
Abstract
Metainferences, or the insights derived from integrating quantitative and qualitative inferences at the end of a study, are crucial for achieving added value and synergy in mixed methods research. There is an ongoing need to understand how researchers generate metainferences, especially considering their pivotal role in helping researchers achieve full quantitative and qualitative integration. While some examples of metainferences generation are available in the mixed methods literature, more explicit guidance is required. Approaches to developing metainferences must also be contextual, as inferences of this type are contingent on the nature and purpose of the mixed methods study, the type of mixed methods design, and the quality of the research data. This paper describes a seven-step process for generating metainferences using a convergent mixed methods study as an exemplar. These steps consist of identifying knowledge, experience, and data-driven inferences from the quantitative and qualitative data; developing inference association maps to draw metainferences; and assessing the validity of metainferences using backward working heuristics. This paper contributes to mixed methods research by shedding light on the development of metainferences in convergent designs and by providing practical and tangible tools for making sense of the complexity of the analysis and interpretation tasks involved in the process of generating metainferences.
Integrating qualitative and quantitative methods, data, and findings is of utmost importance in mixed methods research (MMR) and distinguishes MMR from monomethod research (Bazeley, 2018; Creswell and Plano Clark, 2018; Fetters and Molina-Azorin, 2017). Data integration can occur at multiple levels, including the design (i.e. core and advanced designs), the methods (i.e. connecting, building, merging, embedding), and the interpretation and reporting levels (i.e. joint display, data transformation, and contiguous, staged, and weaving narrative approaches) (Bazeley, 2018; Creswell and Plano Clark, 2018; Fetters et al., 2013; Younas et al., 2020). In the interpretation and reporting levels, data integration involves generating metainferences, which are defined as explanations or conclusions in the form of a narrative, story, or theoretical statement generated at the end of the study from the individual quantitative and qualitative inferences (Creamer, 2018; Hitchcock and Onwuegbuzie, 2022; Tashakkori and Teddlie, 2008). In generating metainferences, researchers compare the qualitative and quantitative findings, look for additional value, and finally draw conclusions. In this process, both findings are compared by assessing confirmation, complementarity, expansion, and discordance (Fetters, 2020). Metainferences require researchers to engage in higher-level reasoning and analysis as they provide knowledge that surpasses the sum of each type of finding (Bazeley, 2018; Creswell and Plano Clark, 2018).
Despite the centrality of metainferences in generating the added value of an MMR study, researchers rarely describe them when reporting the MMR findings. Numerous methodological reviews reveal that MMR studies from multiple disciplines often do not integrate, and even when they do, metainferences are absent or underdeveloped (i.e. metainferences that are inconsistent with the empirical data) (Bartholomew and Lockard, 2018; Fàbregues et al., 2022; McManamny et al., 2015; Younas et al., 2019). Failure to link quantitative and qualitative inferences and generate metainferences hinders the primary objective of an MMR study. The inferences may be derived from a single dominant component, preventing the development of a more comprehensive understanding of the phenomenon under study or the explanation of one type of finding by another (Creamer, 2018). While some examples of generating metainferences have been published in the MMR literature (Fetters, 2020; Schoonenboom, 2022; Venkatesh et al., 2013), more innovative and contextualized approaches are needed, especially considering that metainferences are contingent on the nature and purpose of the MMR study, and the quality of the research data. Also, metainferences are unique to each study design, and even general approaches to drawing them can vary and be tailored across MMR designs.
Meaning of metainferences and existing approaches
In MMR, the critical importance of metainferences and their underlying meaning is well established (Moseholm and Fetters, 2017; Younas et al., 2022). Bryman (2007) notes that metainferences are a “negotiated account” (p. 21). Venkatesh et al. (2013) describe metainferences as “narratives, or a story inferred from an integration of findings” (p. 38) and a process analogous to the “theory development from observations” (p. 39), where observations are inferences from distinct components of an MMR study. Creamer (2018) used the metaphor of “keystone” to illustrate metainferences, arguing that they are highly functional features of MMR and that the structure of MMR is reliant on the power of the keystone. McNabb (2020) stated that metainferences are “greater insights into a phenomenon and its implications” (p. 48). In sum, metainferences imply a process of intensifying the mining of the data to gain a deeper and more accurate understanding of the phenomenon of interest.
Despite the varied definitions of metainferences, there is broad agreement in the literature that they constitute one of the key indicators of rigor and quality of MMR (O’Cathain et al., 2010; Venkatesh et al., 2013). Well-developed and supported metainferences contribute to interpretive rigor in MMR, defined by Tashakkori and Teddlie (2008) as the extent to which credible and plausible inferences and metainferences are drawn from the raw and rigorously analyzed data. However, only a few authors within the MMR discussed thoroughly how to generate plausible metainferences (Fetters, 2020; Schoonenboom, 2022; Venkatesh et al., 2013), and only one has illustrated how to do so by identifying discordant findings (Younas et al., 2022).
Venkatesh et al. (2013) proposed three pathways to develop metainferences, including: (a) merging qualitative and quantitative data and generating metainferences; (b) moving from qualitative to quantitative to metainferences; and (c) moving from quantitative to qualitative to metainferences. These three pathways are merely a representation of how core MMR design function and do not actually illustrate how metainferences are generated. For example, pathway one depicts a convergent MMR research design in which qualitative and quantitative data are integrated and merged following separate analyses to draw metainferences. The second pathway depicts an exploratory sequential MMR design in which qualitative findings inform the quantitative phase before drawing conclusions. Venkatesh et al. (2013) offered no detailed description of these pathways, nor did they shed light on the concrete or strategic process of generating metainferences. Additionally, they proposed bracketing and bridging as two approaches to generating metainferences. They defined bracketing as incorporating diverse views concerning the phenomenon of interest and bridging as reaching a consensus between qualitative and quantitative findings. Despite this additional information, the authors did not demonstrate any tangible methodological guidance for analyzing inferences and then drawing metainferences, so the actual process of developing metainferences remained vague. Furthermore, no published MMR studies were used by these authors to demonstrate the application and use of the proposed pathways and techniques.
Fetters (2020) described metainferences as a result of comparing qualitative and quantitative inferences based on their concordance, expansion, complementarity, and discordance. Concordance arises when qualitative and quantitative inferences are consistent with one another, whereas discordance implies that both qualitative and quantitative inferences are discordant. Expansion and complementarity occur when there is a partial or total divergence between both types of inferences, yet this divergence broadens our understanding of the studied phenomenon by addressing distinct dimensions or complementary aspects. While Fetters (2020) explained that the metainferences generated in MMR could be of four kinds, the procedures for identifying and generating concordant, expanded, complementary, and discordant metainferences were not illustrated. Only Schoonenboom (2022) offered a two-phase process for generating metainferences. The first phase entailed generating claims from the qualitative and quantitative components of an MMR study. The second phase focused on integrating the claims to generate metainferences. The author argued that integrating and generating metainferences is not a standalone process that occurs at the conclusion of an MMR study. Rather, claim integration is a sequential process that occurs multiple times during a study. Furthermore, the author emphasized that when developing metainferences, claim generation and integration are a never-ending process that researchers must determine when to stop.
