
Abstract
The revised hierarchical model seems different from the distributed conceptual feature model in predicting how unbalanced bilinguals would be aware of semantic relations between words for taxonomic categories of basic level (exemplar words) and words for those of superordinate level (category names) in L2. We did a series of four experiments to compare unbalanced bilinguals’ awareness of conceptual relations between exemplar words and between exemplar words and category names in their first (L1) and second language (L2). A priming task of semantic categorization was adopted, and the participants were 72 college students, who began to learn L2 in classroom settings at a late age and achieved an L2 proficiency between intermediate and advanced levels. The reaction times indicated that the participants could automatically process not only the exemplar-word but also the category-name primes in L2. Activations of semantic representations for the category names in L2 seemed to spread to those for the exemplar words in L1 and L2, but activations of semantic presentations for the exemplar words in L2 spread only to those for the example words in L1 for the participants. It was concluded that unbalanced bilinguals appear to have developed asymmetric associations between category names and exemplar words in L2. The implication is that L2 learners should learn L2 words mainly by means of using the language and not taking rote memory of isolated words.
Bilinguals’ semantic representations can be quite complex because of their proficiency in the second language (L2), their L2 learning environment, their age of L2 acquisition, and other factors (Wolter, 2006). Those who learned L2 at a late age in classroom settings are likely to be short of life experiences and language practices in the country of the target language. Given that life experiences and language practices are critical in helping determine one’s development of semantic representations (Andrews, Vigliocco, & Vinson, 2009), bilinguals might be aware of semantic relations among L2 words differently from how they are in their first language (L1). The purpose of the present study was to compare a cohort of unbalanced bilinguals’ awareness of conceptual relations between words for taxonomic categories of basic level (exemplar words) and between exemplar words and words for those of superordinate level (category names) in L1 and how they were aware of these relations in L2.
Background
One line of theories that have been established in the past decades focus on how the semantic representations are shared by the L1 and the L2 lexicons. For example, Kroll and Stewart’s (1994) revised hierarchical model (RHM; see Figure 1) predicts different strengths of links between the three memories: The link is strong between the L1 lexical store and the conceptual store but is weak between the L2 lexical store and the conceptual store. Low-proficiency bilinguals understand L2 words by associating them with the L1 translation equivalents. As their L2 proficiency rises, the strength of link between the L2 lexical store and the conceptual store increases. The RHM has been widely supported (e.g., Basnight-Brown & Altarriba, 2007; Ferré, Sánchez-Casas, & Guasch, 2006; L. Li, Mo, Wang, Luo, & Chen, 2009; Perea, Duñabeitia, & Carreiras, 2008), but it seems to need more specifications on the possibility of direct links between the L2 lexicons and the conceptual store (Blot, Zárate, & Paulus, 2003).

Kroll and Stewart’s (1994) revised hierarchical model.
Another important theory is the distributed conceptual feature model (DCFM; de Groot, 1992), according to which a larger number of conceptual representations are shared by L1 and L2 for concrete words (e.g., apple) than for abstract words (e.g., fruits). The DCFM also seems problematic because it assumes constant overlap of features between L1 and L2 translation equivalents (Finkbeiner, Forster, Nicol, & Nakamura, 2004).
Basing on the DCFM and their findings on polysemous words, Finkbeiner et al. (2004) developed the sense model (see Figure 2). The sense model assumes that each sense of a word constitutes a distinct representation and existence of a representational asymmetry between related words is thus possible. An L2-word prime has fewer senses than its translation equivalent in L1 and can pre-activate only some representations for the L1-word target in a masked priming task of lexical decision. An L1-word prime, however, is likely to pre-activate most of the representations for its L2 equivalent.

A small amount of the senses of the Japanese word “kuroi” shared by the English translation equivalent “black” in a Japanese learner of English.
The organization of semantic representations is like a network (Collins & Loftus, 1975). The RHM, the DCFM, and the sense model all seem to deal with how the nodes of the network are shared by words in L1 and L2. Instead of focusing on the nodes, studies began to address whether the links between the nodes are different in strength in L1 and L2. Indeed, these studies are likely to open a new room of research into bilinguals’ semantic representations. In D. Li, Li, and Yuan (2010), for example, the college-student participants were required to study lists of L1 and lists of L2 words and then to write down what they remembered. Every list consisted of even numbers of pairs of taxonomically (e.g., tiger, lion; apple, orange; moon, sun) and thematically associated stimuli (e.g., nest, bird; lock, key; scarf, neck). In the forced-choice decision-making task, three items, A (e.g., train; dog; cake), B (e.g., bus; cat; bread), and C (e.g., railway; bone; candle), were presented simultaneously to make a triangular contour with A at the apex and B and C at the two base angles in a trial. The participants decided whether B was more closely related to A than to C was or vice versa. B and C were taxonomically and thematically associated to A, respectively. The two experiments yielded similar results: The participants had similar strengths of awareness of thematic and taxonomic relations among the concrete words in L1, consistent with Lin and Murphy (2001), but were aware of thematic associations less than they were of taxonomic relations in L2.
