
Abstract
In this article, we conduct a comprehensive study of online antagonistic content related to Jewish identity posted on Twitter between October 2015 and October 2016 by UK-based users. We trained a scalable supervised machine learning classifier to identify antisemitic content to reveal patterns of online antisemitism perpetration at the source. We built statistical models to analyze the inhibiting and enabling factors of the size (number of retweets) and survival (duration of retweets) of information flows in addition to the production of online antagonistic content. Despite observing high temporal variability, we found that only a small proportion (0.7%) of the content was antagonistic. We also found that antagonistic content was less likely to disseminate in size or survive for a longer period. Information flows from antisemitic agents on Twitter gained less traction, while information flows emanating from capable and willing counter-speech actors—that is, Jewish organizations—had a significantly higher size and survival rates. This study is the first to demonstrate that Sampson’s classic sociological concept of collective efficacy can be observed on social media (SM). Our findings suggest that when organizations aiming to counter harmful narratives become active on SM platforms, their messages propagate further and achieve greater longevity than antagonistic messages. On SM, counter-speech posted by credible, capable and willing actors can be an effective measure to prevent harmful narratives. Based on our findings, we underline the value of the work by community organizations in reducing the propagation of cyberhate and increasing trust in SM platforms.
Introduction
With the increase in the use of digital communication technologies such as social media networks, online hate speech has become an increasingly prevalent and visible problem which threatens cohesion and trust among online citizens, and hence, their ability to work together to control their environment, what social scientists have term “collective efficacy” (Sampson et al., 1997). Social media acts as a polarization amplifier—it opens up a potential space for the galvanizing of attitudes and emotions, through the spread of negative expression toward minority groups and counter-narratives accelerated by algorithm driven partisan network contagion (Sunstein, 2017). Over the past decade, social media has become a safe harbor for launching campaigns of antisemitism, including harassment and criminal threats directed at members of the Jewish community. In the first 6 months of 2019, Community Security Trust (CST, 2019), a charity that supports the Jewish community, recorded 323 online antisemitic incidents in the United Kingdom, representing 36% of all incidents. This represents an increase of 46% on the same period the year before. Understandably, antisemitism on social media has become a matter of concern in the Jewish community and in broader public debate. Although conventional hate crime recording (i.e., police crime records and Crime Survey of England and Wales), has been improving, both online and offline antisemitic incidents are significantly under-reported, leading to a significant dark figure. Unlike previous research that has aimed to outline patterns of online antisemitism (e.g., Anti-Defamation League [ADL], 2018; Finkelstein et al., 2018; Woolley & Joseff, 2019), this article illustrates a scalable methodology that can identify future antisemitic communications and reveal patterns of online antisemitic perpetration at source. Furthermore, this article addresses the “collective efficacy” phenomenon on social media in the case of controlling antisemitic communications.
In this article, we present an analysis of the production and propagation of online antagonistic content targeting Jewish people posted on Twitter between October 2015 and October 2016 in the United Kingdom. We collect data from Twitter’s streaming API using keywords which explicitly make reference to Jewish people and/or to Jewish identity and locate 2.7 million tweets from UK-based users. Drawing on emerging computational criminology methods, we train a machine learning algorithm to classify antisemitic content on Twitter with high accuracy and at scale (Burnap & Williams, 2015, 2016; Williams & Burnap, 2016). After illustrating significant variability in the frequency of antagonistic tweets related to Jewish identity, we identify three “spikes” in antagonistic content, the highest of which follows the suspension of MPs from the Labour party over antisemitism allegations. We then examine these three spikes by building statistical models around 15-day study windows. We model Twitter information flows (retweets) and explore (1) the inhibiting and enabling factors of online antisemitism, (2) the propagation of antisemitic content in terms of size (number of retweets) and survival (duration of retweets), and (3) the types of actors (e.g., Jewish organizations, antisemitic actors, media agents, MPs) that gain significant information flow traction. This article contributes to academic literature in the following three distinct ways: it introduces a supervised machine learning model capable of identifying future antisemitic incidents, it reveals patterns of online antisemitism perpetration at source, and for the first time, it introduces collective efficacy as a useful concept for interpreting the countering of online hate in a social media context.
Literature Review
Hate Crimes, Social Media, Cyberhate
Hate crimes have the potential to damage the fabric of trust between communities within society by undermining social cohesion. Current literature underlines the importance of the social polarization behind the mechanics of hate crime victimization. Gerstenfeld (2017) argues that the motivation behind hate crimes is not necessarily the hate directed toward the individual victim but rather the victim’s perceived “outgroup” status. Complementing this view, Perry (2001, p. 5) explains that hate crimes aim to polarize communities by sending “messages” to the wider community of the “others” that they must “conform to the standards” set by the privileged majority. From a broad societal point of view, fluctuations with regard to polarization can be observed through hate crime statistics. Studying hate crime figures from conventional quantitative data sources such as police crime records and self-report studies (e.g., victimization and crime surveys) may prove to be beneficial in order to understand the patterns of divisive tensions within a society, provided that biases attached to these data sources are carefully considered when drawing conclusions.
Data from conventional sources suggest that hate crime is on the rise in England and Wales. According to the most recent records, hate crimes recorded by the police in England and Wales have increased by 17%, from 80,393 (2016/2017) to 94,098 (2017/2018) (Home Office, 2018). The upward trend in police-recorded hate crime has been seen since 2012/2013. Figures have more than doubled (123%) in England and Wales with an increase from 42,255 (2012/2013) to 94,098 (2017/2018). Although these figures are important barometer of societal tensions between groups, criminologists have long argued that the statistics produced by police are insufficient to paint a complete picture to understand both general and hate crime patterns. Existing criminological literature illustrates a number of limitations of police recorded crime data such as non-uniform recording practices across police forces, improvements, and changes in police recording practices over time, and changes in legislation and classification of offense types (Maguire, 2007; Tilley & Tseloni, 2016). In relation to hate crimes, these data sources are incomplete as at least half of all hate victims do not report their victimization (Williams & Tregidga, 2014). A recent Home Office (2018) report recognizes some of the shortcomings of police recorded hate crime figures, suggesting that the increases in recent years are “largely driven by improvements in police recording” (p. 7).
Another useful conventional data source to understand hate crime victimization figures is the Crime Survey of England and Wales (CSEW). Surveying a nationally representative sample of roughly 35,000 households each year, the CSEW is regarded “as a gold-standard survey of its kind” (Flatley, 2014, p. 199). Recent estimates from the CSEW show that racial and religious aggravated hate crimes increased by 4.5%, from 112,000 per year (2013–2015, two-year average) to 117,000 per year (2015–2017, two-year average). Combined estimates suggests that there were 184,000 hate incidents per year from 2015/2016 to 2017/2018 (Home Office, 2018, p. 7). Despite the robust nature of CSEW statistics, they are limited by their reliance upon victim interviews. Some victims of hate incidents might not be willing to report hate crime in victimization surveys. For instance, the wording (i.e., using the term “hate crime”) of questions in surveys can be problematic. Williams and Tregidga (2014, p. 948) found that while some survey respondents may find the word “hate” too restrictive, others may be confused by the word “crime,” hesitating “whether their experiences constituted acts serious enough to be classified as crimes”. Correspondingly, some victims prefer not to report the prejudiced incidents they experienced either to the police or in surveys, leading to dark figures in hate crime victimization rates.
