
Abstract
We evaluated the relationship between neighborhood sociodemographic factors, community resources, and homicides involving young children. We performed spatial analysis of children under age five murdered in Harris County, Texas, from 1997 to 2003. Data on county population, household, socioeconomic, and residential mobility characteristics were allocated to census block groups. Age-adjusted spatial clusters of the homicides were identified. A Markov Chain Monte Carlo negative binomial regression risk model tested the relationship of age-adjusted number of child homicides to block group characteristics and distance of victim’s residence to community resources. Child maltreatment accounted for 94% of 125 homicides. In all, 64% were concentrated in 12 age-adjusted spatial clusters involving 3% of county area. Predictors for number of homicides were a larger number of single-parent households (male and female) and lower median household income. Distance to nearest community resources was not significant. Spatial clusters of child homicides were associated with low-income neighborhoods and single-parent (male and female) households. No association between the spatial clusters of child homicides and their proximity to community resources was observed. A high percentage of child homicides were concentrated in a small area of the county, which offers the potential for targeted, cost-effective interventions.
Introduction
Child maltreatment is an important medical and public health problem affecting 1 in 58 U.S. children (Sedlak et al., 2010). Children under age five, especially infants and African Americans, are at the highest risk of maltreatment (Hornor, 2005; Jenny, Hymel, Ritzen, Reinert, & Hay, 1999; U.S. Department of Health and Human Services, Administration for Children and Families, Administration on Children, Youth and Families, Children’s Bureau, 2010). According to the National Child Abuse and Neglect Data System (NCANDS), in 2008, there were an estimated 1,740 childhood deaths that were caused by an injury where abuse or neglect was a cause or contributing factor. NCANDS reported that children under age four accounted for 80% of deaths (Child Welfare Information Gateway, 2010). Most homicides in young children are due to maltreatment and occur at home (Bennett et al., 2006; Fujiwara, Barber, Schaechter, & Hemenway, 2009). The parent or relative is the responsible perpetrator in 86% of substantiated cases of child abuse and neglect (U.S. Department of Health and Human Services, Administration for Children and Families, Administration on Children, Youth and Families, Children’s Bureau, 2011).
Child maltreatment is a complex phenomenon. There are multiple personal and environmental factors that interact to contribute to child maltreatment. The ecological model of child maltreatment involves interacting factors between the child, family, community, and society that modify each other over time (Belsky, 1980, 1993; Sidebotham, 2001). These factors are grouped as protective and risk factors. When risk factors overwhelm protective factors, child maltreatment is more likely, and the possibility of negative outcomes increases. Risk factors should not be viewed as a causal mechanism. Rather, it is important to consider all factors that have a role in maltreatment when planning program and policy development in child maltreatment prevention.
The prevailing view is that child maltreatment is a symptom of larger family, community, or societal dysfunction (Coulton, Korbin, Su, & Chow, 1995; Garbarino & Crouter, 1978; Garbarino & Kostelny, 1992; Greeley, 2009), which is more common with poor health insurance, incomplete education and parenting, food insecurity, lack of social support, single parenting, and poverty (Greeley, 2009). It is more common in impoverished neighborhoods where there are larger numbers of children per adult resident, population turnover, and female-headed households (Coulton et al., 1995). Certain relationships are evident (Gilbert et al., 2009). Income and parental education are risk factors for child maltreatment although their importance varies with the type of maltreatment (Hussey, Chang, & Kotch, 2006; Sidebotham, Heron, & Golding, 2002). Deaths due to child abuse are high where there are deep socioeconomic inequalities (Roberts, Li, & Barker, 1998). Sociodemographic characteristics largely explain the ethnic differences in the overall risk of child maltreatment except for children of mixed race (Hussey et al., 2006). Substance abuse is a common factor in spousal and child abuse (Ondersma, 2007). The effect of the environment on child maltreatment appears to be small to moderate. A systematic review reported that 10% of variation in child health and adolescent outcomes, including maltreatment, was explained by neighborhood socioeconomic status and social climate after controlling for important individual and family variables (Sellstrom & Bremberg, 2006).