Similarly, senior high school students’ performance in single-word associations and forced-choice decision makings also revealed a weaker awareness of thematic than of taxonomic relations in L2 (D. Li, Zhang, & Wang, 2011). In the single-word-association task, the participants were asked to write the first word that came to mind for each stimulus word (e.g., banana). The associations between their responses (e.g., apple or monkey) to the stimuli were supposed to provide indications of how semantic representations for specific words were linked.
Thematic associations are cultural-specific. For example, horse is closely associated with carrot in Korean adolescents, because in a traditional Korean story, a horse eats a carrot. Scientific knowledge such as those of taxonomic categories, however, is largely universal. Unbalanced bilinguals such as the participants in D. Li et al. (2010) and D. Li et al. (2011) expand their L2 vocabulary mainly by means of rote memory instead of in using the target language. They appear more able to share taxonomic relations than to share thematic associations among concrete words in L2. Thus, the present study focused on taxonomic relations.
Research Questions
Given the assumption of the DCFM that semantic representations for category names are shared by L1 and L2 to a less degree than those for exemplar words, we wondered whether unbalanced bilinguals are aware of conceptual relations between category names and exemplar words similarly in L1 and L2.
D. Li et al. (2013) tried to address this problem on a cohort of deaf and hard of hearing (DHH) adolescents, whose L1 and L2 were sign language and written language, respectively. DHH students tend to lack ready expressions for taxonomic categories of superordinate level in sign language (D. Li, 2010) and may find it hard to learn category names in written language. They might not be able to develop clear representations for category names. Thus, the authors hypothesized that DHH adolescents would be less able than hearing adolescents to process category-name primes in a priming task of semantic categorization (PTSC). The participants were required to decide whether the exemplar-word target, which was preceded by a briefly presented category-name prime, referred to living or nonliving things in a trial. Consistent with their prediction, the result revealed no priming effect for the category-name primes.
Unbalanced bilinguals are different from D. Li et al.’s (2013) participants in that they had developed a big vocabulary in L1 when they began to learn L2 words through the L1 translations. According to the RHM, they are quite likely to be aware of conceptual relations between category names and exemplar words similarly in L1 and L2. Of universal knowledge, these semantic relations might be of similar patterns in L1 and L2 in unbalanced bilinguals, as indicated in D. Li et al. (2010) and D. Li et al. (2011). According to the DCFM and the sense model, however, fewer semantic representations are shared for category names than for exemplar words in L1 and L2. The semantic relations between category names and exemplar words might be of different patterns in L2 from how they are in L1 in unbalanced bilinguals. Thus, the research question of the present study was whether semantic relations between exemplar words and category names were similar in L1 and L2 in unbalanced bilinguals.
Hypotheses
To have a picture of unbalanced bilinguals’ awareness of conceptual relations between exemplar words and category names in L1 and L2, we would test the following hypotheses on a cohort of college students (35 males and 37 females) at a university in China in a PTSC.
If exemplar words were semantically related to category names similarly in L1 and L2 in unbalanced bilinguals, then their response differences in a PTSC in condition 1 and 2 would be of a similar pattern in L1 and L2. If exemplar words were semantically related to category names differently in L1 from how they were in L2 in unbalanced bilinguals, then their response differences in a PTSC in condition 1 and 2 would be of a different pattern in L1 from how they would be in L2. Condition 1: The prime and the target in a trial were an exemplar word and a category name, respectively. Condition 2: The prime and the target in a trial were a category name and an exemplar word, respectively.
To achieve a full picture, we would do four experiments, across which similar procedures would be adopted of participant recruitment, stimuli presentation, data collection, and data screening. The first two experiments were to compare participants’ awareness of conceptual relations between exemplar words in L1 and L2, and the second two experiments their awareness of conceptual relations between exemplar words and category names in L1 and L2.
Experiment 1
Method
We intended to compare participants’ conceptual relations between exemplar words in L1 and L2. To do so, we examined the facilitating effect of the exemplar-word primes on their responses to the exemplar-word targets in a PTSC in L1 and L2. We manipulated two variables: language and prime. The stimuli were presented in Chinese or English. The same targets of exemplar words were preceded by neutral primes of meaningless symbols or by exemplar words. The word prime and the target were from the same category in a trial. The dependent variables were error rates and reaction times.
