
Abstract
Since their inception, social media platforms have continuously developed innovations and discourses centered on affective and emotional dimensions. Platform owners invest heavily in research and development to both identify and elicit feelings and emotions. However, the research conducted by these companies on this topic remains understudied. In this study, we present a systematic and critical analysis of the scientific literature published by the research teams of Meta (Facebook, Instagram) and Google (YouTube) regarding the analysis and processing of their users’ emotions. We first demonstrate that this literature relies on schematic definitions of emotions, thereby simplifying the complexity of affective phenomena for facilitating their automated detection. We then highlight the objectives pursued by these research efforts, the majority of which aim to promote users’ well-being through the instrumentalization of what affects them. Finally, we examine the various methods employed to identify emotions, which primarily serve to feed these platforms’ machine learning algorithms with data labeled as emotional. Beyond their scientific contributions, we consider these studies as narratives targeted at the scientific community and investors, serving to legitimize and support the development of specific innovations. Analyzing these works enables us to examine how the techniques, methods, and applications developed by these two companies commodify emotions and actively shape users’ online behaviors.
Introduction
“Online messages influence our experience of emotions, which may affect various offline behaviors.” (Kramer et al., 2014, p. 8790). Led by a Facebook researcher in 2014, this controversial study (Metcalf & Crawford, 2016) suggested the possibility of creating “emotional contagion” among users of the social media platform.
Few social science studies document the emotion-related discourses adopted by these platforms or the technologies they develop to capture, recognize and analyze emotion (Hillis et al., 2015; McStay, 2020; Stark, 2020a,b). These discourses can, in part, be found in the literature published by the research teams that work for these companies in peer-reviewed journals or scientific conferences. Beyond their scientific value, we consider these publications as discourses dedicated to competitors and investors. Analyzing this discourse could help us understand the way in which these companies seek to utilize their users’ emotions as a lever when governing platforms. At a minimum, this literature can help us understand the larger R&D orientations of certain web-related stakeholders in matters of emotion and affect.
To achieve this, we conducted a systematic and critical analysis of the scientific literature produced by the Meta teams (n = 30), and the Google teams (n = 28) regarding emotions. This analysis is guided by three research questions:
Research Question 1 (RQ1). How do researchers in these companies define emotions and their related concepts (sentiments, feelings, etc.)? This initial question can help contextualize what does or does not constitute emotions according to these platforms, along with the theoretical assumptions and fields of research involved.
Research Question 2 (RQ2). What is the purpose of this work? This question seeks to establish what the platforms intend to accomplish by analyzing what they name “emotions.”
Research Question 3 (RQ3). What data and processing methods are used to achieve their research objectives?
Finally, we will discuss the communication issues raised by this research, since the technological developments involved could transform our emotions and affects into a central socio-political concern. This article argues that the affective discourses of social media platforms must be considered as a central object of study in the analysis of the communications that take shape on these platforms. These discourses reflect not only a specific vision of affective innovation, but also a normative understanding of user intimacy—one that raises ethical concerns. Without critical examination by social media and internet studies, such narratives risk reinforcing assumptions about emotional life and its potential instrumentalization.
Contagion is valuable: from emotional to affective infrastructures
Scientific research on emotions addresses this polysemous object from two major theoretical perspectives: one biological and the other cultural. From the first perspective, emotions are seen as the product of our cognition (LeDoux, 1995) and enable us to adapt to our environment. Among these approaches is the Basic Emotion Theory (BET) developed by Ekman (1992), which posits that emotions are universal and “encoded” in our facial expressions (Table 1). They are classified according to a specific typology: anger, disgust, fear, joy, sadness. While this theory has been subject to significant debate and criticism for its deterministic nature which overlooks cultural and contextual specificities (Russell, 1994), it has nonetheless spurred research into “affective computing” (Picard, 2000; Stark & Hoey, 2021) for many years. Conversely, emotions can also be viewed as social constructions (Bernard, 2017). Their expression relies on the circulation of signs (linguistic, visual, textual, etc.) that help structure social spaces, and thus become “affects” in the Spinozist sense, which can therefore be analyzed based on the effects they produce and the empowerment they enable.
Key Points and Critics About Ekman’s Basic Emotion Theory.
