
Abstract
Research using online datasets from social media platforms continues to grow in prominence, but recent research suggests that platform users are sometimes uncomfortable with the ways their posts and content are used in research studies. While previous research has suggested that a variety of contextual variables may influence this discomfort, such factors have yet to be isolated and compared. In this article, we present results from a factorial vignette survey of American Facebook users. Findings reveal that researcher domain, content type, purpose of data use, and awareness of data collection all impact respondents’ comfort—measured via judgments of acceptability and concern—with diverse data uses. We provide guidance to researchers and ethics review boards about the ways that user reactions to research uses of their data can serve as a cue for identifying sensitive data types and uses.
Introduction
Online services, including social media platforms, generate rich and varied individual and aggregate behavioral data. For many Americans, social media is at the center of daily activities ranging from socializing to political communication to information seeking. These activities are often conducted across a variety of platforms and leave digital trails of text, photos, videos, and reactions to content. Researchers use these data in the pursuit of knowledge discovery across a variety of topics, such as promoting healthy conversations (Chandrasekharan, Samory, Srinivasan, & Gilbert, 2017), understanding particular life stages (Chakraborty, Vishik, & Rao, 2013), and facilitating collaborative production (Johnson et al., 2016). These online posts and interactions provide researchers with unique access to large-scale data, longitudinal indicators, and direct interventions that can be used to better understand human behavior. However, online data access also raises questions about ethical practices when conducting this research.
In the social and computational science research communities, there is significant disagreement over basic research ethics questions and policies regarding online data, such as what constitutes “public” content and at what stage computational research becomes human subjects research (Vitak, Shilton, & Ashktorab, 2016). Within the social media research community, for example, it is common practice to use large amounts of public online data (such as tweets) for analysis (Bruns, 2013). Although this type of data collection is typically not considered under the purview of university review boards (Moreno, Goniu, Moreno, & Diekema, 2013; Tene & Polonetsky, 2011), the research does impact human subjects (Fiesler & Proferes, 2018; Tufekci, 2015). Furthermore, surveys of researchers using such data reveal varying practices, with some going beyond what is required of them (e.g., seeking out ethics review when not required by policy, obtaining permission to quote, or sharing research outputs with users), while others only take steps that are required by their institution (Proferes & Walker, 2020).
Alongside researcher disagreement over best practices is a lack of knowledge about what research subjects expect and prefer. Traditionally, research subjects’ expectations about, and comfort with, participation in research has been an important (although not entirely deterministic) signal of the ethical principles of self-determination and autonomy (National Commission for the Protection of Human Subjects of Biomedical and Behavioral Research, 1979). And participant expectations of self-determination tend to hold in online spaces as well. Fiesler and Proferes (2018) found that Twitter users largely believe that researchers should seek permission before using tweets in their research. And even when consent is a central part of a research protocol, such as in studies where participants opt in, ethical concerns about study purpose and data protection are a significant factor in individuals’ decisions about participation (Bietz et al., 2016).
Little is known about which factors matter most to users’ comfort with research uses of their social media data. To identify elements associated with comfort and better inform social media research, this exploratory study investigates how users’ attitudes toward data collection on a single platform (Facebook) change based on factors suggested by the framework of privacy as contextual integrity (Nissenbaum, 2009). These include roles (who is collecting data), content (how much and what type of data they are collecting), purpose (the goals of data collection), and conditions of collection (how the data are processed and whether participants are aware of the study). We focus on Facebook to restrict findings to a single platform and its associated data types, enabling future comparative work across platforms. Our analysis focuses on evaluating the following research questions (RQs):
RQ1. How do Facebook users’ demographics, use of the platform, and attitudes toward privacy and trust impact their perceptions of researchers’ use of their data?
RQ2. How do contextual factors associated with social media research impact Facebook users’ perceptions of researchers’ use of their data?
RQ3. How do contextual factors interact to impact users’ perceptions of researchers’ use of their data?
Using factorial vignettes—a survey method that measures the influence of small situational changes on participants’ assessments—we find that a variety of nuanced factors matter to participants’ comfort with social media research data collection. Particular research domains, content types, data use purposes, and awareness of data collection all impact participants’ judgments of both concern and appropriateness, with participant awareness of research playing the biggest role. We use these findings to offer recommendations for researchers in academia and industry, such as increasing user awareness through consent or notification, identifying the transmission principles that surround the data researchers collect, and increasing participant comfort with research through principles such as confidentiality or anonymity.
Background
Growing use of social media has provided rich sources of data for research purposes and increased interest in users’ perception of that research. Fiesler and Proferes (2018) found that Twitter users are largely unaware that researchers are permitted to use public data without explicit consent and believe that researchers should not be able to use tweets without prior permission. However, prior work has also found that users’ attitudes about research use of social media data depend on contextual factors, such as how the research is conducted and the topic of the study (Fiesler & Proferes, 2018), the size of the community (Hudson & Bruckman, 2004), and who is using the data (Dym & Fiesler, 2020; Fiesler & Proferes, 2018; Gruzd & Mai, 2020). Qualitative research by Beninger (2017) explored users’ feelings about social media research, finding diverse responses across participants including skepticism about research using social media data; acceptance, particularly among those who viewed social media data as already public; and ambivalence among those who felt there was nothing that could be done to prevent being studied. Participants also valued principles outlined in the Belmont Report, particularly informed consent, anonymity, and beneficence.