Participants
Fifteen college students (eight females; M = 20.0 years, age range: 19.2-21.5 years) majoring in engineering specialties were recruited on campus by means of a flyer advertisement. All of them were learning College English as their L2. Their level of English proficiency was above the intermediate level, because they achieved 48.3 ± 8.6 (M ± SD) in a Quick Placement Test (QPT; by Oxford University Press and Cambridge English for speakers of other languages [ESOL]). Bilinguals who have a QPT score between 40 and 47, 48 and 54, and 55 and 60 are of intermediate, advanced, and proficient levels, respectively, in the target language. They also reported in a questionnaire to have begun learning English in classroom settings after 10 years of age, to have been of the same level of proficiency in English as indicated in the placement test at the start of their first semester, and to be taking the same course of College English at the time of the experiment. They attended the course 4 class hours a week.
Materials
Thirteen pairs of exemplar words in Chinese from 13 taxonomic categories and the exemplar words’ English translations made the critical materials (see the appendix). The two words in a pair were presented in the same language and referred to exemplars from the same category. Each of the 52 exemplar words would be used as a prime 1 time and as a target 1 time. Twenty-five college students from the same pool as the participants evaluated the familiarity of all the exemplar words on a 7-point scale (1 = very unfamiliar, 7 = very familiar). Similarly, a second and a third 25 students evaluated the typicality and the concreteness of each exemplar, respectively. The materials’ attributes are displayed in Table 1. The prime words were not significantly different from the target words in familiarity, t(12) = 0.158, p = .877; concreteness, t(12) = 1.016, p = .330; typicality, t(12) = 0.384, p = .708; word length, t(12) = 0.562, p = .584; or lexical frequency, t(12) = 0.633, p = .542, in L1. The prime words were not significantly different from the target words in familiarity, t(12) = 1.255, p = .233; word length, t(12) = 1.102, p = .292; or lexical frequency, t(12) = 0.503, p = .624, in L2. The prime words in Chinese and English were replaced with ø and ######, respectively, to create the critical neutral-prime materials. The raters of the materials did not participate in the PTSC. Similarly, 312 prime-target pairs of filler materials were created with exemplar words from taxonomic categories other than those of the critical materials. The two words in a word-prime filler-pair were not related at all. Half of the 364 targets referred to living and the other half to nonliving things.
The Exemplar Words’ Attributes.

Note. L = lexicons.
Procedure
We used DMDX (Forster & Forster, 2003) to control stimulus presentations on personal computers. The screen resolution was 1,280 × 800 pixels. In each trial, a red fixation-cross “+” remained 800 ms at the center of a white screen. The prime was then presented 237 ms at the place where the fixation-cross disappeared. After that, the target appeared and stayed at the screen center 3,000 ms or until a key press was received. The stimuli were in black color in Song-36. Both oral and written instructions were delivered in Chinese. The participants were required to press the key “Z” and “/” if the target referred to a living and a nonliving thing, respectively. The next trial began 1,000 ms after the target disappeared. There were 16 practice trials followed by the experimental trials. Because in Experiments 2 and 4, the prime and the target in a trial would be presented in different languages, we did not block the items by language. Both the practice trials and the experimental trials were randomized for each participant, who received 20 Yan (approximately US$3.26) for participation.
Results
The data were deleted for the trials in which the reaction times were below 200 ms or 3 SD above the average. In all, 2.9% of the collected data were discarded, and the average scores of error rates and reaction times were then calculated for each participant at each treatment level of language by prime (see Table 2).
Participants’ Performance in the First Two Experiments.

The targets were presented in Chinese.
The targets were presented in English.
Error rates
The error-rate data were submitted to 2 (language) × 2 (prime) by-subject and by-item ANOVAs. The main effects were significant for language, F1(1, 14) = 20.03, p = .001, ηp2 = .589; F2(1, 100) = 6.42, p = .013, ηp2 = .060, and prime, F1(1, 14) = 5.66, p = .032, ηp2 = .288. The two-way interaction was significant between language and prime, F1(1, 14) = 9.73, p = .008, ηp2 = .410. Simple effect analyses suggested that the participants’ error rates were significantly higher in L2 than in L1 for the word-primed targets, t(14) = 6.975, p < .001. Their error rates were significantly higher for the targets in L2 preceded by the word than for those preceded by the neutral-string primes, t(14) = 3.409, p = .004.
