
Abstract
Social media provides unique opportunities for researchers to learn about a variety of phenomena—it is often publicly available, highly accessible, and affords more naturalistic observation. However, as research using social media data has increased, so too has public scrutiny, highlighting the need to develop ethical approaches to social media data use. Prior work in this area has explored users’ perceptions of researchers’ use of social media data in the context of a single platform. In this paper, we expand on that work, exploring how platforms and their affordances impact how users feel about social media data reuse. We present results from three factorial vignette surveys, each focusing on a different platform—dating apps, Instagram, and Reddit—to assess users’ comfort with research data use scenarios across a variety of contexts. Although our results highlight different expectations between platforms depending on the research domain, purpose of research, and content collected, we find that the factor with the greatest impact across all platforms is consent—a finding which presents challenges for big data researchers. We conclude by offering a sociotechnical approach to ethical decision-making. This approach provides recommendations on how researchers can interpret and respond to platform norms and affordances to predict potential data use sensitivities. The approach also recommends that researchers respond to the predominant expectation of notification and consent for research participation by bolstering awareness of data collection on digital platforms.
Introduction
Due to the widespread popularity of social media platforms, access to tremendous amounts of pervasive data—information about people generated through digital interactions (Shilton et al., 2021)—has enabled researchers to study a wide range of topics, from online harassment prevention (Matias, 2019) to reducing the spread of misinformation (Bak-Coleman et al., 2022), and evaluating social media use in activist movements (Freelon et al., 2016). However, research uses of pervasive data can also cause distress and harm. In a recent example, a LinkedIn experiment studying the impact of relationship types in securing a job was met with concerns over how it might have affected users’ ability to find work (Singer, 2022).
In the United States, research uses of social media data are loosely regulated, with no federal (and limited state) legislation restricting or structuring pervasive data use. And while the United States regulates research data uses through the Common Rule—which establishes review boards for university researchers—analysis of public data and secondary reuses of existing datasets are allowed without explicit consent. This is concerning given that previous research has shown that social media users do not always know that consent may not be required for research uses of pervasive data (Beninger, 2017; Fiesler and Proferes, 2018; Gilbert et al., 2021). Findings from these studies highlight that many users are uncomfortable with their digital traces being analyzed by external groups—especially when they are not notified beforehand—and that, in the absence of clear data use regulation, users’ attitudes toward data collection are shaped by contextual integrity (CI; Nissenbaum, 2009). In a context in which consent has long been considered a norm for research with human subjects, user uncertainty over norms and expectations for research with pervasive data raise ethical challenges for researchers. This research seeks to guide researchers to anticipate data uses and contexts that users find more or less concerning.
Although context has been found to be critical to users’ evaluation of pervasive data use acceptability, an underresearched consideration in this space is how platforms factor into user evaluations of context. Although the majority of social media research focuses on a single platform (e.g., Fiesler and Proferes, 2018; Gilbert et al., 2021), there is increasing interest in studying how user expectations vary based on different platforms’ features and affordances, as well as user goals and norms on various platforms. Given platforms’ different features, affordances, and use cultures, we expect that the norms of what is considered (in)appropriate use of data may also vary.
Given the relative lack of protections for research uses of American's digital data, this paper considers the attitudes and expectations of American users of three distinct platforms: Instagram, a platform focused on sharing images and videos; Reddit, a pseudonymous platform organized into communities around topics; and dating apps, which require sharing highly personal information. These platforms have also been popular data sources in prior work (e.g., Ellison et al., 2006; Feuston and Piper, 2018; Proferes et al., 2021). In this paper, we ask: How do Americans’ concerns about researcher use of their data vary across platforms? We answer this question by comparing data from three surveys of users. We use factorial vignettes—a method devised to identify nuances in people's attitudes—to explore what factors influence respondents’ judgments about the appropriateness of online data research practices. Our vignettes measure the impact of elements from Nissenbaum's (2009) framework of privacy as CI, which argues that contextual factors determine people's perceptions of appropriate flows of information. Using CI as a framework, we explore why different social media data collection practices may be problematic in one context but not another. Furthermore, we identify unifying norms across platforms that signal users’ perceptions of problematic or even unethical research practices.
Our results highlight the dominance of consent expectations across platforms and indicate that participation in research may shape users’ expectations and norms even more strongly than individual platforms. This finding presents a fundamental challenge for a large amount of social media research that occurs without informed consent, so we conclude by offering best practices for researchers to navigate this challenge.
Background
Variations in platform features, affordances, and norms
Social media platforms are distinguished by differing features, affordances, and norms, making it difficult to generalize the findings of one platform to others. In defining our context of the study, we start from Carr and Hayes’ (2014: 50) definition of social media: “Internet-based channels that allow users to opportunistically interact and selectively self-present, either in real-time or asynchronously, with both broad and narrow audiences who derive value from user-generated content and the perception of interaction with others.” We include messaging and dating apps as “social media” because people use these platforms to selectively self-present to individuals or groups, and they derive value from their use (Ellison et al., 2006).
The differing affordances of social media have been widely studied (DeVito et al., 2017; Evans et al., 2017; Treem and Leonardi, 2013), as they help explain differences in use. Particularly relevant for considering user perceptions of research uses of social media data is understanding how platforms vary in their degree of visibility, which Treem and colleagues (2020: 46) define as “the outcomes of activities through which actors strategically or inadvertently: (a) make their communication more or less available, salient, or noticeable to others, and (b) view, access, or become exposed to the communication of others, as they (c) interact with a particular sociomaterial context.”
