
Abstract
Edwin E. Gordon developed the Advanced Measures of Music Audiation (AMMA) test to quantify the extent of an adult's stabilized audiation as a fundamental indicator of musical ability. Although intended to measure audiation exclusively, AMMA is based on a test design similar to the tonal memory subtest of the much older Measures of Musical Talents (SMMT) test developed by Carl Seashore (1919). However, previous studies have shown mixed results regarding AMMA's construct validity. It therefore remains unclear whether AMMA is suitable for measuring audiation exclusively, as intended by Gordon, or whether it additionally measures tonal memory. Accordingly, we tested this hypothesis in two steps. First, responses of 364 participants were used to identify – in terms of the Rasch model – those items of AMMA that could form a “revised” scale showing measurement invariance; second, we used a Bayesian post hoc correlation analysis (N = 83) to measure the construct (discriminant) validity of the revised version of AMMA compared to an equal number of items in the tonal memory subtest of SMMT. Results from both studies revealed that (a) only five out of 30 items of AMMA showed a model fit that was adequate to form a scale which meets the psychometric requirements of invariant measurement, although with a low internal consistency and an increased probability for ceiling effects, and that (b) both measurements showed a strong correlation (Mdnτ = 0.56, 95% CI [0.42, 0.70], BF+0 = 2.67·1012). We can thus conclude that there is no practical evidence to assume that both test procedures (AMMA and SMMT) are independent.
Keywords
A central question in music education research is how to account for inter-individual differences in music-related achievements (Law & Zentner, 2012; Müllensiefen et al., 2014). With regard to the development of music-related skill, some models still emphasize musical aptitude as an innate variable in (early) childhood. This aptitude is regarded as at least a necessary – if not the most important – factor that may explain and even predict differences between individuals in musical achievement (e.g., Gagné & McPherson, 2019; Schellenberg & Weiss, 2013; Tan et al., 2014). One such approach is Edwin Elias Gordon’s (2012) widely accepted music-learning theory (cf. Shuter-Dyson, 1999, p. 627).
In his music-learning theory, Gordon proposes that the upper limit of people's future music-related achievement is mainly determined by a person's degree of “audiation”, a core component of innate music aptitude (Gordon, 2012). Since its introduction in 1975, and as a neologism combining “audition” and “ideation” (Gerhardstein, 2002, p. 112), the concept of audiation has been revised several times. According to Gordon (2012), “audiation is the process of assimilating and comprehending (not simply rehearing) music momentarily heard performed or heard sometime in the past” (p. 3). Specifically, audiation consists of two interdependent processes, the first of which – the “assimilation” process – is the successful assignment of sensory information to music-related mental patterns regardless of whether this information has been aurally perceived or imagined. The subsequent “comprehension” process of audiation refers to ensuing mental operations including summarizing, generalizing, anticipating, and weighting information based on music-related syntax (Gordon, 2012, pp. 5, 114–116). In the words of Gordon (2012), “sound itself is not music. Sound becomes music through audiation when (…) we translate sounds in our mind and give them meaning” (p. 3). Audiation occurs as a mental activity “by anticipating [emphasis added] in familiar music and predicting [emphasis added] in unfamiliar music what is to come. It involves forward thinking [emphasis added]” (Gordon, 2012, p. 10). Audiation can therefore be characterized as an active cognitive process of creating musical and meaningful units (Gordon, 2012, p. 3). Furthermore, audiation is not a synonym for inner hearing, imitation, memorization, or auditory imagery (Walters, 1989). According to Gordon (2012, pp. 9–12), these skills, unlike audiation, rely on preceding mental events due to their dependence on the successful recall of memorized music without the need to form musical meaning. For example, in contrast to audiation, imitation describes merely a process of copying movements executed on an instrument (or with the voice) without the need for a deeper understanding of one's own activity (Gordon, 2012, pp. 9, 397).
Gordon's music-learning theory assumes that music aptitude refers to the innate potential of learning that is reflected in a student's musical achievements (Gordon, 1989, p. 5, 2012, p. 44), whereby a “window of opportunity” might exist for developing audiation early in life. Once stabilized at around the age of nine, the level of music aptitude developed is presumed to define the upper limit of an individual's future achievement in music, even in optimal learning conditions (Gordon, 1989, p. 15, 2012, p. 46). Therefore, for a student to achieve a maximum level of musical attainment as determined by his or her music aptitude (that is, stabilized audiation), an optimal learning environment is required in which instructions should, above all other learning preconditions and requirements, be designed to match an individual's level of audiation (Gordon, 2012, pp. 46–51). To most effectively identify a student's audiation abilities, music educators should call for a valid measurement tool that meets all criteria governing psychometric standards in the related fields of psychological and educational diagnostics (American Educational Research Association et al., 2014). Moreover, the availability of objective and valid tests is in any case a crucial cornerstone for the development of scientific theories (Watson, 2012).
For this purpose, Gordon developed several music aptitude tests intended to measure the music audiation of individuals from different age groups from pre-school to adolescence (Gordon, 1965, 1979 & 1986, 1989). These tests have been widely used for assessing music aptitude in various types of school (Moore, 1995) as well as informing research in the fields of music psychology (e.g., Bugos et al., 2007; Burgoyne et al., 2019; Hayward, 2009), music education (e.g., Degé et al., 2017; Schleuter, 1993), and neuroscience (e.g., Schneider et al., 2002; Schneider et al., 2005). In particular, the Advanced Measures of Music Audiation (AMMA) test procedure (Gordon, 1989) has been used as a reference for cross-validating new inventory tests (Law & Zentner, 2012; Müllensiefen et al., 2014; Wallentin et al., 2010). The AMMA can therefore be regarded as a gold standard for music psychology research with young adults and in the development of diagnostic procedures for operationalizing musical aptitude as a latent trait.
