
Abstract
The purpose of this research is to present a natural language processing-based approach to symbolic music analysis. We propose Mel2Word, a text-based representation including pitch and rhythm information, and a new natural language processing-based melody segmentation algorithm. We first show how to create a melody dictionary using Byte Pair Encoding (BPE), which finds and merges the most frequent pairs that appear in a collection of melodies in a data-driven manner. The dictionary is then used to tokenize or segment a given melody. Utilizing various symbolic melody datasets, we conduct an exploratory analysis and evaluate the classification performance of melody representation models on the MTC-ANN dataset. A comparison with existing segmentation algorithms is also carried out. The result shows that the proposed model significantly improves classification performance in comparison to various melodic features and several existing segmentation algorithms.
Keywords
Introduction
Music and Language
Although no definitive conclusion has been reached, there is no doubt that music and language clearly share some of the cognitive mechanisms and structural aspects. Despite the existence of differences in semantics and cultural function, a growing body of evidence suggests that language and music are more closely related than previously believed (Patel, 2003). From anthropological claims that language and music evolved in the same ancestral system (Brown, 2001) to empirical evidence that certain parts of the human brain system responsible for language transcend across two domains (Patel, 2003; Chiang et al., 2018; Maess et al., 2001; Koelsch et al., 2004; Tillmann et al., 2003; Brown et al., 2006), various significant scientific findings have revealed common features between music and language. These two share structural features and generate similar expectations for listeners (Besson and Schön, 2001). Studies in music and language include different perspectives such as speech and musical sound (Tervaniemi et al., 1999), melodic and rhythmic patterns (Patel et al., 1998), structural analysis (Lerdahl & Jackendoff, 1996; Patel, 2003; Fadiga et al., 2009; Fedorenko et al., 2009), and linguistic syntax (Patel, 2003; Hoch et al., 2011; Jung et al., 2015; Slevc et al., 2009). In the field of music cognition, music and language are considered to have common ground in the structural aspects of language; both are human universal in which perceptually discrete elements (e.g., words, chords) are organized into hierarchically structured sequences (e.g., sentences, melodies) according to syntactic principles. (Lerdahl & Jackendoff, 1996; Patel, 2003; Fadiga et al., 2009; Fedorenko et al., 2009). As Ycart and Benetos (2020) pointed out, music and language are both: 1) continuous sounds; 2) can be transcribed in symbolic forms such as text and music scores; 3) possess a sequential structure; 4) follow a set of special rules, such as the grammar of natural language and music theory; 5) use these basic rule sets to fill in missing parts in order; 6) use these rules to decide whether to make a valid sequence or not. Most notable in the relationship between music and language is that both music and language are the only old human creative activities that are communicated and used through symbolic representations that originated in ancient times (Wołkowicz & Keselj, 2010).
MIR and NLP
These commonalities between music and language have facilitated a natural language processing (NLP) approach to music processing and analysis. NLP is a field of artificial intelligence (AI) that enables computers to analyze and understand human language. The NLP approach to music can be traced back to pioneering studies that introduced formal grammar. In the early stages, theoretical attempts were made to establish a musical language model and structure similar to the syntax grammar of natural language (Roads & Wieneke, 1979; Smoliar, 1976). In particular, deeply influenced by Chomsky's generative grammar, the generative theory of tonal music (GTTM) (Lerdahl & Jackendoff, 1996) was developed based on similar tree structure-style hierarchical organization uniting musical “phrase groupings”. This model, the first systematic application of language theory to music, had a great influence on music theory, music psychology, and cognitive musicology. Until recently, various computational methods have been developed for symbolic music processing, such as melodic segmentation, generation, and reduction derived from GTTM (Hirai & Sawada, 2019; Hamanaka et al., 2008, 2019; Frankland & Cohen, 2004; Tsushima et al., 2020; Abdallah et al., 2016).
Especially in the field of music information retrieval (MIR), various attempts have been made to formulate a musicological task as a matter of natural language processing that exploits the linguistic features of music. Some early approaches used traditional NLP models such as probabilistic grammars (Bod et al., 2001; Gilbert & Conklin, 2007; García Salas et al., 2011) and N-gram models (Wołkowicz et al., 2008). Several studies defined the similarity or distance between two musical excerpts using edit distance (Mongeau & Sankoff, 1990; Crawford, 1998), N-gram measures (Downie, 1999; Uitdenbogerd, 2002), conducting melodic similarity and classification. Researchers have also increasingly used string-based methods in the NLP community for practical tasks such as pattern discovery (Conklin, 2002), melody reduction (Groves, 2016), composer recognition of musical pieces (Wołkowicz et al., 2008), and prediction (Conklin & Witten, 1995; Pearce, 2005).
Recently, NLP has drawn more attention by revealing a new potential in music analysis and music generation through the breakthrough of deep learning. In particular, the necessity of good word representation to achieve implicit contextual understanding in NLP has become apparent (Turian et al., 2010). NLP techniques such as word2vec (Mikolov et al., 2013) paved the way to represent words in a vector space. Using these methods, words are mapped into vectors in a data-driven manner, and the relationship between words can be captured according to the distance in this vector space. These word embedding techniques have been successfully absorbed into the MIR field as a new type of music representation of chords (Huang et al., 2016; Madjiheurem et al., 2016; Brunner et al., 2017), melody (Shin et al., 2017; Alvarez & Gómez-Martin, 2019), and other note patterns (Herremans & Chuan, 2017).
Research Question
While MIR has adopted a variety of NLP techniques, the fundamental and important issues in dealing with music as a language have been relatively overlooked: How can we define basic musical units for computational analysis that correspond to words in the language? Similar to the way that sentences in a language consist of a hierarchical structure of clauses, phrases, words, and morphemes, melodies in music can also be segmented in a different way according to theoretical approaches and hierarchical levels. In music, however, segmentation involves more complex issues: the terms we use for musical articulations (e.g., periods, phrases, motifs, and notes) reflect a linguistic borrowing of great antiquity, but the hierarchy is not always similar (Lidov et al., 2005), and there is no single and unambiguous set of terms (Cenkerová, 2017). Moreover, although motifs are generally considered one of the most fundamental units of music (Lerdahl & Jackendoff, 1996), it is not known how many notes a motif is made up of, and there are theoretically an infinite number of possible motifs (Sawada et al., 2020). Thus, melodic segmentation, which divides a sequence of notes into meaningful units, has been considered an important but complicated task in the field of MIR.
The sequence segmentation has been an important topic in the field of NLP as well. Due to the nature of language that new words are continuously coined or casually created, NLP systems cannot handle all the vocabulary in the world. Thus, they divide words into meaningful sub-units to represent all possible words by their combinations to avoid the out-of-vocabulary (OOV) problem. One of the notable works is Sennrich's approach (Sennrich et al., 2015), which utilized Byte-Paring Encoding (BPE) (Gage, 1994). BPE is a data compression algorithm that iteratively replaces pairs of bytes that frequently occur adjacently with an unused byte. Sennrich attempted to make these words fit into neural network models by representing rare and unseen words as a sequence of sub-word units through BPE. This approach has been actively used in numerous NLP studies since it was successfully applied to unsupervised word segmentation.
The main contribution of this study lies in the application of natural language processing (NLP) techniques to melodies, enabling the segmentation of melodies into novel encoding units suitable for semantic analysis. To this end, we introduce Mel2Word (M2W), a text-based melody representation. Mel2Word is composed of two processing steps. The first step involves converting the melody into a sequence of morpheme-level units, which consist of pitch intervals and inter-onset intervals (IOI). The second step is to segment this sequence into word-level units, which are combinations of morpheme-level Mel2Words using BPE. Using the “musical words”, we conduct melody classification and compare it to previous NLP-based methods. We adopted music classification in this study because it is related to various symbolic MIR tasks such as music similarity (Bountouridis et al., 2017; Park et al., 2019), pattern discovery (Conklin, 2009; Boot et al., 2016), genre recognition (Li & Sleep, 2004), and cultural origin prediction. (Rodríguez López & Volk, 2015).
This paper proceeds as follows: We begin by discussing studies on vector representations of words in NLP and MIR, as well as existing works on melodic segmentation methods. We next present our proposed method and carry out exploratory data analysis utilizing several datasets and quantitative evaluation experiments on the MTC-ANN dataset tune classification. We also compare this approach to existing segmentation methods to demonstrate its applicability.
Related Work
How Words Represent Meanings in NLP
The representation of word meanings is a fundamental challenge in NLP, and the vectorization of words aims to enable machines to comprehend word meanings. This section reviews two main approaches, 1) vector space model and 2) word embedding, and discusses how they have been applied to melodies in the field of music research.
The idea of the Vector Space Model (VSM) is to represent each document in a collection as a point in a vector space (Turney & Pantel, 2010). In this model, points that are close together in this space are semantically similar, and points that are far apart are semantically distant. The VSM basically has a statistical semantic hypothesis that statistical patterns of human word usage can be used to figure out what people mean. There are two main assumptions for this statistical information: 1) the “bag of words” assumption, and 2) the distributional hypothesis. The first assumption is one of the widely shared practices to treat the linguistic contexts in which a word occurs as unordered sets of words. In this so-called bag-of-words assumption, the linguistic context of any given word is defined by which words co-occur with it and with what frequency. This assumption disregards sequential and syntactic information, but the sequential order in which words occur, the argument structure, and general syntactic relationships within sentences all provide important information about the meaning of the words, consequently limiting the extent to which semantic information is extracted from the text (Andrews & Vigliocco, 2010). The second approach is motivated by the so-called distributional hypothesis (Harris, 1954), which proposes that the meaning of a word can be derived from the linguistic contexts in which it occurs. That is, similar words tend to occur in similar contexts; thus, the rows of any of these matrices can be used for estimating word similarities (Deerwester et al., 1990). Based on these assumptions, the VSM maps a document to a large number of content-related words or phrases, which successfully translates the textual document calculation to the vector calculation. The VSM, on the other hand, has constraints because it separates the original semantic relations of the text and abandons a large number of connections between words. Due to the fact that this results in high-dimensional sparse problems and high information loss, word embedding was proposed to deal with this issue (Bengio et al., 2003; Li & Yang, 2018; Ran & Han, 2020; Kazhuparambil & Kaushik, 2020).
Word embeddings are dense, distributed, fixed-length word vectors, built using word co-occurrence statistics as per the distributional hypothesis (Almeida & Xexéo, 2019). Its main goal is to map textual words or phrases into a low-dimensional continuous space to alleviate data sparseness and the small disjunct problem (Li & Yang, 2018). Since recent word embedding techniques generally induce a reduced, fixed number of dimensions, computation becomes more efficient compared to prior VSM approaches (Mikolov et al., 2013). The principle behind word embedding approaches is originally the distributional hypothesis and the vector space model of meaning. Word embeddings have evolved as a research field in and of itself because of their enhanced efficiency and several conceptual and practical advantages, such as the fact that they encode remarkably accurate syntactic and semantic word relationships (Mikolov et al., 2013). Word embedding encodes the semantic and syntactic information of words, where semantic information mainly correlates with the meaning of words, while syntactic information refers to their structural roles (Li & Yang, 2018). Word embeddings are commonly categorized into two types: 1) prediction-based and 2) count-based models, depending upon the strategies used to induce them (Almeida & Xexéo, 2019; Baroni et al., 2014; Pennington et al., 2014). Embedding models derived from neural network language models are called prediction-based models since they usually leverage language models to predict the next word based on local data (e.g., a word's context). On the other hand, other matrix-based models that use global information, generally corpus-wide statistics such as co-occurrence counts and frequencies, are called count-based models. In brief, Table 1 shows examples of models that have been actively used to infer the semantic meaning of words in NLP.
Models of representative vector representations for inferring semantic word information in the field of NLP.