Most social media platforms include features that make key pieces of information visible, as this helps other users learn about and, on some platforms, locate others. For example, platforms vary in how they treat identity. Facebook is known for its “real name policy,” which requires the use of an “authentic identity” rather than a pseudonym (Haimson and Hoffmann, 2016), while Reddit is characterized by norms of pseudonymity/anonymity (Leavitt, 2015). On platforms such as Twitter and Instagram, users employ a mix of usernames, sometimes related to offline identities and sometimes not. Peddinti and colleagues (2014) found that “anonymous users” on Twitter (who did not list a full name in their profile) exhibited less inhibition in their posts and interactions than those who were identifiable.
Platform features and norms affect how much visibility is given to various pieces of data. Privacy settings provide some control over information visibility. Some platforms only allow users to have a public or private account. Many dating apps require account creation before viewing users’ profiles. Facebook provides the most granular control, with numerous features to adjust profile and post visibility. For platforms where low visibility is preferred, there may be few to no links between a user's posts and a central identity; for example, Leavitt (2015) found that throwaway accounts were commonly used on Reddit to keep specific posts unconnected to main accounts.
Persistence is another important affordance that varies between social media platforms. Persistence refers to communication that “remains accessible in the same form as the original display after the actor has finished his or her presentation” (Treem and Leonardi, 2013: 18). Persistence ranges from completely ephemeral interactions to those that are permanently archived, and many social media platforms retain old posts until a user explicitly deletes them, creating a form of “digital diary” for the user (Vitak and Kim, 2014), and allowing them to reminisce on past memories (Peesapati et al., 2010). However, old content may not reflect users’ current self-presentation. Search features on these platforms may surface content to new audiences and lead to negative outcomes through context collapse (Marwick and boyd, 2011), while algorithms that reshare old content can surface painful memories (Meyer, 2014). Research has found that users of platforms with less persistence (e.g., Snapchat, WeChat, and, to a lesser extent, Instagram) feel more control (Bayer et al., 2016; Huang et al., 2020; Trieu and Baym, 2020).
To summarize, when studying social media platforms, we must consider how each platform's norms, features, and affordances shape users’ perceptions and expectations. To extend this point, we explore prior work on how platform users feel about their data being collected and analyzed for research purposes.
Users’ attitudes toward use of social media data
Growing evidence of user unhappiness with social media data research (Brown, 2020; Halinan et al., 2020) has led researchers to study users’ perspectives on social media data collection and use. For example, Fiesler and Proferes (2018) found that most Twitter users were unaware their public tweets could be used by researchers, and two-thirds wanted researchers to seek their consent before collecting data from Twitter—even though the data were already “public.” Other factors that shaped users’ attitudes toward research uses of Twitter data included the goal of the study, the amount of data being collected, and whether additional information would be collected. Similarly, in prior work on Facebook users, Gilbert et al. (2021) found that various factors, such as researchers’ domain, content type, and awareness of data collection impacted users’ comfort with their data being used for research purposes. As in Fiesler and Proferes (2018), consent prior to data collection had a significant impact on Facebook users’ comfort levels with data use.
Beyond data use by researchers, prior work suggests that the team or institution collecting data plays an important role in users’ comfort with their data being analyzed by third parties. For example, a study of Canadian social media users found they were less comfortable with marketers or political parties accessing their data than they were with academic researchers and employers (Gruzd and Mai, 2020). Although contextual factors have been found to be crucial elements impacting comfort with data use, Beninger (2017) showed how acceptance of data use varies between individuals, where those who viewed social media data as public were generally accepting of data use by researchers, while those who felt they could not prevent their data from being used tended to be more ambivalent.
Contextual integrity
Our assumption that differences in platform norms, features, and affordances may lead to different user expectations for data use is grounded in the theory of privacy as CI (Nissenbaum, 2009). CI describes privacy perceptions as dependent upon social values held within particular contexts, expectations built into roles in those contexts, and conditions (transmission principles) governing information flows within contexts. Applying CI to social media data use predicts that, with such clear differences in norms and information flows, perceptions of appropriateness will likely vary across platforms.
CI is based upon an understanding that different social contexts have different norms and information flows, and therefore, different (but predictable) definitions of acceptable data use. However, operationalizing the theory can be tricky. First, what counts as a social context in the realm of social media? Is each platform its own context? Are there contexts within platforms (say health information-sharing communities on Twitter), or do multiple platforms create a larger context (i.e., online spaces)? There is evidence that platforms have some features of social contexts, such as high-level shared norms and values: see Reddit's norms of anonymous free speech (Massanari, 2017) or Facebook's norms of connecting real-world acquaintances (Haimson and Hoffman, 2016).
That said, platforms also cross offline social contexts and support smaller contexts. For example, a subreddit devoted to a rare disease might best be defined as a medical information-seeking context, while a Facebook group devoted to a local school district could be defined as belonging to an educational context. Or users might use multiple platforms to distribute information about their business. If researchers hope to analyze context-specific acceptable uses of social media data, we need more concrete guidance about where, exactly, users see contexts—and therefore expectations—diverging.
To do this, we consider how concerns about CI's parameters—role, data types, purpose, and information flow conditions—influence user expectations across and between three differing social media platforms. Specifically, we ask: RQ1: What factors affect users’ comfort with data use across Reddit, Instagram, and dating apps?
RQ2: What differences and similarities exist in users’ comfort level with research data use across Reddit, Instagram, and dating apps?
Understanding patterns of similarity and difference across and between platforms can help researchers decide where to draw the lines of contextual expectations, and better predict expectations of, and reactions to, their research.
Methods
Survey design
Building on a prior study of Facebook users’ attitudes toward data use by researchers (Gilbert et al., 2021), we surveyed users of three additional social media spaces: Instagram, Reddit, and dating apps. Because we wanted to explore the impact of technological affordances, information flows, and social norms, we selected platforms that have been used in research but differ along with these dimensions. For example, researchers have used dating app data to learn more about users’ motivations and self-presentation strategies (Birnholtz et al., 2014) and Instagram to evaluate expressions of mental illness on the platform (Feuston et al., 2018). Reddit has been used by researchers from across disciplinary backgrounds to study topics related to online communities, mental health, and gender (Proferes et al., 2021).