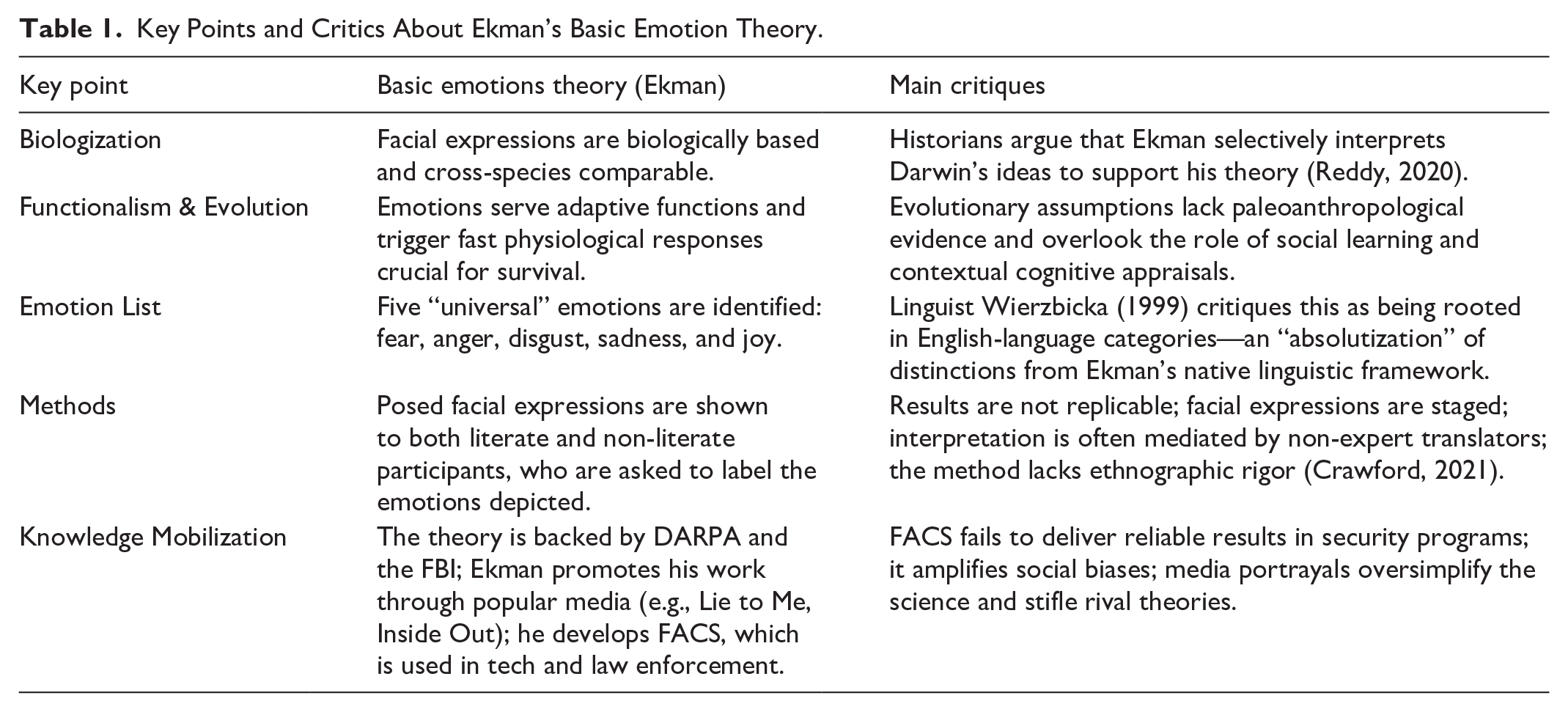
The biological perspective on emotions aligns with the objectives adopted by digital industries and affective computing (Alloing & Pierre, 2021). These platforms can essentially become affective infrastructures (Hallinan, 2019) that provide audiences (Papacharissi, 2015) with “affective timelines” (Gilroy-Ware, 2017). Users need only express emotions to receive content curated by algorithms through video playlists, social media feeds, and immersive worlds. Here, the content and experiences encountered by users come into question, depending on the way in which these emotions are collected and processed. This enhanced experiential value increases economic value for platforms and their advertising partners. Considering this, platform capitalism (Srnicek, 2017) can form part of affective capitalism (Karppi et al., 2016).
Platforms seeking a share of this affective economy (Ahmed, 2004) are developing various functions to produce affective signs, like #hashtags (Papacharissi, 2015) and emojis (Stark & Crawford, 2015). Those signs circulate via sharing functions while attaching them to content through an emotional design (Norman, 2007) where emotional affordances guide usage (Alloing & Pierre, 2023). Users engage with these affordances in various situations: social mobilizations to attract attention (Papacharissi, 2015), political debate that generates “affective polarization” (Lee et al., 2022) and efforts to “build community relationships” (Döveling et al., 2018). Platforms can then process these emotions when sorting, classifying and prioritizing the information made visible. According to Arvidsson (2011), this circulation, combined with affective computing technologies, helps measure the audiences’ affective investment and produces a “general feeling” that defines the value of information, brands and public figures. Rather than merely engaging in a critical confrontation between emotion literature and platform-driven scientific production, it seems crucial to us to examine what platforms themselves define as emotions to better understand their uses, implications and their ability to affect us.