In terms of music, MIR research has embraced classical VSM methods from the beginning. A wide variety of MIR tasks based on VSM approaches include similarity (Marolt, 2008), classification (Madhusudhan & Chowdhary, 2019; Çoban, 2017), plagiarism (Müllensiefen & Pendzich, 2009), phrase recognition (Gulati et al., 2016), music structure analysis (Maddage et al., 2006), segmentation (Rodríguez López et al., 2014; Neve & Orio, 2005), feature extraction (Yanase et al., 1999), and music information retrieval (Melucci & Orio, 1999).
Word embedding techniques, which have been around recently, have been successfully absorbed into the MIR field and have been actively employed as a new type of music representation. The word2vec approach was used in early research to learn music embeddings by predicting musical symbols based on neighboring symbols (Alvarez & Gómez-Martin, 2019; Chuan et al., 2020; Herremans & Chuan, 2017; Huang et al., 2016; Hirai & Sawada, 2019; Madjiheurem et al., 2016). In these studies, low-dimensional embeddings of symbolic melodies have been used to approach the concept of ‘word’ as note event-based or motif-based, resulting in a huge vocabulary with a long-tail distribution of words; hence only embeddings of the most frequently used terms were trained (Liang et al., 2020). Progress has been made over time toward music-specific embedding models that are trained to contain structural (e.g., measures, position) and various types of information (e.g., tempo, instrument, pitch) at the note level (Liang et al., 2020; Zeng et al., 2021; Chou et al., 2021). A brief summary of current music embeddings is listed in Table 2.
A brief summary of music embedding studies.
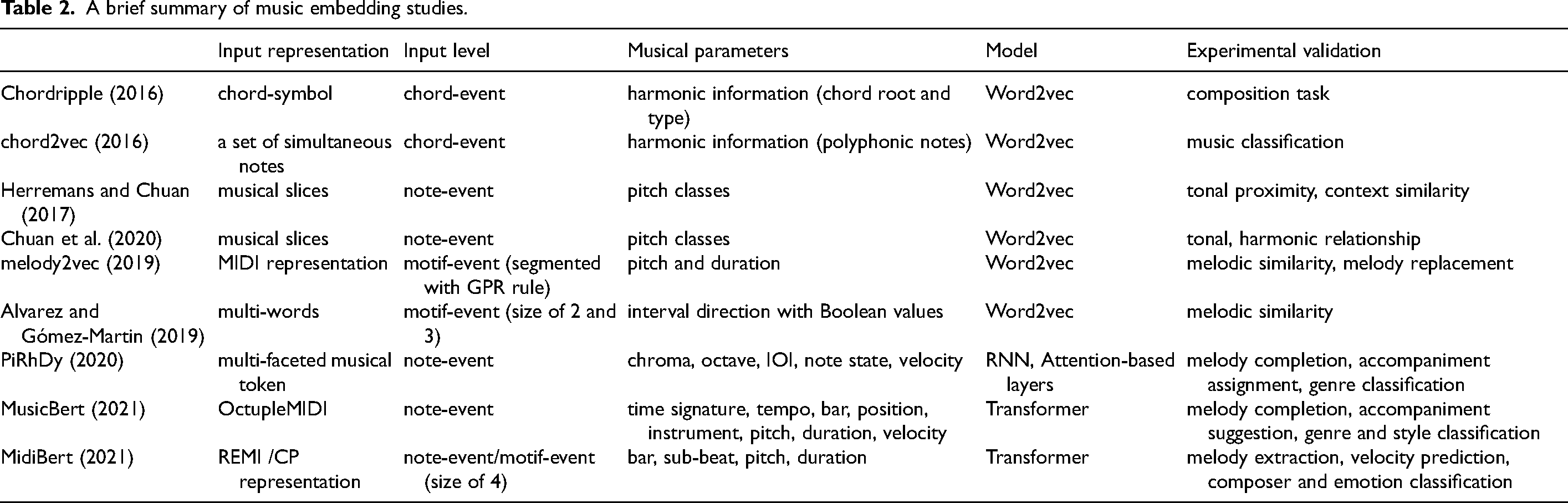
As stated, to encode the semantic information of music, studies on music embedding have been conducted in a variety of ways through the application of new input representations, parameters, and models. However, input levels generally lack the same musical meaning as note levels (single or simultaneous) or units of fixed size, except for the study in Hirai and Sawada (2019), where they utilized the GRP rule. By this point, we propose a textual representation that can be used as an initial seed for NLP-based models that try to understand the semantic meaning of language. By applying approaches that infer the meaning of words to melodies, we aim to fundamentally improve the directions for defining and vectorizing melodic terms that reflect musical semantic and context information.
Melody Segmentation
Segmenting a melody, commonly referred to as grouping or segmentation (Lerdahl & Jackendoff, 1996; Cambouropoulos, 2001), is a fundamental processing step for symbolic music analysis and its applications (Pearce et al., 2010). As speech is perceptually segmented into phonemes or words which subsequently provide the building blocks for the perception of phrases and complete utterances, the low-level organization of melody into groups allows the use of the primitive perceptual units in more complex structural music analysis and may alleviate demands on memory (Pearce et al., 2010). There are a number of models that have been proposed for melody segmentation so far. We review some of notable ones, dividing them into psychological models and computational models.
Psychological Models
The application of Gestalt psychology's perceptual grouping mechanism to musical perception is an essential method for melody segmentation in music theory and cognitive psychology. In this regard, the GTTM model and the Implication-Realization (I-R) model have had a strong influence on empirical music studies as well as melody segmentation and grouping.
Computational Models
Computational segmentation models in the symbolic domain are divided into two categories: rule-based or data-driven models (Ellis, 1996; Rodríguez López, 2016). Rule-based models follow a presumption to determine whether the sequences should be grouped or segmented, whereas data-driven models use a post-assumption that a series of events are likely to be grouped by a listener if they occur frequently; in other words, statistical regularities determine perceptual grouping.
These models studied melody segmentation primarily at a phrase level rather than at lower levels in the structural hierarchy, such as motifs (Cenkerová et al., 2018). The efforts have mainly focused on perception of melody boundaries or understanding of the structural segmentation of music, and hence the performance of the proposed model has mostly been established as the degree of agreement with human ratings. However, a challenge here is the subjective nature of human perception in that there is no “correct” segmentation (Cenkerová et al., 2018), as well as the fact that only a few task-oriented empirical attempts for melodic analysis have been carried out. We believe that melody grouping based on subjective human perception should be distinguished from melody segmentation for MIR tasks. Therefore, rather than perceptually recognizable phrases, the goal of this study is to segment melody in a data-driven way and find representations for symbolic MIR tasks.
Proposed Method
We introduce a novel text-based melody representation, which we term Mel2Word. The key idea is to segment melody into meaningful units, which are equivalent to words in language. This section describes the processing steps.
Morpheme-Level Text Encoding
The first step of Mel2Word is to encode a melody into a sequence of text units. The text unit satisfies the following requirements:
It is notated in a textual format for melodic analysis using NLP techniques. It contains the core information about melodic features: pitch and rhythm. It is invariant to key, time signature, or other variables except for the melodic features. It represents melodies in the same context in an identical notation. The length of the single unit is fixed.
As indicated in requirement (1), the purpose of this encoding is to represent music in a textual format to facilitate the application of methods in NLP. As indicated in requirement (2), this representation carries two main elements of the melody: pitch and rhythm information. To meet requirement (3), pitch and rhythm are notated as pitch interval and IOI rather than absolute pitch and time duration, so that they are invariant to key and tempo. This also addresses requirement (4), where melodies in the same context are notated with an identical representation. Finally, for requirement (5), the length of a single text unit is fixed to a constant number of characters, which is a combination of numbers and alphabets representing the pitch interval and IOI. Since the single text unit is the smallest unit that has a musical meaning, we call it “morpheme-level” text unit
An example of text encoding is shown in Figure 1. The details of the encoding rules are as follows: Each text unit consists of 1) a pitch feature that shows the difference in direction and interval; and 2) a rhythm feature that is represented by IOI between two consecutive notes. The unit corresponds to two consecutive notes which is regarded as the smallest musical unit with the meaning of the expression (Stein, 1979). Pitch information is represented by three letters: ‘U’ (up), ‘D’ (down), or ‘E’ (equal) denoting the direction, followed by a number between ‘0’ and ‘12’ indicating the size of the interval. To cut down on the number of redundant melodic units that are rarely used, the numbers exceeding 12 are substituted by 12. To fix the length, the numbers from 0 to 9 are notated as two digits (for example, 1 is represented as ‘01’). For rhythm information, three-digit numbers are used to represent the inter-onset interval (IOI). When the IOI is converted to text, even small changes in value can be treated very differently. Therefore, in order to minimize noise derived from minor variations, we suggest quantization of rhythm. Quantization can be done in a variety of rhythmic units, such as eighth notes, sixteenth notes, and thirty-second notes. Different quantization units will have their pros and cons. For example, the finer the unit, the better it can reflect rhythmic details such as dotted notes and triplets. But this may also result in an overly large number of rhythmic terms, and complex features may increase the computational load (e.g., when training the embedding model). Therefore, in this study, we set the rhythm in minimum units up to the 16th note, which is very common in general melodies. For better readability, the most common, if not all, quarter notes representing one beat are set to the default unit of 1, and the final rhythm value is multiplied by 100. For example, the number ‘100’ represents a quarter note, and ‘200’ represents one half note. In this study, the maximum of the rhythm is set to 4 quarter notes, so the range of IOI quantized by 16th notes ranges from a minimum of ‘025’ (16th note, original 0.25) to a maximum of ‘400’ (whole note, original 4). According to these principles, the example on the left of Figure 1 has a pitch feature of ‘E00’ (Equal ‘00’), indicating that two consecutive notes are identical, and it contains a rhythm feature of ‘100’, which represents the value of a single beat (a quarter note). Another example on the right has a pitch feature of ‘D02’, indicating that it moves down one whole-tone, and a rhythm feature of ‘050’, indicating that it is an eighth note. Pitch and rhythm can be encoded both together and separately. The table in Figure 1 shows how pitch and rhythm can be encoded individually.