The AMMA is intended to measure the degrees of stabilization in the audiation of college students, high school pupils, and junior-high students (Gordon, 1989, p. 15). In this test, participants listen to a pair of melodies for every item and must decide whether the two melodies differ due to a possible tonal or a rhythmic change in the second melody. All melodies (and their paired variations) are especially composed, mostly based on modal or atonal-harmonic compositional principles, and are often combined with an irregular rhythm or a ternary metrical structure. Participants have to choose between three responses to the second melody of each pair (s = same; t = tonal change; r = rhythm change) while leaving items unanswered in the case of doubt to minimize guessing as a possible confounding variable (Gordon, 1989, p. 23). The AMMA test consists of 30 items, each item being a melody pair. Among the 30 pairs, there are 10 pairs with tonal changes (so-called “tonal” items), 10 pairs with rhythmic changes (“rhythm” items), and 10 pairs with no changes at all (“same” items).
The development of the AMMA was based on two key assumptions. First, once it has been stabilized, audiation is a latent trait like any other aptitude and is thus normally distributed among the population (Gordon, 1989, p. 10). Second, it is solely responsible for a student's response behavior on all test items because “a student is expected to audiate concurrently [emphasis added] tonality, keyality, implied harmony, rhythm, meter, and tempo in a test question” (Gordon, 1989, p. 16). The AMMA test thus differs significantly from Gordon's test procedures for younger children and adolescents, such as the PMMA and the IMMA (Gordon, 1979 & 1986), in which these musical parameters are assumed to be processed independently from each other and are consequently assessed by separate subtests. In essence, the AMMA's overall test score captures the concurrent feature processing of time- and pitch-dependent auditory information along with the music-related mental operations relating to stabilized audiation. Most importantly, this characteristic also implies a theoretically desired unidimensionality of the measured latent trait (Gustafsson & Åberg-Bengtsson, 2010, p. 97), and thus offers more clarity in interpreting test scores (Bond, Yan, & Heene, 2021, pp. 31–35).
Intriguingly, 70 years earlier, Seashore (1919) had used a similar approach for constructing his test items which were designed to measure the ability of memorizing tone sequences as a function of tonal memory. In his test of tonal memory, participants were asked to listen to 30 melody pairs consisting of short tone sequences of varying lengths (10 melody pairs each as a three-tone, four-tone, or five-tone sequence). While listening to the second tone sequence within a melody pair, they were asked to identify the specific tone of the second melody that had been altered compared to the initial sequence. Thus, participants had to memorize every tone of the initial sequence as a prerequisite for a successful tone-by-tone comparison while listening to the subsequent tonal sequence. Each participant's tonal memory span could then be deduced from the number of successfully solved items (Seashore, 1919, pp. 238–243).
To summarize, although Seashore and Gordon intended to measure different and mutually exclusive latent abilities, they used the same construction principle in developing their measurements, namely a melody comparison task in combination with a same/different item response format. To resolve this theoretical conundrum, Gordon decided to separate both melodies within each melody pair by a period of four seconds of silence, which was “found to be optimal for a student to be able to audiate, but not to imitate or memorize the musical question [i.e., the first melody], before he or she hears the musical answer [i.e., the second melody]” (Gordon, 1989, p. 19). However, to the best of our knowledge the question is still unanswered regarding whether the length of silence chosen (i.e., four seconds) between the two melodies is sufficient to isolate or separate the phenomenon of audiation from that of memorization.
The issue of whether the AMMA is an aptitude test that solely measures adults’ music aptitude as a one-dimensional latent variable depends on how far – and with what degree of accuracy – one can infer that audiation is a latent trait based on the test score derived from the measurement (cf. Furr, 2018, pp. 9–11). With regard to the AMMA test procedure we need to take into account the psychometric dimension of invariant measurement (Engelhard, 2013), along with standard psychometric criteria such as reliability (Shrout & Lane, 2012) and validity (Grimm & Widaman, 2012). The procedure hence depends on the degree to which the test's items are sensitive exclusively to a person's level of audiation as a one-dimensional latent variable rather than to other possibly latent traits such as (short-term) tonal memory.