Venkatesh et al. (2013), Fetters (2020), and Schoonenboom (2022) offered useful insights into the broad processes that can be followed to develop metainferences. In addition, they contributed to highlighting the importance of metainferences in maximizing the added value that can be obtained by integrating quantitative and qualitative data. However, while noting that the development of metainferences is a highly contextualized process contingent on the nature of the MMR design, the quality of data, the research aims, and the integration procedures used throughout the study, these authors did not provide specific approaches for drawing metainferences according to the intricacies of each MMR design. Given the diversity of MMR designs and how these designs and their integration procedures are executed in practice, more focused methodological guidance and discussion is needed to advance the field. Our intention is not to critique the scant current methodological literature (Fetters, 2020; Schoonenboom, 2022; Venkatesh et al., 2013) on generating metainferences, as we believe it has provided valuable insights on this activity. Rather, the focus of this paper is on offering additional insights into how metainferences can be generated in practice, with a specific focus on one type of design, to address the ongoing challenge of MMR integration.
Purpose
The purpose of this paper is to outline and illustrate a seven-step process to generate metainferences using a convergent MMR study as an exemplar. We chose a convergent MMR study (Sundus et al., 2020) for this paper because it is one of the most prevalent MMR designs across disciplines (Bartholomew and Lockard, 2018; Fàbregues et al., 2022; McManamny et al., 2015; Younas et al., 2019). Convergent mixed methods designs involve parallel qualitative and quantitative data collection, separate analysis of qualitative and quantitative data, and merging findings from each strand to generate metainferences (Younas and Durante, 2022). Since the method of generating metainferences will likely vary across MMR designs, future publications should illustrate how this can be accomplished in exploratory and explanatory sequential MMR designs.
Overview of the exemplar mixed methods study
The purpose of this convergent MMR study was to develop a comprehensive understanding of nursing students’ perspectives on compassion and compassionate care, as well as to ascertain the extent to which students’ perspectives of compassionate care aligned with the meaning of compassion in nursing literature (Sundus et al., 2020). Ethical approval was obtained from the Ethical Review Committee of Al-Shifa Trust Hospital in Pakistan (07/03/2018). The convergent MMR design used parallel data collection, and both qualitative and quantitative components received equal weight. The study was conducted at two Pakistani nursing institutions in Islamabad and Rawalpindi. The target population consisted of 148 nursing students in the undergraduate Bachelor of Science in nursing and fast-track nursing programs. All 148 nursing students who had completed their clinical rotations during their education and during the summer were invited to participate in the study. We used a purposive sample instead of a random sample. Students were enrolled in the first year (31.6%), the second year (28.2%), the by fourth year (27.4%), and the third year (12.8%) of the bachelor’s program and were studying a National Standardized nursing curriculum. In the quantitative component, 117 students completed an exploratory survey about their perspectives on compassion, compassionate care, and its significance for patients, nurses, and healthcare professionals. Due to the exploratory nature of the survey, a 25-item categorical response set (Yes and No) was used. The survey was developed based on a critical literature review of 29 articles (Younas and Maddigan, 2019). The face and content validity of the survey was established using a pilot study of 21 students and consultations with two nurse educators, three nursing students, and one practicing nurse. Face validity refers to the degree to which a data collection appears to measure what it purports to measure. Content validity is the degree to which a data collection instrument contains items that are relevant to the construct it purports to measure (Streiner et al., 2015). We chose diverse and relevant participants to evaluate the content validity so that the items of the exploratory survey focused on investigating multiple meanings of compassion and compassionate care. The content validity index (i.e. a quantitative measure of agreement among reviewers of a data collection instrument) was 0.83 (Polit and Beck, 2006), and the Kuder-Richardson alpha internal consistency co-efficient was 0.74 (Streiner et al., 2015).
In the qualitative component, a nested purposive sample (Onwuegbuzie and Collins, 2007) of 17 students participated in semi-structured interviews. A semi-structured interview guide was developed based on the literature about compassion and compassionate care to conduct interviews. Nursing students for interviews were selected using purposive sampling based on the inclusion criteria: (a) nursing students enrolled in the first to fourth year of their Bachelor of Science in nursing program, and (b) those students who had completed at least one clinical rotations in hospital settings. We developed a semi-structured interview guide for interviews based on the literature on compassionate care and compassion in nursing education. We revised and refined the interview guide after an in-depth discussion between the researchers and preliminary testing during the first three interviews. The guide included questions about the meaning of compassion, its importance, how it is demonstrated in practice, and students’ personal experiences and concrete examples of providing compassionate care in clinical settings. The interviews, lasting between 30 and 40 minutes, were audio-recorded and transcribed verbatim. At the end of each interview, the responses were summarized, discussed, and clarified with the participants.
We integrated quantitative and qualitative study components in several dimensions in accordance with the integration dimensions (Fetters and Molina-Azorin, 2017). In the philosophical dimension, dialectical pluralism guided the study design, data analysis, and interpretation. Dialectic pluralism is defined as a metaparadigm for MMR which offers a way for researchers to utilize and thrive on the differences in viewpoints originating from multiple ontological, epistemological, and axiological stances or worldviews to generate workable solutions for conducting MMR inquiry (Johnson, 2017). The integration in the researcher and team dimensions included researchers with varying levels of expertise in qualitative, quantitative, and MMR, different values and beliefs about compassion and compassionate care, and diverse backgrounds, such as physicians, nurse educators, and nursing students. In the literature review and rationale dimension, a clear justification for using MMR was provided by identifying qualitative and quantitative research gaps and basing the survey on a critical literature review. In the design dimension, integration consisted of merging data from exploratory surveys and qualitative themes in a convergent design, while in the data collection dimension, integration resulted from quantitative surveys and semi-structured interviews. Integration in the data analysis dimension was achieved through the use of tripartite analysis, which included descriptive statistics of the quantitative data, reflexive thematic analysis (Braun and Clarke, 2022) of the qualitative data, merging integration procedure (Fetters, 2020) and representing the integration through joint displays of the MMR data (Guetterman et al., 2015). The tripartite analysis also included case-by-case integrated analysis (Level I findings) and separate analysis of the whole sample (Level II findings) followed by merged quantitative and qualitative analysis and comparative and integrated analysis of Levels I and II findings (Younas and Sundus, 2022). A detailed description of the study (Sundus et al., 2020) and the tripartite analysis is reported elsewhere (Younas and Sundus, 2022). During tripartite analysis, we employed several steps to generate metainferences. The seven-step procedure is illustrated as follows.
