
Abstract
Repetition and structure have a significant place in music theory, but the structure hierarchy and its influences are often ignored in both music analysis and music generation. In this article, we first describe novel algorithms based on repetition to extract music structure hierarchy from a MIDI data set of popular music and show its effectiveness through evaluation. Then, we introduce new data-driven approaches to estimate and validate structural influences in music. Results show that the automatically detected hierarchical repetition structures reveal significant interactions between structure and harmony, melody, rhythm, and predictivity. Different levels of hierarchy interact differently, providing evidence that structural hierarchy plays an important role in our popular music data set beyond simple notions of repetition or similarity. We further study how musical structure has evolved over decades of popular music writing. Finally, we discuss the importance of this work in highlighting roles that structure can play in music analysis, music similarity, music generation, music evaluation, and other music information retrieval tasks.
Keywords
Introduction
Form and structure are among the most important elements in music and have been widely studied in music theory. Music structure has a hierarchical organization ranging from low-level motives to higher-level phrases and sections. These different levels influence the organization of other elements such as harmony, melody, rhythm, and perceptual predictivity, but these influences are not well formalized. The lack of structure and hierarchy is a common issue in computer-generated music in recent practice. Music information retrieval (MIR) research has developed techniques for detecting music segmentation and repetition structures, but hierarchy is often ignored (Dannenberg & Goto, 2009; Paulus et al., 2010).
A fundamental question about music structure is whether higher levels of hierarchy are essentially just larger groupings or whether different levels play different roles. If the latter is true, then a better representation and understanding of hierarchy should be useful for prediction, generation, analysis, and other tasks. Long-term structure in music is also a recent topic in music generation with deep learning, and attention models such as the Transformer (Vaswani et al., 2017; Huang et al., 2018) seem to improve results. While this suggests some data-driven discovery of structure, results are hard to interpret and, for example, it is not clear whether hierarchy plays a role.
Another significant concern is that there is no data-driven approach to analyze how the multilevel music structures interplay with other music elements from data, such as melody, harmony, rhythm, and perceptual predictivity. In rule-based music generation systems, hierarchy can be achieved directly using explicit models of music hierarchy, but there is little to guide the formation of such rules. In deep learning music generation systems, we also need such analysis to better guide the model design and evaluate the generated results. Moreover, such a data-driven approach has huge potential to enhance the comprehension of music theory, validating existing theories and developing new theories for various genres of music.
We began our study by developing a method to identify low-level structure in popular songs. Our approach identifies phrases with repetition of harmony, melody, and rhythm between phrases, resulting in high agreement with human judgment. Next, we discovered a simple way to infer higher-level structure from this phrase-level structure. Beyond viewing structure as mere repetition, we show that chord progressions, melodic structures, rhythmic patterns, and entropy in music are all related to music structure, and there are significantly different interactions at different levels of hierarchy. Our main contributions are (1) a novel algorithm to extract repetition structure at both phrase and section levels from a MIDI data set of popular music, (2) formal evidence that melody, harmony, rhythm, and perceptual predictivity are organized to reflect different levels of hierarchy, (3) data-driven models offering new music features and insights for traditional music theory, and (4) a demonstration that music structure has evolved over decades of popular music writing. We believe that this work is important in highlighting roles that structure can play in music analysis, music similarity, music generation, and other MIR tasks. This article presents an expanded and extended treatment of earlier work by Dai et al. (2020).
For the rest of the article, we first discuss related work and present our phrase-structure analysis method. Next, we describe the general properties of structures we found and explore the relationships between structures and harmony, melody, rhythm, and predictivity. We also explore some ways that music structure has changed over seven decades of popular music writing in our data set. Finally, we present discussions and conclusions.
Related Work
Computational analysis of musical form has long been an important task in MIR. Large-scale structure in music, from classical sonata form to the repeated structure in pop songs, is essential to music analysis as well as composition. Schenkerian analysis, a reduction technique that also aims to uncover musical structure, has been implemented by Marsden (2010), and the automated reduction has achieved convincing results in recognizing the variation in ten pieces by Mozart. Hamanaka et al. (2014) describes a tool for generative theory of tonal music (GTTM) analysis that matches closely the analyses of musicologists. Allegraud et al. (2019) use unsupervised learning to segment Mozart string quartets. They analyzed the classical sonata form structure from a data set of Mozart's string quartets and discovered that unsupervised learning emits better section boundaries than manually set parameters. The structure analysis of Go et al. (2019) performs structural analyses using homogeneity, repetitiveness, novelty, and regularity. Our work builds on the idea of extracting structure by discovering repetition.
Identifying hierarchical structure is likely to play a role in music listening. Granroth-Wilding (2013) employs ideas from natural language processing (NLP) and performs combinatory categorical grammar parsing to obtain a hierarchical structure of chord sequences. Marsden et al. (2013) state that advances in the theory of tree structures in music will depend on clarity about data structures and explicit algorithms. Jiang and Müller (2013) propose a two-step segmentation algorithm for analyzing music recordings in predefined sonata form: a thumb-nailing approach for detecting coarse structure and a rule-based approach for analyzing the finer substructure. Berardinis et al. (2020) analyze music structure in different levels of resolution based on graph theory and multiresolution community detection. We present a detailed algorithm for segmenting music into phrases and deriving a higher-level sectional structure starting with a symbolic representation.
Segmentation of music audio is a common MIR task with a substantial literature. Dannenberg and Goto (2009) survey audio segmentation techniques based on repetition, textural similarity, and contrast. Barrington et al. (2009) perform audio music segmentation based on timbre and rhythmical properties. However, MIDI has the advantage of greater and more reliable rhythmic information along with the possibility of cleanly separating melody. Many chord recognition algorithms exist; for example, Masada and Bunescu (2018) use a semi-Markov Conditional Random Field model. Jiang and Dannenberg (2019) provide references to systems for melody extraction from MIDI and propose a new method based on maximum likelihood and dynamic programming. Rolland (1999) presents an efficient algorithm for spotting matching melodic phrases, which relates to our algorithm for segmentation based on matching subsegments of music. Lukashevich (2008) proposes a music segmentation evaluation measure considering over- and under-segmentation. Collins et al. (2013) develop a geometric approach to discover inexact intra-opus patterns in point-set representations of piano sonatas. Our work introduces new methods for the analysis of multilevel hierarchy in MIDI.