Work on the acceptability of research uses of social media data has also focused on specific contexts. For example, Bietz et al. (2016) examined individuals’ attitudes toward the privacy of personal health data and the use of those data for health research, finding that people’s perceptions are contingent on the kind of research being done and whether it is being done for commercial or public good purposes. Studying user perceptions of data reuse by journalists, Dubois, Gruzd, and Jacobson (2020) found similar results; for example, Canadian social media users were more comfortable with aggregate use of their data.
A key theme across each of these studies is the lack of simple answers about the acceptability of research using social media data. User expectations are, as Nissenbaum (2009) has argued, contextual: whether individuals find data use acceptable or concerning depends on the learned norms of a particular context. Privacy as contextual integrity explains that norms and expectations for information flows vary between social contexts. Empirical studies employing contextual integrity have demonstrated that consumers’ expectations of data collection and use vary depending on the social context. For example, consumers expect map applications on their phone to use GPS data, but not banking applications (Martin & Shilton, 2016a). Hull, Lipford, & Latulipe (2011) found that particular platform features, such as Facebook applications that share friends’ information as well as one’s own, violate norms of information flow. Furthermore, contextual integrity has been proposed as a framework to identify issues in website privacy policies (Shvartzshnaider, Apthorpe, Feamster, & Nissenbaum, 2019) and contact tracing applications (Vitak & Zimmer, 2020), and as a heuristic for contextually sensitive approaches when making ethical choices during research (Zimmer, 2018).
Nissenbaum’s framework posits that privacy concerns are triggered by conflicts between the norms of a social context and unexpected information flows. Research has shown that such violations of contextual integrity erode user trust (Martin, 2018). Privacy as contextual integrity suggests that the goal of social media research should be to prevent trust erosion and build participant comfort with social media research by either avoiding or addressing unexpected information flows.
However, the general public’s expected information flows for research data were largely shaped by clinical research models where subjects enrolled knowingly in studies and were debriefed by researchers (Metcalf & Crawford, 2016). It is only recently that the public has become aware of how much of their social media data are also used in research, often without their explicit knowledge or consent. Angry and confused reactions to research uses of social media data (Fiesler & Proferes, 2018; Hallinan, Brubaker, & Fiesler, 2020) suggest that users perceive violations of contextual integrity. Although there have long been observational studies of public behavior without explicit subject knowledge, the information available to researchers from social media platforms is increasingly rich and personal. Furthermore, researchers have shown that even when users make public posts, they imagine a narrow audience (Marwick & Boyd, 2011) and underestimate the full reach of that content (Bernstein, Bakshy, Burke, & Karrer, 2013).
Investigating contextual norms for Facebook data reuse—who users expect to reuse data; how data types (e.g., content collected and its sensitivity) and research conditions (e.g., were participants notified? were data anonymized?) impact acceptability; and which research purposes users deem appropriate—is an important next step for understanding participant expectations.
Methods
To identify and explore norms held by American social media users’ regarding research uses of their data, we developed a survey using a combination of traditional survey questions and factorial vignettes. Vignettes are short scenarios that systematically introduce contextual factors and ask participants to make judgments about acceptability. Participants respond to dozens of scenarios, reacting to tangible examples rather than answering questions about their preferences. Factorial vignette surveys allow researchers to gain insight into users’ mental models of norms and how those norms are influenced by variable factors (Alexander & Becker, 1978). Factorial vignettes also reduce response biases for sensitive issues (Aviram, 2012) and have been used in prior investigations of privacy and trust (Martin, 2012; Martin & Nissenbaum, 2016; Martin & Shilton, 2016a).
Survey Design
We chose to study Facebook users for several reasons. First, at the time of data collection, Facebook was the most popular social network site among American adults (Perrin & Anderson, 2019). Second, Facebook affords a variety of “levels” of data publicness (in contrast to more public-facing data of platforms like Twitter and Reddit), making research reuse of Facebook data a thornier ethical question. Finally, controversies around research uses of Facebook data, such as the emotional contagion study and the Cambridge Analytica scandal, demonstrate public and researcher uncertainty about the ethics of data reuse on the platform and have contributed to the platform’s reluctance to share data with researchers (Alba, 2019; Hallinan et al., 2020).
We designed a two-part survey. Section 1 included demographic questions such as age, gender identity, education, and several measures of Facebook use. This section also included four questions about respondents’ attitudes toward privacy and data collection. Three of the four questions were taken from previous work by Martin and Nissenbaum (2016) and measured general privacy expectations, while the fourth asked respondents whether they had pre-existing privacy concerns about Facebook. As recommended by Martin and Nissenbaum (2016), the privacy questions were placed before the vignettes to assess generalized privacy attitudes before respondents were primed by concrete examples of possible reuses of their data
Section 2 contained the vignettes. Guided by Martin and Nissenbaum (2016), we presented each respondent with 35 randomly generated factorial vignettes. For each vignette, respondents responded to two items designed to elicit their comfort with the scenario: (1) “This use of my data is appropriate” and (2) “This use of my data would concern me,” which were presented in a consistent order across respondents. Responses indicated with a sliding scale between 0 (strongly agree) and 100 (strongly disagree). 1 A sliding scale was used as recommended by Jasso (2006), who notes that a sliding scale better represents the response variable continuum felt by respondents when making judgments. The 0–100 scale is similar to that used by Martin and Nissenbaum (2016).
