
Abstract
There is a dearth of research on the public’s beliefs about how social media technologies work. To help address this gap, this article presents the results of an exploratory survey that probes user and non-user beliefs about the techno-cultural and socioeconomic facets of Twitter. While many users are well-versed in producing and consuming information on Twitter, and understand Twitter makes money through advertising, the analysis reveals gaps in users’ understandings of the following: what other Twitter users can see or send, the kinds of user data Twitter collects through third parties, Twitter and Twitter partners’ commodification of user-generated content, and what happens to Tweets in the long term. This article suggests the concept of “information flow solipsism” as a way of describing the resulting subjective belief structure. The article discusses implications information flow solipsism has for users’ abilities to make purposeful and meaningful choices about the use and governance of social media spaces, to evaluate the information contained in these spaces, to understand how content users create is utilized by others in the short and long term, and to conceptualize what information other users experience.
Introduction
Twitter is a prominent venue in the contemporary landscape of social media platforms. The site boasts more than 300 million monthly active users (twitter.com, 2015), a throughput of over half a billion messages (Tweets) a day, and has become a dominant space for real-time cultural, political, and social communication. While Twitter is sometimes touted as an easy and transparent platform (Bruns, Burgess, Crawford, & Shaw, 2012), multiple incidents have revealed users’ confusion about how the site functions.
During the Occupy Wallstreet protests in 2011, several protest organizers suggested Twitter was censoring its Trending Topic lists and keeping Occupy-related hashtags from appearing (Gillespie, 2012; Jeffries, 2011). Subsequent third-party analysis revealed that the Trending Topics algorithm identifies trends based on changing velocity of a given hashtag’s usage, not just volume, and Occupy hashtags had failed to beat-out others and “trend” in this regard (Lotan, 2011). Highlighting another incident, Zimmer (2015) recounts the story of a handful of users discovering Twitter gives all public Tweets to the Library of Congress for archiving. Subsequently, users voiced displeasure with both organizations for the seemingly “newfound” permanence of Tweets, despite the fact Twitter itself had always maintained these older messages. Finally, some users have failed to realize Tweets are public by default, occasionally to embarrassing ends (Burke, 2011).
While it may be easy to pass judgment on the misunderstandings some have regarding how social media platforms work, users are often put in a situation where they are left to infer how these technologies work based on opaque interfaces and kludgy documentation. For example, in relation to the prior anecdotes, Twitter’s Trending Topics algorithm is not open to public examination, while Twitter announced it was giving all public Tweets to the Library of Congress in 2010 (Raymond, 2010), its Privacy Policies made no mention of this until 2012, and finally, users must discover how to change default settings on their own through trial and error after signing up.
Critical algorithm studies scholars have argued that the algorithms of spaces such as Twitter and Facebook are opaque, often misunderstood by users and thus carry the potential to negatively impact users’ experiences (Bucher, 2016; Rader & Gray, 2015). However, social media are more than just algorithms. As Van Dijck (2013) argues, social media are sociotechnical assemblages involving two interlocking, co-productive spheres: techno-cultural constructs (constituted by the site’s data/metadata structures, algorithms, protocols, interfaces, defaults, users, and informational content) and socioeconomic constructs (which include a platform’s ownership status, the governance of the platform, and the business models used by the platform’s purveyors). Van Dijck argues these two spheres intersect and inform each other, and must be understood in tandem to explicate what constitutes social media. For example, the business models of a platform may inform the way default settings are arranged on the site or the kinds of interfaces offered to different kinds of users. Information flow within these spaces is therefore constituted by both technical and social means.
While hundreds of academic studies have been undertaken with data collected from Twitter, there are markedly fewer studies focusing on users’ understandings of how Twitter works, and none that consider the techno-cultural alongside the socioeconomic. To address this gap, I present the results of an exploratory survey probing what users—and as a counter-point, non-users—believe about Twitter’s sociotechnical assemblage. The results reveal a mixed picture of users’ belief. Many users are familiar with the techno-cultural and socioeconomic facets of the platform that they experience firsthand on the site (such as tweeting, following, and Twitter as generating revenue through advertising). However, they are broadly unaware of the facets of Twitter’s platform that are not part of the web-interface and for which they do not have feedback mechanisms (e.g. the fact that Twitter generates revenue by selling access to user content). Ultimately, I propose the term “information flow solipsism” as a way of describing the subjective position of users who are accurate in their beliefs about the techno-cultural and/or socioeconomic facets of the platform they experience through interface feedback mechanisms, but who are broadly unaware of or are misinformed about the techno-cultural or socioeconomic details of the platform beyond the interface feedback mechanisms.
Inaccurate understandings of Twitter’s platform lead users to undesired outcomes. However, the potential consequences of such misunderstandings—of information flow solipsism—extend beyond user embarrassment. As spaces such as Twitter become entrenched as vehicles for communication, our beliefs about how these spaces work (techno-culturally and socioeconomically) will play an ever-increasing role in our ability to make purposeful and meaningful choices about how to use them and to be able to participate in democratic conversations about how these technologies should be governed. Our beliefs about how these technologies work help us assess and evaluate the information we encounter there, to understand how the content on these platforms is used by others in the short and long term, and to conceptualize what information other users may see and experience through these platforms. In essence, our beliefs about how these technologies work help us respond to the larger world these technologies are part of.
Background
Previous research on user understandings of technical facets of social media reveals copious misunderstandings and general unawareness. For example, a study by Eslami et al. (2015) on user perceptions of Facebook’s “News Feed” algorithm found more than half of the study participants were totally unaware of the algorithm’s presence. The authors note the significant implications of this unawareness when they state participants unaware of the algorithm’s presence also used News Feed to make inferences about their relationships with other users, “wrongly attributing the composition of their feeds to the habits or intent of their friends and family” (p. 161). Also studying beliefs about the News Feed algorithm, Rader and Gray (2015) found users “vary widely in the degree to which they perceive and understand the behavior of content filtering algorithms” (p. 181). The authors suggest algorithmic curation may generate “negative outcomes that could be identified and avoided, if system dynamics like feedback loops are better understood” (p. 181). Finally, in a qualitative study of user regret on Facebook, Wang et al. (2011) found users’ confusion regarding the ways Facebook makes posts available to others by default was often a contributing factor when users regretted posting information on the site.
Some work on social media cognition has related user belief to either individual technical skills or the user’s ability to complete site-specific tasks. For example, through a survey of over 500 undergraduate students, Hargittai and Litt (2011) explored the attributes of Twitter users and non-users. The pair found adoption among the sampled student population was not uniform and “those with higher skills . . . [are] more likely to use the service” (p. 835). González and Juárez (2013) elicited users’ mental models of Twitter, correlating these models with users’ success at completing basic tasks on the platform. This research indicates users need not have a detailed picture of how the technology works to communicate through it, suggesting it should not be assumed just because someone uses Twitter that they understand how it works.