An example of melody notated in Mel2Word.
Morpheme-Level Units to Word-Level Units
The second step is to merge the encoded morpheme-level units into word-level units. This step consists of dictionary generation and tokenization using BPE.
Dictionary Generation
We use BPE for dictionary generation. BPE is a bottom-up approach for gradually building a vocabulary from a character unit. BPE was originally devised as a data compression technique that replaces the most frequently occurring pair of bytes in a sequence with a single unused byte iteratively (Gage, 1994). This data-driven approach has been effectively applied to word segmentation as Sennrich et al. (2015) proposed a BPE-based segmentation to acquire a vocabulary that provides a good compression rate of the text by merging character sequences. The basic process of BPE in Sennrich's work is as follows:
The symbolic vocabulary is initialized with a character-level vocabulary. Here, a special word end symbol ‘.’, a period mark, is added to each character to restore the original tokenization back to the word level. Every pair of symbols is counted iteratively, and each occurrence of the most frequent pair is replaced with its concatenation as a new symbol. For example, ‘A’ and ‘B’ are replaced with ‘AB’. Each merge operation creates a new symbol representing the character N-gram, and the final symbol vocabulary size is the number of merge operations in addition to the initial vocabulary size.
The process of creating a dictionary using BPE algorithm is demonstrated with a toy example in Figure 2. The training data initially contains ‘low’, ‘lower’, ‘newest’, and ‘widest’. Each word occurs by the number next to it.