To decide which factors should be included in the vignettes, we used contextual integrity to choose high-level variables (roles, content, purpose, and conditions) and then reviewed relevant literature on privacy and trust in social media platforms to develop a list of contextual factors within those categories most likely to matter to respondents. In developing the list of factors, we sought to balance identifying relevant variables with minimizing cognitive overload for respondents. The final list comprised 31 items across six factors (see Table 1).
Vignette Factor and Item List.

To represent roles, we use domain to investigate whether research field matters to the social context of data collection. We selected roles primarily within academia, but also added the item “tech companies” to explore users’ perceptions of data use by industry researchers. To represent the data collected, we investigated both content and dataset. Items listed in the content factor were chosen to represent varying levels of sensitivity, identified by Nissenbaum (2004) as a factor that plays a key role in individuals’ privacy norms. The composition of the dataset was a factor identified by Dubois et al. (2020) in their study of Canadians’ perception of social media use by journalists. Fiesler and Proferes (2018) found that the purpose of the research was an important factor in participants’ willingness to have their tweets used in research. To investigate purpose, we chose a variety of both research and non-research uses of data, and attempted to represent both descriptive (e.g., analyzing your friend network) and action-oriented research (e.g., assessing mental health). To represent conditions, we investigated both how data would be analyzed (using humans or computers, based on the finding by Fiesler and Proferes (2018) that mode of analysis mattered to Twitter users, which we refer to as tool) and participant awareness of a study (awareness). Participant awareness factors were influenced by Fiesler and Proferes’ (2018) finding that Twitter users were concerned with whether or not permission to use data was granted and whether or not they were informed before the research took place. Figure 1 shows an example vignette from our study.

Sample vignette as presented to survey respondents.
In some cases, combinations of factors may appear problematic—for example, particular types of data may be difficult for some actors in the domain field to access (e.g., academic researchers are frequently unable to obtain all the posts an individual has shared on Facebook) or it may be unlikely researchers in particular domains would conduct research for a given purpose (e.g., Health Science researchers may be unlikely to use Facebook data for the purpose of personalizing advertising). While Jasso (2006) recommends the deletion of logically impossible vignettes, we did not want to limit the vignette hypotheticals to those that are possible or common now, so we opted to retain all combinations. Therefore, although it should be noted that some vignettes shown to respondents are more likely than others, we felt it was valuable to retain all possibilities.
Recruitment
We designed our survey using Qualtrics survey design software, and had it approved by our university’s institutional review board (IRB). Prior to recruitment, the survey was piloted for clarity and face validity by three expert outside researchers in data ethics. We used Qualtrics to recruit adult participants who identified as at least occasional (more than once a month) Facebook users. 2
Each participant was paid US$2.75 cash or equivalent (e.g., gift cards or donation to a selected charity). Data from 350 respondents 3 were collected between May and June 2019 (data from respondents who provided the same response for both questions across all vignettes were removed and replaced). The average response time in the final dataset was 8:23 after a speed check (measured as one half the median time to complete during a soft launch) automatically terminated faster responses. Each question was required.
Data Analysis
First, we answered RQ1 by testing the impact of control variables on vignette judgments. We answered RQ2 by testing how each factor affected users’ perceptions of acceptable data use for research purposes using linear mixed models, which read like analysis of variance (ANOVA) tests. Factors were tested using each participant as the subject, and ratings for both appropriateness and concern as dependent variables (DVs). For RQ3, we tested for interaction effects between factors on the DVs. Again, we used linear mixed models, but added a second variable (e.g., a second factor or one of the privacy measures) to each model. Rather than performing a correction test, such as Bonferroni, we follow Moran’s (2003) recommendation to report exact p-values, which will allow readers to interpret the findings with an appropriate level of caution.
We have omitted analyses for the dataset factor, as we found no clear patterns for this item, which suggests potential problems with how it was presented and/or interpreted by survey respondents. Alternatively, the size or composition of datasets collected might be a secondary concern for users; users may have instead focused on who was collecting the data and why it was being collected, as demonstrated below.
Results
Participant Characteristics, Facebook Use, and Privacy Attitudes
First, we briefly describe our respondent demographics (Table 2). A large majority of survey respondents identified as women, and the average age was 35 years.
Demographics.

Most respondents were long-term Facebook users, with 81.8% reportedly using Facebook for more than 4 years. They frequently visited Facebook: two-thirds (67%) checked into Facebook multiple times a day, and half (51.1%) reacted to posts multiple times a day. They also reported having a large number of friends of the platform; after removing those with unrealistically high responses (>5,000), the average number of friends was 698 (SD = 1,079.4).