Other research has studied how users imagine the kinds of communication social media enables. For example, in their 2011 qualitative study of Twitter users, Marwick and boyd explore how users imagine their audiences on Twitter. They found users engage various cognitive strategies to envision potential recipients. These include conceptualizing audiences as close personal friends, persons resembling themselves, and specific communities of interest. However, many are aware of (and some self-censor in response to) the potential for authority figures (e.g., employers or parents) to discover their Tweets. Wyche and Baumer (2016) investigated how non-users in rural Zambia conceptualize Facebook and its “imagined uses,” finding participants conceptualized the site as useful for making new friends, particularly distant ones, and for visual communication. Absent from these conceptualizations was an awareness “they would be providing a company with their potentially valuable personal data, thus bringing a host of new privacy concerns to populations without much privacy protection” (p. 14). The authors also note user confusion regarding differences between Facebook and the Internet generally, suggesting this conflation may ultimately benefit Facebook, as the business explores expanding its user base by offering free scaled-back Internet access.
Together, these studies demonstrate the important role user perceptions of opaque algorithms have in shaping their interpretation of information from these platforms, the importance user understandings of defaults play in their ability to reach desired outcomes, the reality that users need not maintain accurate understandings of platforms to use them, and that, in some cases these inaccurate understandings carry potential benefits for social media companies. However, none of these studies consider the implications that knowledge about the techno-cultural and socioeconomic facets of platforms together, in tandem, has for users. While this work provides some initial insights into beliefs about social media platforms, research that considers both spheres can provide deeper understandings of users’ beliefs about Twitter.
Methodology
Using a web-based survey, this study elicited both user and non-user beliefs about the techno-cultural and socioeconomic facets of Twitter. Descriptive statistical analysis was used to explore trends in the responses. Given the dearth of survey work on understandings of Twitter, an exploratory approach was the most appropriate first step to address this gap. In exploratory surveys, the research question remains open-ended and there is not a specific hypothesis driving the study (Adams, 1989). Instead, from the initial investigation, specific hypotheses may surface that can serve as a direction for the future research.
Population of Interest
This study’s primary interest is in users and their beliefs about how Twitter works. However, the study is also interested in non-users as a comparison case. As Wyatt (2003) points out, treating users and non-users uniformly obfuscates variances in use and non-use. To mitigate this, the study focuses first on Twitter users (those with a registered account), and then focuses on three types of “non-users”: those who have never used the site, “unregistered users” who have been to Twitter.com but do not have a registered account, and “formerly registered non-users” who previously had a Twitter account but deleted it.
In studying the Twitter-user/non-user population, true “random” sampling is extremely difficult. For example, in sampling registered users, while it is possible to take a random sample from the stream of public Tweets through the application programming interfaces (APIs), this would bias the sample toward users who have tweeted recently and publicly. Furthermore, random digital dialing (such as that used by Pew Research) was beyond the means of the researcher. This project relies instead on a purposive sampling of individuals from the population of students, staff, and faculty at a large public urban university in the Midwestern United States.
Survey Instrument
The survey instrument begins by asking participants demographic and history of Twitter use/non-use questions. Next, the survey probes respondents’ beliefs about Twitter. It does so by presenting them with accurate and inaccurate statements about the techno-cultural elements of Twitter (which van Dijck identifies as the data/metadata, algorithms, protocols, interfaces, defaults, users, and informational content of Twitter) and the platform’s socioeconomic facets (which van Dijck identifies as its ownership status, the governance of the platform, and Twitter’s business models). Developed in September 2014, the prompts are based on a close reading of the Twitter.com web-interface, policy documents, API developer documentation, Twitter’s developer forums, the “Twitter Blog,” Twitter’s help forums, information about Twitter’s business agreements made available through its “Certified Products” page, Twitter’s Securities and Exchange Commission (SEC) filings, accounts found in the popular press, and through secondary sources. Prompts were also developed to address aspects of Twitter where prior work had revealed complications in user understandings.
With the exception of prompts about Twitter’s business models, the survey presents respondents with accurate or inaccurate statements about Twitter and asks the respondent to indicate whether the statement is accurate, inaccurate, or if they are unsure. For example, participants were given the (inaccurate) statement, “Messages on Twitter (also called ‘Tweets’) are limited to 210-characters in length.” For questions about Twitter’s business practices, participants were asked to identify ways Twitter generates revenue from a list of true and fictitious options. Participants were allowed to skip any question, with the exception of the initial informed consent question. To improve the reliability and validity of the instrument, a participant attentiveness question was included in the latter third of the questionnaire.
Procedures
The sample for this population was located through consultation with a technical support team at the university. The team provided 15,000 randomly selected active email addresses from a public directory of students, faculty, and staff (from a total pool of ~60,000 active accounts). Individuals can have their email addresses excluded from the public directory via an opt-out mechanism, thus highly privacy conscious individuals may have been excluded. After Institutional Review Board (IRB) approval, the survey was sent to the sample. The survey was closed after 6 weeks. In total, 449 respondents completed the survey, and 15 participants failed or did not answer the attentiveness question and were thus not considered.
Limitations
As a result of the project’s sampling, there are limitations to the generalizability of the findings. As with any self-administered survey, there is the potential participants will misrepresent their beliefs about technology. However, as Hargittai (2009) argues, “the majority of people do not make up their responses” (p. 130). Given this is an exploratory study, the findings should be used as a starting point for the future development and research. Furthermore, just because a respondent answers a question incorrectly, it does not necessarily mean that they have inaccurate knowledge. Responses are being used in this work as a proxy for knowledge, but it is important to note that they are an imperfect proxy.
There is also critique of offering an “unsure” to survey respondents, as it introduces the possibility of personality-bias into the survey responses (Mondak, 1999). However, a confessed lack of certainty is not treated the same as being misinformed in this analysis. The “unsure” option was given to limit both survey abandonment and guessing. While alternative methodological designs were considered (such as using open-response questions), ultimately, given this study’s goal of broadly surveying users beliefs about many different facets of Twitter, a “quiz” like survey structure was deemed most appropriate to survey a large number of participants. A subsequent limitation of this work is therefore in knowing whether people erred on the side of “unsure” when they may have known the correct answer but had hesitation or some degree doubt. 1 Finally, due to the location of the sample, the findings are likely limited in their generalizability.
Findings
This review of the findings focuses first on registered users’ response patterns before selectively highlighting points of comparisons with non-user groups.
Sample Characteristics
Demographics
Overall, the sample skews young, 2 majority female, 3 highly educated, 4 and has a higher concentration of Twitter users than found among US Internet users 5 (as seen in Table 1). Registered users (n = 235) composed 54.1% of the overall sample, non-users (n = 110) 25.3%, unregistered users (n = 62) 14.3%, and formerly registered non-users (n = 27) 6.2%. Many of the demographic trends are likely due to the sample being from a university. Furthermore, given the subject of the recruitment email contained a call for completion of a survey about Twitter, recruitment was likely biased toward Twitter users.
Descriptive Statistics for Sample Demographics.
