
Abstract
In this study, we use double-robust estimators (i.e., inverse probability weighting and inverse probability weighting with regression adjustment) to quantify the effect of adopting climate-adaptive improved sorghum varieties on household and women dietary diversity scores in Tanzania. The two indicators, respectively, measure access to broader food groups and micronutrient and macronutrient availability among children and women of reproductive age. The selection of sample households was through a multistage sampling technique, and the population was all households in the sorghum-producing regions of Central, Northern, and Northwestern Tanzania. Before data collection, enumerators took part in a 1-week training workshop and later collected data from 822 respondents using a structured questionnaire. The main results from the study show that the adoption of improved sorghum seeds has a positive effect on both household and women dietary diversity scores. Access to quality food groups improves nutritional status, food security adequacy, and general welfare of small-scale farmers in developing countries. Agricultural projects that enhance access to improved seeds are, therefore, likely to generate a positive and sustainable effect on food security and poverty alleviation in sorghum-producing regions of Tanzania.
Keywords
Introduction
According to Dalton and Zereyesus (2013), sorghum is one of the climate change–ready crops grown by the world’s most vulnerable household groups. The sorghum crop has a high potential of improving the livelihood of small-scale farmers in the semiarid tropics of Africa, the region prone to frequent droughts and high incidences of food insecurity. Regional research and extension programs aim to increase both the production and productivity of the sorghum production sector to increase food access and income of sorghum producers. In Tanzania, the colonial government started the sorghum and millet improvement program in the early 1930s. Since then, as described in Mgonja et al. (2005), steps have been taken to develop improved sorghum varieties (ISVs) that are high yielding and tolerant to drought. In the 1970s, Tanzania started a sorghum selective breeding program in collaboration with the Southern Africa Development Community (SADC) and the International Crop Research Center for Semi-Arid Tropics (ICRISAT). The main goal was developing new ISVs with desirable characteristics. The efforts resulted in the release of several ISVs, including Tegemeo (1978), Pato (1997), Macia (1998), Wahi and Hakika (2000), and Mtama 1 and Sila (2008). Supplemental Appendix 1 presents the characteristics of these varieties and the history of sorghum research and development in Tanzania. For more details, see Kilimo (2008) and Kanyeka et al. (2007). However, no studies assess the effect of adopting these varieties on farmers’ welfare.
One of the core goals of most agricultural development programs is improvement in the food security of small-scale farmers. Accordingly, in the impact assessment literature, most studies use food security as measures of welfare or well-being. Studies such as Kassie et al. (2011), Amare et al. (2012), Asfaw et al. (2012), Shiferaw et al. (2014), Mathenge et al. (2014), Kabunga et al. (2014), Mason and Smale (2013), Smale and Mason (2014), and Khonje et al. (2015) try to estimate the effect of adopting improved maize, wheat, groundnuts, pigeon-peas, and other crops on different indicators of farmers’ welfare, including food security. Apart from Smale et al. (2018), who document the effect of ISVs in Mali, there are limited studies that focus on ISVs, especially in the East and Southern African region. Available studies use income and consumption expenditure as measures of welfare. However, these variables are difficult to quantify when record-keeping is not standard across the sample. Small-scale farmers are also both producers and consumers, and most transactions are outside of formal markets. Valuing all sources of income or expenditures (through recall) is prone to measurement errors, as discussed by Ellis (1998) and Chen and Ravallion (2007). Mahlberg and Obersteiner (2001) and World Food Program (2005) present the household dietary diversity score (HDDS) and the women’s dietary diversity score (WDDS) as an easily quantifiable alternative measure of food security and therefore farmers’ well-being.
The 1996 World Food Summit agreed that food security has three critical components (Population Council, 1996): availability, access, and use. Food availability addresses the supply side of food security, determined by the level of food production, stock levels, and net trade. As a measure of nutritional status, use refers to the individual’s biological ability to make use of food for a productive life. Household food access, in the context of food security, is the ability to get enough quality and quantity of food to meet all household members’ nutritional requirements for productive lives. However, food security is an evolving concept (Jones et al., 2013) about issues of terminology, measurement, and validation. Therefore, no one indicator can concomitantly capture all three components of food security (Webb et al., 2006). This article emanates from the main study that documents profitability and adoption of ISVs in Tanzania. Detailed information on profitability has been reported in Kaliba et al. (2017), and a detailed analysis of factors affecting adoption is published in Kaliba et al. (2018).
As reported by Kendall et al. (1996) and Operations Evaluation Department (2011), poverty (a critical indicator of well-being) undoubtedly causes food insecurity. However, the lack of adequate and proper nutrition itself is an underlying cause of poverty. The interwoven nature of poverty and food security justifies using HDDS and WDDS as measures of well-being (Zhao et al., 2017). According to Mahlberg and Obersteiner (2001), Arimond and Ruel (2004), and Martin-Prével et al. (2015), HDDS represents the ability of a family to access food groups that meet all household members’ nutritional requirements. The HDDS is, therefore, a useful tool for measuring household food access and adequacy, the critical dimensions of food security, and well-being in developing countries. Arimond and Ruel (2004), Swindale and Bilinsky (2006), and Luckett et al. (2015) show a high and positive correlation between HDDS and other nutritional factors such as the availability of high-quality proteins that positively influence food security adequacy.
The WDDS reflects one crucial dimension of diet quality—macronutrient and micronutrient adequacy (Gernand et al., 2016)—among children and women of reproductive age (15–45 years). Zhao et al. (2017) validate WDDS as an indicator for evaluating micronutrient inadequacy in Chinese children. Kennedy et al. (2013), Food and Agriculture Organization of the United Nations (FAO, 2014), and Becquey et al. (2010) also indicate that children and women who have access to various diet items have a higher likelihood of meeting both micronutrient and macronutrient requirement. As no single food has all essential micronutrients and macronutrients, a balanced and varied diet is necessary for adequate intake of these nutrients. Hatloy et al. (2000), Gina et al. (2007), Faber et al. (2017), Chakona and Shackleton (2017), and Sibhatu and Qaim (2018) reveal that apart from focusing on food access and quality, HDDS and WDDS are positively associated with wealth or general welfare at the household level. In their studies, Arimond and Ruel (2004), and FAO (2014) also concluded that the two indicators are positively related to household food security and other poverty indicators, such as income and households’ food expenditure levels. Although food security may not encapsulate all aspects of poverty, the inability of households to access enough food for a productive and healthy life is an essential part of households’ socioeconomic status (Ravallion and Chen, 1997). In summary, dietary diversity is a good proxy of food security and the general welfare. They are useful for monitoring changes and effect, especially when data on traditional money-metric measures are unavailable.