We also measured respondents’ attitudes toward privacy and institutional trust. Although our respondents believed privacy was important, they expressed a wide range of privacy and trust attitudes, demonstrated in Table 3 (scale: 0 = strongly disagree; 100 = strongly agree).
Privacy and Trust.
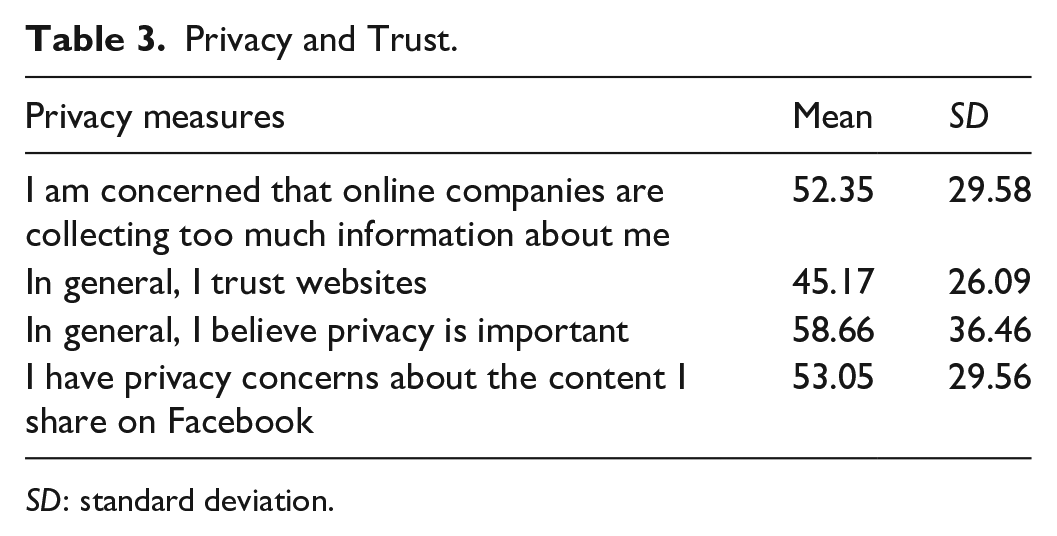
SD: standard deviation.
RQ1: Vignette Ratings by Control Variables
The DVs across all models were the two vignette ratings: the degree to which respondents agreed or disagreed that the use of their data as described in each vignette was (1) concerning and (2) appropriate.
To address RQ1, we looked at whether individual characteristics were related to vignette judgments, using a combination of t-tests, ANOVAs, and correlation. First, we looked at respondents’ reported gender identity, age, and education. Looking at gender identity, men (M = 40.92, SD = 29.10) rated scenarios as significantly less appropriate than women (M = 44.99, SD = 30.27), t(12,143) = 6.28, p < .001; however, no significant difference was found in concern ratings between male and female respondents. To explore the relationship between age and vignette judgments, we used Pearson’s correlation tests. Tests showed a significant positive correlation between age and concern ratings (r = .10, p < .001) and a significant negative correlation between age and appropriateness ratings (r = −.08, p < .001). We used ANOVA to evaluate relationships between education level and vignette rating. We collapsed this measure to create four main categories—high school graduate or less, associate or trade degree, some college or Bachelor’s degree, Masters or other post-graduate degree. The model was significant for appropriateness F(3, 11,686) = 29.51, p < .000, but not for concern F(3, 11,686) = 2.39, p = .07. Scheffe’s post hoc analyses found that those with a high school diploma or less rated scenarios as significantly more appropriate (M = 47.24, SD = 30.141) than those in other educational groups.
For frequency of Facebook use, an ANOVA test revealed a significant relationship between use and vignette ratings. Scheffe’s post hoc analyses showed that those who used Facebook multiple times a day rated data use as more appropriate than all other groups (M = 45.75, SD = 30.608). Likewise, this group rated the vignettes as less concerning (M = 50.5, SD = 30.140) than those accessing the platform once a day (M = 53.76, SD = 29.961) or a few times a week (M = 54.36, SD = 29.584). We had similar findings when looking at respondents’ engagement with content on the platform, with significant differences in both ratings for reacting to content and posting content on Facebook. In general, those who were more active (posting and/or reacting multiple times a day) rated vignettes as more appropriate and less concerning than those who were less active on the platform.
Finally, we examined the relationships between respondents’ attitudes toward privacy and trust and their vignette judgments (Table 4). Pearson’s correlation tests identified significant correlations between all four items and the concern DV, and three items with the appropriateness DV. Overall, lower trust and higher privacy concerns were associated with higher concern ratings on the vignettes, whereas higher trust and lower privacy concerns were associated with higher appropriateness ratings. These correlations are expected and validate the vignettes as effective at measuring respondents’ relative privacy concerns. Next, we examine how particular vignette factors impacted participants’ comfort with research uses of their data.
Pearson’s Correlations Between Privacy Values and Vignette Judgment.