Reaction times
Similar analyses of the reaction-time data suggested that the main effect was significant for language, F1(1, 14) = 83.95, p < .001, ηp2 = .857; F2(1, 100) = 29.75, p < .001, ηp2 = .229. The two-way interaction was significant between language and prime, F1(1, 14) = 4.97, p = .043, ηp2 = .262. Simple effect analyses indicated that the participants’ reaction times were significantly longer in L2 than in L1 when the primes were neutral strings, t(14) = 5.214, p < .001, and words, t(14) = 9.830, p < .001. Their reaction times were significantly shorter for the L1 targets preceded by the word than for those preceded by the neutral-string primes, t(14) = 2.511, p = .025.
Discussion
Sources of information at the feature, the letter, and the word level are automatically processed in parallel (McClelland & Rumelhart, 1981). The participants’ perception of the word primes’ visual information in L2 might have caused interferences to their recognition of the L2 targets. As a result, they had significantly higher error rates to the L2 targets preceded by the L2 word than to those preceded by the neutral-string prime.
The participants had significantly shorter reaction times to the L1 targets preceded by the word than to those preceded by the neutral-string prime. In other words, their automatic processing of the exemplar-word primes facilitated their responses to the exemplar-word targets in L1 (see Table 3), consistent with the spreading activation model (Collins & Loftus, 1975). However, no priming effect was observed in the participants’ reaction times to the L2 targets.
Priming Effect in Reaction Times (ms) in the First Two Experiments.

Given the possibility of direct access to semantic representations from concrete words in L2 for unbalanced bilinguals (Altarriba & Mathis, 1997; Finkbeiner et al., 2004), the participants’ perception of the exemplar-word primes in L2 should have pre-activated the representations for the corresponding targets. Participants’ responses to the targets in a cognitive task are the result of automatic and conscious processes in combination (Shiffrin & Schneider, 1984), and word recognition often requires more attention in L2 than in L1 (Favreau & Segalowitz, 1983). It might have been the attention commitment that helped masking the priming effect in the participants’ effortful process of recognition of the L2 targets.
If this was the case, then exemplar-word primes in L2 would foster participants’ responses of living-or-nonliving categorizations on exemplar-word targets in L1. We would test this prediction in Experiment 2.
Experiment 2
Method
The design was the same as in Experiment 1.
Participants
Seventeen participants (nine females; M = 20.3 years, age range: 19.3-21.7 years) were recruited in the same way as in Experiment 1. They achieved a QPT score of 47.6 ± 8.3.
Materials
The critical materials of Experiment 1 were adopted and were regrouped so that the prime and the target in a word-prime pair were different in language but referred to two exemplars of the same category. Similarly, the two words in a word-prime filler-pair were of different languages.
Results
The data were screened in the same way as in Experiment 1, and 2.4% of the data were discarded. The results are summarized in Table 2.
Error rates
The error-rate data were analyzed in the same way as in Experiment 1. The main effect was significant for language, F1(1, 16) = 15.53, p = .001, ηp2 = .492; F2(1, 100) = 4.35, p = .040, ηp2 = .042. The participants’ error rates were significantly higher for the L2 (10.8%, 1.4%; M, standard error [SE]) than for the L1 targets (5.1%, 0.7%).
Reaction times
Similar analyses of the reaction-time data suggested that the main effects were significant for language, F1(1, 16) = 132.00, p < .001, ηp2 = .892; F2(1, 100) = 31.52, p < .001, ηp2 = .240, and prime, F1(1, 16) = 9.04, p = .008, ηp2 = .361. The two-way interaction was significant between language and prime, F1(1, 16) = 6.12, p = .025, ηp2 = .277. Simple effect analyses suggested that the participants’ reaction times were significantly shorter for the L1 than for the L2 targets when the primes were words, t(16) = 10.027, p < .001, and neutral strings, t(16) = 7.585, p < .001. Their reaction times were significantly shorter for the L1 targets preceded by the word than for those preceded by the neutral-string primes, t(16) = 4.711, p < .001.
Discussion
The participants had significantly shorter reaction times on the L1 targets preceded by the L2 words than on those preceded by the neutral-string prime, confirming the deduction in Experiment 1 that automatic processing of the exemplar-word primes in L2 facilitated reaction times to the exemplar-word targets in L1 for the unbalanced bilinguals. Furthermore, no priming effect was observed in the participants’ reaction times to L2 targets, confirming the deduction in Experiment 1 that the facilitating influence from the L1 primes was concealed in the participants’ effortful recognition of the L2 targets.
Experiments 1 and 2 compared participants’ awareness of conceptual relations between exemplar words in L1 and L2, and Experiments 3 and 4 would compare their awareness of conceptual relations between exemplar words and category names in L1 and L2.