Methodology
We selected two companies that own one or more social media platforms: Meta (Facebook, Instagram) and Google (YouTube). For each platform, we targeted sites dedicated to their research teams, like research.google or research.facebook.com. On September 1, 2023, we queried their search engines using 20 keywords involving the emotional sphere (sentiment, emotion, mood, etc.). We then used a free-floating reading approach to ensure that emotional issues were indeed central to the published works under consideration. We retained 30 publications for Meta and 28 for Google, mostly from conferences and workshops (Table 2). To avoid omitting relevant publications, we used the same keywords associated with the authors’ names (121 for Google and 130 for Meta) through Publish or Perish software (Harzing, 2007).
Type of Publications.

We applied a grid to systematically analyze the selected publications according to 14 items, as the research field, the article’s objectives, the theoretical framework, the key concepts or the methods used.
Results
The Meta contents were published from 2009 onward, with a majority (23) focusing on addressing specific problems in emotion detection and identification and developing new emotion communication technologies. 33% of Google’s publications can be categorized as applied research (20 articles out of 28), the rest seeming more aligned with fundamental research on sentiment analysis techniques (SAT). Meta’s and Google’s corpus include works that cover several research areas (Figure 1).
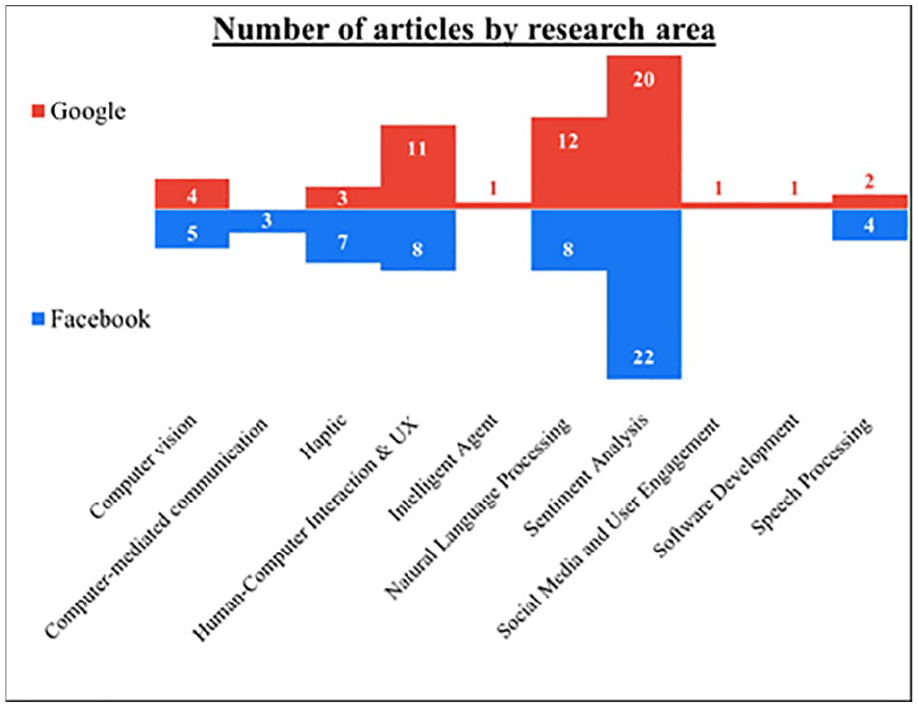
Categorization of publications published annually by Facebook (blue) and Google (red).
The production of articles by both companies increased from 2019 onward, indicating a growing interest in research projects on emotion. Figure 2 illustrates this evolution of research efforts over time and highlights their alignment with the companies’ objectives regarding their marketed products.
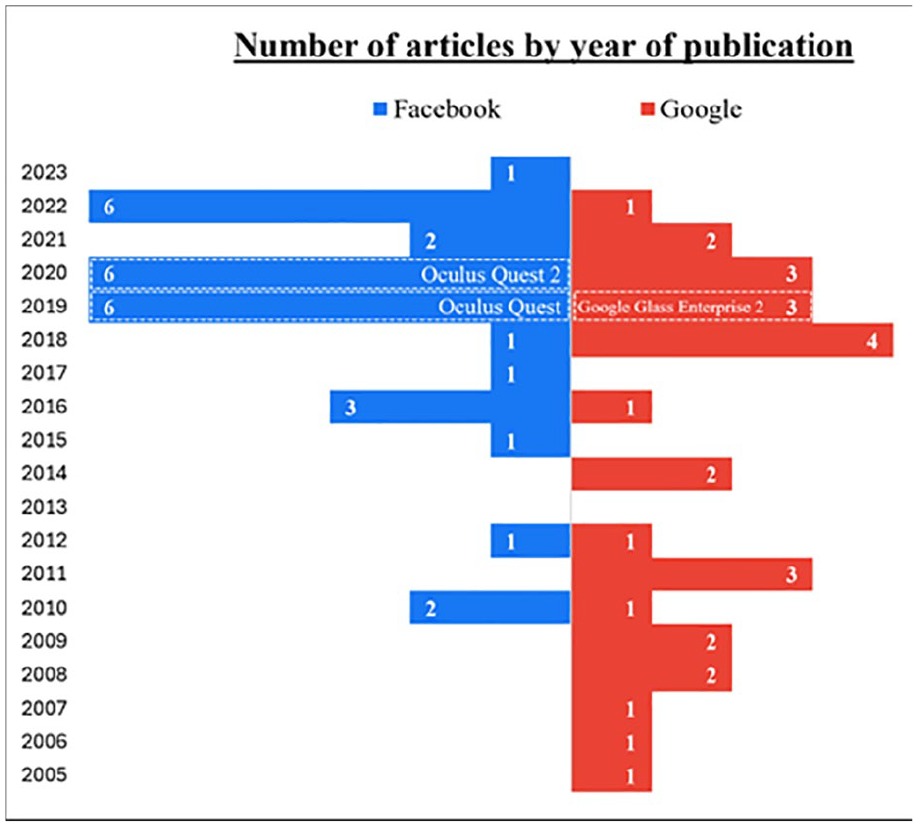
Volume of scientific articles published annually by Facebook (blue) and Google (red).