RQ2: Vignette Ratings by Factors
Next, we looked at the impact of each factor (domain, content, purpose, research tools, and awareness) on vignette ratings. This section highlights the most important factors in user judgments based on our analyses. Because factorial vignettes are designed to identify subtle differences between scenarios, effect sizes were small (Jasso, 2006). Significant results are highlighted.
Domain
Although domain types did not significantly impact users’ concern ratings, results from the linear mixed model using appropriateness as the DV showed that data use within Computer Science, Gender Studies, and Psychology was rated as significantly less appropriate than Health Science (the constant), which was rated as the most appropriate of all domains (see Table 5).
Linear Mixed Model of Domain and Vignette Judgment.

SD: standard deviation.
Content
Respondents rated researchers’ use of photos or videos; posts about sexual habits, preferences, or behaviors; status updates; and comments on friends’ or family’s posts as significantly more concerning than posts about food (the constant), with the strongest significance found in judgments on vignettes showing posts about sexual habits, preferences, or behaviors. Conversely, posts about sexual habits, preferences, or behaviors; status updates; and comments on friends’ or family’s posts were rated as significantly less appropriate (see Table 6).
Linear Mixed Model of Content and Vignette Judgment.

SD: standard deviation.
Purpose of Data Use
Respondents rated use of their data to analyze their friend networks, assess their mental health, and predict user behavior as more concerning than improving user behavior (the constant). No statistically significant results were observed for appropriateness ratings (see Table 7).
Linear Mixed Model of Purpose and Vignette Rating.

SD: standard deviation.
Research Tools
The tool used for analysis (computers vs humans) was not a significant factor in respondents’ perception of concerning or appropriate use of their data (see Table 8).
Linear Mixed Model of Tool and Vignette Rating.

SD: standard deviation.
Participant Awareness of Study
Respondents rated vignettes where researchers gained consent prior to the study as less concerning and more appropriate than those in which study details were disclosed after the study is complete (the constant). Conversely, respondents rated vignettes in which notification was never granted as more concerning and less appropriate than disclosure after the study is complete (see Table 9).
Linear Mixed Model of Awareness and Vignette Rating.

SD: standard deviation.
RQ3: Relationships Between Factors