Experiment 3
Method
The design formed a 2 (language: Chinese or English) × 2 (prime: neutral string or word) × 2 (target: category name or exemplar word) repeated factorial. The dependent variables were error rates and reaction times.
Participants
Eighteen participants (nine females; M = 19.8 years, age range: 19.0-21.3 years) were recruited in the same way as in Experiment 1. They achieved a QPT score of 48.7 ± 9.2.
Materials
The critical exemplar words in Experiment 1 were paired with the corresponding category names (see the appendix). The two members in a pair were of the same language. The familiarity scores for the category names in English and Chinese were 5.41 ± .32 and 5.90 ± .61, respectively. In each language, half of the exemplar words in the 26 pairs would be primes 1 time and the other 13 exemplar words targets 1 time. The neutral-prime materials were created in the same way as in Experiment 1. Similarly, 312 filler pairs were created, and the two words in a word-prime filler-pair were not related at all. In total, half of the targets referred to living things.
Results
The data were screened in the same way as in Experiment 1, and 2.0% of the collected data were deleted. The results are summarized in Table 4.
Participants’ Performance in the Second Two Experiments.

The targets were presented in Chinese.
The targets were presented in English.
Error rates
The error-rate data were submitted to 2 (language) × 2 (prime) × 2 (target) by-subject and by-item ANOVAs. The main effects were significant for language, F1(1, 17) = 17.36, p = .001, ηp2 = .505, and target, F1(1, 17) = 21.16, p < .001, ηp2 = .554; F2(1, 100) = 4.04, p = .047, ηp2 = .037. The two-way interaction was significant between language and target, F1(1, 17) = 15.62, p = .001, ηp2 = .479. Simple effect analyses showed that the participants’ error rates were significantly higher for the exemplar-word (20.8% ± 9.6%) than for the category-name targets in L2 (10.2% ± 5.7%), t(17) = 5.611, p < .001. Their error rates were significantly higher in L2 than in L1 for the exemplar-word targets (10.5% ± 5.9%), t(17) = 6.047, p < .001.
Reaction times
Similar analyses of the reaction-time data indicated that the main effects were significant for language, F1(1, 17) = 74.44, p < .001, ηp2 = .814; F2(1, 104) = 16.66, p < .001, ηp2 = .138; prime, F1(1, 17) = 10.60, p = .005, ηp2 = .384; and target, F1(1, 17) = 15.45, p = .001, ηp2 = .478. The two-way interactions were significant between language and prime, F1(1, 17) = 7.59, p = .014, ηp2 = .309, and between prime and target, F1(1, 17) = 6.18, p = .024, ηp2 = . 266. Simple effect analyses showed that the participants’ reaction times were significantly longer for the L1 targets preceded by the neutral-string (779 ms ± 93 ms) than for those preceded by the word primes (712 ms ± 137 ms), t(17) = 3.828, p = .001. Their reaction times were significantly longer for the L2 (871 ms ± 104 ms; 857 ms ± 87 ms) than for the L1 targets when the primes were neutral strings, t(17) = 7.995, p < .001, and words, t(17) = 7.262, p < .001. The participants had significantly longer reaction times for the exemplar-word (850 ms ± 102 ms) than for the category-name targets (800 ms ± 94 ms) when the primes were neutral strings, t(17) = 5.623, p < .001, and had significantly longer reaction times for the exemplar-word targets preceded by the neutral-string than for those preceded by the word primes (792 ms ± 99 ms), t(17) = 4.907, p < .001.
Discussion
According to Collins and Quillian (1969), the conceptual nodes for exemplar words are semantically further than are those for category names from the conceptual node for living or nonliving things. It must have cost the participants more cognitive resources to make living-or-nonliving categorizations on the exemplar-word than on the category-name targets, especially when the stimuli were in L2. Therefore, the participants had significantly longer reaction times for the exemplar-word than for the category-name targets preceded by the neutral-string prime and had significantly higher error rates for the exemplar-word than for the category-name targets in L2.
The participants’ significantly shorter reaction times on the targets in L1 preceded by the word than on those preceded by the neutral-string primes indicate inter-associations between taxonomic categories of basic and superordinate levels. Similar to the case of the priming effect (see Table 5) from category names to exemplar words in L1, the participants’ reaction times were significantly shorter to the exemplar-word targets in L2 preceded by the category-name than to those preceded by the neutral-string primes. In other words, they were able to automatically process category-name primes in L2 in the PTSC, and direct access to semantic representations from category names in L2 was thus possible for unbalanced bilinguals. Moreover, it seemed to be the associations from category names to exemplar words in L2 that helped the participants’ living-or-living categorizations on the exemplar-word targets in L2, given that priming effect was not observed on the L2 targets in Experiments 1 and 2.