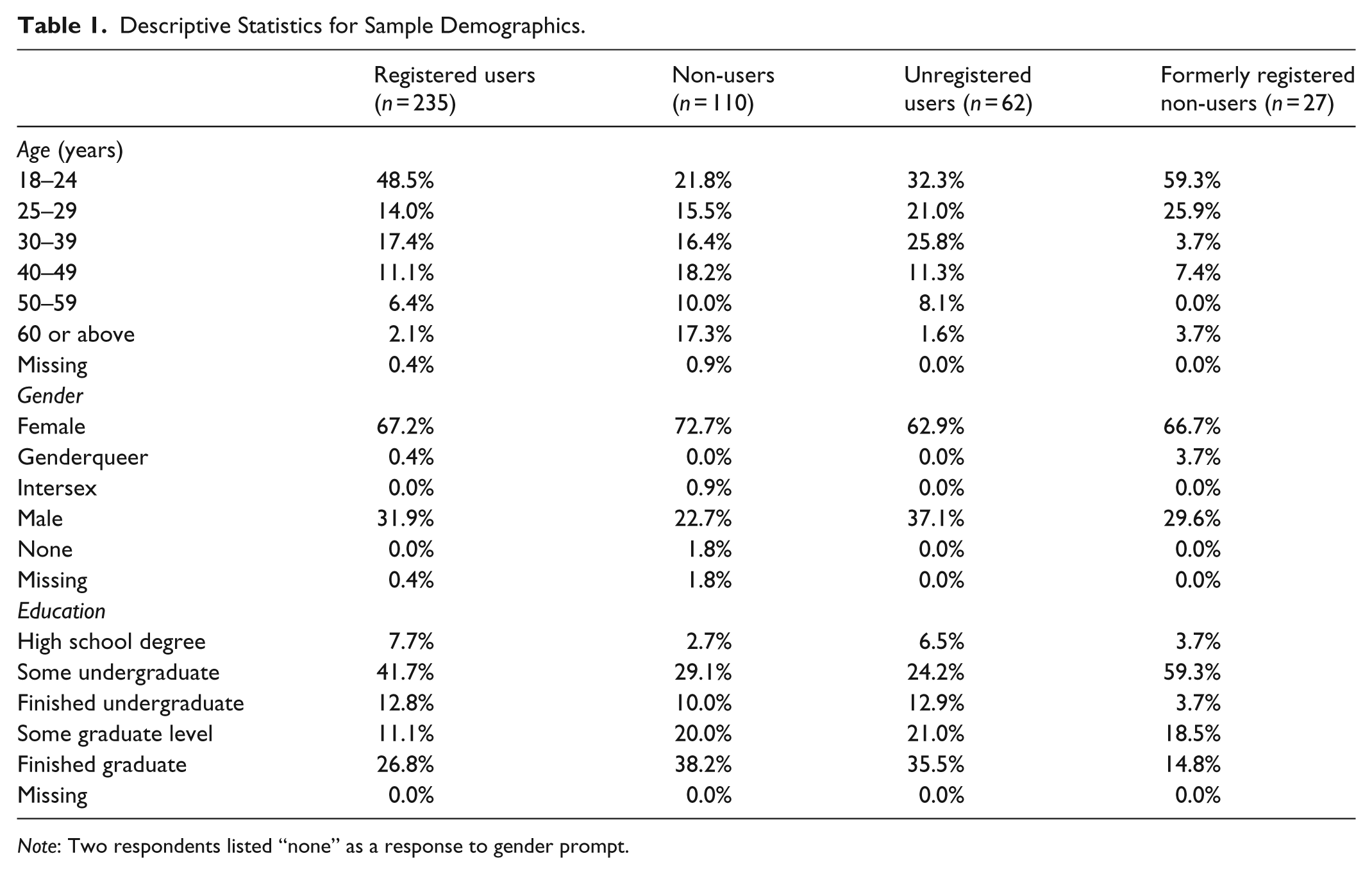
Note: Two respondents listed “none” as a response to gender prompt.
Registered Users’ Use Traits
Registered users were asked how they access Twitter and when they last posted a Tweet. Table 2 shows mobile apps are the most frequently used means of access among the sample, a finding consistent with in-house research published by Twitter, Inc. (twitter.com, 2013). The sample also reported a lower rate (10.6%) of having never sent a Tweet than the overall percentage of Twitter users, which is estimated at 44% (Koh, 2014). This suggests the sample is more active on Twitter than the overall population of registered Twitter users.
Registered User Use Patterns (n = 235).

At the end of the survey, registered users were asked questions about whether they have read the Terms of Service, Privacy Policies, and the Twitter Rules. Table 3 shows few respondents report having read the governing documents. These results are unsurprising given a majority of web-users regularly skip reading these documents (Smith, 2014).
Registered Users Self-Reported Reading of Policy Documents (n = 235).

Registered Users’ Beliefs About How Twitter Works
Techno-cultural Constructs
Perhaps unsurprisingly, as shown in Table 4, respondents gave the most correct responses to techno-cultural prompts about data/metadata, protocols, algorithms, interfaces, defaults, informational content, and users that they would have directly encountered as part of using the Twitter.com timeline interface. For example, as shown in Table 4, a clear majority of sampled users were aware the character limit for Tweets is not 210, that users can include location information within Tweets, how hashtags work, what makes a Tweet a @reply, how “following” works, and what it means for a user to be verified. Furthermore, a majority of respondents correctly indicated the Trending Topics algorithm shows only topics that are immediately popular rather than those that have been popular for some time.
Registered Users Responses to Techno-cultural Construct Prompts (n = 235).

GPS: Global Positioning System; API: application programming interface.
Note: Correct responses are bolded for readability.
However, many users displayed misunderstanding and uncertainty regarding how defaults on the site are set. For example, the majority of registered users incorrectly responded that anyone can send anyone else Direct Messages by default, and a majority of registered users indicated they are unsure about whether Twitter captures Global Positioning System (GPS) information in Tweets by default. While a majority of registered users gave correct responses to the prompt about Tweets being public by default, this majority barely eclipses 50%.
In fact, survey responses revealed mixed beliefs among users regarding what information is public on Twitter and how protecting an account changes information availability. For example, over one-third of participants gave incorrect or unsure responses regarding whether information about “favorites” was available only to the favorited Tweet’s author. The responses regarding whether protected tweets are visible to followers of followers suggest confusion over the reach of protected Tweets. Furthermore, while the majority of registered users understood users must approve followers if they maintain a protected account, the majority was also unsure whether meta-information from protected accounts (such as number of Tweets, photos, followers, followees, and favorites) remains publicly accessible. This suggests while users may be generally aware of the option to protect accounts, what protecting an account means beyond simply getting to approve followers may not be as widely understood.