To explore users’ comfort with data use, we designed a two-part survey replicated across each of the three platforms. All questions were required, save for open-ended questions. Part I of the survey included items capturing demographics 1 (age, gender, education, income, ethnicity, race), platform use, and privacy attitudes. Platform items included length and frequency of use; responses were used to screen for active users. 2 Some items varied between surveys; for example, Instagram and Reddit users were asked about the frequency of posting and reacting to content and whether they had multiple accounts on the platform; dating app users were asked which apps they used and which they used the most.
The survey included six items capturing privacy and trust attitudes using sliders from 0 (strongly disagree) to 100 (strongly agree). The first three questions are taken from Martin and Nissenbaum (2016). Additional questions assessed trust in the platform itself and trust in academic research.
I am concerned that online companies are collecting too much personal information about me. In general, I trust websites. In general, I believe privacy is important. I have privacy concerns about the content I share on [dating apps/Reddit/Instagram]. I trust academic research. People like me are represented accurately in academic research.
Part II of the survey included factorial vignettes, a method that bridges experiments and surveys (Wallander, 2009). In this approach, respondents read 35 short scenarios, each having certain factors systematically varied, then responded to two items assessing that scenario. Factorial vignettes are especially useful for studying nuanced social phenomena and are less susceptible to social desirability bias seen in conventional surveys (Wallander, 2009). They have frequently been used in research assessing complex judgments related to data use and privacy (e.g., Martin & Nissenbaum, 2016, 2020; Utz et al., 2021). Prior to completing the vignettes, participants were told they would be viewing 35 scenarios, each on its own page, and that the scenarios would be similar, with changes marked in bolded and underlined text.
Respondents rated each vignette using a slider from 0 (strongly disagree) to 100 (strongly agree), following Jasso (2006), who recommends using sliders to represent the continuum felt by participants. The 100-point scale is similar to scales used in earlier work by Martin and Nissenbaum (2016). For each vignette, respondents were asked to make two judgment ratings about each vignette: the degree to which they agreed with the statement: “This use of my data is concerning” and “This use of my data is appropriate.”
To select vignette factors, we built on prior work (Gilbert et al., 2021) using CI to identify four high-level variables: role, data, purpose, and conditions. Role is represented by the domain factor to account for the area of study. Data are represented by the content factor to account for the type and subject of data used. 3 Purpose is represented by the purpose factor, which describes the rationale for data collection. Condition is represented by the awareness factor, which accounts for communication between researchers and users. See the supplementary materials for a list of the high-level variables and factors.
Each factor was represented by a series of items randomly selected across the vignettes displayed to participants. Building on Gilbert et al., (2021), domain factor items include researchers from academic domains (Computer Science, Gender Studies, Health Science, Psychology), as well as private (tech companies, advertisers, journalists) and public sectors (law enforcement, public health). Current events also informed the selection of two additional items: law enforcement was included to account for long-standing practices of police surveillance through social media data collection (Brayne, 2018) and public health officials were added in response to the COVID-19 pandemic (Vitak and Zimmer, 2020).
Because the type of content that can be shared varies across platforms, items within the data factor also varied across the surveys, but we attempted to be consistent in including items with varying levels of sensitivity regarding what is shared. For example, we captured content that is more personal (profile photos on dating apps, family photos on Instagram, sensitive content on Reddit) and less personal (lists of people who message you on dating apps, hashtags on Instagram, upvotes/downvotes on Reddit). We also included content types that would have varying expectations of privacy (e.g., content shared publicly vs. content shared through direct messages).
Items within the purpose factor represent a range of possible data uses and included those that were research and nonresearch focused; descriptive, predictive, and action-oriented; and with varying degrees of sensitivity. Our prior work (Gilbert et al., 2021) showed that awareness significantly impacted users’ attitudes toward data use, so we kept the conditions factor largely the same, adding one item (“They will share study results (but not your data) with the general public”). Figure 1 shows an example screenshot of a vignette from the Instagram survey, with factors that changed from one vignette to another bolded and underlined. Vignettes from the Reddit and dating app surveys had the same presentation and structure.

Screenshot of a potential vignette from the Instagram survey.
Recruitment
Following approval from our institutional review board, the three surveys were created using Qualtrics survey software. Respondents—who needed to be American adults who were at least occasional users (defined as more than once per month) and somewhat experienced with the platform (defined as using it for at least three months)—were recruited via national Qualtrics panels during September 2020 (see Table 1 for demographic information). Each participant was paid $2.75 cash or equivalent (e.g., gift cards or donation to a selected charity). Data were collected from 407 dating app users, 402 Instagram users, and 403 Reddit users, for a total of 1212 responses across the three surveys. The average response time for the surveys was 9.6 min for dating apps, 11 min for Instagram, and 13.5 min for Reddit, after a speed check, measured as one-half the median time to complete during the soft launch, automatically terminated faster responses. Data quality was insured by removing and replacing responses that indicated “straightlining” (defined as answering “100” to each of the vignette questions or having more 90% of their responses to the vignettes within 5 points of 100; straightlining in the opposite direction was not observed) and responses to open-ended questions that indicated a potentially bad data source (e.g., entering random numbers/letters or responses unrelated to the survey, such as “Joe Biden is”).
Participant demographics.

Note. “Nonbachelor's” includes: high school diploma/some high school, associate's degree, and trade degree.