An example of sub-word dictionary generation through BPE.
The first step is to split all the words in a dictionary into single characters and take the union as vocabulary (Figure 2(a)). Given that a pair of ‘e’ and ‘s’ is the most frequent, it is merged into ‘es’ (Figure 2(b)). When this operation is repeated twice, a pair of ‘es’ and ‘t’ becomes ‘est’ (Figure 2(c)). When repeated ten times, the dictionary and vocabulary set become as shown in Figure 2(d).
We adapt the BPE technique to the text-based melody representation as follows:
The melody is converted into a morpheme-level text sequence. This text unit corresponds to the character-level unit in Figure 2. The most frequent pair of two consecutive morpheme-level text units is selected. The selected pair is merged with the ‘_’ symbol.
As an example, consider a melody sequence, M0 = ABABABC, where each character represents a morpheme-level text unit. This sequence can be initialized with a single unit: M1 = A,B,A,B,A,B,C. In the first iteration of merging, we convert A,B to A_B (which occurs most frequently in the sequence) to obtain the segmented sequence M2 = A_B,A_B,A_B,C. Repeating this process once again, the most frequently occurring consecutive pair is A_B,A_B. Thus, the melody sequence M0 = ABABABC is segmented into the melody sequence M3 = A_B_A_B,A_B,C after two iterations. Figure 3 shows an example of segmenting a melody and creating a Mel2Word dictionary (denoted characters in the preceding explanation are marked in brackets).