Although the validation of test instruments serves multiple objectives (American Educational Research Association et al., 2014), most studies seeking to validate Gordon's music aptitude tests during the last decades have focused primarily on criterion validity as one indicator of construct validity (Schellenberg & Weiss, 2013, p. 500). In these studies, the degree to which audiation-derived test scores were associated with other music-related achievements that were thought to be predicted by music aptitude was determined by measuring either all variables at the same time (‘concurrent validity’) or in a repeated-measures longitudinal design (‘predictive validity’). In his literature review investigating the criterion validity of Gordon's audiation tests, Hanson (2019) reanalyzed and aggregated the results of studies in the field of music education research that spanned nearly 50 years. He found a mean correlation (weighted by sample size) of only
There is a considerable range in estimates of AMMA's construct validity (Hanson, 2019), with a high proportion of variability due to between-study variability rather than (within-study) sampling error
Another reason for this heterogeneity in the estimation of predictive validity might be the large variety of criterion variables. For example, music-related achievements in academic music courses do not usually share more than 50% of common variance with AMMA scores. For example, in his four-year longitudinal study Sang (1998) found the most highly significant raw correlations between the total score on the AMMA and other music-related achievement tests such as ear training
Heterogeneity was also observed between studies investigating the convergent validity of AMMA (see Table S2 in the Supplementary Material section). For example, whereas Gordon (1989, pp. 49–51) reported strong correlations between the composite score of AMMA and the composite score of the Musical Aptitude Profile (MAP) for undergraduate music majors
In brief, according to Hanson (2019), the question remains open as to why the criterion validity of AMMA seems relatively low and its validity estimation appears heterogeneous and thus imprecise – even after controlling for study-related factors (by using meta-regression for subgroup analyses) that might be a reason for the observed heterogeneity. Whereas the majority of studies has focused on the external validity of AMMA by investigating associations between the test score and other variables not directly covered by AMMA, only a few studies have concentrated on another facet of construct validity, which is the internal test validity of the AMMA. Generally, in these studies the degree of fit has been investigated between test takers’ observed response behavior against the expected one, ideally predicted by a test theory model (cf. Grimm & Widaman, 2012, p. 623). One of the earliest studies focusing on AMMA's internal test validity is Gordon's investigation of the latent-factor structure of AMMA for which he used a principal axis factoring approach (Gordon, 1991, pp. 8–21). Based on 5,336 responses from undergraduate and graduate music major and non-music major students, he extracted nine unrotated factors accounting for only 44% of the variance. The rotated factor matrix, however, showed at least one stable factor with an eigenvalue
Therefore, in order to conclusively affirm that AMMA is suitable for solely measuring audiation exclusive of memorizing as a function of tonal memory, we first have to identify those items in our investigation that can best be assigned to a single, one-dimensional joint variable (of persons and items) as a key requirement of an invariant measurement (Engelhard, 2013, p. 14) while removing all other items that contribute to other latent factors resulting in a significant model misfit. Following Verdis and Sotiriou (2018), we also propose the Rasch methodology as a statistical approach to model participants’ observable responses as a function of their latent trait and of items’ attributes (Bond et al., 2021). The Rasch model explains and predicts the probability of participants’ observable response behavior for dichotomous items as a result of the difference between participants’ ability and items’ difficulties (Bond et al., 2021). Applying this logic to AMMA, the probability of a participant's j correct response on a dichotomous item i of the AMMA