Data analysis
To test the impact of each of the factor items on participants’ ratings of the vignettes as either concerning or acceptable, we used linear mixed models (LMMs), which allow us to account for the hierarchical nature of the data (i.e., data were generated at the individual and vignette levels) and read like ANOVA tests. Factors were tested using each participant as the subject, and ratings for both appropriateness and concern as dependent variables. Rather than performing a correction test, we follow Moran's (2003) recommendation to report exact p-values in the full model tables included in the supplementary materials; this allows readers to interpret the findings with an appropriate level of caution.
Results
Participant characteristics and privacy attitudes
Demographics
We collected basic demographic information in each survey. Means and percentages for responses to these items in each survey are presented in Table 1. Across all three surveys, respondents tended to be in their 30s, white/non-Hispanic, and college educated with a high household income. Gender distribution was relatively equal in each survey. In our dating apps survey, 74.7% of respondents identified as heterosexual.
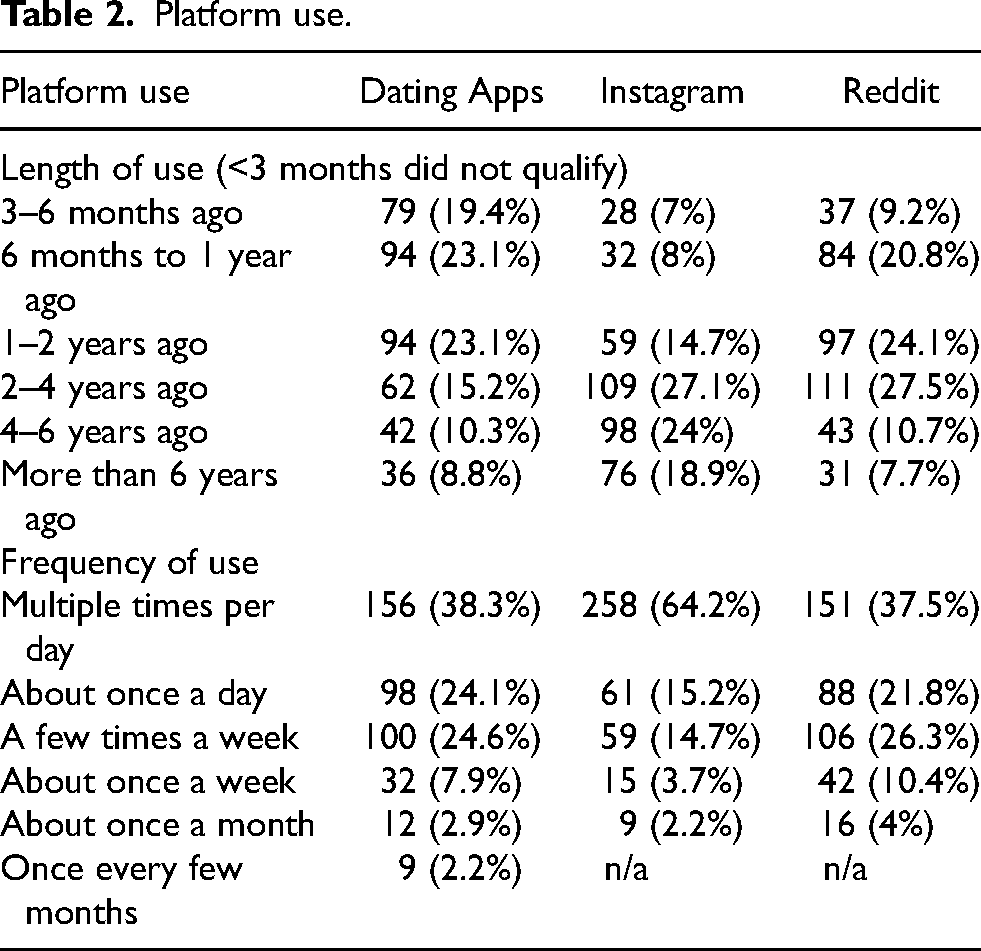
Platform use
Respondents to the dating app survey tended to be newer users—46.2% (n = 188) said they began using dating apps within the previous two years. However, they were also heavy users, with the majority (n = 254, 62.4%) using dating apps at least once per day. We also asked respondents which dating app they used most frequently. The plurality used Tinder (n = 148, 36.4%), followed by Match.com (n = 71, 17.4%), and Bumble (n = 47, 11.5%).
Respondents to the Instagram survey were experienced users, with most (n = 283, 70.4%) using the app for longer than two years. They were also heavy users, with the majority checking the app multiple times per day (n = 258, 64.2%) and reacting to content (e.g., through likes) once a day or more (n = 279, 69.4%), and many posting content once a day or more (n = 168, 41.8%).
Respondents to the Reddit survey were also experienced and active users: 45.9% (n = 185) had used the platform for at least two years, 44.5% (n = 178) said they reacted to content (e.g., upvoting or downvoting) at least once per day, and 30.8% (n = 124) said they contributed content (e.g., writing posts or comments) at least once per day. See Table 2 for the length of use and general use (i.e., checking into the app).
Platform use.
Privacy attitudes
Survey respondents completed six items regarding their attitudes toward privacy, trust in social media platforms, and trust in academic research. Means and standard deviations for each item are included in Table 3, as are F-tests comparing the three samples. Respondents across all three platforms shared similar (high) concerns that online companies collect too much information about their users; however, differences emerged when considering general attitudes toward privacy and trust. Sheffe post hoc analyses found that Reddit users rated privacy as generally more important than dating app users. Reddit users also reported significantly lower trust in websites than dating app users. These differences were even greater when considering privacy concerns related to the content shared on specific platforms, with statistically significant differences in scores for each survey. Dating app users reported the highest concerns, likely because users share personally identifiable information (e.g., their real name and photographs of themselves), and sensitive information (e.g., information about their sexuality and sexual interests). They were followed by Instagram users, who reported higher levels of concern than Reddit users, who reported the lowest concern—perhaps due to the anonymous nature of platform interactions. Finally, in considering attitudes toward academic research, we found no differences across the three surveys in general trust toward academic research, but when looking at representation in research, we found that dating app users reported significantly higher agreement with the statement, “People like me are represented accurately in academic research” compared with Instagram and Reddit users.
