
Abstract
Background
Machine learning (ML) models for suicide risk prediction show promise, but their real-world discriminative ability and the sources of performance variation remain unclear.
Methods
We systematically searched databases for studies evaluating statistical or ML suicide prediction models in real-world clinical settings. Random-effects meta-analyses pooled the area under the receiver operating characteristic curve (AUC) overall and by outcome type. We conducted exploratory univariable meta-regression with cluster-robust inference for outcome type, evaluation timing, and model type. Sensitivity analyses assessed the influence of within-study dependence.
Results
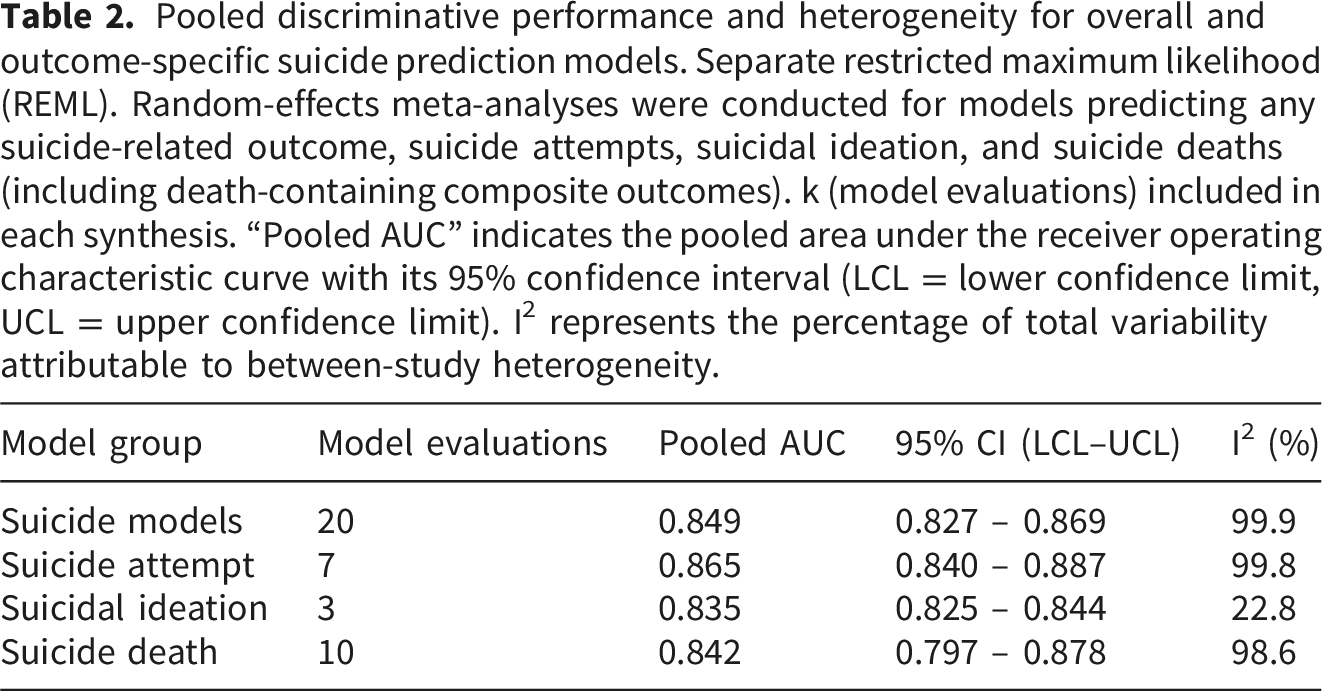
Nine studies (20 evaluations) were included. The overall pooled AUC was 0.849 (95% CI 0.827–0.869). Pooled AUCs were 0.865 (0.840–0.887) for suicide attempts, 0.835 (0.825–0.844) for suicidal ideation, and 0.842 (0.797–0.878) for suicide death. Heterogeneity was extreme (I2 = 99.9%). Sensitivity analyses yielded similar pooled estimates. Exploratory univariable meta-regression showed no clear associations for outcome type, evaluation timing, or model type.
Conclusions
Suicide prediction models show good real-world discrimination, but performance varies substantially across evaluations. We found no clear evidence that outcome type, evaluation timing, or model type explained this heterogeneity. These findings support rigorous local validation and workflow-sensitive implementation rather than assuming that more complex algorithms will perform better in practice.
1. Introduction
Suicide is a major global public health challenge, accounting for more than 700,000 deaths annually. 1 Because it is a leading cause of preventable mortality, effective prevention depends on identifying individuals at high risk accurately and in a timely manner. However, traditional risk assessment approaches, including clinical interviews and standardized questionnaires, have shown limited predictive validity. Their accuracy has changed little over the past 50 years. 2 The subjective nature and low predictive power of these approaches remain major barriers to suicide prevention.
Recent advances in artificial intelligence (AI), particularly machine learning (ML), together with the increasing availability of large-scale digital data, have created new opportunities for suicide risk prediction. ML models can identify subtle and complex patterns in diverse data sources, such as electronic health records (EHRs), administrative claims, survey responses, and social media data. As a result, they may offer more objective, scalable, and timely predictions than conventional approaches. Interest in this field has grown rapidly, and many systematic reviews have reported promising predictive performance, often with pooled area under the receiver operating characteristic curve (AUC) values above 0.85.3,4
Despite these encouraging findings, important questions remain about whether such performance translates into real-world clinical effectiveness. First, most published models have been evaluated retrospectively using historical data. In contrast, prospective studies in real-world clinical settings, in which predictions may trigger alerts or interventions, remain rare. 5 This research-practice gap is a major obstacle to understanding the true clinical utility of suicide prediction models. Second, the literature shows substantial heterogeneity in reported performance. This variation may reflect differences in target outcomes, such as suicidal ideation, attempt, or death, as well as differences in patient populations and care settings. In addition, although more complex ML algorithms are increasingly favored, it remains unclear whether they outperform traditional and more interpretable statistical models, such as logistic regression, when applied in practice. 6 Without a clearer understanding of whether these study-level characteristics and algorithmic choices explain performance differences, 7 it is difficult to develop practical guidance for clinical adoption.