The correlation between crime and health disparity have been described. In Chicago, Illinois, and Cincinnati, Ohio, neighborhoods with the highest rates of violent crime also have high rates of infant mortality. These neighborhoods, which exhibit poverty, higher school dropout rates, and unemployment, also have higher rates of childhood asthma, obesity, and unintentional injuries (McClaine & Garcia, 2011). Since self-reported potential abuse or neglect is significantly more prevalent in poor areas (Coulton, Korbin, & Su, 1999), we hypothesize that child maltreatment and, in its worst form, child homicide are clustered in poor neighborhoods. Apart from Paulsen (2003) who examined the geographic locations of maltreatment reports and found that incidents of child neglect had a very compact spatial distribution while child abuse incidents and juvenile assaults were more widely distributed, there is a paucity of research on spatial clustering of child maltreatment and its relationship with the neighborhood (Coulton, Crampton, Irwin, Spilsbury, & Korbin, 2007). To our knowledge, there has been no previous spatial analysis of child homicides.
Child well-being comprises many factors such as a good child health status, the availability of health care, school activities, community services, and neighborhood resources (U.S. National Survey of Children’s Health, 2011). The role played by accessibility of community resources in mitigating the effects of neighborhood social disorganization on child maltreatment is also little studied. The aims of this study are to demonstrate that spatial clustering exists in child homicide and to study the access to health and community resources, both in terms of the degree of spatial clustering of child homicides and as partial consequences of the population, household, socioeconomic, and residential mobility characteristics of the community.
Method
Design, Setting, and Population
This was a cross-sectional study of homicides of children under age five in Harris County, Texas, from 1997 to 2003. Harris County, one of the largest counties in the United States, had a year 2000 population of 3.4 million people (U.S. Census Bureau, State and County Quick Facts, 2011) that was 59% White, 18% African American, 5% Asian, and 33% Hispanic (U.S. Census Bureau, American FactFinder, 2011b). There were 281,361 (8.2%) children under age five in 2000 (U.S. Census Bureau, American FactFinder, 2011b). Houston, the fourth largest city in the United States, is situated within Harris County.
Data Collection and Analysis
Homicide Data
Data on child homicides were obtained from the Harris County Child Fatality Review Team (HCCFRT). This period was chosen to match data to the 2000 U.S. Census. The method of child death investigation by HCCFRT is described elsewhere (HCCFRT). All inflicted and injury deaths within Harris County that were identified as homicides by the death certificate or medical examiner’s autopsy report were included. Deaths due to accidents, natural causes, undetermined causes, and sudden infant death syndrome were excluded.
Case Definition for Child Maltreatment
Maltreatment injuries were defined as those that were either inflicted directly by a parent or another adult caregiver responsible for the child at the time of injury, or that resulted from the parent or caretaker failing to protect the child from a hazardous circumstance (Christoffel et al., 1992; Stiffman, Schnitzer, Adam, Kruse, & Ewigman, 2002).
Age-Adjusted Spatial Clusters
Spatial clustering of incidents was examined using an age-adjusted nearest neighbor clustering algorithm. This identified incidents that were spatially close to each other. The purpose was to indicate to which the child homicides are spatially concentrated.
Census Block Group Data
Incidents were allocated to 1911 census block groups in Harris County and aggregated to examine demographic and socioeconomic correlates of the child homicides and to account for the spatial clustering. Block groups are small geographical areas defined by the U.S. Census that are typically six to eight city blocks in size and are the smallest geographical unit for which detailed household and individual data are released. Even though there is some spatial distortion by assigning the locations of individual homicides to the centroid of each block group, this was necessary to relate the homicides to social conditions. Demographic and socioeconomic data at the block group level were obtained from U.S. Census Bureau, American FactFinder (2011a) 2000 SF 1A (100% data) and SF 3A (sample data) files.