An example of creating word-level units of Mel2Word using pitch features for dictionary generation through BPE.
Tokenization
Once the dictionary is generated, each melody is segmented into the word-level units of Mel2Word as the tokenization process in NLP. This process is based on two criteria: 1) the length of a single text unit, and 2) the frequency of occurrence. The BPE algorithm implicitly assumes that longer or more frequent units are more essential. Following the first criterion, a melody is segmented in descending order of the unit length, with longer Mel2Word taking precedence. The second criterion is applied when the lengths of Mel2Word are equal. Therefore, the melody is tokenized in the order of its frequency. For example, to tokenize any raw melody by a dictionary with a maximum length of 11, scanning from the beginning to the end of the melody, all phrases of length 11 in the melody are scanned from beginning to end for a phrase that matches the most frequent Mel2Word phrases of length 11. Then it moves on to the next frequently occurring Mel2Word of length 11. If no matching phrase is found in all Mel2Word phrases of length 11, the tokenization process continues and moves on to the most frequent Mel2Word of length 10. This sequential procedure preferentially merges longer and more frequent phrases, matching all Mel2Word phrases in word-level units between maximum length 11 and minimum length 2 in the Mel2Word dictionary. The tokenization process ends when only morpheme-level units of Mel2Word without any matching phrases remain. Figure 4 shows an example of the process of tokenizing a melody with the generated Mel2Word. As shown, since the example phrase of ‘U03100_D02050_D01050_D02050’ is inside the melody, the matching parts (in the red dotted box) are merged and tokenized into Mel2Word as one phrase.

An example of segmenting a melody with the word-level units of Mel2Word.
Experiments
Datasets
We collected symbolic monophonic melody datasets to examine various musical sequences from different genres and construct a Mel2Word dictionary. Table 3 gives a brief overview of the datasets we used. Out of a total of 3,044 digitally encoded songs in the large corpus, we discarded melodies that could not be read with music21
A summary of the monophonic melody datasets used for dictionary generation.

Dictionary Generation
We converted all the melodic sequences in the datasets from MIDI to morpheme-level text units and then performed BPE to build the Mel2Word dictionary. Each iteration of BPE resulted in a new set of Mel2Word in the word-level unit, and the iteration stopped when there were no more identical Mel2Word pairs. Following the claim of Stein (1979) that one meaningful phrase is 2 to 12 notes, the maximum length of a single Mel2Word was set to 11 (i.e., 12 notes). If the merged pair was longer than 11, the second most common pair was chosen instead. Since the morpheme units in Mel2Word have both pitch and rhythm units together or independently, we can use all of these features to build three different types of dictionaries (pitch only, rhythm only, or both). We created dictionaries using all three features, and when a new Mel2Word was generated, the frequency of occurrences in the dataset was also saved in the dictionary for tokenization. Table 4 shows a summary of the dictionaries built in this experiment.
A summary of generated dictionaries.

Tokenization
Since the Mel2Word dictionary includes the frequency of each term in occurrence, it is possible to tokenize melodies in various dictionary sizes based on the prevalence of each term. For example, using 100 most frequently used Mel2Word phrases, we can create a dictionary size of 100.
With this approach, melodies can be divided into segments with different levels. Figure 5 demonstrates tokenizing melodies with two different sizes of dictionaries. A two-bar melody with 12 pitch intervals is tokenized into 7 segments with a small dictionary (N = 100) or 4 segments with a large dictionary (N = 5,000). For exploratory data analysis and evaluation, we tokenized melodies with dictionaries of different sizes, from small to large. The largest dictionary was built with the Mel2Word phrases that had at least 10 frequency occurrences (full-token N = 3529, 2043, and 5026 for pitch, rhythm, and pitch+rhythm, respectively).

Examples of tokenization according to different Mel2Word dictionaries (A melody from MTC-ANN).
Exploratory Data Analysis
We examined two datasets for exploratory data analysis to compare melodies using Mel2Word tokens from different genres. We chose the annotated Meertens Tune Collection (MTC-ANN), version 2.0.1 (van Kranenburg et al., 2016), the folk-tune dataset containing 360 melodies divided into 26 tune families annotated by musicological experts, and the Weimer Jazz Database (WJazzD) (Pfleiderer et al., 2017), the database of jazz solo transcriptions, as sample examples. Figure 6 shows the statistical distribution. The left side shows the number of songs by the melody length (i.e., the number of segments in one song) when pitch intervals are used. It indicates that the range of segment lengths becomes narrower as the dictionary size is larger. The same trend is found when rhythm intervals or both pitch and rhythm intervals are used. The right side shows the distribution of Mel2Word tokens by length when each dataset was tokenized with the Mel2Word dictionary. In both datasets, the combined (pitch+rhythm) feature has the most frequent Mel2Word at the length of 2, while pitch only has the most at the length of 4. In rhythm alone, the lengths of Mel2Word are evenly distributed since repetition is more frequent.

Statistical distribution of datasets (Left: the number of songs according to the length of the melody. Right: the number of Mel2Word phrases according to the length of the Mel2Word).
Figure 7 is a visualization of these two different datasets using a wordcloud

Wordclouds created by different datasets.

