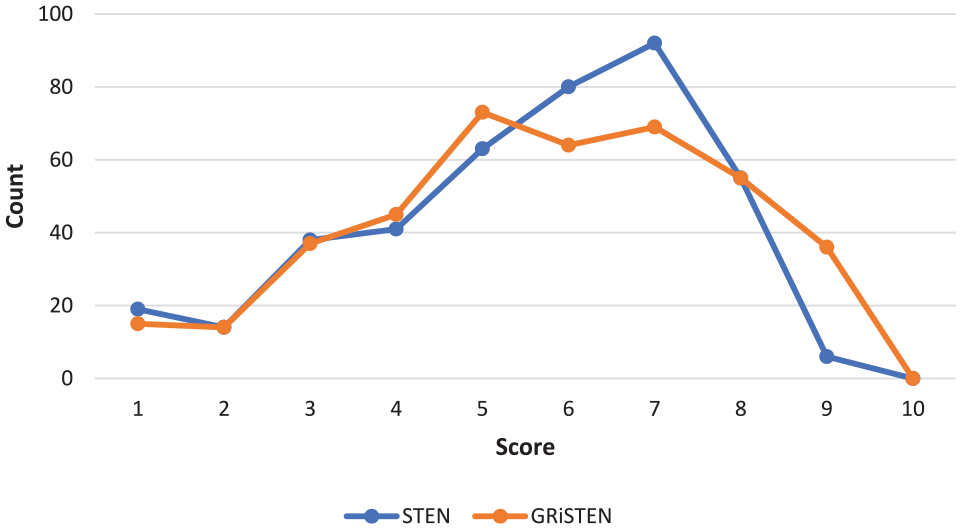
Comparative low velocity watch test for STEN and GRiSTEN scores.

Comparative medium velocity watch test for STEN and GRiSTEN scores.

Comparative high velocity watch test for STEN and GRiSTEN scores.
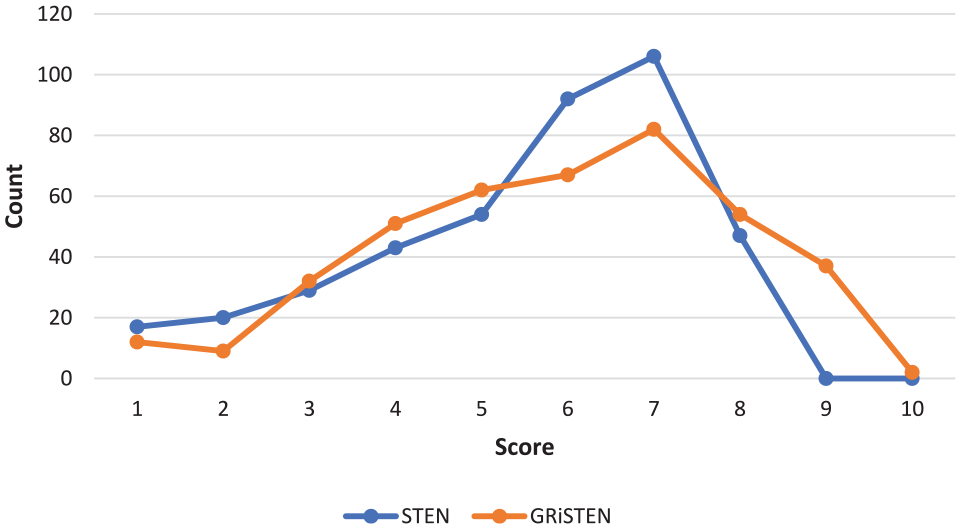
Comparative watch performance score for STEN and GRiSTEN scores.
Low velocity watch test (Figure 7), medium velocity watch test (Figure 8), and high velocity watch test (Figure 9) graphics are made by transforming the total time lags presented by the respondent into norm scores.
Discussion
As it is clearly visible in this study, the distributions of each score are highly skewed. The skewness is a very common statistical fact that is usually overlooked (Newell & Hancock, 1984; Tsiang, 1972). As there is skewness, the arithmetic mean is formed away from the median, and it also generates a huge standard deviation (Ryu, 2011), which generates norms with STEN scores misleadingly (Fastenau et al., 1998). For all scores, the respondent must score a negative time lag in order to get 10 in STEN norm, which is definitely impossible.
When skewness is excessive, statisticians usually perform some arithmetic operations such as removing outliers, trimming the data, Box-Cox transformation (Sakia, 1992), and most frequently logarithmic transformation (Smith, 1993) in order to form a symmetry (Canay et al., 2017) and make both the arithmetic mean and standard deviation useful. Hence, not only is the data ruined at this stage but also “normal” outcomes are generated from “non-normal” data (Stevens, 1946).
It aims to obtain different “mean” and “deviation” outcomes from the scores with a method that takes skewness into account. For all scores, STEN is incapable of providing the most capable score, that is, 10. It cannot even provide 9 for medium velocity watch test and high velocity watch test. STEN norms tend to generate more “normal” norm-referenced scores (from 3 to 8) and less “extreme” norm-referenced scores (1, 2, 9, or 10). Having “dislocated” arithmetic mean and “huge” standard deviation caused by skewness reveal misleading norms with STEN method, but GRiSTEN generates fair norms. A norm-referenced scoring procedure which eventually becomes insufficient leads to ambiguity in the test results because it ends up with excessive normals or no extremes. Referring to GRiSTEN instead of STEN provides the correspondents with the ability to choose their “most capable” or “least capable” respondents regarding the test. Because GRISTEN produces outputs without distorting the nature of the distribution in spite of the existing deviance, it takes the contribution of each element in the data stack to the central point as the basis as a solution for the misleading effect of the deviance. Also, it produces two different parameters for the right and left tails. This capability of GRISTEN gives us the possibility of observing the real distribution, which is usually seen in nature and discriminates the extreme values (1, 2 and 9, 10). As an alternative to some of the drawbacks of STEN, the above mentioned superiorities of GRISTEN yields results which are much closer to the reality in the distorted data sets. Thus, a test user will be able to discriminate the differences among the individuals taking part in the test more clearly, and to make more effective interpretations.
In this study, we were able to generate more realistic norm scores on skewed data. Psychometrics is not the only area where norm scores are used. For example, in educational achievement and intelligence and attitude tests etc. norm-based scores are used. GRISTEN is open to use in different disciplines. New studies are needed on this subject.
Footnotes
Acknowledgements
Data Availability Statement
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.