Apart from music theory research, there have been some efforts in music psychology and perception to explore the relationship between music phrases, rhythm, and pitch in Western music. For instance, Palmer and Krumhansl (1987) conduct four listening experiments to illustrate the effects of pitch and temporal contributions to musical phrase determination. Lehne et al. (2012) exposes the relationship between tonal structure and tension-resolution patterns by qualitatively analyzing musical tension ratings for two piano pieces from Mendelssohn and Mozart. In this article, we further investigate the interplay of different levels of music structure with harmony, melody, rhythm, and perceptual predictivity and propose new approaches to estimating and validating essential features of music theory, such as the idea of ‘tension’ and ‘resolution’ in Lehne et al. (2012).
Phrase-Level Structure Analysis
We introduce a novel algorithm based on repetition and similarity to extract structure from annotated MIDI files. Given input consisting of a chord and melody sequence for each song together with its time signature (obtained from MIDI pre-processing), the algorithm outputs a repetition structure. In this section, we will introduce the design motivation, structure representation, details of the algorithm and some evaluation results.
Motivation and Representation
We represent the structure of a song with alternating letters and digits that indicate phrase labels and phrase length in measures (all boundaries are bar lines). We indicate melodic phrases (where a clear melody is present, mostly a vocal line or an instrument solo) with capital letters and non-melodic phrases with lower-case letters. For example, i4A8B8x4A8B8B8X2c4c4X2B9o2 denotes a structure where A8 and B8 represent different repeated melodic phrases of eight measures in length. The B9 indicates a near-repetition of the earlier B8, but with an additional measure. In addition, i indicates an introduction with no melody and o is a non-melody ending; both are otherwise equivalent to x. X and x denote extra melodic and non-melodic phrases that have no repetition in the song. (The first and second occurrence of X2 in the structure do not match. We could have labeled them as D2 and E2 but X2 makes these non-matching phrases easier to spot.) Non-melodic phrases such as c often refer to a transition or bridge, while X indicates non-repeating phrases or just inserted measures.
Song structures are often ambiguous. Consider a simple song with measures qrstuvwxqrst. Here, matching letters mean repeated measures, based on overall similarity of chords, melodic rhythm onset times, and melodic pitches. We assume that shorter descriptions are more ‘natural’ (Simon and Sumner, 1968). Therefore, we model structural description as a form of data compression; for example, we can represent this song more compactly as ABA where A = qrst and B = uvwx. This description requires us to represent three phrase symbols (ABA) plus the descriptions of A (qrst) and B (uvwx) for a total of three phrases and eight constituent measures. The description length here is

Data Pre-Processing
We use a Chinese pop song MIDI data set (POP909) consisting of 909 manual transcriptions of audio performances (Wang et al., 2020). POP909 contains the most popular Chinese pop songs from over seven decades. Although the songs are Chinese, their compositions closely follow Western pop music conventions, especially for form structure and chord progressions. The MIDI manual transcriptions have high quality in general, characterized by their cleanliness and minimal errors, surpassing other MIDI data sets in terms of accuracy.
We use key and chord labels from audio in combination with labels automatically derived from MIDI, resolving differences with heuristics to improve the labeling. For key labels, we manually resolved conflicts between automatic key labels in 135 of the songs. For chord labels, we compared audio with MIDI chord labels after quantizing the chords into 2-beat units. To resolve conflicts, we rate the labels using
Our MIDI files have a melody track, simplifying melody extraction, and we quantized the melodies to 16ths. Our source data is not precisely aligned to beats, so we manually labeled and eliminated downbeat offsets so that every bar line aligns to the correct downbeat. Thus, we have accurate transcriptions and harmonic analyses of 909 Chinese pop songs.
Algorithm Design
Our structure analysis begins with the identification of repetition of harmony, melody, and rhythm. We then use a combination of dynamic programming, A* search, and heuristics to find good structure descriptions guided by the
Similarity Metrics
We use three different similarity metrics to detect repetitions in the song.
The chord progression similarity metric is based on the number of common pitch classes between chords. For example, given chord sequences ‘Cmaj Dmin’ and ‘Cmin Ddim Dmin,’ Cmaj ({C, E, G}) and Cmin ({C, E♭, G}) share two out of three notes, Dmin and Ddim also share two out of three, and we consider the similarity of the extra Dmin to be 1, so the total score is
The rhythm similarity metric is based on matching note onset times. Onsets times are quantized to 16th notes. Given two melodic sequences we define
The melody pitch contour similarity is based on a dynamic time warping (DTW) (Berndt and Clifford, 1994) algorithm applied to melody pitch contour. First, we transform two melody note sequences by sampling at a rate of 16th notes; for example, a note with pitch p and duration 4 in the original melody will become 4 consecutive copies of p in the new sequence. We compute the edit distance using a substitution cost based on similar absolute pitch difference and similar melodic direction. We normalize the DTW distance and subtract from 1 to get a similarity using

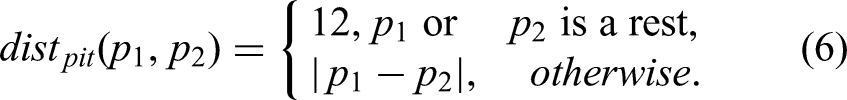


The DTW calculation for the distance between sequences
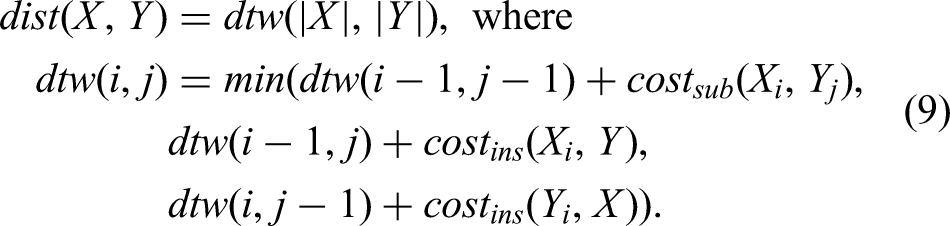

Finding Repetition
To determine if a segment of music repeats an earlier segment, we use thresholds such as

Algorithm Description
Given a song consisting of melody, chord analysis, and time signature, we can determine the song structure with the best structure description length (
Input: phrase sets
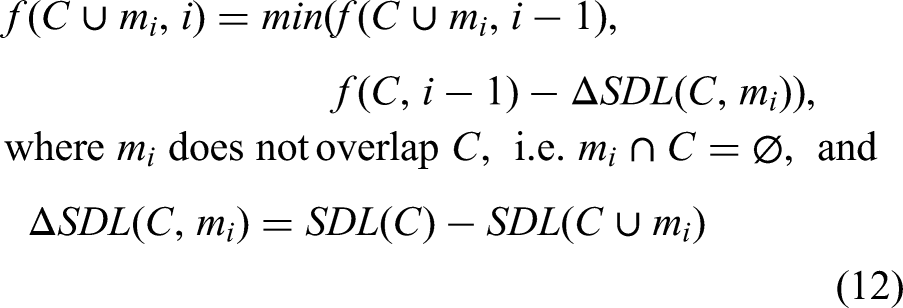
Dynamic programming

More precisely, what is the largest 
Complexity, Optimizations, and Evaluation
Let n be the number of measures of the song. In step 1, there are Exclude phrases that begin with melody and end with more than two non-melody measures, forcing a split and reducing the number of matching phrases. Transform all operations in the algorithm into bit manipulation operations. Take the top 10–20% of the phrase sets with the largest covering and use the best Approximation option 1. In each decile of M (ordered by starting measure), pick 10–20% with the largest covering size. Run the algorithm on these phrase sets. Approximation option 2. In each decile of M, pick the 10–20% with the highest similarity metrics scores. Run the algorithm on these phrase sets. Approximation option 3. Randomly pick 10% of M and get the best possible result. Run the random process 10 to 20 times and pick the best result among them.