In terms of scale construction, following Rasch's methodology and based on the premise of only one “true” latent variable, it is not our objective to find a statistical model that best describes the data, as would generally be the case in social science (“model fits data approach”), but rather to identify those items that could be calibrated on a Rasch scale without showing significant misfit (“data fits model approach”). For determining invariance of measurement as an element of construct validity there exist goodness-of-fit statistics for scales and items that vary with regard to their statistical power (Debelak, 2018; Stone & Zhang, 2003). These include parametric tests of Infit and Outfit (Wright & Masters, 1982, p. 100), Andersen's Likelihood Ratio test (1973), the Wald test (1943), the Martin-Löf test (1973), bootstrapping tests (e.g., von Davier, 1997), and non-parametric tests (Ponocny, 2001). By applying these tests, it is possible to identify items that do not reflect the same ability and which are thus responsible for the increase in a model's misfit. We can then exclude these from the resulting final scale. This strict method of item exclusion results in a scale with a high degree of measurement invariance.
Thus, to investigate whether AMMA is suitable for measuring exclusively audiation and not concurrently the ability of memorizing tone sequences as a function of tonal memory, we followed a two-step approach. First, to arrive at a revised version of AMMA with a high degree of unidimensionality, we pursued a strategy of identifying through Rasch methodology those items that best fit Gordon’s (1989) theoretical model (Study 1). Second, we used a correlational design to identify the discriminant validity of the revised version of the AMMA compared to the tonal memory test from Seashore's Measures of Musical Talent (Butsch & Fischer, 1966; Seashore, 1919). The ultimate goal here was to determine the degree to which both tests correlated due to their similarity in item construction (Study 2). In line with Gordon's model we expect a null correlation
Study 1
Method
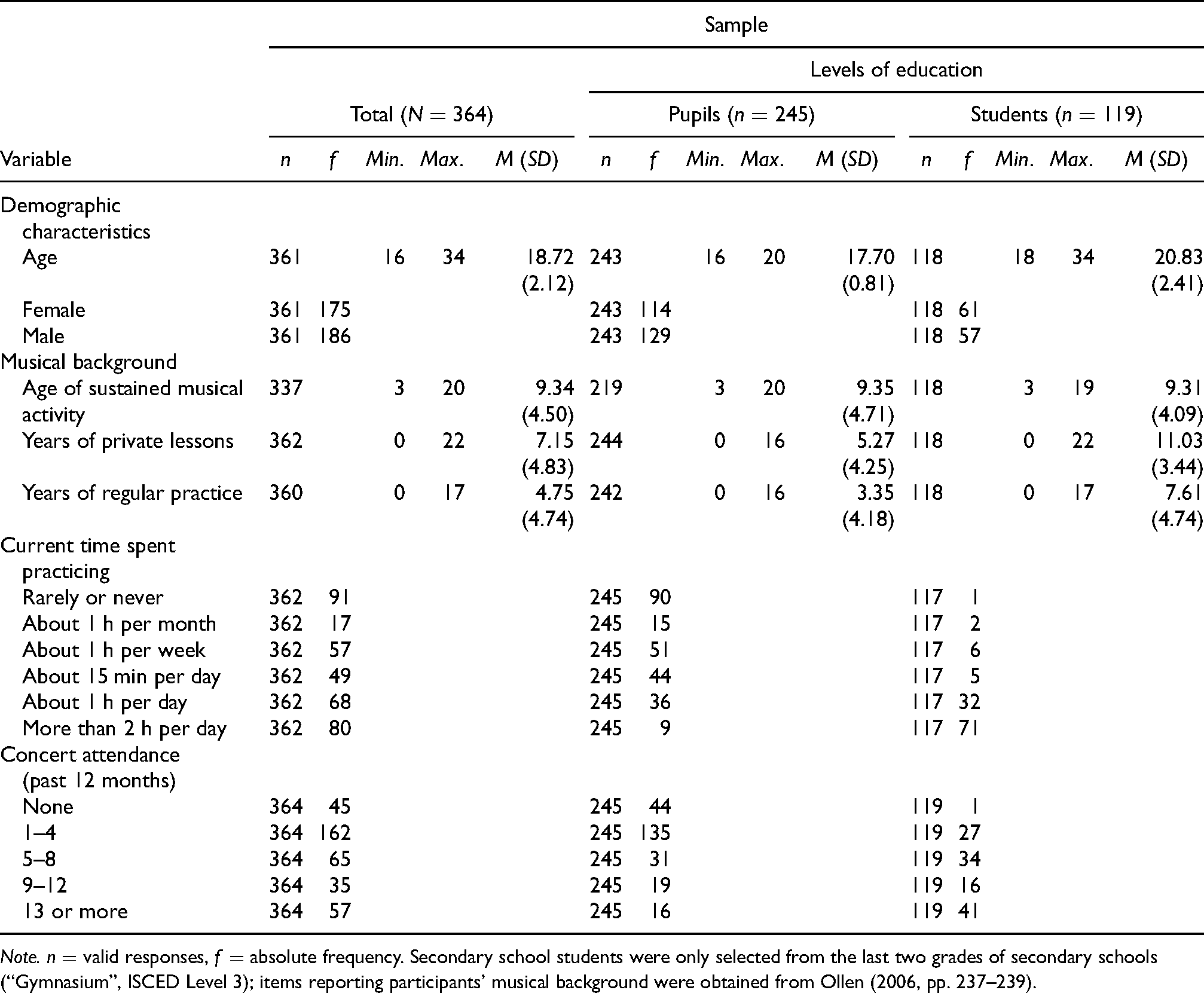
Sample
A total of
Summary of total sample's demographic characteristics and musical background as a function of educational level (Study I).
Note.
Although the subsamples’ age and musical background differed, Table 2 reveals equal performances of our subsamples compared to their norm groups (Gordon, 1989, p. 44): secondary school students did not show any significant differences by means of one-sample t-tests corrected for six multiple comparisons
Summary of test performance as a function of educational level compared to norm groups.
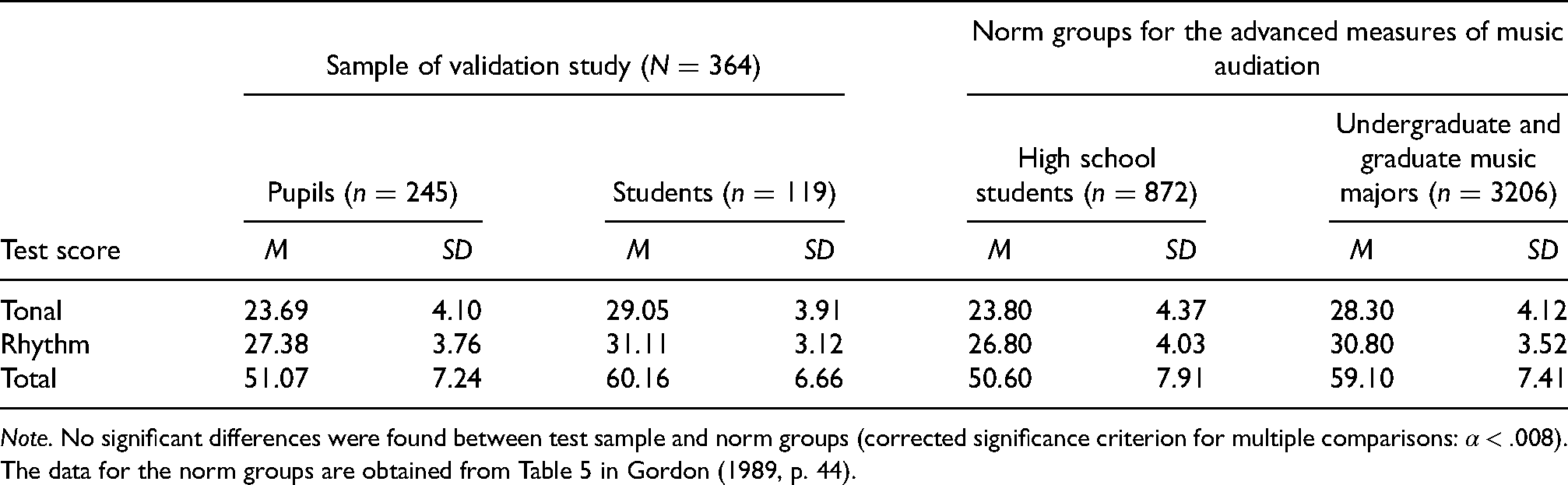
Note. No significant differences were found between test sample and norm groups (corrected significance criterion for multiple comparisons:
Procedure
Data were collected in small groups with a group size of
Results
The data analysis was performed in three steps, starting with (a) an analysis of response data as well as total scores using classical test theory, followed by (b) a person and item parameter estimation based on the Rasch model (Bond et al., 2021). Finally, to obtain a Rasch-conforming test version of the AMMA, we conducted (c) a test optimization procedure in which model-fit reducing items were removed from AMMA until a sufficient model fit was reached.