Therefore, this study aimed to synthesize current evidence on the real-world applicability and effectiveness of suicide prediction models by estimating pooled predictive accuracy using AUC. We also explored potential sources of heterogeneity through subgroup analyses and exploratory univariable meta-regression focused on clinically important study-level characteristics, including outcome type, evaluation timing, and model type. By examining the gap between technical performance and real-world clinical effectiveness, we sought to suggest evidence-based directions for the future implementation of AI-based suicide prediction models.
2. Methods
2.1. Protocol and reporting guideline
This systematic review and meta-analysis were conducted and reported in accordance with the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) statement. 8
2.2. Search strategy
A comprehensive literature search was conducted in PubMed, Embase, Scopus, and Web of Science for studies published up until September 30, 2025. The search strategy was developed around four core concepts joined by the ‘AND’ operator: (1) the outcome of interest (suicide), (2) predictive modeling terms, (3) real-world implementation terms, and (4) effectiveness and performance metrics.
For the first concept, terms for suicide were used (e.g., suicide, “Suicide” [Mesh]). The second concept included keywords for predictive models, such as “prediction model” and “risk score”. The third concept captured the implementation context using terms like “implementation” and “real-world”. The final concept focused on evaluation with keywords such as “effectiveness”, “validation”, and “performance”.
The search strategy combined both controlled vocabulary (i.e., MeSH in PubMed and Emtree in Embase) and free-text keywords searched in titles and abstracts ([Title/Abstract]). No language or date restrictions were applied during the initial search to ensure a comprehensive retrieval of all potentially relevant studies. Additionally, the reference lists of all included articles were manually screened for further eligible publications. The full, detailed search query for each database is provided in Supplementary Table S1.
2.3. Study selection and eligibility criteria
2.3.1. Study Selection process
The study selection was performed in a multi-stage process by two independent reviewers, following standard procedures recommended by the Cochrane Handbook for Systematic Reviews of Interventions. 9 First, titles and abstracts of all retrieved records were screened for initial eligibility. Next, the full texts of potentially relevant articles were thoroughly assessed. Finally, a third screening was conducted to confirm that the studies met all criteria for quantitative synthesis in the meta-analysis.
Any disagreements between the reviewers at any stage were resolved through discussion and consensus or, if necessary, by consulting a third reviewer. This entire process was conducted and reported transparently in adherence with the PRISMA 2020 statement. 8
2.4. Inclusion and exclusion criteria
2.4.1. Studies were included in the systematic review if they met the following criteria
• Population: Studies involving any human population where suicide risk was assessed. • Intervention/Exposure: Studies that developed or validated a statistical or machine learning model to predict suicide-related outcomes (i.e., suicidal ideation, suicide attempt, or suicide death). • Outcomes: Studies that reported at least one quantitative performance metric for the prediction model. For inclusion in the meta-analysis, studies were required to report an Area Under the Curve (AUC) value with its corresponding 95% confidence interval (CI), or provide sufficient data to calculate them. • Study Design: Original, peer-reviewed research articles.
2.4.2. Studies were excluded based on the following criteria, identified during the screening process
• Studies that were not prediction models (e.g., scale validation studies, cost-effectiveness analyses without model application). • Studies where the primary predicted outcome was not a suicide-related event (e.g., treatment-resistant depression, opioid overdose). • Review articles, editorials, commentaries, or conference abstracts. • Studies that did not report sufficient quantitative performance data to assess the model’s validity or to be included in the meta-analysis (e.g., missing AUC values).
2.5. Data extraction and quality assessment
A standardized data extraction form was used to collect relevant information from each included study. Two reviewers independently extracted the data, and any discrepancies were resolved by consensus after reviewing the source article.
The following variables were extracted from each study: study information (e.g., first author, publication year), study characteristics (e.g., country, sample size), model and implementation characteristics (e.g., model type, data source, implementation), outcome, and performance metrics (e.g., AUC with 95% CI).
The methodological quality of the included studies was assessed by two reviewers during the data extraction process, focusing on key domains of the Prediction model Risk Of Bias Assessment Tool (PROBAST) framework. 10 We specifically evaluated the clarity regarding participants, predictors, and outcomes, as well as the appropriateness of the statistical analysis, to understand the overall robustness of the evidence base.
2.6. Statistical analysis
The primary effect measure for all quantitative syntheses was the area under the receiver operating characteristic curve (AUC) for discrimination.
11
For each model evaluation, we extracted the reported AUC and its 95% confidence interval (CI), when available. Model evaluations that did not report a CI were summarized descriptively in tables but were not included in the meta-analytic pooling. When multiple model evaluations were reported within a single study, they were treated as independent estimates in the primary analysis, acknowledging this as a pragmatic approach for variance estimation in the presence of extreme heterogeneity
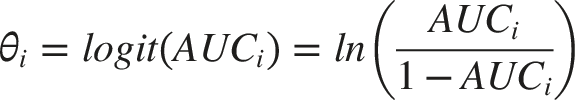
When 95% CIs were available, standard errors of logit (AUC) were derived from the reported CI bounds on the AUC scale. Specifically, the lower and upper CI limits were first transformed using the logit function, and the standard error was calculated as
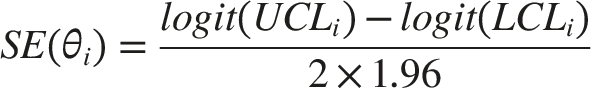
This approach provides an approximate standard error because it relies on reported confidence interval bounds rather than individual-level data and assumes interval symmetry after logit transformation.