These projects align with the companies’ objectives surrounding their marketed products. Facebook’s publications between 2019 and 2020 primarily address the development of tactile devices for emotional stimulation, particularly within virtual reality (VR) environments. During this same period, the company announced the release of the Oculus VR headset. In 2019, Google’s scientific publications focused on emotion recognition using facial expressions, which coincided with the launch of the Google Glass Enterprise 2 edition. We can therefore hypothesize that the publication of certain results when commercializing innovation falls within a public relations strategy designed to reassure investors of the reliability and innovative nature of the new technology while convincing regulators of the innovation’s scientific basis (implying risk assessment). The fact that the majority of publications are conference presentations suggests that the discourses they convey are aimed at the scientific community, particularly to highlight certain technical standards.
How do Google and Meta researchers define emotions (RQ1)?
Meta’s published research rarely provides an explicit definition of the term “emotions.” Generally, the research builds upon authoritative psychological studies, including those by Paul Ekman (1992), particularly in terms of Meta’s automated emotion classifications (Dwivedi-Yu et al., 2022; Dwivedi-Yu & Halevy, 2022; Jegorova et al., 2023; Kiela et al., 2020; Kreuk et al., 2022; Mesnil et al., 2015; Shukla et al., 2021; F. Yang et al., 2019). Emotions are characterized by their “valence”—positive, negative, or neutral (Burke & Develin, 2016; Jegorova et al., 2023; Kramer, 2012; Rognon, Stephens-Fripp, et al., 2022; Shukla et al., 2021; Wang et al., 2016), as well as by their level of “arousal” (Kreuk et al., 2022) or intensity. Both indicators are specifically used to label data intended for processing by machine-learning (ML) algorithms (Shukla et al., 2021). Even when both characteristics form the core of these studies (Kramer, 2010, 2012; Wang et al., 2016), researchers use software like Linguistic Inquiry and Word Count (LIWC) when attempting to define the term, thus avoiding the polysemic nature of emotion.
This approach mirrors Google’s own research, where valence follows a positive/negative/neutral scale (Attia et al., 2018; Blair-Goldensohn et al., 2008; Councill et al., 2010; Cui et al., 2006; Karunakaran & Ramakrishnan, 2019; Lerman et al., 2009; Lu et al., 2020; McDonald et al., 2007; Oneață et al., 2018; Shafran & Mohri, 2005; Täckström & McDonald, 2011b; R. Yang et al., 2016) to simplify what would otherwise be an overwhelmingly complex task, considering the large variety of emotions involved (Attia et al., 2018). Similarly, 20 out of 28 articles at Google provide no explicit definition of emotion. The authors refer to pre-established categories without discussing or adapting them to their study contexts. When emotions are specifically named, they follow Paul Ekman’s typology (Demszky et al., 2020; Hickson et al., 2019; Müller & Sedley, 2014).
In response to RQ1, these articles avoid characterizing emotion according to the cultural context of its manifestation, instead aligning themselves with the dominant paradigm without questioning it. Emotions are thus treated as defined objects with universal expressions. As a result, they can be coded, identified, and manipulated. Through this process of standardization, emotions are epistemologically reduced to the status of data, thereby overlooking the cultural variations and contextual nuances that shape how emotions are experienced and expressed across different cultures. As Eva Illouz (2017) suggests, Meta and Google’s research contributes to constructing “emotions as commodities.” Valence and arousal are framed as bounded “qualities” (Callon et al., 2002) that can be evaluated based on the affective responses they elicit in individuals through media content. The devices and programs that enable their instrumentalization, capture, and provocation thus become a means of capitalizing on this commodification.