Given the shortcomings of conventional police hate crime and victimization data, it is important to supplement these with other sources to paint a more complete picture. New data sources, such as internet searches and social media communications, lend themselves well to the analysis of public sentiment trends. Recent computational and social science advances in machine learning and statistical modeling allow researchers to utilize new “big data” sources to address a variety of social research questions, such as tracking the spread of influenza (Ginsberg et al., 2009) or to build psychological constructs of nations linked to GDP (Noguchi et al., 2014). Furthermore, Twitter posts have been used to investigate the spread of hate speech following terrorist attacks (Williams & Burnap, 2016) and to estimate offline crime patterns (Williams et al., 2017). Besides conventional hate crime statistics, othering and divisive sentiment trends within society can also manifest in subtler forms, such as prejudiced online communications. Referred to as cyberhate, these divisive and prejudiced online communications have been present since the dawn of the public internet in the 1990s (Wall & Williams, 2007; Williams, 2006). Similar to offline hate crimes, the motivation of cyberhate perpetrators is rarely the hate of individual victims, but the community of “others” in which they represent (Douglas et al., 2005). Previous cyberhate literature illustrates that perpetrators target victims because of their perceived belonging to groups with protected characteristics such as sexual orientation (McKenna & Bargh, 1998), race (Leets, 2001), and religion (Williams & Burnap, 2016). By analyzing prejudiced online communications, we can identify the ebb and flow of societal tensions through the monitoring of subtler “hate incidents,” many of which would not reach the criminal threshold used by law enforcement agencies, and therefore, would not be included in conventional hate crime statistics. Therefore, current researchers and practitioners should take advantage of the affordances provided by online communications data and supplement conventional statistics with cyberhate perpetration in order to shed light on “dark” figures of hate crime victimization trends.
Collective Efficacy and Social Media
Social media companies have generally presented themselves as strong advocates of free-speech and have until very recently allowed hate speech to proliferate on their platforms. Online hate speech has become an increasing problem that to date has been largely controlled by online community cooperation, what social scientists term “collective efficacy” (Sampson et al., 1997, p. 918). Sampson (2001) describes collective efficacy as “the linkage of mutual trust and shared willingness and intention to intervene for the common good” (p. 95). On social media platforms, an abundance of cyberhate speech in the absence of capable and willing counter-speech actors can reduce collective efficacy which, in turn, can result in decreased trust in platforms, their users, and online communities. On the contrary, if capable, trustworthy and willing actors on social media platforms can successfully intervene cyberhate perpetrators with counter-speech, we can observe the benefits of online collective efficacy. Current research on online collective efficacy is scarce. In a demographically balanced survey of Americans, Costello et al. (2017) explored the presence of online collective efficacy and found that 21.3% of respondents reported that they observe others telling perpetrators of cyberhate to stop, and 21% indicated that they witnessed others defending victims of cyberhate. However, their logistic regression model failed to demonstrate a statistically significant association—neither positive nor negative—between either form of collective efficacy and being targeted by cyberhate. 1 Therefore, unlike the long-proven negative correlation between the perception of collective efficacy in offline communities and offline crime rates (Mazerolle et al., 2010; Sampson et al., 1997), the effectiveness of collective efficacy on social media platforms is yet to be proven in the literature.
Data from social media platforms can be utilized to explore the effectiveness of collective efficacy on online communities. Social media communications can be amplified and redistributed through platform-specific dissemination mechanisms such as retweeting (Boyd et al., 2010). This unique conversational aspect of online communications enables researchers to study online information propagation networks and information flows. Unlike traditional methods, such as surveys or interviews, through studying information flows through retweets, researchers can “identify what information or sentiment is being endorsed and propagated by users, and which users have the most or least influence in the spread of such messages” (Williams & Burnap, 2016, p. 215). By comparing the retweet rates of trustworthy and capable users engaged in counter-speech practices to rates of retweets of biased and prejudiced users engaged in spreading divisive messages and cyberhate, arguably researchers can measure a proxy of collective efficacy in online communities.
Related Work: Offline and Online Antisemitism
In this article, we focus our attention solely on the growing problem of online antisemitism in the United Kingdom, which is an important policy and community safety issue. In a survey conducted by the European Union Agency for Fundamental Rights (FRA) among individuals who consider themselves Jewish in eight European countries, including the United Kingdom, 75% (n = 5,847) stated that they consider online antisemitism as a problem (European Union Agency for Fundamental Rights, 2013, p. 12). In addition, 75% of the respondents who were exposed to negative statements toward Jews (n = 5,385), cited the internet as the medium that exposed them to negative sentiments (European Union Agency for Fundamental Rights, 2013, p. 25). 2 Of those who were exposed to antisemitic harassment (n = 1,941), which can be both online and offline, only 23% stated that the incident was reported to the police, to another organization or both, while 76% stated that the event was not reported at all (European Union Agency for Fundamental Rights, 2013, p. 49). Given the staggering rates of non-reported antisemitic victimization and the growing concerns about online antisemitism, FRA suggested that the “EU Member States should consider establishing specialised police units that monitor and investigate hate crime on the internet and put in place measures to encourage users to report any antisemitic content they detect to the police” (European Union Agency for Fundamental Rights, 2013, p. 12). To our knowledge, there are no specialised units dedicated to tracking online antisemitism at the source in any EU states to date.
Previous research on detecting and analyzing online antisemitic incidents at the source is of particular interest to this study. Analyzing over 100M posts from multiple social media platform hosting “fringe” communities, 4 chan’s Politically Incorrect board (/pol/) and Reddit’s The_Donald subreddit and Gab, Finkelstein et al. (2018) argued that online antisemitism and racist online communications increased considerably following divisive offline political events such as the 2016 US election. 3 By training word2vec models, they devised a text-based methodology which predicts similar words that are likely to appear together in the same context. Although useful for exploring keyword-based discussions of online fringe communities, the unsupervised nature of this methodology limits its practicality for classifying future individual antagonistic instances. Barring this article, most of the existing research on the detection of online antisemitism are commissioned or conducted by Jewish civil society organizations such as the Anti-Defamation League (ADL) and Community Security Trust (CST). 4 From January 2017 to January 2018, ADL collected more than 18 million tweets using keywords referring to Jews and Jewish identity (ADL, 2018). By randomly sampling 1,000 tweets per week that matched with a complex Boolean query and manually annotating n = 55,000, ADL predicted 4.2 million tweets (23.5% of all tweets collected) were antisemitic within the study period. In another mixed-methods study on Twitter, Woolley and Joseff (2019) explored antisemitism among 5.8 million tweets containing political hashtags during the 2018 US midterm election campaign. Human annotation of 99,075 filtered tweets revealed that 54.1% contained antisemitic conspiracy theories and 46.45% contained derogatory terms. 5 Although these three studies are important to understanding trends in online antisemitic sentiment, none detail the accuracy of the content classification results or provide a discussion of common information retrieval metrics such as precision, recall, and F-measure. Finally, none of these studies suggests a methodology to accurately identify future antisemitic incidents without human annotation.
Given the limitations of current research, new research on the automated detection of antisemitic cyberhate and the statistical dynamics of its propagation is needed. Instead of relying on conventional “terrestrial” data sources, this article reveals patterns of online antisemitic perpetration at source. Although there are multiple social media platforms where antisemitism can be traced, we exclusively draw on Twitter data due to the ease of access and the ability to explore information propagation networks through the retweeting mechanism. Following a human annotation phase, we trained a supervised machine learning classifier that is capable of classifying antisemitic content at scale. Informed by the collective efficacy theory, our hypotheses address the enablers and inhibitors of antisemitic content within UK-based Twitter communications.
Hypotheses
H1: Offline events and discussions concerning Jews will act as “trigger events” and be observed as spikes in online communications related to Jewish identity.
The event-specific increase in hate crimes is an established phenomenon in the literature. For instance, Hanes and Machin (2014) observed significant increases in hate crimes reported to the police in the United Kingdom following 9/11 and 7/7 terror attacks. Similarly, in the aftermath of Woolwich terror attack in 2013, Williams and Burnap (2016) observed a sudden spike and a rapid de-escalation in the frequency of racial and religious cyberhate speech within the first 48 hours of the attack. Findings from these studies indicate that galvanizing “trigger” events such as socially divisive political events and terror attacks motivate prejudiced incidents against outgroups and lead to an increase in incidents targeting minorities, which is reflected in hate crime statistics. Informed by previous research, we hypothesize that offline events that trigger debate around Jewish identity will migrate to social media.