Process to generating metainferences in convergent mixed methods design
Our process for generating metainferences comprised seven steps illustrated in Figure 1 and described with an exemplar MMR study as follows. We provided a linear process for generating metainferences. However, it is noteworthy that in actual practice, knowledge-based inferences, experience-based inferences, and data-driven inferences could be generated in a parallel manner, and there could be an overlap in these steps. Nevertheless, we offered a linear process to highlight that each of these three types of inferences should be separated from each other to create valid and plausible metainferences.
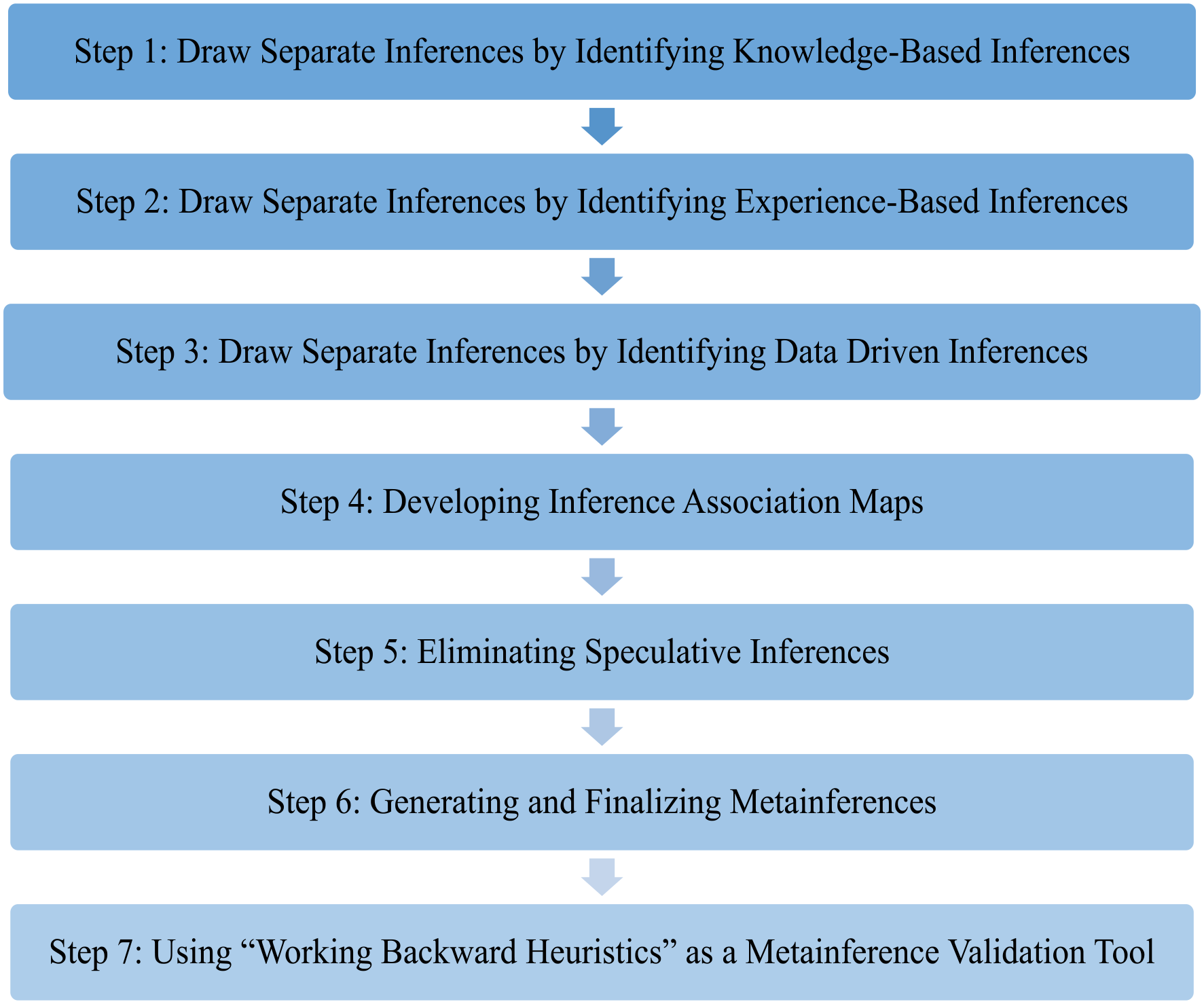
Seven step process to generating metainferences in convergent mixed methods research.
Step 1: Draw separate inferences by identifying knowledge-based inferences
The literature in the field of reading and comprehension offers ample evidence that background knowledge is a significant contributor to generating inferences (Barth et al., 2021; Cain et al., 2001; Smith et al., 2021). Knowledge-based inferences are drawn from the researchers’ background knowledge about a particular topic, that is, the information gained from reading literature about the topic and mundane knowledge (Strohl-Goebel and Rickheit, 1985). Identifying researchers’ knowledge-based inferences is critical because failing to recognize them or relying excessively on background knowledge can prevent acquiring new information that conflicts with prior beliefs (Elbro, 2018). From an epistemological (i.e. how we develop knowledge) standpoint, Luzzi (2019) argued that individuals could draw inferences based on false knowledge or mere ignorance, thereby generating erroneous or implausible knowledge about a particular phenomenon. Therefore, identifying knowledge-based inferences when analyzing data in MMR and preparing to generate metainferences is necessary to make appropriate comparisons and linkages between these types of inferences, and experience-based and data-driven inferences, as well as to reduce the likelihood of generating biased metainferences about a particular topic.
To identify knowledge-based inferences, three guiding questions can be used: (a) What do we know about the phenomenon of interest (i.e. compassion and compassionate care) based on our reading of the literature? (b) What knowledge-based inferences are founded on information gained from research literature? and (c) What knowledge-based inferences can be drawn from our mundane knowledge of the phenomenon (i.e. compassion and compassionate care)?