Swindale and Bilinsky (2006), Kennedy et al. (2007), and FAO (2014) give a detailed account of quantifying the HDDS and WDDS at the individual or household level. The process allows itemizing food items consumed over the last 24 hr. Supplemental Appendix 2 lists the food groups. A new method uses Minimum Dietary Diversity–Women (MDD-W) to assess the micronutrient adequacy of women’s diets. The new indicator reflects (Martin-Prével et al., 2015) consumption of at least five of 10 food groups. The tool was not available during data collection for this study. The estimate of HDDS is from a set of 12 food groups, including cereals; fish and seafood; root and tubers; pulses/legumes/nuts, vegetables; milk and milk products; fruits, oil, and fats; meat, poultry, and offal; sugar and honey; eggs; and other food groups. The HDDS ranges from 0 to 12, and a score of less than 5 shows low dietary diversity or food insecurity (Arimond & Ruel, 2004). Nine food groups are used to construct the WDDS and include grains; white roots and tubers, and plantains; pulses (beans, peas, and lentils); nuts and seeds; dairy and dairy products; meat, poultry, and fish; eggs; dark green leafy vegetables; and, other vitamin A–rich fruits and vegetables. As the calculation of WDDS involves nine food groups, the score should range from 0 to 9, and a score of less than or equal to 4 shows macronutrient and micronutrient inadequacy (Huang et al., 2018).
As summarized by Webb et al. (2006) and Kennedy et al. (2013), the use of HDDS and WDDS as measures of food access and quality has two main advantages. The data collection is not time-consuming, is inexpensive, and does not require specialized professionals (e.g., nurses) for data collection, analysis, and interpretation. Carefully trained extension agents could get the technical skills required to collect and analyze the data on both HDDS and WDDS. Savy et al. (2005), Kennedy et al. (2007), and Luckett et al. (2015) underscore the importance of these indicators in terms of minimizing measurement errors when using trained enumerators. Becquey et al. (2010) emphasize that the questions used to collect the data are not complicated, not intrusive, and not burdensome. The United States extensively uses the 24-hr dietary recall technique (Thompson & Byers, 1994) due to its speed and ease of administration (Nelson & Bingham, 1997). The Demographic and Health Surveys (https://dhsprogram.com/) have used the 24-hr dietary recall approach for more than two decades, and the approach is also recommended by the European Food Safety Authority (2009). See supplemental Appendix 2 for the part of the survey instrument used to collect the data on the two indicators, and for details, see FAO (2014).
In Tanzania, sorghum is both a cash and food crop. Theoretically, the adoption of ISVs may induce the consumption of various food items through two pathways: an increase in income and unlocking the land and other resources to produce other food crops. Increased production and productivity create opportunities to improve farm income by selling surpluses. Excess production allows farmers to take part in the food and crop markets that increase food security as explained in Koppmair et al. (2017) and Jones (2017). Increased productivity also allows farmers to use fewer resources to produce more sorghum. The saved production inputs are for producing other crops that generate more income and broaden access to healthier and diverse food groups. See, for example, Smale et al. (2015) and Ecker (2018).
When conducting an impact assessment using observational data, Shadish et al. (2008) emphasize the importance of adjusting for self-selection and confounding effects. We, therefore, adapted the inverse probability weighting (IPW) and the inverse probability weighting with regression adjustment (IPWRA) for estimating the effect of adopting ISVs. The two techniques allow estimating consistent and unbiased results as explained in Austin et al. (2007), Wooldridge (2007), and Linden (2017). The contributions of this study are as follows. Explaining the complex linkage between improved seed adoption and food access adds the required literature on sorghum effect assessment for the Eastern and Southern African region. Also, showing the effect of ISVs encourages governments, policymakers, and the private sector to increase funding for agricultural research and extension systems that support small-scale sorghum producers. Results from effect studies also help the internal learning processes by showing changes that enhance the probability of adoption and capturing the linkages between innovations and sustainable agricultural development.
The use of HDDS and WDDS as measures of food access and food quality that are essential measures of food security and general welfare allows the study to be easily replicable. Importantly, most studies that use inference models are common in disciplines other than agriculture and are presented in unclear language for applied agricultural economists. In this study, we try to use familiar words in agricultural technology adoption and impact assessment literature for replication purposes. We organize the rest of the article as follows. In the following section, we summarize the history of sorghum research and development in Tanzania. We use section “A Conceptual and Empirical Framework” to, respectively, discuss the source of data, analytical methods adopted in this study, and the covariates used in the study. In sections “Results and Discussion” and “Conclusion,” we, respectively, present key findings and the policy implications.
Source of Data
The data for this study are from Central, Northern, and Northwestern Tanzania. The survey included the main sorghum-producing regions of Dodoma, Manyara, Kilimanjaro, Singida, and Shinyanga. The enumerators were extension agents working in these regions, supervised by sorghum research scientists from Selian Agricultural Research Institute (SARI) in Arusha and Homboro Agricultural Research Institute (HARI) in Dodoma. These enumerators took part in a 1-week training workshop on data collection using a structured questionnaire. The trainers were scientists from ICRISAT in Nairobi, Kenya, and the principal author. The pretesting of the clarity of questions in the questionnaire was by using 30 randomly selected samples of sorghum producers in Singida Rural and Rombo Districts (Map 1). The responses and gained experience from pretesting helped to set the final questions.