In detail, we first prepared the sample's raw response data for our data analysis by calculating all scores of the subscales as well as the adjusted total score according to the AMMA manual's scoring procedure (Gordon, 1989). Following Gordon’s (1991) proposed procedure, we also transformed the raw response data from three different response categories for the 30 items (1 = “same”; 2 = “tonal”; 3 = “rhythm”) into a binary matrix, reflecting each participant's response behavior on every item of the AMMA manifested either as an incorrect (= 0) or correct (= 1) solution as the only two and mutually exclusive solution possibilities.
We then conducted descriptive item and scale analyses of the AMMA test using JASP (Version 0.13.1; JASP Team, 2020). We computed all item parameters such as item difficulty, item variance, corrected item-scale correlation, and internal consistency (see Tables S4 and S5 in the Supplementary Material section) as well as all scale parameters in terms of score means, standard deviations, and scales’ intercorrelations (Table S6). Next, we investigated not only the sample's achievement reflected by the subscales’ scores and the total score of the AMMA (Table S6) but also the participants’ test performances as a function of education level (Table S7) for the purpose of comparing them with their corresponding reference groups (Gordon, 1989, p. 44).
From this point on we used the statistical platform R (Version 4.0.2; R Core Team, 2020) and the eRm package (Version 1.0-1; Mair et al., 2020) to calculate item and person parameter estimates of the Rasch model. First, we included all 30 AMMA items in the initial model (Table 3).
IRT parameter estimation for AMMA (model no. 1) and model optimization as a function of a stepwise item selection procedure based on goodness-of-fit-test statistics.

Note. a = item excluded from the LR and/or Wald test analysis due to inappropriate response patterns within subgroups. All model analyses as well as model improvements by removing inappropriate items causing a significant model misfit were performed with the eRm package (Version 1.0-1; Mair et al., 2020) within the statistical environment R (Version 4.0.2 [2020-06-22]; R Core Team, 2020). The median of sample's raw scores was used as internal split criterion as well as
To test whether the initial Rasch model was suitable as a valid formalization of the sample's response data, we conducted several parametric goodness-of-fit tests, such as the Andersen goodness-of-fit test (Andersen, 1973), the Wald test (Wald, 1943), and the Infit mean-square test (Wright & Masters, 1982) as implemented in the eRm package (Mair et al., 2020). The test results were significant, which indicated that the first model did not meet all criteria of the Rasch model (Table 3). We subsequently performed a model optimization approach in order to arrive at a revised test version of AMMA showing measurement invariance by removing those items that were responsible for the reduction of construct validity (and thus for the significant results from the goodness-of-fit tests). For this purpose, we used Mair et al.’s (2020) optimization strategy, an iterative stepwise item selection procedure whereby the item with the strongest misfit – and thus most responsible for the significant reduction of test validity – is removed in each step until model fit has been attained (Bond et al., 2021; Koller et al., 2012). Rasch conformity of a measurement associated with its uniqueness of unidimensionality and local-specific objectivity (Bond et al., 2021) should thus be achieved with the remaining items. By the end of this iterative, algorithmic approach only five of the original 30 items remained in the revised scale, now optimized in terms of Rasch homogeneity (see Table 4).
Parameter estimation for the revised IRT model of the AMMA (model no. 2) after removing items causing a significant model misfit.

Note. Stepwise item selection procedure indicated no item for exclusion due to model misfit, that is, all remaining items of the revised model fit the Rasch model. The global LR-Test (split criterion: raw score) revealed a non-significant test result
We used a more conservative strategy as recommended by Koller et al. (2012, p. 162), because of problematic multiple testing and the low statistical power of the parametric goodness-of-fit tests used in this algorithmic approach, i.e., a stepwise model optimization approach for k = 30 items and n > 300 respondents with an unknown number of items that might have violated the model's properties (Debelak, 2018). Accordingly, to reduce the Type-II error of the a posteriori software-based item diagnostic, we chose a Type-I error of 10%
With the exception of one test, indicating that item no. 3 (I 03) showed a significantly lower correlation compared to four of the remaining five items
Discussion
Our initial study focused on investigating the inner structure of AMMA items in terms of measurement invariance along with homogeneity, unidimensionality, specific objectivity, and their relation to one latent variable by means of the Rasch model. As a main result, the majority of the 30 items showed insufficient psychometric characteristics in accordance with Item Response Theory (Bond et al., 2021). However, we were able to develop a revised 5-item version of AMMA, showing sufficient empirically determined measurement invariance as well as an acceptable reliability–considering the low number of items
Study 2
Aims and Hypotheses
The purpose of the second study was to investigate whether the overall score of the revised version of AMMA exclusively reflected participants’ audiation abilities (Gordon, 1989, p. 16) but not their capacity of memorizing music (without the need of audiation) as a result of tonal memory as we suspected. Although the item construction of AMMA tends to show a high correspondence with the tonal memory subscale of Seashore's Measures of Musical Talents (Seashore, 1919), these two measures of musical ability differ concerning their construction of melodic item pairs.