The purpose of the literature: capture the emotion, direct the contagion (RQ2)
Generally, the scientific publications of both companies precede new products and services, or enhance existing ones, by developing emotion analysis technologies. One particularly ambitious research project at Meta, published 14 years ago, sought to analyze the emotional well-being of an entire nation (Kramer, 2010). Here, measuring and manipulating emotions not only becomes possible but necessary to ensure collective well-being. Following this research, five studies (Burke & Develin, 2016; Burke et al., 2010, 2020; Kramer, 2012; Scissors et al., 2016) sought to understand the well-being, loneliness, and social capital of individuals based on their Facebook activities. Others developed specific SAT using textual data (Mesnil et al., 2015), as well as emotion detection methods using images and sound (Averbuch-Elor et al., 2017; Dwivedi-Yu & Halevy, 2022; X. A. Li & Parikh, 2020). Measuring a “general sentiment” (Arvidsson, 2011) therefore becomes feasible when emotions, treated as computer data, are processed using “big data” logic (in the early 2010s) and later through artificial intelligence (toward the end of the 2010s).
Expressed emotions can also cause discomfort and may require moderation. Consequently, the Meta teams undertook research to identify hate speech (AlKhamissi et al., 2022; Jegorova et al., 2023; Kiela et al., 2020; Kreuk et al., 2022; Sabat et al., 2019; Shukla et al., 2021; F. Yang et al., 2019). Here, levels of valence and arousal in written expression serve as indicators of potentially malicious speech. Negative and highly emotional writings could affect other platform users, leading to moderation that can be automated using artificial intelligence (AI). The epidemiological potential of (negative) emotions appears in multiple publications at Meta (Burke & Develin, 2016; Burke et al., 2020; Kramer, 2010, 2012; Scissors et al., 2016). These publications examine how emotions are shared online and the responses they generate. Combined with SAT, computational models can predict affective responses to both textual (Dwivedi-Yu & Halevy, 2022) and audiovisual (Jegorova et al., 2023) social media content. Inversely, it can also help develop innovations that can generate emotion-inducing content, like images representing emotions described by users (X. A. Li & Parikh, 2020), or digital artworks that can arouse positive emotions (Chen et al., 2021). Moreover, the Meta research involves the development of haptic devices that enable remote emotional communication through touch (Hauser, McIntyre, et al., 2019; Hauser, Nagi, et al., 2019; Israr & Abnousi, 2018; McIntyre et al., 2019; Rognon, Bunge, et al., 2022; Cang & Israr, 2020; Rognon, Stephens-Fripp, et al., 2022). Considering Meta’s development of virtual environments like the Metaverse, along with immersive technologies like the Oculus Rift VR headset, these publications can be viewed as forward-looking research meant to steer the company toward its intended goals.
In addition, Google has published research on online harassment and attacks (Thomas et al., 2022), utilizing a SAT-based classification system to categorize negative experiences. Most studies use ML applied to natural language processing (Cui et al., 2006) to improve sentiment analysis (Täckström & McDonald, 2011a, 2011b), while creating large annotated data sets for emotion prediction (Demszky et al., 2020) and to expand the scope of measurable, evaluable, and supportable user behaviors (Attia et al., 2018; Liu et al., 2018; Müller & Sedley, 2014; R. Yang et al., 2016). At the platform, content and usage levels, one study attempts to predict media’s emotional impact on viewers (Sun et al., 2018), thus creating the groundwork for more refined algorithmic content recommendations on YouTube. Another project intends to quantify the effects of mobile video advertising (Pham & Wang, 2019), in alignment with the core of Google’s online advertising business model. Emotions are considered indicators of the user’s affective response to devices and platforms. These feelings correlate with the user’s subsequent written contributions (comments, company reviews, etc.). As with Meta, emotions are characterized by their ability to circulate through user and document interactions (Egelman et al., 2020). Measuring the “emotional impact” to reviewers (Karunakaran & Ramakrishnan, 2019) therefore becomes essential when restricting exposure to content that generates negative emotions. Analyzing emotions and protecting users represent common objectives in the discourse that underpins Google’s publications.
AI plays a vital role in this research when analyzing written emotions and evaluating interactions through various emotional expressions, including voice (Lu et al., 2020) and facial expressions (Hickson et al., 2019). Emotions as clear-cut data points allow AI to determine the user’s feelings while assessing the same user’s response to AI (Kelley et al., 2021). Early research in this field sought to “design [. . .] more natural human-machine speech interfaces” (Shafran & Mohri, 2005, p.1). Fifteen years after Google’s initial research, recent publications have highlighted the possibility of “building empathetic chatbots” (Demszky et al., 2020) alongside more ambitious goals like “developing believable agents that adapt to their environments and users in an emotionally plausible manner” (Francis et al., 2009, p.1).