We selected 50 songs in the data set for training and tuning hyper-parameters in the model, and chose another 100 songs as testing data. Our full algorithm correctly produced 93% of the human-labeled structures (Table 1) for the test data (labeled with numbers 001 to 100 in the data). In the evaluation, we only consider the exact same structure representations as the correct match; there might be some under-segment or over-segment cases that are partially right, but we label them as all incorrect analyses. The average run time of each song on a laptop with a 2.3 GHz 8-Core Intel Core-i9 and a 64GB-2667MHz-DDR4 RAM is 345 s, but for 80% of the songs, the average run time is only 21 s. Approximation option 1 has an accuracy of 68% and a run time of only 13 s.
Evaluation on structure analysis experiments.

Hierarchical Structure Exploration
In this section, we characterize the lower-level phrase structure and the higher-level section structure we found in our data set.
Phrase-Level Structure Statistics
What portion of the song is covered by repetition structure? Figure 1 shows that in most songs, repeated melodic phrases cover 50% to 90% of the whole song.

Distribution of proportion of repeated melodic phrases.
Figure 2 shows the distribution of different phrase lengths among phrases. The majority of melodic phrases have for or eight measures (but we consider longer, higher-level sections later).
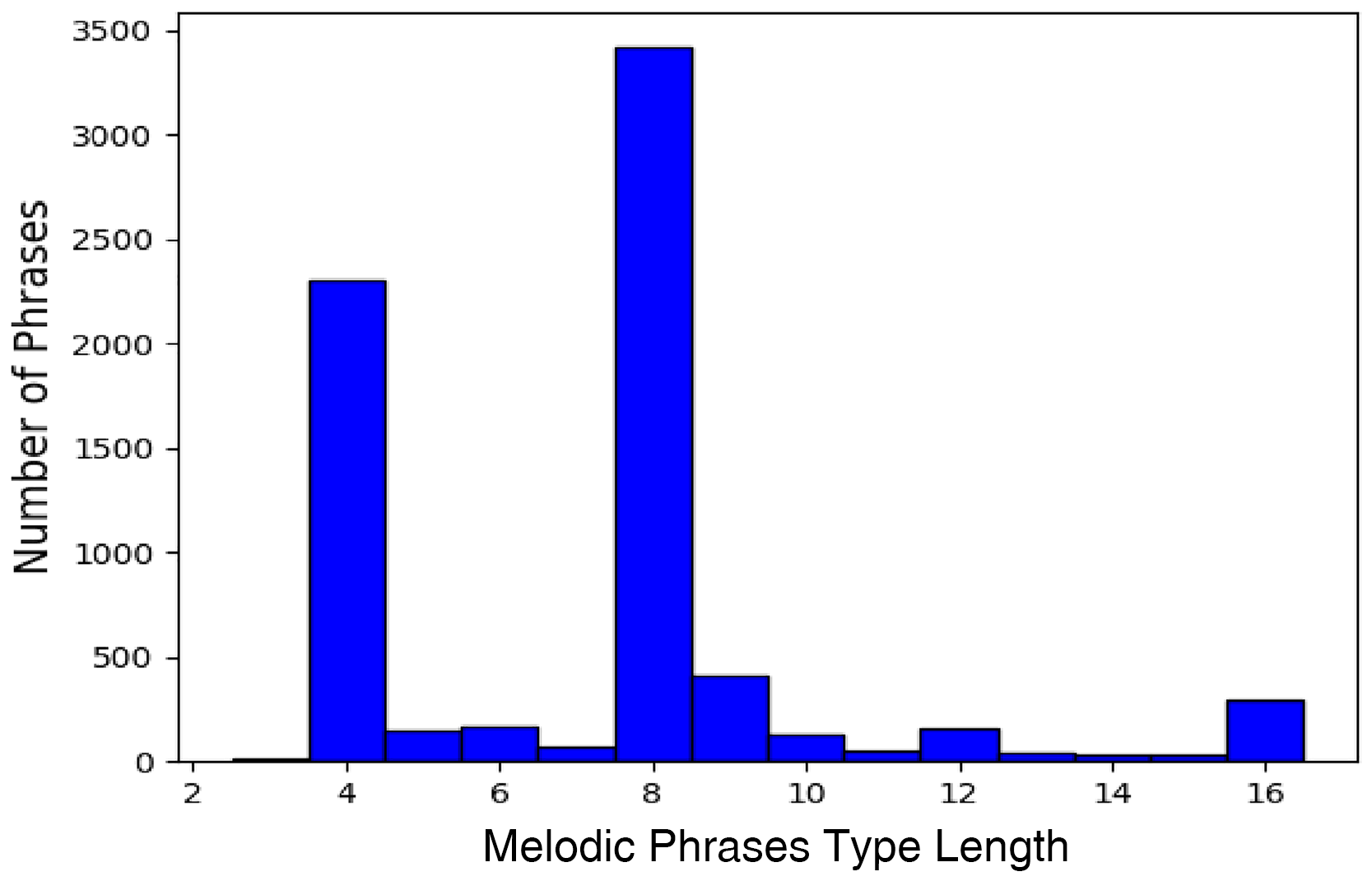
Distribution of melodic phrase length.