Priming Effect in Reaction Times (ms) in the Second Two Experiments.

The participants’ reaction times remained statistically unchanged on the category-name targets in L2 when the primes were changed from neutral strings into words. This result cannot be explained by the participants’ inability to semantically process the exemplar-word primes in L2, given the priming effect from the L2 primes to the L1 targets in Experiment 2. It cannot be explained off either by assuming that category names in L2 were more difficult to categorize than exemplar words in L2, with Collins and Quillian’s (1969) theory taken into consideration. The lack of priming effect from the exemplar-word primes to the category-name targets in L2 can only have stemmed from the fact that the participants’ activations of the L2-exemplar-word primes’ semantic representations did not spread to the L2-category-name targets’ semantic representations. In other words, unbalanced bilinguals seem to have an asymmetric pattern of conceptual associations between category names and exemplar words in L2: There are semantic associations from category names to exemplar words in L2 but not vice versa.
Would their automatic activations of semantic representations for category names in L2 and L1 prime their responses to exemplar words in L1 and L2, respectively, or would their automatic activations of semantic representations for exemplar words in L2 and L1 prime their responses to category names in L1 and L2, respectively? Experiment 4 was to provide an answer to this question.
Experiment 4
Method
The design was the same as in Experiment 3.
Participants
Twenty-two participants (11 females: M = 20.1 years, age range = 19.0-21.6 years) were recruited in the same way as in Experiment 1. They achieved a QPT score of 47.7 ± 9.0.
Materials
The critical materials of Experiment 3 were adopted but were regrouped so that the two words in each word-prime pair were different in language but referred an exemplar and the exemplar’s superordinate-level category. Similarly, the two words in a word-prime filler-pair were of different languages.
Results
The data were screened in the same way as in Experiment 1, and 1.5% of the collected data were discarded. The results are summarized in Table 4.
Error rates
The error-rate data were analyzed in the same way as in Experiment 3. The main effects were significant for language, F1(1, 21) = 43.97, p < .001, ηp2 = .677; F2(1, 104) = 6.30, p = . 014, ηp2 = .057; prime, F1(1, 21) = 8.40, p = .009, ηp2 = .286; and target, F1(1, 21) = 26.94, p < .001, ηp2 = .562; F2(1, 104) = 5.00, p = .029, ηp2 = .045. The participants’ error rates were significantly lower for the targets preceded by the neutral-string (8.8%, 1.0%) than for those preceded by the word primes (11.7%, 1.1%). The two-way interaction was significant between language and target, F(1, 21) = 18.87, p < .001, ηp2 = . 473; F (1, 104) = 4.21, p = .043, ηp2 = .039. Simple effect analyses showed that the participants’ error rates were significantly higher for the exemplar-word (20.1% ± 9.7%) than for the category-name targets in L2 (7.8% ± 6.9%), t(21) = 5.269, p < .001, and were significantly higher in L2 than in L1 for the exemplar-word targets (6.7% ± 4.1%), t(21) = 6.445, p < .001.
Reaction times
Similar analyses of the reaction-time data showed that the main effects were significant for language, F1(1, 21) = 73.51, p < .001, ηp2 = .778; F2(1, 104) = 21.13, p < .001, ηp2 = .169, and prime, F1(1, 21) = 11.49, p = .003, ηp2 = .354. The three-way interaction was significant between language, prime, and target (see Figure 3), F1(1, 21) = 14.74, p = .001, ηp2 = .412. Simple effect analyses showed that the participants’ reaction times were significantly longer for the exemplar-word targets in L1 preceded by the neutral-string than for those preceded by the word primes, t(21) = 4.184, p < .001, and were significantly longer for the category-name targets in L2 preceded by the neutral-string than for those preceded by the word primes, t(21) = 4.188, p < .001. Their reaction times were significantly shorter for the category-name targets than for the exemplar-word targets in L2 preceded by the word primes, t(21) = 3.337, p = .003. The participants had significantly longer reaction times for the category-name (the exemplar-word) targets in L2 than for those in L1 when the primes were neutral strings, t(21) = 6.286, p < .001, t(21) = 5.140, p < .001, and words, t(21) = 5.792, p < .001, t(21) = 8.560, p < .001.