Community Resource Data
Community resource data included the service locations of Head Start (Office of Head Start, 2013) community health clinics with pediatric services, and the Supplemental Nutrition Program for Women, Infants, and Children (WIC) in Harris County that operated during the study period and the location of religious institutions (churches, synagogues, mosques). Service center information was obtained from the Texas Department of State Health Services and St. Luke’s Episcopal Health Charities, Houston, while the location of religious institutions was provided by the Houston-Galveston Area Council. The community resources (U.S. National Survey of Children’s Health, 2011) were chosen because they are believed to represent basic family resources for nutrition, education, and health care. Unfortunately, we were not able to obtain information on service quality provided by the service centers (e.g., number of visits, number of clients). Thus, our analysis can only account for accessibility to the centers.
Geographical Mapping
Victims’ residence locations and community resources were geographically coded using ArcGIS 9.3.3 initially using latitude and longitude coordinates (ESRI, 2010). They were manually searched and double-checked for accuracy. The coordinates were converted to Texas State Plane South Central, NAD 83. The distance from each block group to the nearest community resource was calculated using CrimeStat III (Version 3.3; Levine, 2010).
Data Analysis
Two types of analysis were conducted: 1. Risk-adjusted spatial analysis of individual homicide victim residential
locations to identify concentrations.
First, the CrimeStat Risk-Adjusted Nearest Neighbor Hierarchical Clustering (RNNH)
routine was used to identify spatial clusters relative to the number of children, ages 0
to 4 (Levine, 2010; see
Appendix A). The method selects events that are closer together than a threshold
distance, which is determined for a cell in a fine grid overlaid on the study area by
the random nearest neighbor distance based on the number of children aged 0 to 4 in that
cell. Cells with many children aged 0 to 4 will have smaller threshold distances,
whereas cells with few children aged 0 to 4 will have larger threshold distances. The
method was developed in 2002 and is available in the current version of
CrimeStat.
1
To
avoid obtaining very small clusters, a minimum of five child homicides was used to
select clusters.
2
The
purpose is to identify where homicides are concentrated relative to that expected on the
basis of the number of children aged 0 to 4. 2. Multivariate analysis of homicide risk by census block groups to examine
predictive factors for the number of homicides relative to the number of children
aged 0 to 4.
Second, to examine spatial correlates of the distribution of child homicides, the individual homicides were assigned to census block groups for which demographic and economic information was available. The number of child homicides by block groups was related to predictive variables that are associated with the distribution of child homicides by block group. Table 1 lists the independent variables that were explored with an exposure variable (number of children, ages 0 to 4) and two additional statistical control variables that have been shown to effect the distribution of homicides. 3
Year 2000 Predictive Variables for Harris County Child Homicide Frequency: Census Block Groups.

Note: WIC = Women, Infants, and Children.
Spatial autocorrelation tests were conducted on the number of child homicides by census block groups both before and after the model was estimated to determine the extent to which the selected independent variables accounted for the spatial clustering. The Moran’s “I” and Getis-Ord General “G” statistics were used for these tests, both of which are appropriate for zonal data (Griffith, 1987). The Moran statistic tests for spatial autocorrelation and identifies whether nearby zones demonstrate positive (similar values) or negative spatial autocorrelation (dissimilar values). The Getis-Ord statistic is applied only to positive spatial autocorrelation and identifies whether the clustering is primarily due to zones with high values being near zones also with high values or whether it is due to zones with low values being near zones also with low values. 4
Because data were skewed, a risk-adjusted negative binomial regression model was utilized (Cameron & Trivedi, 1998; Hilbe, 2008). The number of child homicides per block group relative to the number of children, aged 0 to 4, is assumed to be Poisson distributed and independent over all block groups and has the form,

where Yi is the number of child homicides, µ i is the expected number of child homicides based on k independent predictors, Xk, Ai is the number of children aged 0 to 4, β0 is the constant (intercept), β1…β k are coefficients, and ei is an error term that is assumed to be gamma distributed (Hilbe, 2008).