In summary, and in response to RQ2, the emotion-related philosophy of both companies reveals notable differences. In Meta’s view, emotion evaluation serves as a tool to measure and potentially improve individual well-being through the activation of positive emotions. For Google, identifying emotions and reducing negative ones helps provide security for its platform users. To achieve their goals, both companies must support users when expressing and regulating emotions. Such support primarily relies on AI technologies. Fourteen Facebook publications and twenty-three Google publication address this topic. While Google focuses on engineering across various topics, Meta’s researchers incorporate human and social sciences, particularly psychology, while seeking to optimize social interactions and platform functionality. Researchers tend to focus on developing a series of emotional sensors specific to each company’s devices or platforms, while fewer efforts are made to encourage emotional and affective expression. The identification of emotions helps regulate those that circulate between users in comments, virtual reality devices, and recommended content. The combined implementation of these sensors produces an overall sentiment. This aggregate sentiment becomes crucial when seeking to continuously adapt business models to user behavior and expectations.
What data for what type of processing? (RQ3)
Within the studies published by Meta, Facebook serves as the primary source of data through status updates (Burke & Develin, 2016; Burke et al., 2010; Kramer, 2010, 2012; Wang et al., 2016) and user characteristics based on interactions such as “likes” (Scissors et al., 2016). Other sources of data are used extensively, including Reddit posts and comments (Dwivedi-Yu & Halevy, 2022), film reviews on IMDb (Mesnil et al., 2015), along with memes from various social media platforms (Kiela et al., 2020; Sabat et al., 2019). In terms of hate speech, researchers rely on existing research databases like OffensEval 2019 (Rajamanickam et al., 2020) and HateXplain (AlKhamissi et al., 2022). For emotion recognition in non-textual content, researchers use several open databases (Jegorova et al., 2023; Shukla et al., 2021), like CREMA-D or IEMOCAP.
Meta researchers primarily use massive data sets to train ML models. The various computational methods involved demonstrate the company’s interest in all innovations in this field. To produce texts or images, studies use generative models (AlKhamissi et al., 2022; Kiela et al., 2020; Kreuk et al., 2022; X. A. Li & Parikh, 2020; Mesnil et al., 2015; Rajamanickam et al., 2020; Rashkin et al., 2019; Shuster et al., 2020) like Generative Adversarial Networks (Chen et al., 2021). For automatic content annotation (emotion type, valence and arousal), researchers use self-supervised ML approaches (Jegorova et al., 2023; Shukla et al., 2021), along with popular models like HuBERT (Kreuk et al., 2022).
Using widely adopted data and algorithmic architectures helps standardize computer science and work on emotion detection. This allows Meta to showcase its AI innovation capabilities while providing potentially reproducible results through freely available software libraries (like PyTorch), ML models (LLAMA) and data sets. For instance, Dwivedi-Yu and Halevy (2022) use the CARE method (Common Affective Response Expression), typically used in psychotherapy, to facilitate automated content annotation in an effort “to predict the affective response to a post.” Their dataset and method are freely available, allowing others to annotate content, analyze emotions, and promote the gradual adoption of their standards by scientific and IT communities. This accessibility encourages the development of innovations compatible with Meta’s platforms.
Despite the strong emphasis on AI, the need for manual work remains when annotating publications (Burke & Develin, 2016; Dwivedi-Yu & Halevy, 2022; Jegorova et al., 2023; Rajamanickam et al., 2020), conversations (Kreuk et al., 2022; Shukla et al., 2021), and filmed gestures (Hauser, McIntyre, et al., 2019; Hauser, Nagi, et al., 2019), sometimes by user panels (Averbuch-Elor et al., 2017). Through its social science work, Meta also conducts perception tests and research into tactile devices to explore human interactions. These studies involve human participants, typically a toucher and a receiver (Hauser, McIntyre, et al., 2019; Hauser, Nagi, et al., 2019; McIntyre et al., 2019; Rognon, Stephens-Fripp, et al., 2022), along with “psychophysical” analyses (Israr & Abnousi, 2018). During these experiments, touch and behavior are measured using questionnaires (Rognon, Bunge, et al., 2022), along with various technologies like motion tracking and algorithms to quantify the effects of tactile interactions.
Google’s publications include non-computational data, like multinational surveys on public emotional responses to content consumption (Egelman et al., 2020; Karunakaran & Ramakrishnan, 2019; Kelley et al., 2021; Liu et al., 2018; Müller & Sedley, 2014; Thomas et al., 2021, 2022). For more experimental research involving human subjects, researchers use specific data collection methods like the analysis of facial expressions in individuals exposed to potentially affecting content or images (Hickson et al., 2019; Pham & Wang, 2019; Ryokai et al., 2012).