Application in exemplar study
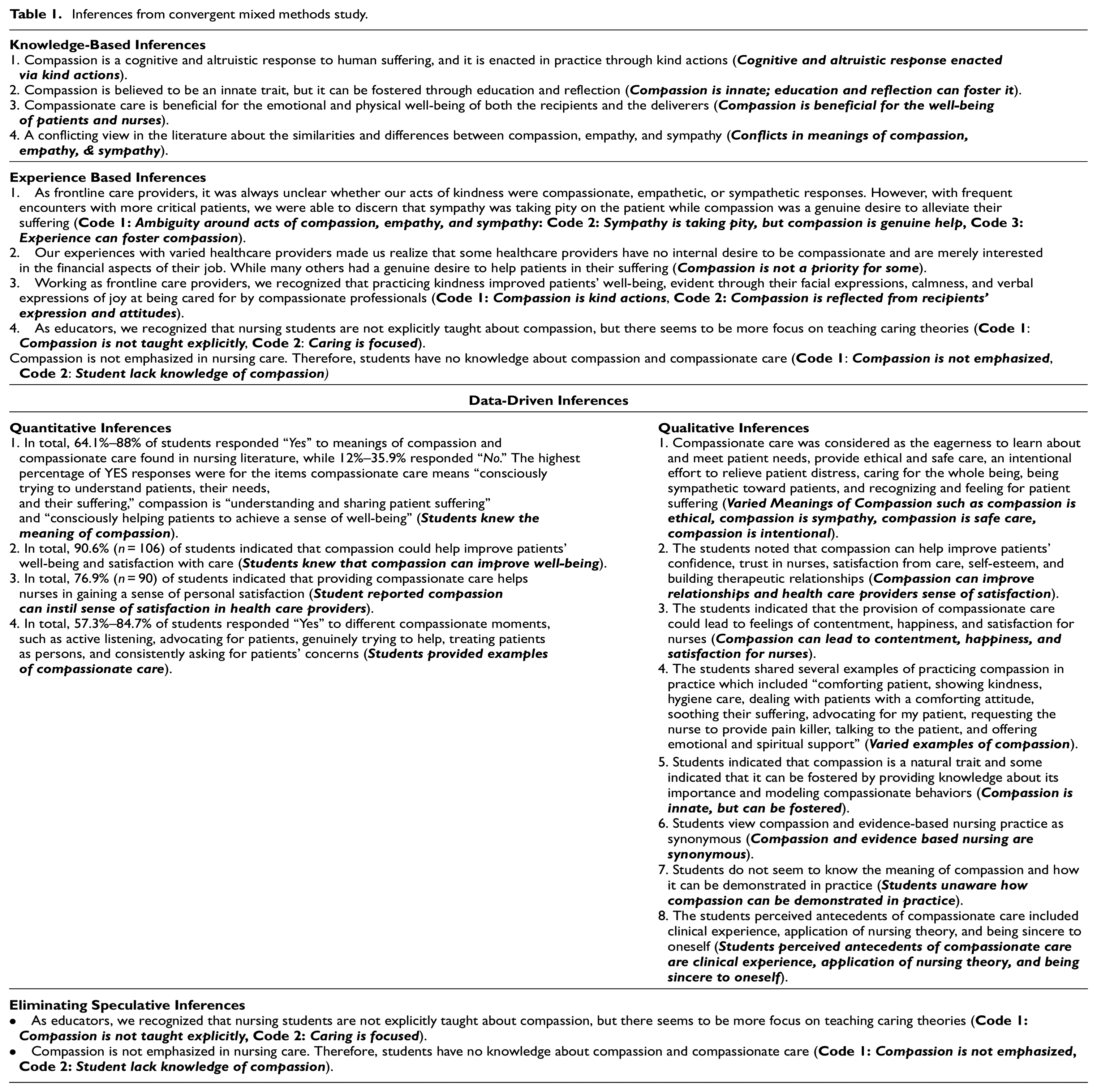
Before drawing the MMR metainferences at the end of the study, Sundus et al. (2020) identified and set aside several knowledge-based inferences about compassion and compassionate care to make comparisons and generate links between other types of inferences. The authors identified four knowledge-based inferences. First, compassion is a cognitive and altruistic response to human suffering enacted in practice through kind actions. Second, compassion is believed to be an innate trait but can be fostered through education and reflection. Third, compassionate care benefits the emotional and physical well-being of both the recipients and the deliverers. Fourth, there is a conflicting view in the literature about the similarities and differences between compassion, empathy, and sympathy. These knowledge-based inferences were generated from and informed by the extant literature about compassion and compassionate care in nursing, health care, and psychology (Table 1).
Inferences from convergent mixed methods study.
Step 2: Draw separate inferences by identifying experience-based inferences
Inferences about a phenomenon are influenced by individuals’ experiences, regardless of the veracity of the source of those experiences (Lichtenberg, 2004; Schwarz, 2010). It is widely acknowledged that researchers’ experiences shape their decision-making when conceptualizing and conducting research, understanding participants’ experiences, and interpreting and analyzing datasets (Flick, 2022; Ravitch and Riggan, 2016). Therefore, researcher reflexivity is essential for all types of research, particularly qualitative research and MMR (Field and Derksen, 2021; Walker et al., 2013). Reflexivity on personal experiences enables researchers to analyze, interrogate, and adapt their interpretations of research processes and methods and draw conclusions (Field and Derksen, 2021). Identifying experience-based inferences is critical for ensuring the critical assessment of personal biases or preconceptions and their impact on generating inferences. Therefore, researchers conducting MMR should make explicit how their experiences may have informed or shaped the design, analysis, and interpretation of data.
There is no available definition of experience-based inferences. In this paper, we define this type of inference as conclusions researchers draw about research data based on their intrapersonal, interpersonal, and sociocultural involvement with the phenomenon of interest. For example, a researcher with experience in teaching research methodology can incorporate their personal experiences into data analysis and interpretation in a study about the effectiveness of teaching strategies to enhance research thinking. Agazzi and Faye (2001) argue that experience-based inferences can be broadly categorized as inductive, deductive, and inference to the best explanation/interpretations. All these inferences made by researchers during data analysis and interpretation are based on their experience. Therefore, recognizing the variability of experiences and experience-based inferences and how they affect researchers’ inference-making (Lichtenberg, 2004) is crucial for ensuring that experiences are used for interpretation or bracketed when needed to generate inferences (Agazzi and Faye, 2001). For example, in descriptive phenomenology, researchers bracket (i.e. suspend judgments about the living world and personal experiences about the studied phenomenon) their prior experiences when drawing interpretations about the participants’ experiences, whereas in hermeneutic phenomenology, the experiences are incorporated during analysis and interpretation (Neubauer et al., 2019).
Four questions can be used to identify our experience-based inferences: (a) What are our individual experiences demonstrating and seeing compassion in clinical practice? (b) What are the similarities and differences in our (team members) individual experiences? (c) What experience-based inferences can be drawn after comparing and collating our collective experiences of demonstrating, teaching, and learning about compassion? and (d) Are our experience-based inferences consistent or inconsistent with our knowledge-based inferences?
If experience-based inferences are not made explicit, they might influence researchers’ interpretation formed from the data, making it difficult to discern whether the insights are grounded in the views of the research participants or in the researchers’ preconceived notions.