Higher-Level Sectional Structure
The importance of multilevel hierarchy in music is firmly established. Structure in traditional forms ranges from subdivisions of beats to movements of symphonies. We looked for automatic ways to detect structures above the level of our ‘phrases,’ which are based on repeated patterns. One indication of higher-level structure is the presence of non-matching (X) and non-melodic phrases that partition the song structure. Based on the repetition structure, we can further determine a high-level sectional structure. The non-melody transitions/bridges and extra non-matching phrases we found in the repetition structure divide the song into big sections. In our analysis, successive non-melodic phrases and X phrases with total lengths of more than two measures indicate the boundaries of high-level sections. For example, the song with structure analysis i4A8B8x4A8X2B8B8c4c4B9o2, after removing separator phrases i4, x4, c4c4, and o2, has three sections: A8B8, A8X2B8B8, and B9. For lack of more standard terminology, we refer to our low-level repetition segments as phrases and these higher-level segments as sections.
We found that most of the songs have two or three sections (Figure 3), and each section typically has one to six phrases (Figure 4). Over 90% of songs have two or three distinct phrases with melody (e.g., A, B, …). Within each section in the song, there are typically one to three distinct melodic phrases (Figure 5).
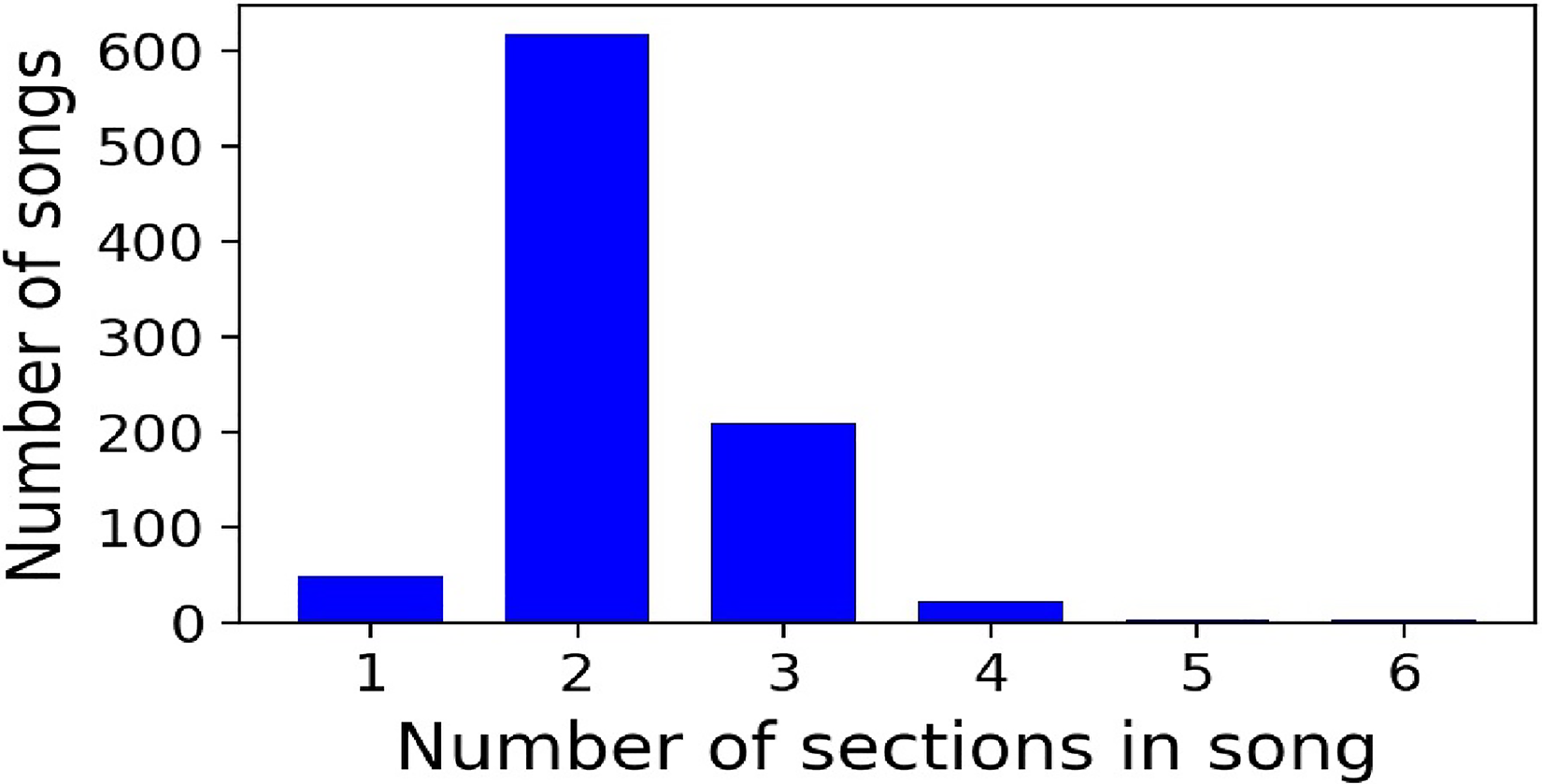
Distribution of the number of high-level sections in a song.

Distribution of the number of phrases in a section.

Distribution of the number of phrases in a section.
Data further show that 20% of sections are exact repetitions of the previous section in terms of phrases; 29% of the successive sections repeat a suffix of the previous section (e.g., AAB AB), while 18% repeat a prefix (e.g., ABB AB).
If we use A
Interactions with Segment Structure
We could have used any number of ways to form higher-level structure (sections), but we wanted an objective procedure that is independent of musical features (e.g., ‘sections end on a long tonic note’). Our choice is supported by the finding of interactions between sections, melody, harmony, and rhythm that are not explained by interactions at the phrase level, suggesting that the section structure is not just an arbitrary construction. On the other hand, we suspect there are even better constructions in terms of matching human analyses or consistency with musical features.
Structure-Based Harmonic Analysis
We begin by looking at how structure interacts with harmony. Specifically, we see that chord distributions are different at the beginning, middle, and end of phrases and sections.