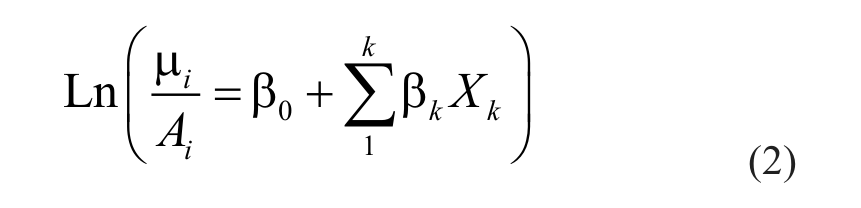
and

Therefore,
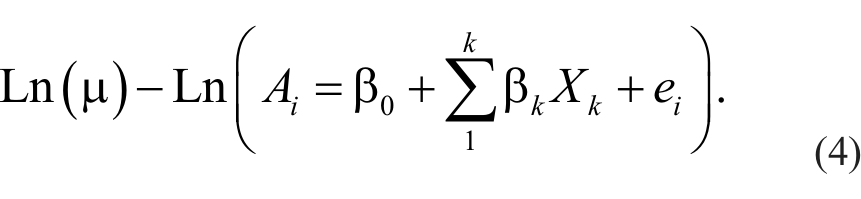
The model is a Poisson–gamma mixed function model (negative binomial; Cameron & Trivedi, 1998; Hilbe, 2008). This type of model is used to model variables that are extremely skewed (called overdispersion).
The interpretation of Equation 4 is that the number of child homicides per block group relative to the number of children, ages 0 to 4, changes exponentially with a unit change in one of the predictors, controlling for the others. The exposure variable, Ai , is treated as a block group-specific constant, and the log of Ai is estimated without a coefficient (Besag, Green, Higdon, & Mengersen, 1995). Because of the complexity of the model, it was tested with a Markov Chain Monte Carlo (MCMC) simulation method using the CrimeStat software (Levine, 2010; see Appendix B). The MCMC method is used with complex functions where the usual maximum likelihood method does not work well or where the assumptions of normally distributed errors is questionable (which is what we expect with these data since the variable is extremely skewed). To produce reliable estimates of the parameters, the model was run with 150,000 samples, with 50,000 “burn-in” samples being discarded (Denison, Holmes, Mallick, & Smith, 2002). Coefficients with 95% confidence intervals were estimated to test the effects of independent variables.
The aim of the regression modeling was to determine predictors of child homicides controlling for the population at risk (children aged 0-4), the size of the block group, and its proximity to downtown Houston. Implicit in this is the goal of explaining the spatial concentration. Two spatial auto correlation tests were used—Moran’s “I” and the Getis-Ord “G,” to determine whether the model had accounted for the concentration of homicides compared with the values of those tests on the raw data.
Results
Characteristics of Child Homicides
There were 125 homicides. Mean age was 1.2 years (SD = 1.1). Infants (48%), males (57%), and minorities (African American 43%, Hispanics 35%) were the most common groups. There were 120 known perpetrators (9 missing), which included the mother’s male partner (27%), biological mother (26%), biological father (22%), relative, (5%), and babysitter (5%; Table 2). Four percent of perpetrators were under the age of 18. The average number of adults per household was three. A total of 71% of homicides occurred in families with unmarried partners. Child maltreatment accounted for 94% of homicides. More than a third had prior contact with child protective services (CPS; 39%). The mechanisms included blunt trauma (62%), asphyxia due to drowning (10%), suffocation (6%), and gunshot wounds (6%; Table 3).
Multivariate Predictors of Harris County Child Homicide Risk: Poisson Model Coefficients and 95% Confidence Intervals (N = 1,911 block groups).