Inverse-variance weights were then obtained as
We conducted random-effects meta-analyses of logit-transformed AUCs using a restricted maximum likelihood (REML) estimator for the between-study variance
For each synthesis, we first calculated the Cochran Q statistic and then estimated
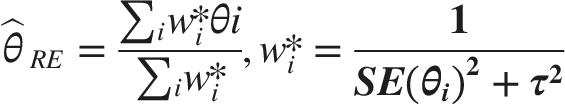
Although both fixed- and REML random-effects models were fitted and displayed in the forest plots, our primary interpretations rely on the random-effects estimates due to the anticipated extreme between-study heterogeneity. The pooled effect and its 95% CI on the logit scale were subsequently back-transformed to the AUC scale using the inverse logit function to facilitate interpretation. Between-study heterogeneity was quantified using
Pre-specified subgroup meta-analyses were performed according to outcome type: (1) suicide attempt–related outcomes, (2) suicidal ideation, and (3) suicide death or death-containing composite outcomes. Within each subgroup, a separate random-effects model was fitted on logit (AUC), and pooled estimates with 95% CIs and I2 were reported. Forest plots were constructed to display study-specific AUCs with 95% CIs and the corresponding pooled AUCs for the overall analysis and each outcome subgroup.
In the primary analysis, multiple model evaluations reported within the same study were treated as separate estimates. To assess the potential influence of within-study dependence, we conducted two sensitivity analyses. First, we aggregated multiple evaluations within each study into a single study-level estimate using inverse-variance weighting and repeated the random-effects meta-analysis. Second, we applied cluster-robust variance estimation using study as the clustering unit in the evaluation-level model.
To explore potential sources of heterogeneity, we conducted exploratory moderator analyses with logit (AUC) as the dependent variable. Given the limited number of model evaluations and the risk of overfitting, we did not retain the original multivariable meta-regression model including seven study-level covariates. Instead, we focused on three clinically and methodologically central covariates—outcome type, evaluation timing, and model type—each examined separately in univariable random-effects meta-regression models.
Because some studies contributed multiple model evaluations, we additionally applied cluster-robust inference using study as the clustering unit to obtain more conservative standard errors and confidence intervals. These moderator analyses were treated as exploratory and underpowered, and were interpreted cautiously. All analyses were two-sided (p < 0.05) and conducted in R 4.4.0 15 using the metafor package, 16 with cluster-robust inference implemented for the revised univariable meta-regression analyses. Small-study effects were explored using funnel plots and Egger’s regression test. 17
3. Results
3.1. Characteristics of included studies and models
A total of 9 studies reporting 20 evaluations of suicide prediction models were included in this review (Figure 1). The predicted outcomes encompassed suicide attempts, suicidal ideation, and suicide deaths, with models targeting suicide death being the most common. Several studies contributed multiple evaluations because models were assessed using different prediction horizons and/or modeling approaches. PRISMA 2020 flow diagram of study selection via databases and registers. The diagram summarizes the number of records identified through database and registry searches, the number remaining after deduplication, records excluded after title/abstract and full-text screening (with reasons), and the final number of studies included in the meta-analysis.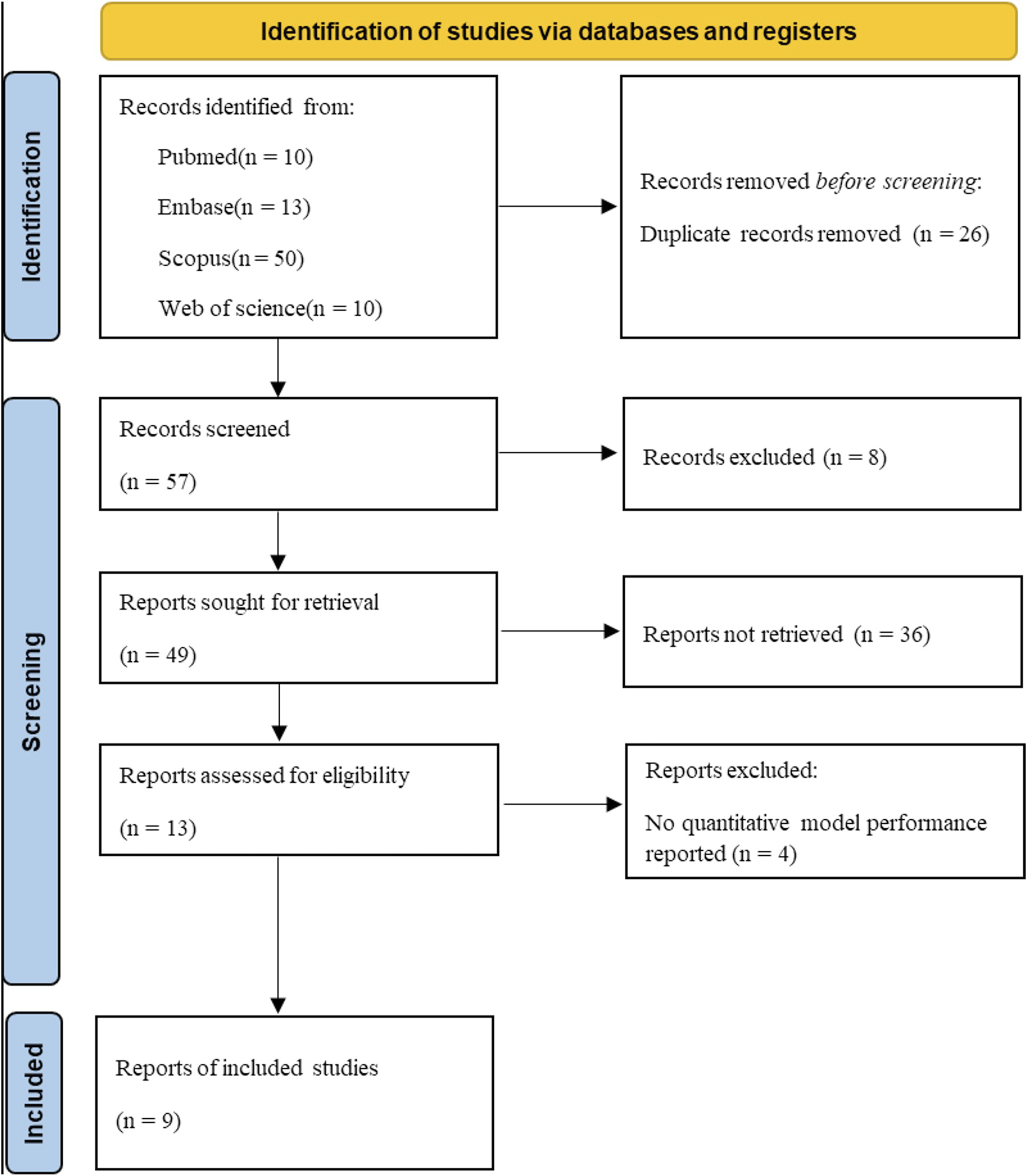
Characteristics of included model evaluations and discriminative performance (AUC). Each row represents a distinct model evaluation within a given study. The table summarizes the study, country, sample size, predicted outcome, data source, evaluation timing, model type, prediction window, and the AUC with its 95% confidence interval (lower and upper bounds).