To the best of our knowledge, it is unclear whether both measurement scores (a) show a statistical association and thus a low discriminant validity due to the marked similarity of their item construction, which would point to at least partly identical cognitive processes without a clear distinction between audiation and (short-term) memorization resulting in a positive correlation
Consequently, our aims in this study were to compare the discriminant validity of AMMA against tonal memory scores (as measured by the SMMT test). Our study therefore followed a correlational design investigating the strength of the discriminant validity of the revised AMMA version compared to a short version of Seashore’s (1919) tonal memory test.
Method
Sample
In an a priori power analysis
Material
Two measurements were used, one for quantifying participants’ audiation and one measurement for tonal memory. To measure audiation we used the revised 5-item version of the AMMA from Study 1. Although the short scale was Rasch-optimized, we found a somewhat low internal consistency (Cronbach's
Given the time constraints for the entire test procedure in the schools, we selected five items from the tonal memory subscale of the German SMMT (Seashore, 1919) to create a short version of the original test. The item selection was based on the difficulties reported in the manual for the German version (Butsch & Fischer, 1966) and resulted in a uniform distribution of item difficulties. For the short version of SMMT we selected items A6, B2, B8, C4, and C10. Post hoc descriptive item and reliability analyses of the SMMT short scale for the measurement of tonal memory (Table S8 in the Supplementary Material section) revealed that items were generally of a medium to low difficulty level
All melody pairs were presented by means of compact disc. A silent period of 3.3 s was set as a response time for the short form of the tonal memory test, after which the next melody pair was announced and presented immediately. For the revised AMMA version, participants gave immediate responses within a silent period of 2 s inserted after each melody pair. Three practice examples were presented for each of the measurements. While the original practice examples were used for the short version of AMMA, the three items A5, B5, and C5 from SMMT were adopted as practice items for measuring tonal memory.
Procedure
Data were collected in class sizes of
First, participants were welcomed and informed about the objectives of the study. After giving written informed consent, participants carefully read the instructions of the short version of the AMMA. Next, all three practice examples were presented, followed by the evaluation of the five test items of the revised AMMA scale from Study 1. Afterwards, participants read the instructions of the subsequent SMMT test for tonal memory before listening to the practice examples, followed by the presentation of five items of the SMMT short scale. Finally, participants gave a self-disclosure about their musical background based on the general factor items of the Goldsmiths Musical Sophistication Index (Müllensiefen et al., 2014). No reimbursement was paid. Participants were informed about their test performance two weeks later.
Data Analysis
The data analysis followed a two-step approach. First, participants’ responses given on all items of both measurements (AMMA and SMMT) were dichotomized (0 = incorrect answer; 1 = correct solution) following Gordon's procedure for investigating construct validity (Gordon, 1991, p. 8). Next, using JASP (Version 0.13.1, JASP Team, 2020), we conducted item and scale reliability analyses for both scales (see Table S8 in the Supplementary Material section) and calculated overall scores of both measurements by summing up all the correct answers. Due to missing responses for one or more items of AMMA, the response sheets of four participants were excluded from further data analyses. Based on the remaining 83 response sheets, a correlation between total scores of both measurements was calculated (“raw correlation”). To arrive at the latent “true” correlation as a quantification of the statistical association between both variables if both measurements had shown perfect reliability, raw correlations were corrected for attenuation effects (Hunter & Schmidt, 2004). Because of a ceiling effect of the overall scores of both measurements we used a non-parametric correlation analysis. Finally, in addition to the non-Bayesian frequentist correlation approach, we conducted a Bayesian post hoc analysis using JASP (Version 0.13.1, JASP Team, 2020) with default settings for less informative priors on the correlation corrected for artifacts (“summary statistics”).
Results
Based on the 83 valid cases, we found a significant positive raw correlation between SMMT tonal memory measurements and AMMA audiation scores of moderate effect size
The post hoc Bayesian analysis provided further insights. The Bayesian parameter estimation of the disattenuated correlation between audiation and tonal memory showed a small 95%-credible interval in addition to the point estimator

Prior and posterior probability as well as the Bayes factor of the disattenuated correlation between overall scores for the AMMA and SMMT tonal memory subtest for the alternative hypothesis (JASP team, 2020).