H2: Pre-identified antisemitic Twitter users will be positively correlated with the production of antagonistic content about Jews.
The second hypothesis tests whether Twitter users flagged by Jewish civil society organizations as antisemitic due to their previous online behavior are predictive of cyberhate production.
H3: Trustworthy and capable actors will be positively associated with larger size of information flows.
H4: Trustworthy and capable actors will be positively associated with longer survival of information flows.
H3 and H4 operationalize collective efficacy theory on Twitter. Sampson (2001) underlines the importance of “mutual trust and shared willingness” for the capable and trustworthy actors who are willing to “intervene for the common good.” On Twitter, by comparing the retweet rates of trustworthy and capable users to rates of retweets of biased and prejudiced users engaged in spreading divisive messages and cyberhate, researchers can measure a proxy of the collective efficacy phenomenon. These hypotheses test whether trustworthy and capable agents, such as Jewish community organizations, verified accounts, official police accounts, and Members of Parliament (MPs), are associated with larger size and longer survival of information flows, lending evidence for the effectiveness of collective efficacy within the particular community of interest on Twitter.
H5: Antagonistic content about Jews will not propagate further in size, within the study period.
H6: Antagonistic content about Jews will not survive over time, within the study period.
H5 and H6 extend the previous research on computational criminology by exploring the propagation dimension of the antagonistic speech targeting Jews and Jewish identity (Williams & Burnap, 2016). Within the study period, if cyberhate does not propagate in size and if it does not survive over time, we can tentatively infer an association between collective efficacy and a reduction in the impact of the information flows containing antagonistic sentiments within the particular community of interest on Twitter. Informed by previous research, we assume that antisemitic tweets will be negatively associated with both size and survival of information flows.
Methodology
Data Collection and Preprocessing
The data used in this study were collected using the COSMOS platform (Burnap et al., 2015), a free software tool that allows researchers to connect directly to Twitter’s streaming Application Programming Interface (API) to collect real-time social media posts by specifying keywords. The following keywords were used for data collection: “jew, jewish, jews, antisemitic, antisemitic, antisemitism, antisemitism, anti semitic, anti semitism, bonehill, stamford hill, golders green, neo nazis, neo nazi, neonazi, neo-nazis, nazi, nazis.” 6 These keywords are a combination of generic terms and terms relating to a far-right demonstration directed at the Jewish community in Golders Green in north London, reflecting events in the United Kingdom at the time of the data collection. This list was not intended to be a comprehensive set of keywords relating to all aspects of antisemitic hate speech. In particular, much antisemitic hate speech comes in the form of conspiracy theories (or allusions to such theories) and image-based hate speech—such as memes—that would not be captured by these keywords (Finkelstein et al., 2018; Woolley & Joseff, 2019). This caveat should be borne in mind when assessing the overall quantity of antagonistic content measured by this research and the generalizability of the findings. The data used for this analysis include tweets posted between 16 October 2015 and 21 October 2016 and were collected in real-time, ensuring all tweets matching with the keywords are collected. The raw dataset for the complete study period contained 31,282,472 tweets. 7 The dataset was imported into the R environment (R Core Team, 2018), which is an open-source statistical programming language, for preprocessing and exploratory data analysis (EDA).
The first aim of preprocessing was to infer the location of users from tweet metadata and extract UK-based tweets from the whole dataset. Unless Twitter users explicitly opt-in to share their geo-locations each time they post a tweet, latitude and longitude coordinates are not provided in the metadata. The majority of Twitter users in this dataset (>99%) opted out of sharing these exact geo-data. Three different approaches were adopted to infer Twitter communications from the United Kingdom, using the metadata of each tweet. First, we derived a list of UK-based place names (referenced as the UK pattern henceforth). Using pattern matching techniques, the UK pattern was identified within the account description of the users. Second, the UK pattern was identified within the user reported locations field (shown under profile pictures). Finally, London and Edinburgh were selected from Twitter time-zone user selections (the only two UK-based time zones Twitter provides). In total, 2,677,058 tweets were identified as emanating from UK-based users. 8 The number of tweets identified as emanating from the United Kingdom in this study is therefore 8.5%. This figure is in line with general global usage patterns: in Q2 2016 there were circa 313 million active Twitter accounts, and approximately 6.4% of these accounts were located within the United Kingdom (Statista, 2019).
The second aim of preprocessing was to classify user types that were of interest for analysis. Using conventional data science methods and tweet metadata and collaborating with organizations with subject expertise, six user types of interest were identified, that is, Media Agents, MPs, Celebrity Agents, Police Agents, Jewish Organisation Agents, and known Antisemitic Agents. To identify Media Agents, pattern matching was used against a list of keywords that the media frequently employ in their account descriptions (the media pattern). In total, 181,363 tweets were identified as emanating from Media Agents. 9 Drawing on previous work by Bejda (2015), we used a list of the most followed celebrities on Twitter and by matching them with the users in the dataset, identifying 80 tweets from Celebrity Agents. To identify MP Agents, we used a list of Twitter handles of 590 MPs who served between the 2015 and 2017 general elections, identifying 2,950 tweets. 10 To identify Police Agents, a list of force area Twitter accounts was used in combination with identifying lower level accounts (e.g., at basic command unit). In total, 162 tweets were identified as emanating from Police Agents. To identify Jewish Organization agents, we pattern matched user descriptions against the terms “Jew,” “Jewish”, and “Jewry” and identified all Jewish organizations followed by @CST_UK. A resulting 102 Jewish organization agents were found in the UK dataset, generating 11,599 tweets in the study period. To identify known antisemitic agents, we used a pre-defined list of 24 accounts which was supplied by CST. In total, 13,240 tweets were identified as posted by these agents. 11 All other users that did not fall into any of these agent types were classified as “other” agents.
Tweet Classification
We devised a supervised machine learning methodology to classify antagonistic content related to Jews in the Twitter dataset. Work on identifying hate speech has shown variable success rates with accurate classification across multiple protected characteristics. In particular, machine learning has been found to be most accurate at classifying anti-Muslim hate speech (see Burnap & Williams, 2015). Building a classifier to identify antisemitic hate speech proved particularly problematic due to the high degree of disagreement between human coders on what they considered as hateful. Much of the confusion stemmed from a conflation of antisemitic and anti-Israel content on Twitter. 12
Given this complexity, a two-stage process to attaining gold standard, human annotation was performed to create a training dataset for the machine learning classifier (see Appendix A for a detailed discussion). The training dataset included 853 human-validated tweets, where 388 instances were annotated as antagonistic toward Jews and Jewish identity and 465 were annotated as non-antagonistic. This human-annotated dataset was used as the gold standard to train the machine learning classifier. We experimented with multiple supervised learning techniques when building the classifier. Both 10-fold cross-validation and 70/30 split validation results suggested that overall, the most efficient machine learning technique for classifying antagonistic content in this dataset was Support Vector Machines combined with a Bag of Words approach (see Appendix B for a detailed discussion of other algorithms we experimented with and Appendix C for the computational cost of the study). In total, this method identified 9,008 original tweets as antagonistic, representing 0.7% of the 1,232,744 original tweets in the UK dataset. This is commensurate with the volume of antagonistic tweets related to Muslim identity following terror attacks in the United Kingdom (0.9%; see Williams & Burnap, 2016). Upon inspection of the classification results, we are confident that the classifier was able to distinguish between antagonistic content related to Jews and non-antagonistic posts that contained a combination of the keywords used to generate the dataset over the 12-month period of the study.