In Figure 6, we show probabilities of different harmonies at different locations in phrases and sections in major mode. We are much more likely to see I at the beginning of a phrase and at the end of a section. I and V chords are more popular at the ends of phrases (about equally). We expected to see a predominance of I chords at the ends of phrases, but as the last two categories reveal, the V is a more common ending within a section, while the I chord is more common at the end of a section. Here, we see significant interactions not only between structure and harmony but also between different structural levels. We evaluate the significance of these differences by assuming a null hypothesis of equal probability everywhere (the background category in Figure 6) and using one-tailed unpaired t-tests. All the test results are significant (

Chord frequency probability at different level of structure in major mode. X-axis represents different locations in phrase and sections. Background means no location constraint, for comparison.
Chord transitions at the ends of phrases or sections proved to be significantly different from general transition probabilities at other positions in the phrase. For example, in major mode, 58% of progressions at the end of the section are V–I (authentic cadence in music theory). Transition probabilities from V–I at the end of phrase, end of phrase in the middle of a section, and end of section are 0.89, 0.84, and 0.94, while the average transition probability in all other positions is only 0.47.
Structure-Based Melody Analysis
Phrase and section structures also influence the distribution of melody pitches. We have already seen that harmony interacts with structure, and one would expect strong interactions between melody and harmony, so it is an almost trivial assertion that pitch content is interconnected with structure. To study pitch and structure interactions in more detail, we consider only melody pitch classes over the I chord. Thus, the choice of melodic scale degree is influenced not only by harmony but also by placement within at least two different levels of structure. Figure 7 shows probabilities of different melody pitches at different locations in phrases and sections, counting only pitches in the context of a I chord in the major mode. Scale degree
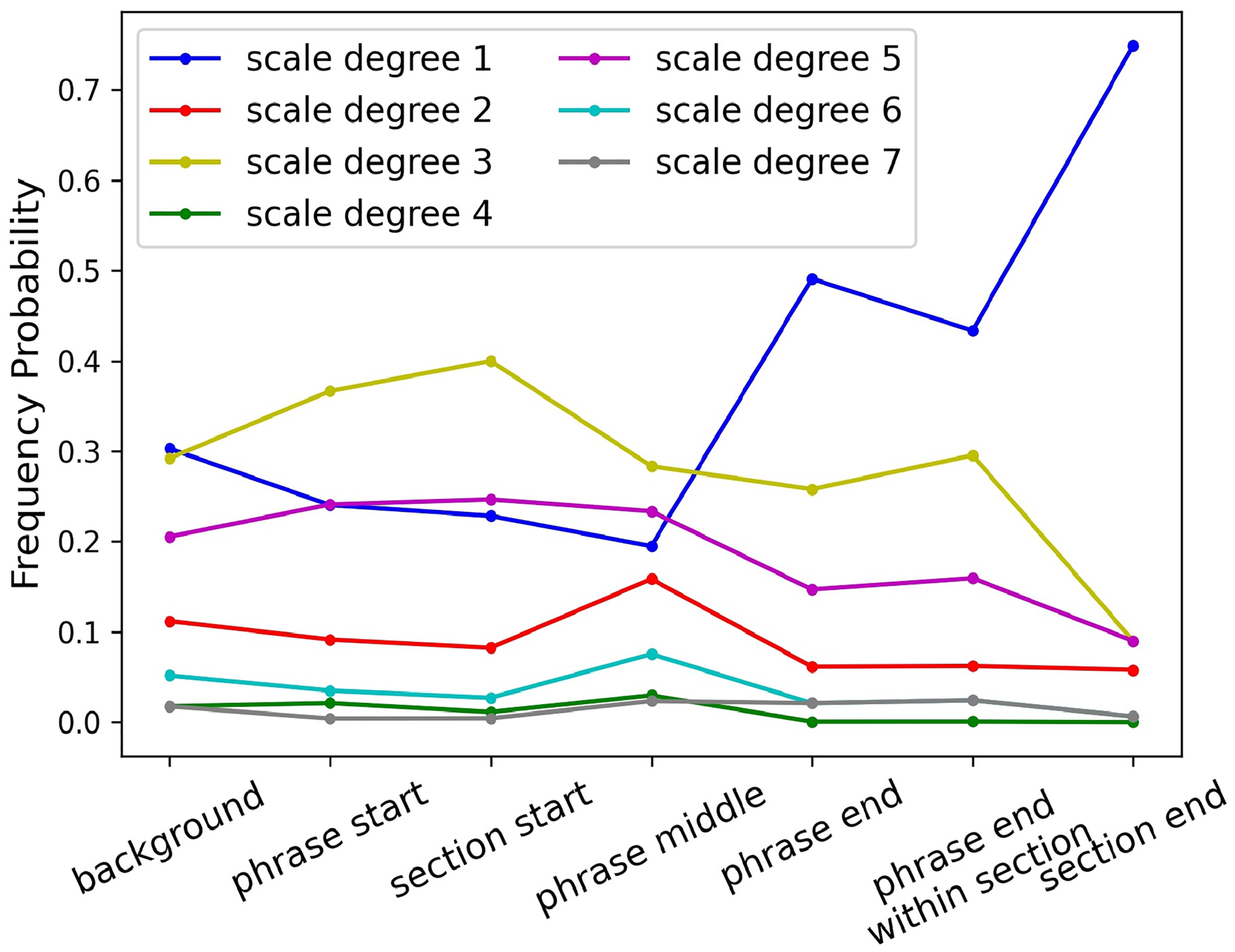
Melody pitch distribution probabilities conditioned on I chord at different levels of structure in major mode.
Structure-Based Rhythm Analysis
We are also interested in the duration and rhythm of the melody. Our smallest duration unit is the 16th, and Figure 8 represents a distribution of the note durations in the corpus. Notice that because the melody duration is extracted from the quantized performance MIDI with rest notes, note durations might be shorter than the original durations in the sheet score. The distribution of note length at the beginning and middle of phrases is about the same as the overall distribution, consisting mostly of short notes. In contrast, the phrase endings mostly consist of longer notes. We also observed a difference in phrase endings depending on position. For example, only 6.4% of whole-or-longer notes occur at the ends of phrases in the middle of a section, while 72% occur at the ends of phrases at the end of a section.