Privacy and trust attitudes across platforms.

Vignette ratings
Before exploring the impact of particular variables on vignette ratings, we calculated average ratings across all of the vignettes. In each survey, participants rated how appropriate and how concerning a given scenario was on a scale from 0 (strongly disagree) to 100 (strongly agree). Table 4 includes means and standard deviations for each dataset, as well as results from a one-way ANOVA (with Scheffe post hoc tests) comparing average vignette responses across the three samples.
Average scores for two vignette ratings across three surveys.

When looking at perceived appropriateness across all vignettes, dating app users reported significantly higher scores (M = 6732, SD = 23.07) than both Instagram users (M = 57.20, SD = 27.66) and Reddit users (M = 56.51, SD = 24.07), indicating they generally found data collection practices to be more appropriate. When looking at perceived concerns, a different pattern emerged, with Reddit users reporting significantly lower concern across all vignettes (M = 61.86, SD = 20.06) compared to dating app (M = 69.36, SD = 20.15) and Instagram (M = 69.92, SD = 20.42) users.
In the following sections, we examine differences both within and across the three platforms to begin identifying aspects of research that are especially concerning to platform users. For full details from the linear mixed model testing, see the supplementary materials.
Domain
In each survey, respondents evaluated nine domains. Unsurprisingly, law enforcement was consistently viewed as the most concerning and least appropriate domain for collecting user data. In general, domains linked to academic research were seen as less concerning and more appropriate than the nonacademic domains. To further compare domains, we conducted LMMs using Advertisers as the referent category, given that advertising is a well-known domain for data collection. Compared to advertisers, law enforcement was viewed as significantly more concerning (Dating apps: Est = 1.839, p = 0.004; Instagram: Est = 1.802, p = 0.012; Reddit: Est = 2.488, p = 0.002) than advertisers and psychology researchers were viewed as more appropriate (Dating apps: Est = 1.456, p = 0.023; Instagram: Est = 1.584, p = 0.030; Reddit: Est = 2.947, p = 0.0002) than advertisers on all three platforms. Looking at other domains, however, there were significant differences across platforms. For example, most research domains were seen as significantly more appropriate than advertisers among dating apps users and Reddit users but were not perceived as different from advertisers by Instagram users.
Table 5 presents means and standard deviations for each domain and denotes domains that were significantly different from the referent category (advertisers) in the LMMs.
Domain ratings across platforms.
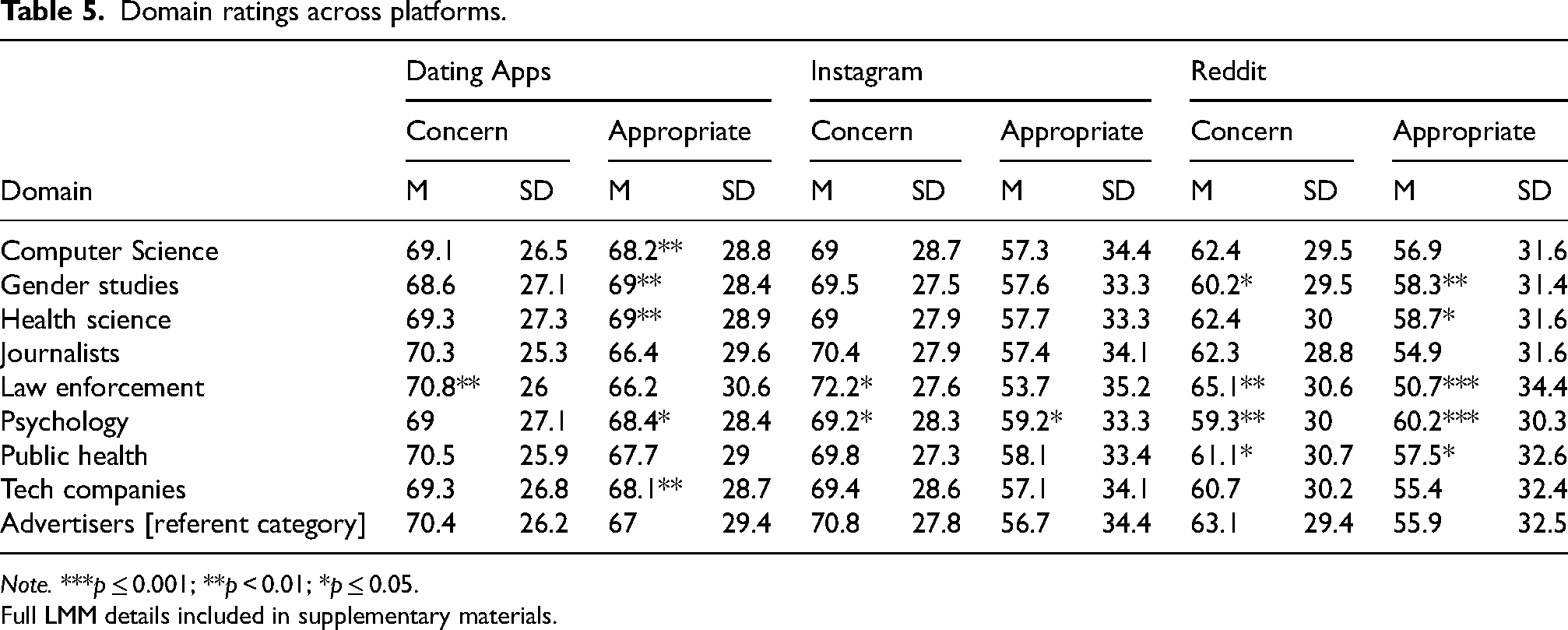
Note. ***p ≤ 0.001; **p < 0.01; *p ≤ 0.05.