Exploratory Data Analysis and Descriptive Statistics
In the first stage of EDA, we visualized the UK dataset and the antagonistic sub-dataset to identify periods of interest to the next stage of analysis. The periods of interest were then isolated for statistical modeling to identify the enablers and inhibitors of the production of antagonistic content, and the factors that predict information flow size and survival. Figure 1 presents a daily aggregated time-series line graph of overall tweet frequency (black line) and antagonistic tweets (red line) based on the UK dataset. The volume of tweets containing the keywords used for the collection varies considerably over time. For instance, the highest peak in the complete study period for all tweets is around 28 April 2016, the day that Ken Livingstone was suspended from the Labour Party, and the day after Naz Shah MP was suspended, both for alleged antisemitic comments. This observation indicates offline events probably trigger online discussions that contain the keywords used in the collection, confirming both H1 and previous research (Hanes & Machin, 2014; Williams & Burnap, 2016). The Figure 1 also compares the volume of antagonistic tweets to all tweets using the same scale, illustrating their relatively low frequency over the study period.
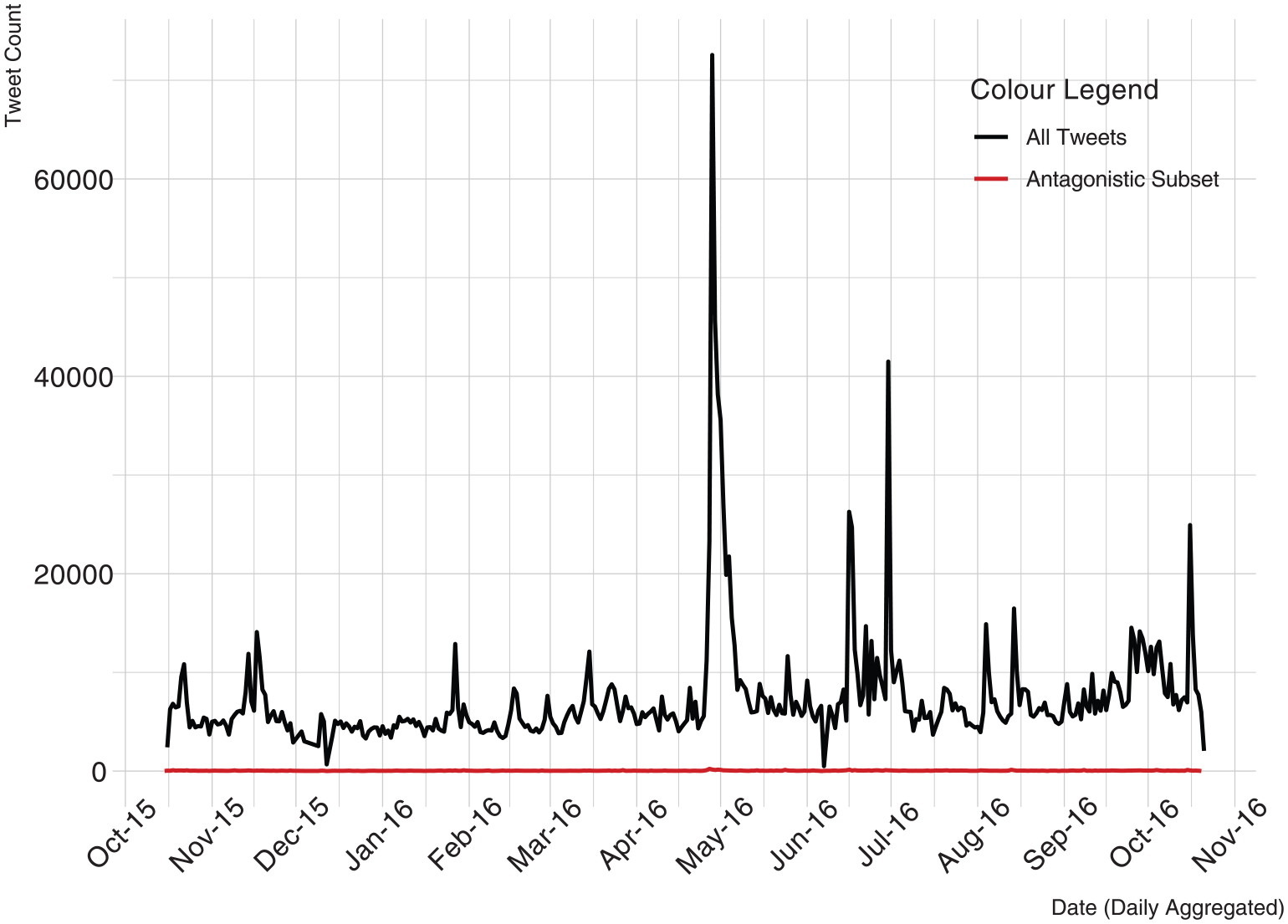
Tweet frequency (12 months).
Figure 2 presents a line graph of antagonistic content related to Jews in the UK dataset. Even though the frequency pattern of antagonistic tweets is not identical to the pattern of all tweets presented in Figure 1, there are similarities. For example, the highest peak in antagonistic tweets is late April/early May 2016, following the Shah/Livingstone events. The second highest peak in antagonistic content is mid-June 2016, which is also in line with the peak in mid-June in Figure 1, indicating antagonistic content peaks and falls are in line with general discussions about Jews on Twitter. The EDA enabled us to visualize the temporal patterns of both antagonistic and non-antagonistic tweets in the UK dataset. As the primary aim of the analysis was to predict the enablers and inhibitors of the production of antagonistic content and of the propagation of information flows through statistical modeling, we selected three events of interest around the highest three peaks in Figure 2: Event 1 includes all tweets posted between 27 April 2016 and 13 May 2016, Event 2 includes all tweets posted between 15 June 2016 and 1 July 2016, and Event 3 includes all tweets posted between 12 August 2016 and 28 August 2016.