Note: BIC = Bayesian information criterion; CI = confidence interval; WIC = Women, Infants, and Children. Dependent variable: log of number of child homicides per block group, 1997-2003. Values in bold indicate statistical significance (i.e., the coefficients fell outside of the 95% confidence interval).
p ≤ .001.
Mechanisms of death in child homicides.

Spatial Clustering of the Child Homicide Risk
Using the RNNH routine, 12 risk-adjusted spatial clusters (hot spots) that had 5 or more child homicides and that were closer together than would be expected based on the distribution of number of children aged 0 to 4 were identified. This was confirmed by a Monte Carlo simulation where only one or two clusters would be expected on the basis of chance.
A total of 80 of the 125 child homicides (or 64%) occurred within the 12 clusters. Figure 1 shows a map of individual homicide cases along with the convex hulls that define the 12 risk-adjusted hot spot areas. The clusters were mostly concentrated within the City of Houston. The 12 hot spot areas covered about 3% of the area within Harris County. Thus, the relative concentration of child homicides in these hot spots is about 21:1 compared with what would be expected based on their area. The block groups associated with the clusters had a higher percentage of the population that were ethnic minorities (71% vs. 56%), living below the poverty level (21% vs. 14%), and with a higher percentage of households headed by single parents (24% vs. 17%) and lower household incomes (average median household income of US$33,964 in 1999 vs. US$47,663) compared with block groups in the rest of Harris County that did not overlap the clusters.

Child homicide risk in Harris County, Texas: 1997 to 2003: Homicide locations and risk-adjusted hot spots.
However, the percentage of the population that was under age 5 was about the same in the clusters compared with the rest of Harris County (9% vs. 8%). In other words, the clusters appear to represent the concentration of socioeconomic factors that facilitate child homicides, namely, poverty, rather than a disproportionate number of young children who could be “at risk.”
Multivariate Analysis of Child Homicides by Block Groups
To examine the demographic and economic correlates of child homicides, the individual child homicides were assigned to census block groups within which they fell and aggregated. The spatial coordinates were assigned to the centroid of the block group. The number of child homicides by block group varied from 0 to 3.
There was substantial spatial autocorrelation even after the aggregation. The Moran’s “I” statistic for spatial autocorrelation of the block groups was 0.0046 and was statistically significant (p ≤ .0001). 5 This indicated that there was positive spatial autocorrelation in the number of child homicides per block group, consistent with the spatial clusters identified above with the individual homicides. The Getis-Ord global “G” test, which is applied only when positive spatial autocorrelation exists, was tested with a 1-mile search radius and produced a G value of 0.0059. This was significantly higher than the expected G value of 0.0021 (p ≤ .05). This indicated that positive spatial autocorrelation was primarily due to block groups with several child homicides being adjacent to other block groups also with several child homicides.
A risk-adjusted negative binomial regression model was run to identify variables
predicting the number of child homicides for the Harris County block groups. The full
model tested the variables listed in Table 1, including the exposure variable (number of children, ages 0-4) and two
statistical control variables, while the reduced-form model demonstrates the best fit
after eliminating nonsignificant and multicollinear (correlated) variables. Table 4 shows the results for both
models. A. Full model results:
Multivariate Predictors of Harris County Child Homicide Risk: Poisson Model Coefficients and 95% Confidence Intervals (N = 1,911 block groups).