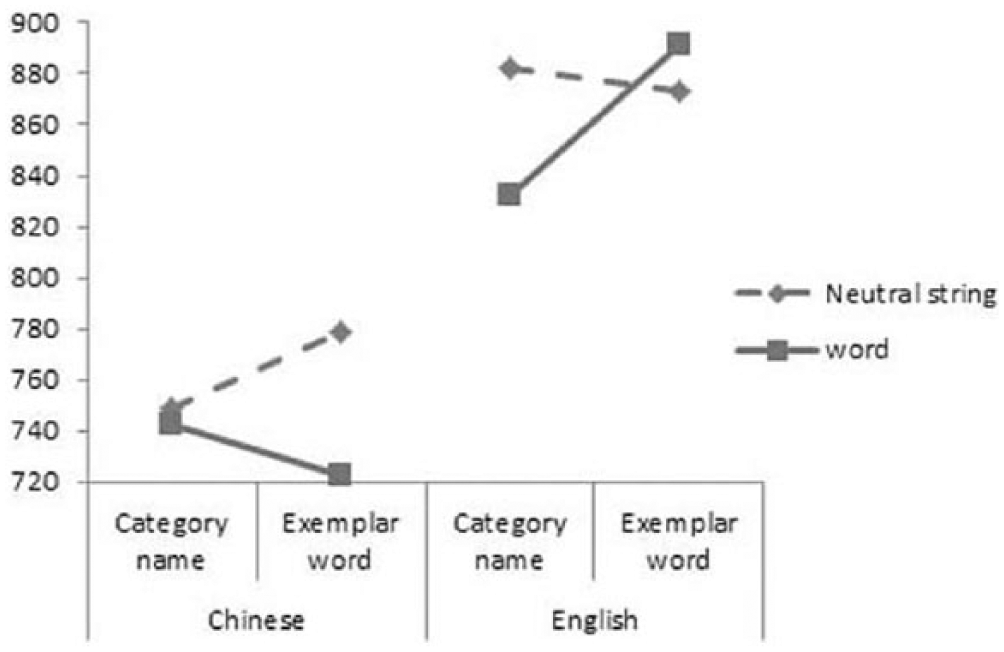
Three-way interaction between language, prime, and target in the reaction-time data.
Discussion
The participants had significantly higher error rates for the exemplar-word than for the category-name targets in L2 and significantly longer reaction times for the exemplar-word than for the category-name targets in L2, in agreement with Collins and Quillian (1969). The word prime in L1 and L2 was paired with the target in L2 and L1, respectively, in a word-prime trial. This language switch might have caused interferences to the participants’ performance, according to Orfanidou and Sumner (2005). Thus, the participants had significantly higher error rates when the primes were words than when they were neutral strings. This kind of interference was not observed in Experiment 2, probably because both the primes and the targets were concrete words, and the language-switch cost was smaller in Experiment 2 than in Experiment 4.
However, the category-name primes in L1 did not seem to have facilitated the participants’ reaction times to the exemplar-word targets in L2, nor did the exemplar-word primes in L2 seem to have facilitated the participants’ reaction times to the category-name targets in L1. The participants’ reaction times were significantly shorter on the exemplar-word targets in L1 than on the category-name targets in L2 when the primes were changed from neutral strings into words. These results together seem to suggest that category names in L2 semantically inter-relate to exemplar words in L1, but category names in L1 and exemplar words in L2 might not be semantically associated to exemplar words in L2 and category names in L1, respectively, for unbalanced bilinguals.
General Discussion
To compare unbalanced bilinguals’ awareness of conceptual relations between exemplar words and between exemplar words and category names in L1 and how they were aware of these relations in L2, a series of four experiments were conducted in a priming task of semantic categorization with a set of stimuli on a cohort of college students, who began to learn L2 in classroom settings at a late age and whose L2 proficiency was between intermediate and advanced levels. In a word-prime trial, the target was in the same language as the prime in Experiments 1 and 3 but was different from the prime in language in Experiments 2 and 4. Language (L1 or L2) and prime (primes of neutral strings or words) were the two repeated factors in the first two experiments, and target (targets of category names or exemplar words) was the third repeated factor in the second two experiments. The participants were required to make living-or-nonliving categorizations on the targets.
Aside from the consistent result across the four experiments that the participants had a poorer performance on the targets in L2 than in L1, as predicted by the RHM, the most inspiring results were the priming effects revealed in the participants’ reaction times under the influence of language in Experiments 1 to 4 and under the influence of the conceptual relations between the primes and the targets in Experiments 3 and 4 (see Figure 4).

Priming effects between exemplar words and between exemplar words and category names in L1 and L2.