Application in exemplar study
Sundus et al. (2020) maintained reflective journals and engaged in in-depth discussions to document their beliefs and experiences throughout the conceptualization, data collection, analysis, and interpretation stages. Using tripartite analysis, three team members worked together to complete the analysis and interpretation at three levels (Younas and Sundus, 2022). One of the team members was a nursing student, while the remaining two were nurse educators. Therefore, they had diverse experiences with compassion and compassionate care in clinical practice and teaching and learning compassion in the classroom and clinical settings. During data analysis, the team identified four experience-based inferences concerning the meaning of compassion and how it differs from empathy and sympathy in clinical practice: (a) the lack of content on compassionate care in nursing curricula in Pakistan; (b) the need for more emphasis on caring; (c) health care providers’ demonstrations of compassion in clinical practice; and (d) the positive impact of compassionate care on the well-being of patients (Table 1).
Step 3: Drawing separate inferences by identifying data-driven inferences
Before drawing and identifying data-driven inferences, researchers should compare their knowledge-based and experience-based inferences to gain insights into the extent of data analysis required to support, refute, or expand on their prior inferences. Then, separate analysis of qualitative and quantitative data (Bazeley, 2018; Younas et al., 2022) should be undertaken using use the required data analysis methods, specific to qualitative and quantitative research, and generate data-driven inferences for each component. Since the quality and rigor of metainferences in MMR are dependent upon the quality of inferences drawn from each component (Tashakkori and Teddlie, 2008), researchers should pay attention to the relevance and consistency of the metainferences with the raw datasets (Creswell and Plano Clark, 2018).
We define data-driven inferences as the insights gained from analyzing and interpreting raw datasets collected in the qualitative and quantitative components. This process begins with the identification of data-driven inferences, which can be causal, statistical, probabilistic, descriptive, case-based, phenomenon-based, sample-based, or theme-based, depending on the nature and type of data (Epstein and Martin, 2014; Morse, 2006; Plümper et al., 2019). For example, if the quantitative phase of an MMR design consisted of a randomized controlled trial, researchers might be more interested in generating statistical and probabilistic inferences. If a qualitatively-oriented MMR was used, and the qualitative phase was prioritized, descriptive, case-based, or phenomenon-based inferences may be generated.
In any type of research, inferences can be low-level or high-level based on the extent and depth of analytical and inferential reasoning. Compared to high-level inferences, low-level inferences are more descriptive, less abstract, more speculative, less standardized, more particular, and less universal (Ercikan and Roth, 2006). To assess the value added of MMR, Creamer and Tendhar (2015) compared the number and types of inferences drawn from 120 qualitative, 251 quantitative, and 78 MMR studies and reported inferences across qualitative, quantitative, and mixed phases. They identified eight types of inferences, namely: (a) alternative hypothesis; (b) explanatory; (c) future research; (d) implications for practice; (e) limitations; (f) literature; (g) projection for future; and (h) repeats a result. At this step, researchers can compare the inferences with knowledge- and experience-based inferences using any of these inference types alone or in combination.
Six guiding questions can inform the identification of data-driven inferences: (a) What do the data reveal about our study purpose? (b) What trends and patterns are apparent in the raw data that could be transformed into data-driven inferences? (c) What are the most pertinent findings for generating data-driven inferences? (d) To what extent should the context of the findings be made explicit in the generated inferences? (e) What level and type of inferences should be drawn based on the data type and study purpose? (f) How do data-driven contribute to better understanding the studied phenomenon?
Application in exemplar study
Sundus et al. (2020) generated 12 inferences from the quantitative and qualitative data (Table 1). The quantitative inferences were descriptive, abstract, low-level, explanatory, and repetitive. For example, these authors used an exploratory survey to gather students’ views on compassion. One of the low-level inferences was that 90.6% of students believed compassionate care could enhance patients’ well-being. This data-driven inference was directly drawn from the study findings. The qualitative inferences were, on the other hand, more abstract, high-level, explanatory, and repetitive in nature. For example, Sundus et al. (2020) generated several themes about compassion and compassionate care after reflexive thematic analysis, which produces abstract themes about the topic under consideration. Within each theme, they generated qualitative inferences. One of the abstract sub-themes was Integrating learned care approaches into actual practice. They inferred from this theme that knowledge about nursing theory and clinical practice experience are prerequisites to enacting compassion in real-life practice.
These data-driven inferences were both case-based and sample-based since the intention was to first gather insights at the case level to inform the analysis at the sample level. Furthermore, the inferences were phenomenon-based, as the authors were interested in understanding students’ perspectives and meanings of compassion and compassionate care. To generate data-driven inferences, Sundus and colleagues followed a two-step process. First, they collated the key findings from separate quantitative and qualitative data analyses under broad concepts drawn from the survey results and the qualitative analysis themes. Second, they validated these key findings against the raw datasets to ensure that the inferences were based solely on the data, not on their prior knowledge and experiences regarding compassion and compassionate care. The second step in evaluating qualitative inferences was more important than the first because experience-based inferences can affect the interpretation of qualitative data, particularly if researchers’ experiences with the studied phenomenon and their knowledge of the context are intertwined with the inferences that can be drawn from the datasets. Data-driven qualitative inferences could be insights drawn about the themes, the linkages among themes and sub-themes, a storyline based on the themes, or analytical generalizations about the phenomenon (Stake, 1995). In this convergent MMR, qualitative inferences about compassionate care focused on the themes and the connections between themes and sub-themes.
Step 4: Developing inference association maps
Visual presentation of study findings can enable the development of linkages and associations more effectively than narrative alone (Anderson, 2010; Patricia, 2020). Visuals can be used in several ways in a research study, such as pre-existing visuals, models or frameworks, forms of data, modes of analysis, and for the presentation of integrated findings (Guetterman et al., 2021; Shannon-Baker and Edwards, 2018). Visuals can be valuable because the qualitative and quantitative inferences are not the final conclusions and should be integrated further to generate metainferences. Therefore, developing inference association maps is a pertinent approach to using visuals as forms of data and modes of analysis. We define inference association maps as visual tools to illustrate linkages among knowledge, experiences, and data-driven inferences using arrows and various shapes. This step also allows for effectively comparing various types of qualitative and quantitative inferences. Researchers can be innovative in linking the three types of inferences in terms of their similarities, differences, or connections when creating inference maps.
Application in exemplar study
Sundus et al. (2020) developed inference association maps utilizing concepts, color codes, descriptive codes, and linking arrows for each inference. Two steps were involved in developing inference association maps. First, to collate the inferences, descriptive codes (i.e. brief statements describing the content of the inference) were developed for each of the inferences and listed them separately. The use of descriptive codes enabled the authors to fit lengthy inferences in the maps and facilitated the efficient linking of inferences. It is possible to extract multiple descriptive codes from each inference to develop additional associations and linkages between the ideas and concepts underlying inferences. Figure 2 shows the first step to developing inference association maps that entails listing the descriptive codes for each type of inference.