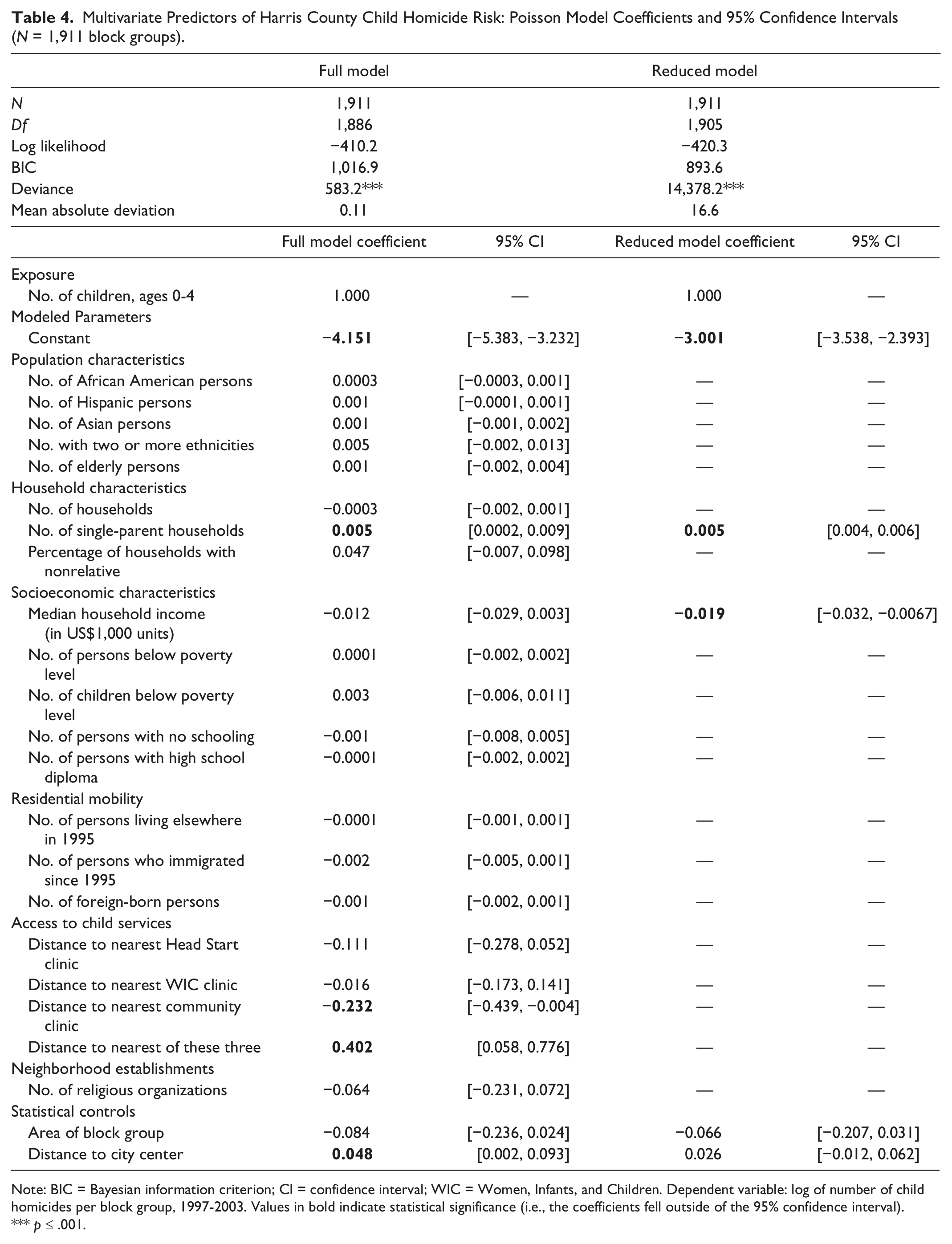
Note: BIC = Bayesian information criterion; CI = confidence interval; WIC = Women, Infants, and Children. Dependent variable: log of number of child homicides per block group, 1997-2003. Values in bold indicate statistical significance (i.e., the coefficients fell outside of the 95% confidence interval).
p ≤ .001.
For the full model, the deviance statistic was significant, indicating that the log likelihood was greater than would be expected on the basis of chance. The intercept (constant) and four variables were significant: (a) number of single-parent households (positive), (b) distance to the nearest community clinic (negative), (c) distance to the nearest of the community health clinics (positive), and (d) distance to downtown (positive).
The other variables did not appear to be related to the number of child homicides.