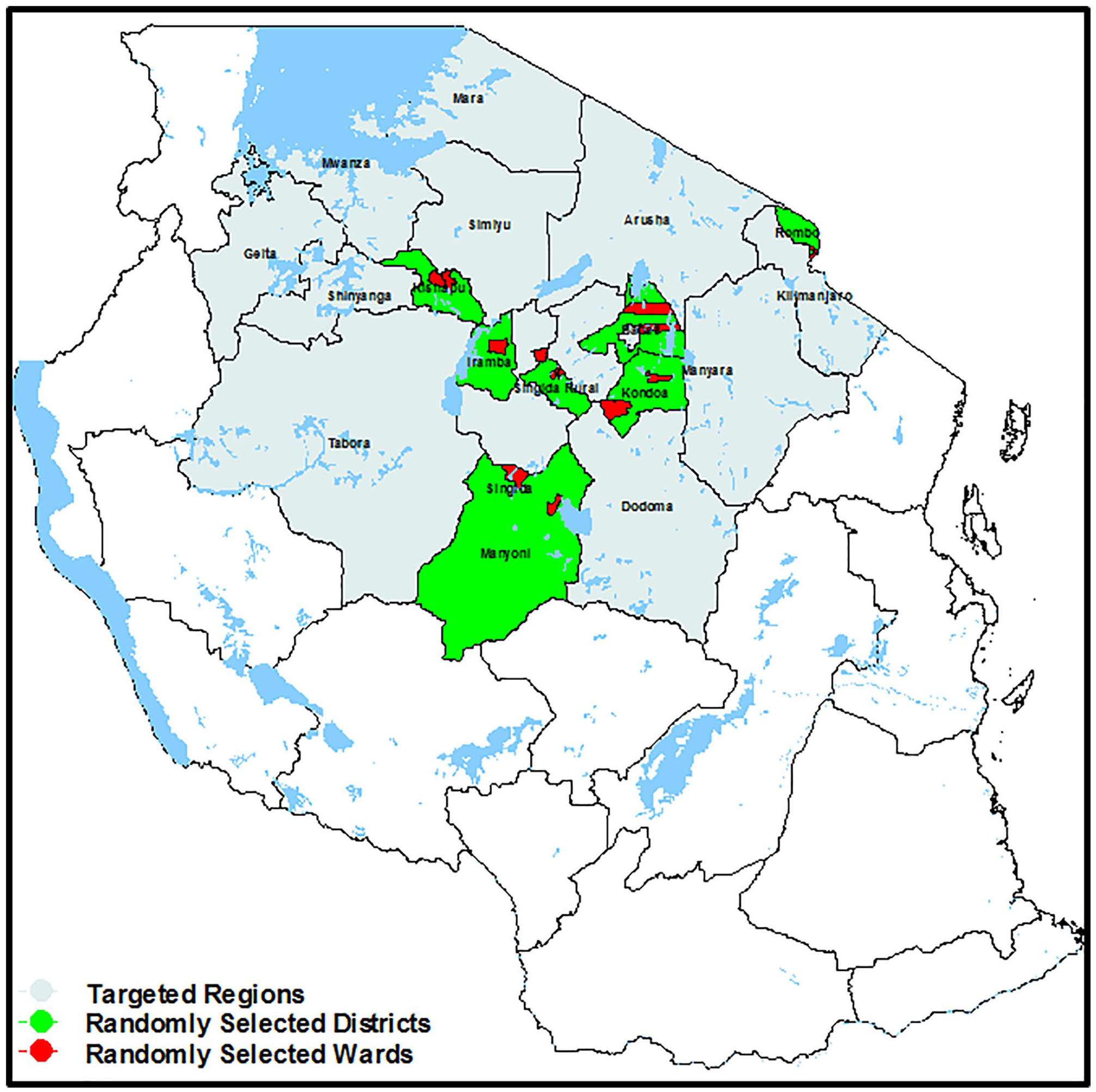
Location of targeted regions and randomly selected districts and wards.
Tanzania is administratively divided into Regions, Districts, Ward, and Villages. A region constitutes more than three districts, a district constitutes more than five wards, a ward constitutes more than five villages, and the village is the lowest administrative unit. The sample households were selected using a multistage sampling design (Etikan & Bala, 2017), that is, Regions, Districts, Wards, and Villages from the primary sorghum farming system in Central, Northern, and Northwestern Tanzania (Map 1). The target area produces more than 70% of the national sorghum. The randomly selected regions were Dodoma, Manyara, Kilimanjaro, Singida, and Shinyanga. From these regions, we randomly selected seven districts to take part in the study. The districts included Iramba, Singida Rural, and Manyoni districts (Singida Region), Kondoa District (Dodoma Region), Babati District (Manyara Region), Rombo District (Kilimanjaro Region), and Kishapu District (Shinyanga Region) (see Map 1). We then randomly selected two Wards per selected District and one Village per selected Ward. For statistical purposes, about 50 randomly selected households per village took part in the survey. Previously trained enumerators interviewed 822 respondents using a structured questionnaire. In the sample, 505 respondents were from adopters of ISVs (61.44%), and 317 respondents were from nonadopter group (38.56%). Based on the type of questions in each section, the respondents were knowledgeable or informed members of the sample households.
The survey instrument had several parts to collect data on the geolocation of the sample households, household and farm characteristics, farm inputs and outputs, harvesting, processing, transportation, marketing, and access to services offered by government and nongovernmental organizations. To estimate the HDDS and WDDS, we adapted the food access questions from Swindale and Bilinsky (2006) as modified in FAO (2014). The questions asked about consumed food groups listed in supplemental Appendix 1 by members of households in the last 24 hr during breakfast, lunch, dinner, and in-between snacks.
During data collection and entry, we instituted three measures to ensure data quality. First, we grouped enumerators into seven individuals: six enumerators and a supervisor. All enumerators had a Diploma in Crop Production, and they were working in the region as extension agents for more than 5 years. All supervisors were research scientists with graduate-level training in Crop Production or Agricultural Economics and had experience in conducting farm-level surveys through other projects implemented by their respective research institutions. After administering the questionnaire, the enumerator and the supervisor reviewed the responses before leaving the respondent household to ensure clarity and completeness of the answers. The supervisor asked additional questions if more information and explanations were needed. Second, after administering the questionnaire, the responses were entered into an SPSS spreadsheet by the supervisor with the help of enumerators. Third, the data scientists at SARI and ICRISAT, and the principal author rechecked the combined data from the survey groups (questionnaire by questionnaire) to ensure the accuracy and consistency of data. We completed the study in about 6 months (from the training workshop, data collection, and data entry and cleaning).
A Conceptual and Empirical Framework
Dehejia and Wahba (1999), Kang and Schafer (2007), and Skelly et al. (2012) discuss the challenge of estimating the effect of an intervention using observational data while accounting for putative confounding factors and self-selection bias. After releasing ISVs, the adoption processes occur naturally, and as the adoption process is not random, adopters and nonadopters tend to differ systematically. Adapted from the causal inference model of Rosenbaum and Rubin (1983, 1985), the IPW and IPWRA estimators allow adjusting for both self-selection and confounding effects. Bang and Robins (2005), Robins et al. (2007), Wooldridge (2002, 2007), and Funk et al. (2011) present the justification and statistical properties of these estimators. Glynn and Quinn (2010), Funk et al. (2011), and Uysal (2015) present the advantages and disadvantages of each approach.