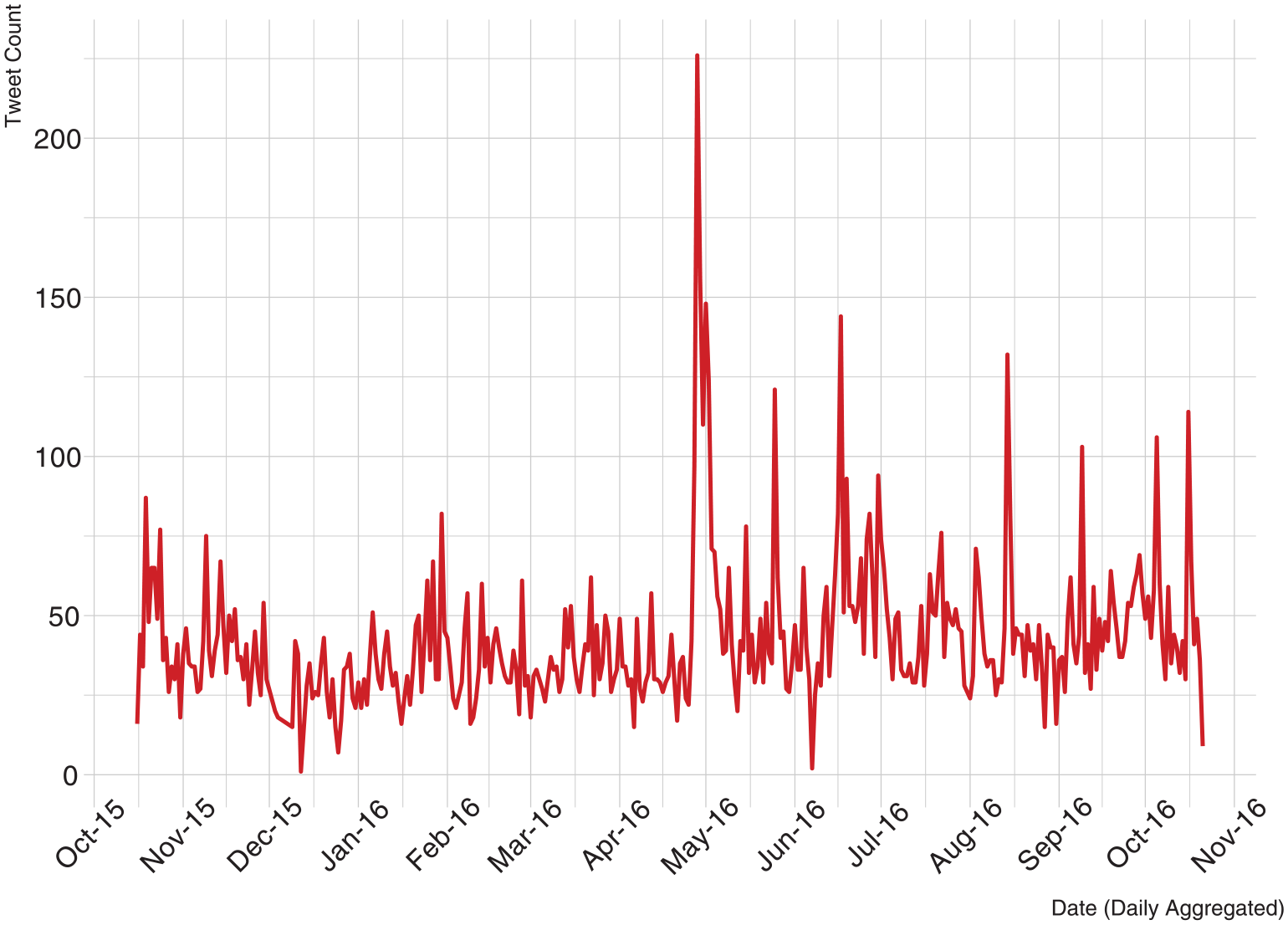
Antagonistic tweet frequency (12 months).
Information Propagation Models
Dependent Measures
There are two dependent measures in information propagation modeling: Size of information flows (measured by counting the number of retweets) and Survival of information flows (measured by counting the seconds between the first and last retweet within the study period). In terms of size, the number of retweets is a measure of the volume of public interest and endorsement of the information, while survival (or duration) is a measure of the persistence of interest over time. These measures are established in the literature on online social networks and information propagation (Burnap et al., 2014; Yang & Counts, 2010).
Independent Measures
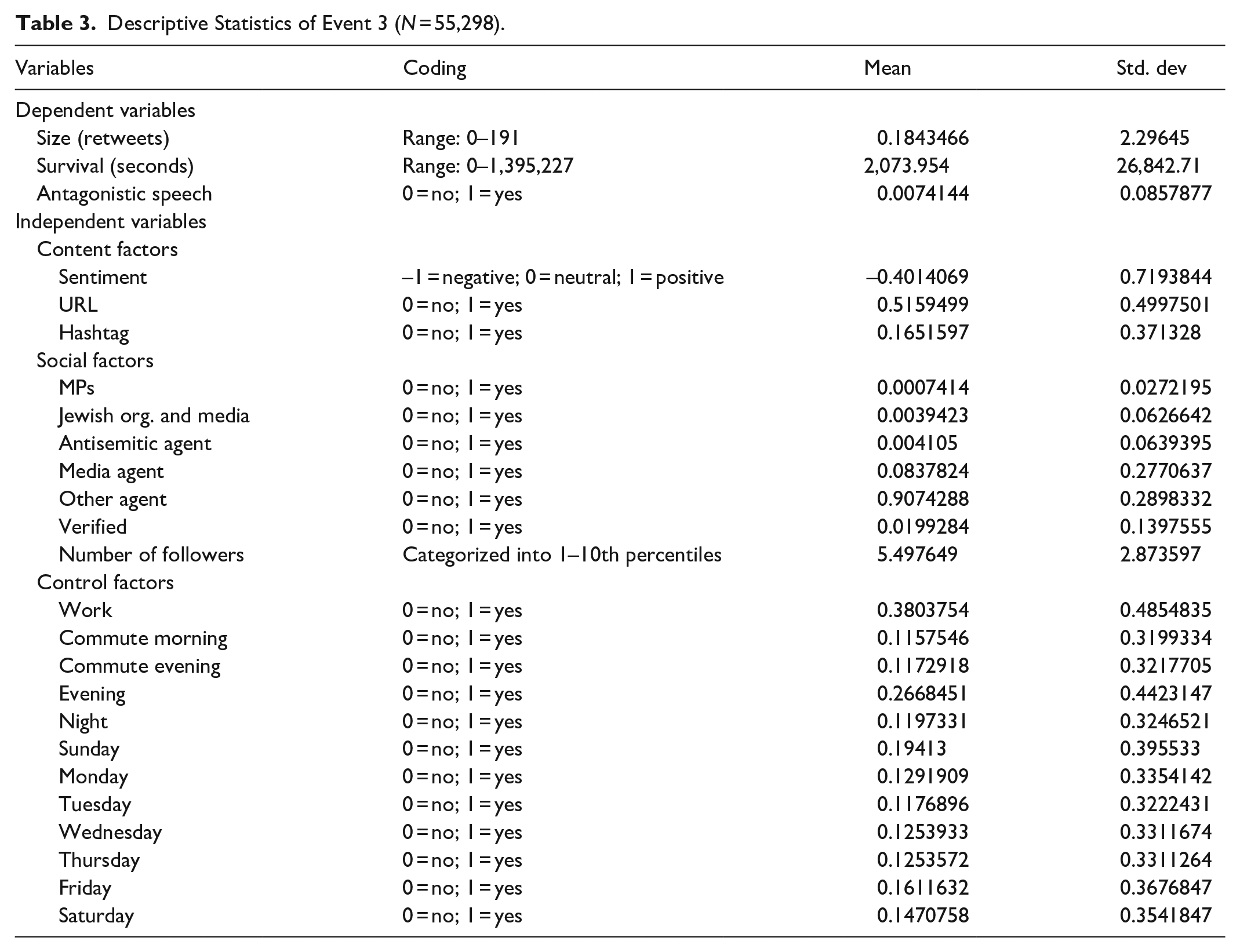
Three sets of variables were entered as independent predictors of information flow size and survival in the models: Content factors, Social factors, and Control factors. Content factors relate to the text of the tweet. The following text content factors were included: sentiment (binary negative/positive), URLs pointing to an external source (such as a news item), hashtags which create an interest-based micro-network, and antagonistic content, which is the outcome of our machine learning classifier. Social factors relate to the characteristics of user accounts. In the models, the following user social features were included: number of followers, verified status, and agent type. The presence of police agents and celebrities were either extremely small or non- existent across all three events of interest. Therefore, police and celebrity agents were re-classified under other agents and five agent types were included: media, MPs, Jewish organizations, known antisemitic accounts, and other agents. Multiple control factors were included that have been shown to influence the flow of information in social media networks (Zarrella, 2009). These include time of day and day of week. Tables 1 to 3 present descriptive statistics for each event we selected to model in this study.
Descriptive Statistics of Event 1 (N = 156,498).

Descriptive Statistics of Event 2 (N = 78,432).

Descriptive Statistics of Event 3 (N = 55,298).
Antagonistic Content Models
Dependent and Independent Measures
For predicting the production of content, which was antagonistic toward Jewish identity, we used the results of our machine learning classifier for the original text as the dependent variable. We converted classification results into a binary numeric format where “1” represents antagonistic content and “0” represents non-antagonistic content. For independent variables, we used the same independent variables (i.e., content factors, social factors, and control factors), as described in the information propagation models.