As with Meta, Google teams frequently develop and apply ML techniques (23 out of 28). Large data sets are crucial and readily available through its services, like Google Map (Blair-Goldensohn et al., 2008) and Google Shopping (Cui et al., 2006). The sentiments expressed in customer reviews is strategic for Google when sorting, prioritizing and moderating these reviews, particularly for its search engine and comparators. Google is therefore conducting extensive research on this topic (Attia et al., 2018; Blair-Goldensohn et al., 2008; Councill et al., 2010; Cui et al., 2006; Demszky et al., 2020; Joshi et al., 2011; McDonald et al., 2007; Täckström & McDonald, 2011a; Täckström & McDonald, 2011b; Titov & McDonald, 2008). To ensure the robustness of their learning algorithms and the resulting models, researchers working at Google tend to diversify their sources of data. These sources include, among others, TripAdvisor.com (Titov & McDonald, 2008), Twitter (Attia et al., 2018), data from telephone conversations (IEMOCAP (Lu et al., 2020)), ImageNet and YouTube-8M for still and moving images (Sun et al., 2018), and DE-ENIGMA data for developing empathetic robots (Oneață et al., 2018). This variety speaks of the multitude of activities and investments conducted at Google and, more broadly, its parent company, Alphabet Inc. These sources can also provide a greater diversity of expressed emotions and studied affects, along with a wider range of propagation and circulation contexts to define. Several research projects are developing emotion classification models based on these data sets (Attia et al., 2018; Blair-Goldensohn et al., 2008; Cui et al., 2006; Demszky et al., 2020; Hickson et al., 2019; Shafran & Mohri, 2005).
Since text forms the core of Google’s economic (advertising) and technical (PageRank) model, and many of its platforms, natural language processing algorithms are used extensively (Blair-Goldensohn et al., 2008; Councill et al., 2010; Cui et al., 2006; Demszky et al., 2020; Lerman et al., 2009; Lu et al., 2020; McDonald et al., 2007; Shafran & Mohri, 2005; Sun et al., 2018; Täckström & McDonald, 2011a; Täckström & McDonald, 2011b; Titov & McDonald, 2008). While this text-focused research reflected the company’s interests in the early 2000s, more recent work has called upon methods that can help develop AI, like convolutional neural networks (Attia et al., 2018; Hickson et al., 2019; Oneață et al., 2018; Sun et al., 2018). Google has made Transformer, its “neural network” for language comprehension, available to both computer developers and the scientific community at large. Finally, and like Meta, Google is currently studying emotion physiology by gathering data that can help construct algorithms for facial recognition (Francis et al., 2009; Hickson et al., 2019; Pham & Wang, 2019; Ryokai et al., 2012) and “photoplethysmography” (Pham & Wang, 2019), which detects blood volume variations.
Both companies collect extensive primary, secondary, numerical and physiological data for their research. But what of the ethics behind this data collection and processing, which is largely automated? Research on this topic is all but non-existent. Only six out of 30 Meta articles and six out of 28 Google articles address the ethical issues involved. For the first, when data is collected directly from individuals, particularly through university project partners, consent must be obtained (Hauser, McIntyre, et al., 2019; Hauser, Nagi, et al., 2019; McIntyre et al., 2019). For the second, the issue of data anonymization collected without consent (typically on a massive scale) is addressed in four publications that primarily deal with local regulations (Egelman et al., 2020; Karunakaran & Ramakrishnan, 2019; Kelley et al., 2021; Thomas et al., 2022) Only Liu et al. (2018) describe an ethical training program for those taking part in their study.
In response to RQ3, and more broadly to synthesize our finding, the types of methods and data addressed in this literature reflect the way in which platform development strategies evolve depending on their objectives as well as their understanding of emotions (Table 3).
Summary of the Platforms’ Research and Development Strategies.

These include analyses of their own data to improve their services (content distribution for Meta and review ranking for Google), along with the development of AI and specific technologies (chatbots for Google and haptic devices for Meta). Researchers are following trends and innovations in affective computing which, in turn, helps platforms evolve alongside other stakeholders in the field. The work focuses on the same type of data used to identify emotions and qualify affections: physiological, textual, visual, and auditory. Other results, derived from psychological approaches, add an emotional dimension to the algorithmic architectures used for the language processing and image analysis work that is currently underway. To sustain their own devices and platforms, Google and Meta are proposing their own standards, much like they did with their APIs at the companies’ inception.