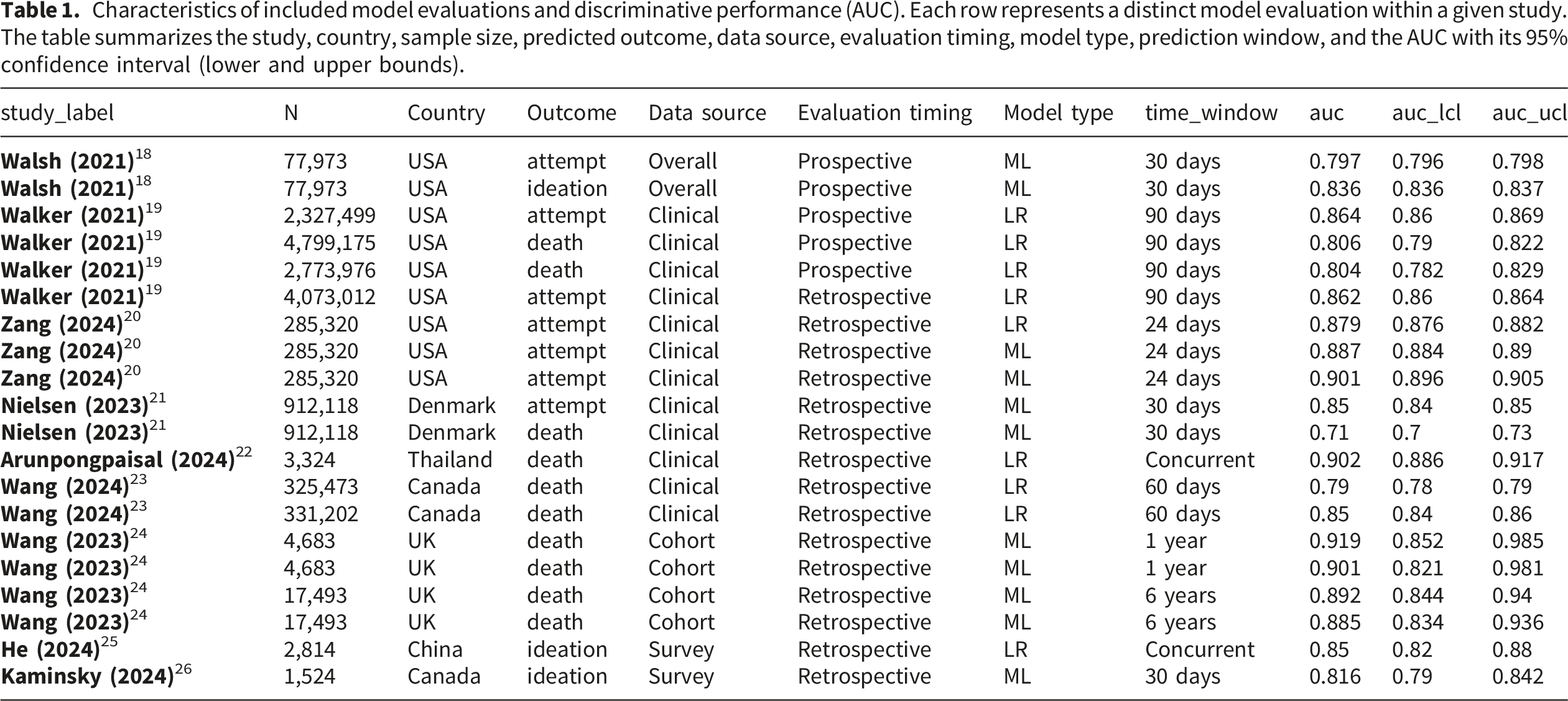
Risk-of-bias assessment using PROBAST indicated that methodological concerns were identified most often in the analysis domain, particularly in relation to limited reporting of calibration. Additional concerns in some studies related to outcome ascertainment based on unvalidated administrative codes and, in a smaller number of cases, to applicability issues in specific validation settings.