Methods of Estimation
Information Propagation Size Model
To predict the size of information flows, we use zero-inflated negative binomial (ZINB) regression. 13 We fit ZINB regression models as the size measure is best described as a count of retweets, where zeroes were present (i.e., some tweets were not retweeted during the study period). Zero-inflated count variables represent types of events that are largely not experienced by the majority of the sample. In this case, it is retweets where the majority of tweets are not retweeted with a minority being retweeted. Linear regression models are not appropriate for count variables given the nonnormal distribution of the errors. We opted to use ZINB regression over zero-inflated Poisson (ZIP) regression because the dependent variable was overdispersed.
Information Propagation Survival Model
To predict the survival of the information flows, we used Cox’s proportional hazards regression (1972). Our interest here was to model the factors that pose hazards to the survival of information flows, that is, duration of a retweet (in seconds) within the study period. Therefore, positive relationships indicate an increased hazard to survival of information flows.
Cyberhate Model
Since this variable was best described as binary (0 = non-antagonistic; 1 = antagonistic), we estimated the production of antagonistic content by using generalized ordered logit regression, which allows for the identification of predictive factors.
Results
Cyberhate Model
Results of cyberhate models for each event are presented in Table 4. Across all events, accounts identified as antisemitic by CST were most likely to produce antagonistic content related to Jews, lending strong evidence in support of H2. This is unsurprising given the nature of these accounts and their posting history. This finding also lends strong evidence in support of the semantic accuracy of the machine learning classifier built for this study. The only other variables that increased the likelihood of the production of antagonistic content were the control factors of day of week and time of day.
Generalized Ordered Logit Regression Predicting Production of Antagonistic Content for Each Event.
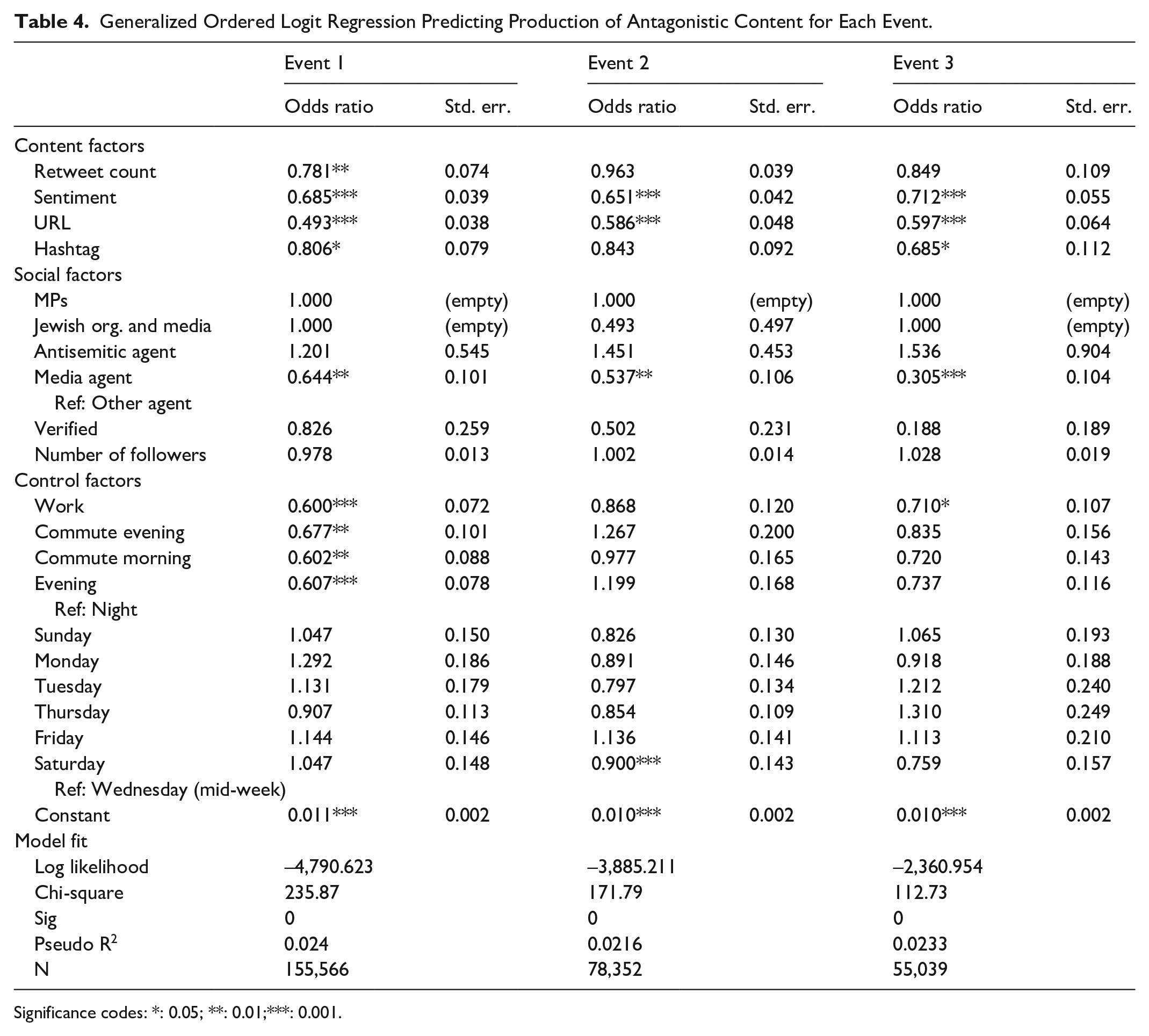
Significance codes: *: 0.05; **: 0.01;***: 0.001.
All remaining factors in the analysis decreased the likelihood of the production of antagonistic content. Social factors, such as type of tweeting agent, account verification status, and retweet count, were all negatively associated with the production of antagonistic content. Across all events, verified accounts, those that Twitter deem are “of public interest and authentic,” were significantly less likely to be associated with antagonistic content, compared to non-verified accounts. Many of these accounts belong to celebrities, public figures, politicians, news organizations, charities, corporations, and government departments. Media Agents and, unsurprisingly, Jewish organizations and media were also significantly less likely to produce antagonistic content. These negative associations add further evidence in support of the accuracy of the machine learning classifier.
Similar to previous research on the spread of online hate speech, tweets containing links to other content (URLs) were less likely to contain antagonistic content. URLs are possibly less common in antagonistic tweets given linked content (most often popular media sources) is less likely to support antisemitic opinion. Contrary to previous research (Williams & Burnap, 2016), the inclusion of hashtags in tweets was negatively associated with the production of antagonistic content across the three events. This may suggest users publishing antisemitic content do not aim to increase the discoverability of their messages outside their follower networks.
Information Propagation Size Model
Table 5 presents the results of the size models. Sample size in each event only indicates original tweets, with the number of retweets entered as the dependent variable. Incidence-Rate Ratios (IRRs) are used to indicate the magnitude of the effect on retweets. 14 Of particular note is the negative relationship between antagonistic content and the size of retweets. In all three events, antagonistic content did not propagate in terms of size (IRR: 0.285, 0.510, and 0.441, respectively), providing strong support for H5 and confirming previous work on anti-Muslim online hate speech (Williams & Burnap, 2016). Correspondingly, the content posted by antisemitic agents identified by CST did not propagate to a significant extent across the three events. This double negative pattern provides further confidence in the accuracy of the machine learning classifier for antagonistic content related to Jewish identity. It is important to note that while this content did not propagate, it was produced and published by a minority of Twitter users during the events under study.
Zero-Inflated Negative Binomial Regression Predicting Counts of Retweets (Size Models).

IRR: Incidence-Rate Ratio; LRT: Likelihood Ratio Test; MPs: Members of Parliament.
Significance codes: *: 0.05; **: 0.01;***: 0.001.