A Bayes factor robustness check indicated that the choice of the default less-informative prior
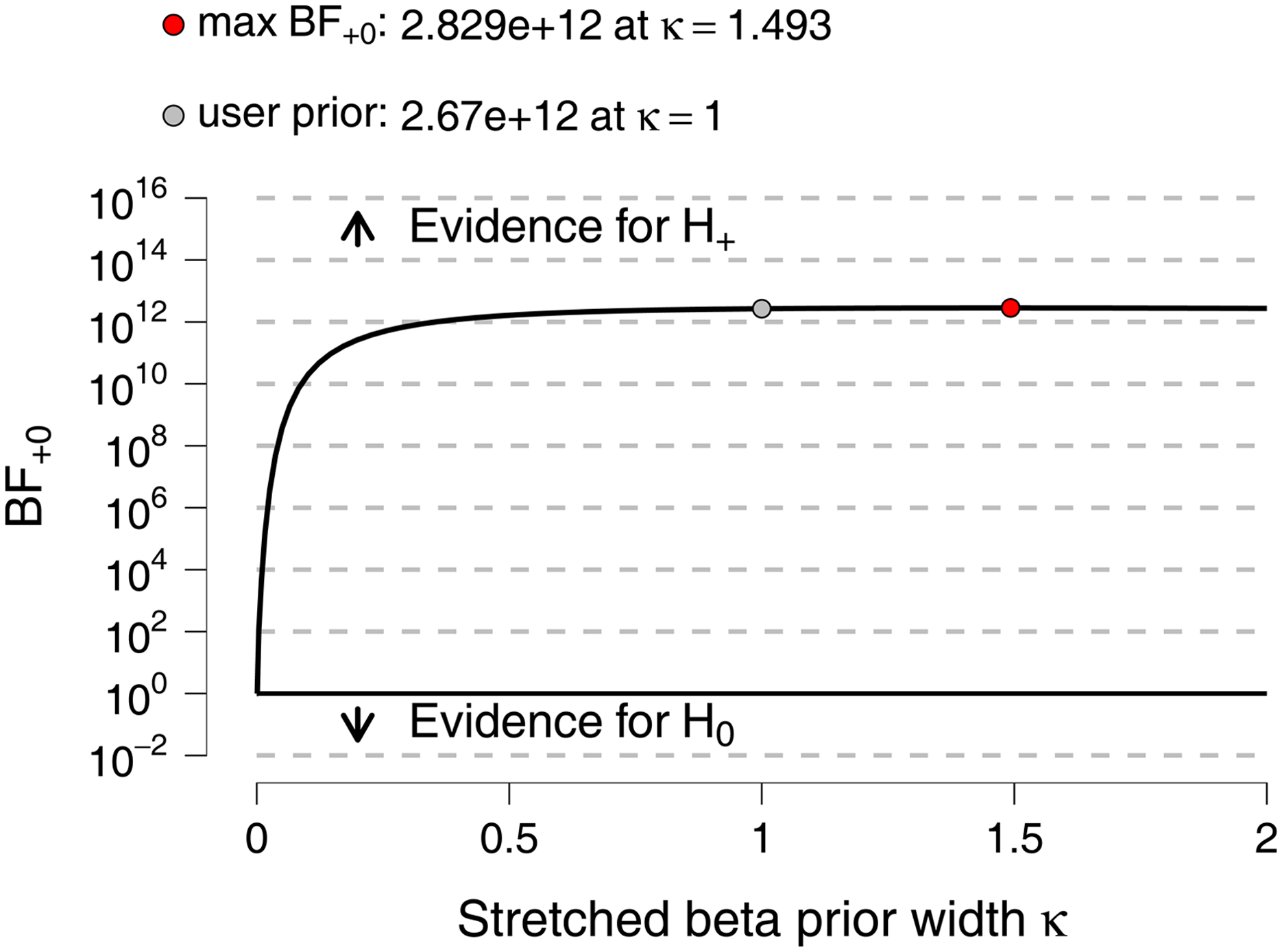
Bayes factor robustness check indicating the influence of different values of κ for shaping the a Priori probability on the strength of the Bayes factor for the alternative hypothesis compared to the null hypothesis (JASP team, 2020).
General Discussion
There were two main aims of this investigation: first, we wanted to evaluate the item characteristics of AMMA in terms of up-to-date psychometric standards so we could draw conclusions about the quality of the AMMA test (Study 1). Second, we wanted to evaluate AMMA's construct validity to test Gordon's claim that AMMA is an inventory for the exclusive measurement of audiation as a latent variable (Study 2). If this latter assumption were true, only a (very) small correlation should have been observed between AMMA scores and scores from analogously constructed tests for tonal memory (in the present study the tonal memory subtest of the SMMT).
In Study 1, we focused on participants’ overall test scores. Although our sample performed similarly to that of the norm group reported by Gordon (1989), our results revealed a slightly lower internal test reliability for the total test score
As a consequence of using an algorithmic-based model optimization strategy,
Although this optimization followed an objective and statistically driven approach for the enhancement of AMMA's measurement invariance as part of meeting construct validity, the probability of ceiling and floor effects increased significantly due to the small number of remaining items. Moreover, the risk of ceiling and floor effects was compounded by the fact that the variance in the difficulty of the remaining items was low and fell within a narrow range of a medium skill/task level demand (Table 4). Another consequence was that AMMA in its revised version would probably not be a suitable tool for identifying people with high audiation abilities as an indicator of “giftedness”. In other words, the difficulty of the remaining five test items was too low with ensuing ceiling effects. For example, someone with an average level of audiation
The large number of excluded items due to model misfit might be plausible in light of earlier studies focusing on the latent-factor structure of the AMMA test. For example, in 1989 Gordon expected one general factor but was unable two years later to identify it. Instead, he found nine factors accounting for no more than 45% of variance. His own results in essence support our assumption that AMMA's items might be characterized by great heterogeneity, leading to a multidimensionality rather than a unidimensionality in test scores. Moreover, as in our study, the items on the strongest factor accounted for a low proportion of variance (13.4% of the variance, and only 11.2% after Varimax rotation; Gordon, 1991, p. 17). Likewise, Gordon (1991, pp. 1–21) and Verdis and Sotiriou (2018) were unable to identify a one-dimensional solution for the latent structure underlying AMMA, despite their using different statistical approaches. In essence, the large number of excluded items does not come as a surprise, but rather confirms earlier findings. But even with few items the revised scale does not lose much reliability (Cronbach's
In Study 2, the main result of a high correlation between the score from the revised AMMA version and five selected items from the tonal memory subtest of the SMMT stood in contrast to Gordon’s (1989) assumption that effects based on short-term memory would not play any role in the measurement of audiation as long as a four second long gap of silence separated the two melodies in a melody pair. Yet all our statistical analyses – especially the large Bayes factor with its small credible interval of the correlation corrected for reducing artifacts – suggested otherwise. They supported our alternative hypothesis: namely, that AMMA scores are confounded with (short-term) tonal working memory performance as an operationalization of the ability to memorize music (SMMT score). One explanation for the significant association between tonal memory and audiation might relate more to the conceptual design of the items and less to the length of the intermittent pause between both melodies within each AMMA item. In line with Sang's critique (1998, p. 136) the AMMA test seems to only operationalize a combination of the first type of audiation, such as “listening to familiar or unfamiliar music” (Gordon, 2012, p. 13) with the lowest stage of audiation (“momentary retention”, p. 19). This simpler first type and stage of audiation is generally constructed from “immediate aural impressions” (Gordon, 2012, p. 24) as an unconscious process in assigning musical meaning to aurally perceived events (p. 14). However, although retention in terms of (short-term) musical working memory is a prerequisite for and core element of audiation, it “does not strictly incorporate audiation” (p. 19). The significant correlation between both measurement scores in Study 2 might reflect how audiation depends on the ability of memorizing music as a function of (short-term) memory, which is especially characteristic for the early stages of audiation. One could speculate that more advanced types of audiation would yield lower correlations with memory. But some reliance on tonal memory seems inevitable.