3.2. Overall discriminative performance of suicide prediction models
Across the 20 model evaluations that reported AUCs with 95% confidence intervals, the random-effects meta-analysis produced a pooled AUC of 0.849 (95% CI 0.827–0.869) for predicting any suicide-related outcome (Figure 2). This pooled estimate indicates that, on average, suicide prediction models evaluated in real-world settings achieve good discriminative performance, although the individual evaluation estimates show variability. Forest plot of AUCs for all suicide prediction model evaluations. Each line represents an individual model evaluation with its AUC and 95% confidence interval; the diamond at the bottom indicates the pooled AUC from the random-effects meta-analysis for any suicide-related outcome.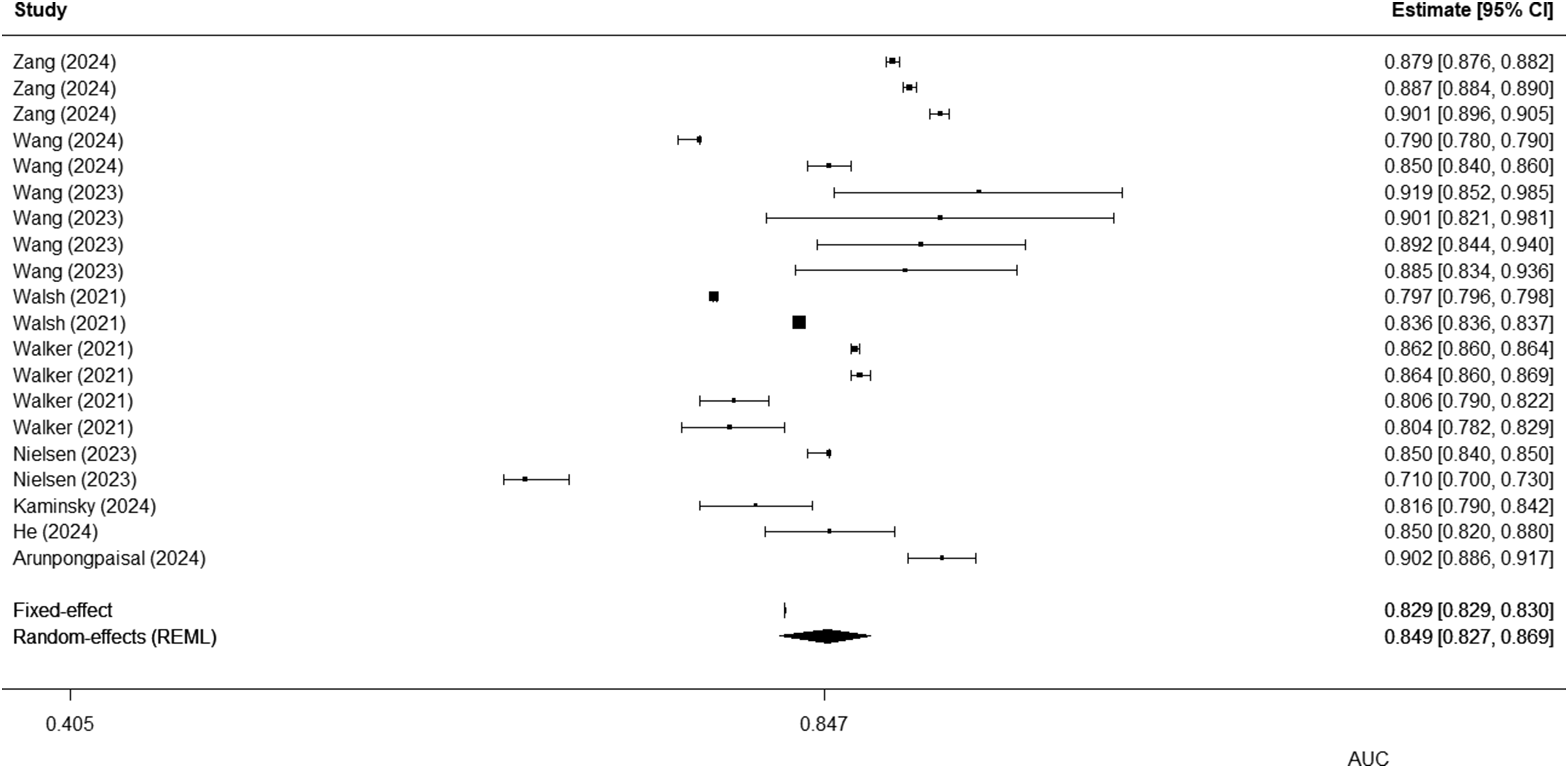
Pooled discriminative performance and heterogeneity for overall and outcome-specific suicide prediction models. Separate restricted maximum likelihood (REML). Random-effects meta-analyses were conducted for models predicting any suicide-related outcome, suicide attempts, suicidal ideation, and suicide deaths (including death-containing composite outcomes). k (model evaluations) included in each synthesis. “Pooled AUC” indicates the pooled area under the receiver operating characteristic curve with its 95% confidence interval (LCL = lower confidence limit, UCL = upper confidence limit). I2 represents the percentage of total variability attributable to between-study heterogeneity.
Potential small-study effects were explored in the overall analysis using Egger’s regression test. Although the test was not statistically significant (p = 0.110) (Supplementary Figure S1), this result should be interpreted cautiously because the extreme between-evaluation heterogeneity limits the validity and interpretability of funnel plot–based asymmetry assessments.