Full LMM details included in supplementary materials.
Content
Because content shared across each of the three platforms is different, items within this factor varied across each survey. Among dating app users (see Table 6), the use of photographs and private communications was generally viewed as most concerning and least appropriate. We ran an LMM using profile photos as the referent category, given that profile photos are usually made widely available. Compared to the use of profile pictures, biographic information and match preferences were viewed as significantly less concerning (biographic information: Est = −1.439, p = 0.027, match preferences: Est = −1.539, p = 0.02) and more appropriate (biographic information: Est = 2.368, p = 0.0004, match preferences: Est = 2.845, p = 0.00003), and use of demographic information (Est = 2.725, p = 0.0001), and a list of people who choose to message you (Est = 2.229, p = 0.002) were viewed as more appropriate.
Content ratings for dating apps.

Note. ***p ≤ 0.001; **p < 0.01; *p ≤ 0.05.
Full LMM details included in supplementary materials.
Similarly to dating app users, Instagram users rated the use of photographs containing people (e.g., family photos, photos of users and their friends, photos of the user in a bathing suit) and private communications as more concerning and less appropriate (see Table 7). Conversely, the use of content that was less personal in nature, such as photos of food and memes were rated as more appropriate, and the use of lightweight forms of engagement as data, such as likes and hashtags, was rated as less concerning. For this LMM, we used hashtags as the referent category because they are frequently analyzed by researchers and, while user-generated, may be less personal or sensitive than other forms of engagement. We found that photos containing people were rated as more concerning (family: Est = 2.744, p = 0.0004; friends: Est = 1.951, p = 0.012; bathing suit: Est = 5.725, p = 0.000) and less appropriate (family: Est = −4.792, p = 0.000; friends: Est = −2.939, p = 0.0003; bathing suit: Est = −7.857, p = 0.000) than hashtags, as were private messages (concern rating: Est = 4.555, p = 0.000; appropriateness rating: Est = −5.354, p = 0.000).
Content ratings for Instagram.

Note. ***p ≤ 0.001; **p < 0.01; *p ≤ 0.05.
Full LMM details included in supplementary materials.
As with Instagram users, Reddit users rated lightweight forms of engagement, notably votes, as less concerning and more appropriate than most other types of content, while direct messages were rated more concerning and less appropriate than other types of data (see Table 8). In constructing our LMM, we used throwaway accounts as the referent category because it was anticipated that, as found in prior work (Leavitt, 2015), they are often used to share sensitive content. Results indicate that direct messages (concern rating: Est = 5.069, p = 0.000; appropriateness rating: Est = −4.542, p = 0.000) and full comment histories (concern rating: Est = 2.527, p = 0.0005; appropriateness rating: Est = −2.892, p = 0.0001) were seen as significantly more concerning and less appropriate than posts from throwaway accounts.
Content ratings for Reddit.

Note. ***p ≤ 0.001; **p < 0.01; *p ≤ 0.05.
Full LMM details included in supplementary materials.
Purpose
When looking at ratings for the 11 items under the purpose factor (Table 9), system-specific purposes (e.g., as combatting online harassment, and improving user experience), tended to be less concerning and more appropriate across the three platforms, while predicting future use of the app was rated as less concerning but not necessarily more appropriate across all three. To further evaluate differences, we conducted LMMs using the purpose of assessing mental health as the referent category, given this is a common purpose for collecting social media data (e.g., Proferes et al., 2021) and may be considered sensitive yet beneficial to users. Compared to assessing mental health, system-specific purposes, with combating online harassment in particular, were viewed by users as significantly less concerning (Dating apps: Est = −2.317, p = 0.001; Instagram: Est = −2.887, p = 0.0002; Reddit: Est = −4.940, p = 0.000) and more appropriate (Dating apps: Est = 2.633, p = 0.0003; Instagram: Est = 4.918, p = 0.000; Reddit: Est = 5.855, p = 0.000) across all three platforms. Looking at other purposes, however, there were significant differences across platforms. For example, predicting drug or alcohol use was rated significantly more concerning and less appropriate than the referent by Instagram users (Est = 3.063, p = 0.0001) but not dating app or Reddit users, and predicting sexuality or sexual preferences was rated as significantly more concerning and less appropriate by Reddit users and Instagram users, but not dating app users.
Purpose ratings across platforms.

Note: ***p ≤ 0.001; **p < 0.01; *p ≤ 0.05.
Full LMM details included in supplementary materials.
Awareness
Items within the awareness factor represented various degrees of awareness (from none to informed consent) and ways researchers could make social media users aware their data had been used, such as direct contact (informing after the fact or gaining consent prior to data collection) and indirect contact (via public scholarship). As expected, gaining consent prior to the study was rated as significantly less concerning and more appropriate across all three platforms (see Table 10). Similarly, never being notified was consistently rated as more concerning and less appropriate. In our LMMs, we used disclosure after the study as the referent category, given prior findings (Gilbert et al., 2021) that placed disclosure as a middle ground between prior consent and never informing. These findings held: across all three platforms, compared to disclosure after the study, never being notified was viewed as more concerning (Dating apps: Est = 1.169, p = 0.006; Instagram: Est = 0.950, p = 0.044; Reddit: Est = 4.462, p = 0.000) and less appropriate (Dating apps: Est = −1.769, p = 0.00005; Instagram: Est = −2.410, p = 0.00000; Reddit: Est = −4.986, p = 0.000), while consent prior to the study was viewed as more appropriate (Dating apps: Est = 1.915, p = 0.00001; Instagram: Est = 2.767, p = 0.000; Reddit: Est = 5.957, p = 0.000) and less concerning (Dating apps: Est = −1.640, p = 0.0001; Instagram: Est = −1.813, p = 0.0002; Reddit: Est = −5.450, p = 0.000). There were no significant differences in ratings between sharing results with the general public and disclosure after the study for Instagram and Reddit users; however, dating app users rated sharing results with the public as less concerning and more appropriate.