Formally, let Dit(Ti) represent an indicator of adoption status and
Step 1: Adoption equation

Step 2: Welfare equation

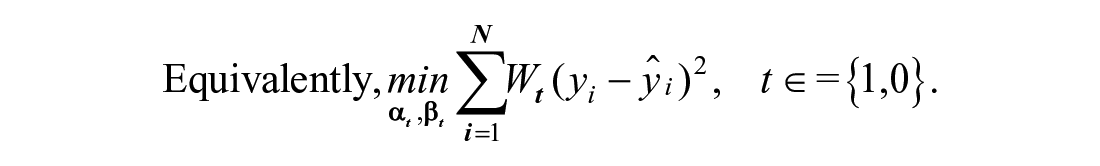
In Equations 1 and 2,
Results from Equation 2 are for estimating three common estimands: the average treatment effect for the treated (ATT) or the effect among adopters of ISVs; the average treatment effect (ATE) for the entire sample; and the average treatment effect for the controls (ATC) or the potential effect among nonadopters. Lee et al. (2011) and Uysal (2015) discuss how to estimate and apply right weights (
In terms of covariates to include in Equations 1 and 2, Angrist and Pischke (2009) and Stuart (2010) argue that the variables in matrix Z should influence both adoption status and welfare of farmers, but should not be affected by the adoption decision. For example, although farmer and farm characteristics influence both adoption decisions and well-being of farmers, institutional support systems directly influence adoption decisions and not the welfare of farmers. Suggestion is not to include institutional support variables in the welfare equation. Holden et al. (2001), Doss et al. (2003), Thomson et al. (2014), Ainembabazi and Mugisha (2014), Mwangi and Kariuki (2015), Kebede and Tadesse (2015), and several other authors present the covariates to include in the adoption and welfare equations and associated rationales not replicated here. Supplemental Appendix 3 presents the definitions and explanations for each covariate included in this study.
The covariates included in the model represented farmer characteristics including the quantity of available labor, education of household head, weighted mean household-level literacy index, dependency ratio, the weighted mean age for adults, marital status of household head, the gender of household head, and a log of total wealth. For institutional support systems, we include variables measuring the quality of extension services received by the farmers, availability of credit, market participation (through selling surplus crop), and household participation in research and extension activities. To capture the general built environment in which the farmer operates, we constructed a built environment index using data envelopment analysis (DEA). As defined in Farrell (1957) and Charnes et al. (1978), DEA is a linear programming technique for identifying the most efficient unit where the benchmark is the best practice in the sample. Mahlberg and Obersteiner (2001) and Despotis (2005) used DEA to develop human development index. Authors such as Somarriba and Pena (2009), Sharpe and Andrews (2010), and Sisay et al. (2015) used the technique for constructing the quality of life and economic well-being of communities and productive efficiency of small farms. When all inputs are binary, the index is estimated by imposing a free disposability hull with no convexity assumption. The DEA allowed aggregating different binary variables, showing the availability of agricultural support services such as extension and veterinary services, and agricultural input suppliers. The constructed built environment indicator varied from 1 (remarkably high support) to 0 (no support). Regional dummy variables (i.e., Singida, Kilimanjaro, Manyara, Shinyanga, and Dodoma) were also included in the model to represent geolocation, resource base, production potential, farming conditions across regions, and specific attributes of the adopted varieties. The analysis was conducted in the R environment (R Core Team, 2019) using a Benchmarking package (Bogetoft & Otto, 2018) for DEA and survey package (Lumley, 2018) for weighted regression analysis.
Results and Discussion
Summary Statistics of Estimated HDDS and WDDS From the Survey
The summary statistics of covariates included in the welfare model and the results of the pairwise comparison of food diversity indicators across regions are shown in Table 1. The comparison is by using the t-test with pooled standard deviation. The overall results in Table 1 show a statistically significant difference between the adopter and the nonadopter at more than .1 probability level. The average HDDS was, respectively, 5.364 and 4.568 among adopters and nonadopters, with standard deviations of 2.137 and 1.987, respectively, for the entire sample. Also, the average HDDS in all regions were higher among adopters compared with nonadopters, implying that adopters were diverse food-adequate compared with nonadopters. Except for Dodoma and Shinyanga regions, the standard deviation of adopters was large and statistically significant when compared with the standard deviation of nonadopters, showing evidence of widely distributed scores among adopters in comparison with nonadopters. The estimated mean HDDS are comparable to other studies in Tanzania. For example, at 95% confidence level, Ntwenya et al. (2017) estimated HDDS for Kilosa District (Eastern Tanzania) to be 4.7 [4.5, 5.0] during the rainy season and 5.9 [5.7, 6.1] during the harvest season. Mbwana et al. (2016) also estimated the mean HDDS to be 4.7 for the Morogoro Region in Eastern Tanzania and 4.1 for the Dodoma Region in Central Tanzania.
Summary Statistics of Indicators of Dietary Diversity by Regions.

Significant at 10% level. **Significant at 5% level. ***Significant at 1% level.
The results in Table 1 also show that except for the Shinyanga Region, WDDS of adopters and nonadopters were statistically different at more than 10% level. The average scores for the pooled sample were, respectively, 2.382 and 1.741 for adopters and nonadopters, and the standard deviations were, respectively, 1.2 and 1.26. Although the WDDS among nonadopters were lower and more variable compared with the distribution of WDDS among adopters, on average, all regions exhibited micronutrient and macronutrient inadequacy for both adopters and nonadopters. In both cases, sample households in Kilimanjaro had the highest HDDS and WDDS, and sample households in Shinyanga had the lowest scores.
Compared with other studies, Chakona and Shackleton (2017), using a survey instrument that measured MDD-W, estimated the mean scores of 3.78 for Richards Bay, 3.21 for Dundee, and 3.36 for Harrismith townships in Southern Africa. All three townships signified micronutrient and macronutrient inadequacy for children and women of reproductive age. Smale et al. (2015) found that women living in households that adopted improved maize seeds in Zambia had access to broader food items, but the score was below the threshold of micronutrient and macronutrient inadequacy. Keding et al. (2012) reported comparable results about the adoption of improved vegetable seeds in rural Tanzania.
Focusing on the distribution of HDDS at the regional level, the results in Table 1 show that 77.19% of households in Kilimanjaro were diverse food-adequate, the highest score in the sample. The lowest percentage was in the Shinyanga Region where 25.42% of households were food-adequate. Analogous results were 51.96%, 50.91%, and 45.98% of households in the Dodoma, Manyara, and Singida regions, respectively. In terms of WDDS and from Table 1, all sample households in Manyara and Shinyanga regions were in the micronutrient and macronutrient inadequacy class. Only 10.53% of sample households in the Kilimanjaro Region, 3.92% in the Dodoma Region, and 2.99% in the Singida Region reported micronutrient and macronutrient adequacy with an implication that very few households have access to different food items that ensure nutrient adequacy for children and women of reproductive age in the study area. A study by Huang et al. (2018) also supports the evidence that limited numbers of households in the Dodoma Region meet macronutrient and micronutrient demand of children and women of reproductive age. Although using a different method to estimate food adequacy, Kinabo et al. (2016) concluded that women undernutrition in Tanzania was attributable to poorly diversified diets and macronutrient and micronutrient inadequacy.