Examples of Mel2Word tokens in different datasets.
Evaluation
To empirically evaluate our approach, we conducted a tune classification experiment using the MTC-ANN dataset, which serves as a benchmark for music analysis in various studies (Boot et al., 2016; Bountouridis et al., 2017; Walshaw, 2017; Park et al., 2019). In this experiment, our primary focus was to demonstrate the effectiveness of our tokenization method, utilizing minimal features (pitch and rhythm) and a straightforward similarity evaluation. We compared the results of our proposed method with a basic baseline using raw morpheme-level representations, thereby emphasizing the robustness and significance of our approach without the need for more advanced algorithms or complex feature sets. To achieve this, we conducted the classification task using different input units corresponding to various dictionary sizes.
Mel2Word Embedding
For semantic vectorization for Mel2Word, we utilized word2vec, a widely used NLP technique to represent a word in a distributed vector space (Mikolov et al., 2013). The learned representation is obtained based on the affinity of words within a context window and, as a result, words with similar meanings are located closely in the vector space. Word2vec has been actively exploited as a new representation in music analysis to capture semantic meaning in the musical corpus (Alvarez & Gómez-Martin, 2019; Chuan et al., 2020; Herremans & Chuan, 2017; Huang et al., 2016; Hirai & Sawada, 2019; Madjiheurem et al., 2016). We also applied word2vec to Mel2Word tokens to investigate the melodic similarity. For word2vec training, we used Gensim13, a Python implementation of word2vec (Rehurek & Sojka, 2010). We chose the skip-gram model (predicting context words according to the target word) over the CBOW model (predicting the target word according to the context) because it is considered to better represent sparse words (Landgraf & Bellay, 2017). To construct a comprehensive and versatile embedding model for melodic representations, we utilized a melody corpus composed of various datasets, which were also used for dictionary generation (refer to Table 3). We tokenized all of the melodies using dictionaries of different sizes and made several models to examine each dictionary. All of the basic model parameters were set to 512 dimensions, a context window size of 10, and 300 training iterations, based on our preliminary experiment. These models were used to obtain the vector representation of each Mel2Word, and the single melody vector can be derived by averaging the vectors of all the Mel2Word phrases in the melody. Figure 9 shows the t-SNE representation of all training melodies vectorized by the word2vec model with full tokens. Here, we can observe that the melodies are well clustered by genre. Accordingly, we assessed the performance of MTC-ANNs in terms of these models built with varying dictionary sizes and segmentation models.
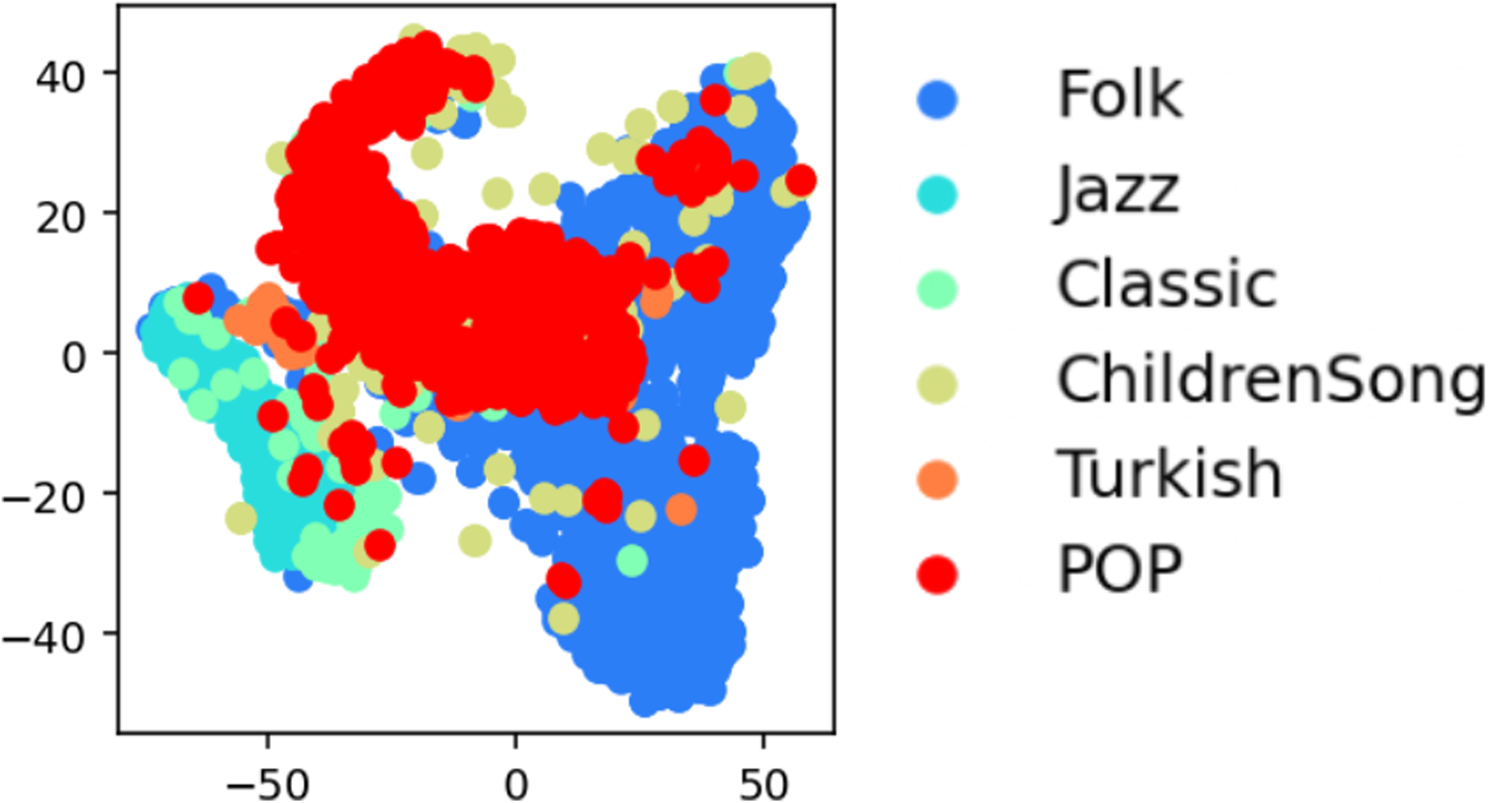
t-SNE visualization for training melodies for word2vec (full-token).
Segmentation Algorithms
For comparative evaluation of the proposed algorithm, we performed melody classification using melody tokens segmented by existing segmentation models. First, we employed three segmentation algorithms developed in MIDI Toolbox (Eerola & Toiviainen, 2004): 1) a Gestalt-based approach described in Tenney and Polansky (1980), 2) the Local Boundary Detection Model proposed by Cambouropoulos in Cambouropoulos (2001), and 3) Markov's model presented in Bod et al. (2001). For the segmentation boundary, we used the default parameters for the Gestalt-based and Markov models in the toolbox, as well as a threshold value of 0.1 based on our preliminary analysis of the LBDM model. Briefly introducing each approach, a Gestalt-based method detects “clang” changes, which correspond to large pitch intervals and large inter-onset intervals (IOIs). The Markov-model-based algorithm uses the probabilities derived from the analysis of melodies In this technique, the probabilities of phrase boundaries have been derived from pitch class, interval, and duration distributions at the segment boundaries in the Essen folk song collection. LBDM derives boundary strengths that are proportional to the degree of change between two intervals. For the segmentation boundary, Gestalt-based values were binary values of 0 and 1, hence they were utilized as-is for the segmentation boundary. In the case of the Markov-model-based approach, it was set as the segmentation boundary if it exceeded 0; in the case of LBDM, it was set as the segmentation boundary if it exceeded 0.1, based on our preliminary analysis. Since these algorithms were defined in terms of individual notes rather than the relative values of intervals and IOI employed in Mel2Word, we set the segmentation boundary as the second note of two consecutive notes. The melodies were also segmented into fixed sizes of 2-gram and 3-gram. In addition, we implemented GPR rules following Hirai and Sawada (2019), i.e., when considering a series of four notes (i.e., n1, n2, n3, and n4), it is considered that there is a boundary between n2 and n3 if the following requirements are satisfied: IOIn2–n3 > IOIn1–n2 and IOIn2–n3 > IOIn3–n4.
We used Music21 written in Python whereas the existing segmentation methods are implemented with MIDI Toolbox written in MATLAB. They gave different melodic features for some melodies, presumably because the two libraries parse MIDI files differently (for example, MIDI Toolbox misses some repeated notes, and the way they read multi-channel notes is different). Therefore, we excluded melodies whose pitch and rhythm features were different in the two libraries. As a result, we used a total of 2,752 melodies for the comparative analysis.
Similarity Metrics
In our study, to compare the similarity of the two melodies, each melody was compared with a value obtained by averaging the vectors of all Mel2Word segments in the word2vec embedding vector space. Cosine similarity was employed to determine vector similarity, as it is the most common way to measure the similarity of two frequency vectors (Turney & Pantel, 2010). Despite its limitation in discarding positional information as discussed in Le and Mikolov (2014), we chose this approach considering its common use in measuring vector similarity, and it provides a straightforward and effective way to assess similarity in our context.
For the compared melodic sequence with Mel2Word Ma = (a1,a2,–an), and Mb = (b1,b2,–bm), where A and B are averaged vectors of Mel2Word of Ma and Mb, and Ai and Bi are components of vectors A and B respectively, the cosine similarity cos (θ) is expressed using dot product and magnitude as: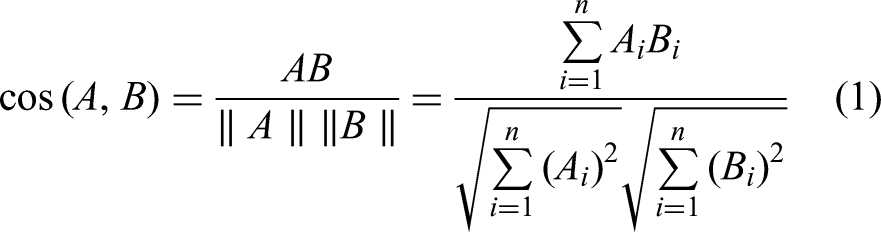
Evaluation Metrics
To evaluate classification performance, the similarity between each melody of MTC-ANNs with 26 classes (or tune families) was calculated, and the following three evaluation metrics were utilized:
Results
Comparison of Dictionary Size
Figure 10 shows the classification performance with different melodic features and dictionary sizes. As shown, all evaluation metrics showed that the proposed method outperformed morpheme-level text units in tune classification performance. Even with a small size of dictionary (N = 100, for example), performances improved considerably. In the case of pitch and combination features (pitch+rhythm), the performance improves modestly as the dictionary size increases, resulting in the best performance when full tokens are used. However, a larger dictionary does not necessarily increase the classification accuracy. With a larger dictionary, we can obtain richer Mel2Word variants in word-level units but this can also have a negative impact because the frequency of particular terms decreases across the entire dataset. If the melody is tokenized into fewer segments, it also means the amount of data (or segments) used for training will be also reduced. Our results show that the performance does not improve much as the dictionary size continues to increase, and in the case of rhythm, the performance becomes lower. Therefore, we believe that advanced research with a bigger dataset is further needed to find the optimal size of the dictionary.