Respondents demonstrated uncertainty regarding the visibility of certain messages on Twitter. For example, a majority of users indicated they were unsure whether @replies do or do not become visible within a user’s timeline based on user following relationships and were unsure whether unregistered Twitter.com users could use the search function. Some response patterns also raise questions about users’ understanding of the differences in global information flows. For example, a majority of respondents were also uncertain whether or not Twitter ever withholds Tweets within specific countries if they have been asked to do so. Together, these findings suggest that users may have some uncertainty regarding how other users experience information through the platform.
Respondents showed a mixed understanding of how Twitter uses data it gathers about users from outside the platform to shape those individual’s experiences on the site. For example, while a majority of registered users responded correctly that Twitter tailors its suggestions of accounts to follow based on the user’s visits to websites with integrated Twitter buttons or widgets, a majority also indicated they are unsure whether Twitter tailors the advertisements they see based on information collected from third parties. Furthermore, a majority of registered users indicated they were unsure whether or not Twitter receives user browsing behavior information on third-party websites that have Twitter buttons or widgets if the user does not interact with the button or widget (it does). This suggests many users may not be aware of the ways Twitter can effectively track users across the Web.
Finally, users responded with uncertainty about what happens to Tweets in the long term. For example, a majority of registered users were unsure whether old Tweets are deleted by Twitter after 2 years and most respondents indicated they are unsure whether Twitter’s “Certified Products” resell access to old Tweets.
Socioeconomic Structures
Like the techno-cultural facets explored in the previous section, users gave more correct responses to prompts about socioeconomic facets of Twitter that they may have encountered as part of their use of Twitter.com’s web-interface. For example, as shown in Table 5, a majority of registered users correctly identified promoted Tweets and promoted trends as ways Twitter generates revenue, and just shy of half correctly identified promoted accounts as a revenue generation method. However, only 21.7% of registered users correctly indicated Twitter sells access to the full stream of real-time tweets to third parties, suggesting this component of Twitter’s socioeconomic structure is less familiar among users. Registered users are more likely to have directly experienced advertising as a result of using Twitter, and appear more unaware of the revenue generation practices Twitter does not make visible through interface feedback mechanisms, such as sale of access to third parties.
Registered Users Responses to Socioeconomic Structures: Business Model Prompts (n = 235).

Note: Correct responses are bolded for readability.
Responses to the remaining socioeconomic prompts about governance (seen in Table 6) were marked by high volumes of uncertain responses. For example, prompts about the kinds of content Twitter forbids (such as spam, abuse, phishing), what API users are and are not allowed to do with Twitter content, and the arrangement between Twitter and the Library of Congress all had “uncertain” responses in excess of 50%. Given that few users indicated they had read Twitter’s governance documents, perhaps these findings should be unsurprising.
Registered Users Responses to Socioeconomic Structures: Governance and Ownership Prompts (n = 235).

API: application programming interface.
Note: Correct responses are bolded for readability.
Prompts about who the current CEO of Twitter is and whether or not Twitter is a publicly traded company also garnered a high-degree of “unsure” responses. While uncertainty about who the CEO of Twitter is may not be shocking, given the prevalence of popular press stories about Twitter’s Initial Public Offerings (IPO) in 2013 (a year before the survey took place), participant unawareness that Twitter is a publicly traded company seems more surprising. This uncertainty also suggests users may be unfamiliar of the external pressures Twitter faces in terms of monetization and stock performance, which has implications for the commodification of users’ information.
Comparison With Non-Users, Unregistered Users, and Formerly Registered Non-Users
A more comprehensive account of non-user’s beliefs about Twitter is deserved, which, for reasons of space, I cannot give here. However, the Appendix contains a full account of the response patterns of all user groups.
Perhaps the most important takeaway from comparing response patterns of user/non-user groups is that all user/non-user groups performed worse at correctly responding to prompts about the “socioeconomic” side than the “techno-cultural” of Twitter. All groups appeared broadly unsure of Twitter as a business and the fact that Twitter generates revenue by selling access to user content. With two exceptions, non-users predominantly chose “unsure” in response to all survey prompts. The exceptions are that a majority of all four user/non-user groups gave correct responses to how hashtags and following work. This suggests the logic of these two protocols has, to some degree, permeated the public consciousness (at least within the university setting).
There were also a number of cases where non-user response patterns closely resembled those of users. These cases suggest tensions points where being a user entails little more accurate belief about how Twitter works than people who have never used the site. For example, when given the prompt, “Twitter does not ever withhold tweets or user accounts from being accessed within specific countries, even if they have received a legal request to do so” (an inaccurate statement), only 17.9% of registered users correctly identified the statement as inaccurate: among non-users, the percentage was 16.4%. This suggests broad unfamiliarity with the realities of global information flow, and that being a user does not necessarily clue one to a greater degree. When given the inaccurate prompt, “When you visit a website with Twitter buttons or widgets like the ‘Tweet This’ button, Twitter does not receive information about that visit unless you click on the button or widget” only 15.3% of registered users correctly identified the statement as inaccurate, compared to 12.7% among non-users. Again, this suggests that Twitter’s data collection practices of user behavior are not well known, and that being a Twitter user does not necessarily entail better knowledge of this facet over non-users. When given the inaccurate prompt that Twitter’s “Certified Products” partners are prohibited from reselling historical Twitter data to third parties, only 9.4% of registered users correctly identified the statement as inaccurate, and only 2.7% of non-users did likewise, suggesting broad unawareness of how user content is commodified. And finally, when asked if Tim Cook was the current CEO of Twitter (he is not) only 16.6% of registered users correctly indicated this was an inaccurate statement, and only 10.0% of non-users did as well, suggesting knowledge of Twitter, Inc.’s leadership is limited.
Discussion
The findings of this study offer a number of insights into users’ knowledge about the techno-cultural and socioeconomic facets shaping information flows on Twitter. Many of the results speak to specific facets of Twitter that may be troublesome for users. To underscore the value of such analysis, I will return first to the anecdotes about Occupy, the Library of Congress, and “public by default” from the beginning of the article, and then will discuss what can be learned from looking at broader trends in the response patterns.
Despite the tribulations of Occupy protestors, a majority of registered users correctly identified the Trending Topics algorithm as showing only topics that are immediately popular. This suggests a (perhaps growing since 2012) familiarity with the algorithmic logic of trending. Given that Facebook has also introduced “Trending” topics of conversation, it seems as though a larger cultural understanding of what it means for something to trend may be developing.
Over two-thirds of users were unsure whether Twitter gives public Tweets to the Library of Congress for archiving (and another 11.5% were incorrect). This raises questions about what Twitter users think happens to Tweets in the long term. It also raises questions about whether they are truly giving informed consent for this archiving.
Finally, only a slim majority of users accurately indicated that Tweets are set to be public by default. Given the common refrain that Twitter is a “public” platform, having 33% of respondents indicate they are uncertain whether or not Twitter is public by default suggests some users may not actively perceive it this way. This raises many questions about the kinds of literacy work that needs to be done to improve user understanding of what it means for a platform to be “public.” Together, these individual findings suggest that the problems of inaccurate knowledge of information flow highlighted by these three anecdotes may be more common across a wider swath of users.