Awareness ratings across platforms.
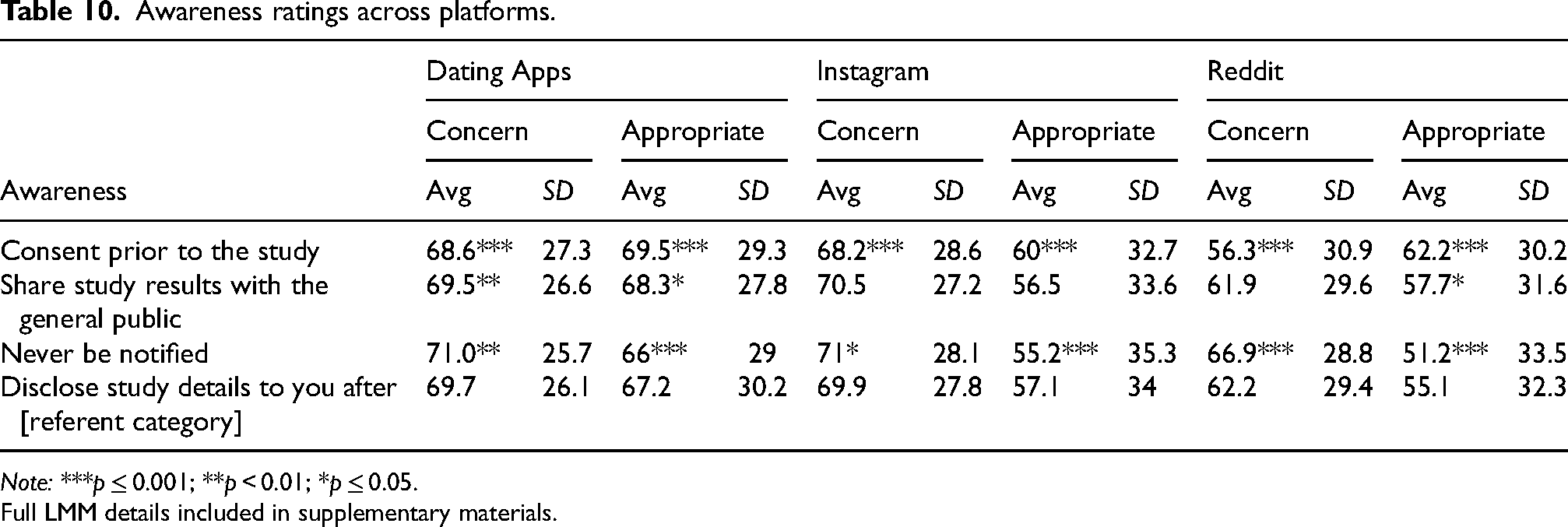
Note: ***p ≤ 0.001; **p < 0.01; *p ≤ 0.05.
Full LMM details included in supplementary materials.
Discussion
Across the vignette surveys, we found that general acceptability of, and concern with, research uses of data varied between platforms, and that those variations depended upon contextual factors. Researchers were seen as more appropriate data collectors than advertisers on dating apps and Reddit, but not on Instagram. Photos and private communication are especially sensitive on dating apps; predicting drug or alcohol usage is concerning for Instagram users but not to dating app or Reddit users; and predicting sexuality or sexual preferences is more concerning for Reddit and Instagram users than dating app users. We interpret these findings as influenced by both norms and affordances of each platform. Instagram is fueled exclusively by advertising, unlike Reddit or most dating apps. The fact that researchers rank evenly with advertisers for concern makes sense in that context, but advertisers collecting data in Reddit or dating apps is seen as a violation of CI. Photos and private communication are likely more intimate in nature on dating apps than they are on Reddit or even Instagram. Similarly, users seem to have intuitive expectations of what can be predicted based on their platform data. Predicting sexuality or sexual preferences fits the contextual norms of dating apps—where this is a highly salient piece of information that many people willingly disclose—but not Reddit or Instagram, where it is likely unrelated to most people's use of those platforms.
Our findings highlight the need for platform-specific approaches to ensure that research data uses meet users’ expectations. We recommend that researchers take a sociotechnical approach to ethical decision-making when collecting social media data—to account for the impact of both social roles and norms (who is using data and why), as well as the technological affordances (identity, visibility, and persistence and the expectations that flow from these) that may frame how people feel about their data use, as well as platform norms and culture. Instagram researchers hoping to predict drug and alcohol use based on site data should seek consent before doing work that labels users, or risk violating user expectations. Researchers should not make accounts on dating sites just to harvest photos and private messages without awareness—consistent with the public backlash against research which has done so (e.g., Wiggers, 2021). And Reddit researchers should be careful about trying to predict participant identities based on site data without participant awareness.
Although no previous work has compared research use expectations across platforms, researchers deeply embedded in social media research have long felt the importance of platform distinctions. For example, Devito et al. (2017: 748) write: As a research community, our design of studies and interpretation of results should account for different affordances provided by different platforms, and further consider the implications of these differences for expected behavior. We should be cautious in interpreting results from studies of one platform that attempt to generalize to “social media” broadly.