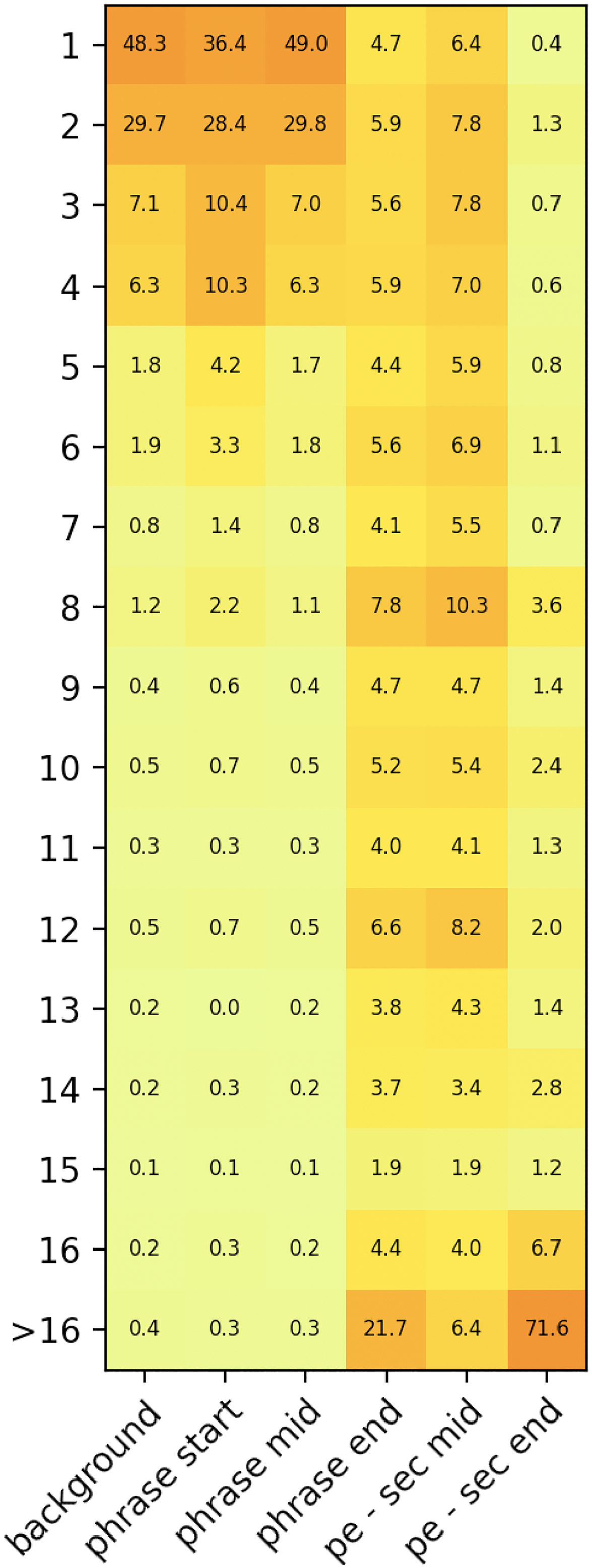
Heatmap of phrase note length distribution. Similar to Figure 6 and Figure 7, x-axis presents different locations in the phrase and section. ‘pe - sec mid’ means the end of phrase within section, and ‘pe -sec end’ represents the end of section. Y-axis represents note durations in units of 16th notes. The float numbers in the heatmap represent percentage of distribution.
Structure-Based Prediction Entropy Analysis
Entropy measures uncertainty or lack of confidence in predictions. Entropy depends upon the model used for prediction, and in this case we use simple histograms to estimate the probability of each chord or melodic scale degree. Maximum entropy is obtained when all choices are equally likely, and entropy is minimized by highly skewed distributions. In Figure 9, we show that prediction entropy is significantly influenced by different levels of structure. Entropy is much lower (predictions are more confident) at the start and end locations compared with overall (background) entropy or phrase middle. Furthermore, the starts and ends of sections have even lower entropy than starts and ends of phrases.

Entropy of chord distribution, and entropy of melody pitch distribution conditioned on I chord at different levels of structure in major mode.
Evolution of Structural Style