Step 1 of developing inference association maps.
Once all the descriptive codes are listed separately, all the descriptive codes for the inferences were subsequently collated under concepts and themes in accordance with the study objectives and/or the main qualitative and quantitative findings to generate figures/maps linking. Figure 3 illustrates the inference association maps generated by collating all the descriptive codes.
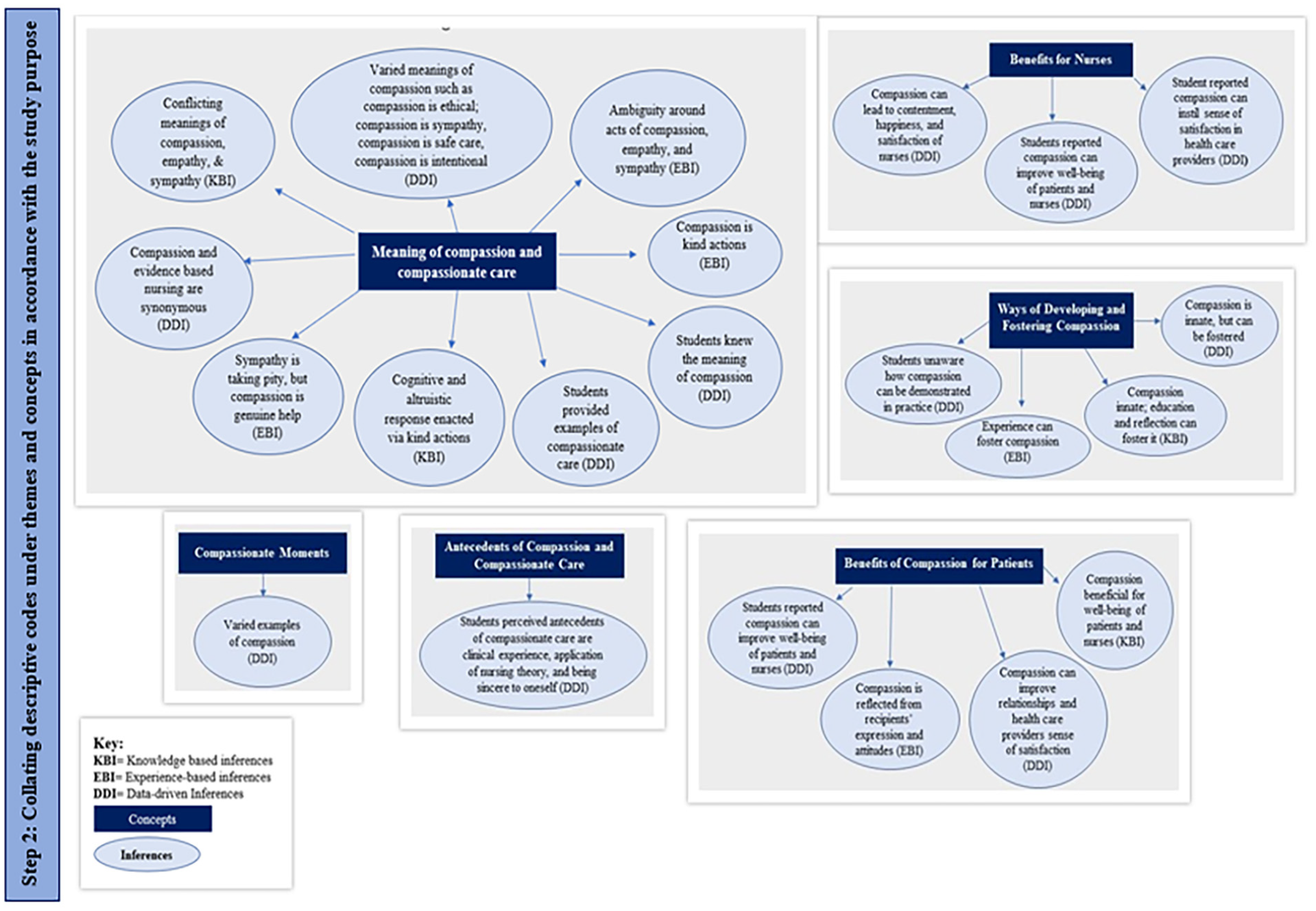
Step 2 of developing inference association maps.
If qualitative and quantitative findings inform the generated theme, the same themes should be reported under inferences in the MMR report. For example, Sundus et al. (2020) used their themes as overarching headings in their joint display of qualitative and quantitative inferences and MMR metainferences. The joint display is illustrated in Table 2.
Joint display of final inferences and metainferences.