Higher food diversity in Kilimanjaro is associated with the regional staple food, banana. The region is also suitable for growing other crops such as legumes and avocado, fruits, and leafy vegetables. They raise dairy cattle and small stocks for meat and milk consumption. As discussed in Faber et al. (2017), households with access to these kinds of food items are more likely to have access to more diverse food items. In the Shinyanga Region, the staple food has historically been “ugali,” a stiff porridge made by mixing maize flour (cornmeal) or sorghum or finger millet or cassava powder with boiling water and served mainly with vegetable soups. The meal is starchy with high calories and tends to lack high-protein food items and fruits. According to Kinabo et al. (2016) and Ochieng et al. (2017), when households’ staple food depends on cereals, dietary diversity is typically low as crops and livestock products are usually sold to stock the staples to the detriment of dietary diversity.
Propensity Score Diagnosis
Propensity score diagnosis or analysis is for examining whether the propensity score model or the adoption equation has been correctly specified. The diagnosis is for proving whether the covariates of farmers with the same propensity score have the same distribution among adopters and nonadopters. Standardized mean difference (SMD) and distributional analysis are the most used statistics to examine the balance of covariate distribution between the two groups (Greifer, 2019; Stuart et al., 2013). Because SMD is independent of the unit of measurement, it allows comparison among variables with different units. Before using the SMD, side-by-side comparisons of the density plots of adopters and nonadopters allow testing for both the ignorability and common-support assumptions, as shown in Figure 1. The density plots of the estimated propensity score among adopters and nonadopters indicate a substantial overlap between the two groups (left part of Figure 1). Also, the densities do not have too much mass around 0 or 1 (right part of Figure 1), which could lead to the violation of the common-support assumption.

Distribution of propensity scores among adopters and nonadopters.
Based on the distribution of density plots in Figure 1, the estimated mean propensity score for the adopter group was 0.6721, and the interval was [0.0558, 0.9685] at a 95% confidence level. The mean propensity score for the nonadopter group was 0.5223, and the interval was [0.0066, 0.937] at a 95% confidence level. Using the minima and maxima criterion, the interval for the regional of common-support is [0.0558, 0.937]. The common-support is, therefore, truncated at 0.0558 to the left and 0.937 to the right. Because there are more adopters than nonadopters, nearest neighbor matching with replacement was applied with a caliper set at 0.2 to allow selecting matches within a specified range as suggested in Imai and van Dyk (2004). The matching models excluded the 22 nonadopters, and the full model included all samples but assigned a propensity score of 0.0558 or 0.937 if the estimated score was, respectively, less than 0.0558 or more than 0.937. Observations outside the common-support included 22 (6.93%) sample households from the nonadopter group not matched to any adopters. However, the minima and maxima criterion is valid when estimating ATE; otherwise, for ATT and ATC, it is enough to ensure that each adopter has a nonadopter neighbor.
To assess the ignorability assumption (Rosenbaum & Rubin, 1985; Rubin, 1974), we use the distribution of the SMD of all covariates in the welfare equation before and after balancing, as shown in Figure 2. The general rule is that if the absolute value is significantly higher than 0.1 (10%) after covariate balance, then the variable is poorly balanced (Austin, 2009, 2011). In Figure 2, the threshold of 10% is the vertical dotted line. Before weighting using the propensity score, poorly balanced variables are covariates representing material wealth accumulation, quality government extension services, educational level of household head, and the weighted average of education for all adults (18 years and older). After weighting, all these variables were balanced, as shown in Figure 2.
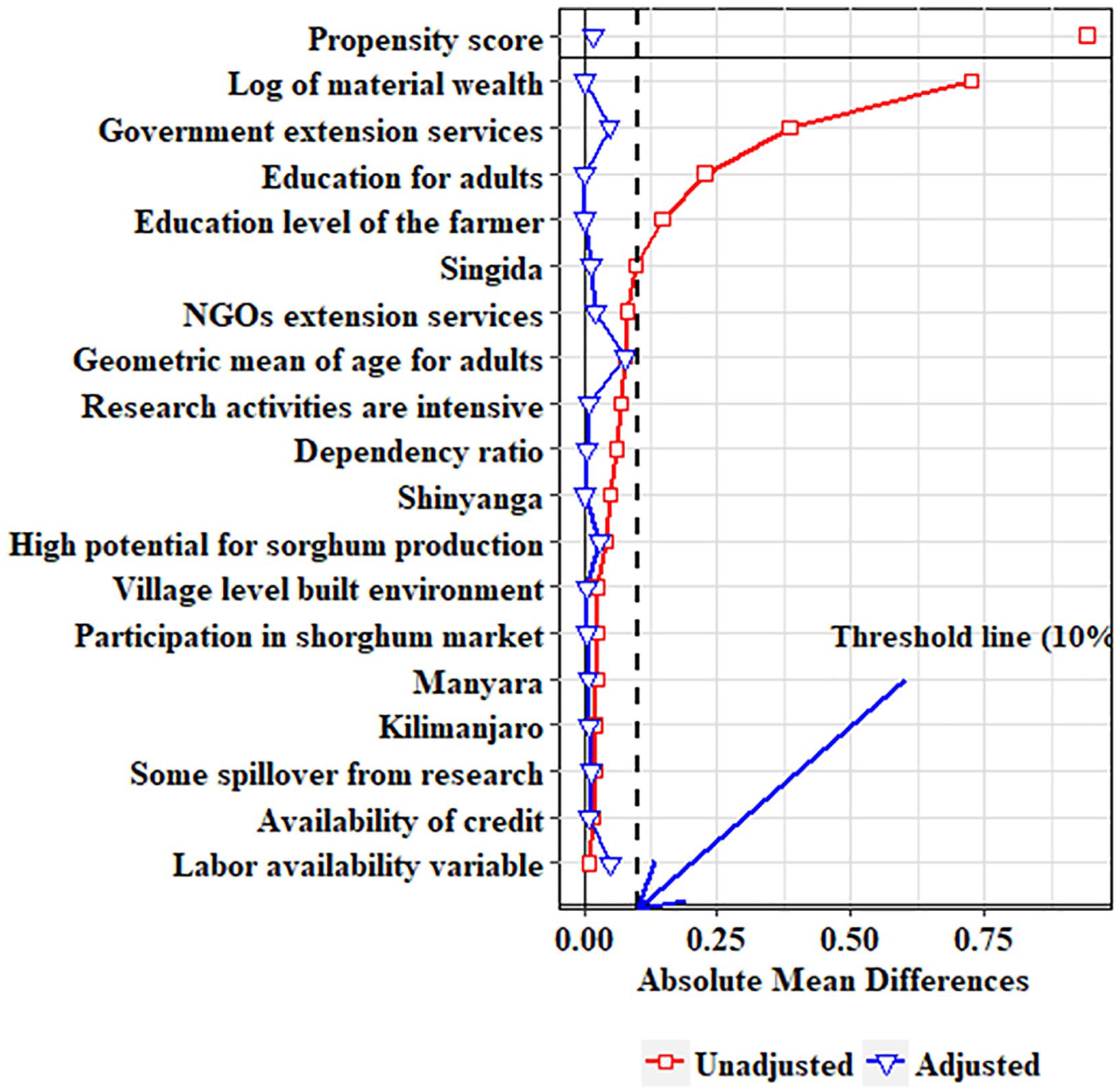
Distribution of absolute mean/proportion difference before and after matching.