Next, we explored interaction effects between factors found to be important in our previous analyses, focusing on awareness, as we observed the most significant effects between vignette judgments and awareness. For clarity, Table 10 only includes items that had at least one significant relationship between the factor and vignette judgments.
Linear Mixed Model of Interaction Effects between Awareness and Other Factors.

Significant relationships were found between aware-ness and items in each of the other factors. The average appropriateness rating of vignettes was higher when Psychology researchers never provided notification of data use compared to the constant, Health Science researchers disclosing details after the study. Average appropriate ratings were also higher when photos or videos were used and no notification was provided compared to the constant, posts about food used, and disclosing details after the study. Average concern ratings were higher when researchers combatting online harassment provided no notification than the constant, improving user experience and disclosing details after the study. Finally, average appropriateness ratings were lower when humans were used as the analytical tool and no notification was provided than the constant, computers used as the analytical tool, and disclosing details after the study.
Because individual privacy attitudes had significant effects on overall vignette ratings, we also tested interaction effects between privacy attitudes and awareness. Table 11 shows interaction effects on vignette judgments between the four privacy values measured and awareness ratings when consent was given prior to data collection, compared to the constant.
Linear Mixed Model of Interaction Effects between Privacy Measures, Awareness, and Vignette Ratings.
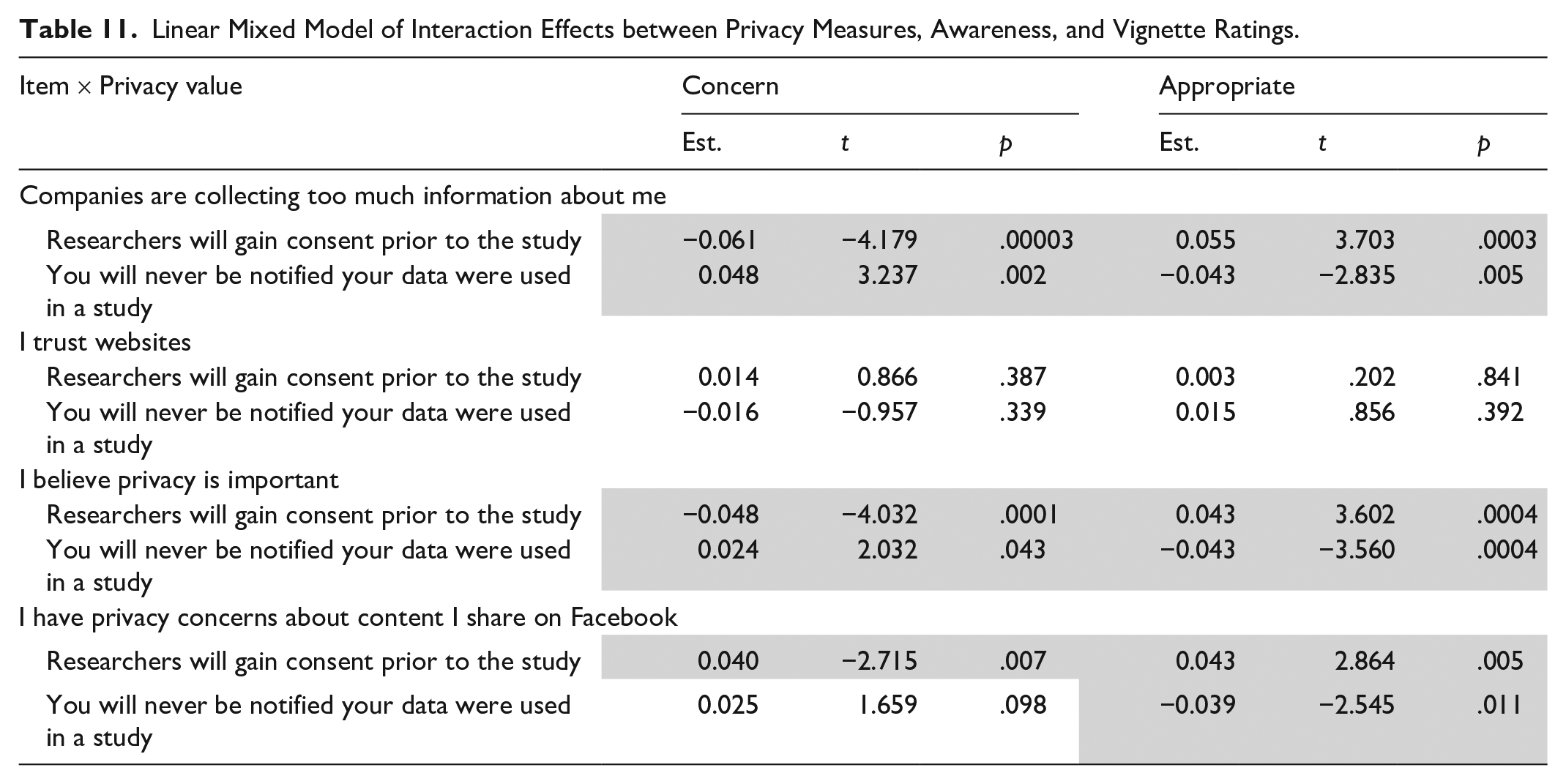
Figure 2 plots the interaction effect on vignette judgments of respondents’ agreement with the statement, “I believe that companies collect too much information about me” and awareness. Plots of two other privacy measures—belief that privacy is important and privacy concerns about content shared on Facebook—showed similar patterns. Where significant interaction effects were found, greater concern for privacy was associated with higher concern ratings when never notified and with lower concern ratings when consent was given prior to data collection, compared to being made aware that data were used after the study (the constant). Conversely, greater concern for privacy was associated with lower appropriateness ratings when never notified and higher appropriateness
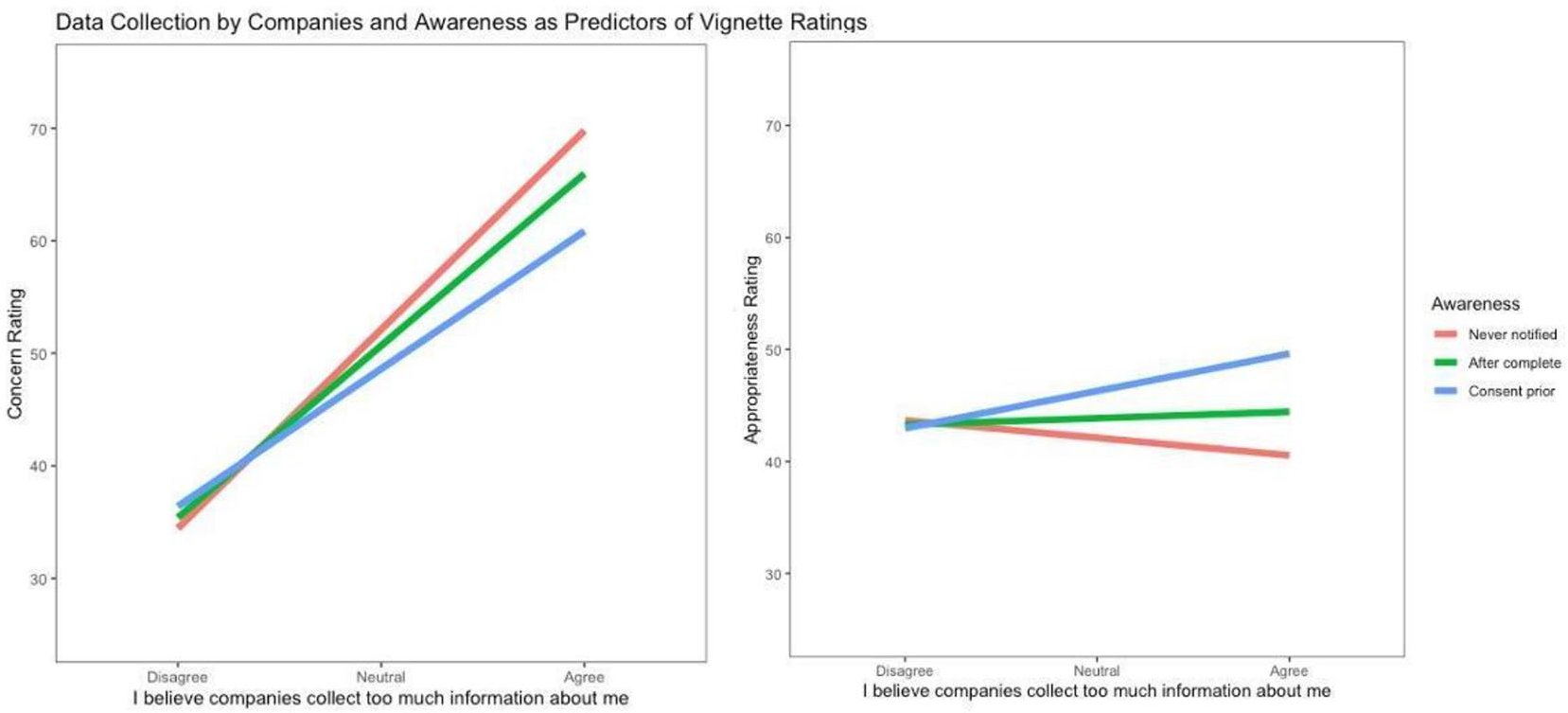
Interaction effects of data collection and awareness on vignette ratings.