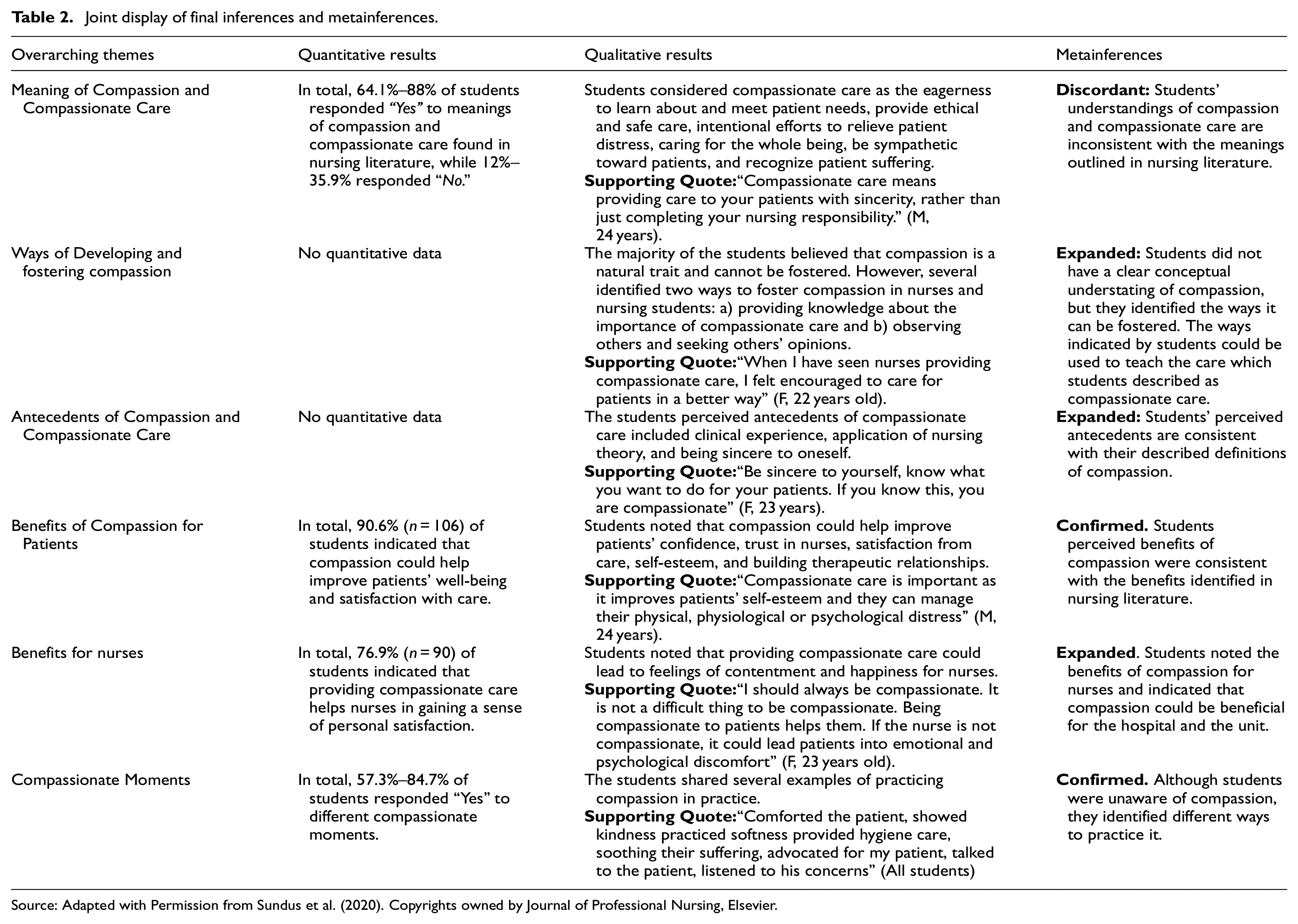
Source: Adapted with Permission from Sundus et al. (2020). Copyrights owned by Journal of Professional Nursing, Elsevier.
Step 5: Eliminating speculative inferences
After drawing inference association maps and comparing inferences, researchers must eliminate speculative inferences. Based on Currie’s (2023) account of speculation, we define speculative inferences as conclusions that lack evidential support and reinforce pre-existing beliefs and ideas. Speculative inferences may display two unique characteristics in comparison to data-driven inferences. First, these inferences are based solely on the knowledge and experience of researchers, whereas data-driven inferences cannot be speculative because, irrespective of the intensity and the volume of data supporting the inferences, they are always based on actual data from the study participants. Second, speculative inferences are inconsistent with data-driven inferences as can serve as candidates for future research.
Application in exemplar study
Sundus et al. (2020) identified four descriptive codes from inference association maps that could be considered speculative inferences: (a) compassion is not taught explicitly; (b) caring is focused; (c) compassion is not emphasized; and (d) students lack knowledge of compassion. The authors used two verification methods to determine that these inferences were speculative. First, to assess the mismatch between inferences and the overarching themes and data-driven inferences, they re-examined their raw datasets to determine if there was sufficient data support to reassess the relevance and utility of speculative inferences for generating metainferences. If the inferences remained unsupported after reanalyzing the data, they were labeled as speculative. The second strategy consisted of reviewing the knowledge base, such as available literature from the same context, to determine whether there is supporting evidence. However, the limited literature did not support the speculative inferences; hence they were eliminated.
Step 6: Generating and finalizing metainferences
After removing speculative inferences, the remaining inferences under each theme are assessed for confirmation, disconfirmation, expansion, or complementarity (Fetters, 2020; Fetters et al., 2013) prior to being converted into MMR metainferences. To generate the final metainferences, the knowledge-based, experience-based, and data-driven inferences should be compared and assessed for fit. If the inferences provide a similar understanding of the theme, they are labeled as confirmed and converted into confirmed metainferences. This labeling of inferences is based on the commonly used labeling of metainferences in MMR (Fetters, 2020; Younas et al., 2022). If the inferences offer discordant meanings, they are labeled as discordant metainferences. Finally, expanded metainferences are labeled as such if knowledge, experience, or data-driven inferences offer additional meaning and support for one another. This stage of analysis also helps to identify “silent themes” that are not across both datasets (O’Cathain et al., 2010) and may be based on only knowledge and experiences of the researchers and/or qualitative and quantitative data.
Application in exemplar study
Sundus et al. (2020) generated four metainferences and illustrated those in statistics-by-theme joint display: one that was discordant, one that was expanded, and two that were confirmed (Table 2). The discordant metainference related to the theme meaning of compassion and compassionate care, which included nine inferences: two knowledge-based, three experienced-based, and four data-driven. Two of the four data-driven inferences were derived from qualitative data and two from quantitative data. From the knowledge-based and experience-based inferences, it was extrapolated that compassion and compassionate care were ambiguously understood among practitioners and scholars. When this extrapolation was cross-examined with the quantitative and qualitative data-driven inferences, it was found that quantitative data offered conflicting results to knowledge and experience-based inferences, as a large proportion of students responded that they understood the meaning of compassion and compassionate care. Nevertheless, when qualitative data-driven inferences were included in the comparison and assessment of integration fit, it was apparent that students had some understanding of compassion. However, they also equated compassion with ethical, evidence-based, and safe patient care, contradicting their views and the definition of compassion derived from the literature. Since qualitative and quantitative data contained conflicting information, three of the four types of inferences supported conflicting results. Therefore, this finding was finalized as discordant MMR metainferences.
For the remaining three metainferences, a similar process was used by asking four guiding questions: (a) What are the differences between knowledge-based and experience-based inferences within a particular theme? (b) Do knowledge- and experience-based inferences exhibit consistency, discrepancy, or expansion? (c) Is the result of comparing knowledge- and experienced-based inferences supported, refuted, or rendered ambiguous by data-driven inferences? and (d) What consensus can be drawn from comparing all three types of inferences based on the number of inferences reporting the same, different, or expanded conclusions?