Combining the results in Figures 1 and 2 implies that, after weighting, the empirical distributions of adopters’ and nonadopters’ covariates were statistically identical. The welfare model (i.e., the second expression of Equation 1) was, therefore, statistically valid, and according to Hansen (2008), the estimable three effect measures (i.e., ATT, ATE, and ATC) are unbiased and efficient.
Effect of Adoption on Welfare
During the estimation of the welfare model, we could either exclude or include all observations outside the regional common-support [0.0558, 0.937] based on estimated propensity scores explained above (Stuart et al., 2013). Therefore, we applied DiCiccio and Efron’s (1996) bootstrapping technique and different permutation test statistics to determine whether the adoption status coefficients for the two models were from similar empirical cumulative distribution functions. The graphs in Figure 3 are plots of the observed distributions of bootstrapped adoption status coefficients that estimate ATT using IPW and IPWRA estimators. In Figure 3, WTRts denotes the results from the Wilcoxon test statistics, MWWts indicates the results from the Mann–Whitney–Wilcoxon test statistics, and KSMts presents the results from the Kolmogorov–Smirnov test statistics. For all three tests, the ps in Figure 3 denote probability levels (α = .05). The conclusion is that the results from the two models follow a symmetric distribution around zero or from the same population with similar mean and variance. Supplemental Appendix 4 presents similar permutation test statistics results for bootstrapped ATE and ATC from the two models. As explained in Stuart and Ialongo (2010), when estimating effect using IPW and when adopter and nonadopter groups have similar covariate distributions, the results from matched and full samples should be identical due to reduced bias.

Bootstrapped ATT results from Wilcoxon, Mann–Whitney–Wilcoxon, and Kolmogorov–Smirnov tests.
Because the results of the two models in Figure 3 are almost similar, Table 2 presents the estimated effect of ISVs on HDDS and WDDS using the full sample for both IPW and IPWRA. The columns in Table 2 show estimated ATT (treated), ATE (average), and ATC (control). For each estimator, the values in the first part of the table are weighted regression coefficients. The numbers in brackets are associated intervals at a 95% confidence level. The second part shows the results when testing for model fit. The RS-LRTS represents Rao-Scott likelihood ratio χ2. Test statistics and AIC and BIC denote, respectively, Akaike information criteria and Bayesian information criteria discussed in Burnham and Anderson (2004) and Lumley and Scott (2014, 2015). We compare the full model (model with all covariates) and the null model (model with intercept only). The model with small values of RS-LRTS or AIC or BIC is preferred. All three test statistics reject the null hypothesis that all coefficients associated with covariates in Equation 1 are zero and conclude that the full models perform better than the null models. The full results from the IPWRA are provided in supplemental Appendix 5.
Results on the Impact of Adopting ISVs on Dietary Diversity Scores.

Note. ISVs = new sorghum varieties; AIC = Akaike information criteria; BIC = Bayesian information criteria; RS-LRTS = Rao-Scott likelihood ratio χ2.
The intercept coefficient in Table 2 is the expected weighted mean scores adjusted for self-selection and confounding effects. In that case, some observations contribute more weight than others. As we are using stabilized weights, the outliers contribute minimum influence in calculating the weighted mean scores. As shown in Table 2, both weighted HDDS and WDDS were higher among adopters as expected. The adopters’ (treated) weighted HDDS from IPW and IPWRA estimators was, respectively, 4.48 and 4.38. Analogous values for weighted WDDS were, respectively, 1.77 and 1.75. For nonadopters (control), the weighted HDDS and WDDS were 4.23 and 4.32 and 1.69 and 1.58, respectively. For the sample (average), the weighted average scores for both HDDS and WDDS were, respectively, 4.31 and 4.37 and 1.76 and 1.61. These results imply that after accounting for self-selection and confounding effects, the three dietary diversity estimands are below the cutoff points of diversity and micronutrient and macronutrient adequacy. The estimated weighted dietary diversity scores are comparable to results from other studies such as Mbwana et al. (2016), Kinabo et al. (2016), Ochieng et al. (2017), Ntwenya et al. (2017), and Huang et al. (2018) that focus on estimating the sample HDDS and WDDS.
Note that the intervals from the IPWRA estimator in Table 2 are wider and comparatively tighter than the interval from the IPW estimator. The expected weighted mean score for both HDDS and WDDS among nonadopters and the sample follows a similar distribution pattern where intervals from the IPWRA estimator have a wider range when compared with intervals from the IPW estimator. Statistically, while the IPW estimator produces precise results, IPWRA that adjusts for nonrandomness produces more accurate results (Abadie & Imbens, 2006).
Table 2 also presents the estimated ATT, ATE, and ATC represented as coefficients of adoption status variable from IPW and IPWRA estimators. The estimated coefficients are statistically significant at more than .05 probability level, suggesting that the adoption of ISVs has a positive effect on both HDDS and WDDS. On average, the HDDS among adopters (ATT) was, respectively, higher by about 0.88 (using IPW estimators) and 0.85 (using IPWRA) scores when compared with nonadopters with similar characteristics. For ATE and ATC, the results are, respectively, 0.75 and 0.76 and 0.62 and 0.58. Analogous values on WDDS are 0.61 for ATT, 0.56 for ATE, and 0.55 for ATC from the IPW estimator and 0.57 for ATT, 0.55 for ATE, and 0.52 for ATC from the IPWRA estimator. As these scores are determined using unobserved potential outcomes approach, the ATE values are average of the differences between the scores when each sample household adopts ISVs, and the ATC is an average gain if nonadopters take up ISVs. For example, if nonadopters had taken ISVs, the average scores could have increased by about 0.60 points. Notice that the estimated ATE was the averages of ATT and ATC as expected.