Discussion
Results from this study highlight patterns in Facebook users’ perceptions of research data uses. Particular researcher domains, content types, and data use purposes, as well as general awareness of data collection, all impacted respondents’ comfort with data use, as measured by their judgments of concern and appropriateness. Below, we discuss the factors with the largest impact on respondents’ judgments and use them to provide guidance to researchers and IRBs.
Identifying Data Use Expectations
Our results revealed several cases where users appear comfortable with research uses of Facebook data: cases where participants consistently rated data use by researchers as more appropriate and less concerning. First, respondents rated data use by Health Science researchers as slightly more appropriate than other domains. This may be a reflection of expected norms within health research contexts, or the assumption that health research has direct benefits to individuals or society (Vitak & Zimmer, 2020). Our vignettes, however, did not specify whether health researchers were from academic or commercial contexts (e.g., pharmaceuticals); future research might illuminate whether adding additional contextual information influences comfort with health science.
On the other end of the comfort spectrum, data use by Gender Studies researchers was viewed as less appropriate overall. While it is difficult to know exactly why vignettes about Gender Studies research surprised respondents, results from surveys of social media users (Fiesler & Proferes, 2018; Hallinan et al., 2020) have suggested that a portion of politically conservative social media users object to research uses of their data. “Gender Studies” may read as ideologically liberal to some respondents. We are not suggesting that Gender Studies researchers should avoid collecting or analyzing Facebook data, but rather highlighting that academics in fields more frequently interpreted as political may be at greater risk of user backlash to data collection than researchers in other fields.
Next, respondents expressed comfort with research uses of particular types of content. Posts about food or science and comments on public posts were rated as both more appropriate and less concerning for research use. We believe that posts about food and science represent less sensitive data in the context of social media research. Comments on public posts incorporate what Nissenbaum (2009) calls a transmission principle or condition of collection: in this case, public, rather than restricted, sharing. Our survey cued respondents to this transmission principle, and participants expressed more comfort with research uses of publicly shared data than content shared through private channels (e.g., in groups or via messenger). This finding bolsters earlier work from studies of other social media contexts, such as chatrooms, where participants were less likely to object to research when the chatroom was large (more public) than small (more private; Hudson & Bruckman, 2004).
As predicted by contextual integrity, the purpose of data use impacted participants’ comfort. Respondents rated the collection of data to improve user experience as more appropriate and less concerning than most research uses of data, and the use of data for combating online harassment as less concerning. Improving user experience and combating online harassment are instrumental, system-appropriate uses of data that provide a benefit to users. On the contrary, research uses of data such as assessing users’ mental health can trigger surprise and discomfort. This finding recalls the analysis by Hallinan et al. (2020) that one reason for public unhappiness about the Facebook emotional contagion study was objections to feelings of living in a lab while using social media. These findings show that, though companies like Facebook collect user data and conduct experiments routinely, users may not expect data collection for knowledge creation rather than service delivery.
The factor with the largest impact on comfort was respondents’ awareness of data use. Gaining consent is still the gold standard in research participation: research that gained consent prior to data use was consistently rated as more appropriate and less concerning by respondents. Conversely, research without notification was viewed with the most discomfort: vignettes in which respondents were never notified about data use were consistently rated as more concerning and less appropriate. Post hoc analyses found these differences to be significant: comfort scores were significantly higher in vignettes where users were notified after the fact, than vignettes where respondents were never notified, suggesting that notifications following data collection may be an alternative in cases where obtaining informed consent is difficult, impossible, or could compromise the findings, for example, via tools such as those proposed by Zong and Matias (2018). Like all of the findings in our study, the impact of participant awareness could also depend on the other contextual variables in play, such as who is doing the research, the purpose of the research, and sensitivity of content used.