Moreover, due to the AMMA test design, participants only have to discriminate between the two melodies of a melody pair to give a correct response on the items. They do not require further domain- or task-specific knowledge. This results in a perceptually and not audiation-driven “same or different” decision (with respect to tonal or rhythmic structure). From a theoretical perspective, however, there are two reasons why this kind of perceptually driven discrimination task has a reduced diagnostic value for measuring music ability: (1) Solving basic auditory discrimination tasks without further need for content- or task-knowledge is not restricted to human behavior but also occurs in animals (e.g., Brooks & Cook, 2010; Cook et al., 2016; Hagmann & Cook, 2010; Porter & Neuringer, 1984; Watanabe & Sato, 1999). Thus, the item design refers to a cognitive skill that is not unique to human behavior but which is also manifested in certain animal species. Nonetheless, such a paradigm can be applied convincingly when the content of the items mirrors the cultural specifics of the particular skill and the respective test items are so distinctive that they require the use of the relevant domain-specific skill or, inversely stated, if basic perceptual processing is not sufficient to solve the items. (2) Perceptually driven aural discrimination is a general cognitive skill which is not domain-specific. For example, in a study imposing similar demands on the participants as in our studies, Stepanov et al. (2020) demonstrated that auditory discrimination is a general cognitive process primarily determined by the capacity of working memory. They asked 70 children (mean age 9.17 years) in a prosodic discrimination task to decide whether there was a difference within pairs of sentences
Although we found convincing evidence for deficient psychometric properties of AMMA, such as low internal validity, low reliability, heterogenous item characteristics, underlying multi-dimensional latent structure, and low construct validity, we cannot pass final judgment on the existence of audiation as a latent variable. However, compared to previous critical evaluations of Gordon's test development, we do not think that AMMA's fundamental problem of lacking validity can be resolved by re-norming the test (as suggested by Grashel, 2008). We are not convinced that observed weaknesses in test construction should be attributed to differences in societal contexts when the test was designed, nor to “characteristics of the music students in the 21st century” (Hanson, 2019, p. 208). Instead, we argue for a more radical renewal. We are convinced that, in its current form, AMMA is unsuitable for a valid and reliable operationalization of the audiation construct. Measuring audiation thus calls for new diagnostic instruments to be developed that focus on the multi-faceted structure of audiation with more consideration of domain-specific tasks and the cognitive processes that underlie them. In recent years, several tools have been developed for measuring skills related to the types and stages of the phenomenon of audiation, such as notation-evoked sound imagery (e.g., Wolf et al., 2018) or auditory mental imagery (e.g., Gelding et al., 2020). It is time to develop a new series of tests for measuring audiation that adhere to the high standards of today's psychometric testing, including Rasch model conformity, automatic item generation (Gierl & Haladyna, 2013), and adaptive testing (Harrison et al., 2017).
Supplemental Material
sj-pdf-1-mns-10.1177_20592043221105270 - Supplemental material for Measuring Audiation or Tonal Memory? Evaluation of the Discriminant Validity of Edwin E. Gordon's “Advanced Measures of Music Audiation”
Supplemental material, sj-pdf-1-mns-10.1177_20592043221105270 for Measuring Audiation or Tonal Memory? Evaluation of the Discriminant Validity of Edwin E. Gordon's “Advanced Measures of Music Audiation” by Friedrich Platz, Reinhard Kopiez, Andreas C. Lehmann and Anna Wolf in Music & Science
Footnotes
Acknowledgements
The authors would like to thank Maria Lehmann for the manuscript editing; Marcus Büring for his support in data collection; Johannes Hasselhorn and Fanny Empacher for helpful comments on earlier versions on the manuscript.
Contributorship
FP and RK conceived the study. All authors were involved in study design, data collection, and analysis. FP wrote the first draft of the manuscript. All authors reviewed and edited the manuscript and approved the final version of the manuscript.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Action editor
Graham Welch, University College London, Institute of Education.
Peer review
Adam Ockelford, University of Roehampton, Applied Music Research Centre.
Peter Webster, University of Southern California, School of Music.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.