The reported marginal changes in Table 2 for both HDDS and WDDS from nonadoption to adoption (estimated effect) may seem small (about 1 point). However, due to limited access to broader food items among sample households, a minor change has a meaningful result. Although postharvest storage innovations had a positive and significant effect on HDDS, due to a low level of dietary diversity, Tesfaye and Tirivayi (2018) estimated ATT and ATC to be about, respectively, 0.25 and 2.01 in Ethiopia. Results from Passarelli et al.’s (2018) study show that access to improved irrigation system leads to increased HDDS in both Ethiopia and Tanzania by about 1 point. These results differ from Smale et al.’s (2018) study, which suggests that the adoption of ISVs did not spiral into dietary diversity adequacy in Mali. The discrepancy is due to differences in yields and intensity of adoption that are higher in Tanzania compared with Mali.
To determine whether farmers at the bottom of the social-economic pyramid benefit from adopting ISVs, Figure 4 presents comparative analysis results (between adopters and nonadopter). The focus is on the variability relative to the wealth of farmers, farmer’s education, the gender of the household head, and the marital status of the household head. For the wealth variable, the comparison included the lower quartile of the wealth distribution. For education, the contrast was between farmers with less than 7 years of education (primary education). The comparison is also between female farmers and unmarried female farmers and widows. The boxplots in Figure 4 (first part left panel) show the HDDS distribution, and the right panel shows the WDDS distribution estimated using IPW and IPWRA estimators through bootstrapping. Even the poorest adopters (low quartile) had higher total wealth compared with nonadopters. Total wealth averaged to US$2,550 per household and ranged from US$1,800 to US$3,850 for adopters and averaged to US$1,000 and ranged from US$400 to US$1,850 for nonadopters. Regarding the HDDS, the distribution ranged from 1.56 to 5.9, with a median of 5 for adopters. Similar values are 0.5 to 4.9, with a median of 4.5 for nonadopters who were equally poor. The weighted score for the middle 50% of adopters within the first quartile ranged from 4.7 to 5.2 and ranged from 3.8 to 4.1 for nonadopters. As for WDDS (Figure 4, the first part of the right panel), it ranged from 0.4 to 2.4 with a median of 2.2 for adopters and from 0 to 1.9 with a median of 1.6 for nonadopters. Similarly, the WDDS for the middle 50% of adopters of the first quartile of wealth ranged from 2.1 to 2.25 and ranged from 1.4 to 1.7 for nonadopters. Although in both cases the HDDS and WDDS are skewed to the right, poor adopters performed better in all five number categories compared with nonadopters.

Distribution of ATE for poor farmers and farmers with low education.
The results presented in the second part of Figure 4 show that even farmers with low education benefit from the adoption of ISVs. For HDDS (Figure 4, second part left panel), the weighted mean for adopters (head of household has less than 7 years of education) was 3.5. The median and maximum weighted means were, respectively, 5.2 and 5.9. For nonadopters (with low literacy), the minimum and the median were, respectively, 2.5 and 4.3, and the maximum was 5.0. Regarding the value of WDDS (Figure 4, second part right panel), the value was higher among adopters in which the head of the household has less than 7 years of education compared with nonadopters with a similar level of education. Due to biases that exist within the extension system that favor connected farmers (Awotide et al., 2016), educated farmers tend to have more access to extension services. Suvedi et al. (2017) also contend that farmer’s education influences extension participation and, therefore, training, advice, and information received, especially in a developing country such as Tanzania. Results from this study also show that even impoverished farmers and farmers with low education accrue higher benefits from the adoption of ISVs compared with nonadopters, which emphasizes the importance of inclusive and targeted agricultural education and extension systems.
Figure 5 presents comparative analysis results for female farmers (first panel) and single farmers (second panel) for both adopters and nonadopters. For female farmers, the minimum and maximum scores of the HDDS were, respectively, 4.4, and 6.2 with a median of 5.2 among adopters, and the minimum and maximum scores were, respectively, 3.2 and 5.5 with a median of 4.3 for nonadopters. The minimum, maximum, and median scores for the WDDS among adopters (female farmers) were, respectively, 1.4, 2.0, and 1.7, and similar values among nonadopters were, respectively, 1.1, 1.8, and 1.4. The adopters’ median was 17.65% higher compared with the nonadopters’ median. The comparison of unmarried female farmers also produced comparable results where both HDDS and WDDS were higher among adopters compared with nonadopters, as illustrated in the second panel of Figure 5. For unmarried adopters, the HDDS varied from 4.5 to 6.3, and the median was 5.5. For unmarried nonadopters, the HDDS varied from 3.4 to 5.6, and the median was 4.5. The WDDS for unmarried adopters ranged from 1.5 to 2.1, with a median of 1.8, and WDDS ranged from 1.2 to 1.9, with a median of 1.5 for unmarried nonadopters. Female farmers and unmarried female farmers stand to benefit if they adopt ISVs.