Finally, we observed interactions between vignette ratings and diverse measures of generalized privacy concern. Although previous research has shown that contextual norms are more important than personal preferences to privacy judgments (Martin & Nissenbaum, 2016; Martin & Shilton, 2016a, 2016b), we identified meaningful variations in users’ comfort with research data use. Researchers might consider whether their populations of interest are likely to be more or less comfortable with data sharing in online environments overall, or more or less privacy sensitive for historical or demographic reasons, and adjust their online data research practices accordingly.
Despite previous research finding that the way data were analyzed (humans vs machines) mattered to respondents (Fiesler & Proferes, 2018), our study found no significant results between the tool factor and participant ratings. While it may be that individuals care about analysis tools and scale when explicitly asked, when this information is included as part of a more complex vignette, analysis tools do not impact decision-making in the same way that content types, data uses, and awareness do. While previous research has used automated analysis to distance researchers from users’ sensitive data (Chancellor, Pater, Clear, Gilbert, & De Choudhury, 2016), this may have less impact on Facebook users’ comfort with research data uses than other research practices.
Recommendations for Pervasive Data Researchers
We build on prior work that recommends researchers take reflexive, context-oriented approaches when using social media data (e.g., Franzke, Bechmann, Zimmer, Ess, & Association of Internet Researchers, 2020; Hennell, Limmer, & Piacentini, 2020; Williams, Burnap, & Sloan, 2017). For researchers struggling with questions of how to use social media data in research, our analysis provides some guiding data on participant concerns and comfort to shape inquiry. First, researchers should be aware that research uses of data are generally more concerning to users than using data for platform improvements. These concerns are higher for younger adults, infrequent Facebook users, and people with higher privacy concerns. Because of this wariness, researchers should always ask themselves whether the groups they are studying are likely to experience elevated concern, and if so, what degree of awareness researchers can reasonably provide to participants.
Next, researchers can ask themselves: are we collecting data shared in confidence? A focus on the transmission principles that surround data—the implicit and explicit promises a platform has made to its users—is a traditional question within contextual integrity and particularly important for online social media researchers. If norms of information flow are guided by the transmission principle of notice and choice, users may expect to be notified about specific data uses and, ideally, be able to opt out of such research. If Facebook—or any social platform—engages in practices that go against this transmission principle, this may be a violation of contextual integrity.
Finally, we sound a note of caution about potential differences in how Facebook users perceive research disciplines. There is some evidence that users are more comfortable with research in disciplines where surveillant research has long been a norm and less comfortable with research in disciplines that may scan as politically oriented. Participants may also be uncomfortable with research uses of content types considered to be surprising for a particular discipline, or a particular purpose. We do not think this means researchers in, for example, health disciplines should have more access to social media data than others. Rather, we want researchers to be conscious of these preferences and potential biases so that they can protect themselves during the research process. In particular, our work suggests that increasing respondents’ awareness of online research can help mitigate user concerns. When gaining informed consent prior to data use is not possible, practical, or advisable, awareness after the fact (e.g., through public scholarship) may be viewed as an acceptable alternative. However, it is also important to note that awareness and public scholarship present unequal challenges for researchers that echo the differences in user expectations we found; for example, people of color, women, and genderqueer researchers are already at greater risk of online harassment or abuse when sharing the results of their work with the public (Massanari, 2018).
Limitations
While this work provides empirical evidence identifying factors that impact users’ comfort with data use by researchers, there are limitations. We did not ask respondents about how much they know or understand about data reuse, which may be an explanatory factor. Our sample is also limited to Americans, meaning we have not captured cross-cultural norms. Our study focused on research within a primarily academic context, only including one domain (tech companies) from outside this context. Future studies should include domains across a variety of research and regulatory environments. Finally, our study only focused on users’ perceptions on a single platform. Future work should explore the impact of diverse platforms on perceptions of data use.
Conclusion
Social media research that violates privacy norms and expectations can result in strong negative reactions from users. This article used factorial vignettes to explore users’ comfort with research conducted on a single platform, Facebook. Our findings show that factors such as the domain of the researcher, the type of content collected, the purpose of the research, and level of awareness of the research all impact how users view researchers’ use of their data. We recommend that researchers use these findings to shape their own social media data practices. Researchers working with groups less likely to trust social media sites or collecting unexpected data types should increase user awareness of their research through consent or notification. Researchers should identify the transmission principles that surround the data they are collecting, and increase the transparency of their research for data types with transmission principles such as confidentiality or anonymity. Finally, our findings highlight that researchers within specific disciplines may be at greater risk of participant surprise or discomfort.
A challenge for social media research (and for contextual integrity more generally) is that users’ judgments of concern and appropriateness do not dictate what is ethical or right—they only dictate what users expect. User expectations and comfort are a critical component, but not the only component, of research ethics. Researchers must weigh participant expectations against factors such as other potential risks to participants and the importance of the knowledge generated by the research. We do not advocate that our findings be translated as prohibitions, but instead, as information for researchers to consider when designing social media studies. Increased consideration of participant comfort, and the broader role it has in enabling social media data research over a long term, is critical for our field’s future.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Science Foundation under grant #1144934.