Interpret platform data use norms: Our findings echo our previous work exploring the use of Facebook data (Gilbert et al., 2021), where data uses related to in-platform improvements, such as combatting online harassment and predicting future use of the app, were perceived as more appropriate across platforms. Considering this through the lens of CI, this makes sense: researchers using data to help improve a platform—a contextually relevant use—will likely fall within the norms of user expectations. However, such norms were not monolithic across platforms. Predicting sexuality or sexual preferences was highly concerning for both Reddit and Instagram users, but not dating app users.
The fact that people's expectations for research purposes vary across platforms may sometimes create a bind for researchers: the more novel and surprising your research finding is likely to be, the more alarming it may be for users. Predicting sexuality from dating app data is much less alarming (but also less surprising) than predicting sexuality from Reddit posts. It is critical that researchers not make assumptions about research on one platform applying universally to others without consideration of how these norms vary and adjusting data collection based on those differences.
Read the affordances of your platform: Technical affordances on platforms can also help researchers identify when there might be pushback, controversy, or feelings of inappropriate invasion. Across all three platforms, users tended to find the collection and use of limited-visibility communication features as more concerning and less appropriate; this is consistent with CI (Nissenbaum, 2009), which notes that private or direct messages likely carry an assumption of confidentiality. If users view private messages as having limited access, collection, and analysis of that data would likely be seen as a privacy violation. Similarly, lightweight public forms of participation, such as likes, hashtags, and votes, were viewed as less concerning and more appropriate types of content to use for research.
Researchers should use platform cues—ranging from affordances and features to disclosure-related norms—to shape their data use decision-making. Capturing ephemeral data—an increasingly common feature on platforms such as Snapchat, Facebook, WeChat, and Instagram—may very well be problematic because users expect that content to have a limited shelf life. Likewise, platforms where users are more likely to be identifiable, either because they are required to use their real name or because they share text or visual content that identifies them—may carry higher risks to using data than platforms where users are largely anonymous. On the other hand, engagement metrics like ‘likes’ were consistently rated as more appropriate for secondary uses. Researchers should carefully consider how platform features and affordances shape user behaviors and expectations and adjust data collection when possible to avoid violating those expectations.
Ask for consent or bolster awareness: Finally, as prior research has found (Beninger, 2017; Fiesler and Proferes, 2018; Gilbert et al., 2021), participants across all three platforms expressed the least concern and judged research the most appropriate when informed consent was included in a vignette. Respondents very clearly associate consent with the social context and social performance of research, despite the large amount of social media research that does not (and perhaps cannot) gain consent.
Whenever possible, we urge social media researchers to collect informed consent. However, this finding suggests a fundamental challenge for much social media research, and one where research communities lack consensus—a prior survey of researchers working with online data found significant disagreement over when informed consent was needed and whether it was possible when conducting large-scale data collection (Vitak et al., 2016). Assuming that consent is not always needed (or possible), this brings us to the question: What does it mean to use social media data without consent when the people described by that data expect us to ask for consent? And in what conditions is operating without consent, despite user expectations, appropriate? We advise researchers using data that might otherwise surprise or upset users—whether because of platform norms or contextual expectations—to carefully consider whether and how they might gain consent, or to participate in awareness mechanisms such as discussing the appropriateness of data collection with community members and gatekeepers, and debriefing participants when appropriate.
Finally, it is important to note that our findings and recommendations may only apply in US contexts, as privacy norms and users’ expectations for social media data reuse may vary between countries. For example, Gruzd and Mai (2020) found that less than half of Canadians were uncomfortable with legal professionals using their social media data, whereas participants in our survey consistently rated use by law enforcement as uncomfortable and inappropriate. Considering that datasets often contain data from users outside the US, exploring non-American users’ comfort with social media data use is a key avenue for future research.
Conclusion
Comparing user perceptions toward (in)appropriate and concerning uses of their data across three different platforms—dating apps, Instagram, and Reddit—enabled us to explore how platform norms and affordances impact users’ comfort with the reuse of their data. We observed consistent patterns across factors and platforms deriving from normative expectations around research, such as increased comfort with data use when informed consent was gained prior to data collection, as well as technological affordances of platforms, such as increased comfort when data content consisted of lightweight forms of social media interactions, such as likes and votes. However, we also observed inconsistencies between platforms, likely due to a combination of technological affordances and normative expectations that vary between platforms.
Although the ability to collect what is, technically, publicly available social media data are relatively new and often alarming to users (Hallinan et al., 2020), researchers using ethnographic methods have grappled with similar challenges. Drawing from this, Shilton et al. (2021) recommend that those collecting social media data consider issues of power and awareness to help inform ethical decision-making in this space. Analysis of the expectations of American social media users adds to this call. Although expectations of informed consent—and the practicalities of obtaining—present a thorny issue for researchers, our findings provide empirical evidence that context at the platform level matters to participant expectations. Researchers may be guided by surveys of participant expectations, such as this one, but as expectations may change over time (and as new platforms arise), social media researchers may also need techniques for assessing platform norms and data use expectations themselves. Although formal methods such as factorial vignette surveys are useful for assessing the factors that matter most to participants’ expectations, spending time on a platform or in a community, and interpreting the sociotechnical context afforded by platform features, will also help researchers identify the context-dependent norms and platform affordances that impact users’ comfort.
Finally, we counsel researchers to remember that research is, in many ways, the most important context for social media users: the fact that new knowledge will be produced with user data introduces expectations for awareness and consent across platforms. As social media researchers continue conversations about when and how consent is required, we must center user expectations for research contexts.
Supplemental Material
sj-docx-1-bds-10.1177_20539517231164108 - Supplemental material for When research is the context: Cross-platform user expectations for social media data reuse
Supplemental material, sj-docx-1-bds-10.1177_20539517231164108 for When research is the context: Cross-platform user expectations for social media data reuse by Sarah Gilbert, Katie Shilton and Jessica Vitak in Big Data & Society
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
This research was funded by NSF award IIS-1704369.
Supplemental material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.