When the survey response patterns are considered holistically, it becomes clear that registered Twitter users gave more accurate responses to the prompts they have informational feedback mechanisms for within the Twitter.com web-interface. This includes techno-cultural facets associated with information production and information consumption on Twitter (such as Tweeting, following, hashtags), as well as the socioeconomic facets associated with Twitter generating revenue through advertisements. Respondents gave far fewer accurate responses to prompts that addressed facets of Twitter beyond their firsthand experiences of using the interface. For example, what other users can see or send, what data Twitter collects about users from third parties, how Twitter makes information accessible via the APIs, how Twitter and its partners generate revenue by selling access to user-generated content, and what happens to Tweets in the long term.
Notably, respondents performed poorly on aspects of the site described in the governing documents, but for which there is not a feedback mechanism within the timeline interface—for example, the Library of Congress archive. This is not surprising given the number of users indicating they have never read Twitter’s policy documentation. According to Jensen and Potts (2004), privacy policies “are meant to inform consumers about business and privacy practices and serve as a basis for decision making for consumers” (p. 471). However, informing is far from what appears to be taking place. Instead, the findings of this study suggest that if companies such as Twitter want to actively promote users’ knowledge of information flows, they need to find ways to build notification or feedback mechanisms into the interface itself.
When looking at the kinds of ends that users’ accurate knowledge is geared toward, users appear oriented toward producing information and understanding how it flows to a user’s followers in the short-term (in the “real-time”). Users also appear to be primed for consuming information from hashtags, building following networks, and conceptualizing the platform as supported by advertising. These user competencies stand in contrast to the wider techno-cultural and socioeconomic context in which Twitter exists, and in which user-generated information flows. I suggest that this state of individuals’ understandings can be described as one of “information flow solipsism.”
I offer the term “information flow solipsism” to describe the subjective position of the user who is familiar with the facets of a platform for which the interface provides informational feedback mechanisms, but who remains unaware of how the technology operates at a broader techno-cultural or socioeconomic level. Information flow solipsists may be unaware of the kinds of information flow others on the platform do or do not have access to. They may be unaware of disparate interfaces a platform offers to other kinds of users (such as the APIs data aggregators make use of). They may be unaware of differences in how a platform’s information flows vary globally, of the ways in which user-produced information is commodified, or of the wider economic information-ecosystem user-generated content feeds into. Information flow solipsists may also be more broadly unaware of what happens to the information they produce beyond the “real-time.”
A state of information flow solipsism can have a number of serious consequences. For example, despite Twitter’s claim “What you say on Twitter may be viewed all around the world instantly,” users may not realize Twitter restricts content in certain geographic regions. With such knowledge, users might protest Twitter’s decision to block Tweets based on geographic region (as many users did, Tsukayama, 2012). They might become more interested in issues of censorship by social media companies around the world. Users might write to their elected officials to ask them to put pressure on companies that comply with censorship requests from repressive regimes. Or conversely, a user might decide they are entirely comfortable with the status quo of information flow and continue to use the service as they always have. But the possibility of making any of these choices is closed off when a user does not have an accurate understanding of how information flows on a social media platform. To put this in another way, a user’s field of potential actions is diminished when they do not understand the conditions within which they communicate.
In describing “information flow solipsism,” I am not denigrating users. Instead of castigating users for failing to read pages upon pages of policy documentation written at the college-level, for failing to parse a sometimes opaque platform, or for not scouring Twitter’s 222 page initial public offering documentation, we might ask the following questions: How does a company like Twitter, that derives revenue from users producing “a first draft of the present” (Bruns & Weller, 2016), and offers access to the “real-time” zeitgeist of the Internet, benefit from information flow solipsism? How does information flow solipsism manifest on other platforms? How might/does such a subjective state among users fuel the power imbalances between individuals and massive multinational corporations? Instead of chastising users, I wish to emphasize that greater research is needed to understand how information flow solipsism may instead be a produced, and perhaps in some ways, encouraged, phenomenon.
Conclusion
In application, information flow solipsism may help explain why Marwick and boyd (2010) found users imagine their audiences as predominantly users like themselves, rather than data aggregators, Twitter’s business partners, or users in geographically disparate regions. Information flow solipsism can add to conversations about filter bubbles. It can build on the work of authors such as Nissenbaum (2009) who observe privacy is not just about the revelation of certain pieces of personally sensitive information, but is instead about the contextual norms that govern the information flow among different parties. Information flow solipsism suggests considering how users (and non-users) may be setup to develop a narrow understanding of what information flows exist in social media space, thereby putting social media companies in a position to manage beliefs about contextual norms.
Ultimately, information flow solipsism is a pressing issue because, if social media sites such as Twitter become further entrenched as dominant vehicles for social, cultural, and political communication, our beliefs about how these technologies function will play an ever-increasing role in our abilities to make purposeful and meaningful choices about the use and governance of these spaces. A solipsistic understanding of information flow limits the scope of our horizons as digital citizens. Further work is needed to examine how representative these responses are of the broader population of Twitter users. More study is needed to probe the antecedent conditions shaping how users construct beliefs about the platform, for example, work that investigates how different sources of information (such as the Twitter website, reports in the media, interviews with Twitter’s founders) might relate to differences observed in users and non-users. Work is also needed to explore how different sets of user beliefs correlate with use behaviors.
While some have praised the Twitter platform for its relative simplicity and transparency in comparison to other social media sites, this work suggests that this “simplicity” does not necessarily translate to users fully understanding the constitutive elements of Twitter. Indeed, if Twitter is a shining beacon of simplicity and transparency among social media sites, there is much to be concerned about regarding users’ understandings of information flows in the contemporary social media landscape.