The classification result of the MTC-ANN dataset, where N denotes the dictionary size for melody tokenization.
The Gensim library we used allows us to find the word most similar to a specific word or derive similarity values between words through the distance of the embedding vector of the trained model. Here, a closer vector representation of Mel2Word indicates that the word2vec algorithm has modeled them as words that are semantically closer in context. To show the difference between vectors of words and embedding spaces created by different dictionaries, Figure 11 shows two case examples of finding the most similar words through the word2vec embedding model obtained by tokenized melodies with several dictionaries (N = 100, 500, and full). For example, in the case of ‘U01050_U02050’ in the example on the left, the most similar word on a vector space trained with tokenized melodies with a dictionary of size N = 100 is ‘U02050_U01050’ with a cosine similarity of 0.55. We also used PCA to visualize the 3-D space of the embedding model built through each dictionary (the left is with N = 100, the middle is with N = 500, and the right is with full-token; the reds are the original object, the blues are the most similar Mel2Word, and the yellows are all other Mel2Word phrases). We can see here that as the size of the dictionary increases, more Mel2Word variants with word-level units are created and densely distributed. In addition, it can be observed that the Mel2Word derived as the most similar phrases have similar pitch directions and contain or share the same pitch and rhythm as the original phrases. This demonstrates that training in word embedding can be used to vectorize melodic phrases with similar contexts. Further investigation is required to determine whether these Mel2Word units are used more frequently in the same musical context and to explore whether phrases that are close in the embedding space exhibit perceptually more similarity compared to distant phrases. This analysis is particularly important as it would have been difficult to identify these phrases if pitch and rhythm were split into discrete units. We consider this exploration as a promising first step toward understanding the semantic meaning of melodic phrases and their perceptual relationships.