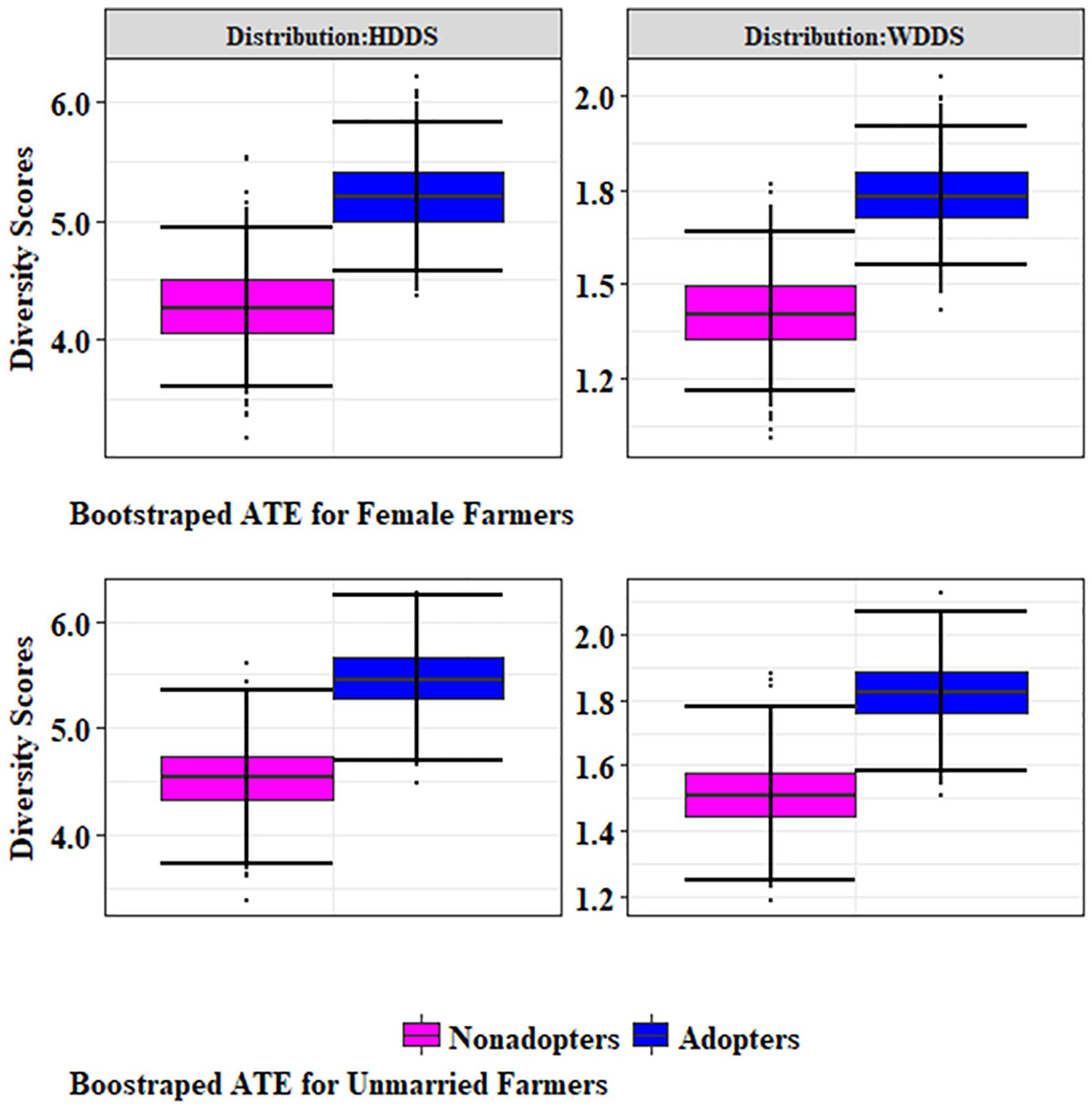
Distribution of ATE for female farmers and unmarried female.
Note that in both Figures 4 and 5, there is no overlap between the boxplots of HDDS and WDDS for adopter and nonadopter groups, which show that the values are statistically higher among adopters. The overall visible spread was over 50%, meaning that the scores for adopters were statistically significantly higher than the scores for nonadopters. Kassie et al. (2011) and Amare et al. (2012) also report improved general welfare among adopters of improved seeds. As improved seeds can increase the productive efficiency of all available resources, ISVs have the potential for both increasing access to diverse food groups and income. Evidence from this study suggests that even those farmers who often appear at the bottom of the socioeconomic pyramid stand to gain from adopting ISVs in Tanzania.
Conclusion
The goal of this study was to explain the complex linkage between improved seed adoption on household and women dietary diversity scores in Tanzania. The study adopts concepts of observational studies explained by Evenson and Gollin (2003) when estimating the effect of adopting agricultural technologies. Observational studies are crucial when randomized controlled trials are infeasible or impractical. Potential for self-selection bias and the presence of cofounder variables that distort the observed relationship between the incidence of adoption and welfare of farmers are the main limitations of observational studies. Controlling for both effects is, therefore, critical in justifying whether the effect of adoption is real or due to chance. The IPW and IPWRA that account for both effects were adapted when estimating the effect of improving sorghum varieties in Tanzania. The household and women dietary diversity scores (i.e., WDDS and HDDS) were indicators of farmers’ general welfare. The HDDS is a qualitative measure of access to varied food groups at the household level, and the WDDS is a measure of micronutrient and macronutrient adequacy (quality) among children and women of reproductive age.
The main results show that the Kilimanjaro Region had the highest scores for both indicators, with the lowest scores recorded in the Shinyanga Region. The marginal effects of adoption were statistically significantly higher among adopters at the 5% probability level. The adoption of ISVs increased HDDS and WDDS by 1 point or food group in the sample. The small but statistically significant marginal changes reflect the low level of access to broader food items in Tanzania. A minor change to increase access will have a significant effective result. Comparative analyses show that even households at the bottom of social-economic pyramids such as female farmers benefited from adoption.
The goals of most agricultural programs include enhancing the welfare of diverse groups of farmers. As proven in this study, the adoption of improved sorghum seeds could increase access to various food groups. Notably, the results from weighting with regression adjustment attest that the existence of institutional support systems is vital in terms of enhancing the welfare of farmers. Advisory services and other extension activities help farmers access these technologies and assess technology costs, risk profiles, and potential economic profitability.
Moreover, research and agricultural extension are the most common model to transmit information to farmers. To scale up and sustain the effect of adoption, a robust pedagogical linkage among research–extension–policy stakeholders is essential in promoting farmer-tailored, easily accessible, and modern agricultural innovations. Training to incentivize extension agents and engagement of policymakers at the community level, such as during farmers’ training and field days, are vital in maintaining the linkage, sustaining, and advocating policies that support farmers’ access to improved seeds and other improved agricultural practices. There is also a need to focus on female and poor farmers to promote universal access to dietary diversity. In general, small-scale agriculture supported by a sustainable and improved crop system will expand the availability and consumption of various food items, which in turn will improve nutritional status and promote positive health outcomes. Poor health outcomes are deeply interrelated with lower agricultural productivity and mutually reinforce each other. There is a genuine appeal to address these problems jointly. The question is, how do we begin to find these linked outcomes? Accordingly, conducting more studies should answer this question.
Supplemental Material
sj-pdf-1-sgo-10.1177_2158244020979992 – Supplemental material for Impact of Adopting Improved Seeds on Access to Broader Food Groups Among Small-Scale Sorghum Producers in Tanzania
Supplemental material, sj-pdf-1-sgo-10.1177_2158244020979992 for Impact of Adopting Improved Seeds on Access to Broader Food Groups Among Small-Scale Sorghum Producers in Tanzania by Aloyce R. Kaliba, Anne G. Gongwe, Kizito Mazvimavi and Ashagre Yigletu in SAGE Open
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The International Crop Research Institute for Semi-Arid Tropics (ICRISAT) in Nairobi, Kenya, funded this study under the Monitoring, Evaluation, Impact, and policy East Africa Program. However, the view expressed in this paper are those of the authors and do not necessarily represent ICRISAT’s view.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.