Footnotes
Appendix
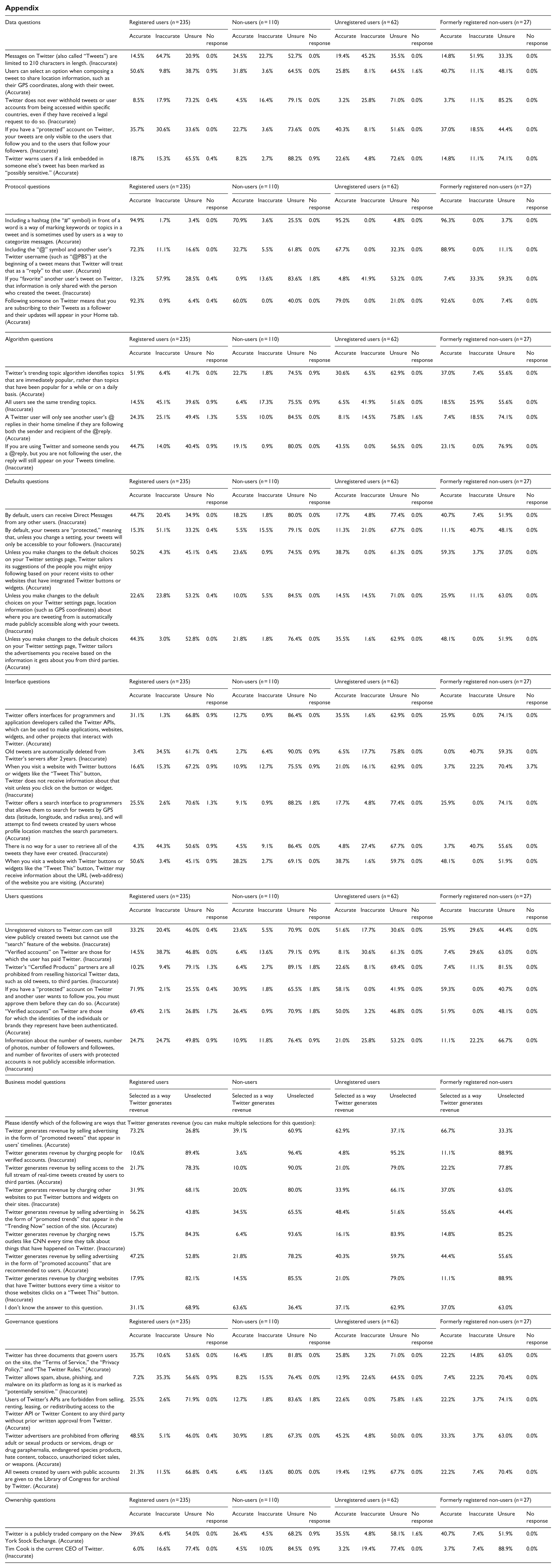
| Data questions | Registered users (n = 235) | Non-users (n = 110) | Unregistered users (n = 62) | Formerly registered non-users (n = 27) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Accurate | Inaccurate | Unsure | No response | Accurate | Inaccurate | Unsure | No response | Accurate | Inaccurate | Unsure | No response | Accurate | Inaccurate | Unsure | No response | |
| Messages on Twitter (also called “Tweets”) are limited to 210 characters in length. (Inaccurate) | 14.5% | 64.7% | 20.9% | 0.0% | 24.5% | 22.7% | 52.7% | 0.0% | 19.4% | 45.2% | 35.5% | 0.0% | 14.8% | 51.9% | 33.3% | 0.0% |
| Users can select an option when composing a tweet to share location information, such as their GPS coordinates, along with their tweet. (Accurate) | 50.6% | 9.8% | 38.7% | 0.9% | 31.8% | 3.6% | 64.5% | 0.0% | 25.8% | 8.1% | 64.5% | 1.6% | 40.7% | 11.1% | 48.1% | 0.0% |
| Twitter does not ever withhold tweets or user accounts from being accessed within specific countries, even if they have received a legal request to do so. (Inaccurate) | 8.5% | 17.9% | 73.2% | 0.4% | 4.5% | 16.4% | 79.1% | 0.0% | 3.2% | 25.8% | 71.0% | 0.0% | 3.7% | 11.1% | 85.2% | 0.0% |
| If you have a “protected” account on Twitter, your tweets are only visible to the users that follow you and to the users that follow your followers. (Inaccurate) | 35.7% | 30.6% | 33.6% | 0.0% | 22.7% | 3.6% | 73.6% | 0.0% | 40.3% | 8.1% | 51.6% | 0.0% | 37.0% | 18.5% | 44.4% | 0.0% |
| Twitter warns users if a link embedded in someone else’s tweet has been marked as “possibly sensitive.” (Accurate) | 18.7% | 15.3% | 65.5% | 0.4% | 8.2% | 2.7% | 88.2% | 0.9% | 22.6% | 4.8% | 72.6% | 0.0% | 14.8% | 11.1% | 74.1% | 0.0% |
| Protocol questions | Registered users (n = 235) | Non-users (n = 110) | Unregistered users (n = 62) | Formerly registered non-users (n = 27) | ||||||||||||
| Accurate | Inaccurate | Unsure | No response | Accurate | Inaccurate | Unsure | No response | Accurate | Inaccurate | Unsure | No response | Accurate | Inaccurate | Unsure | No response | |
| Including a hashtag (the “#” symbol) in front of a word is a way of marking keywords or topics in a tweet and is sometimes used by users as a way to categorize messages. (Accurate) | 94.9% | 1.7% | 3.4% | 0.0% | 70.9% | 3.6% | 25.5% | 0.0% | 95.2% | 0.0% | 4.8% | 0.0% | 96.3% | 0.0% | 3.7% | 0.0% |
| Including the “@” symbol and another user’s Twitter username (such as “@PBS”) at the beginning of a tweet means that Twitter will treat that as a “reply” to that user. (Accurate) | 72.3% | 11.1% | 16.6% | 0.0% | 32.7% | 5.5% | 61.8% | 0.0% | 67.7% | 0.0% | 32.3% | 0.0% | 88.9% | 0.0% | 11.1% | 0.0% |
| If you “favorite” another user’s tweet on Twitter, that information is only shared with the person who created the tweet. (Inaccurate) | 13.2% | 57.9% | 28.5% | 0.4% | 0.9% | 13.6% | 83.6% | 1.8% | 4.8% | 41.9% | 53.2% | 0.0% | 7.4% | 33.3% | 59.3% | 0.0% |
| Following someone on Twitter means that you are subscribing to their Tweets as a follower and their updates will appear in your Home tab. (Accurate) | 92.3% | 0.9% | 6.4% | 0.4% | 60.0% | 0.0% | 40.0% | 0.0% | 79.0% | 0.0% | 21.0% | 0.0% | 92.6% | 0.0% | 7.4% | 0.0% |
| Algorithm questions | Registered users (n = 235) | Non-users (n = 110) | Unregistered users (n = 62) | Formerly registered non-users (n = 27) | ||||||||||||
| Accurate | Inaccurate | Unsure | No response | Accurate | Inaccurate | Unsure | No response | Accurate | Inaccurate | Unsure | No response | Accurate | Inaccurate | Unsure | No response | |
| Twitter’s trending topic algorithm identifies topics that are immediately popular, rather than topics that have been popular for a while or on a daily basis. (Accurate) | 51.9% | 6.4% | 41.7% | 0.0% | 22.7% | 1.8% | 74.5% | 0.9% | 30.6% | 6.5% | 62.9% | 0.0% | 37.0% | 7.4% | 55.6% | 0.0% |
| All users see the same trending topics. (Inaccurate) | 14.5% | 45.1% | 39.6% | 0.9% | 6.4% | 17.3% | 75.5% | 0.9% | 6.5% | 41.9% | 51.6% | 0.0% | 18.5% | 25.9% | 55.6% | 0.0% |
| A Twitter user will only see another user’s @replies in their home timeline if they are following both the sender and recipient of the @reply. (Accurate) | 24.3% | 25.1% | 49.4% | 1.3% | 5.5% | 10.0% | 84.5% | 0.0% | 8.1% | 14.5% | 75.8% | 1.6% | 7.4% | 18.5% | 74.1% | 0.0% |
| If you are using Twitter and someone sends you a @reply, but you are not following the user, the reply will still appear on your Tweets timeline. (Inaccurate) | 44.7% | 14.0% | 40.4% | 0.9% | 19.1% | 0.9% | 80.0% | 0.0% | 43.5% | 0.0% | 56.5% | 0.0% | 23.1% | 0.0% | 76.9% | 0.0% |
| Defaults questions | Registered users (n = 235) | Non-users (n = 110) | Unregistered users (n = 62) | Formerly registered non-users (n = 27) | ||||||||||||
| Accurate | Inaccurate | Unsure | No response | Accurate | Inaccurate | Unsure | No response | Accurate | Inaccurate | Unsure | No response | Accurate | Inaccurate | Unsure | No response | |
| By default, users can receive Direct Messages from any other users. (Inaccurate) | 44.7% | 20.4% | 34.9% | 0.0% | 18.2% | 1.8% | 80.0% | 0.0% | 17.7% | 4.8% | 77.4% | 0.0% | 40.7% | 7.4% | 51.9% | 0.0% |