The data set we used consists of 909 pieces of Chinese pop music dating from 1950s to 2020, with the majority of the songs originating after 1990 (Figure 10). The dates combined with our structure analysis allow us to study how typical song structures have changed over time in Chinese pop music. For each of the following structural and harmonic properties, we assume a null hypothesis of no linear correspondence between year and the property, and set a significance level of 0.05. The first observation is that section repetition has increased over time (
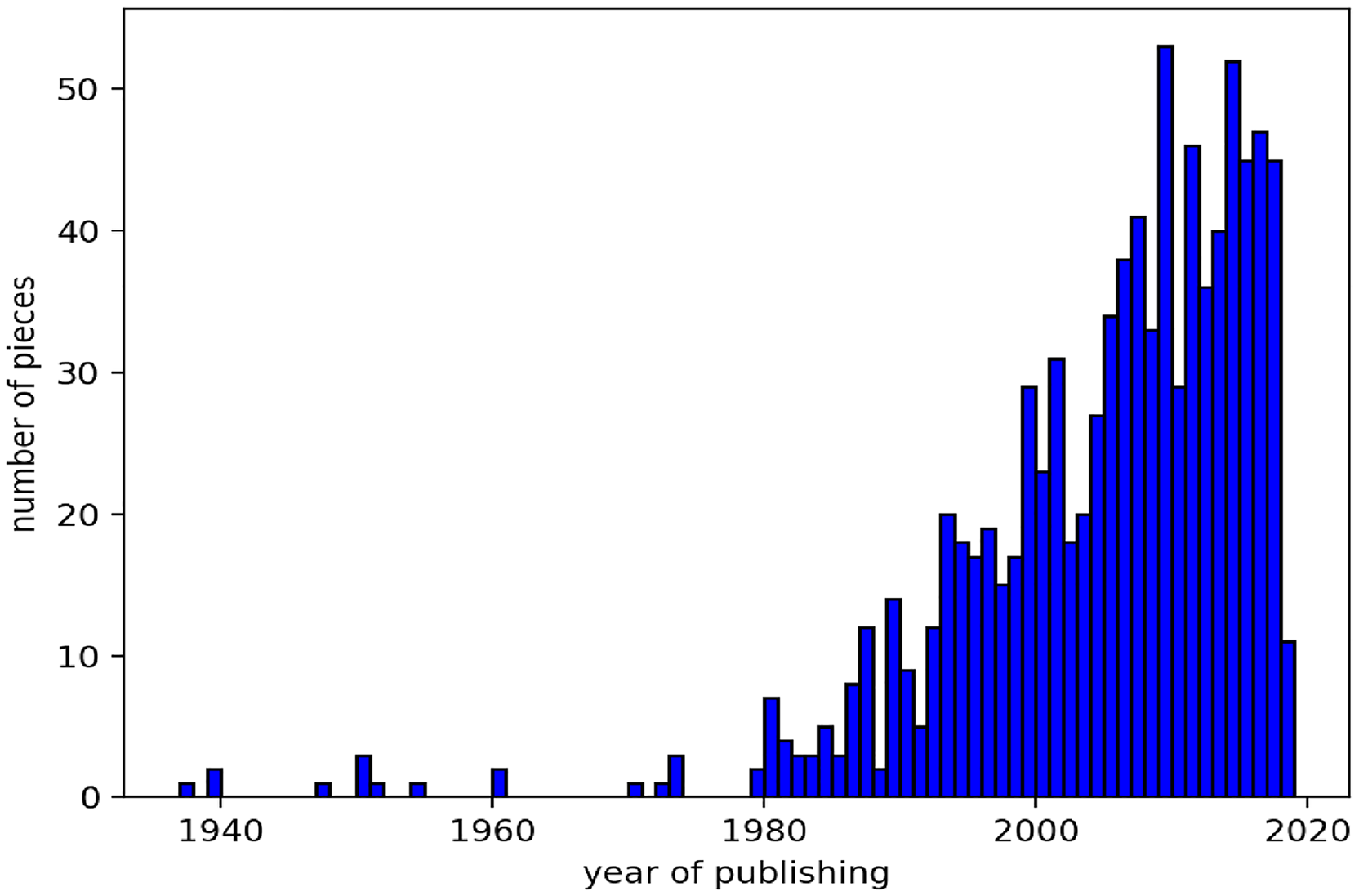
Distribution of the song publishing years.

Time vs. phrase repetition amount.
We also discovered two measures of phrase harmonic structure that correlate with year of composition. The metrics are calculated for each type of melodic phrase that shows up in the phrase segmentation. We found cross-phrase similarity decreases with date (contrast between song sections increases) (
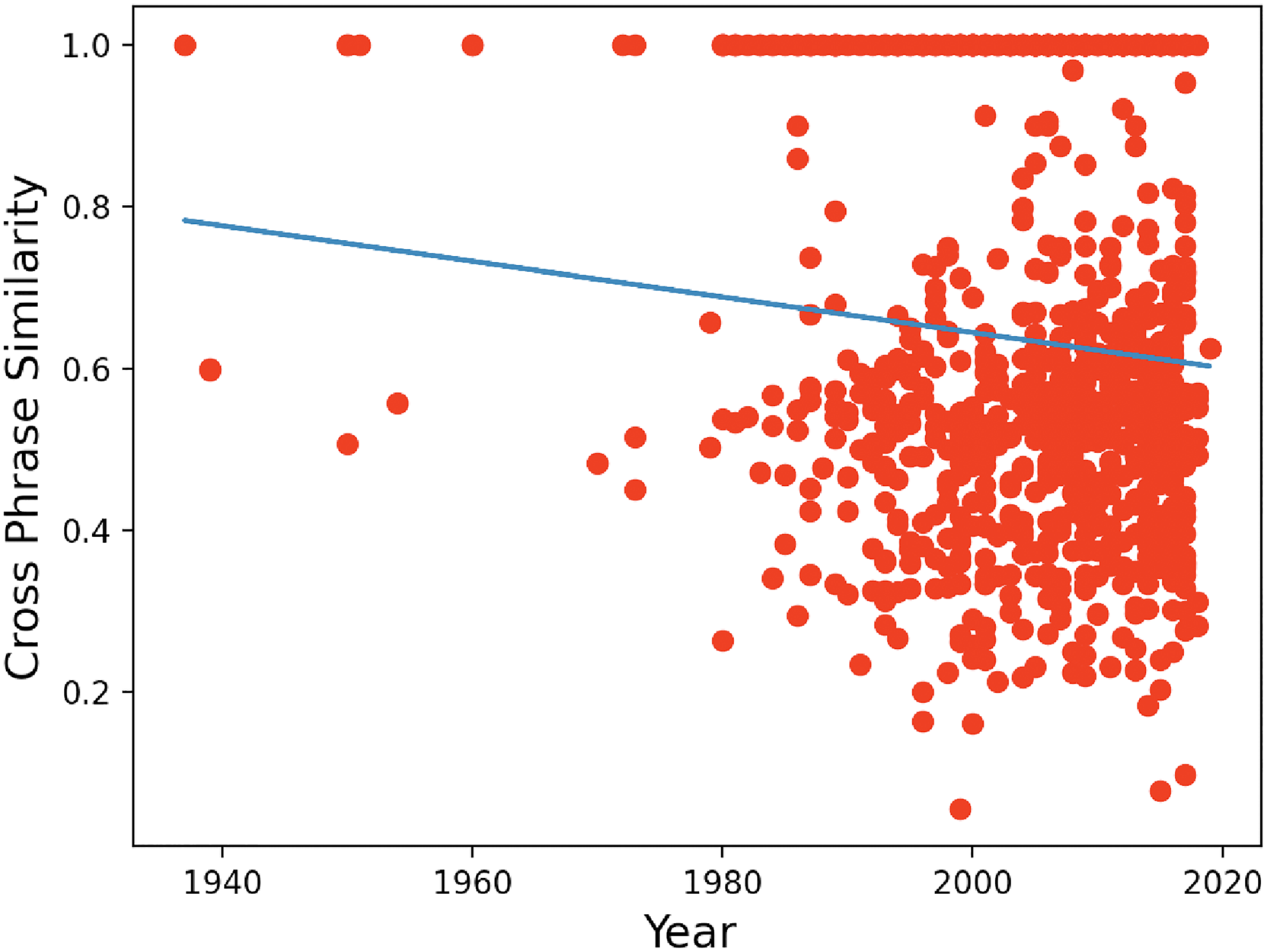
Time vs. cross-phrase harmonic similarity.

Time vs. phrase harmonic complexity.
In all, the cross-phrase similarity exhibits a strong negative linear relation with time, which indicates we are getting greater contrast between the different parts within songs. Phrase harmonic complexity demonstrates that phrases in more recent music tend to be longer and contain more infrequently used chords.