Across all three events, content posted from Twitter verified accounts was most likely to be retweeted in volume, an unsurprising finding given the types of users behind these accounts. In all but one of the events (Event 3), MPs were highly likely to be retweeted. This pattern is repeated in relation to Jewish organizations, providing strong support for H3. Across all three events, Media Agents were positively associated with larger size of information flows, supporting previous research that indicates “old media” greatly influence the flow of information on “new media” platforms (Williams & Burnap, 2016).
Information Propagation Survival Model
Table 6 presents the results of the information flow survival models for the three events. Positive estimates in the Cox regression models are interpreted as increased hazards to survival and, therefore, a reduction in the duration of information flows on Twitter. In all events, antagonistic content is negatively associated with long-lasting information flows. In two of the events, it emerges as having the highest positive hazard ratio. Supporting H6, this finding corroborates previous that shows online antisemitic hate speech does not propagate in terms of size or survival (Williams & Burnap, 2016). Figures 3, 5 and 7 visualize the survival estimates of antagonistic content in the 15-day analysis windows of each event. They show that these antisemitic information flows survived between 1 and 3 days. This sharp de-escalation once again lends evidence to H6 and resonates with research that shows offline hate crime following trigger events has a “half- life” (King & Sutton, 2013; Legewie, 2013). It seems likely that this offline pattern is replicated in relation to online antagonistic content concerning Jews.
Cox Regression Predicting Hazards to Tweet Survival (Survival Models).

Significance codes: *: 0.05; **: 0.01;***: 0.001.

Kaplan-Meier survival estimates for antagonistic tweets in event 1.
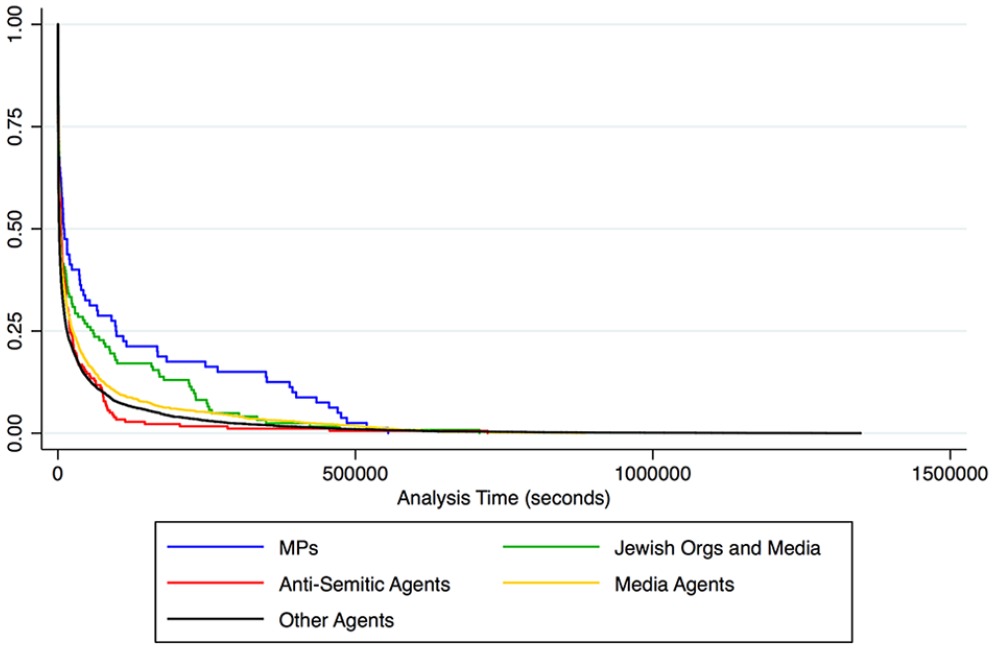
Kaplan-Meier survival estimates for agent type in event 1.

Kaplan-Meier survival estimates for antagonistic tweets in event 2.
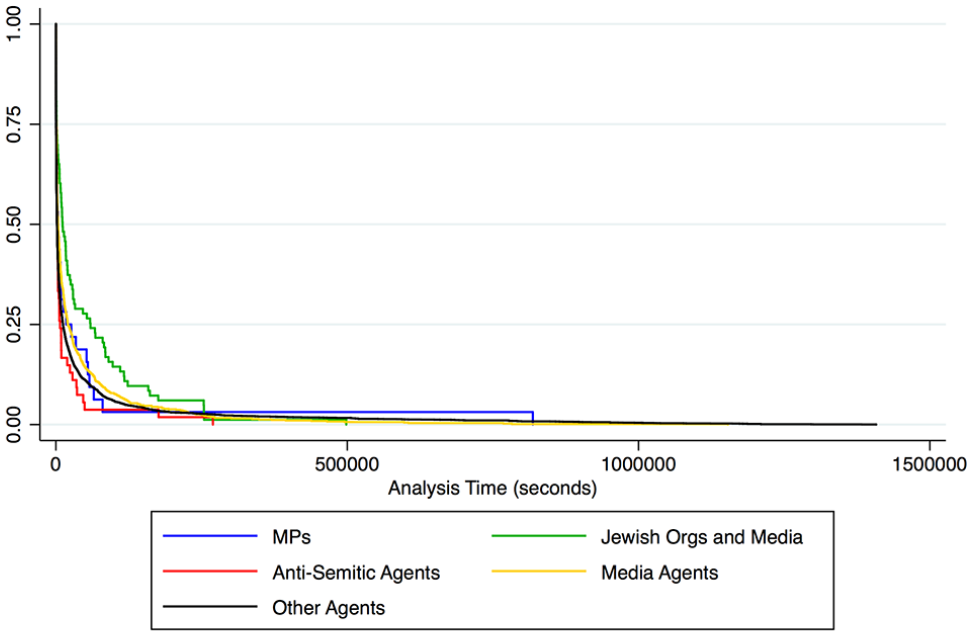
Kaplan-Meier survival estimates for agent type in event 2.

Kaplan-Meier survival estimates for antagonistic tweets in event 3.
Figures 4, 6, and 8 visualize the survival estimates for different agent types. Unexpectedly, antisemitic agents emerged as having the fourth and fifth highest negative hazard ratios in Event 1 and Event 3. This indicates that information flows emanating from some of these agents during these events were likely to outlast those emanating from other agents at some points in the 15-day analysis windows. These figures show that, while information flows from antisemitic agents can last between 3 and 7 days, these are in a minority, as many of them die out rapidly (indicated by the steep decline in the red lines). Conversely, many more information flows emanating from Jewish organizations survive between 3 and 7 days in all events (indicated by a less steep decline in the green lines). This finding is novel and shows information flows from antisemitic agents gain less traction in terms of duration than flows produced by organizations challenging these negative narratives on social media. Furthermore, information flows emanating from Jewish organizations emerge as having the lowest hazard to survival across all events, strongly supporting H4.
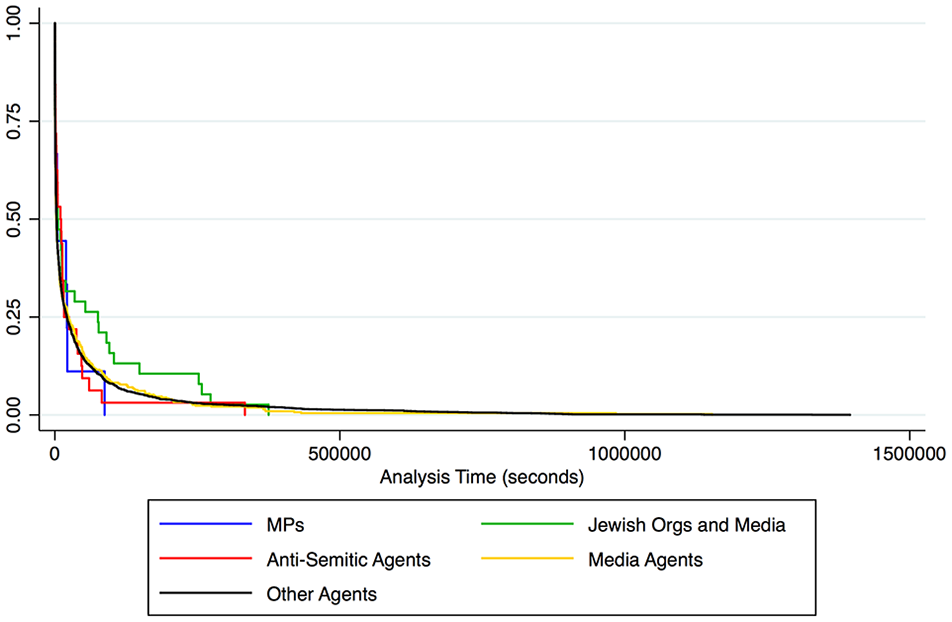
Kaplan-Meier survival estimates for agent type in event 3.