| By default, your tweets are “protected,” meaning that, unless you change a setting, your tweets will only be accessible to your followers. (Inaccurate) | 15.3% | 51.1% | 33.2% | 0.4% | 5.5% | 15.5% | 79.1% | 0.0% | 11.3% | 21.0% | 67.7% | 0.0% | 11.1% | 40.7% | 48.1% | 0.0% |
| Unless you make changes to the default choices on your Twitter settings page, Twitter tailors its suggestions of the people you might enjoy following based on your recent visits to other websites that have integrated Twitter buttons or widgets. (Accurate) | 50.2% | 4.3% | 45.1% | 0.4% | 23.6% | 0.9% | 74.5% | 0.9% | 38.7% | 0.0% | 61.3% | 0.0% | 59.3% | 3.7% | 37.0% | 0.0% |
| Unless you make changes to the default choices on your Twitter settings page, location information (such as GPS coordinates) about where you are tweeting from is automatically made publicly accessible along with your tweets. (Inaccurate) | 22.6% | 23.8% | 53.2% | 0.4% | 10.0% | 5.5% | 84.5% | 0.0% | 14.5% | 14.5% | 71.0% | 0.0% | 25.9% | 11.1% | 63.0% | 0.0% |
| Unless you make changes to the default choices on your Twitter settings page, Twitter tailors the advertisements you receive based on the information it gets about you from third parties. (Accurate) | 44.3% | 3.0% | 52.8% | 0.0% | 21.8% | 1.8% | 76.4% | 0.0% | 35.5% | 1.6% | 62.9% | 0.0% | 48.1% | 0.0% | 51.9% | 0.0% |
| Interface questions | Registered users (n = 235) | Non-users (n = 110) | Unregistered users (n = 62) | Formerly registered non-users (n = 27) | ||||||||||||
| Accurate | Inaccurate | Unsure | No response | Accurate | Inaccurate | Unsure | No response | Accurate | Inaccurate | Unsure | No response | Accurate | Inaccurate | Unsure | No response | |
| Twitter offers interfaces for programmers and application developers called the Twitter APIs, which can be used to make applications, websites, widgets, and other projects that interact with Twitter. (Accurate) | 31.1% | 1.3% | 66.8% | 0.9% | 12.7% | 0.9% | 86.4% | 0.0% | 35.5% | 1.6% | 62.9% | 0.0% | 25.9% | 0.0% | 74.1% | 0.0% |
| Old tweets are automatically deleted from Twitter’s servers after 2 years. (Inaccurate) | 3.4% | 34.5% | 61.7% | 0.4% | 2.7% | 6.4% | 90.0% | 0.9% | 6.5% | 17.7% | 75.8% | 0.0% | 0.0% | 40.7% | 59.3% | 0.0% |
| When you visit a website with Twitter buttons or widgets like the “Tweet This” button, Twitter does not receive information about that visit unless you click on the button or widget. (Inaccurate) | 16.6% | 15.3% | 67.2% | 0.9% | 10.9% | 12.7% | 75.5% | 0.9% | 21.0% | 16.1% | 62.9% | 0.0% | 3.7% | 22.2% | 70.4% | 3.7% |
| Twitter offers a search interface to programmers that allows them to search for tweets by GPS data (latitude, longitude, and radius area), and will attempt to find tweets created by users whose profile location matches the search parameters. (Accurate) | 25.5% | 2.6% | 70.6% | 1.3% | 9.1% | 0.9% | 88.2% | 1.8% | 17.7% | 4.8% | 77.4% | 0.0% | 25.9% | 0.0% | 74.1% | 0.0% |
| There is no way for a user to retrieve all of the tweets they have ever created. (Inaccurate) | 4.3% | 44.3% | 50.6% | 0.9% | 4.5% | 9.1% | 86.4% | 0.0% | 4.8% | 27.4% | 67.7% | 0.0% | 3.7% | 40.7% | 55.6% | 0.0% |
| When you visit a website with Twitter buttons or widgets like the “Tweet This” button, Twitter may receive information about the URL (web-address) of the website you are visiting. (Accurate) | 50.6% | 3.4% | 45.1% | 0.9% | 28.2% | 2.7% | 69.1% | 0.0% | 38.7% | 1.6% | 59.7% | 0.0% | 48.1% | 0.0% | 51.9% | 0.0% |
| Users questions | Registered users (n = 235) | Non-users (n = 110) | Unregistered users (n = 62) | Formerly registered non-users (n = 27) | ||||||||||||
| Accurate | Inaccurate | Unsure | No response | Accurate | Inaccurate | Unsure | No response | Accurate | Inaccurate | Unsure | No response | Accurate | Inaccurate | Unsure | No response | |
| Unregistered visitors to Twitter.com can still view publicly created tweets but cannot use the “search” feature of the website. (Inaccurate) | 33.2% | 20.4% | 46.0% | 0.4% | 23.6% | 5.5% | 70.9% | 0.0% | 51.6% | 17.7% | 30.6% | 0.0% | 25.9% | 29.6% | 44.4% | 0.0% |
| “Verified accounts” on Twitter are those for which the user has paid Twitter. (Inaccurate) | 14.5% | 38.7% | 46.8% | 0.0% | 6.4% | 13.6% | 79.1% | 0.9% | 8.1% | 30.6% | 61.3% | 0.0% | 7.4% | 29.6% | 63.0% | 0.0% |
| Twitter’s “Certified Products” partners are all prohibited from reselling historical Twitter data, such as old tweets, to third parties. (Inaccurate) | 10.2% | 9.4% | 79.1% | 1.3% | 6.4% | 2.7% | 89.1% | 1.8% | 22.6% | 8.1% | 69.4% | 0.0% | 7.4% | 11.1% | 81.5% | 0.0% |
| If you have a “protected” account on Twitter and another user wants to follow you, you must approve them before they can do so. (Accurate) | 71.9% | 2.1% | 25.5% | 0.4% | 30.9% | 1.8% | 65.5% | 1.8% | 58.1% | 0.0% | 41.9% | 0.0% | 59.3% | 0.0% | 40.7% | 0.0% |
| “Verified accounts” on Twitter are those for which the identities of the individuals or brands they represent have been authenticated. (Accurate) | 69.4% | 2.1% | 26.8% | 1.7% | 26.4% | 0.9% | 70.9% | 1.8% | 50.0% | 3.2% | 46.8% | 0.0% | 51.9% | 0.0% | 48.1% | 0.0% |