Discussion and Future Direction
Data-Driven Music Theory Analysis
The data-driven analysis results in this article show that music elements such as harmony, melody, and rhythm behave differently at different positions relative to the hierarchical music structure. Moreover, our music predictivity (entropy) results suggest that composers intuitively, if not consciously, manipulate surprise and expectation in relation to a multilevel structural hierarchy. These music-structure-related features support many aspects of traditional music theory. For example, in our analysis, half cadences are more often seen at the ends of phrases, but only in the middle of sections, consistent with the music theoretic concept that a half cadence calls for continuation.
It is worth noting that the phrase structure extraction algorithm is fully based on repetition and similarity without using any knowledge of other music concepts. Conventional music theory tells us that phrase boundaries are likely to occur after I chords or after long notes. Undoubtedly, humans analyze music using heuristics such as these to guide segmentation. Thus, discovering connections between structure and harmony, melody, rhythm, and even entropy would not be surprising when music structure analysis is driven by these very same features. In this work, we developed a hierarchical structure analysis algorithm that eliminates human judgment and operates without considering any specific musical features. (We do compare features to discover repetition, but make no assumptions about what features appear in the beginnings, endings, or middles of phrases or sections.) Thus, our approach forms a good test for music theory and existing domain knowledge.
Future work might strive to learn more about variations between similar phrases and how contrasting phrases are constructed. We have only begun to look for interactions between structure, melody, harmony, rhythm, and predictivity, and these initial results show this to be a promising research direction. For example, one could expand the melody analysis in the article, further modeling the interplay between melody pitch contour and different levels of structure. Instead of treating rhythm and pitch separately, they could be modeled together to see how the music melody tension varies at different levels of structure. The idea that structural tendencies change over decades is also promising, and we would like to try data sets featuring a more uniformly distributed range of song publishing years.
Our work also has applications to the further development of music theory. Measures of entropy offer new ways to characterize song construction. It would be particularly interesting to discover a more perceptual basis for observed distributions, perhaps relating to the manipulation of listeners’ feelings of anticipation and surprise. Considering our analysis of song trends over decades, it would be interesting to look for additional trends and see whether these trends could be useful in genre recognition or better characterizations of musical styles.
Moreover, we do not consider any expressivity information in MIDI, such as dynamics. In this article, we focus on the musical elements at the compositional level, but it would be very interesting to further investigate the relationship between music structure hierarchy and expressive performance elements in MIDI or audio.
Last, our results with Chinese pop music are consistent with basic concepts of Western music theory, so we suspect that similar results would be obtained with Western pop music. Still, it would be interesting to conduct a comparative study with Western pop songs, and even apply the data-driven music analysis to explore other music genres that are underrepresented or less mainstream.
Structure Segmentation Algorithm
The algorithms we proposed for extracting hierarchical repetition structures from MIDI files have a high accuracy of 92.8% on the POP909 test sets, compared with human labeling, and can be used to analyze other MIDI data sets. Our findings can guide music imitation or generation and can also be used to evaluate whether songs follow structural conventions.
Notice that in the phrase-level structure analysis algorithm, parameters are manually tuned, which leads to over-fitting to the current POP909 data set, but perhaps they could be adjusted automatically according to different styles of music and data sets in the future. The hard-coded hyper-parameters in the algorithm, such as the fixed phrase length range of 4 to 20 bars, should also be adjusted in the future for more flexibility.
Moreover, the algorithm requires a melody track and at least one accompaniment track in the MIDI file, which might be hard to obtain in other music genres with more complex polyphonic textures, such as classical music. Most existing MIDI data sets do not have clean labels for bar line and beat alignment, which might also decrease the algorithm's performance. In addition, since the algorithm is based on repetition detection, it would fail for short songs without any repetition structure, and be too time-consuming for long-duration songs.
Future work might also investigate more robust indicators of sections. It seems that the non-melodic phrases we use to detect sections are not present in all styles. Consider a repeated form such as AABA|AABA. There might be ways to identify these higher-level sections that are not separated by non-melodic phrases.
Music Generation and Other Applications
Symbolic music generation (composition) using deep neural networks and sequence learning techniques has become an active area of research, but results have not exhibited conventional popular music structure even when trained on data sets such as POP909. Both structure segmentation analysis and structural influence analysis results in this work can be used to guide different approaches to music generation and be used as novel structure grading metrics in music evaluation. For instance, the probability distributions of different music elements at different structure level positions can be used to evaluate the structure score in computer-generated music.
In addition, the analyses can be used as representations in music generation by learning the relations between phrases and sections. For example, given a structure A8B8B8x4A8B8B8B9, one could investigate what is the motive pattern inside A, and how to vary from the first A to the other As and the Bs. Then we can represent a complete song by using a motive pattern, a hierarchical structure, and variation relations. In addition, if we apply another motive pattern to the structure and variations, we will get a new song with the same music structure style.
Furthermore, the structure segmentation analysis results contain a massive amount of human-labeled phrases, together with the section and song information, which are great resources for other MIR analysis tasks and also for models to learn music variations and similarity metrics.
Conclusion
We believe this is the first study to analyze connections between different levels of music structure and the elements of harmony, melody, rhythm, and entropy using a data-driven approach. We introduced a new hierarchical structure analysis algorithm. With it, we analyzed aspects of harmony, melody, rhythm, and entropy in the context of multilevel structure. We also studied how the structure of pop songs in our data set evolved over different decades. This work suggests there is still much to be learned about the role of structure in music, and that we can use hierarchical structure to inform future work on music style, analysis, evaluation, and generation.
Our data set, annotations, and experimental results are released at: https://github.com/Dsqvival/hierarchical-structure-analysis.
Footnotes
Action Editor
David Meredith, Aalborg University, Department of Architecture, Design and Media Technology.
Peer Review
Mark Hanslip, University of York Faculty of Arts and Humanities, School of Arts and Creative Technologies.
Jemily Rime, University of York Faculty of Arts and Humanities, Music.
Data Availability Statement
The dataset used in this study is available at: https://github.com/Dsqvival/hierarchical-structure-analysis.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Ethical Approval
This research did not require ethics committee or IRB approval. This research did not involve the use of personal data, fieldwork, or experiments involving human or animal participants, or work with children, vulnerable individuals, or clinical populations.