General Media Agents emerged as having positive hazard ratios for all three events, with many information flows dying out evenly over the study window (the yellow line). As indicated in previous research, this is likely to be a result of frequent news turnover, where new stories replace old ones on a daily basis. These new stories create new information flows that replace the old (Williams & Burnap, 2016).
Discussion
In this article, we demonstrated how using social media (meta)data when coupled with computational criminology methods (i.e., pattern matching, supervised machine learning classification detecting cyberhate, information propagation modeling) can contribute to conventional hate crime recording practices and extend our understanding of online trends of antisemitism. Our analysis showed significant variability in the frequency of antagonistic tweets related to Jews over the 12-month study period. Supporting H1, we demonstrated offline events, such as the antisemitism row in the Labour party, can trigger online discussion around Jewish identity and antisemitic sentiments. The analysis also revealed the frequency of antagonistic content was on average 32% higher in the second-half of 2016. CST found a similar sustained increase in incidents reported both on and offline in the same period (CST, 2017). Similar to previous research related to anti-Muslim sentiment on Twitter (Williams & Burnap, 2016), we found that only 0.7% of tweets referring to Jews and Jewish identity were classified as antagonistic. Although this finding contradicts with previous higher antisemitism rates of global tweets (ADL, 2018), it suggests that only a small proportion of the content relating to Jews on UK-based Twitter are antagonistic, confirming previous research (Williams & Burnap, 2016).
Across all three events subjected to statistical modeling, our logit model predicting the presence of hate speech suggests that accounts identified as antisemitic by CST were most likely to produce antagonistic content, while verified and media accounts were least likely. These findings lend strong support for the H2 and provide evidence in support of the accuracy of the machine learning classifier built for this study. H5 and H6 also demonstrated that antisemitic content was less likely to be retweeted in volume and to survive for long periods across all events, supporting previous research on the “half-life” of hate speech on social media (Burnap et al., 2014; Williams & Burnap, 2016). Non-propagation in terms of size means that antagonistic content was not retweeted (shared by other Twitter users) to a great extent and most of the time none at all. This is an encouraging finding which indicates that the majority of Twitter users do not endorse these types of posts through the act of retweeting. Non-propagation of hate within the Twitter community might be interpreted as a demonstration of collective efficacy on Twitter. However, we would like to remain conservative with this claim as there may be other confounding factors. Research shows that where antagonistic content is retweeted, it is contained within online “echo chambers” of like-minded individuals and if the size of this community is likely to affect the volume of information propagation.
The small (in terms of retweeting) but sustained (in terms of survivability) information flows of a minority of antisemitic agents indicate that there is limited endorsement of these Twitter narratives. Yet, where there is support, it emanates from a core group who seek out each other’s messages over time: an “echo chamber” of like-minded individuals who encourage and amplify each other. This suggests that contagion of antagonistic information flows appears to be contained and, while it may be viewed by others, it is unlikely to be accepted and disseminated widely by other users beyond such groups.
We also reported some positive results, particularly with regard to the representation of collective efficacy on social media (Sampson, 2001; Sampson et al., 1997). In support of H3 and H4, this study revealed that information flows emanating from Jewish organizations gained significant traction during two of the three events, as evidenced by the combined positive size and survival findings. We found that information flows from antisemitic agents on Twitter gain less traction in terms of duration than information flows produced by organizations challenging these negative narratives lending tentative support to the effectiveness of “collective efficacy” on social media. This suggests that when organizations which aim to counter harmful narratives such as antagonistic speech become active on social media platforms, their messages propagate further and achieve higher longevity than antagonistic messages. This is a positive finding that underlines the importance of the work of organizations that aim to protect communities and increase collective efficacy on social media.
Conclusion
Police crime and CSEW figures indicate that hate crimes have increased significantly in the past few years in the wake of the vote over the UK’s future in the EU and recent terror attacks. Despite being useful, conventional hate crime recording practices are limited by their reliance on victims or witnesses reporting incident. Correspondingly, the FRA survey shows more than three-quarters of antisemitic harassment are never reported, leading to a dark figure in hate crime records. There is a clear policy and community safety need to devise new methodologies to detect and analyze online antisemitic incidents, as highlighted by the FRA. Given the sheer size of social media communications at any given hour, manually sifting through millions of posts every month to detect cyberhate would be extremely laborious, if even possible. Computational approaches without human input, such as unsupervised learning and clustering, are limited when detecting future instances of cyberhate. Instead of relying on “terrestrial” data or reports from the public on antisemitic victimization, this study used a relatively novel online source, Twitter, to mine big social media data to reveal patterns of perpetration at the source using a supervised machine learning classifier. By doing so, this study has demonstrated how a unique blend of computational and social science techniques can be harnessed to transform and analyze these new forms of data to gain insight into the growing problem of online antisemitism in the United Kingdom.
Findings from this study should be a source of some optimism. A key finding of this study is that information flows emanating from Jewish organizations, capable and willing counter-speech actors, had a significantly higher size and survival of retweets. While antisemitism is present on Twitter and can cause severe offense when it is not removed, it is challenged by positive content, which is present in greater amounts, lasts longer, and spreads further than hate content. Measuring the production of cyberhate, and the size and survival of information flows, this study is the first to evidence the classic sociological notion that collective efficacy can be observed on social media. Our findings suggest that counter-speech posted by credible organizations can be an effective measure to prevent harmful narratives, such as online antisemitism. Based on our findings, we underline the value of the work of charities and organizations that aim to protect communities, such as ADL and CST. The presence of such organizations on social media is key to increasing trust in digital communications and platforms and reducing the propagation of cyberhate.
We end this article with suggestions for future research. The online pattern of antagonistic content related to Jews, as identified by text-based classification methods, can act as a proxy for the ebb and flow of antisemitism in the United Kingdom. However, it should be noted that we did not capture tweets that expressed antisemitic conspiracy theories (or allusions to such theories) or antisemitic images posted without accompanying the antisemitic text. Future research investigating the production and propagation of image-based cyberhate and antisemitic theories can further improve our understanding of online antisemitism. Furthermore, the quantitative nature of our collective efficacy observation prevents us from understanding which type of actions from willing and credible actors helps reduce cyberhate perpetration. Future research should look at whether publishing counter-hate speech and counterclaims reduce cyberhate on social media platforms and if so, which types of counter-messages are more effective to reduce the negative effects of hate speech.
Footnotes
Appendix A
Appendix B
Appendix C
Acknowledgements
This research was undertaken using the supercomputing facilities at Cardiff University operated by Advanced Research Computing at Cardiff (ARCCA) on behalf of the Cardiff Supercomputing Facility and the HPC Wales and Supercomputing Wales (SCW) projects. The authors acknowledge the support of the latter, which is part-funded by the European Regional Development Fund (ERDF) through the Welsh Government.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclose receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by Community Security Trust.