| Information about the number of tweets, number of photos, number of followers and followees, and number of favorites of users with protected accounts is not publicly accessible information. (Inaccurate) | 24.7% | 24.7% | 49.8% | 0.9% | 10.9% | 11.8% | 76.4% | 0.9% | 21.0% | 25.8% | 53.2% | 0.0% | 11.1% | 22.2% | 66.7% | 0.0% |
| Business model questions | Registered users | Non-users | Unregistered users | Formerly registered non-users | ||||||||||||
| Selected as a way Twitter generates revenue | Unselected | Selected as a way Twitter generates revenue | Unselected | Selected as a way Twitter generates revenue | Unselected | Selected as a way Twitter generates revenue | Unselected | |||||||||
| Please identify which of the following are ways that Twitter generates revenue (you can make multiple selections for this question): | ||||||||||||||||
| Twitter generates revenue by selling advertising in the form of “promoted tweets” that appear in users’ timelines. (Accurate) | 73.2% | 26.8% | 39.1% | 60.9% | 62.9% | 37.1% | 66.7% | 33.3% | ||||||||
| Twitter generates revenue by charging people for verified accounts. (Inaccurate) | 10.6% | 89.4% | 3.6% | 96.4% | 4.8% | 95.2% | 11.1% | 88.9% | ||||||||
| Twitter generates revenue by selling access to the full stream of real-time tweets created by users to third parties. (Accurate) | 21.7% | 78.3% | 10.0% | 90.0% | 21.0% | 79.0% | 22.2% | 77.8% | ||||||||
| Twitter generates revenue by charging other websites to put Twitter buttons and widgets on their sites. (Inaccurate) | 31.9% | 68.1% | 20.0% | 80.0% | 33.9% | 66.1% | 37.0% | 63.0% | ||||||||
| Twitter generates revenue by selling advertising in the form of “promoted trends” that appear in the “Trending Now” section of the site. (Accurate) | 56.2% | 43.8% | 34.5% | 65.5% | 48.4% | 51.6% | 55.6% | 44.4% | ||||||||
| Twitter generates revenue by charging news outlets like CNN every time they talk about things that have happened on Twitter. (Inaccurate) | 15.7% | 84.3% | 6.4% | 93.6% | 16.1% | 83.9% | 14.8% | 85.2% | ||||||||
| Twitter generates revenue by selling advertising in the form of “promoted accounts” that are recommended to users. (Accurate) | 47.2% | 52.8% | 21.8% | 78.2% | 40.3% | 59.7% | 44.4% | 55.6% | ||||||||
| Twitter generates revenue by charging websites that have Twitter buttons every time a visitor to those websites clicks on a “Tweet This” button. (Inaccurate) | 17.9% | 82.1% | 14.5% | 85.5% | 21.0% | 79.0% | 11.1% | 88.9% | ||||||||
| I don’t know the answer to this question. | 31.1% | 68.9% | 63.6% | 36.4% | 37.1% | 62.9% | 37.0% | 63.0% | ||||||||
| Governance questions | Registered users (n = 235) | Non-users (n = 110) | Unregistered users (n = 62) | Formerly registered non-users (n = 27) | ||||||||||||
| Accurate | Inaccurate | Unsure | No response | Accurate | Inaccurate | Unsure | No response | Accurate | Inaccurate | Unsure | No response | Accurate | Inaccurate | Unsure | No response | |
| Twitter has three documents that govern users on the site, the “Terms of Service,” the “Privacy Policy,” and “The Twitter Rules.” (Accurate) | 35.7% | 10.6% | 53.6% | 0.0% | 16.4% | 1.8% | 81.8% | 0.0% | 25.8% | 3.2% | 71.0% | 0.0% | 22.2% | 14.8% | 63.0% | 0.0% |
| Twitter allows spam, abuse, phishing, and malware on its platform as long as it is marked as “potentially sensitive.” (Inaccurate) | 7.2% | 35.3% | 56.6% | 0.9% | 8.2% | 15.5% | 76.4% | 0.0% | 12.9% | 22.6% | 64.5% | 0.0% | 7.4% | 22.2% | 70.4% | 0.0% |
| Users of Twitter’s APIs are forbidden from selling, renting, leasing, or redistributing access to the Twitter API or Twitter Content to any third party without prior written approval from Twitter. (Accurate) | 25.5% | 2.6% | 71.9% | 0.0% | 12.7% | 1.8% | 83.6% | 1.8% | 22.6% | 0.0% | 75.8% | 1.6% | 22.2% | 3.7% | 74.1% | 0.0% |
| Twitter advertisers are prohibited from offering adult or sexual products or services, drugs or drug paraphernalia, endangered species products, hate content, tobacco, unauthorized ticket sales, or weapons. (Accurate) | 48.5% | 5.1% | 46.0% | 0.4% | 30.9% | 1.8% | 67.3% | 0.0% | 45.2% | 4.8% | 50.0% | 0.0% | 33.3% | 3.7% | 63.0% | 0.0% |
| All tweets created by users with public accounts are given to the Library of Congress for archival by Twitter. (Accurate) | 21.3% | 11.5% | 66.8% | 0.4% | 6.4% | 13.6% | 80.0% | 0.0% | 19.4% | 12.9% | 67.7% | 0.0% | 22.2% | 7.4% | 70.4% | 0.0% |
| Ownership questions | Registered users (n = 235) | Non-users (n = 110) | Unregistered users (n = 62) | Formerly registered non-users (n = 27) | ||||||||||||
| Accurate | Inaccurate | Unsure | No response | Accurate | Inaccurate | Unsure | No response | Accurate | Inaccurate | Unsure | No response | Accurate | Inaccurate | Unsure | No response | |
| Twitter is a publicly traded company on the New York Stock Exchange. (Accurate) | 39.6% | 6.4% | 54.0% | 0.0% | 26.4% | 4.5% | 68.2% | 0.9% | 35.5% | 4.8% | 58.1% | 1.6% | 40.7% | 7.4% | 51.9% | 0.0% |
| Tim Cook is the current CEO of Twitter. (Inaccurate) | 6.0% | 16.6% | 77.4% | 0.0% | 4.5% | 10.0% | 84.5% | 0.9% | 3.2% | 19.4% | 77.4% | 0.0% | 3.7% | 7.4% | 88.9% | 0.0% |
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.