3.3. Discriminative performance by outcome type
We conducted outcome-specific random-effects meta-analyses (Figure 3(a)–(c)). The pooled AUC was 0.865 (95% CI 0.840–0.887) for suicide attempt, 0.835 (95% CI 0.825–0.844) for suicidal ideation, and 0.842 (95% CI 0.797–0.878) for suicide death. Heterogeneity was substantial across outcome strata, with high inconsistency for suicide attempt and suicide death (I2 = 99.8% and 98.6%, respectively) and lower inconsistency for suicidal ideation (I² = 22.8%), although the suicidal ideation subgroup included only three evaluations. Forest plots of pooled discriminative performance by outcome type. Forest plots of area under the receiver operating characteristic curve (AUC) from random-effects meta-analyses stratified by suicide-related outcome. Diamonds represent pooled AUCs with 95% confidence intervals, and squares represent individual model evaluations weighted by the inverse of their variance. (a) Suicide attempt–related outcomes (pooled AUC = 0.865, 95% CI 0.840–0.887). (b) Suicidal ideation outcomes (pooled AUC = 0.835, 95% CI 0.825–0.844). (c) Suicide death–related outcomes, including death-containing composite outcomes (pooled AUC = 0.842, 95% CI 0.797–0.878).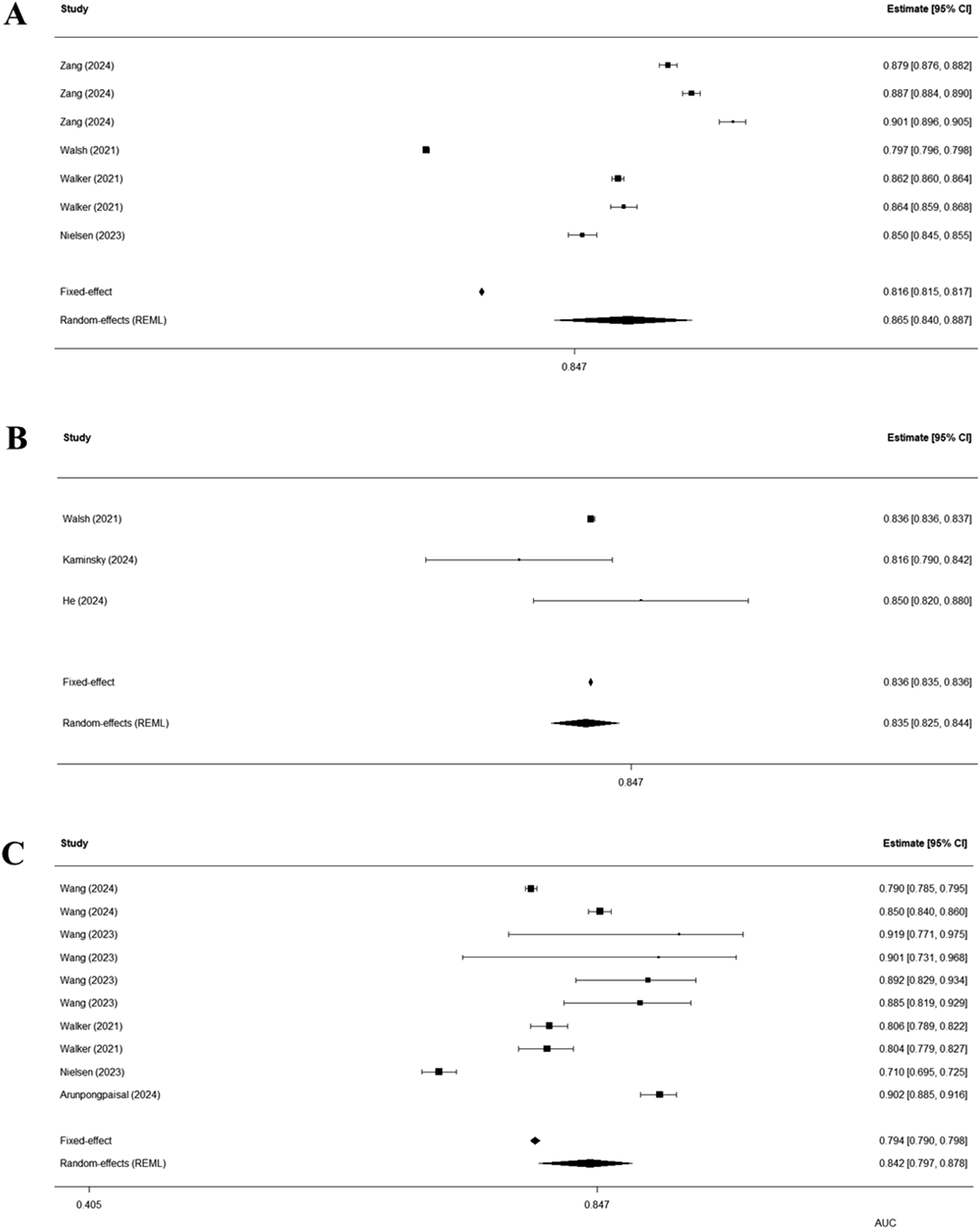
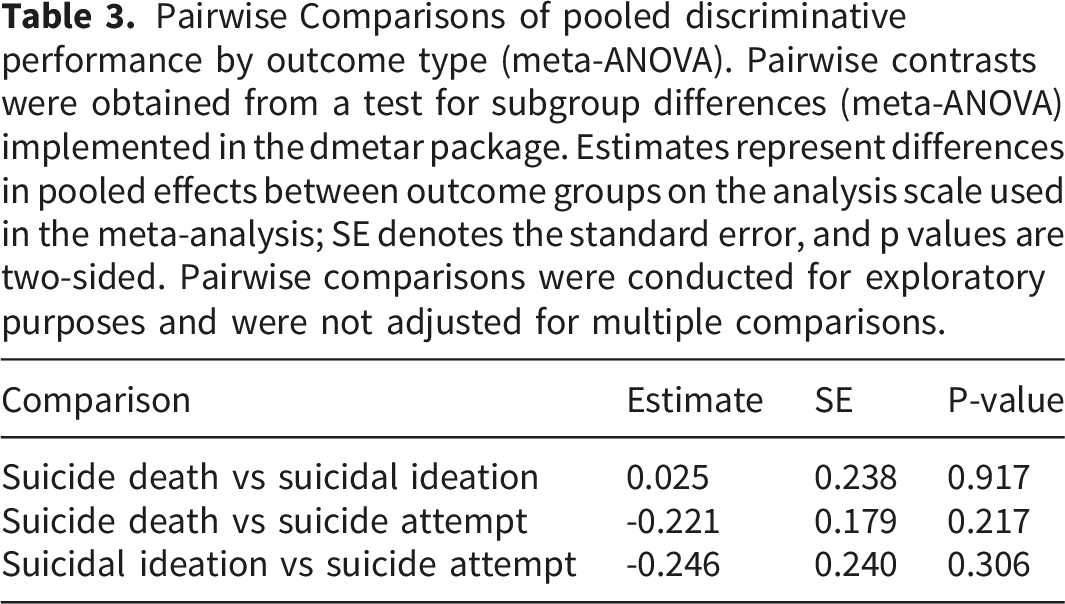
Pairwise Comparisons of pooled discriminative performance by outcome type (meta-ANOVA). Pairwise contrasts were obtained from a test for subgroup differences (meta-ANOVA) implemented in the dmetar package. Estimates represent differences in pooled effects between outcome groups on the analysis scale used in the meta-analysis; SE denotes the standard error, and p values are two-sided. Pairwise comparisons were conducted for exploratory purposes and were not adjusted for multiple comparisons.