However, several of these variables are highly correlated (e.g., median household income,
persons living below poverty level, children living below poverty level, persons with no
schooling). B. Reduced model results:
We ran a reduced model that excluded highly correlated independent variables and those that were not significant with the exception of the exposure variable (children, ages 0-4) and the two statistical control variables.
In the reduced model, the constant and two independent variables were statistically significant. First, the strongest effect was shown by a positive association with the number of single-parent households. Block groups with more single-parent households had a higher likelihood of having a child homicide.
The second variable was a negative association with median household income. Block groups with lower median household income had a higher likelihood of having child homicides. The statistical control variables were not significant. The two proximity variables that were significant in the full model (distance to the nearest community center and distance to the nearest community clinic of any type) were no longer significant in the reduced model, suggesting that their significance in the full model may have been an artifact of a highly collinear model.
The effects of each significant variable on child homicide risk were not estimated
because they are socioeconomic variables, not intervention variables. Unfortunately, we
did not find a relationship with distance, the one policy variable for which an effects
estimate might be meaningful. C. Modeling additional spatial effects:
To examine whether the predictive model accounted for the degree of block group spatial clustering, both the Moran’s “I” and Getis-Ord global “G” statistic were run on the residual errors from the reduced model. The Moran’s “I” value was now 0.0017, still statistically significant (p ≤ .05) but substantially reduced from its initial value of 0.0046 with the raw data. The Getis-Ord “G” on the residual errors (−0.119) was not significant. This indicated that the study-selected independent variables had accounted for most of the spatial clustering.
Discussion
Our results support findings from other studies regarding the characteristics of victims and their perpetrators. Infants and minorities are the predominant groups affected by child homicides. Biological parents accounted for half of all perpetrators, which is similar to that reported in the National Violent Death Reporting System (NVDRS; Bennett et al., 2006; Fujiwara et al., 2009). Biological parents and father surrogates (stepfathers or mother’s male partner) accounted for 82% of all fatalities. Nearly two out of five perpetrators had prior involvement with CPS, suggesting disordered parent–child relationships or inadequate social supports. However, more importantly, we observed that child homicides were highly concentrated in a limited number of spatial locations (hot spots), controlling for the number of children aged 0 to 4. The 12 age-adjusted child homicide hot spots identified covered only 3% of the area of Harris County but included neighborhoods where 64% of the child homicides occurred. This is of importance for policy planning and preventive interventions.
In our analysis, after controlling for confounding factors and collinear variables, we found that the spatial clusters of child homicides were associated with low-income neighborhoods and single-parent (male and female) households. The results are consistent with other studies that have shown child homicides being related to poverty and communities with a high proportion of households headed by single mothers (Coulton et al., 1995; Graif & Sampson, 2009).
The association for single-parent households was stronger than that for either the number of female-headed or male-headed households in predicting the number of child homicides. The reason may be that approximately one quarter of single-parent households are headed by males, and neighborhoods with many female-headed households also have more male-headed households. This needs to be taken into account when planning interventions.
However, there was still a small amount of clustering that was not accounted for by the model, indicating additional factors that need to be identified. These could include the lack of support groups (family and friends) to mediate environmental pressures, what is known as collective efficacy (Sampson, Raudenbush, & Earls, 1977). Spatial analysis is the first step in identifying “prevention zones” for targeted preventive interventions such as home visitation, education programs, and crime prevention (Bair-Merritt et al., 2010; Gonzalez & MacMillan, 2008).
We did not find any association between the spatial clusters of child homicides and their proximity to community centers for early childhood education, health and nutrition, and faith organizations. The lack of an association could stem from inadequate community outreach for parents of young children or indicate chronic problem areas that overwhelm outreach efforts. We speculate that the higher frequency of child homicides in the cluster in southwest Houston and another cluster in southeast Houston probably reflects a general crime-generating environment since they have been associated with general crime patterns for a long time (Turner, 2006; Wang, 2010). For the other 10 clusters, however, there appear to be unique factors that need further research, such as interviews of the local at-risk population.