Examples of finding the most similar Mel2Word based on word2vec vectorization.
Comparison of Melodic Features
Figure 12 illustrates the classification performance by different melodic features, t-SNE visualizations by models trained with morpheme-levels of pitch, rhythm, and combination features, respectively, from left to right. The right-most visualization is from a model trained with the combination level as a full-token14. In the lower right corner, we’ve also marked the feature-by-feature performance at the morpheme level and the full-token level to show how the performance of each feature varies. As shown, Mel2Word performed best with the combination feature at both the morpheme and full-token levels, while Mel2Word with only a rhythm performed worst. This t-SNE visualization demonstrates that various melodic features and tokenizations can facilitate more effective clustering, emphasizing the need for precise melodic representations.

t-SNE visualizations and feature-to-feature performance at morpheme-level and full-token level on the classification evaluation of the MTC-ANN dataset.
Comparison of Segmentation Models
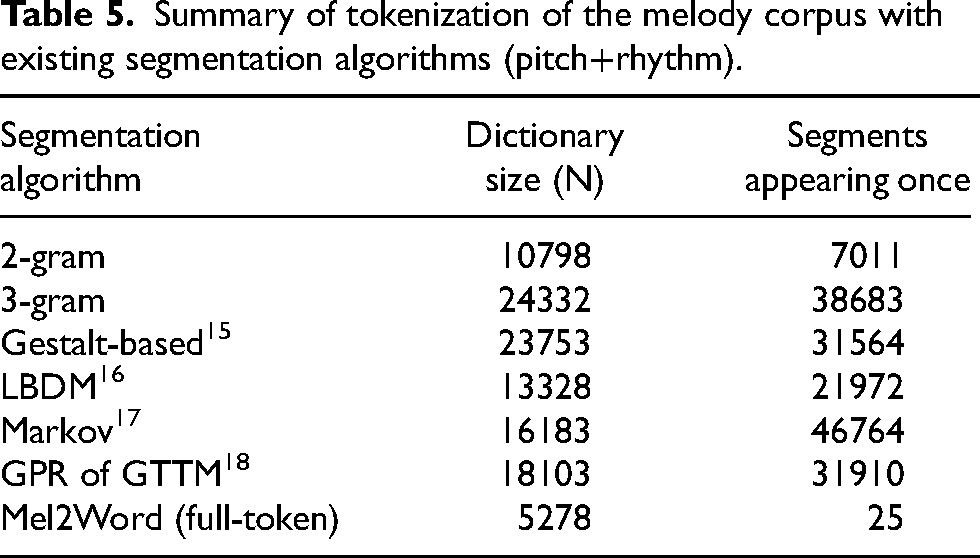
The comparison results between the segmentation algorithms are shown in Figure 13. They are arranged from left to right in an ascending order of AUC performance. The existing segmentation algorithms have higher performance over the morpheme-level units but the proposed method showed the highest performance and outperformed all existing algorithms. Even more remarkable is that this approach can build more precisely compressed and effective melodic units. Table 5 outlines the segmentation of the melody corpus using the existing segmentation algorithms. As shown, most existing algorithms generated much larger dictionaries and there were many useless segments that only appeared once in the entire dataset, suggesting that they might not be the ideal approach. But with our approach, even when all tokens were used up, there were still only 25 segments that showed up once in the whole dataset. We expect that this approach will enable the employment of current NLP-based algorithms with a variety of existing MIR tasks by allowing the utilization of small-to-large dictionary sets for music analysis.

Comparison between segmentation algorithms.
Summary of tokenization of the melody corpus with existing segmentation algorithms (pitch+rhythm).
Conclusions
In this study, we introduced Mel2Word, a text-based representation with pitch and rhythm information, and a natural language processing-based approach for tokenizing melodies into word units. We applied our method to build Mel2Word dictionaries for exploratory data analysis across multiple datasets and performed tune classification experiments with the word2vec word embedding on the MTC-ANN dataset. We also conducted a comparative analysis with representative existing segmentation methods in the area of symbolic music research. As a result, the proposed method improved performance on basic melodic features across all evaluation metrics and outperformed existing segmentation methods used in this experiment, showing that our approach could be employed efficiently and effectively for NLP-based word embeddings. One benefit of this data-driven method is that it can establish simple, concise, but powerful text-based musical words that would be difficult to construct with a rule-based method. As demonstrated, empirical experiments have shown that classification performance is improved even with a small dictionary size (e.g., N = 100), indicating the potential applicability of Mel2Word for other kinds of computational music analysis. It is considered that this method is applicable to practical tasks such as auto-music composition. Since this method can identify different phrases and patterns based on certain classes, it can be extended to genres, artists, emotions, etc., and used to generate melodies based on them, for example.
Beyond outstanding performance, the most promising aspect of this research is that it can serve as a starting point for comprehending the semantic relationship of melodic terms. Defining musical words as basic units for computational analysis in melodies can also mean that they can also be “vectorized” as significant units. When we understand a language, we don't break words into individual characters or fixed-length words. We perceive the meanings of words similarly or differently depending on their context and relationship to other words. For example, “word” and “vocabulary” differ in length by more than twice as much, but their meanings are similar. Similarly, as we observed in our example (Figure 11), “mi-fa-sol” and “re-mi-fa-sol” may have semantic meanings of music that are more closely related than other melodic segments. And if such semantic relationships across melodic terms can be understood, we believe that a more qualitative level of musical analysis will be possible to help address some of the critical and challenging topics in computational music analysis. Consider, for example, the issue of plagiarism. While similarity analysis of symbolic melodies has great potential in the context of plagiarism (Yin et al., 2022), how would we define the creativity (or uniqueness) of a melody? Fortunately, in language, examining the similarity of “words” in documents enables the commercial and academic deployment of such plagiarism detection systems (e.g., Turnitin19). How about musical emotions? Psychologists have defined emotional vocabulary in language, and a quantitative analysis of these emotional vocabularies helps to give a quantitative measure of emotion (Danner et al., 2001). Thus, we believe this simple music-to-NLP scheme could be a powerful means to employ the most recent advances in natural language processing, opening up a potential for fundamental or practical music analysis and applications.
Footnotes
Action Editor
David Meredith, Aalborg University, Department of Architecture, Design and Media Technology
Peer Review
Aitor Arronte-Alvarez, University of Hawai’i at Mānoa, Center for Language and Technology
One anonymous reviewer
Contributorship
Saebyul Park: main author, writing, code implementation. Eunjin Choi: code development, data organization. Jeounghoon Kim: research questions, supervision. Juhan Nam: research direction, corresponding author, review editing.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Ethical Approval
This research did not require ethics committee or IRB approval. This research did not involve the use of personal data, fieldwork, or experiments involving human or animal participants, or work with children, vulnerable individuals, or clinical populations
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.