Sensitivity analyses addressing within-study dependence produced results similar to the primary analysis. The pooled AUC was 0.853 (95% CI 0.827–0.878) in the study-level aggregation analysis and 0.849 (95% CI 0.820–0.874) in the cluster-robust analysis, indicating that the overall findings were not substantially altered. These sensitivity results are summarized in Supplementary Table S2.
3.4. Meta-regression analyses
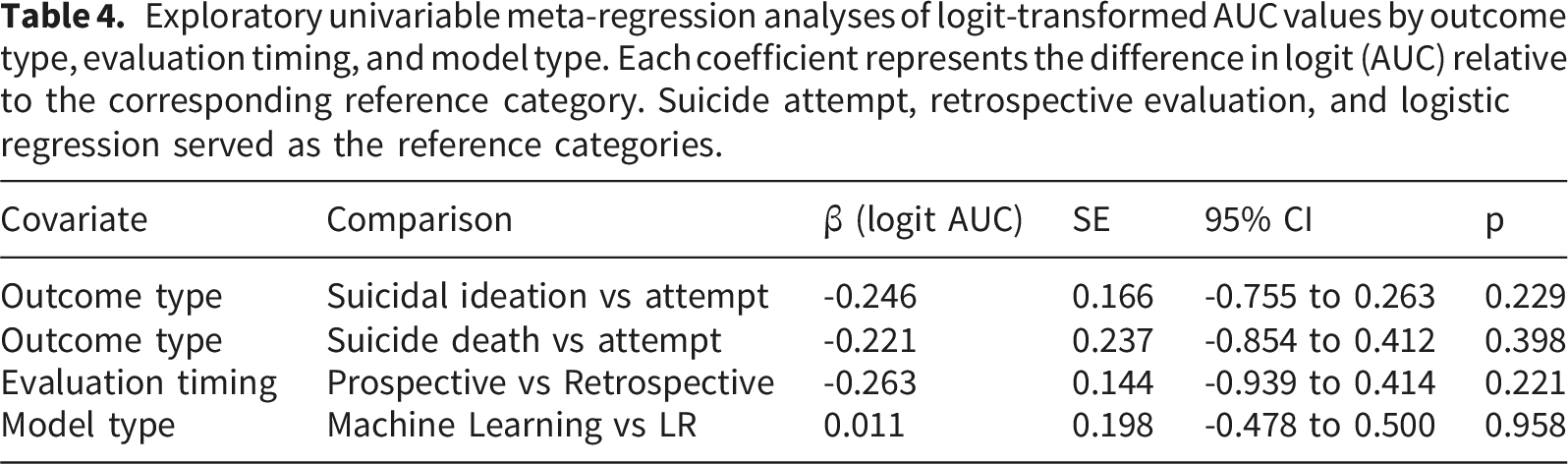
Exploratory univariable meta-regression analyses of logit-transformed AUC values by outcome type, evaluation timing, and model type. Each coefficient represents the difference in logit (AUC) relative to the corresponding reference category. Suicide attempt, retrospective evaluation, and logistic regression served as the reference categories.
4. Discussion
4.1. Principal findings
In this systematic review and meta-analysis of real-world suicide prediction models, we found that models evaluated in routine clinical settings showed generally good overall discrimination. This suggests that data-driven suicide risk prediction can retain meaningful predictive value beyond development-only studies. At the same time, performance estimates varied substantially across evaluations, indicating that real-world effectiveness is not uniform across settings. Taken together, these findings support a balanced interpretation: suicide prediction models show promise in practice, but their performance is strongly context-dependent and should not be assumed to generalize automatically across institutions or workflows.
Importantly, our revised exploratory moderator analyses did not identify clear associations between discriminative performance and three clinically central study-level characteristics: outcome type, evaluation timing, and model type. These findings do not rule out the possibility that such factors matter in specific contexts. However, they suggest that broad study-level labels alone may be insufficient to explain the marked heterogeneity observed across evaluations. Instead, real-world performance may also depend on more localized factors, such as data quality, documentation patterns, feature construction, case-mix, and clinical workflow integration.