Step 7: Using “working backward heuristics” as a metainference validation tool
The final step involves validating the generated and finalized metainferences to guarantee they are grounded in the literature, knowledge, experience, and participants’ data. This step aims to ensure the interpretive and theoretical consistency of metainferences. Interpretive consistency refers to the coherence of the inferences drawn from the individual strands with each other and with the analyzed data and research purpose. Theoretical suggests the congruence of the drawn inferences to the existing theoretical and research knowledge on the phenomenon (Tashakkori and Teddlie, 2008). We suggest using backward working heuristics as the validation tool to determine if the drawn metainferences are valid and grounded in knowledge, experiences, and data. The working backward heuristic enables individuals to solve a given problem by assuming that the problem has already been solved and working mentally backward to examine the decisions and approaches that solved the problem (Dale, 2015). Working backward heuristics reverses thought processes, thereby uncovering differences in judgments and analytical approaches and gaining additional insights to enhance the final product (Ericsson and Smith, 1991). This type of heuristic is useful when examining a limited number of options and decisions at a particular step (Weisberg, 2006). In our process, there are limited choices to be examined when moving from the metainferences and tracing them back to the first step of data analysis. If discrepancies are noted, researchers can revisit their inferences and refine their metainferences. These heuristics can be particularly helpful for assessing the validity of quantitative and knowledge-based inferences, as it may be simpler to trace the steps backward to re-examine the issues in quantitative data and refine inferences, as well as the literature or research sources that dictated the knowledge-based inferences.
Application in the exemplar study
Sundus et al. (2020) used backward working heuristics to validate their metainferences. This backward working process was guided by three guiding questions: (a) What is the quality of the metainferences concerning our study purpose and data? (b) Are the metainferences supported by our knowledge, experience, and data-driven inferences? (c) What steps or approaches should we take to ensure the validity and plausibility of our metainferences? Each metainference was examined individually before reviewing the study data, literature review, and available information from the study context. In addition, a research colleague who was not involved in the study was invited to assess the validity of inferences and metainferences based on the analyzed data. The lead analyst (Ahtisham Younas) worked with the researcher colleague to examine each step completed to reach the metainferences. This activity resulted in no revisions to the final metainferences. It is important to note that the purpose of this activity was not to seek guidance and insights about the metainferences. Instead, it was to examine each step of the metainference generating process from step seven to step one. To determine the validity of knowledge-based inferences, the sources of knowledge-based inferences were re-evaluated to ensure that the interpretation was accurate. Lastly, the authors’ experiences and observations were validated by other nurse educators with experience working in the same settings and practitioners who had worked in clinical settings.
Discussion
Generating metainferences in MMR involves more than merely combining and integrating data from the quantitative and qualitative components to form an integrated whole (Bazeley, 2018; Younas et al., 2020). Metainferences in MMR can be considered both a process and an outcome (Tashakkori and Teddlie, 2008). As a process, the generation of inferences entails several steps that a researcher must complete to extract meaning from a substantial amount of quantitative and qualitative data. As an outcome, an inference is a conclusion drawn from both types of data. Quantitative and qualitative inferences should be coherent and consistent and convey adequate knowledge about the subject to the readers (Bazeley, 2018; Tashakkori and Teddlie, 2008). However, coherent and consistent quantitative and qualitative inferences are insufficient for ensuring high-quality MMR inferences. To obtain “credible, trustworthy, dependable, transferable, and/or confirmable” (Onwuegbuzie and Johnson, 2006: 52) MMR metainferences, researchers need to ensure that they follow the appropriate procedures for effectively integrating the quantitative and qualitative findings “into a conceptually coherent and substantively meaningful metainference” (Creamer, 2018, p. 111). Since this can be a daunting task, in this paper, we present a method for generating metainferences by incorporating knowledge, experiences, and data, examining rival explanations, and eliminating speculations.
The two steps of this process are prerequisites for laying the groundwork for generating metainferences. Identifying knowledge- and experience-based inferences can foster reflective thought in researchers, enabling them to develop insights for generating data-driven inferences from distinct qualitative and quantitative components. This step-by-step process brings to attention the necessity to fully engage with the literature, knowledge base, and experiences early to develop metainferences. The development of metainferences should not be an afterthought following the collection and analysis of data. Instead, researchers should consider the nature and type of inferences in light of their study objectives and intentions. Metainferences require robust procedures throughout the analysis and interpretation stages. The remaining five steps are the essence of this metainference generation process. The development of inference association maps to develop links and connections among concepts, themes, and individual findings, and examine nuanced differences is critical as it allows researchers to generate metainferences grounded in the context and study data. While developing inference association maps, researchers can utilize innovation to tailor the maps to their analytic procedures.
There are several challenges to implementing the process described in this paper. First, differentiating knowledge-based inferences from experience-based inferences can be difficult due to the intertwined nature of everyday experience and knowledge. Keeping reflective journals before initiation and throughout the data analysis and interpretation phases can help researchers manage this complex task. Second, generating descriptive codes and assigning meaning and relevance to inferences and metainferences is a subjective process involving value and experiential judgments. Therefore, a team-based approach to exploring potential biases and judgments can effectively address discrepancies early in analysis. Finally, backward working heuristics is not a fully developed type of heuristics, and its application can vary across contexts, situations, and types of problems and purposes. Therefore, transparency in the choices and decisions can enhance the reproducibility of the steps undertaken to reach the final interpretation.
There are limited approaches to explicate how metainferences are generated in actual research practice, even though researchers’ personal experiences and interpretations can potentially affect the quality of drawn inferences and metainferences. This paper contributes to the field of MMR by offering a seven-step practical process to generate metainferences in convergent MMR designs and provide some tangible tools and guidance for making sense of the complexity of MMR analysis and interpretation, and inference generation. This paper outlined the practicalities of identifying and integrating knowledge, experiences, and data-driven inferences and generating meaningful and valid metainferences. The proposed strategies consider the complexity of MMR designs and the data analysis and offer tangible guidance on handling and making sense of discordant findings in line with the research purpose and the study context and needs. Applying this process may allow researchers to enhance their decision-making during inference generation by using relevant steps and tailoring them to meet their study needs. The proposed process enables researchers to apply analytical, reflexive, and visual tools concurrently to make explicit how metainferences are linked to the knowledge base, the researchers’ experiences, and the actual qualitative and quantitative data from the participants.
Limitations
The seven-step process outlined in this paper is based on a single convergent MMR study. Therefore, further application and adaptions of this process can result in developing more insights into refining this process. The process can be time-consuming and challenging due to its lengthy nature. Therefore, inference association maps can be an optional step. Nevertheless, we highly recommend using all seven steps as honing onto the strength of visual approaches to analysis can generate usefulness insights contributing to effective metainference generation.
Conclusions
Generating metainferences is a hallmark of MMR, but it is frequently time-consuming and tedious, involving back-and-forth discussion and engagement with qualitative and quantitative data. Researchers’ prior knowledge of and experiences with the studied phenomenon can influence the drawn inferences and metainferences. Our seven-step process of generating metainferences can be potentially useful to optimize the inference and metainferences drawn in convergent MMR designs. Eliminating speculative inferences and using backward-working heuristics can allow researchers to minimize their biased judgments, which may affect the validity of generated metainferences.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Data availability statement
Data sharing not applicable to this article as no datasets were generated or analyzed during the current study.