Discussion: toward affective platform capitalism
The analysis of this literature highlights two different models of user governance through emotions in terms of social media. For Google, documents are still their entry point, regardless of their format or content. Identifying and evaluating the user’s emotions can help optimize recommendations by defining what is or is not interesting and useful while avoiding negative emotions. Information access devices must be empathetic to reassure and build confidence. In this type of research, platform users are essentially viewed as content consumers who make decisions based on what affects them. Their feelings help adjust their consumption as effectively as possible. For Meta, whose model is based primarily on self-disclosure, the entry point involves relationships with people, content, and current events. Emotions are viewed as indicators of relationship intensity and its resulting behaviors (sharing, commenting, liking, etc.). Identifying them makes it possible to encourage or discourage their propagation. Platform users are viewed as fragile beings who need technological support to regulate what affects them, starting with their social relationships. Each of these governance models and approaches to user emotions increasingly depends on AI. This growing automation for both the detection and instrumentalization of what affects a user leads the digital economy stakeholders to develop their own standards, as they have always done when guiding users and securing dominant market positions (Helmond, 2015).
Our study also belongs to a broader debate on affective capitalism where social media platforms develop tools to produce, exploit, and transform our emotions into commodities. This capturing process is facilitated by a limited view of emotion itself, which is never problematized and rarely defined, except in terms of Ekman’s universalizing grid. As mentioned earlier, this reductionist approach to emotion can be easily coded and operationalized by various cognitive computing and AI programs. These innovations intervene at several levels in the production, circulation, identification, and capture of emotions within platforms. Beyond commercial interests, the social engineering associated with these emotion analysis techniques generally involves a broader behavioral system based on various stages of the emotion production and reaction process. These models, intended to recognize and capture emotions, rely on massive data from multiple sources and require substantial upstream qualification work by a digital workforce (Tubaro et al., 2020) when describing, annotating, and prioritizing data. In turn, this qualification work helps normalize the affective expressions mediated on the platforms. The user’s emotional expressions and reactions must therefore correspond to what the models can classify as joy and sadness, for example, as opposed to what they cannot classify.
Beyond technical issues, these processes raise significant ethical concerns. First, anonymization procedures are rarely provided, potentially enabling broader biometric surveillance. Second, users become invisible, reduced to entries in annotated databases. Rouvroy and Berns (2013) discuss algorithmic governmentality which, from the moment of collection to the anticipation of individual and collective behaviors, systematically bypasses its subjects. Emotional data are collected without genuine user consent since users remain unaware of the highly sophisticated and diverse techniques used to capture their emotions. The analysis phase relies on automated data processing using ML techniques that can reveal correlations between various objects (media, comments, etc.) and emotional reactions (joy, anger, etc.) without any prior hypotheses, allowing norms to emerge spontaneously from reality. This production of knowledge, which is entirely inductive despite claims of objectivity, leads to the implementation of emotional profiling that can anticipate, produce, and regulate affective behaviors on platforms.
Limitations
Our work highlights what research teams funded by Meta and Google claim to aim for and achieve with users’ emotions. However, we are unable to concretely demonstrate the applications and benefits of this research for these companies or its direct impact on platform usage. Consequently, this literature review calls for further investigation under the EMOTICONES project, 1 including a cross-analysis based on patents and official “best practices” to assess their effects on public debate through a longitudinal case study of online social mobilizations.
Conclusion
This critical examination of the scientific literature produced by two major social media platform-owning corporations allows us to discern their developmental objectives from the narratives designed to showcase their capacity for innovation. In both instances, the comparative analysis highlights the establishment of conventions, and potentially norms, concerning the (lack of) definition of emotions, as well as the insights their computational capture and processing can yield about users, and the means through which they can shape user behaviors. Beyond social media, these technologies—through the subsidiaries and partners of major companies—are deployed across numerous economic and institutional sectors. This diffusion complicates any ethical or legal regulation, as algorithmic and conceptual biases become increasingly opaque through their integration into diverse technologies. While affective technologies are presented in Meta’s and Google’s publications as tools for enhancing personalized exposure to information, they paradoxically lead to a standardization of what affects us—without considering that what moves us empowers us to act based on context and experience. For scientific research, this raises critical questions about the paradigms embedded in these standards when we rely on them, and about our capacity to construct frameworks that preserve the sensitivity and cultural particularities of the individuals we study. For regulators, the challenge lies in addressing the antidemocratic potential of biometric technologies designed to capture the most intimate dimensions of the self for advertising purposes, as well as the already visible consequences of regulating information flows based on what platforms deem emotionally engaging. For users, the digital spaces we navigate daily shape what we are expected to “like” rather than what might foster genuine connection. Escaping this digital affective economy thus requires a deliberate affective labor—one that involves reclaiming and economizing our own affect. Our study offers empirical and critical contributions to the development of the affective turn in social media studies. Future research must account for the platform-generated representations of emotions and the affective publics they construct, to avoid uncritically reproducing the epistemological biases embedded in these narratives and the innovations they produce.
Footnotes
Acknowledgements
The authors thank the reviewers for their constructive feedback.
Ethical considerations
This study did not involve human participants or sensitive personal data and therefore did not require ethical approval.
Consent to participate
This study did not involve human participants or sensitive personal data and therefore did not require informed consent.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Social Sciences and Humanities Research Council of Canada (grant number 435-2023-1001).