4.2. Interpretation and implications
A notable finding from the revised exploratory moderator analyses was the absence of a clear association between model type and discriminative performance. Within the limits of the current evidence base, this suggests that greater algorithmic complexity does not necessarily translate into better real-world discrimination.3,27–29 From a clinical implementation perspective, this is important because simpler and more interpretable approaches, such as logistic regression, may remain reasonable options when their performance is not clearly inferior.27–29
We also did not observe a clear association between evaluation timing and model discrimination. This should not be interpreted as evidence that implementation timing is unimportant. Rather, it suggests that prospective versus retrospective labeling alone may not fully explain the wide variability in real-world performance.30,31 Taken together, these findings shift attention away from the search for a universally superior algorithm and toward the practical conditions under which models are validated, calibrated, and integrated into local workflows.30–32 Because discrimination alone does not guarantee accurate absolute risk estimation, future evaluations should report calibration and clinical utility metrics alongside AUC.30,32
4.3. Comparison with previous literature
Previous reviews have highlighted both the promise of machine learning for suicide prediction and the substantial heterogeneity across studies.3,4,28,29 Implementation-oriented reviews have further emphasized that predictive performance alone is insufficient for clinical value unless models are supported by effective workflow integration, governance, and intervention pathways.30–32 Our findings are broadly consistent with this literature and extend it by focusing specifically on real-world evaluations. Together, these results suggest that performance differences across health systems are likely shaped by contextual factors beyond broad study-level categories, reinforcing the need for careful local validation before transport across settings.29,31
4.4. Strengths and limitations
The main strength of this study is its strict focus on model evaluations conducted in real-world or pragmatic contexts, which directly informs health-system deployment decisions. We synthesized discrimination using logit-transformed AUCs and explored potential sources of variability through meta-regression, allowing us to examine both average performance and the extent of real-world variability.12,14
Several limitations should be acknowledged. First, the available evidence focused mainly on discrimination, whereas calibration and clinical utility metrics were rarely reported. This limits conclusions about absolute risk estimation and net clinical benefit.30,32 In addition, the PROBAST-based assessment suggested that methodological concerns were most often concentrated in the analysis domain, particularly because of limited reporting of calibration. Therefore, strong AUC values should not be interpreted as evidence that these models are ready for implementation without further evaluation of calibration, threshold performance, and clinical usefulness. Second, heterogeneity remained extreme and largely unexplained despite exploratory moderator analyses, which may reflect residual differences in local clinical processes. Third, although we included 20 model evaluations from 9 studies, some subgroups were small, making the meta-regression findings exploratory. Fourth, while multiple evaluations from the same study were treated as independent in the primary analysis to maximize data use, this approach carries a risk of within-study correlation. We addressed this issue through sensitivity analyses, and the overall findings remained materially unchanged. Fifth, the revised moderator analyses were limited to a small number of clinically central covariates. Finally, the assessment of small-study effects should be interpreted cautiously. Although Egger’s regression test was not statistically significant, the extreme heterogeneity in effect estimates limits the interpretability of funnel plot asymmetry methods in this review.
4.5. Future directions
Future research on suicide prediction should move beyond a purely algorithm-centered agenda focused on small gains in AUC and place greater emphasis on implementation science. 31 In highly heterogeneous real-world settings, the key challenge is no longer identifying a universally superior algorithm. Instead, it is determining how models can be effectively validated, calibrated, and integrated into local clinical environments.29,30
Accordingly, future studies should prioritize rigorous local validation and prospective testing across diverse institutions. Models should be embedded into context-specific clinical workflows so that alerts are actionable, acceptable to clinicians, and capable of improving decision-making without increasing alert fatigue.30–32 Routine validation should also include fairness assessments across vulnerable subgroups and continuous post-deployment surveillance to monitor performance drift and calibration decay over time.10,29 Future implementation studies should therefore move beyond discrimination alone and evaluate whether predicted risks are well calibrated and clinically actionable in practice.30,32
5. Conclusions
AI-based suicide prediction models demonstrate good discriminative performance in real-world clinical settings, with a pooled AUC of 0.849. However, this overall performance masks substantial heterogeneity that was not clearly explained by outcome type, evaluation timing, or model type. These findings suggest that the future of suicide prediction lies not in a universally optimal algorithm, but in careful local validation and workflow-sensitive implementation. Ultimately, unlocking the clinical utility of these models depends on adapting them to the realities of specific health systems while maintaining fairness, calibration, and actionability.
Supplemental material
Supplemental material - Real-world implementation and predictive performance of suicide prediction models: A systematic review and meta-analysis
Supplemental material for Real-world implementation and predictive performance of suicide prediction models: A systematic review and meta-analysis by KangHyun Kim, JuHee Kim, Myung-Gwan Kim, Hyun Wook Han in DIGITAL HEALTH
Supplemental material
Supplemental material - Real-world implementation and predictive performance of suicide prediction models: A systematic review and meta-analysis
Supplemental material for Real-world implementation and predictive performance of suicide prediction models: A systematic review and meta-analysis by KangHyun Kim, JuHee Kim, Myung-Gwan Kim, Hyun Wook Han in DIGITAL HEALTH
Footnotes
Author contributions
KH.K. conceptualized the study, conducted the main analyses, and drafted the manuscript. JH.K. assisted with data collection and conducted the literature review for the meta-analysis. MG.K. provided critical statistical and methodological advice. HW.H. supervised the overall research process, provided the research infrastructure, and critically revised the manuscript. All authors read and approved the final manuscript.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Institute of Information & Communications Technology Planning & Evaluation(IITP)-ICAN(ICT Challenge and Advanced Network of HRD) grant funded by the Korea government(Ministry of Science and ICT) (IITP-2026-2710093245).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
AI use disclosure
The authors used an artificial intelligence–based language tool only for language editing, translation support, and improvement of readability during manuscript revision. The authors reviewed and approved all revisions and take full responsibility for the final content of the manuscript.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.