Focusing on a limited number of areas defined by the hot spots allows service agencies to make their outreach more efficient. However, while the distribution of the community health centers was concentrated in low-income neighborhoods, only 11% of them (4 of 52 WIC centers, 9 of 78 Head Start centers, and 9 of 78 community clinics) were located within the 12 high-risk child homicide hot spots. Three hot spots with 20 homicides did not have any community health center located within their area. Nevertheless, the identification of the high-risk hot spots suggests a cost-effective approach to help reduce the number of child homicides.
Future research should examine negative community factors as well as positive ones. Sampson et al.’s (1977) work on “collective efficacy” does show that lack of community organization can encourage crime. We explored two variables that might have influenced child homicides, number of bars in the City of Houston, and number of crimes in the City of Houston, but did not find much of a relationship unlike that by Freisthler, Gruenewald, Remer, Lery, and Needell (2007) and Freisthler, Gruenewald, Ring, and LaScala (2008). However, our data were limited by information from only the City of Houston so that a fuller data set might actually have helped find a relationship. There are clearly negative environmental variables that should be examined in future work.
Residents in neighborhoods with high concentrations of poverty may live there because of the availability of publicly subsidized housing as well as lack of sufficient resources to live elsewhere (Coulton et al., 2007). This may lead to conditions that predispose a small proportion to child maltreatment. While residential turnover and mobility are believed to be significant predictors of child maltreatment (Coulton et al., 1995), in our study, we did not find this to be a significant factor associated with child homicides.
The policy implication of the clustering is important and has not been previously described. The results can drive policy changes to improve public health outreach to reduce child maltreatment: First, it identifies specific geographic areas with concentrations of child homicides and ascertains important environmental correlates. While many of the relationships have already been shown in the literature (poverty and fluid family structures), our model identifies these environmental factors that correlate with child homicide with greater precision. The environmental correlates have been determined at the block group level, which is a sufficiently small geography to base focused and efficient community-based interventions. Second, we disseminate these findings to all stakeholders who have a common aim of reducing child maltreatment. Using the public health approach as a model, the eventual goal is to develop community-based outreach that uses evidence-based interventions to reduce child maltreatment at these identified spatial clusters.
Our study attempts to address the paucity of research on spatial clustering of child maltreatment and its relationship with neighborhood factors (Coulton et al., 2007). The study controlled for the size and location of neighborhoods because it identified individual age-adjusted clusters of homicides prior to assigning them to block groups. Block groups were used as the primary unit of multivariate analysis since these are the smallest geographical units for which the census bureau publishes sample data. This enabled a more focused description of the neighborhood than other studies that have utilized larger areas such as census tracts (Paulsen, 2003) or ZIP codes (Drake & Pandey, 1996).
There are several limitations in the study. First, we did not study nonfatal child maltreatment cases. Since they are far more frequent than homicides, a spatial analysis of child maltreatment is necessary to test the accuracy and precision of our findings. This would also determine whether spatial distributions for different types of child maltreatment exist. Second, while we were able to describe spatial influences on child homicides, we could not identify any contextual influences to explain the observed distribution of child homicides other than poverty variables. Access to a community health service defined in terms of distance may not represent the outreach from that service. Third, the study data are also dated. However, since U.S. Census 2010 block group socioeconomic data are currently unavailable, we had to use an earlier study period. Finally, our results are from one major city in southern United States and may not generalize to other cities with different population characteristics.
Conclusion
Spatial clusters of child homicides were associated with low-income neighborhoods and single-parent (male and female) households. No association between the spatial clusters of child homicides and their proximity to community resources was observed. A high percentage of child homicides were concentrated in a small area of the county, which offers the potential for targeted, cost-effective interventions.
Footnotes
Appendix A
Appendix B
Authors’ Note
The study was not considered human participants research by the Baylor College of Medicine Institution Review Board since it involved deceased individuals.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research and/or authorship of this article.
Notes
Author Biographies