An obvious indication of these results is that the participants were able to automatically process not only the exemplar-word primes in L2, strongly confirming the possibility of direct access to semantic representations for concrete words in L2 (Altarriba & Mathis, 1997; Finkbeiner et al., 2004), but also the category-name primes in L2, clearly suggesting a possibility of direct access to semantic representations for category names in L2 for unbalanced bilinguals.
Specifically, the priming-effect patterns across the four experiments seem to reflect three specific phenomena for unbalanced bilinguals. First, activations of semantic representations for exemplar words in L1 automatically spread to those for exemplar words in L2 and vice versa. Second, activations of semantic representations for category names automatically spread to those for exemplar words in L1 and vice versa. Activations of semantic representations for category names automatically spread to those for exemplar words in L2 but not vice versa. Third, there exist semantic inter-associations between exemplar words in L1 and category names in L2, but semantic associations are absent between exemplar words in L2 and category names in L1.
The last two phenomena might not be readily explained by the RHM, the DCFM, or the sense model, but the key point with the three phenomena together can be summarized as follows. Category names in L2 can be associated with exemplar words in L1 and to exemplar words in L2, but exemplar words in L2 can only be associated with exemplar words in L1 for unbalanced bilinguals. The difference between category names and exemplar words in L2 in richness of associations can be further explained by how unbalanced bilinguals acquired words in L2.
Unbalanced bilinguals such as the participants in the present study learn L2 words mainly by means of rote memory of the L1 translation equivalents. As predicted by the RHM, they can quickly set up associations between concrete words in L2 and the L1 translation equivalents and match the L2 words with the mental representations for the corresponding entities. Language uses are necessary for semantic representations to be well developed (Andrews et al., 2009). Short of practice in L2, however, unbalanced bilinguals have a smaller number of senses for a concrete word in L2 than for the L1 translation equivalent (Finkbeiner et al., 2004). Furthermore, they have an asymmetric pattern of awareness of thematic and taxonomic relations among concrete words in L2 (D. Li et al., 2010; D. Li et al., 2011). Similarly, the lack of associations from exemplar words in L2 to category names in L1 and L2 revealed in the present study also seems to strongly suggest a kind of isolatedness of representations for concrete words in L2 for unbalanced bilinguals.
Not referring to concrete entities, abstract words have to be learned through associating to objects, situations, experiences, and so on (Borghi & Cimatti, 2012). Thus, when leaning an L2 category name, for example, unbalanced bilinguals may associate it not only to the L1 translation equivalent, as predicted by the RHM, but also to the common exemplar words in L1 and/or L2. They are quite likely to know fewer and to be less familiar with exemplar words in L2 than they are likely to in L1, and the one-way associations from the category name in L2 to the exemplar words in L1 might gradually become very strong and turn to be two-way associations. Although unbalanced bilinguals must have a smaller number of senses for a category name in L2 than they have for the L1 translation equivalent, according to the sense model, they do seem able to set up semantic associations of the L2 category name with exemplar words in L1 and to exemplar words in L2 in the process of learning the abstract word. However, semantic associations are not likely to exist from exemplar words in L2 to category names in L1 or L2, largely because the learners did not need to experience these associations in learning exemplar words in L2.
In conclusion, unbalanced bilinguals can automatically process the primes of not only exemplar words but also category names in L2 in a priming task of semantic categorization. Activations of semantic representations for category names in L2 spread to those for exemplar words in L1 and L2, but activations of semantic presentations for exemplar words in L2 spread only to those for exemplar words in L1. Given individual differences in reading abilities in English, the relatively small sizes of samples in the present study may cast some limitations to the generalization of the findings. Furthermore, comparisons of this population of bilinguals’ automatic processing of thematic associations and other kinds of semantic relations across L1 and L2 will be necessary to provide a clearer picture of their semantic representations. However, the present study does seem to imply that unbalanced bilinguals like the participants should not take rote memory of isolated words as the main means of vocabulary learning. They should learn L2 words through a way of associating them with one another. Reading and listening practices as traditionally required would be time-consuming and even boring for many L2 learners. We suggest that L2 teachers create scripts of scenes and events and even short stories with the target words so that students can learn them in an associative way. Accordingly, awareness of semantic associations among L2 words should also be one of the main constructs in L2 exercises and tests. Potentially, those who will learn L2 words mainly as suggested here will be more likely than the participants of the present study to develop representations for semantic relations that are similar in L1 and L2.
Footnotes
Appendix
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research and/or authorship of this article: The present study was supported by the National Social Science Foundation of China under Grant 11&ZD188, the Social Science Foundation of China Ministry of Education under Grant 14YJA740016, and Excellent Young & Middle Aged Academic Leader of Zhejiang Province under Grant PD2013079.